
Abstract
‘Unexplained residuals’ models have been used within lifecourse epidemiology to model an exposure measured longitudinally at several time points in relation to a distal outcome. It has been claimed that these models have several advantages, including: the ability to estimate multiple total causal effects in a single model, and additional insight into the effect on the outcome of greater-than-expected increases in the exposure compared to traditional regression methods. We evaluate these properties and prove mathematically how adjustment for confounding variables must be made within this modelling framework. Importantly, we explicitly place unexplained residual models in a causal framework using directed acyclic graphs. This allows for theoretical justification of appropriate confounder adjustment and provides a framework for extending our results to more complex scenarios than those examined in this paper. We also discuss several interpretational issues relating to unexplained residual models within a causal framework. We argue that unexplained residual models offer no additional insights compared to traditional regression methods, and, in fact, are more challenging to implement; moreover, they artificially reduce estimated standard errors. Consequently, we conclude that unexplained residual models, if used, must be implemented with great care.
Keywords
1 Background
Within the field of lifecourse epidemiology, there is substantial interest in modelling the relationship between an exposure x measured longitudinally at several time points (i.e. (a) Nonparametric causal diagram (DAG) representing the hypothesised data-generating process for k longitudinal measurements of exposure x (i.e. x1,x2 ,…, xk) and one distal outcome y . The terms ex2,…,exk and ey represent all unexplained causes of x2,…,xk and y , respectively, and are included to explicitly reflect uncertainty in all endogenous nodes (whether modelled or not). (b) Path diagrams depicting the k standard regression models that would be constructed to estimate the total causal effect of each of x1,x2,…,xk on y (i.e. equation (5)). For each model, only the final coefficient may be interpreted as a total causal effect; all other coefficients are greyed to illustrate that no such interpretation should be made for them. (c) Path diagrams depicting the UR model, consisting of k − 1 preparation regressions (i.e. equation (6)) and a final composite regression model (i.e. equation (7), with i = k ).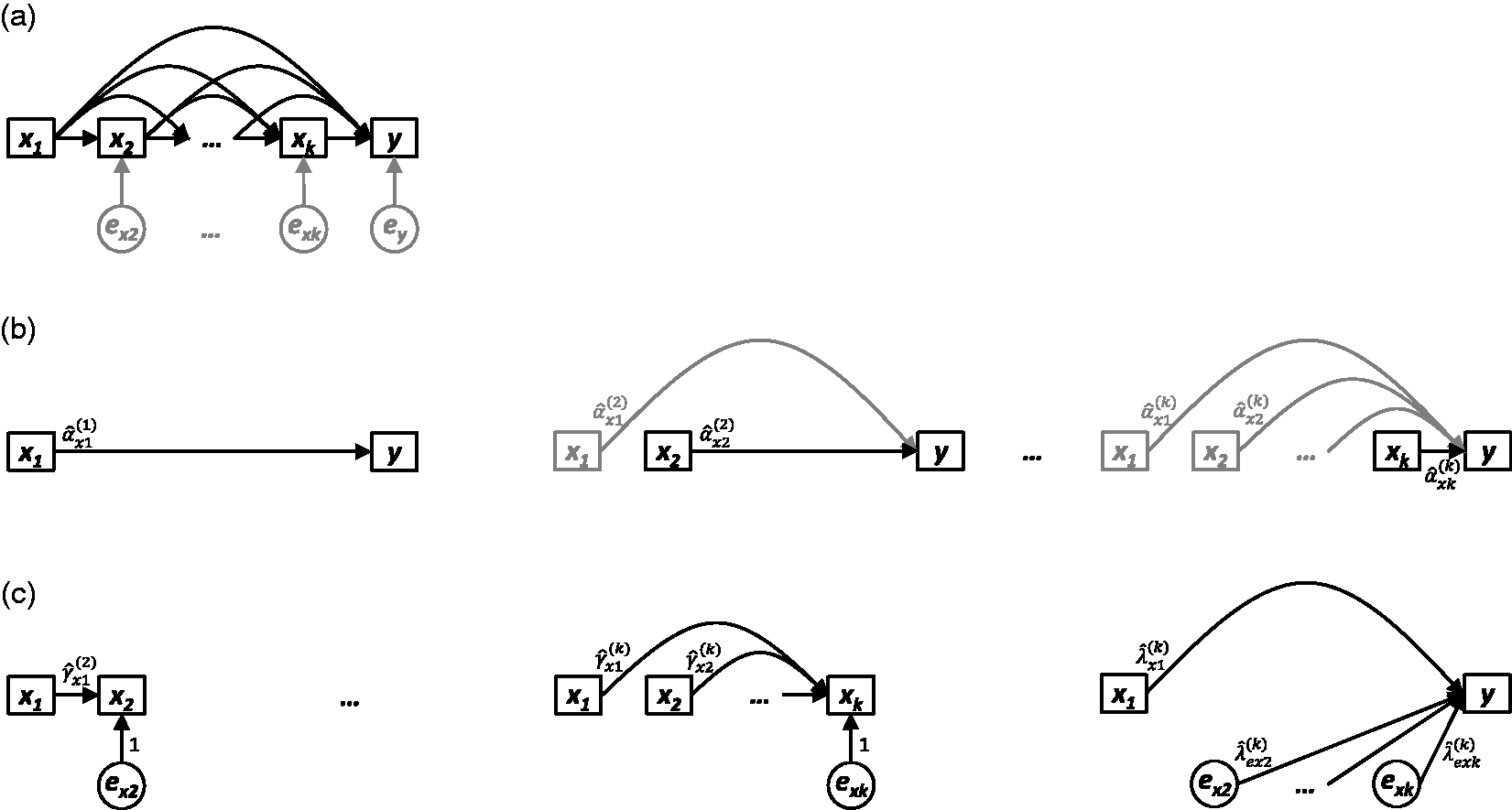
Using a causal framework to (correctly) model the scenario in Figure 1(a) may also have additional utility in identifying and quantifying important periods of change in the exposure that are causally related to the outcome. However, one challenge to such applications is that successive measurements of an exposure over time may be highly correlated with one another and therefore likely to suffer collinearity when analysed in relation to a distal outcome. Consequently, there has been extensive debate regarding the best way to model these types of longitudinally measured variables; a recent review 5 of analytical and modelling techniques has identified a range of different approaches, including z-score plots, regression with change scores, multilevel and latent growth curve models, and growth mixture models. Nonetheless, one of the most straightforward methods in use is a series of standard multivariable regression models.
1.1 Standard regression method
When using this approach, each longitudinal measurement of the exposure variable is treated as a separate entity that is subject to confounding by all previous measurements of that variable – the total number of models needed therefore being equal to the total number of time points at which the exposure has been measured.
As an example, the simplest scenario would involve just two measurements of the exposure x (i.e. x1 and x2, measured at time points 1 and 2, respectively), and a distal outcome, y, where all variables are continuous in nature. Here, two standard regression models (denoted


Importantly, to estimate the total causal effect of x1 on y in equation (1), adjustment for x2 is inappropriate, as it lies on the causal path between x1 and y (i.e. x2 is a mediator); in fact, adjustment for x2 might invoke bias in the causal interpretation due to a phenomenon known as the ‘reversal paradox’.5–7 In contrast, to estimate the total causal effect of x2 on y in equation (2), adjustment for x1 is appropriate, since it confounds the desired relationship (i.e. x1 causally precedes both x2 and y, potentially creating a spurious relationship between them). For this reason, in either model, it is only possible to interpret the coefficient of the last/most recent measurement of x (the exposure) as a total causal effect, 1 which encompasses all direct and indirect causal pathways between an exposure and outcome. No such interpretation is possible (nor should it be attempted) for the coefficient of the earlier measurement of x in equation (2), as it operates purely as a confounder.
1.2 Unexplained residuals method
To circumvent the need for multiple models, Keijzer-Veen
8
has suggested an alternative approach that would combine the information contained within each of the two separate models (equations (1) and (2)) into a single composite regression model using ‘unexplained residuals’. As originally proposed,
9
such a model allows the researcher to quantify the total effects of both the initial measurement of x (i.e.
First, the most recent measurement of x (i.e. x2) is regressed on the earlier measurement of x (i.e. x1):

This produces a measure of each observation’s ‘expected’ value of x2 as predicted by its value of x1. The difference between the expected value of x2 (i.e.
Second, y is regressed on both the initial exposure x1 and subsequent residual term

According to Keijzer-Veen et al.,
9
the key advantages of conducting regression using the composite ‘unexplained residuals’ (UR) model (4) are that:
The UR model produces the same estimated outcome values as the standard regression model in equation (2) (i.e. The estimated total effect sizes (coefficient values) produced by individual standard regression models (equations (1) and (2)) are equal to those estimated within the UR model (i.e. The UR model provides additional insight (via the coefficient The initial exposure x1 and subsequent residual term
Succinctly, the two models
Within the epidemiological literature, UR models have been used under a number of different names. In addition to ‘regression with unexplained residuals’ (as first proposed by Keijzer-Veen et al.9–11), other studies have referred to: ‘unexplained residual regression’ 12 ; ‘method of unexplained residuals’ 13 ; ‘conditional linear regression’ 12 ; ‘conditional (regression) models’5,14; ‘regression with conditional growth measures’ 14 ; ‘conditional growth models’15–18; ‘conditional weight models’ 19 ; and ‘conditional (regression) analysis’.20–24 The terms ‘conditional growth’ and ‘conditional size’ – and additional variations thereof – are also commonly used to refer to the difference between observed and expected size measurements.5,15,18,25–39 To avoid further confusion, the residual term representing the difference between the observed and expected values of an exposure produced in the manner proposed by Keijzer-Veen et al. (as in equation (3)) will be henceforth referred to as the ‘unexplained residuals (UR) term’, and the models themselves (as in equation (4)) will be referred to as ‘unexplained residuals (UR) models’.
Despite the numerous names given to these models, the process remains essentially the same as that first proposed. Indeed, several authors have extended the original model to examine scenarios involving several measurements of an exposure x (i.e.
Many researchers have further extended the original UR models by adjusting for additional confounding variables (i.e. over and above the confounding of prior measurements of the exposure), though there is, as yet, little consensus as to whether or how such adjustments should be performed. For example, Horta et al. 16 made no adjustments for potential confounders when deriving their UR terms, but did make adjustments within their composite UR model. In contrast, Gandhi et al. 18 adjusted for just one potential confounder (gender) when creating their UR terms, but also made further adjustments to the composite UR model (for gender and other variables). Adair et al. 25 created their UR terms using site- and sex-stratified linear regressions that were also adjusted for age, and made further adjustments for age, sex, and study site in their subsequent composite UR models. Indeed, there are many other examples of different approaches to confounder adjustment, but none of these have been adequately and explicitly justified by the researchers concerned, even though it appears that they did so in order to make causal inferences.
2 Research aims
The potential impact of using alternative approaches to adjust for confounding when constructing and using UR terms has yet to be fully evaluated. Indeed, Keijzer-Veen et al. 9 did not address confounding variables in their original paper, and there has been little to no discussion or analysis of this issue by subsequent authors using this approach. It therefore remains unclear whether UR models that include confounders offer the same purported benefits as those lacking (or ignoring) confounders, and there is no clear indication of how potential confounders should be treated by analyses using these models. This is an issue of particular relevance to researchers seeking to infer causality from individual coefficient estimates, since inappropriate adjustment for covariates (which includes both the failure to adjust for genuine confounders and the adjustment for mediators mistaken for confounders) can lead to biased causal inferences. For this reason, UR models are likely to have limited practical utility unless they are able to accommodate confounding variables appropriately. The fact that UR models have not been developed or analysed within a causal framework also creates uncertainty about their utility for making causal inferences.
Therefore, the aims of the present study were to: (1) confirm that the approach proposed by Keijzer-Veen et al. may be extended to a scenario involving k longitudinal measurements of an exposure x in the absence of any additional confounding; (2) determine whether it is possible (and if so, how might it be possible) to adjust for additional confounders within the UR modelling framework; (3) evaluate the benefits of UR models claimed by Keijzer-Veen et al.; and (4) offer recommendations for future use of UR models The present study examines two very different types of potential confounders: time-invariant (which require/provide measurements taken at a single time point and remain constant across the lifecourse, e.g. sex); and time-varying (for which measurements are collected at multiple time points across the lifecourse – usually concurrent to measurements of the exposure – because the value of the variable may change, e.g. socioeconomic position).
These aims are summarised in the DAGs presented in Figures 1(a), 2(a), and 3(a), which depict three general scenarios drawn from lifecourse epidemiology, each of which will be examined in the analyses that follow. Each DAG relates k longitudinally measured exposure variables (a) Nonparametric causal diagram (DAG) representing the hypothesised data-generating process for k longitudinal measurements of exposure x (i.e. x1,x2,…,xk), one distal outcome y , and one time-invariant confounder m . The terms em, ex1,…,exk and ey represent all unexplained causes of m, x1,…,xk, and y, respectively, and are included to explicitly reflect uncertainty in all endogenous nodes (whether modelled or not).(b) Path diagrams depicting the k standard regression models that would be constructed to estimate the total causal effect of each of x1,x2,…,xk on y (i.e. equation (9)). For each model, only the final coefficient may be interpreted as a total causal effect; all other coefficients are greyed to illustrate that no such interpretation should be made for them. (c) Path diagrams depicting the UR model, consisting of k − 1 preparation regressions (i.e. equation (10)) and a final composite regression model (i.e. equation (11), with i = k ). (a) Nonparametric causal diagram (DAG) representing the hypothesised data-generating process for k longitudinal measurements of exposure x (i.e. x1,x2,…,x
k
), one distal outcome y, and k longitudinal measurements of one time-varying confounder m1,m2,…,m
k
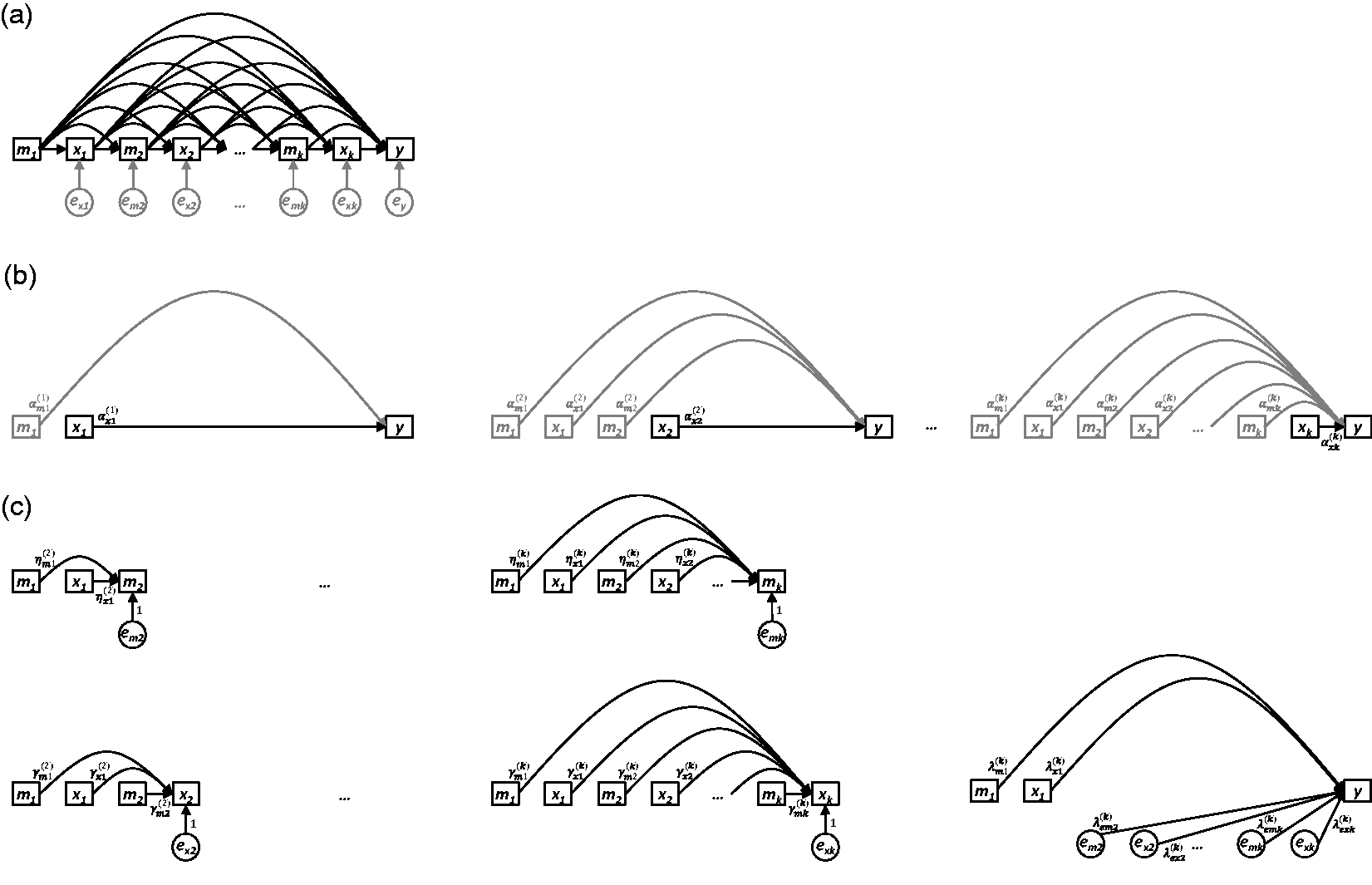
. The terms em2, …, emk, ex1,…,exk and ey represent all unexplained causes of m2,…, mk, x1 ,…, xk, and y, respectively, and are included to explicitly reflect uncertainty in all endogenous nodes (whether modelled or not). (b) Path diagrams depicting the k standard regression models that would be constructed to estimate the total causal effect of each of x1, x2 ,…, xk on y (i.e. equation (12)). For each model, only the final coefficient may be interpreted as a total causal effect; all other coefficients are greyed to illustrate that no such interpretation should be made for them. (c) Path diagrams depicting the UR model, consisting of 2(k − 1) preparation regressions (i.e. equations (13) and (14)) and a final composite regression model (i.e. equation (15), with i = k ).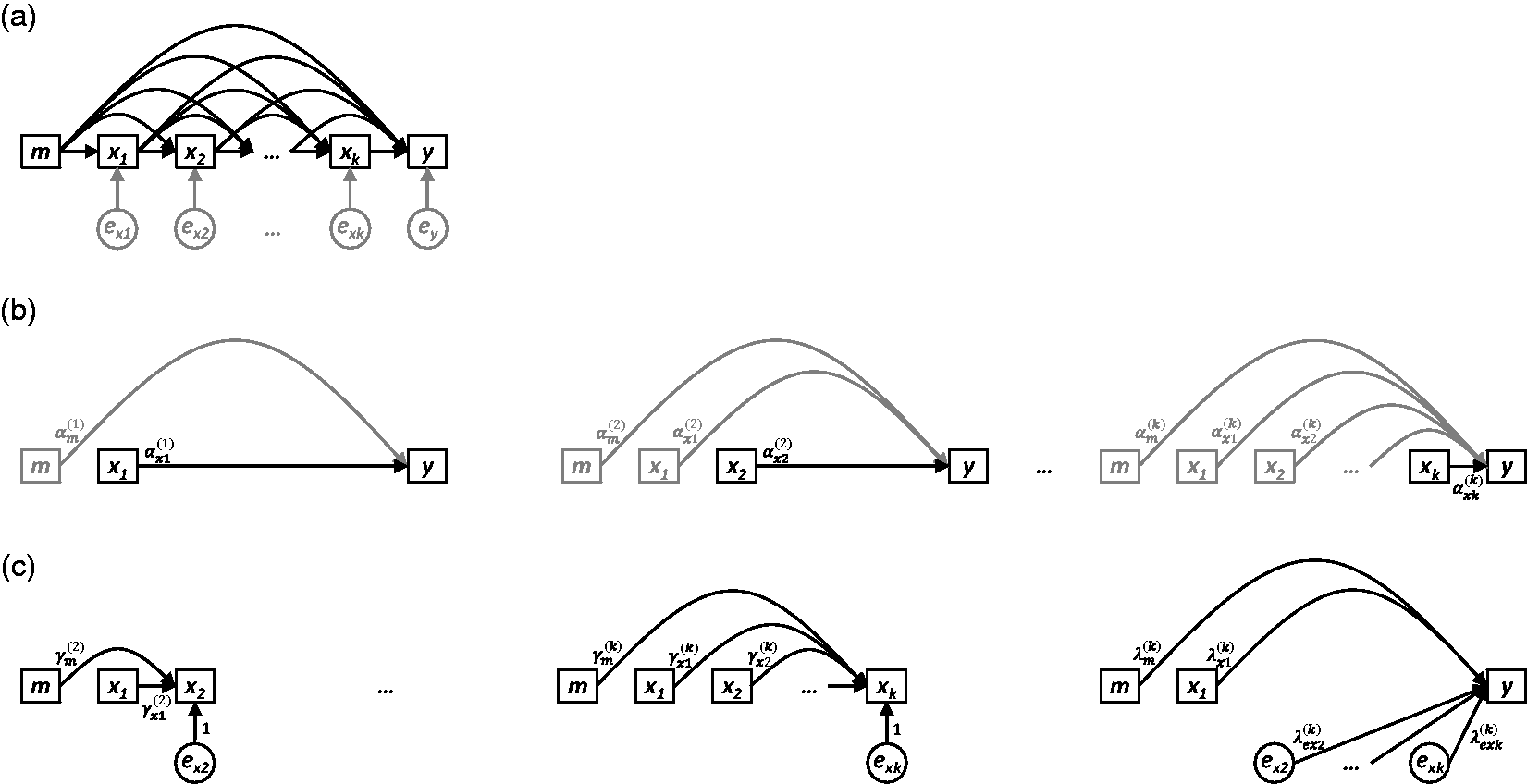
Sections 3 through 9, which follow, provide: the three key properties of UR models that will be evaluated for the scenarios in Figures 1(a), 2(a), and 3(a) (§3); DAG-based and mathematical examinations of the UR models for the scenarios given in Figure 1(a) (§4), 2(a) (§5), and 3(a) (§6); a discussion of several interpretational issues that arise for UR models when placed within a causal framework, including an evaluation of the claim that UR models provide greater insight than standard regression methods (§7); an argument outlining how UR models produce artificially reduced standard errors (SEs) and how this might be corrected (§8); and recommendations for future use and interpretation of UR models, particularly as these relate to the inclusion of confounders (§9).
3 Key properties of UR models
In the following sections, we evaluate the mathematical properties of the original UR models after extending them to include k measurements of a continuous exposure x: in the absence of any additional confounding (§4); in the presence of a single additional time-invariant confounder m (§5); and in the presence of a single additional time-varying confounder with sequential values
From a causal inference perspective, only Properties (ii) and (iii) are meaningful, since the focus is on individual coefficient estimates as opposed to predicted outcomes. Nevertheless, we evaluate all three properties in Sections 4 through 6, and leave discussion of interpretational issues until later in the paper (§8).
4 UR models: No confounders (Figure 1(a))
Before considering any additional confounding variables, we first consider the straightforward scenario depicted in Figure 1(a). We provide: definitions of the standard regression models, UR terms, and UR models (§4.1); an analysis of UR models within a causal framework (§4.2); and arguments for why Properties (i)–(iii) are upheld (§4.3).
4.1 Definitions
We define the ordinary least-squares (OLS) regression model
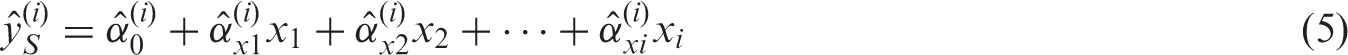
A visual depiction of equation (5) is given in Figure 1(b). Because the relationship between each xi and y is confounded by all previous measurements of x (i.e.
To create UR terms according to the process established by Keijzer-Veen et al.,
9
each measurement of the exposure xi is regressed on all previous measurements ofx (for
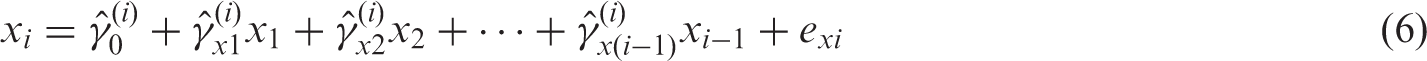
The UR term
Lastly, we define the UR model
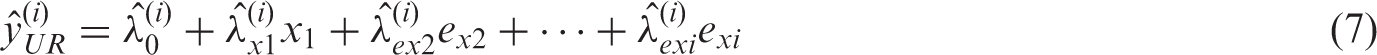
The composite UR model
4.2 A causal framework
Within the causal framework provided by Figure 1(a), the unique properties of UR models can be visualised. If we were naively to model
Total effect of x2 on y estimated by a standard regression model compared to total effect of
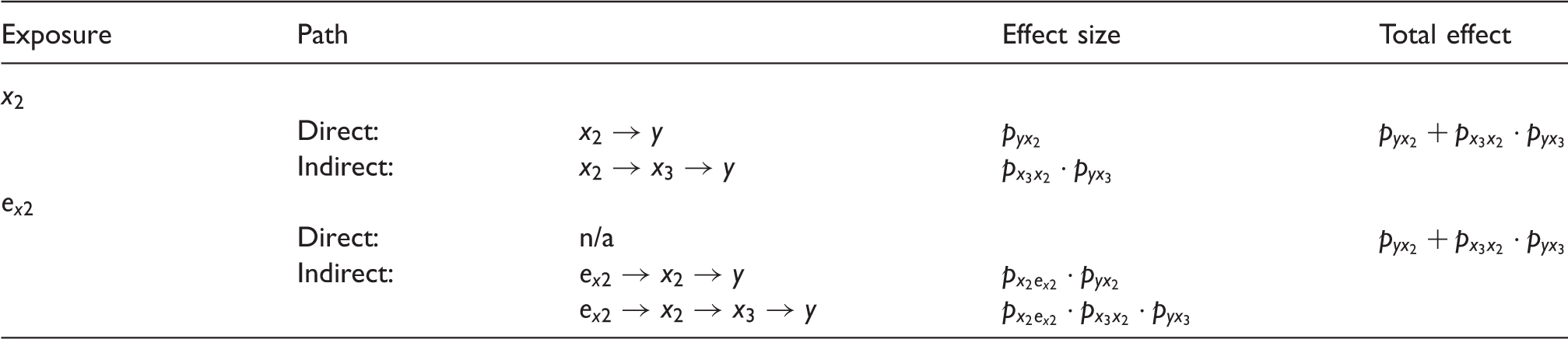
4.3 Covariate orthogonality and Properties (i)–(iii)
In addition to the graph-based approach in the preceding section, we are able to prove mathematically that Properties (i)–(iii) are upheld for the scenario given in Figure 1(a). In summary, these properties are:
For the scenario depicted in Figure 1(a), the standard regression model

We illustrate this property, and explain how it is exploited to ensure Properties (i)–(iii) are upheld. Formal proofs are provided in online supplementary Appendix 1.
In Table 2, note that each regression model (for both the standard and UR methods) contains one more covariate than the model preceding it. In the column of standard regression models, each row contains an additional xi term; in the column of UR models, each row contains an additional
Typically, the inclusion of an additional covariate in a regression model changes the coefficient(s) estimated for other covariates because their covariance would be nonzero. For example, the addition of x2 in
However, a UR model upholds Properties (ii) and (iii) specifically because its covariates do not covary. The addition of
In fact, it can easily be shown that all UR terms
Property (i):
First, it must be noted that each UR model is nothing more than a reparameterisation of the corresponding standard regression model (i.e.
Property (ii):
It is trivially true that the coefficients estimated for x1 in the first standard regression model
Property (iii):
Lastly, we can show that the coefficient for 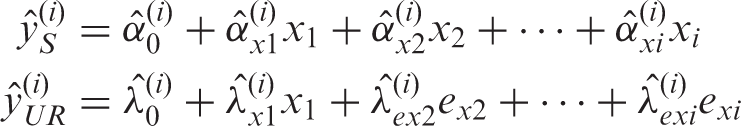
We may set these two equations equal to one another (due to Property (i)), substitute the expansions for 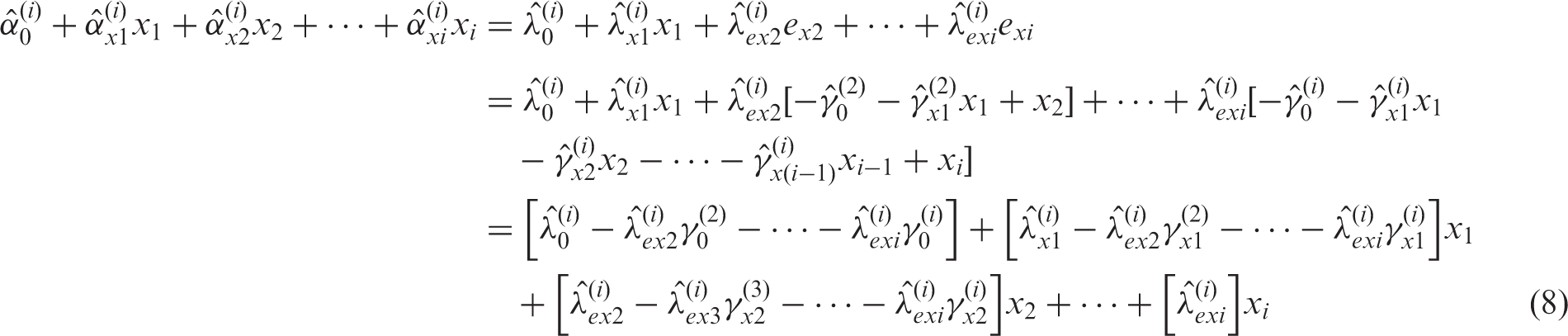
From equation (8) above, it becomes clear that the coefficients for xi in
5 UR models: Time-invariant confounder (Figure 2(a))
We next consider the scenario in Figure 2(a), in which a time-invariant covariate m confounds the relationship between
5.1 Definitions (with correct adjustment for
)
Using the DAG in Figure 2(a) as guidance, we extend the original definitions of the standard regression models, UR terms, and UR models (equations (5) to (7), respectively) to properly account for the confounding effect of m, a time-invariant covariate.
We define the OLS regression model 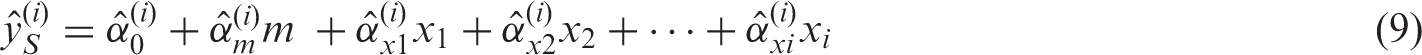
Because the relationship between each xi and y is confounded by all previous measurements of x (i.e.
We further extend the process of Keijzer-Veen et al.
9
to create UR terms for this scenario. As is evident, the relationship between each measurement of the exposure variable xi and all previous measurements 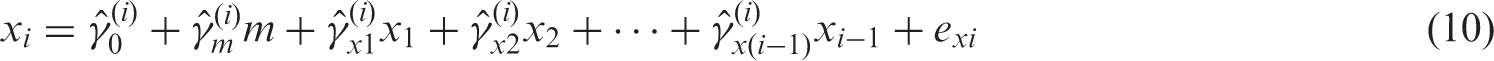
Therefore, the UR term
Finally, we define the UR model 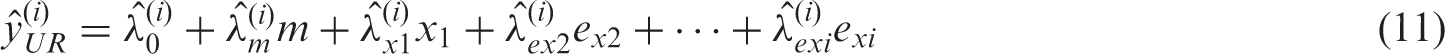
The composite UR model
As in the preceding section, visual depictions of the previous equations are provided, with Figure 2(b) corresponding to equation (8) and Figure 2(c) corresponding to equation (8) and equation (9) (with
5.2 A causal framework
We may easily extend the reasoning from the previous scenario (§4.2) to explain why the UR model (equation (11)) satisfies Properties (i)–(iii) before resorting to mathematics, by considering the diagram in Figure 2(a) as a path diagram. A regression model containing all of
5.3 Covariate orthogonality and Properties (i)–(iii)
In addition to the graph-based approach in the preceding section (§5.2), we are able to illustrate mathematically that adjustment for m both when generating each UR term
For the scenario depicted in Figure 2(a), the standard regression model

5.4 Incorrect adjustment for
We have used the causal diagram in Figure 2(a) to argue for the necessity of adjusting for a time-invariant confounder m during both stages of the UR modelling process, and have demonstrated how such adjustments will produce a composite UR model that satisfies Properties (i)–(iii), as Keijzer-Veen et al. intended. We now consider the implications of insufficient adjustment.
Without adjustment for m when generating each UR term
6 UR models: Time-varying confounder (Figure 3(a))
Finally, we consider the scenario in Figure 3(a), in which a time-varying covariate
In this section, we again provide: definitions of the standard regression models, UR terms, and UR models, all adjusted for the confounder
6.1 Definitions (with correct adjustment for
)
Using the DAG in Figure 3(a), we extend the original definitions of the standard regression models, UR terms, and UR models (equations (5) to (7), respectively) to properly account for the confounding effect of
We define the OLS regression model 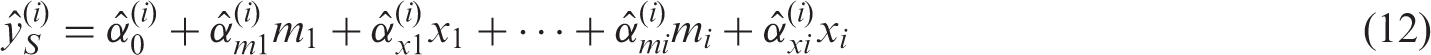
The relationship between each xi and y is not only confounded by all previous values of the exposure
Extending the process of Keijzer-Veen et al.
9
to create UR terms for each measurement of the exposure xi in this scenario necessitates adjustment for the current measurement and all previous measurements of the confounder 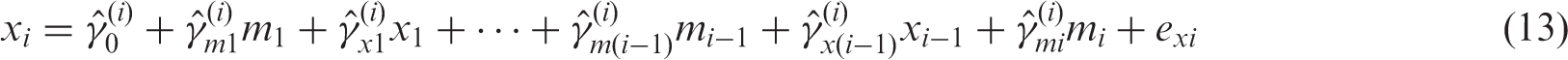
In this way,
As we have demonstrated previously (§4.3, §5.3), UR models rely upon the orthogonality of terms in the composite UR model. This necessitates the creation of UR terms 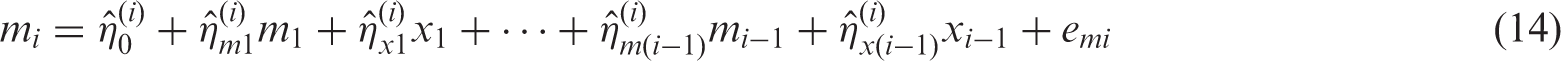
Thus,
Lastly, we define the UR model 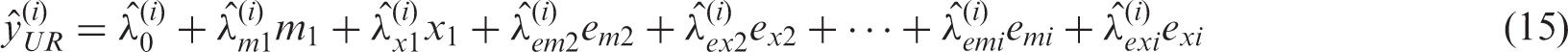
As previously, visual depictions of these equations are provided. Figure 3(b) corresponds to the standard regression models given by equation (12); Figure 3(c) corresponds to the
6.2 A causal framework
The similarities amongst the three causal scenarios depicted in Figures 1(a), 2(a), and 3(a) are evident, and shed light on how the reasoning from the previous scenarios (§4.2 and §5.2) can be extended to demonstrate why the UR model in equation (15) satisfies Properties (i)–(iii). In a regression model containing all of
6.3 Covariate orthogonality and Properties (i)–(iii)
In addition to the graph-based approach in the preceding section (§6.2), we can illustrate mathematically that the standard regression models
For the scenario depicted in Figure 3(a), the standard regression model
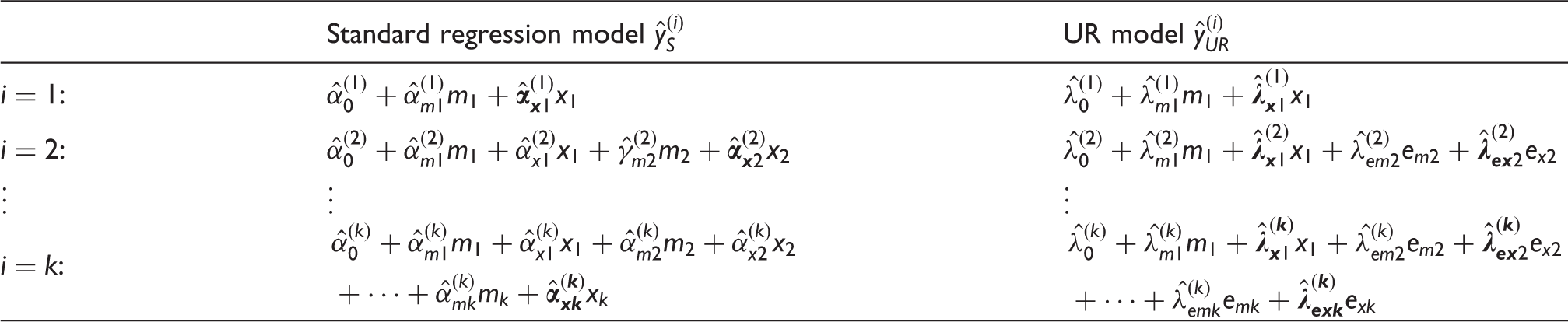
Proving this is relatively straightforward. For any UR term
6.4 Incorrect adjustment for
The DAG in Figure 3(a) demonstrates the necessity of adjusting for a time-varying confounder
The requirement of orthogonal covariates within the composite UR model also sheds light on the necessity for generating UR terms
7 UR model interpretation
Having demonstrated that confounder adjustment within UR models is possible, we consider the claim
9
that UR models offer additional insight via the coefficients for each UR term
Consider again the simple example with two longitudinal measurements of a continuous exposure x (i.e. x1 and x2), outcome y, and no additional confounders (i.e. Figure 1(a), with 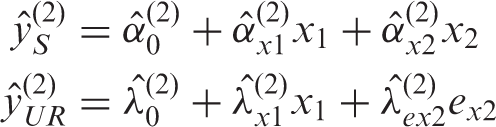
It has been shown (§4.3) that
We also raise a more philosophical point, which speaks to the need for any model to reflect accurately the underlying data-generation process of a given scenario. As an artefact of OLS regression, the UR terms will always be mathematically independent of the value of the initial measurement of the exposure and all subsequent measurements. This is unlikely to be an accurate representation of real-world exposure variables. Many of these, such as body size, exhibit a consistent, cumulative presence that is only manifest at the discrete time points at which it is measured; these measurements are thus distinct only as a result of the discretisation of time within the measurement processes adopted. Moreover, in auxological studies, the phenomenon of so-called compensatory (or ‘catch up’) growth has been well documented, with accelerated growth being observed in individuals who begin with a low value of some measure, e.g. birthweight.45,46 Therefore, however convenient and mathematically sound it may be to model data in a way that implies complete statistical independence amongst an exposure variable’s initial value and its subsequent measurements, this assumption is likely to be implausible and unrealistic for most biological and social variables of interest to epidemiologists. This is a weakness shared by all conditional approaches (of which UR models are one), which has led several authors 47 to recommend that the results be considered alongside those produced by other methods, rather than in isolation.
8 Standard error reduction
Finally, we address an important consequence of the use of UR models; namely, that they underestimate the standard errors (SEs) of estimated coefficients, thereby resulting in artificial precision of estimated effect sizes. Although focus on statistical significance by way of p-values and confidence intervals is not in and of itself justifiable within a causal framework (as focus is effect size and likely functional significance, e.g. the absolute risk posed or the potential for substantive intervention), we consider it an important issue to address as a matter of clarity for researchers seeking to use UR models.
To demonstrate, we have simulated 1000 non-overlapping random samples of 1000 observations from a multivariate normal distribution based upon the DAG in Figure 1(a) with
By definition, the SE of an estimated regression coefficient is a point estimate of the standard deviation of an (infinitely) large sampling distribution of estimated regression coefficients. We have shown that standard regression and UR models elicit identical point estimates of the total causal effects of each measure of the longitudinal exposure (§4); from this, it follows that the associated SEs should themselves be equal.
Violin plots of the SEs estimated for each coefficient representing a total causal effect across the 1000 simulations are displayed in Figure 4 for each method considered. As is evident, the reported SEs within the UR models are reduced in comparison to those within the first standard regression models (for designated exposure x1) and equal to those within the final standard regression models (for designated exposure x2). This demonstrates an apparent paradox: the coefficient values are equivalent, yet the associated SEs are unequal.
Violin plots comparing the standard errors associated with equivalent coefficients estimated in standard regression vs. UR models, for data simulated based upon the scenario depicted in Figure 1(a) (with k = 2). Horizontal bars within each distribution represent the mean ± 1 standard deviation.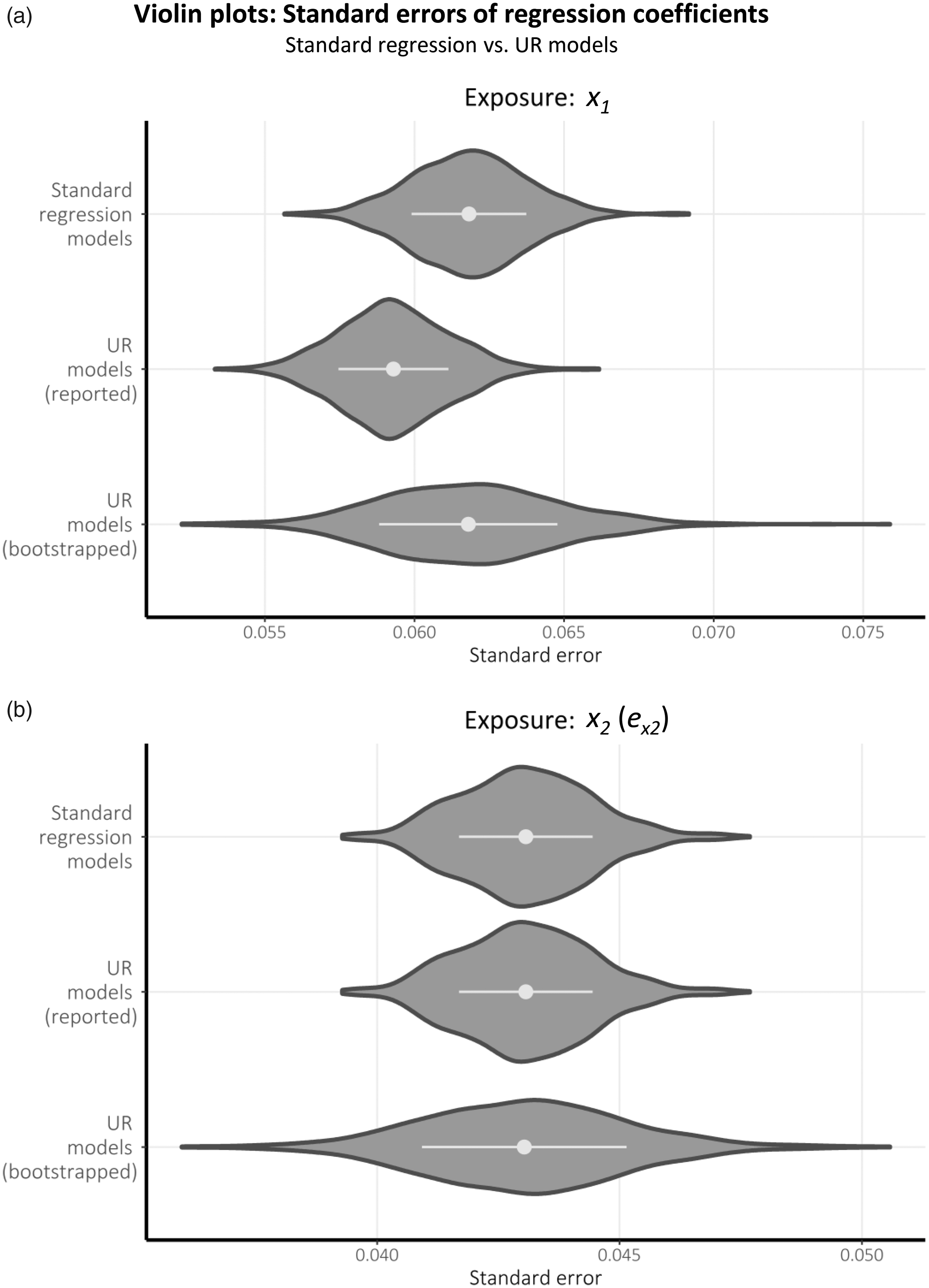
We argue that the apparent reduction in SEs achieved by using UR models is purely artefactual and arises from the explicit conditioning on future measurements of x within a UR model. In the standard regression analysis, the only information within the data that is used to inform SE estimation lies in the past (i.e. past measures of the exposure plus any confounders). In contrast, the UR modelling process generates (orthogonal) residuals for the entire exposure period and combines these into a single model, thereby using information within the data that is from both the past and the future. If we possessed data pertaining to any true independent causes of future measurements of the exposure, such a method would indeed be valid; however, the UR terms are simply estimated using prior measurements of the exposure. Moreover, due to the fact that they are estimates, the UR terms themselves contain additional variation that is not accommodated by traditional regression methods which assume covariates are measured without error. Consequently, the SEs of estimated causal effect derived from UR models are artefactually reduced and should not be inferred as robust. Indeed, when the SEs within the UR models are estimated via bootstrapping, they are similar to those within the standard regression models.
Comparing the two plots in Figure 4 offers clarity to this argument: (a) displays differing distributions of the reported SEs for the coefficient estimates of x1 (where conditioning on the future information given by x2 reduces the standard error in the UR model); whereas (b) displays the same distribution of the reported SEs for the coefficient estimates of x2 and
9 Conclusion
The mathematical appraisal of UR models that we have undertaken confirms that the method proposed by Keijzer-Veen et al.
9
is capable of accommodating more than two longitudinal measurements of an exposure variable and demonstrates how adjustment for confounding variables should be made in this framework to uphold the property that the coefficients for the terms
As our proofs only consider one confounding variable, the causal framework provided by DAGs should aid future researchers who wish to extend robustly UR models to situations involving multiple, possibly causally linked, time-invariant and time-varying confounders. Such a DAG will be useful in identifying confounders and establishing the temporal ordering of variables, thereby ensuring that all preceding variables are adjusted for when generating the necessary UR terms.
Although UR models can accommodate multiple measurements of an exposure variable in addition to confounding variables, we have concerns about their practical implementation. Although only one UR model need ultimately be presented, the necessity of generating orthogonal covariates for that UR model requires that many models be created; this has the potential to be quite substantial when multiple confounders are considered. For an exposure x measured at k points in time, the standard regression approach necessitates k separate models for estimating the total causal effect of each measurement on the outcome regardless of the number of confounders. In the case of one time-invariant confounder (§5), k models are also created (
We therefore have strong reservations about the use and implementation of UR models within lifecourse epidemiology, and suggest that researchers considering using them should instead rely on standard regression methods, which produce the same results but are much less likely to be mis-specified and misleading. However, for researchers wishing to use these models, the hypothesised DAG or causal diagram should be presented so that any readers and/or reviewers can confirm that sufficient adjustment for confounders has been undertaken; moreover, SEs should be estimated via bootstrapping and not simply reported as in the model output, as these have the potential to be misleading. We support the recommendation of previous authors 47 that additional analytical approaches should be considered alongside conditional approaches (e.g. UR models) in order to achieve robust causal conclusions. For example, multilevel, latent growth curve, and growth mixture models may be used to estimate the effects of growth across the lifecourse on a distal outcome, and are more flexible than standard regression methods. 5 Moreover, the three G-methods50,51 are explicitly grounded in a causal framework and allow for the simultaneous consideration of multiple measurements of a longitudinally measured exposure, as well as time-varying confounding; these methods provide exciting avenues of research for lifecourse epidemiologists.
Supplemental Material
Appendix -Supplemental material for Adjustment for time-invariant and time-varying confounders in ‘unexplained residuals’ models for longitudinal data within a causal framework and associated challenges
Supplemental material, Appendix for Adjustment for time-invariant and time-varying confounders in ‘unexplained residuals’ models for longitudinal data within a causal framework and associated challenges in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: KFA and SCG were supported by the Economic and Social Research Council [grant numbers ES/J500215/1 and ES/P000746/1, respectively]. GTHE, PWGT, AH, and MSG were supported by the Higher Education Funding Council for England.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.