
Abstract
In this article, we introduce the
Keywords
1 Introduction
The interest in modeling quantiles, such as the median and the 90th percentile, of a variable of interest given a set of covariates has spurred research in many fields of science. Applications and new methods have been increasingly appearing in the literature (among others, Koenker et al. [2018]). Quantile regression is arguably the most popular method for modeling conditional quantiles given covariates. The
Quantile regression can estimate a conditional quantile at a time, imposing no restrictions on the quantile function but on the assumed functional relationship between quantile and regression coefficients. For example, linear quantile regression assumes that a given quantile (for example, median) is a linear combination of covariates and unknown regression coefficients. While this gives ordinary quantile regression flexibility, it can also cause high variability of its estimator. Erratic estimates occur frequently in applications and often lead to uncertain inferences. For example, the coefficient at one percentile may be significantly different from zero, while those at adjacent percentiles are not; the induced quantile function may be decreasing for some covariate patterns; the estimated interquartile range may be smaller than the 20th-to-80th-percentile range.
In this article, we introduce the
As a motivating example, we now introduce a simple linear parametric quantile model, on which we further elaborate in section 3. We analyze data from 930 subjects over 20 years old and with body mass index (BMI) over 30 kg/m2 from the 2017 U.S. National Health and Nutrition Examination Survey (NHANES). Figure 1 shows the box plots of BMI over age groups. The bottom quantiles (for example, the 10th percentile) do not vary with age, while the top quantiles (for example, the 90th percentile) decline steeply.

Box plots of BMI over age groups with data from NHANES
We define a model for the conditional quantile function of BMI given age
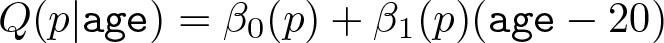
For example, Q(0.5|20) represents the conditional median in 20-year-old individuals.
Figure 2 displays the regression coefficient estimated with both ordinary quantile regression and a parametric quantile model. The top row shows the estimated intercept, β 0(p), and coefficient for age, β 1(p), as functions of p, along with shaded areas indicating their 95% confidence intervals. The inclusion criteria explain the vanishing confidence intervals at the smallest quantiles. The estimates show a markedly erratic behavior, which can be explained only by sampling variability.
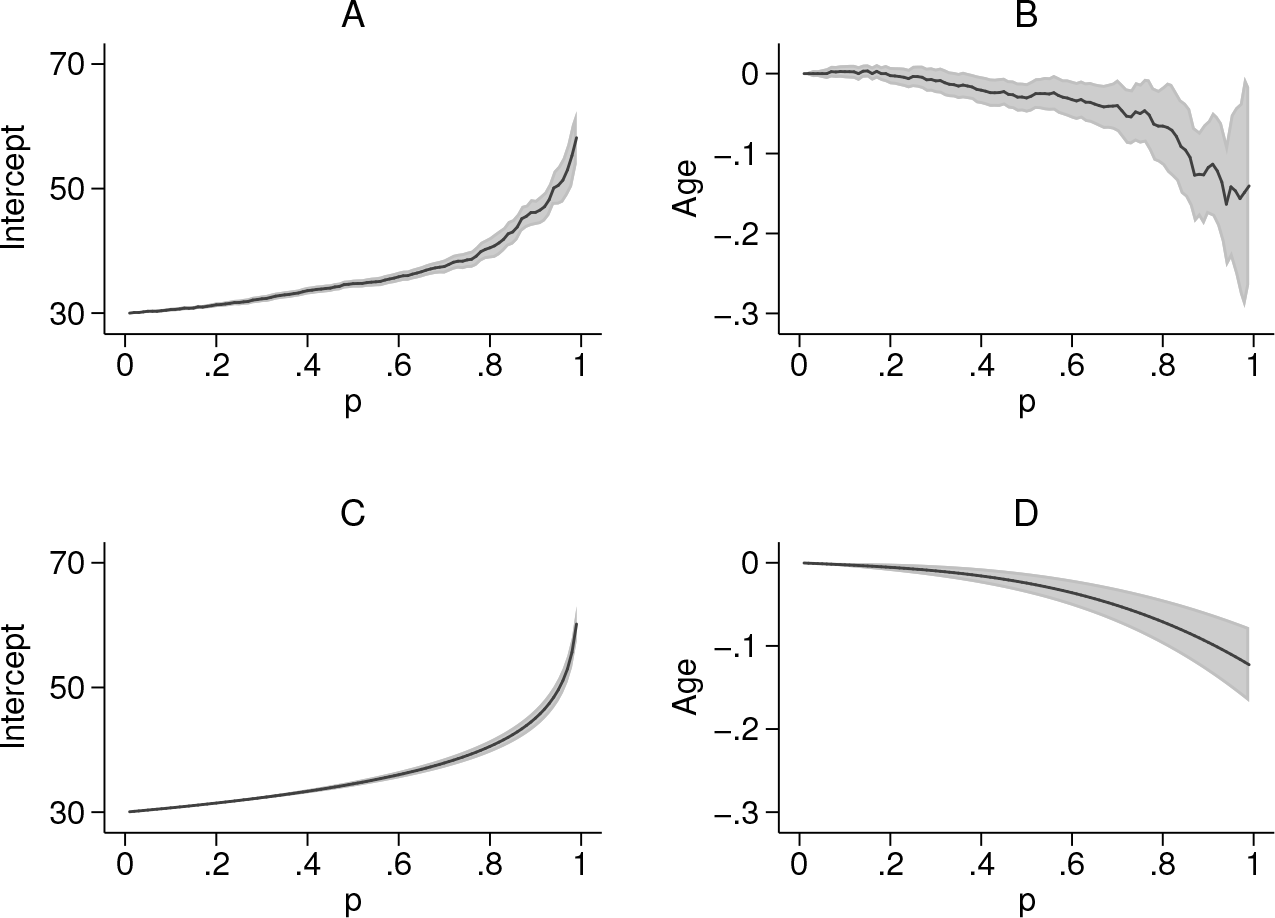
Point estimates (lines) and 95% confidence intervals (shaded areas) for the intercept (first column) and the coefficient for age (second column) from ordinary quantile regression (first row) and from the parametric quantile model (second row) as functions of the order of the quantile, p, with data from NHANES
The bottom row in figure 2 shows the estimates for the intercept and the coefficient associated with age obtained with a parametric quantile model. These can be compared with the 99 percentiles, Q(0.01|
The above is an example of a simple parametric quantile model. In the remainder of this article, we illustrate the potential of parametric quantile models. Section 2 contains the syntax of the
2 Syntax
This section describes the syntax of the
2.1 qmodel

exp varname is the variable whose quantile function is modeled or an expression of it such as
quantile function is an expression representing the parametric quantile model. It can be any combination of built-in functions, substitutable expressions, and mathematical functions. Its argument is indicated by the letter
Options
Built-in functions

Stored results

2.2 predict
The

Options
2.3 qmodel plot
The

Options
twoway options are any of the options documented in [G-3]
2.4 qmodel quantile
The

Options
nlcom options specifies standard
3 Example 1: Body mass and age
In this section, we describe the use of the
The data arise from all the male participants in the 2017 NHANES who were at least 20 years old and had a BMI of at least 30 kg/m2. We consider the simple linear regression model introduced in section 1,

The variable
To construct parametric models for the regression coefficients, β 0(p) and β 1(p), one can obtain point estimates for a set of proportions with ordinary quantile regression, as shown in the top panels of figure 2, and then find a parametric quantile model that most closely approximates them.
Based on panel A in figure 2, we start by approximating the quantile function β 0(p) with the quantile function of an exponential distribution with support BMI ≥ 30,

with θ 0 > 0. Because the individuals were included in the study if their BMI was at least 30 kg/m2, the smallest BMI value is known to be 30 with no sampling variability. Hence, we do not include a parameter representing a location shift of the baseline value but rather the fixed number 30.
We chose an initial approximating function for β 0(p) based on the estimates for the intercept of ordinary quantile regression. If these were unavailable, we could consider the quantile function of BMI within a range of small age values. For example, we build the empirical quantile function of BMI in individuals between 20 and 25 years of age shown in figure 3.

Empirical quantile function of BMI in individuals between 20 and 25 years old with data from NHANES

The quantile function of a variable is its cumulative distribution function, where the x axis and y axis are swapped. The quantile function maps from the proportion (x axis) to the values of the outcome variable (y axis). □
When no graphical representations are available, one can start with flexible models such as cubic splines or step functions. Understanding the substantive meaning of the outcome variable can help one make sound decisions. For example, in our model, β 0(p) represents the top tail of the conditional distribution of BMI truncated at 30 kg/m2. While the exponential function would not be a reasonable choice for the entire distribution of BMI, which may be expected to be unimodal, it is a sensible initial approximation for its extreme top tail.
We now consider the regression coefficient associated with age, β 1(p). Based on panel B in figure 2, we start by approximating it with a third-order polynomial with no intercept,

Other flexible functions, such as splines or step functions, could be used instead.
The quantile parametric model resulting from the above specifications is

The above model constrains the smallest BMI value to be equal to 30 kg/m2, Q(0|
We estimate the parameters of the above model with the
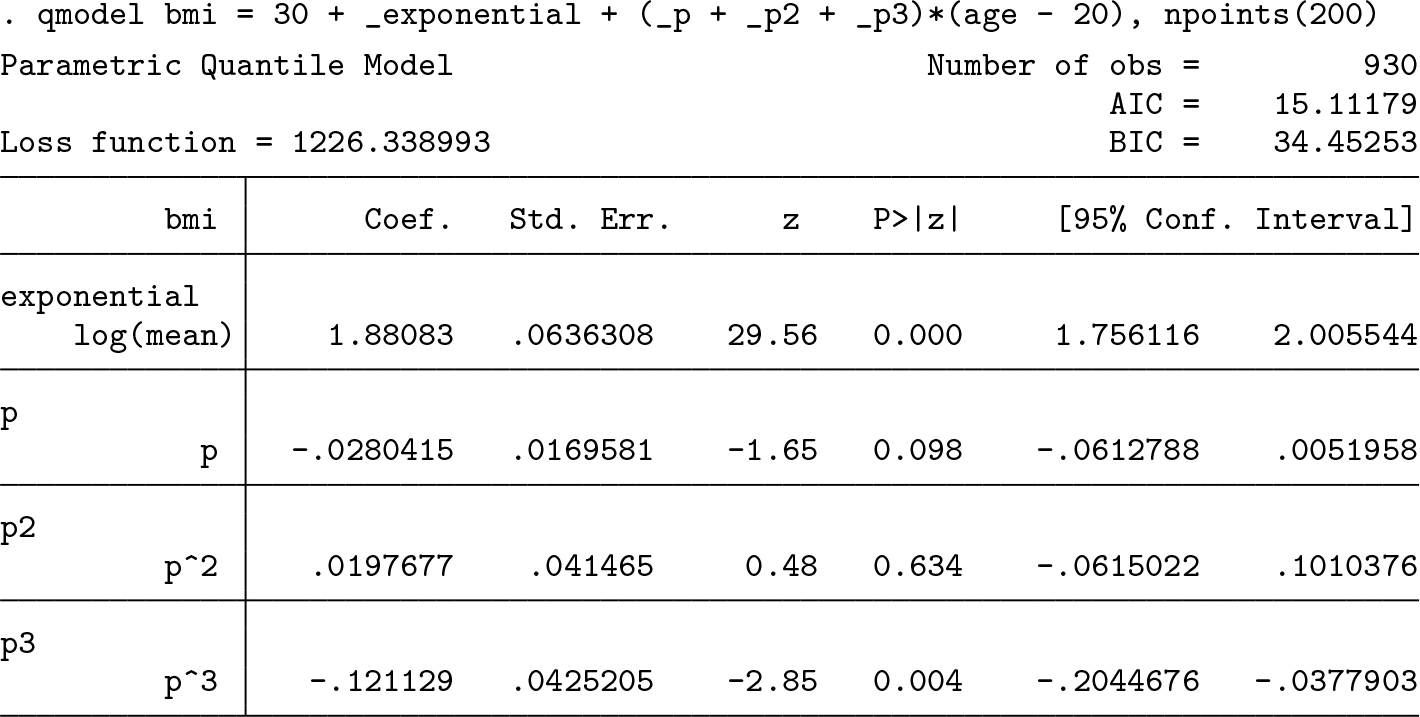
The table reports the estimates for all the model parameters along with their standard errors, z statistics, p-values, and 95% confidence intervals. The level of the confidence intervals can be changed with the
The
The built-in functions are internally expanded into standard substitutable expressions.

Typing the following command would give identical output to the above. For brevity, we suppress the output with the
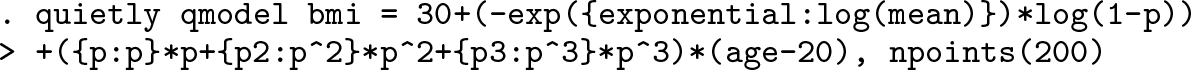
The model parameters are named within curly brackets. The letter
The exponential built-in function constrains its mean to be positive by estimating the logarithm of the mean, which can take on any real value. This is a popular method for constraining parameters that must be positive. It ensures positive estimates for the mean and often improves the performance of the estimation algorithm. □
The above
The quadratic term of the coefficient for age is not significant, and we omit it from the model.

After we remove the quadratic term from the model, the near collinearity among covariates vanishes, and specifying the
We now check the goodness of the fit of the exponential function by fitting the more flexible Weibull function, of which the exponential is a special case. We use the

The logarithm of the shape parameter of the Weibull quantile function is not significantly different from zero, which is equivalent to stating that the shape parameter is not significantly different from one. A Weibull distribution with shape equal to one is an exponential distribution. We therefore opt for the exponential quantile function. The values of Akaike’s information criterion and the Bayesian information criterion with the exponential function are smaller than those with the Weibull, further supporting our decision.
Akaike’s information criterion and the Bayesian information criterion are often used to compare parametric quantile models that are nonnested. Although they are widely accepted, they are not always reliable and should generally be regarded as guidelines (Burnham and Anderson 2004). □
We consider the model with the exponential intercept our final model. It can be written as
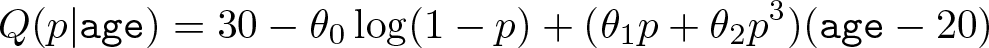
Its estimates for the functions β 0(p) = 30 − θ 0 log(1 − p) and β 1(p) = θ 1 p + θ 2 p 3 are displayed on the bottom row of figure 2.
The above final model sets the conditional distribution of BMI among 20-year-olds to be exponential, Q(p|20) = 30 − θ 0 log(1 − p), with mean equal to θ 0 and support over the half line (30, ∞). For increasing values of age, the conditional distribution smoothly morphs into a sequence of different distributions that are progressively farther away from the exponential. Their quantile function is the weighted sum of an exponential function and a cubic function, with weights varying with age. Except at age equal to 20 years, the corresponding conditional cumulative distribution function and conditional probability density function do not have a closed-form expression. Attempting to estimate the model parameters by maximizing the likelihood function would therefore be cumbersome. □
3.1 The qmodel plot command
This and the following two subsections describe the three postestimation commands of
The
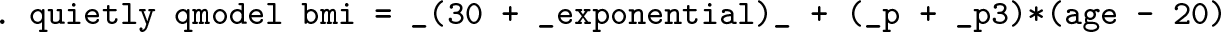
If the function to be plotted is specified by the special brackets in the

Panel C in figure 2 shows the resulting plot. The
The special brackets in the
We now use the

When multiple sets of special brackets are included, the

When multiple graphs are specified, these are given default names, and the
As noted in section 1, the overall trend of the parametric and nonparametric estimates are similar, the former are smoother, and their confidence intervals narrower than the latter. The confidence intervals vanish as the proportion p tends to 0 because of the inclusion criterion BMI ≥ 30 kg/m2.
3.2 The predict command
The

The estimates for the quantiles are stored in the newly created variables named
We list the estimates for the specified sets of parameters at the median, β 0(0.5) and β 1(0.5), with their respective standard errors.

Plotting the newly generated variables,
3.3 The qmodel quantile command
The

The above table shows the estimated quantile along with its standard error, z statistic, p-value, and 95% confidence intervals. The estimated median is 34.3 kg/m2 with a standard error of 0.170 and a 95% confidence interval equal to [34.0, 34.6].
Above, we did not specify any proportion, and the

In our study population, the 95th percentile is estimated to be 48.5 kg/m2 with a standard error of 0.753 and a confidence interval equal to [47.1, 50.0].
The above
Thanks to the parametric assumptions, we can obtain estimates for any percentile, however extreme. For example, we estimate the 0.9999 quantile as follows:

Our data contain only 930 individuals. This implies that the above estimate of 89.1 kg/m2 is an extrapolation, valid only if the parametric quantile model is true. Ordinary quantile regression would be unable to estimate such an extreme percentile. As with any other statistical method, one should generally be cautious when interpreting extrapolated inferences.
4 Example 2: Nonlinear dose–response relationships
Parametric quantile models extend beyond the ordinary linear quantile regression framework. Some examples of the range of possibilities are described in section 5. This section describes the estimation of a nonlinear parametric quantile model frequently used in pharmacological research.
We analyze the data from a fictitious laboratory experiment in which 200 animals were injected with 5 doses of an agent, and 400 more animals were injected with the same 5 doses but of a different agent. The liver concentration of the agent was measured one hour after injection. Figure 4 shows the data and true conditional median of the liver concentration for the two agents.
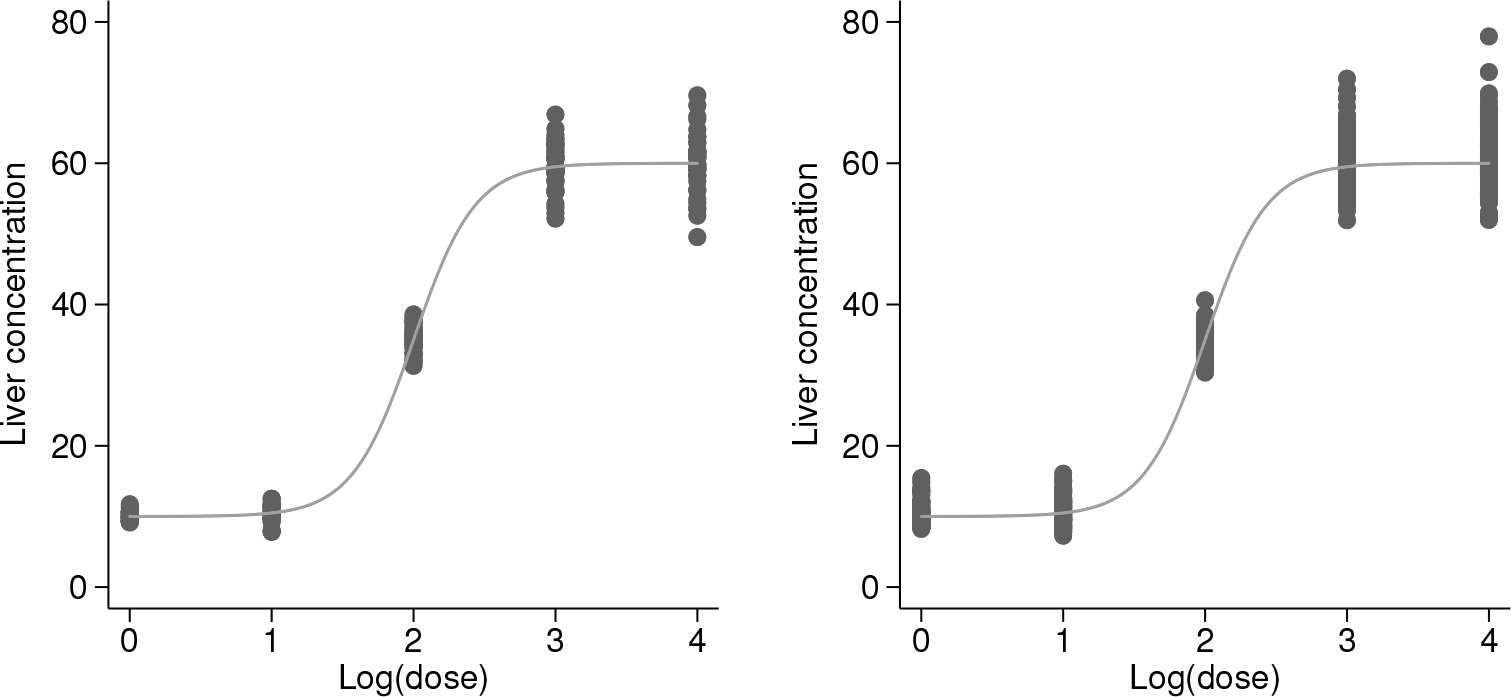
Observed liver concentration (dots) and true median concentration (line) at 5 injected doses of the first agent (left panel) and the second agent (right panel) with simulated data
In our data, the location, spread, and overall shape of the distribution of liver concentration change over dose and between agents. We consider a popular dose–response function, the Hill function,
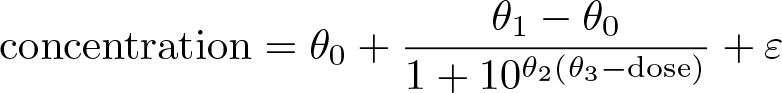
The parameters of the above model can be interpreted as follows: minimal response (θ 0), maximal response (θ 1), slope (θ 2), and dose corresponding to half the maximal response (θ 3). The error term, ε, is generally assumed to follow a normal distribution.
A possible specification of the Hill quantile function is

For the error term, we use the specification
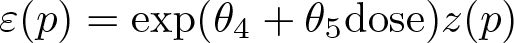
with the first injected agent and

with the second injected agent. The term z(p) denotes the standard normal quantile function.
The error term with the first agent follows a heteroskedastic normal distribution. With the second agent, the quantile function of the error term is the sum of a heteroskedastic normal quantile function and an exponential quantile function centered at the median. The two parameters θ 4 and θ 5 allow for the observed increasing variability of liver concentration and dose. The exponential function is applied to constrain the standard deviation of the error term to be positive. The parameter θ 6 models the changing shape of the error distribution between agents.
Because ε(0.5) = 0, the conditional median concentration given dose is

We generated the data shown in figure 4 with the following code:

We use the

The confidence intervals of all the parameters are approximately centered at the respective true values used in the above data-generating code, θ 0 = 10, θ 1 = 60, θ 2 = 2, θ 3 = 2, θ 4 = −0.3, and θ 5 = 0.4.
The expression of the quantile function in the above
To facilitate convergence of the estimation algorithm, we specified the initial values of the parameters with the
We now use the

The estimated 95th percentile is equal to 11.2 mg/ml with a standard error of 0.2 and a 95% confidence interval equal to [10.8, 11.6].
Presently, no command can estimate ordinary quantile regression with nonlinear models (Koenker and Park 1996). We therefore compare the above estimates with those from the

The above
Finally, we model the differences between the two injected agents with the
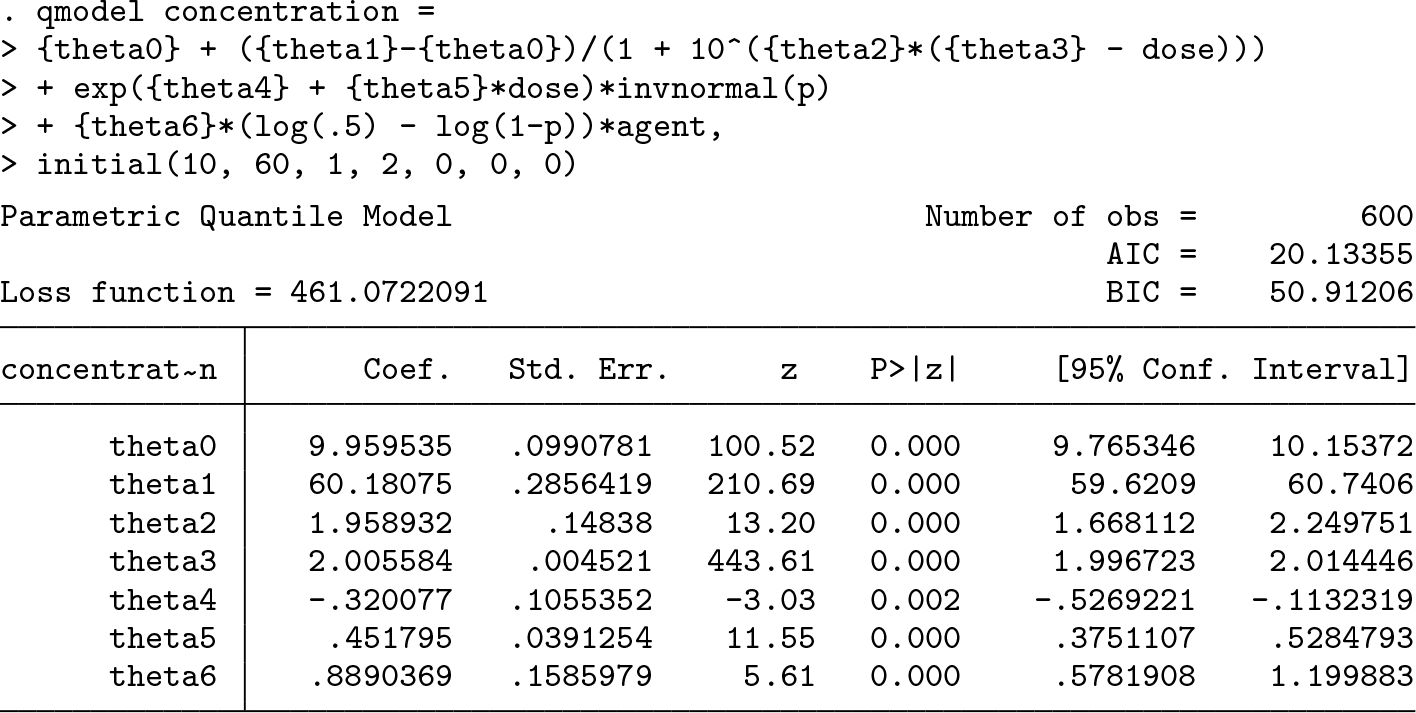
The confidence intervals of all the parameters are approximately centered at the respective true values used in the above data-generating code. The true value for the additional parameter is θ
6 = 1. With the second agent, the conditional median is different from the conditional mean, and the above estimates cannot be compared with those from the
All the
5 More details about parametric quantile models
This subsection contains further details about parametric quantile models and their potentials. Parametric quantile models were introduced by Frumento and Bottai (2016, 2017) and Bottai and Cilluffo (2017). See those articles for more information.
The conditional quantile function of an outcome variable of interest y given a k-dimensional vector of covariates x is defined as

The symbol p ∊ (0, 1) represents the order of the quantile. For example, p = 0.5 corresponds to the conditional median. The function Q(p|x) is nondecreasing with respect to its argument, the proportion p.
Parametric quantile models assume the quantile function to be known up to a parameter vector θ. For example, the quantile function of a variable uniformly distributed between zero and θ > 0 is

and that of an exponential variable with mean equal to θ > 0 is

Parametric quantile functions provide a flexible framework for modeling shapes of distributions because of their properties. First, they are invariant to monotone transformations of the outcome variable. For example, if Q(p) is the quantile function of a variable y, then

is the quantile function of g(y) for any monotone function g : ℛ ↦ ℛ. For example, the quantile function of a variable whose square root is exponential with mean equal to θ is
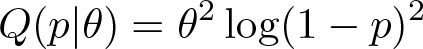
and that of a standard log-normal variable is
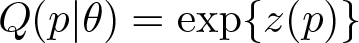
where z(p) indicates the standard normal quantile function.
Second, the modeling potential of parametric quantile models can be expanded by considering that sums, products, and functions of nondecreasing functions are themselves nondecreasing. For example, if two functions g 1(p) and g 2(p) are nondecreasing over the interval p ∊ (0, 1), then
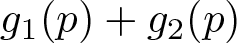
is nondecreasing. If g 1 is nondecreasing on the entire real line, then

is nondecreasing. If two functions g 1(p) and g 2(p) are nondecreasing and positive over p ∊ (0, 1), then
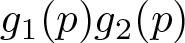
is nondecreasing.
The possible dependence of the quantile function on the covariates can be evaluated by including the covariates in the model. For example,

defines a uniform distribution with support between zero and a value that depends on the values of the two covariates x 1 and x 2;

defines a unimodal, asymmetric, and zero-median logistic distribution whose variance and skewness depend on the covariate values; and
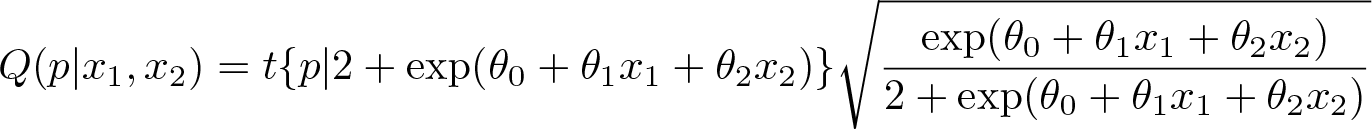
with t(p|ν) representing the quantile function of the Student’s t-distribution with ν degrees of freedom, defines a distribution whose kurtosis changes along with values of covariates, while the mean, variance, and skewness remain unchanged.
Ordinary quantile regression assumes

The above conditional quantile function is the weighted sum of three functions of p, β 0(p), β 1(p), and β 2(p), with weights defined by the covariate values, x 1 and x 2.
All the above models can be fit with the
5.1 Transformations of the outcome variable
This subsection illustrates the potentials of transforming the outcome variable. The

The first syntax models log(y) with a normal distribution, the second models y with a log-normal distribution using the
As a second example, we generate 1,000 random observations from a logit-normal distribution and estimate its parameters with three alternative and equivalent syntax specifications.

The logit normal is a flexible distribution for outcome variables that are bounded within a known interval, such as visual analogue scales and percentages. It constitutes an alternative to the beta distribution, which is implemented in the
5.2 Sums of functions for modeling skewness and kurtosis
This subsection briefly introduces the use of sums of quantile functions as a flexible modeling tool. In particular, we discuss sums of functions for modeling skewness and kurtosis. As an example of a model for skewness, we consider a quantile function defined as the sum of a standard normal quantile function and a standard exponential quantile function. The left-hand-side panel shows the right-skewed histogram of the 1,000 generated observations. The quantile function is depicted by the thick line in the right-hand-side panel of figure 5. Its two components are shown as the solid thin line (standard normal) and the dashed thin line (standard exponential).

Left-hand-side panel: histogram of 1,000 observations generated from a quantile function defined as the sum of a standard normal and standard exponential distribution; right-hand-side panel: the estimated quantile function (thick line) and its constituent parts, standard normal (solid thin line) and standard exponential (dashed thin line).
We generate 1,000 random observations and estimate the parameters with
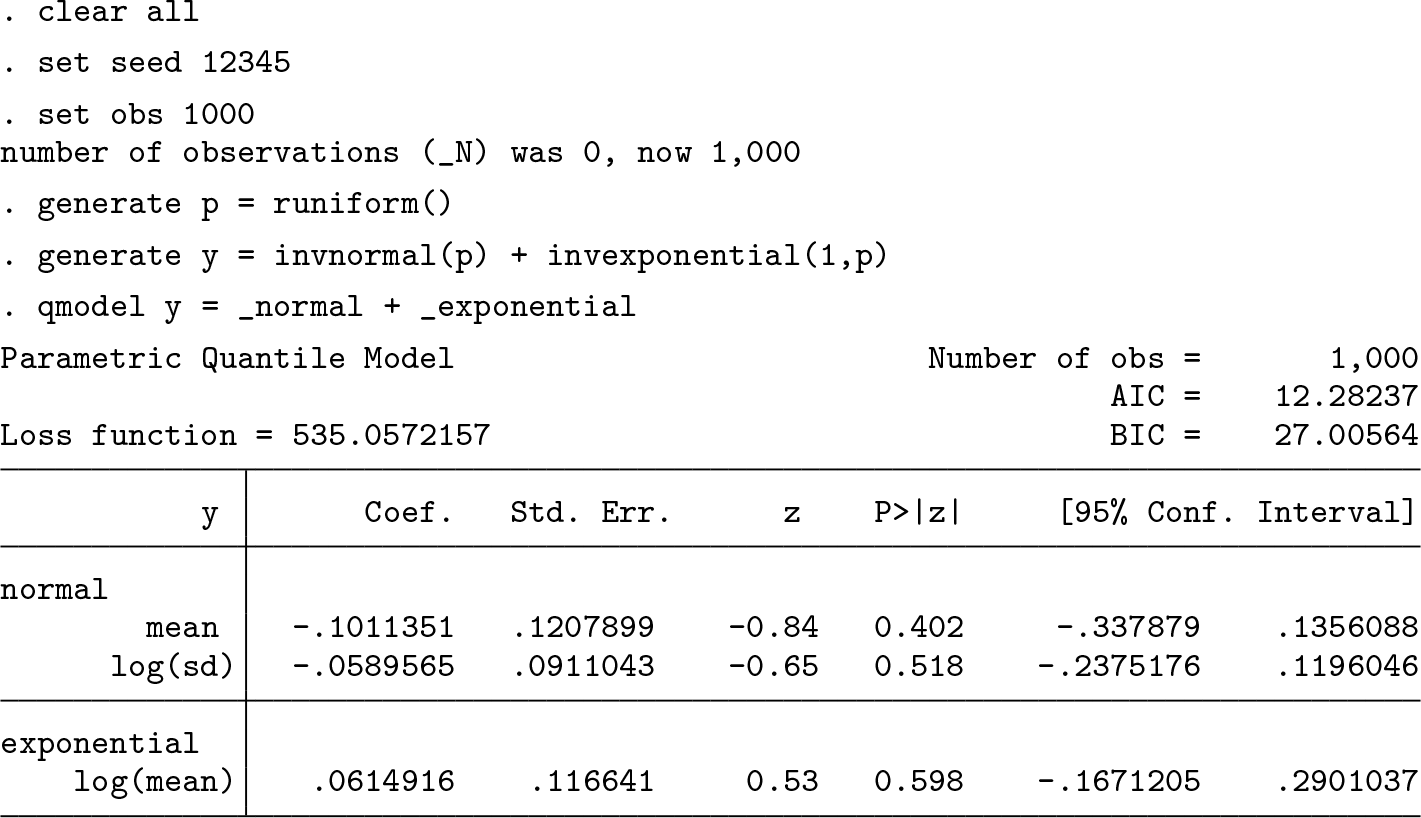
The estimated parameters are not significantly different from zero, which is their true value.
As an example of a model for kurtosis, we consider a quantile function defined as the sum of the standard normal quantile function and another standard normal raised to the third power. The left-hand-side panel shows the thick-tailed histogram of the 1,000 generated observations. The resulting quantile function is depicted as the thick line in the right-hand-side panel of figure 6. Its two components are shown as the solid thin line (standard normal) and the dashed thin line (standard normal cubed).

Left-hand-side panel: histogram of 1,000 observations generated from a quantile function defined as the sum of the standard normal quantile function and another standard normal raised to the third power; right-hand-side panel: the estimated quantile function (thick line) and its constituent parts, standard normal (solid thin line) and the standard normal cubed (dashed thin line).
We generate 1,000 random observations and estimate the parameters with

All the confidence intervals contain their respective true values. With the same thick-tailed yet symmetric data as above, we fit a model with the three built-in functions

The
5.3 Modeling conditional parametric quantile functions
This section illustrates the use of

where z(p) represents the standard normal quantile function, x 1 is a binary covariate with 0.5 probability, and x 2 is a standard normal covariate. The above conditional distribution is normal with unit standard deviation and mean that depends on a linear combination of the two covariates.

We estimate the parameters with the two built-in functions
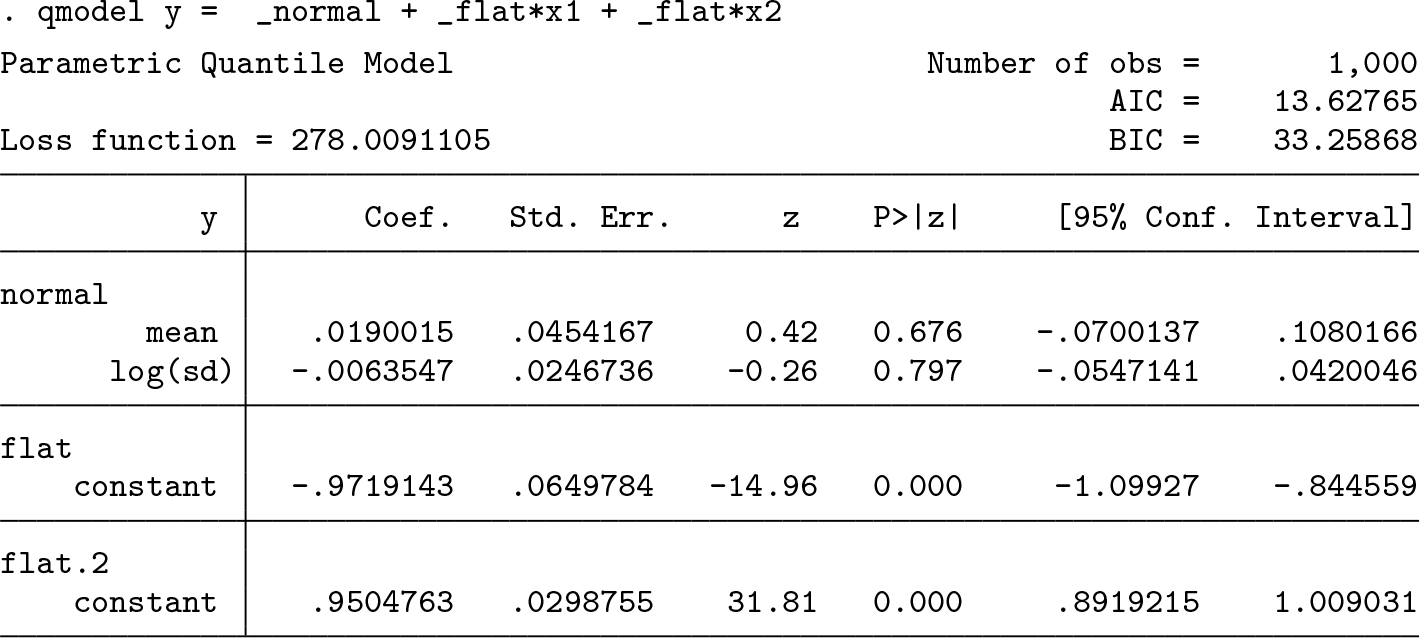
All the estimates are close to the true values with which the data were generated. The estimates are similar to those from linear regression.

The data were generated with a homoskedastic error with standard deviation equal to 1. Hence, the true value of the logarithm of the standard deviation of the normal function in the quantile model is zero. The estimate from

To help explain parametric quantile models and the

The estimated mean of the normal for the coefficient of x 2, 0.95, is close to the estimate for the flat function in the previous model, and its estimated standard deviation, exp(−14.5226) = 0.0000004931, is nearly 0. Therefore, the resulting function for the coefficient of x 2 is essentially flat, which is the true shape under which the data were generated. The estimates of all the other parameters are nearly unchanged from the previous model, where the coefficient of x 2 was correctly specified as a flat function.
5.4 Ordinary quantile regression as a special case of quantile models
Ordinary quantile regression can be seen as a special case of the more general parametric quantile models. For example, we estimate the conditional median of a variable y given a covariate x.

The above estimates are similar to those that can be obtained with the

When the interest is only in the median and not in the entire quantile function, a computationally faster alternative is to specify only one quadrature point at 0.5 with the

Any quantile can be estimated by specifying the corresponding proportion in the

6 Final remarks
Parametric quantile models define the entire conditional distribution of the outcome variable of interest. If of interest, they can be used to generate simulated data, plot quantile functions and cumulative distribution functions by simply swapping the axes, plot probability density functions by differentiating the cumulative distribution function with the
Supplemental Material
Supplemental Material, st0555 - qmodel: A command for fitting parametric quantile models
Supplemental Material, st0555 for qmodel: A command for fitting parametric quantile models by Matteo Bottai and Nicola Orsini in The Stata Journal
Footnotes
7 Acknowledgment
We are grateful to an anonymous referee for helpful comments on earlier versions of the article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.