
Abstract
The purpose of the present article is to propose an alternative short form for the 199-item Arizona Life History Battery (ALHB), which we are calling the K-SF-42, as it contains 42 items as compared with the 20 items of the Mini-K, the short form that has been in greatest use for the past decade. These 42 items were selected from the ALHB, unlike those of the Mini-K, making direct comparisons of the relative psychometric performance of the two alternative short forms a valid and instructive exercise. A series of secondary data analyses were performed upon a recently completed five-nation cross-cultural survey, which was originally designed to assess the role of life history strategy in the etiology of interpersonal aggression. Only data from the ALHB that were collected in all five cross-cultural replications were used for the present analyses. The single immediate objective of this secondary data analysis was producing the K-SF-42 such that it would perform optimally across all five cultures sampled, and perhaps even generalize well to other modern industrial societies not currently sampled as a result of the geographic breadth of those included in the present study. A novel method, based on the use of the Cross-Sample Geometric Mean as a criterion for item selection, was used for generating such a cross-culturally valid short form.
The Psychometric Assessment of Life History (LH)
LH theory is a mid-level evolutionary theory governing optimal resource allocation among different components of fitness. The theory implicitly relies on regarding both the parent and the offspring as partially interchangeable vehicles for the ultimate function of genetic propagation. Selection upon the genome therefore allocates bioenergetic and material resources among those dedicated to parental survival (somatic effort) and those dedicated to offspring production and preservation (reproductive effort). Sexually reproducing organisms further partition reproductive effort among those resources needed for obtaining and retaining sexual partners (mating effort) and those needed for the longer term survivorship of the offspring produced (parental/nepotistic effort).
Although LH selection is ultimately based on genetic propagation, selection acts by shaping the proximate adaptive profiles of resource allocations. Bioenergetic and material resources need to be mobilized to achieve the functional objectives of survival and reproduction. These resource mobilizations power the expression of the biological and behavioral adaptations that are the individual tactical elements deployed by the governing LH strategies.
The rationale that undergirds the psychometric approach to the assessment of LH strategies is to tap into the dynamics of these proximal resource allocations, rather than monitoring the attainment of the distal achievements to which they are directed. This is based upon the evolutionary psychological conception of organisms as adaptation executers rather than as fitness maximizers, where the resource allocations are the adaptations being executed and the distal achievements are the specific components of fitness being maximized. In contrast, the biodemographic approach directly samples the distal achievements eventually produced by these resource allocations, such as age of puberty, age of first sexual contact, number of sexual partners, age of first birth, interbirth interval, number of offspring at completed fertility, and so on.
Although the biodemographic approach has also proven useful in the study of LH strategies, it suffers from various limitations, as all single methods ultimately do. Among them is the well-known fallibility of the relation between motivation and performance in psychology. According to one formulation of this problem (Mitchell, 1982), performance can be modeled as the multiplicative product (or statistical interaction) of the individual’s motivation, the individual’s ability, and the individual’s environment. This model states explicitly that, aside from the individual’s motivation, the individual requires the physical and mental ability to perform the task as well as an environment that affords the requisite resources for the goal’s attainment.
Applying this specifically to LH strategies, a human adolescent male’s age of first sexual contact and number of sexual partners are not uniquely determined by his motivational state, which in most cases we can safely presume to be quite high. It is also codetermined by a number of intrinsic individual characteristics, such as his sexual attractiveness, social skills, and social status, and additionally by a number of extrinsic ecological characteristics, such as the availability of willing female sexual partners, the degree of direct access to such willing female sexual partners afforded by the environment, and the socially imposed restrictions (or lack thereof) governing adolescent sexual activity. A human adolescent male’s age of first sexual contact and number of sexual partners are thus not very pure measures of his either slower of faster LH strategy, which is a highly heritable trait and thus not very contingent upon such transient ambient circumstances (h 2 ∼ .65; Figueredo & Rushton, 2009; Figueredo, Vásquez, Brumbach, & Schneider, 2004). Similarly, a human female’s age of first birth, interbirth intervals, and number of offspring at completed fertility is codetermined by a number of individual difference factors, such as her physical condition and a number of ecological and sociocultural factors, such as environmental resource abundance and any socially imposed regulation of either the timing or the relational context of reproductive activity. At the present time, we believe that there is insufficient empirical evidence reported in the published literature to determine whether there might or might not be any sex differences in the heritability of LH strategy.
This is not to say that the psychometric approach is somehow more valid than the biodemographic approach or vice versa. The idea is that they are complementary, as they each provide windows into different successive stages of the same causal processes (Garcia et al., 2016). The psychometric approach is based on sampling behavioral and cognitive indicators of the LH resource allocations among different component domains of fitness. For example, the Arizona Life History Battery (ALHB) contains seven subscales (not including the Mini-K, which is designed as domain general) that sample the following domain-specific psychosocial resource allocations: (1) Insight, Planning, and Control; (2) Mother/Father Relationship Quality; (3) Family Social Contact and Support; (4) Friends Social Contact and Support; (5) Romantic Partner Attachment; (6) General Altruism; and (7) Religiosity. This sampling of resource allocation domains is not represented as completely exhaustive. However, we believe that it provides reasonably adequate coverage of the major areas of psychosocial resource investment that LH theory would predict as characterizing a slower LH strategy; faster LH strategists are thus predicted to score lower on the latent common factor that can be extracted from these seven more domain-specific subscales.
The Mini-K and the K-SF-42
Since it was first published 10 years ago (Figueredo et al., 2006), the Mini-K has been a highly successful 20-item short form for the psychometric measurement of LH strategy. It has fared very well in meta-analyses (e.g., Figueredo et al., 2014), with a mean bivariate correlation of
An acknowledged disadvantage of the Mini-K is its limited reliability (
The 20 items on the Mini-K are not a subset of the 199 items on the ALHB but are instead unique items written to assess its content areas more globally. For example, 2 items (“While growing up, I had a close and warm relationship with my biological mother” and “While growing up, I had a close and warm relationship with my biological father”) were written to summarize the substantive content of the 26-item Mother/Father Relationship Quality subscale (adapted from Brim et al., 2000; Figueredo, Vásquez, Brumbach, & Schneider, 2004, 2007) of the ALHB. This strategy was deemed optimal for producing a 20-item short form in comparison with selecting the “best” items from the subscale, as even the 2 best-performing individual items (by whatever criterion) were unlikely to cover the entire substantive content of the subscale and reflect the full breadth of the construct. The Mini-K was originally developed for use in situations wherein time constraints made use of the full ALHB prohibitive. It was never recommended for situations where the psychometric assessment of LH strategy was intended as a cornerstone of the research; in such cases, the full ALHB was to be preferred and was presumed to be worth the cost in added response burden. Additionally, the recent completion of a large cross-cultural survey using the ALHB (Figueredo et al., 2016) presents an opportunity to create a short form that can also stand up to tests of cross-cultural validity. We illustrate a novel method for generating such a cross-culturally valid short form.
Description of the Present Study
These characteristics of the Mini-K offer an opportunity, after a decade of productive use, to propose a somewhat longer short form that might retain some of its advantages, avoid its major disadvantages, and allow for more flexibility in research application. The purpose of the present article is to propose such an alternative short form for the ALHB, which we are calling the K-SF-42, as it contains 42 items (see Appendix for a complete listing). These 42 items are directly selected from the ALHB, unlike the 20 items of the Mini-K, making direct comparisons of the relative psychometric performance of the two alternative short forms a potentially valid and instructive exercise.
The purpose of this article is not, however, to present a review of the construct validity of the ALHB itself, as we have already published a rather extensive meta-analysis on both the predictive (“nomological”) and convergent validity of the Mini-K and the ALHB (Figueredo et al., 2014). We have also published a more complete treatment of the construct validity of the hierarchical latent structure of the Mini-K, the ALHB, and related measures using multiple data sets and applying confirmatory factor analyses as well as other methods (Olderbak, Gladden, Wolf, & Figueredo, 2014). Furthermore, we have also expounded eloquently elsewhere upon the epistemological and methodological rationales underlying the psychometric approach to assessing LH strategy (Figueredo, Cabeza de Baca, & Woodley, 2013; Figueredo et al., 2015).
To maintain the breadth of the construct at each level of aggregation, 6 items were selected from each of the seven subscales of the ALHB (not including the Mini-K), representing several domains of potential allocation of bioenergetic and material resources in a manner consistent with the execution of a slow LH strategy. Where appropriate, these 6 items were balanced across the multiple subdomains sampled by each subscale. As novel item selection procedures were applied to obtain items and subscales that functioned at the highest levels of cross-cultural generality, we followed up with item response theory (IRT) Rasch modeling (Bond & Fox, 2001) of both individual items and aggregated subscales to ascertain whether our procedures performed as intended. We also performed a generalizability theory (GT) analysis (Figueredo & Olderbak, 2008) on the IRT-generated subscale difficulty estimates to test for the degree of cross-cultural invariance that our procedures managed to achieve.
This series of secondary data analyses were performed upon a recently completed five-nation cross-cultural survey, which was originally designed to assess the role of LH strategy in the etiology of interpersonal aggression (Figueredo et al., 2016). Only data from the ALHB, collected in all five cross-cultural replications, were used for the present analyses. The single immediate objective was producing the K-SF-42, such that it would perform optimally across all five cultures sampled, and perhaps even generalize well to other cultures not currently sampled as a result of the geographic breadth of those included in the present study.
Method
Participants and Procedures
A total of 738 undergraduate students participated in the study, enrolled in introductory psychology courses in five different major universities located in Australia (AU; N = 131), Italy (IT; N = 172), Mexico (MX; N = 160), Singapore (SG; N = 115), and the United States (US; N = 160). In the original study from which these data are derived (Figueredo et al., 2016), participants completed a series of computerized self-report questionnaires assessing the following constructs: LH strategies; executive functioning; mating strategies; mate values; mating effort; revenge ideologies; psychopathic and aggressive attitudes; and their coercive, aggressive, and possibly violent behavioral interactions over the past year with any and all members of their same sex and with any and all members of the opposite sex (whether or not they were intimate romantic partners) with which they might have interacted. Participants signed up for the study, provided informed consent, and completed the questionnaires through a secured Internet website.
Measures
The ALHB
The ALHB (Figueredo et al., 2007) is a set of cognitive and behavioral indicators of LH strategy compiled and adapted from various original sources. These self-report psychometric indicators measure graded individual differences along various complementary facets of a coherent and coordinated LH strategy, as specified by LH theory, and converge upon a single multivariate latent construct. These were scored and aggregated directionally to indicate a slow (high-K) LH strategy, on the fast–slow (r–K) continuum. Not including the Mini-K, the seven subscales of the ALHB are as follows: Insight, Planning, and Control (20 items; adapted from Brim et al., 2000; Figueredo et al., 2004, 2007); Mother/Father Relationship Quality (26 items; adapted from Brim et al., 2000; Figueredo et al., 2004, 2007); Family Social Contact and Support (15 items; adapted from Barrera, Sandler, & Ramsay, 1981; Figueredo et al., 2001); Friends Social Contact and Support (15 items; adapted from Barrera et al., 1981; Figueredo et al., 2001); Experiences in Close Relationships (ECR: 36 items; adapted from Brennan, Clark, & Shaver, 1998; Alonso-Arbiol, Balluerka, & Shaver, 2007; Figueredo et al., 2005); General Altruism (50 items; adapted from Brim et al., 2000; Figueredo et al., 2004, 2007); and Religiosity (17 items; adapted from Brim et al., 2000; Figueredo et al., 2004, 2007). As the internal consistency reliabilities of the ALHB subscales are a major subject of the present analyses, presentation of these psychometric properties will be deferred to the Results section.
The Mini-K
The Mini-K (Figueredo et al., 2006) is a 20-item short form of the ALHB. Meta-analytically (e.g., Figueredo et al., 2014), the Mini-K has shown a high mean bivariate correlation (
Statistical Analyses
All statistical analyses were performed using MS Excel 2003 (Microsoft, 2003), SAS 9.3 software (SAS Institute Inc., 2011), and WINSTEPS 3.68.1 (Linacre, 2016).
Certain theoretically motivated decisions were made at the beginning of this process regarding items that would not be the candidates for inclusion in the new short form, the K-SF-42. One such decision was to eliminate from consideration the set of items in the General Altruism scale sampling Altruism Toward Children, as it tended to produce an overabundance of missing data in younger samples of participants, and was not deemed theoretically essential to the construct being measured.
The cross-sample geometric mean (CSGM) method for optimal item selection
To maintain the breadth of the construct at each level of aggregation, 6 items were selected from each of the seven subscales of the ALHB (not including the Mini-K), representing several domains of potential allocation of bioenergetic and material resources in a manner consistent with the execution of a slow LH strategy. Where appropriate, these 6 items were balanced across the multiple subdomains sampled by each subscale. For the Mother/Father Relationship Quality subscale, the 6 items were selected by sampling the best 3 items from each of the parental (Mother and Father) subdomains. Similarly, for the General Altruism scale, the 6 items were selected by sampling the best 2 items from each of the following three subdomains: Altruism Toward Kin, Altruism Toward Friends, and Altruism Toward Community.
The way that we operationalized which items were “the best” defined the novelty of this approach and has the beauty of its great simplicity. We first calculated the part-whole correlation of each item score with the unit-weighted (UW) factor score for the subscale in which it was nested, conceptually representing the UW factor loadings of each item. We did this separately for each of the five cross-cultural replications and pasted these as columns on a single MS Excel spreadsheet. We used the spreadsheet to compute the geometric mean of these part-whole correlations across all five cross-cultural replications. Next, we selected the 6 items with the highest geometric means from each subscale (within the subdomain constraints outlined above) for inclusion in the K-SF-42, by simply using the spreadsheet to sort the data by the columns containing the subscales and the geometric means in descending order.
The rationale for using the geometric rather than arithmetic mean is that it involves the multiplication rather than the addition of the parameter estimates for each of the five cross-cultural replications. In the case of the arithmetic mean, the sum is divided by n; in the case of the geometric mean, the nth root of the product is instead calculated. Multiplication is equivalent in Boolean algebra to a logical “AND” statement or logical conjunction; whereas addition is equivalent in Boolean algebra to a logical “OR” statement or logical disjunction. A high product term is thus only produced when the values in all the coefficients being multiplied are high; a high additive term, on the other hand, can still be obtained if one or more of the coefficients being summed are sufficiently high to compensate for any that might be lower. Thus, a higher geometric mean is a stronger filter than a high arithmetic mean for selecting items that perform sufficiently well across all (rather than mere some) of the multiple cultures sampled. We have therefore named this the CSGM method for optimal item selection, having been first pioneered in a previous study but gone without any special designation (Patch, Garcia, Figueredo, & Kavanagh, 2016).
In contrast, other short form construction methods that rely on empirical selection of variables will often experience problems of replication when applied to independent samples, especially cross-cultural ones. Part of this problem arises from model fitting to sample-specific characteristics that are not present in other samples. For example, empirical selection methods may capitalize on chance differences (stochastic fluctuations) among item characteristics that are purely due to sampling error; as a result which items are truly the best may not replicate between one independent and another even if they are drawn from the same population, being analogous to statistical “Type I Errors.” Furthermore, empirically based selection of locally optimal items can lead to disastrous results when applied outside of the population upon which the new scale was originally developed. Although this latter circumstance is obviously less of a problem the more alike the samples are to each other, between-sample differences on relevant characteristics can be quite large in the case of cross-cultural research.
After implementing the CSGM procedures, we had to assess whether this seemingly clever tactic actually worked in practice by performing each of the following psychometric assessment procedures: (1) We compared the internal consistency reliabilities of the short form with the long form for each of the seven subscales of the ALHB, (2) we compared the part-whole correlations (UW factor structures) of the short form with the long form for each of the seven subscales of the ALHB, (3) we examined the simple bivariate correlations of the short form with the long form for each of the seven subscales of the ALHB, (4) we examined the relative internal consistency reliabilities of the two alternative short forms (Mini-K and K-SF-42) of the ALHB, each as a unitary scale irrespective of internal structure, as well as the correlations of those UW scale scores with the UW factor score of the full ALHB, and (5) we examined the relative incremental validities of the two alternative short forms (Mini-K and K-SF-42) of the ALHB in multiple regression models predicting the UW factor score of the full ALHB.
IRT Rasch modeling of item and subscale difficulties
To validate the results obtained by means of this novel method by more conventional means, we ran a one parameter Rasch model to obtain IRT parameter estimates on the K-SF-42 items and subscales. The IRT parameter of primary interest was the so-called item difficulty, which indicates how high a factor score on the underlying latent variable (θ) is required to produce a “correct” response on any given item (Bond & Fox, 2015). The latent variable of interest is typically cognitive ability (g), but in the present case it is simply LH speed (K). The IRT method chosen was the single parameter Rasch model and analyzed with WINSTEPS. First, countries were combined within subscales, and each subscale was analyzed with countries as items. This was done as a way to see whether countries differed in their relative rank within each subscale, a rough indication of differential item functioning of countries within subscales. Second, subscale totals were computed and then designated as items in an overall total scale score, also in a Rasch analysis. This allowed for subscales to be ranked in terms of “difficulty” in terms of their ease of endorsement in their overall LH strategy. The easiest subscales would be those with the highest priority of endorsement—a strategy most commonly shared in the population. After computing subscale difficulties by country, they could be inspected for relative difficulty or relative importance to each population.
The rationale behind these analyses was that it was important to determine whether our novel item selection procedure, based on classical test theory (CTT), might have selected items that were too similar on item difficulty as a result of being highly correlated with each other. CTT item selection procedures have been criticized for having this bias (Bond & Fox, 2015), as a scale composed of items of similar difficulties will not adequately measure individual persons throughout the extent of the latent trait, and thus may incorrectly assess the latent trait score of persons either substantially above or substantially below that central tendency. In the case of the K-SF-42, we had endeavored to preserve the autonomy among these subscales by the hierarchical design of our item selection procedure, as we understood that limitation in advance and took that step to hopefully avoid it. That is why the CTT procedure that we used only selected the best (most highly correlated) items within each subscale. We hypothesized that although the items within subscales might have similar item difficulties, each of the aggregated 6-item subscales should nonetheless have different difficulties. Assessing difficulties was in this case assessing their range of sensitivity of each of the subscales to the latent construct of LH speed (K). This latter prediction was based on the premise underlying the development of the ALHB, where each of the subscales represents a distinct domain-specific opportunity for an LH-based resource allocation decision to differentially invest (or not) in that particular system of social relationships. As each specific resource allocation domain should have a different item difficulty in terms of LH speed, we should therefore be able to observe substantial variance among the subscale difficulties. The hierarchical item selection procedure that we used should therefore enable the K-SF-42 to measure the full range of LH speed (K) along the broader difficulty distribution of subscales.
Generalizability analyses of item and subscale difficulties
The other important question that we hoped to address by these analyses was whether the subscale difficulties differed substantially across the sampled cultures. As we did not have enough data in each sample for a formal differential item functioning analysis (Acar, 2011; Linacre, 2013, 2016; Scott et al., 2009; Tristan, 2006), we instead subjected the individual-level subscale difficulty estimates to general linear modeling (GLM) and GT analyses (Figueredo & Olderbak, 2008). We restricted these analyses to aggregate subscale scores, as the cross-cultural functioning of the individual items within subscales was of lesser interest, for reasons already stated.
A GLM was constructed, analogous to a two-way analysis of variance, where we tested for effects on the person-level difficulty estimates of: (1) the different cross-cultural samples, (2) the different subscales, and (3) the two-way interaction between them. We then followed up with estimated mean squares and variance components analysis using the same design to obtain estimates of the latent variance components hypothetically underlying these observed variances, first using Type 1 and then using reweighted maximum likelihood (REML) estimation for comparison. Finally, we used these variance component estimates to calculate generalizability coefficients for each of the two random effects of interest with respect to their interaction with each other, based on the Type 1 and REML estimates obtained.
Results
Table 1 presents side-by-side comparisons of the internal consistencies of the K-SF-42 and the full ALHB for all five cross-cultural sites. All Cronbach’s α for both the K-SF-42 and the full ALHB met the criterion for “acceptable” (α ≥ .70) with 64 of 70 meeting the criterion for “good” (α ≥ .80) and 40 of 70 meeting the criterion for “excellent” (α ≥ .90). Across all five cross-cultural sites, only one scale (General Altruism) demonstrated an appreciable decrease in internal reliability when going from the full ALHB to the K-SF-42 (mean Δα = −.16). This difference, however, did not drop the value of Cronbach’s α below the acceptable threshold (range α = .71–.78, median = .77). The other six scales showed a decrease of no more than .11 in Cronbach’s α when using the K-SF-42 (range Δα = −.11 to .04, median Δα = −.03).
Internal Consistency Reliabilities for Convergent Indicators of Life History Strategy in Australia (AU), Italy (IT), Mexico (MX), Singapore (SG), and the United States (US).
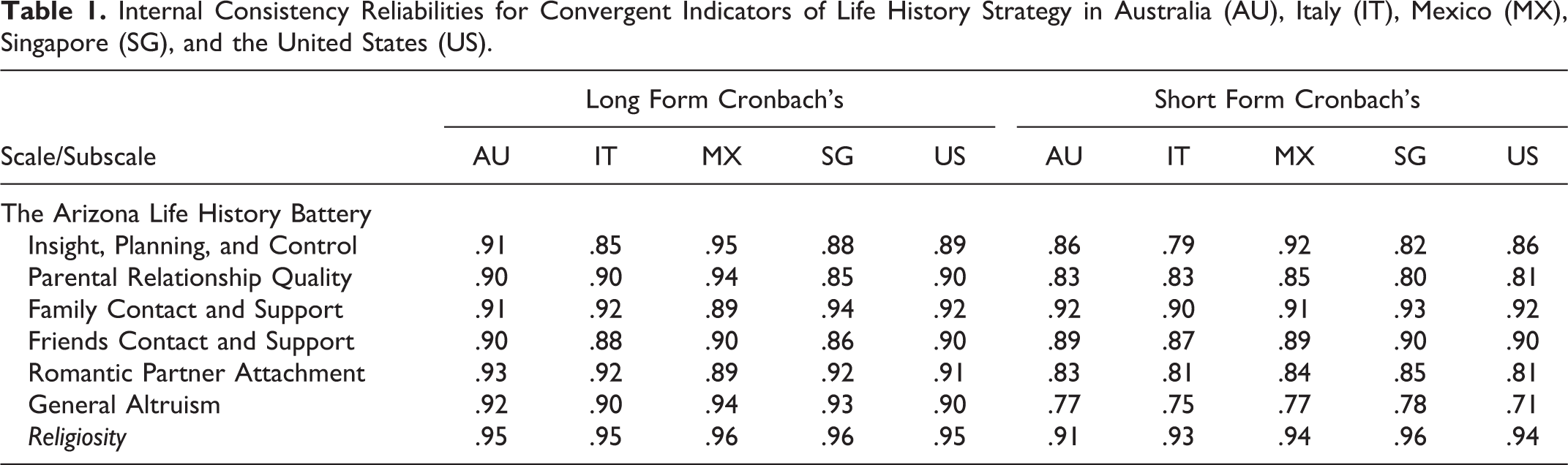
Table 2 presents the UW factor structures of the K-SF-42 and the full ALHB for all five cross-cultural sites. Only two part-whole correlations showed a change of greater than .10 when going from the full ALHB to the K-SF-42, Religiosity in SG (ΔUW λ = +.10) and General Altruism in IT (ΔUW λ = −.10). Nevertheless, these changes do not appear to decrease the part-whole correlations into a range of questionable validity. The statistical nonsignificance of average scale part-whole change between forms seems to support this (AU mean ΔUW λ = −.01, p > .05; IT mean ΔUW λ = −.02, p > .05; MX mean ΔUW λ = −.02, p > .05; SG mean ΔUW λ = .00, p > .05; US mean ΔUW λ = −.00), p > .05).
Unit-Weighted (UW) Factor Structures for Convergent Indicators of Life History Strategy in Australia (AU), Italy (IT), Mexico (MX), Singapore (SG), and the United States (US).

*All part-whole correlations (UW factor loadings) are statistically significant at p < .05.
Table 3 presents the short–long correlations between the K-SF-42 and the full ALHB for all five cross-cultural sites. All short–long correlations are strong and positive (range = .74–.98, median = .90), indicating a high degree of agreement between the short and long form when measuring each domain-specific component of slow LH.
Short-Long Form Correlations for Convergent Indicators of Life History Strategy in Australia (AU), Italy (IT), Mexico (MX), Singapore (SG), and the United States (US).

*All short-long form correlations are statistically significant at p < .05.
Table 4 presents side-by-side comparisons of the internal consistencies and short–long form correlations of the Mini-K Short Form and the K-SF-42 for all five cross-cultural sites. On all metrics and for all sites, the K-SF-42 outperformed the Mini-K Short Form. Cronbach’s α comparison tests showed a statistically significant improvement of the K-SF-42 over the Mini-K Short Form, AU χ2(1) = 8.74, p < .05; IT χ2(1) = 30.30, p < .05; MX χ2(1) = 3.94, p < .05; SG χ2(1) = 13.64, p < .05; US χ2(1) = 25.79, p < .05, by a median of .12 (range = [.04, .18]). The same was true for short–long correlation comparison tests, AU t(130) = −4.81, p < .05; IT t(171) = −4.22, p < .05; MX t(159) = −8.4, p < .05; SG t(115) = −6.18, p < .05; US t(159) = −6.97, p < .05, which showed improvement by a median of .13 (range = [.10, .18]).
Internal Consistency Reliabilities of Alternative Short Forms (Mini-K and K-SF-42) for Latent Multivariate Construct of Life History Strategy in Australia (AU), Italy (IT), Mexico (MX), Singapore (SG), and the United States of America (US).

*All short-long form correlations are statistically significant at p < .05. †All Cronbach’s α and short–long correlations for the K-SF-42 are statistically greater than those of the Mini-K at p < .05.
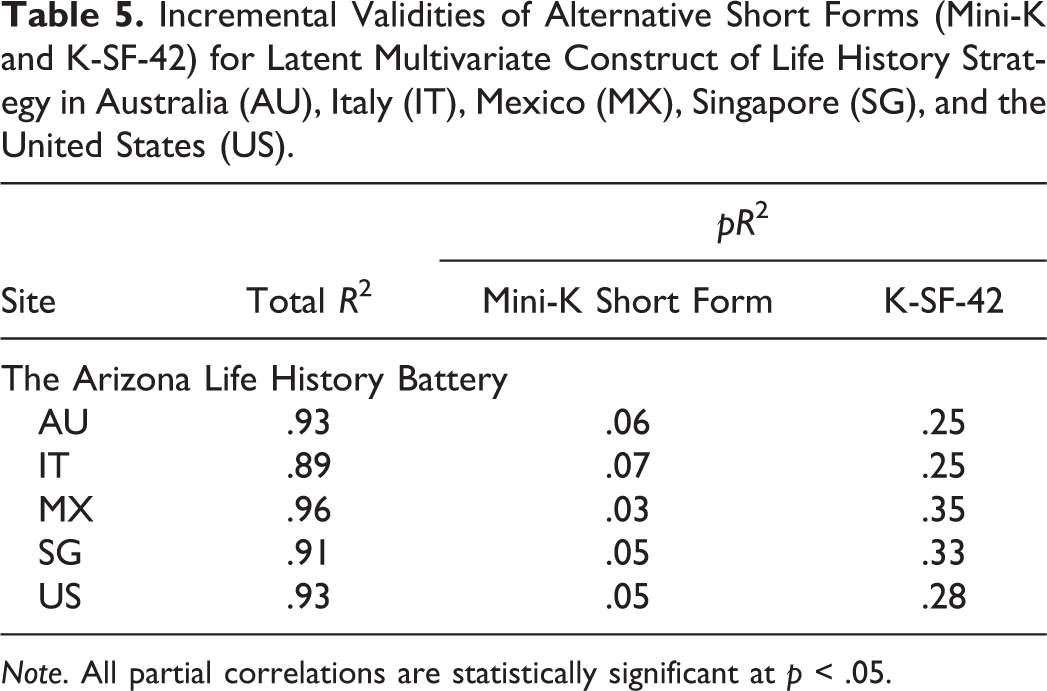
Table 5 presents the incremental validities of the Mini-K Short Form and the K-SF-42 for all five cross-cultural sites. When both short forms were entered into a regression to predict the full ALHB, the total explained variance was high (R 2 range = range = [.89, .96] median = .93), indicating that the two short forms taken together capture most of the variance of the full ALHB. The partial R 2 for each short form represents the proportion of the variance that is uniquely explained by that short form. In other words, it is the incremental validity of that short form over the other. All partial R 2s were statistically significant; however, the partial R 2s of the K-SF-42 were approximately between 3.5 and 11.5 times greater than those of the Mini-K Short Form (median = 4 times). This means that while the Mini-K Short Form and the K-SF-42 captured much of the same variance of the full ALHB, the K-SF-42 alone accounted for more uniquely; it had greater incremental validity.
Incremental Validities of Alternative Short Forms (Mini-K and K-SF-42) for Latent Multivariate Construct of Life History Strategy in Australia (AU), Italy (IT), Mexico (MX), Singapore (SG), and the United States (US).
Note. All partial correlations are statistically significant at p < .05.
Column 1 of Table 6 displays the standard deviations of the raw item difficulties within subscales. We believe that these were adequate dispersions, with the possible exception of the General Altruism subscale. Although we do not know why the dispersion among items for that one subscale was lower than the others, we believe that these standard deviations generally indicate a reasonably adequate dispersion of the items within subscales. Columns 2–5 of Table 6 display the standardized subscale Infit/Outfit Mean Squares and standardized subscale Infit/Outfit Standard Deviations for each of the subscale scores. For efficiency of presentation, subscale scores were aggregated across all five cross-cultural samples. We believe these to be excellent indices of both infit and outfit for all of the subcales, indicating an adequate data–model fit.
Standard Deviations (SD) of Raw Item Difficulties Within Standardized Subscale Infit/Outfit Mean Squares (MNSQ) and Standardized Subscale Infit/Outfit SD for Convergent Indicators of Life History Strategy.
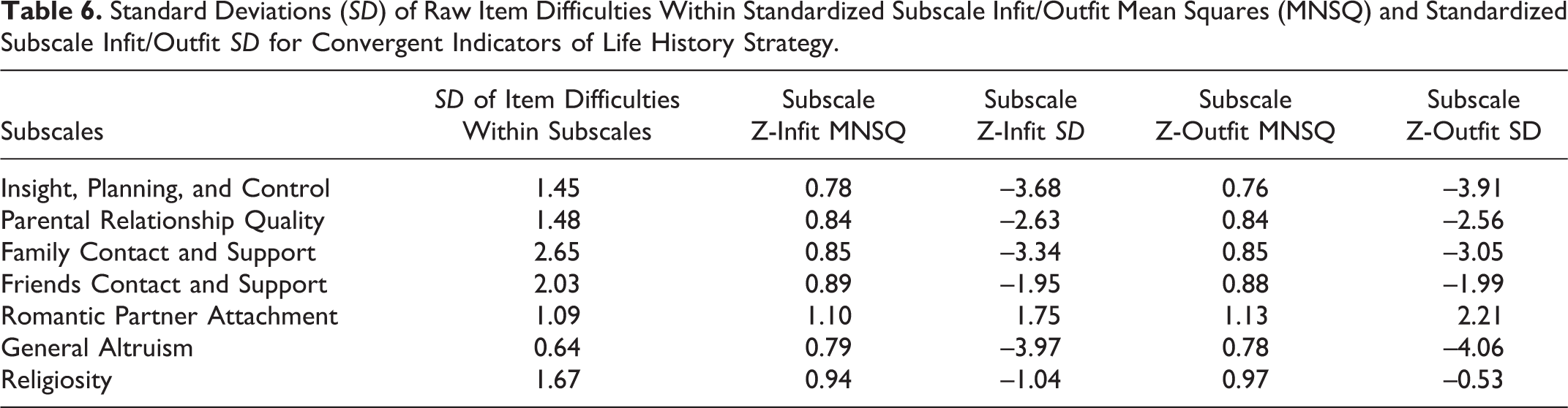
Table 7 displays the results of our generalizability analyses of the IRT-based subscale difficulties for the K-SF-42. We did not estimate the generalizability across cultures of individual item scores as these were of lesser interest given that using the CSGM method as a criterion for item selection does not guarantee preserving optimal ranges of difficulties among items within subscales.
Generalizability Analysis of IRT-Based Subscale Difficulties for the K-SF-42.

Note. IRT = item response theory; REML = reweighted maximum likelihood.
*Statistically significant at p < .05.
First, the preliminary GLM shows that the preponderance of the systematic variance in difficulties is accounted for by the main effect of subscale (73.9%), supporting the greater variance among subscales we predicted, with only relatively trivial amounts accounted for by the main effect of Sample (7.9%) and the Sample × Subscale interaction (18.1%), indicating that the variance in difficulties among the different cross-cultural samples was not very substantial and that the variance in the rank ordering of subscale difficulties different among cross-cultural samples was also relatively minor.
Second, we performed an expected mean squares analysis, modeling both Sample and Subscale as random factors, such that the interaction term (Sample × Subscale) intruded on each of them and thus served as the common denominator term for both main effects in all further calculations. This permitted the estimation of the hypothetical variance components by two convergent methods, hierarchical Type 1 sums of squares (conservatively assigning causal priority to Sample) and REML, and these are tabulated for comparison within the last two columns.
Third, these estimated variance components were used to compute the following two generalizability coefficients, using each of these two estimation methods: (1) for Sample as the focal facet, being generalized across the Sample × Subscale interaction as the random facet and (2) for Subscale as the focal facet, being generalized across the Sample × Subscale interaction as the random facet. These indicated that the variance in difficulties among cross-cultural samples did not generalize very well across the subscales (
As a visual illustration of these results, Figure 1 shows a consistency in the relative difficulty of the seven subscales across the five countries, a consistency observed in the “all” countries category. The one apparent inconsistency is the family scale difficulty for the Singapore sample. Specifically, the Singapore family score was rated as very easy in comparison to the other four countries. This especially low score on that subscale, as compared with the other cross-cultural samples, may be attributable to traditional Asian family values ultimately based on the “filial piety” preached by the Eastern Sage Confucius (孔夫子 Kǒng Fūzǐ, 551–479 BC; Soothill, [1910] 1937).

Item response theory subscale difficulties for K-SF-42.
Discussion
The new and slightly longer short form of the ALHB (as compared with the Mini-K), which we named the K-SF-42, performed very well with respect to various psychometric standards against which it was evaluated. The K-SF-42 reduced the number of items needed to assess slower LH from 199 items in the original ALHB to only 42 items in the new short form, and it did so with minimal losses of internal consistency reliability and convergent validity among the constituent subscales. We believe that these psychometric indices of performance would have been deemed adequate had we submitted the original interpersonal aggression study for publication using the K-SF-42 in place of the full ALHB; it is doubtful that any reasonable editor or peer reviewer would have been concerned with the adequacy of reported psychometric benchmarks had they not seen the slightly better ones provided by the full ALHB.
In addition, we found high correlations between the UW factor scores for the reduced K-SF-42 subscales and the full ALHB subscales, between the UW factor scores for the overall K-SF-42 and ALHB, and even between the UW factor scores for the overall K-SF-42 and Mini-K. Treating the K-SF-42 as a unitary scale, irrespective of internal subscale structure, we found small but statistically significant improvements in the K-SF-42 with respect to the Mini-K in their internal consistency reliabilities and predictive validity coefficients in relation to the full ALHB. Testing for incremental validity of the K-SF-42 with respect to the Mini-K in predicting the full ALHB score, we found their overlap to be quite substantial, but the unique proportions of variance predicted by the K-SF-42 to be substantially greater in magnitude predicted than those predicted by the Mini-K, although these latter variance components were also statistically significant.
We therefore conclude that the K-SF-42 has been developed such that it performs optimally across all five cultures sampled, and that these results will perhaps prove to generalize similarly to most other modern industrial societies that were not currently sampled as a result of the geographic breadth of those included in the present study. We would therefore recommend the K-SF-42 for use over the Mini-K for situations in which the total acceptable response burden of the study can bear the weight of more than 20 items but less than 199 items for the psychometric assessment of LH strategy.
As the K-SF-42 has been newly introduced with the present article, there are as yet no data on its predictive validity. Nevertheless, we believe that the magnitudes of the reported correlations of the K-SF-42 with both the Mini-K and the full ALHB are sufficiently high that we can confidently expect that its predictive validities would be comparable to the latter, lying somewhere between that of the Mini-K and the full ALHB, and moderated only by its intermediate reliability. As cited above, the meta-analytically disattenuated correlation coefficient (ρ) between the Mini-K and the full ALHB was .91 (Figueredo et al., 2014); although we do not yet have sufficient data on the K-SF-42 to make such a precise estimate, there is not reason to believe that it would not be even higher, given the evidence that we presented in the present article. Under that assumption, it is a straightforward logical inference to predict that the K-SF-42 should have stronger predictive power than the Mini-K for all criterion variables that have been assessed so far.
Finally, we have validated a novel methodology for producing cross-culturally valid short forms of longer measures using the CSGM method for optimal item selection. We have also cross-validated this novel method using IRT Rasch analyses of the item and subscale difficulty levels, followed by GT analyses that showed acceptable levels of consistency in the rank ordering of aggregate subscale difficulties across the cultures sampled. Thus, we have shown that the CSGM method can produce psychometrically acceptable and robust results, at least in application to the present data.
We understand that we have not conformed to the conventional “best practices” psychometric standards in these empirical demonstrations, mostly due to limitations in the sample size available from each cross-cultural replication, but we emphasize that one of our major objectives in writing this article was to introduce a novel method for creating short forms out of long forms by using data from multiple independent samples in a creative new way. Nevertheless, we have compared the performance of this novel method with those of a more conventional one, and we interpret the results of the IRT Rasch analyses and associated GT analyses as generally supporting the efficacy of the CSGM method for creating the K-SF-42, in that: (1) The dispersion of item difficulties within each subscale sufficiently covered each content domain, (2) the dispersion among aggregate subscale difficulties within the overall K-SF-42 scale also showed a satisfactory degree of coverage, and (3) the rank ordering of subscale difficulties across samples showed a relatively high degree of cross-cultural invariance.
Footnotes
Appendix
Acknowledgments
We wish to thank Marco Del Giudice and Romina Angeleri, formerly of the Biology of Social Behavior Laboratory, University of Turin, Italy, for having collected the Italian Sample for the original study.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.