
Abstract
In order to improve the automatic production efficiency of the textile workshop and reduce the labor cost and error rate, this study designed a multi label recognition model YoloColor-Net based on deep learning, which aims to realize the automatic detection and recognition of the bobbin shape and yarn color on the yarn frame in the textile workshop. Firstly, according to the research needs, a dataset sample containing 12,173 textile bobbin images was collected and constructed independently. Then, the traditional yolov5 model is improved by designing the convolution network of yarn color recognition, which solves the problem of missing detection of the bobbin when detecting the bobbin shape and yarn color at the same time. Secondly, the lightweight DSConv module is used to replace the ordinary convolution of the Backbone layer to reduce the parameters of YoloColor-Net and improve the running speed. Finally, the improved attention mechanism (ICBAM) is added to the Backbone and Neck layers of YoloColor-Net to improve the accuracy of bobbin recognition. The experimental results show that the detection accuracy of the improved YoloColor-Net model is 99.3%, the number of model parameters is reduced by 10.4%, and the GFLOPS is reduced by 17.1%. FPS increased from 43.13 to 67.23, an increase of 55.9%. Therefore, the proposed model can basically meet the task of bobbin automatic detection and recognition, and consider the initial localization deployment.
Keywords
Introduction
In the textile industry, due to the continuous rise of textile raw materials and labor costs, the profit space of textile enterprises is shrinking. With the rapid development of machine vision technology, deep learning has been widely used in various industries and has made outstanding contributions to the cost reduction and efficiency increase of the industry. Therefore, the textile industry is also constantly committed to using machine vision technology to replace labor, improve the efficiency of automated production in textile workshops, and realize lean production.1,2
At present, the shapes of commonly used bobbins in textile workshops can be divided into cylindrical and conical bobbins, as shown in Figure 1(a). Commonly used textile yarns have a variety of colors, as shown in Figure 1(b). In the production process, the remaining yarn of each color on the yarn frame is different. Manual replacement of the remaining insufficient yarn on the yarn frame is inefficient and easy to cause wrong yarn color replacement. In order to avoid this situation, a high-precision and high-efficiency bobbin detection model is developed to detect the bobbin shape and yarn color in real time and accurately, which is of great significance to improve production efficiency and reduce production costs in the textile industry. Common bobbins in factories: (a) bobbin shape; (b) yarn color.
The main research object of this paper is the shape of the bobbin and the color of the yarn in the textile workshop, aiming to realize the automatic detection and recognition of the shape of the bobbin and the color of the yarn. In the process of studying the field of bobbin recognition in textile workshop, it is found that although the existing target detection algorithms have their own advantages, they all have different degrees of limitations. Karimanzira et al. 3 constructed a general target detection system through the pre trained convolutional neural network RCNN, and the detection accuracy can reach 98.392%, but the image processing speed is slow, which is not suitable for high-efficiency production scenes; Lei et al. 4 improved the PANet to achieve multi-scale feature fusion, and optimized the confidence loss function to enhance the detection ability of the network for the target in the fuzzy underwater image, but the model parameters are large and the detection speed is slow. Zhang et al. 5 improved the recall rate and average detection accuracy of target detection by improving the backbone network of YoloV3, but the improved model has large size and low training efficiency, which is not suitable for subsequent deployment in the factory production environment with limited resources and environment; Tang et al. 6 improved the convolutional neural network vgg-16 model, weakened the joint adaptability between the neuron nodes of the model, improved the generalization ability of the model, and achieved an image recognition accuracy of 90.58%, but the model needed a lot of experiments and debugging to find the optimal super parameters; Su et al. 7 refined the feature transmission of the model during feature fusion by adding spatial and channel attention mechanisms to the target detection model to reduce the interference of complex scenes. But it increases the time cost of training and reasoning, and may lead to training over fitting.
For the research of target color recognition, Yue et al. 8 proposed a method to directly process multi-spectra using a diffusion model (Dif-Fusion), generating images with high color fidelity through a multi-channel fusion module, significantly improving the accuracy of color detection. Rabie et al. 9 proposed a detection technology based on color histogram contour (CHC), which achieved robustness to light changes by constructing high-precision chroma feature vectors and emphasizing unique color features. Wang et al. 10 designed a deep convolutional network framework for small infrared target detection, which eliminates false alarms caused by random noise and clutter through the similarity of motion and radiation between the detection results, and integrates the target optical flow information into the trajectory to realize the spatial domain detection of infrared targets. Qian et al. 11 proposed a color segmentation algorithm combining self-organizing map neural network and efficient dense subspace clustering, which achieved high-precision color segmentation, and the accuracy of color recognition on complex printed fabrics reached 88.3%. Ismael AM et al. 12 proposed the solution of wavelet transform (WT) and adaptive neuro fuzzy inference system (ANFIS) in color texture classification, and achieved a classification success rate of more than 96% in different color spaces, which verified the effectiveness of the method for color texture classification. The above convolutional neural network (CNN) has a certain effect in the research of target detection and color recognition, but it can not achieve the task of multi label recognition.
At present, in the application research of textile factory automation, multi label recognition technology can detect the shape of the bobbin and the color of the yarn at the same time, which can reduce the dependence on labor, improve the detection efficiency, and avoid errors caused by human factors. In order to realize the rapid and accurate detection of the bobbin shape and yarn color on the yarn frame, we use yolov5
13
model and the original convolutional neural network for yarn color recognition to ensure the high accuracy of the model in the task of multi label recognition. Because the model needs to be deployed to embedded devices in the future, the lightweight of the model is also crucial. We named this model for the detection of bobbin shape and yarn color YoloColor-Net. The contributions of this study can be summarized as follows: (1) Based on the official yolov5 model, the convolutional neural network specially used for yarn color recognition is fused behind the Head layer to form a preliminary YoloColor-Net to complete the multi label recognition task of detecting the shape of the bobbin and the color of the yarn. (2) Improve the Backbone layer of YoloColor-Net: Replace the ordinary convolution with distribution shift convolution (DSConv).
14
DSConv uses quantization and distribution shift to simulate the behavior of the convolution layer, and achieves the purpose of increasing the model speed and reducing the number of parameters by storing only integer values during the operation process. (3) Improve convolution block attention module: Improve convolution block attention module (CBAM)15,16 and propose ICBAM attention mechanism. Then an improved attention mechanism ICBAM is introduced in the early stage of YoloColor-Net feature extraction and feature fusion to improve the detection accuracy of the model.
The work of this paper is arranged as follows: in
Proposed model
The overall framework of YoloColor-Net model, as shown in Figure 2, is divided into a bobbin shape detection module and a yarn color recognition module, which is composed of four parts: (1) The Backbone layer mainly extracts the features of the input image; (2) The Neck layer is responsible for feature fusion of feature maps with different scales and transferring these features to the Head layer; (3) The Head layer receives the fused feature map information and performs regression prediction; (4) The Output layer extracts the color information according to the feature map information, and outputs the final result. The DSConv convolution module is used to replace the ordinary convolution in the Backbone layer of YoloColor-Net to improve the model speed and reduce the amount of parameters. The improved ICBAM attention mechanism is inserted into the Backbone layer and Neck layer of YoloColor-Net, and the channel attention module is optimized by using one-dimensional convolution instead of multi-layer perceptron structure in the channel attention mechanism module to reduce the loss of feature information; The multi-scale hole convolution path is introduced into the spatial attention module to enhance the comprehensiveness of feature extraction YoloColor-Net model.
Yarn color recognition module
Color detection convolutional network structure.
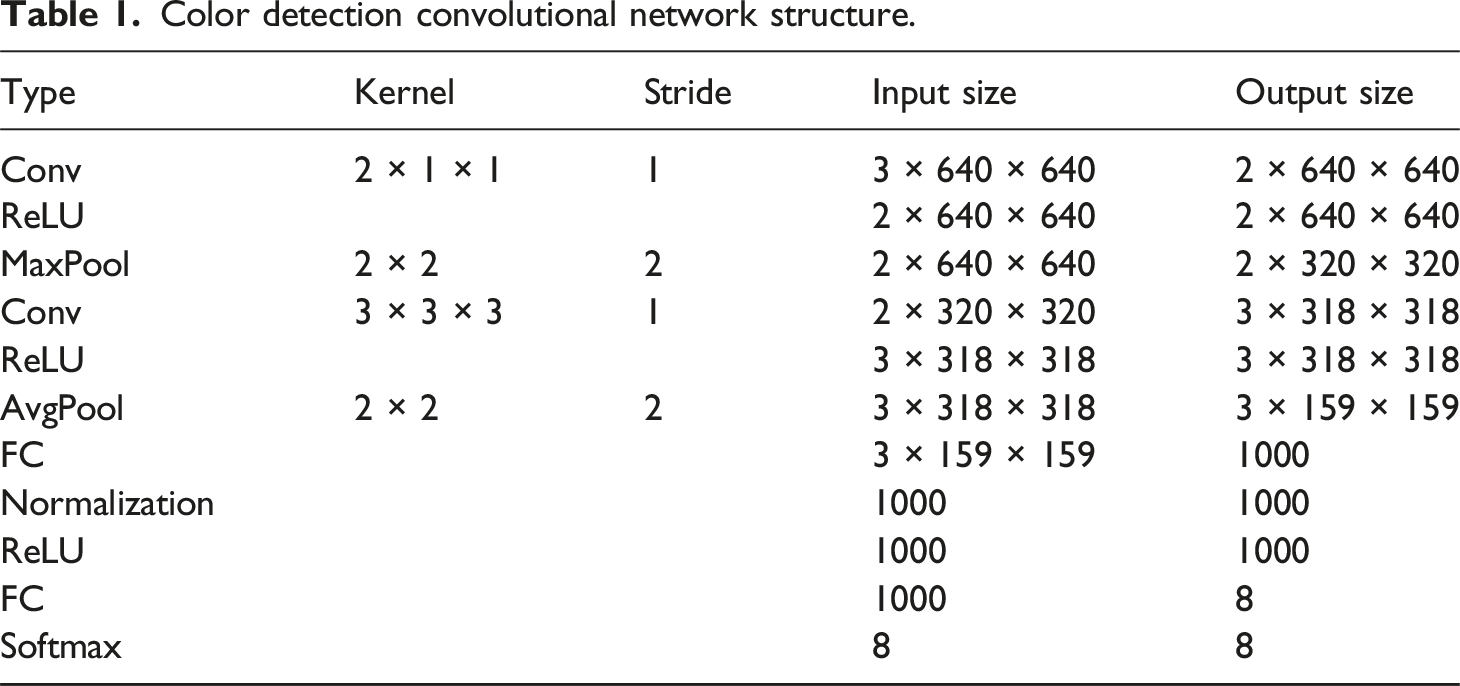
This branch can accept features from FPN as input, and then output the color recognition of each target bounding box. Because the convolution kernel of 1 × 1 focuses on the correlation between pixels in the same position of different channels, rather than the correlation of pixels in the same channel. Therefore, 1 × 1 convolution kernel is not commonly used 3 × 3 or 5 × 5 for the first layer of the network. In this experiment, 1 × 1 convolution means paying more attention to color channel information, integrating cross channel information, and reducing learning parameters through dimensionality reduction. 20 The convolution layer is transformed nonlinearly by using the ReLU activation function and the maximum pooling layer, and the size of the feature map is reduced by down sampling. Then the convolution of 3 × 3 × 3 is used to upgrade the dimension, and the first full connection layer is used for linear transformation to generate 1000 maps, and the normalized output is used.21,22 Finally, the activation function ReLU is used to accelerate the training again, and the second full connection layer is used for the final output. Softmax is used as the color classifier at the end of the network. 23
Bobbin shape recognition module lightweight
In the research of YoloColor-Net, DSConv convolution module is used to replace the ordinary convolution of Backbone layer. When YoloColor-Net model is used to train bobbin samples, DSConv convolution decomposes the convolution kernel into two components: variable quantization kernel (VQK) and distribution offset, and applies kernel based and channel based distribution offset to maintain the same output as the original convolution. By storing only integer values to achieve lower memory usage, the purpose of improving model speed and reducing the amount of parameters is achieved. The model structure of DSConv is shown in Figure 3. DSConv model structure.
The original convolution tensor is
DSConv in the quantization process, the quantization function takes the number of bits to be quantized in the network as the input, and uses the complement of two to save the integer value. For the number with bit length B, there is the following relationship:
Then, the weight of each convolution layer is scaled so that the maximum absolute value of the original weight 
By moving the VQK value through KDS and CDS, the weight of each block of the pre training network will be stretched or rounded to fit the interval in equation (1) and stored in VQK. The optimal value of KDS is:
Its closing form is:
In summary, we choose to replace the ordinary convolution of the YoloColor-Net Backbone network with DSConv convolution to speed up model training and reduce model storage space.
Add attention mechanism ICBAM
In the neural network, the output of each neuron only depends on the output of all neurons in the previous layer. In the attention mechanism, the output of each neuron not only depends on the output of all neurons in the previous layer, but also can be weighted according to different parts of the input data and given different weights. Therefore, adding attention mechanism can make the network pay more attention to the key information of the input image, so as to improve the accuracy and efficiency of the model.
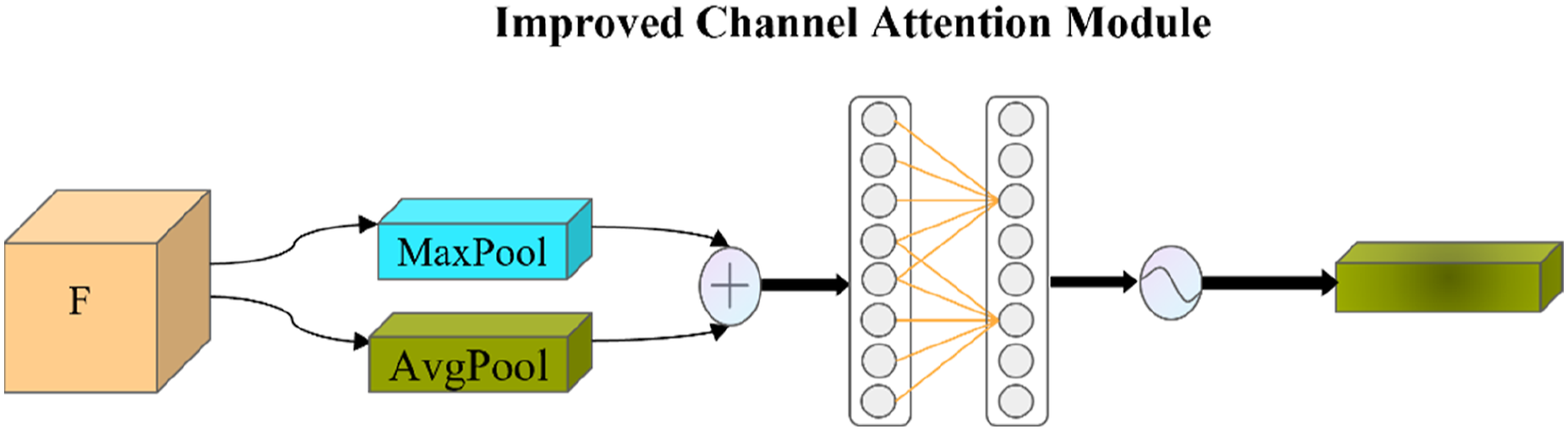
Considering the background interference when detecting the bobbin, the attention mechanism CBAM can suppress the complex background interference and extract the key pixel area. 16 Research and analyze the shortcomings of CBAM attention mechanism. By optimizing the channel attention module and spatial attention module, the improved ICBAM attention mechanism is inserted into the Backbone and Neck of YoloColor-Net, which not only improves the ability of the model to suppress complex background interference when detecting the bobbin, but also effectively improves the detection accuracy of the model. The specific improvement research is as follows:
Improvement of channel attention module
The improvement process of the channel attention module of ICBAM is as follows: given the input feature map ICBAM channel attention module structure.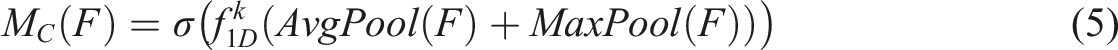

Improvement of spatial attention
The improvement process of spatial attention module is as follows: given the input feature map ICBAM spatial attention module structure.


Experiments and discussion
Experimental platform parameter settings.

Construction of experimental samples
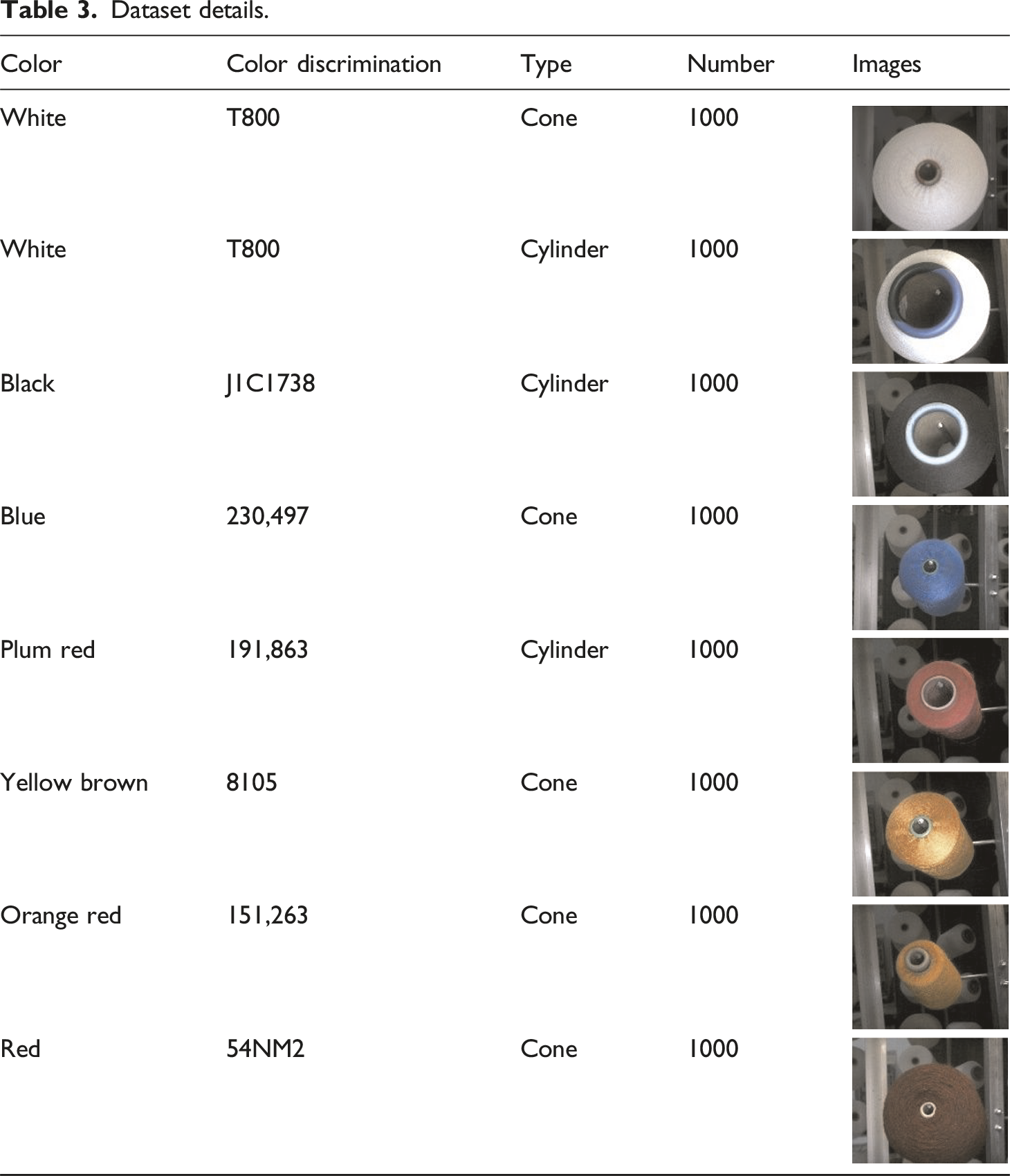
The experimental sample collection site is the Textile Intelligent Manufacturing Laboratory of Zhejiang Sci-Tech University. The collection equipment is a Hikrobot MV-CA060-10 GC color camera with a camera resolution of 3072 × 2048. The distance between the camera end face and the creel end face is 695 mm, the camera focal length is 6 mm, the pixel size is 2.4um/pix, and a strip light source is used as the working light source during image collection.28–30 The sample collection scene is shown in Figure 6. Sample collection site: (a) Strip light source; (b) Camera installation location.
Dataset details.
Color recognition module experiment
When processing the multi label recognition task, adding the color recognition module to the convolutional neural network (CNN) can extract the features of the bobbin shape and yarn color respectively, avoid the difficulty of feature fusion due to the different representation of the bobbin shape and yarn color in the image, and make the details of the bobbin feature change prominent, and the contour of the feature map change clearly, as shown in Figure 7. Comparison of feature maps before and after adding the color recognition module.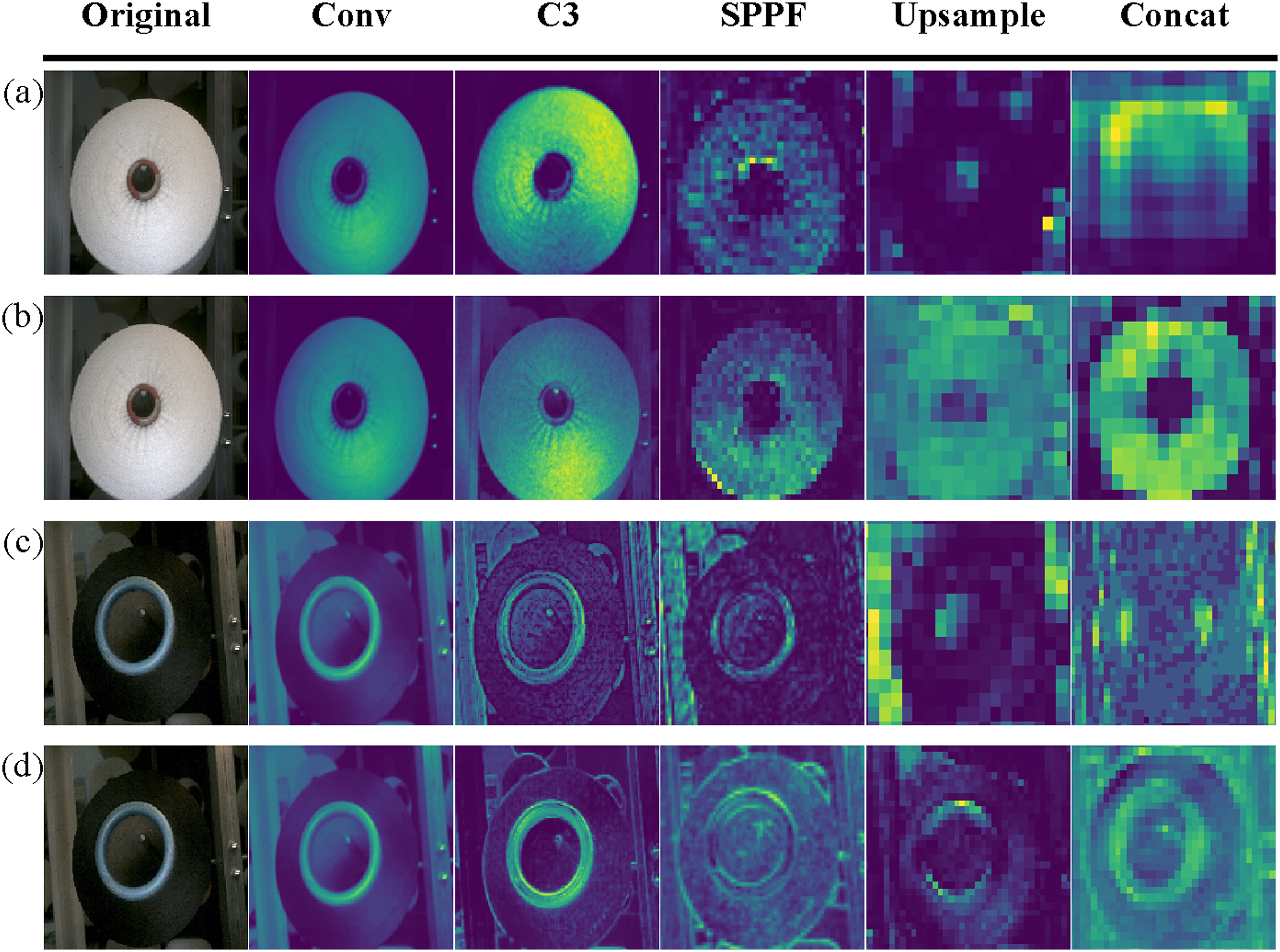
In the experimental process, we can set loss functions for shape and color features respectively to ensure that the model pays attention to these two features at the same time in the optimization process, so as to improve the detection accuracy. The contrast effect before and after adding color recognition convolution layer is shown in Figure 8. Experimental diagram of bobbin detection (a) bobbin missed detection before adding color recognition module (b) full detection of bobbin after adding color recognition module.
Detection accuracy
In order to illustrate the advantages of the improved model, the performance of the improved model is quantitatively analyzed on the test set of the bobbin data set with accuracy, recall and average accuracy. Before calculating these indicators, we first calculate true positive (TP), false negative (FN), false positive (FP), true negative (TN), and their specific meanings are shown in Figure 9: Definition of TP, FN, FP and TN.
Precision refers to the proportion of the number of positive samples correctly predicted by the model to the number of all positive samples predicted by the model. Its formula is:
Recall refers to the proportion of the number of positive samples correctly predicted by the model to the number of true positive samples. Its formula is:
AP (average precision) measures the average accuracy of the model in a single category, which reflects the performance of the model in predicting positive samples. When multiple categories of objectives are involved, the average AP (mAP) is used as the evaluation index of the whole model, and its formula is:
Comparison of detection accuracy of YoloColor-Net.

mAP values of YoloColor-Net with different attention mechanisms.

As shown in Figure 10, it is the distribution diagram of the heat map of the bobbin. The redder the red area in the heat map, the greater the weight information of the model there. ICBAM attention mechanism can more completely locate the weight information of the model to the end face of the bobbin, followed by CBAM attention mechanism. And it can be seen from the figure that the Shuffle-Attention, SENet and CA attention mechanisms added to the model can not be well positioned to the end face of the bobbin, which is prone to false and missed detection of the model, resulting in the model detection accuracy of the bobbin is not high enough. Therefore, when ICABM attention mechanism is added to the model, the detection accuracy of the model is higher. Heat map distribution of YoloColor-Net with different attention mechanisms added.
Computational cost analysis
In the follow-up study, the YoloColor-Net model we proposed needs to be deployed in the textile workshop with limited computing resources. 31 The computational cost of the model is directly related to whether it can be deployed and run in the automated production process. Therefore, this section analyzes the computational cost of the model to provide guidance for further optimization of the model.
Comparison of YoloColor-Ne detection performance indicators.

As shown in Figure 11, it is the size of computer memory occupied by the model. The memory of YoloColor-Net model before improvement is 27.56Mb, and the memory occupied by the improved model is 24.69Mb. By comparing the performance of Parameters, GFLOPS and FPS of the model in different improvement stages, the impact of different improvement schemes on the calculation cost of the model is intuitively displayed, and it is further demonstrated that the model proposed in this paper has reached the current optimal state in terms of balance performance and calculation efficiency. Although the current algorithm model has achieved some results in detection performance, its large number of parameters and high memory consumption are still the main problems restricting the detection speed of the model.32,33 Comparison of memory usage at different improvement stages.
Conclusions
In this paper, we propose a deep learning framework YoloColor-Net, which can realize multi label recognition. It aims to detect and recognize the bobbin shape and yarn color in the textile workshop at the same time.
By adding a yarn color recognition module to the detection head of Yolov5, it can avoid missing detection when Yolov5 model detects the shape of the bobbin and the color of the yarn at the same time, and form the initial YoloColor-Net model. In order to reduce the amount of model parameters, the distributed shift convolution (DSConv) is used to replace the ordinary convolution to improve the Backbone layer of YoloColor-Net. In addition, the convolution block attention module (CBAM) is improved, and the ICBAM attention mechanism is proposed, which is added to the Backbone and Neck layers of YoloColor-Net to realize the lightweight of the model and improve the detection accuracy, effectively improving the shortcomings of CBAM attention mechanism
In the multi label recognition experiment, YoloColor-Net model can complete the task of simultaneous detection of bobbin shape and yarn color, with Precision of 99.1%, Recall of 98.9%, mAP@0.5 of 99.3%. By improving the Backbone layer and adding ICBAM attention mechanism, the Parameters of the model are reduced by 10.4%, GFLOPS is reduced by 17.1%, and FPS is increased by 55.9%, which has a good industrial application prospect. However, the current large number of parameters and memory occupation of the model are the main factors affecting the further improvement of the model detection speed.
The lightweight model can not only reduce the demand for hardware resources, but also reduce production costs. And it can respond to production demand faster, reduce the production stagnation caused by calculation delay, and improve the overall production efficiency. Therefore, while ensuring the accuracy of the model, optimizing the model compression technology to realize the lightweight of the model is the direction of further research.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.