
Abstract
The current study examined to what extent a valid instrument that predicts repeat victimization can be based on a victim's prior police contacts. Police records between 2010 and 2017 were retrieved for a sample of 68,229 victims. The data was split into a training set (n = 34,224) and a test set (n = 34,005). Using logistic regression analyses in the training set, three models were developed linking prior police contacts to repeat victimization. The predictive validity was assessed in the test set. Results indicated that (a) prior police contacts as victims, suspects and witnesses were associated with an elevated risk of repeat victimization and (b) the model correctly classified a majority of both repeat victims and non-repeat victims across various cut-off points. Findings demonstrated moderate to acceptable predictive validity, thereby suggesting that there is considerable room for improvement.
Introduction
Experiencing criminal victimization can severely impact an individual's life. Crime victims are more likely than non-victims to report physical and mental health issues, drug use and violent offending (Bouffard and Koeppel, 2014; Turanovic, 2019). Experiencing multiple incidents of victimization, that is repeat victimization, increases the likelihood of these adverse outcomes even more (Obsuth et al., 2018; Turner et al., 2006). Institutions, therefore, aim to support victims and protect them from further harm, for instance with intervention programs aimed to reduce the risk of repeat victimization (Grove et al., 2012; Shorrock et al., 2020). To find out which victims these interventions should be targeted at, institutions across Europe have introduced instruments to assess the risk of repeat victimization (Pavlou et al., 2019). Most of these instruments are used by police officers (e.g. Svalin et al., 2018; Turner et al., 2019), as they are often the first persons victims encounter after a victimization incident. Inspired by the growing attention on repeat victimization, the aim of the present study was to investigate to what extent a valid risk assessment instrument could solely be based on official police records and thereby enable Dutch police officers to identify victims at risk of repeat victimization.
In 2012, the European Parliament and Council of Europe accepted the Victims’ Directive to set minimum standards and to strengthen the position of victims within the criminal justice system of European Union (EU) member states (European Parliament, 2012). The Victims’ Directive gives particular attention to vulnerable victims including, as described in Article 22, a timely individual assessment in order to determine, amongst other things, a victim's vulnerability to repeat victimization and their specific protection needs. Police officers in EU member states play an important role in safeguarding the standards set in the Directive since they are regularly confronted with victims. Following the implementation of the Victims’ Directive in 2017, national legislation obliges the Dutch police to assess a victim's vulnerability, specifically of repeat victimization. Without a supportive tool, however, such an assessment is complex since (a) only a small percentage of victims experience repeat victimization and (b) this group is highly heterogeneous in terms of the frequency and severity of their victimization experiences (Hope and Norris, 2013; Obsuth et al., 2018).
Therefore, it is important to offer a tool that assists police officers in assessing the risk of repeat victimization. For this purpose, we developed ProVict (short for ProtectVictims). The current study focused on the development and the validation of ProVict: a collection of statistical models aimed to predict the risk of repeat victimization for different types of serious crimes. For the development of this instrument, we used information on victims’ police contact history, available in the police registration system. In practice, ProVict aims to support police officers in their assessment of a victim's vulnerability, by indicating which victims are at risk of repeat victimization and by providing an overview of the relevant police contact history used in the risk calculation. Based on this information, police officers can decide which victims may be in need of protection measures, thereby aiding them in assessing a victim's vulnerability and subsequently planning their approach towards a victim. The use of police registration data enables an automated risk assessment instrument, which avoids time-consuming and error-prone manual calculations. Hence, ProVict contributes to policing practice as it supplies police officers with quick information on a victim's vulnerability, enabling them to allocate their limited time and resources effectively.
The current study describes the development of ProVict and investigates the predictive validity of the instrument. In doing so, it aims to answer the following question: to what extent can a valid instrument to classify the risk of repeat victimization be based on a victim's prior police contacts?
Previous research on victim risk assessment instruments
A small but growing body of literature has addressed instruments aimed to aid police officers in protecting at-risk victims from further harm. As the Victims’ Directive promotes the use of risk assessment instruments to support and protect victims, several member states have studied and implemented such instruments (Pavlou et al., 2019; van der Put et al., 2019). European examples are B-SAFER in Sweden (Kropp and Hart, 2004), the risk assessment instruments of the VioGén system included in Spain (López-Ossorio et al., 2019), the Screening Assessment for Stalking and Harassment (SASH) in the Netherlands (Hehemann et al., 2017) and the Domestic Abuse, Stalking and Honor Based Violence (DASH) form in the United Kingdom (Turner et al., 2019). The majority of these instruments consist of a questionnaire that police officers manually fill out to help them assess the risk of future harm, that is, professional structured judgements. Most instruments focus on a single type of crime, particularly violent crimes in an intimate setting, such as Intimate Partner Violence (IPV; Messing and Thaller, 2013; Svalin and Levander, 2019; van der Put et al., 2019).
Although these instruments are designed to assess the risk of future harm, they focus on a specific form of repeat victimization, namely the risk that the same offender will commit the same offence to the same victim. Repeat victimization, however, also manifests in other forms, where prior victimizations of a certain type of crime result in victimization of different types of crimes, potentially committed by different offenders (de Vries and Farrell, 2018; Hope et al., 2001). Corresponding with the emphasis on the offender, most existing instruments use risk factors regarding the offender and the incident (Hehemann et al., 2017; López-Ossorio et al., 2019; van der Put et al., 2019). B-SAFER and the DASH, however, also incorporate victim vulnerability factors such as fear of crime, pregnancy or mental health problems as risk factors (CAADA, 2012; Svalin et al., 2018).
Subsequently, the DASH is the only known instrument that aims to predict the risk of repeat victimization for several types of crimes (CAADA, 2012). The DASH consists of a questionnaire that addresses the victim's situation (e.g. whether the victim is injured frightened, isolated, and showing depressive symptoms) and the offender's behaviour (e.g. his or her offending history). Police officers fill out the DASH to determine which high-risk victims should be referred to Multi-Agency Risk Assessment Conferences (MARAC), that is, multi-agency panels aimed to coordinate protection plans for vulnerable victims (Robbins et al., 2014). Nevertheless, Turner et al. (2019) demonstrated that the instrument has poor predictive validity and insufficiently enables police officers to identify high-risk victims. A possible explanation is that police officers collected data on risk factors during hectic circumstances and thus preferred to use information directly connected to the incident, while these factors have weak predictive power (Robinson et al., 2018; Turner et al., 2019). Risk assessment instruments consisting of forms, that is, professional structured judgements, however, may face this problem due to the manual and error-prone collection of information (see also Svalin et al., 2018). In this context, van der Put et al. (2019) demonstrate that actuarial instruments, which rely on statistical methods to include risk factors in the assessment, outperform professional structured judgements.
In conclusion, most existing risk assessment instruments predict repeat victimization from the perspective of the offender and not the victim. Moreover, most existing instruments aimed to predict repeat victimization are limited to specific types of crimes, whereas victims may also be at risk of being confronted with other types of crimes and harms (Clay-Warner et al., 2016; Farrell et al., 1995; Lantz and Ruback, 2017). This study, therefore, addressed the development and validation of an actuarial instrument (ProVict) aimed to estimate the risk of repeat victimization directly from the victim's perspective and for a wider range of crimes than typically addressed. The validation of this instrument is set in the setting of the Dutch National Police as Dutch regulations oblige police officers to assess a victim's vulnerability in terms of repeat victimization.
Risk factors for repeat victimization
Relevant risk factors for repeat victimization, such as substance abuse or psychological distress (e.g. Daigle and Teasdale, 2018; Ruback et al., 2014), are rarely available in police data. Yet, police data do contain prior crime experiences, which are also considered important risk factors for repeat victimization (e.g. DeCamp et al., 2018; Iratzoqui, 2018; Obsuth et al., 2018). In this study, we, therefore, incorporated a victim's prior crime experiences into the risk assessment. Prior crime experiences here represent the prior police contacts of a victim as registered in the police database. The study builds upon the growing literature on predictive policing in which records on prior police contacts are regularly used to identify high-risk victims and offenders (e.g. Brimicombe, 2018; Wientjes et al., 2017). Prior police contacts may pertain to different types of contacts, depending on the role of the individual involved: victim contacts, offender contacts and witness contacts.
First, previous contacts as a victim are a key risk factor for repeat victimization (Farrell et al., 1995; Farrell and Pease, 1993). Experiencing violent victimizations (Clay-Warner et al., 2016; Turanovic et al., 2018) or property victimizations (Bernasco, 2008; Lantz and Ruback, 2017) strongly influence the risk of repeat victimization. From the victim's perspective, several studies find that victims may change their behaviour in ways that increase the risk of repeat victimization (Clay-Warner et al., 2016; Iratzoqui, 2018). Victims may, for instance, start to engage in risky lifestyles, such as substance abuse (Engström, 2018; Pratt and Turanovic, 2016; Ruback et al., 2014). Obsuth et al. (2018) furthermore demonstrated that experiencing victimization implied an increased risk of repeat victimization and pointed out that the risk was further increased when victims had experienced various types of crimes.
Second, previous offending contacts relate to repeat victimization. Offenders too are more exposed to the risk of victimization since they are more likely to be engaged in a risky lifestyle (DeCamp et al., 2018; Sullivan et al., 2015). Offending may be connected to revengeful or protective behaviour and result in initial offenders becoming victimized themselves (Averdijk and Bernasco, 2015). Aaltonen (2017) demonstrated that previous co-offenders are often the ones who victimize persons with prior offending experiences.
Third, experiencing crimes as a witness may also increase the likelihood of future victimization. Studies showed that people who witness crimes are more prone to future victimization since they pass more time in criminogenic settings (Engström, 2018; Pratt and Turanovic, 2016). Grubb and Bouffard (2015) found that witnessing parental IPV as a juvenile increases the risk of victimization in adulthood. Pinchevsky et al. (2014) demonstrated that witnessing a crime may result in behavioural changes such as substance abuse and thereby increase the risk of future victimization.
The present study focuses on the influence of prior police contacts, but also includes age and gender in the risk assessment since both are considered to be important risk factors for repeat victimization. The risk of victimization varies between different age categories (DeCamp and Zaykowski, 2015). Furthermore, Savard et al. (2017) found that for several types of crime women were more likely to be victimized. In conclusion, the present study addresses an instrument that includes a victim's prior police contacts, age, and gender in the risk assessment.
Present study
The present study focused on the development and validation of ProVict: a collection of statistical models aimed to assess the risk of repeat victimization. This study expands prior research in several ways. First, this study focuses directly on classifying repeat victims, whereas existing instruments often focus on offenders. Hence, this study only addressed individual-specific risk assessment, implying that area-based risk assessments to predict near-repeat victimization fall beyond the scope of this study. The victim-centred approach of this study aids police officers by indicating which victims are at risk and thus in need of protection measures, thereby guiding police officers in their approach towards victims. Second, this study aimed to predict repeat victimization for a broad range of serious crimes, thereby including a wider range of victimization types than previous instruments. Third, and most importantly, ProVict was based on data available in the police database. In contrast to existing manual risk assessment instruments, the use of police registration data enabled an automated risk assessment instrument. This avoids time-consuming and error-prone manual risk assessments and thus enables police officers to use their limited time more effectively. In sum, the current study thus aimed to determine to what extent prior police contacts can be used to develop a valid risk assessment instrument for repeat victimization.
Method
ProVict relies on data stored in BVH: the registration system in which Dutch police officers record daily reports, incidents and small-scale investigations. More precisely, BVH includes victims’ reports to the police, witness statements and the results of interrogations of suspects. BVH thus comprises the bulk of police data with the exception of for instance information on large-scale projects, such as organized crime, for which different systems are in use. In BVH, police officers record different types of contacts by means of a wide range of crime codes reflecting the type of crime (e.g. robbery or assault). Furthermore, police officers assign a specific role (e.g. victim or offender) to natural and legal persons involved in a police contact, reflecting the person's involvement in the event. In this study, we use the combination of crime types and roles to determine the nature of a victim's prior police contacts (e.g. victim of an assault or witness of a robbery).
Sample and design
For the development and validation of the instrument, we used a simple random sampling technique to obtain a sample (n = 70,000) of individuals who registered in the police system as a victim in 2014 (total N = 638,683). Next, we obtained all police records regarding these individuals for the period 2010–2017. Victims who passed away between 2014 and 2017 and victims with an unknown date of birth or gender were excluded. The final dataset was anonymized and included 68,229 victims (54.9% male, 45.1% female) aged between 0 and 100 years (M = 41.3, SD = 17.3).
We defined the last victimization incident in 2014 as the index incident. Next, police contacts during the 4 years prior to the index incident were used to estimate the risk of a victimization incident in the two years after the index incident (Figure 1). We chose a 4-year period of police contact history to include the most substantial history as possible, considering our data and the applicable legal data restrictions. 1 We chose a 2-year period to predict victimization in the short to mid-long term. As each individual included in the sample experienced victimization at least once in 2014 (the index incident), any victimization incident in the two years after the index incident was defined as repeat victimization. This does not rule out that victims may have experienced repeat victimization prior to the index incident.
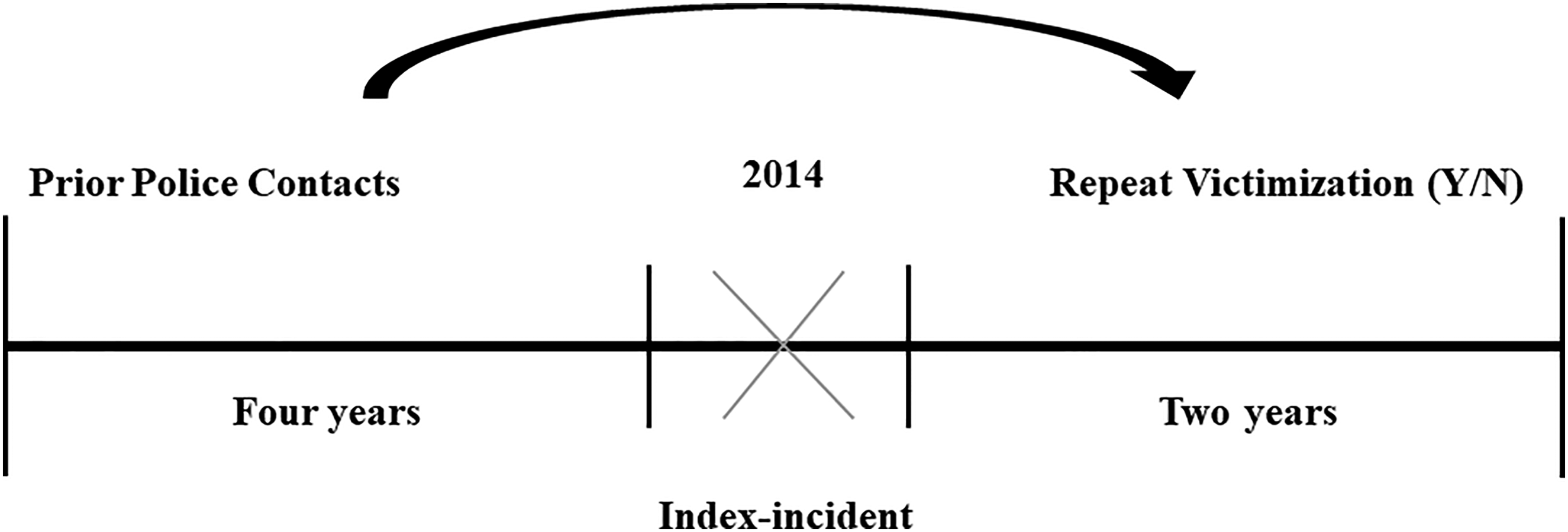
Research design.
Following other studies aimed at developing risk assessment instruments based on police records (e.g. Assink et al., 2015; Van der Put, 2014; Wientjes et al., 2017), we used a simple random sampling technique to split the data 50–50 into a training set (n = 34,224) and a test set (n = 34,005). Using the training set, models that predicted repeat victimization in the two years after the index incident was developed. Subsequently, the models’ predictive validity was assessed in the test set. Although other studies that develop risk assessment instruments have often used larger training sets than test sets (e.g. 75–25 or 80–20), we wanted both samples to be as large as possible. A larger training set provides more accurate parameter estimates, while a larger test set provides more accurate estimates of model performance. Since we preferred to optimize both at the same time, we opted for a 50–50 split.
Dependent variables: Repeat victimization
The dichotomous dependent variables reflected whether or not the victim had experienced a victimization-incident in the two years after the index incident. Three types of repeat victimization were distinguished: repeat victimization of severe crimes, less severe crimes, and a combination of the prior two outcomes. According to policy documents of the Dutch police, severe crimes include crimes such as stalking, sexual assault and human trafficking. These crimes are included in the individual assessment. Victims of these crimes are considered to have an elevated risk of repeat victimization, secondary victimization, intimidation and retaliation. Experiencing these crimes may thus have severe consequences and predicting these crimes would help prevent serious future harm. Therefore, we included this type of repeat victimization as a dependent variable. Although less severe crimes are excluded from the individual assessment procedure that was implemented by the Dutch police, they may still have major consequences for the victim. Therefore, we also investigated repeat victimization of less severe crimes. Examples of less severe crimes are burglary, blackmail and threat. A full list of the included severe and less severe crimes is added in the Supplemental Materials (Supplemental Table s1). Finally, we investigated repeat victimization combined, a category combining the categories of severe and less severe crimes. Victimization experiences in the two years after the index incident, either from severe or less severe crimes, are referred to as this variable. By including this variable, we could test the predictive validity of a model that predicts repeat victimization of serious crimes in general, which may be preferable in police practice.
We classified the three types of repeat victimization as dichotomous variables that each reflected whether or not a victim experienced at least one new victimization incident in the two years after the index incident. For instance, if a victim experienced a severe crime in the two years after the index incident, this victim experienced repeat victimization for severe crimes. In the total sample, 0.7 % of the victims experienced repeat victimization of severe crimes (n = 452), while 2.4 % of the victims experienced repeat victimization of less severe crimes (n = 1647). With regard to repeat victimization combined, 3 % of the victims were revictimized in the two years after the index incident (n = 2027).
Independent variables
This study uses a victim's prior police contacts, age and gender as the independent variables. All police contacts registered in the four years prior to the index incident were used to construct the independent variables reflecting the victim's prior police contacts. The variables were based on the combinations of crime codes, reflecting the type of crime under which the police classified the incident and the role of the person involved. Police contacts include the roles of suspect, victim and witness. For this study, the wide range of different crime codes available in BVH was assigned to more comprehensive crime categories on the basis of the literature (Lauritsen and Cork, 2017) and discussions with experienced police officers. The most important categories referred to ‘violent acts against a person’, ‘violent acts of a sexual nature’, ‘property crimes’, ‘acts involving fraud, deception or corruption’, ‘acts against property only’, ‘acts against public order and authority’ and ‘acts involving controlled substances’. These categories were divided into sub-categories. For example, ‘property crimes’ was split into ‘theft without violence’, ‘robbery’, ‘burglary’, among other types of property crimes. Altogether, this resulted in 164 crime categories.
To these categories we added the three roles, resulting in (164 × 3 =) 492 crime category-role combinations. The variables reflected the number of police contacts during the four years prior to the index incident regarding that specific crime category-role combination. For example, a score of 5 on the predictor variable victim stalking indicated that the individual had five registrations as a victim of a stalking incident in the four years prior to the index incident. Likewise, a score of 2 on the variable suspect abuse indicated that the individual had two registrations as a suspect of an assault in the four years prior to the index incident.
In addition to these crime category-role combinations, we included variation in types of victimization, age, age-squared and gender as independent variables. The variation in types of victimization (M = 0.4, SD = 0.7, range = 0–7) was measured by counting the number of crime categories for which an individual had a registration as a victim during the four years prior to the index incident. For example, if a victim had experienced a victimization incident in the crime categories ‘theft without violence’ and ‘stalking’, the variation in types of victimization was two. Age reflected the age at the date of the index incident. Age squared was included to account for the possibility of a quadratic association between age and victimization (DeCamp and Zaykowski, 2015). Gender was included as a dichotomous variable, that is, females and males. Eventually, 496 predictors were included in the models.
Analysis strategy
Forward stepwise logistic regression analysis, comprising both the stepwise modelling and the final logit model fit, was used to develop the model in the training set. A practical advantage of logistic regression analyses is that it, in contrast to machine learning methods, allows us to easily explain the calculation of risk scores through an interpretable formula. Furthermore, the forward stepwise procedure results in a parsimonious model. In a stepwise procedure, variables are individually added to the model and only included when, based on the likelihood ratio, the addition provides a significant change in the log likelihood. After each entry, variables already included in the model are evaluated for possible removal. Variables are removed from the model if they no longer significantly improve the model. The process ends when no variables are left that meet either the entry or the removal criteria. Based on the resulting models, risk scores for repeat victimization could be calculated.
Next, we evaluated the predictive validity of the model in the test set using the following discrimination and calibration indicators: Area Under the Curve (AUC), sensitivity, specificity, the Positive Predicted Value (PPV) and the Negative Predicted Value (NPV). Discrimination indicators, such as the AUC, sensitivity and specificity reflect to what extent an instrument distinguishes between high-risk groups and low-risk groups. The AUC is a traditional indicator for evaluating an instrument's accuracy (Messing and Thaller, 2013; Rice and Harris, 2005; van der Put et al., 2019) and reflects the probability that a randomly selected repeat victim has a higher risk score than a randomly selected non-repeat victim. According to the rules of thumb proposed by Hosmer and Lemeshow (2000), AUCs between 0.6 and 0.7 are moderate, AUCs between 0.7 and 0.8 are acceptable and AUCs between 0.8 and 0.9 are excellent.
Sensitivity refers to the proportion of repeat victims classified as high-risk. Specificity refers to the proportion of non-repeat victims classified to be low-risk. Calibration indicators, such as the PPV and NPV, reflect the correspondence between the calculated risk scores and the actual observed risks of repeat victimization in the sample. The PPV refers to the proportion of high-risk victims who do indeed experience repeat victimization (i.e. true positives), whereas the NPV reflects the proportion of low-risk victims who do not experience repeat victimization (i.e. true negatives). Although The PPV and NPV both rely heavily on the distribution of the outcome in the sample (Singh, 2013), these indicators provide useful insights into the practical consequences of the choice of specific threshold levels for distinguishing low-risk from high-risk victims.
We used the AUC as an indicator to generally evaluate the accuracy of the models. The other predictive validity indicators were calculated to illustrate the consequences of the models across a range of cut-off points. To obtain the cut-off points, we calculated the percentile values associated with the risk scores in the training set. These percentile values were subsequently used as cut-off points. Individuals who scored lower than a cut-off point were classified in the low-risk category, whereas individuals with scores higher than or equal to a cut-off point were classified as high-risk. The first cut-off point was set at the percentile value corresponding to the point where the top 50% of the risk scores belonged to the high-risk category. The next cut-off point was set at the point where the top 45% of the risk scores was high-risk. Eventually, by taking steps of 5%, the predictive we calculated validity indicators for 10 cut-off points.
Results
Model development
The model for repeat victimization of severe crimes performed best (Nagelkerke R2 = .13, χ2 = 343.09, p < .001, 20 predictors included). The models for repeat victimization of less severe crimes (Nagelkerke R2 = .09, χ2 = 590.90, p < .001, 21 predictors included) and repeat victimization combined performed slightly less well (Nagelkerke R2 = .10, χ2 = 792.08, p < .001, 32 predictors included). All models included police contacts as suspect, victim and witness. Suspect contacts mostly referred to violent crime categories, such as abuse or human smuggling, and violations. Victim contacts referred to a variety of violent crimes, such as human trafficking, abuse or stalking, and property crimes, such as theft. A considerable number of risk factors in each model referred to witness contacts, such as witnesses of abuse or threat. Specific information on the models can be found in Supplemental Tables s1a to s1c in the Supplemental Materials.
There were some similarities across all models regarding the included risk factors. Variation in types of victimization positively related to repeat victimization in all three models (Exp(B) range = 1.291–1.340, p < .001), indicating that being a victim of a greater variety of crime types increased the risk of repeat victimization. Likewise, suspect human smuggling (Exp(B) range = 12.961–46.906, severe crimes: p < .001, combined and less severe crimes: p < .010), victim insult (Exp(B) range = 1.297–1.573, combined and severe crimes: p < .001, less severe crimes: p <.010), witness abuse (Exp(B) range = 1.354–1.759, p < .001), witness violence without follow-up (Exp(B) range = 1.059–1.086, combined and severe crimes: p < .001, less severe crimes: p < .010) and witness unwell individual (Exp(B) range = 1.422–1.705, combined and severe crimes: p < .001, less severe crimes: p < .010) correlated positively with the risk of repeat victimization, indicating that having more registrations in these crime-role categories increased the risk of repeat victimization.
Age was included in the models for severe crimes (Exp(B) = .969, p < .001) and repeat victimization combined (Exp(B) = .995, p < .050). In both models, age was negatively correlated with repeat victimization of severe crimes and repeat victimization combined, implying that older victims had a lower risk of repeat victimization. Gender was only included in the model for less severe crimes (Exp(B) = .757, p < .010), indicating that women run a lower risk of repeat victimization of less severe crimes than men.
Predictive validity
Table 1 presents the AUC values for all three outcomes in the test set. The AUC for repeat victimization of severe crimes was highest (.773) and indicated acceptable discrimination. The AUC value for repeat victimization combined was close to 0.7, indicating moderate to acceptable discrimination. For repeat victimization of less severe crimes, the AUC indicated moderate discrimination. The non-overlapping CI's suggest that the AUC value of the model for severe crimes was significantly higher than the AUC values of the other two models.
AUC values test set.

Note: Test set n = 34,005.
Tables 2 to 4 present the predictive validity indicators for all three outcomes across different cut-off points. Focusing on sensitivity and specificity, Tables 2 and 3 show that repeat victimization of severe crimes and repeat victimization combined correctly classified a majority of repeat and non-repeat victims for cut-off points between the top 50% and top 20%. A trade-off between sensitivity and specificity can be noted for all outcomes. Sensitivity decreased with a higher cut-off point, while specificity increased. In line with the AUC values, the model for severe crimes demonstrated a higher sensitivity across all cut-off points than repeat victimization combined. Based on the results regarding the AUC as well as sensitivity and specificity, repeat victimization of severe crimes and repeat victimization combined demonstrated acceptable predictive validity.
Predictive validity indicators for repeat victimization combined.
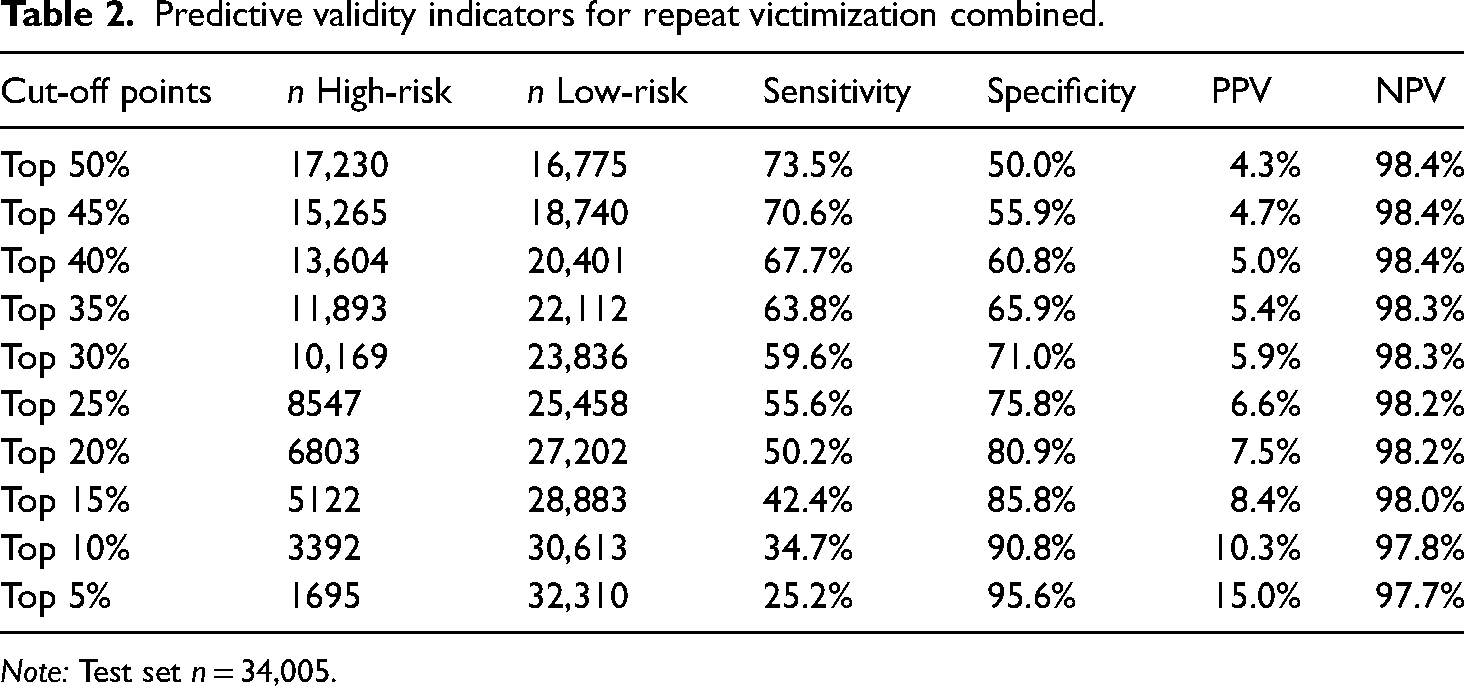
Note: Test set n = 34,005.
Predictive validity indicators for severe crimes.
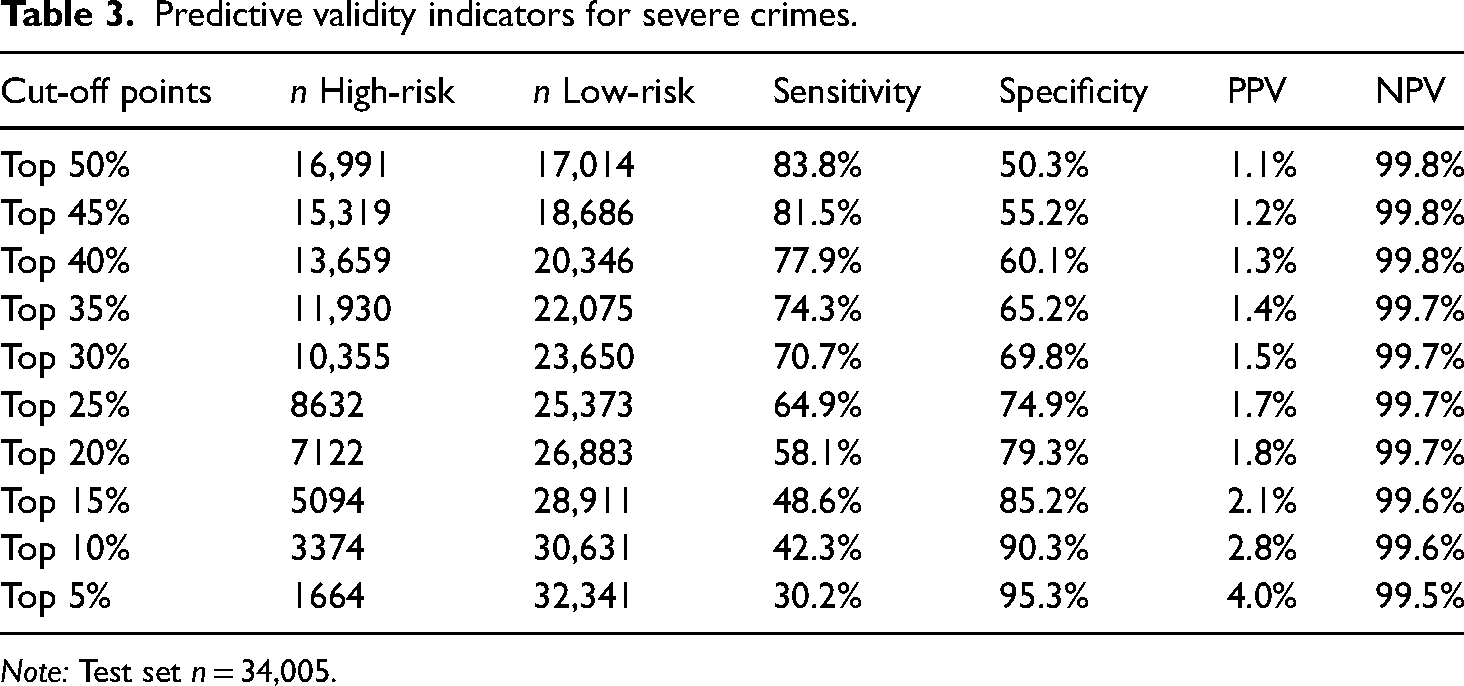
Note: Test set n = 34,005.
Predictive validity indicators for less severe crimes.
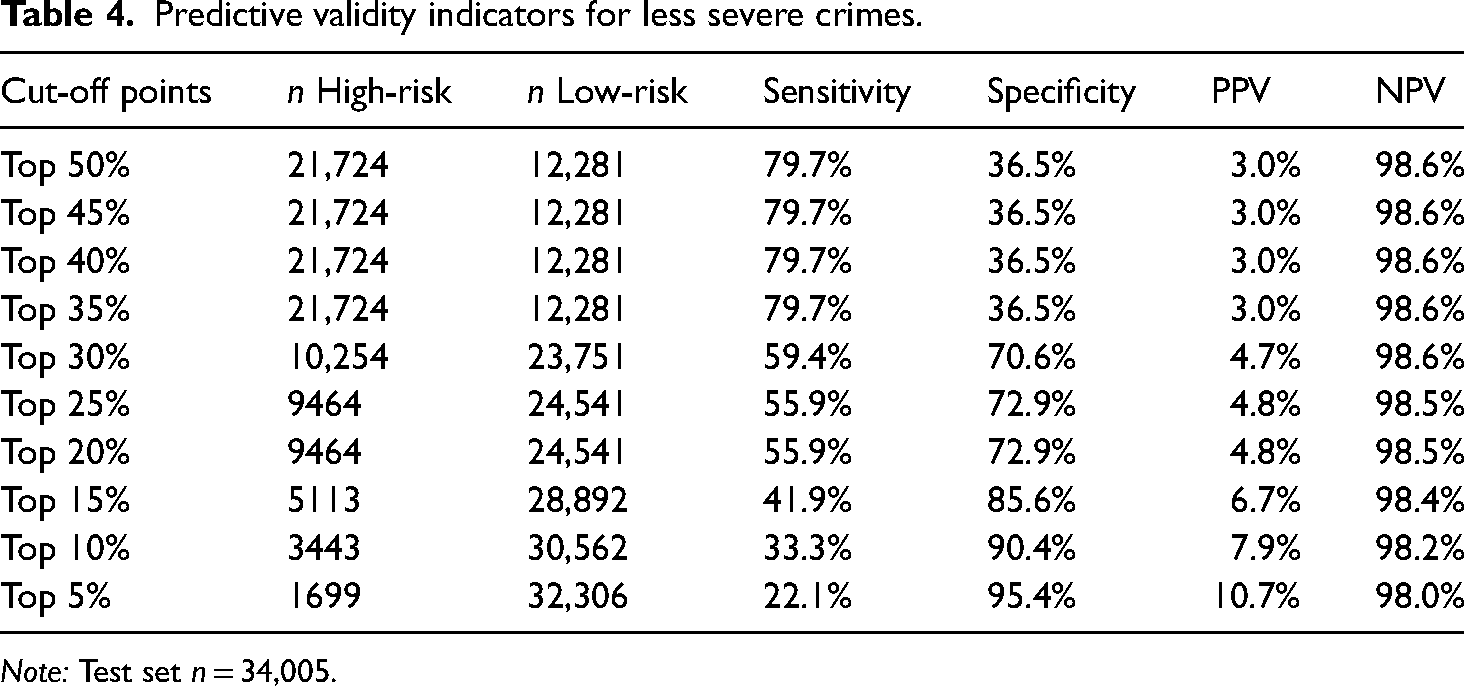
Note: Test set n = 34,005.
In correspondence with the AUC values, the model for less severe crimes showed moderate predictive validity. Focusing on sensitivity, Table 4 illustrates that a majority of repeat victims of less severe crimes was correctly classified as high-risk for cut-off points between the top 50% and the top 30%. With respect to specificity, however, it can be seen that for only a number of cut-off points (top 50% to top 35%), the model classified a relatively small proportion (36.5%) of non-repeat victims correctly as low-risk.
Across the three models, the PPVs indicated that for all cut-off points the high-risk category included a small proportion of repeat victims (4.3−15% for repeat victimization combined; 1.1−4.0% for severe crimes; 3.0−10.7% for less severe crimes). Simultaneously, the NPV indicates that, for all cut-off points, the low-risk category is largely comprised of non-repeat victims (98.4−97.7% for repeat victimization combined; 99.8−99.5% for severe crimes; 98.6−98% for less severe crimes).
Discussion
The current study focused on the development and validation of ProVict, a collection of logistic regression models that calculate the risk of repeat victimization based on prior police contacts. For this purpose, we examined to what extent prior police contacts could be used to develop a valid risk assessment instrument for repeat victimization of severe crimes, less severe crimes and a combination of the two prior outcomes. ProVict provides police officers with an indication, of which victims are at risk of repeat victimization and an overview of police contacts used for the risk calculation. With this information, the instrument aids police officers in assessing which victims may be in need of protection measures. ProVict improves existing risk assessment instruments by using police registration data, thereby enabling an automated risk assessment instrument, which avoids time-consuming and error-prone manual risk assessments.
The risk factors in our models mostly corresponded with prior research, suggesting that being a suspect of violent crimes, a victim of property or violent crimes and witness of violent crimes increases the risk of repeat victimization (e.g. Aaltonen, 2017; Clay-Warner et al., 2016; DeCamp et al., 2018; Grubb and Bouffard, 2015; Turanovic, 2019). Academic literature proposes two theoretical perspectives explaining repeat victimization: the state dependency perspective and the population heterogeneity perspective (Farrell et al., 1995; Nagin and Paternoster, 2000). State dependency implies that an initial crime experience ‘boosts’ the risk of subsequent crime experiences. For example, after experiencing victimization, victims may start engaging in risky lifestyles, such as substance abuse, or may experience mental health issues (Blokland and Nieuwbeerta, 2010; Clay-Warner et al., 2016; Turanovic et al., 2018). Considering our findings, this implies that victims of insult crimes or witnesses of violent crimes may start experiencing mental health issues or adapt their behaviour, making them more prone to repeat victimization (Pinchevsky et al., 2014; Randa et al., 2019). Population heterogeneity implies that some individuals have an underlying propensity for victimization (e.g. specific individual characteristics, such a low self-control) thereby making them more prone to both initial and repeat victimization (Nagin and Paternoster, 2000). Such individual characteristics may, partly, explain the associations we found between prior police contacts and future revictimization. Yet, interpreting the coefficients from our models requires some care, since they do not necessarily point to causal effects. Our aim for this study was not to investigate what factors explain repeat victimization, but rather to assess which factors could contribute to identifying high-risk and low-risk individuals regarding repeat victimization.
With regard to the predictive validity of this instrument, the AUC values suggested that the models performed moderate to acceptable in terms of discrimination. The model for severe crimes demonstrated the highest AUC value (.773) and indicated acceptable discrimination (Hosmer and Lemeshow, 2000), thereby suggesting that this model may be preferred in practice. The AUC value for repeat victimization combined was close to the threshold of .70, indicating moderate to acceptable discrimination. Prior research on, for example, the DASH, reported AUC values of .50 to .60 (Turner et al., 2019), while other risk assessment instruments demonstrated AUC values ranging from .50 to .78 (Messing and Thaller, 2013; van der Put et al., 2019). Hence, repeat victimization of less severe crimes and repeat victimization combined performed similarly to existing instruments, while the model for severe crimes had a somewhat better AUC value. The discrimination indicators demonstrated here are similar to those reported in previous studies (Messing and Campbell, 2016; Svalin and Levander, 2019). For a range of cut-off points, repeat victimization of severe crimes and repeat victimization combined correctly classified a majority of the repeat victims in the high-risk category and a majority of the non-repeat victims in the low-risk category.
Our findings suggest that there is still room for improvement since some repeat victims were classified as low-risk, that is, false negatives and a considerable percentage of non-repeat victims were classified as high risk, that is, false positives. False negatives may go undetected due to the possible exposure to risk factors that are not included in our models, such as mental health issues, risky lifestyles or social networks (e.g. Daigle and Teasdale, 2018; Rokven et al., 2017; Ruback et al., 2014). On the other hand, some false positives may not have been revictimized due to the buffering effects of protective factors, such as family bonds (DeCamp et al., 2018), which are also not included in the models. Additional data on these risk and protective factors could improve the correct classification of both repeat victims and non-repeat victims, thus reducing the number of false negatives and false positives. Information on these factors may be present in verbatim reports written by police officers. Text-mining analysis of these reports may be a promising avenue for future research. Note that some false positives, however, may actually be ‘true’ positives as they may have been revictimized beyond the time frame of our study or may not have reported new victimization, possibly as a result of prior negative experiences with the police (Koster, 2017).
The high number of false positives is not surprising, since calibration indicators strongly depend on the distribution of an event in the sample (Singh, 2013), and repeat a victimization is a rare event. On the one hand, the considerable amount of false positives may be too costly in practice, since police officers may have to give extra attention to a large group of victims. Providing measures to the false-positive victims may furthermore frighten them, thereby increasing the fear of crime and subsequently the risk of repeat victimization. On the other hand, the benefits of protecting victims from serious harm may outweigh the costs of incorrectly classifying non-repeat victims in the high-risk category. As the results demonstrated, for most cut-off points, a majority of the repeat victims were correctly classified in the high-risk category. In other words, from the large group of victims that the Dutch police encounter, the instrument distinguishes a substantial proportion of the repeat victims. Subsequently, police officers can plan their approach towards these victims and potentially take specific measures to protect them from serious harm in the future. Regarding the severity of the crimes studied here, the benefits of protecting these victims from this type of serious harm may be considerably high, and thus outweigh the costs of the incorrectly classified non-repeat victims. In addition, the use of this instrument may improve victims’ perceptions of the police. Giving extra attention to victims may result in more positive attitudes towards the police as victims may feel more supported by police officers (Elliott et al., 2014).
Nevertheless, it is important that a solid cost-benefit analysis accompanies the implementation of the instrument in practice. The outcome of such an analysis should guide the eventual choice of a specific cut-off point. Additionally, it is important to comprehensively assess the fairness of the instrument and the decision-making the instrument informs (Mitchell et al., 2021). Moreover, it is important to evaluate the instrument from both a statistical and policing perspective, thereby taking into consideration not only it's predictive validity and discrimination (in terms of, e.g. AUC), but also the consequences of false positives and false negatives in police practice.
The present study has several other limitations. First, although stepwise modelling is frequently used for the development of predictive risk models (e.g. Billings et al., 2006, Henning et al., 2021, Palazzo & Evans, 1993), several studies argue that it may not always result in the best model due to multiple testing issues (Kuhn and Johnson, 2013). Other methods such as lasso or elastic net regression might provide better results in terms of predictive performance. By performing a thorough validation procedure with independent data, however, we attempted to minimize the limitations possibly associated with the use of the forward stepwise procedure. Nevertheless, we acknowledge the importance of critically assessing whether other variable selection methods may provide better outcomes in samples with specific characteristics. Additionally, future studies could investigate whether the models can be improved by including interactions between predictors.
As indicated, we performed the validation on a subsample of the total sample, that is, the test set. While this validation procedure reduces the risk of model overfitting, a more optimal validation procedure would be to use a more recent validation sample (Van der Put et al., 2019). Unfortunately, however, this was not possible for the current study, since such a sample was not available. Validation of the model on a more recent sample is an important suggestion for future research, as it provides better insights into the predictive validity of the instrument when used in practice.
Second, this study may underestimate the prevalence of repeat victimization since victims may not report new crimes to the police. Willingness to cooperate with the police, namely, decreases when victims were disappointed with prior police performance (Koster et al., 2018). In reality, the number of repeat victims may thus be higher than police registration data suggests, thereby implying the number of false positives may be overestimated in this study, as not all repeat victims will report a revictimization to the police. An instrument like ProVict, in addition to effective follow-up, may help to increase the willingness to report new crimes as victims may perceive the police performance more positively (Koster, 2017).
Third, the current study does not include the professional judgment of police officers. A risk assessment instrument that automatically calculates the risk of repeat victimization may, however, benefit from these judgements (Oswald et al., 2018). Although assessing the risk of repeat victimization may be a complex task without the aid of a validated tool, police officers are able to identify a certain amount of risk factors (Robinson et al., 2018). Yet, the predictive validity of a risk assessment instrument may decrease when professionals can overrule predictions (Orton et al., 2020). Future research should, for example, through experimental vignette designs, aim to understand how police officers judge possible high-risk cases and what indicators they use in this assessment.
Furthermore, special attention should be given to the implementation of the instrument. Successful implementation of risk assessment instruments is strongly related to positive attitudes of the users towards the instrument (Viljoen et al., 2018). Further research should therefore address police officers’ attitudes towards ProVict in order to ensure a successful implementation and effective use of the instrument.
Finally, ProVict was developed and validated to apply to the Dutch police practice. While direct applications of the instrument in other European countries depend on the specific availability of registration data, the general avenue of automated risk assessment instruments may be interesting for any type of victim-supporting authorities across Europe. It is however important to assure that procedures, in analysis or eventual implementation, are in line with the EU General Data Protection Regulation (GDPR) when reliant on sharing registration data.
Although there is considerable room for improvement, this study demonstrated that prior police contacts may be used to develop a valid instrument to assess the risk of repeat victimization. Such an instrument has the potential to aid Dutch police officers in identifying victims at risk of repeat victimization and eventually guiding them in the support and protection of these victims need.
Supplemental Material
sj-docx-1-euc-10.1177_14773708221105790 - Supplemental material for Assessing the predictive validity of a risk assessment instrument for repeat victimization in the Netherlands using prior police contacts
Supplemental material, sj-docx-1-euc-10.1177_14773708221105790 for Assessing the predictive validity of a risk assessment instrument for repeat victimization in the Netherlands using prior police contacts by Niels Raaijmakers, Roos Geurts, Marc J. M. H. Delsing, Alice K. Bosma, Jacqueline A. M. Wientjes, Toine Spapens and Ron H. J. Scholte in European Journal of Criminology
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Internal Security Fund (ISF) – Police, European Commission (grant no. S100111).
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.