
Abstract
In this article, we introduce two commands,
Keywords
1 Introduction
Power calculations are used when designing experiments and field work in various disciplines in social, behavioral, and medical sciences. Recently, many empirical researchers have designed and implemented surveys using regression-discontinuity (RD) designs. See Imbens and Lemieux (2008); Lee and Lemieux (2010); Calonico, Cattaneo, and Titiunik (2015a); Cattaneo and Escanciano (2017); Cattaneo, Titiunik, and Vazquez-Bare (2017); Cattaneo, Idrobo, and Titiunik (Forthcoming a,b); and references therein for introductions to RD designs. In this article, we introduce two commands (and companion R functions) specifically developed to conduct power calculations and survey sample selection when using RD local polynomial estimation and inference methods.
There are two main approaches to interpret and analyze RD designs in modern applied work. The first approach is based on continuity or smoothness assumptions and typically uses local polynomial methods (for example, Calonico, Cattaneo, and Titiunik [2014b]; Calonico, Cattaneo, and Farrell [2018a,b,c]; Calonico et al. [Forthcoming]; and references therein). The second approach is based on a local (to the RD cutoff) independence assumption and hence uses ideas and methods from the classical literature on the analysis of experiments (Cattaneo, Frandsen, and Titiunik [2015]; Cattaneo, Titiunik, and Vazquez-Bare [2017]; Sekhon and Titiunik [2017]; and references therein). Both methods can be used for estimation, inference, and falsification in empirical work using RD designs.
In this article, we focus on local polynomial methods and introduce the commands
The underlying main calculations (bandwidth selection, bias estimation, and variance estimation) in both commands rely on the package
Our two commands complement the recently introduced Stata and R commands for RD designs. See Calonico, Cattaneo, and Titiunik (2014a, 2015b) and Calonico et al. (2017) for an introduction to the commands
The rest of the article is organized as follows: Section 2 briefly reviews the main conceptual and methodological issues underlying power calculations for RD designs when using local polynomial inference techniques. Sections 3 and 4 provide details on the syntax of the commands
The latest version of this software and related software for RD designs can be found at https://sites.google.com/site/rdpackages/.
2 Overview of methods
We briefly describe the main formulas and methods used in the commands
Analyzing the statistical power of widely used RD inference procedures is important for at least two distinct reasons. We briefly mention both now, but we will further discuss them below in our methodology summary (this section) and in our numerical illustration (section 5).
Ex-post (or observational) RD analysis. The researcher already has the final data for analysis, and the goal is to assess the statistical power underlying the testing procedures implemented in
Ex-ante (or experimental) RD design. The researcher is designing a new survey for an RD design, and the final data are not available yet. In some circumstances, for instance, the RD design might be a preferable alternative to a classical random assignment design, especially when such design is unfeasible for some reason (ethical or otherwise). For example, the RD design allows for a normal program operation—as opposed to purely randomized designs—because treatment assignments for the study population are determined by rules developed by program staff or policymakers rather than randomly assigned. In this sense, the treatment can be targeted to those who normally receive them (for evaluations of existing interventions) or to those who are likely to benefit most from them (for evaluations of new interventions). In this case,
The methods developed and implemented in this article are useful for both ex-post analysis and ex-ante design. In the remainder of this section, we first review classical design of experiments in the context of randomized control trials and then present the corresponding methodology for RD designs.
2.1 Review: Experimental designs
We first review standard approaches for power calculations and sample selection in simple experiments or randomized control trials. Suppose {(Yi, Ti ) : 1 ≤ i ≤ n} is a random sample from a large population, with Ti denoting treatment status and Yi = (1−Ti )Yi (0)+TiYi (1), with Yi (0) and Yi (1) denoting the underlying potential outcomes without and with treatment, respectively. Here, by assumption, Ti is statistically independent of [Yi (0), Yi (1)].
We assume the population parameter of interest is the average treatment effect

where N 0 and N 1 are the sample sizes of the control and treatment groups, respectively. If we employ a central limit theorem under appropriate regularity conditions, and if τ is the true ATE (for example, τ = τ ATE under the true model), then

where
respectively. Consider the two-sided hypothesis testing problem:

Then, the associated (asymptotic) two-sided α-level power function based on the t test statistic and large-sample distribution theory given above is
where Φ(
Given the parameter of interest (τ ATE) and test statistic [t ATE(τ)], one can use the large-sample Gaussian approximation to determine i) the total sample size n = N 0 + N 1 needed to achieve a predetermined level of power against a given alternative hypothesis and ii) the optimal assignment of relative sample sizes N 0 and N 1. We briefly discuss these choices next because the same logic will be used further below for RD designs. For simplicity and without loss of generality, we set τ ATE = 0.
First, we determine the optimal relative sample size between control and treatment groups by minimizing the asymptotic variance of the estimator, given an overall choice of sample size n = N
0 + N
1. To be specific, set ϱ = N
1
/n, and observe that minimizing

For example, if σ
0 = σ
1, then ϱ = 1/2; thus, equal sample sizes for control and treatment units are chosen. More generally, this approach leads to a relatively larger sample size for the group with a relatively larger variability in the outcome variable. This optimal choice of sample-size assignment between control and treatment groups is easily estimable in practice:
Second, given the choice of ϱ, we determine the total sample size

using the (asymptotic) power function. Specifically, given a choice of alternative τ A 6= 0 (usually determined as a fraction of σ 0) and the desired power β ∈ [0, 1] (usually set at β = 80%), the overall sample size n is chosen as the unique integer value n solving the equation β = β ATE(τ A); that is,

where the only unknown is n after ϱ,
The approach above is used in empirical work to determine the total sample size, n, and the relative proportion of sample sizes of control and treatment units, ϱ. In the following sections, we build on these ideas and apply them to the context of RD designs using local polynomial methods.
2.2 Regression discontinuity designs
For the remainder of this article, we study power calculation and sample selection in RD designs. We assume that {(Yi, Ti, Xi
) : 1 ≤ i ≤ n} is a random sample from a large population, where for each unit i in the sample, Yi
= (1 − Ti
)Yi
(0) + TiYi
(1) is the outcome variable, with Yi
(0) and Yi
(1) denoting the underlying potential outcomes without and with treatment; Ti
=
Our presentation is sufficiently high level enough that we avoid unnecessary repetition and overwhelming notation required to discuss each RD setting in detail, so we refer the reader to Calonico et al. (2017) and the references therein for specific details. To be more concrete, we denote a generic RD parameter of interest by τ
To describe how to do power calculations and sample selection in RD designs, and continuing with our high level of generality, we let τb

with
B− and B+ denote the left and right (to the RD cutoff) misspecification biases, and V− and V+ denote the left and right (to the RD cutoff) asymptotic variance of the RD estimator. Depending on the estimand and estimator under consideration, the exact form of these quantities is different. Nevertheless, the generic result above applies to all main RD cases at this level of generality, including cases where the estimand of interest is the fuzzy, kink, or fuzzy–kink RD parameter; cases where preintervention covariate adjustment is considered; and cases where clustered sampling is present. For more details, see Calonico, Cattaneo, and Titiunik (2014b) as well as Calonico et al. (Forthcoming) and references therein.
We use the generic large-sample Gaussian distributional approximation in (1) to construct asymptotic power functions and to select sample sizes for survey design based on them. Without loss of generality, we assume τ
Power calculations with misspecification bias
In this section, we consider an approach to power calculation and sample selection in RD designs that explicitly ignores misspecification bias. This approach is not the default in the
Misspecification bias arises when the local polynomial approximation used to estimate the RD treatment effect is not good enough near the cutoff because it occurs when a mean squared error (MSE) optimal or other “large” bandwidth is used. As in the case of experimental designs discussed previously, the distributional result for RD designs (1) gives a generic asymptotic power function for the corresponding (nominal) α-level two-sided hypothesis test about τ

In practice, the unknown biases, variances, and bandwidths are estimated using nonparametric methods and accounting for the specific sampling assumptions and the specific choice of estimand and estimator. These estimates are all already available in the package
Therefore, in practice all the unknown quantities can be estimated, and hence, the power function can be computed. However, an interesting implication of the presence of misspecification biases implies that the estimated power function will generally exhibit size distortions (under the null hypothesis τ = τ

where

Hence, conventional inference with misspecification bias will show higher power but at the expense of size distortion, which depends on the magnitude of the bias relative to the standard error. We discuss this point further in the empirical illustration given below.
Power calculations with robust bias correction
Calonico, Cattaneo, and Titiunik (2014b) and Calonico et al. (Forthcoming) develop robust bias-correction inference methods for RD designs, which allow for MSE optimal bandwidth selection and provide higher-order refinements. See also Calonico, Cattaneo, and Farrell (2018a,b,c) for related results. The idea is to first use an estimator of the bias to correct the point estimator and then adjust the variance estimator to account for the additional variability introduced by the bias estimate.
In the robust bias-correction approach, under regularity conditions, bandwidth sequence restrictions, and the assumption that τ is the population RD treatment effect, the following distributional approximation holds:

Therefore, in the robust bias-corrected framework, the generic (estimated) asymptotic power function for the α-level two-sided hypothesis test about τ takes the form

This power function is the default in
rdpow: User-chosen bandwidths and sample sizes
The command
However, in practice, researchers may want to set different biases, variances, bandwidths, and effective sample sizes.
To account for the above possibilities,

M
− and M
+ denote the new (postulated by the user) sample sizes in the neighborhoods [c−h
−
, c) and [c, c+h
+], respectively, for control and treatment. h
− and h
+ denote the new bandwidths chosen below and above the cutoff, respectively. If M
− and M
+ are not specified by the user, then
Finally, for power calculations with misspecification bias, the adjusted power function takes the form

where m is constructed exactly like robust bias-corrected inference.
rdsampsi: Sample-size selection
The command
We first discuss selecting the relative sample sizes of control and treatment groups within a given neighborhood around the cutoff c. Recall that
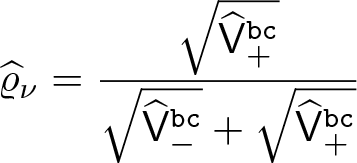
Suppose that M is the effective sample; that is, M is the number of selected observations in the neighborhood [c − h − , c + h +], then we recommend sampling (rounding to the closest integer) the following number of observations on either side of the cutoff:
Finally, we discuss how to select the total number of effective observations M = M
0 + M
1. As with experimental designs, the total number of observations can be determined by preselecting a desired level of power β for a given alternative hypothesis τ
A, using the power functions presented above and the already determined factor of proportionality

where

How to survey or sample in RD designs
For internal validity in RD designs, it is always best to first sample observations that are the closest to the cutoff c in terms of their running variable Xi because of the same assumptions underlying identification, estimation, and inference methods based on continuity or smoothness of the unknown conditional expectations. In this framework, the parameter of interest is defined at the cutoff c, so having observations as close as possible to Xi = c is most useful.
Therefore, once M
0 and M
1 are determined, the actual sampling or field work is straightforward:
Order control (Xi < c) and treatment (Xi
≥ c) observations in terms of their distance to the cutoff (|Xi
− c|). Begin sampling with the closest observation to the cutoff in each group, and continue sampling in order according to their distance to the cutoff, within each group, until the desired M
0 and M
1 sample sizes are reached.
Clustered sampling
All the results above apply directly to independent and identically distributed sampling and can be extended to clustered sampling. Estimation of unknown biases and variances, both with misspecification and with robust bias correction, is readily available via
3 The rdpow command
In this section, we describe the syntax of the command
3.1 Syntax
where depvar is the dependent variable and runvar is the running variable (also known as the score or forcing variable).
3.2 Options
The following options are passed to
4 The rdsampsi command
This section describes the syntax of the command
4.1 Syntax
where depvar is the dependent variable and runvar is the running variable (also known as the score or forcing variable).
4.2 Options
The following options are passed to
5 Illustration of methods
We illustrate our commands using the dataset from Cattaneo, Frandsen, and Titiunik (2015), which has also been used to illustrate related RD methods (Calonico, Cattaneo, and Titiunik 2014a, 2015b; Cattaneo, Titiunik, and Vazquez-Bare 2017; Cattaneo, Jansson, and Ma 2018b).
The dataset
We start by loading the dataset and providing some descriptive statistics:

The running variable ranges from −100 to 100 with an average of 7 percentage points. The outcome of interest is
5.1 Power calculations using rdpow
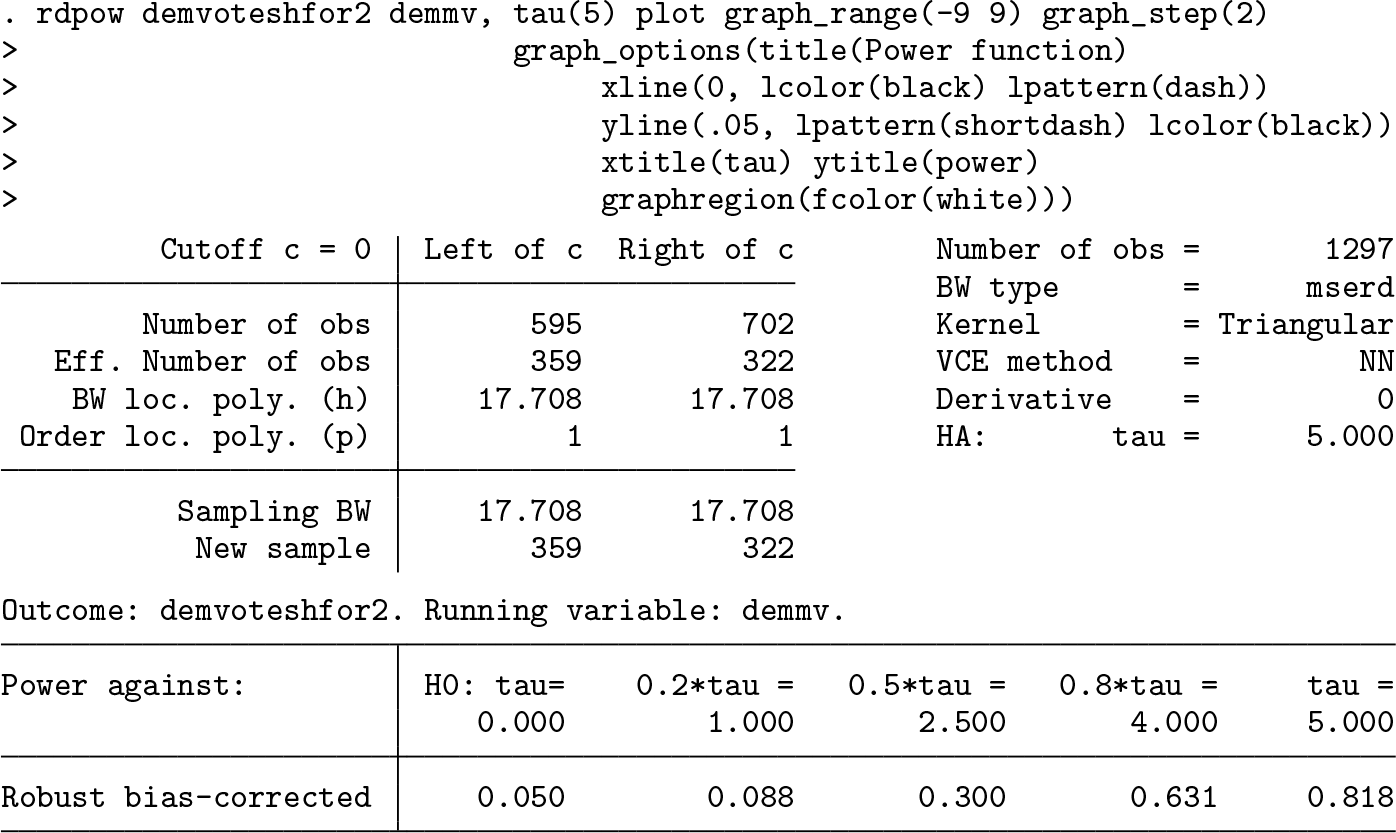
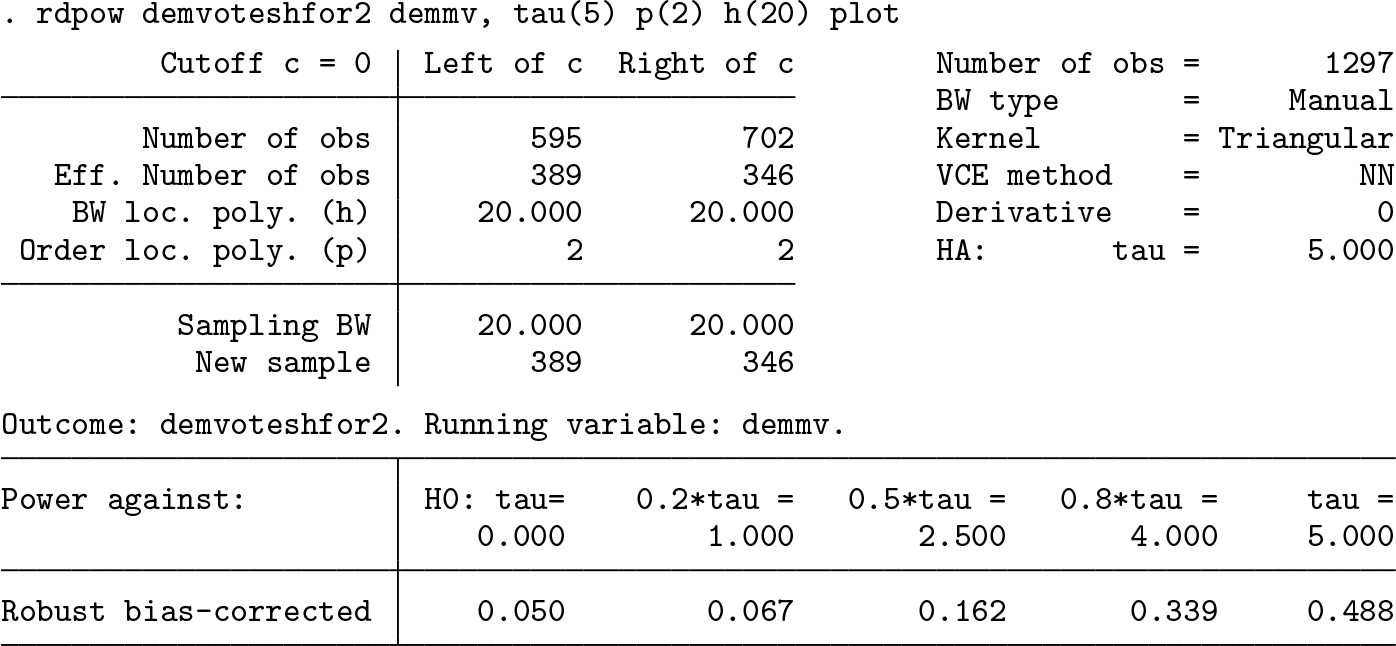
The most basic syntax to calculate power against an alternative hypothesis of τ = 5 is the following:

The output of
The output shows that the power against τ = 5 is 0.818, which is slightly above the usual threshold of 0.8. In many contexts, empirical researchers include covariates hoping to reduce the variability of the estimator. This option can be added to the

However, in this case there seems to be no gain in power by including covariates. Note that when the
The

Robust bias-corrected power function
By default,


On the other hand, the following syntax specifies different CER-optimal bandwidths at each side of the cutoff, a heteroskedasticity-robust plugin residuals variance estimator with

Finally, the
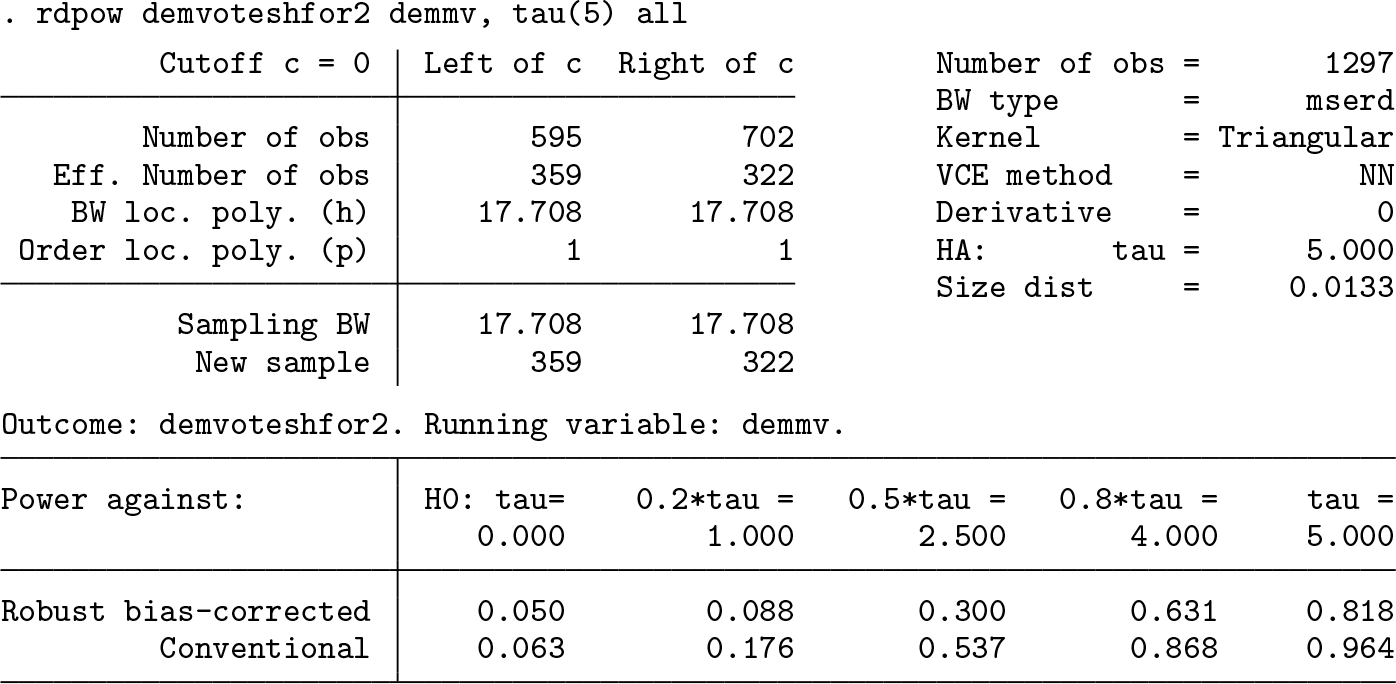
In this case, we see that the conventional approach yields higher power but at the expense of ignoring the misspecification bias, which creates a size distortion of 0.0133.
Manually setting bias and variance
By default,

The first line simply runs
The asymptotic variances of the local polynomial estimator at each side of the cutoff take the following form,

where
These terms may be hard to interpret in practice, so the user will rarely have a specific number for these magnitudes to specify as an option of
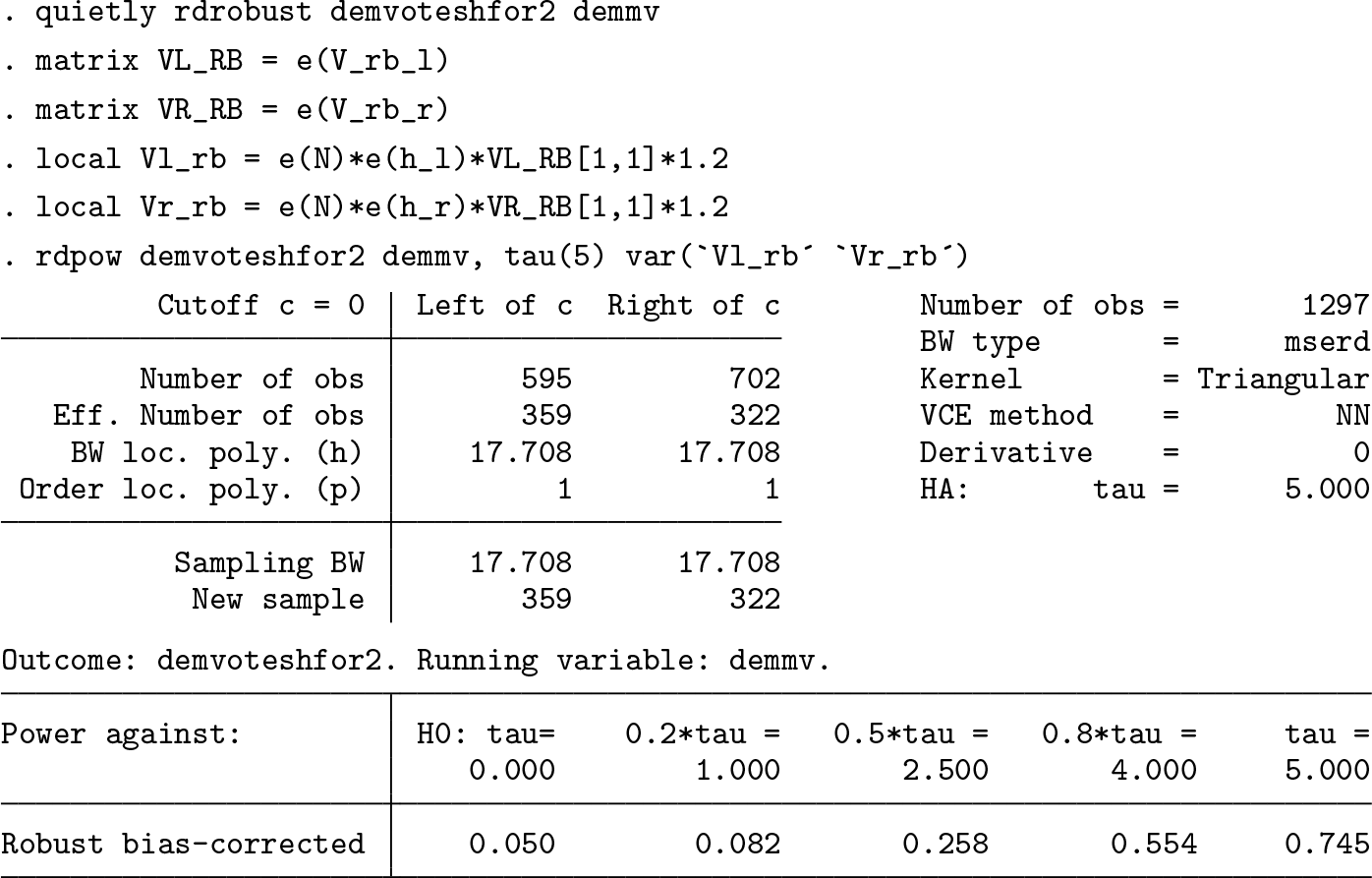
We see that the power decreases from 0.818 to 0.745 after increasing the variance terms by 20%.
Finally,

5.2 Comparing power across specifications
By changing the different options in

The two outputs below illustrate the same idea but using optimal bandwidths for each specification. Using the optimal bandwidth increases power compared with the previous case, and again, the linear specification has higher ex-post power compared with the quadratic specification.


These facts are illustrated in figure 2, which depicts the power functions for these cases.

Comparing power across specifications
5.3 Sample-size calculation using rdsampsi
The syntax of

As with
The user can specify the desired power level, sampling bandwidths, and proportion of treated units, then plot the resulting power function (see figure 3). The syntax is the following:


Robust bias-corrected power function
Note that the variances can be adjusted exactly as explained in the previous subsection for

The conventional approach yields a smaller sample size but generates a size distortion of 0.057.
A final check can be done by evaluating

As we can see from the above output,
Like

Finally,


These facts are illustrated in figure 4. We can see that, with both fixed and MSE optimal bandwidth choices, the local constant specification requires a smaller sample size (between half and a third of the required sample size for a local linear specification). The reason is that the linear specification introduces multicolinearity, which increases the variance of the local polynomial estimator. Goldberger (1972) pointed out this fact in the context of power calculations for classical linear regression settings. However, this feature should not be interpreted as implying that the constant specification is superior because, as discussed in section 2, a lower polynomial order implies a higher-order misspecification bias.
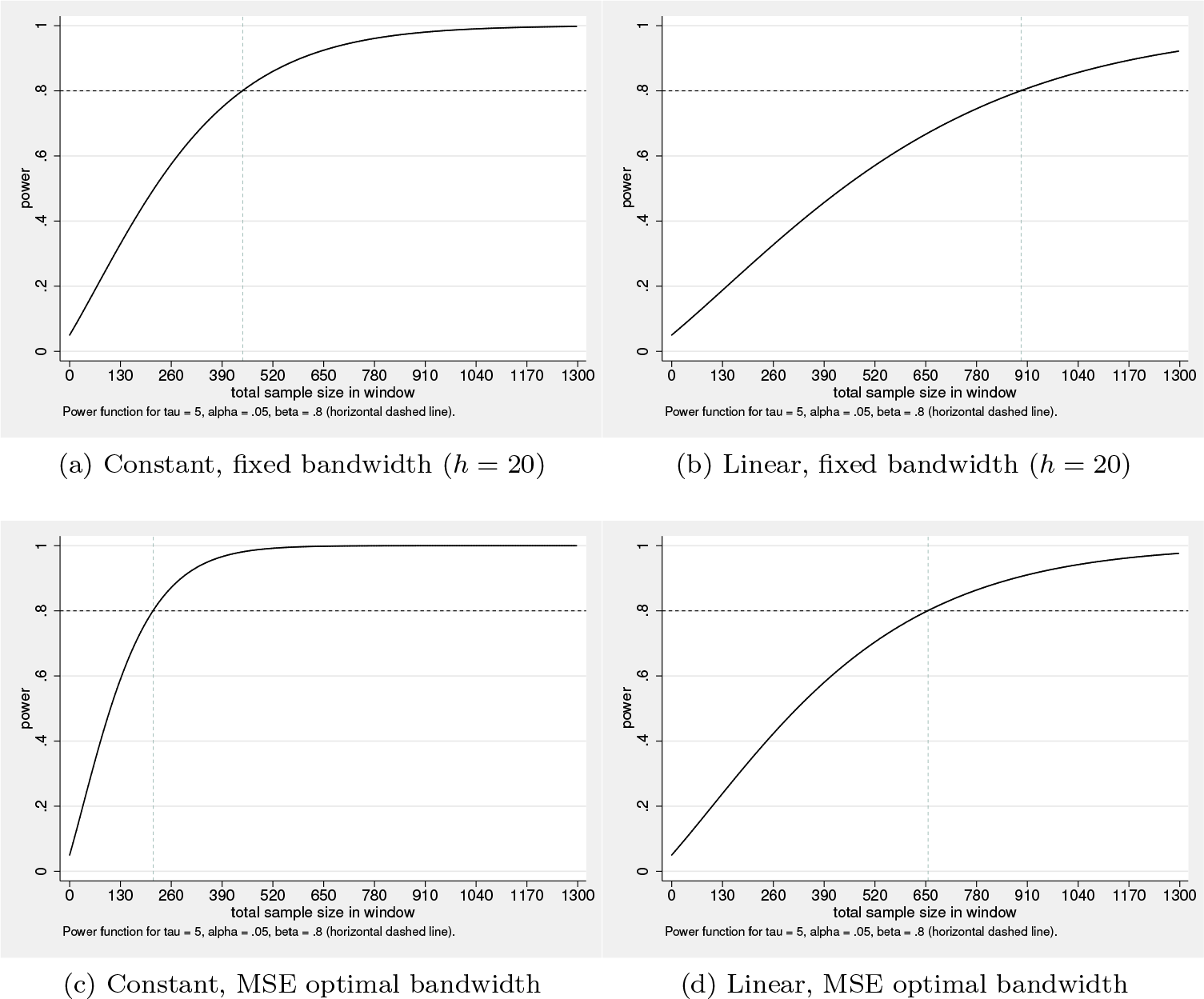
Comparing sample sizes across specifications
6 Conclusion
We introduced the command
7 Acknowledgments
This article and commands were motivated by impact evaluation work conducted at the Philippine Institute for Development Studies, Manila, Philippines, in the summers of 2014 and 2016, which were sponsored by the Asian Development Bank. We thank these institutions for their hospitality and support. We also thank an anonymous reviewer, Sebastian Calonico, David Drukker, Xinwei Ma, David Mckenzie, Aniceto Orbeta, and participants at short courses and workshops at the Abdul Latif Jameel Poverty Action Lab, the Asian Development Bank, the Inter-American Development Bank, and the Georgetown Center for Econometric Practice for useful questions, comments, and suggestions that improved this project. The authors gratefully acknowledge financial support from the National Science Foundation through grant SES-1357561.
Supplemental Material
Supplemental Material, st0554 - Power calculations for regression-discontinuity designs
Supplemental Material, st0554 for Power calculations for regression-discontinuity designs by Matias D. Cattaneo, Rocío Titiunik, and Gonzalo Vazquez-Bare in The Stata Journal
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.