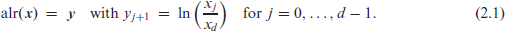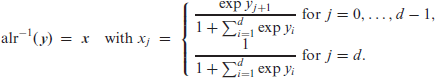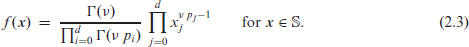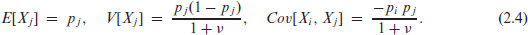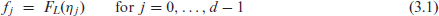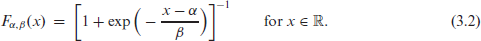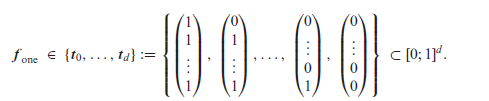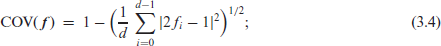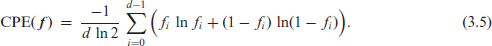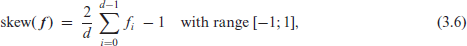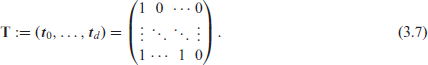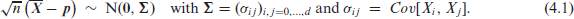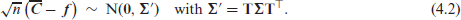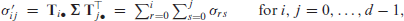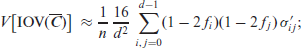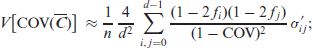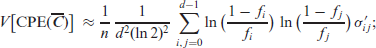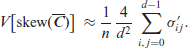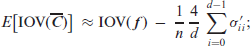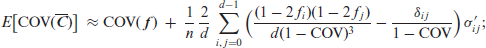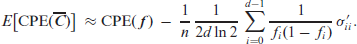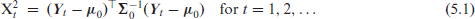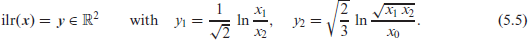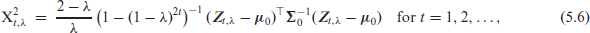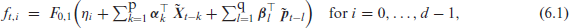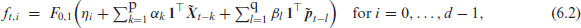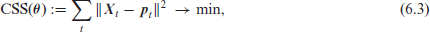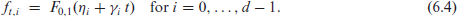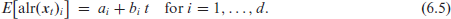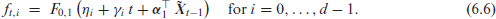There are several real applications where the categories behind compositional data (CoDa) exhibit a natural order, which, however, is not accounted for by existing CoDa methods. For various application areas, it is demonstrated that appropriately developed methods for ordinal CoDa provide valuable additional insights and are, thus, recommended to complement existing CoDa methods. The potential benefits are demonstrated for the (visual) descriptive analysis of ordinal CoDa, for statistical inference based on CoDa samples, for the monitoring of CoDa processes by means of control charts, and for the analysis and modelling of compositional time series. The novel methods are illustrated by a couple of real-world data examples.
Compositional data (CoDa) describe the ‘proportions of some whole’ (Aitchison, 1986, p. 1). If ‘the whole’ consists of parts with , labelled as , then the vector is said to be a normalized -part composition iff its components sum up to one. Thus, the range of is given by the -part unit simplex . At this point, a connection to categorical data (Agresti, 2002) becomes clear, because CoDa vectors might serve as the probability mass function (PMF) of a categorical random variable (RV) having the qualitative range . During the last decades, there has been enormous research activity regarding the theory and applications of CoDa, see Pawlowsky-Glahn and Buccianti (2011), Filzmoser et al. (2018) for comprehensive surveys. In many applications, the categories behind are unordered, that is, is indeed a nominal range (and would be a nominal RV), and the ordering of categories implied by the notation ‘’ is just a lexicographic order. Thus, it is reasonable that Pawlowsky-Glahn and Buccianti (2011, p. 17) emphasize that ‘the conclusions of a compositional analysis should not depend on the order of the parts’. This rule is carefully considered by the common CoDa approaches, because if ‘applying a compositional analysis, the information due to the order of the different classes, plays no role’.
But as conceded by Pawlowsky-Glahn and Buccianti (2011, p. 17), ‘in some cases the parts can be assumed to be ordered’, that is, the categories in exhibit the natural order such that the aforementioned categorical RV is indeed an ordinal RV (Agresti, 2010). In this case, shall be called an ordinal composition, and a couple of such examples shall be discussed in the present article. Our first data example in Section 3.2, for instance, is about 3-part compositions (i. e., ) expressing the proportions of people in the ordered age categories , and . Certainly, it is still justified to apply the well-established approaches to such ordinal CoDa, although they ignore the ‘information due to the order of the different classes’. In this article, however, it is shown that additional insights might be gained if the existing CoDa approaches are complemented by new ones that explicitly account for the order within (e. g., for the order among the age categories). Such new ordinal CoDa approaches are derived by adapting well-established concepts from ordinal data analysis.
The remainder of this article is organized as follows. In Section 2, a brief survey on relevant concepts about is provided. Section 3 starts with a review of basic methods for ordinal data analysis, and potential benefits of their application to ordinal CoDa are demonstrated with two real-world data examples. Section 4 then turns from a purely descriptive analysis to the statistical inference regarding ordinal CoDa. The asymptotic distribution of the proposed statistics for ordinal is derived, and the corresponding finite-sample performance is investigated with simulations. A further real-data example demonstrates the application of the asymptotic results in practice. Section 5 then turns to the monitoring of an ordinal CoDa process, and novel control charts are proposed for this purpose. It is shown through simulations and a data application that these novel charts allow for a targeted diagnosis of the actual out-of-control scenario and, thus, constitute a valuable complement to existing CoDa control charts. In Section 6, we turn our attention to compositional time series (CoTS). It is demonstrated how models for ordinal CoTS can be constructed such that they account for the natural order among the categories. Real-world CoTS are used to illustrate the benefits of using the novel approaches. Finally, Section 7 concludes the article and outlines possible directions for future research. Further results as well as R codes used for data analysis are provided by the supplementary materials.
Basics about CoDa
An important property of CoDa is given by the fact that the -part simplex can be mapped bijectively onto a -dimensional Euclidean space of real vectors, such that approaches for the analysis and modelling of real-valued vectors are transferred to corresponding CoDa counterparts. The most simple among the common transformations is the additive-log-ratio transform, alr : (Aitchison, 1986), which requires to first choose a divisor, the ‘ratioing variable’ (Filzmoser et al., 2018, p. 44). In common CoDa applications, however, where the categories in are nominal, any such choice is arbitrary (Pawlowsky-Glahn and Buccianti, 2011, p. 5). In the case of ordinal CoDa, however, it appears reasonable to either take the highest category or lowest category for ‘ratioing’. To summarize an ordinal distribution, it is common to consider the cumulative distribution function as it preserves the natural order, see the details in Section 3.1 below. Here, the probability and is, thus, not informative, so one usually substitutes the highest category by all remaining categories . For this reason, we shall also always use for ratioing the ordinal , that is, we uniquely define
The inverse of alr, the additive logistic transform, has the expression
This backward transformation is also well-known in categorical data analysis, because it is the multinomial logit being commonly used for nominal regression and time series models (Agresti, 2002; Fokianos and Kedem, 2003).
Remark 1. While alr is attractive in view of the aforementioned connection to categorical data as well as the simplicity of (2.1)-(2.2), it has also been critized as it is not isometric and leads to disparate differences between the transformed points if using different ratioing variables (Pawlowsky-Glahn and Buccianti, 2011, p. 5). If isometry is crucial for applications, then one better uses an isometric log-ratio (ilr) transform (see Egozcue et al., 2003), such as the one defined by (5.5) later in Section 5.2. Also for ilr, it is possible to emphasize the role of by assigning it as the ‘pivot coordinate’, see Filzmoser et al. (2018, Section 3.3.3). On the other hand, the definition of ilr and its inverse are more complex than (2.1)-(2.2), and alr and ilr differ only by a linear transformation anyway (Egozcue et al., 2003, p. 298). Thus, we shall mainly focus on the alr in the following, but we also account for ilr at appropriate places.
In this research, we are not only concerned with the descriptive analysis of ordinal CoDa, but approaches for statistical inference are considered as well, see Sections 4-6. For this reason, let us now turn to compositional RVs with range (random compositions), where several parametric distributions are available in the literature. The probably most well-known model is the Dirichlet distribution, see Chapter 49 in Kotz et al. (2000) and Chapter 2 in Ng et al. (2011) for comprehensive surveys. depends on a mean vector and a scale parameter , and is defined by the density function
The first- and second-order moments, for , are given by
The last formula implies that the Dirichlet distribution is only applicable if all cross-covariances of are negative, which is a strong limitation for practice (see Aitchison, 1986, p. 59). Therefore, the logistic normal distribution (Aitchison, 1986, Chapter 6) might be an attratcive competitor model for . We say that if is normally distributed according to , with and positive definite . While, by contrast to (2.4), closed formulae for the marginal moments of do not exist, some ratio moments are provided by Aitchison (1986, p. 116), and the ‘compositional mean’ provides the component-wise medians of (Billheimer et al., 2001, p. 1208). Note that a CoDa-normal distribution might also be defined with respect to the ilr (as later done in Section 5.2). But as ilr and alr are linearly related to each other (recall Remark 1), a normally distributed implies a normal distribution for as well, and vice versa.
Applying ordinal statistics to CoDa
As outlined in Section 1, it shall be demonstrated for various application areas that we may gain additional insights into ordinal if the existing CoDa approaches are complemented by methods derived from ordinal data analysis. Therefore, Section 3.1 starts with a brief survey on ordinal approaches, while Section 3.2 already presents their first application, namely to a descriptive analysis of ordinal CoDa.
Properties of ordinal distributions
Let be an ordinal RV with range and PMF . To account for the natural order among the categories, one commonly does not focus on Q’s PMF but on its CDF, which can be summarized in the -dimensional vector . Here, we define for , where is omitted in as it necessarily equals one. For this reason, we also used the largest category for ratioing in (2.1) when defining the alr transform.
Remark 2. A popular approach for a parametric modelling of ordinal data is the latent-variable approach (Agresti, 2010, p. 11). If is a -dimensional CDF vector, and if is a (latent) realvalued with specified , then one represents by selecting the threshold parameters such that
holds. In a sense, is reparametrized in terms of . The most popular choice for is the (standard) logistic distribution, , leading to the cumulative logit model. Here, denotes the logistic distribution with location parameter and scale parameter (see Johnson et al., 1995, Chapter 23), which is defined by the CDF
The CDF can be used to compute important stochastic properties of . The location of is commonly expressed in terms of the median (as this uses the order information), but also the mode (which is already well-defined for a nominal scale) might be used. Both median and mode take values in , where the mode does not need to be unique. As is typically of small size, the location measures provide only roughly graduated information about . Much more measures are available to quantify the dispersion of , see Blair and Lacy (1996), Kiesl (2003), Kvålseth (2011), Klein et al. (2016), Weiß 2019, 2022) for approaches and references. These measures are defined with respect to two extreme cases. Minimal dispersion happens if we are concerned with a one-point distribution on , that is, if all probability mass concentrates in one category (maximal consensus):
By contrast, exhibits maximal dispersion if it follows the extreme two-point distribution (polarized distribution), , that is, if we have probability mass in each of the outermost categories (maximal dissent). Note that the latter extreme differs from maximal nominal dispersion, which manifests itself in terms of a uniform distribution (maximal uncertainty). Ordinal dispersion measures are typically normalized to the range , and they take the value 0 (1) iff exhibits minimal (maximal) dispersion. A few examples (see the above references for many further options) are the index of ordinal variation,
the coefficient of ordinal variation,
and the cumulative paired entropy (using the convention ),
Finally, the (a)symmetry of ’s distribution can be evaluated by measures of ordinal skewness, see Klein and Doll (2021), Weiß (2020) for details. We speak of symmetry if for all , or equivalently, if for . By contrast, maximal positive (negative) skewness is present if , that is, the extreme left (right) one-point distribution. This corresponds to the CDFs or , respectively, where denotes the vector of ones (zeros). These definitions of extreme skewness go along with the well-known rule of thumb that a positively skewed (= right-skewed) distribution appears to be left-leaning, and vice versa. A simple example of a normalized ordinal skewness measure is
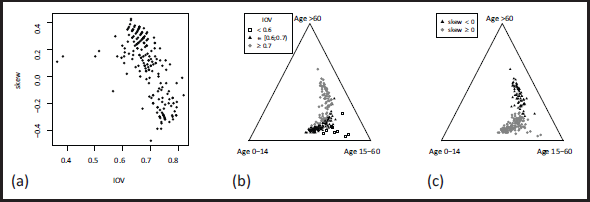
Age proportions in 195 countries from Example 1: plot of skew against IOV in (a), ternary diagrams in (b) and (c).
where skew for maximal positive (negative) skewness, and where skew for a symmetric distribution.
Properties of ordinal CoDa
To apply the ordinal measures of Section 3.1 to ordinal CoDa , we have to accumulate these vectors first, that is, to compute with the matrix
Then, we can evaluate the ordinal dispersion and skewness of by applying formulae (3.3)-(3.6) to instead of . Let us illustrate this approach and its benefits by two real-world data examples.
Example 1. The dataset ageCat World from the R-package robCompositions contains the proportions, of people with age, andin195 countries. These 3-part compositions refer to ordered categories, recall Section 1, thus constituting an example of ordinal CoDa. Since the dimension of theis three, a visual representation of the data by a ternary diagram is possible, see Figure 1. This shall help us to get an intuitive understanding of the ordinal measure (3.3)-(3.6) if being applied to the vectors.
As indicated in Section 3.1, the location measures do not provide much discriminative power: in 191 out of 195 cases, the median category is(‘age 15-60’), andis also the mode category for 163 of the. Next, let us turn to ordinal dispersion. Here, we solely focus on thevalues, as the IOV is most popular among practitioners, and asandprovide essentially equivalent insights in the present example, in the sense of strong positive correlation to, beingin both cases (also see the discussion in Supplement S.1). As can be seen from Figure 1 (a), the values ofvary between 0.4 and 0.8, that is, we are concerned with medium to strong dispersion. In fact, only few countries lead to an IOV less than 0.6. These information are related to a ternary diagram of the data inFigure 1 (a). The few countries with IOV less than 0.6 (shown as empty circles) are those with a high proportion of people with age 15-60, that is, these compositions are quite close to a onepoint distribution (the three possible one-point distributions correspond to the corners of the triangle). Countries having an IOV, in turn, are plotted (by grey dots) relatively close to the axis between the lowest and largest age category, that is, the outermost categories are more dominant.
Next, we consider thevalues. Figure 1 (a) shows that we have at most moderate skewness values, with maximal absolute extent around 0.4, where positive skewness values are slightly more frequent than negative ones. Note that countries with negative skewness tend to show larger dispersion than in the case of positive skewness. The ternary diagram in Figure 1 (c) shows that positive skewness values refer to the lower-left half of the triangle, which is easy to interpret: right-skewed compositions are left leaning, so the lower categories dominate the upper ones.
Example 1 showed that for ordinal 3-part compositions, the IOV-skew diagram provides similar insights into the data as the ternary diagram. However, an IOV-skew diagram can also be drawn for higher-dimensional compositions, whereas a ternary diagram is not immediately applicable (one could combine individual categories into larger ones before plotting). By contrast, the IOV-skew diagram allows to directly visualize the high-dimensional ordinal compositions, being easy to interpret by a practitioner, see the data example in Supplement S.1. To sum up, Section 3 demonstrated that ordinal measures such as IOV and skew, if applied to ordinal CoDa, provide new insights into the data (which may also be presented visually) and, thus, constitute a valuable complement to existing methods for descriptive CoDa analysis.
Statistical inference for ordinal CoDa
In Section 3.2, we applied the proposed statistics for ordinal in a descriptive way. To be able to compute confidence regions or to test for significant differences, we shall now consider the distributional properties of such statistics. In Section 4.1, we derive their asymptotic distribution and investigate the corresponding finite-sample performance. A further real-world data example is discussed in Section 4.2.
Asymptotic distributions and simulation results
Let be an independent and identically distributed (i.i. d.) sample of ordinal compositional RVs with mean , let denote their sample mean. Then, the central limit theorem (CLT) implies that is asymptotically normally distributed (see Serfling, 1980), namely
While (4.1) holds for nominal CoDa as well, we now turn to the accumulated versions of and , that is, to for with mean , where is the transformation matrix from (3.7). These are meaningful only for ordinal CoDa, and they are required for the computation of the ordinal statistics (3.3)-(3.6). The asymptotics of the sample mean follow immediately from (4.1) and the linearity properties of the multivariate normal distribution, namely
The entries of are computed as
where abbreviates the th row vector of . Finally, the asymptotics of the ordinal statistics (3.3)(3.6), if applied to the estimator , are derived based on Taylor expansions (‘Delta method’), see Supplement S.2 for details. The obtained results are summarized in the following theorem.
Theorem 1. Letbe computed from an i.i.d. ordinal CoDa sample, let thebe given as in (4.2). Then, the ordinal measures (3.3)-(3.6) are asymptotically normally distributed with asymptotic variances
Whileholds exactly, the means of the remaining measures are approximately equal to
Proportions of education levels in 31 European countries from Section 4.2: ternary diagram in (a), plot of skew against IOV in (b), estimates in (c).
For the practical implementation of the asymptotics, it is suggested to compute the separately, and to plug-in the results into the formulae of Theorem 1. In the special case of a Dirichlet distribution, see Example 1 in Supplement S.2, closed-form formulae for the exist such that further simplifications are possible.
In practice, the asymptotic distributions of Theorem 1 are used to approximate the true distributions of the ordinal statistics according to (3.3)-(3.6). Therefore, it is important to check the approximation quality of these distributions for finite sample sizes . For this purpose, the simulation study summarized in Supplement S.3 was done, where i. i. d. ordinal CoDa samples according to a -distribution and a -distribution were simulated (with replications per scenario). The actual parametrization of these distributions is inspired by the subsequent data example in Section 4.2. Details on the simulation procedures as well as on required numerical approaches for the LN-case are discussed in Supplement S.3. It turns out that we generally have an excellent agreement between simulated and asymptotic properties. Thus, the bias and SD being observed in finite samples are well described by the asymptotics of Theorem 1 .
Illustrative data example
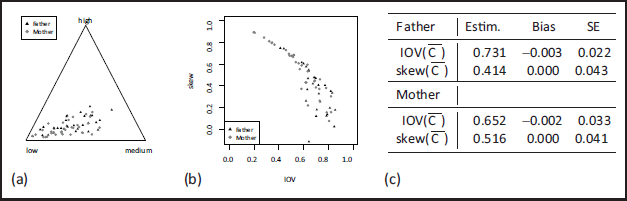
We analyse the dataset educFM in the R-package robCompositions (also see Filzmoser et al., 2018, Section 10.7.3), which provides the proportions of low, medium, and high education levels of father and mother in European countries. So for each country , two 3-part compositions are available, say and for father and mother, respectively. The category (‘low’) is the median (mode) of in 19 (22) cases, and the median (mode) of in 22 (25) cases; otherwise, it is the category (‘medium’). The ternary plot in Figure 2 (a) shows that the CoDa concentrate in the low-to-medium corner, which goes along with the positive skew values in part (b), implying left-leaning distributions. The values cover a wide range from low to high dispersion. It also interesting to note the pronounced structure in the IOV-skew diagram, where low dispersion is connected to strong positive skewness, that is, the corresponding CoDa vectors are close to a one-point distribution in the lowest category.
Next, we analyse if there are significant differences (on a 5%-level) between the education proportions of father and mother; from the plots in Figure 2 (black vs. grey dots), no such difference can be recognized. For this purpose, models for both datasets are required. A natural first idea is to try a Dirichlet distribution, but a problem becomes clear: the sample covariance matrices for the fathers’ and mothers’ compositions are and , respectively, that is, some cross-covariances are positive, which is not consistent with a Dirichlet distribution, recall (2.4). Thus, logistic normal distributions seem more appropriate, as also confirmed by the distributional analyses presented in Supplement S.4. Thus, the following discussion focusses on the LN model (fitted by mvnorm.mle in the R-package Rfast), whereas results regarding the Dirichlet model are presented in Supplement S.4.
The fitted -models are and , respectively, which both lead to a rather good fit to the CoDa's means and cross-covariances. Hence, the LN-models are used as the base for asymptotic computations. The point estimates from and skew , as well as the corresponding asymptotic biases and standard errors (SEs) according to Theorem 1, are shown in Figure 2 (c). The biases of are negligible relative to the actual estimates, and skew is unbiased anyway. Comparing the IOV and skew estimates between father and mother, we recognize a notable difference, which is larger than twice a standard error. So in view of the estimators’ asymptotic normality, we conclude that the IOV and skew estimates are significantly different between father and mother. In fact, we have less dispersion and stronger positive skewness for mothers, that is, the mothers’ education proportions are (in the mean) closer to a one-point distribution in the category ‘low’. This might be interpreted as an indication of unequal opportunities for education among males and females in the past.
Monitoring ordinal CoDa
In applications related to manufacturing industries or health surveillance, one commonly monitors an ongoing process of certain quality characteristics for the possible occurrence of a process change. The main tool for such an online monitoring are control charts, see Montgomery (2009) for detailed information. Control charts are designed with respect to a specified in-control model, that is, when the process runs in a stable state. If the process’ distribution changes at a certain time point (out-of-control situation), then is said to be a change point, and the aim is to detect this process change as soon as possible. More precisely, the in-control distribution of the process is used to compute so-called control limits (CLs), and the incoming process observations (or statistics computed thereof) are sequentially plotted on a chart being equipped with these CLs. If a plotted statistic violates the CLs, then an alarm is triggered at this time to indicate that the process might have run out of control (the time until the first alarm (stopping time) is called the run length of the control chart). An alarm under in-control (out-of-control) conditions is classified as a false (true) alarm. To evaluate the performance of a control chart, one computes the mean of the run length (average run length, ARL), that is, the mean number of plotted statistics from the beginning of process monitoring until the first false alarm. The in-control ARL should be sufficiently large for practice to avoid too frequent false alarms. An out-of-control ARL, by contrast, expresses the mean delay from the change point to the true alarm, and this number should be as small as possible. For chart design, one first specifies a target value for the in-control ARL, say , then one computes the CLs such that is met at least in good approximation.
Control charts for ordinal CoDa
In what follows, we are concerned with the monitoring of an ordinal CoDa process , which is assumed to be i. i. d. in time under in-control conditions. There are several proposals for CoDa control charts in general (i. e., nominal CoDa), see Holmes and Mergen (1993), Vives-Mestres et al. 2013, 2014 and references therein, but none for the particular case of ordinal CoDa. In fact, the data application (manufacturing of grit) considered in the aforementioned articles exhibits ordered categories, because it refers to the particle size proportions with categories ‘large’, ‘medium’, and ‘small’; see Table 2 in Holmes and Mergen (1993) for a sequence of 56 CoDa vectors. This ordinal information, however, was not used for defining the control charts. Instead, Holmes and Mergen (1993), Vives-Mestres et al. 2013, 2014 used types of Hotelling- chart (see Montgomery, 2009, Section 11.3), which apply to unordered categories as well: while Holmes and Mergen (1993) computed the statistic based on two of the three components of , Vives-Mestres et al. (2013, 2014) first mapped the 3-part simplex onto and then computed the -statistic. Generally, see Section 11.3 in Montgomery (2009), if is a multivariate vector-valued process with in-control mean and covariance matrix , the -chart is defined by plotting the statistics
against an upper CL (UCL) chosen such that the -target is met, that is, an alarm is triggered if . The Hotelling- chart differs from (5.1) by using estimates for and instead (and by adapting the UCL appropriately). Besides not using the ordinal information, statistic (5.1) has the drawback that an alarm is difficult to interpret (see Montgomery, 2009, p. 505), because the value of does indicate the actual type of out-of-control situation; see Vives-Mestres et al. (2013) for a discussion. Thus, if monitoring ordinal CoDa, it is suggested to complement the CoDa - or -chart by further control charts based on the ordinal statistics in Section 3.1, such that a targeted diagnosis of the actual out-of-control state is possible.
To monitor the process or , respectively, two types of IOV-chart are developed by adapting the corresponding proposals in Ottenstreuer et al. (2023). Let and denote the in-control means of and , respectively. We shall consider two-sided chart designs, that is, with both a lower and upper CL (LCL and UCL, respectively). Then, the Shewhart IOV-chart is defined by plotting
against LCL and UCL, which are chosen such that the in-control ARL is close to . An alarm is triggered if either or . As this decision relies solely on the observation , Shewhart-type charts typically react quickly to very large process shifts, but rather slow to small process changes.
To equip the IOV-chart with an additional memory and to, thus, improve the sensitivity towards small process changes, we also consider an exponentially weighted moving-average (EWMA) approach in analogy to Ottenstreuer et al. (2023). For the smoothing parameter , we recursively compute with . Then, the EWMA IOV-chart is defined by plotting
against appropriately chosen LCL, UCL. Note that leads to the Shewhart chart (5.2), whereas decreasing values of increase the inherent memory of (5.3).
Both IOV-charts (5.2) and (5.3) are defined to detect changes in the ordinal dispersion. A violation of LCL (UCL) indicates a decrease (increase) of dispersion and, thus, allows for a targeted diagnosis. Instead of the IOV (3.3), one could also use the COV (3.4) or CPE (3.5), but we focus on the IOV for convenience. However, it seems reasonable to also consider the Shewhart and EWMA version of a skew chart based on (3.6), as such a chart could react to changes in ordinal skewness, see Ottenstreuer et al. (2023). Hence, we also plot
against appropriate , where corresponds to the Shewhart skew-chart, and to the EWMA skew-chart. To sum up, at least theoretically, the IOV- and skew-charts offer the potential for a targeted diagnosis of the actual out-of-control scenario. In the subsequent Section 5.2, we provide empirical evidence that such targeted conclusions are indeed possible.
Empirical illustrations
As mentioned in Section 5.1, Vives-Mestres et al. 2013, 2014 applied a -type control chart to the CoDa process , namely after first mapping the 3-part simplex onto . A possible solution for this mapping could have been the alr transform , but Vives-Mestres et al. 2013, 2014 used types of ilr transforms instead. To make the subsequent results comparable to those in Vives-Mestres et al. (2014), in this section, we shall consider their specific ilr transform defined by
It should be noted, however, that because of the relation , it holds that , that is, ilr and alr only differ by a linear transformation, also recall Remark 1. We use the CoDa-normal distribution implied by requiring that with and positive definite , also see Mateu-Figueras et al. (2013), which is a reparametrization of the LN-distribution discussed in Section 2. This distribution is relevant for chart design, as we have to specify the in-control model for the process . Like in Vives-Mestres et al. (2014), we define the in-control model as with and , which are the sample values from the ilr-transformed particles dataset in Table 2 of Holmes and Mergen (1993). For comparability, we also use the same target , namely . Note that the above corresponds to the component-wise means (computed by numerical integration) and component-wise medians ilr-1 for , that is, we have a nearly symmetric mean/median particle size proportion under in-control conditions, which also exhibits only low dispersion. More precisely, and . Note that a monitoring of ordinal location would not be promising: because of the large mean/median proportion of category (‘medium’), we can hardly ever expect to observe any other median or mode category than . In fact, for the data in Table 2 of Holmes and Mergen (1993), is the median and mode category without exception.
The aforementioned in-control model is now used for chart design. For given values of the design parameters, in-control processes are simulated and the run lengths (i. e., the numbers of statistics until the first signal) are determined; the mean across these run lengths approximates the true ARL value. For chart design, the design parameters are varied (and ARL simulation is repeated for each revised design) until the -target is met in close approximation. In this way, we determine the chart design of the Shewhart and EWMA versions of IOV- and skew-chart (5.2)-(5.4), where the EWMA charts use . As a competitor, we consider the Shewhart -chart (5.1) in analogy to Vives-Mestres et al. (2014). Furthermore, for the sake of completeness, we also consider the multivariate EWMA version of this chart defined like in Section 11.4 of Montgomery (2009):
where with . Although both EWMA charts (5.3) and (5.6) are not directly comparable because of a different implementation of the EWMA approach, we use again for illustration. The resulting designs and in-control ARLs are summarized in the first block (italic font) of Table S.6.1 in Supplement S.6.
Next, these chart designs are used for a simulation-based analysis of the out-of-control performance. Based on an ordinal logit approach (recall Remark 2), we define several out-of-control scenarios for ilr-1 (μ) (medians of CoDa distribution), see Supplement S.5 for details. The logit approach accounts for the order among the categories, and it allows to distinguish between dispersion and skewness shifts for compared to . The simulation results discussed in Supplement S. 6 show that the IOV-, skew-, and -charts have a quite different out-of-control performance. While the -chart is universally applicable but does not allow to conclude from the signal on the type of out-of-control scenario, the IOV-and skew-charts are sensitive only to specific out-of-control scenarios, namely such affecting dispersion and skewness, respectively. Thus, running an IOV- and skew-chart in parallel to a -chart (preferably always the EWMA version), we can expect that a dispersion shift leads to an early alarm of the IOV-chart, and a skewness shift to one of the skew-chart. In this way, the types of alarm allow us to conclude on the type of out-of-control situation.
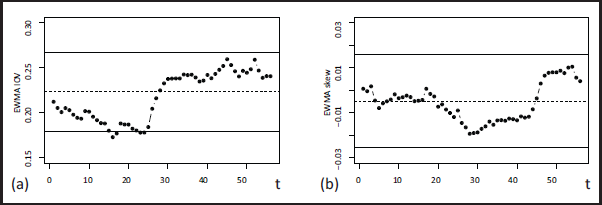
This type of diagnostic feature is illustrated by Figure 3, where the EWMA IOV-and skew-chart are applied to the particle size proportions of Table 2 in Holmes and Mergen (1993). The skewchart in (b) does not trigger any alarm during the monitoring period, so we have no indication of a systematic skewness change. The IOV-chart in (a), by contrast, triggers alarms at times as well as . In both cases, the LCL is violated, indicating that there was an exceptionally low dispersion for and . Further analysing the raw data, we indeed note that and are considerably less dispersed than (but still nearly symmetric). Note that are close to the second scenario in the fifth block of Table S.6.1. Analogous results (though less pronounced) hold for observations . Finally, although it did not suffice for an alarm yet, we recognize increasing dispersion and skewness towards the end of the monitoring period in Figure 3.
Particle size proportions from Section 5.2: EWMA IOV-chart in (a) and EWMA skew-chart in (b), where .
Ordinal compositional time series
Let . We refer to a stochastic process , which consists of CoDa RVs, as a processes. A compositional time series (CoTS) is a finite-length segment taken thereof.
Analysis and modelling of ordinal CoTS
Several models for CoDa processes and the resulting CoTS have been proposed during the last years. The most common approach for modelling CoTS is to first map the part compositions onto -dimensional real vectors (e. g., by taking the alr transform (2.1) or an ilr transform), and to then apply a vector autoregressive moving-average (VARMA) model to the transformed time series , see, for example, Mills (2010), Dawson et al. (2014). Because of the large number of VARMA model parameters, for short time series, also simple regression approaches have been proposed, that is, the component series of the transformed CoTS are considered as linear or quadratic regression models in time , see, for example, Wang et al. (2007), Mills (2010). A parsimonious ARMA-type model for CoTS relying on the use of a variation operator was proposed by Möller and Weiß (2020). Also Zheng and Chen (2017) proposed a class of ARMA-type models for CoTS, being based on a conditional regression approach. For references on further model types, see Pawlowsky-Glahn and Buccianti (2011, Chapter 7) and Zheng and Chen (2017).
All the aforementioned time series models are developed to deal with general (nominal) CoDa, that is, a possible order among the categories is not considered. However, several of the examples presented in the literature are ordinal CoTS. For example, Wang et al. (2007) discuss a time series of yearly proportions of employed persons in China, where the proportions refer to the three production sectors ‘primary industry’, ‘secondary industry’, and ‘tertiary industry’; also see Supplement S.7. Mills (2010) modelled obesity trends in England, expressed by yearly proportions of persons falling into ordered weight categories, ranging from ‘not overweight’ to ‘obese’; also see Section 6.2. As a last example, Dawson et al. (2014) analysed a time series expressing the attitude of UK people towards the Olympic Games, with ordered categories from ‘strongly against’ to ‘strongly supportive’. In any of these examples, it could be beneficial to explicitly account for the ordered categories while analysing the data, which is illustrated by the data example discussed in Supplement S.7.
Not only for their analysis, but also for the modelling of ordinal CoTS, it could be relevant to account for the ordered categories. As a possible solution, we combine the conditional regression model of Zheng and Chen (2017) with the cumulative logit approach of Remark 2, in analogy to the ordinal time series models of Pruscha (1993); Fokianos and Kedem (2003). Zheng and Chen (2017) propose a conditional modelling of . If denotes the -field generated by all information up to time , then is assumed to follow a specified CoDa distribution with parameter vector , say , where is computed from the information up to time . For example, we would define if is conditionally Dirichlet-distributed with time-invariant scale parameter , that is, according to (2.3), where . In this case, the conditional mean of equals , and the conditional (co)variances are adjusted by the factor , recall (2.4). As suggested by Zheng and Chen (2017), could be modelled by an ARMA-type recursion of the form , where expresses the autoregressive order and the ‘moving-average’ order (it is more appropriate to interpret as forming a feedback term). Specific examples for choosing in the case of nominal CoDa are discussed by Zheng and Chen (2017).
In what follows, to account for the natural order of ordinal and to reduce the number of model parameters at the same time, we present possible specifications for being derived from the cumulative logit approach, in analogy to Pruscha (1993); Fokianos and Kedem (2003). Define and , and let denote the corresponding -dimensional conditional CDF vector. Recall that denotes the CDF of the standard logistic distribution (inverse logit function). An ARMA-type model for ordinal CoTS is defined by the recursion
which has the parameters involved in . The parameters control the serial dependence structure, which is unique across the categories. The individual ordinal categories are accounted for by the parameter with . A more parsimonious model specification, also see Pruscha (1993), is
which has only parameters. If the data are then generated according to , for example (where follows from by taking discrete differences), we also have the additional scale parameter from the Dirichlet distribution. Models (6.1) and (6.2) are easily adapted to account for possible covariate information by adding the summand ‘’ within the parentheses.
Proportions of weight categories from Section 6.2: (a) plot of proportions over time, and (b) table with model fits and corresponding CSS values.
Parameter estimation can be done by a conditional least-squares (CLS) approach, that is, by numerically minimizing the conditional sum of squares (CSS) defined by
where comprises all parameters involved in (6.1) or (6.2), respectively, and where denotes the Euclidean norm. The CLS approach is semi-parametric in the sense that it does not require to specify the full conditional distribution of but only the equation for the conditional mean, which, in turn, is useful for predicting future values. It is also easy to formulate a conditional log-likelihood approach for models (6.1) and (6.2), but this requires to fully specify the distribution of and is computationally more demanding (due to the complex structure of typical CoDa distributions).
Illustrative data example
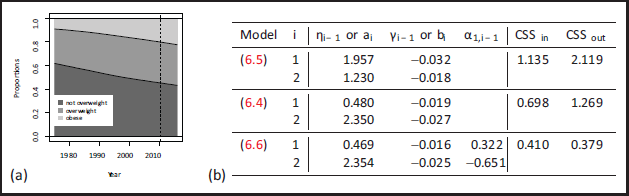
The following data example is inspired by the one in Section 4.2 of Mills (2010), who modelled obesity trends in England for the years in 1993-2005. We consider, however, a much longer period, namely yearly proportions for the period 1975-2016. More precisely, based on the (agestandardized) percentages for different BMI classes (body mass index) offered by the World Health Organization at https://apps.who.int/gho/data/node.main.BMIANTHROPOMETRY?lang=en, the CoTS for Germany is derived, with the three categories (hence ) ‘not overweight’ (BMI < 25), ‘overweight’ (BMI in [25;30)), and ‘obese’ (BMI ). The data are plotted in Figure 4 (a), where the proportions correspond to the heights of the grey areas (the curves between the grey areas refer to the cumulative proportions). The vertical dashed line between the years 2010 and 2011 expresses the following partition: the data for 1975-2010 are used for model fitting, whereas the data for 2011-2016 are left for out-of-sample forecasting.
Looking at Figure 4 (a), an obvious first candidate for modelling the CoTS is a simple (logistic)linear model, that is, (6.1) with
This is analogous to the model used by Mills (2010) for their UK series, being linear in the components of the alr-transformed data:
Model (6.5) is used as a competitor here. Note that (6.5) could be equivalently expressed in terms of the ilr transform (5.5), which would lead to a reparametrization of the model. Finally, we also consider a version of (6.1) having both a linear trend and a first-order AR-component, namely
The results of CLS estimation (based on ) are summarized in Figure 4 (b). The linear coefficients for the fitted ordinal models (6.4) and (6.6) are negative, which is reasonable in view of the decreasing curves for and in Figure 4a. The negative linear coefficients for model (6.5) refer to the alr transform (2.1) of the non-cumulative proportions, so they indicate decreasing quotients (if we would use the ilr (5.5) instead of the alr, the parameter estimates of would change to for and for . It is also interesting to note that the estimates for are quite similar between models (6.4) and (6.6), that is, one may interpret the estimate of the AR-coefficient in (6.6) as a refinement of the baseline linear model (6.4). To compare the performance of the fitted models, two types of CSS are computed: ‘’ equals times the CSS (6.3) computed for the in-sample data (the summand is left out for all models for a fair comparison, because this summand is not defined for the AR model (6.6)), and ‘’ equals times the CSS (6.3) computed for the out-of-sample data . Here, the unique scaling factor was used to improve the readability of the printed CSS values. It can be seen that the ordinal linear model (6.4) clearly outperforms the linear alrmodel (6.5), because both CSS values of (6.4) are equal to only about of the (6.5)’s CSS values (the CSS values of the ilr-version of model (6.5) are identical to those of the alr-version). However, a further improvement (especially in terms of the out-of-sample performance) is achieved by the additional AR-term in (6.6). This term, given by ‘’, shows that the past proportion for ‘not overweight’ has an increasing effect on , whereas the one of ‘overweight’ has a decreasing effect. As strongly decreases for while is rather stable, the AR-term becomes increasingly negative over time and, thus, intensifies the linearly decreasing trend in .
Conclusions
This article gave a broad overview of such CoDa areas, where consideration of the natural order of ordinal CoDa might be beneficial. For the (visual) descriptive analysis of ordinal CoDa, for the statistical inference from i. i. d. CoDa samples, for the monitoring of i. i. d. CoDa processes as well as for the modelling of CoDa time series, solutions have been developed and investigated, which make use of the order information in ordinal CoDa. In particular, the asymptotic distribution of diverse ordinal statistics was derived and checked by simulations, the ARL performance of different EWMA control charts was analysed with respect to various out-of-control scenarios, and a novel conditional regression model for ordinal CoTS was successfully applied. Any of the proposed approaches was illustrated with real-world data applications, and the broad variety of such data examples clearly showed the great practical relevance of the new methods.
Because this article was intended to cover a wide a range of subjects, the individual areas were not discussed in too much detail. Thus, for future research, an in-depth analysis of these areas is recommended. Among others, the performance of ordinal CoDa control charts should be investigated also for the case, where serially dependent (i. e., time series data) are monitored. Furthermore, it could be tried to adapt methods from ordinal time series analysis (see Weiß, 2020) to the ordinal CoTS case.
Footnotes
Acknowledgments
The author thanks the editor, the associate editor, and the two referees for their useful comments on an earlier draft of this article.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
This research was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) - Projektnummer 516522977.
Supplementary Materials
References
1.
AgrestiA (2002) Categorical Data Analysis. 2nd edition. Hoboken, New Jersey:John Wiley & Sons, Inc.
2.
AgrestiA (2010) Analysis of Ordinal Categorical Datae. 2nd edition. Hoboken, New Jersey:John Wiley & Sons, Inc.
3.
AitchisonJ (1986) The Statistical Analysis of Compositional Data. New York:Chapman and Hall Ltd.
4.
BillheimerD, GuttorpP, and FaganWF (2001) Statistical interpretation of species composition. Journal of the American Statistical Association, 96, 1205–1214.
5.
BlairJ, and LacyMG (1996) Measures of variation for ordinal data as functions of the cumulative distribution. Perceptual and Motor Skills, 82, 411–418.
6.
DawsonP, DownwardP, and MillsTC (2014) Olympic news and attitudes towards the Olympics: a compositional time-series analysis of how sentiment is affected by events. Journal of Applied Statistics, 41, 1307–1314.
7.
EgozcueJJ, Pawlowsky-GlahnV, Mateu-FiguerasG, and Barceló-VidalC (2003) Isometric logratio transformations for compositional data analysis. Mathematical Geology, 35, 279–300.
8.
FilzmoserP, HronK, and TemplM (2018) Applied Compositional Data Analysis - With Worked Examples in R. Cham:Springer NatureSwitzerland AG.
9.
FokianosK, and KedemB (2003) Regression theory for categorical time series. Statistical Science, 18, 357–376.
10.
HolmesDS, and MergenAE (1993) Improving the performance of the T2 control chart. Quality Engineering, 5, 619–625.
11.
JohnsonNL, KotzS, and BalakrishnanN (1995) Continuous Univariate Distributions, Volume 2. 2nd edition. Hoboken:John Wiley & Sons, Inc.
12.
KieslH (2003) Ordinale StreunngsmaßeTheoretische Fundierung und statistische Anwendungen (in German). Lohmar, Cologne:Josef Eul Verlag.
13.
KleinI, and DollM (2021) Tests on asymmetry for ordered categorical variables. Journal of Applied Statistics, 48, 1180–1198.
MöllerTA, and WeißCH (2020) Generalized discrete ARMA models. Applied Stochastic Models in Business and Industry, 36, 641–659.
20.
MontgomeryDC (2009) Introduction to Statistical Quality Control. 6th edition. New York:John Wiley & Sons, Inc.
21.
NgKW, TianG-L, and TangM-L (2011) Dirichlet and Related Distributions - Theory, Methods and Applications. Chichester:John Wiley & Sons, Ltd.
22.
OttenstreuerS, WeißCH, and TestikMC (2023) A review and comparison of control charts for ordinal samples. Journal of Quality Technology. doi:10.1080/00224065.2023.2170839
23.
Pawlowsky-GlahnV, and BucciantiA (2011) Compositional Data Analysis - Theory and Practice. Chichester:John Wiley & Sons, Ltd.
24.
PruschaH (1993) Categorical time series with a recursive scheme and with covariates. Statistics, 24, 43–57.
25.
SerflingRJ (1980) Approximation Theorems of Mathematical Statistics. New York:John Wiley & Sons, Inc.
26.
Vives-MestresM, Daunis-i-EstadellaJ, and Martín-FernándezJ-A (2013) Out-ofcontrol signals in three-part compositional T2 control chart. Quality and Reliability Engineering International, 30, 337346.
27.
Vives-MestresM, Daunis-i-EstadellaJ, and Martín-FernándezJ-A (2014) Individual T2: control chart for compositional data. Journal of Quality Technology46, 127–139.
28.
WangH, LiuQ, MokHMK, FuL, and TseWM (2007) A hyperspherical transformation forecasting model for compositional data. European Journal of Operational Research, 179, 459–468.
29.
WeißCH (2019) On some measures of ordinal variation. Journal of Applied Statistics, 46, 2905–2926.
30.
WeißCH (2020) Distance-based analysis of ordinal data and ordinal time series. Journal of the American Statistical Association, 115, 1189–1200.
31.
WeißCH (2022) Measuring dispersion and serial dependence in ordinal time series based on the cumulative paired ϕ-entropy. Entropy, 24, 42.
32.
ZhengT, and ChenR (2017) Dirichlet ARMA models for compositional time series. Journal of Multivariate Analysis, 158, 31–46.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.