
Abstract
Monitoring structural integrity through accurate crack detection is fundamental to ensuring the safety and longevity of civil engineering infrastructure. Vision-based methods, supported by advancements in deep learning, have gained prominence in structural health monitoring (SHM). However, these methods often suffer from limited performance due to insufficient diversity and scale in crack image datasets, which are costly and challenging to acquire. This study introduces a novel framework that integrates a text-to-image generative model with large language models to synthesize realistic crack images for training deep neural networks. A prompt engineering approach is utilized to generate high-quality textual descriptions, guiding the creation of a large-scale, diverse dataset that simulates a wide range of crack scenarios. The synthesized dataset significantly enhances model training, as demonstrated in two key SHM tasks: crack classification and crack object detection. Neural networks trained with the augmented dataset show up to a 60% improvement in precision over baseline models trained on real-world data alone. These results highlight the potential of generative models to address data scarcity in SHM, enabling more robust and accurate crack detection. This research provides a scalable and efficient solution for improving machine learning-based SHM applications and paves the way for further exploration of generative methods in structural monitoring tasks.
Keywords
Introduction
Regular assessments are essential to maintain the safety of civil structures and safeguard these critical assets. A key aspect of these evaluations is the detection of cracks, which is often an early indicator of potential structural issues.1,2 Traditional visual inspection methods for detecting cracks are ineffective, time consuming, require significant manpower and are prone to human error and subjective conclusions. These methods are also costly, and often struggle with accessibility issues, especially in large-scale, long-span and high-rise structures.
Advancements in computer vision (CV) technologies have led to a shift towards using image-based methods for crack detection in structural health monitoring (SHM). These methods, which capture digital images of structures and analyse them with software to detect cracks, provide a faster, more cost-effective, and robust alternative to traditional inspection methods. Vision-based crack detection methods primarily fall into two categories: image processing and machine learning (ML). Image processing techniques employ hand crafted filters, 3 morphological operations 4 and percolation theories, 5 among other techniques, to detect cracks without the necessity for training a model. Over the past decade, ML has emerged as a dominant technique in CV-based crack detection, 6 known for its exceptional performance across various tasks and gaining popularity in numerous fields.7–10 When provided with sufficient data, ML algorithms can autonomously identify complex features and hidden patterns, making them highly effective for precision-critical tasks, such as crack detection.
The task of crack detection within ML can be divided into three primary functions: crack image classification, crack object detection and crack segmentation. The goal of crack image classification11–13 is to ascertain whether an image or image patch contains cracks. A notable study by Gopalakrishnan et al. 13 utilized a Visual Geometry Group (VGG) model 14 to detect cracks on hot-mix asphalt and Portland cement concrete surfaces, achieving successful classification of pavement crack images. Different from crack image classification, crack object detection tasks15–19 involve generating bounding boxes around regions identified as containing cracks. Currently, prominent object detection models like Fast Region-based Convolutional Network 20 and Single Shot MultiBox Detector 21 are employed for this task. Crack segmentation22–24 provides the most detailed, pixel-level detection of images, classifying each pixel as either part of a crack or not. Among these methods, convolutional neural networks (CNNs) are popular for crack segmentation. Schmugge et al. 25 developed a CNN-based technique to segment cracks in nuclear power plant inspections by aggregating pixel-level classification confidence across video frames under different lighting conditions. Islam and Kim 26 developed a crack segmentation system using a fully convolutional network (FCN) with a VGG backbone. Trained on an open-source concrete crack dataset, the optimized FCN achieved around 92% in both accuracy and F1 scores on test data.
Despite the rapid advancements in ML methods for crack detection, the scale and diversity of training datasets remain limited. In the realm of ML, contemporary research increasingly supports that diverse large-scale datasets significantly enhance the robustness and effectiveness of Deep Neural Networks (DNNs). For instance, the popular deep learning model Segment Anything 27 used extensive datasets to enhance its segmentation capabilities, showing that with ample data, DNNs can achieve high-precision segmentation in various scenarios and adapt effectively to new environments. In the field of ML-based crack detection, there is a keen interest in gathering more crack images to train ML models. This demand stems from the need to train models that can accurately reflect the wide variability in crack appearances, which depend heavily on factors such as the material of structures, the types of damage they have sustained and environmental influences. However, gathering diverse crack images is challenging due to restricted access, high costs and environmental constraints. Restricted access means that safety regulations or property rights often limit entry to damaged structures. High costs arise from the need for specialized equipment and trained personnel. Environmental constraints include challenges such as lighting conditions and seasonal variations, which can affect the visibility and detectability of cracks. These challenges underscore the difficulties in collecting real crack images and the urgent need to develop methods for acquiring large-scale, diverse datasets. Consequently, enhancing existing datasets with synthesized data has become a promising area of research.
Many studies have explored the creation of synthesized datasets for training neural networks. Among these methods, physics-based approaches28,29 employed intricate mathematical models to simulate the physical properties and behaviours of real-world structures. This often involves creating three-dimensional models of structures and then applying simulated forces (e.g., wind, earthquakes) to assess how these structures might react. Conversely, data-driven approaches, particularly generative adversarial networks (GANs), 30 have been employed to create visually realistic image datasets for SHM tasks.31,32 For example, GANs have been utilized to generate synthesized data for wind turbine fault detection to enhance fault detection, 33 and for railway crack detection. 34 Both physics-based methods and GANs present innovative approaches to synthesized dataset generation, yet each exhibits distinct limitations. Physics-based models produce data with high physical realism and require extensive domain knowledge and significant computational resources, which can limit their scalability and practical application in large-scale dataset generation. GANs have demonstrated success in producing realistic visual patterns; however, ensuring consistent performance across highly diverse structural scenarios can be challenging, and careful training is often needed to maintain image fidelity and diversity.
In response to the challenges, this article proposes a framework for synthesized crack image dataset generation that leverages a diffusion model in combination with a large language model (LLM). Diffusion models have emerged as a powerful tool for generating high-quality and diverse images from textual prompts. Compared to GANs, diffusion models offer improved controllability and variation in output, as they can be guided by richly descriptive prompts to generate images that align with specific structural contexts. Furthermore, modern diffusion models are typically large-scale, pretrained on vast and diverse datasets. This broad training foundation equips them with strong generalization capabilities, enabling them to synthesize realistic images even for unseen or complex scenarios. These advantages make diffusion models particularly suitable for applications such as SHM, where the ability to generate visually and contextually accurate damage scenarios is critical for training robust deep learning models. Furthermore, the integration of LLM accelerates the creation of varied and precise prompts, substantially increasing the diversity of the generated images. This approach outperforms traditional physics-based methods, producing 1K high-resolution, realistic images in just a few hours with a single GPU – an achievement unattainable with conventional methods. The efficacy of the synthesized data is evaluated through two experiments: crack image classification and crack object detection, using selected public datasets as benchmarks. By adding the synthesized images to the training set, the same DNN models become significantly more robust, achieving much better evaluation results. Crack image classification precision increased from 33.6 to 93.96%, and crack object detection precision improves from 24.25 to 83.82%.
Figure 1 illustrates a comparison between crack images from public crack datasets and synthesized crack images generated using the proposed framework. The synthesized images demonstrate a high level of realism, capturing various crack types, textures and environmental conditions that closely mimic those found in real-world scenarios.

Comparison of crack images from public datasets (right) and synthesized crack images generated using the proposed framework (left).
The organization of this article is as follows: the second section elaborates the methodology of the data generation framework, detailing the integration of the diffusion model and an LLM for crafting synthesized images. The third section presents the methodologies employed and the results obtained for crack image classification and crack object detection. The fourth section provides a conclusion, summarizing the principal findings and suggesting for future research.
Synthesized crack image generation
Figure 2 presents a schematic overview of the synthesized crack image generation framework, employing a large text-to-image rectified flow model (RFM) 35 that has been extensively trained on a vast dataset of billions of diverse text-image pairs, encompassing a wide array of scenes from urban environments to structural materials. Guided by textual prompts, the model can reconstruct images from noisy images to generate high-quality synthesized visualizations. To enrich the text prompts, the LLM Generative Pre-trained Transformer (GPT)-4 36 is employed to create varied and detailed text prompts. A crucial step involves a prompt engineering process that preprocesses raw text from GPT-4, selecting prompts that are preferred by the diffusion model for optimal results. These selected prompts are then processed by a text encoder, which converts the descriptions into a feature space representation that the diffusion model can utilize for image generation.
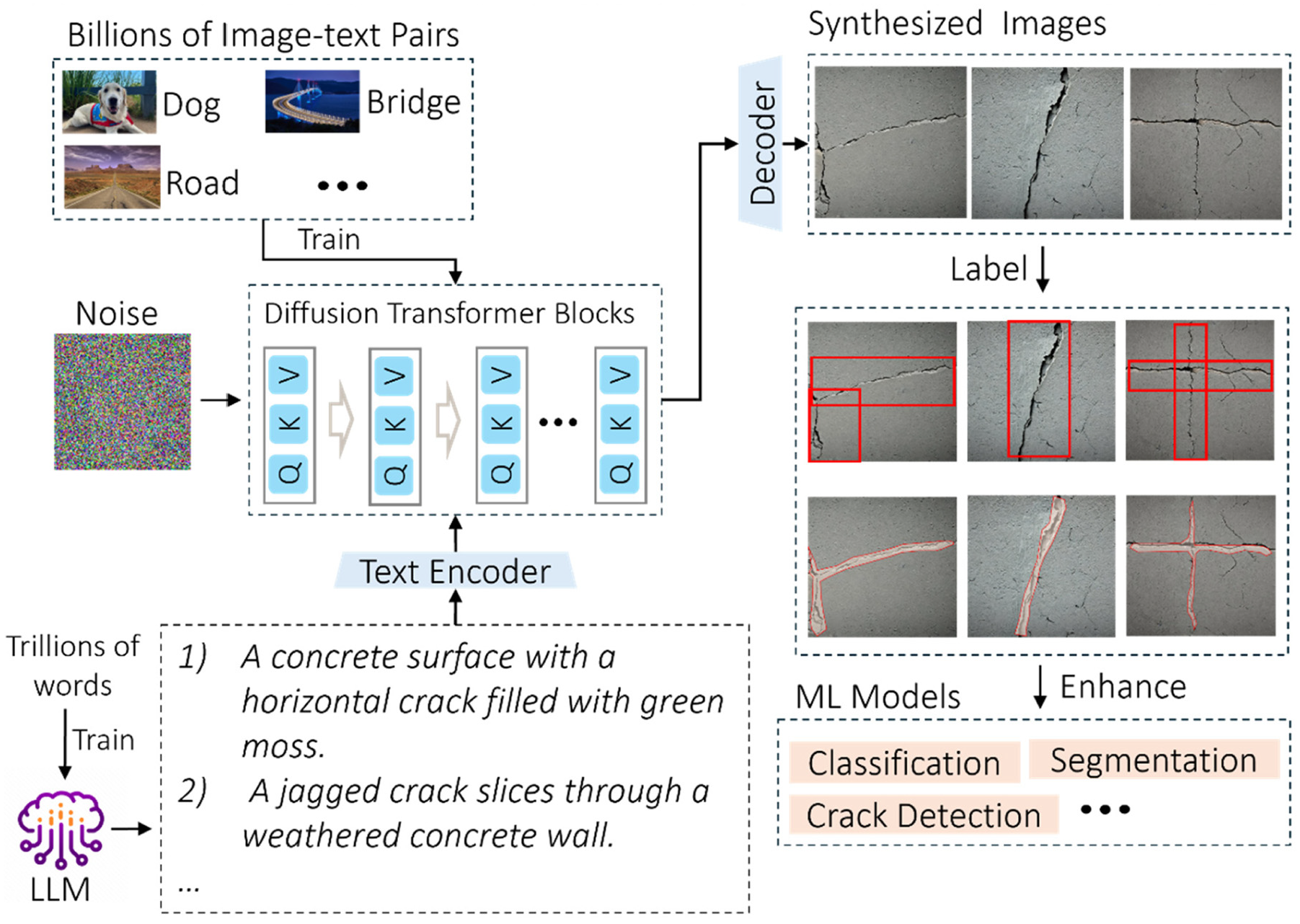
Overview of the proposed synthesized crack image generation framework.
Text-to-image generation with RFM model
The diffusion process consists of two parts, one is forward diffusion, and the other is reverse diffusion. Forward diffusion is to add noise to the image, and reverse diffusion is to remove noise. Firstly, it is assumed that the image side is
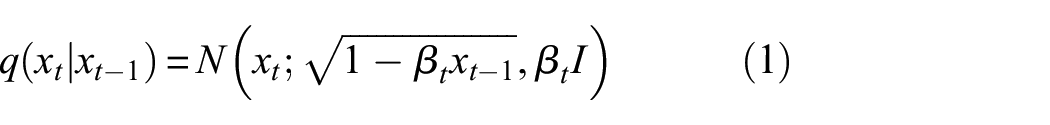
In the forward diffusion process, noise is added to an image incrementally through a sequence of steps. The transformation of the state variable
The process of adding noise to an image is defined as
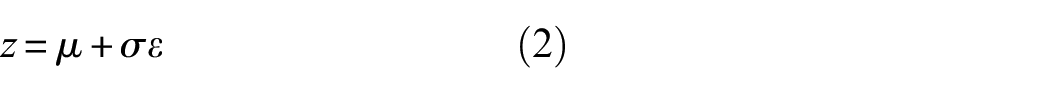
where

Assume

Through the application of Equation (4), the state of the sample image

The Progressive degradation of a concrete crack image using a linear noise schedule.
The reverse diffusion process is the opposite of the forward diffusion process. It is no longer about finding the distribution of
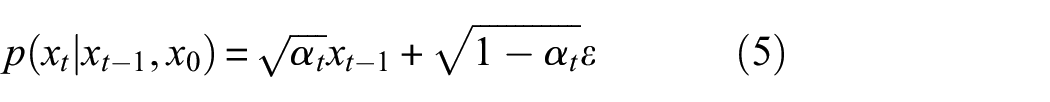
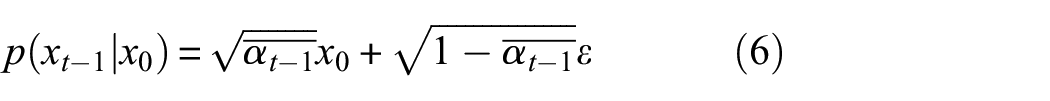
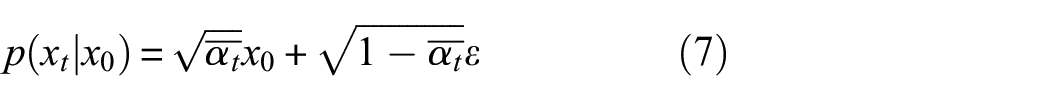
Equations (5)–(7) can be rewritten into the Gaussian function form as follows:
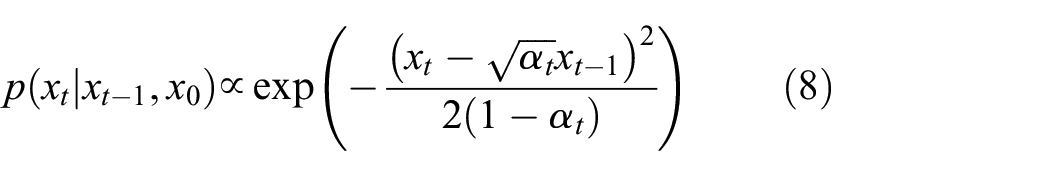
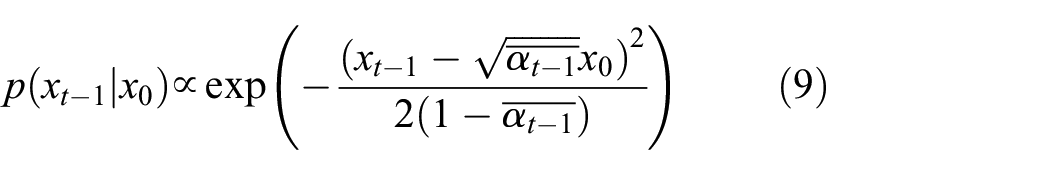
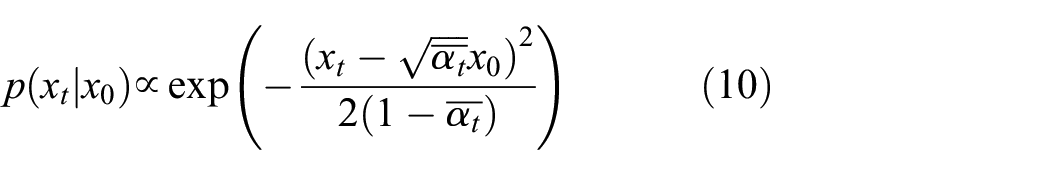
According to the Bayesian formula, it can be derived that:
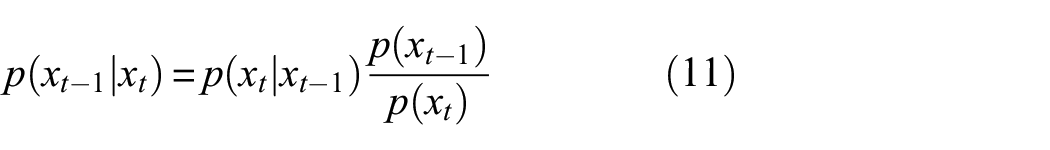
Using the Bayesian formula in Equation (11), and substituting Equations (8)–(10) into
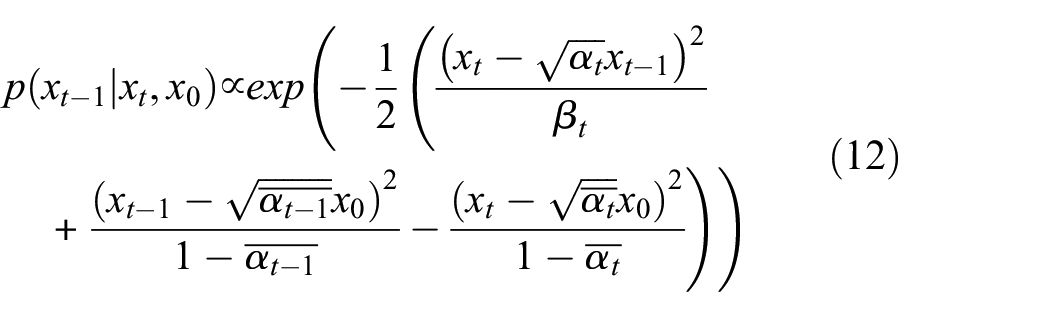
Rearranging Equation (12) into a general form obtains:
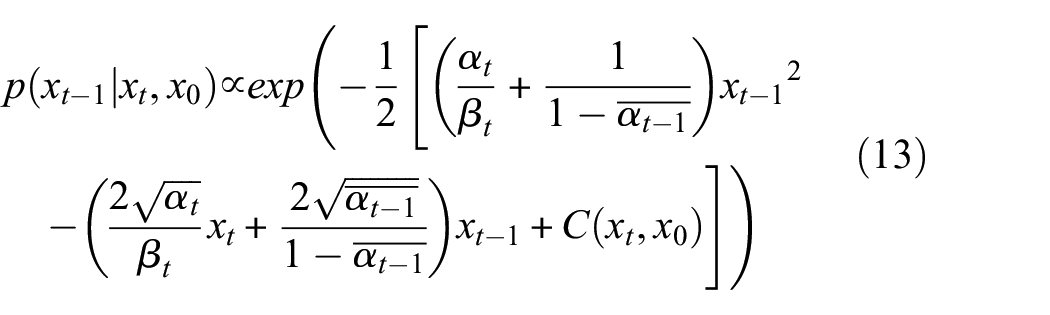
According to Equation (13), the mean and variance can be solved as follows:

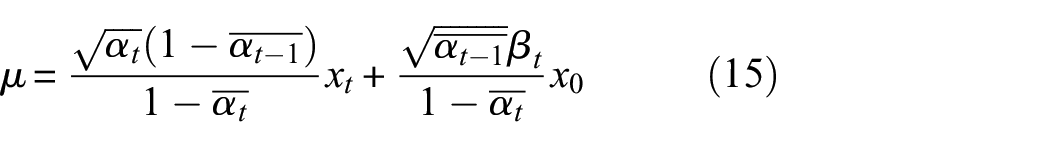
Since it is initially assumed that
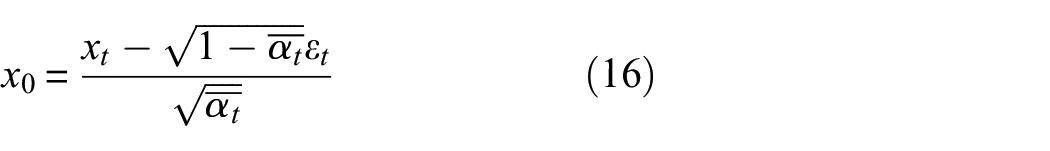
Substituting Equation (16) into Equation (15), the mean expression is obtained as:
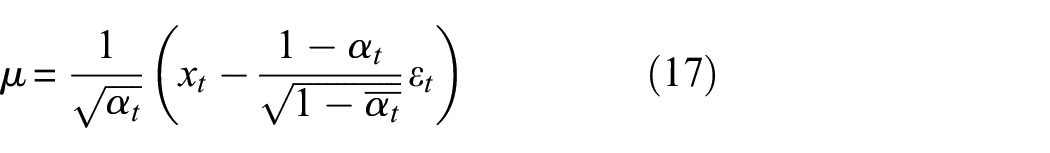
Assume that the mean expression obtained by neural network learning is:
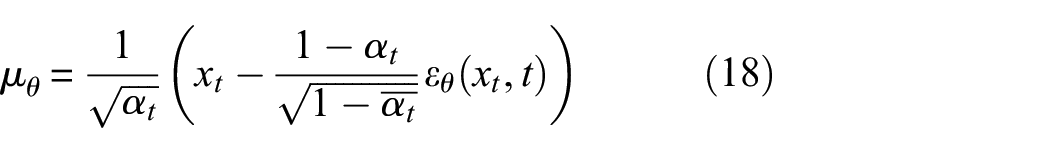
After obtaining the mean, the mean square error can be used to obtain the loss function:

where
In the realm of diffusion models, the complexity of noise addition and reversal poses significant computational challenges. To address this, Rectified Flow 37 offers a simplified approach by employing a linear interpolation method for noise addition. Unlike traditional recursive Gaussian models, Rectified Flow introduces noise through a straightforward linear blend between the original image and noise across the diffusion timeline. This method is represented mathematically as:
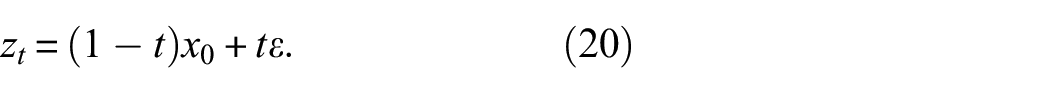
It simplifies both the understanding and computation of noise dynamics. The replacement of complex noise addition equations with Rectified Flow can lead to significant reductions in computational overhead and enhance the model’s transparency.
The training for text-to-image RFM, as guided by the framework in the study by, 38 involves using a pretrained encoder to convert both images and text into latent representations. This approach ensures that both modalities are represented in a compressed format that retains essential information while reducing dimensionality. Images are transformed into a lower-dimensional latent space, which effectively captures the visual content in a more manageable form. Similarly, text conditioning is processed through pretrained text models that convert textual data into corresponding latent representations.
The text conditioning, denoted as
The Multimodal Diffusion Transformer 35 architecture, based on diffusion transformer, 42 is used for image reconstruction. The Diffusion Transformer integrates the diffusion timestep with the class label, while the Multimodal Diffusion Transformer incorporates embeddings of both the diffusion timestep and text conditioning vectors into its process. Also, a sequence that merges embeddings from both text and image inputs is constructed. Positional encodings are incorporated, and the latent pixel data is transformed by flattening pixel blocks into a sequence of patch encodings. These patch encodings, along with the text sequence, are then adjusted to a common dimensionality and concatenated. Following the Diffusion Transformer, a series of modulated attention mechanisms and Multi-Layer Perceptron (MLPs) are implemented, which are designed separately for the text and image data due to their distinct characteristics. The designs mimic the functions of two transformers, each dedicated to one modality. Subsequently, the sequences from both modalities are combined for the attention mechanism. This allows for an integrated processing where each modality can influence and be influenced by the other.
Prompt generation and prompt engineering
Achieving diversity in generated images requires diverse prompts. Manually writing detailed prompts can be incredibly time-consuming. Fortunately, advancements in the field of natural language processing have enabled LLMs to efficiently generate vast, varied prompts. In this article, GPT-4 is employed to generate text prompts. GPT-4 is a state-of-the-art LLM developed by OpenAI, which includes numerous transformer layers 43 known for their ability to process and generate complex language patterns. Its proficiency in analysing vast amounts of text data enables it to produce varied text prompts, facilitating the creation of unlimited synthesized images.
Not all text prompts generated by GPT-4 can effectively guide the RFM to produce high-quality images. Although these prompts might be well-composed, they do not always resonate with the RFM’s optimal processing capabilities due to a lack of specificity in tuning to the RFM’s preferences. In this study, we use the term ‘RFM-preferred prompt’ to refer to prompts that empirically lead to consistently high-quality image outputs from the RFM. This preference is not derived from fixed linguistic rules or predefined semantic structures. Rather, it reflects the latent tendencies learnt by the RFM during pretraining on large-scale datasets. Since the internal functioning of the RFM is governed by high-dimensional neural representations, the exact preference criteria are not directly interpretable. Instead, we identify these prompts through systematic qualitative evaluation of the images they produce. Figure 4 illustrates an example of RFM-preferred and RFM-non-preferred prompts and the images they generate.

Comparison of images generated using RFM. (a) shows an image generated from an RFM-preferred, while (b) shows an image generated from an RFM-non-preferred prompt. RFM: rectified flow model
To ensure that RFM can consistently generate diverse, high-quality images that reflect the reality and meet engineers’ preferences, a systematic prompt engineering approach is employed. This process includes the selection of text prompts to enhance their interpretability by the RFM. Figure 5 illustrates the prompt engineering process through which text prompts generated by GPT-4 are selected. Initially, a varied pool of raw prompts is automatically generated using GPT-4. This is done by directly interacting with GPT-4 with specific requests, such as: ‘Hi GPT-4, could you please generate 50 prompts for diffusion models? These prompts should focus on cracks in various civil engineering structures’. GPT-4 then produces a range of text prompts concerning cracks, which include both RFM-preferred and non-preferred types, collectively referred to as raw prompts. Each raw prompt generated by GPT-4 is subsequently used to produce an image using the RFM, with all hyperparameters set uniformly to maintain consistent testing conditions. After the images are generated, a rigorous quality check is performed manually by the proposed prompt engineering strategy. During this evaluation phase, each image is assessed to determine if it meets the user preferences and quality standards. Prompts that lead to the creation of images favoured by users are retained for further use, while those that result in subpar or undesirable outcomes are removed from the pool. Once the quality check is completed, the selected prompts are designated as RFM-preferred prompts and are employed for further image generation.
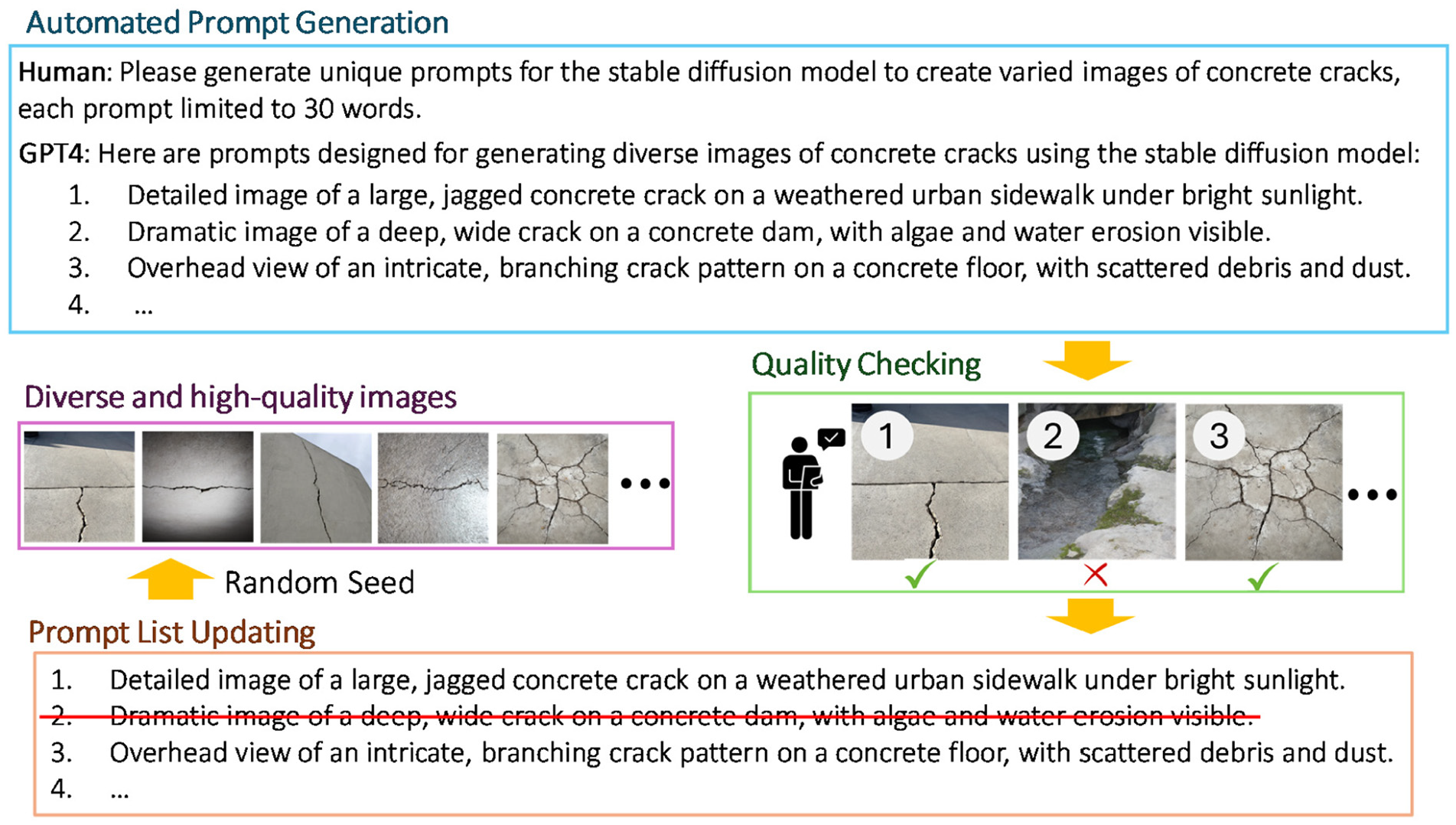
The prompt engineering process of selecting RFM-preferred text prompts from a pool generated by GPT-4. RFM: rectified flow model; generative pre-trained transformer (GPT).
To maintain a consistent quality across generated images, each RFM-preferred prompt is used to produce multiple images by randomly varying the RFM’s seed value. The seed value determines the initial noise pattern in the image generation process, setting the starting point for the noise that the RFM manipulates during its diffusion processes. While the RFM is governed by several hyperparameters, our research indicates that the text prompt itself is the paramount hyperparameter, exerting the most significant influence on the quality of the generated images. Modifying a text prompt can dramatically impact the resultant image quality. However, if the prompt is RFM-preferred, subsequent adjustments to other hyperparameters, especially the seed value of the RFM, typically have an insignificant impact on image quality. Although changing the seed may slightly alter image details, it does not significantly affect the overall quality and style of the images. Figure 6 presents an example where the RFM-preferred prompt from Figure 4 is used, maintaining all hyperparameters at their default settings while changing the seed value. It is evident that the image quality remains consistently high, and the style is unchanged but the details, such as the shape and size of the crack, differ.

The effect of changing the seed value while using the same RFM-preference prompt from Figure 4. RFM: rectified flow model.
Experimental validation of synthesized data for enhanced crack detection
Experiment setup
To evaluate the efficacy of the proposed image generation framework, two distinct experiments involving vision-based tasks, crack classification and crack object detection, are conducted. These experiments are designed to determine how synthesized data, when added to training datasets, can improve the accuracy and robustness of neural networks in detecting and categorizing crack features. The methodologies of evaluation for both the crack classification and crack object detection tasks are depicted in Figure 7. This figure outlines the workflow used for each of the two tasks, from data preparation through model training to the final testing phase.
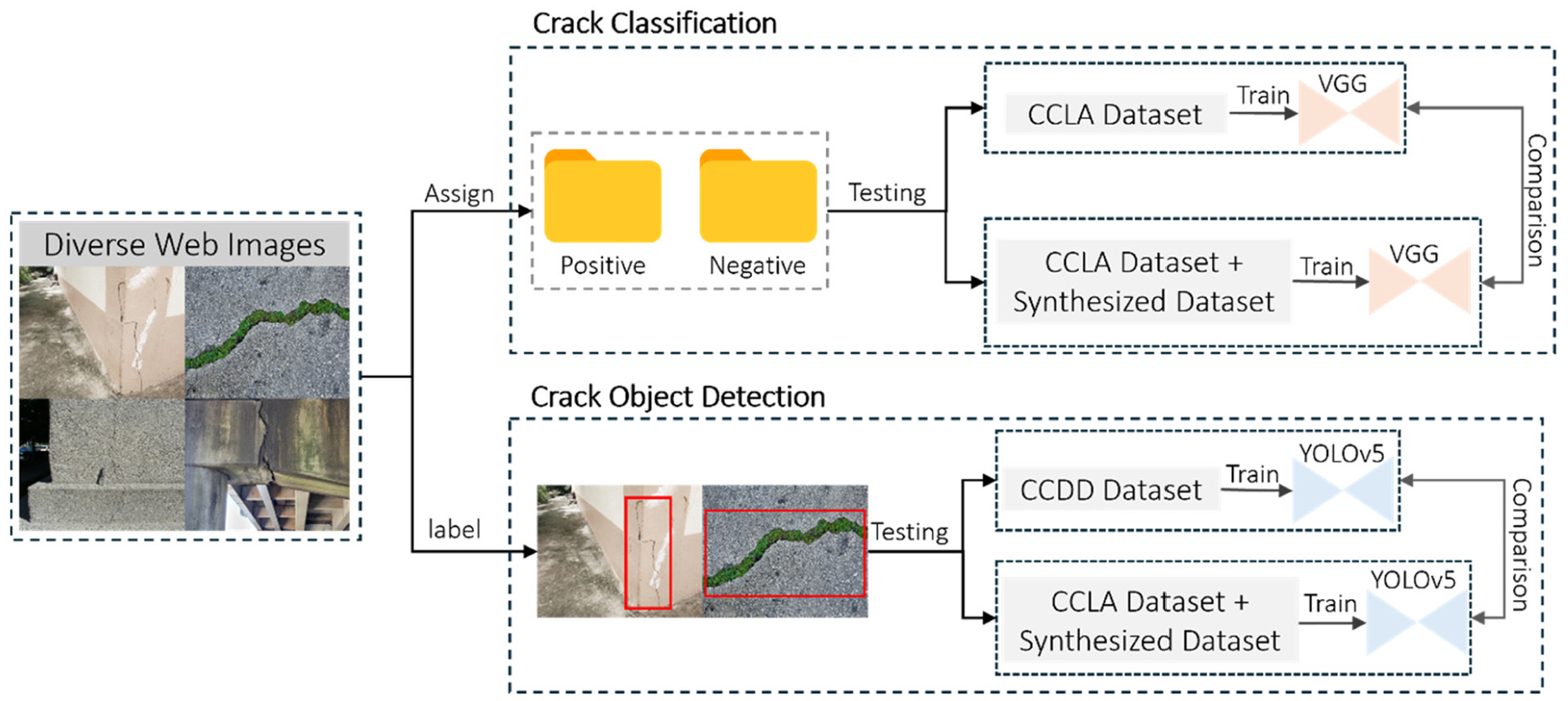
Experimental setups and workflow for the crack classification and object detection tasks.
Deep learning-based crack classification task involves training a neural network to classify images as either containing a crack (positive) or not (negative). The primary goal is to assess the network’s ability to accurately identify the presence of cracks based on the visual data provided in the images. Differing from simple classification, the DL-based object detection task requires the trained model not only to detect the presence of a crack but also to pinpoint its exact location within the image. The output includes bounding boxes around each detected crack, accompanied by confidence scores. To perform these evaluations, two public datasets, the Crack Classification Dataset CCLA 44 for crack image classification and the Comprehensive Crack Detection Dataset (CCDD)45–47 for crack object detection are utilized, alongside a synthesized dataset by the proposed framework and the Web-sourced Crack Evaluation Dataset (WCED). The CCLA dataset consists of images of concrete structures from various buildings, with half of the images tagged as negative and the other half as positive. These images are captured using a 16-MP Nikon camera, strategically positioned at a working distance of 500 mm to ensure consistent image quality and scale. Each image within this dataset maintains a resolution of 256 × 256 pixels. The CCDD is compiled by aggregating several public datasets from Roboflow 48 for crack object detection. This compilation draws from three datasets,45–47 summing up to 1020 positive images for training. CCDD and CCLA datasets serve as the base training datasets for the crack classification and crack detection neural networks.
To test the generalization and robustness of the trained models, 400 diverse, real-scenario images from the web are collected and annotated, forming the WCED dataset, which are used only for testing the trained neural networks. WCED dataset comprises 200 negative images of undamaged structures such as buildings and infrastructure, representing scenarios with no crack, and 200 positive images that include a range of crack manifestations, such as small cracks, occluded cracks, cracks obscured by moss and so on. This diverse testing dataset presents a challenging environment for the trained neural networks in detecting and classifying cracks under varied conditions. A few positive images from WCED are displayed in Figure 8.

Examples of positive images from the WCED dataset. WCED: Web-sourced Crack Evaluation Dataset.
4K synthesized images are generated using the proposed framework as discussed in the second section, 2K positive and 2K negative, to augment the training data. For the crack classification task, these images are integrated with the CCLA dataset. For the object detection domain, 1200 positive synthesized images, also labelled using Roboflow, 48 are merged with the CCDD dataset. The integration followed a staged approach, allowing the evaluation of the impact of the synthesized data on model performance. The effectiveness of this strategy is determined by observing any improvements in the models’ performance when testing on the same web-sourced images (WCED), before and after the integration of synthesized data. A noticeable improvement in model performance upon integrating the synthesized images would validate the inclusion of the synthesized dataset and confirm the effectiveness of the proposed synthesized data generation framework.
Synthesized training data generation
For synthesized training data generation, the framework proposed in the second section is used which integrates GPT-4 and RFM. 35 The synthesized crack dataset (SCD) generation begins with the creation of 600 raw prompts related to cracks using GPT-4. From them, 200 RFM-preferred prompts are selected manually through the proposed prompt engineering method introduced in “Prompt generation and prompt engineering” section to optimize prompt suitability for the RFM. Additionally, 600 raw prompts are created for images depicting undamaged structures, from which 200 are chosen following the same prompt engineering process. Upon establishing these 400 RFM-preferred prompts, all hyperparameters are fixed to ensure uniformity across data generation. For each of the selected prompts, 10 unique images are generated by changing the seed value across 10 distinct random numbers. As a result, a total of 2K positive images depicting various crack scenarios and 2K negative images showcasing various undamaged structures are produced. Figure 9 presents three examples produced using the positive prompts. Figure 9(a) displays images generated from a prompt designed for concrete, illustrating a ‘cluster of small, shallow cracks on a concrete wall’. Figure 9(b) shows images from a prompt for asphalt, depicting an ‘asphalt Road surface with a branching crack filled with small vertical pebbles’. Figure 9(c) presents images of a ‘concrete bridge with visible cracks and misalignments from recent earthquake damage, under emergency inspection lights’. These images collectively demonstrate the capability of the proposed synthesized image generation framework to create detailed and context-specific images that reflect different materials and damage scenarios under various conditions.

Examples of images from the synthesized training dataset generated using RFM with three distinct prompts. (a) Cluster of small, shallow cracks on a concrete wall, (b) asphalt road surface with a branching crack filled with small vertical pebbles, and (c) concrete bridge with visible cracks and misalignments from recent earthquake damage, under emergency inspection lights.
Dataset diversity evaluation
Ensuring dataset diversity is essential for training deep learning models that can generalize effectively to real-world SHM tasks. To evaluate how well different datasets capture variations in crack patterns, we compare the real training dataset (CCDD) and the synthetic dataset (synthetic positive images) against a subset of the real-world testing data (WCED positive images). To quantify the differences between these datasets, we leverage two widely used diversity assessment metrics: Fréchet Inception Distance (FID)49,50 and Structural Similarity Index Measure (SSIM). 51 FID measures the similarity between two datasets in the feature space of a pretrained neural network. 52 A lower FID score indicates that the dataset is more similar to real-world data. SSIM analyses the structural consistency between images by comparing luminance, contrast, and texture, with a higher score indicating greater similarity to real-world images.
Table 1 presents a quantitative comparison of dataset similarity using FID and SSIM. The results show that CCDD versus WCED (Pos) achieves an FID of 194.9 compared to Synthetic (Pos) versus WCED (Pos) with an FID of 232.5, suggesting that CCDD is more aligned with WCED (Pos) in feature space. However, SSIM, which evaluates structural consistency in the image domain, exhibits the opposite trend. Synthetic (Pos) versus WCED (Pos) achieves a higher SSIM score (0.0427) than CCDD versus WCED (Pos) (0.0244), indicating better local structural similarity to WCED. This apparent contradiction arises from the fundamentally different sensitivities of the two metrics. FID captures overall image structure but is relatively insensitive to fine-grained texture. In contrast, SSIM captures local structural details, such as crack edges and surface patterns, which are critical for SHM. Therefore, while FID suggests greater semantic divergence, the higher SSIM indicates that the synthetic data better reflects the fine-grained textures seen in real crack images.
Diversity metrics comparison.
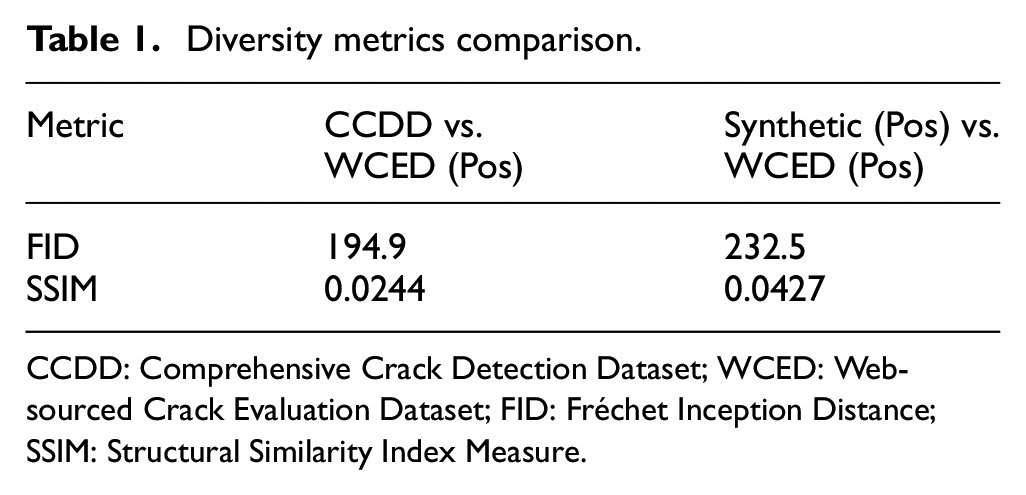
CCDD: Comprehensive Crack Detection Dataset; WCED: Web-sourced Crack Evaluation Dataset; FID: Fréchet Inception Distance; SSIM: Structural Similarity Index Measure.
Moreover, the absolute values of both metrics (e.g., FID ∼195–230, SSIM ∼0.024–0.043) fall outside conventional interpretability ranges. This is likely due to the fact that both metrics are originally designed for tasks requiring near-exact image reproduction (e.g., super-resolution or denoising), whereas our goal is to generate diverse, structurally realistic, but not identical images to real data. Additionally, FID’s reliance on ImageNet-trained networks can underrepresent intra-domain relevance for crack imagery, as these networks are not optimized for civil infrastructure patterns. To mitigate these limitations and provide a more domain-relevant visual interpretation, we present a t-distributed Stochastic Neighbor Embedding (t-SNE) visualization of the image embeddings.
Figure 10 visualizes dataset clustering in feature space using t-SNE. The t-SNE visualization results indicate that Synthetic (Pos) versus WCED (Pos) demonstrates better clustering and alignment compared to CCDD versus WCED (Pos). This aligns with the higher SSIM score observed for Synthetic (Pos), suggesting that it maintains a closer resemblance to WCED (Pos) in terms of structural consistency. Conversely, CCDD versus WCED (Pos) shows a more dispersed distribution in the t-SNE space, which is consistent with its lower SSIM score. These results suggest that, despite its higher FID score, Synthetic (Pos) outperforms CCDD in both SSIM and t-SNE clustering, indicating a stronger overall alignment with WCED (Pos).
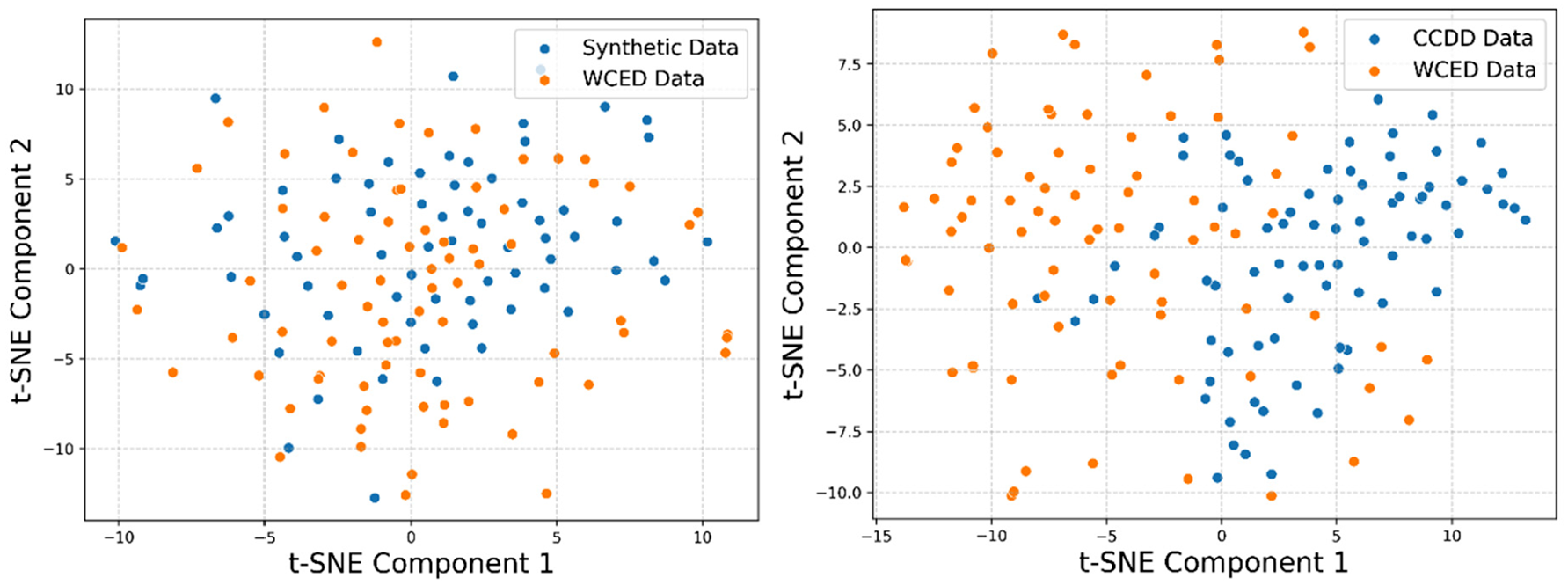
t-SNE visualization of feature distributions, comparing CCDD and Synthetic (Pos) against WCED (Pos). CCDD: Comprehensive Crack Detection Dataset; WCED: Web-sourced Crack Evaluation Dataset.
While these metrics provide valuable insights, they have inherent limitations in capturing dataset diversity, particularly given the limited size of the real testing dataset. To further evaluate the effectiveness of the synthesized dataset, we assess its role in improving crack classification and detection performance.
Synthesized data evaluation – crack classification
The model employed for the crack classification task is a VGG-16 architecture, 14 initially trained on the ImageNet dataset. 53 The architecture of the neural network is shown in Figure 11. The base model consists of five convolutional blocks, each followed by max pooling layers, effectively capturing hierarchical features from the input images. The first two blocks contain two convolutional layers with 64 and 128 filters, respectively, while the subsequent blocks have three convolutional layers each, with 256, 512 and 512 filters. These layers are activated by the Rectified Linear Unit (ReLU) function and progressively reduce the spatial dimensions of the input through max pooling. The flattened output from the last max pooling layer, a one-dimensional vector of 25088 elements, is fed into two fully connected layers, each with 4096 units and the ReLU activation. Finally, a dense layer with a single unit and the sigmoid activation function is added to output a probability value for binary classification.
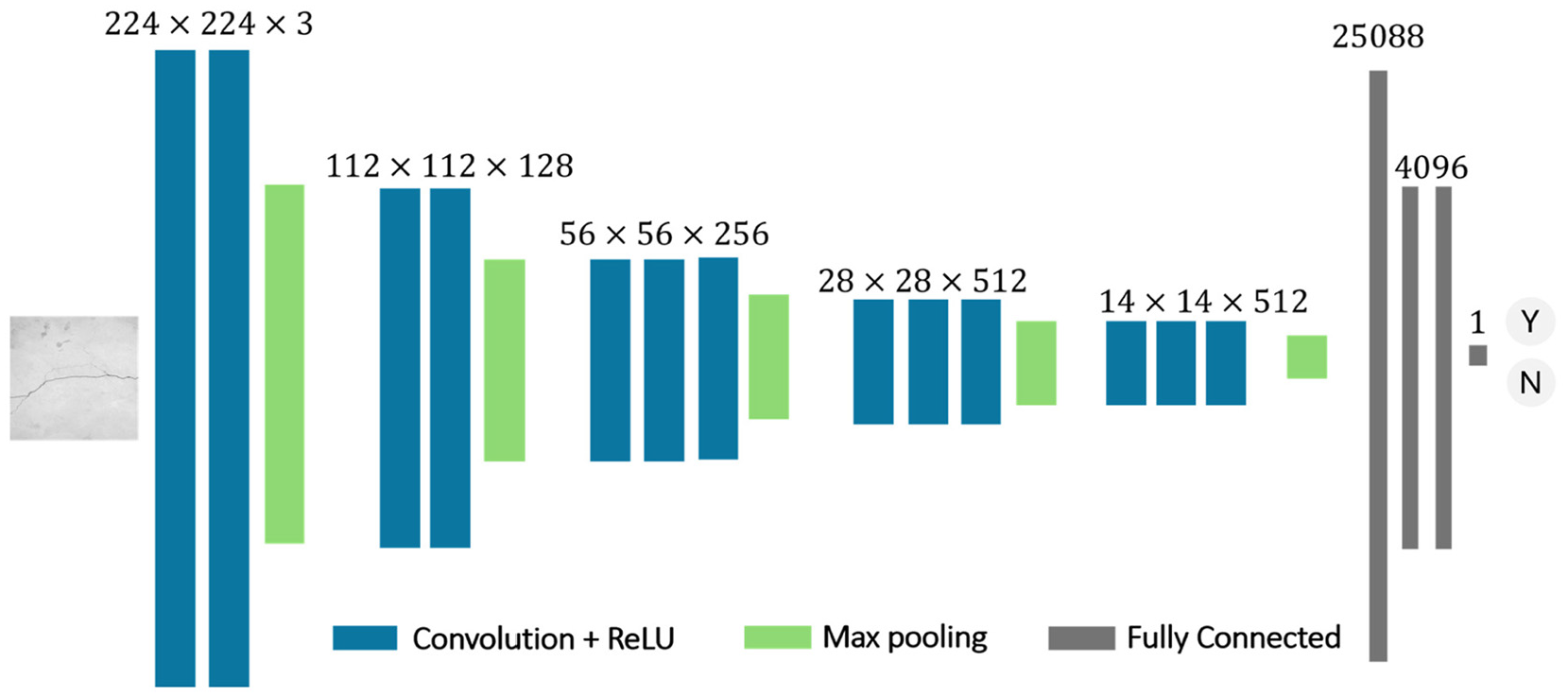
The architecture of VGG-16 neural network. VGG: Visual Geometry Group,
The CCLA dataset is initially employed to train the neural network, establishing a baseline performance. Subsequently, the synthesized dataset from the proposed framework, comprising both positive and negative images, is progressively integrated with the CCLA dataset. This integration follows a staged approach: starting with an addition of 500 positive and 500 negative images, followed by increments to 1K positive and negative, then 1.5K, and finally culminating with 2K of each. The progressive integration aims to quantitatively evaluate the effect of augmentation with purposely-generated synthesized images. All model evaluation is conducted on the WCED dataset. The performance of the models is assessed using three metrics: Precision, Recall and the F1-score. Precision measures the accuracy of the positive predictions for the cracked class:

where True Positives (TP) represents the number of correct identifications of cracks, and False Positives (FP) denotes the model incorrectly identified cracks in non-cracked images or locations. Recall is used to evaluate the model’s effectiveness in identifying all actual instances of cracks:
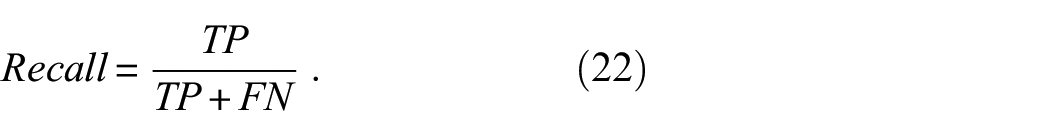
where False Negatives (FN) are cases where the model fails to identify actual cracks. The F1-score combines both Precision and Recall into a single metric by calculating their harmonic mean, providing a balanced measure of the model’s accuracy and completeness:
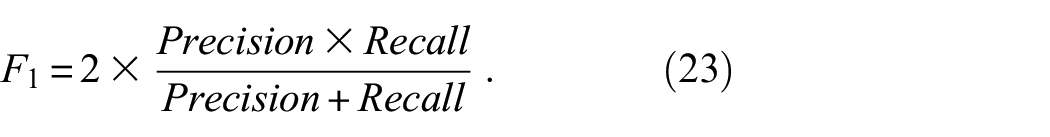
A summary of the model performances is given in Table 2. Across different stages of synthesized data augmentation, a significant improvement in performance is yielded. The baseline model, trained solely on the CCLA dataset, achieves an F1-score of 0.347, indicating modest performance that may stem from a limited diversity of training examples, potentially hindering the model’s ability to handle complex crack patterns. The introduction of 500 positive and 500 negative synthesized images (denoted as SCD(P&N)) markedly enhances the model’s capabilities, as evidenced by the F1-score rising to 0.740. This substantial increase suggests that even a moderate addition of the synthesized images from the proposed framework to the training images can significantly boost the model’s ability to generalize across different scenarios. As more synthesized data are progressively added, the F1-scores continue to climb to 0.897 and 0.921, respectively. This trend underscores the enhanced Precision and Recall, illustrating the model’s improving proficiency in accurately identifying and classifying crack images. The optimal performance is observed when the dataset is expanded to include 2K positive and 2K negative synthesized images, culminating in an F1-score of 0.932. The clear benefits in Precision, Recall and overall F1-score through the synthesized data integration affirm the effectiveness of the proposed image generation framework in training better neural network models for crack image classification task.
Performance of VGG-16 across different stages of synthesized data integration.
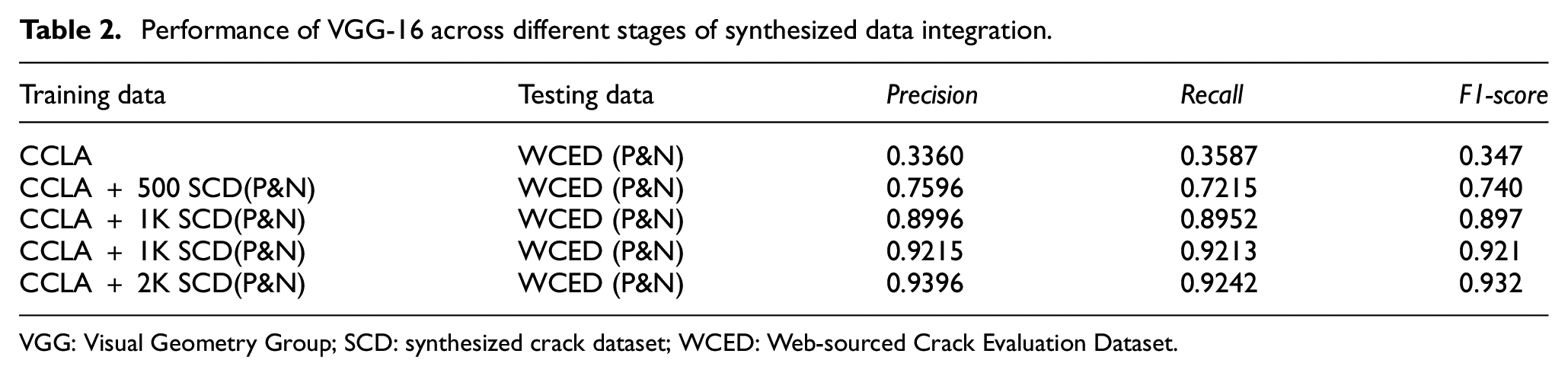
VGG: Visual Geometry Group; SCD: synthesized crack dataset; WCED: Web-sourced Crack Evaluation Dataset.
Synthesized data evaluation – crack detection
To further evaluate the efficiency of the proposed dataset generation framework, the synthesized dataset is employed to train a crack object detection model. Different from the crack image classification, object detection not only identifies the presence of cracks but also predicts bounding boxes around the cracks, making it a more complex challenge. For this purpose, the YOLOv5 54 neural network is utilized. YOLOv5 is a popular object detection model renowned for its speed and accuracy. The architecture of YOLOv5 is based on the Darknet model, 55 but it has been optimized and improved to enhance performance. It features a backbone designed for feature extraction, a neck responsible for feature integration, and a head for bounding box prediction. The backbone is based on the CSPDarknet53, 56 which reduces the computational complexity and improves the learning capability of the model through cross-stage partial connections that allow for more efficient feature propagation. In the neck, YOLOv5 uses a series of feature pyramid networks 57 and path aggregation networks 58 to merge features from different stages of the backbone, enhancing the model’s ability to detect objects at various scales.
Similar to the crack classification experiment, the object detection experiment begins by utilizing the CCDD to fine-tune a YOLO, establishing a baseline crack detection model. Subsequently, 200 positive images from the WCED are annotated and used to conduct an initial evaluation of the model’s performance, providing base metrics for comparison. Following this initial assessment, synthesized images are progressively integrated into the training dataset in stages: 200, 400, 600, 800 and up to 1.2K images. To evaluate the accuracy of the neural network for crack detection, four key metrics are utilised: Precision, Recall, mAP-0.5 and mAP-0.5:0.95. The metrics mAP-0.5 and mAP-0.5:0.95 are for evaluating the precision and reliability of object detection models, particularly in their ability to accurately predict bounding boxes around detected objects. mAP-0.5 measures how closely the model’s predicted bounding boxes align with the ground truth boxes, requiring at least a 50% overlap. It calculates the average Precision (AP) for each class at this threshold, where precision is the proportion of correct positive predictions and recall is the detection of actual positives. The mAP-0.5:0.95 offers a more stringent assessment by averaging APs across a range of Intersection over Union (IoU) thresholds, from 0.5 to 0.95 in increments of 0.05. This metric evaluates the model’s accuracy at various levels of strictness in bounding box overlap, from the minimum acceptable overlap to near-perfect precision.
Table 3 and Figure 12 depict the performance of a YOLOv5 neural network fine-tuned on an incrementally enlarged SCD dataset. Each training configuration within the table is differentiated by the number of synthesized images added to the initial CCDD dataset. All trained models are consistently tested on positive images from the WCED dataset. The consistent improvement in Precision and Recall metrics with the addition of synthesized data indicates that the extra images significantly enhance the model’s ability to accurately identify and classify crack features. The mAP at various IoU thresholds provides further insights into the model’s accuracy. Both mAP metrics show marked improvements as more synthesized data is integrated, highlighting a better alignment of predicted bounding boxes with actual crack positions. The progression of model performance metrics, from the baseline using only the CCDD to subsequent stages with added synthesized images, shows significant enhancements. Notable performance gains are observed with the first additions of synthesized data (200 and 400 images), though the rate of improvement slows slightly as more data is added. Figure 13 showcases some examples of crack detection performance on the WCED dataset. In these images, a label of ‘0’ indicates a detected crack, followed by a confidence value. For all analyses, a confidence threshold of 0.5 is established; only detections exceeding this threshold are considered valid. The depicted cracks are initially undetectable by the YOLOv5 model when solely fine-tuned on the CCDD dataset. Subsequent fine-tuning of YOLOv5 with the addition of 1200 positive images from the SCD dataset markedly enhanced the model’s detection capabilities.
Performance of YOLOv5 across different stages of synthesized data integration.
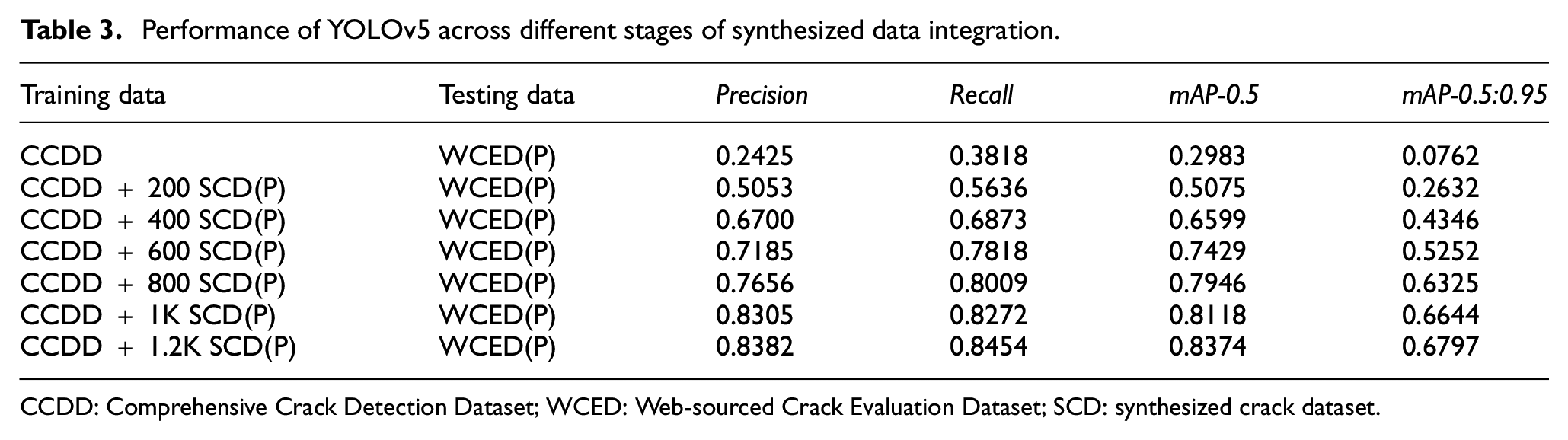
CCDD: Comprehensive Crack Detection Dataset; WCED: Web-sourced Crack Evaluation Dataset; SCD: synthesized crack dataset.
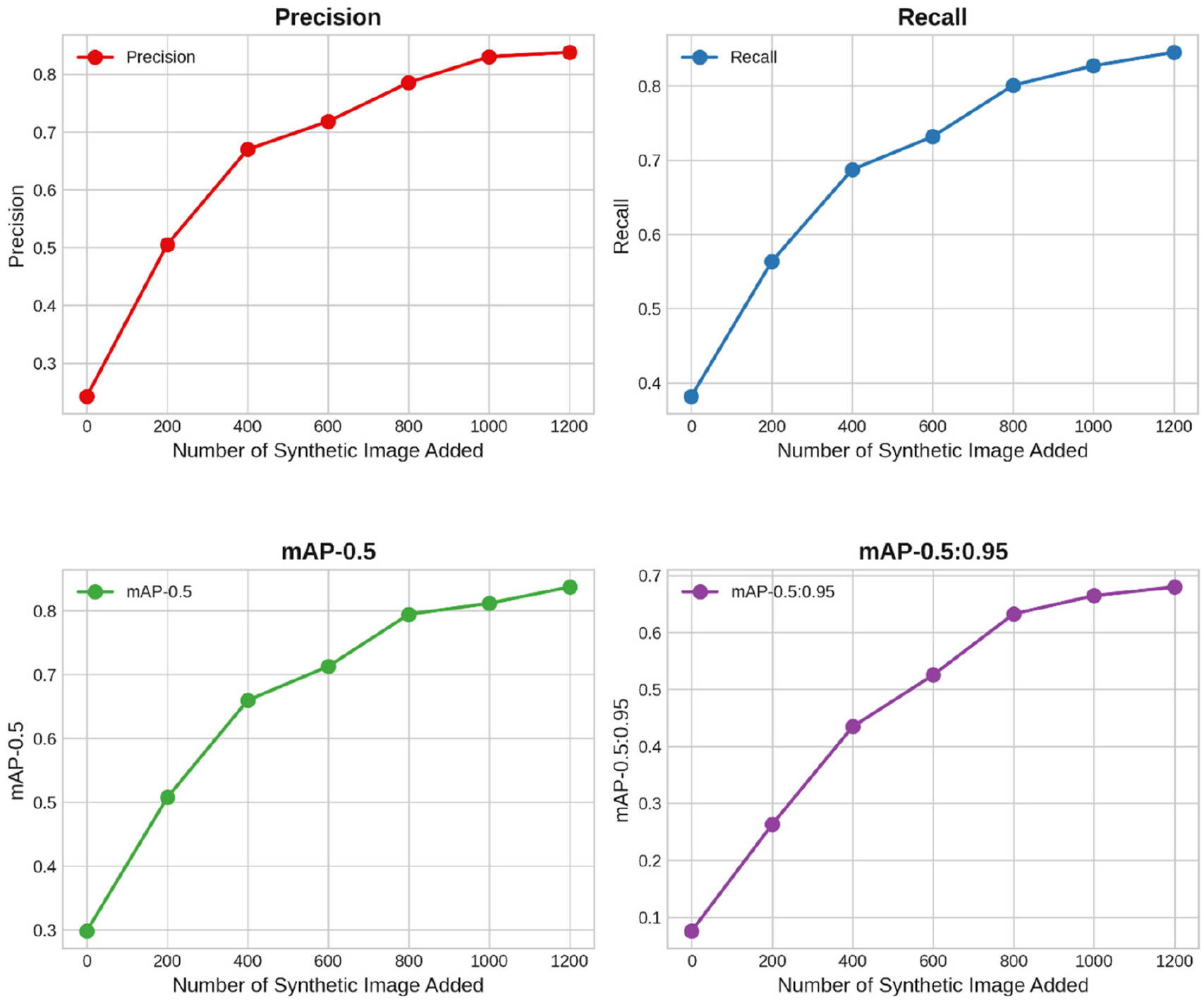
Line graph showing the progression of Precision, Recall and mAP at different stages of synthesized data integration in YOLOv5 training. mAP: mean Average Precision.

Examples of enhanced crack detection performance on the WCED dataset using YOLOv5, post-integration of the entire SCD dataset for fine-tuning. WCED: Web-sourced Crack Evaluation Dataset; SCD: synthesized crack dataset.
Conclusion and future work
In this study, a novel framework for synthesized image dataset generation is proposed to enhance the capabilities of DNN models in structural crack detection. This framework combines the RFM with GPT-4, along with a prompt selection process to generate an ideally unlimited number of synthesized crack images. It enables the simulation of a broad spectrum of crack scenarios (from minor surface cracks to major structural damages) that can be inaccessible under normal operational conditions. Additionally, the image generation process is highly efficient, producing thousands of images in just a few hours hence significantly speeding up the training and development cycles for SHM applications. Experiments demonstrate significant improvements in crack image classification and object detection performance metrics. These enhancements validate the usage of the synthesized datasets in addressing the challenges associated with the limited and homogeneous training data typically available in SHM. Despite the high efficiency of image generation, manual annotation of the synthesized images remains essential. Future advancements in automating the annotation process, such as for crack segmentation tasks, could significantly streamline the workflow. This would help reduce both time and labour costs, ultimately enhancing the overall effectiveness and scalability of SHM systems.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The support from Australia Research Council Laureate Fellow project FL180100196 is acknowledged.