
Abstract
Despite leading models of mental health care encouraging user involvement, users in forensic mental health (FMH) report poor involvement given the difficulty in reconciling shared approaches with risk-averse and legally mandated settings. While previous research has demonstrated qualitative benefits to shared approaches in FMH and has led to a proliferation of self-rated assessment tools, there remains to quantify agreement on self-rated tools and to clarify the impact of shared approaches on care. This meta-analysis examines (1) the correlation between clinician and user ratings, (2) the predictive validity of self-ratings for violence, and (3) the effects of shared risk management on violence and restriction in FMH. Five databases were searched from inception to April 2024, selecting for adult FMH inpatients, shared risk assessment, needs assessment or violence management as interventions, and quantitative outcomes (correlation, agreement, predictive validity, and effect on violence or restriction rates). Fifteen quantitative evaluations were retained. One of three planned meta-analyses could be conducted, with seven records providing paired clinician–user t-tests. Eleven more records provided clinical recommendations on operationalizing shared approaches. Random-effects meta-analysis showed a significant and large paired standard difference of .95 (95% CI = [.49,1.42]) across tools, with significant differences in DUNDRUM-3, DUNDRUM-4, and CANFOR sub-models. While acknowledging between-study heterogeneity, results substantiate quantitative differences where clinicians generally rate more needs and lesser progress than users across tools, showing that self-ratings can and should be used to broach collaborative discussions on needs and progress during FMH treatment. There remains an evidence gap for quantitative benefits in care outcomes and a need to standardize agreement measures for future comparisons and clinical sub-group analyses.
Keywords
Introduction
Patient Involvement in Mental Health Care
Best practices for healthcare delivery worldwide have increasingly included patient involvement or participation as a central component for providing high-quality and person-centered care (Valderas et al., 2016; van Dulmen et al., 2015). Within the general mental health field, shared decision-making (SDM) has emerged as one of the main methods for operationalizing patient involvement in care planning and delivery. While the definition of SDM varies with care context, it is generally understood as a collaborative process between at least two parties (i.e., a healthcare practitioner and a service user at minimum) in which information is shared bidirectionally, efforts are made to build consensus or reconcile evidence-based information and user preferences, and a joint decision relating to treatment is ultimately made (Charles et al., 1997; Coulter & Collins, 2011; Substance Abuse and Mental Health Services Administration, 2011). Outcome studies in mental health report a small effect of SDM on treatment-related empowerment (Stovell et al., 2016) and positive associations with both empowerment and user satisfaction (Tambuyzer et al., 2014). Moreover, higher perceived involvement in decision-making, along with clinician preference for active versus passive involvement, are both related to increased user satisfaction (Clarke et al., 2016). While SDM is a widely-researched participatory method (Chmielowska et al. 2023), patient involvement can be thought of more broadly as including participatory decision-making, involvement spread across multiple care-related activities (i.e., evaluation, planning, delivery, research, and training), the user as an active participant in said activities, the user as an expert on lived experience, and collaboration with professionals (Jørgensen & Rendtorff, 2018; Tambuyzer et al., 2014). Further positioning patient involvement as a broader goal than SDM, persons with serious mental illnesses have more often expressed interest for receiving information, discussing care options, and sharing their views, rather than making final care decisions (Huang et al., 2019).
Numerous barriers to implementing practices for patient involvement in mental health care have been documented. For one, the persistence of the biomedical model in psychiatry and its traditionally paternalistic care delivery approach represents an important barrier (Jørgensen & Rendtorff, 2018). The tendency to focus on a user limitations more often than their strengths is also highlighted (Jørgensen & Rendtorff, 2018), with professionals often citing a lack of decision-making ability (relating to capacity, insight, and cognitive function) and low motivation as key barriers to SDM or patient involvement (Huang et al., 2019). There are added difficulties for inpatient settings specifically, with the bulk of studies on SDM having been conducted in community settings (Chmielowska et al., 2023). These include establishing equal relationships, user-provider disagreements, and the duality between a user’s participatory needs and the collective setting rules (Storm & Edwards, 2013). Such barriers are further amplified in forensic mental health (FMH).
Patient Involvement in Forensic Mental Health: Risk Assessment and Management
FMH settings have the dual task of providing treatment to reduce psychiatric symptomatology and support user recovery, while also lowering individual violence risk. These care responsibilities are often legally mandated, as forensic service users have either been involved with the criminal justice system or are evaluated as high risk for future justice involvement. Users held in secure inpatient care or followed under mandated community treatment are thus particularly at risk of being cut out of decision-making regarding their legal trajectory and care. Among the chief treatment processes for their care are risk assessment and management, as an international review placed the proportion FMH inpatients demonstrating aggression or violence at 48% during long-term hospitalization (Bowers et al., 2011). Unfortunately, FMH inpatients are seldom informed about risk assessment and risk management (Dixon, 2012; Langan, 2008), and thus report poorly understanding the rationale and processes for such interventions (Nyman et al., 2022). What is more, professionals in FMH have been found to rate quality of care as higher than do users (Lundqvist & Schröder, 2015). Finally, FMH users also report that risk management can lead to unnecessary restrictions and loss of autonomy (Tomlin et al., 2020), including but not limited to the use of seclusion and restraint.
In accordance with the global emphasis on person-centered care and SDM in general and mental health fields, and given current evidence for low involvement in FMH, it follows that FMH inpatients should also be offered shared approaches which could improve their involvement in risk assessment and management processes, but also the assessment of their needs, treatment progress, and recovery. First, SDM was born out of an ethical imperative to ensure informed consent in the physical health field. It is equally imperative to involve FMH inpatients in their care (where legally possible), especially as they are often legally unable to opt out of unsatisfactory care. Second, meaningfully engaging users in assessment and management is an essential part of recovery-oriented practice in FMH (Senneseth et al., 2021). Personal recovery is generally understood as the personal and unique process of developing new meaning and purpose to recover a satisfying life, notwithstanding the limitations imposed by illness (Anthony, 1993). Recovery-oriented practice is widely recognized as a guiding orientation for all mental health services, including FMH (Senneseth et al., 2021). Thirdly, there are numerous benefits that could be derived from shared approaches in this setting. A recent meta-synthesis of qualitative literature on shared risk assessment and management identified, amongst other benefits, that FMH patients could better understand themselves, had improved therapeutic relationships with their care team, were provided with new coping skills and management choices, and gained in self-agency (Luigi et al., 2024). Increased patient involvement could also help users navigate the complexity of legal and healthcare trajectories in FMH (McKeown et al., 2016). While the perceived benefits of shared approaches have been synthesized, it remains to clarify their quantitative effect on central FMH care outcomes, such as violence or restrictive measures.
Among the unique barriers that FMH settings face are the legal frameworks and risk-averse culture of some care teams, which may hinder a clinician’s ability or desire to work collaboratively (Ahmed et al., 2021). Also related to legal frameworks, interventions to increase involvement should be designed to address some of the powerlessness experienced by FMH users as a result of the removal of daily responsibilities (i.e., meals, planning out their routine, etc.), the uncertainty surrounding duration and trajectories of care, and the ultimate discretionary power of decision-making which is afforded through legal mechanisms (Luigi et al., 2024; Söderberg et al., 2022). Finally, other interpersonal and institutional-level barriers to patient involvement in FMH include a lack of transparent information sharing, uncertainty on how to reconcile disagreements, and the absence of accompanying organizational strategies to ensure culture change and ongoing evaluation of user-rated participation (Luigi et al., 2024). Because of these barriers, FMH has fallen behind the general mental health field in adopting shared approaches. This state of practice remains despite potential benefits and current risk management guidelines (Markham, 2020; National Institute for Health and Care Excellence [NICE], 2015).
The Present Study
Two previous reviews have examined the use of shared risk assessment and management in FMH, revealing a small quantitative literature (Eidhammer et al., 2014; Ray & Simpson, 2019). Amongst the interventions surveyed, some improvement in the use of restrictive measures and incident severity was highlighted with a structured shared management strategy, the Early Recognition Model (ERM; Fluttert et al., 2010). Further, within the most recent review, Ray and Simpson (2019) highlighted three research tracks in the field: structured risk management, such as the ERM, the completion of structured professional judgment tools for assessment by both staff and users, and joint ratings of needs assessment tools. Since then, research on joint ratings for concepts other than risk has multiplied in FMH, with tools such as the Camberwell Assessment of Need–Forensic and Health of the Nation Outcome Scales–Secure (CANFOR-S—Thomas et al., 2008)and Dangerousness, understanding, recovery, and urgency manual (DUNDRUM—Kennedy et al., 2010) prominently featured. Given the relatively recent emergence and the multiplication of said self-rated tools, there is now a need to synthesize findings on the agreement between clinician and user ratings and the predictive validity of self-rated tools. Moreover, the effectiveness of all shared approaches for assessment and management should also be reviewed if they are to be considered as evidence-based practices in FMH (Ahmed et al., 2021; Ray & Simpson, 2019).
Objectives of the Study
The primary aim of this review and meta-analysis is to quantify existing evidence for the use of shared approaches to violence risk or needs assessment and risk management within inpatient FMH. Specifically, we aimed to answer three research questions through meta-analyses where possible: (1) What is the level of agreement between violence risk assessment or needs assessments rated by clinicians and FMH service users (Outcome 1), (2) What is the predictive validity of FMH assessment ratings by service users in comparison to clinician ratings (Outcome 2), and (3) What are the effects of shared approaches, including shared ratings and risk management, on subsequent rates of violence and restrictive practices (Outcome 3)? As a secondary objective, we aimed to synthesize accompanying literature that included recommendations on how to conduct clinical work in the context of shared approaches in FMH.
Methods
Registration and Protocol
Our systematic review and meta-analysis protocol was published in the International Prospective Register of Ongoing Systematic Reviews in January 2023 (CRD42023389044) and updated in June 2024. Selection criteria were also expanded to include needs assessment tools.
Search Strategy
MEDLINE, Embase, CINAHL, PsycINFO, and ProQuest databases were searched from inception to April 2024. The search strategy combined three keyword strings for: FMH patients, patient involvement, and violence/needs assessment or management. An example of the full search strategy employed in MEDLINE is presented in Appendix A. Moreover, collateral search methods included hand-searching reference lists for all included records, consulting previous reviews (Ahmed et al., 2021; Eidhammer et al., 2014; Ray & Simpson, 2019), and conducting targeted searches for follow-up studies. In targeted searches, the Google Scholar and PubMed profiles of the lead authors on all included studies were searched for any additional records. No restrictions were imposed on language or geographical location. Where records were published in languages other than English or French, a FMH librarian attempted to locate translations. Where insufficient data were available for meta-analysis, authors were contacted by e-mail. As a second group of selected records, relevant commentaries, books, reviews, recommendations, and guidelines from the primary search were set aside to review existing clinical recommendations.
Inclusion Criteria and Record Selection
Retrieved records were selected as quantitative evaluations if they met the following inclusion criteria: they reported (1) original research, (2) on adults (at least 50% of sample was 15 years or older, accounting for emerging adults (Anderson et al., 2022)), (3) in secure inpatient forensic settings, and (4) on shared risk or needs assessments, or shared management interventions for violence against others or objects (including physical, verbal or threat-based hetero-aggression). Exclusion criteria included (1) general psychiatric settings, (2) incarcerated offenders who were not undergoing psychiatric treatment, (3) samples without a psychiatric condition other than a personality disorder or substance use disorder, and (4) child samples.
Authors 1 and 2 independently screened title and abstracts for 50% of records in a stepwise process in Zotero. This process involved discussing disagreements and adjusting until consensus for every 15%, 15%, 15%, and finally 5% of records screened. While a third author was available for resolving disagreements, this was not needed. Author 1 screened the remaining 50% of titles and abstracts. Records were then imported into Rayyan (Ouzzani et al., 2016) for both reviewers to independently screen all full texts. Disagreements were resolved in discussions to consensus.
Data Extraction and Critical Appraisal
Quantitative Evaluations
Authors 1 and 2 independently extracted data from all of the selected quantitative evaluations into a Google Form, which was piloted on 5% of selected records. After piloting, the final extraction form included study information (i.e., authors, year of publication, country, level of security, data collection methods), sample characteristics (i.e., size, age, sex and/or gender, psychiatric diagnoses), details on the intervention or assessment under study, quantitative outcome data for all three primary outcomes (e.g., means, standard deviations, correlations, agreement measures, AUCs, etc.), data on possible secondary outcomes, and limitations. Secondary outcomes included the time necessary to score assessment tools, adverse events, economic evaluations, and user perspectives on usability of the shared approach tools.
Moreover, risk of bias was assessed independently by Authors 1 and 2 for meta-analyzed articles, using the COnsensus-based Standards for the selection of health Measurement INstruments (COSMIN) (Mokkink, 2018). Given that only studies on correlation or agreement between clinicians and users could ultimately be meta-analyzed, only the interrater reliability sub-section of the COSMIN was scored (Bockhorn et al., 2021). In keeping with COSMIN principles, the lowest item score (scored as very good, adequate, doubtful, or inadequate) out of all eight items was retained as each study’s overall risk of bias (Mokkink, 2018). Furthermore, three Grading of Recommendations Assessment, Development and Evaluation (GRADE) ratings were assigned for each meta-analysis, as suggested for the evaluation of patient-reported measures (Mokkink et al., 2018): inconsistency (i.e., unexplained differences across studies), imprecision (i.e., sample size), and indirectness (i.e., population different than that of interest).
Non-Quantitative Studies
Relevant commentaries, book chapters, guidelines, and reviews were screened by Author 1 for available clinical recommendations on shared approaches in FMH. Recommendations outlined in these publications were extracted into Excel for narrative synthesis. Any clinical recommendations from selected quantitative studies were also included.
Data Analysis
Quantitative Evaluations
Available effect sizes were entered into Comprehensive Meta-Analysis version 4 (Borenstein, 2022) for meta-analyses. In view of the variability in assessment tools (generating heterogeneity) and because results were intended to be generalized beyond the included studies, random-effects models were conducted (Tufanaru et al., 2015). Based on the availability of data, only Outcome 1 was meta-analyzed by entering paired t-tests into models for pooled standard differences. In addition, tool-specific sub-models were generated for Outcome 1 where there were at least three independent effect sizes on a single rating tool. Significance of the pooled estimates was assessed through 95% confidence intervals (95% CI; where all values are on the same side of the null) and Z-values (where the null hypothesis can be rejected if p ≤ .05). Heterogeneity was assessed using the Q statistic (Cochran, 1954) and the I2 (Higgins & Thompson, 2002). Sensitivity analyses consisted in using the one-study-removed method on the global model, where substantial changes in the pooled effect represent a lack of homogeneity and unreliable results (Viechtbauer & Cheung, 2010). Moreover, 95% prediction intervals (PI) were calculated as per Borenstein et al., (2009). Publication bias was not investigated, as the difference in clinician-user ratings was unlikely to influence publishing. That is, both widely different and similar scores would hold clinical and publication interest.
Non-Quantitative Studies
Author 1 conducted a narrative synthesis of clinical recommendations.
Results
Record Selection
A total of 2013 non-duplicate records were identified. Authors 1 and 2 determined that 44 records were eligible for full-text assessment, comprising 22 quantitative evaluations and 22 records for potential recommendations (see Figure 1). As detailed in Figure 1, most of the records at the full-text stage were excluded because of sample characteristics (i.e., service users in community settings or offenders without a psychiatric condition). Most disagreements (4/7) at the full-text stage regarded the population studied, especially where it was later agreed between raters that study populations were entirely outpatient or incarcerated. Ultimately, 15 quantitative evaluations were included in the review, 7 in the meta-analysis global and/or sub-models for outcome 1, and 8 reserved for narrative synthesis of all three outcomes. Eleven more records were set aside for the narrative synthesis of clinical recommendations for shared approaches.
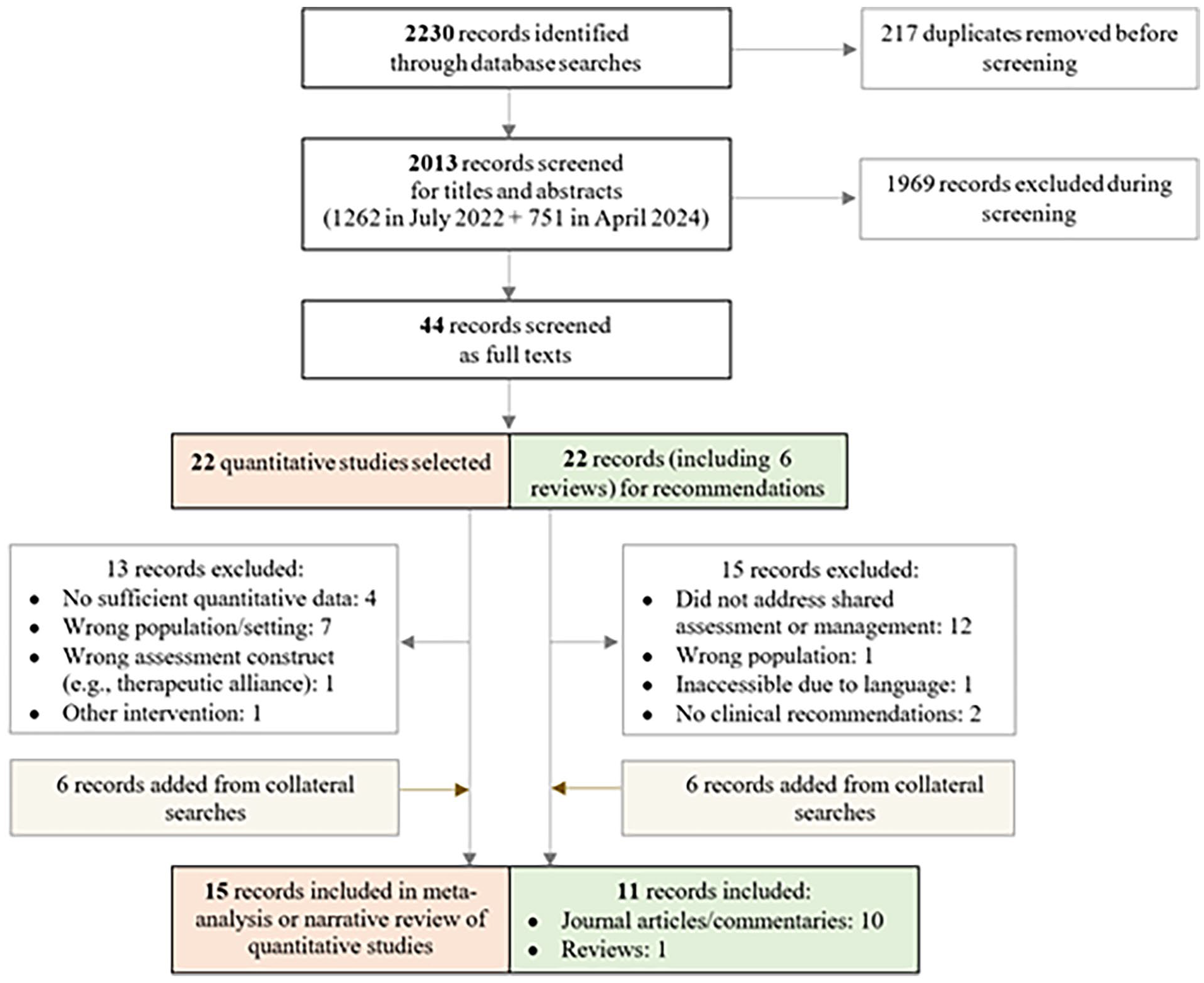
Flow diagram for review on shared assessment and management.
Study Characteristics
The characteristics of selected quantitative evaluations are presented in Table 1 for studies included in meta-analytical models, and Table 2 for those only included in the narrative synthesis. Studies were primarily set in FMH hospital settings (k = 14), with one in a correctional treatment unit (Lasher et al., 2015). Quantitative evaluations spanned across continental Europe (k = 8), North America (k = 4), Australia (k = 2), and Japan (k = 1). Most were published in peer-reviewed journals (k = 13), with one thesis (Rangan et al., 2020) and one conference abstract (Synnott et al., 2022) included. All selected studies were observational and only three were multisite (Oberndorfer et al., 2023; Rice et al., 2004; Ryland et al., 2024). Sample sizes ranged from 13 to be 221, with a weighted average of 90.03% male participants and 64.91% with schizophrenia. The mean weighted age of participants was 38.83 years (SD = 10.84). Across all 15 quantitative studies, 14 reported on Outcome 1, 1 on Outcome 2, and 1 on Outcome 3.
Study Characteristics of Quantitative Studies Included in the Meta-Analysis.
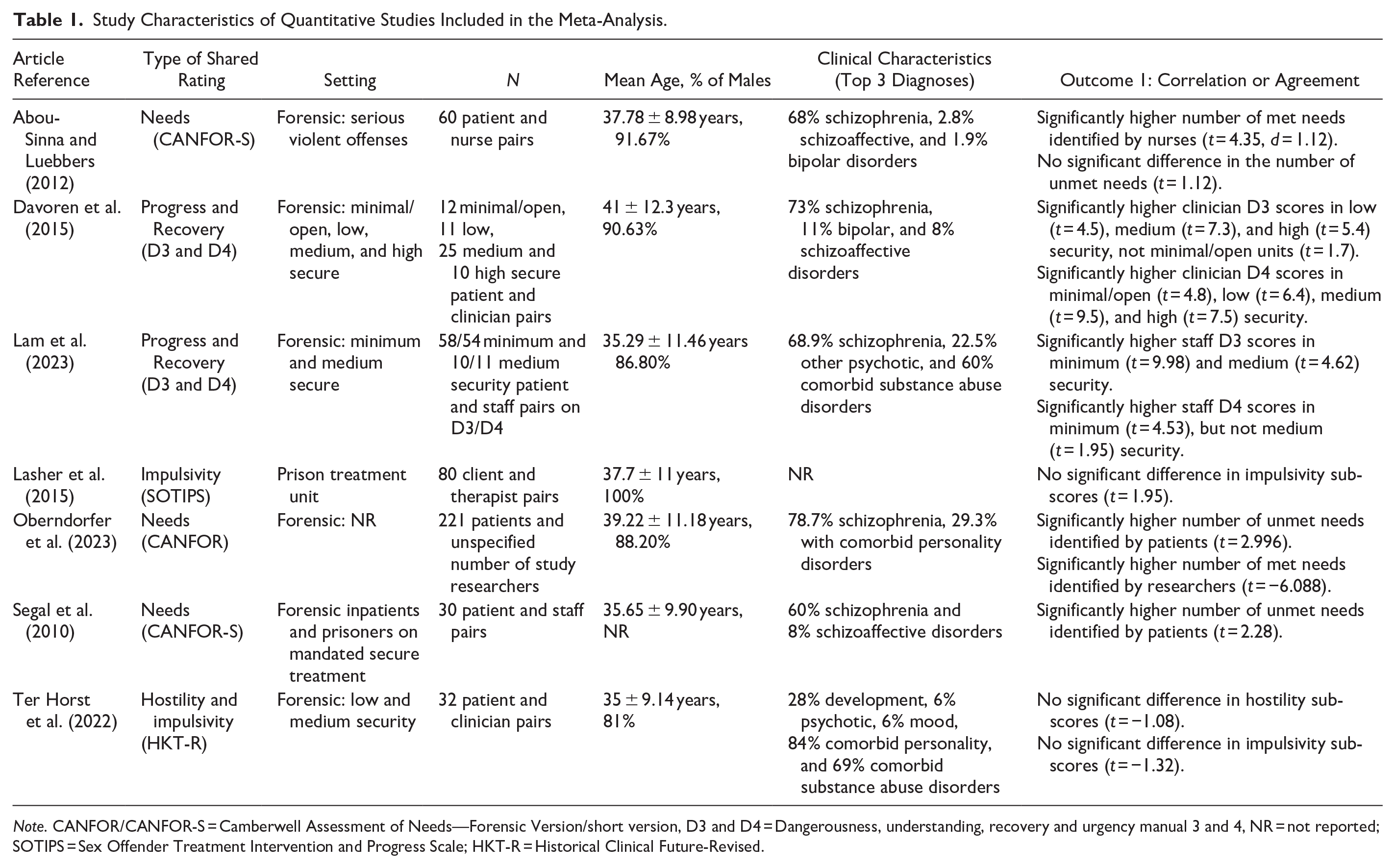
Note. CANFOR/CANFOR-S = Camberwell Assessment of Needs—Forensic Version/short version, D3 and D4 = Dangerousness, understanding, recovery and urgency manual 3 and 4, NR = not reported; SOTIPS = Sex Offender Treatment Intervention and Progress Scale; HKT-R = Historical Clinical Future-Revised.
Study Characteristics of Quantitative Studies Included in Narrative Synthesis Only.
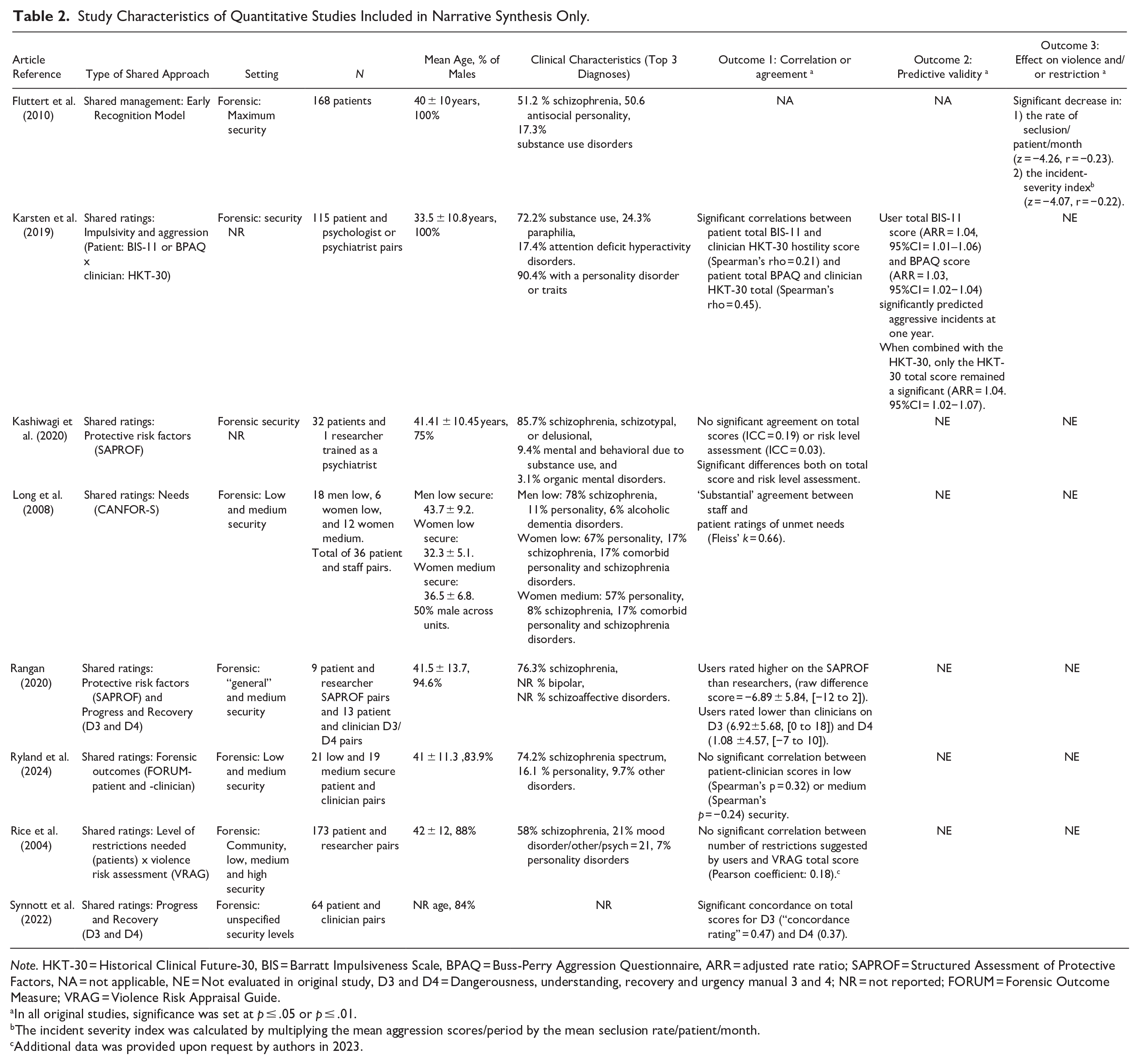
Note. HKT-30 = Historical Clinical Future-30, BIS = Barratt Impulsiveness Scale, BPAQ = Buss-Perry Aggression Questionnaire, ARR = adjusted rate ratio; SAPROF = Structured Assessment of Protective Factors, NA = not applicable, NE = Not evaluated in original study, D3 and D4 = Dangerousness, understanding, recovery and urgency manual 3 and 4; NR = not reported; FORUM = Forensic Outcome Measure; VRAG = Violence Risk Appraisal Guide.
In all original studies, significance was set at p ≤ .05 or p ≤ .01.
The incident severity index was calculated by multiplying the mean aggression scores/period by the mean seclusion rate/patient/month.
Additional data was provided upon request by authors in 2023.
The 11 records selected for recommendations included two book chapters (Shingler & Mann, 2006; Weinberger & Sreenivasan, 2018), a review (Eidhammer et al., 2014), a guidance document (NICE, 2015) and seven journal articles (Baird & Stocks, 2013; Baird et al., 2017; Horstead & Cree, 2013; Markham 2018, 2020; Moore & Drennan, 2013; Papapietro, 2019).
Types of Shared Approaches
All seven studies included in meta-analyses operationalized shared approaches through user ratings on needs, treatment progress, recovery, impulsivity, or hostility. Most effect sizes were extracted from two studies on the DUNDRUMs 3 (treatment progress) and 4 (recovery) (Davoren et al., 2015; Lam et al., 2023), with others from three studies on the CANFOR regular or short versions, one study on the Sex Offender Treatment Intervention and Progress Scale (SOTIPS—(Lasher et al., 2015)), and one on the Historical Clinical Future-Revised (HKT-R—(Ter Horst, 2022)). Within the meta-analyzed studies, users rated the same assessment tool as clinicians (k = 6/7) or researchers (k = 1/7). In complement, among the narrative synthesis studies, eight employed assessment tools for general FMH outcomes (Ryland et al., 2024), violence risk or protective factors (Karsten et al., 2019; Kashiwagi et al., 2020; Rice et al., 2004), impulsivity and aggressivity (Karsten et al., 2019), treatment progress and recovery (Rangan, 2020; Synnott et al., 2022), or needs (Long et al., 2008; Rice et al., 2004). With regards to outcome 3, one study reported on a shared risk management intervention, the ERM (Fluttert et al., 2010).
Few details were available on how service users completed their ratings. Only one study reported briefly training users to complete the CANFOR-S (Long et al., 2008). Four studies specified that ratings were formulated in a session with a staff mentor (Fluttert et al., 2010), psychologist (Kashiwagi et al., 2020), nurse (Abou-Sinna & Luebbers, 2012) or researcher (Ryland et al., 2024). In a fifth study, ratings were discussed in a user group (Lasher et al., 2015).
Outcome 1: Correlation and Agreement Between User and Clinician/Researcher Ratings
Eight distinct effect sizes from four studies were inputted into a global random-effects model of t-tests for the correlation between clinician and user ratings on the DUNDRUM 3, SOTIPS, and HKT-R. Because studies provided DUNDRUM-3 ratings on the same users as for the DUNDRUM-4, only DUNDRUM-3 results were included in the global model. Treatment progress was more closely related to other tools in said model than recovery. The global model (see Figure 2) showed a significant and large pooled standard paired difference of 0.95 (95% CI = [0.49, 1.42], 95% PI [−0.61, 2.52], z = 4.02, p < .001). Heterogeneity was significant (I 2= 86.87, p < .001). Using the one-study removed method (Appendix B), eliminating effect sizes from Ter Horst et al. (2022) or Lasher et al. (2015) would slightly increase the pooled estimate without changing conclusions.
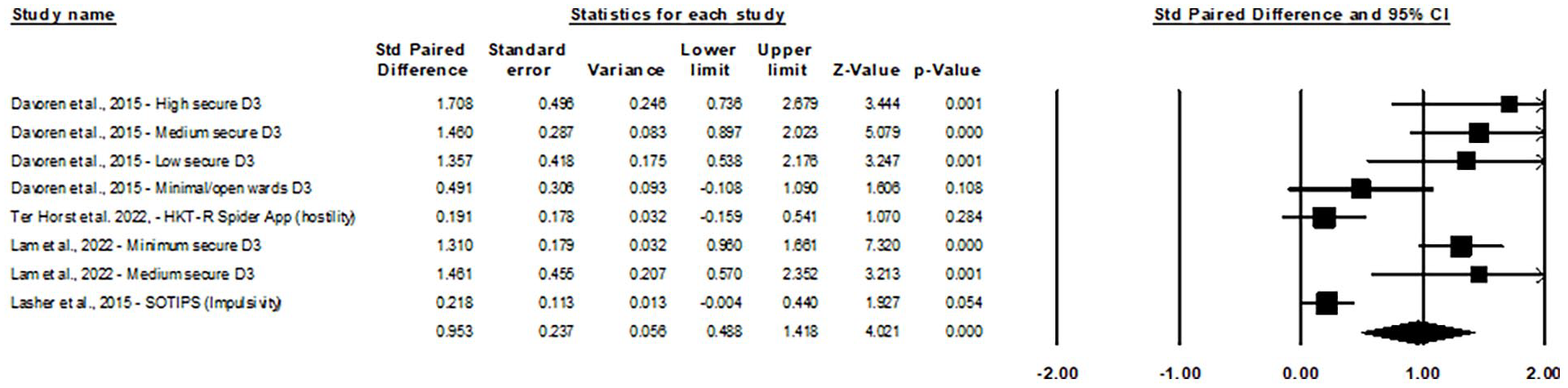
Forest plot of user–clinician score correlation studies using paired t-tests.
Three sub-models were carried out to examine pooled correlations for specific tools. First, the DUNDRUM-3 sub-model (Figure 3a) showed a significant and large pooled standard paired difference of 1.25 (95% CI [0.92, 1.58], 95% PI [0.42, 2.07], z = 7.465, p < .001), with no significant heterogeneity. Furthermore, the D4 sub-model (Figure 3b), which included effect sizes not inputted in the global model, also showed a significant and large difference of 1.37 (95% CI [0.76, 1.97], 95% PI [−0.64, 3.36], z = 4.40, p < .001). Heterogeneity was significant (I2 = 79.57, p < .001). The third sub-model for the CANFOR—unmet needs (Figure 3c) showed a small but significant pooled standard difference of 0.35 (95% CI [0.12, 0.59], 95% PI [−2.22, 2.93], z = 2.98, p < .005) with no significant heterogeneity.
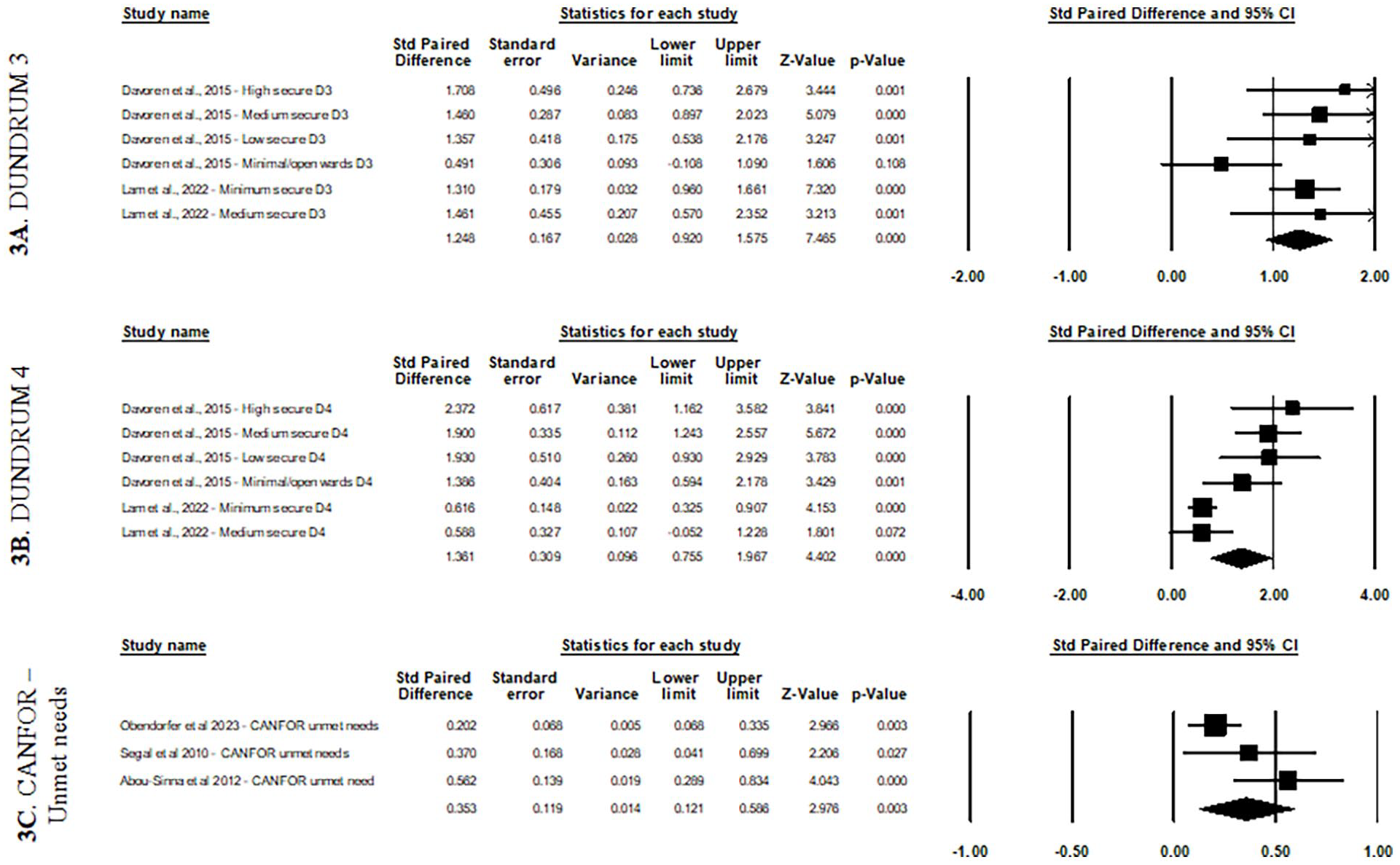
Forest plots for sub-models by assessment tool using paired t-tests
Eight more studies were included in the narrative synthesis for Outcome 1. Rangan et al.’s (2020) small sample study (n=13) also reported differences between user and clinician total scores, with users rating themselves as further along in treatment progress and recovery (i.e., lower scores – significant for DUNDRUM-3 only 1 ). However, Rangan et al., (2020) reported smaller differences in mean DUNDRUM-4 scores than DUNDRUM-3 scores (raw difference scores of 1.08 for D4 and 6.92 for D3), to the opposite of pooled effect sizes in our meta-analysis sub-models (i.e., 1.37 for D4 and 1.25 for D3). Further, Synnott et al. (2022) reported significant correlations between user-clinician DUNDRUM total scores in a larger patient sample (n = 64), without citing mean differences which would enable comparisons in this review. To complement the CANFOR-unmet needs sub-model, Long et al., (2008) reported “substantial agreement” in user-staff ratings of unmet needs (Fleiss’ Kappa = 0.66; n = 36), except for the “safety to others” item which staff were significantly more likely than users to rate as an unmet need.
In line with this mismatched assessment of risk on the CANFOR, there was no significant correlation between staff total scores on the Violence Risk Appraisal Guide (VRAG—Harris et al., 1993) and the number of restrictions recommended by 173 users in Rice et al.’ s study (2004). Kashiwagi et al. (2020) also reported significant differences and no significant agreement on the risk level assessment of the Structured Assessment of Protective Factors for violence risk (SAPROF) in 32 users. As an outlying study, Karsten et al., (2019) reported modest but significant correlations between user self-ratings of Barratt Impulsiveness Scale (BIS-11) and Buss-Perry Aggression Questionnaire (BPAQ) and clinician risk ratings on the Historical Clinical Future-30 (HKT-30) in 115 patients.
Finally, three studies examined user-clinician agreement on measures of other concepts. No significant correlation was found on the FORensic oUtcome Measure (FORUM) (Ryland et al., 2024), which contains 12/20 and 13/23 overlapping questions on patient and clinician versions, respectively. The FORUM assesses forensic outcomes in six domains: “about me,” “my quality of life,” “my health,” “my safety and risk,” “my progress,” and “my life skills” (Ryland et al., 2021). Moreover, Kashiwagi et al. (2020) reported low agreement and significant differences on SAPROF total scores (ICC = 0.19) and individual items, except for external factors (ICC = 0.49) and intimate relationships (ICC = 0.69). Rangan (2020) also reported a difference in the SAPROF total score. In both studies, users rated their protective factors higher than clinicians.
Outcome 2: Predictive Validity of User Ratings
Karsten et al. (2019) quantitatively examined the predictive validity of user ratings. While user-rated total BIS-11 (ARR = 1.04, 95%CI = 1.01–1.06) or BPAQ scores (ARR = 1.03, 95%CI = 1.02–1.04) alone significantly predicted hospital-based incidents within 1 year, they failed to reach significance when inputted into a combined regression with the clinician-rated HKT-30.
Outcome 3: Effect of Shared Approaches on Rates of Violence and Restriction
One study reported quantitative outcome data on the effects of a shared approach, that is the ERM, which is a structured four-phase risk management protocol (Fluttert et al., 2010). ERM phases involve introducing the user to the method, identifying early warning signs of aggression with them, their social network, and nurses, learning to monitor their behavior, and applying pre-outlined preventive measures. The ERM was reported to significantly decrease the number of seclusion events, and the severity of incidents compared to usual treatment in 168 users.
Secondary Outcomes: Rating Time and Usability
One study (Long et al., 2008) reported that the average time for completing the CANFOR-S was 25 minutes. In addition, three studies surveyed or interviewed users on usefulness/relevance, comprehensiveness, and/or ease of use (Ter Horst et al., 2022; Karsten et al., 2019; Ryland et al., 2024). In using the new FORUM-patient measure, 61 users rated its comprehensiveness a 4.0/5, ease of use a 4.6/5 and relevance a 3.9/5 (Ryland et al., 2024). Regarding the app-based HKT-R (Ter Horst et al., 2022), authors also reported a certain ease of use, specifying that some users were already familiar with the paper-based version of the tool. Possible issues with comprehensiveness and perceived relevance were, however, highlighted, given that some users only scored factors they felt were relevant to discuss with the team and not all of them used the many additional markers available. That is, users could use “traffic lights” to indicate if they accepted help from the team or wanted the team to take control, “red flags and green thumps” to highlight important risk or protective factors, and/or written comment fields. Finally, HKT-R users reported the content as “interesting but sometimes confrontational” (author quote) (Ter Horst et al., 2022). Inversely, in a study of self-rated BIS-11 and BPAQ tools, patients described the content as “probing but unobtrusive” (Karsten et al., 2019).
Critical Appraisal of Studies
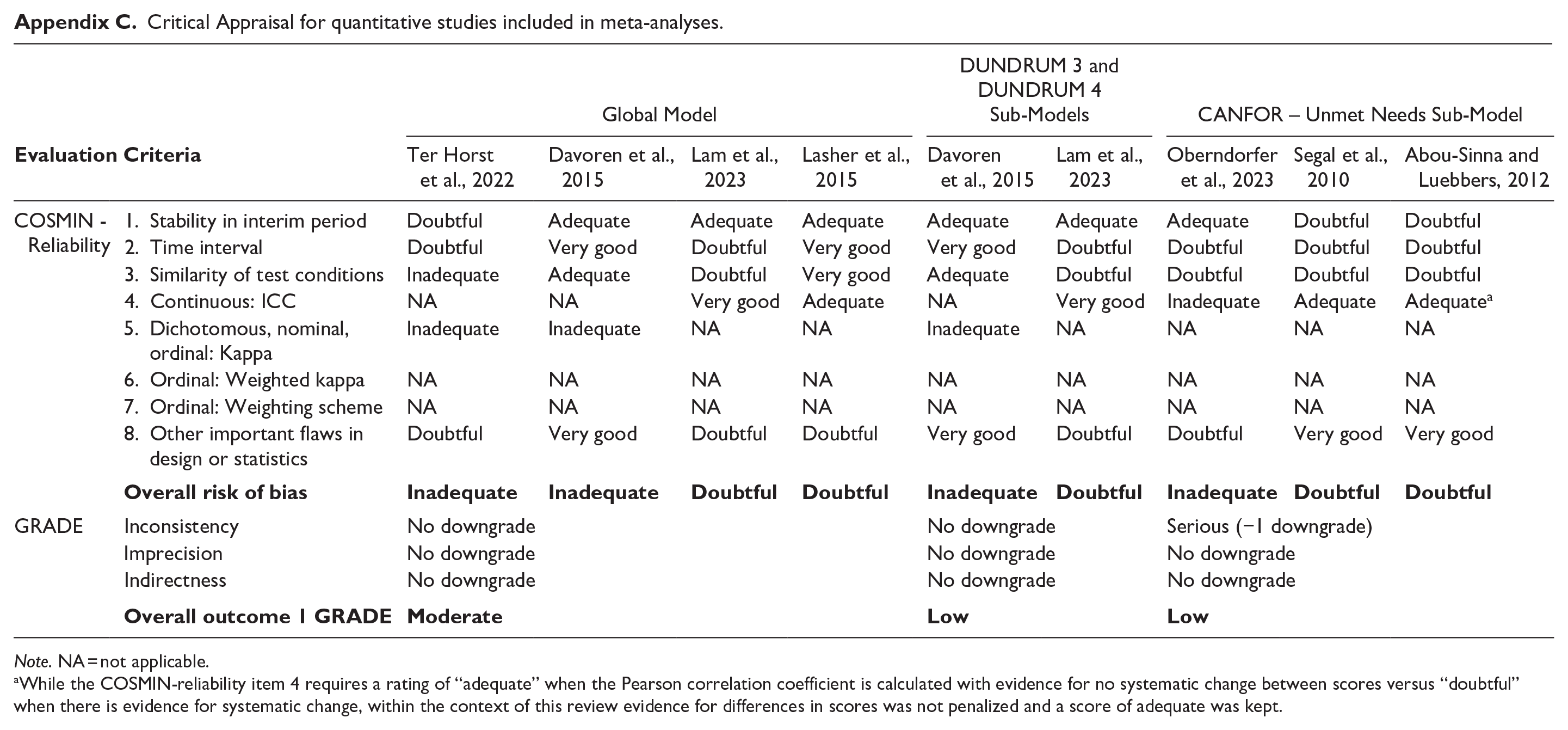
The evaluation of risk of bias and overall study quality for the seven meta-analyzed studies are summarized in Appendix C, classified by global or sub-models. COSMIN-reliability ratings indicated serious risk of bias in the global model and CANFOR sub-model, and very serious risk of bias for the DUNDRUM sub-models. Serious risk of bias set the GRADE quality rating at “moderate” and very serious at “low.” These results were driven by “Inadequate” ratings, almost all due to the incorrect choice of statistics as per the grading tool, where intra-class correlations and kappas were rarely calculated for continuous and ordinal scores, respectively. In subsequent GRADE ratings, there were no downgrades in quality rating for imprecision or indirectness, and one downgrade for inconsistency in the CANFOR sub-model. Using the stepwise GRADE downgrade approach, which combines COSMIN and GRADE ratings, the resulting quality of evidence was moderate for the global model and low for all sub-models.
Clinical Recommendations for Shared Approaches in FMH
Existing recommendations on shared approaches are presented in Table 3. Most recommendations address how to practically include a user or their designated representative at different stages of a violence risk assessment, that is when conducting the primary evaluation, providing feedback if allowed to do so, and providing an accessible summary to the user. In addition, two records examined involvement in care planning (Moore & Drennan, 2013; Papapietro, 2019), two discussed how to tackle refusals to participate (NICE, 2015; Papapietro, 2019) and three mentioned the need for tailored training on shared assessment (Eidhammer et al., 2014; Markham, 2018, 2020). Only one recommendation highlighted the need to develop specific professional training on collaborative assessment. Across recommendation domains, multiple authors have stressed the importance of flexibility and providing multiple opportunities for involvement, whether by adapting language, revisiting a refusal at a later date, offering participation again when capacity is improved, inviting the user to review part of the material, or involving alternative representatives (family, carer, or trusted professional).
Clinical and Development Recommendations for Working with Shared Approaches in Forensic Mental Health.

Discussion
Our study builds on previous reviews, which concluded to the feasibility of shared approaches to risk assessment and management and limited evidence on the positive effects of shared management interventions (Eidhammer et al., 2014; Ray & Simpson, 2019), by quantifying and synthesizing the rapidly growing literature on user self-assessments of risk, needs, progress, and recovery in FMH specifically. The present study is, to our knowledge, the first meta-analysis of self-ratings across tools and within tool-specific sub-models, demonstrating statistically significant and large differences in user-clinician scores across multiple tools (i.e., the DUNDRUMs 3 and 4, HKT-R, SOTIPS, and CANFOR), large differences for DUNDRUM-3 and DUNDRUM-4 sub-models, and a small difference in the CANFOR sub-model. As in previous reviews, these models are however still limited by sparce quantitative data on paired ratings. Moreover, prediction intervals reported with our meta-analyses also suggest caution in interpretating differences in clinician–user ratings, given between-study heterogeneity and the small number of studies per model. To complement quantitative effects, narrative synthesis also showed discordance on most measures, supporting the conclusion that self-ratings can feasibly be employed and are pertinent to bring attention to needs and treatment goals that are important to users and may be otherwise missed. For Outcomes 2 and 3, very little evidence (i.e., only single studies) was identified that showed the predictivity of self-ratings and the improvement in rates for violence and restriction following a shared intervention. Table 4 presents a summary of our critical findings.
Critical Findings.

Using Self-assessments in FMH
Interpreting differences in our global model, the direction of scores in all studies translated to clinicians rating the users as having more needs related to treatment and recovery (Davoren et al., 2015; Lam et al., 2023), impulsivity (Lasher et al., 2015), and hostility (Ter Horst et al., 2022). Despite these significant results, visual observation of the forest plot (Figure 2) reveals two clusters of effect sizes, with scores on the DUNDRUM-3 in minimal/open wards, as well as for the SOTIPS and HKT-R, showing closer clinician-user agreement. This result is in line with additional analyses in the original DUNDRUM studies (Davoren et al., 2015; Lam et al., 2023), which demonstrated better concordance as users grew closed to discharge and moved to lower security levels. This is notably why concordance has been proposed as a measure of insight evolving through hospitalization. Thus, future studies on clinician-user ratings must carefully consider users’ security risk, treatment progress, and how this might affect the level of agreement or disagreement in ratings, notably as the PI for the global model spanned both sides of the null, indicating between-study heterogeneity. Furthermore, because the global model and narrative synthesis combined assessment tools, we discuss findings accordingly to distinct assessment concepts below (i.e., treatment progress vs impulsivity/hostility).
In the global model, while varying findings for the SOTIPS and HKT-R subscales could be interpreted as better concordance on concepts of impulsivity and hostility, we would not assume this given our narrative synthesis revealed lower agreement on risk versus needs measures (Kashiwagi et al., 2020; Long et al., 2008; Rice et al., 2004). More likely, users in these studies might have had more stable mental health profiles, as one was set in a prison treatment setting (Lasher et al., 2015) and the other (Ter Horst et al., 2022) included the lowest percentage of users with psychotic disorders (i.e., 6%) in the present review. Moreover, narrative synthesis of findings on the assessment of risk-related concepts specifically (i.e., through the VRAG, BIS-11, BPAQ, and HKT-30) was uniquely limited by the fact that users and professionals did not rate the same scale.
Concerning treatment progress, for which there was the most evidence on shared ratings, the global meta-analysis model, DUNDRUM-3 sub-model, and narrative synthesis (Rangan, 2020) all showed that disagreements on treatment progress are non-negligeable and present across studies and high to low-security levels. These studies also speak to the feasibility of soliciting self-ratings on treatment progress. Taken together, our results support that self-ratings can and should be used to include FMH users in discussions about their longitudinal treatment planning. Qualitative work shows that such collaboration can lead FMH service users to better understand themselves, improve therapeutic relationships, and gain in self-agency (Luigi et al., 2024).
Meta-analysis results were more heterogeneous in the DUNDRUM-4 sub-model for recovery. That is, Lam et al., (2023) showed lower agreement on recovery principles than in the previous Davoren et al., (2015) study. Despite this, within individual studies, differences in DUNDRUM-4 user-clinician scores were more pronounced than on the DUNDRUM-3 within the Davoren et al., (2015), and less pronounced than the DUNDRUM-3 in Lam et al.’s work (2023). Such variability in DUNDRUM-4 scores (as well as the between-study heterogeneity quantified through I2 and PI metrics) is unsurprising when we consider that what personal recovery means to FMH services users has only started to be clearly defined (Senneseth et al., 2021), and there might thus be a greater need to accompany both users and staff in interpreting recovery ratings in the same way. While not yet examined, it is also possible that concordance on recovery ratings specifically is more dependent on therapeutic alliance given that recovery principles are more entrenched in self-identity and a user’s internal perceptions (for example, through items R3 – Therapeutic rapport or R7 – hope). In line with this hypothesis, Lam et al. (2023) reported the lowest ICC in all DUNDRUM-3 items on the item “Family and social networks, friendship and intimacy,” and Kashiwagi et al. (2020) report significant disagreements on factors such as empathy, coping, life goals, and motivation for treatment.
Lastly, looking to the third sub-model for CANFOR-unmet needs and one study included in the narrative synthesis (Long et al., 2008), important item-level differences emerged. While the meta-analysis showed a small difference in scores across studies, it must be noted that one study in the model (Abou-Sinna & Luebbers, 2012) and the record not meta-analyzed (Long et al., 2008) both failed to show significant differences on most items. Moreover, the CANFOR sub-model showed the largest PI in our study, indicating that future studies could identify greater clinician-user agreement than reported here. However, in all studies within the sub-model, the CANFOR item “information about condition” was always amongst the top three items with the least agreement. That users consistently reported a lack of information about their condition as an unmet need more often than clinicians is a further incentive to work more collaboratively toward a mutual understanding of treatment needs, goals, and progress.
In short, results from our meta-analysis and the narrative synthesis all aligned to support the relevance and feasibility of examining differences in user perspectives on needs, progress, and recovery, with the clinical significance of differences in specific tool- or item-level concepts to be examined further for the DUNDRUM-4 and CANFOR. While limited by the use of different tools, studies of other outcomes and protective factors in the narrative synthesis also showed a misalignment of perspectives, reinforcing these conclusions. Because concordance in scores cannot be reached without users and clinicians having the same information (Lasher et al., 2015), existing recommendations that were retrieved through our collateral review highlighted the necessity to incorporate robust training when introducing shared assessments and collaborative practices (see Table 3). The preparation users receive in order to meaningfully participate in collaborative assessments could explain some of the heterogeneity reported here for the estimated true effect (through PIs). Importantly, we join other authors in stressing that concordance must not be overemphasized looking forward (Ryland et al., 2024). Shared ratings, as an operationalization of larger patient involvement and not simply SDM, are more likely clinically useful as tools to stimulate an exchange of views on treatment planning and progress tracking.
In addition to the instruments included in our review, a self-rated version of the Dynamic Appraisal of Situational Aggression (DASA) is currently being developed. Moreover, the SeQuIn (McKeown et al., 2023) and the Patient Participation in Forensic Psychiatric Care instrument (Selvin et al., 2023) have been designed as benchmarking and evaluation tools to appraise ongoing initiatives toward patient involvement. The latter can notably be used by patients both as an evaluation tool and to encourage dialogue about one’s care (Selvin et al., 2023). Such a tool could be integrated in future studies on the impact of shared approaches, as the current review points to a persistent need in quantitative outcome studies.
Diversity of the Reviewed Research
Looking at the diversity of our pooled user sample, an important strength for generalizing our findings across legal frameworks for FMH is that studies were conducted across three continents and multiple countries. Still, our sample was overwhelmingly composed of men with psychotic disorders, without intellectual disability, and from the ethnic majority in their country. Findings thus remain to be replicated for women forensic users (Ray & Simpson, 2019) and to evaluate how self-assessment tools may need to be adapted according to intellectual capacity. Future research in larger samples should also examine the feasibility and validity of self-ratings in those with primary mood disorders and compare results in those with vs without psychopathy or personality disorders. Given the importance of cultural and spiritual dimensions for measures of recovery and risk (Shepherd & Lewis-Fernandez, 2016; Wharewera-Mika et al., 2020), it will also be important to determine whether the success of shared interventions is contingent on cultural competency or the slight adaptation of assessment tools to the local cultural context.
Regarding the diversity of methods, there is still a paucity of outcome studies for shared approaches. As the field of FMH patient involvement evolves, we must be wary not to replicate the situation by which research has overemphasized the validity of risk assessment tools without outlining how to translate utility to management (Hutten et al., 2022; Viljoen & Vincent, 2020).
Limitations
The present study has multiple limitations. First, quantitative data could only be meta-analyzed for Outcome 1, with encouraging albeit very limited evidence for Outcomes 2 and 3. It is possible that studies on shared ratings may be limited by the administrative barriers to accessing high-risk users as well as decompensation early on during hospitalization. Second, the included studies reported little detail on how self-ratings were collected, leaving some questions on the validity and comparability of the self-ratings unanswered. Were users sufficiently educated about tools to make informed ratings? Were users in some studies better accompanied in the process than others, making concordance more likely? Would longer assessments lead to user fatigue and lower concordance? Future studies can tackle these questions by detailing how to practically conduct self-ratings, considering recommendations in the current study such as providing prior psychoeducation. Third, because of the variability in statistical measures used, several quantitative evaluations were narratively synthesized (with similar conclusions as the meta-analysis) but could not be included in pooled models. Fourth, it must be noted that although the present study employed the risk of bias tool most adapted to inter-reliability ratings, more reflection should be given as to what the most appropriate statistical measure is for quantifying and interpreting differences in clinician-user scores. We maintain that these differences are clinically meaningful and can be used toward optimizing treatment effect in FMH, which may mean statistical measures aiming to demonstrate equivalence are not the most appropriate in this specific case of interrater reliability (see Table 5, research implication 2). Ultimately, quality ratings assigned to each outcome in this meta-analysis were heavily skewed toward statistical considerations. Fifth, as described above, multiple factors related to the lack of diversity in our sample may have affected the generalizability. As with all studies on voluntary interventions, generalizability is also limited by some patients declining to participate or being excluded by clinical/research teams because of capacity. Where participation rates were reported in the included studies, refusal rates ranged from 5 to 49% (Davoren et al., 2015; Fluttert et al., 2010; Kashiwagi et al., 2020; Long et al., 2008; Oberndorfer et al., 2023; Ryland et al., 2024). It is possible that users who refused participation or who were excluded may have particular clinical profiles (e.g., higher psychopathy (Fluttert et al., 2010)), were the ones least likely to understand rating items, or would be the ones to particularly benefit from strengthening therapeutic alliances through shared approaches. Sixth, our synthesis included ratings by a variety of professionals (e.g., psychologists, nurses, researchers trained or not as clinicians, etc.), which might have reduced the comparability of studies. Indeed, clinicians may have rated users from distinct professional perspectives (Abou-Sinna & Luebbers, 2012) and the absence of a relationship between researchers and users may have reduced researcher insight and agreement (Rangan, 2020). Coupled with the scarcity of studies available for meta-analysis, limitations relating to variability in self-rating collection and professional raters could explain some of the observed heterogeneity and larger prediction intervals.
Implications for Practice, Policy, and Research.
Implications for Practice, Policy, and Research
A summary of study implications is presented in Table 5. The current meta-analysis demonstrated significant pooled differences in clinician-user scores across assessments of needs, treatment progress, and recovery. While it’s been suggested to follow concordance longitudinally as a clinical measure of user insight or recovery (Davoren et al., 2015; Lam et al., 2023), lack of concordance does not necessarily mean incorrect interpretations by users (Ryland et al., 2024). Self-ratings can be more usefully employed to identify previously missed needs that are important to users, increase user knowledge on risk and management, discuss and adjust treatment goals, and hopefully improve user engagement because of this shared approach. To inform this clinical work, our narrative synthesis identified several recommendations on how to prepare users and clinicians for employing shared ratings, include the user (and their meaningful representatives) in assessment and management, provide a palatable summary, and navigate refusals to participate in shared approaches. While identified recommendations were largely formulated in the context of risk assessment, most outline important therapeutic principles and methods that should be applied to any collaborative assessment, such as needs and treatment progress evaluations from our meta-analyses. From a policy standpoint, the present study along with a synthesis of qualitative benefits to shared approaches (Luigi et al., 2024) underscore the importance of formerly introducing shared approaches into routine clinical workflow. We present preliminary evidence which also suggests this could lead to improved care outcomes. Finally, we have highlighted opportunities for future research, namely investigating the quantitative effects of shared management approaches on violence and restrictive measures, standardizing statistical measures of agreement between user and clinician ratings, and examining the feasibility and validity of self-assessment tools in underrepresented user groups.
Footnotes
Appendices
Critical Appraisal for quantitative studies included in meta-analyses.
| Global Model | DUNDRUM 3 and DUNDRUM 4 Sub-Models | CANFOR – Unmet Needs Sub-Model | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
|
Ter Horst et al., 2022 | Davoren et al., 2015 | Lam et al., 2023 | Lasher et al., 2015 | Davoren et al., 2015 | Lam et al., 2023 | Oberndorfer et al., 2023 | Segal et al., 2010 | Abou-Sinna and Luebbers, 2012 | |
| COSMIN - Reliability | 1. Stability in interim period | Doubtful | Adequate | Adequate | Adequate | Adequate | Adequate | Adequate | Doubtful | Doubtful |
| 2. Time interval | Doubtful | Very good | Doubtful | Very good | Very good | Doubtful | Doubtful | Doubtful | Doubtful | |
| 3. Similarity of test conditions | Inadequate | Adequate | Doubtful | Very good | Adequate | Doubtful | Doubtful | Doubtful | Doubtful | |
| 4. Continuous: ICC | NA | NA | Very good | Adequate | NA | Very good | Inadequate | Adequate | Adequate a | |
| 5. Dichotomous, nominal, ordinal: Kappa | Inadequate | Inadequate | NA | NA | Inadequate | NA | NA | NA | NA | |
| 6. Ordinal: Weighted kappa | NA | NA | NA | NA | NA | NA | NA | NA | NA | |
| 7. Ordinal: Weighting scheme | NA | NA | NA | NA | NA | NA | NA | NA | NA | |
| 8. Other important flaws in design or statistics | Doubtful | Very good | Doubtful | Doubtful | Very good | Doubtful | Doubtful | Very good | Very good | |
|
|
|
|
|
|
|
|
|
|
|
|
| GRADE | Inconsistency | No downgrade | No downgrade | Serious (−1 downgrade) | ||||||
| Imprecision | No downgrade | No downgrade | No downgrade | |||||||
| Indirectness | No downgrade | No downgrade | No downgrade | |||||||
|
|
|
|
|
|||||||
Note. NA = not applicable.
While the COSMIN-reliability item 4 requires a rating of “adequate” when the Pearson correlation coefficient is calculated with evidence for no systematic change between scores versus “doubtful” when there is evidence for systematic change, within the context of this review evidence for differences in scores was not penalized and a score of adequate was kept.
Acknowledgements
We acknowledge the contribution of Marie-Christine Stafford, M.Sc., in conducting statistical analyses for this article, as well as Ashley Lemieux, PhD, and Eric Latimer, PhD, in the methodological planning for the systematic review protocol.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Author 1 acknowledges financial support from the Canadian Institutes of Health Research (CIHR) in the form of a Vanier Canada Graduate Scholarship (FRN 186874), and the Observatoire en Justice et Santé Mentale. The last author holds a Tier 1 Canada Research Chair in Mental Health, Justice, and Safety. No further funding was associated with this research.