
Abstract
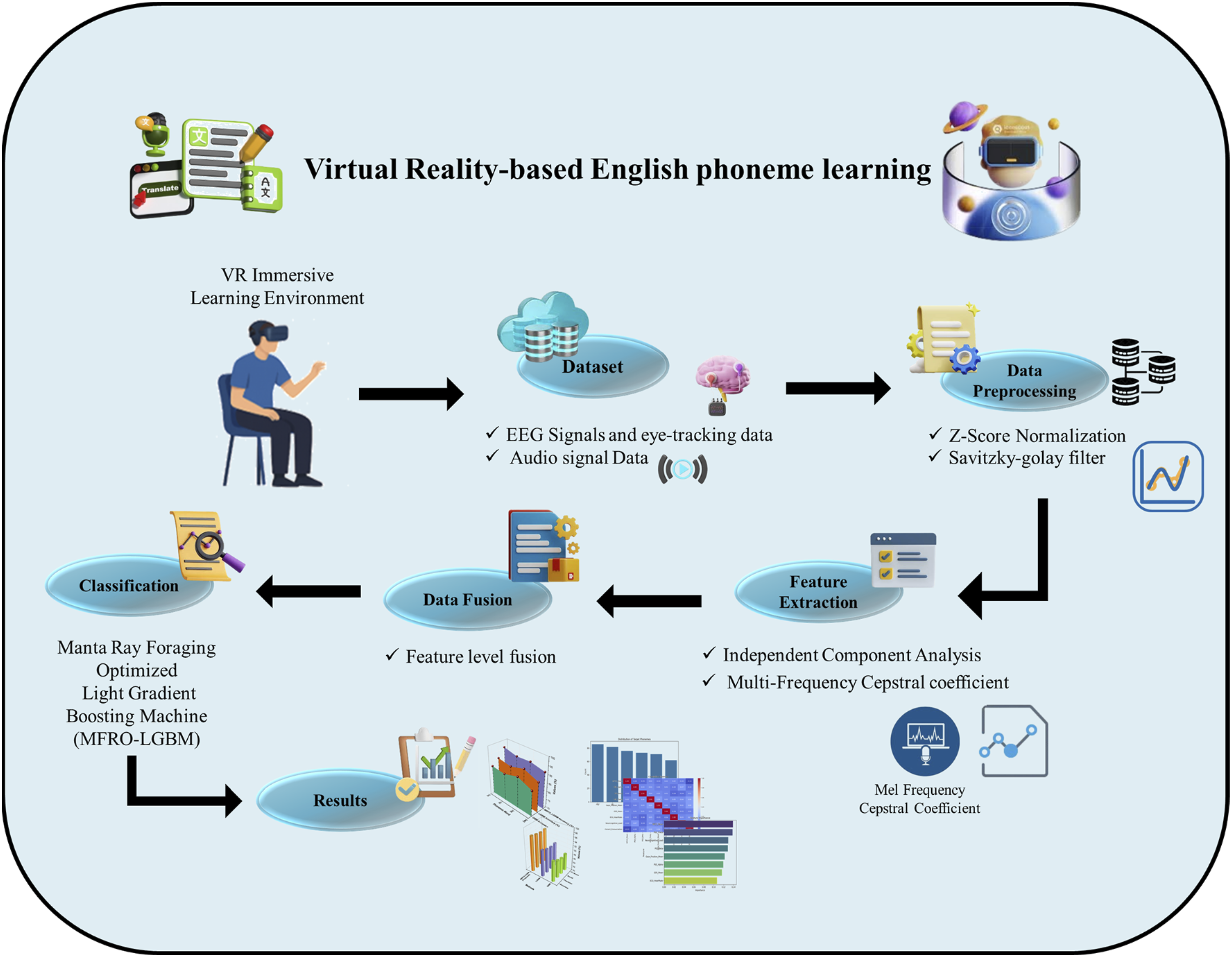
Virtual Reality (VR) transforms second language acquisition by immersing learners in interactive, context-rich environments that foster cognitive engagement and enhance phonemic competence. This research explores the neurocognitive enhancements induced by VR-based English phoneme learning through multimodal bio-signal analysis and advanced machine learning (ML) techniques. A total of 450 English learners participated in immersive VR scenarios designed to target challenging English phonemes within authentic conversational tasks. Two types of datasets were collected: one in the form of a CSV file containing EEG signals and eye-tracking data, and the other comprising audio signal data. EEG and eye-tracking data were preprocessed using Z-score normalization to ensure consistency. Audio data were denoised using the Savitzky–Golay filter, which effectively preserves phonetic information while removing environmental noise. The cleaned data were fed into the feature extraction process. For the EEG and eye-tracking data, feature extraction was carried out using Independent Component Analysis (ICA), while Mel-frequency cepstral coefficients (MFCCs) were extracted from the audio data to capture detailed phonetic features essential for phoneme classification. This approach ensures accurate classification of phonemic performance and prediction of neurocognitive load in immersive VR-based phoneme learning. A feature-level fusion technique was employed to integrate the normalized event-log features and audio-based MFCCs into a unified, high-dimensional feature space, enabling comprehensive multimodal analysis. The Manta Ray Foraging Optimized Light Gradient-Boosting Machine (MRFO-LGBM) was introduced to optimize the LGBM model, enabling accurate classification of phonemic performance and prediction of neurocognitive load. The proposed method was implemented using Python 3.10.1. Experiments demonstrate that the proposed VR-enhanced cognitive phoneme recognition framework significantly outperforms other models, achieving superior results in terms of accuracy, F1-score, precision, and recall, with all metrics ranging from 95% to 96% in predicting neurocognitive states during immersive language acquisition. This research introduces a novel, scalable VR-based system that integrates bio-signal fusion and intelligent modeling to deliver personalized, measurable improvements in phonemic competence.
Keywords
Get full access to this article
View all access options for this article.