
Abstract
Sir Ronald Fisher’s venerable experiment “The Lady Tasting Tea” is revisited from a Bayesian perspective. We demonstrate how a similar tasting experiment, conducted in a classroom setting, can familiarize students with several key concepts of Bayesian inference, such as the prior distribution, the posterior distribution, the Bayes factor, and sequential analysis.
Over 80 years ago, Sir Ronald Fisher conducted the famous experiment “The Lady Tasting Tea” in order to test whether his colleague, Dr Muriel Bristol, could taste if the tea infusion or the milk had been added to the cup first (Fisher, 1937, p. 11). Dr Bristol was presented with eight cups of tea and the knowledge that four of these had the milk poured in first. Dr Bristol was then asked to identify these four cups. Fisher analyzed the results using null hypothesis significance testing:
1. Assume the null hypothesis to be true (i.e., Dr Bristol lacks any ability to discriminate the cups). 2. Calculate the probability of encountering results at least as extreme as those observed. 3. If that probability is sufficiently low, consider the null hypothesis discredited.
This probability is now known as the p-value and it features in many statistical analyses across empirical sciences such as biology, economics, and psychology (for recent critique, see Benjamin et al., 2018; Wasserstein & Lazar, 2016).
Decades later, Dennis Lindley (1993) used an experimental procedure similar to that of Fisher to highlight some limitations of the p-value paradigm. Specifically, the calculation of the p-value depends on the sampling plan, that is, the intention with which the data were collected. Consider the Lindley setup: the lady is offered six pairs of cups, where each pair consists of a cup where the tea was poured first, and a cup where the milk was poured first. She is then asked to judge, for each pair, which cup has had the tea added first. A possible outcome is the sequence RRRRRW, indicating that she was right for the first five pairs, and wrong for the last pair. However, as Lindley demonstrated, the original sampling plan is crucial in calculating the p-value. Was the goal to have the lady taste six pairs of cups – no more, no less – or did she need to continue until she made her first mistake? The observed data are compatible with either sampling plan; yet in the former case, the p-value equals 0.109, whereas in the latter case the p-value equals 0.031. The difference lies in the inclusion of more extreme cases. In the “test six cups” plan, the only more extreme outcome is RRRRRR (i.e., the binomial sampling distribution), whereas for the “test until error” plan the more extreme outcomes include sequences such as RRRRRRW and RRRRRRRW (i.e., the negative binomial sampling distribution). It seems undesirable that the p-value depends on hypothetical outcomes that are in turn determined by the sampling plan. Harold Jeffreys summarized: “What the use of p implies, therefore, is that a hypothesis that may be true may be rejected because it has not predicted observable results that have not occurred. This seems a remarkable procedure” (Jeffreys, 1961, p. 385; see also Berger & Wolpert, 1988).
In this article we revisit Fisher’s experimental paradigm to demonstrate several key concepts of Bayesian inference, specifically the prior distribution, the posterior distribution, the Bayes factor, and sequential analysis. Furthermore, we highlight the advantages of Bayesian inference, such as its straightforward interpretation, the ability to monitor the result in real-time, and the irrelevance of the sampling plan. For concreteness, we analyze the outcome of a tasting experiment that featured 57 staff members and students of the Psychology Department at the University of Amsterdam; these participants were asked to distinguish between the alcoholic and the non-alcoholic version of the Weihenstephaner Hefeweissbier, a German wheat beer. We describe how classroom tasting experiments can acquaint students with Bayesian inference, noting that beer can be substituted with anything else suitable (e.g., red and green M&M’s, Coca Cola and Pepsi, decaf and regular coffee). We analyze and present the results in the open-source statistical software JASP (JASP Team, 2019).
The Tasting Experiment
On a Friday afternoon, May 12th 2017, an informal beer tasting experiment took place at the Psychology Department of the University of Amsterdam. The experimental team consisted of three members: one to introduce the participants to the experiment and administer the test, one to pour the drinks, and one to process the data. Participants tasted two small cups filled with Weihenstephaner Hefeweissbier, one with alcohol and one without, and indicated which one contained alcohol. Participants were also asked to rate the confidence in their answer (measured on a scale from 1 to 100, with 1 being completely clueless and 100 being absolutely sure), and to rate the two beers in tastiness (measured on a scale from 1 to 100, with 1 being the worst beer ever and 100 being the best beer ever). The experiment was double-blind, such that the person administering the test and interacting with the participants did not know which of the two cups contained alcohol. For ease of reference, each cup was labeled with a random integer between 1 and 500, and each integer corresponded either to the alcoholic or non-alcoholic beer. A coin was flipped to decide which beer was tasted first. The setup was piloted with nine participants; subsequently, we tested as many people as possible within an hour, and also recorded which of the two beers was tasted first. On average, testing took approximately 30 seconds per participant, yielding a total of 57 participants. Of the 57 participants, 42 (73.7%) correctly identified the beer that contained alcohol; in other words, there were s = 42 successes and f = 15 failures. 1
Theoretical Analysis
In order to assess statistically whether and to what extent participants were able to discriminate between alcoholic and non-alcoholic beer we apply the binomial model, where the rate parameter θ governs the probability of a correct response for each of the participants. Chance performance corresponds to
In the Bayesian framework, we start by specifying a prior distribution. The prior distribution quantifies our beliefs about the parameter of interest before seeing the data. For convenience, we may specify a beta distribution: a probability distribution on the domain
The beta prior distribution is then updated to a posterior distribution using Bayes’ rule, such that values of θ that predicted the data well receive a boost in credibility, whereas values of θ that predicted the data poorly suffer a decline (Rouder & Morey 2017; Wagenmakers et al., 2016):
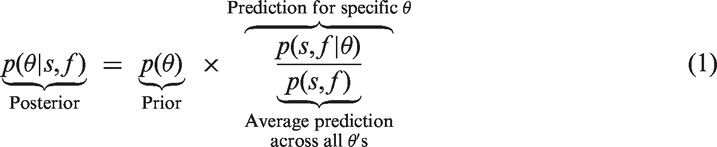
The right-most term is the predictive updating factor that quantifies the change from prior to posterior beliefs brought about by the data. This predictive updating factor indicates how well each value of θ predicted the data, relative to the average prediction across all values of θ. When a specific value of θ predicted the data better than average, the posterior density at that point will be higher than the prior density.
We used the binomial likelihood to assess the quality of each value’s prediction (i.e., the likelihood of observing s successes and f failures, given a specific value of θ). Because we used the binomial likelihood and a beta prior distribution, the updated posterior distribution will also be a beta distribution – a property known as conjugacy (Gelman et al., 2003).
The obtained posterior distribution can be used for both parameter estimation and hypothesis testing. For parameter estimation, either a point estimate or an interval estimate can be obtained. Commonly used point estimates include the posterior median and posterior mean. Interval estimation can be done with a so-called credible interval, which is an interval that contains x% of the posterior mass
3
and can be interpreted as follows: there is an x% probability that the true parameter lies in this interval. For example, if we obtain a 95% credible interval of
The posterior distribution can also be used for hypothesis testing, where the traditional goal is to examine specific values of θ. For instance, we can test the hypothesis
As before, hypotheses that predict the data well receive a boost in credibility, whereas hypotheses that predict the data poorly suffer a decline. In the Bayesian framework, hypothesis testing is traditionally achieved through the Bayes factor (Etz & Wagenmakers, 2017; Kass & Raftery, 1995).
4
The Bayes factor can be seen as a weighing of one hypothesis’ predictive quality relative to that of another. The following equation illustrates this principle, and is very similar to equation (1):
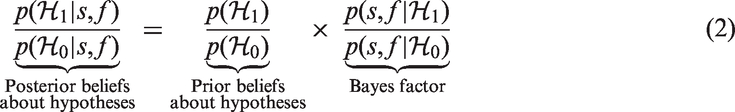
It is important to note here that the Bayes factor is a relative metric of the hypotheses’ predictive quality. For instance, if the Bayes factor equals 5, this means that the data are 5 times as likely under
The computation of the Bayes factor is usually not straightforward; however, when the two hypotheses are nested, a convenient computational shortcut can be used, known as the Savage–Dickey density ratio (Dickey & Lientz, 1970; Wagenmakers et al., 2010). The shortcut entails that the Bayes factor equals the ratio of the prior density and the posterior density at the test value θ0. For instance, in the current study,

We stress that the mathematical details are not critical for students’ understanding of the Bayesian procedures. The following section shows how the example and the associated graphs suffice to clarify the key Bayesian concepts at an intuitive level.
Bayesian Inference with JASP
When the statistical explanation does not resonate with students, a practical demonstration of the analysis might. This can be done with the statistical software JASP, which offers a graphical user interface for conducting Bayesian (and frequentist) analyses. In order to analyze the collected data, the Bayesian binomial test can be used, which can be found under the menu labeled “Frequencies”. Several settings are available for the binomial test, allowing students to explore different analysis choices. Figure 1 presents a screenshot of the options panel in JASP. For this analysis, we specify a test value of The input panel for the Bayesian binomial test in JASP. The upper-left box displays all available variables. The upper-right box displays the tested variables. Below are other options, such as setting the test value, the alternative hypothesis, and the shape parameters of the beta prior.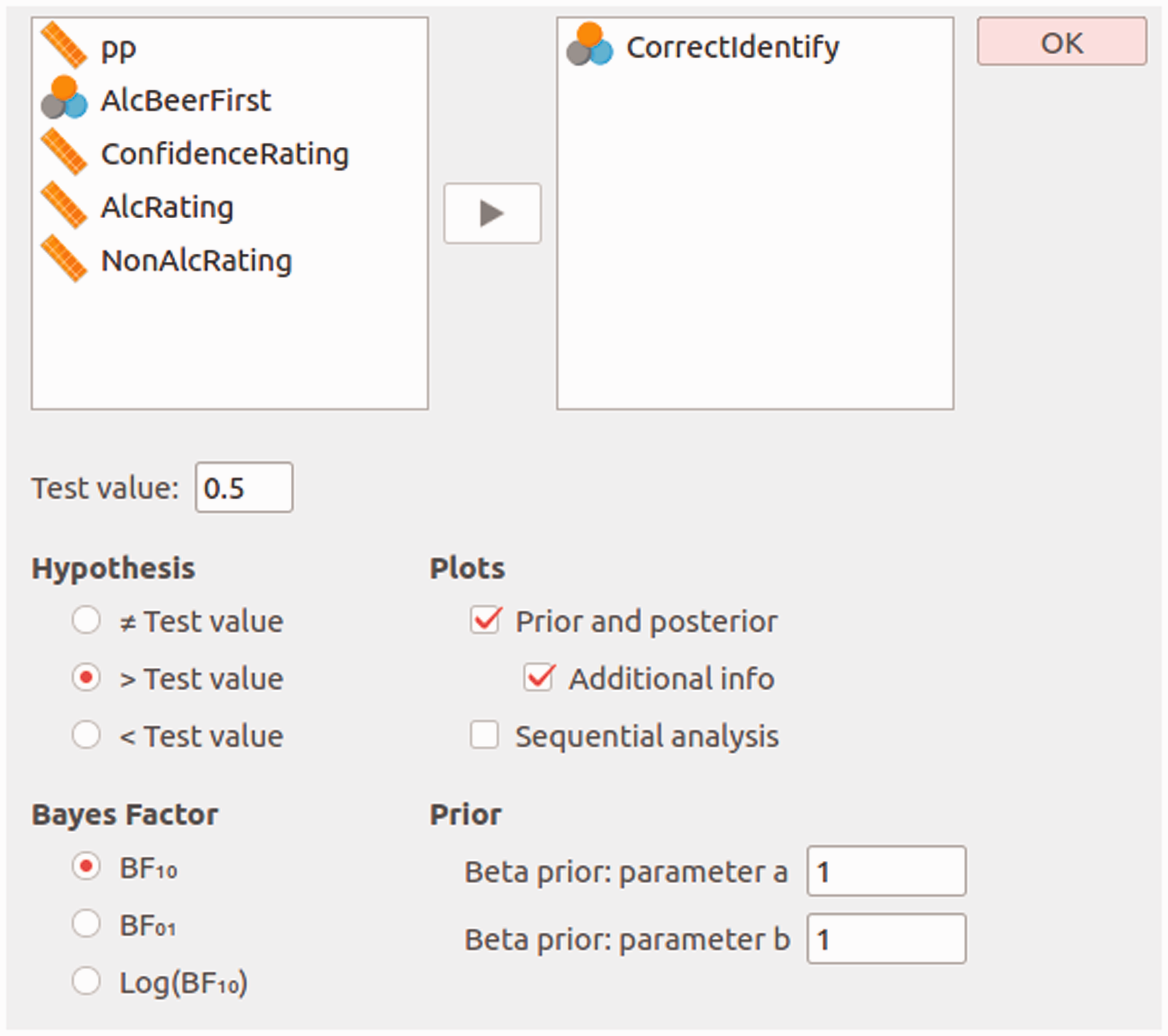
The null hypothesis postulates that participants performed at chance level, whereas the alternative hypothesis postulates that this is not the case. For instance, in the case of two-sided hypothesis testing, the hypotheses are specified as follows

However, since we wish to test whether or not participants’ discriminating ability exceeds chance, we can specify the alternative hypothesis to allow only values of θ greater than

Figure 2 illustrates the results of the binomial test. The left panel shows the prior and the posterior distribution of θ for the two-sided alternative hypothesis, along with the median and credible interval of the posterior distribution. The posterior median equals 0.731 and the 95% credible interval ranges from 0.610 to 0.833, indicating a substantial deviation of θ from Bayesian binomial test for the rate parameter θ. The probability wheel at the top illustrates the ratio of the evidence in favor of the two hypotheses. The two gray dots indicate the prior and posterior density at the test value—the ratio of these is the Savage–Dickey density ratio. The median and the 95% credible interval of the posterior distribution are shown in the top-right corner. The left panel shows the two-sided test and the right panel shows the one-sided test. Both figures from JASP. (a) 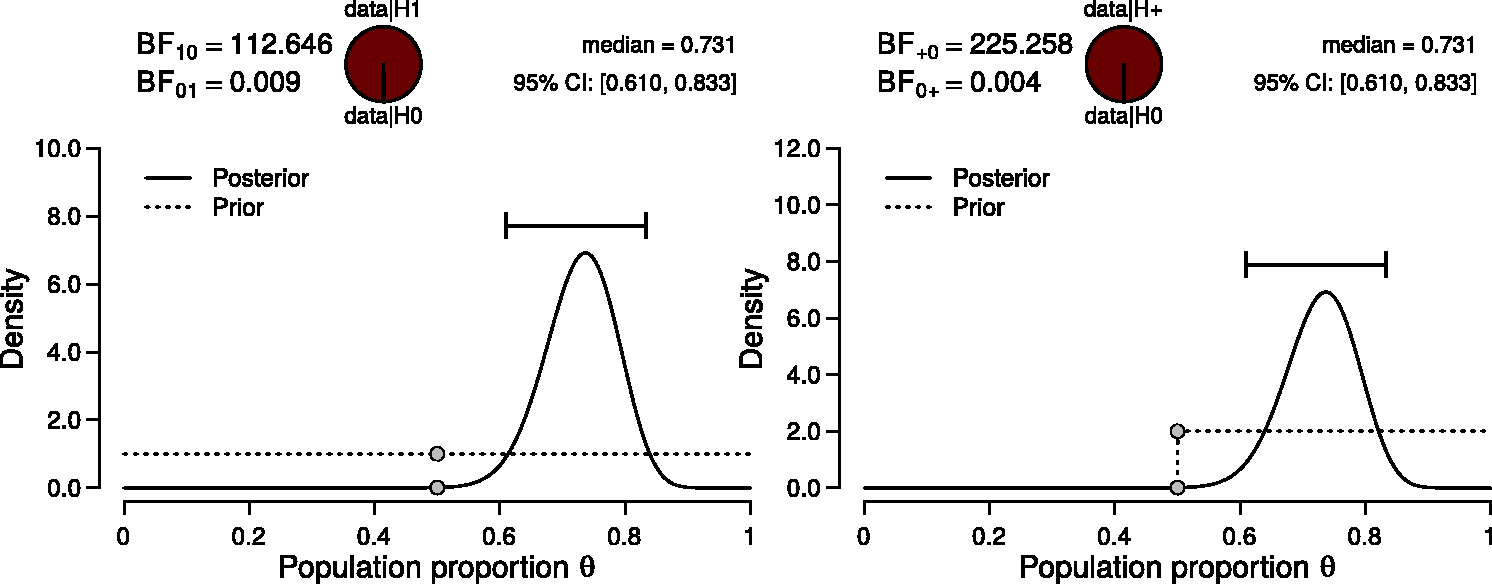
The right panel shows inference for the one-sided positive hypothesis (i.e.,
The experimental procedure also highlights one of the main strengths of Bayesian inference: real-time monitoring of the incoming data. As the data accumulate, the analysis can be continuously updated to include the latest results. In other words, the results may be updated after every participant, or analyzed all at once, without affecting the resulting inference. To illustrate this, we can use Equation 1 to compute the posterior distribution for the first nine participants of the experiment for which s = 6 and f = 3. Specifying the same beta prior distribution as before, namely a truncated beta distribution with shape parameters Sequential updating of the Bayesian binomial test. The left panel shows results from a one-sided Bayesian binomial test for the first n = 9 participants (s = 6, f = 3). The shape parameters of the truncated beta prior were set to a = 1 and b = 1. The right panel shows results from a one-sided binomial test for the remaining 48 participants. Here, the specified prior is the posterior distribution from the left panel: a truncated beta distribution with 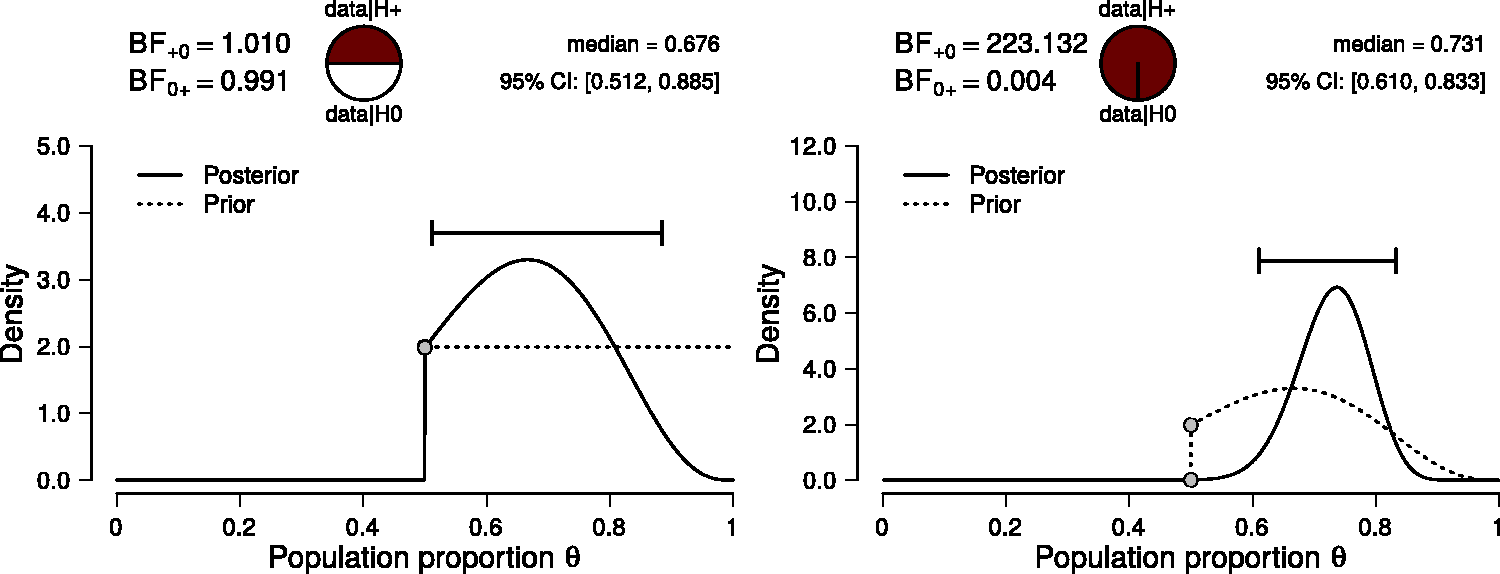
In this case, we can specify a truncated beta prior distribution with a = 7 and b = 4, and update this with the data of the remaining 48 participants using Equation 1. Out of the 48 participants, 36 were correct, and 12 were incorrect. Updating the prior distribution with this data yields a posterior distribution with shape parameters
The ability to monitor the data in real-time and update the inference accordingly prevents wasteful data collection: if there is sufficient evidence to discredit either hypothesis with 50 observations, why collect another 10? Wasteful testing is a serious issue, and monitoring the evidence is important in fields such as medicine, biology, and industry. The Bayesian framework for planning experiments is discussed in more detail by Rouder (2014), Schönbrodt & Wagenmakers (2018), and Schönbrodt et al. (2017). Figure 4 shows the evolution of the Bayes factor as more data are collected. Initially the evidence is inconclusive, but after 30 participants the evidence increasingly supports Sequential analysis, showing the evolution of the Bayes factor as n, the number of observed participants, increases. After an initial period of inconclusiveness, the Bayes factor strongly favors 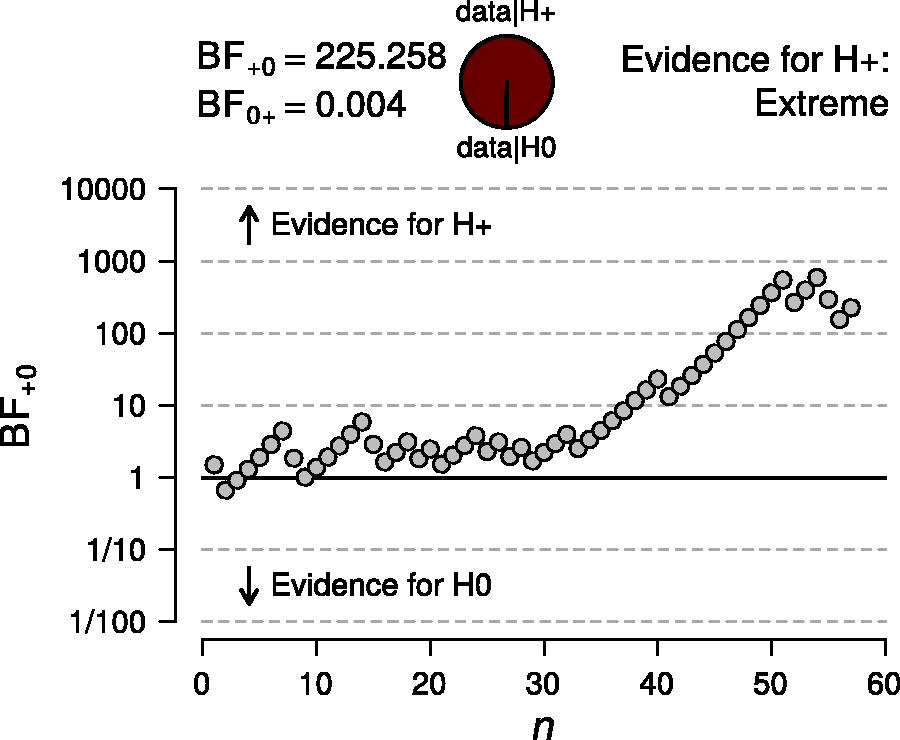
Concluding Remarks
Bayesian concepts that students will learn during the tasting experiment and how these concepts can be demonstrated

We have created an Open Science Framework repository that contains the original data set, as well as a fully annotated JASP-file that presents additional analyses, such as a t-test on the difference in ratings for the alcoholic and non-alcoholic beer. The repository can be found at http://tinyurl.com/yyyc928g.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by a Vici grant from the Netherlands Organization of Scientific Research awarded to EJW (016.Vici.170.083). DM is supported by a Veni grant (451-15-010) from the Netherlands Organization of Scientific Research (NWO).
Footnotes
Notes
Author biographies
![]() ).
).
![]() ).
).