
Abstract
Indicator or dummy variables record whether some condition is true or false in each observation by a value of 1 or 0. Values may also be missing if truth or falsity is not known, and that fact should be flagged. Such indicators may be created on the fly by using factor-variable notation.
Keywords
1 Introduction
We define indicator or dummy variables at the outset as numeric variables taking on a value of 1 when some condition is true and a value of 0 when that condition is false. We leave open the possibility of the definition being a little more complicated, which we discuss later. We also leave open the possibility of true and false states being coded in some other way, which we also discuss later, although we will fall far short of a complete discussion of the possibilities.
After a fairly broad introduction to the subject, we will explain good ways to produce such variables. We further highlight some unnecessarily incomplete or indirect methods that we often encounter.
For more on the idea that 1 and 0 may encode true and false conditions, including some historical notes and references, see Cox (2016b).
2 What’s in a name?
Some discussion of terminology is needed before we get to the main business. There is a simple, wider use of indicator variables for anything quantitative that indicates, say, health, well-being, or general system state or operation. Systolic blood pressure, stock price, or soil moisture content can be key indicators for people in particular fields. In practice, that does not conflict with the specialized use here.
The specialized sense of a variable with values of 0 and 1 seems to grow out of the mathematical idea of an indicator function. See, for example, Zeitz (2007) for a friendly explanation of that and much else. In some parts of mathematics, the term “characteristic function” has the same meaning, but for statistical people, that term is already used for a quite different function arising in the analysis of probability distributions. Both indicator function and indicator variable are key ideas in probability theory, which is perhaps the main way in which they entered statistical science generally. Feller (1971, 104) attributed the term to Michel Loève. Other references include Moran (1968, 7), Whittle (2000, 7), and Blitzstein and Hwang (2015, 100).
The term “dummy variable” for a variable encoded with values of 0 and 1 seems to have arisen around 1950 in statistical science. Freedman (2009, 113) cites Oakland (1950) and Klein (1951). We can add a reference to Quenouille (1950). Whatever the roots, “dummy variable” seems especially popular at present as a term in economics and other social sciences. As you may recall from your mathematical education, there is a different and older sense of the term (for example, in calculus) as an arbitrary variable playing a filler role in some formalism.
Training and taste affect what terms people use. We try to avoid the term “dummy variable” because it is at least a little awkward. We have heard too many stories of the term being horribly misunderstood as pejorative or disparaging. That has sometimes happened when quantitatively minded researchers try to explain what they are doing to people with different backgrounds. Misunderstanding can run in any direction, which is why terms that can possibly offend should be avoided.
We should mention other terms used for variables indicating which of two possible states occurs in each observation, such as binary, dichotomous, 1 Boolean, or quantal. “Binary” is an excellent term likely to be familiar already. The other words have interesting histories but also a need to explain to beginners how to spell them and what they mean.
3 Why use indicator variables?
We can identify three main reasons why indicators might be useful:
Coding a response or outcome or dependent variable. Many responses of interest are binary, such as survived or not, present or absent, or success or failure. Many standard models, such as logit and probit regression and various more exotic relatives, are dedicated to analysis for such response variables.
Coding a predictor or descriptive variable. Many variables that are descriptive or possibly predictive can be coded 0 or 1, and this can be useful too. You may already be familiar with simple or even complicated uses of binary or indicator predictors. If this is new to you, here is a first example. Given x
1 that is counted or measured and x
2 that is 0 or 1, a regression of y on those predictors,
In general, this is the territory of categorical variables. Even multistate categorical variables can be coded using indicators. For example, collectively being an orange, apple, or banana, or some other fruit can be coded using two or more indicator variables for orange or not, apple or not, and so forth. One of those variables will be redundant. In this example, if the only possibilities are orange, apple, or banana, then not being an orange or apple is enough information to identify a banana.
Other uses, especially for data management. This reason is a catch-all for all the other possibilities. We often find that an indicator is a useful stepping stone for data management. It might flag which observations have missing values, deserve keeping, deserve dropping, and so on. A small but often overlooked trick to get proportions is to take the mean of an indicator that is 0 or 1, often with [D]
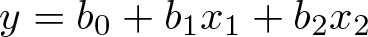
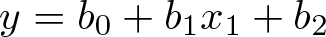
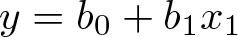
4 How to produce indicator variables: Automation
This section includes the most important advice in this column.
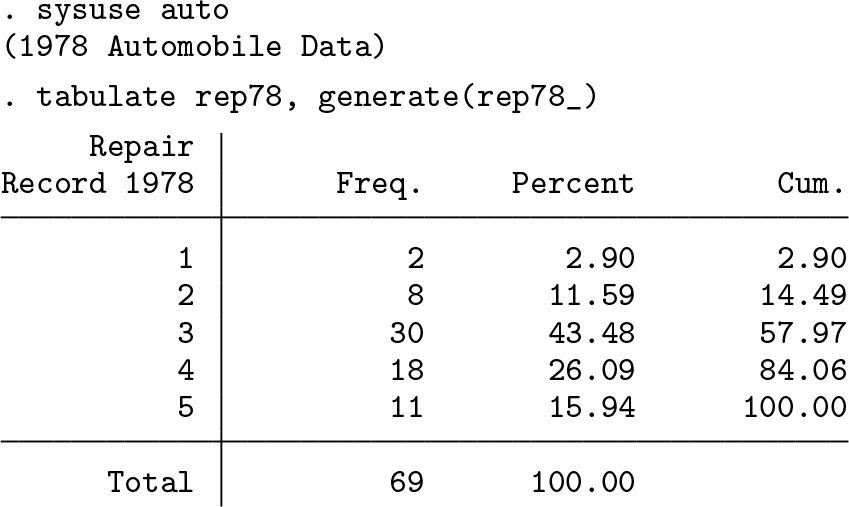
We created the new variables
Once you know how to do it, factor-variable notation can easily be used to specify that numerically coded categorical predictor variables should be treated as one or more indicators. There are many advantages to that and no real disadvantage beyond needing to learn the syntax. For an introduction, see [U]
The rest of this column applies to situations where you have the need or inclination to generate indicators directly.
5 How to produce indicator variables: Do it yourself
Let us continue to work with Stata’s
We quite often see something like this on Statalist:
This creates a variable that is 1 if
That has the merit of spelling out—to those reading a log file as a transcript of a Stata session, which could include the researcher who produced the log at a later date—that values that are not 1 are all missing. Otherwise, the statement is redundant because it changes nothing.
Such a variable with values of 1 and missing is of limited use in Stata. It cannot be used in statistical modeling because the observations with missing values will be omitted, and the observations with a value of 1 will define a constant variable, which itself will be omitted from any model as a predictor. At the end of this column, we will mention an exception to our assertion.
This is better:
Now we will have a variable that is 1 or 0, assuming naturally that there are some observations satisfying each of the two states, as indeed there are in
There is a better way still. Did you know that you can do this?
Given an expression that can be true or false when evaluated, Stata will return 1 when the expression is true and 0 when it is false. So, with such a
Incidentally, many programming languages (we include Stata in that group) are way ahead of general mathematical practice in allowing such expressions. It is possible to specify indicator functions in mathematical writing, but no one seems to have thought up a notation that everyone else likes. For x > 30, we have seen I(x > 30), i(x > 30), 1(x > 30), and others yet, to say nothing of different choices of fonts or pushing those expressions into subscripts. Iverson (1962), de Finetti (1967, 1972, 1974, 1975), and Knuth (see, particularly, his 1992 paper) encouraged x > 30 as acceptable notation, although sometimes with surrounding parentheses or square brackets.
Also incidentally, but a crucial question for researchers: examples like this where we split a measured variable into two intervals raise the key question of whether that splitting is a good idea. Cox (2018) airs this question and points to detailed critical discussions elsewhere.
6 What about missing values?
We have not told the whole truth yet. Most importantly, the
Now there are three possible values: 1 or 0 as before, and missing if
We may exclude missing values with the condition To save a keystroke over To exclude extended missing values
That said, many people may find
more transparent. Your collaborators or reviewers may know little or no Stata but still want to look at your code. If so, you should want to avoid tricks specific to Stata. Indeed, people you work with may be more familiar with some alternative software with the opposite convention: missing values are treated as arbitrarily large negative numbers. Naturally, it remains true that
7 In a subset?
We can say that indicator variables take on a value of 1 if observations lie in a subset of possibilities and 0 if they lie in the complementary subset. We now mention some other problems in which this idea arises, with references to discussions elsewhere.
In this section, the possibility of missing values is set aside. If you want a small challenge, think through what happens in these commands if missing values are present and so what might need to be changed.
7.1 Compound conditions
Sometimes true-or-false conditions involve compound conditions using two or more relational and logical operators. See
The flavor is given by
because being a foreign car with high mileage requires both a condition of being foreign and a condition of high mileage. Here, the parentheses are dispensable but may help to underline the logic.
7.2 Any and all problems
Do you know these twin tricks?
Finding whether any values satisfy a condition corresponds to looking for a maximum over indicator values. Finding whether all values satisfy a condition corresponds to a looking for a minimum.
Let’s imagine data on people (observations) within households (groups of observations). Suppose we are trying to classify households into those with and without children. To be concrete, we take children to mean
is an answer in one line. The expression
We could flip the problem around and look for households in which every person is an adult (18 or over in
If all values are 1, then so is the minimum; otherwise, 0 is returned. Or to translate all to any: if any value is 0, so is the minimum.
Various types of problems can arise when the comparison is not between the values of a single variable in a group of observations, but between the values of two or more variables. Solutions for this version of the problem are both easy and plentiful. The functions
and
are equivalents so long as the possible values are just 0 and 1. Similarly,
and
are equivalents with the same reservation.
However, if the condition involved, say, 42 variables of a similar kind (for example,
For more on any and all problems, see Cox (2016a). For more on working rowwise, see Cox (2009).
7.3 inlist() and inrange()
Two further functions that can be extremely useful in producing indicators are
is another way to write
In between those statements, and also equivalent, would be
Different ways of doing the calculation in Stata match different ways that we could write down the corresponding algebra. That is, 1 = x 1 or 1 = x 2 is another (if unconventional) way to write x 1 = 1 or x 2 = 1. Despite the apparent symmetry implied by the equals sign, there is a strong sense in which a = 1 (think a is 1) does not have the same connotation as 1 = a (think 1 is a). See de Bruijn (1958) for instructive and entertaining discussion of the ways in which notation connoting equality is handled, or mishandled, in mathematics.
7.4 Intersection alongside union
Sometimes a subset is specified by inclusion in quite a long list of possible values. You might have a dataset of many countries (perhaps 200 or so, depending on your definition, purposes, and data availability) and wish to indicate which belong to the Organisation for Economic Co-operation and Development (OECD). At the time of writing (27 November 2018), there are 36 countries in OECD. So you might just grimace and write out lengthy code mentioning them all.
There is an alternative that is increasingly attractive as the list of possibilities grows longer, so long as somehow you can put that list into a data file. You can use the
Even the OECD countries as a subset of countries is too lengthy an example to be comfortable. No matter; the principle can be shown by a tiny sandbox. Let’s imagine a panel dataset with string identifiers and (being realistic about a common complication) a time variable too. Our

Now we need a dataset with just the wanted values, say, like this:

The key trick is then just a one-to-many

The

There is naturally no rule that you must type the identifiers into a file or into Stata yourself. The ideal will be that they are already in a separate data file of some kind.
For the main idea and another example, see Baum (2011).
8 Storage types
We have not specified variable or storage type. Many careful Stata users insist to Stata that indicator variables can and should be stored in byte variables:
We will confess to being a little careless about this point on occasion. A defense for such caprice is that we can always type
if memory looks short or we need to make a dataset as small as possible. Then Stata will let us catch up on being careless about storage by using more efficient storage types whenever possible.
9 Fond of cond()?
Next comes a matter of taste. One of us (more than the other) is quite fond of
Even when familiar with the construct, we find it helpful to spell it out mentally (even aloud when alone!) as informal pseudocode.
if else return
One reason for using
That can be translated to
if else if else return 0
Only you will know if this syntax appeals to you. The tutorial in Kantor and Cox (2005) has more tips on how to use the function. 2
10 Choose informative variable names
One point has remained implicit so far, but now should be brought forward. A variable name like
Making variable names explanatory is standard and good advice and perhaps too obvious to deserve mention, except that daily we see variable names in researchers’ datasets that carry no evident meaning. In the case of indicators, we can add further emphasis: choose a name that describes the state coded as 1.
11 Alternatives to 0 and 1 as codes for binary states
Some Stata users seem to find it more convenient or congenial to code binary states as 1 and 2. That can be fine except that you will need to use factor-variable notation to use such variables as predictors and will need to subtract 1 before you can use such variables as responses or outcomes. Similar remarks apply to any other choice.
As a small programming trick, we sometimes negate indicator variables so that true becomes −1 and false remains 0. The point of doing so is that if we next
We finally redeem an earlier promise. Indicators that are 1 or missing can sometimes be useful in data management. One example is looking for the first nonmissing value of some variable in a panel, a problem discussed at greater length by Cox (2016b). Here we acknowledge gratefully an example with similar flavor by Romalpa Akzo on 7 November 2018 on Statalist; see https://www.statalist.org/forums/forum/generalstata-discussion/general/1469251-select-first-event-or-last-non-event.
We could type
so that the indicator variable
How could we extend that idea to get at the last nonmissing value in each panel?
Now the observations with missing values rise to the start of each panel. After breaking ties on the time variable, the observation we want to use is at the end of that panel.
If all values of a variable are missing in a panel, then each new variable,
12 Conclusions
Far from being trivial as might be supposed on first acquaintance, indicator variables are fundamental and extremely useful. Without pretense at being encyclopedic, we have here tried to bring together the main possibilities—and some of the pitfalls—for the Stata user wanting to create and use indicator variables. We have also tried to discourage the dismal and disparaging term “dummy variables”.