
Abstract
This article discusses an application for classifying urban spaces using convolutional neural networks (CNNs). A seed dataset was initially generated composed of 630 photographs of urban spaces from the Adobe Stock repository. This dataset was topped up with images produced by two generative artificial intelligence (AI) engines, namely, Deep Dream Generator and Midjourney, making two additional augmented datasets, each composed of 2200 images. The training process was carried out using four well-known CNNs, namely, GoogLeNet, ResNet-18, ShuffleNet, and MobileNet-v2. The results show an increase of roughly 30% in the predicting capabilities in both augmented datasets when compared to the seed dataset. Furthermore, performance metrics are generally higher when using ResNet-18 which may suggest that this CNN architecture is more applicable to urban classification projects. Finally, although both generative AI engines have similar performance, Midjourney seems to slightly outperform Deep Dream Generator as a data augmentation engine for urban spaces.
Keywords
Introduction
Urban spaces play a vital role in shaping the livability, functionality, and sustainability of cities. They are designed for human use and interaction and, as such, are crucial for the well-being of individuals and communities.1,2 Thus, the classification of urban spaces becomes a relevant topic for policymakers and city planners in order to make informed investment decisions to best serve the function of interaction in cities. 3 Several attempts to classify urban spaces have been published in the literature4–6 depending on a wide range of characteristics, such as (i) design-functional perspectives, (ii) socio-cultural perspectives, and (iii) political-economic perspectives. Design-functional perspectives classify spaces according to their intended purpose, characteristics, and physical layout,7,8 for example, public parks, markets, and playgrounds. Socio-cultural perspectives classify spaces according to the type of individuals who utilize them and how they interact with them, 9 for example, everyday places, social environments, and negative spaces. Political-economic perspectives classify spaces according to the ownership, responsibilities, or management associated to them,10,11 for example, public property, secured public space, and themed public space. Even with these varied perspectives, it is widely accepted in the literature 12 that the increasing complexity of urban spaces makes their classification a somewhat complicated task. In this light, machine learning models are ideal candidates to facilitate such a process due to their capacity to learn patterns based on analyzing large amounts of data. This article deals with the classification of urban spaces as described in Carmona, 4 who defines 20 types that, to some extent, are a combination of all abovementioned perspectives, using four overarching categories that move in a highly continuous manner from clearly public spaces to clearly private spaces.
Convolutional neural networks (CNNs) are a type of deep learning model that are specifically designed for image and video analysis based on the concept of convolution, which is a mathematical operation that is used to extract features from an image. 13 They can learn hierarchical representations of the input data by successively applying convolutional and pooling layers to the input image, which eventually allows the model to determine whether or not the input image falls into a given category or class. CNNs are particularly relevant in data science, as they have demonstrated considerable effectiveness in a wide range of image and video analysis tasks, such as object recognition, object detection, and semantic segmentation, as well as in other fields, such as natural language processing, speech recognition, and medical image analysis.14,15 The application of CNNs in architecture and urban design is a relatively recent field, though it has gained increasing attention in research and practice.16,17 In architectural design, CNNs have been applied building façades for the classification of their Gestalt principles, 18 architectural styles, 19 and their components. 20 Other examples in urban design include the classification of land use and land cover types, such as residential, commercial, industrial, and green spaces,21–23 recognition of different street-level features by means of street-view image analysis, such as urban versus non-urban settlements, 24 quality of street frontage, 25 and vegetation. 26 The use of CNNs in this context is accomplished by training a model on a relatively large dataset of labelled images, where the model learns to recognize different patterns and features associated with the classes specified in the dataset.
For meaningful deep learning models such as CNNs, generally large datasets must be used for training in order to allow generalization of results and avoid overfitting issues; a well-known technique to address these potential problems is data augmentation. 27 Some popular data augmentation techniques include (i) geometric transformations, such as flipping, cropping, rotation, and noise injection, and (ii) generative-based models, such as generative adversarial networks (GANs)28,29 and diffusion models (DMs),30,31 where artificial instances are generated in an attempt to emulate similar characteristics of the dataset needing augmentation.
GANs are basically composed of two sub-modules: a generator and a discriminator. The generator, given a vector of random values, generates data with the same structure as the training data; the discriminator attempts to classify data as real or fake when shown observations from both the training data and data coming from the generator. 32 GAN-based augmentations have been used previously to enlarge datasets for deep learning models in a wide range of fields, most notably in medical sciences research.33–35 DMs, on the other hand, follow a different path: during training, they progressively destruct data by injecting noise, which allows them to then learn how to reverse this process. In this way, new instances can then be generated from just random noise as a starting point. 30 Text-to-image models are specific DMs that generate images from a descriptive text or prompt. They have recently stunned the architectural visual culture (see Steinfeld 36 for a recent thought-provoking discussion and recount of events on the rise of text-to-image generative models in architecture). The use of DMs as a data augmentation technique is becoming a predominant method as they seem to outperform GANs due to superior image quality and diversity.37,38 Under the generic umbrella term of ‘generative AI’, both GANs and DMs have garnered increasing interest in architecture and urban studies due to the possibility of generating a virtually infinite number of new designs/images.39–42
Once a suitable and meaningful dataset has been curated for classification, a CNN architecture is needed to conduct the training. The architecture can be set up from scratch or based on an architecture and corresponding weights from an already trained CNN in a related domain, the latter being commonly referred to as transfer learning. 43 Transfer learning techniques have been extensively applied in a wide range of applications, for example, text sentiment classification, image classification, human activity classification, software defect classification, and multi-language text classification (see Weiss et al. 44 for a comprehensive review on transfer learning).
This work has three main objectives: first, to validate the suitability of CNNs as an effective AI technique for classifying urban spaces; second, to assess the effectiveness of publicly available generative AI engines in producing images for data augmentation purposes; and third, to identify, if any, a specific CNN architecture among a set of well-known CNN architectures traditionally used for general image classification that consistently performs higher when classifying urban spaces. Following the urban classes described in Carmona, 4 this work uses three datasets for the classification of urban spaces: a seed dataset composed of 630 photographs downloaded from the Adobe Stock repository 45 and two augmented datasets, which are each composed of the seed dataset topped up with generative AI images to make a total of 2200 instances. The images used in the enlarged datasets were generated using the generative AI engines Deep Dream Generator 46 and Midjourney-v4 47 (these enlarged datasets are called ‘DDG-augmented dataset’ and ‘MJ4-augmented dataset’, respectively, hereafter). These generative AI engines were selected because they are two of the most popular and highly regarded image generators publicly available and accessible at the time of writing. 48 The generated images, although possessing high definition and detail, are sometimes disjointed and do not necessarily coherently represent the urban space specified in the text prompt when judged by a human. Nevertheless, they preserve many of the features of the particular class that make the urban space recognizable when observed by a human; therefore, they were considered suitable for the purposes of this work. Due to the varying number of photographs in the seed dataset, it is highly unbalanced; on the other hand, the augmented datasets are perfectly balanced, as every urban category or class has the same number of elements. For the training of these datasets, a transfer learning technique was used where the architectures of well-known CNNs used for image classification were transferred to the domain discussed in this article. Four CNNs widely used in data science for image classification problems were used for training in this work, namely, (i) GoogLeNet, 49 (ii) ResNet-18, 50 (iii) ShuffleNet, 51 and (iv) MobileNet-v2. 52 It was found that prediction capacity increases roughly 30% when enlarging the dataset in all CNNs, even though the GAN-enlarged dataset possesses images of urban spaces that are not always coherent. It was also observed that ResNet-18 outperforms the other three CNNs used in this work in all prediction metrics, suggesting that this architecture could be more capable of handling much larger datasets for urban classification. Finally, it was possible to observe that Midjourney-v4 slightly outperforms Deep Dream Generator when used as a data augmentation technique in the urban spaces domain, although both are decidedly capable of interpreting the main features of each class of urban space studied in this work.
This article is organized as follows: the next section describes the generation of the seed and augmented datasets for each category or class of urban space; the subsequent part covers the training process for the four CNN architectures used on the datasets described in the previous section; then, the following section analyses the results obtained and presents comparisons among the CNNs and datasets; the following section presents a thorough discussion of the results, finishing with a section covering the conclusions of this work.
Dataset generation
This section covers how the datasets were generated for this research. It is worth mentioning that the seed dataset has been made publicly available for reproducibility purposes and can be found on Kaggle, 53 a widely used platform for data science resources. The augmented datasets are available upon request to the corresponding author.
Seed dataset
Urban space types 4 (categories in bold were used in this work).

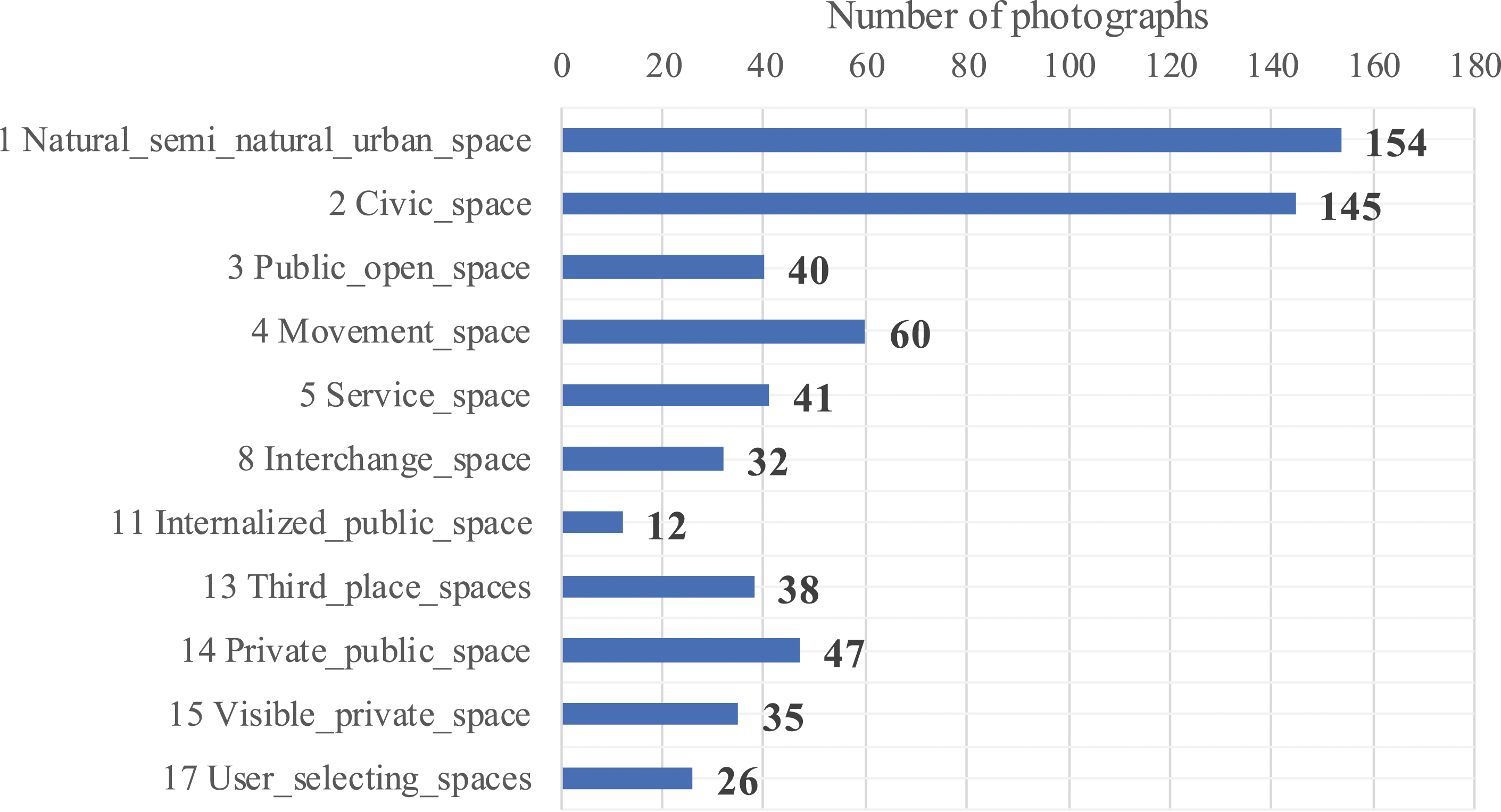
Distribution of photographs per class in the seed dataset.

Sample photographs in the seed dataset.
From Figure 1, it is possible to see the unbalanced nature of the seed dataset; class imbalance is a common problem in real-world datasets and can have a detrimental effect in the performance of CNNs in classification problems. 55 Generally speaking, there are two types of class imbalance: (i) step or inter-class imbalance, where there is a minority of classes with a similar number of samples, say S1, in comparison to a majority of classes that also has a similar number of samples, say S2, but S1 and S2 differ substantially; and (ii) linear or intra-class imbalance, where the number of samples among all classes varies in such a way that the difference between consecutive classes is nearly constant (see Buda et al. 56 and Ali et al. 57 for comprehensive reviews on class imbalance problems in classification problems using CNNs). In this light, the seed dataset used in this work possesses a clear step or inter-class imbalance, as there is a minority of classes with a similar number of instances (classes 1 and 2, which have ∼140 samples on average) compared to a majority of classes with a relatively similar number of instances (classes 3 to 17, which have ∼36 samples on average). Certainly, the number of samples between the majority and the minority is significantly different. It has been reported that CNNs trained using datasets with step or inter-class imbalance, as is the case for the seed dataset, are more likely to perform poorly when classifying those classes with a low number of samples because they are predicted as rare occurrences. 55 The imbalance problem with the seed dataset was then corrected by using augmented datasets, which, from a data science perspective, can be regarded as ideal datasets, as they contain an equal number of samples within each category.
Augmented datasets
The aim of the augmented datasets was to balance the seed dataset by topping up all classes with images produced by popular text-to-image DMs until every one of the 11 classes is composed of 200 images; hence, each augmented dataset is composed of 2200 images. Images were generated using the Text 2 Dream tool from the Deep Dream Generator engine
46
and the command/imagine in Midjourney-v4.
47
Only text prompts (no base images) were inputted in the generation of the images, which, in turn were the keywords and description used for each urban class, as shown in Table 1 (e.g. ‘a car park’ was used as a prompt to generate images from the category ‘service space’). All prompts included additional descriptors to make the images more in line with those from the seed dataset, such as ‘in broad daylight’ and ‘as seen at street level’. Figures 3–5 show examples of generated images for every urban class in both enlarged datasets studied in this work. It is worth highlighting the unpredictable nature of these images, as they may sometimes be incoherent by having constituting elements that are fragmented or disorganized. Nevertheless, they do overall possess similar feature maps for the urban space for which they were created in comparison with the photographs in the seed dataset; hence, they were deemed suitable for the classification problem studied in this work. This assumption has been previously validated in the literature: complete realism is not needed when using artificial instances for data augmentation.
58
Figure 6 shows a small sample of instances for interchange spaces with a degree of incoherence or misplaced components that can be detected by human curation. Such misplacement is mainly related to the position of trains, which are depicted in positions other than on tracks. Sample of generated images for ‘positive’ urban spaces. (a) Natural/semi-natural urban spaces; (b) civic spaces; (c) public open spaces. Sample of generated images for ‘negative’ urban spaces. (a) Movement spaces; (b) service spaces. Sample of generated images for ‘ambiguous’ urban spaces. (a) Interchange space; (b) internalized public space; (c) third place spaces; (d) private public space; (e) visible private space; (f) user selecting spaces. Sample instances with a degree of incoherence or misplacement in interchange spaces. (a) From DDG-enlarged dataset; (b) from MJ4-enlarged dataset.



Convolutional neural network training processes
Training was carried out in MATLAB’s Deep Learning toolbox
59
using the three datasets described in Section 2 by making use of the architecture and weights of four CNNs widely used in data science for image classification problems, namely, (i) GoogLeNet,
49
(ii) ResNet-18,
50
(iii) ShuffleNet,
51
and (iv) MobileNet-v2.
52
They are all classed as deep neural networks with a varying number of layers, specifically 22, 18, 50, and 53 layers for GoogLeNet, ResNet-18, ShuffleNet, and MobileNet-v2, respectively. All of them have been previously used in computer vision research in a wide range of fields and applications, such as aerial image classification,
60
face recognition,
61
bruised nectarine detection,
62
variants of cancer identification,
63
handwritten character recognition,
64
garbage classification,
65
dairy cow identification,
66
crop diseases identification,
67
palmprint recognition,
68
and classification of retinal diseases,
69
among many others. It is worth adding that the four CNNs selected in this work have previously successfully performed in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), which allows researchers to test algorithms for object detection and image classification at large scale.
70
ILSVRC uses a dataset of more than one million images, which are grouped into 1000 categories, including animals, vehicles, fruits/vegetables, landscape elements, home appliances, and clothing items. The generic architectures of these CNNs are shown schematically in Figure 7. Generic architectures of the CNNs used in this work compared to a classic CNN architecture shown in (a); (b) GoogLeNet; (c) ResNet-18; (d) ShuffleNet; (e) MobileNet-v2.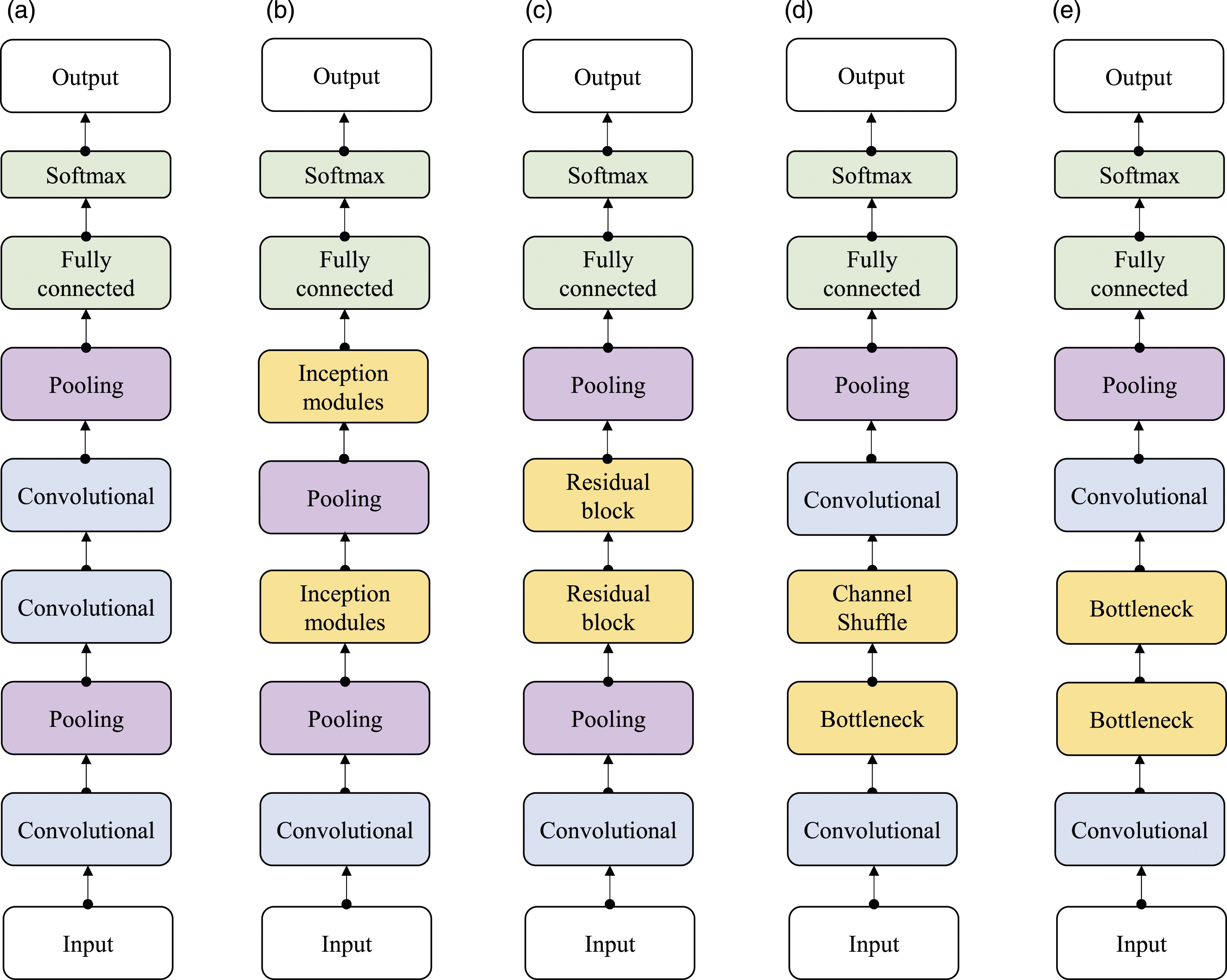
Regarding the training parameters, for all datasets, the learning rate was fixed to 0.01 and the size of the subsets for training/test was defined as 80% and 20%, respectively. These were selected for the sake of simplicity, as they are within typical ranges used in classification projects in the architectural domain.18,20 Additionally, the number of iterations per epoch was set to 3 (maximum of 20 epochs) for the seed dataset and 13 (maximum of 30 epochs) for the augmented datasets. These were selected after observing convergence during previous trial runs with all datasets. In this line, Figure 8 summarizes the training accuracy (%) versus the number of iterations for all the training processes carried out in this work using the three datasets and four CNNs. From this figure, it is possible to see that all four CNNs are able to reach high accuracy at the end of the training process; however, the rate at which such accuracy is reached varies significantly for the three datasets, as indicated by the slope of each curve. For the augmented datasets, ResNet-18 and MobileNet-v2 seem to be the architectures that reach higher levels of accuracy during training, which is a significant characteristic, especially when it comes to datasets that are substantially larger than the ones used in this work (as is likely to be the case in a real-world application in urban studies). Training accuracy for all training processes carried out in this work for the three datasets. (a) Seed dataset; (b) DDG-augmented dataset; (c) MJ4-augmented dataset.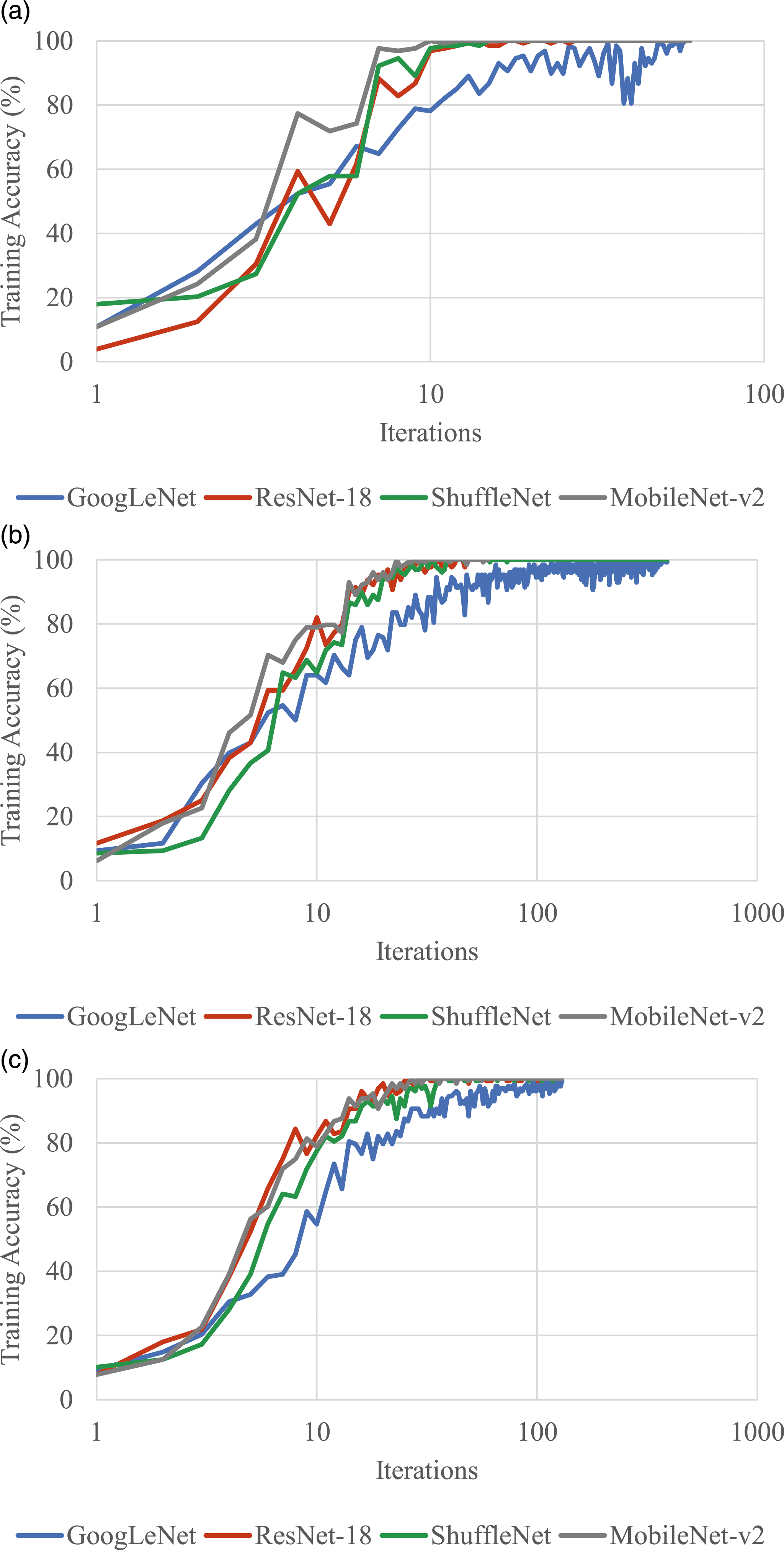
Analysis of the results
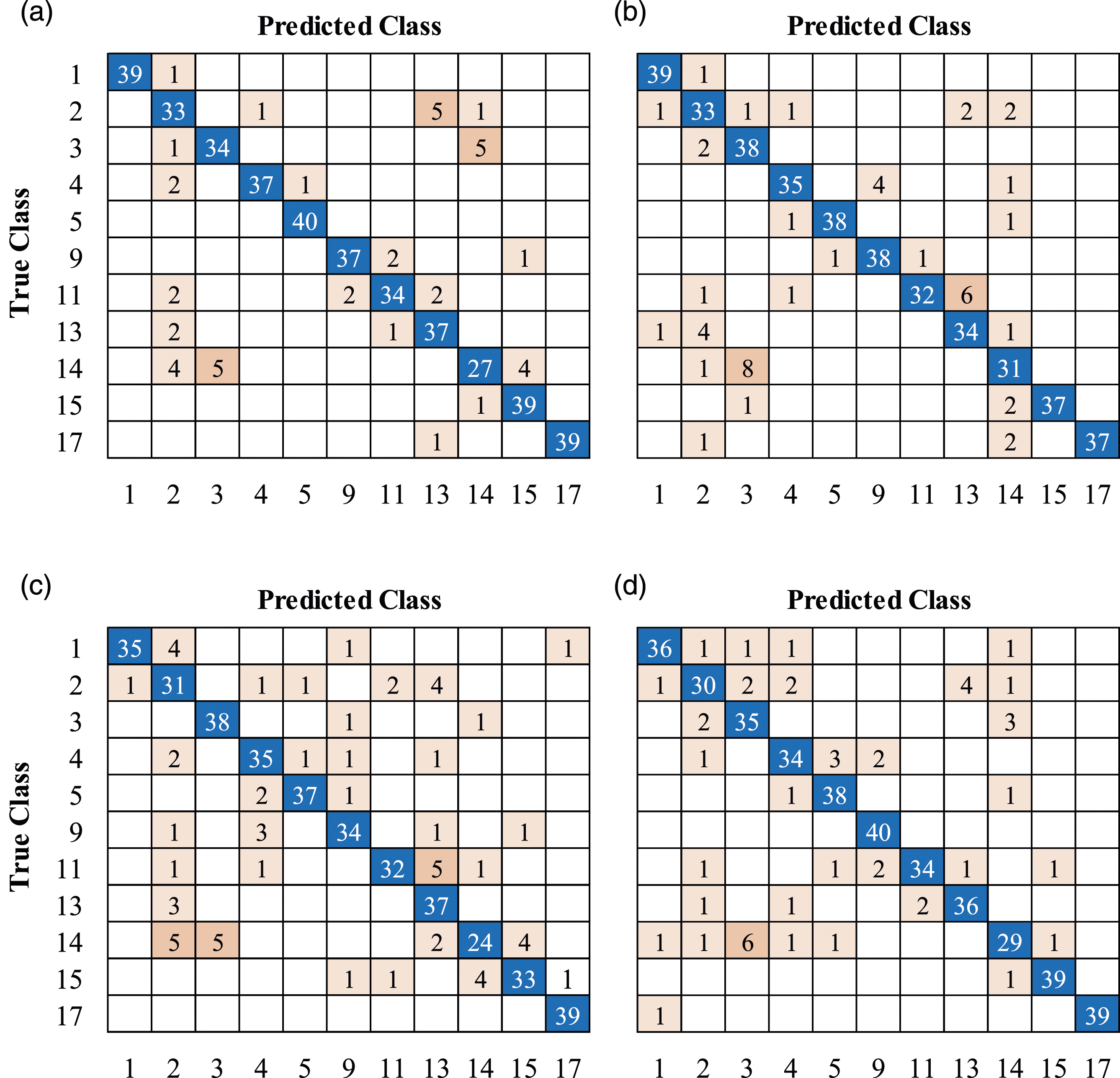
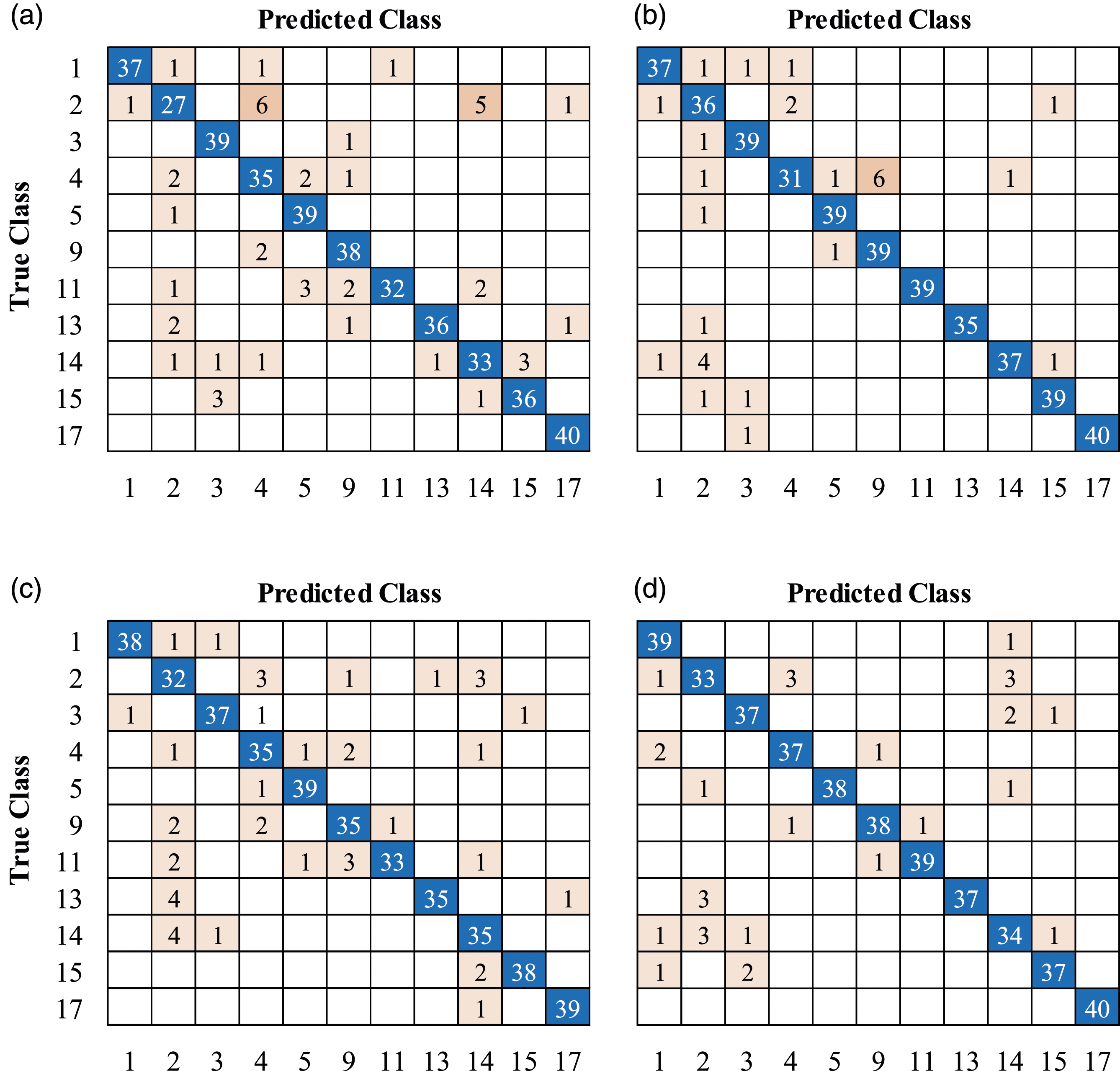
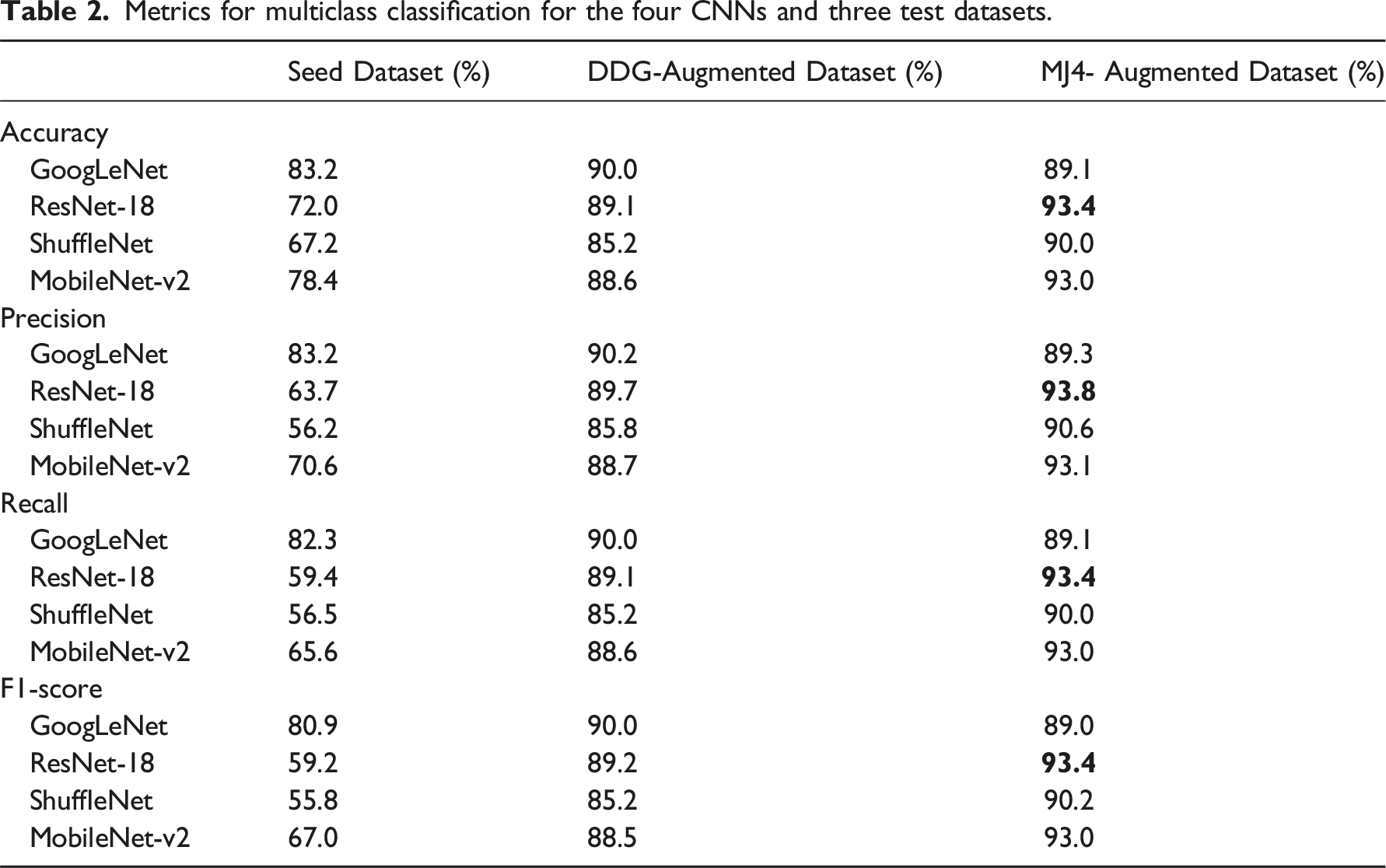
Once training was carried out, the predictive capacity of the CNNs was measured against the test datasets, which were generated by randomly choosing 20% of the images from the original datasets (i.e. 126 photographs for the seed dataset and 440 images for each augmented dataset). Figures 9–11 show the confusion matrices obtained for the test datasets from the seed dataset, DDG-augmented dataset, and MJ4-augmented dataset, respectively. It is worth mentioning that the confusion matrix for the test seed dataset (Figure 9) shows a higher prediction capacity for those classes better populated (e.g. classes 1 and 2), which is an expected outcome considering the class distribution in the seed dataset, as shown in Figure 1. Using the results shown in Figures 9–11, performance evaluation was conducted using four well-known metrics for multiclass classification, namely, accuracy, precision, recall, and F1-score. Confusion matrices for the test seed dataset; (a) GoogLeNet; (b) ResNet-18; (c) ShuffleNet; (d) MobileNet-v2. Confusion matrices for the test DDG-augmented dataset; (a) GoogLeNet; (b) ResNet-18; (c) ShuffleNet; (d) MobileNet-v2. Confusion matrices for the test MJ4-augmented dataset; (a) GoogLeNet; (b) ResNet-18; (c) ShuffleNet; (d) MobileNet-v2.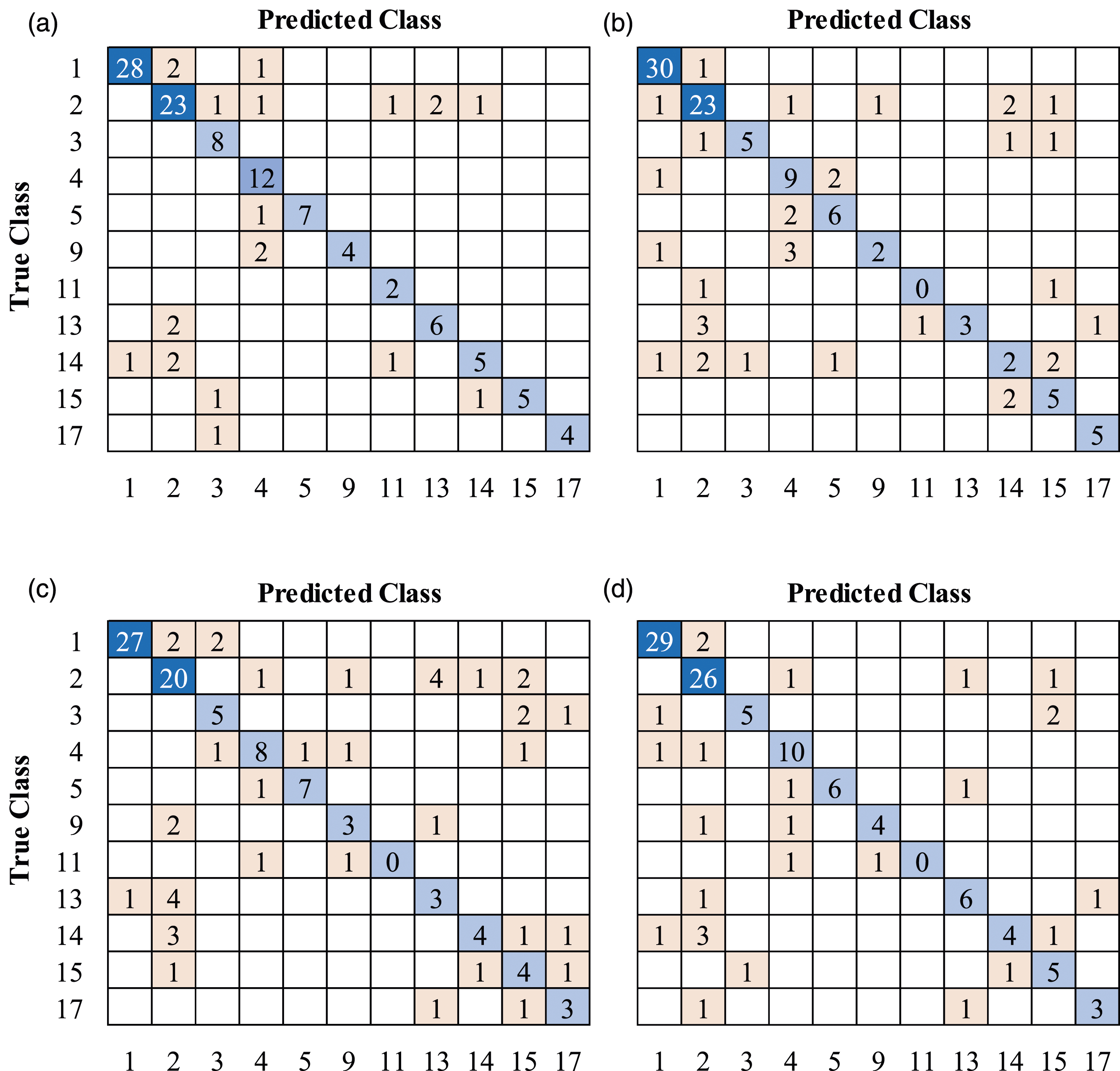
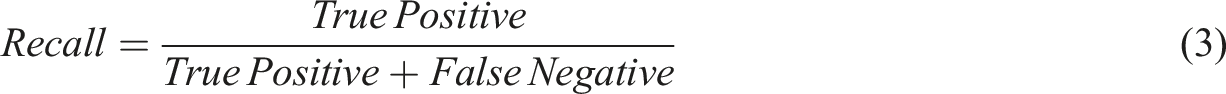
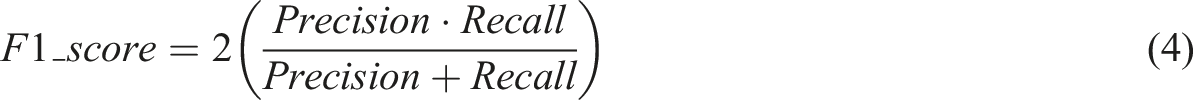
Metrics for multiclass classification for the four CNNs and three test datasets.
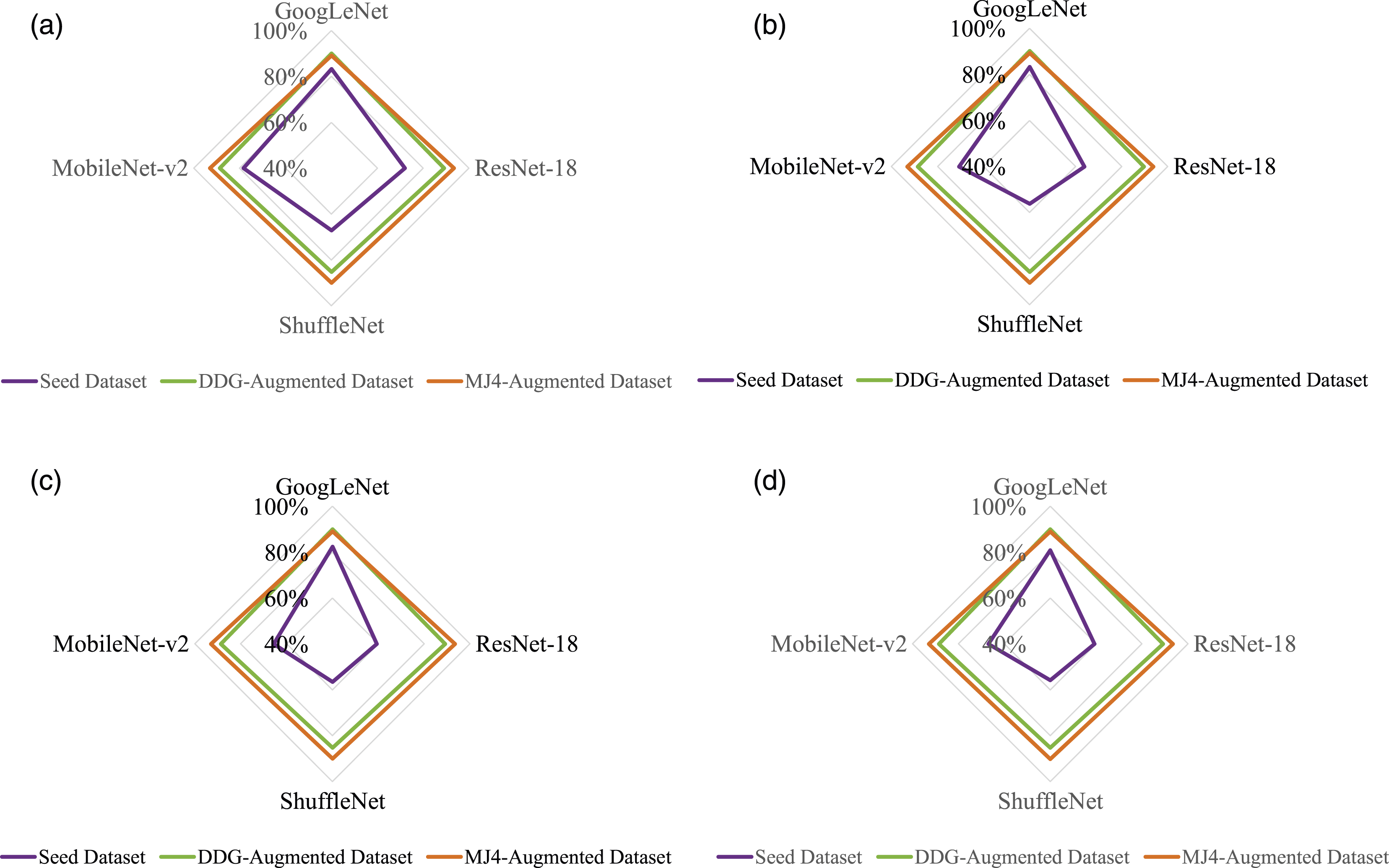
Metrics for multiclass classification for the four CNNs and three test datasets. (a) Accuracy; (b) precision; (c) recall; (d) F1-score.
Discussion
- Seed (imbalanced) vs augmented (balanced) datasets: when assessing the performance of the four CNN architectures and three datasets, it is possible to observe from the confusion matrices in Figure 9 that all CNNs naturally struggle to correctly classify instances that belong to classes with few instances. This is a known result when training CNNs architectures using imbalanced datasets; it has been reported in the literature
55
and was confirmed in this work. On the other hand, when the same CNN architectures are trained using a perfectly balanced dataset, their performance substantially increases, where all classes have equal probability of being correctly classified, as seen from the confusion matrices shown in Figures 10 and 11. - Labelling process: the results reported in this work are valid when a whole image labelling process is used for urban space classification. However, it is acknowledged that the results could be different when approaching the problem as a multi-label classification task, that is, where each instance can be associated with several labels simultaneously.
71
Such an approach would require a different labelling process to the one used in this work, such as bounding box labelling. This would allow identification of individual components that belong to more than one urban space, for example, streets or trees, where the model could then identify an urban space by integrating its different components. In any case, the approach used in this work can be considered as a first approximation to the problem, and the use of other labelling processes is left as a matter of further research. - Training parameters: the results in this work were obtained for a specific set of numerical values for the training parameters, namely, learning rate, size of subsets for training/test, number of iterations per epoch, and maximum number of epochs. Although the numerical values selected for these parameters were within traditional values typically used for this type of problem, it is acknowledged that they remained unmodified throughout the training process. Hence, the results could be improved if these parameters were fine-tuned and/or enabled to dynamically change in an adaptive manner. Such an approach has been reported in the literature18,20 and shown to be an effective and efficient way of training. However, further improvement to the already high accuracy achieved with static training parameters is left as a matter of future research on this topic. - Generative AI engines: As seen from Figure 12, both generative engines used in this work seem to have a fairly similar performance when used as an augmentation technique for classifying urban spaces. However, when curated by a human, the generated images produced by Midjourney seem to have a superior coherence, that is, it is less likely for components to be misplaced in comparison to those produced by Deep Dream Generator. This is in line with a research result already reported in the literature:
58
complete realism is not absolutely necessary when using generative images as a data augmentation technique; this is because the actual features that appear on the produced images, not their placement therein, will likely dictate the quality of the image for classification purposes. Certainly, this statement might not be valid for applications where realism and accuracy are required. Considering that Midjourney and Deep Dream Generator were the two generative AI engines used, the topic discussed in this paragraph is not necessarily valid when other publicly available generative AI engines are used, such as DALL-E, Stable Diffusion AI, or Runway. - Limitations: This work has been conducted using a specific set of CNN architectures that were trained using three particular datasets. Therefore, the results reported in this article are limited to such a domain and are not necessarily valid outside of it. Other well-known CNN architectures used in classification problems, such as VGGNet or AlexNet, may also be well suited to perform in classification problems of urban spaces and could potentially compete against the highest-performing architecture in this work, namely, ResNet-18. In addition, and aiming at generalization, it is yet to be seen how these CNN architectures would perform when including the other urban spaces defined by Carmona
4
that were not included in this work. Finally, the results reported in this article are constrained by the specific urban space classification used, that is, the design-functional perspective proposed by Carmona.
4
In summary, how the results reported in this work could be impacted by the use of other CNN architectures, the inclusion of urban spaces left void in this work, and even a totally different system to classify urban spaces is left as a matter of exploration in future research.
Conclusions
Classification of urban spaces is a pertinent topic for policymakers and city planners in order to make informed investment decisions to foster interaction in cities. This is an ever-growing topic due to the increasing complexity of contemporary cities, which makes the task of classification also progressively more difficult. This makes machine learning models an ideal candidate for this purpose due to their capacity to learn patterns based on analyzing large amounts of data. Among the several attempts made in the literature to establish categories or classes of urban spaces, one such approach is based on a design-functional perspective. This standpoint focuses on the intended use, character, and shape of the public space. Following a design-functional perspective widely used in the literature, this work used three datasets to classify urban spaces using CNNs. A seed dataset composed of 630 photographs, which was highly imbalanced, was initially used in the training process and was later topped up with GAN-generated images to make two augmented datasets composed of 2200 images each, which were perfectly balanced. Four CNNs widely known for their data science and AI applications were used in the training processes, namely, GoogLeNet, ResNet-18, ShuffleNet, and MobileNetv2, which are 22, 18, 50, and 53 layers deep, respectively. These CNN architectures demonstrated their suitability as effective AI techniques for classifying urban spaces, as their metrics for multiclass classification averaged 75% in accuracy, 68% in precision, and 66% for both recall and F1-score. These results validate the first research objective of this work. When using the generative AI engines for data augmentation purposes, results showed that prediction performance for the test datasets (images not used during training) increases substantially when CNNs were trained with the enlarged datasets in comparison with those trained with the seed dataset. Although both generative AI engines demonstrated their suitability for this purpose, Midjourney seems to slightly outperform Deep Dream Generator: when using the former, metrics for multiclass classification improved by 21% in accuracy, 35% in precision, and 38% for both recall and F1-score, averaging roughly a 30% improvement. These results validate the second research objective of this work. Additionally, ResNet-18 seems to perform better in comparison with the other three CNN architectures studied in this work; therefore, it might be more capable of handling larger training datasets, such as those associated with big data projects in urban studies. This result validates the third research objective of this work. This article’s expected contributions to the public space design domain include facilitating the analysis of public space utilization through automation and improving understanding of public spaces’ roles in fostering community engagement for governance and policymaking. Some real-life examples of projects for which the results reported in this article could be useful are (i) urban revitalization projects for the redevelopment of neglected public spaces to enhance aesthetic appeal, accessibility, and functionality; (ii) placemaking initiatives to transform public spaces into inclusive and people-centric areas; and (iii) temporary urban interventions to test and improve public spaces, such as pop-up parks or street closures. Further improvement in prediction performance by using other labelling processes, training parameters, generative AI engines, and CNN architectures is left as a matter of further research in the field of urban classification projects.
Footnotes
Acknowledgments
The authors thank two anonymous reviewers for their valuable comments that substantially improved the quality of the manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.