
Abstract
Structural health monitoring and assessment (SHMA) is exceptionally essential for preserving and sustaining any mechanical structure’s service life. A successful assessment should provide reliable and resolute information to maintain the continuous performance of the structure. This information can effectively determine crack progression and its overall impact on the structural operation. However, the available sensing techniques and methods for performing SHMA generate raw measurements that require significant data processing before making any valuable predictions. Machine learning (ML) algorithms (supervised and unsupervised learning) have been extensively used for such data processing. These algorithms extract damage-sensitive features from the raw data to identify structural conditions and performance. As per the available published literature, the extraction of these features has been quite random and used by academic researchers without a suitability justification. In this paper, a comprehensive literature review is performed to emphasise the influence of damage-sensitive features on ML algorithms. The selection and suitability of these features are critically reviewed while processing raw data obtained from different materials (metals, composites and polymers). It has been found that an accurate crack prediction is only possible if the selection of damage-sensitive features and ML algorithms is performed based on available raw data and structure material type. This paper also highlights the current challenges and limitations during the mentioned sections.
Keywords
Introduction
Structural health monitoring and assessment (SHMA) can be described as the process of monitoring the status of a structure and detecting structural damage over time. Here, the damage is referred to as any change in structure or material (as crack) that negatively affects the behaviour of the structure and shortens its operating life. SHMA technologies provide early warnings of damage occurrences to support asset management decisions and hence eliminates unscheduled maintenance and in-service failures. Structural damage is a term that represents a change that negatively affects the performance of structures. 1 The SHMA tools permit operators to formulate a predictive maintenance strategy and retain the optimal performance of the structure.
The SHMA can present various economic benefits by reducing system failures, increasing the efficiency of maintenance and providing cost-effective data-based designs. The implementation of SHMA strategies extend structure design life and improve safety. These benefits and objectives of SHMA are widely implemented across different industries, for instance, civil infrastructure, manufacturing, aerospace and power generation. Rytter
2
has defined a hierarchy of levels that is required to perform a particular task of SHMA as shown in Figure 1. It must take into consideration that moving to the next level of the hierarchy, previous levels must be completed, where a higher level of desired detail leads to increased difficulty. It is well recognised that prognosis is different from the other hierarchy level. It can only be accomplished with an understanding of the damage physics.
3
Rytter’s hierarchy for SHMA tasks.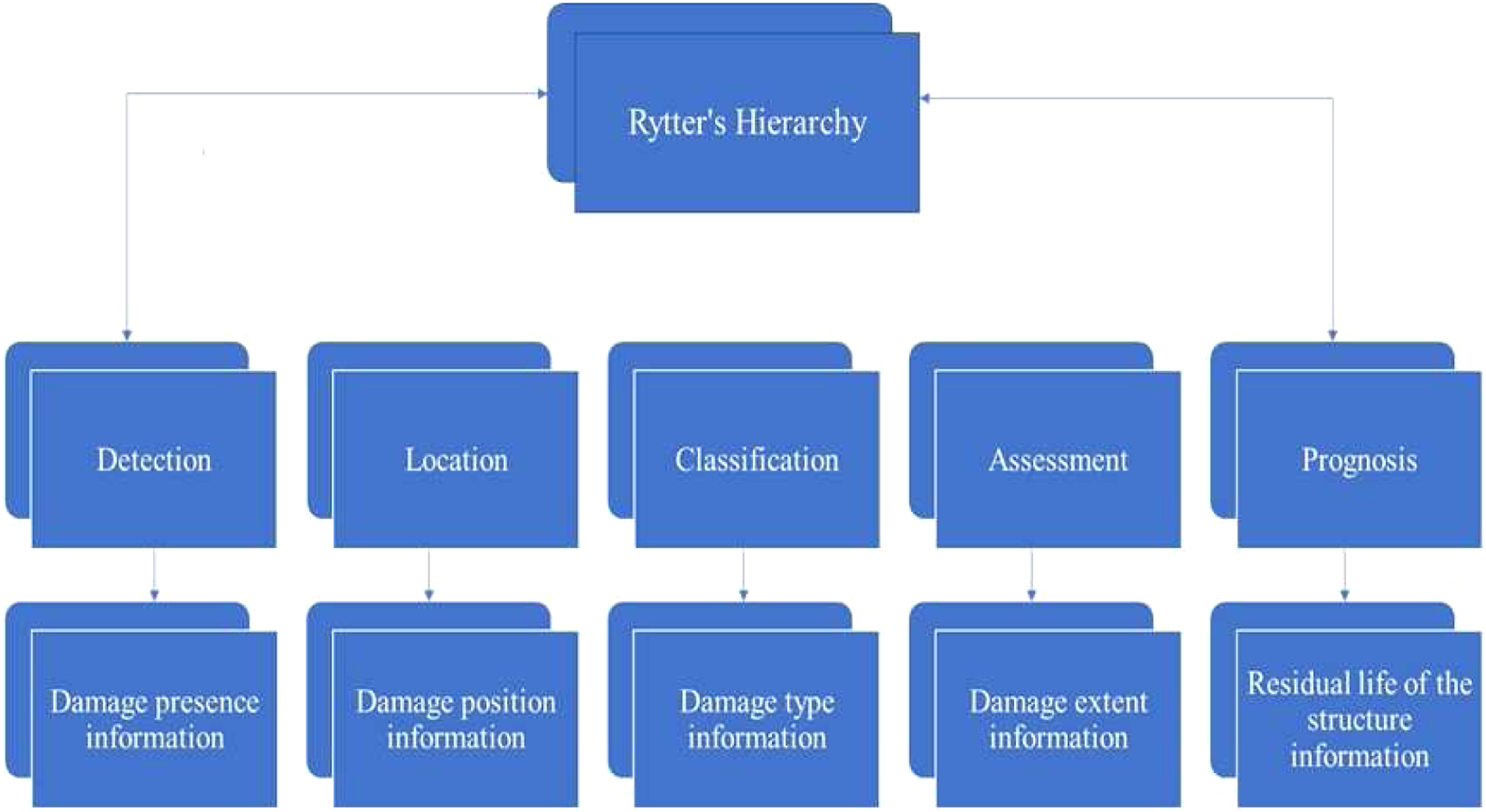
In process of SHMA, statistical analysis, damage-sensitive features extraction and dynamic responses are employed to monitor the structure. 4 Scholars applied different non-destructive methods in the SHMA field such as vibration/model analysis, X-rays, ultrasonic testing and holography or Shearography (one of the optical methods). 5 Montalvão et al. 6 reviewed the damage assessment, detection and localisation vibration-based for composite structures. Mba and Rao 7 critically review the rotating machinery diagnostics using acoustic emission technology. Wang et al. 8 used vibration measurement to analyse the limitations and merits of different gear damage monitoring techniques. Staszewski et al. 9 employed passive and active methods to estimate the severity in composite plates and to locate delamination using 3D laser vibrometry. The optical fibre sensors were used to evaluate the strain of concrete structures. The structure failure is commonly caused by damage occurring in the geometry and materials themselves. It is extremely essential to analyse the engineering structural response concerning various factors such as boundary conditions, environment factors, loading patterns and material state. Therefore, it is valuable to monitor the structure regularly to avoid sudden failures, predict and manage the structure’s deterioration such as corrosion, fatigue and creep. In general, the development of robust SHMA technologies tends to have three main challenges. First, the damage is not directly measurable. 10 This means that huge amounts of data are collected with the expectation that will include information on the structural health state. This information is extracted through the process of feature selection to identify damage-sensitive features; however, this is a highly personalised procedure at the moment. Second, confounding factors such as changes in boundary conditions and/or obscure load patterns in data associated with damage and environmental conditions. Therefore, it is necessary to eliminate them before implementing health decision strategies. Third, numerous techniques of structural health monitoring require damage situation data from all damage scenarios of interest, often in a set of operational conditions. The obtained data usually is not feasible practically and economically or would cause safety concerns.
According to the literature, SHMA methods are split into two categories: physics-based and data-based. 10,11 Physics-based (known as model-driven or model updating) approaches employ inverse techniques in combination with law-based models to update or infer set parameters. 12,13 Health-related decisions are then made through the interpretation of these updated parameter values. In contrast, data-based approaches (known as data-driven) aim to learn the relationships between structural damage states and measured response data based on machine learning-based models or pattern recognition without a physics-based model construction. 10,14,15 Decisions regarding the structural health state are later made by prediction or classifications of in-service data using the inferred statistical model. In addition to the aforementioned, there is a third approach category (known as forward model-driven approaches) which combines statistical pattern recognition methodologies and physics-based models, applied in a forward manner. The following subsection indicates some challenges of SHMA approaches.
Structural health monitoring and assessment approaches
Inverse model-driven approaches
Inverse model-driven approaches usually include constructing a high-fidelity of the structure, for which health decisions need to be taken, generally in the produce of a finite element analysis (FEA) model. The process of making health decisions often follows two stages. In the first stage, the model is calibrated to have a more accurate structural representation. This is generally achieved through updating the model, depending on the undamaged in-service data condition. The second stage includes collecting in-service monitoring data, which have an unknown health condition. Subsequently, the model is again updated relied on in-service data and changes in the inferred model parameters from the calibration of baseline are applied to carry out damage detection and assessment at Rytters hierarchy levels. The prognosis can also be feasible because it is possible to generate an updated physics-based model through the inverse model-driven process. 3 Therefore, SHMA through an inverse model-driven approach depend on the model updating procedures. Model updating refers to methods where it can adjust certain model parameters to decrease the residual between observational data and model prediction. 16 This task is mostly attempted in two general methods: Sensitivity methods, the error between observations and predictions are reduced by changing defined parameters set. Direct methods, where structural matrices are updated to regenerate measured data. 12,17,18
Commonly in structural health monitoring, sensitivity-based techniques are used more than direct approaches. This is because of the direct approach to updating full structural matrices. The direct approach also leads often inferred parameters with little physical meaning and leading to a lack of control over the updated matrix values. Initial development of model updating methodologies dealt with the problem from a deterministic view such as the well-established iterative sensitivity-based approach. 13 Such approaches dealt with the problems of model updating by applying optimisation technologies, whereby a cost function is established, frequently in parameter steps are made by sensitivity matrices and a least-squares formulation. 13,19 On the other hand, these approaches demand regularisation because the problem of model updating has been ill-posed. 20
These deterministic approaches have difficulties in dealing with uncertainties and variability that are present (e.g. Parametric variability, environmental conditions and model form uncertainties). For these causes, alternative frameworks for approaching model updating have been developed. 13,19 Bayesian and Fuzzy methods are two popular philosophical approaches to handle uncertainties within model updating. 21
Technologies of inverse model-driven face numerous challenges when applied as part of the SHMA strategy. First of all, the number and type of parameters to use must be chosen. 22 In scenarios where both the type and location of the damage is unidentified, as is often the case, this can result in an increased number of parameters. As the fidelity of the model increases, where there are numerous sets of the potential parameters, Parameterisation becomes increasingly challenging. A further challenge is to interpret the parameters updated to decide regarding the health of the structure. This can be particularly challenging when parameters influence structural stiffness, as multiple phenomena affect changes in stiffness. A thorough accurate understanding of physics must illustrate whether the updated parameters are no longer meaningful physically instead of being changed by damage presence. There are recent studies that shed light on other challenges and opportunities of the inverse model in several SHMA applications; see Yuan et al. 23 Gomes et al. 24 and Bureeate and Pholdee. 25 As mentioned, uncertainties and variability within ‘target’ data must be managed as part of the update process. Due to ill-conditioning, the inverse approach cannot always be achieved. These non-identification problems become a concern when parameter values are used in health diagnoses, as repetitions of the update can lead to different misleading conclusions.
Data-based approaches
Data-based methods deal with SHMA as a pattern recognition problem. It is a statistical model which learns from a set of training and cluster in-service data or applied labels to new in-service data.
10
Because the data sets originate from the in-service structure, the complete loading environment is integrated into creating an undamaged, normal condition. This category of approach eliminates the need for the development of physics-based models of the structure, based only on the information contained in the data, by intrinsically capturing the uncertainties and variations. A general framework of data-based approaches consists of the below steps
10,15
: • Sensing and data collection: This step is to ensure the location of sensors on the structure is optimal to acquire useful data. • Prepossessing: Data cleaning, normalisation, fusion and compression occur, to discard the problems appearing from the data collection phase, combining multiple information sources and reducing the dimensionality. • Feature extraction: Data is transformed into damage-sensitive features and quantities that indicate the function of the damage to be learnt. This step is to ensure the location of sensors on the structure is optimal to acquire useful data. • Post-processing: The extracted feature may require further cleaning, normalisation, fusion and compression. • Machine learning: A density estimation algorithm, regression or classification is trained using damage-sensitive features that have been extracted in the last step. • Decision: Confirm the structural health condition is damaged or undamaged through evaluating and analysing the outcome of machine learning models.
Machine learning and extracted features are crucial for a data-based approach decision. Klunnikova et al.
26
define a clear chart of machine learning workflow for structural damage prediction shown in Figure 2 which declares the steps of machine learning applications. There are three steps as follows: data prepossessing and cleaning, train model, and test and evaluate the model. This emphasises the importance of cleaning raw data, selecting and extracting sensitive features before training machine learning models could enhance the performance and accuracy of the model prediction. Machine learning workflow.
26
Figure 3 also indicates the two common machine learning with their commonly adopted algorithms. The aim of using machine learning algorithms (MLA) within SHMA is to infer functions or trends of structures in different conditions such as the relationships that identify a normal condition of the structures. These techniques can be categorised in solutions for three major problems outlined as follows
16,27
: • Regression: An unknown function is inferred based on mapping an input to output. • Density estimates: Probability density clusters are inferred from the data. • Classification: Data are labelled based on an inferred decision boundary. The categories of machine learning with commonly adopted algorithms.
34
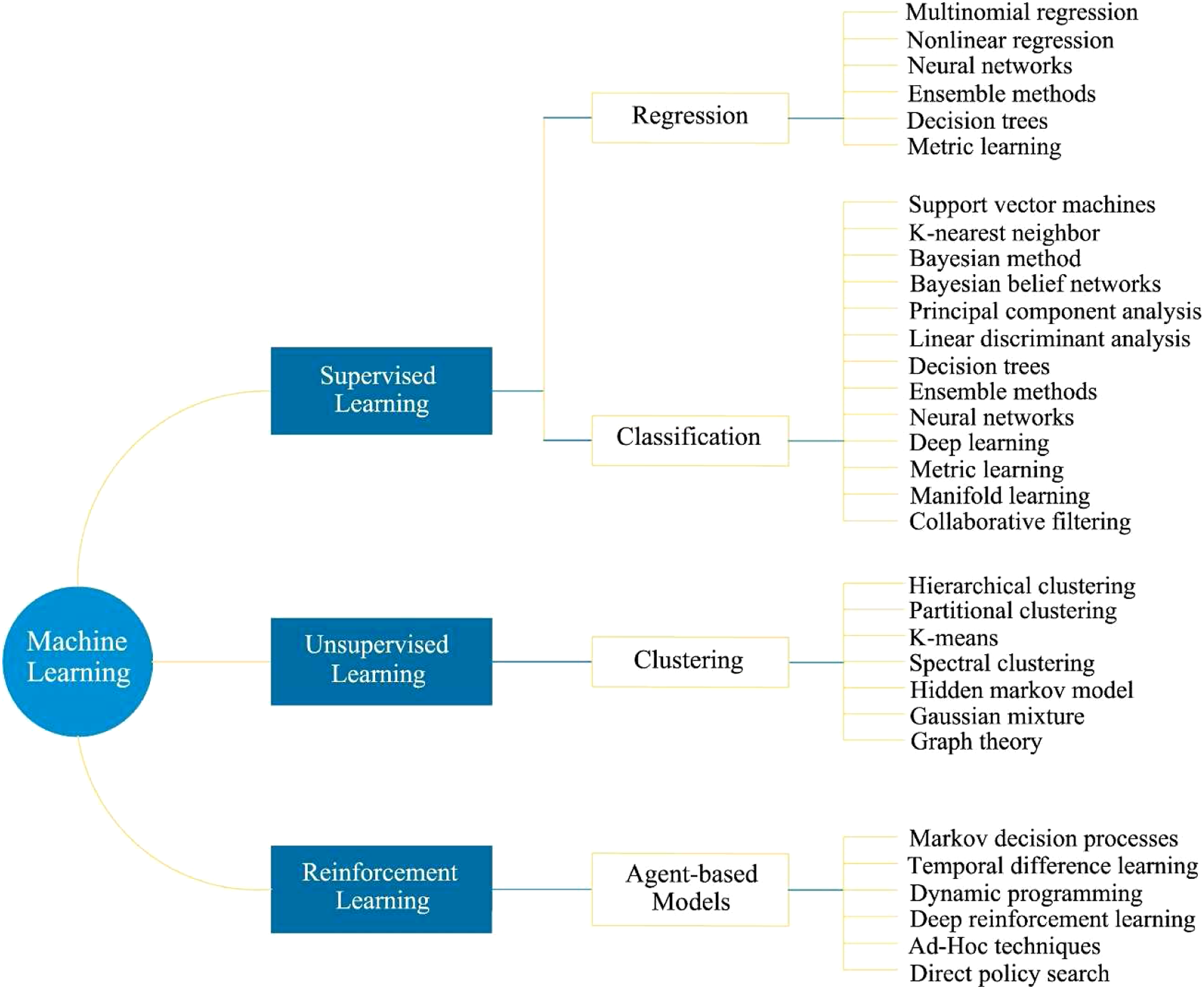
Besides these divisions, machine learning methods can be classified as supervised, semi-supervised, unsupervised and reinforcement learning based on the nature of input data. Unsupervised and supervised algorithms are characterised by whether the labels for the data (as structural damage state) are unknown or, known, respectively. Normally, density estimation is an unsupervised problem whereas classification and regression are supervised. Due to the unlabelled data and lack of labelled data, unsupervised methods can only be utilised to implement novelty detection. In contrast, supervised methods can be used to perform levels 1–4 of Rytter’s hierarchy. Various classification methods are reported in the literature such as artificial neural networks (ANN) and support vector machine (SVM). Density estimation approaches as K-nearest neighbours (KNN), kernel density estimation, Gaussian mixture models have been applied within the SHMA applications. Semi-supervised learning is the combination of both unlabelled and labelled data. Note that semi-supervised learning is not involved as a primary category, combine elements of both unsupervised and supervised learning. The least popular of the categories is reinforcement learning which is employed to acquire knowledge on how to behave or act under uncertainty. 28 For a review on machine learning methodologies implemented within SHMA and their successes, the reader is referred to Farrar and Worden 10 and Fuentes. 29 Since early studies in the SHMA area, efforts have been focused primarily on the correlation of AE signals to various kinds of crack mechanisms due to it can be applied in-situ and has a high sensitivity to the initial, local damages. 30 For example, the relationship between the frequency content of AEs and fracture mechanisms. 31 An assessment of various clustering algorithms for AE using traditional AE parameters such as functions implementing a self-organising neural network, the K-nearest-neighbour classifier and the k-means method was performed. 32 Deep machine learning and acoustic emission have been used to investigate the health of ship hulls. 33 The implementation of data-based methods suffers some challenges. Unsupervised techniques suffer from challenges in obtaining labels when in-service data appears outside the normal condition, as well as all the complexities of performing density estimation. Supervised learning techniques require labelled and in-service data from all damage conditions to infer a robust decision threshold. This is often not economically feasible or viable at full system levels and making their implementation an essential challenge. Semi-supervised learning presents a degree of solution to these issues, but they still have unlabelled data that should be leveraged to improve the machine learning model.
Forward model-driven approaches
Forward model-driven is a less implemented category of approach to SHMA. In this case, models are used in a forward manner, whereby forming their predictions by training data using supervised learning approaches. This category includes elements of both inverse model-based and data-based, where machine learning approaches and model calibration theory are combined. The purpose to develop forward model-driven approaches is to remove complexities in inferring damage from parameter updates, as well as assistance in collecting labelled damage condition data. There are few examples in the literature that focus on using the forward model-driven method. Satpal et al. 35 employed SVM and model updating approach to model predictions trained the classifier. Hariri-Ardebili and Pourkamali-Anaraki 36 utilised a similar methodology for concrete dams. Finite element analysis models have been utilised to generate features for ANNs in performing damage identification in bridges. 37 Forward model-driven for SHMA offers a solution to the limitation of available damage state data problems within data-based methods. Moreover, models provide other tools to perform feature selection along with the monitoring system’s design, such as type, location and positions of a specific sensor network before application. The physics-based models established in a forward model-driven provide a methodology to perform prognosis and achieve the complete Rytter’s hierarchy levels.
Comprehensive reviews are reported in the form of experimental and analytical investigations in the literature to explain the efficiencies and limitations of machine learning approaches in SHMA. 16,38,39 However, none of these review papers has emphasised the compatibility of damage-sensitive features with a selected machine learning approach. Therefore, the purpose of this paper is to present a comprehensive review of previous research efforts with a focus on the role of damage-sensitive features available in different types of damaged material structure. While compiling this review, analysis is presented on the past efforts in machine learning approaches with a special focus on structures made of metals, composites and polymers. This can assist the reader in selecting a suitable combination of machine learning tools and damage-sensitive features while performing damage assessment for any structure. The rest of the paper is organised as follows. Some machine learning applications in fracture mechanics are reviewed in the Machine Learning Applications in Crack Mechanics section. The importance of damage-sensitive features and relevant tools are discussed in the Importance of Feature Engineering and Tools section. In the Crack Assessment of Smart Structures with Machine Learning section, the application of machine learning approaches on structural damage assessment made of different materials is reviewed. The paper findings are concluded in the last Section.
Machine learning applications in crack mechanics
There is a wide range of reasons for cracks in a structure. They may be caused by thermal expansions, existing flaws, stress concentrations or overloading. Crack initiation and crack growth analysis is critical when predicting future performance and possible manner of failure, as well as assessing the structural integrity of the component. The mechanical field of crack growth analysis is called fracture mechanics. Fracture mechanics is the area of mechanics that study crack propagation in materials.
40–42
The subdomains of fracture mechanics are defined as follows: • Crack diagnosis and detection: Crack might be in macro, meso and micro scale and take the lead to the mechanical failure. Mechanical damage is a physical characterisation that defines the existed defect on the structure. • Fracture parameters and mechanical fracture: Different parameters such as fracture energy, fracture toughness, crack propagation and fractography are concerned with mechanical fracture. Fracture is the fragmentation or separation of a solid body into two or more pieces. • Fault and error diagnosis and detection: faults and errors on the mechanical system or components are defined as losing the ability to do required mechanical actions. In other words, it is a deviation from the expected and occurred conditions and values. • Failure mode and mechanism identification: A mechanical failure mode is a physical process that combines their effects or takes place to create a failure. In this regard, a detailed description of a failure mode is known as a failure mechanism.
The study of fracture mechanics, including performing empirical and analytical solutions are quite a time consuming, are required a high level of technical expertise and are not always an easy task. There are serious challenges for detecting faults and failure of mechanical systems, parts and machinery.
40–42
The major concerns founded in the current studies in the fracture mechanics field are as shown in Figure 4. In some cases, both empirical and analytical cannot handle some complicated engineering difficulties such as complex and nonlinear relationships amongst higher-dimensional data. Thus, successful monitoring and assessment for different mechanical material’s structures afford reliable and robust information on the serviceability, health, safety and integrity of materials. The maintenance of the continuous performance of the structure relies highly on formation, monitoring the occurrence and propagation of damage. The major concerns in the crack mechanics’ field.
Machine learning algorithms can be informed directly by simulations and experiments and present machine learning solutions. These machine learning solutions are a promising substitute for empirical and analytical solutions if they can provide accurate and rapid results. Machine learning methods were applied in subdomains of fracture mechanics to improve the performance of engineering applications. Nasiri et al. 42 reviewed artificial intelligence methods (fuzzy logic, Bayesian network (BN), case-based reasoning, ANNs and genetic algorithms) which were applied in fracture mechanics and mechanical fault detection.
Kang et al.
43
compared BN, probabilistic neural networks (PNN) and backpropagation neural network (BPNN) in fault detection of the gear train system. The result of this study indicated that there are no wrong diagnosis results by BN which is based on statistical parameters of vibration signal in the time domain for the same system. BN was employed in Rovinelli et al.
44
to define relevant microstructural and micromechanical parameters that affect the rate and direction of fatigue crack propagation. Wang et al.
45
have proposed fatigue crack growth calculation based on genetic algorithms optimised backpropagation network, radial basis function network and extreme learning machine. Levenberg-Marquardt backpropagation algorithm was used to predict the natural frequency and buckling load of laminated composites. MLA (KNN, Decision tree, Random Forest and SVM) and FEM were employed in Balcıoğlu and Seçkin
40
to analyse the fracture behaviour (toughness) of hybrid and pure knitted fabric reinforced laminated composites in Mode I, Mode I/II and Mode II loading angles. In this study, the J-integral method was used to analyse the linear elastic fracture behaviour at the crack tip. Arcan test apparatus was also used to test the fracture behaviour of the pure carbon and glass/carbon hybrid knitted fabrics, laminated composite reinforced with pure glass. The result of this study indicated that KNN, decision tree and random forest present good results for experimental data (see Figure 5). However, it found that it was not possible to achieve a natural behaviour curve for angles that are not examined experimentally. Therefore, the researchers suggested that the loading angles should be selected close to each other and, if possible, consider all the values of the examination range in the preparation of the dataset or these algorithms in fracture mechanics studies. The next sections present the importance of feature extraction and machine learning in damage monitoring and assessment. Changing of fracture toughness values that obtained from experimental, FEA and MLA, according to the loading angle.
40
FEA: finite element analysis; MLA: machine learning algorithms.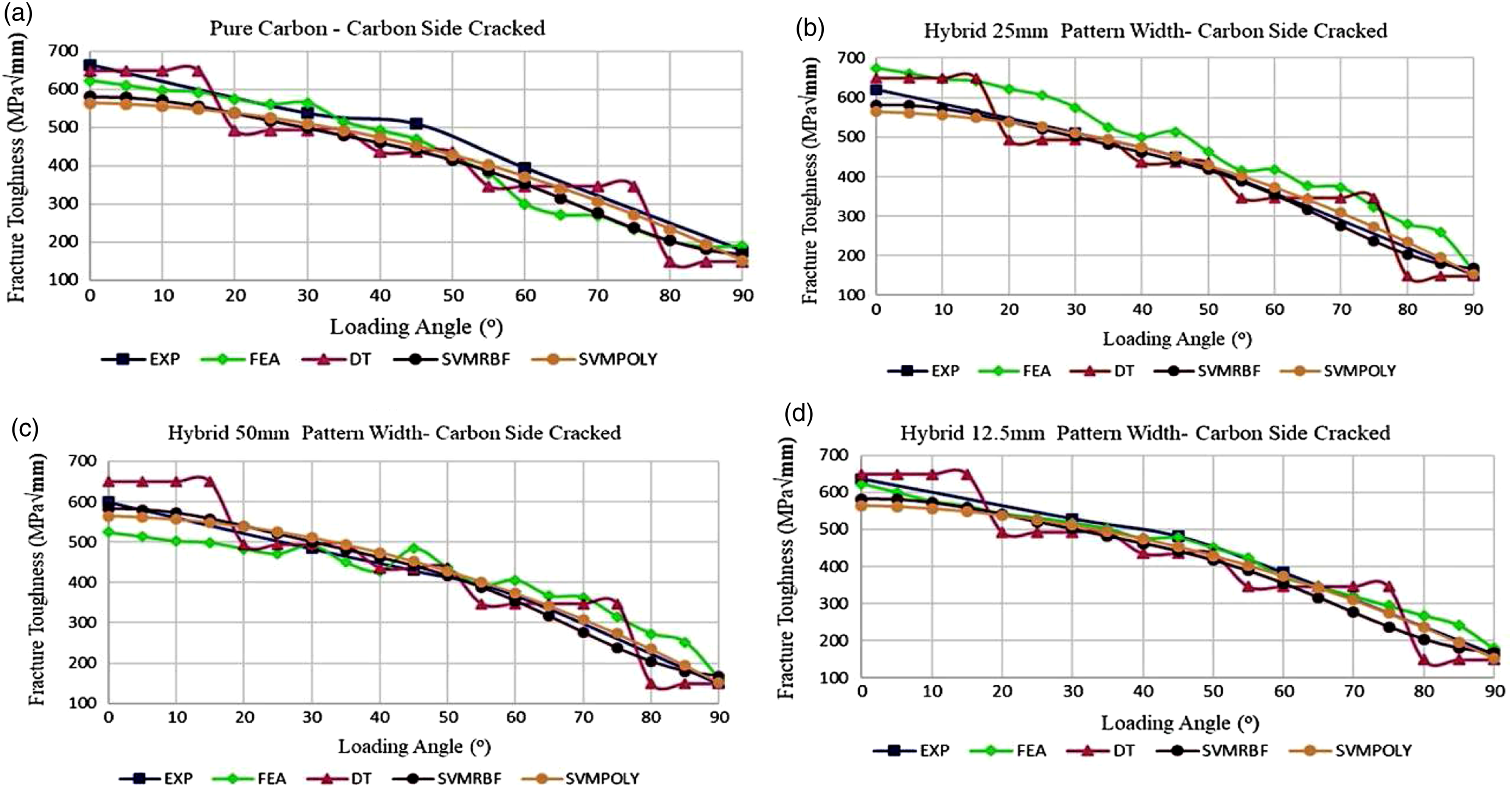
The importance of feature engineering and tools
Worden and Manson 15 have proposed seven axioms for SHMA. These axioms confirm that feature extraction through statistical classification and signal processing is fundamental to alter sensor data (raw data) into damage information. Therefore, feature extraction and selection must be performed before training the machine learning (ML) model to improve the model’s performance, flexibility and efficiency. Most ML approaches deploy standard feature extraction and selection algorithms. However, some also can modify features to reach the best potential prediction performance. Feature extraction involves transforming the measured signal into features (also known as attributes) which will be the inputs of a learning algorithm. The extracted features should hold the maximum amount of information included in the collected signals by deleting all redundant data. The suitability of features can be quantified according to their sensitivity to crack and noise immunity. A further constraint is defined by insensitivity to the various operating and environmental conditions. In other words, if the measured signals are influenced by a difference in these operational and environmental conditions, the extracted features should be stable and robust in these conditions. 46,47 To address these problems, a preliminary step to feature extraction is usually required. It includes applying some signal processing procedures to correct the collected signals to ensure a fair comparison with the baseline signal. A popular method for reducing the effects of noise is discrete wavelet transformation. 47,48
Feature extraction involves two essential tasks that improve the effectiveness of ML models. The first task is dimensionality reduction which can be achieved by using various methods such as linear discriminant analysis (LDA), generalised discriminant analysis (GDA) and principal component analysis (PCA). The second task includes transforming the data into a higher-dimensional space to the patterns becoming sparse and separable, such as in kernel-based ML algorithms. 49 Feature selection is the process of pick out the most relevant features that can predict outputs with high accuracy. 47,50 By analogy with SHMA applications, feature selection is employed to find features that present high performance of detection and classification of damage. Thus, features which not have redundant information will be excluded and discarded from the final dataset or involve information about the damage presence. 47 Through that, the global dataset dimension will be immensely decreased and then avoiding the dimensionality curse. 47,51 In terms of the number of features, adding more features to the learning algorithm may cause a decrease in the accuracy of the classification algorithm. In Theory, the increase of the dimensions of feature should be correlated with a growing increase in the training dataset, which is impracticable in most instances and requires significant computing time. If this condition is not tested, it will cause an overfitting issue. 52 This can be seen when the misclassification of training data reduces as it raises for validation data. In other words, the classifier can excellently predict the sets of belonging for training data by memorising them but loses its ability to generalise unknown data. A cross-validation is an approach applied to evaluate the accuracy and the validity of a classifier by testing it on different partitions of the training data. 47
Feature selection can be classified into three methods: • The filter methods classify the original features according to an important measure such as the scores from correlation coefficients between individual features and the response variable or chi-square test. It uses statistical methods for the evaluation of a subset of features. • The wrapper methods exclude or include features from the original features recursively and select a set of the best-performing feature depending on the feedback of the ML model. They use cross-validation to evaluate a subset of features. • The embedded methods are used by those algorithms that have their built-in feature selection methods (e.g. LASSO and Ridge regression).
Both wrapper and filter methods are good to avoid overfitting problems by reducing highly correlated features and model complexity. Since filtering approaches do not consider the performance of the classifier, they cannot be utilised to pick out damage-sensitive features. Wrapper approaches are well adapted to the process of damage detection.
Although feature selection is an important stage in the process of damage detection, this subject has not taken that much consideration within the SHMA community. This is perhaps because the intuitive thought argues that the more features, the better the classification performance. It might be also implicitly incorporated into the feature extraction process. However, Bagheri et al. 53 presented a feature selection using ANN to categorise three types of faults in immersed plates. Feature extraction was performed in time-frequency, time and frequency domains. Eight features were selected to represent a signal. As ANN is considered a comprehensive approach, finding the optimal number of features is impractical, especially when the number of hidden neurons may also be adjustable. The authors, therefore, decided to assess each feature individually and to compare it with the case of combinations of four features. Although the case of four features indicates no substantial enhances in comparison with the case of a single feature, there is no assurance the optimal number of features was found because the other combinations were not considered. Similar work using the probabilistic neural network has been undertaken by Zhang et al. 54 Among the six features extracted, four were chosen as the most discriminatory. Once again, no explanation was given for relying on which criterion, this feature, was founded.
Jiang et al.
55
used spatial filtering to pre-process the microphone signals. Pre-processed signals and the original sensor signals were fed into NN5. The result of this study showed the comparison in classification accuracy of the NN5 model without and with spatial filtering in both training and cross-validation. Filtered signals achieved 97.7% and 97.5% accuracy in training and cross-validation respectively, compared against 86.4% and 80.4% without the spatial filtering. In addition to the above-mentioned features selection and extraction techniques, domain-specific feature engineering techniques have been developed to deal with specific data structures and issues such as scale invariant feature transform (SIFT) features,
56
histogram of oriented gradients (HOG) features
57
and HAAR-like features.
58,59
It also should consider that these techniques require error and trial testing and are developed to only work for very specific problems and data structures. The associated deep learning (DL) and neural networks (NNs) approaches (see Figure 6) automate feature engineering to enhance the performance level in various data mining and pattern recognition domains.
60
Currently, NNs have become popular because of the increase in computation power, which cause complex NNs architecture trainable, thus achieving superb feature extraction.
61
The complex architecture of deep neural networks allows to carry out feature extraction automatically. In contrast with shallow learning, or conventional machine learning, feature extraction is performed outside the algorithmic stage. In other words, the data scientists and experts and not machines are responsible for analysing the raw data and transforming it into valuable features. The extraction of sensitive features is crucial to the successful damage assessment application within the machine learning paradigm. However, in practice, it seems difficult to identify damage-sensitive features superset to estimate and evaluate the conditions of all types of structural systems.
16
The architecture of the simple neural network and deep learning neural network.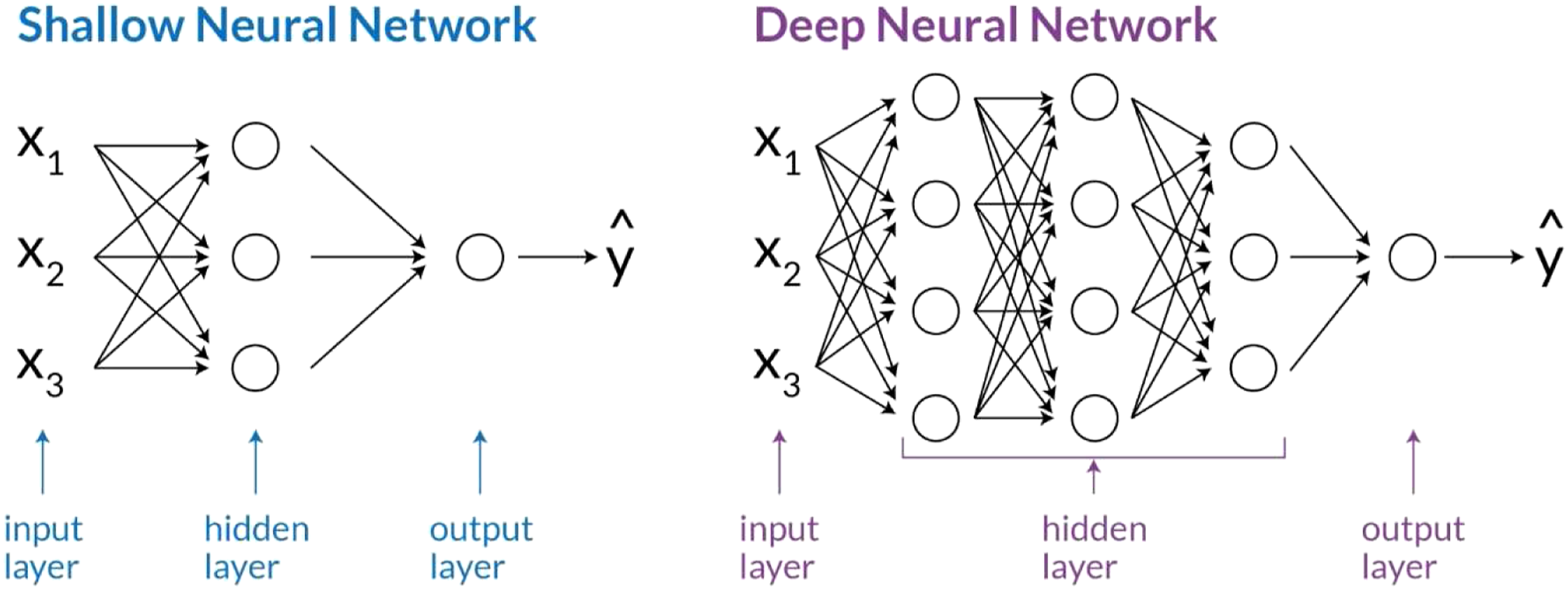
Crack assessment of smart structures with Machine learning
Smart materials can respond to external factors (such as temperature, stress, magnetic field and humidity.) via changing one or more of their fundamental properties in a controlled manner. Smart materials’ integration (surface bonded or embedded, continuous, or discrete) with structures in the sensor and actuator form make them intelligent structures. These intelligent structures are able of sensing and adapting their dynamic and static responses (refer to as adaptive structures) and monitoring the damage existence, location and severity continuously. 62,63 There are two essential requirement stages for structural damage assessment and detection based on machine learning:
Feature extraction and selection where it can use the measured signals to extract certain hand-crafted characteristics.
Training the model where it can use the extracted features as input to train the model and inherently map to the output or cluster data to several groups (state of the structure being monitored). The modal parameters (damping ratios, frequencies and mode shapes) of the monitored structures are considered as extracted features in parametric machine learning-based methods.
64
On other hand, other feature techniques such as wavelet transform,
65
autoregressive modelling,
66
basic statistical analysis (using the variance and mean of the signals),
67
time-frequency methods
68
and PCA
69
are implemented in non-parametric machine learning-based methods. From the literature, time domain, frequency domain, time-frequency domain, modal analysis and impedance are the popular domains to extract sensitive features for undamaged and damaged structures.
70,71
The sensitive features can be extracted either from high frequency, low-wavelength guided waves, or low frequency, high wavelength structural response.
72
The commonly used damage-sensitive features (known as descriptors) for acoustic waves, low-wavelength guided, or high frequency are duration, rise time, count to peak, peak amplitude, average frequency, energy and peak frequency.
73,74
For the classification stage, different classifiers were implemented in both non-parametric and parametric machine learning-based methods such as fuzzy neural network (FNNs) ,
75
ANNs,
67
PNNs,
60,76
SVM,
77
singular value decomposition
66
and online sequential extreme learning machine algorithm (OS-ELM) .
78
Intuitively, the success of structural damage detection techniques based on ML is expected to depend primarily on the choice of the classifier as well as extracted features. Therefore, the extracted features ought to be cautiously chosen so that they can analyse signals to capture the most important characteristic condition. Similarly, based on the extracted feature types, a suitable classifier requires to be implemented to classify them accurately. Therefore, there have been efforts to find the best possible combination of classifier/extracted features mostly by trial-and-error. However, there is no guarantee that a specific classifier/feature combination would be the best selection for different structures. In other words, a specific combination observed to be appropriate for a certain structure may not certainly be a good possibility for another. Employing inappropriate classifier and/or hand-crafted features is expected as it causes poor damage detection performance. This section presents a review of the structural damage assessment (i.e. quantification, detection and localisation) made of different materials via ML approaches. It also mainly focuses on the damage-sensitive features and suitable ML algorithms. Therefore, it presents a general guideline that can assist the readers to decide a suitable combination of ML tools and damage-sensitive features while performing damage assessment for any structure.
Composite structures
Composite materials consist of two or more materials that have different chemical and physical properties without any chemical reaction or solubility; thus, the consequent materials have the best characteristics from their components. 16 In the last 10 years, numerous algorithms were employed in the applications of composite-based structure’s health monitoring and assessment including neural network, convolutional neural network, backpropagation, K-nearest neighbour and SVM. The usage of those algorithms in several applications (i.e. wind turbines, bridges, high rise buildings) is summarised below. The neural network approach was applied in the Jamboree Road overcrossing, Irvine California to evaluate features involving long-term structural parameters, ageing, mass and stiffness. 79
Islam and Craig 80 used a BPNN for delamination localisation and quantification for the composite laminates. The model was trained with the first five model frequencies as sensitive features. The trained model was tested with undetected cases of delamination at different locations. Sung et al. 81 combined the Levenberg-Marquardt algorithm with neural network and generalisation method for reliable and accurate localisation of low-velocity impact damage in composite laminates. The proposed model was cross-validated, trained and tested with the differential arrival time of impact-generated acoustic wave to lead zirconate titanate (PZT) sensors as input and impact location as the target output. The proposed model predicted the impact location under the error of 5 mm. Multilayer perceptron neural network (MLP) was employed in Chetwynd et al. 82 for regression and classification problems of damage detection in a stiffened curved carbon fibre reinforced panel with surface bonded piezoelectric transducers. Twenty-eight sensors paths of eight surface-mounted sensors were utilised as an input to the regression and classification networks. MLP regression network was used for predicting the exact location of the damage on the panel, whereas the MLP classification network was employed for the classification of undamaged and damaged regions of the panel. The overall classification accuracy of MLP networks was 90.9%. Hoang and Nguyen 83 compared the performance of six MLAs (include classification tree, naïve Bayesian classifier, radial basis function neural network, backpropagation artificial neural networks, least-squares support vector machine and SVM) used for automatic recognition of Asphalt pavement cracks based on image processing. This study used Steerable Filter, Projective Integral and Median Filter to remove the noisy and complex texture of pavement background, image processing techniques and to extract useful features from pavement images. The result showed that the SVM and least square’s support vector machine have high rates of classification accuracy 91.91% and 92.62%, respectively, for classifying their dataset of pavement images. One class of support vector mechanics (SVMs) was used to detect and classify four classifications of damage (saw cut, notches, delamination, drilled holes) in composite laminates. Time embedding technique (tapped-delay approach) and time-frequency-based technique (Gabor’s spectrogram technique) were employed to extract damage-sensitive features from the piezoelectric sensor’s response. The result revealed that the classification accuracy of one-class SVMs with time-embedded features was better than time-frequency features. 84
Unsupervised and supervised classifiers were employed for clustering the AE signals obtained from unidirectional polyester/glass composite tests. AE signal was first clustered through K-means based on the amplitude, rise time, number of counts, duration and counts to the peak of the AE signal. The cluster identified with K-means was employed as labelled data for the K-nearest neighbours (supervised classifier). The trained K-nearest neighbours’ classifier was used to classify new data. The proposed method successfully classified the AE signal related to interfacial decohesion and matrix cracking. 32
Li et al.
85
performed cluster analysis of AE signals collected from the damage initiation and development of 2D and 3D epoxy/glass woven composites. The AE signals were clustered via PCA and K-means++ clustering algorithm. Peak frequency (PF) and peak amplitude (PA) of AE signals were pointed out as the most efficient sensitive features. Davies-Bouldin index and Silhouette coefficient were used to define the optimum number of clusters. It can be noted that the most common sensitive features were used for cross-validation, training and testing of machine learning models are: • Rise time, arrival time, energy, ring down counts, average frequency, peak amplitude, peak frequency, central frequency, amplitude, counts to peaks and duration from AE signals. • The difference of amplitudes and time of occurrence of fundamental modes, phase change, correlation coefficient, wavelet energy, amplitudes and frequency centroids from guided Lamb waves. • Vibration hub loads, natural frequencies, autoregressive parameters, wavelet energy packets and wavelet coefficients from low-frequency structural vibration responses.
16
Metal structures
Metal’s crack growth or fracture is one of the most serious reasons behinds the catastrophic failures of structures and engineering components. For instance, bridges, 86 automobiles, 87 steel buildings, 88 aerospace structures 89 and oil and gas pipelines. 90 Machine learning has flexible approaches to the modelling of fatigue crack growth because of its multivariable learning ability and excellent nonlinear approximation. 45,91
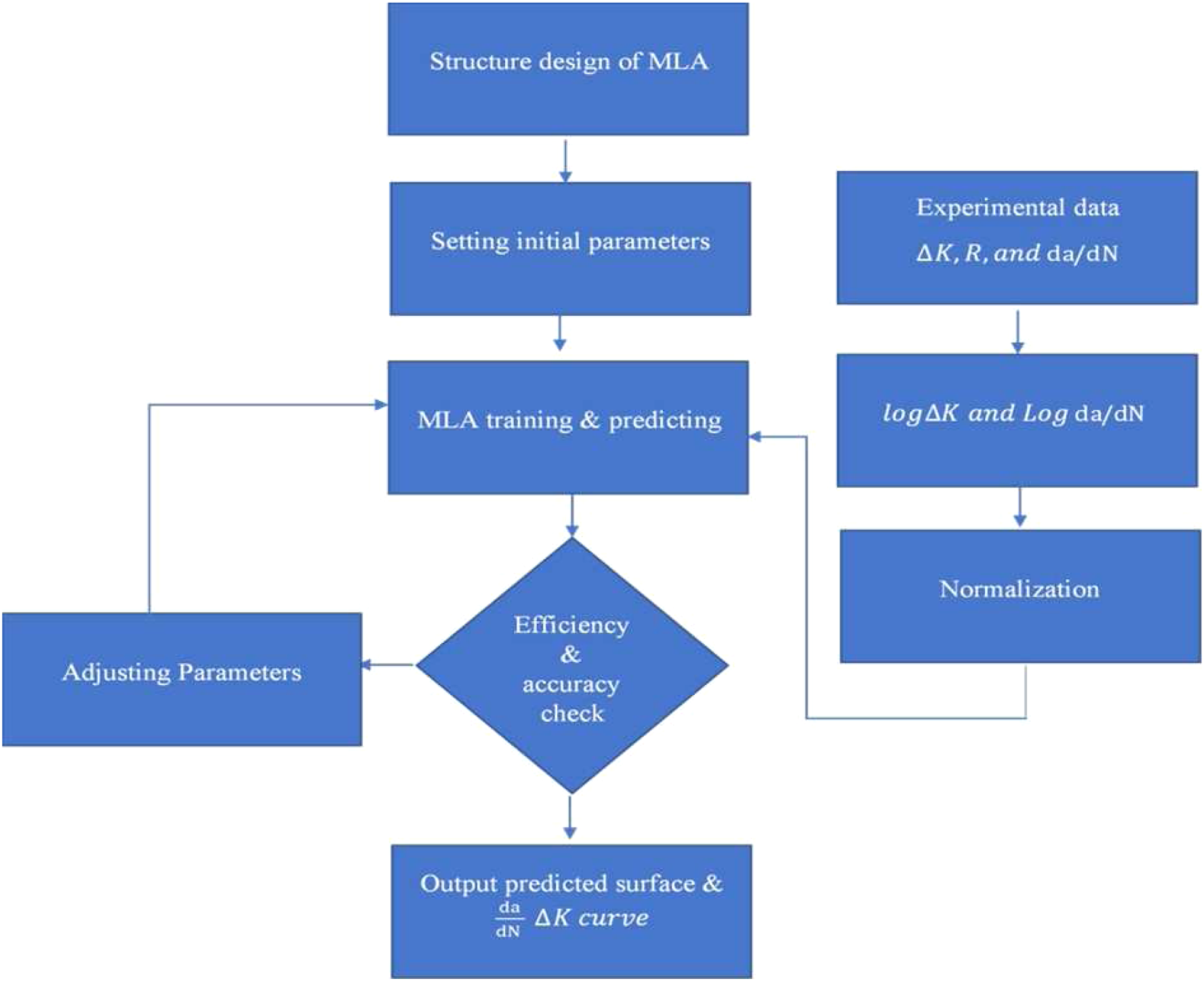
Wang et al.
45
proposed a fatigue crack growth calculation method based on three different MLAs including genetic algorithms optimised backpropagation network, radial basis function network and extreme learning machine. Experimental data (including specimen type, size, initial crack length and loading type) of different materials (including 7050-T7451 aluminium alloy, Ti6Al4V titanium alloy, ADB610 steel and D16 alumina) were used for training and testing the proposed ML methods. They suggested the following procedures for developing the well-trained model of machine learning for fatigue crack growth as shown in Figure 7. Raja et al.
91
investigated the relationship between stress intensity factor range Procedures of designing a well-trained machine learning algorithm.
45
Fatigue crack growth rate (FCGR) experimental data of cryo-rolled Al 2014 alloy.
91
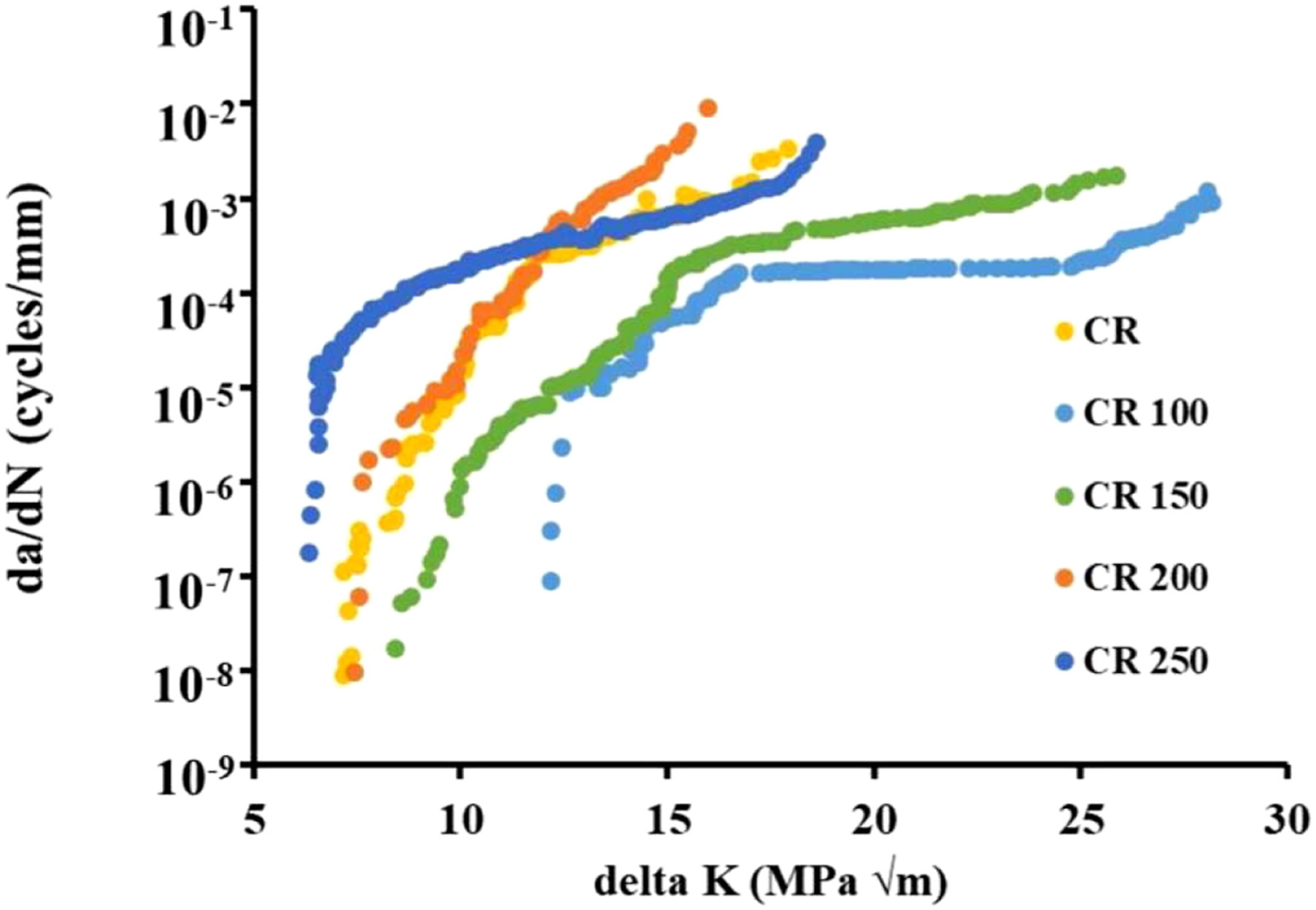
González and Zapico
92
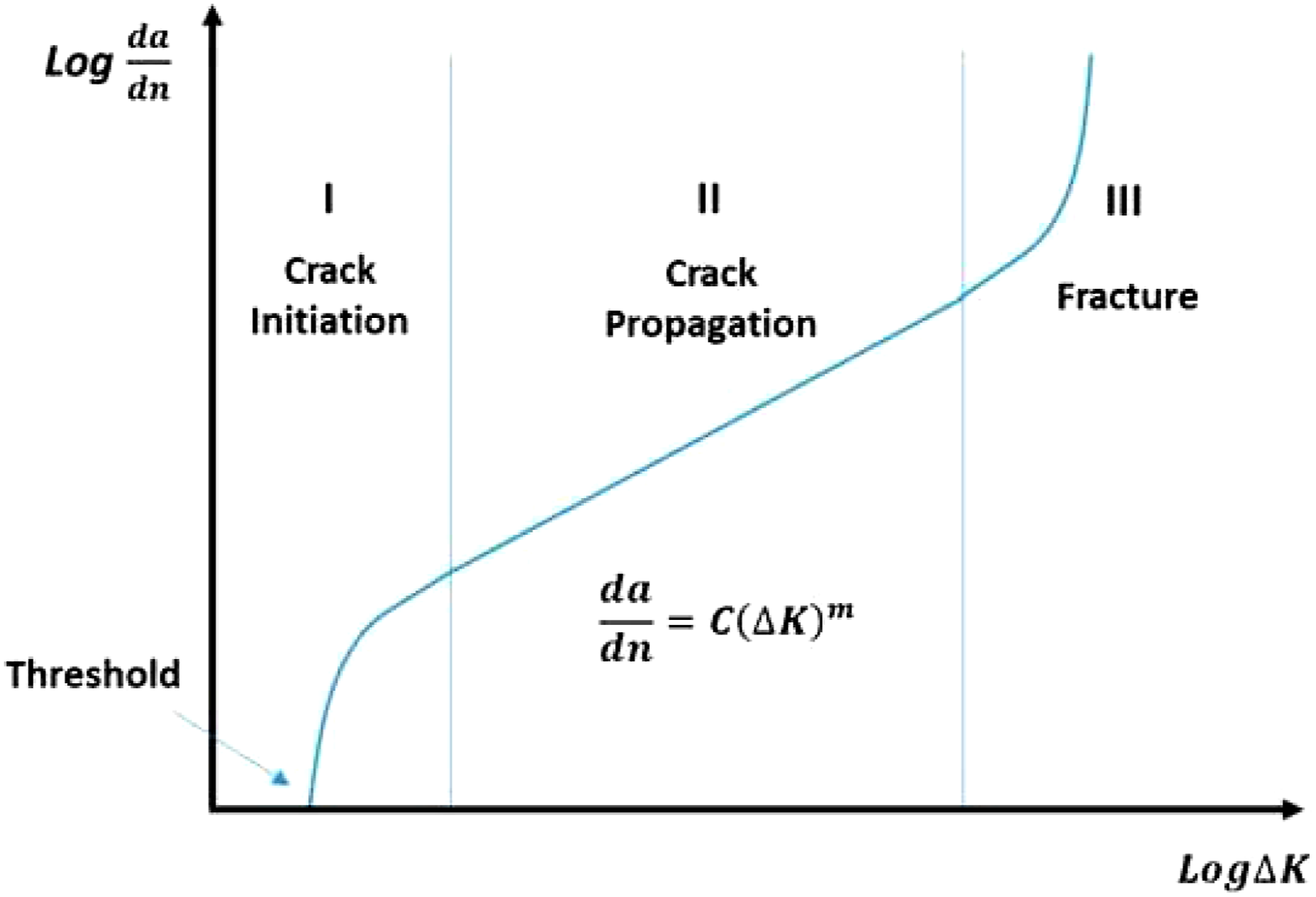
employed NNs and FEM to identify damage in steel moment frame structures. The mode shape and frequencies (collected by finite element model for five-story office buildings) were used as input to train the ML model. The model output predicted the stiffness and mass of the structure to deliver a damage index at each story. Another study investigated three machine learning models (K-nearest neighbour regression, polynomial regression and ridge regression) using experimental data of metal plate to predict fatigue crack growth rate in stage II and stage III regions (see Figure 9) model of K-nearest neighbour regression was identified as better suited for their application. They also founded that the accuracy of the machine learning model is strongly reliant on the selection of training data, prepossessing of experimental data.
93
The three-stage of crack growth.
93
Polymer structures
A ridge regularised multiple linear regression were used to predict the damage location, damage severity and fundamental behaviour of acrylonitrile butadiene styrene (ABS) structure. This study used raw experimental data (damaged and undamaged data of aluminium and ABS under coupled mechanical loads at various temperatures) from Baqasah et al.
94
and Zai et al.
95
to train the model. The model indicated that tip amplitude and natural frequency appear to be the most important predictive features for ABS (see Figures 10 and 11). The model results also confirmed that the crack position appears to be of little importance for either. The model results also confirmed that the crack position appears to be of little importance for both materials. The crack position is not identified through the theoretical model. Thus, in future studies, the training of the data requires to be performed utilising the theoretical models so that more rigorous ML models can be achieved.
96
Relative feature importance derived from model coefficients (scaled).
94
Relative feature importance derived from model coefficients (scaled).
94
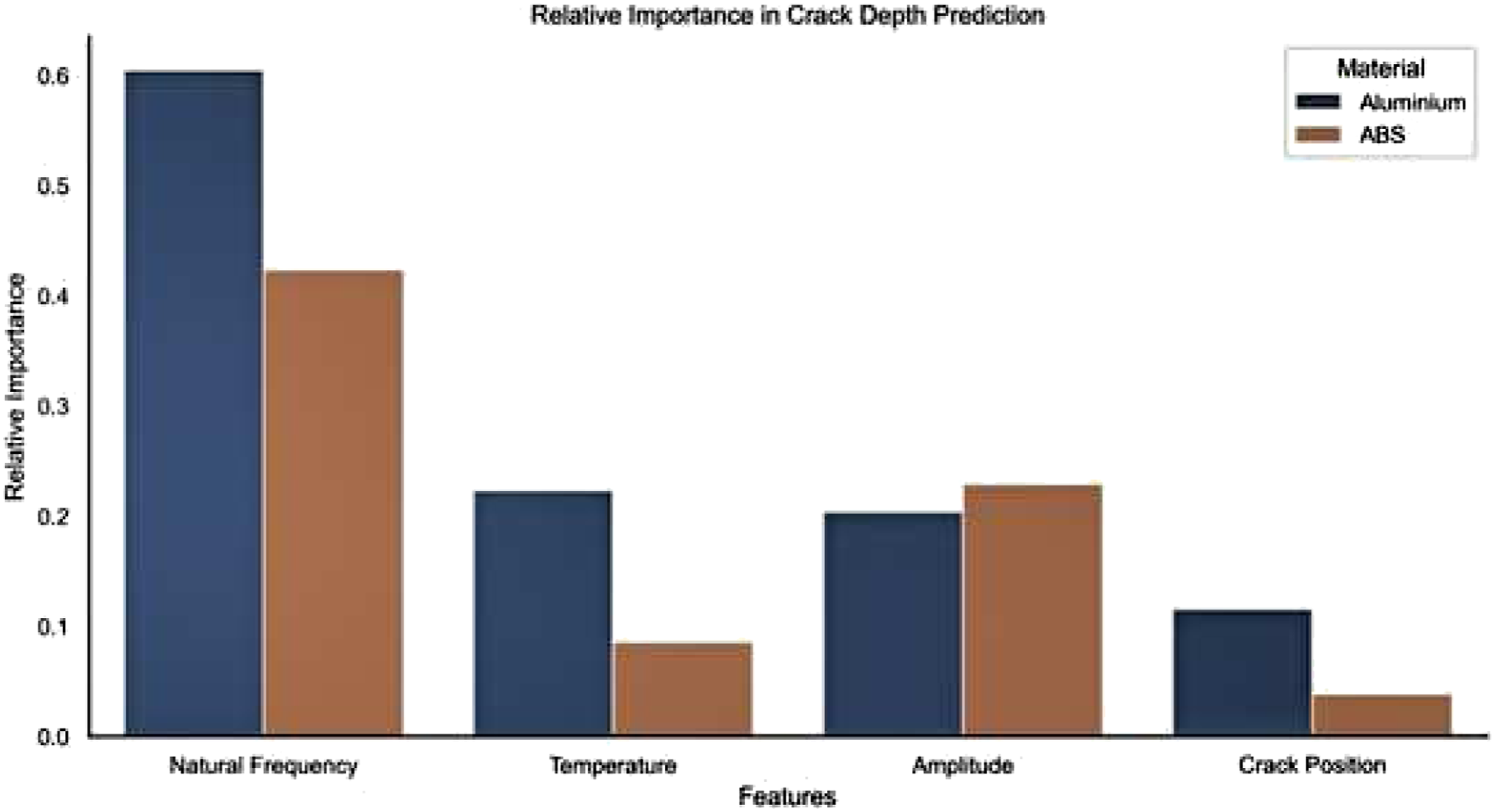
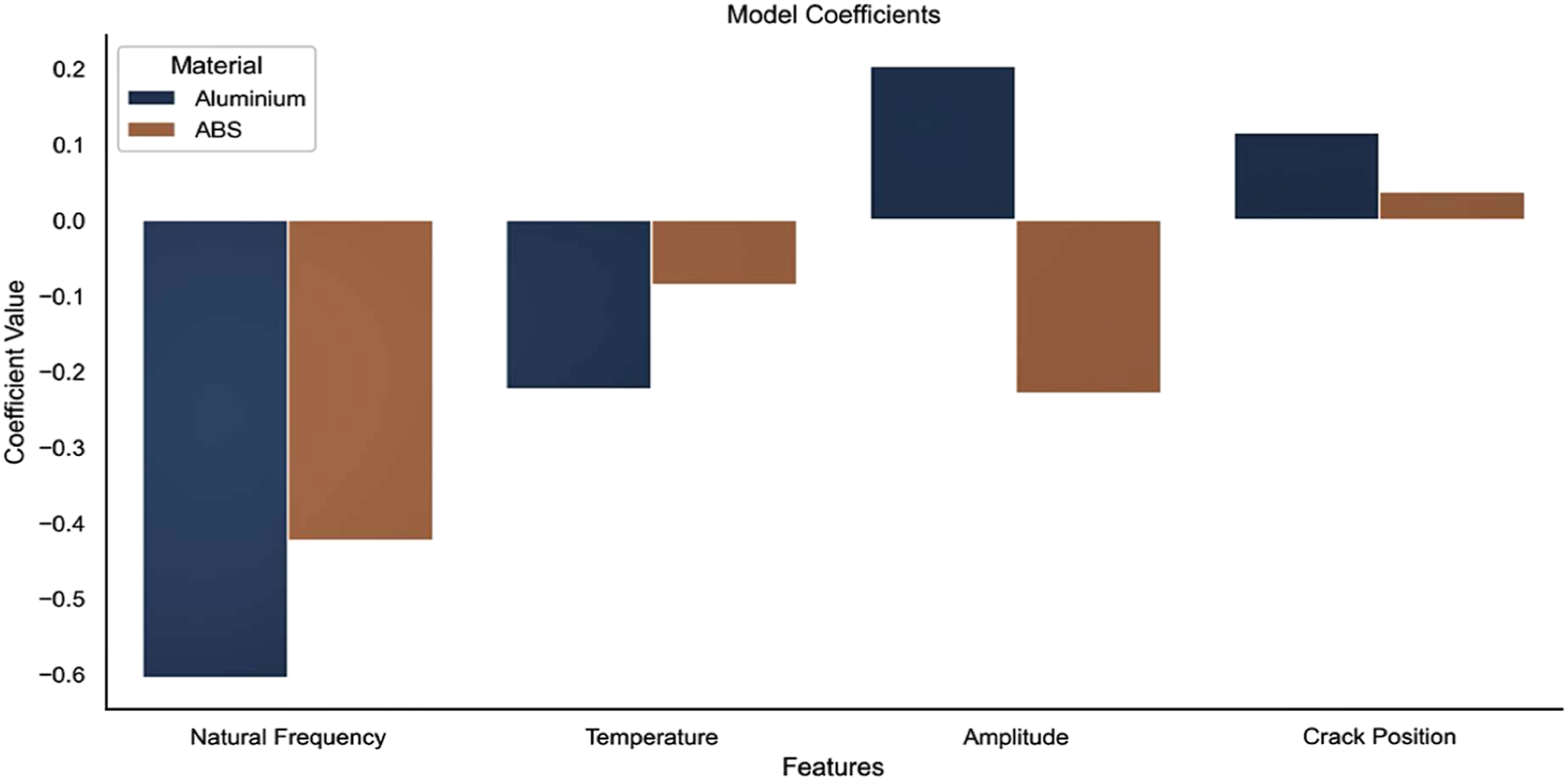
Tibaduiza et al.
97
proposed a damage detection and classification approach (see Figure 12). The proposed method is evaluated and tested a carbon fibre reinforced polymer (CFRP) structure. This approach involves the use of data collected from a structural under different structural states through a piezoelectric sensor network taking advantage of using the hierarchical nonlinear PCA, discrete wavelet transforms and MLAs (K-nearest neighbour and decision tree). The researchers emphasised that to work with MLAs, it is very important properly selecting the training data. Otherwise, results in the trained machine can be different to the system expectations. RFs, ANNs and Haar wavelet discrete transform was applied to predict the severity and location of a crack in the Bernoulli cantilever beam.
98
Analysing the results of the prediction, it was found that the depth of the cracks was more difficult to predict accurately than its location. The dataset of eight Haar wavelet coefficients produced more precise predictions on the crack locations; meanwhile, the dataset of eight natural frequency parameters produced more accurate predictions on the crack depth. Damage classification methodology in Tibaduiza et al.
97
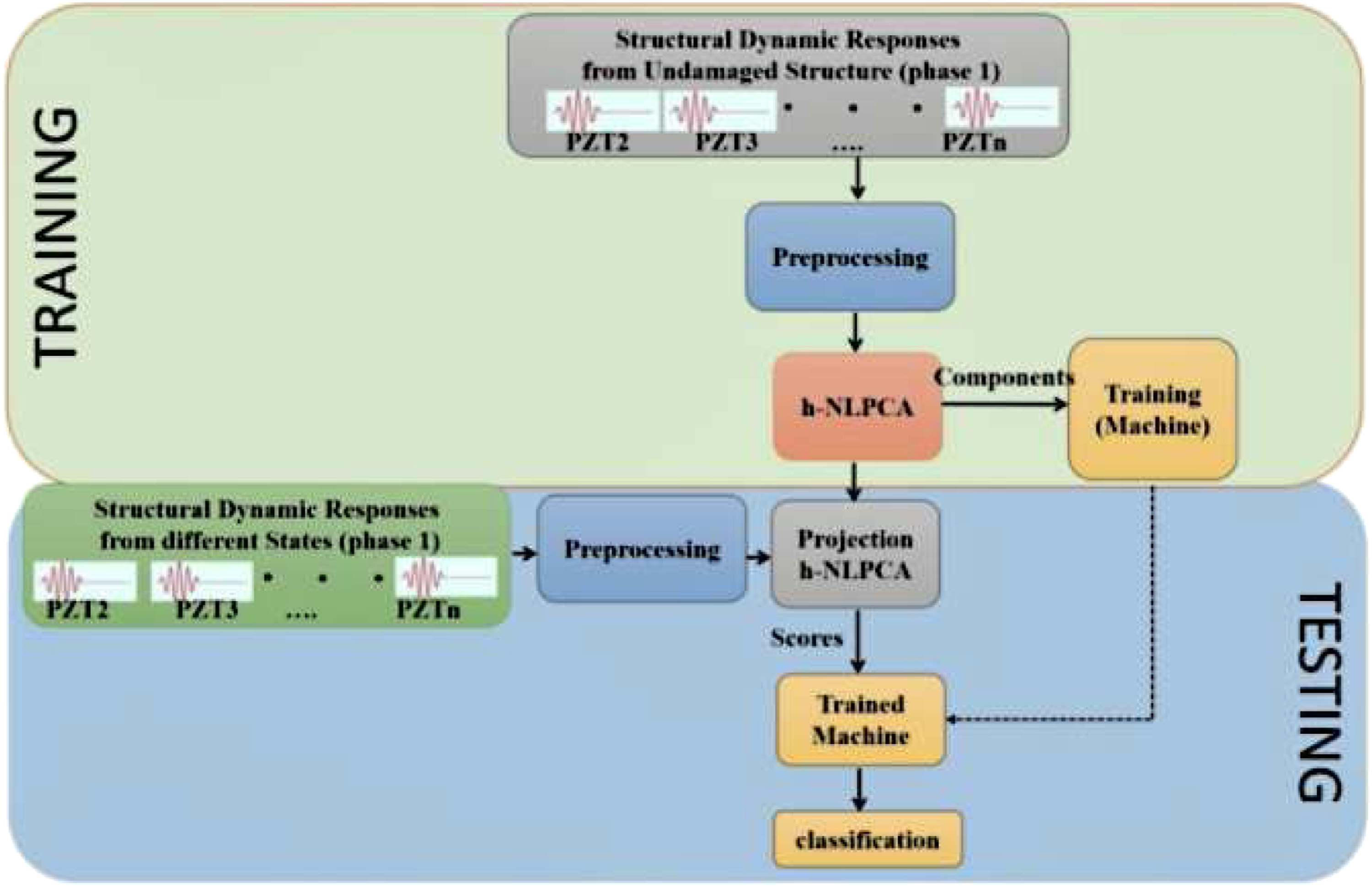
Chen et al.
99
developed a damage identification scheme by combining hierarchical cluster analysis based on complex network theory and waveform chain code (WCC) analysis. Waveform chain code analysis was carried out using the PCA reduced frequency response function (PCA-reduced FRF) and the areas under the slope differential value curves were calculated as damage-sensitive WCC features. Unsupervised machine learning using hierarchical cluster analysis was then conducted on these damage-sensitive features. A rectangular Perspex plate was studied using the newly developed damage identification scheme as an example. Experimental results showed that the proposed scheme can successfully separate all the damage conditions from the undamaged state with 100% accuracy. In terms of damage severity and location identification, the proposed scheme is sensitive to detect damage severity with a damage index as low as 0.17. In addition, the combination of PCA-reduced FRF and mode shapes showed a positive correlation between the magnitude of the resonant peak and the displacement of the impact point in identifying different damage locations of the plate. It can be seen from the aforementioned the following points: • Data-driven approaches can play an essential role to find the relationship (often nonlinear) between material structure and its properties. • The majority of studies developed ML applications to predict and monitor the health of composite and metal structures whereas, there is limited literature on ML applications for structural made of polymer material. • Most previous studies used simple to use ML algorithms and straightforward such as decision tree and linear kernel models for different applications even though input-data are complex and huge. • Usually, a machine learning model cannot achieve the expected accuracy when employed in some tasks because of insufficient structural data. Thus, reprocessing and cleaning data before training the models are highly important for the future development of machine learning in structural made of different materials. • Some studies used ANNs and conventional neural networks because they can extract damage-sensitive features during training the model and no needs to apply another approach for feature selection and extraction. This might cause consuming more high-end machines (such as GPUs) and time. • Artificial neural networks have the potential to minimise the needs of huge data of structural inspection and/or experimental investigation applied in different applications, therefore, causing large economic benefits.
100
• The reasonable design of ML algorithms and data augmentation can assist address the data sparsity thus enhance the performance of the application. The next section presents more challenges of machine learning and some future work.
Common challenges of machine learning and future work
For ML in SHMA applications to advance from conception and research into practice, several challenges must be overcome. A synthesis of those challenges, as well as opportunities for future work, is presented in this section.
Availability and quality of data
One of the main contributors to the success of machine learning ML in other fields is the capability to obtain the needed data. Although the quantity of data needed to obtain reasonable performance for ML models relies on the goal and problem, it is important to have sufficient high-quality data that may represent the true distribution. This allows the adopted ML algorithms to determine underlying patterns and make predictive models that are truly generalisable within the problem scope. One of the significant difficulties ML in SHMA applications is that the datasets are frequently restricted in diversity and quantity. In the experiments that tried to predict the structural performance and response utilising ML approaches, the data was collected from nonlinear response history analyse by other researchers. 101,102 However, these datasets were not publicly available to understand a truly representative dataset of structural response requirements; an open access repository with restricted quality control measures should be instituted. 61 Over time, resources such as Data Centre Hub (http://datacenterhub.org) and the National Hazard Engineering Infrastructure (http://rapid.designsafe-ci.org) will assist reduce this challenge. While there are hundreds of data points, the datasets generated by physical experiments are more diverse. In other words, the previous studies have used data obtained from a wide range of experiments carried out by numerous researchers such as Jeon et al., 103 Huang and Burton, 104 and Hoang et al. 105 As part of the solution to the shortage of data from physical experiments is to integrate ML algorithms into the domain knowledge. This will decrease the complexity of the model space and therefore decrease the amount of data is required to perform effectively. Transfer learning (TL) can be applied to tackle the data shortage challenge. The fundamental idea behind TL is that knowledge obtained from training one model for a specific domain or problem can be transferred to another.
Azimi and Pekcan 106 have presented a novel convolutional neural network-based approach for crack identification and localisation that uses a form of measured compressed response data through TL-based methods. The results indicate that TL can be implemented effectively for crack identification of similar structural systems with different sensor types. In addition, Variational Autoencoder, Generative Adversarial Networks and Monte Carlo Simulation) can enhance current datasets through synthetic data generation. Future studies should focus on the following points: (1) gathering and preserving more diverse datasets, (2) providing synthetic data, (3) integrating domain knowledge into the design of the ML model and (4) using transferable learning.
Another important consideration is the quality of the data, which is a common difficulty for ML models. There are no standard methods for synthesising and collecting datasets obtained by the community of SHMA. This absence of deliberate curation methods can prompt problems such as the presence of anomalies in the information, which can adversely affect the exhibition of ML models. This is particularly valid for ML approaches as logistic regression, which is less equipped for managing noise. In other words, the common data filtering procedure of ML models ought to be carefully incorporated with the knowledge domain of SHMA knowledge. Thus, a large number of the difficulties identified with the nature of datasets quality can be tended to if processing techniques and precise collection are instituted and adopted. Therefore, Hsieh and Tsai 107 have recommended that data quality and quantity are significant factors in the improvement of ML crack detection model. Accurate, robust and fast ground-truth labelling and data acquisition should be further developed.
Overfitted machine learning models
Overfitted models (see Figure 13), which bring about deficient execution outside of the data utilised for training and/or testing, is an area of significant challenge that is looked at by the more extensive ML community. In other words, one of the reasons for the overfitting problem is training and learning from inaccurate and noise data entries in the collected dataset therefore the model does not classify the data correctly. Difference between Underfitting, appropriate fitting and overfitting.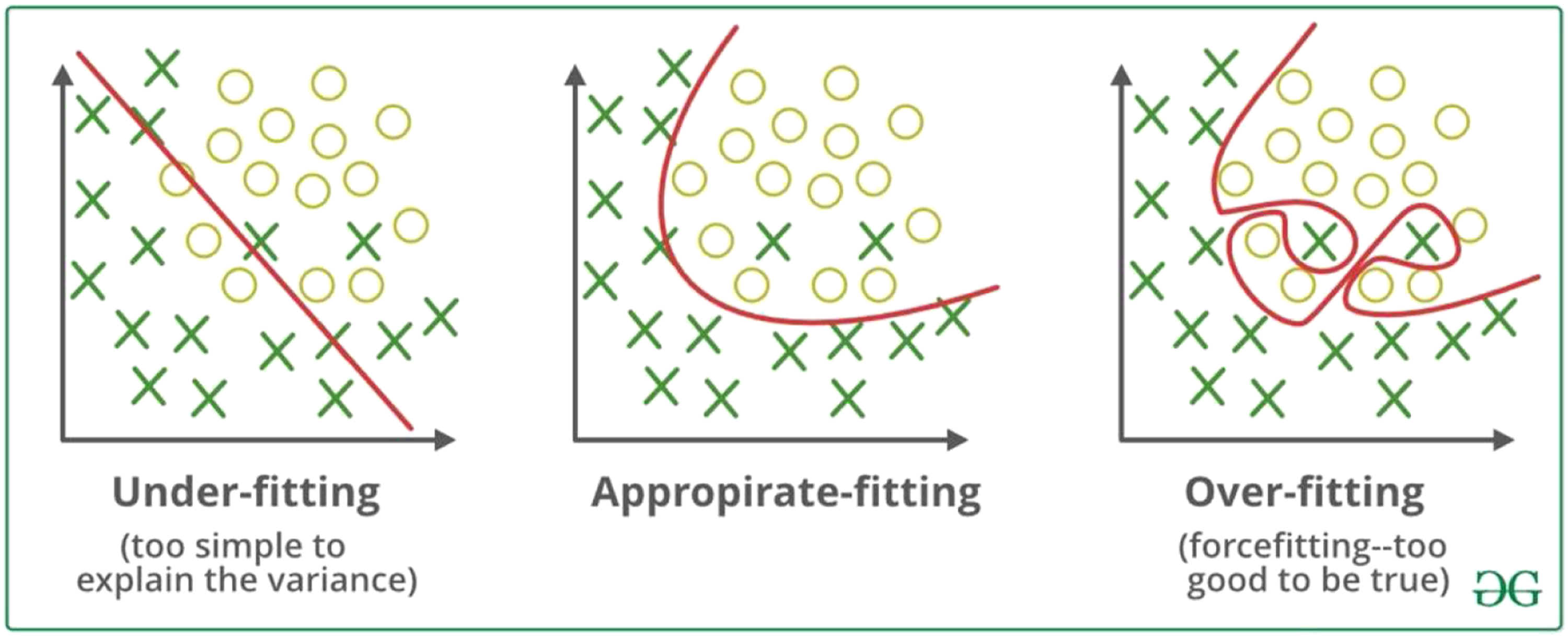
The reasons for overfitted are also the nonlinear and non-parametric methods that have more flexibility and freedom in building the model. The result of these methods can be unrealistic models. Standard ML methods try to address the overfitting problem by using training/testing split, bootstrapping, bagging and k-fold cross-validation as other approaches. For example, the stochastic methodology utilised by RF to produce trees was intentionally created to overcome the overfitting challenge related to the decision tree. 106,108
It ought to be noticed that overfitting isn’t just connected with model training but also with model selection. A complex nonlinear model trained on a dataset with low dimensional features could be overfitted. For the SHMA community, the use of domain knowledge can also assist with eliminating overfitting issues and build robust crack prediction and detection application. The blend of domain knowledge with the data-based procedure, as the approach utilised to manage data sparsity, may demonstrate to be a powerful combination Although overfitting has been widely investigated throughout the ML community, it might be more vital to build SHMA applications given the complexity of some of the mechanics-based relationships that data-based models try to replicate. Therefore, the ML-SHMA model usually needs large quantities of data, careful adjustment and better noise filtering processes to minimise the effects of overfitting. 104,109
Interpretability and explainability of machine learning model
Perhaps one of the main difficulties related to ML models is interpreting the physical meaning of the model parameters and explaining the feature effects. A usually held view is that ML models, particularly the further developed and complex ones, are black boxes. In other words, they are hard to extricate the mechanics-based relationship between features (input) and response variables (outputs) parameters in data-based models. To increase model explainability should carry out feature importance tests to realise their side effect on the model output variables, which would then be able to be benchmarked apposed the essential rules. Analysis of variance (ANOVA) 101 and statistical methods such as the F test 110 can be employed to assess the relative strengths of the relationships between features and response variables. Furthermore, individual conditional expectation curves (ICE), the partial dependence plot (PD plot) and its variant are also widely used. 111,112
Besides these feature importance measurements, model-specific methods such as the utilisation of class activation mapping (CAM) to envision centre zones around the image of CNN models 113,114 have been established. Feature attribution or feature visualisation enables better interpretability and understanding of black-box models. But, it sometimes may be reasonable to trade model accuracy for better explainability. 100 Some new endeavours on the interpretability of ML have shown the advantage of bringing domain knowledge into ML approaches by combining a physics-based loss function. A particular model is to implant hard conditions with a Lagrange multiplier into the loss function. 114,115 This method combines a physics-based law into the objective function which, present a means to explain some models of machine learning. A recent paper 116 in the structural health monitoring field combines unlabelled simulation data with observed labelled field data using a physics guided neural network with a loss function. The used method involves further conditions presenting the difference between observed and simulation output.
Overall, these studies 30,117–124 highlight the need for combining ML models with the physics-based model in different SHMA applications to interpret the physical meaning of the model parameters and explaining the effects of the feature on the accuracy of the ML model. However, combining physics-based models and machine learning continues a challenging problem particularly for the community of structural crack performance assessment and will remain to be investigated in future research.
Machine learning method selection
A various range of algorithms was implemented in the presented ML-SHMA studies. Unfortunately, there is no agreement or general stance about ML method selection. In certain studies, the researcher(s) focused on a single method. 110,111 However, a clear and cogent reason is never provided for the selected method. Other studies have concentrated on comparing the performance of ML models developed using various methods. Hsieh and Tsai 107 compared a performance evaluation of eight ML-based crack segmentation models using three-dimensional pavement images and consistent evaluation metrics with varied conditions to identify potential directions and challenges for future crack detection development. However, the results of such comparative evaluations are difficult to generalise, because they are highly conditioned by the adopted dataset and model testing (e.g. partition point for training–testing split, performance metric) and model training (e.g. whether k-cross-validation is adopted). Future efforts are expected to focus more on analysing domain-specific characteristics of adopted datasets and apply knowledge-informed approaches in selecting ML algorithms instead of using a solely performance-based search. For instance, multi-output models are particularly useful in predicting baseline network curves because they can predict multiple response variables.
Tackling some of the above challenges by creating well-organised and systematic datasets would also assist in the selection of methods. The advantage of having such benchmark datasets is that a standard dataset will encourage particular attention to the integration of domain knowledge and associated data models. However, performance-based model selection is often the perfect solution where there is no sense of how domain knowledge can be incorporated. An instant strategy that can be employed to guide method selection is to begin by training and evaluating the performance of a linear (basis function) ML model logistic regression for classification problems and (OLS, LASSO, ridge) for regression problems. Except for very specific problems, it has been demonstrated that linear models work reasonably well, yet are easy to implement (e.g. Burton et al. 112 and Mangalathu and Jeon 113 ), and more critically, have high model interpretation and transparency. In cases where the initial linear models do not work well, they should be further examined before moving to more complex models. For instance, poor performance may be due to the simplicity of the linear ML model or noisy data. The first situation requires an advanced exploration (e.g. non-parametric models) able to capture the data complexity. However, noise problems within the data can be handled by filtering.
Conclusion
This paper presents a review of ML applications in SHMA for different materials made of composite, metal and polymer. The increase in computational power in recent years has enhanced the capability of ML in complex applications involving large-scale, high-dimensional nonlinear data. With the advantages in pattern recognition and function approximation, ML offers a natural choice to help address the challenges in SHMA. Several key challenges need to be tackled to take advantage of using machine learning in SHMA practice. Firstly, collecting high-quality data sources critical for the development of machine learning model are currently limited within the SHMA community. Therefore, a unified effort is required to curate diverse, collect and generate datasets to an open-source storage area that can be used and populated by practitioners and researchers. This effort should also include the creation of benchmark data sets for specific SHMA subdomains to align and focus research resources. Reasonable design of ML algorithms, TL and data augmentation, and domain knowledge can also help address the data sparsity. Second, the results from ML models are often difficult to interpret. This can be addressed by using importance testing to better understand the individual effects of features on the response variable. The introduction of physics-based loss functions can offer insight into ML model training and interpretation and can potentially improve robustness. Third, overfitting is a significant issue for ML models, especially when attempting to capture complex mechanics-based relationships in SHMA problems. This issue can be further studied by examining the SHMAS data space and proposing physics-based validation and evaluation techniques. Future research should also focus on finding ways to combine data-based procedures with SHMA domain knowledge, which will serve to boost performance and provide model insights. Lastly, previous studies did not establish general guidelines for the selection of ML models. Future studies should incorporate more knowledge-informed selection strategies. As a rule of thumb, initial exploration should focus on simple linear models which are usually easy to interpret and explain. The complexity of the data space can also inform the model selection. Sufficient sources of high-quality data are important for the development of the ML model. Therefore, reasonable design of ML algorithms and data augmentation can assist address the data sparsity. The extraction of sensitive features is also mainly crucial for the successful damage assessment application within the machine learning paradigm.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.