
Abstract
The emergence of text-to-image generative models (e.g., Midjourney, DALL-E 2, Stable Diffusion) in the summer of 2022 impacted architectural visual culture suddenly, severely, and seemingly out of nowhere. To contextualize this phenomenon, this text offers a socio-technical history of text-to-image generative systems. Three moments in time, or “scenes,” are presented here: the first at the advent of AI in the middle of the last century; the second at the “reawakening” of a specific approach to machine learning at the turn of this century; the third that documents a rapid sequence of innovations, dubbed “clever little tricks,” that occurred across just 18 months. This final scene is the crux, and represents the first formal documentation of the recent history of a specific set of informal innovations. These innovations were produced by non-affiliated researchers and communities of creative contributors, and directly led to the technologies that so compellingly captured the architectural imagination in the summer of 2022. Across these scenes, we examine the technologies, application domains, infrastructures, social contexts, and practices that drive technical research and shape creative practice in this space.
Introduction
Despite appearances, contemporary imaging technologies based on neural networks—such as Midjourney, DALL-E, and Stable Diffusion—are neither sorcery nor sentient. Rather, they are tools produced in a specific socio-technical context. While the impact of the broad adoption of these tools may feel like “a rock from the sky,” the events of the summer of 2022 were rooted in a particular social context and arose out of a specific technical history. This paper seeks to illuminate exactly this. The history presented here finds relevance in architectural visual culture not only as a way of ensuring accurate attribution for our tools, but also in that it reveals the providence of the specific biases that have been “baked” into an emerging architectural visualization technique. Further, the broader history surveyed here demonstrates that themes of accessibility and access have permeated research and creative practice in AI since its inception.
Three scenes, four lenses
Our story unfolds in three scenes, with the first two setting the stage for a culmination in the third—a carefully documented history of informal innovations in text-to-image systems that were developed by non-affiliated researchers and creative communities. Although text-to-image systems were built using foundational elements developed in large institutional settings, here on the steep incline of yet another hype cycle, an important aspect of their origin might otherwise be overlooked. This paper aims to ensure the recognition of the contributions of independent and amateur developers that produced innovations core to the development of the better-known systems that captured the architectural imagination in the summer of 2022. To do so, this history by necessity draws from a dynamic set of primary sources—blog posts, Discord servers, Colab notebooks, GitHub repos, and social media posts—that are not formally structured and sometimes unattributed, undated, or incomplete.
To help us understand what led to the summer of 2022, this paper offers a look at the socio-technical forces across the following three moments in time: • Scene 1—the middle of the last century—1950’s and 1960’s • Scene 2—the turn of this century—the 2000’s and 2010’s • Scene 3—the months leading up to the summer of 2022.
Across these scenes, we offer the following four lenses through which to view the context for creative technical work, and that shape the perception of what creative ML is “for”: • Technology—This includes both the “hard” technology (e.g., algorithms, architectures, models, data, and data formats), as well as domains of application (i.e., those real-world problems that AI researchers seek to address). • Social Contexts—This includes those organizational structures—public and private research institutions, conferences, informal online communities, social networks, and creative collectives—that support ML research and creative practice. • Infrastructures—This includes those tools, resources, software, platforms, programming languages, and hardware accessibility that make ML research and creative practice possible. • Practices—This includes those influential creative works, aesthetic theories, and impactful cultural events that expand the space of possibilities. This will be looked at through the lens of architectural design in particular.
These four lenses must be considered together because technologies, infrastructures, social structures, and creative practices are intimately interlinked. Creative practices, for example, are often organized around and catalyzed by specific technologies. Similarly, technologies are rarely developed outside of a conception of their application in a specific social context. There are layers of dependencies at work here that require more than a single point of view to effectively to pull back. Such an holistic account is a prerequisite for the critical examination of text-to-image systems in particular, of generative AI in general, and of the impact that these technologies may hold on architectural culture. Critical contemporary issues of technological accessibility and data bias, for example, are more clearly illuminated by an account of the cultures in which these technologies were developed and the audiences they were intended to serve.
The first section of this text concerns the scene at the middle of the last century—the 1950s and 1960s—and describes this context through the lenses described above as a baseline for subsequent periods of time. The second section of this text concerns the scene at the turn of this century—the 2000’s and 2010’s. Here, we go into more detail on the technologies, application domains, social contexts, practices, and (in particular) the infrastructures established in this period that hold particular sway on the current state of things. The final section concerns the present, and departs from this pattern somewhat. We begin with an account of the social groundwork that underpins the recent rise of text-to-image generative models, including a detailed unpacking of the social prerequisites to this phenomenon. Next, we offer a section that discusses the technical groundwork for this period, and that “takes apart” the current state-of-the art approach to text-to-image generation—CLIP-Guided Diffusion—and conducts a biography of the constituent elements. Finally, we offer a history of the rapid-fire series of innovations—what has been termed a series of “clever little tricks” that directly preceded contemporary text-to-image systems.
Scene 1—the 1950’s and 1960’s
In this section, we describe the socio-technical context of artificial intelligence research and applications as it stood in the middle of the last century—that is, from the late 1940s to the early 1970s. While the history of AI in this period of time is well-accounted for in scholarship, we offer a brief summary here through the socio-technical lens described above, in order to provide a comparison to later periods.
The field of AI developed in the 1950s, proceeding through the application of a “systems theory” model of human cognition as the basis for machine logic.1,2 In what became known as the “connectionist” approach to AI, some of the earliest work in the late 1940s and 1950s used networks of connected circuits to simulate intelligent behavior. Notable among these early models was the concept of the “Perceptron” a classification algorithm 3 first invented in 1943 by Warren Mcculloch and Walter Pitts, 4 and first implemented as a physical machine in 1958 by Frank Rosenblatt. 5 The Perceptron was a binary classifier, that is, a function that decides if a given input belongs to a specific class. Similar to important advances in machine vision in the early 2000s that set the stage for contemporary image generation techniques, the Perceptron was a machine designed for image recognition.
In stark contrast with our current context that finds AI in everything from web applications to household appliances, early AI research was far removed from practical application. While advocates extolled potential applicability to a broad set of general problems, 6 the work wasn’t propelled by academic interest alone, but rather was supported for its promising applications in national defense in particular. The Perceptron, for example, was developed at the Cornell Aeronautical Laboratory in research funded by the US Navy. 7 Nearly all early AI work was conducted at academic research institutions, primarily in the UK and the US, and was propelled by generous national defense funding. For instance, at MIT alone, ARPA (later DARPA) contributed 2–3 million dollars per year to AI research from 1963 through the mid-1970s. 8 This money was provided with few strings attached, and contributed to what has been termed a “technological libertine” atmosphere at MIT an atmosphere strongly related to what we would now call “hacker culture.” 1
A summary of the socio-technical context of AI in the mid-twentieth century.

Intersections with architectural discourse and culture
The technological milieu in this period held sway in the creative and architectural world, as many of the early founders of AI directly intersected with architects and architectural thinking. Luminaries such as Allen Newell and Herbet Simon influenced, and were influenced by, figures in the early history of design and computation. These include Christopher Alexander, Richard Saul Wurman, Cedric Price, Nicholas Negroponte, and others. 3 The concurrence of early AI and the early history of computer-aided-design resulted in these two fields shaping one another.
As an illustration, consider the position of Stephen Coons—a progenitor of computer aided design and the inventor of the mathematical foundation of surface descriptions still used by contemporary geometric modeling software. For Coons, computation in design held a liberatory promise similar to claims often made about AI. Writing in 1996 on the potential of CAD as transformative force in design, Coons referred to the computer as a “compliant partner,” an “appropriate kind of slave,” and a “magic instrument of creative liberation.” 19 Such characterizations not only find echoes in the current climate of over-hyped AI-assisted, augmented, and automated design, they also mark the crystallization of a particular position on the role of technology in the design process that persists to this day. Coons understood design as a “conversation between humans and machines” with distinct creative and mechanical stages. In what Daniel Cardoso Llach observed as “Albertian” in the implicit privileging of mind over matter, Coons celebrated the computer as “an obedient agent dealing with the toils of construction work” while designers were “liberated from the drudgery of materials and physical work.” 20 This theme of the “liberation” of design and designers enabled by artificial intelligence recurs across the subsequent decades, and may be found in the scenes documented in the sections that follow.
Scene 2—the early 2000s
To jump forward 50 years from the early history of AI to the 2000s and early 2010s leaves aside a body of history that is inexcusably large, but that is also well-represented in existing scholarship. For our purposes, a coarse overview will suffice: the AI Winter of the late 1970s led to an AI summer in the mid-1980s,
4
which led to a second winter in the early 1990s. The most recent thaw occurred in the period we discuss here, the early 2010s, which directly proceeded the springtime we currently enjoy, and re-established connectionism as the dominant “tribe” in AI research. As always, none of the technological development of the intervening period occurred in a vacuum. Much changed across this 50-year span, but two major developments are particularly relevant to this discussion: • Computers got faster—both in terms of general processing and dedicated graphic processing (GPUs). • The world began producing and storing vastly more data.
While the first point above—the expansion of computing power across this half-century span—is plain to see, the second point is worth emphasizing. Looking at just the first decades of the current century, access to large amounts of data, and cheaper computers to store and processes this data, radically transformed the global economy. It is difficult to overstate the scale of this shift. To illustrate, consider Figure 1, which shows: • In 1997, Michael Lesk, the head of the Division of Information and Intelligent Systems at the National Science Foundation, estimated that there was a “few thousand petabytes” of information in the world, and that data storage would match this capacity by the year 2000.
22
This is roughly equivalent to 3 billion gigabytes of information in the world, in total (not data produced per-year, as expressed below). • In 2011, McKinsey Global Institute estimated that 13 exabytes of new data was being created and stored by companies and consumers per year.
23
This is roughly equivalent to 13 billion gigabytes per-year. • The volume of data produced today (2021) is estimated to be around 94 zettabytes.
24
This is roughly equivalent to 94,000 billion gigabytes per-year. A visualization of estimates of the relative amount of data produced per year in 1997, 2011, and 2021.

A summary of the socio-technical context of machine learning in the early 21st century.

Intersections with architectural discourse and culture
In this period of time, the problem of “big data” was clearly recognized in architectural discourse and practice. Further, the specific technologies and methods devised to deal with this problem in the context of AI were often adopted by architects both rhetorically and instrumentally. In the early 2000s, we find appeals to large accumulations of data deployed rhetorically in architectural circles, often to lend design proposals “the authority of retroactive inevitability.” 45 This tactic—an appeal to the ethos of data as an unimpeachable authority—may be found across the period, from Winy Maas and MVRDV’s “Metacity Datatown” 46 to Bjarke Ingels’ “data-based approach that drives design.” 47 While the 2009 financial crisis shifted the terms of the argument “from gee-whiz form-making” to “social relevance and environmental stewardship,” 45 appeals to the authority of incomprehensible volumes of data remained a prominent rhetorical device.
Also notable in this period is the shift in the instrumentality of computational design as a response to the technologies and methods related to “big data.” Paralleling the shift in AI from the encoding of rules (i.e., expert systems) to the discovery of correlation (i.e., computational statistics), this period anticipates a shift in computer-aided design from systems that facilitate the composition of rules and relationships (e.g., parametric modeling) and systems that manage and coordinate information (e.g., BIM) to new forms of computer augmentation that operate on data at a higher level of abstraction. As an example, consider Mario Carpo’s 2015 speculation on the potential of “searching without sorting (also known as the art of finding stuff without knowing where it is)” as a generative instrument in design. 48 Years before animated “latent space walks” entered into the architectural imagination, Carpo offered the prescient observation that unstructured search may provide an antidote to both the explicit rule-based approaches of parametric design and the highly structured semantic approach found in BIM systems. Carpo observed that this “new big-data science of searching” appears to be alien to existing methods of design, and possibly also deeper aspects of the Western philosophical tradition. Carpo envisioned “a new digital style in architecture, one that is based on the integration of real-time data streams and dynamic modeling,” and speculated that this new style would require architects to think differently, with more focus on data analysis and algorithmic design. Carpo’s predictions take on new relevance in light of the nascent cultures of architectural visualization that are taking root around text-to-image generative models.
Scene 3—January 2021 to June 2022
Our current “springtime”—including the text-to-image generative models that seemingly suddenly appeared in the summer of 2022, and that disrupted certain segments of architectural visual culture—came about in the specific social and technological context discussed above. In many ways, there is little new about the period of time we discuss here. The technology that so compellingly produces synthetic images of imaginary architecture, for example, is the direct decedent of Rosenblatt’s Perceptron, which we may recall was itself a machine designed for image recognition. A key factor in the success of today’s systems is access to data. We can only speculate what Rosenblatt or Minsky, LeCun or Hopfield, might have accomplished in their time given the quantity of data produced by our world today. In other ways, much has changed to bring us to this moment. Infrastructural shifts established in the early 21st century have since flourished, and have brought about an unprecedented level of accessibility—to computing resources, to data, to communities of collaborators, and to knowledge that was not possible in the past. This accessibility has allowed a new generation of unaffiliated and uncredentialed creative technologists 11 to thrive. As we demonstrate below, it has also enabled this community (in parallel with large-scale institutions) to produce innovations that at first glance may appear to be mere “clever little tricks,” 12 but that turn out to be serious contributions and that hold deep cultural impact.
It is better at this point to depart slightly from our chronological account, and to instead tell an instrumental story. To understand the emergence of text-to-image generative models in the summer of 2022, we shift the emphases of both our technical and social account of this history. On the technical side, we move from a discussion of changes in the general theory and foundational technologies of AI, to one that focuses on smaller-scale innovations and specific applications. In this way, the second section below combines a discussion of technologies and application domains across this period of time. On the social side, more will be illuminated through a detailed account of the specific mechanisms by which individuals, communities, and corporations are enabled by certain technological infrastructures. For this reason, the first section that follows combines a discussion of the social context of text-to-image models with an account of the technical infrastructure that supports it.
Social Groundwork—Infrastructures and Social Contexts
In this section, we account for the social context that gave rise to the text-to-image models under consideration, as well as the technical infrastructure that supports it. Here we ask: What were the prerequisites for this rise, and which conditions enabled it? What empowered “unaffiliated” research groups and casual technologists to make contributions that hold impact on the social production of creative work? As we describe below, the establishment of a specific set of social and technical infrastructures in the time immediately proceeding this period directly gave rise to these changes. This set includes both infrastructural technologies—including the availability of published model architectures, the open-sourcing of foundational code, the availability of data for training—as well as social technologies—such as cheap access to compute; collaboration technologies (e.g., GitHub, Google Golab); and communication and coordination technologies (e.g., Discord, Reddit, and Twitter), all of which fueled novel structures of communal labor.
Published Models and Open-Source Code
In ML research, it has long been a standard practice to include the details of how novel neural networks are structured as a part of publication, which is often expressed as a diagrammatic description
13
of the architecture of a model, such as those shown in Figure 2 and Figure 3. Alongside technical information described in a paper, these diagrams allow other researchers to reproduce the published work. The first neural network architectural diagram—Warren Mcculloch and Walter Pitts, 1943.
4
A selection of neural network architectural diagrams from the “Neural Network Zoo”—Fjodor VanVeen and Stefan Leijnen, 2016.
49
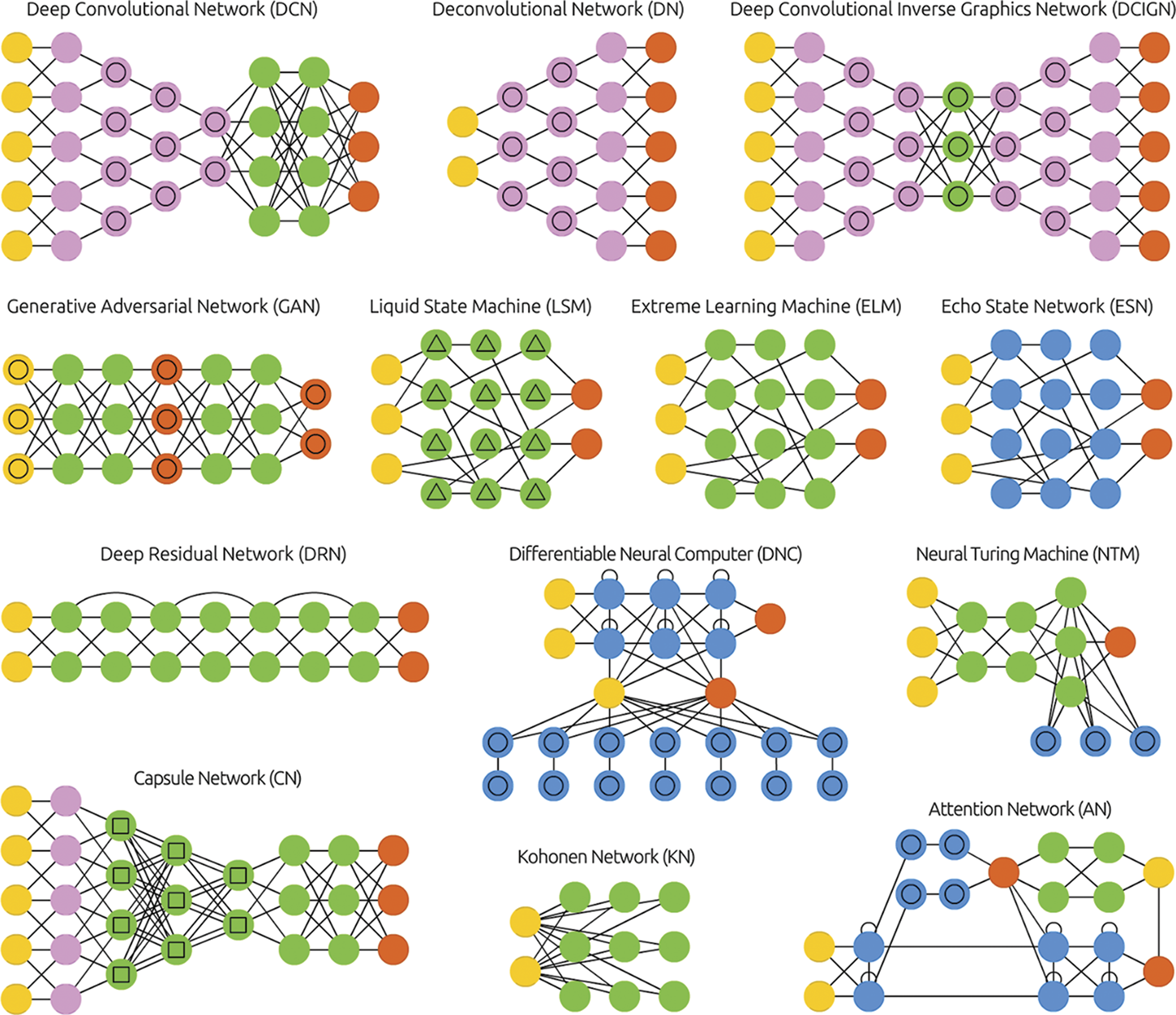
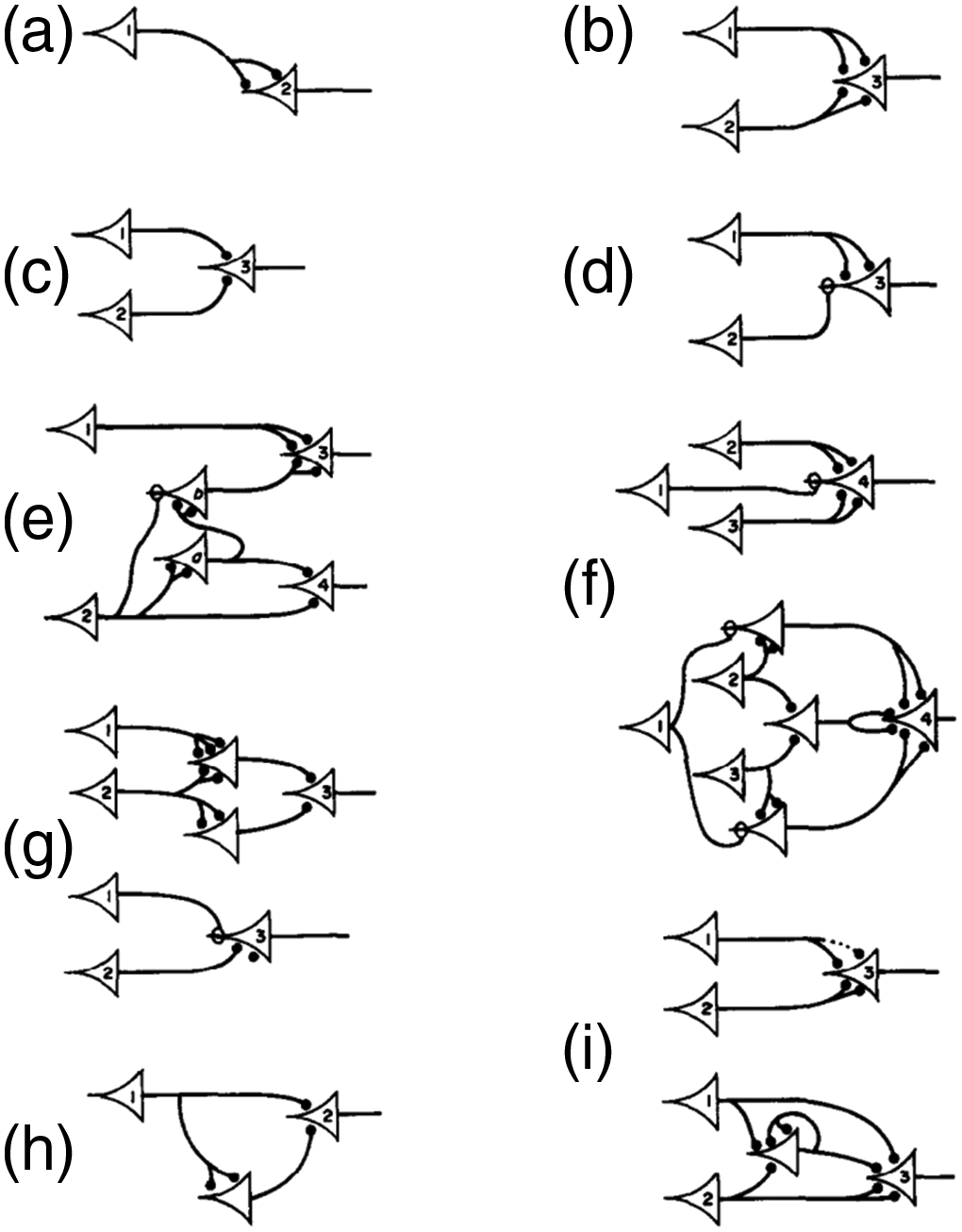
In practice, this sort of information alone is not sufficient to duplicate published research. Among other capacities, 14 such an endeavor would also require: the translation of architectural diagrams into functional code, the possession of appropriate data for training the model, and access to the computational power required for performing the training. While practices around publishing model architectures had long been established, a shift in other publishing norms played an important role in enabling innovations in this period.
First, we find in recent years more willingness to publish not only model architectures (such as the diagrams shown above), but also implemented code. For example, when researchers at NVIDIA published the paper that introduced StyleGAN in 2019 50 it was closely followed by a repository of code 51 that implemented the proposed architecture. Repositories of functional code such as this not only allowed researchers to verify claims made in the paper, but also enabled creative practitioners to directly apply leading edge technologies in their work. As a direct result, we find in the mid-2010s and early 2020s the emergence of ML-driven creative work in a diverse set of fields from fine art, 15 to music, 16 to design. 17 We see this trend reflected in the establishing of “creative ML” events, workshops, and exhibitions. 18
Another shift in the culture of ML research has amplified this first factor: it has become commonplace for research to be posted to open-access preprint repositories 19 before being published via the typical academic channels. In the context of the period described here, we can see that preprint publication acts as an accelerant, since papers are approved for posting in the repository after a quick (and mostly automated) moderation process and do not need to wait for the slow mechanism of peer review to find a public audience. As such, just as the pace of publishing in ML in general has increased in recent years, it has also become more immediate, with research moving from the lab out into the public sphere more quickly.
Finally, while it is more common to release only the model architecture and source code, we do find instances of researchers including the “weights” of a model publicly. 20 This information, in conjunction with the source code, effectively provides a functional model for those with access to the expertise and compute required to run it. While not eliminated, the barriers are significantly lowered here, since any technologist that follows up on this work is free to bypass the training step altogether, thereby side-stepping the need for access to data and the high-powered computers required by training.
As we show in the sections that follow, the pivot toward open model architectures, open source code, and open model weights enabled the contributions made by “casual technologists” across this period of time. A model released in such a way is distinct from consumer-facing software, and still requires significant expertise to run, modify, and extend, but nonetheless represents an important prerequisite of the small-scale innovation discussed below.
Cloud Compute
As described above, one of the most impactful shifts in the previous period of time was the establishment of cloud infrastructure, which made accessible the storage and GPU compute required to train and run ML models. While certainly technical in nature, we see the widespread adoption of cloud computing services (e.g., AWS and Google App Engine) as holding important social ramifications as well. This is because these services provide cheap access to powerful hardware thereby allowing relatively under-resourced groups to perform compute-demanding tasks, such as training, running, and serving large models. In recent years, something like a secondary market has developed 21 around providing “wrappers” around core cloud computing services that ease access even further.
Datasets
A clear prerequisite for working in machine learning is data. The centrality of data in this work is evidenced by the breathless comparisons to essential natural resources 22 that became prevalent at the time. As is the case with natural resources, access to data is not evenly distributed. A wide variety of datasets were required to train the assorted text-to-image generative systems mentioned in this text. Some of these datasets are known, while others were developed without revealing the provenience of this data. Where the data sources are known, some are openly available and some are proprietary. These distinctions can make all the difference to a creative technologist seeking to make contributions in this area. In this context, a number of private and public initiatives have been established in recent years 23 to connect ML practitioners with data for training and testing. Access to these resources remain a critical piece of infrastructure, and can enable relatively small-scale contributors reproduce, verify, amplify, and extend the work larger and better-funded labs. For example, OpenCLIP 66 (an implementation of OpenAI’s CLIP) was trained and released open-source 67 by LAION, a German non-profit organization (as detailed in a section below) that has collected, maintained, and publicly released a number of large datasets widely used by AI researchers. 68 Another organization, EleutherAI (detailed below), created and maintains an open source language modeling dataset called the “Pile” 69 to facilitate the training of open-source large-language models to compete with closed systems (such as GPT-3). 70 The construction and maintenance of these datasets is crucial to the development of ML research, and the public and private research communities rely equally on such organizations.
Collaboration, communication, and coordination technologies
Colab and GitHub are simultaneously social and technical infrastructure, as they function as platforms for both collaboration and dissemination of technical work. Further, these platforms connect to and intersect with social platforms, such as Reddit, Twitter, and Discord. As demonstrated in the sections that follow, this infrastructural network has played a crucial role in the development of the technologies considered here. • GitHub (est 2008)
24
—a collaborative version control service often used to support the development of open source software projects. GitHub repositories are open by default, and an essential feature is the ability to “fork” and “merge”—that is, for anyone in a community to work on their own private copy of some code, and then later integrate any changes that work back into the communal source. The Stable Diffusion GitHub repository, for example, shows 5600 “forks” at the time of writing—this represents five thousand potential community contributors to the project. There are currently more than 350 million repositories of code are reported to be hosted on the site.
71
• Google Colaboratory (“Colab,” released 2017)
72
—a “freemium” web-based environment that allows users to write and execute Python code in the cloud. This Google initiative builds on earlier nonprofit initiatives—specifically, Project Jupyter, an open-source project intended “to support interactive data science and scientific computing”
73
—and connects these existing systems to internal Google services that provide storage and compute. Colab was an essential piece of infrastructure to the development of text-to-image generative models. Nearly all the innovations documented in the section below were implemented in and disseminated via Colab notebooks. • Discord (released 2015)—an instant messaging social platform established with an online gaming audience in mind,
25
and as a way for the founders “to talk to their gamer friends.”
74
Discord holds a unique place in relation to text-to-image generative models. Importantly, it is the platform that supported certain tools (e.g., Midjourney and Stable Diffusion) in their “alpha test” phase before moving to stand-alone web apps. Further, Discord is the social platform of choice for the creative technologists that laid the technical groundwork for contemporary text-to-image systems; important organizations—such as Disco Diffusion, Eleuther and Stability—organize community efforts using this app.
The social context in 2021
The technologies described above—including published models, open-source code, cloud compute, public datasets, and collaboration technologies—supported the emergence of novel social organizations that directly gave rise to the text-to-image generative models under consideration. While the academic institutions and private research labs that dominated our earlier scenes still loom large in this period, we see here a surge in the importance of small-scale and informal social organizations, as well as the emergence of novel forms of collective work. Specifically, the technological changes described above empowered “unaffiliated” and “uncredentialed” casual technologists to make contributions of significance. As demonstrated in a section below, we use the latter term, “uncredentialed,” in that many of the central contributors involved are largely self-taught, without formal education in machine learning, and were not working as ML engineers at the time of their most important contributions. Our former term, “unaffiliated,” is meant less to describe the status of individuals, and more to refer to the loose social associations that these individuals employ to organize their labor. To illustrate this point, we offer here three examples that are emblematic of the time: • LAION, mentioned above, is a German non-profit that “aims to make large-scale machine learning models, datasets and related code available to the general public.”
68
The work of organizations like LAION are critical to providing access to data, and the specific datasets assembled by LAION have served to train many of the text-to-image generative systems that we consider here. Notable among these are LAION-400M (August 2021), a collection of 400 million image-caption pairs that was scraped from the Internet and that has been used to train text-to-image generative models.
26
Perhaps the most traditional of the organizations discussed here, there is nothing particularly novel about a non-profit organization that is dedicated to the maintenance of “common good” resources like datasets, and that operates in the space between academic institutions and private interests. What is notable, however, is the way in which organizations like LAION intertwine academic, governmental, and private interests. As an analogous example, consider ImageNet—an organization established in 2009 in order to manage a foundational dataset of images, that is led by researchers at Stanford and Princeton, and is financially supported by Google, NVIDIA, and the National Science Foundation.
78
• EleutherAI is a deeplearning research lab founded in July of 2020. In contrast with academic labs, with privately funded labs such as OpenAI, and with labs that are a part of established tech companies, EleutherAI is largely “unaffiliated.” Self-described as “a decentralized collective of volunteer researchers, engineers, and developers focused on … open source AI research,” Eleuther was started as a counter-point to larger initiatives: to “give OpenAI a run for their money like the good ol’ days.”
79
This grassroots collective has indeed found remarkable success, and has started a number of initiatives that have held wide impact. As mentioned above, Eleuther’s “Pile” dataset has been used to train open-source large-language models that approach the performance of state-of-the art models such as GPT-3. More recently—in partnership with MilaQuebec, LAION, IBM Research and Stability AI—Eleuther was awarded computation time on a supercomputer by the U.S. Department of Energy’s Office of Science,
80
a sign of their increasing prominence. Eleuther organizes its efforts on an open Discord server, and a number of the individuals discussed in the sections that follow continue to be active in this community. • Disco Diffusion, is both a generative text-to-image model (as detailed in a section below) and a community of creative technologists that created and maintain this tool, which is expressed through a collection of shared and commonly forked Colab notebooks. Although the first Disco Diffusion notebooks date back to October 2021,
81
the Discord server that the group uses to organize their efforts was established in February of 2022.
27
The social organizations described above demonstrate that, in contrast with earlier periods, and due in no small part to the infrastructural and social technologies describe above, innovation in this period of time is no longer the providence of large academic institutions and closed corporate labs. Rather, non-affiliated labs and independent contributors can make breakthroughs of significance. The text-to-image technologies we consider here are the product of just this, and, as we demonstrate in a section below, a number of “clever little tricks” developed by relative amateurs led to innovations that are directly responsible for the events of summer 2022.
Technical groundwork—technologies and application domains
The text-to-image generative models that are our subject are an amalgam of technologies, each holding its own provenance. In this section, we “take apart” one such model that has become the dominant approach—CLIP-Guided Diffusion—and conduct a biography of the constituent elements. Through this, we can see how large-scale organizations, such as academic institutions and large corporate labs, laid the necessary groundwork for later innovations by smaller-scale actors. As mentioned in the section above, although the fruit of some of these efforts remains proprietary, without the openness of publicly published research that include detailed descriptions of model architecture (at times accompanied by open source code) much of the novel structures of communal labor discussed above would not be possible. The interdependency of large-scale private interests with small-scale and public ones is also visible in the reliance that some of these efforts hold on public datasets maintained by volunteers.
Before detailing the specific technologies that can be seen as the “ancestors” of CLIP-Guided Diffusion, we detail below parallel and proceeding approaches to generating images from text.
Proceeding and parallel approaches to text-to-image synthesis
Described in this section are approaches to text-to-image synthesis that are unrelated to the CLIP-Guided Diffusion approach that is currently the state-of-the-art. These approaches find relevance here not only in that they represent alternative means to similar ends, but also in that they have directly inspired some of the “clever little tricks” described in the section that follows.
Tracing the origins of text-to-image synthesis brings us relatively quickly to a different problem. Machine learning researchers did not start out intending to generate images from text. To the contrary, modern approaches are derived from automatic image captioning systems. It turns out that text-to-image systems grew out of image-to-text systems. These include systems such as “BabyTalk,”
83
developed in 2013 as the first system to automatically generate natural language descriptions from images. The first system capable of generating images from text was created just a year later, in 2014. In “Generating Images from Captions with Attention,”
84
a team of researchers from the University of Toronto demonstrated a system capable of synthesizing 32 × 32 pixel images from natural language descriptions, samples of which are shown. Technically, this work bears little relation with contemporary approaches Figure 4.
28
Synthetic images generated in 2014 with the following captions (from left to right): “A toilet seat sits open in the grass field”, “A herd of elephants flying in the blue skies”, “A stop sign is flying in blue skies”, “A person skiing on sand clad vast desert”. From “Generating Images from Captions with Attention” [84].
Three years later, a separate effort that brought together academic researchers into a partnership with Microsoft was the first to recognize “art generation and computer-aided design”
87
as a domain of application for this technology, the results of which may be seen in Figure 5. AttnGAN
88
proposed the use of a modified GAN—an “attentional generative network”—combined with a system capable of determining the similarity between a synthetic image and a caption. An image generated from the caption “A man and women rest as their horse stands on the trail.” using AttnGAN—Connie Fan, 2018.
89

Two years after AttnGAN, we are approaching text-to-image generative models that appear quite similar to CLIP-Guided Diffusion systems, and that were developed in parallel with such systems. Despite these similarities, here we find a number of notable examples that use entirely different technological approaches. Most prominent among these is the original DALL-E system,
90
developed by OpenAI and first reported publicly in 2021. The components of the first DALL-E system were completely different than the second release: it did not use CLIP for understanding text (instead relying on something closer to GPT-3), and did not use diffusion as the generative engine (instead employing a variational autoencoder, or VAE). While the technological underpinnings were different, the cultural effect of the public release of this system held direct impact on subsequent events, with the image of the now-iconic “armchair in the shape of an avocado” (shown in Figure 6) entering into the consciousness of technical popular media at the time.
91
An image generated from the caption “an armchair in the shape of an avocado” using DALL-E 1, 2021.
92

While the first DALL-E was widely publicized by OpenAI in 2021, and was promoted with an on-line demo, the technical components of this system was only selectively released. Despite this limited information, the architectural details discussed in the paper were sufficient for others to reproduce this work in an open-source way. The ruDALL-E (Nov 2021) model is “comparable to the English DALL-E from OpenAI”
93
in terms of architecture, and offers only somewhat diminished performance. Here, the research arm of the Russian financial services company Sber AI re-created OpenAI’s DALL-E by combining the components that OpenAI released with custom-trained elements. Resulting synthetic images may be see in Figure 7. Sber AI was much more open with their work, and publicly released the code
94
for their “Russian clone” along with model weights, and published a Colab notebook
95
that has since been copied and modified widely. An image generated with the prompt “Sneakers, Nike, color: black” generated with ruDALL-E—Alex Nikolich, 2022.
96

A biography of CLIP-guided diffusion
Having detailed the parallel history of technical work that has held similar functional aims to the current state-of-the-art text-to-image generative system, we now turn our attention to CLIP-Guided Diffusion itself. As seen in the section that follows, the specific architecture of CLIP-Guided Diffusion was invented by Katherine Crowson. 97 However, this was not an isolated breakthrough, as Crowson’s was just one in a rapid series of innovations made by communities of creative contributors from 2021–22. This architecture set the basic approach that has since been adopted by all the public-facing text-to-image generative systems, including DALLE-2, Midjourney, Stable Diffusion, and others. As the name implies, there are two basic components at play in CLIP-Guided Diffusion: Diffusion and CLIP. The former is a system that generates images through a “de-noising” process, while the latter is a system that guides the generation of images in order to better match a given caption. In this section, we trace the technical lineage of each of these components.
We begin with Diffusion.
As is often the case in ML research, diffusion-driven image generation did not find its origins in images at all. Here, inspiration was drawn from non-equilibrium statistical physics. In 2015, a team of researchers at Stanford and UC Berkeley developed a system that teaches a neural network to restore structure in noisy data by “systematically and slowly” destroying structure in a given sample, and then learns to restore the sample to something that meaningfully resembles its previous state.
98
Building on this work, in 2020, a separate team from UC Berkeley applied a similar “de-noising” approach to image synthesis problems, specifically as an alternative to a GAN-based approach to generating synthetic images that match a given class of images.
99
Results from this work may be seen in Figure 8. Images generated by a team at UC Berkeley to match the LSUN Church class, 2020.
99

In 2021, following closely after this work completed in academic labs, OpenAI published an approach to image synthesis that, by trading “diversity for fidelity,” successfully brought some of the advantages previously held by GANs to diffusion systems. 100 The open-source release of this work 101 marks the first time that a diffusion-based approach outperformed a GAN, thereby establishing diffusion as the new state-of-the-art in image synthesis.
We turn now from the image synthesis component to the system that accounts for text-to-image relationships—CLIP.
A summary of the socio-technical context of creative machine learning from January 2021 to June 2022.

Clever little tricks
Documented here is the recent history of a series of critical innovations expressed through informal pieces of software (typically Colab notebooks) that directly precede contemporary text-to-image systems. While these systems rely on architectural designs and technical components developed in larger institutional settings (most notably OpenAI’s CLIP), their assembly was completed by non-affiliated researchers and communities of creative contributors. Such “assemblages” represent significant innovations that directly led to the technologies that drew the attention of architectural visual culture in the summer of 2022. Although these technologies were essentially developed by amateurs, without this work there would be no DALLE-2, Imagen, Midjourney, or Stable Diffusion.
Before proceeding, a note on the way in which this history was constructed. The nature of the innovations that we account for here resist the formal documentation mechanisms we would typically expect when writing in a technical context. When seeking to account for the contributions of a dispersed community and non-affiliated (and often non-credentialed) technologists, we cannot count on the same reliable sources found in the context of an academic lab or a research group in a large tech firm. By necessity, the following account was pieced together from a number of informal sources 30 that include blog posts, Discord servers, log files found in GitHub repos, attributions included in code comments, and posts found on a variety of social media such as Reddit and Twitter.
The specific software discussed are listed in overview below. In the section that follows, we describe the unique architecture of each, who contributed to its development, and present images generated by these systems at the time of their creation. Wherever possible, we have also retroactively re-created images using each system, employing a standard set of text prompts to facilitate comparison in an architectural visualization context. • SIREN and CLIP (Jan 2021) • The Big Sleep/BigGANxCLIP (∼Feb 2021) • Aleph2Image (∼Feb 2021) • VQGAN + CLIP (∼April 2021) • CLIP-Guided Diffusion (∼July 2021) • Disco Diffusion (Oct 2021) • Aphantasia/Illustra/FFT + CLIP (Nov 2021) • JAX CLIP-Guided Diffusion (Nov 2021) • Looking Glass (Dec 2021) • CLIP Guided Deep Image Prior (Jan 2022)
Within this landscape, a number of individuals—largely self-taught and not affiliated with any formal lab at the time of their most important contributions—stand out as particularly instrumental. We list a selection of such individual contributors here, alongside a brief biography to offer context: • Ryan Murdock (@advadnoun) contributed in significant ways to a number of the innovations described below, and was the first person to connect CLIP to an image generation function (outside of OpenAI). A “self taught”
106
machine learning engineer, Murdock holds a Bachelor’s in Psychology from the University of Utah. Murdock joined Adobe in 2021 to work on “neural filters”
107
for Photoshop. • Katherine Crowson (@RiversHaveWings) is a central figure in the AI art community, and initiated a number of foundational approaches—such as VQGAN + CLIP and the first CLIP-Guided Diffusion notebook—that have since been widely forked and modified by others. Crowson is a self-described “AI/generative artist” that “writes her own code.” She has been a member of the Eleuther AI Discord since its establishment in August of 2020, and currently works as a Principal Researcher at Stability AI. • Maxwell (Max) Ingham (@Somnai_dreams) created and initially maintained Disco Diffusion, an influential image generation model and creative community that directly proceeded DALL-E 2 and Midjourney. Ingham holds a diploma in graphic design from the Canberra Institute of Technology (2014), and has worked as a web designer and front-end developer since 2012. Ingham now works as a developer at Midjourney.
SIREN and CLIP (Jan 2021)
The SIREN + CLIP notebook,
108
by Ryan Murdock, represents the first attempt to connect CLIP to an image generation function; in this case, a sinusoidal representation network (SIREN)
109
serves as the image generation model. This work produced the first published CLIP-guided synthetic image, shown in Figure 9. The first published CLIP-guided image—Ryan Murdock, 2021.
110

In comparison to state-of-the-art synthetic image generation techniques (e.g., StyleGAN)
51
and text-to-image generation techniques (DALL-E 1)
90
of the time, the quality of the synthetic images produced by SIREN + CLIP, such as those shown in Figure 10 and Figure 11, is not particularly noteworthy. The given prompt appears to affect the image nearly exclusively in terms of texture, tone, and color. Distinct figures are impossible to discern, and there is little observable compositional coherence. At times, the image will contain certain sections of the prompt itself, rendered as barely decipherable text. An image generated by SIREN + CLIP using the prompt “A professional photograph of a Brutalist museum in Berkeley, California.” Image courtesy of the author, 2023. An image generated by SIREN + CLIP using the prompt “Interior photo of a house. Thin wooden construction scaffolding. Architectural HD, HQ, 4k, 8k.” Image courtesy of the author, 2023.

The Big Sleep/BigGANxCLIP (∼Feb 2021)
The Big Sleep notebook, 111 also by Murdock, was the first to connect CLIP to a generative adversarial network (GAN), and uses BigGAN 112 as the generative model.
Because this technique uses BigGAN as the generator, the aesthetic of the resulting images, such as those seen in Figures 12–14, are easily recognizable as such. In contrast with earlier incarnations of GANs, BigGAN was capable of representing a wide range of subjects, and could produce higher-resolution work, but was also far too expensive to custom train. Because of this, images produced by BigGAN tend to be more visually homogeneous then other GAN models, a characteristic that is evident in the results of the Big Sleep notebook, seen nearby. Here, while figures are more distinct, textures remain dominant, and small-scale details are not discernible. An image generated with the prompt “a cityscape in the style of Van Gogh”—Ryan Murdock, 2021.
113
An image generated by BigGANxCLIP using the prompt “A professional photograph of a Brutalist museum in Berkeley, California.” Image courtesy of the author, 2023. An image generated by BigGANxCLIP using the prompt “Interior photo of a house. Thin wooden construction scaffolding. Architectural HD, HQ, 4k, 8k.” Image courtesy of the author, 2023.


Aleph2Image (∼Feb 2021)
While the Aleph2Image notebook 114 doesn’t employ CLIP, it is worth including in our timeline in that it demonstrates the diversity of architectures that may be applied to text-to-image problems. Here, Murdock takes apart DALL-E, using only the image generation part (the variational autoencoder, or VAE) of Open AI’s process in order to generate images.
Aesthetically, Aleph2Image may represent a step backward from Murdock’s earlier experiments. Without the reliable image synthesis capacities of BigGAN, figures are once again lost in these images, such as those seen in Figures 15–17, and we again begin to see text from the prompt present in the results. An image generated with the prompt “Godzilla attacks the University of Chicago”—Ryan Murdock, 2021.
115
An image generated by Aleph2Image using the prompt “A professional photograph of a Brutalist museum in Berkeley, California.” Image courtesy of the author, 2023. An image generated by Aleph2Image using the prompt “Interior photo of a house. Thin wooden construction scaffolding. Architectural HD, HQ, 4k, 8k.” Image courtesy of the author, 2023.


VQGAN + CLIP (∼April 2021)
The VQGAN + CLIP notebook, 116 authored by Katherine Crowson, builds on Murdock’s success in employing GANs for image synthesis, and represents a significant leap forward in image coherence and figuration. Here, BigGAN is swapped out in favor of VQGAN, 117 which combines a variational autoencoder (VAE) as the generator with a standard GAN discriminator to produce higher-quality results. It was at this point that the generative art scene took notice of the potential of CLIP-guided systems, and marked the VQGAN + CLIP notebook as one of the most widely forked X + CLIP image generation systems at the time. It is also notable that at this moment we begin to see prompts that address not only subject matter, but also style through the invocation of individual artists and movements. Consider, for example, Crowson’s image below of a “pencil sketch in the style of beksinski (sic).”
In large part due to the advances in image quality provided by VQGAN—seen in Figures 18–20—Crowson’s work shows a remarkable advance in the aesthetic range and coherence in synthetic image-making. Here, figures are as clearly visible as textures, and spatial arrangements and compositions begin to appear in meaningful ways. An image generated with the prompt “a black and white pencil sketch in the style of beksinski”—Katherine Crowson, 2021.
118
An image generated by VQGAN + CLIP using the prompt “A professional photograph of a Brutalist museum in Berkeley, California.” Image courtesy of the author, 2023. An image generated by VQGAN + CLIP using the prompt “Interior photo of a house. Thin wooden construction scaffolding. Architectural HD, HQ, 4k, 8k.” Image courtesy of the author, 2023.


CLIP-guided diffusion (∼July 2021)
In July of 2021, a Colab notebook authored by Katherine Crowson
97
was publicly posted. This release marks a seminal milestone in the history of machine-augmented visualization, as it was the first time that CLIP was paired with a diffusion model, and established the basic architecture that persists in contemporary text-to-image systems. The technical components of this first CLIP-Guided Diffusion model are described in detail above. The notebook produced “absolutely unbelievable results,” including the image seen in Figure 21, but because it was resource-heavy and very slow by today’s standards, it failed to gain the traction of Crowson’s VQGAN + CLIP notebook. An image generated with the prompt “Psychic Sermon in the Temple of the Mind”—KaliYuga, 2021.
105

While in terms of texture, figure, and spatial composition, the early incarnations of CLIP-Guided Diffusion are not so aesthetically distinct from the best GAN-based models that proceeded, we can see from our current vantage point, and also in the resulting images shown in Figure 22 and Figure 23, that this diffusion-based approach held more promise. An image generated by CLIP-Guided Diffusion using the prompt “A professional photograph of a Brutalist museum in Berkeley, California.” Image courtesy of the author, 2023. An image generated by CLIP-Guided Diffusion using the prompt “Interior photo of a house. Thin wooden construction scaffolding. Architectural HD, HQ, 4k, 8k.” Image courtesy of the author, 2023.

Disco diffusion (Oct 2021)
As discussed above, Disco Diffusion is both a generative text-to-image model and a community that created and maintain this tool. The project is expressed through a loose collection of shared and commonly forked Colab notebooks. The original model was authored by Katherine Crowson, while the original notebook was written by Maxwell Ingham. Thereafter came a steady stream of monthly revisions starting in October of 2021, and extending through the first major release of the current version in Feburary of 2022.81,119–122 Across this time, contributions were made by a considerable number of programmers, 31 many of whom now work for organizations—such as Midjourney, Stable Diffusion, and Palmweaver, that have brought text-to-image technology into the public consciousness.
Aesthetic progress in Disco Diffusion—demonstrated in Figures 24–26 may be seen less in terms of image coherence (the texture, figure, and spatial composition attributes discussed above) and more in terms of the capacity of this community for innovative variation. The widespread popularity of Disco Diffusion inspired a number of forks and adaptations,
32
each with its own aesthetic quality (e.g., “pixel art diffusion,” “pulp science fiction diffusion,” “watercolor diffusion”). The proliferation of “disco variants,” each authored by a subset of enthusiasts and each fine-tuned on its own narrowly focused datasets, upends the problem of data bias: while harmful and discriminatory content remains a critical issue, the question of bias among small subcultures and focused models is more a function of the intentional decisions within these communities than the providence of large tech firms managing general-purpose models. An image generated by Disco Diffusion—Adam Letts, 2022.
123
An image generated by Disco Diffusion using the prompt “A professional photograph of a Brutalist museum in Berkeley, California.” Image courtesy of the author, 2023. An image generated by Disco Diffusion using the prompt “Interior photo of a house. Thin wooden construction scaffolding. Architectural HD, HQ, 4k, 8k.” Image courtesy of the author, 2023.


Disco Diffusion marks an inflection point in the history described here. While small-scale experiments in this space continued well after the introduction of Disco, the creative community catalyzed by this technology (as well as the specific architecture of CLIP-Guided Diffusion) was central to most of the well-known text-to-image software that are the subject of this paper. These larger efforts directly benefited from the technical innovations developed in this small community. Perhaps more importantly, the large organizations that developed systems such as Midjourney and Stable Diffusion benefited from the human capital of the Disco Diffusion community, and directly hired many of the central contributors in early 2022. Although the parallel and subsequent experiments listed below have not yet made as significant an impact, we list them here both to complete the historical record and in anticipation of the possibility of future developments.
Aphantasia/Illustra/FFT + CLIP (Nov 2021)
Aphantasia 126 is the first of a number of experiments by Vadim Epstein that attempt to improve upon the established CLIP + Diffusion architecture by again swapping out one of the basic components. Here, CLIP is combined with FFT (Fast Fourier Transform) as an alternative generator to diffusion.
Aesthetically, as shown in Figures 27–29, Epstein’s work recalls Murdock’s early pre-GAN assemblages. Figures that operate at the scale of textures dominate these images, which suggest a collage of merged spaces and vanishing points. An image generated by Aphantasia—Vadim Epstein, 2022.
126
An image generated by Aphantasia using the prompt “A professional photograph of a Brutalist museum in Berkeley, California.” Image courtesy of the author, 2023. An image generated by Aphantasia using the prompt “Interior photo of a house. Thin wooden construction scaffolding. Architectural HD, HQ, 4k, 8k.” Image courtesy of the author, 2023. A still of an animation generated with JAX Clip-Guided Diffusion—@huemin, 2022.
129




JAX CLIP-guided diffusion (Nov 2021)
This variant of CLIP-Guided Diffusion by Katherine Crowson and John David Pressman (@jd_pressman)
127
is a ground-up re-implementation of the original CLIP-Guided Diffusion model in the JAX framework. The notebook
128
was authored by @huemin and @nshepperd. Since aesthetically, there is little distinction from the July 2021 CLIP-Guided Diffusion, as shown in Figure 30, we do not present comparison images here. An image generated with the prompt “a moody painting of a lonely duckling”—Daniel Russell, 2022.
132

Looking glass (Dec 2021)
This experiment 130 authored by @Mx. AI Curio, @Bearsharktopus, and others (exact attribution is unclear) is perhaps the most radical experiment presented here, as it abandons both CLIP and diffusion. Instead RuDALL-E is adpated as a “One-Shot Finetuner” that necessarily starts with a initialization image. This departs from our text-to-image history in that textual prompts are not required. As such, we do not present comparison images here.
CLIP guided deep image prior (Jan 2022)
This experiment by Daniel Russell (@russelldc, now at Midjourney) combines CLIP with Deep Image Prior 131 as the generator in place of diffusion.
While aesthetically less developed than contemporaneous efforts, CLIP Guided Deep Image Prior offers the most successful non-diffusion text-to-image synthesis system at the time of writing. As shown in Figures 31–33, in contrast with early diffusion-based systems, these images do not suffer from the dominance of textural fields, and instead begin from a place of strongly coherent image composition and arrangement. While much work remains at the level of fine detail and figural coherence, the approach appears to hold promise. An image generated by CLIP Guided Deep Image Prior using the prompt “A professional photograph of a Brutalist museum in Berkeley, California.” Image courtesy of the author, 2023. An image generated by CLIP Guided Deep Image Prior using the prompt “Interior photo of a house. Thin wooden construction scaffolding. Architectural HD, HQ, 4k, 8k”. Image courtesy of the author, 2023

Subsequent developments in larger institutional settings
While not rightfully a part of the timeline of informal innovations that are the subject of this section, it is worth noting that the technologies established by the non-affiliated technologists detailed above continued to develop with the support of larger institutional players. With the benefit of significant capital investment, and the attendant professional labor force that comes with it, these technologies were considerably refined and adapted for a commercial audience since being released widely in the summer of 2022. To facilitate a comparison with the images shown above we extend our sequence of synthetic images using our standard set of text prompts to two of the more popular text-to-image systems—Midjourney and Stable Diffusion—and chart their progression through the latest versions.
Reflection
This text documents the socio-techincal context that gave rise to the text-to-image generation tools that found prominence in architectural visual culture in the summer of 2022. To facilitate a critical examination of these tools, we present three scenes in time, and four interlinked lenses through which to view this creative and technical labor: technology, social contexts, infrastructures, and practices. In placing particular emphasis on the recent history of informal innovations developed by non-affiliated researchers and communities, we aim to ensure recognition of the contributions of independent and amateur creative technologists that produced innovations core to the development of better-known systems. The specific story of the development of these tools parallels larger shifts in the culture across these periods, and holds lessons for how we understand the broader landscape of forces that shape creative work.
The history presented here reveals that issues of accessibility and access have been present since the inception of AI, and also illuminates the origin of certain biases implicit in an emerging architectural visualization technique. Computation in design has historically been seen as a liberating force, and themes of emancipation and labor replacement remain prevalent in contemporary dialogs surrounding AI-augmented design. Just as an “appeal to data” was used rhetorically across the early 2000s to lend authority to design proposals, we may expect to find similar claims will be made regarding the “new digital styles” that are sure to emerge in relation to text-to-image generation systems.
From the perspective of creative work, the alternative models of labor found across our three scenes echo trends and suggest alternatives for the AEC industry. Specifically, the communal models of labor described here (e.g., those at work in the Disco Diffusion community) may hold relevance for technical architectural labor. Technical innovation in our final scene is marked by a fluid and diffuse sense of authorship. Work is completed in collectives that may only know one another by their Discord handles, and attribution occurs in “blobs” rather than in clear hierarchical lines of contribution. To illustrate, consider the characterization of attribution made by one core contributor to Disco—“I just spam a long list of what people did.” 33 Such a posture cuts both ways. On the one hand, it offers an appealing alternative model for creative technical practice for an industry dominated by the near-monopoly of a small number of software companies that serve the AEC industry. Deeply impactful innovation, it would seem, need not cross the threshold of Autodesk’s San Fransisco headquarters. On the other, the loss of clear lines of attribution risks exploitation—it is no wonder that tools that emerge from such a context are beset by criticisms of visual plagiarism and intellectual theft.
Limits and Future Work
This study suggests multiple layers of dependencies—technological, infrastructural, financial, social, and cultural—that cannot be effectively examined from a single perspective, nor within the confines of this format. Even a cursory review of the details of any one of our lenses reveals that we are not conducting an apples-to-apples comparison. A look at the application domains across these three periods, for example, shows the limits of comparing the significance of, say, research that aimed to develop a “general problem solver” in 1969 to that of a system that generates pixel art animations from text prompts in 2022. Since the ambitions, audiences, and proportions of the creative and intellectual workforce brought to bear on these applications are markedly different across these contexts, this text is suggestive of more comprehensive future work that accounts for these distinctions. Further, our account of the recent history of informal innovations would benefit from an oral history approach, and would be enriched by a series of interviews with the key figures in the field.
Footnotes
Acknowledgements
The research that led to this publication was supported by a Fellowship at Stochastic Labs in Berkeley in the summer of 2022, and could not have proceeded without the insights and inspiration found in this generous community. The authors would like to thank Vero Bollow, Alexander Reben, Joel Simon, and Virj Kan of Stochastic for their kindness and hospitality in sharing their magnificent Victorian home. We would also like to thank the summer 2022 residents – Lisha Li, Chigozie Nri, Adam Letts, Max Kremenski, Evan Casey, Joel Lehman, Nick Shaheed, and Cory Li – for their guidance into the world of creative machine learning.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.