
Abstract
Fiber masterbatch production suffers from inherent agglomeration effect of high-concentration color masterbatches, negatively impacting color uniformity, particle dispersion, and thermal stability in fiber masterbatch, and ultimately the quality of fiber products. However, accurately recognizing and classifying the agglomeration in scanning electron microscopy (SEM) images remain a challenge due to the complexity of agglomeration status, difficulty in distinguishing micro-size agglomeration, and limited data availability. To address this challenge, this paper proposes a novel microstructure recognition architecture, named Micro-KTNet, which is designed for segmenting SEM images of fiber masterbatch aggregation. First, Micro-KTNet leverages transferable microstructural features to initialize the proposed network, mitigating the impact of limited data. Then, to handle multi-scale features in the microstructure, an encoding-decoding structure is constructed and skip connections are used to transfer the output features of the encoding layer. Finally, the decoder incorporates a novel attention module to effectively process both global and local features. To evaluate Micro-KTNet, a unique fiber masterbatch SEM database is built as the benchmark for micro-size agglomeration recognition. Experimental results indicate that Micro-KTNet surpasses existing state-of-the-art methods and improves the recognition precision from 75. 37% to 87. 04%.
Keywords
Introduction
Fiber masterbatch, a fundamental component within the chemical fiber industry, is a blend of different materials. It mainly comprises high-level thermoplastic polymers, micro-nano functional powders, and various additives. The complex industrial fabrication process of fiber masterbatch encompasses multiple stages such as mixing raw material, extruding the mixture, cooling, and quality inspections. However, During the formation of fiber masterbatches, the agglomeration status of particles is unavoidable due to charge forces between particles and the action of dispersants. 1 In the mixture formed by the raw materials, those particles, develop significant positive and negative charges on their surfaces. Then, particles of inconsistent sizes can accumulate and stick together due to the charge force between them. While inherent to the manufacturing process, particle agglomeration has a negative impact on the quality and performance of the final products. 2 Traditionally, researchers have primarily evaluated agglomeration effects by focusing on filtration efficiency. 3 Additionally, industry experts in the fiber field can reply on their expertise to manually evaluate the agglomeration results through the analysis of the captured electron microscope images (SEM). 4 However, due to the low efficiency and high labor intensity associated with human inspection, automated detection based on machines or computers has drawn considerable attention in recent decades.
At present, deep learning employs multi-layer neural networks to extract high-level abstract features from data and achieves remarkable success. 5 It has significantly enhanced the performance of tasks such as image classification, 6 object detection, 7 and semantic segmentation, 8 owing to its self-learning and training capabilities. 9 In the field of fiber textiles, deep learning has shown remarkable efficacy in textile image classification, 10 optimizing chemical fiber processes, 11 and online detection of fiber quality. 12 For instance, Wei et al. 13 proposed an integrated learning framework called the bio-inspired visual integrated framework (BIVI-ML) for efficiently classifying multi-label textile defects. In this work, three bio-inspired visual mechanisms (the visual gain mechanism, the visual attention mechanism, and the visual memory mechanism) were proposed and built within the BIVI-ML. In addition, Tan et al. 14 proposed a scale and context information fusion network for multi type medical image segmentation, called SCIF-Net. SCIF-Net showcasing its superior capability in effectively capturing multi-scale features and spatial information, thereby enabling accurate segmentation of diverse human tissue structures. Additionally, Wu et al. 15 proposed a novel generative adversarial network (GAN)model, called SSGAN-ASP. SSGAN-ASP is designed to enhance fundus images by preserving anatomical structures and employing semi supervised learning, demonstrating improved visual quality and diagnostic accuracy. Moreover, Wei et al. 16 proposed a novel detection model to tackle the challenge of identifying small-scale textile defects, called Faster VG-RCNN. By incorporating attention-related visual gain mechanisms into Faster RCNN, this approach promises to enhance the accuracy and reliability of defect detection in textile manufacturing processes. Du et al. 17 applied an artificial intelligence technology into waste textile identification and sorting. Developing two online NIR qualitative identification models covering thirteen kinds of waste textiles using the convolutional neural network (CNN)and Baidu’s deep learning plat form PaddlePaddle. Furthermore, for the task of textile defect recognition with few labeled samples, a semi-supervised spatial-spectral neural network 18 was proposed, which could capture both spectral and spatial feature information from textile images. Experimental results showed that the textile defect recognition model achieved outstanding performance in a series of textile defect recognition challenges. Meanwhile, in terms of identifying the internal microstructure of fiber masterbatch, scanning electron microscopy (SEM) imaging is a well-established methodology at different length scales, allowing for an in-depth structural investigation and physical properties evaluation.
In Current research on SEM microstructure recognition, several deep neural network models have demonstrated impressive performance. For example, Quan et al. 19 pro posed a deep fully residual convolutional neural network for image segmentation in connect omics, called FusionNet. FusionNet introduces sum-based skip connections to deepen the network structure and enhance the segmentation accuracy across several electron microscopy segmentation datasets. Furthermore, Chen et al. 20 proposed a pioneering Transformer-based Attention Guided Network to advance automatic medical image segmentation, called TransAttUnet. Integrating self-aware attention modules and multi scale skip connections, TransAttUnet adeptly captures long range contextual dependencies, thereby enhancing semantical segmentation accuracy. Additionally, Wei et al. 21 introduced a methodology utilizing deep learning feature pyramid networks (FPN)to tackle the complexities of multi-class fabric defect detection, addressing challenges such as intersecting defects and small-size anomalies. Meanwhile, Zhou et al. 22 developed a physics-informed deep learning framework to predict the strength of composite materials with microstructural uncertainties using RVE images generated by a random fiber packing algorithm. The framework significantly accelerates uncertainty analysis and outperforms traditional methods, with its effectiveness validated through systematic case studies and statistical cross-validation. Besides, Zeng et al. 22 proposed an improved neural network based on Unet for nuclei segmentation in histology images. Moreover, Zhang et al. 23 proposed a very deep residual channel attention network (RCAN)for electron microscopy image super-resolution (SR). However, these models share a common limitation: data dependency. They rely on extensive annotated datasets for training. Acquiring high-quality annotations for SEM images can be challenging and time-consuming in practice. This limitation restricts the generalization capability and robustness of these models. To address this issue, transfer learning methods are often employed. For instance, Tamarina 24 et al. proposed a transfer learning approach using Convolutional Neural Networks (CNNs) pre-trained on the ImageNet dataset. This method utilizes CNN layers as feature extractors to derive features from the ImageNet dataset, which are then passed to a support vector machine with a linear kernel. However, this method still faces some issues in practice. On one hand, there may be feature distribution differences and missing data labels between the source domain and the target domain. In such cases, it is necessary to identify and utilize the similarities between the source domain and the target domain to transfer knowledge from the source domain to the target domain. On the other hand, the knowledge learned in the source domain may negatively impact learning in the target domain.
In this paper, building upon the advancement of deep learning for SEM microstructure recognition, we explore the microstructure knowledge transfer learning-based agglomeration recognition network (Micro-KTNet), which has not been widely recognized and studied, but is of significant importance. The integration of several modules in the proposed model focuses on the dispersion superstructure and the action mechanism of parent particles. Furthermore, the proposed Micro-KTNet utilizes feature learning and complex modeling capabilities to segment aggregated particles, showcasing its recognition performance in fiber masterbatch industry process. The primary contributions of this paper are: 1. We propose a novel end-to-end framework for masterbatch agglomeration recognition with few labeled SEM images, which transforms the task of agglomeration recognition into a task based on microstructure knowledge transfer learning-based method. 2. We present a novel attention encoding-decoding structure, in which the encoder with skip connections is capable of producing multi-scale features and decoder with attention module can process both global and local features effectively. 3. We build a benchmark dataset for masterbatch agglomeration to evaluate the empirical performance of Micro-KTNet. Experimental results show that the proposed model achieves outstanding performance in masterbatch agglomeration recognition with few labeled SEM images.
The remainder of this paper is organized as follows. In Related works section, we briefly summarize the basic concept of transfer learning and encoder-decoder. Details of the proposed framework are presented in The proposed Micro-KTNe section. Performance comparisons between the proposed approach and current state-of-the-art approaches are described in Experimental evaluation and discussion section. The paper is concluded in Conclusions and future work section.”
Related works
Transfer learning
Transfer learning aims to improve the performance of a target task represented as
Encoder-decoder
The encoder-decoder is an important network structure in deep learning, which comprises two components: the encoder and the decoder. The encoder is responsible for transforming the input into an intermediate state known as the feature, while the decoder decodes the feature to produce the desired output. As the encoder-decoder is a generic framework rather than a specific model, it has the flexibility to handle various types of data.32–34 Meanwhile, the design of diverse models can be facilitated by the encoder-decoder architecture. For example, recurrent neural networks (RNN) can be regarded as encoder-decoder structures. The encoder converts input text into vectors, and the decoder decodes the vectors into the desired outputs. Consequently, the RNN encoder-decoder architecture finds its application in sequence-to-sequence tasks, where the input and output are sequences of varying lengths. This approach is commonly known as the encoder-decoder Seq2Seq model.
35
In this model, the RNN can be a simple RNN, a long short-term memory (LSTM), or a gated recurrent unit (GRU). For a simple RNN, each intermediate state, denoted by


The decoder output is given by formula (3)

The proposed Micro-KTNet
System overview
In this study, we define the task as the recognition of the microstructure aggregation of fiber parent particles at the pixel level in SEM images. As depicted in Figure 1, our proposed framework comprises three main components: (a) transfer Learning for microstructure features (b) the SENetEncoder, and (c) the UnetDecoder. The proposed method, the Micro-KTNet Encoder-Decoder network, comprises three key components: transfer learning microstructure features, SENetEncoder, and UNetDecoder. The transferable microstructural features are used to initialize the proposed network. The SENetEncoder reuses convolutional layers trained on MicroNet to encode the input image into feature maps. The UNetDecoder is responsible for decoding these feature maps. Finally, the SegmentationHead processes the decoded feature maps to obtain per-pixel class probabilities, generating the segmentation mask.
The complete structure of Micro-KTNet, comprising its three key modules (the transfer learning microstructure features, the SENetEncoder module, and the UNetDecoder module), is illustrated, with detailed information regarding the training parameters and the learning process for the Micro-KTNet network provided in Section.
Traditionally, the weights of a neural network are initialized randomly. However, this may lead to overfitting problems that occur when the model fits too closely to the training data and fail to generalize effectively to new data. This challenge is more likely in the domain of fiber parent particle microstructure aggregation, where data is scarce and creating segmentation masks is costly. To address this, we adopt a transfer learning approach to initialize our network. Initially, a batch of pre-processed images, along with their corresponding ground truth, are fed into the model. The SENetEncoder is then employed to encode these inputs into feature maps with various resolutions, which contain valuable semantic information. Subsequently, the UnetDecoder is used to upsample these feature maps. The segmentation head is applied to the upsampled output to generate a segmentation mask. This mask contains class probabilities for each pixel, facilitating the identification of fiber parent particle microstructure aggregation. Eventually, the network delivers classification results for each pixel. Throughout the learning process, the segmentation network extracts feature information related to fiber parent particle microstructure aggregation from input images through forward propagation. The loss computation occurs during forward propagation, and network parameters are adjusted through backward propagation to minimize this loss, thereby optimizing the network’s performance in pixel-wise segmentation tasks. Ultimately, the output of the segmentation network precisely segments fiber parent particle microstructure aggregation, enabling automated analysis of specific structures within the images.
Transfer learning-based microstructure features
Collecting and manually creating segmentation masks can pose challenges and be costly, resulting in a relatively small self-made dataset. To mitigate the risk of overfitting, we utilize transfer learning to initialize our network. Initially, we train a ResNeXt50 network for classification tasks using a large microscope dataset. The objective is to learn a target function




The overall loss function of transfer learning is defined as formula (8)
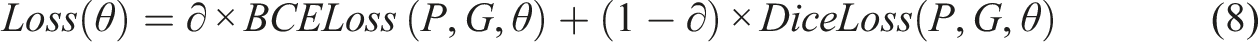
SENetEncoder module for few-labeled SEM images
Due to lacking the labeled SEM images of masterbatch agglomeration microstructure, we repurpose the convolutional layers of the ResNeXt50 network as part of the SeNetBlock. Figure 2 illustrates the structure of the SeNetBlock with downsampling, which comprises several processing blocks. The input image goes through convolutional layers, batch normalization layers and nonlinear activation layers to generate feature maps as formulas (9)–(11) The diagram illustrates the structure of the SeNetBlock with Downsampling.





Figure 2 illustrates the hierarchical structure of the encoder path, which comprises five layers. Each layer takes as input from either the original image or the encoding feature map from the previous layer. The output of each layer is both forwarded to the next layer and directly transmitted to the decoder through skip connections. The initial layer of the encoder consists of a convolutional layer with a 7 × 7 kernel size, a stride of 2, and a padding size of 3. This convolutional layer’s primary purpose is to extract initial features, which are subsequently subjected to batch normalization and ReLU activation before being downsampled by a max pooling layer. This operation reduces the feature map’s size by half while keeping the number of channels unchanged. The first SeNetBlock block in the encoder is redesigned for downsampling feature information. Each downsampling step diminishes the feature map’s size by half while doubling the number of channels. The encoder progressively reduces resolution through convolution and pooling operations, generating multi-level features with varying resolutions. These features are subsequently transmitted to the decoder via skip connections. In contrast, the decoder gradually increases resolution through operations such as transposed convolution. The inclusion of skip connections serves two key purposes: firstly, it enables high-resolution feature information to flow seamlessly between the downsampling and upsampling processes. Secondly, skip connections aid in preserving finer details when handling small targets or boundaries.
UnetDecoder module for microstructure features
Our decoder comprises four layers, with each layer receiving the encoding feature maps from its corresponding layer and higher layers. The fourth layer of the decoder is taken as an illustrative example: the encoding feature map from the fifth layer undergoes an initial upsampling process, increasing the number of feature maps while reducing their size. This upsampled feature map, achieved through transposed convolution, matches in size with the encoding feature map of the fourth layer


The channel number of the concatenated feature map The diagram depicts the structure of the scSE attention module.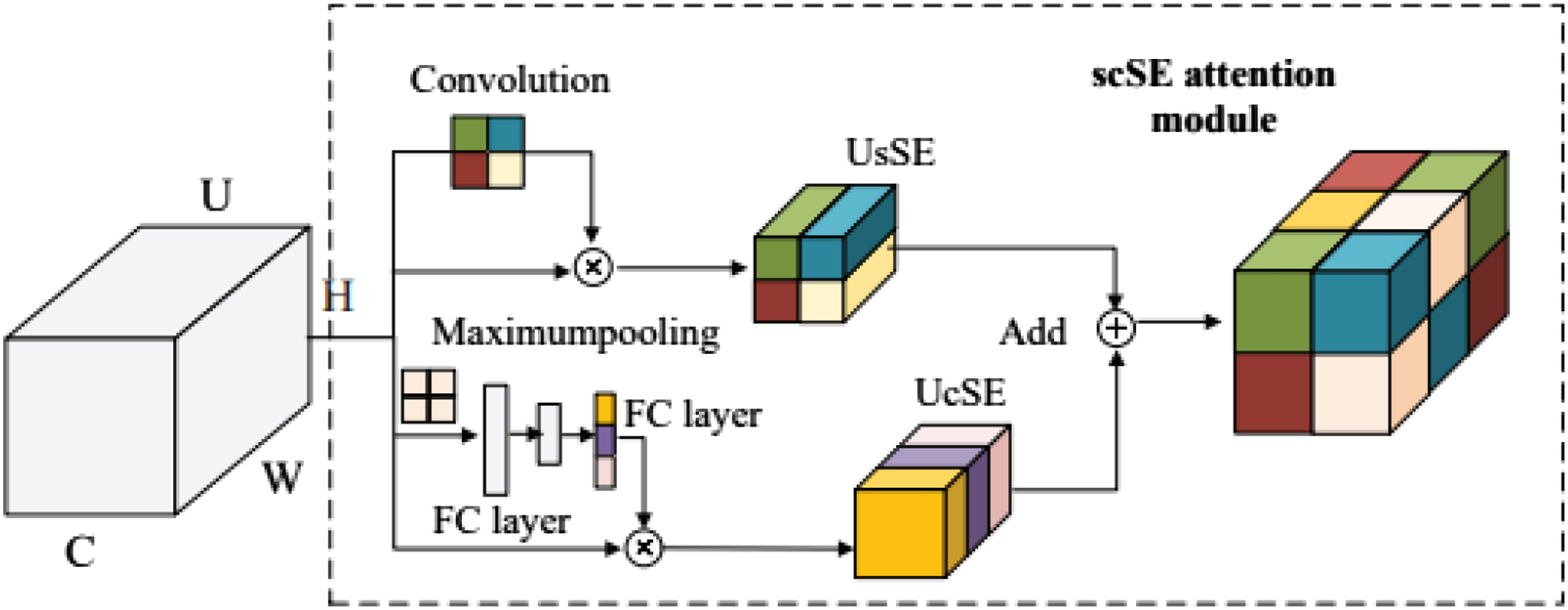

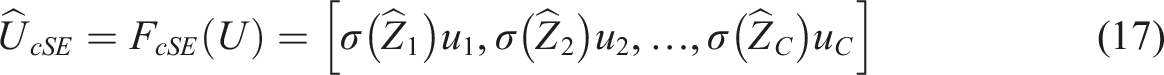
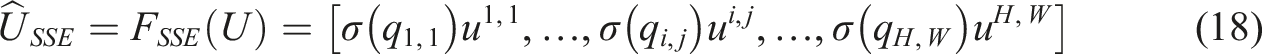
Learning the proposed network
A network initialized with transfer learning requires only a small amount of training data. In this study, the Micro-KTNet model was trained using a small dataset of fiber granule aggregation and its performance was evaluated on test samples. During the training process, the Adam50 optimizer was employed with an initial learning rate of 2e-4. The loss function used was a weighted combination of the balanced cross-entropy (BCE) and Dice loss, with BCE assigned a weight of 70%. BCE (Binary Cross-Entropy) is generally more stable during the initial phases of training, which aids in speeding up model convergence. On the other hand, Dice Loss places greater emphasis on pixel-level similarity and promotes the generation of smoother and more continuous segmentation results. By combining BCE with Dice Loss, a reduction in overall loss was achieved while still benefiting from the stability conferred by BCE. The implementation of the Micro-KTNet model was carried out using PyTorch, the segmentation models library, and other relevant third-party libraries. These experiments were conducted on a personal computer with 24 GB of memory and an Nvidia GeForce RTX 3090 graphics processing unit, utilizing Python for implementation.
Experimental evaluation and discussion
In this study, the performance of the Micro-KTNet model was assessed through a series of experiments focused on segmenting fiber granule microstructure aggregation. The following sections provide detailed explanations of the experimental setup and the implementation of the Micro-KTNet network. Furthermore, its performance was compared with other algorithms designed for segmenting fiber granule microstructure aggregation. Finally, an ablation study was conducted to dissect various components of the Micro-KTNet model.
Data creation and evaluation metrics
A scanning electron microscope (SEM) was used to capture high-resolution microstructure images of fiber granules. These images are detailed, but they also contain some unwanted interference, such as stains. To mitigate these issues stemming from the acquisition process, a series of preprocessing steps involving transformation, segmentation, and diversification techniques were employed. This culminated in the creation of a dataset termed SEM DHU-150, consisting of microstructure aggregation data from fiber granules. In SEM-DHU-150, positive labels denote particles resulting from aggregation in fiber granule microstructures, while negative labels are assigned to other structures, such as gaps between fibers.
To construct the dataset, image patches of size 512 × 512 were randomly extracted from the high-resolution original images. The segmentation results of the original images are demonstrated in Figure 4. Positive samples were manually labeled. Ultimately, around 150 samples were assembled for the dataset, with 90 samples allocated for the training set, 40 samples for validation, and the remaining samples earmarked for prediction. Given the limited number of training set samples, data augmentation techniques were adopted to enhance the model’s performance. Firstly, random horizontal flips were applied to the images with a 30% probability to make the model learn invariant image features. Additionally, random adjustments to contrast, brightness, and gamma were introduced to increase data diversity and enhance the model’s adaptability to variations in lighting conditions. Lastly, blurring and image sharpening effects were incorporated, prompting the model to focus more on critical features, such as image edges, during training. The segmentation results of the original images are demonstrated in Figure 5. The results of data augmentation are shown in Figure 6. An example illustrating the segmentation process of an original image. The result of data augmentation: Images (a) and (e) are the original unprocessed images, while images (b) and (f) represent the modified versions with a horizontal flip, (c) and (g) represent adjustments to brightness and contrast respectively, (d) and (h) are undergoing blurring and sharpening processes. Figure (a–f) showcase examples of fiber masterbatch aggregation segmentation. In these examples, yellow pixels represent true positives, green pixels represent false negatives, red pixels represent false positives, and blue pixels represent true negatives.


To evaluate the effectiveness of the Micro-KTNet model, four quantitative metrics were employed: IOU, precision, recall, and F1-Score, which are defined as follows




Experiment results
In this study, the effectiveness of the fiber granule microstructure segmentation method was assessed and a comparative analysis of its segmentation results was conducted against other methodologies.
The Micro-KTNet model demonstrates impressive performance in segmenting fiber granule aggregates. When dealing with SEM images containing only large-sized aggregate particles within fiber granules, the proposed network accurately segments these particles. Even in scenarios where SEM images contain multiple aggregates with slight variations in size, our network still performs admirably. However, challenges arise when SEM images feature a substantial number of aggregate particles with considerable size differences, leading to occasional mis-segmentation or missed segmentation instances. This observation is evident in Figure 6(a) and (e), and it could be attributed to two key factors. Firstly, some aggregate particles may be situated at the edges of the image, where the model lacks adequate contextual information to effectively learn these features, resulting in instances of missed segmentation, as depicted in Figure 6(a). Secondly, the complexity of the fiber texture can complicate the differentiation process, as certain areas of the fiber texture may resemble the texture of small-sized aggregates. This similarity makes it challenging for the model to distinguish between them accurately. In summary, this model achieves an IOU (Intersection over Union) score of 86. 65% on the SEM-DHU-150 dataset, signifying its overall strong performance in segmenting fiber granule microstructures.
Comparative analysis
In the evaluation on the SEM-DHU-150 dataset, the segmentation results produced by Micro-KTNet were compared with several commonly used segmentation methods. Among the chosen approaches, Lin et al. 41 leverages a multi scale feature pyramid to integrate semantic information from different levels. Zhao et al. 42 employs a structure called Pyramid Pooling to capture multi-scale contextual information. Additionally, Unet, 43 LinkNet, 44 MANet, 45 UnetPlusPlus, 46 and DeepLabV3Plus 38 all follow an Encoder-Decoder architecture. Unet distinguishes itself with skip connections, while MANet introduces attention mechanisms based on the Unet framework. UnetPlusPlus extends network depth and adopts a more densely connected structure. DeepLabV3 47 employs dilated convolutions to expand the receptive field, along with global average pooling and multi-scale information fusion to enhance object boundary segmentation. DeepLabV3Plus further enhances segmentation accuracy by adopting an encoder-decoder structure.
The performance of different models on the fiber masterbatch microstructures aggregation dataset.

Bold values represent the best statistically significant results.

The F1-score of each method during learning procedure.

The segmentation results of different models on the fiber masterbatch super microstructure aggregation dataset. (a) to (e) show the results of aggregate particle size decreasing in the input images, where (a) exhibits the largest aggregated particles and (e) the smallest. In these results, yellow pixels represent true positives, green pixels represent false negatives, red pixels represent false positives, and blue pixels represent true negatives.
When the input consists of Figure 8(d) and (e), both DeepLabV3 and Unet tend to miss the desired parts of the aggregate particles (indicated in green). Particularly, Unet struggles with segmenting the edges, and its performance decreases significantly when the input is Figure 8(c), where nearly 60%of the aggregate particles are not properly segmented. UnetPlusPlus, while an improvement over Unet, still suffers from issues such as segmenting out undesired aggregate particles at the image edges (highlighted in red). Comparatively, the proposed Micro-KTNet network exhibits fewer misidentifications at the image edges and significantly outperforms both DeepLabV3 and Unet in segmenting the desired aggregate particles. In fact, the Micro-KTNet network achieves nearly perfect segmentation in these cases. In summary, the proposed Micro-KTNet network demonstrates the most robust performance in binary segmentation, outperforming the other methods considered in benchmark dataset of masterbatch agglomeration.
Ablation experiments
The performance of the Micro-KTNet model on the fiber masterbatch microstructure aggregation dataset under different conditions.

Bold values represent the best statistically significant results.
Table 2 also sheds light on the impact of reusing convolutional layers pre-trained on various datasets, including the MicroNet dataset, the ImageNet dataset, and a combined Image-MicroNet dataset, on the model’s segmentation performance. Remarkably, the model performs exceptionally well in all three cases. However, it’s noteworthy that the model pre-trained on the MicroNet dataset outperforms the one trained on the ImageNet dataset. One plausible explanation is that the filters trained on the ImageNet dataset may not be entirely suited for the unique characteristics of fiber mother grain nanostructure aggregation images. Nevertheless, the optimal approach appears to be pre-training the convolutional neural network on ImageNet and subsequently fine-tuning it on the MicroNet dataset.
Assessing the impact of architectures
In this study, A large number of experiments were conducted to explore the effects of replacing ResNeXt-50 with various popular network architectures. These architectures include DenseNet121, 24 DPN107, 48 EfficientNet-B5, 49 Inception-ResNet-V2, 50 Inception-V4, 51 MobileNet-V2, 52 ResNet-50, 53 ResNeXt-50_32 × 4d, 54 SENet-154, 55 VGG-16_bn, 56 and Xception. 57 All networks were fine-tuned using transfer learning, with the same training configurations applied to ensure consistency. The results showed notable differences in performance. The IOU (Intersection over Union) scores ranged from 66.01% (MobileNet-V2) to 86.65% (ResNeXt-50_32 × 4d).
The performance of the Micro-KTNet model on the fiber masterbatch microstructure aggregation dataset with different encoder.

Bold values represent the best statistically significant results.
Assessing the impact of hyperparameters
In this experiment, some hyperparameters, such as learning rate and batch size, were found to affect the performance of the proposed method. To explore the relationship between hyperparameters and segmentation results, four experiments with different batch sizes were conducted, and the model’s performance was evaluated using four metrics (IOU, F1-score, precision, recall), as shown in Figure 9. A larger batch size enables the model to consider more samples in each update step, facilitating the learning of complex patterns and structures in the data. For example, when the batch size increased from 2 to 14 in the experiment, the IOU improved from 81.12% to 86.59%, the F1 score rose from 86.93% to 94.50%, and the precision and recall increased from 82.33% and 88.31% to 91.85% and 97.21%, respectively. These improvements demonstrate how a larger batch size can stabilize the gradient updates and enhance the model’s ability to generalize patterns within the data. Evaluation of performance with different batch size.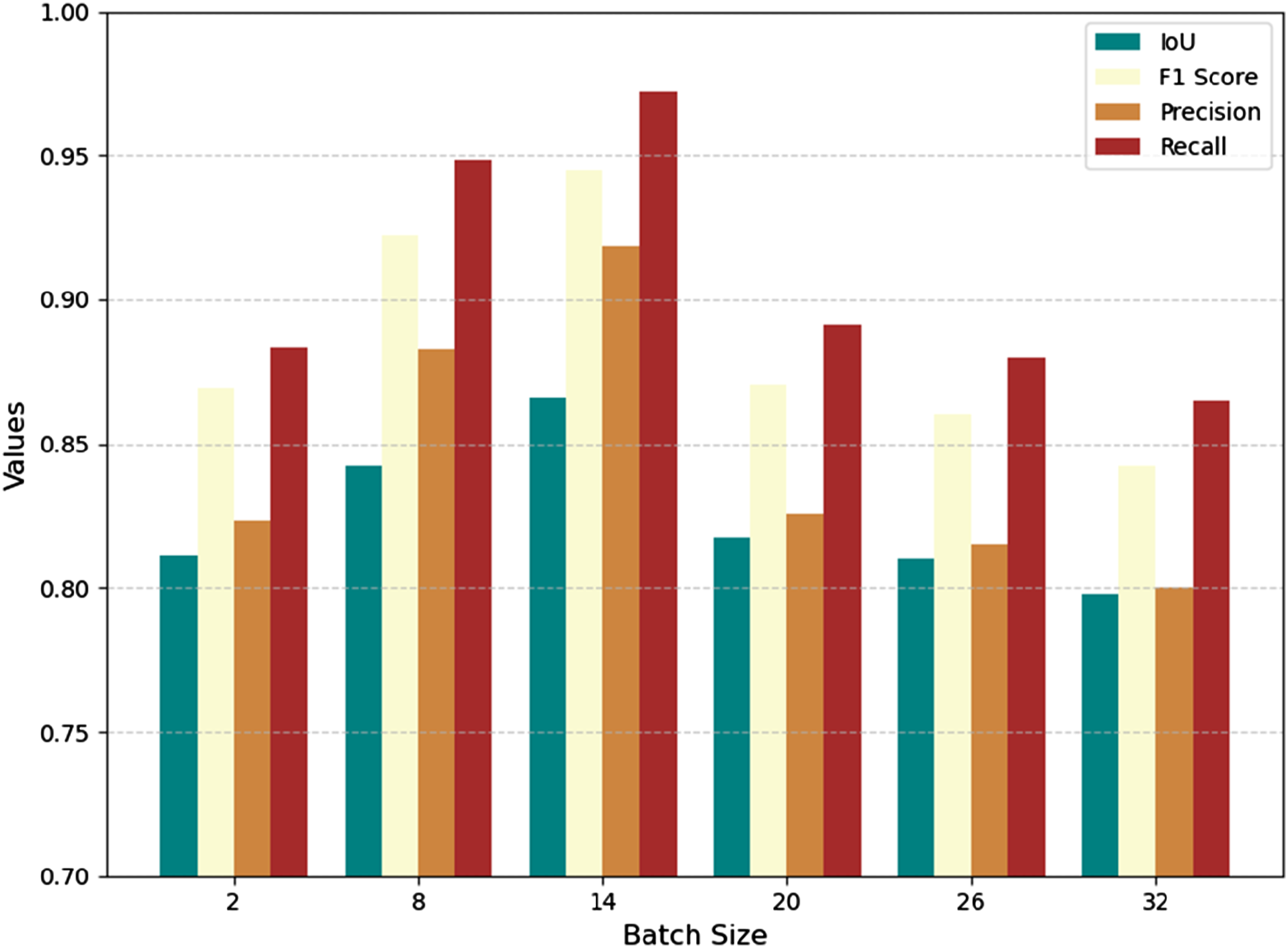
However, when the batch size became too large, such as increasing it to 20, the metrics began to decline. For instance, the IOU dropped to 81.72%, the F1 score decreased to 87.03%, and both precision and recall fell to 82.56% and 89.13%, respectively. This decline suggests that while larger batch sizes allow the model to process more data in a single iteration, they also reduce the number of gradient update steps within an epoch. This can lead to less frequent weight updates and the loss of fine-grained gradient information, which is critical for learning subtle patterns in the data.
Furthermore, in the context of smaller datasets, this problem can be exacerbated. Excessively large batch sizes mean that the model might process the entire dataset in just a few iterations, limiting its ability to fully explore the data distribution and learn diverse features. As seen in this case, when the batch size continued to increase to 26 and 32 (hypothetical data), the IOU further decreased to 81.00% and 79.80%, while the F1 score fell to 86.00% and 84.20%. These trends illustrate the trade-off: while larger batch sizes improve computational efficiency, they can hurt the model’s generalization ability if set excessively high.
Assessing the impact of hyperparameters
The purpose of this experiment was to investigate the impact of the number of training samples on the performance of the model, providing further validation of its adaptability and generalization ability under limited data conditions. By adjusting the size of the training set, the study aimed to evaluate the model’s performance in scenarios with extremely few labeled samples and reveal its behavior as the amount of data increases.
In the experimental setup, the test set was fixed at 40 images, while the training set was divided into subsets with 1 image (40:1), 5 images (8:1), 10 images (4:1), 20 images (2:1), and 40 images (1:1). The model’s performance was evaluated using the Intersection over Union (IoU) metric as the primary indicator, complemented by pixel-level classifications illustrated in the provided visual results (Figure 10). (a) shows an example from the test set of the SEM-DHU-150 dataset. (b) shows the evaluation of performance with different numbers of training samples. In these results, yellow pixels represent true positives, green pixels represent false negatives, red pixels represent false positives, and blue pixels represent true negatives.
The IoU results demonstrated that the model achieved 79.55% IoU with 40 training samples, 75.61% IoU with 20 samples, 68.59% IoU with 10 samples, 46.32% IoU with 5 samples, and 23.74% IoU with only 1 sample. Several observations can be drawn from these results. First, even under conditions with very few samples, such as 5 images (46.32% IoU), the model still exhibited relatively reasonable performance. This is attributed to the use of a pre-trained encoder, which was trained on Micronet and possesses strong feature extraction capabilities, thereby enabling effective performance with limited training data. Second, as the number of training samples increased, the model’s performance improved steadily. For example, IoU increased from 23.74% with 1 image to 79.55% with 40 images. This improvement is due to the additional training data enabling the model to enhance its recognition and generalization ability when the ratio of training to testing data is below 1:1. Third, in the most extreme case, with only 1 training image, the results were suboptimal. This is likely because the information contained in a single image is significantly less representative compared to the 40-image test set, causing the model to focus excessively on limited features and struggle with generalization.
The results of this experiment provide further evidence of the model’s strong performance in low-resource scenarios while also highlighting the advantages of increasing training data for achieving optimal performance. Under extremely limited data conditions, the results depend heavily on the quality of the pre-trained features, as demonstrated in the 5-training scenario, where the pre-trained encoder contributed significantly to the relatively strong performance.
Conclusions and future work
This paper proposes a novel microstructure recognition architecture, named Micro-KTNet, which is designed for segmenting SEM images of fiber masterbatch aggregation. The model incorporates a transfer learning-based encoder, pre-trained on the MicroNet dataset, to extract domain-specific features effectively. The decoder, enhanced with SCSE attention modules, combines global and local features to achieve precise segmentation. The encoder-decoder architecture with skip connections facilitates multi-scale feature utilization, ensuring detailed and contextually consistent predictions. On the SEM-DHU-150 dataset, Micro-KTNet achieves state-of-the-art performance, with an IOU of 86.65% and an F1-score of 94.50%. Despite its strong performance, challenges remain in segmenting aggregation particles near image edges and in distinguishing fine textures within complex regions. Future work will address these limitations while also focusing on integrating explainable AI methods, such as visualizing attention maps, to enhance the transparency of the model’s decision-making process. This addition will improve industry trust and facilitate broader adoption in industrial environments.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Shanghai Sailing Program (22YF1401300), Cultivation Project of Discipline Innovation (XKCX202313) and Postdoctoral Research Foundation of China (2024M752306).