
Abstract
The development of Generative Adversarial Networks (GANs) has accelerated the research of Artificial Intelligence (AI) in architecture as a generative tool. However, since their initial invention, many versions have been developed that only focus on 2D image datasets for training and images as output. The current state of 3DGAN research has yielded promising results. However, these contributions focus primarily on building mass, extrusion of 2D plans, or the overall shape of objects. In comparison, our newly developed 3DGAN approach, using fully spatial building datasets, demonstrates that unprecedented interconnections across different scales are possible resulting in unconventional spatial configurations. Unlike a traditional design process, based on analyzing only a few precedents (typology) according to the task, by collaborating with the machine we can draw on a significantly wider variety of buildings across multiple typologies. In addition, the dataset was extended beyond the scale of complete buildings and involved building components that define space. Thus, our results achieve a high spatial diversity. A detailed analysis of the results also revealed new hybrid architectural elements illustrating that the machine continued the interconnections of scale since elements were not explicitly part of the dataset, becoming a true design collaborator.
Introduction
The most common use of generative adversarial networks (GANs) 1 is for form exploration in architecture through image datasets. The training information is a series of 2D images that yield images. 3D GANs, however, develop slowly and are still a problematic issue because of the increased complexity of higher dimension data that exponentially extends computing time and the inconsistency of cohesive 3D data representation, which may vary in formats such as meshes, point clouds, or NURBs. This also entails the fact that 3D models vary significantly more in detail and resolution than plan or image slicing datasets, and this is particularly true for 3D models that also include all interior information.
While GANs open up the possibility of learning from an almost infinite amount of data, it also raises the question of how to design 3D models of different scales ranging from an entire building to individual building components since, in a GAN, no scale is provided.
To tackle these restrictions, this work presents a novel 3D deep learning approach to architectural space across different scales and typologies. By transforming datasets into voxelized depositional descriptions, we show that datasets commonly divided into morpho-topological object classes or typologies can be transformed into heterogeneous architectural spaces. Our approach reduces the need to (pre)classify datasets, preventing data modification or generalization of different representation formats. We will demonstrate that our approach can be used across a variety of scales and data types.
Implementation of GANs in architecture
In current 2D-GAN research, the third dimension is added by extrusion, which prioritizes the 2D plan drawing by neglecting the third dimension. We believe this approach complicates the possibility of finding novel spatial configurations and obstructs the advances in 3D computation in architecture made in recent decades.
Some breakthroughs in using 3D data as datasets for GANs have been made, but with finite progress, especially in the field of architecture. Hang Zhang, 2 and Stanislas Chaillou, 3 used ML-generated sections and plans as stretched-style images, which were serially stacked with no spatial correlation in the third dimension so that the information between the layers was lost, causing an information jump between the cut layers. While these examples derived 3D models from a single axis, others used a multiple-axis approach.4,5,6,7 This research used pixel projection from GAN-generated facades, sections, or plans. However, through the projection of 2D images, a linear interpolation was needed that significantly reduced information and ultimately aligned with 2.5D extrusions. As Zhang and Blasetti5 5 concluded, serial stacking kept the uniaxial slicing aesthetic, but the multi-view results lost all special interior information.
In Immanuel Koh’s “3D-GAN-Housing,” 8 another attempt at 3D geometry with GANs was explored by sampling and remixing predefined housing typologies in a 3D voxel grid. David Newton’s 9 method involves voxel techniques, the same as our method, but by implementing 3D IWGAN, they can evade the decoding process from 3D to 2D and back but must accept decisive losses in resolution. Therefore, like Koh, Newton implements 3D GANs solely on massing models and excludes the spatial complexity of interior spaces.
Other studies exploring the 3D qualities of GANs in architecture have used extrusion and 2.5D heightfield techniques to achieve the third dimension. 10 Graph convolutional networks require triangled meshes as closed volumes and, therefore, can barely extend beyond deforming topological shapes of the same degree. 11
The above examples all contribute to the development of 3D-GANs in architecture; however, for interior spatial sequences, there is either a lack of resolution, a loss of information (and therefore preservation of spatial complexities), or topological invariance. These problems are primarily due to the methodological problem of encoding complex 3D geometry into vectors that a GAN system can train.
Additional research, such as the MIT CSAIL 12 and Kaolin Pytorch library13,14,15 research on 3D deep learning, have accelerated the development of 3D-GANs, with a focus on objects and volumetric shapes. 12 Both libraries use the technique of voxelizing and encoding the voxel information into n-dimensional vectors. The Kaolin API mainly focuses on streamlining the workflow with 3D data in different formats and implementation in larger frameworks, including rendering and animation data. Research by Kleineberg and his team also proposed a valuable GAN method to train and generate 3D shapes. Comparable to them and other 3D GAN research, we use signed distance fields (SDFs) to visualize in the form of postprocessing the GAN results. 15 They even used SDFs structure to directly train the GAN system. But like others before they employed the ShapeNet library, and their method doesn’t disclose if it can train and successfully generate interior shapes beyond the envelope. Next to voxel information, point clouds equally have proven to be a suitable method for 3D GAN generations 14 but also demonstrate difficulties to capture interior spaces and sequences. Most recent developments of Neural Radiance Fields (NeRFs) 16 and AI-aided 3D methods based on diffusion models impress by their speed but also struggle with the complexity beyond the envelope. 17 Nerfs in particular remind about pixel projection and image stacking methods while diffusion model based methods are promising for future development but still resolution and topological complexity.
Like in architecture, these studies in computer science have demonstrated the use of various formats of 3D data including voxels, stacks of images, point clouds, and depth maps, in deep learning models, nevertheless it remains unsolved how to deal with an inside and outside form simultaneously. Thus, it should be noted that these studies are all limited to what art historian Henri Focillon 18 describes in relation to the discipline of architecture as external form. He emphasized that architecture, as an art form, possesses a unique privilege in that it is mandated to address both the exterior and interior. The art historian’s brilliant expression highlights that these two forms cannot be perceived simultaneously; nevertheless, they are intimately interrelated and cannot be comprehended entirely in isolation from one another. This is the main difference of our research from the other studies dealing with the application of 3D GANs listed above: Can the machine process both the interior space and the exterior shape simultaneously?
In brief, past investigations have been confined to generating either the external envelope or the internal layout of a building, rather than both concurrently. A noteworthy challenge pertains to the internal spatial information, as the machine’s comprehension of the spatial logic governing architectural imagery (induced by slicing 3D buildings into 2D images for instance) is limited, leading to results that lack the spatial continuity that characterizes the original edifices. Building on relatively uncharted 3D-GANs research in architecture and the lack of 3D interpretations of image-based GANs, this study examines a 3D-GAN workflow that hybridizes 2D-GANs using a voxelized encoding technique. Our method allows 3D architectural datasets to be trained with the result that their spatial complexity can yield hybridized 3D outputs.
Method
We developed a novel 3D-GAN method that hybridizes image-based GANs with 3D-voxelization techniques. Our work draws upon research by Nvidia and MIT CSAIL. Specifically, we use a DCGAN algorithm 19 to train 2D images representing the spatial syntax and complexity of the 3D dataset. 20 First, the dataset is created by translating 3D voxel information into a 2D image. Then, once trained and new images are generated from the DCGAN latent space, the 2D images are translated back into 3D models by inverting the translation process. The special feature is that the workflow presented here overcomes the hurdles and associated information loss of spatial continuity in translating data from 3D to 2D and generating new spatial configurations.
3D to 2D and back to 3D translation process
3D geometry can be described and represented in many formats, including polygon meshes, point clouds, or NURBs. As these formats vary in complexity, file size, and information they hold concerning a specific geometry, it is almost impossible to find common ground to vectorize this information directly to train it to a GAN. This is especially true when the spatial complexity and topologies of various degrees of 3D geometry are considered. Thus, we have developed a 3D voxel technique that allows any geometry to be used regardless of its format (e.g., mesh, NURBs, voxel, point cloud) and translate this data into a 2D image without losing information. This technique significantly reduces labor time compared to modeling hundreds of buildings to achieve structural consistency, which is necessary for other approaches8,21 and excessive formatting to triangulated mesh faces. 11
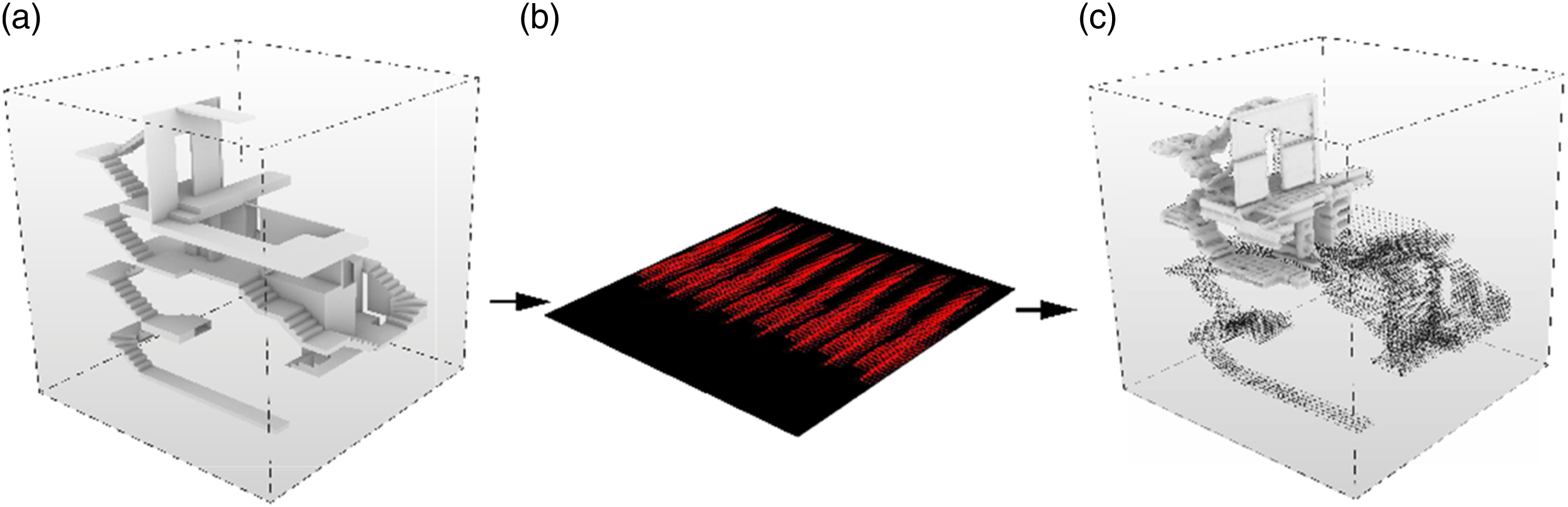
We use a specific 64 × 64 × 64 voxel grid to describe the geometry. Each voxel in the grid is tested to determine whether it is consistent with the geometry or does not represent the geometry. If a voxel is determined to be part of the 3D geometry, it is saved as a distinct RGB pixel in the 512 × 512 image. If it is not part of the geometry, it is saved as a black RGB (0,0,0) value in the image. Put differently, the geometry (materiality) deposition instructions could be binary raster layers encoding whether or not a pixel should be deposited at a voxel’s location. The voxel grid and the pixel grid are a specific size; they must be rendered equal for our method to work; 262,144 voxels correspond to the same number of pixels and can translate information seamlessly without loss from 3D to 2D and back (Figure 1). The success of the encoding and decoding process of the 3D data is qualitatively evaluated by comparing the original model with the SDF reconstruction, which are notably similar (Figure 2). Encoding process illustrating the translation of 3D voxel to 2D pixel. The precise voxel and pixel grids are linked to equal counts (262,144) for precise translation but also derive from the limitations of maximum VRAM of GPUs to load datasets. For our method, an image resolution of 512 × 512 pixels was ideal for training with a batch size of one and a reasonable training time of 16–24 h on an Nvidia RTX 2080 Ti GPU. However, this constraint is partially bound to GPU technology. The visual examination of the results illustrates the degree of details between the (a) original and (c) reconstructed forms.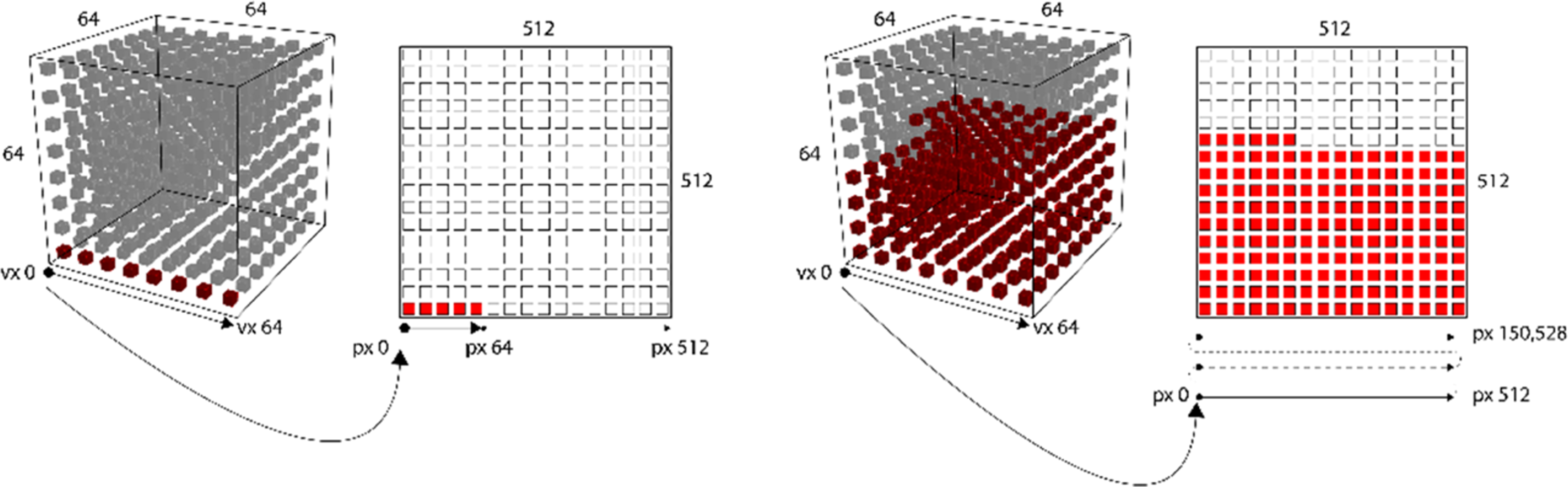
Encoding the 3-dimensional object into a single image allows the information and geometrical relations of each voxel to be retained in all three axes and train the entire 3D object as a whole rather than as a series of unrelated sliced image layers. This makes any intermediate or additional preprocess, such as pixel continuity, unnecessary, which otherwise generates fragmented and chaotic results using image slicing methods.5,6 The decoded images are trained on a DCGAN algorithm. After training, the resulting images are translated into 3D models and reconstructed into polygonal meshes using the inverse translation process from pixel to voxel in the specific grid (Figure 3). The 3D geometry produced by 3D GAN may be opened to more varied postprocessing modeling methodologies. We specifically explored the technique of procedural reconstruction using SDFs comparable to marching cubes algorithms. This technique allows us to reconstruct large assemblies and intricate details across scales simultaneously that are inherent in the diverse datasets. Overview of the 3D GAN-based design process. The first step is the participatory collection of 3D building datasets (a). Once the data is available, the buildings are divided into multiple bounding boxes and voxelized with a 64 × 64 × 64 grid (b). As an intermediate result of processing the data, 2D images of 512 × 512 pixels are created (c). These 2D images are retrained to a DCGAN (d). The DCGAN extracts and hybridizes essential features (e). Finally, the resulting 2D images are seamlessly translated back into 3D geometry through procedural reconstruction (f).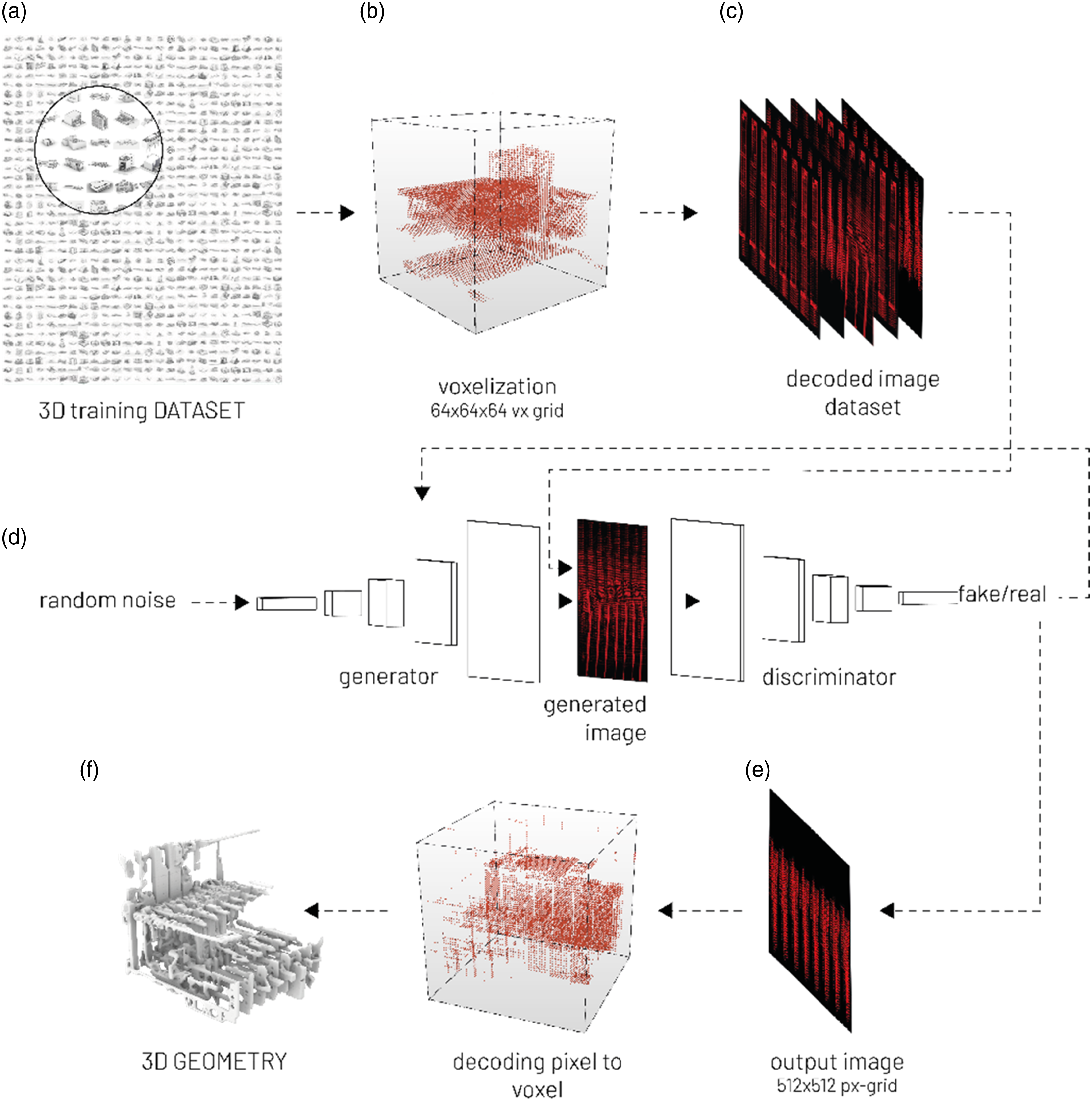
Another advantage of our method is that almost any representational format, a polygon mesh, NURBs, point cloud, or multi-object model, can be trained without any formatting or editing. Additionally, our approach alleviates the need to preprocess data sets, preventing alteration of data and loss of information in the decoded 3D models. Additionally, parameters such as normal orientation, manifold edges, or surface versus solid geometry are insignificant. Spatial and geometric qualities, volumes, and interior spaces such as walls, slabs, and stairs are accounted for and translated.
3D datasets
There are 3D model dataset repositories such as ShapeNet.org 22 that have extended 3D model collection and are the benchmark datasets for the above-mentioned research projects in particular in computer science. But they are not useful for analyzing architectural datasets by our research method due to the limited number of model details, which mainly represent only a building mass. The main criteria for our 3D datasets were that they contain all interior information such as walls, columns, ceilings, stairs, doors, and windows to detect different spatial qualities. Rather than synthetically generating a 3D dataset that is biased as it repeats its predefined parameters, 23 we used a vast collection of architectural precedents and canonical buildings collected during our research investigations and teaching at the University of Innsbruck and Texas A&M University throughout the last decade. Even though most precedents are still drawn from the Western canon, we are increasingly trying to integrate vernacular architectural structures from elsewhere. The advantage compared to synthetic datasets is that our dataset is more diverse in its spatial organization, scale, and complexity.
Our aim is to investigate spatial compositions which the machine could detect across scale in 3D data that we could not see. To do so, developing a scale-aware method is crucial in particular since there is no architectural scale provided in GANs. Therefore, scale awareness needs to be implemented in the dataset. For the experiments, we pursued a pair of strategies and developed two different sets of data. In the first experimental setup, buildings and components were scaled to fit into the bounding box; in the second enhanced experiment, the 3D model was split to maintain the same scale throughout the dataset.
Experiments and results
Dataset preparation
The required data from 632 buildings were collected in the first research stage. In the second stage, we could extend the number of buildings to 728.3D models with diverse typologies, different epochs, and geographical regions were harvested from online open-source repositories and precedents, resulting from a series of workshops, design courses, and seminars. Hence, the dataset used for this research is founded on a collaborative ground where professionals, students, and non-specialists create and collect data collectively. The high diversity of typologies, from single-family housing to museums and from office buildings to churches, was intentional as we wanted to avoid any pre-classification and examine the machine purely for its formal/aesthetic “understanding” of architecture. The only requirement and criteria for building curation was to include all essential elements and details, such as partitions or stairs. To ensure the quality of the generated 3D data, the 3D input data was scaled to a common size (meter) that can be used as input for the GAN model. These datasets were used to train the machine specifically concerning architectural space. The buildings were also manually examined by subjects in terms of the building’s composition, specific spatial ordering principles, connectivity of rooms, proximity, and organizational forms. These parts were extracted, resulting in an additional 3D dataset (Figure 4). On the one hand, these data sets served to validate the results in order to prove the successful application of the method (Figure 7). On the other hand, it served to investigate whether the machine can be trained on formal knowledge. Thus, these data were added once to the entire building dataset (resulting in 2184 datapoints) and trained separately to evaluate the process. That means for both experimental setups presented here, we created three data sets each: (a) entire buildings and groups of buildings, (b) further spatial sequences as building components based on the distinct configuration of their form-defining elements;
24
(c) and circulation systems that represent small, detailed building parts. The 3D dataset of 2184 models comprises 728 buildings or building ensembles of various typologies and the building components extracted from them. The building components, which either trace the circulation system through the building or provide the characteristic spatial organization, are subjected to a separate training process.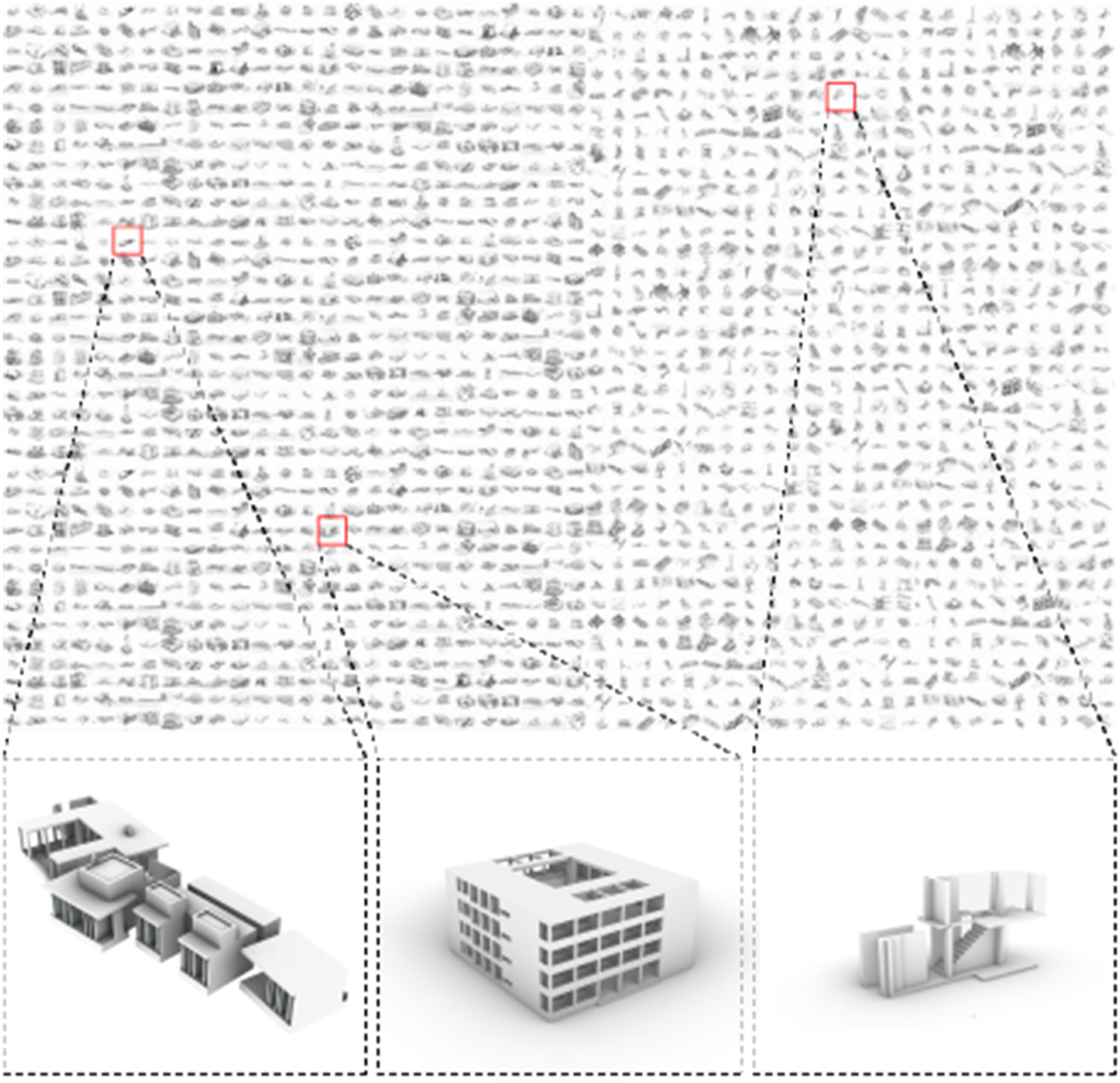
GAN training
In both experiments, the first training process and duration were initially 250 epochs in the DCGAN, with a batch size of 1, a latent space dimension of 100, and a learning rate of 0.0002. For the second experiment, we extended to 500 epochs and 1000 epochs of training by qualitatively evaluating the results from epochs 200–250; we recognized their fidelity, particularly within the dataset containing the circulation components, was still evolving. We have finally settled at 500 epochs as the optimum training duration because, after around epoch 500, no significant improvement in the training was observed.
Design implementation
The following experimental setups attempt to use deep neural networks for architectural design and fully spatial configurations beyond 2D or 3D massing representation. The results vary according to the dataset distribution, diversity, and refinement of the method based on the preceding experimental setting. The two experimental setups approach the interconnection across scales, from spatial components to building scale, in different ways exploring the aesthetic and spatial potential.
Implementing a multi-scale space diversity in the dataset
In terms of a machine’s ability to perceive and interpolate architectural space across scale, we wanted to investigate whether the machine “sees” spatial configurations in a more nuanced way than our conventional perception and thus generates new designs we could not see.
Therefore, we used a series of fully modeled real-world building data and extracted building parts, from each of which one single coded image was created, regardless of their differences in scale. The aim was to examine if the machine detects spatial organizations and formal similarities across scales beyond the known canon. Through the encoding process from voxel to pixel, a change in scale was simultaneously implemented and inscribed in the data. The result was an increase in the diversity of volumes and room heights and staircases’ rise/run ratio as the machine interpolates between diverse building scales, spatial arrangements, and typologies (Figure 5). Visual and numerical evaluation of the reconstructed data demonstrate the spatial diversity within a single object, displayed as an X-ray.
This employment of multiscale feature extraction into the GAN process disrupts the normative interpretation yet also facilitates the detection of new spatial arrangements and different ideas for circulating through the building that goes beyond simple stacking of self-similar floors on top of each other, which usually results from an extrusion of 2D plans generated through an ML process. The diversity of room heights and different scales of stairs result in the hybridity of the architectural elements: ceiling and stairs that remind us of Adolf Loos’ Raumplan but exaggerate it in a new direction. Hybridization of the elements results from the variety of scales inherent in the dataset and because the machine does not distinguish in purely formal terms what is a ceiling and what is a step, or what is a wall and a riser. In this crucial phase of the research, the newly generated geometries were subjected to critical analysis and interpretation by the subjects (Figure 5).
Scale persistence of 3D models
With the insights gained from the previous processes, we developed a second approach that differs in two main aspects. First, to accurately detect interconnectivity across scales and diverse data samples, we developed a method with a discrete bounding box into which the voxel grid is translated to eliminate scaling in the translation process. Determining the optimal size of the bounding box is crucial; it must cover the largest possible building area and trace smaller details, such as each step and riser, with a sufficient number of voxels.
9
To do so, we manually conducted tests on some of the geometries in the dataset that exhibited high diversity in function and scale. Discretization of the bounding box means the reconstruction process can be significantly more efficient. Labor-intensive and computationally expensive exploration for the optimal bounding box size was eliminated, and the newly generated geometries were easily comparable. As a second crucial difference, we ran three separate GAN training processes: the buildings per se, the circulation, and the extraction of specific spatial sequences (Figures 6–8). Discretization of the bounding box allowed a large dataset to be created for each training run. Large buildings generated more than 60 decoded images from a single data sample. Scale accuracy inevitably leads to distinctly legible spatial dimensions and elements such as stairs and corridors and significantly reduces working and computing time. Results from the validation process where the dataset solely consisted of circulation components illustrating the method’s accuracy as it produces plausible details of circulation systems as well as room heights and corridor widths (measurements are in meters). Creating a scale awareness within the dataset results demonstrate the precision of the process as it reconstructs very detailed elements such as windows, staircases, and even entrance situations besides containing the spatial continuity of the original 3D data. Thus, the results sometimes demonstrate remarkable similarities to the original architectural dataset. Excerpt of results illustrating plausible but also unfamiliar interpolations of spatial configurations across scales and typology.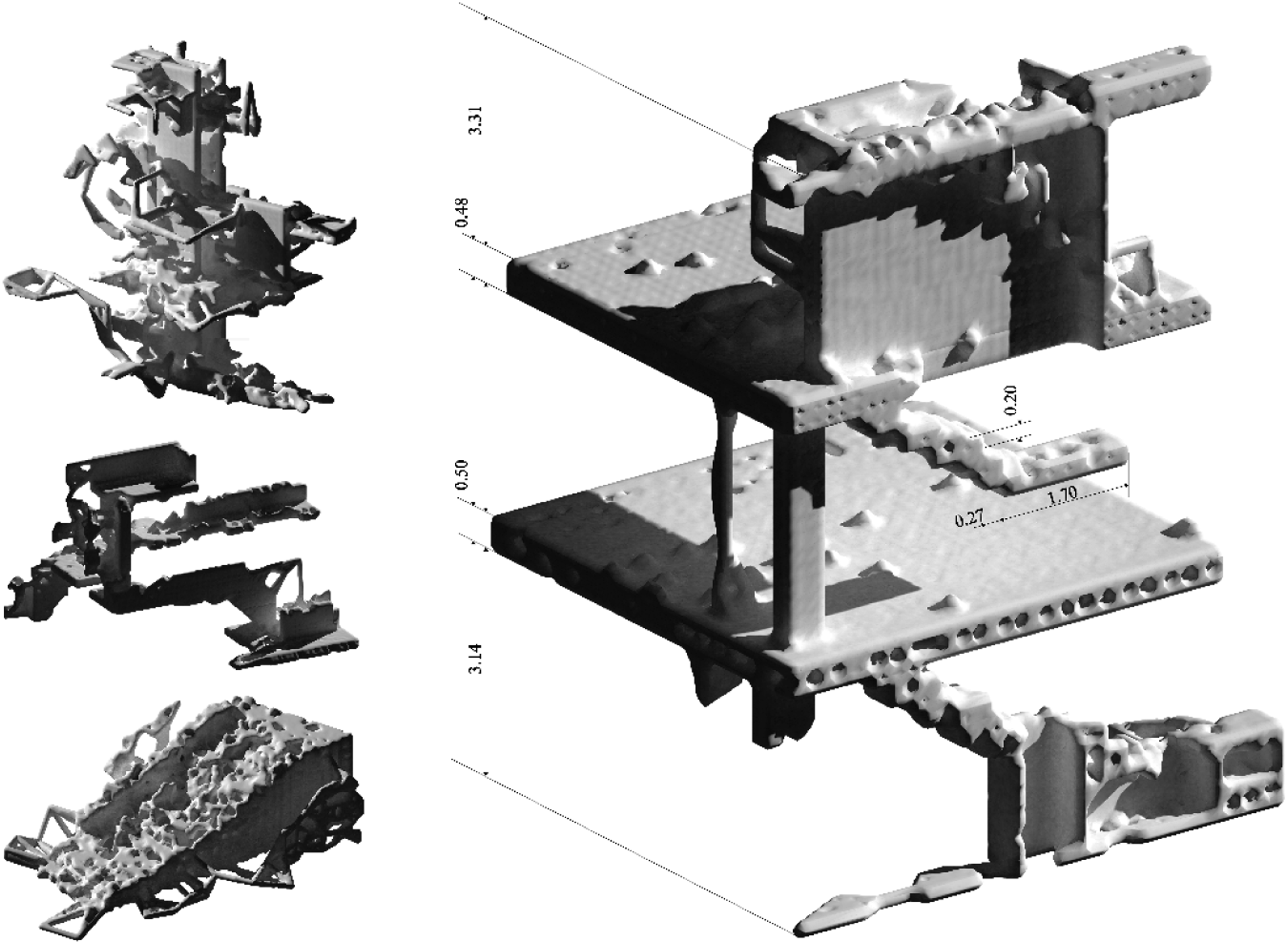


Although this allows a relatively controlled experimental phase and systematic observation of the cause and effect of the interventions of the three different datasets, it also leads to losses in spatial diversity. This is because the dataset consists of fragments of buildings in favor of detailed resolution, and thus overall spatial relationships are lost. In this process, these newly generated parts often force unconventional spatial arrangements because, although they are often very clear in their reconstruction in themselves and show familiar elements, their otherness is revealed by the assembly (Figure 9). Nevertheless, for us it rendered to be crucial to investigate scale persistency. Especially because we are looking to promote data justice by including data samples beyond our known canon and look for measured interconnection across these planetary precedents. Example of assembly of 3DGAN generated components exposing the tension between conventional spatial configurations and inventiveness.
Critical interpretation and assessment
We performed a qualitative and quantitative assessment to evaluate the results. Human subjects interpreted the selected GAN geometries (Figure 5). After the selection, the subjects critically analyzed the generated 3D models to identify, reflect, and externalize spatial diversity and to detect further estrangements embedded in the spatial constructs.
In the quantitative procedure, the 3D models were subjected to another GAN process to test our hypothesis that 3DGANs interpolate across scales to achieve novel compositions. In this setup, the space-defining elements
24
were labeled with different color ranges (Figure 10). Colors with RGB values of 0 or 255 were used to differentiate the labels as much as possible; three main RGB combinations were used to label walls and columns (R:0 G:255 B:0), the circulation (R:255 G:0 B:0), and ceilings (R:0 G:0 B:255). In this way, a dataset of 1340 models was created. When we compare the input labeling and the results of the 3DGAN visualizing the ML-aided segmentation, we can see how the machine hybridize architectural elements from the dataset on many scales. The occurring dithering—instead of linear interpolation—indexes elements and their relationship within the voxel field (Figure 11). Quantitative assessment: space defining elements of each object in the 3D dataset are labeled with RGB values (a). The results of the 3DGAN process illustrating the dithering of architectural elements into synthetic hybrid objects (b). Voxel data containing material-specific attributes (c). (d) Shows representative 3D models. Each voxel within the 3D geometry is queried for nearby voxels, which are interpolated to generate the specific material data. Material information is dithered into material descriptions and reconstructed through SDFs during postprocessing.

Discussion
We have proposed a viable method to generate architectural space across scales using 3DGANs. The assessment process has proven that the interpolation continues into the smaller scale of the architectural element.
The main limitation in the experimental setups is still the relatively small dataset size for unsupervised learning processes and access to high-quality data containing all necessary spatial details. This limitation is evident in many deep learning approaches and is especially true for 3D datasets. In this regard, it is important to note, that the samples in our datasets were partially dominated by iconic buildings from a western canon due to their accessibility. To promote data justice and expand our samples for 3DGANs, further research could increase accuracy and spatial diversity by increasing the quantity and diversity of 3D models that are beyond our known precedents.
In this pursuit and in the context of our approach presented here, which allows detail-oriented recognition of architectural features, we see great potential in the future through, for example, the increasing number of LiDAR scans that have been performed in recent years to record many buildings and entire ensembles down to the smallest detail.
Building upon the human mind is accustomed to and trained to generate ideas and concepts from a variety of empirical facts through abstraction. We extract different domains of knowledge and scales—from the overall shape of the component to the detail—and analyze and thus design them in a very linear way. GAN algorithms allow a new approach by processing architectural features and scales simultaneously, reordering and reweighting them and subjecting them to a circular process. 3D models of LiDAR scans, which record reality with all its details, offer the possibility to unlock this potential and eliminate a biased process of abstraction. Future research in this area related to the workflow presented here could thus provide a completely new perspective on architecture. Furthermore, LiDAR scans are often created by neighboring disciplines such as archeology, conservation, and heritage preservation. Interdisciplinary collaboration could not just open access additional libraries but also contribute to diversity in the datasets. This would promote data justice by including various historical and geographical focus and points of views from these disciplines.
In exchange, other factors are becoming critical to applying 3D deep learning and 3D GANs. First, dataset curation is crucial in terms of steering the diversity and complexity of GAN-generated output. Our experiments illustrate that with a more accurate dataset, the results precisely reproduce the information in the input data. In this application, the architect’s creative process is shifted to the subsequent assembly and composition process. In contrast, humans and machines are mutually conditioned if the dataset is diverse and hybridizes across multiple scales, as in the first experiment. As a result, the architect is more directly involved in the GAN process, and the outcome is dependent on the architect’s creative interpretation and imagination. Although the diversity of volumes and masses in the results is promising, this approach requires significant computing time and is labor-intensive due to the trial-and-error process in approaching the appropriate bounding box size. Second, GANs hybridize spatial arrangements and show promise in creating speculative architectural spaces that disrupt normative disciplinary understanding and encourage unconventional designs.
Furthermore, even we did not pursue the idea of crowd-sourced datasets in depth in our experimental setup we see great potential within a GAN workflow we presented here. For future research, not only the demographic data of the participants has to be taken into account, but also ethical explanations on how subjects are selected.
Conclusions
In our method, we were able to show that any type of 3D data format—such as meshes, point clouds, and NURBS—can be used without translating or preprocessing the 3D models to a uniform format, which considerably reduces the workload while at the same time increases the flexibility in the data that can be used. Thus, the research contributes significantly to decoding spatially complex datasets, which could not previously be decoded into n-dimensional vectors without loss of information. Furthermore, the experiments demonstrate that entire 3D buildings and components can be processed in one single step using the more powerful and elaborate 2D-convolutive networks. This step excludes the loss of information that usually accompanies translation from 2D to 3D and back. Furthermore, the single-step approach eliminates further decomposition and reassembly operations needed for the machine to understand the spatial sequence rules and the relations between adjacent image slices inherent in the spatial continuity of the original 3D model. The presented method provides the necessary workflow for future research to further implement 3D convolutional networks to develop a spatial knowledge of GANs.
Our study demonstrates that the method of decoding 3D voxels into 2D images to train a DCGAN is a promising workflow for 3D architectural datasets and generating architectural spaces. The results show that it is possible to generate hybrid spatial configurations beyond 3D massing or 2D floor plan extrusion with high diversity in scale and scope, ensuring higher flexibility and sustainability than mono-functional space categories. A statistical approach to renewing spatial organization can be tremendously beneficial in rethinking discrete pre-classifications of architecture traditionally considered with a notion of typology, program, or preconceived modernistic norms such as room heights, doorway widths, and stair ratios based on an average white male. 25
Footnotes
Acknowledgements
Special thanks go to our undergraduate research assistants (in alphabetical order) Lorenz Foth, Quinn McCormack and Keller O'Quinn. We would like to thank our students at the University of Innsbruck and Texas A&M University, Digital Futures 2022 who participated in the seminars and design studios and helped along this process. There is no conflict of intellectual property in terms of data usage, permissions to involve data was acquired if needed.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Early-Stage funding (2021) of the of the Vice Rectorate for Research of the University of Innsbruck and funding from the department of architecture and the Academy of Visual and Performing Arts (AVPA) Grant (2022) at Texas A&M University.