
Abstract
Generative design in architecture has long been studied, yet most algorithms are parameter-based and require explicit rules, and the design solutions are heavily experience-based. In the absence of a real understanding of the generation process of designing architecture and consensus evaluation matrices, empirical knowledge may be difficult to apply to similar projects or deliver to the next generation. We propose a workflow in the early design phase to synthesize and generate building morphology with artificial neural networks. Using 3D building models from the financial district of New York City as a case study, this research shows that neural networks can capture the implicit features and styles of the input dataset and create a population of design solutions that are coherent with the styles. We constructed our database using two different data representation formats, voxel matrix and signed distance function, to investigate the effect of shape representations on the performance of the generation of building shapes. A generative adversarial neural network and an auto decoder were used to generate the volume. Our study establishes the use of implicit learning to inform the design solution. Results show that both networks can grasp the implicit building forms and generate them with a similar style to the input data, between which the auto decoder with signed distance function representation provides the highest resolution results.
Keywords
Introduction
Integration of Artificial Intelligence into the design process has the potential to revolutionize the way architects and designers approach their work. The AI-aided generative design leverages the computational power of AI to generate design alternatives, taking into consideration the constraints of the project and the designer’s multiobjectives. This approach can help designers to overcome the limitations of traditional design processes, where generating numerous design options is time-consuming and requires significant manual effort. Besides, AI-aided algorithms have the capability to uncover patterns and generate solutions for complex problems that may not have been otherwise apparent to human designers. 1 AI-aided generative design can also provide novel and innovative design solutions that would not be feasible to generate through conventional methods. By utilizing AI in the design process, designers can explore a broader range of design possibilities and make informed decisions, leading to more efficient, effective, and creative design solutions.
The recent development of generative models, such as the generative adversarial neural network (GANs), encoder-decoder, and diffusion networks has brought forth vast opportunities to improve the creativity of artificial neural networks in architectural design. Many studies have investigated the ability of generative networks to create new content based on a given dataset, including but not limited to building facades, 2 architectural drawings, 3 and plans. 4 Architecture exists in three dimensions, so the refining process of architectural design is also conducted in a three-dimensional space. Volume generation considered in a spatial context will provide richer information and insights than in the planar domain. However, most of the studies were confined to a 2D space, although a few studies have provided workaround strategies to achieve a final 3D product through overlapping 2D planes. 5 The transition of the generative model from a 2D to a 3D environment requires a significant increase in computational complexity, and demands an exponential jump in computational power. To date, three-dimensional architectural volume generation has not been intensively investigated, and its research and application in the architecture field are still highly limited. Therefore, a direct architecture generation methodology in 3D is highly desired.
One critical reason for machine learning to thrive in computer vision and natural language processing is the availability of large datasets on the Internet. However, three-dimensional volume synthesis and generation in the architectural field are hindered by three major difficulties: the insufficient amount of useable data, the lack of consentaneous evaluation matrices, and the tangled procedures to adjust and fine-tune hyperparameters in an artificial neural network with high dimensionality. The progress of 3D generative models has been comparatively slower than that of 2D neural networks, partly attributable to the high cost and requirement for details in constructing 3D databases. The acquisition of sufficient and high-quality 3D data is a persistent problem not only in the field of architecture but also in the broader machine learning domain. Although there exist curated 3D datasets, such as ShapeNet,
6
primarily comprising furniture and transportation facilities, and 3D-Front,
7
consisting of interior scenes, they have already demanded a high level of manual effort in data collection, labeling, and post-processing.
6
Compared with current 3D datasets, architecture models are far more complex in both detail and resolution (Figure 1). How to efficiently collect, transform and represent the architectural models as trainable data remains an unsolved question. Selecting the correct representation format also influences the efficiency, performance, and robustness of the machine learning algorithm. Besides, detailed 3D data for major cities is available, but obtaining such data for less recognized cities is more challenging, leading to data bias in the learning and generation process not only on the building morphology, but also on the cultural granularity.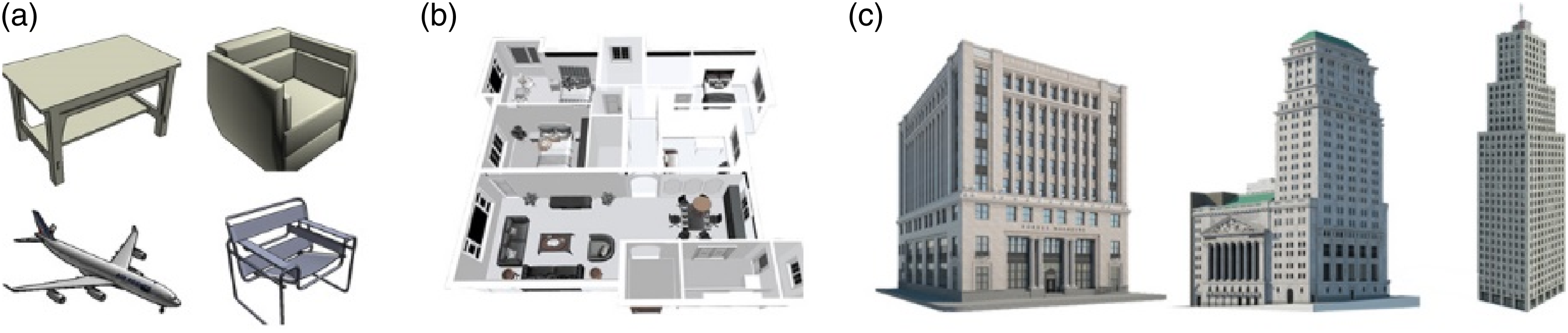
Other than dataset construction and representation complexity, properly defining the evaluation matrix is another predicament in applying machine learning to architecture design. Architectural design is a wicked problem, 8 which is ill-defined and requires extensive trial and error. Though humans have strong intuition on esthetic evaluation, there exists no explicit loss function nor structured evaluation metrics to distinguish a better design from a worse design. With self-constructed building modeling dataset in two formats, voxel matrices, and signed distance function representations, this study experiments with two popular generative models, feed-forward decoder networks 9 and generative adversarial neural networks 2 to generate 3D architectural volumes, and provides analysis on the generated results. We chose these two models because both networks have demonstrated their ability to capture 3D data features and provide new 3D shapes by sampling and interpolation.10,11 However, these two models have their pros and cons: while the auto decoder is easily interpretable, it can generate data with a lower resolution; GAN may not be explicitly interpreted, but it can generate high-quality data and the generation is less blurry.
Using generative models for building volume generation, this study hypothesizes that after feeding a decent amount of data and iterative training, the generative network will map the complex building shape to a lower-dimensional latent vector, which captures the abstract and high-level core features of the intaking architecture style. The proposed pipeline is shown in Figure 2. The first step is to collect 3D data of the building envelope, typically in obj format. The collected data is preprocessed for standardization. After normalization and alignment, the building envelope data are converted into two data formats that are commonly used in training neural networks. Two generative models are trained, and the generative results are analyzed qualitatively and quantitatively. Proposed pipeline for 3D architectural volume generation.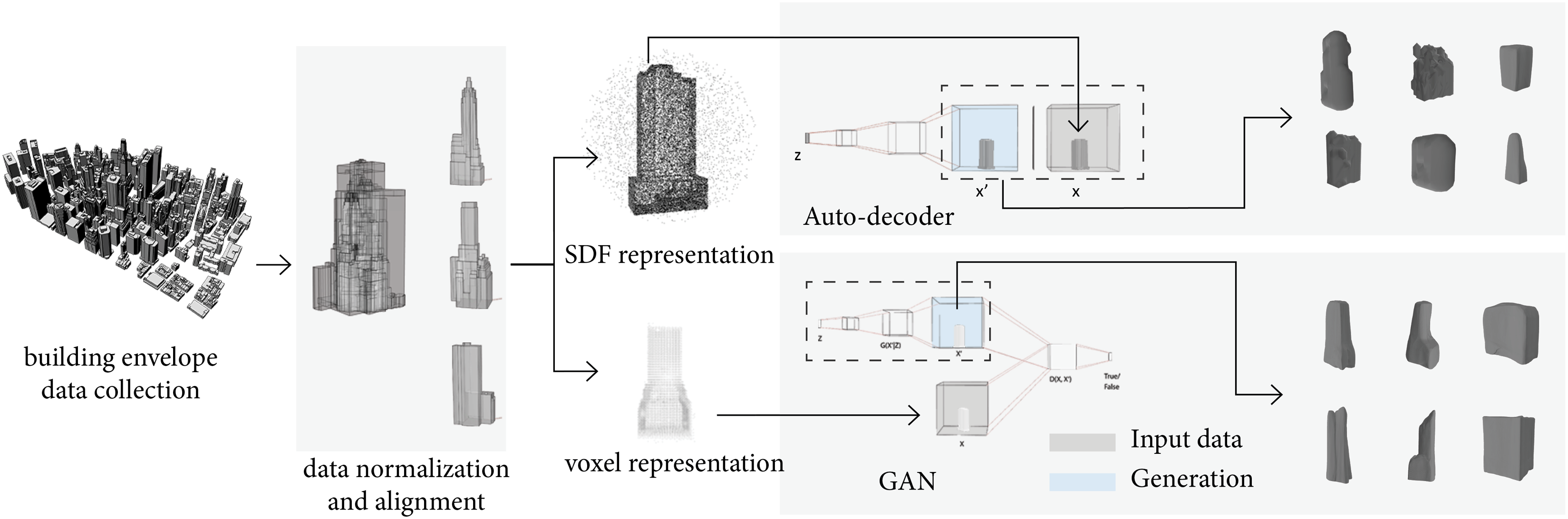
This study provides a generative design strategy that helps to push the boundary of AI-aided architectural design from a two-dimensional to a three-dimensional level and provides a high-dimensional solution space for architects to explore. Besides, it provides an alternative perspective to explore whether machine learning methods can capture the abstract and high-level features of a particular architectural style, which can contribute to the understanding of the implicit design process.
Related studies
Three-dimensional volume learning has become popular in recent years. Inspiring attempts are made for 3D learning, with various combinations of networks and shape representations. Most of the studies aimed to build reconstruction neural networks, and use different sampling strategies or interpolation methods to generate new shapes. Popular models include variational autoencoders,
12
consisting of two sequential networks, encoder, and decoder, to perform dimension reduction and reconstruction. Taking a 3D object as input, the encoder maps the object into a compact latent vector space, and the decoder maps the latent vector back to the 3D object. Alternative to variational autoencoder, Generative Latent Optimization (GLO), recently introduced by Bojanowski,
13
can also optimize the latent vector with fewer layers and parameters in the neural network. Optimizing latent vectors using decoder-only networks, also referred to as auto decoder,
11
is used for dimension reduction and generating new shapes from random vectors. Besides, generative adversarial neural networks (GAN) obtained enormous attention as soon as it was first proposed by Goodfellow et al.
14
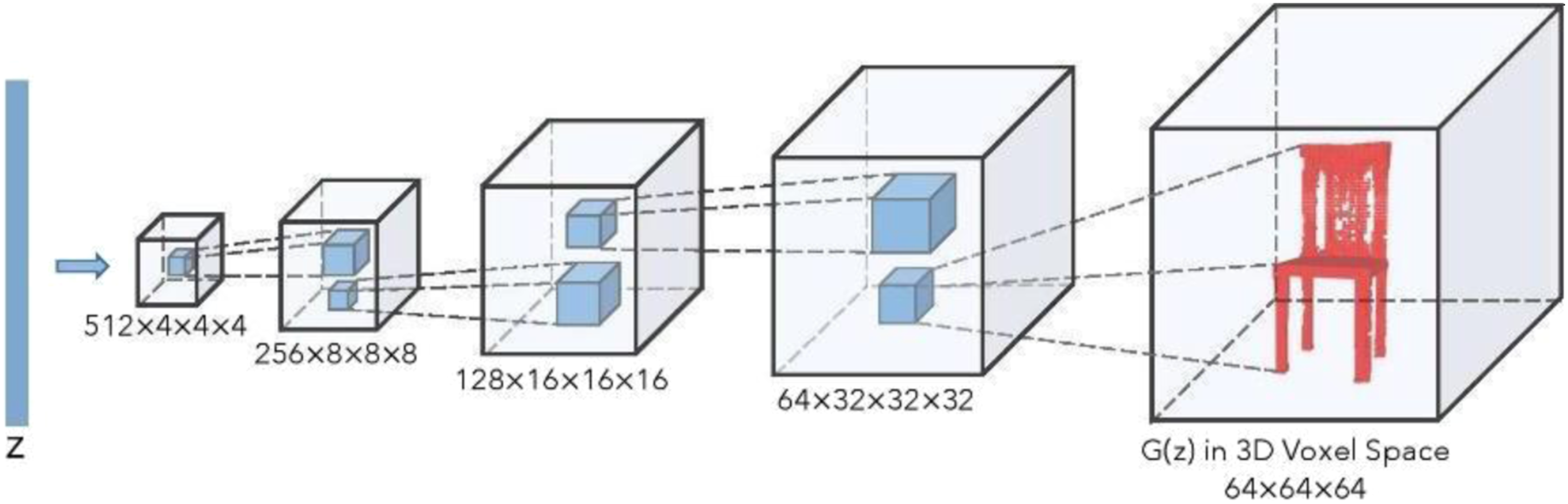
(2014). GAN also has two sequential networks, a generator and a discriminator, which compete with each other. Compared with other artificial neural networks, the generative neural network is to train the two networks with a min-max game. Given a set of data, the generator does not calculate the data distribution and probability, but tries to imitate real data distribution without certain formulae; the discriminator tries to distinguish real data from the generated one. The combined network aims to achieve a Nash equilibrium, a global minimum of the min-max equation. A generator within one of the newly developed 3D GANs is illustrated in Figure 3. The generator of 3D generative adversarial networks.
10
To efficiently train the neural network and generate new shapes, previous studies investigated different shape representation formats, such as reconstructing from point cloud dataset,
11
voxel dataset,10,15 and signed distance function (SDF)
16
(Figure 4). Each representation scheme has its advantages and disadvantages. Voxel-formatted data is easy to obtain and less memory-intensive since it contains only binary data on a fixed discrete grid. SDF is complex to work with and requires differential calculation; however, it inherently preserves a gradient dataset that is more suitable for training neural networks with gradient-based loss functions.
Though there is lack of common evaluation matrices for 3D generation results, in the literature, there exist several matrices focusing on different perspectives of the generated shapes. Johnson et al. (2016) 17 proposed conceptual loss, which uses a pre-trained neural network to provide the loss function to enforce the visual similarity between image features instead of pixel-level similarities. For geometry evaluation, Butt et al. (1998) 18 proposed chamfer distance for the discrepancy between two geometries, which is useful for comparison between the reconstruction result and the original geometry. McWherter et al. (2020), 19 focusing on the boundary representation (B-rep), introduced the B-rep graph to annotate the number of nodes and straight surfaces.
Other generative models
The generative models have been a hot spot in computer vision, reinforcement learning, and many other disciplines. Since 2014, the number of research papers on generative models has exploded, and the generative models’ quantity and quality have improved in a weekly resolution. For example, in 2021, the disco diffusion 20 defeated the adversarial neural networks with extremely realistic quality. 21 In less than 2 months, the stable diffusion 22 provides another record-breaking model to generate realistic images with better computational efficiency and high resolution. However, the diffusion networks do not include an interpretable latent space as the compression-based generative models. The diffusion models map the input data to a higher dimensional space, and the generation process is guided by the text from an intercorrelated high-dimensional space with the image space. This space, by far, has not been fully understood for its structure, and the uncoupled relationship between latent space and the dataset will be an obstacle to harnessing the colossal network as well as its latent space to generate images or 3D objects.
In this paper, we use compression-based generative models, generative neural networks and auto decoder. In these types of generative networks, the latent space will provide decoupling between vectors in high-dimensional space and the corresponding 3D models. In this high-dimensional space, the encoded vectors of the inputting 3D object correspond with the implicit characteristics that the network captures, and we can explore the latent vector in a gradient linear manner by interpolation and extrapolation. This gradient linearity enables dimension reduction algorithms, such as principal component analysis (PCA) 23 and t-distributed stochastic neighbor embedding (t-SNE), 24 to map the high-dimensional latent space to a lower-dimensional space (2D or 3D) for visualization.
Applications of generative models in architecture
Most of the studies in 3D synthesis, reconstruction, and generation are in the computer vision and computer graphics field, but since 2018, a few attempts have been made for architecture generation. Most applications are confined to 2D, such as interior floor plans recognition and generation,3,4,25 campus masterplan generation, 26 and urban street view evaluation. 27 There exist studies on 3D generation and reconstruction, but the algorithm inherently performs the 2D generation and reconstructs 3D volumes from 2D slices instead of synthesizing the data in a 3D space. 5 On the urban scale, recent studies have developed networks for the reconstruction of 3D building volumes from satellite images,28,29 but these studies are focusing on reconstruction accuracy instead of generation capability. The field of 3D volume generation has not been sufficiently explored.
Methodology
In this study, we preprocessed data into voxel and SDF format and used both VAE and GAN to perform 3D generation tasks. We adopted the chamfer distance as an evaluation matrix for its simplicity in integrating into the neural network, but it per se cannot tell the whole story of complex geometry. We intend to integrate other loss functions and more comprehensive evaluation matrices in the future.
We take a set of 3D models as inputs, to synthesize and generate new building forms with artificial neural networks. The data comprises 1521 building models of the financial district from New York City, which are collected from the NYC open data portal. 30 The original data is in Wavefront OBJ file format. To compare the efficiency of different shape representation methods, we preprocessed the OBJ file into two data formats, voxel matrix, with a 3D matrix consisting of binary data of 0s and 1s, and signed distance function (SDF) format with floating-point numbers. We experimented with two neural network structures, auto decoder and generative adversarial neural networks (GAN). Both networks try to find a lower-dimensional latent vector that can grasp the geometrical characteristics of the input data, and by sampling among latent space, generate new data. However, the two networks are different in terms of the learning and reconstruction process. The decoder learns the latent vector to the 3D object, which tries to be as close as the input data by backpropagation, while the generative adversarial neural networks involve two competing networks, a generator, and a discriminator. The generator maps a random vector to a 3D geometry, and the discriminator then figures out whether a geometry is generated or real. Two networks evolve together through iterations, and in the end, ideally, the generator will also achieve shape reconstruction from a latent vector with minimal discrepancy from the original input.
Data collection and preprocessing
With the collected building models, the first step is to perform normalization on the input geometries to enhance a better training process. We align all buildings to the origin point but preserve their orientation, and then we scale the building data into a unit bounding box. Since the data is in wavefront format, which is difficult to be mathematically represented, we preprocessed the data into explicit and implicit representations to explore the possibilities and efficiencies in machine learning with different shape representations.
Point clouds are the dominant data structure in the field of computer science and have been developed quite maturely. The implicit surface, or the signed distance function (SDF), can also be preprocessed to handle large amounts of 3D models, and it can be easily encoded into neural network layers without ambiguity. It is noteworthy that in the architecture field, CAD models are preferred because they preserve basic geometry, such as points, lines, curves, and surfaces. CAD models have the problem that one model can be interpreted into multiple geometry compositions, and at this stage there is no solid solution to resolve these ambiguities in the neural network, except by walkaround solutions such as detecting vanishing points, detecting line segments, and the algorithms are still in development. 31
For voxel representation, we built a bounding box of 228 m × 228 m × 228 m. Within the bounding box, we voxelize the building volumes with a resolution of 3.5 m. The final voxelized buildings contain a 3D matrix with a size of 64 × 64 × 64, and each entry of the matrix contains a binary value, 0 or 1, where 0 stands for void space, and 1 represents the solid space inside the geometry. The preprocessed volumes represented in the voxel matrix are shown in Figure 5(a), where the black dots are the sampled voxel space within the building model. Signed distance function format preprocessing.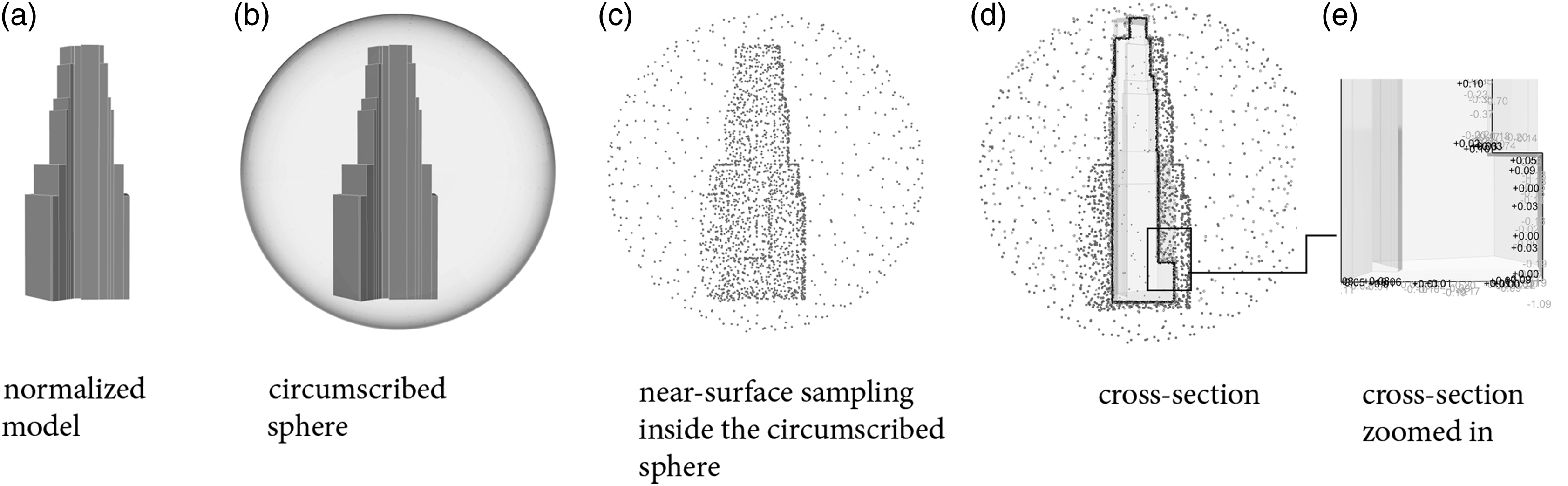
The signed distance function
32
is a popular implicit geometry representation method in computer graphics that encodes the distance between a point in space and the nearest point on the surface of the object. It consists of rich geometrical information coded in continuous floating numbers. Instead of sharp value change between 0s and 1s as voxel representation does, SDF representation stores a matrix of gradient values of distance, which can be represented as
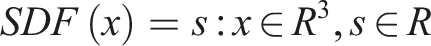
To convert the .obj file into SDF, a preprocessing step is required. We first unevenly sample 50,000 points within a circumscribed sphere of the object. These sample points are dense near the surface of the object and sparse in the surrounding space. For each sample point, the nearest distance from the point to the surface of the object is computed. We use signs to represent the relationship between points and geometry. A negative sign indicates that the point is within the volume of the object, while a positive sign indicates that the point is outside the object. For example, a sample point used for network training might be represented as (19, 25, 60, −0.5), where the first three entries are the position coordinates (x, y, z) and −0.5 represents that the point is inside the object, with a distance of 0.5 units from the nearest surface. An illustration of preprocessing can be found in Figure 5.
It is noted that each voxelized geometry contains a total of 262,144 elements, which is 5 times more than the sample points compared with the SDF with near-surface sampling, but the information contained within the voxelized building is sparser and the resolution of the geometry is lower than the SDF sampling. One downside of SDF representation compared to voxel-based representation is that it requires more computational power to convert the SDF representation into a 3D model that can be used in 3D modeling software.
To train a network with data that has a flexible point cloud concentrating on the surface, the algorithm has to be invariant to permutations of the input set. With permutation-invariant point-processing networks, the points can be independently projected into high-dimensional space using the permutation-invariant max-pooling operation. Previous studies such as PointNet are using this algorithm to do semantic segmentation.
33
The example geometries with voxel and SDF representation are shown in Figure 6. Demonstration and examples of the preprocessed dataset. (a) binary voxel representation; (b) signed distance function representation.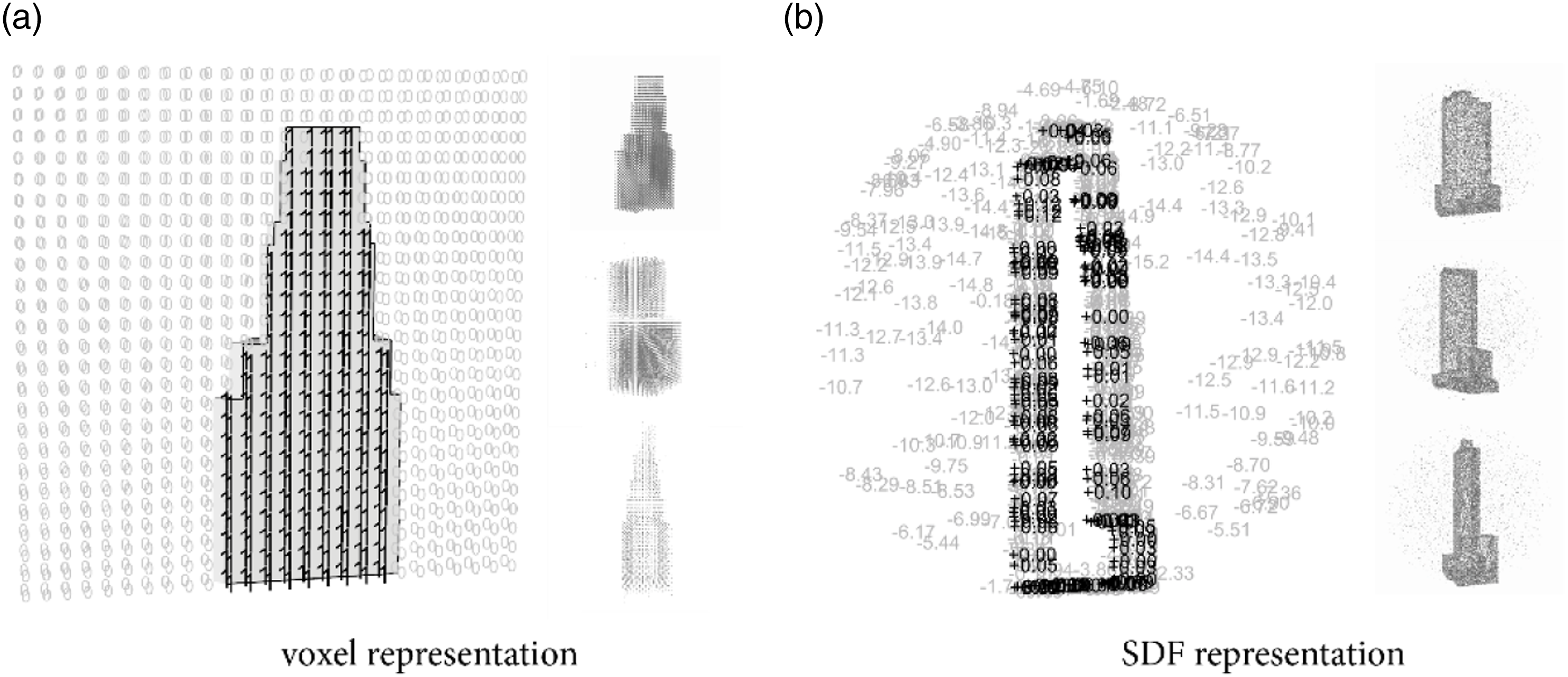
Auto decoder
We refer to the work from Park et al. (2019)
11
to construct our auto decoder-SDF model. Auto decoder learns to generate an SDF value given a query point to be as close to the input SDF value as possible. We learn weights of a multi-layer fully connected neural network to make an approximation of SDF in the target domain Ω with L1 loss function. The whole network comprised nine fully connected layers, followed by ReLU to introduce nonlinearity with a dropout rate of 0.2 to avoid overfitting. We predict the final SDF value with the hyperbolic tangent function tanh(x) as the activation function. An illustration of the auto decoder used in this study is shown in Figure 7. For training the auto decoder, we run stochastic gradient descent on mini-batches of 100 samples each, with a learning rate of 0.001 in the first epoch, decaying to half every 500 epochs. Architecture for auto decoder.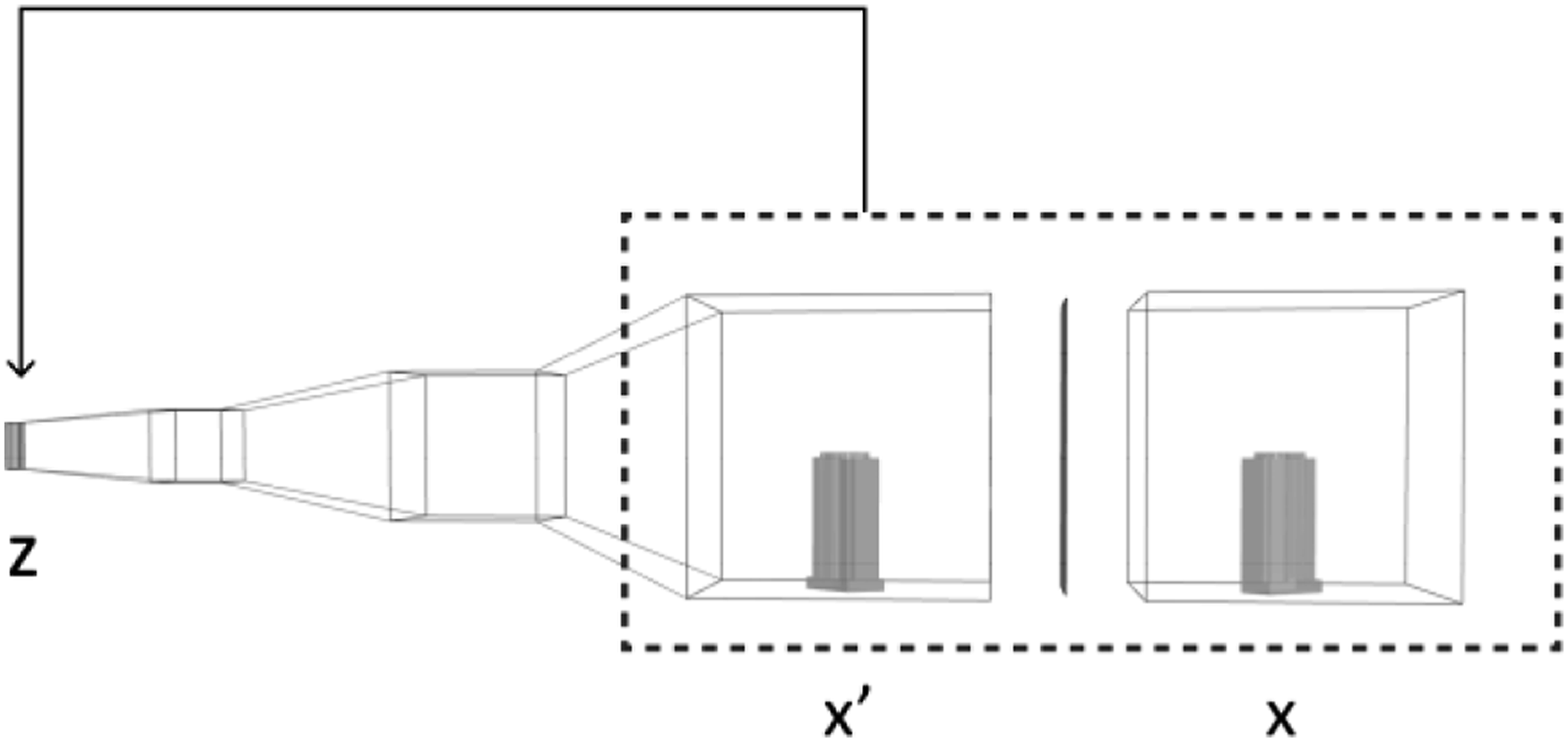
Generative adversarial neural network
We built the generative adversarial neural network based on the structure provided by Wu et al.
10
(2017). We constructed the generator with five sequent 3D convolution layers that map a latent vector of 1 by 100 dimension to a three-dimensional matrix with a shape of 64 by 64 by 64. The discriminator intakes the generated 3D matrix, and maps it to a one-dimensional binary vector, where 1 stands for true, or real data, and 0 for false, or generated building form. We used patches of the point set P for evaluation because the discriminator is not able to distinguish between real data and generated data solely based on the occupancy of a single sample point. The loss function used in this study is defined as
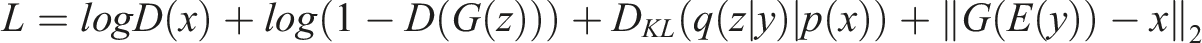
We integrate three terms in this loss function, a binary entropy loss for the generator, the Kullback–Leibler (KL) divergence loss for sampling the latent vector, and a reconstruction loss to evaluate the discrepancy between the generated shape and the ground truth. The illustration of the generative adversarial neural network is shown in Figure 8. Architecture for generative adversarial neural network.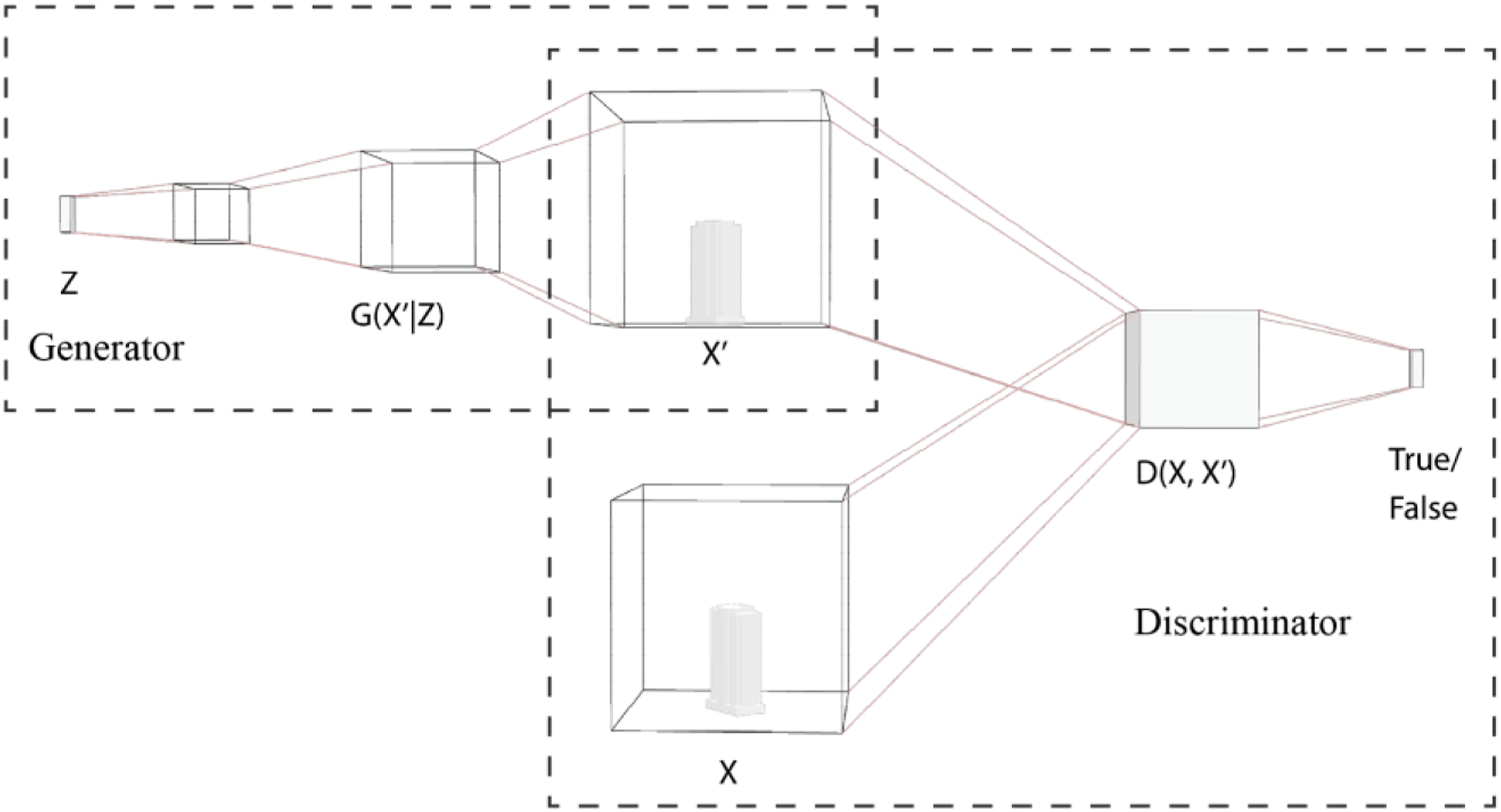
Results
We train the above models by passing the training set with 1200 samples. We leave the remaining 300 samples as a test set to evaluate the reconstruction performance. The training and test sets are randomly separated and kept the same for the auto decoder and the generative adversarial neural network.
Reconstruction performance
We train auto decoder with 100 batches with Google Colab GPU. Each epoch takes 15 s–28 s. The total training time for 5,000 epochs is 22.78 h. The training process with auto decode is more efficient than a generative adversarial network due to its simpler network architecture with fewer layers and parameters.
Figure 9 shows several reconstructed test samples using the networks trained by the auto decoder-VAE model from 100 epochs to 1000 epochs. It can be observed that at the beginning, all buildings are reconstructed similarly because their latent vectors are almost encoded randomly. After around 200 epochs, rough shapes have been learned but barely any structural details such as annex buildings can be found. Details appear after 500 epochs. After 1,000 epochs, some significant features of the volume have been reconstructed, which enables us to distinguish them from each other. Due to limited time, we stopped at 5,000 epochs but we expect the performance can be further improved with more epochs. Reconstruction training progress by auto decoder-SDF model with epochs from 20 to 5,000.
Training a GAN model with 100 batches for one epoch consumes around 60 s–90 s. Visualization of test cases trained by the GAN-Voxel model is shown in Figure 10. We find that voxel representations can be less efficient for pattern learning than SDF format. 3D voxel representation suffers from the curse of dimensionality and has a lower resolution than SDF, of which the points are more frequently sampled near the surface. Though the data matrix is 5 times larger than the SDF data, the matrix is sparse and exterior voxels are redundant, meaning the voxelized data has little information for training the network and requires a longer time to train. However, the voxel dataset outperforms the SDF dataset in that the generated results can provide vertical and horizontal edges due to the intrinsic data structure: matrix. Reconstruction by GAN-voxel model with 200 epochs.
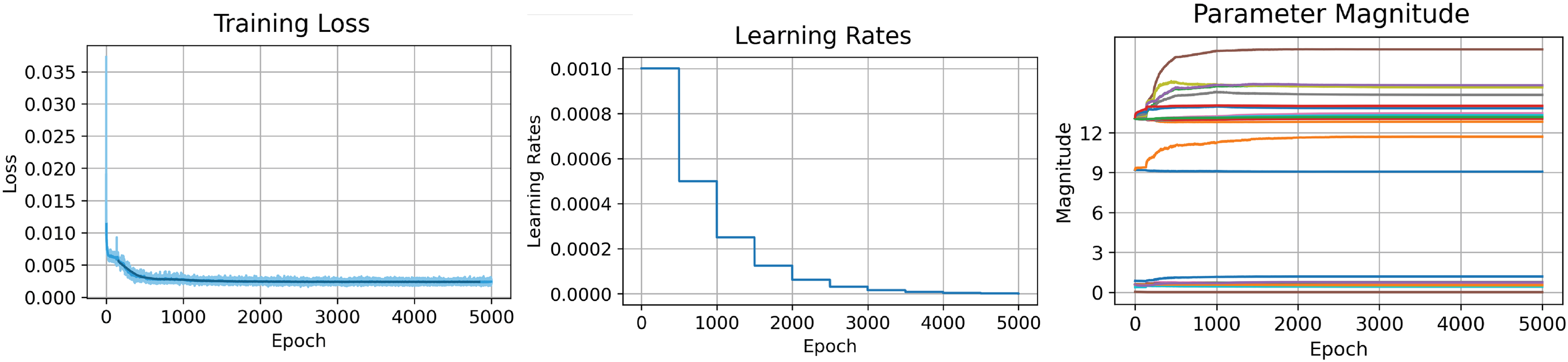
We further investigated the training loss and the evaluated test performance of the auto decoder-SDF model. Results are plotted in Figure 11 and Figure 12. Training loss is a compound of L1 distances of clamp SDF differences and a regularization term on the latent vectors, and the performance evaluation metrics is a scaled chamfer distance between the ground truth point cloud and the reconstructed one. The scaled chamfer distance, calculated by the original distance divided by the building scale, is to make results among cases comparable. With more epochs, training losses keep decreasing and test performances keep improving. After 1,000 epochs, we achieve an average normalized chamfer distance of around 10%. One observation is that although humans can easily tell the huge differences between 250 and 500 epochs and 500 and 1,000 epochs, the evaluated performances improved very slightly, which indicates that in the next step we should look for particularly designed penalty terms to be included in the loss function besides those general ones to accelerate the training process. Visualization of the chamfer distance between generated volume versus input. Evaluation of training loss per epoch (left), learning rate per 500 epochs (middle), and the magnitude of parameters per epoch (right).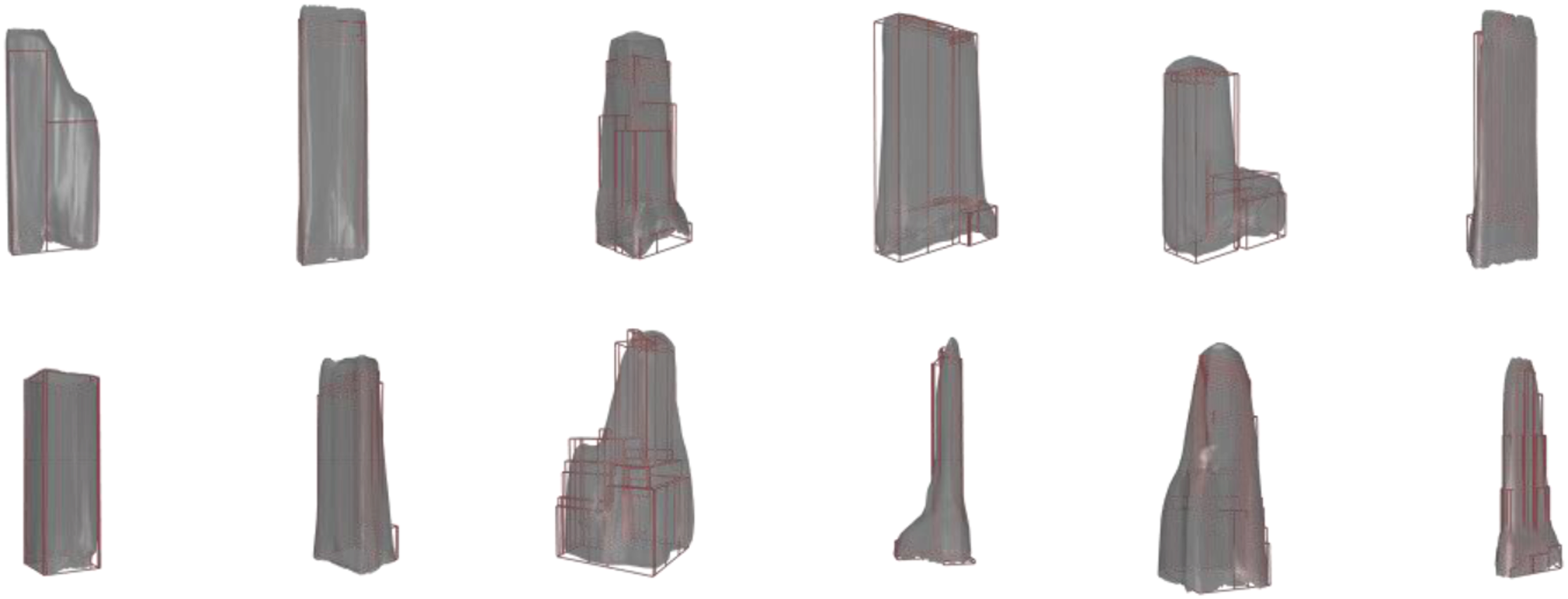
Design solution space
We propose to use the generative models to construct a rich exploration space for design solutions. We interpolate with latent vectors of different buildings, either existing ones or generated ones, to generate multiple design solutions that haven’t been seen in reality but are reasonable. Figure 13 demonstrates six design candidates by interpolation within generated results, and Figure 14 demonstrates an illustration of the idea of clustered volumes as a design exploration space provided for designers. A framework to generate context-consistent buildings is also feasible by using one building’s latent vector as labels and concatenated latent vectors of its surrounding buildings as features. Design candidates by interpolation. Exploration space interpolation and extrapolation by volume properties.
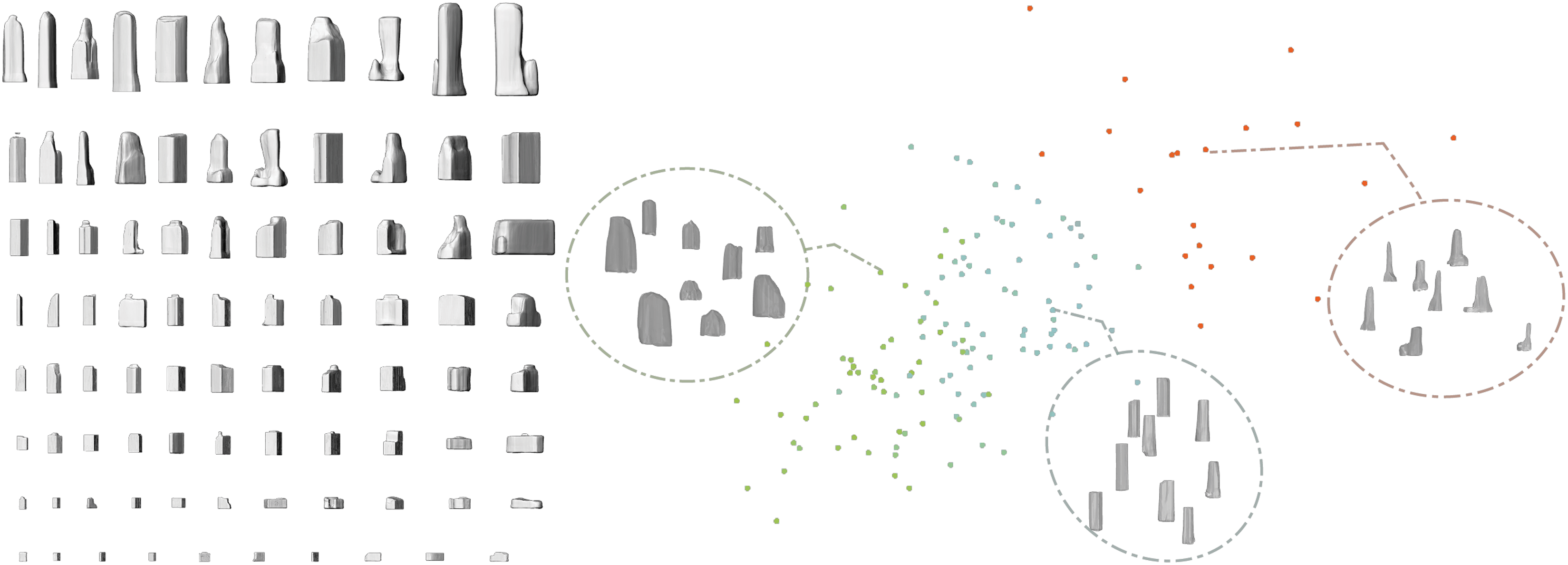
We treat the encoding phase as a dimensionality reduction process and expect the latent vector to grasp the implicit design styles of the original buildings. Then, we are able to employ clustering algorithms to conduct various architecture genre research. We evaluate the generated architecture volumes, perform dimension reduction, and cluster the generated volume in a high-dimensional space with multiple axes such as footprint shape, aspect ratio, floor area ratio, etc. as references for architects to navigate and explore.
In the case of a design problem, architects would first be able to explore the design solution space, which is tailored to the morphology of the specific city, and by sampling portions of the generated volume, architects and urban designers would be able to engage with the design solution interactively. The design process involves first encoding the immediate surrounding buildings into a latent vector representation. Subsequently, relevant and similar latent vectors are identified by sampling from the latent space, resulting in multiple design candidates. These generated building volumes are then incorporated into the overall urban context for further analysis and evaluation (Figure 15). This approach can also be extended to mass volume generation at an urban design level by taking multiple adjacent samples in the latent space (Figure 16). (a), (b) Examples of building scale implementation with design candidates sampling from the design pool. Example of urban scale implementation with (a) original urban morphology and (b) generated urban morphology.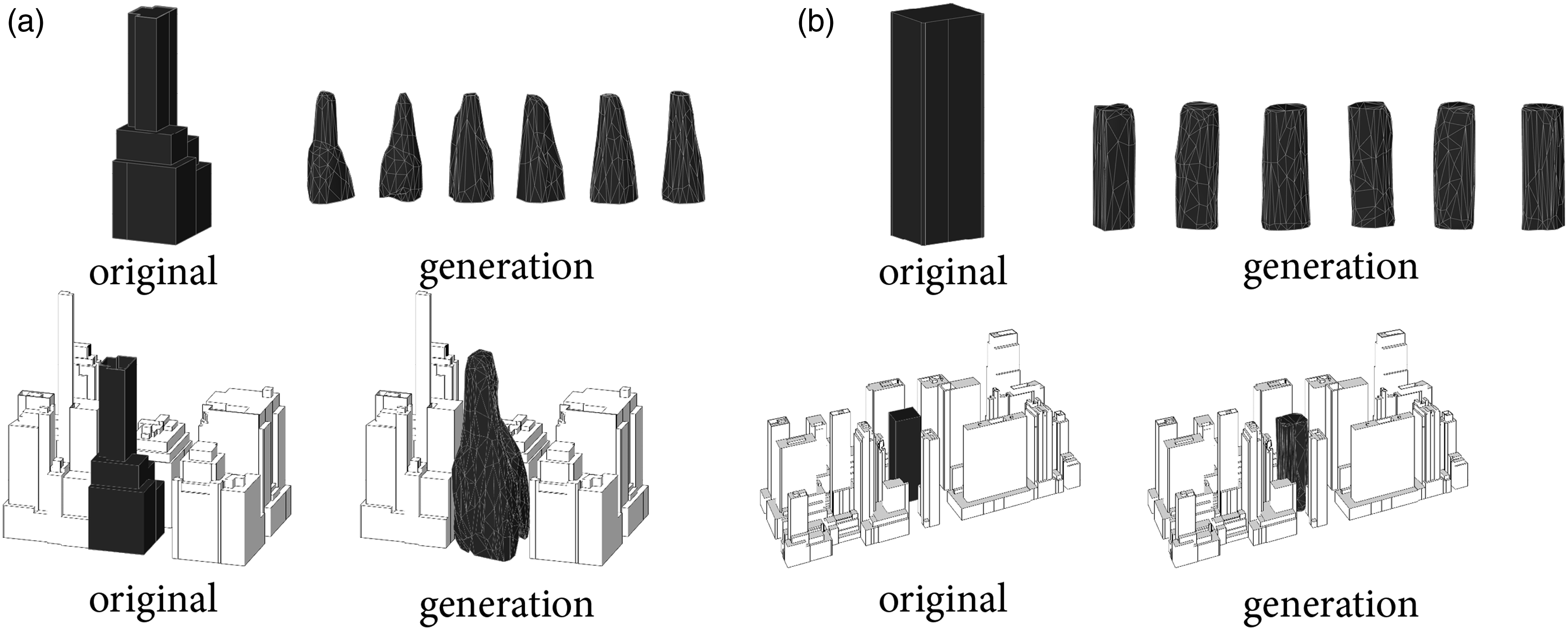
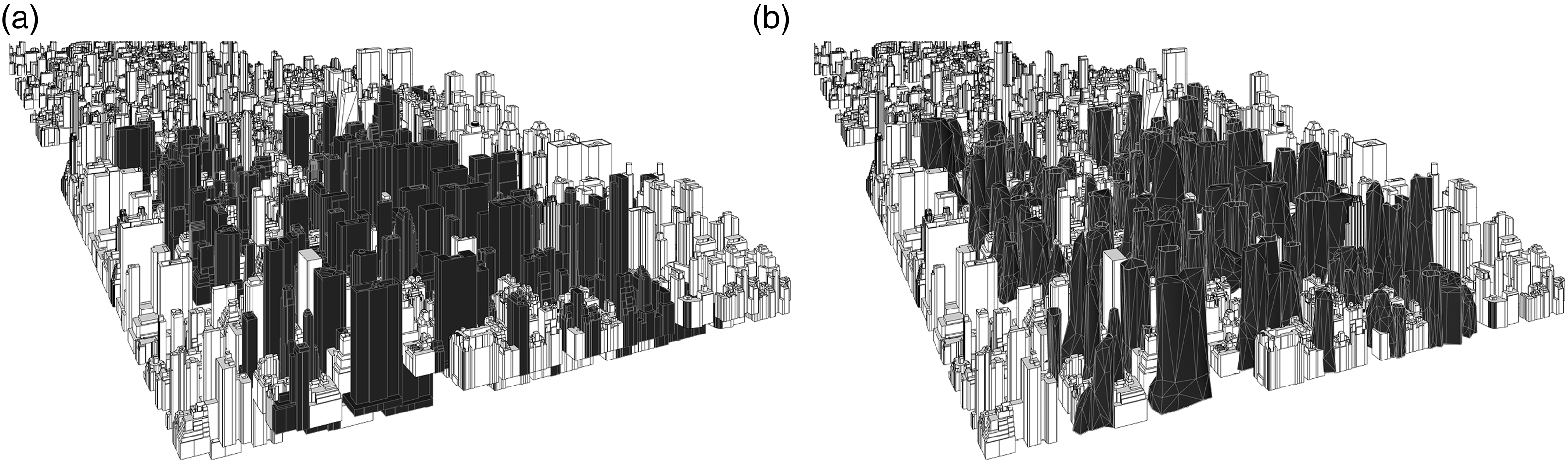
Discussion
Generation performance
The signed distance function representation outperforms voxelized representation in both dimension and information richness. The signed distance function contains gradient data which is suitable for artificial neural network training. Regarding network efficiency, though generative adversarial neural networks take longer to train and, in this study, don’t provide satisfying results, we didn’t perform the exact same training on both networks so we may not reach a conclusion in network comparison. In the recent studies in computational geometry and machine learning discipline, generative neural network exemplifies themselves in latent space learning and generating new data.10,15 More research and experiments, such as fine-tuning hyperparameters, and transfer learning from another dataset, need to be done to further investigate the performance variation between different networks.
This study shows that given sufficient amounts of data, the generative models exhibit the ability to learn important features of buildings. However, as proposed to be a design tool, the current performance needs further development. There are two major difficulties in improving the current network structure. On the other hand, while SDF has been found to be more efficient compared to voxel-based volume representation, the use of SDF in the representation of 3D buildings still poses challenges with regard to the authenticity of the representation. This can be attributed to limitations in the non-semantic representation method, the quality of the data used, or other factors that lead to the inaccurate representation of the building’s form and details. To improve the results from the training perspective, explicitly enforcing geometrical constraints, such as straight lines, junctions, planes, vanishing points, and symmetry can lead to a more accurate, reliable, and interpretable 3D learning process. 31 Augmenting the data structure by incorporating surface normal can preserve the input geometry’s features such as sharp edges and straight faces. 34 Additionally, expanding the database by incorporating mass 3D reconstructions from photos can increase diversity and richness.
Generative design with neural networks
Generative design with neural networks has been studied ever since the generative models in computer science were proposed in 2014. 14 Due to the limited amount of discipline-curated data, its application mainly confines to 2D plan generation, and the generated quality is acceptable for inspiration, but may not be sufficient to apply as practical design solutions. The newly emergent latent diffusion models also provide intriguing possibilities for architectural design. However, like previous neural network-based algorithms, the applications are still confined to 2D conceptual exploration.35–37 This study furthers the work into the 3D domain, the intrinsic essence of generation is enabled by sampling, interpolation, and extrapolation. We took a closer look at the latent vector of the compression-based network, and focusing on the latent space of the network provides a better understanding of the data-driven approach and a higher control to harnessing the generation process.
This study shows the potential to revolutionize the early design process in a number of ways. By leveraging data representation and geometric constraints, the proposed method can help designers quickly generate and explore a vast array of design options. As a result, the design process can be significantly sped up, allowing designers to identify optimal solutions more quickly and efficiently. Additionally, AI-aided generative design can help designers focus their time and energy on the most critical and creative aspects of the design process by automating many of the tedious and repetitive steps. The current objective functions and constraints are derived from pure geometry. A variation of this method allows other constraints, such as daylighting accessibility and energy consumption, to be incorporated into the loss function of the network in order to automatically generate energy-conscious design distributions for architects and urban designers to explore.
Data bias
Data bias has been a problem in machine learning since its inception, and architecture is no exception. 38 In AI-aided architectural design, data bias can lead to systematic tendencies favoring dominant cities and cultures, resulting in biased design solutions. Generally, this occurs because the training data do not represent the diversity of the population or are based solely on designs from one cultural context. 39 To mitigate these biases in data-driven design, it is crucial to ensure that the training data utilized is both diverse and representative.
In this study, we adopt the commonly used validation split method to minimize bias in our dataset. To enhance training quality and eliminate data bias, we randomly divide the dataset into training and testing sets, and we use cross-validation to further divide training for each iteration. Though randomly split, as illustrated in Figure 17, the distribution of morphologies in both the training and testing sets is within a reasonable range, ensuring that the algorithm will be able to learn and generate new shapes effectively. Morphology distribution in the training and testing set.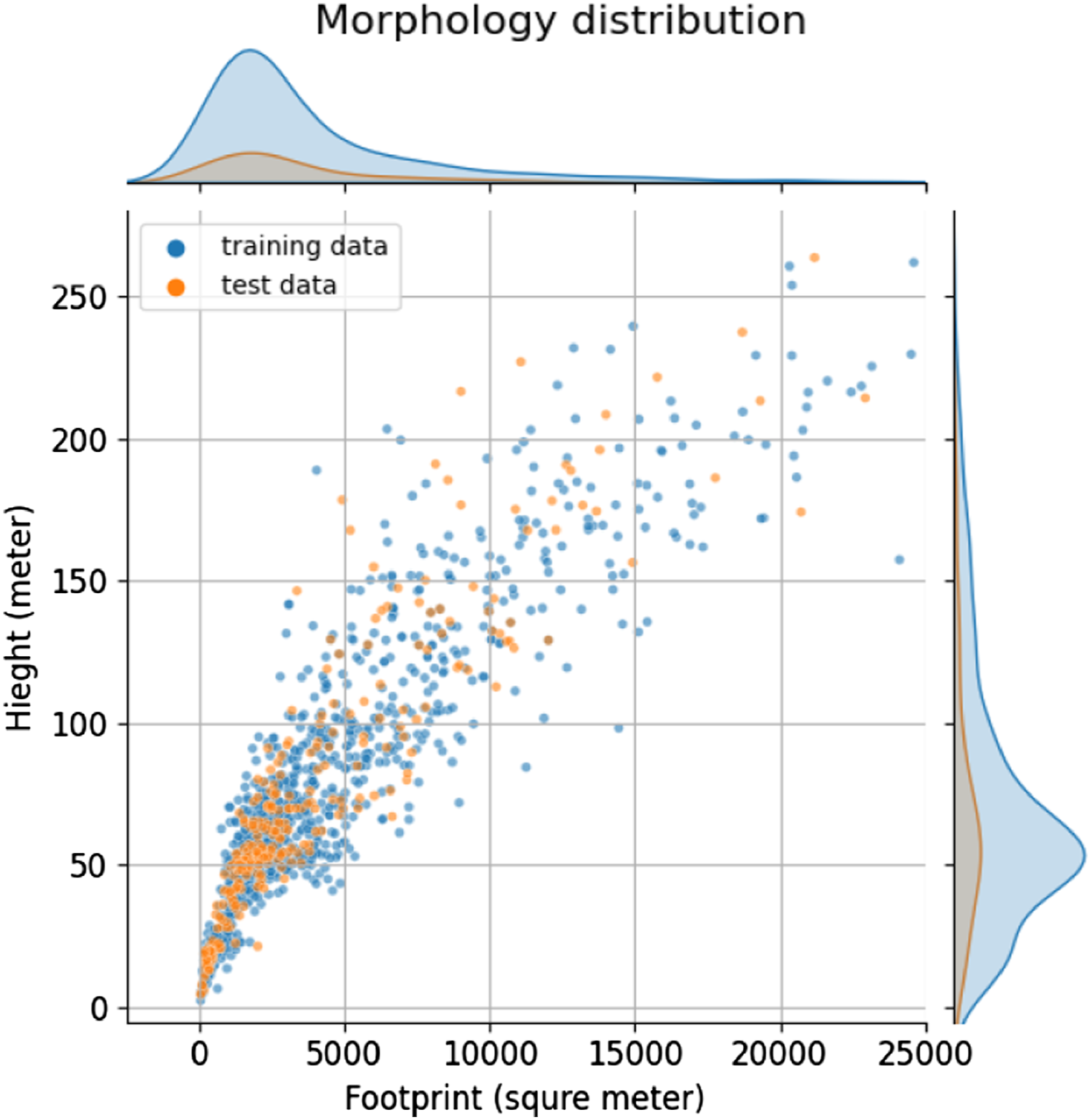
Unfortunately, the acquisition of 3D architecture models and database construction is a protracted and resource-intensive undertaking, requiring significant time and resource costs. The expense encompasses every stage of the dataset construction, from data acquisition to post-processing with manual model adjustment and labeling. Scanning technology such as LiDAR can capture 3D models with a high level of automation, and drones can facilitate scaling up the 3D scanning to the building and city levels. However, the resulting 3D-scanned models are typically in a point cloud format, necessitating post-processing algorithm or manual effort for semantic segmentation in geometry and material. Consequently, only a few districts in major cities have a curated dataset for buildings, such as New York City, 30 Berlin, 40 and London. 41 The inequity of data between cultures and locations will affect the coverage of applications and exacerbate inequalities in the design of generative architectures. As a result, the generated design solution may adopt more features from dominant cultures and wash away the characteristics of underrepresented cultures. To reduce the data bias on cultural gratuity, it is imperative to integrate data from less-dominant cultures and cities. While progress has been made in improving universal 3D database formats 42 and creating new datasets, 40 addressing the challenge will require continued investment and collaboration from both industry and academia.
We offer three potential ways to enhance biased data by incorporating underrepresented cultures and increasing cultural diversity. One solution is to use satellite images for mass 3D reconstruction, which can provide a comprehensive view of worldwide building morphology. Another solution is to use zero-shot learning or transfer learning, which allows the transfer of knowledge from a large database with a small amount of data. This can be especially useful when data is scarce or when it is difficult to obtain representative data for certain cities or cultures. Additionally, procedural generative algorithms can be used to create synthetic training data that can augment real-world data to increase the data size of the underrepresented cities.
Other than augmenting the database, we can also address the data bias by consciously monitoring the generated design solution by using interpretable models. With a close investigation of the latent space of a machine learning model, architects and designers can gain insights into the underlying pattern that drives the model’s generations, and makes decisions for adjusting the distribution of the training data, or replenishing the underrepresented data to ensure that model reflects the entire design population.
Conclusion
This study demonstrates the potential that AI-aided generative design has to revolutionize the early design process in architecture. The ability of AI-aided generative design to synthesize patterns and process vast amounts of data at much faster rates than humans allows for the identification of innovative design solutions that may not have been considered otherwise. By integrating this approach into the early design phase, architects and designers are able to quickly generate and compare multiple design options based on specific design constraints and goals, freeing up time and resources to focus on the more creative and strategic aspects of the project. This study provides evidence of the effectiveness of AI-aided generative design by utilizing artificial neural networks to synthesize and learn 3D building volumes, leading to a broader design solution space for architects to explore.
We demonstrated that by feeding a large amount of 3D data, artificial neural networks can learn the implicit features of the input geometry. The network maps building volumes to a latent vector that encapsulates the major features of the building. The experiments with two data representations show that though voxelized building volume can be inferior to the implicit surface in resolution and efficiency, it can preserve critical building features and avoid over-smoothing surfaces due to the intrinsic characteristics of the matrix data structure. Both networks tested in this paper exhibit the capability to learn from the input dataset and output building volumes that resemble the intaking dataset, opening the potential for a vast design exploration space.
It is worth noting that the proposed generation method has the following limitations. First, the database is based on point clouds, resulting in a network that does not preserve building characteristics such as sharp edges. In addition, the loss function is still premature and cannot catch the most significant discrepancies among building envelopes. Thirdly, the evaluation matrix calculates differences in the generated volume and input data. Further criteria can be added to tailor the results to the architecture design specifications.
The results of this study, albeit limited in granularity, represent a crucial first step in unlocking the full potential of AI-aided 3D volume generation. The inadequacy of details in the results is attributable to the upsurge demand for dataset and computational resources, and is a compromise between models with lower resolution models with expedited training versus high fidelity models with slower training speed. In order to further enhance the accuracy and precision of the generated forms, improvements can be made in data representation, dataset construction, and algorithm improvement. For dataset representation, we can incorporate semantic information, such as function and program, into the dataset. This will guide the generation process and enhance the relevance and interpretability of the latent variables and the generated forms. By capturing the intricacies and variations of real-world building forms, the model will generate more detailed and nuanced design solutions. Besides, the current dataset should be expanded to encompass other districts, cities, and countries to promote diversity and avoid cultural bias. Strategies to increase the diversity and representativeness of the dataset include mass 3D reconstruction from satellite images, zero-short learning for transferring knowledge from major cities to smaller cities, and synthetic data generation for cities with less available data. Improving generation performance can also be achieved through algorithmic changes. Customizing loss functions and evaluation metrics with domain-specific knowledge can contribute to the improvement of the generation process with tailored constraints.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.