
Abstract
Researchers who model fractional dependent variables often need to consider whether their data were generated by a two-part process. Two-part models are ideal for modeling two-part processes because they allow us to model the participation and magnitude decisions separately. While community-contributed commands currently facilitate estimation of two-part models, no specialized command exists for fitting two-part models with process dependency. In this article, I describe generalized two-part fractional regression, which allows for dependency between models’ parts. I show how this model can be fit using the community-contributed
1 Introduction
In many disciplines, researchers need to fit regression models where the dependent variable is in the form of a fraction, percentage, or proportion. In finance, a commonly examined fractional dependent variable (FDV) is the financial leverage ratio of firms, that is, the amount of debt a firm issues relative to its amount of capital. Empirical research suggests that the financial leverage decision of firms is best described as a two-step process; first, the firm decides whether to issue debt, and then it decides how much debt to issue (Ramalho and da Silva 2009). However, the process determining which firms choose to issue debt is nonrandom because firms self-select into a leveraged position. Thus, we need a model that not only can separate the effects on the debt versus no debt from the effects on the amount-of-debt decision but also can account for the nonrandom selection that leads to some firms issuing debt. The generalized two-part fractional regression model (GTP-FRM) is such a model.
Before we dig into the GTP-FRM, I will give a short introduction on modeling FDVs. Modeling an FDV requires a fractional regression model (FRM). If we use the quasi– maximum likelihood estimator (QMLE) and the logit link, the model is known as the fractional logit; it is known as the fractional probit if we use the probit (Papke and Wooldridge 1996). An FRM is preferable because it ensures predictions within the unit interval and requires only correct specification of the conditional mean. Estimation of FRMs with various link functions is straightforward in Stata with the
In many cases, an FDV may contain many values at one or both boundaries. The values at, for example, the zero boundary may be governed by a different process than the values between the boundaries. For instance, the covariates that affect a firm’s decision to issue debt are likely to be different from those affecting how much debt to issue (Cook, Kieschnick, and McCullough 2008). For such purposes, Ramalho and da Silva (2009) proposed a two-part fractional model (TP-FRM). The TP-FRM allows for specification of a binary model for the participation decision (y = 0 versus y > 0), for example, debt versus no debt, and an FRM for the magnitude decision (the magnitude of y when y > 0), such as how much debt to issue. Using this model, we allow the effects of a covariate on the participation decision to be different from the magnitude decision. In Stata, TP-FRMs can be fit using the community-contributed
In some cases, we may need even more flexibility than what is offered by the TP-FRM, such as when the participation and magnitude decisions are dependent. Continuing the example from above, there may be a selection bias in the types of firms that choose to issue debt. This problem is analogous to the well-known sample selection problem. Recently, Schwiebert and Wagner (2015) proposed the GTP-FRM as a means to model fractional two-part processes with dependence. The GTP-FRM formulation is advantageous because it nests the TP-FRM as a special case when the two processes are independent.
Currently, the GTP-FRM does not have a dedicated Stata command. In this article, I demonstrate how Stata users can fit GTP-FRMs by using the conditional mixed-process framework implemented by the
2 Brief review of generalized two-part fractional regression
In many practical applications, FDVs naturally give rise to many zeros. For example, some firms do not have any exports (0% of total sales attributed to foreign sales), some individuals do not smoke (0% of their income spent on cigarettes), and some firms do not issue any debt (0% leveraged capital). When encountering such FDVs, researchers must decide how to qualitatively interpret the zeros (Ramalho, Ramalho, and Murteira 2011), because the zeros may actually be best described by a different mechanism than the positive values. Consider, for instance, the financial leverage decisions of firms. While a financing life-cycle approach would argue that older firms are more likely to issue debt, pecking-order theory would suggest that older firms prefer a lower proportion of debt because of a large amount of accumulated retained earnings (Ramalho and da Silva 2009). In such cases, a TP-FRM is ideal because it allows us to model the participation and magnitude decisions separately.
If a two-part process constitutes the best description of our data, we need to consider whether the two decisions are dependent. If unobserved factors affecting the decision to issue debt are correlated with factors that influence the proportion of debt sought by firms, the TP-FRM estimates will be biased (Wooldridge 2010). For instance, research suggests that a moderate degree of CEO narcissism is associated with greater corporate risk taking (Aabo and Eriksen 2018). If CEO narcissism is related to firm profitability but is not accounted for, then the estimate of firm profitability on the proportion of debt is likely to be biased. The GTP-FRM models the correlation between the two decisions, thus attempting to both estimate and adjust for the dependency between the processes. This makes the GTP-FRM ideal for FDVs best described by dependent two-part processes.
2.1 Model formulation
Following Schwiebert and Wagner (2015), we start by specifying the process determining the participation decision, where we assume an FDV, y, with values in the unit interval:

where s is an indicator variable that takes the value 1 if the value of the outcome, y, is nonzero;

where Φ(·) is the standard normal cumulative distribution function. We specify the conditional mean of the magnitude decision as follows:
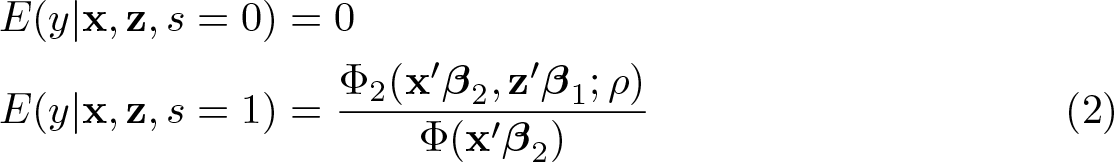
Based on the above formulation, the GTP-FRM is clearly a more complicated model than the TP-FRM. In contrast to the TP-FRM, the GTP-FRM lets both
2.2 Marginal effects
As for the regular binary probit model, we should abstain from interpreting the model coefficients directly. Instead, we should rely on marginal effects preferably accompanied by graphical illustrations of predicted values of the FDV (Wulff 2015). As shown by Schwiebert and Wagner (2015), the predicted values of the FRM given values of the covariates are given by


As for other two-part models, it is possible to obtain other types of predictions based on the GTP-FRM. For instance, we can compute the expected value of y conditional on y > 0, that is, the term E(y|
Based on (4), the marginal effect of xk in the GTP-FRM is given by

As I illustrate later, marginal effects and predicted values of the FDV can be obtained using
2.3 Model fit measures
When comparing various fractional model specifications, we can rely on the Akaike information criterion (AIC) and Bayesian information criterion (BIC). Comparing measures based on pseudolikelihoods from different models can be tricky. Papke and Wooldridge (1996) argue for defining R 2 in terms of the actual and predicted values. Like R 2, information criteria can also be defined in terms of the residual sum of squares (RSS). Thus, I suggest using the following definitions of AIC and BIC when comparing FRMs, TP-FRMs, and GTP-FRMs:


where n is the sample size and K is the total number of parameters from each part of the GTP-FRM. Defining information criteria in this way has two major advantages when working with FDVs. First, they are comparable across any model for the conditional mean and for any estimation method (Papke and Wooldridge 1996). For instance, we can compare our GTP-FRM with its tobit equivalent—the exponential type II tobit model for corner solution responses (Wulff and Villadsen 2018). Second, we do not have to worry about unintentionally comparing information criteria across models with different (pseudo)likelihood functions.
2.4 RESET test
For the GTP-FRM, we can use Ramsey’s (1969) RESET test as a simple functional form diagnostic. Essentially, the test can be used to check for missing nonlinearities in the GTP-FRM or any other index model (Pagan and Vella 1989). For each model part, we obtain the index predictions. These are added in squared and cubic form to the relevant model part, after which we can perform a joint hypothesis test of the coefficients of the two extra terms (Ramalho and Ramalho 2012). For the fractional part, it is important that we use the robust version of the test. However, because robust standard errors are computed by default by
3 Stata implementation
The FRM, TP-FRM, and GTP-FRM can be fit using QMLE. As noted in the introduction, the fractional probit is already implemented in the
3.1 Data example
To illustrate the use of

First, I generate a nonzero indicator variable indicating the firms that have issued debt. To simplify the syntax, I assign the regressors to a global macro. I exclude the

3.2 Model estimation strategy
Some readers might have noticed how the GTP-FRM looks conceptually similar to the Heckman (1976) sample-selection model. In fact, the GTP-FRM is also applicable to fractional missing-data problems (Schwiebert and Wagner 2015). In the current setting, however, we do not have a sample-selection issue. Instead, we have a fractional response where the FDV is always observed yet is generated by two different dependent processes.
Conveniently, we can exploit the similarities to the sample selection model by using the same approach to fit the GTP-FRM. We do this by estimating systems of equations with errors that are jointly normally distributed. If our FDV had been binary, this estimation could have been performed using the
3.3 Syntax
The syntax for
The
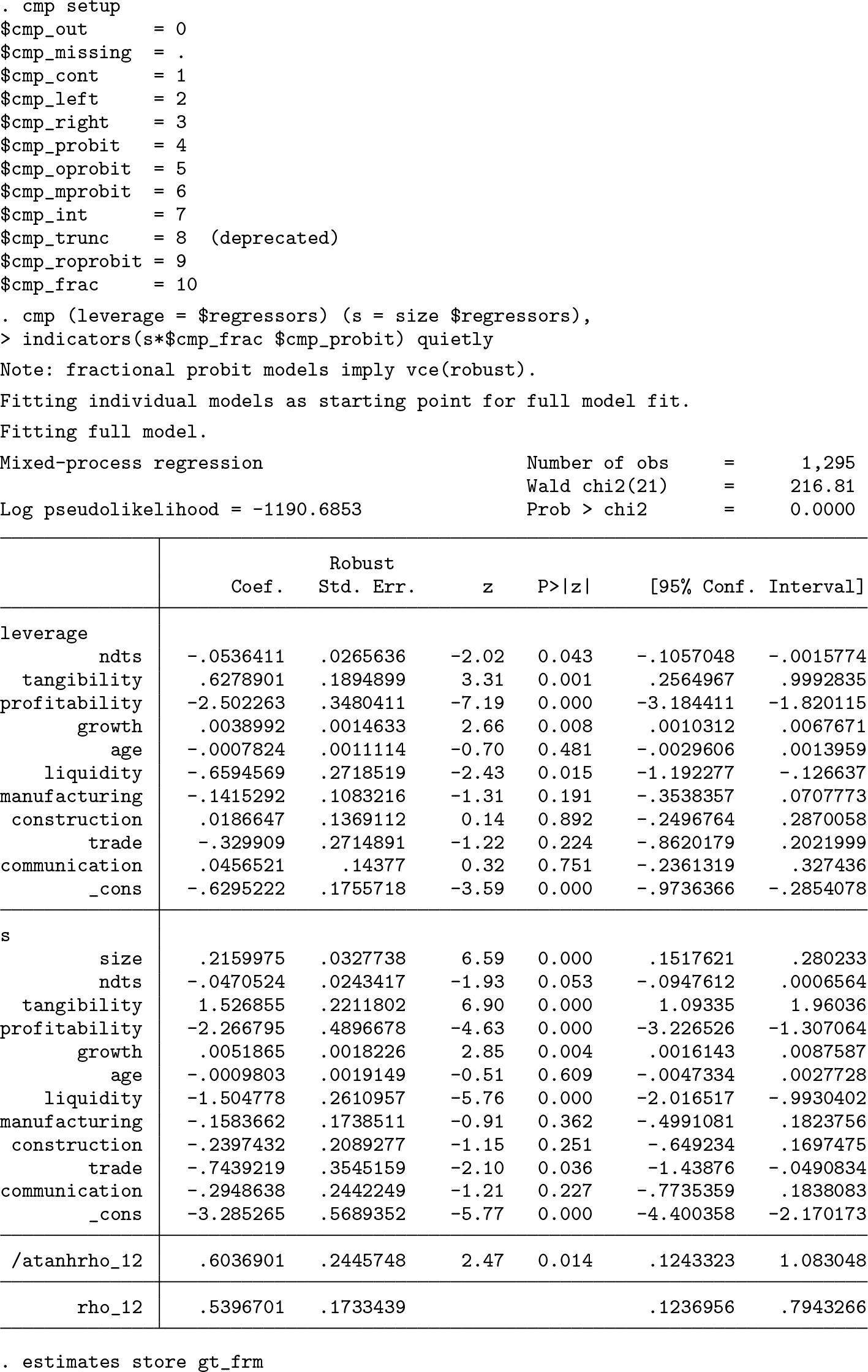
The first part of the output relates to the amount decision (
For illustration, we can compare the GTP-FRM estimates with those of the TP-FRM and regular FRM by using

In the
3.4 Predictions and marginal effects
To substantially interpret the results from the GTP-FRM, we can compute the (average) predicted proportions at selected values of

Figure 1 shows the average predicted proportion of debt for various levels of firm profitability. At a tangibility around 0, the GTP-FRM predicts a debt proportion around 0.08. For firms with a higher ratio of tangible to total assets, the model predicts a dramatically higher debt proportion. For instance, for firms with roughly equal parts of tangible and intangible assets, the GTP-FRM predicts an average debt proportion of around 0.16.

Marginsplot with predicted proportions
For computation of the average marginal effect on the conditional mean of

We can observe that a one-unit increase in
By slightly modifying the syntax above, we can quite easily obtain other types of predictions if we wish. For instance, we can compute the average marginal effect on the predicted probability of issuing debt by specifying only the

A one-unit increase in
Finally, we can compute the average marginal effect on the proportion of debt conditional on the firm having issued debt:

The estimated average marginal effect is much smaller than the one on the conditional mean and is nonsignificant. This suggests that for firms that have issued debt,
3.5 Model fit
While the procedure illustrated above automatically yields a test comparing the GTPFRM with the TP-FRM, we may want to compare the GTP-FRM with other specifications. Using (5) and (6), we can compare the GTP-FRM with any fractional specification we like. For instance, we can compare the GTP-FRM with the much simpler FRM specification:

The AIC and BIC values indicate that the GTP-FRM is not improving its fit enough to make up for its added complexity. Thus, it would seem that the FRM provides a better tradeoff between parsimony and fit than the GTP-FRM. As explained above, we can use this procedure to compare any model for the conditional mean as long as we can obtain RSS on the fractional scale.
3.6 RESET test
For testing the conditional mean specification, we can implement the RESET test. This can be done for each part separately by using the following procedure:

At an alpha of 1%, neither test rejects the H 0 that the model specification is correct. In contrast, the RESET test rejects the H 0 that the first part of the TP-FRM with a probit link is correctly specified:

4 Conclusion
FDVs are often modeled by researchers across many disciplines. When such variables are best described by a two-part process with dependence, researchers should apply the GTP-FRM. Currently, no dedicated Stata command exists to fit the GTP-FRM. In this article, I showed how GTP-FRMs can be fit with the community-contributed
Supplemental Material
Supplemental Material, st0558 - Generalized two-part fractional regression with cmp
Supplemental Material, st0558 for Generalized two-part fractional regression with cmp by Jesper N. Wulff in The Stata Journal
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.