
Abstract
The testing effect is a robust empirical finding in the research on learning and instruction, demonstrating that taking tests during the learning phase facilitates later retrieval from long-term memory. Early evidence came mainly from laboratory studies, though in recent years applied educational researchers have become increasingly interested in the effects of retrieval practice. We investigated the extent that the testing effect can also be observed and effectively used in psychology classes. Inspection of the research literature yielded 19 publications that tested the effect in the context of learning and teaching psychology. A total of 72 effect sizes were extracted from these publications and subjected to a meta-analysis. A significant overall effect size of d = 0.56 demonstrated that testing was beneficial to the learning outcomes. Further analyses focussed on the role of potential moderator variables, a possible publication bias, and the dependency between effect sizes. The results are discussed in the context of applications in learning and teaching psychology.
Introduction
“The term evidence-based teaching refers to […] tools and techniques that have shown through rigorous experimentation to promote learning” (Dunn, Saville, Baker, & Marek, 2013, p. 5). Recently, several authors have published collections of such tools, techniques, and strategies to raise attention to the concept of evidence-based teaching in various contexts (e.g., Cranney, 2013; Dunlosky, Rawson, Marsh, Nathan, & Willingham, 2013; Dunn et al., 2013; Graesser, 2009; Graesser, Halpern, & Hakel, 2008; Pashler et al., 2007; Roediger & Pyc, 2012; Schwartz & Gurung, 2012). Testing or retrieval practice is one of the most frequently studied techniques, the research of which has produced numerous publications recommending evidence-based teaching strategies (e.g., Dunlosky et al., 2013; Dunn et al., 2013; Graesser et al., 2008; Pashler et al., 2007; Roediger & Pyc, 2012).
In the classroom, tests are commonly applied to assess students’ learning performance and to evaluate academic achievement. Many experimental studies, however, indicate that taking tests also facilitates students’ learning. Often, the accessibility of previously retrieved learning material is enhanced in a later, final test – a phenomenon called the testing effect (cf. Roediger & Karpicke, 2006a). In this context, the focus of testing is shifted from the assessment of learning outcomes to supporting the learning process – assessment for learning rather than assessment of learning.
The effect was first empirically investigated in the early 1900s (e.g., Abbott, 1909; Gates, 1917). Despite a century of interest in the topic, research on the testing effect has increased enormously during the past 15 years producing a considerable number of studies investigating various conditions under which the effect occurs (for recent reviews and meta-analyses, see, for example, Dunlosky et al., 2013; Roediger & Butler, 2011; Rowland, 2014).
Theoretical accounts explaining the beneficial effect of testing differentiate direct and indirect effects. Direct effects refer to the impact of retrieving information from memory. Retrieval practice is assumed to strengthen the memory trace by elaborating the encoded information and by creating different retrieval routes to the information in long-term memory (cf. Dunlosky et al., 2013). Several empirical findings further indicate that the amount of retrieval effort directly influences the extent of the effect. Testing effects are larger following more difficult tests (e.g., Glover, 1989; Kang, McDermott, & Roediger, 2007) and following longer intervals between initial learning and testing (e.g., Karpicke & Roediger, 2007; Pyc & Rawson, 2009). Indirect effects refer to the modulation of learning behaviours after retrieval practice. From a metacognitive perspective, for example, tests can serve as monitoring tools that provide information about the current state of learning (Winne & Hadwin, 1998). Learners can use this diagnostic information for adapting subsequent learning activities. For example, learners can intensify encoding of learning content that they had failed to retrieve or were unsure of during retrieval. Providing feedback about the test result can further support this process by disclosing cognitive and metacognitive errors during retrieval (e.g., Butler, Karpicke, & Roediger, 2008).
Research on the Testing Effect: From the Laboratory to the Classroom
Early research focussing on the underlying memory processes of direct testing effects was more conducive to laboratory studies. Numerous experimental studies have demonstrated the testing effect as a robust phenomenon across a wide variety of samples, learning materials, test formats, criterion tasks, and retention intervals. For example, testing effects were shown across a wide range of age, in pre-school (e.g., Fritz, Morris, Nolan, & Singleton, 2007) and school children (e.g., Bouwmeester & Verkoeijen, 2011), in university students (e.g., Karpicke & Roediger, 2007), and in older adults (e.g., Balota, Duchek, Sergent Marshall, & Roediger, 2006). Studies on the testing effect also encompassed different types of learning materials such as simple word lists (e.g., Karpicke & Roediger, 2007), definitions (e.g., Metcalfe, Kornell, & Son, 2007) and factual knowledge (e.g., Butler et al., 2008), prose text materials (e.g., Roediger & Karpicke, 2006b), and videos and animations (e.g., Butler & Roediger, 2007). Moreover, beneficial effects of testing were found using various criterion tasks in the final tests, including recognition, cued and free recall, and tasks involving learning transfer (e.g., Chan, 2010) or inferences (e.g., Agarwal & Roediger, 2011).
As the experimental studies indicated growing generalizability of the testing effect, applying tests as retrieval practice to educational contexts became a new focus of research in this field. The practical relevance of the testing effect was highlighted by the two core findings of beneficial effects of retrieval practice with classroom-relevant learning materials (e.g., Butler & Roediger, 2007; Kang et al., 2007; McDaniel, Anderson, Derbish, & Morissette, 2007) and the long-term beneficial effects even after intervals of several weeks (e.g., Butler & Roediger, 2007), months (e.g., McDaniel, Agarwal, Huelser, McDermott, & Roediger, 2011), and years (e.g., Bahrick, Bahrick, Bahrick, & Bahrick, 1993). These findings inspired a growing number of field studies investigating the testing effect under real classroom conditions (e.g., Bjork, Little, & Storm, 2014; Carpenter, Pashler, & Cepeda, 2009; Roediger, Agarwal, McDaniel, & McDermott, 2011). As a result, the implementation of retrieval practice in everyday educational settings has been a focus of discussion, and it was recently highly recommended for classroom use (e.g., Dunlosky et al., 2013; Dunlosky & Rawson, 2015). Roediger and Pyc (2012) further promoted retrieval practice as one of the “inexpensive techniques to improve education” (p. 242).
In conclusion, researchers of cognitive and educational psychology strongly recommend to apply evidence-based teaching methods, but do they follow their own instructions and can they demonstrate in empirical studies how to adapt successfully evidence-based teaching methods such as retrieval practice to their own teaching of psychology? This is a relevant question for two reasons, at least. First, such empirical demonstrations would underpin the credibility of recommendations given by psychologists to teachers and instructors in the field. Second, such empirical demonstrations could encourage other researchers of psychology to innovate and implement techniques in the teaching of psychology based on their own empirical findings. With regard to the testing effect literature, this question is still open. Studies investigating the testing effect with psychological learning materials are seldom and not easily detectable. Many studies were conducted with students of psychology but did not involve psychological learning material (e.g., Pyc & Rawson, 2012). Furthermore, some of the studies examining the testing effect in the context of teaching psychology only comprised small samples and yielded inconclusive results (e.g., Bell, Simone, & Whitfield, 2015). Finally, the only meta-analysis investigating the testing effect in classroom studies (Bangert-Drowns, Kulik, & Kulik, 1991) is over thirty years old, included studies using psychological learning materials but also studies from other domains, and investigated a specific research question, namely the role of multiple testing. Therefore, the current study investigated the extent that the testing effect can be observed and effectively used in learning and teaching psychology using meta-analytic methods to summarize the current state of evidence on this question. Based on evidence demonstrating the generalizability of the testing effect and a growing number of field studies demonstrating beneficial effects of testing in the classroom, we expected a positive overall effect of retrieval practice on the measures of learning performance in psychology classrooms.
Scope of the Meta-Analysis
We searched the literature for studies investigating testing as retrieval practice in the context of learning and teaching psychology and applied two inclusion criteria for identifying relevant studies. First, studies were classified as relevant when retrieval practice was applied in teaching psychology students or in the context of teaching psychological learning content to non-psychology students. Second, studies were only included when effects of testing could be compared with adequate control conditions such as restudying or no testing. Although the implementation of retrieval practice in these studies varied substantially, the study design typically included three phases: An initial learning phase in which the learning materials are presented to the participants for the first time; an intervening phase in which the content is tested, re-studied, or not presented again; and a final test.
With regard to the heterogeneity of the included studies, three study characteristics were systematically coded and controlled because of their influence on the occurrence and the extent of a testing effect. (a) Studies were classified according to whether the study method included a between- or within-subjects design. In between-subjects’ designs, one group of participants takes an intermediate test and another group does not. A testing effect is indicated by higher performance in the intermediately tested group compared to the participants who took only the final test. In within-subjects’ designs, all participants are intermediately tested but not on the complete learning material. The testing effect is indicated by higher accessibility of the previously tested items compared to the non-tested items. Within-subjects’ designs seem to be the more conservative option, because some studies demonstrated that not only the performance on tested material was enhanced but also on non-tested, semantically related material (e.g., Carpenter, 2011; Pyc & Rawson, 2010). Moreover, within-subjects’ designs are more suitable for controlling effects of individual differences. (b) Studies were classified according to whether they applied a restudy or a no-test control condition. Both control conditions cannot completely isolate the testing effect from other potential influences (cf. Rowland, 2014). The no-test condition, for example, lacks additional presentation of the learning material in the intervening phase and thus implies unequal learning times in the test condition and the no-test condition. This method might result in an overestimation of the testing effect which can be addressed by a restudy control condition. However, the availability of learning content in the intervening phase is still different in the restudy condition and the test condition. In the restudy condition, the complete learning content might be presented, but the learning content presented in the test condition is restricted to the correctly recalled information. This contrast might result in an underestimation of the testing effect which can be addressed by providing feedback on the test results so that non-recalled information can be recalled after the test. (c) Given the importance of feedback, studies were classified according to whether or not feedback was given in the test condition. Feedback can address the problem of learning content availability in the intervening phase. Moreover, it can also support the process of adapting learning activities subsequent to retrieval practice as stated earlier. Thus, additional moderator analyses were used to determine the potential influences of the study design, the type of control condition, and the implementation of feedback.
Methods
Search Strategy and Selection Process
All studies contributing data to the current meta-analysis were identified by screening reference lists of current review articles and book chapters on the testing effect, especially those considering research in applied settings and by searching the PsycINFO database using the following search algorithm: (1) testing effect AND learn*; (2) publication range: 1941–August 2015; (3) age group range: 13–64 years; and (4) method: empirical study, and field study. The database search initially provided 485 results from which only 13 publications met the inclusion criteria. The small number of hits resulted from the fact that the search algorithm also included studies that did not address the testing effect, but still contained the search terms testing, effect and learn* (e.g., Schmeck, Mayer, Opfermann, Pfeiffer, & Leutner, 2014). A large number of other studies examined the testing effect, however, confronting learners with material like word pairs (Kang & Pashler, 2014; Tse & Pu, 2012) or prose texts (Einstein, Mullet, & Harrison, 2012; Jonge, Tabbers, & Rikers, 2015) unrelated to the field of psychology.
Another six studies were identified by using the backward snowballing technique and by directly contacting authors with a corresponding research focus. Finally, 19 publications dating from July 1984 to February 2016 fitted the inclusion criteria and provided 72 individual effect sizes ranging from a minimum of one effect size to a maximum of 20 effect sizes for a single publication. All included publications are listed in Appendix A.
Coding of Study Characteristics and Moderator Variables
A coding scheme was installed a priori, taking into account basic information about individual studies (e.g., author/s, year and type of publication), data relevant to calculate individual effect sizes (e.g., sample size, means, and standard deviations) and information about the respective level of moderator variables. All three potential moderators were coded as dichotomous categorical variables: study design (between vs. within); type of control condition (restudy vs. no-test); and implementation of feedback (yes vs. no).
Individual Effect Size Calculation
In the first step, individual effect sizes were calculated as the standardized mean difference (Cohen’s d) of final test performance between the testing condition and the control condition. The standard formula based on the difference between means divided by the pooled standard deviation of test and control condition was used for data coming from between-subjects’ designs (Borenstein, Hedges, Higgings, & Rothstein, 2009, pp. 26–28). Normally, the standard deviation of difference scores is recommended to replace the pooled standard deviation component for data coming from within-subjects’ designs (Borenstein et al., 2009, pp. 28–30). However, this approach was not feasible, because often the necessary data could not be reconstructed from the original studies. Therefore, the formula for independent data was also used for matched data. Given that this procedure generally results in an underestimation of effect sizes for studies using within-subjects’ designs (cf. Hays, 1994, p. 339) we deemed the procedure to be a conservative and thus appropriate way of assessing effect sizes under these conditions.
Depending on the type of data reported in the original studies, various modifications of the basic formula for calculating Cohen’s d were used to determine the individual effect sizes, all implemented in a web-based effect size calculator (Lipsey & Wilson, 2001). A correction factor introduced by Hedges (1981) was used for five effect sizes from small sample studies, because Cohen’s d is known to result in a slight overestimation of the effect size in small samples (< 20 subjects).
Method of Analysis
To calculate a combined overall mean effect size (Cohen’s d) from the individual effect sizes, a random-effects model was run using the Metafor package (Viechtbauer, 2010) in R (R Core Team, 2014). An assumption of a random-effects model is that several true effect sizes underlie the observed effect sizes, and they usually follow a normal distribution. Thus, differences in observed effect sizes are regarded not to result from sampling error alone but also from a true variation between studies. Accordingly, the overall effect calculated from a random-effects model represents the mean of the normal distribution of all true effect sizes. This statistical model seemed appropriate for the current study, because it included studies with heterogeneous sample characteristics and implementations across different field conditions. Therefore, the assumption was justified that differences in the individual effect sizes probably did not only originate from sampling error. Furthermore, assuming that we considered all possible moderators causing differences in the observed effect sizes beyond the sampling error would be unrealistic.
Between-study variance was calculated using the restricted-maximum-likelihood estimator implemented in Metafor. In a comparative review, this method was shown to provide a good balance between being unbiased and efficient, both important criteria for optimality of effect size estimators (Viechtbauer, 2005). Each individual effect size was weighted using inverse-variance weights, taking into account the sampling error and the estimated between-study variance.
A mixed-effects model was used for categorical moderator analysis. This approach combines the two steps of assigning studies to levels of the respective moderator and calculating a mean effect size for studies within these levels by using a random-effects model. The present model included an estimate of the overall mean effect size as the intercept and the three categorical moderators as additional factors.
Two additional analyses were conducted to explore potential biases. First, we checked the data for a possible publication bias. Egger's regression test (Egger, Davey Smith, Schneider, & Minder, 1997) was used to check whether a relationship exists between the observed outcome values from the random-effects model and their respective standard errors. Significant results indicate the existence of a publication bias that originates from a lower chance of publication for small sample size studies that yield only small or moderate effects. Second, a robust variance estimation (RVE) in the form of a meta-regression implemented in the Robumeta package (Fisher & Tipton, 2015) in R was computed to inspect and correct for the influence of dependent effect sizes in the random-effects and mixed-effects models. This analysis was important, because several effect sizes were based on different dependent variables (in the same sample) or based on the same dependent variable compared in overlapping subsamples (same control group or same experimental group). These dependencies could result in correlated estimation errors. The RVE procedure used a correlated effects model as a weighting method to correct for this error. To optimize the RVE procedure for the current data set (comprising only 19 studies), an adjustment for small samples with less than 40 studies was used (Tipton, 2015).
Results
To give a first impression of the current state of research in this field, the distribution of the individual effects sizes is visualized in a forest plot (see Figure 1). The majority of the effect sizes (n = 57) were positive, suggesting a higher learning outcome in the testing condition compared to the control condition. Considering the 95% confidence intervals (Cis) of the effect sizes, however, indicates that only 33 of these positive effects significantly differed from zero. One of the remaining 15 effect sizes was exactly d = 0, and 14 effect sizes were negative suggesting a lower learning outcome in the testing condition compared to the control condition. Inspecting the 95% CIs of these 14 effect sizes, however, revealed that only one CI did not include zero, indicating that only one out of 72 effect sizes designated a significant negative effect of testing.
Forest plot of the individual effect sizes with 95% confidence intervals and overall effect size (total) for the full data set, based on data uncorrected for dependencies.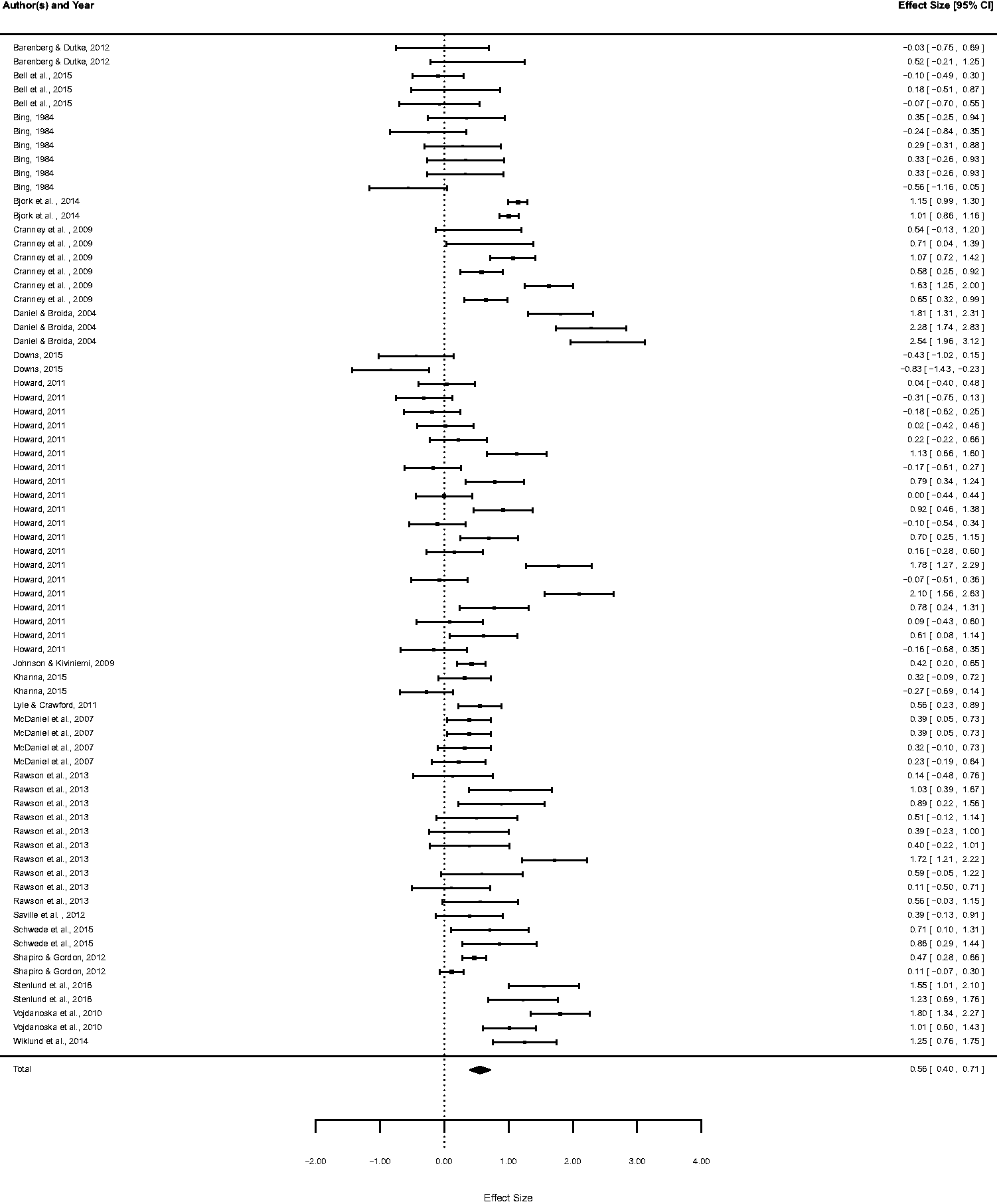
In the uncorrected random-effects model of the full data set, the analysis revealed a mean weighted effect size significantly different from zero, d = 0.56, 95% CI [0.40, 0.71], indicating a beneficial effect of testing. Final test performance in the experimental condition (test condition) was significantly higher than in the control condition (no test or restudy).
Categorical Moderator Analyses
Moderator Analyses
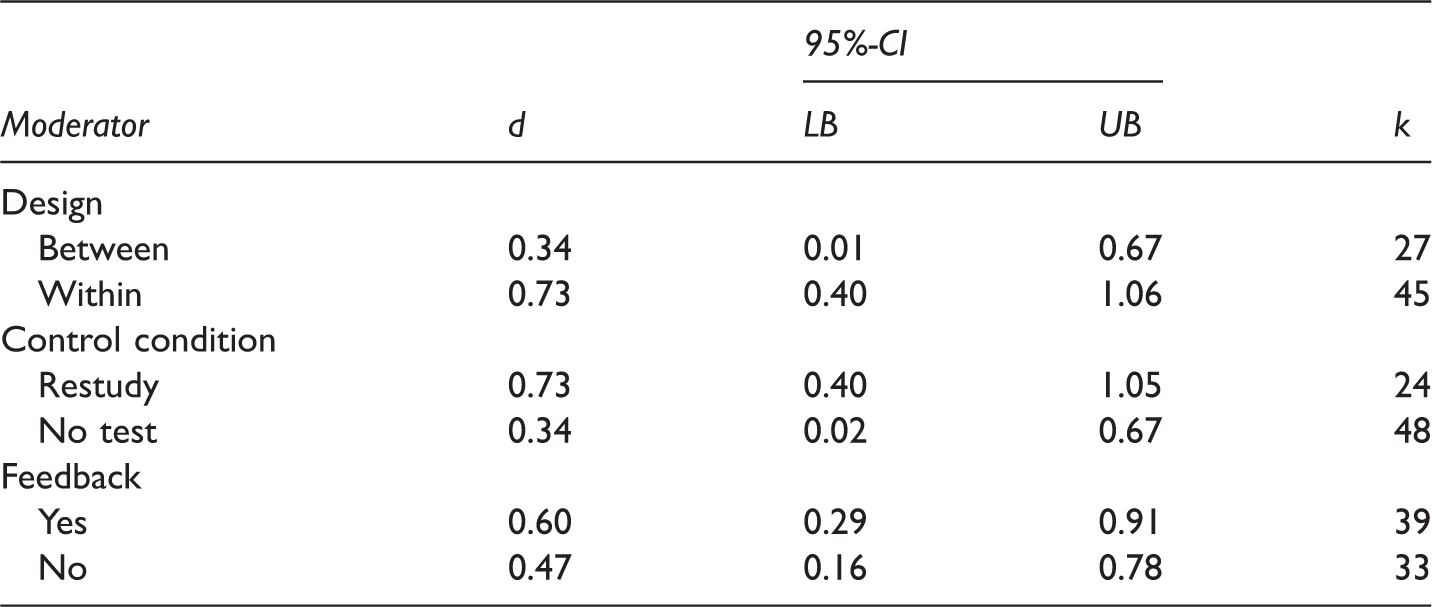
Notes. d = mean weighted effect size Cohen’s d; CI = confidence interval; LB = lower bound; UB = upper bound; k = number of effect sizes; based on data uncorrected for dependencies.
Exploratory Analyses
We first tested for a potential publication bias. Egger's regression test did not reach the conventional level of significance (z = -0.33, p = 0.74). Thus, there was no indication of a publication bias in the current data set that originates from a systematic correlation between sample size and effect size.
We then explored the potential effect of dependency among effect sizes. Applying the RVE procedure to the random-effects model slightly increased the overall effect size, d = 0.62, 95% CI [0.32, 0.93]. A forest plot depicting the distribution of the individual effect sizes clustered by publication can be found in Appendix B. Applying the RVE procedure to the mixed-effects model produced no significant effects of the three moderator variables study design (t = 0.23, p = 0.82), control condition (t = -0.70, p = 0.50), and feedback (t = 1.84, p = 0.10). This result indicates that the dependency of several effect sizes led to a slight underestimation of the overall effect and a slight overestimation of the influence of feedback.
Discussion
Researchers of cognitive and educational psychology argue for the concept of evidence-based teaching which refers to the idea of using theoretically grounded and empirically supported phenomena from the research on learning and memory to improve teaching and student learning. The testing effect is one of the most often cited phenomena in the context of evidence-based teaching and repeatedly recommended to be adopted in the classroom. Whether researchers can support this recommendation by proving effective applications of this idea in their own teaching of psychology, is still an open question. Therefore, we investigated the extent that testing effects can also be demonstrated in teaching and learning psychology. To this end, we identified 19 studies on the testing effect applying psychological learning materials, and we meta-analysed the effects of intermediate testing on learning outcome.
The central result of our analysis is that testing between the acquisition phase and a final test enhanced performance in the final test. Feedback on the result of the intermediate test increased this effect, although the moderator effect of feedback was not significant after controlling for dependencies among the individual effect sizes. A publication bias was not detected, but this result should be carefully interpreted because of the comparably small number of studies. Furthermore, non-statistical causes for a publication bias like individual study quality cannot be detected by Egger’s test.
These results are comparable to the results of other meta-analyses in testing effect research. For example, an early meta-analysis by Bangert-Drowns et al. (1991) summarized 35 field studies from diverse learning contexts (some of them also included psychological learning content). Frequent testing in the classroom was demonstrated to have a positive overall mean effect size on learning outcome variables (0.23 standard deviations). This result indicates a smaller effect of testing compared to the effect found in the current meta-analysis. However, Bangert-Drowns et al. (1991) included studies with different types of control conditions, some of which also included testing but to a smaller extent than in the experimental conditions. The overall mean effect size (0.54) of their 11 studies that compared testing with control conditions without any testing components resembled the mean effect size in the current meta-analysis (0.56). More recently, Rowland (2014) meta-analysed the data of 61 experimental studies examining the effects of testing compared to restudying. The analysis yielded a positive overall mean effect size of 0.50 standard deviations. Although this result was based on experimental studies, the overall mean effect size was comparable to the mean effect size found in the current analysis. Moreover, Rowland (2014) demonstrated that intermediate testing that included feedback yielded larger effects (0.73 standard deviations) than intermediate testing without providing feedback (0.39), which is also in line with the result of our moderator analysis (see Table 1). In sum, even though the current meta-analysis was limited to field studies of learning and teaching psychology, the overall mean effect size matched the results of both earlier meta-analyses. We interpret this result in terms of the robustness of the testing effect, and we conclude that the effect can successfully be adopted to teaching psychology.
Consequently, the implementation of retrieval practice in psychology classrooms is recommendable. First, the current meta-analysis indicates that retrieval practice can be beneficially applied in the psychology classroom to foster students’ learning outcomes. These results, combined with earlier findings, suggest that tests should be implemented not only as assessment and evaluation tools but also as tools to enhance learning. However, teachers are recommended to make this distinction transparent to their students. Learners should know beforehand whether a test is used to evaluate performance or to practice retrieval. Second, practice tests can be easily implemented in the context of psychology learning and teaching. Practice tests are not particularly time-consuming, and in contrast to other learning strategies (e.g., concept mapping or note-taking), they do not need particular instruction and training effort. Third, feedback can further enhance the beneficial effects of the practice tests. Beyond the direct effects of retrieval practice on the memory representation, feedback can serve as an instrument to stimulate indirect beneficial effects by stating explicitly the learning contents retrieved correctly from memory or not. This information can guide the learners’ following learning activities and strengthen the learning progress. Finally, the risk to deteriorate the learning process is extremely low. Only one study indicated a significant, negative effect of intermediate testing on final test performance. Generally, however, it should be recognized that harms and benefits of an intervention as identified in a meta-analysis are only harmful or beneficial in relation to the specific learning procedures and control conditions implemented in the original studies. Thus, implementing practice tests in a specific context does not necessarily lead to the optimal learning design as the learning and teaching goals might diverge from the goals addressed in the meta-analysed studies.
Drawing conclusions from the current results should be made with the following study limitations in mind. First, the meta-analysis comprised only 19 studies, a relatively low number for summarizing empirical results. Thus, further research on implementing retrieval practice in the psychology classroom is needed to confirm the effect when using learning materials on psychology. Moreover, there was a high number of dependent effect sizes, which is a potential source of bias. Although inspection and control of the correlation of estimation errors revealed no indication of a bias corresponding to dependency, a higher number of independent effect sizes is desirable. In the current data, we were unable to control variables potentially influencing the learning outcome in addition to study design, type of control condition, and feedback. For example, future studies should investigate how practice tests are implemented in the psychology classroom. Although the current results add to earlier findings indicating the testing effect to be a robust phenomenon that is also effective in real classroom situations, the high number of effect sizes not significantly different from zero is remarkable. Significant effect sizes from small samples (e.g., Howard, 2011; Rawson, Dunlosky, & Sciartelli, 2013) and non-significant effect sizes from larger samples (e.g., Khanna, 2015; Shapiro & Gordon, 2012) indicate that the lack of significance was not solely due to low statistical power. Thus, future research should focus on the circumstances under which the implementation of retrieval practice in the psychology classroom fosters learning. In addition to our results, such a more advanced analysis could encourage teachers and instructors of psychology to adopt the findings of their own research discipline and encourage teachers and instructors of other fields of academic learning to rely on psychologists’ recommendations.
Footnotes
Acknowledgements
We thank Jörg-Tobias Kuhn and Paul-Christian Bürkner for valuable discussions.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.