
Abstract
The availability of high-quality datasets is increasingly critical in the field of computer vision-based civil structural health monitoring, where deep learning approaches have gained prominence. However, the lack of specialized datasets for such tasks poses a significant challenge for training a reliable model. To address this challenge, a framework, 3DGEN, is proposed to swiftly generate realistic synthetic 3D datasets which can be targeted for specific tasks. The framework is based on diverse 3D civil structural models, rendering them from various angles and providing depth information and camera parameters for training neural networks. By employing mathematical methods, such as analytical solutions and/or numerical simulations, deformation of civil engineering structures can be generated, ensuring a reliable representation of their real-world shapes and characteristics in the 3D datasets. For texture generation, a generative 3D texturing method enables users to specify desired textures using plain English sentences. Two successful experiments are conducted to (1) assess the efficiency of generating the 3D datasets using two distinct structures, (2) train a monocular depth estimation network to perform 3D surface reconstruction with the generated dataset. Notably, 3DGEN is not limited to 3D surface reconstruction; it can also be used for training neural networks for various other tasks. The code and dataset are available at: https://github.com/YANDA-SHAO/Beam-Dataset-SE
Introduction
In recent decades, numerous research studies have highlighted the significant utility of computer vision technologies in civil structural health monitoring. These technologies, including object detection, segmentation, optical flow, key point detection and tracking, image super-resolution, etc., have been employed to facilitate tasks such as structural response to loadings, displacement measurement and damage detection. Their applications offer valuable assistance to civil engineers for analysis the structural health conditions.
Most of such studies are focused on 2D image analysis, such as in-plane displacement measurement,1–5 damage detection,6–8 structure recognition9–11 and so on. The integration of 3D information is of paramount importance in structural health monitoring, as it provides a more comprehensive understanding of the structural geometry, deformation patterns and volumetric characterization as civil structures are inherently 3D objects. In more recent developments, researchers have shifted their focus from working solely in the 2D domain to exploring 3D techniques in civil structural health monitoring. This shift allows for the extraction of detailed and holistic information, enabling enhanced analysis, monitoring and assessment of civil structures. By employing computer vision-based 3D methodologies like structure from motion, multi-view 3D reconstruction, 3D object detection, monocular depth estimation, etc., researchers can delve into the complexities of civil structures in three dimensions. These technologies have diverse applications, including 3D structural displacement measurement, detection of 3D structural defects, etc. They contribute to a more comprehensive understanding of the intricate nature of civil structures, resulting in the generation of advanced and precise insights.
The 3D civil structure health monitoring can be divided into multiple camera-based methods and monocular camera-based methods. Multiple camera-based 3D methods12–17 involve the use of multiple cameras placed at different viewpoints to capture the scene. These cameras provide different perspectives and enable to estimate the 3D model or displacement of objects or features. Hu et al. 12 introduces a learning-based topology-aware 3D method that utilizes images captured from multiple cameras. The proposed method takes advantage of prior knowledge regarding the regular spatial layouts and component relationships within complex structures. By leveraging this knowledge, the method is capable of extracting high-level structural graph layouts and low-level 3D shapes from the input images. Pan and Yang 14 introduces a deep learning-based 3D computer vision-based framework for measuring out-of-plane displacements of steel plate structures. The framework leverages multi-view vision algorithms to create a comprehensive 3D point cloud representation of the structures and their surrounding environment. By utilizing this framework, measurements of 3D displacements can be obtained. Park et al. 15 proposes a framework for automated damage evaluation in structural maintenance, leveraging 3D laser scanning technology as an alternative to manual visual inspection. The proposed framework processing point clouds obtained from 3D laser scanning of a bridge, accommodating different shapes and employing a tailored fitting strategy to identify surface damage on the edges prone to false detections.
Monocular vision-based method is a significant advancement in computer vision that enables the inference of 3D information from a single 2D image. It has emerged as a powerful tool in the fields of civil engineering and structural health monitoring. Chang and Xiao 18 presents a single-camera approach that can measure both 3D translation and rotation of a planar target attached to a structure. By establishing the relationship between camera coordinates and image coordinates, the rotation and translation of the target can be extracted from recorded image sequences. The technique cannot measure translation along the direction perpendicular to the image plane, requiring careful consideration of target and camera placement. Shao et al. 19 introduced a novel system that utilizes a single camera for 3D vibration displacement measurement, leveraging deep neural networks to learn depth information from monocular images. Sun et al. 20 proposes a 3D structural displacement measurement method using monocular vision and deep learning-based pose estimation. The method utilizes virtual rendering to synthesize a training set based on 3D models of target objects, trains a deep learning model to estimate target object poses, and measures 3D translations of structures based on original and destination poses or keypoint matching.
As demonstrated by existing work, advanced computer vision-based technologies leverage deep learning to efficiently extract valuable information from images. In contrast to traditional computer vision technologies, neural networks rely heavily on the quality and diversity of the training datasets to achieve optimal performance. In the field of civil engineering, researchers have made significant contributions by generating datasets that serve as valuable resources for advancing the development and evaluation of computer vision-based methodologies.20–28 By sharing these datasets with the civil engineering community, the development and benchmarking of novel neural networks have been facilitated.
The majority of existing datasets focus on 2D domains. These datasets encompass a wide range of structures’ 2D images, including bridges, buildings and various structural components. They also incorporate instances of damages such as cracks. SDNET2018 22 is an annotated image dataset designed for training, validating and benchmarking deep learning based crack detection algorithms in concrete structures. The dataset consists of over 56,000 images capturing both cracked and non-cracked concrete bridge decks, walls and pavements. A wide range of crack sizes are covered, from narrow cracks as small as 0.06 mm to wider cracks measuring up to 25 mm. The dataset also incorporates various challenging factors such as shadows, surface roughness, scaling, edges, holes and background debris, making it more representative of real-world conditions. SDNET2018 facilitates the advancement of crack detection algorithms based on deep convolutional neural networks, a prominent area of research in structural health monitoring. Segnet 25 makes use of 2068 self-labelled bridge crack images, each with a size of 1024 × 1024 pixels. Data augmentation techniques are employed to improve the generalization capability of the network. Experimental results demonstrate that the SegNet model surpasses traditional edge detection algorithms when applied to the dataset. Yeum et al. 26 manually annotated and compiled a dataset obtained from earthquake reconnaissance missions. The dataset comprises 5270 images, with 1850 images labeled as collapse (positive) and 3420 images labeled as non-collapse (negative). The non-collapse images encompass undamaged buildings, damaged buildings and irrelevant pictures, sourced from their image database, which represents a typical dataset acquired during earthquake reconnaissance missions. The labeled images are then divided into three sets, with 50% (2636 images) allocated for training, 25% (1317 images) for validation and another 25% (1317 images) for testing purposes.
The utilization of 3D datasets in training neural networks has proven to be more beneficial for structural health monitoring. 20 However, collecting real 3D annotations (e.g. depth maps, 3D point clouds, meshes) of civil structures can be technically challenging and time-consuming. To overcome this limitation, researchers have started utilizing synthetic 3D datasets20,21,23,24,28 to train neural networks, which have demonstrated impressive performance and great potential for real-world tasks and applications. Additionally, the generation of these synthetic 3D datasets proves to be more cost-effective and efficient. The study conducted by Sun et al. 20 utilizes virtual rendering to create a dataset for 3D computer-aided design (CAD) structure models. The dataset comprises a combination of random backgrounds and multi-view rendered images of the 3D objects. This inclusion of random backgrounds enables the model to detect the target objects in diverse real-world scenes. During the rendering process, multi-view RGB images are generated along with first-stage outputs that pertain to the poses and normal vectors of the model surface. To enhance the visual quality of the rendered RGB images, lighting adjustment is applied based on the normal vectors using the Phong reflection model. 29 Subsequently, the adjusted RGB images are merged with random backgrounds, which can either be relevant environmental backgrounds or samples sourced from a diverse large-scale image dataset. Another dataset 24 is specifically developed for reinforced concrete railway viaducts on the Tokaido Shinkansen line in Japan, aiming to support the training and evaluation of visual recognition algorithms in the field of structural condition assessment. This dataset provides a valuable resource as it includes images with ground truth annotations for semantic segmentation and depth estimation. The availability of such annotations facilitates the training of fully convolutional network-based algorithms, enabling accurate identification and localization of structural components, as well as the estimation of depth information. With its comprehensive and detailed annotations, the dataset enables researchers to advance the development of automated systems for structural condition assessment, ultimately contributing to improved maintenance and safety of railway viaducts 28 generated a 3D defect dataset composed of artificially generated 3D CAD models with labelled defect features, simulating defects commonly found on the surface of concrete columns, such as cracks or spalls. The proposed 3D Inspection Net exhibits the capability to effectively learn and distinguish complex defect features from geometric data.
Overall, deep learning-based computer vision technologies have demonstrated considerable success in the field of civil engineering. Unlike traditional methods, deep learning models rely heavily on training datasets to achieve optimal performance. However, in both the 2D and 3D domains, and particularly in the 3D domain, there is a notable limitation in the availability of civil structure datasets suitable for training efficient neural networks for related tasks. This limitation can be observed in both the diversity of structures covered in the datasets and the quantity of annotated data available for these structures. As a result, there is a need for more diverse and extensive datasets to enhance the training of neural networks in civil engineering applications. It is not feasible to generate a single comprehensive dataset that encompasses all civil structures simultaneously since civil structures vary greatly in terms of their structural types and are subjected to different loading scenarios. Researchers typically focus on specific structures or loading scenarios in their research. Instead of providing a general large dataset, it could be more beneficial to offer researchers a tool that allows them to rapidly generate quality customized datasets suitable for particular types of structures for training specific deep neural networks for their specific research goals.
This article proposes a framework 3DGEN for rapidly generating synthetic 3D civil structure datasets, for the training of neural networks for specific civil engineering tasks. 3DGEN can generate an unlimited number of images of desired 3D civil structure models from different viewpoints. Moreover, it also generates the corresponding metric depth maps and camera matrices for these images. The generated datasets can be utilized for training neural networks for various tasks vital to civil structural health monitoring. As an example, Table 1 lists five potential tasks that can benefit from deep learning, along with the corresponding training data required for each of them. The framework’s capability to produce diverse and quality training data reinforces its potential as a versatile tool, enabling the training of a broad spectrum of deep neural networks to address multifaceted challenges within the evolving field of structural health monitoring.
Five tasks that can be addressed using deep neural networks and the corresponding training data required for each task.

NeRF: neural radiance fields.
3DGEN accepts any prebuilt 3D base models as input, which can be obtained through various means such as CAD software, Python Application Programming Interface (API) or other methods that generate models in commonly used 3D file formats. Analytic solutions or finite element models are applied to the 3D base model, allowing the generation of diverse deformation of civil structures. This step expands the range of structural variations within the synthetic dataset. To achieve the desired texture for the 3D models, a text-guided 3D generative texturing neural network 44 is employed. This neural network is utilized to render the 3D model, ensuring that the texture aligns with the specified input texts or prompts. Subsequently, Blender 45 is employed to render multi-view images and generate depth maps, according to various automatically synthesized camera matrices. The generated 3D models, multi-view images/depth maps and camera parameters can then be used for training neural networks for vision-based structural health monitoring tasks.
Two experiments are conducted to evaluate the effectiveness and efficiency of the proposed 3DGEN. In the first experiment, two datasets are generated using the 3DGEN for two different types of structures: column-shaped structures and a silo structure. The second experiment focuses on training a monocular depth estimation network for 3D structural surface reconstruction. This experiment explores the potential of the synthetic datasets by 3DGEN for accurate 3D modelling of structures.
The rest of the paper is organized as follows: section ‘Methodology’ presents the methodologies for the proposed 3DGEN in detail, using column-shaped structures as examples. Section ‘Experimental validation A’ describes the first experiment, which involves generating datasets using the framework for two different structures: column-shaped structures and a silo structure. Section ‘Experiment B: utilisation of the generated datasets for monocular vision based 3D surface reconstruction’ details the second experiment for monocular vision-based 3D surface reconstruction. Finally, conclusions are provided in section ‘Conclusion’.
Methodology
To present the methodology of the 3DGEN framework, column-shaped structures are utilized as an example. However, the approach is versatile and not confined to just columnar forms; it can be adapted for any custom structures. The dataset generation process begins by constructing the base 3D mesh models, which represent the structures in their undeformed state. These base models are then analyzed using mathematic formulations to obtain their various deformed shape under different boundary/loading conditions. Subsequently, a generative texturing method is employed to add desired textures to the 3D mesh models. Finally, the textured mesh models are rendered from different angles using the Blender rendering engine, 45 generating images, depth maps and camera matrices as the final output. For output images and depth maps, augmentations like zoom-in/out, cut-out and so on are conducted to improve the diversity of the dataset. An overview of the 3DGEN system is shown in Figure 1.
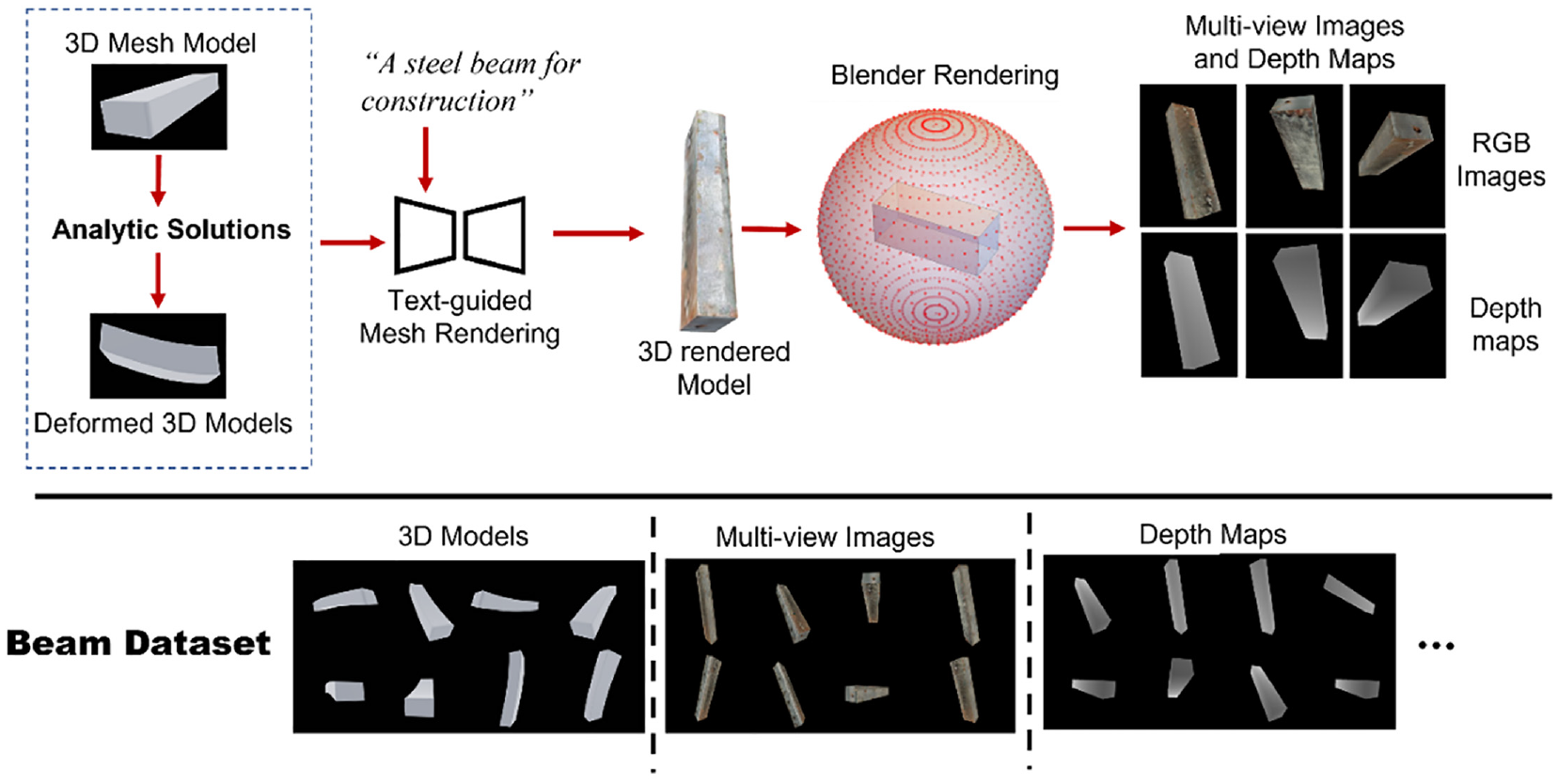
The overview of proposed 3D data generation method with an example of a steel beam.
Synthetic 3D model generation
Triangular meshes are commonly used to represent 3D models, providing a discrete representation of the continuous geometry of 3D objects, as shown in Figure 2.
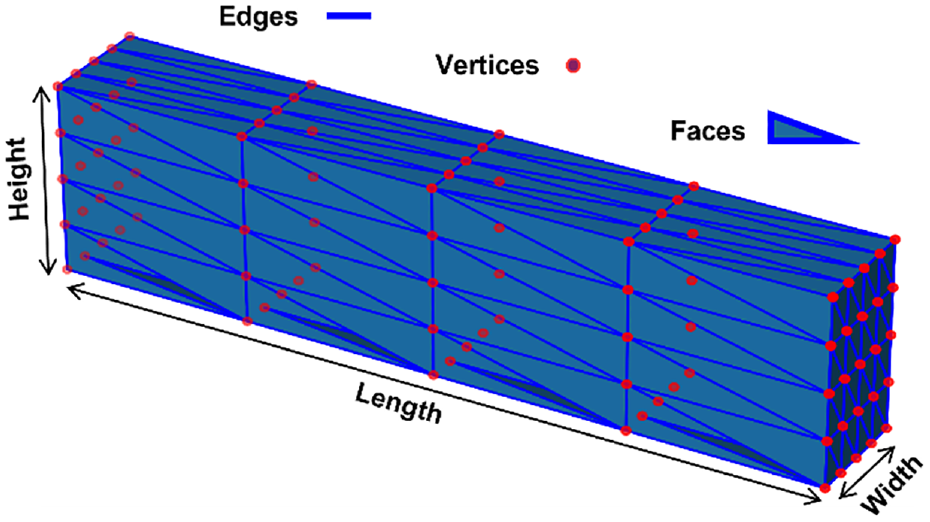
An example of 3D triangular mesh of a column-shaped structure. The vertices are represented by red points; the edges are plotted by short blue lines; the faces are blue triangles.
Using the base 3D mesh model as a foundation, deformed 3D models can be generated by utilizing analytical solutions or finite element method to calculate the displacement of each vertex, resulting in the generation of various shapes of the structure under different loading conditions.
To enable an efficient training process, normalization is performed on the 3D mesh models. The process involves two steps: scaling and translation. During scaling, an axis-aligned bounding box is generated for each object which completely encloses the object and has sides parallel to the coordinate system axes. Next, the normalization factor is computed based on the diagonal length (
Generative 3D mesh texturing
Adding texture to 3D meshes improves their visual realism and appearance, and also provides additional feature representation and semantic information. In the proposed 3DGEN framework, a generative mesh texturing neural network 44 is employed. Unlike traditional mesh texturing methods that primarily rely on geometric or procedural techniques, the generative mesh texturing incorporates text as a guiding prompt input for the texturing process. This approach offers users a flexible and accessible method to generate desired textures for 3D mesh models. Figure 3 illustrates the utilization of the generative mesh texturing method. By providing the 3D mesh model and an appropriate prompt in plain English, appropriate textures can be generated for the 3D mesh model based on the given text prompt.
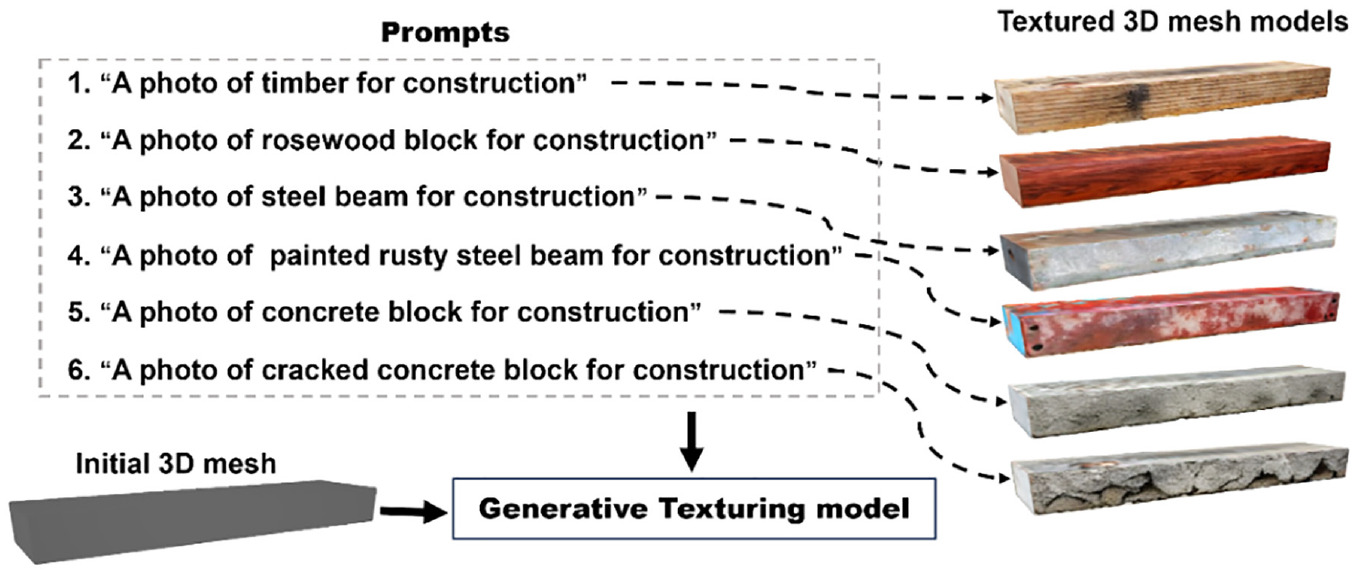
Utilization of the generative mesh texturing method.
The generative mesh texturing method offers a convenient and adaptable approach to apply textures to the 3D mesh. For instance, in prompt 2 as shown in Figure 3, a specific description ‘A photo of a rosewood block for construction’ is provided. The texturing method can utilize this prompt to generate the desired texture, which in this case is a rosewood block, and apply it to the 3D mesh.
Generative 3D mesh texturing is implemented using a diffusion-based generative neural network. This network is trained to take a text prompt and an untextured 3D mesh as input and produce 3D meshes with the desired texture described in the prompt as output. Through the training process, the network learns to understand the text prompts and generate corresponding textures that match the provided descriptions. By leveraging the power of neural networks, the generative texturing method enables the synthesis of textured 3D meshes based on textual prompts. The texturing process is shown in Figure 4.
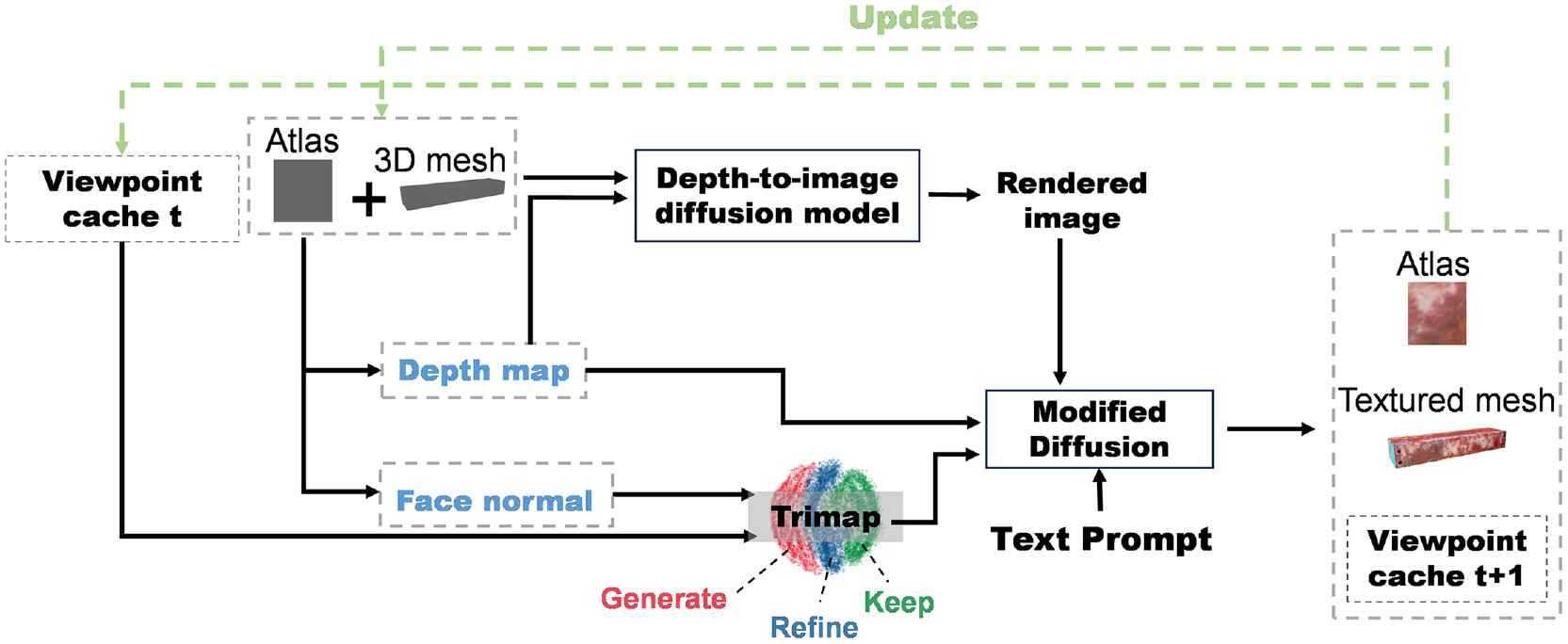
An overview of the text-guided mesh texturing process.
All the texture of the mesh is represented as an Atlas, generated using Atlas. 46 The process of mesh rendering involves iteratively painting the mesh from different viewpoints. The generative texturing method is supported by a pretrained depth-to-image diffusion model, which is based on stable diffusion techniques. 47 Stable diffusion is a generative model designed to iteratively refine a noise distribution into a coherent image that aligns with a given set of conditions. In this case, the conditions are spatial data provided by depth maps and text prompts. The process initiates with the depth map (a greyscale image where each pixel’s intensity correlates with its distance from the viewpoint) from initial 3D model rendering. This depth map is then utilized as a direct input alongside a noise vector as a conditional layer to guide the diffusion process. During the iterative refinement stages of stable diffusion, the model employs depth map to adjust the image’s features, ensuring that elements at different distances are rendered with appropriate clarity, texture and scale. For instance, objects closer to the camera are detailed more vividly, whereas those in the background may appear more subdued or blurred. This depth-aware adjustment is facilitated through a series of denoizing steps, where the model progressively learns to fill in details, guided by the depth map to maintain spatial accuracy.
To enhance the detail in the text-guided mesh texturing process, the geometric data such as face normal, current camera perspectives and historical viewpoint caches are employed to segment the rendered image into three specific regions: ‘keep’, ‘refine’ and ‘generate’. The ‘generate’ regions are earmarked for areas being visualized for the first time, necessitating the introduction of new textures that are seamlessly blended with existing textures to ensure a coherent visual appearance across the mesh. This necessity arises from the challenge of texturing over complex geometries where every viewpoint can reveal new surfaces that were previously occluded or not optimally positioned for texturing. In instances where a new viewpoint offers a more optimal angle for texturing previously colored regions, these areas are classified under ‘refine’ for texture enhancement to correct or improve the fidelity of details, such as sharpness and alignment with the mesh’s geometry. Conversely, regions that do not benefit from the new viewpoint, either because they are already optimally textured or because the new angle does not offer a significant improvement, are classified as ‘keep’, thereby preserving their original texture and ensuring continuity and consistency across views. This dynamic segmentation process is facilitated by a masking strategy that employs the trimap to precisely identify which regions of the mesh should undergo the texturing process. This mask guides the diffusion model in its generative task, considering the cumulative knowledge of prior texturing steps, the defined masks to manage texture application with precision, and the contextual cues from the textual prompt. The generative model, thus informed, synthesizes the next iteration of the textured mesh, ensuring that new textures are accurately aligned with the mesh’s surface details and intricacies. Then the newly generated or refined textures being meticulously projected onto the mesh’s texture atlas. The depth map, face normal and camera position corresponding to the current viewpoint are rendered using the Kaolin framework. 48 All the camera viewpoints during the process are stored in a viewpoint cache. The method of embedding text prompts within a pre-trained text-to-image model is meticulously described in Gal et al., 49 outlining a structured approach to optimizing visual concepts through language guidance. The embedding of text prompts into a pre-trained text-to-image model involves converting text into tokens using an encoder, where each token is linked to a unique embedding vector. A novel concept is introduced as a pseudo-word in the model’s vocabulary, with its embedding vector optimized through images that depict the concept in various scenarios. This optimization aims at visually reconstructing the concept, leveraging the model’s rich visual priors for intuitive and detailed rendering of language-guided concepts. The texture generated by this text-guided method significantly contributes to the richness and realism of the generated synthetic 3D dataset. By incorporating these textures, the overall quality and authenticity of the data are enhanced.
3D rendering
With the textures of various 3D meshes generated, Blender rendering engine 45 is utilized to generate synthetic cameras for capturing images and depth maps. The camera locations are randomly sampled from a sphere surface surrounding the structure, as shown in Figure 5. Multiple camera views are synthesized, capturing the textured structures from various angles. For each of these camera views, the camera intrinsic matrices and extrinsic matrices are also calculated and stored.
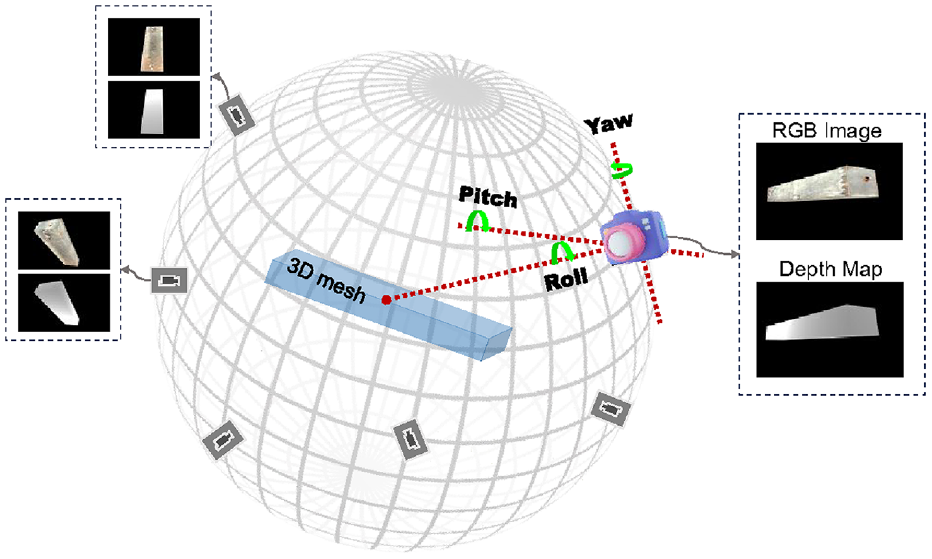
The generation of camera positions by modifying a look-at matrix, which is calculated using roll, pitch and yaw angles.
The sphere represents a range of possible camera positions, with each point on the sphere indicating a potential camera location, which is always oriented towards the central point of the column mesh. The creation of look-at matrices involves adjusting the camera’s pitch (
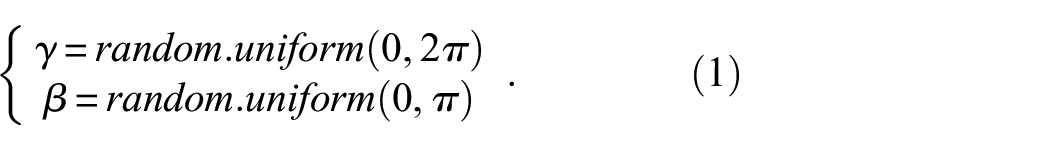
To account for the influences of camera movement, random angles are utilized to determine a random camera look-at matrix, which can be considered as an extrinsic matrix. This extrinsic matrix provides information about the camera’s position and orientation within the world. It is defined as
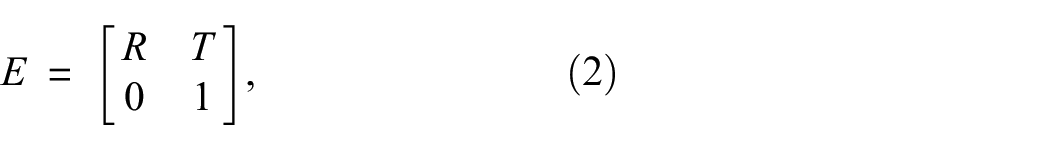
where
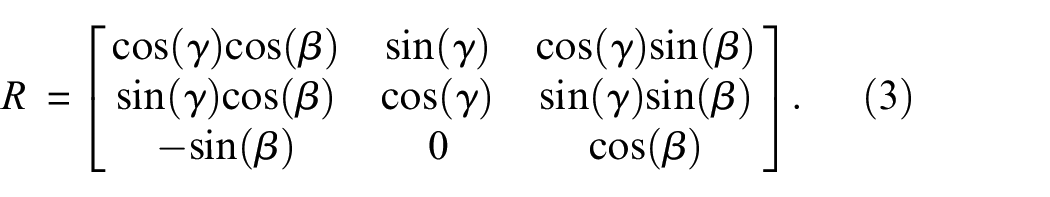
To calculate the translation vector
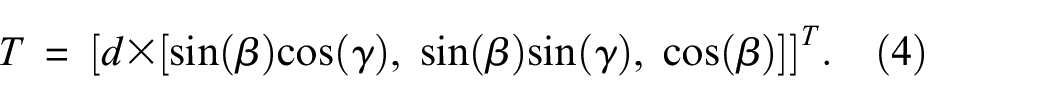
The translation vector
To increase the diversity of the images in dataset, four data augmentation techniques are applied to render images: (1) Random Cut-out: There is a certain probability of a region randomly erased from the image. The erased area is a random value sampled uniformly from 2% to 5% of the total image area. The aspect ratio (width/height) of the erased area is randomly selected between 0.08 and 0.3. The erased regions are filled with black pixels. (2) Colour Jittering: The brightness, contrast, saturation and hue of the images are randomly adjusted. Brightness is modified by a factor uniformly distributed between 80% and 120% of the original image’s brightness. Contrast is altered using a factor within the range of 80%–120% of the original image’s contrast. Saturation is adjusted with a factor randomly chosen between 80% and 120%. Hue is modified using a factor uniformly distributed between −0.1 and 0.1. (3) Zoom-in/out: The size of the images is randomly scaled between 80% and 120% of the original size. (4) Random rotation: the images are rotated at a random degree between 0 and 360. Training a deep learning model on such a dataset, enriched with diverse augmentations, ensures that it is not only proficient in recognizing patterns but also resilient to variations and anomalies. By simulating a wide range of conditions, the model becomes robust and less susceptible to overfitting.
Experimental validation A
Experiment A1: 3D column-shaped structure dataset generation
To demonstrate the effectiveness of 3DGEN, a comprehensive dataset specifically focusing on column-shaped structures is successfully generated in the first experiment. Column-shaped components are the most prevalent in civil engineering, as shown in Figure 6 which consists of two pictures captured from a university campus, illustrating the presence of many column-shaped civil structures in the real world.

Column-shaped structures are widely used in civil engineering. In the field of civil engineering, various components of buildings can be categorized as column-shaped structures.
3DGEN initially utilizes Trimesh API 50 to generate 100 base column-shaped meshes with different ratios of length, width and height. These base column-shaped meshes exhibit different characteristics, with some being ‘fat’ and others being ‘thin’. Some example images are shown in Figure 7. In this experiment, the base column-shaped structures are represented by simply supported beams and cantilevers.

Some examples of the base column-shaped mesh.
From the base 3D mesh models, deformed 3D models are generated by applying theoretical closed-form solutions for structural deformation. The key difference between the two column-shaped structures is that both ends of a simply supported beam are fixed, while for the cantilever only one end is fixed. By employing analytical solutions of single point loading to each of them, the loading conditions and the corresponding deformed structure configurations can be formulated.
The deflection
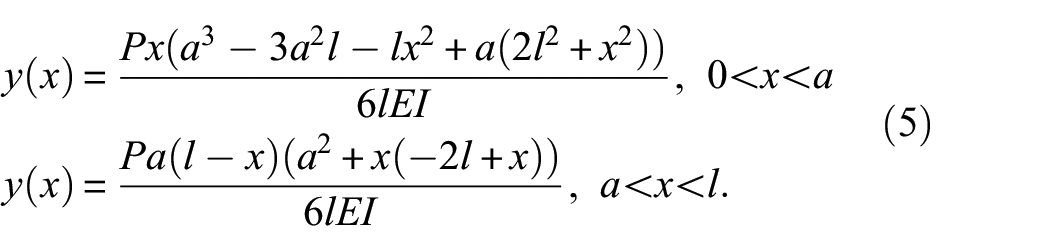
Similarly, the analytical solution for the deflection of a cantilever under a point load is

where
In the case of cantilevers, the point load is applied at different locations along the length of the column-shaped structures. These locations start from one end of the beam (position 1) and shifts
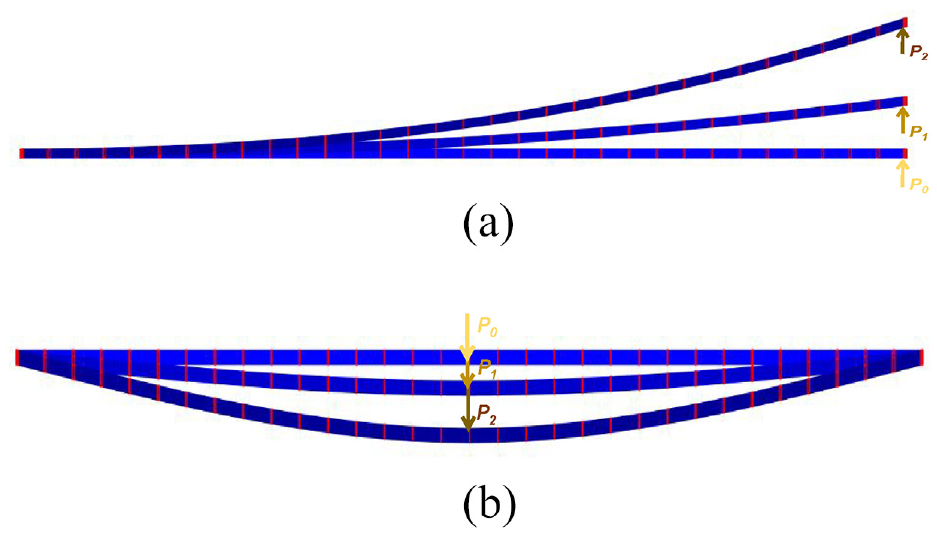
The experimental setups for assessing structural responses under varying conditions: (a) Three cantilevers with each subjected to different loading intensities applied at the free end and (b) three simply supported beams, with each subjected to different loading intensities at the middle point.
In total, 39,000 3D deformed shapes of beam structures are generated: 20,000 for cantilevers and 19,000 for simply support beams. These deformed shapes are similar to the shape of the structures during vibration in real-world when they are under ambient or applied dynamic loads. This allows the modelling process to encapsulate dynamic behaviour, reflecting the real-world scenarios where structures are subject to vibrational forces. Figure 9 provides some examples of the deformed column-shaped structures.

Some examples of the deformed simply support beams.
For all the column-shape 3D mesh, the generative mesh texturing model can be used to produce realistic images. In this experiment, three text prompts are used: ‘A photo of rusty steel beam for construction’, ‘A photo of plastic board for construction’, ‘A photo of cracked timber for construction’. Some examples are shown in Figure 10.

Some example images of the column-shaped structures textured by three different text prompts: (a) prompt: ‘A photo of rusty steel beam for construction’, (b) prompt: ‘A photo of plastic board for construction’ and (c) prompt: ‘A photo of cracked timber for construction’.
Perspective cameras are used for the 3D rendering of the column-shaped mesh models. The image resolution is set as 960 × 960 pixels. The cameras’ optical centers are located at pixel coordinates (480, 480). The field of view is specified as π/3, which indicates that the angle between the top and bottom edges of the image is approximately 60°. For each mesh, 40 images are generated. Some sampled images and their corresponding depth maps are shown in Figure 11.

Some sampled images and depth maps from the generated beam dataset.
The generated synthetic column-shape structure dataset includes a diverse range of column geometries, covering different sizes of 3D column-shaped structures and various deformation shapes of them generated through analytic solutions. It comprises a total of 19K meshes of simply supported beams and 20K meshes of cantilevers, representing different structural sizes under varying loading conditions. By rendering these meshes from multiple viewpoints, a collection of images and depth maps capturing the structures from various perspectives is generated. Each mesh yields 20 images, culminating in a dataset consisting of 780K pairs of images and depth maps. Generating this huge column-shaped structure dataset took 450.3096 h, utilizing the computational capabilities of a 12th Gen Intel® Core™ i7-1255U CPU. The process could be expedited if more powerful computational tools like GPUs are employed. The scope for data generation is virtually limitless – as long as there is sufficient storage space, one can produce an endless amount of data.
Experiment A2: 3D silo dataset generation
To demonstrate the effectiveness of 3DGEN for complex structures, a more intricate 3D mesh of silo structure is generated using Blender, as depicted in Figure 12. The mesh of the silo structure consists of 26,260 vertices and 18,200 faces. Since the focus of 3DGEN is on generating images and corresponding depth map of specific structural model, deformed shapes of the silo structure are not included in this experiment. They can be easily included by adding analytical solutions for any components of the structure, if a deformable silo is of interest.
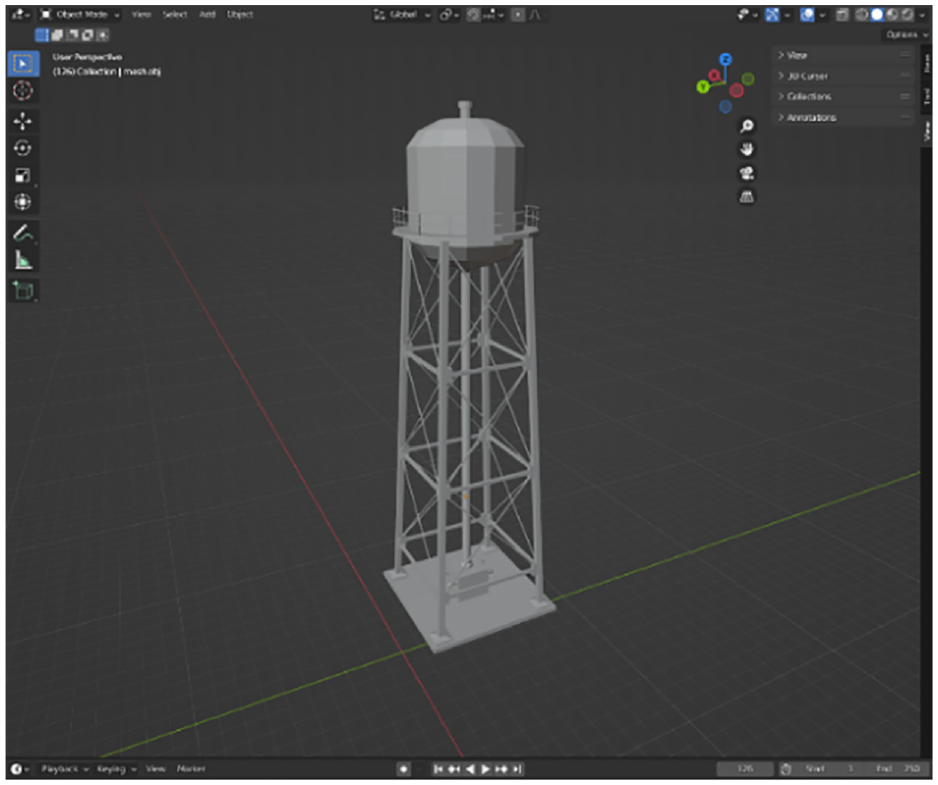
A 3D mesh of a water silo structure generated using Blender.
The generative texturing model is again used to generate realistic textures for the silo. Three prompts are used: ‘A photo of a steel water silo’, ‘A photo of a blue water silo’, ‘A photo of a yellow water silo’. Some examples are shown in Figure 13.

Some example images of the water silo structure textured by three different text prompts.
By using the proposed data generation framework, a collection of images and depth maps that capture the structures from different perspectives is generated. This results in a dataset that consists of 20K pairs of images and depth maps. The dataset generating time was 10.2646 h utilizing a 12th Gen Intel Core i7-1255U CPU. Some sampled images and the corresponding depth maps of the silo structures are shown in Figure 14.
Some sampled images and depth maps from the generated water silo dataset.
Experiment B: utilization of the generated datasets for monocular vision based 3D surface reconstruction
The goal of this experiment is to assess the efficacy and potential applicability of the synthetically generated dataset when employed for training deep neural networks in civil structural health monitoring tasks. Specifically, the task of 3D surface reconstruction using monocular vision is chosen for evaluation. The reconstruction of 3D surfaces and the assessment of deformation displacements in civil structures play a pivotal role in contemporary civil engineering. These processes offer essential insights into the structural integrity, design refinement and strategic maintenance planning of edifices.14,38 By mitigating distortions stemming from camera projections and resolving 3D ambiguities, the reconstructed 3D point cloud presents a distortion-free representation of the structure.
A neural network is trained on the synthesized dataset for monocular vision-based depth estimation. Monocular depth estimation refers to the process of inferring depth information of a scene using only a single RGB image as input. It aims to estimate the depth of each pixel in the image. In this study, a popular depth estimation neural network referenced in Yin et al., 42 is trained to estimate depth maps using the synthesized dataset. This neural network is named the ‘Custom-made network’ here for easy reference, since it is trained using the custom-made synthesized dataset for specific structure shapes, compared to the ‘original’ pre-trained network which can be used for any shape (with limited accuracy) in Yin et al. 42 The estimated depth information can then be used for 3D surface reconstruction, allowing the calculation of 3D coordinates of the scene. The 3D coordinate of a pixel can be calculated by the formula:

where
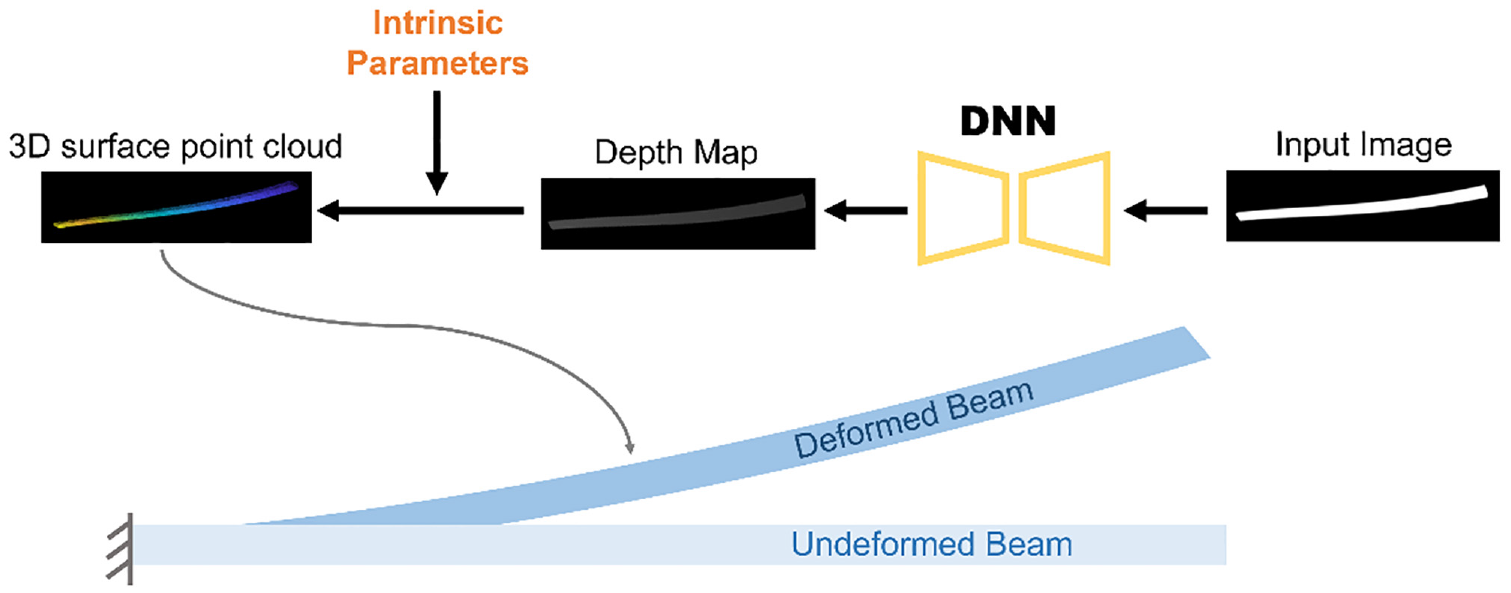
The pipeline of the method for 3D surface reconstruction.
In this experiment, 40K pairs of images and depth maps randomly chosen from the generated column-shaped structure dataset introduced in Experiment A1 are used for training the ‘Custom-made network’. The dataset is divided such that 95% of the image pairs are used for training the network, while the remaining 5% is set aside for testing and evaluating the network’s performance. The network is trained using stochastic gradient descent optimization algorithm. During the training, the data are divided into batches of size 4. The network weights are updated using an initial learning rate of 0.01, with a learning rate decay of 0.1 applied. Before feeding images to the neural network, pretrained Segment Anything model 51 is applied to remove background of all the images, enhancing the accuracy of the depth estimation.
The absolute mean relative error (AbsRel) metric is used as the evaluation criterion for the neural network’s performance on depth estimation:
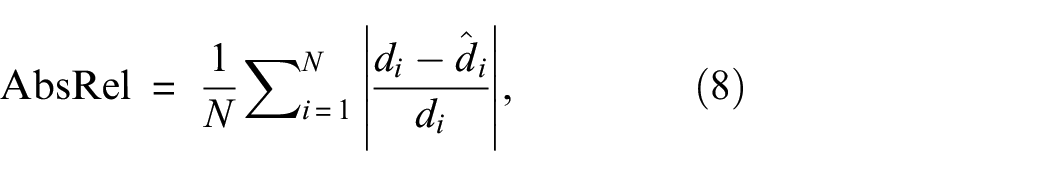
where
Table 2 presents the quantitative evaluation of the estimated depth from both the original pretrained network provided by Yin et al. 42 and the custom-made network using the generated column-shape structure dataset. Both the original network and custom-made networks are evaluated on the 2K validation split.
Quantitative comparison of the predicted depth using absolute mean relative error.

The results show that the original network has an AbsRel of 26.32%. In contrast, the custom-made network, which conducts training on 40K pairs of synthesized column-shape structure images, showcases a dramatically improved AbsRel of just 0.01468%. This indicates that the custom-made network’s reconstructions are much closer to the ground truth compared to the original network, highlighting the benefits of training on the custom-made synthetic datasets.
To evaluate the accuracy of the reconstructed 3D surface model, the commonly used chamfer distance is used to estimate the distance between the reconstructed point cloud and point cloud generated by ground truth. The Chamfer distance is defined as
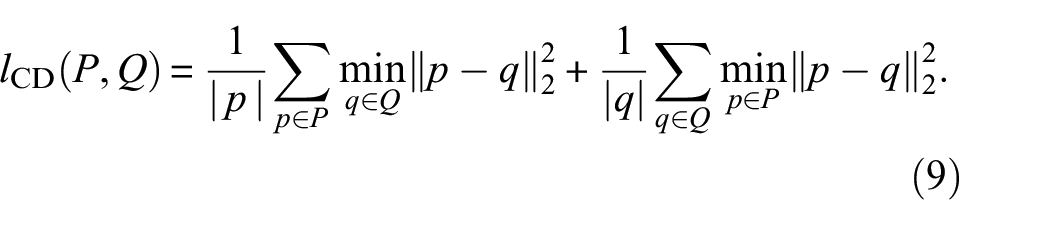
where
The quantitative evaluation of the reconstructed 3D point cloud is shown in Table 3. The original network has a chamfer distance of 5.2763, while the custom-made network significantly outperforms it with a chamfer distance of just 0.0668. This clearly demonstrates the significantly improved accuracy of the 3D model reconstructed by the custom-made network.
Chamfer distance of the reconstructed 3D point cloud.

The results clearly demonstrate the superior performance of the custom-made network in both depth estimation and 3D surface reconstruction. The targeted training on the generated column-shaped structure dataset has evidently endowed the network with a heightened ability to estimate depths and reconstruct 3D models with remarkable precision.
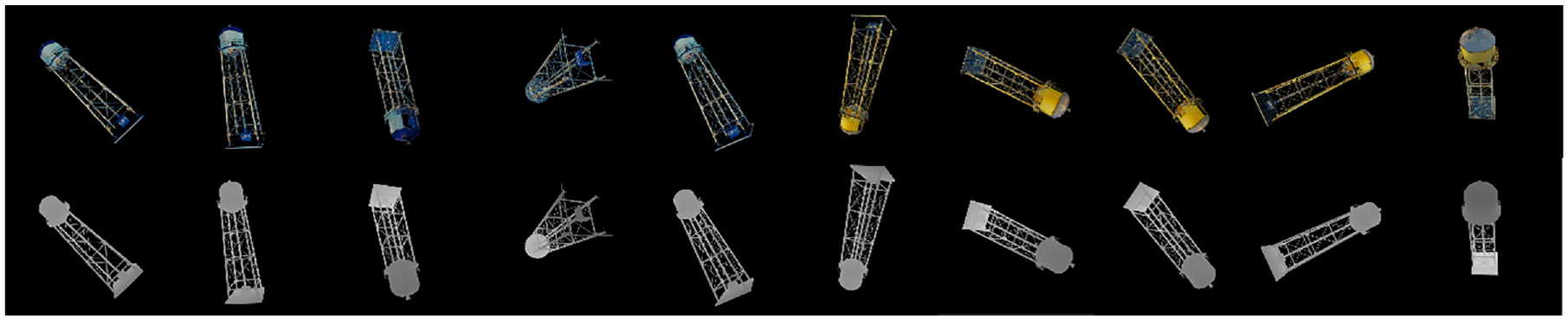
To evaluate the generalization capabilities of the custom-made network, images of column-shape structure, some are deformed from their original shapes, are downloaded from various websites for 3D surface reconstruction. Figure 16 offers a two-part visual comparison. Figure 16(a) displays a selection of images collected from the web. Figure 16(b) shows the point clouds for the 3D surface that the custom-made network reconstructed. The experiment reveals that the model, when trained on the generated synthetic dataset, demonstrates a high degree of generalizability. This is a significant achievement, as it indicates that the model is not overfitting to its training data but has genuinely learned the underlying patterns and features associated with column-shaped structures. Such a high degree of generalizability is crucial for practical applications, ensuring that the model remains reliable and accurate even when presented with unseen data.

A two-part visual comparison: (a) a selection of images that are collected from web and (b) the 3D point clouds that are reconstructed by custom-made network, which is trained on the generated dataset.
Conclusion
This article proposes a novel framework 3DGEN for rapidly generating synthetic datasets for computer vision-based civil structural health monitoring. Some generated datasets and codes have been made available to the public. The proposed framework combines advanced 3D modeling techniques, texture generation methods and rendering algorithms to create realistic and diverse custom-made 3D datasets that can closely resemble real-world civil structures, hence enable many downstream applications which can use them to train more targeted, ‘custom-made’ neural networks. Through a series of experiments, the efficacy of the data generation framework is established. It successfully produced a diverse dataset mirroring real-world 3D civil structures. When this dataset is used to train monocular depth estimation neural networks, the 3D reconstruction results are very accurate, and the model is generalizable. The current limitations of the 3D synthetic dataset generation framework stem primarily from its focus on generating structural deformations, with less emphasis on generating and controlling other types of damage such as cracks. While the framework can generate dataset for deformations of complex structures in theory, including those composed of multiple components, the generation of these more intricate structures and their specific damages has not yet been fully explored. In the future, the primary objective is to expand the scope of the datasets to include a broader variety of damages, such as cracks, spalls and corrosion, among others. Exploration and enhancement of the framework’s capabilities for generating datasets of more complex structures, inclusive of those with intricate geometries and composite materials, are also anticipated. Furthermore, refinement of the approach is aimed at providing more precise control over specific attributes of damage, such as location, dimensions and types. Beyond just depth and images, there is an intention to expand the annotations within the dataset to include optical flow, and segmentation maps, etc. These enriched annotations will help to build more effective tools for more holistic understanding of structural dynamics and characteristics.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: The support from Australia Research Council Discovery Project 16: AI Assisted Probabilistic Structural Health Monitoring with Uncertain Data, is acknowledged.
Data availability
The data in this study are available upon reasonable request.