
Abstract
This article aims to explore the relatively under-researched text–image relationships within reply GIFs, with and without embedded text and/or user-added text. Drawing on existing frameworks for analysing text–image relationships, the article qualitatively examines a set of 41 response GIFs replying to the @AITA_Online Twitter account between May 2019 and August 2020. Each text (the stimulus, the user-added text and the embedded text) is related separately to the visual content to tease out the relationships therein, to ultimately answer what role, if any, the GIFs’ visual element plays in the interpretation of a reply as a whole.
Introduction
While text–image relationships have been of interest in communication research for some time (see, e.g., Kress, 2000; Kress and Van Leeuwen, 1996), with the advent of social media, multimodal posts have become more complex, with visual elements such as emoji, images, GIFs, stickers and videos available for use. Graphicons on social media have been previously examined (e.g. Herring and Dainas, 2017), with many papers investigating specific types of multimodal posts, especially memes (e.g. Vásquez and Aslan, 2021; Yus, 2019). However, GIFs have not received as much attention (although see Bourlai and Herring, 2014; Hautsch, 2018; Highfield and Leaver, 2016; Lindholm, 2024; Miltner and Highfield, 2017; Tolins and Samermit, 2016). In particular, many of those articles which have looked at GIFs have presented only examples without embedded text, which therefore misses a significant number of the present text–image relationships in GIF posts. Others (e.g. Hautsch, 2018; Lindholm, 2024) present examples with embedded text and note its relevance in terms of reacting to a stimulus or engaging in a dialogue, but do not strongly differentiate between those GIF examples with text embedded versus text added by the user. For example, Lindholm (2024: 113) notes that ‘captions and superimposed text . . . create a link between the verbal and the visual’ but does not describe the different effects that superimposed text versus a caption may have.
Tolins and Samermit’s (2016) article specifically focusing on GIFs contains no examples with embedded text and, interestingly, Miltner and Highfield (2017: 2) mention that ‘the separation of GIFs from their original texts imbues them with multiple layers of meaning’, implying that there were no GIFs with embedded text in the data they analysed either. Bakhshi et al. (2016: 584) specifically noted that ‘Future work can also look at the text embedded in animated GIFs and analyse their impact on changing the meaning of the media.’
Hautsch (2018: 2.9), on the other hand, mentions text extensively, showing an example of a conversation on Tumblr between the fans of Sherlock and Supernatural in which the text embedded in the GIFs forms part of a coherent dialogue made up of both GIF and text posts. She also argues that, as ‘imagetexts’, GIFs can fulfil a wide range of rhetorical functions (p. 1.2). However, the focus of Hautsch’s article is not to exhaustively deconstruct the text–image relationship, but rather to show the possible rhetorical uses of GIFs, thus taking a macro viewpoint and considering whole stretches of discourse for their overall structure and meaning, as opposed to diving into the minutiae of possible text–image relationships in GIFs, a gap this article will address.
This article will analyse how the relationship between visuals and their embedded text influences meaning-making. It will also compare this to the relationship between GIF visual and user-added text (henceforth co-text), or GIF visual and stimulus text (i.e. the text to which the GIF comment replies). Our aim is innovative for a number of reasons: first, because GIF embedded text has not previously been discussed in this manner; and, second, because we relate the visual element to the stimulus text, the co-text and the embedded text, showing how the meaning-making may differ in each case.
With the main goal of further exploring the complex relationship between text(s) and GIFs, this article addresses two primary questions:
1. How do GIF visuals relate to the texts with which they co-occur, including the wider context?
2. What is the function of GIF embedded text in terms of meaning-making?
The GIF data in this article have been collected from replies on Twitter to posts by @AITA_Online, which reposted submissions from the subreddit ‘Am I the Asshole?’ (henceforth AITA). In this subreddit, users put forward morally questionable/ambiguous situations in which they, or another person, could feasibly be blamed for whatever transpired. The purpose of telling the story is to ask the wider community for their judgement on who was to blame. The Twitter user @AITA_online posted screenshots of such posts (often the more controversial/popular ones) sharing them so that their Twitter followers could also participate in judging.
Within the AITA subreddit, the administrators have disabled the ability to make multimodal posts using images, GIFs, or videos; only textual comments and emoji can be used to reply. Therefore, the affordances of Twitter offer the community there a new way of creating multimodal and intertextual links. The section below provides a brief overview of AITA since it will be helpful for understanding the relationships between original posts and their replies.
This article examines a small dataset of 41 GIF-containing replies made by Twitter users to nine AITA subreddit reposts by @AITA_Online from May 2019 to August 2020. The analysis will focus on the relationships between image and text(s) in these replies, including how they relate to the original post. AITA posts are long and narrative – hence @AITA_Online needing to use screenshots in order to circumvent the Twitter character limit. Because of the long narrative structure and discussion of multiple involved parties, the GIF replies may relate to the content in a variety of ways, from showing the writer’s emotional reaction, to depicting events in the narrative. Thus, each of the three textual elements: AITA post, co-text and embedded text, can potentially relate to the visual in a different way.
‘Am I the Asshole?’ on Reddit and Twitter
The AITA space, on both platforms, uses a set of acronyms to pass judgement, and encourages users to share their rationale for their verdict. The judgement is always directed at the ‘OP’ (Original Poster), i.e. the person who submitted the story to AITA. Depending on this person’s actions, they could be dubbed: NTA (not the asshole), YTA (you’re the asshole), NAH (no assholes here) or ESH (everyone sucks here), with the latter two judgements indicating that either nobody or everybody was to blame for the situation. On Reddit, since the AITA posts are directly submitted by the OP, dialogue with the OP is common. However, once the post is reshared on Twitter, this dialogue is lost and the OP may or may not be present. Nevertheless, replies still frequently address them directly.
We should note that, since our data collection from mid-2019 to mid-2020, Twitter (now X) 1 has been through seismic changes, causing many users to abandon the platform entirely. This includes the poster @AITA_Online, who issued a statement on 5 January 2023 that stated: ‘The website may still be here (as of this moment) but this account is done.’ 2 Therefore, references to the account and its followers refer to our data collection period. At that time, the Twitter account had around 400,000 followers, while the subreddit had around 2.8 million.
Multimodality and GIFs
The relationship between text and image has not been systematically analysed in GIFs; however, researchers have examined the links between images and their accompanying text in a broad range of media including memes, educational texts, cartoons, advertising and art (see, e.g., Kress and Van Leeuwen, 1996; Martinec and Salway, 2005; Tsakona, 2009; Yus, 2019). A number of possible relationships exist between text and image content, from either aspect being the primary source of meaning conveying to both taking an equal role, each sending divergent messages, or text and image only being interpretable when in combination (Yus, 2019). Or in Tsakona’s (2009: 1172) terms, the image being illustrative, supportive or essential (specifically regarding the creation of humour in cartoons).
Martinec and Salway (2005: 343) describe how images and texts may modify each other, with one being dependent on the other, or can be in a complementary relationship. They note that one must look to the text in order to determine if the image is elaborative, e.g. the text mentions the same ‘participants, processes and circumstances’ or enhancing, e.g. the text provides ‘related temporal, spatial or causal information’ (p. 366). They describe in another article (Salway and Martinec, 2005: para 3) how, for example, while a news photograph may capture a single aspect of a story, in comparison a painting in a gallery is the main object of interest, not its accompanying text description.
In Yus’s (2019) analysis of 100 random image macro memes, he found that the text was the primary carrier of information more often than the visual. In addition, the ‘interdependent’ category, where text and image in combination conveyed an idea together that they could not convey alone, was frequently found (pp. 120–121). He also created a further category distinct from memes of ‘ad hoc visual referent adjustment’ through which ‘different texts used for the very same picture constrain the meanings of the picture’. In other words, what specific emotion the pictured person or entity is communicating will be inferred from the text, even though the image remains the same across multiple memes (e.g. positive emotions expressed by a fist pump could be pride, joy, satisfaction, success, etc.). This idea is also present in Hautsch’s (2018) analysis of GIFs; however, in Yus’s (2019) analysis, the text component of the meme had to change, whereas Hautsch (2018: 5.1) notes that ‘The subjective connotations of images mean that the same GIF can be afforded in various rhetorical situations and for various rhetorical purposes’; in other words, GIFs take more of their meaning from their surrounding context.
When it comes to analysis strictly of GIFs, Tolins and Samermit’s (2016) model attempts to categorize GIFs by how they create meaning as replies. They can ‘present an embodied/affective response to the prior speaker’s talk’ (Tolins and Samermit, 2016: 78), or be used as co-speech gestures, either displaying emotional content, or enacting events provided in the preceding text. Their categories are fundamentally distinguished by whether the GIF presents old or new information: either it reacts to (new) or re-enacts (old) what is in a prior text.
GIFs, like images and memes, are community-oriented formats (Miltner and Highfield, 2017:4) and a part of participatory culture, where netizens can create and circulate new content (Grădinaru, 2016). Through this ‘mashing up’ (Jones et al. 2015: 6), GIFs, which typically previously existed as some kind of TV broadcast, have undergone a process of resemiotization (Iedema, 2003: 41), i.e. the media has gone through a transformative process from broadcast, including sound, moving image and optional text (subtitles) to GIF, losing the audio, gaining looping movement and also becoming decontextualized. This loss of a semiotic mode, as well as the decontextualization and recontextualization (Hautsch, 2018: 1.1; Lindholm, 2024: 103), contributes to the graphicon being highly adaptable to a variety of uses in new contexts (Schankweiler, 2020: 256) where the ‘stimulus’ for whatever is depicted can be creatively reinterpreted. This makes them powerful vectors for transmitting new ideas.
Through such intertextual links, people also demonstrate competence as members of specific communities (Hautsch, 2018; Jones et al., 2015: 7). One way this competence can be demonstrated is through understanding of shared knowledge, which ensures that a user’s intertextual links can be recognized and correctly interpreted by the viewer (Hautsch, 2018: 6.2). As Hautsch mentions, this can open up the possibility for inside jokes and ‘complex interpretive arguments’. Like memes (Vasquez and Aslan, 2021: 116), GIFs may have multiple layers of meaning, with their interpretation depending on inference. For example, a particular scene from a TV show may only be interpretable in context if one knows the characters and situation depicted (Jiang et al., 2018), or if one has certain background cultural knowledge (Lindholm, 2024: 111).
Methodology
Data composition and collection
The data in this article come from nine of AITA_Online’s 10 ‘most popular’ 3 threads posted between May 2019 and August 2020. Each AITA thread used in the analysis is summarized in the Appendix, which we recommend readers consult before moving to the Analysis. Unfortunately, the length of AITA posts prohibits putting the full text of each in the article. One full text has however been included in its ‘screenshot’ form alongside Example 2 to give the reader an idea of what a full post looks like.
We collected all the GIF-containing direct replies to these threads which had over 100 likes, producing a dataset of a manageable size (41). This included any co-text. Given the relevance of intertextuality, where possible the original GIF source was found using reverse image search plus the authors’ personal knowledge in order to view the wider context of the clip. Exact identification was not possible in some instances due to the GIF being, for example, a close-up of a single character, with no embedded text, which could be from almost any episode of a long-running series. The origin list is:
• 29 examples: we found exact origins;
• 9 examples: we found the general series/broadcast;
• 3 examples: we found only basic information or none at all.
In order to present GIFs in the article so that their animations remained recognizable, we followed Tolins and Samermit (2016) in showing four to nine frames per GIF, depending on their length and amount of movement, created using https://ezgif.com/video-to-jpg
Theoretical framework
Our original focus in analysing our GIF data was not to look at intersections between visuals and each individual text, but rather to identify what role the GIF was playing as part of the reply (see Marsden and Milà-Garcia, in press). However, as previously mentioned, while analyses have been conducted on GIFs with embedded text, none of these papers (e.g. Hautsch, 2018; Lindholm, 2024) present a systematic model of GIF analysis. While working with the Tolins and Samermit (2016) and Herring and Dainas (2017) models for GIF and graphicon usage respectively, we noticed that the embedded text was having a strong effect on our categorizations, which prompted us to pivot our analysis and look at the relationships between the GIFs’ visual and textual elements.
At this stage, we therefore applied the categorizations from Yus (2019), whose article analyses memes, using a model originally from McCloud’s (1994) (cited in Yus, 2019) analysis of text–image relationships in comics. This model proved suitable and we applied each category below separately to each text–image relationship: image-co-text (user-added text), image-embedded text (text which is part of the GIF) and image-stimulus text (AITA post). The categories are as follows:
The following category was also utilized, which was invented by Yus (2019: 124–128) to describe a particular relationship between text and image found in memes:
These categories have somewhat fuzzy boundaries. For example, it can be difficult to tell if the visual element is merely illustrating the text (word specific) or enhancing it (additive). Nevertheless, the framework provides a helpful way of categorizing each text–image relationship.
To identify each relationship separately (where one existed), it was important to consider the GIFs’ visual as an independent element, i.e. when looking at the image–co-text relationship, we ignored embedded text if it was present. While of course the entire reply as a unit is what readers will see and respond to, this article hopes to examine how each text relates individually to the visual content to build a coherent picture and tease out all possible interrelationships.
Finally, regarding ethical concerns relating to online sources, we have removed usernames, profile pictures and @mentions from our data. Additionally, we have chosen publicly available and popular postings, which participate in a group with a large membership; therefore, those posting must have a reasonable expectation that their posts will be viewed and potentially shared both on and off Twitter.
Analysis
The small dataset of 41 GIFs allows for a detailed and nuanced analysis of the inter-relationship between image and text(s), considering each relationship therein in detail. However, it is unsuitable for a statistical or quantitative analysis. Table 1 offers brief descriptive percentages simply to give an idea of the composition of the dataset; we do not intend to claim that our data is generalizable, or that this distribution would be found in other datasets.
Textual elements present in posts.

Of the 20 GIFs that contain some kind of embedded text, the majority are the original subtitles of the clip’s audio (18); however, many of these have been put into a new font for emphasis and some have been abbreviated. Four have text which is non-original and, in two cases, the origin of embedded text is unknown. In 37 replies (90% of the data), there was accompanying text written by the tweet author, which could be as little as a two-word comment, or as long as 56 words.
The analysis proceeds in three sections, beginning with the smallest category: posts with embedded text only, then moving to only co-text. Finally, those with both co-text and embedded text are considered.
Embedded text only (N = 4)
Posts in this category add no co-text, but they do contain a text–image relationship with their embedded text, and with the original post. In all four cases, embedded text is the original subtitle, as shown in Figure 1 and Figure 2. Figure 3 shows an original screenshot from Reddit’s AITA shared by AITA Online on Twitter for illustrative purposes. Since, as shown, these texts are extremely long, we have not included the full posts for other examples but direct the reader towards the summaries in the Appendix. This illustrative example shows not only the complexity of an AITA post, to which the image may relate in different ways to different parts, but also how a later edit to the AITA post is displayed.

Example 1 (thread 4).

Example 2 (thread 5).
AITA for telling my boyfriend his masculinity was fragile after he refused to buy me pads
Figure 1 does not show a recognizable gesture; instead, the GIF shows only the character saying the words shown in the embedded text. This would be difficult or impossible to lip-read, so the embedded text is crucial. The relationship between embedded text and visual is word specific, the serious expression of the character and her lip movement (Whoopi Goldberg in Ghost) serves only to illustrate the text (Tsakona, 2009: 1172).
In Figure 2, the character is shown crying, but without the embedded text, one would not know if this was, for example, a sad crying, nostalgic crying or happy crying. The embedded text allows us to arrive at the correct interpretation of the image, making this relationship, like two further examples (not shown), an example of visual referent adjustment (Yus, 2019: 126).
In both examples, if the visual element were divorced from its embedded text, it would cease to have a clear relationship to the original post (unless one was so familiar with the original content from which the GIF was taken that one could remember the dialogue that accompanied the scene). In both cases, the embedded text makes the reply a complete and coherent comment on the events of the AITA post, not the visual: for Figure 1, the embedded text indicates that OP is in danger, and could function alone as a coherent textual comment on the thread, while the visual alone would lack relevance. The same could be said of Figure 2, in that the text alone would be comprehensible; it is this text which also points the reader towards a specific part of the AITA post, the later edit made by OP, i.e. the ‘happy ending’, without which the crying emotion could be linked to other parts of the narrative and interpreted differently. The relationship between the visuals and AITA posts in both cases is parallel since they are representative of the poster’s reaction, not the AITA events.
Co-text only (N = 17)
When including only one type of text in a reply, writing one’s own textual comment is more flexible than relying on embedded text, allowing easy linking to the original post. In this category, there are frequent word-specific relationships between image and co-text (Yus, 2019: 113): in these, the main meaning is conveyed via the words, with the picture serving as an attention-grabbing or amusing addition. There are also further examples of visual referent adjustments (p. 116), where the visual contributes minimally to the interpretation of the text.
In Figure 4, the GIF is an event enactment (Tolins and Samermit, 2016: 78) portraying the fictional, humorous scenario of the poster rushing to collect and punish OP. Both this post, and Example 4, come from the same account, which posts as if from a fictional ‘agency’ known as ‘Whole Man Disposal’ which ‘exists’ to dispose of bad men.

Example 3 (thread 9).
The visual in Figure 4 is made relevant by the inclusion of Star Trek related jargon in the co-text, e.g. a ship identifier number, ‘bat’leth’ (a Klingon weapon) and ‘warp’ (faster-than-light travel). The co-text–image relationship is word specific, since the co-text carries the meaning with the visual being illustrative only. However, the image and co-text also relate intertextually to thread 9, which contains a mention of Star Trek, thus creating a word-specific relationship between image and thread different from the parallel relationships observed in Section 4.1.
Figure 5 shows an embodied affective response (Tolins and Samermit, 2016: 78), with the shrugging gesture expressing that being on the ‘TEAM VAN’ side of the AITA debate (Van being the name of OP’s son), is an obvious stance (de Vries et al., 2024: 3). 5 The co-text–image relationship here is word specific, but the image–thread relationship is parallel, unlike Figure 4, as the Power Rangers have no connection to the post.

Example 4 (thread 6).
Many of the replies with only co-text contain GIF representations of actions, i.e. simple, recognizable, affective gestures (Herring and Dainas, 2017). These can also be termed ‘reaction GIFs’ and are typically used to communicate emotion (Bourlai and Herring, 2014: 170):
Figure 6 shows a shocked expression (exaggerated by the fast zoom-in on the character’s face). This GIF is aptly chosen to reply to the thread, the post is related to an excessive collection of the toy Funko Pops,™ with the GIF showing a Funko Pop version of the popular character Deadpool. The exaggerated shocked expression is also mirrored in the repeated question marks in the co-text. Image and co-text are in a duo specific relationship since they both express the emotion of shock/confusion, while there is a word-specific relationship with the original post; the character depicted provides a kind of humorous illustration.

Example 5 (thread 7).
Figure 7 shows an additive relationship between GIF and co-text, with the salute building on the phrase ‘ty [thank you] for your service’ and noun ‘hero’, which generally connote those in emergency services or the armed forces, where a salute is a relevant way of showing respect. The text amplifies and elaborates on the image, which would be at least partially interpretable as a reply without the textual content.

Example 6 (thread 8).
Posters can also combine an embodied action with a text in order to alter the specific interpretation. In contrast to Figures 6 and 7, where the user-added text provides some affective lexis or punctuation cues mirrored in the GIF visual, the text in Figure 8 simply states that the name was examined three times. Without the visual, we may infer a number of emotional reasons for this: confusion, horror, humour, etc., but with the addition of the GIF, in which the character appears to go through stages of emotion (having an idea, realizing a flaw, becoming resigned), each instance of the poster ‘looking’ takes on a slightly different meaning, i.e. the tone is modified by the GIF, being a visual referent adjustment, as also described by Herring and Dainas (2017: 2188). The visual cannot be seen as illustrative of the thread, however, so it has a parallel relationship.

Example 7 (thread 6).
Finally, in a couple of examples, the visual does not represent the poster, but rather portrays either a hypothetical scenario involving OP, or a kind of reenactment of the thread’s events. Figure 9 refers to the ‘penis in peanut butter’ AITA thread (see Appendix), doing so using a very specific ad reference for Reese’s Peanut Butter Cups 6 in which a man eating chocolate drops it into a girl’s open cup of peanut butter. The reference to ‘specially flavoured’ in the co-text creates an intertextual link between the GIF and the original post (as does ‘peanut butter’ written on the girl’s cup, although this is quite hard to see in the small moving image). The relationship between GIF and co-text is additive, with the picture tangentially illustrating the word ‘goober’. This GIF illustrates and riffs on the events in OP’s story (Herring and Dainas, 2017: 2188), demonstrating the poster’s competence in choosing context-specific GIF resources. This creates a word-specific relationship with the thread, with the GIF being loosely illustrative.

Example 8 (thread 1).
Figure 10 shows OP in an imagined scenario. The co-text gives OP advice via a rhetorical question (with the ‘no’ answering the question ‘am I the asshole?’), whilst illustrating what it might look like for OP if the advice were followed. The packing looks rushed and chaotic, making this additive, with the GIF contributing detail to the co-text. The visual could be understood as a riff on the thread even without the co-text. However, despite portraying (a version of) OP, this example cannot be claimed to illustrate the AITA post itself, rather, it is in a parallel relationship since it animates a hypothetical scenario not mentioned in the post.

Example 9 (thread 4).
Co-text and embedded text (N = 20)
Posts in this category, containing both textual elements, are the most prevalent, accounting for half of our data. They are the most complex category in our analysis, since not only do the texts have relationships to each other, but each text may also relate to the visual element differently. To structure this section and avoid repetition, we have arranged the examples according to the relationship between embedded text and image. Among these 20 GIFs, there are 10 different combinations of relationships between image–co-text, image–embedded text and image–AITA thread; since we do not have the scope to discuss them all in detail, instead we demonstrate the diversity of interrelationships which can occur with multiple texts in play.
Additive
In the following three examples, the images enhance or extend their embedded text, but have different relationships to the co-text and AITA thread.
In Figure 11, the co-text relates strongly to the visual as there is explicit mention of ‘sith lords’ (indicating the character pictured), creating a second additive relationship. The image also functions as an illustration of the Home Owners Association members mentioned in the original post, creating a word-specific relationship.

Example 10 (thread 8).
Figure 12 indicates through the co-text that the embedded text represents the writer’s utterance and the visual their embodied action (Tolins and Samermit, 2016: 76), e.g. ‘serv[ing] as [a] stand-[in] for users’ own verbal and nonverbal (re)actions’ (Lindholm, 2024: 104). This creates an additive relationship between the open-handed gesture and both the co-text and embedded text. The co-text here leads into the embedded text with ‘to everyone else’, forming a complete sentence and reinforcing it with the gesture. Regarding the post it forms a reply to, this reply is from @AITA_Online themselves, relating to the co-text that accompanied their Reddit repost. Therefore, the image–thread relationship is parallel.

Example 11 (thread 5). 7
In Figure 13, part of the visual is from Game of Thrones, creating an intertextual link to OP’s story making this a riff on (Herring and Dainas, 2017) or enactment of the story’s events (Tolins and Samermit, 2016). This creates an additive relationship, with the scene pictured – where the character burns her enemies – creating a positively connoted metaphor for OP kicking out her ungrateful family. This GIF combines the series’ visuals with the ‘deal with it’ meme, 8 often used as a retort to disapproval. This embedded text mirrors OP’s reported utterance to her family members: ‘I said “don’t like it? Too bad. Deal with it”.’ These intertextual links create ‘new meanings and . . . interpretive possibilities through their recontextualization’ (Lindholm, 2024: 104). The co-text and visual have an interdependent relationship, creating a meaning together that neither would have alone, i.e. that the character and her actions represent something ‘queenly’ and worthy of ‘stanning’ (enthusiastically supporting).

Example 12 (thread 3).
Duo specific
For the two posts in this category, the visual sends essentially the same message as the embedded text.
In Figure 14, the word ‘yeet’, meaning ‘to throw with force’, 9 is paired with a doctored visual from The Lion King of the baboon Rafiki throwing the lion cub Simba. The co-text links the visual to the ending of the original post, portraying an exaggerated version of what happened to OP’s former boyfriend, i.e. he became an ex-boyfriend. The throwing motion dramatizes the story events which simply stated ‘I told him that we needed to break up’, thus creating humour, amplifying and enhancing the events of the original post (Yus, 2019: 116). The GIF also stands in an interdependent relationship with the co-text, functioning to complete the sentence visually, while the embedded text, which can be read as a continuous whole along with the co-text, completes the sentence textually, sending the same message.

Example 13 (thread 5).
As we have shown throughout the article, when the GIF visual is intended to represent the poster, or where it represents the OP but in a hypothetical future scenario, there is less of a link between visual and thread. Contrastingly, where the visual represents ‘enactments of events mentioned’ (Tolins and Samermit, 2016), then it understandably has a much stronger link to the thread, as the example below shows.
Figure 15 has a close relationship between embedded text and visual, with the character gesturing exaggeratedly for someone to leave the room – and the embedded text repeated as part of the visual itself on the whiteboard. The GIF is additive in its relationship with the thread: it links specifically to OP asking their family to leave, albeit with the less offensive reported line of ‘you may all leave now’, making this a riff (Herring and Dainas, 2017: 2188) on the original post and adding humour through exaggeration (Tsakona, 2009). Like Figure 14, the visual is interdependent with its co-text, with the visual exemplifying the ‘favourite part’, without which the co-text could not be understood.

Example 14 (thread 3).
Visual referent adjustment
Figure 16, the only example in this category, shows another way a GIF can be creatively manipulated (as with Figures 13 and 14). Here, however, while the footage remains unchanged, it is taken from very few frames (9) in which Wendy (pictured) blinks only once. The looping effect isolates and repeats this movement (Highfield and Leaver, 2016: 55) extending and intensifying the reaction (Lindholm, 2024: 113), thus transforming it from a simple blink into a never-ending expression which could be used to show shock, confusion, incredulity, etc.

Example 15 (thread 4).
Combined with the embedded text, the visual guides the interpretation towards a meaning of frozen internal anguish/discomfort. Without this embedded text, the intended meaning of the GIF would not be clear, or would at least be ambiguous. The relationship between visual and co-text is additive since the visual, even without its embedded text, aids the understanding of the emotion embodied.
Word specific
Fifteen examples in our dataset have a word-specific relationship between embedded text and image, meaning that the embedded text carries the majority of the sentiment or meaning. In all but one of these cases, the pictured character is clearly saying the embedded words, which come from original subtitles.
In seven examples, the visual is in a parallel relationship with both AITA thread and co-text, meaning that if a version of the GIF without embedded text was used, it would appear to have little to no relevance unless one was extremely familiar with the source material. This indicates that embedded text plays a large role in motivating GIF choice. One such example is the following GIF, used by three separate posters, from the TV show Arrested Development.
Figure 17 was exclusively used to reply to AITA threads in which a woman could be seen to have achieved a successful outcome. In all co-texts accompanying this GIF, a female was mentioned or a female pronoun used, thus linking the embedded text ‘Good for her!’ to the co-text, and to the original post. In Figure 17 the embedded text is necessary for GIF interpretation since the visuals alone do not link directly to either the co-text or the original post – in other words, it is the text which carries the meaning, with the picture simply serving as an attention-grabbing image (Bakhshi et al., 2016).

Example 16 (thread 9).
In Figure 18 and another not included, the image has a word-specific relationship with each of the three texts, meaning that in all cases the text carries the primary meaning, but the visual can be clearly seen as illustrative, rather than unrelated as in Figure 17.

Example 17 (thread 2).
In this example, characters JD and Turk from Scrubs can be seen as illustrative of ‘friendship goals’ in the co-text, ‘guy love’ in the embedded text, and OP and his male friends’ close relationship in the AITA post (see summary in Appendix). In this reply, the co-text and embedded text comment on the AITA post from different perspectives, with the co-text illustrating the poster’s strong positive judgement of OP, and the embedded text and visual riffing on events in the AITA post.
Discussion And Conclusion
In this article, we have analysed text–image combinations within GIF-containing reply tweets, also noting if and how the visual relates to the stimulus. The majority of examples in our dataset simply have internal coherence between image and co-text/embedded text; however, many images also relate to events, actions and emotions in the stimulus text (the AITA post). In these cases, the way in which that GIF visual links to the AITA thread is altered depending on whether the GIF shows something mentioned in the post, or a hypothetical scenario of the poster’s imagining. While most replies throughout our dataset have visuals in a parallel relationship with the AITA post (27/41), meaning they do not relate at all, others are illustrative or additive, augmenting the interpretation of the original post.
The approach taken is innovative, since text–image relationships have typically been solely investigated in terms of their internal coherence – for example, in how picture and text combine to make a coherent guide to starting a computer (Iedema, 2003: 45), form a surprising advertisement (Martinec and Salway, 2005: 345, see Figure 19), or create a comprehensible meme (Yus, 2019). In these examples, the text–image combination is not a response but a more-or-less fixed unit of meaning. For example, an advert containing text and graphics can be pasted here and remain fully comprehensible.
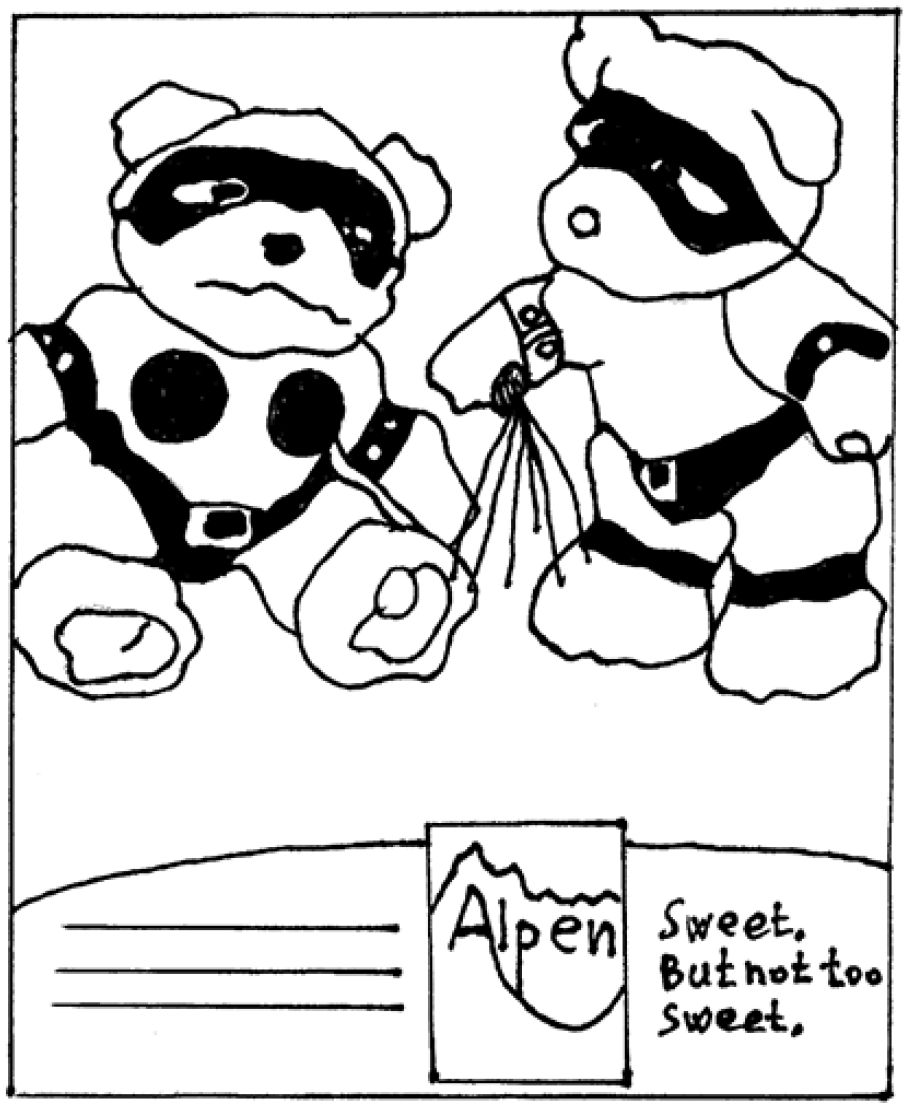
Alpen advert (from Martinec and Salway, 2005: 345).
One may of course need some existing knowledge about BDSM gear and also to know that Alpen is a breakfast cereal in order to fully appreciate the advert, but the same can be said of any text – such as needing to know which particular ‘advice animal’ macro meme one has encountered (Vickery, 2014: 303). However, no questions remain: one does not need to ask ‘what is sweet but not too sweet’ since the question is asked and resolved within the advertisement itself. No such inbuilt interpretation exists for most GIFs with or without embedded text; they are remarkably flexible and rely on being combined with further texts (or other content) within their environment to gain full meaning (Hautsch, 2018: 2.5). GIFs, like emoji, were made to be utilized creatively in conversation to convey a variety of meanings, and are thus ideally suited to replying and creating intertextual links (Jones et al., 2015: 6–7).
GIF embedded text, unlike meme text (e.g. Vásquez and Aslan, 2021; Vickery, 2014), is much less frequently altered in its pairing with the visual, leading to greater longevity of the pairing between text and animation. The embedded text of a GIF (where included) often has a strong relationship with the original post and with any user-added text; however, the visuals for these GIFs generally have a weaker relationship. The visuals in GIFs with embedded text generally do not contribute significantly to meaning construction, but either convey information about the affective stance of the poster, or have a purely illustrative function (Tsakona, 2009; Yus, 2019).
As Martinec and Salway (2005: 366) note when discussing text–image relations in general:
If the same participants, processes and circumstances are depicted and referred to, then there is elaboration. If new but related things are referred to or depicted, then there is extension. If related temporal, spatial or causal information is provided, then there is enhancement.
These descriptions cannot fully describe the relationship between GIF and embedded text in most cases: without contextual knowledge or excellent lipreading, given GIF images and their associated texts separately, it would be difficult to pair them up. For GIFs where the depicted entity ‘mouths’ the words, we have categorized the embedded text–image relationships as word specific (Yus, 2019: 113–114), since mouthing the words in some way illustrates them, but the text carries the majority of the meaning; however, there would be an argument for defining these relationships as parallel, i.e. both taking different lines. In such cases, the choice of GIF seems largely due to the content of the embedded text and its ability to link to the co-text (if used) and/or the AITA thread. Why then do posters not just type this text, or similar, themselves? While we cannot know precisely why posters choose to express themselves with GIFs in cases where the visual is largely irrelevant, it is likely to be for their eye-catching qualities, additional emotion or humour (Bakhshi et al., 2016; Jiang et al., 2018; Tolins and Samermit, 2016;) or as a demonstration of cultural knowledge (Hautsch, 2018: 6.2; Miltner and Highfield, 2017).
Contrasting with GIFs with embedded text, GIFs with only visuals tend to relate that visual strongly to the co-text. However, for both GIF types in our data, the AITA thread or ‘stimulus’ text is the least important source for the image to relate to, with text–image relations rarely being stronger than word specific. However, we have demonstrated the occasional additive relationship, such as Examples 12, 13 and 14.
This article provides an insight into the use of GIFs when replying to specific threads on Twitter. While GIF usage has previously been analysed in messaging apps (see, e.g., Jiang et al. 2018; Tolins and Samermit, 2016), Tumblr reply chains (Bourlai and Herring, 2014; Hautsch, 2018; Lindholm, 2024) and in decontextualized multimodal posts (Miltner and Highfield, 2017), by using data with a complex but finite surrounding context (i.e. each reply is to one AITA thread, there are no further messages ‘up’ the chain that they can relate to), we have been able to describe the intertextual links between text(s) and visual content systematically. By including the stimulus to which the multimodal post is the response in our analysis, we have shown the interaction between original post, co-text, embedded text and visual where all four elements are present.
The findings of this article offer nuanced insights that would have been impossible with a larger dataset, but cannot be taken as generalizable. Further studies of GIFs as replies, with their posting context across different platforms and communities, could reveal different image–text and text–text relationships and would significantly enhance this research area as a whole. User preferences for choosing GIFs with and without embedded text would also be an interesting avenue for further studies. While our data is confined to a relatively small number of posts, it clearly shows the complexity in posting practices, especially where overlapping relationships between multiple texts paired with a single visual element are concerned, and thus contributes to furthering descriptions of the nuances of GIF usage as a social media posting practice.
Footnotes
Appendix

| Heading | Synopsis |
|---|---|
| AITA for putting my penis in peanut butter and leaving it in the kitchen? | OP has a policy with housemates that they label and don’t share food. OP used some peanut butter for sex play, then returned it to his cupboard. His housemate confessed to eating some the next day, at which point OP told him what it had been used for. Housemate said he should have kept the ‘used’ butter in his room. |
| AITA for kissing the homies goodnight? | OP and his straight male friends started kissing goodbye (on the lips) due to a meme and it became their tradition. OP’s new girlfriend doesn’t like it and asked him to stop, but he doesn’t want to. |
| AITA for ruining Christmas & NYE because I was removed from my mom and dad’s wills? | OP and husband are childless, and had hosted OP’s family (parents, siblings, niblings) for Christmas and New Year for 6 years. OP’s father said at Thanksgiving that he doesn’t think she contributes to the family (no children) and may disinherit her. None of her siblings defended her. She and husband kicked everyone out and told them to find somewhere else to go for Christmas and New Year. |
| AITA for banning my husband and father-in- law from the delivery room due to their intensely stressful/creepy behaviour during my pregnancy? | OP is pregnant. Her husband’s mother died in childbirth. Husband and father-in-law seem convinced she’s going to die, asked her to inventory her possessions and get life insurance. She’s convinced FIL wants her to die so husband can be an ‘amazing single father’, which is FIL’s identity. She finds their behaviour stressful and doesn’t want them in the delivery room. |
| cw: transphobic slur AITA for telling my boyfriend that his masculinity was fragile after he refused to buy me pads? |
OP asked her male partner to buy her pads while she was having her period. He refused saying it was embarrassing. She said he was childish and his masculinity was fragile. An edit shows she confronted him, found out he was transphobic and would refuse to help her if they had kids, so she left him. |
| AITA for telling my sister her daughter’s name is stupid? | OP and husband gave their unborn baby a traditional Vietnamese name (husband’s heritage). On a video call, OP’s sister was joking about the chosen name, OP said it was no worse than what the sister named her daughter and told her it was a cringy white mom name. (The name was revealed in comments on the Reddit post). |
| AITA for choosing Funko Pops over my wife? | OP has been an avid Funko Pop collector since before he married. His wife told him his recent spending was excessive, but he knows they can afford it. Eventually she broke down and told him to stop collecting or she would divorce him. He told her he would not give up his passion. |
| AITA for destroying my HOA? | OP ran for HOA [Home Owners’ Association] president after the existing HOA started giving fines for what OP considered unreasonable things. They and their friends took roles in the HOA in order to abolish it. OP estimates around 40 percent of the neighbourhood is angry about this as they wanted a HOA. |
| AITA for trying to test a girls ‘nerd’? | OP has a friendship group which a new girl joined 2 years previously. He thought she was faking an interest in nerdy things so decided to test her knowledge. He asked an accidental wrong question and got called out on it. His friends and brother accused him of gatekeeping, and the friends chose the girl over him. A later edit shows he does not accept the asshole judgement Reddit gave him. |
Data Availability Statement
The dataset analysed during the current study are not publicly available due to ethical concerns regarding the identities of the participants but is available from the corresponding author on reasonable request.
Notes
Biographical Notes
ELIZABETH MARSDEN has recently completed a three-year postdoctorate at Åbo Akademi University in Finland at which she is now an affiliated researcher. Her research focuses on human online interaction, multimodality, relational work and social media. She is also the Assistant Managing Editor of the Journal of Politeness Research, and has previously published in Journal of Pragmatics with co-author Xiaoyi Bi.
Address: Faculty of Arts, Psychology and Theology, Department of Languages, Åbo Akademi University, Tehtaankatu 2, Åbo 20500, Finland. [email:
ALBA MILÀ-GARCIA holds a PhD in Translation and Language Sciences (Universitat Pompeu Fabra, 2017) devoted to the study of (dis)agreement in three different discourse genres. Her research interests include facework, conversation analysis and digital discourse. She is currently an Assistant Professor at the Department of Translation and Language Sciences at Universitat Pompeu Fabra in Spain.
Address: Universitat Pompeu Fabra, Roc Boronat 138, Barcelona 08018, Spain. [email: