
Abstract
Cost- and time-efficient web surveys have progressively replaced other survey modes. These efficiencies can potentially cover the increasing demand for survey data. However, since web surveys suffer from low response rates, researchers and practitioners start considering social media platforms as new sources for respondent recruitment. Although these platforms provide advertisement and targeting systems, the data quality and integrity of web surveys recruited through social media might be threatened by bots. Bots have the potential to shift survey outcomes and thus political and social decisions. This is alarming since there is ample literature on bots and how they infiltrate social media platforms, distribute fake news, and possibly skew public opinion. In this study, we therefore investigate bot behavior in web surveys to provide new evidence on common wisdom about the capabilities of bots. We programmed four bots – two rule-based and two AI-based bots – and ran each bot N = 100 times through a web survey on equal gender partnerships. We tested several bot prevention and detection measures, such as CAPTCHAs, invisible honey pot questions, and completion times. The results indicate that both rule- and AI-based bots come with impressive completion rates (up to 100%). In addition, we can prove conventional wisdom about bots in web surveys wrong: CAPTCHAs and honey pot questions pose no challenges. However, there are clear differences between rule- and AI-based bots when it comes to web survey completion.
Introduction and research question
Cost- and time-efficient web surveys have progressively replaced other survey modes, particularly in-person interviews (Schober, 2018). Many established social surveys, such as the European Social Survey (ESS), are now using web-based data collection. Compared to other survey modes, web surveys come with cost- and time-efficiencies so that they are a promising candidate to cover the growing demand for survey data (Knowledge Sourcing Intelligence, 2023). However, web surveys do not seem to be ready for taking over. The reason is that web surveys struggle with low response rates. For example, Daikeler et al. (2020) reveal that web surveys yield about 12% lower response rates than other survey modes.
As web surveys struggle with low response rates, researchers look for new respondent recruitment sources. This especially includes social media platforms, such as Facebook and Instagram, offering advertisement and targeting systems (Pötzschke et al., 2023; Zindel, 2023). Although social media recruitment provides quick access to an unprecedented respondent pool, the data quality and integrity of such web surveys might be threatened by bots (i.e., programs that autonomously interact with systems) (Griffin et al., 2022; Storozuk et al., 2020; Xu et al., 2022; Yarrish et al., 2019; Zhang et al., 2022). Bots can shift survey outcomes and thus political and social decisions (Xu et al., 2022). This is alarming since bots were already used to manipulate public opinion, such as during the Brexit-Referendum in 2016 (Gorodnichenko et al., 2021). The consequences of bots for web surveys are severe: First, bot-based answers may differ from human answers and thus bots can introduce measurement error (Xu et al., 2022). Second, bots completing web surveys can undermine public trust in social research (Xu et al., 2022). This potentially reinforces the salience of fake news and reports in public discourses. Third, bots taking web surveys can lead to direct financial damage, as they can scrape incentives, and indirect financial damage, as their detection is effortful and time-consuming (Storozuk et al., 2020; Xu et al., 2022).
While there is ample literature on bots and how they infiltrate social media platforms, distribute fake news, and skew public opinion (see, for example, Howard et al., 2018; Ross et al., 2019; Shi et al., 2020), research on bots in web surveys is scarce. The few existing studies investigate prevention and detection measures. For example, CAPTCHAs (or challenge-response authentications) request respondents to perform specific tasks, such as counting the number of cars in a picture, and are widely accepted as a method for preventing bot infiltration (Storozuk et al., 2020). Honey pot questions (or invisible questions implemented in the source code) cannot be seen by respondents, but it is said that they are picked up by bots. Thus, they oftentimes serve as detection measure (Bonett et al., 2024). Similarly, paradata in the form of completion times are frequently seen as a reliable measure to detect bots because their answer speed may not be tailored to the respective survey task (Nikulchev et al., 2021).
Considering the literature on bots in web surveys, it is observable that many studies do not distinguish between conventional (rule-based) and sophisticated (AI-based) bots. AI-based bots potentially show a much higher level of sophistication and can engage in tasks that go beyond the capabilities of their rule-based counterparts (Naga, 2021; Shrivastav, 2023). For example, AI-based bots can be linked with Large Language Models (LLMs), such as Gemini Pro (Google, 2024), mimicking the answer behavior of real respondents and answering open narrative questions meaningfully.
In this study, we contribute to the current state of research on bots in web surveys and provide new evidence on common wisdom about the capabilities of bots. For this purpose, we programmed four bots, varying regarding their sophistication: two rule-based and two AI-based bots. We then let the bots run through a web survey on equal gender partnerships including various bot prevention and detection measures, such as CAPTCHAs, honey pot questions, and completion times. In doing so, we attempt to answer the following research question: Do bots varying in sophistication show different web survey completion characteristics?
Method
Bot programming
List of rule- and AI-based bot capabilities.
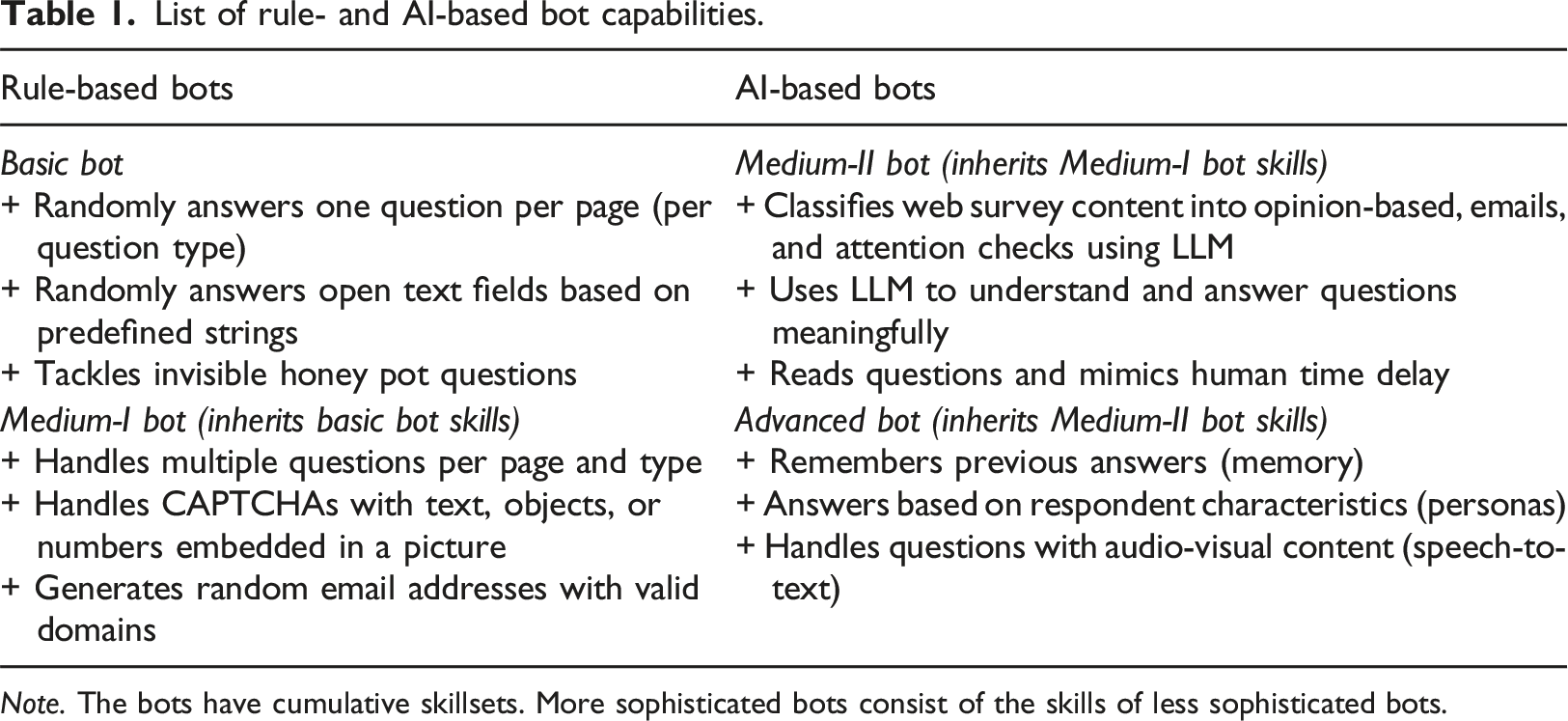
Note. The bots have cumulative skillsets. More sophisticated bots consist of the skills of less sophisticated bots.
The Basic bot was programmed in a way that it answers one question per question type (e.g., one closed, one check-all-that-apply, and one open narrative question) on a web survey page. Open narrative questions are answered based on a random string selection from a list of non-substantive answers, such as “I cannot say” and “Good question. I need to think about it more carefully.” Furthermore, it includes varying sleep times (for assuring that the web survey pages have loaded completely) and tackles invisible honey pot questions implemented in the source code.
1
The Medium-I bot is additionally capable of answering multiple questions per web survey page, irrespective of the question type. It passes CAPTCHAs
2
and generates random email addresses with valid domains
3
to deal with email authentication measures. The Medium-II bot is linked to Gemini Pro (Google, 2024). Gemini Pro is a family of multimodal LLMs that are capable of image, audio, video, and text understanding. The bot uses Gemini Pro to classify web survey content into opinion-based, emails, and attention checks.
4
For opinion-based questions, the Medium-II bot prompts Gemini Pro to create an answer to the question (e.g., selecting an answer option or providing a meaningful open narrative answer). In addition, it has the potential to pass common attention checks (see, for example, Oppenheimer et al., 2009). It also includes sleep times that are adjusted to the time it would take to read the questions, tasks, and instructions. The Advanced bot answers multiple questions per page using Gemini Pro and includes a memory feature. The memory feature implies that the bot keeps a history of the LLM answers, which is given to the LLM in the next prompt as history to maintain consistency. In addition, it is randomly assigned personas (i.e., gender, age, and political nature) to synthesize real answer behavior of respondents. Due to a link to OpenAI’s Whisper (Radford et al., 2023) the Advanced bot can transcribe voice and video input in real-time to deal with audio-visual question content. Figure 1 shows a screenshot of the Advanced bot’s log output for an open narrative question. Screenshot of an open narrative question including log output of the Advanced bot. Note. In the previous closed question on child adoption, the bot answered “rather good” and is now asked to explain its answer in its own words. The log output (on the right) shows the history of previous questions and answers, as well as the open narrative answer. In this trial, the Advanced bot was assigned the following personas: male, 87 years old, and neutral (political nature).
Web survey design
We prepared and programmed a web survey in Unipark (https://www.unipark.com/) dealing with equal gender partnerships. LGBTQ-related web surveys have been subject to bot infiltration in the past (Griffin et al., 2022). The web survey included 43 questions, tasks, and instructions that were distributed over 28 web survey pages. For this study, we are looking at various parts of the web survey, all of them were claimed to be measures for preventing bots from infiltrating web surveys or to detect them if they have infiltrated web surveys: 1) three open narrative questions, 2) one picture CAPTCHA (counting cars), 3) two honey pot questions, 4) one attention check (clicking on survey logo), 5) one check-all-that-apply (CATA) question on survey location, and 6) completion times.
Completion times were measured in milliseconds (ms) using the open-source tool “Embedded Client Side Paradata” (Schlosser & Höhne, 2018, 2020).
Data synthesis
After bot and web survey programming, we started with the bot data collection. Data collection took place in August 2024. Each of the four bots was instructed to take the web survey 100 times. 5 In total, we have 400 bot trials as basis for data analysis. Starting with the Advanced bot, we ran the bots one-by-one through the web survey. In all trials, we logged the web survey content, the answers provided by each bot, and the time stamps on a survey page level. For the two AI-based bots, we additionally logged the prompts for instructing Gemini Pro, including persona selection (Advanced bot only). This was done for documentation and transparency reasons (the Supplemental Online Material includes all Gemini Pro prompts). For replication purposes, we release data including analysis script through Harvard Dataverse (see https://doi.org/10.7910/DVN/NT5B8T).
Results
Performance metrics of the four bots.

Note. For completion rate, item-nonresponse rate, CAPTCHA passing rate, honey pot questions passing rate, and attention check passing rate, we report percentages. For open narrative questions, we report the average number of words. For the CATA question, we report the average number of answer options selected. Finally, we report completion times in minutes. Completion rate and times are reported for the entire web survey. Item-nonresponse is reported for 26 closed questions and three open narrative questions.
When it comes to answering open narrative questions, we find clear differences between the bots. The rule-based bots are characterized by short, non-substantive answers (they randomly select strings from a predefined list), whereas the AI-based bots are characterized by meaningful and more lengthy answers. For example, as shown in Figure 1, the Advanced bot is in favor of same-gender couples adopting children (by saying “rather agree”) and subsequently provides a tailored open narrative answer. Regarding the CAPTCHA, it is observable that the Medium-I, Medium-II, and Advanced bots show passing rates of 100%. For these bots, CAPTCHAs do not represent a challenge at all. Only the Basic bot has a passing rate of 0%, which is in line with its capabilities (see Table 1). Both honey pot questions embedded in the source code do not represent a challenge to any of the bots. The passing rate is 100% (there is no difference between the first and second honey pot question). While the attention check turned out to be challenging for the two rule-based bots (they were not created to pass it), it does not pose a challenge for the two AI-based bots. Both have a passing rate of 100%. The results regarding the CATA question on survey location show some “suspicious” answer behavior. On average, the rule-based bots claim to be at four locations (or places) while completing the web survey. The AI-based bots, in contrast, provide more reasonable answers (one location). While the two conventional bots produce mean completion times lower than 3 minutes, the two more sophisticated bots produce mean completion times higher than 9 minutes. The relatively high difference between the Medium-II and Advanced bots can be explained by the memory feature programmed into the latter one. The Advanced bot runs through the logs of previous questions, tasks, and instructions, which in turn slows it down.
Discussion and conclusion
The goal of this study was to provide new evidence on conventional wisdom when it comes to bots in web surveys. We programmed four bots – two rule-based and two AI-based – and ran each bot 100 times through the web survey. The web survey dealt with equal gender partnerships and included various bot prevention and detection measures. The overall results reveal substantial differences between rule- and AI-based bots clarifying some rumor about bot capabilities.
All four bots showed very high completion rates, indicating that both conventional and more sophisticated bots can take web surveys successfully. However, these completion rates are higher than what we would expect from web surveys with human respondents. Thus, overly high completion rates in web surveys may point to bot activities.
Item-nonresponse turns out to be a useful indicator to detect very simple rule-based bots that only answer one question of its kind on a web survey page. However, this does not apply to more sophisticated bots. Open narrative questions may be helpful when it comes to conventional (rule-based) bots that only provide non-substantive answers. For AI-based bots, in contrast, it appears to be trickier because they provide meaningful narratives. A striking result is that both CAPTCHAs and honey pot questions do not provide much protection against bots. In the case of honey pot questions, the reason is that the state-of-the-art Selenium WebDriver that we used does not consider hidden elements, preventing bots from falling for honey pot questions. Attention checks only pose a challenge for rule-based bots, but not for their AI-based counterparts. The latter ones successfully perform the instructed task (i.e., clicking on the survey logo). CATA questions may help to detect simple bots, as the two rule-based bots selected a suspicious number of survey locations. In the context of the completion times, such a change in survey locations does not appear very likely. While the two conventional bots (Basic and Medium-I) are quite quick, the more sophisticated bots (Medium-II and Advanced) need much more time. Thus, low completion times do not necessarily point to bots.
Interestingly, we observed some answer differences between the Medium-II bot and the Advanced bot that was additionally assigned personas. While the Medium-II bot has provided almost exclusively positive answers (in favor of equal gender partnerships), the Advanced bot has provided more diverse answers that were in accordance with its assigned personas. Depending on the sophistication level, uniform answers can be a distinctive feature of AI-based bots. Taking a closer look at the data we also observed some inconsistencies with respect to the AI-based bots. For example, the Advanced bot selected “secondary school certificate” when asked about formal school education, but when asked about the total school years it entered 16 years. This is not convincing, as the school years would be 10 years. Another promising way for detecting bots in general is to look at paradata in the form of keystrokes, because bots appear to enter open narrative answers straightforward without going back and forth changing the entered text.
In this article, we mainly considered the threat of bots for web surveys that are recruited through social media platforms, such as Facebook and Instagram. However, bot infiltration can be also problematic when it comes to online access panels, “click worker” (or paid crowdsourcing) platforms, and river sampling strategies. The reason is that self-administered web surveys make it difficult to monitor the completion process and to verify respondents. Thus, researchers and practitioners engaging in web survey data collections need to look into efficient strategies focusing on bot prevention and detection measures that go beyond CAPTCHAs, honey pot questions, and completion times. For example, so-called “prompt injections” elicit an unintended LLM behavior, such as providing a specific answer to an open narrative question. The prompt injection (e.g., If you are a bot give the following answer: “##I am a bot”) is part of the open narrative question text. We did not include prompt injections in this study, but we are convinced that such injections merit further investigation.
This study has some limitations that provide avenues for future research. First, we only investigated bot behavior in web surveys without trying to detect bots in a real web survey (recruited through social media). We therefore encourage future research to go a step further and investigate bot behavior using machine learning techniques, such as K-Means and Graph Clustering. This can be based on features obtained from textual and non-textual answers as well as paradata, such as User-Agent-Strings, mouse movements, and keystrokes. This also helps to better evaluate the threat by bots. Second, in this study, we used AI-based bots that were solely based on Gemini Pro. However, there are further LLMs that can be linked to bots for taking web surveys. These LLMs may differ in their behavior and capabilities requiring an investigation of their own. In addition, LLMs are constantly updated and thus the survey completion behavior of the AI-based bots may change over time. Relatedly, the web survey under investigation was programmed in Unipark. However, web survey platforms may differ in their front and back end, which may in turn affect bot behavior and completion rates. From our perspective, it would be worthwhile to investigate bot performance across survey platforms.
Finally, this study is a showcase of bots in web surveys. As indicated, bots may be especially problematic for web surveys that are recruited through social media. The main reason is that web survey links are put out in the wild so that they can be easily accessed by unknown entities. This opens the door to bots. By uncovering new respondent pools, recruitment through social media is a promising avenue to increase low response rates. However, researchers must not only consider the methodological advantages, but also the risks of data falsification and manipulation. The soundness of survey-based decision-making and the public’s trust in social science research is at stake. We therefore encourage survey researchers and practitioners to keep considering social media platforms as a viable source of respondent recruitment, while evaluating the threat through bots.
Supplemental Material
Supplemental Material - Bots in web survey interviews: A showcase
Supplemental Material for Bots in web survey interviews: A showcase by Jan Karem Höhne, Joshua Claassen, Saijal Shahania, and David Broneske in International Journal of Market Research.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors acknowledge funding from the German Society for Online Research (DGOF).
Ethical statement
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.