
Abstract
While GIFs (Graphics Interchange Format) have been studied as digital communication tools, their repositories – these databases of visual expressions – remain largely unexamined as sites that generate emotional expressions across different modes of communication. This research introduces the concept of “emotional transcoding,” examining how it operates in major repositories Giphy and Tenor through the conversion of paralinguistic vocal expressions – auditory reactions like “aww,” “duh,” and “wow” – into visual representations within silent GIF formats. Through multimodal analysis, this study documents the semiotic strategies involved in emotional transcoding, revealing systematic patterns for visually encoding auditory emotional expressions. Using qualitative content analysis of 1000 GIFs, this study identifies the visual techniques used in cross-modal conversion and analyzes the demographic patterns among performers who represent these expressions. The findings reveal how emotional transcoding operates through specific representational conventions and highlight questions about whose bodies become available as vehicles for emotional communication in digital platforms.
Keywords
Introduction
GIFs have been significant in contemporary visual culture and social media communication for almost two decades (Eppink, 2014; Miltner and Highfield, 2017). These silent, looping sequences have evolved into a unique form of nonverbal communication. With low-resolution aesthetics and jerky motions reminiscent of slapstick comedy, GIFs serve as vehicles for online “visual representation of how they [users] are feeling [. . .] expressions which are perhaps less well suited to text” (Miltner and Highfield, 2017: 5). Social media platforms have facilitated their ubiquity by offering extensive repositories of ready-made GIFs for instantaneous use through word-based search functions integrated into mobile device keyboards. These comprehensive repositories have transformed GIFs into a standardized form of digital interaction across platforms like WhatsApp and Facebook. GIFs encompass original images, edited content, and repurposed visuals, which are used as emotional signifiers or reactions. Reaction GIFs exemplify this phenomenon by isolating moments from popular media that users deploy in new contexts to express emotions or responses. Such visual elements transcend their original contexts, becoming integral to communication practices and gaining layers of meaning through their circulation across social media environments (Highfield and Leaver, 2016).
However, GIF repositories – the databases that curate and organize these expressions – remain underexplored. Previous research has examined GIFs as emotional signifiers (Miltner and Highfield, 2017) and embodied enactments (Tolins and Samermit, 2016) but has treated GIF databases as transparent intermediaries rather than active cultural agents. This gap becomes particularly significant given that major repositories like Giphy and Tenor now serve as primary gatekeepers of standardized emotional communication across multiple platforms. These repositories perform what can be termed “emotional transcoding” – a complex multimodal process involving the conversion of emotional expressions across different semiotic modes. This process is perhaps most acutely evident in the phenomenon at the heart of this study: the translation into visual GIF representations of auditory utterances such as “aww,” “duh,” “wow,” and “yay” – paralinguistic elements that, while not conventional words, have evolved into widely recognized emotional slang. Despite lacking audio capabilities, many popular reaction GIFs depict moments where these expressions are vocalized, creating a transformation whereby auditory elements are communicated solely through visual means. The silent GIF format must rely on facial expressions, body language, and mouth movements to convey sounds that derive their meaning from their auditory qualities. This cross-modal conversion reveals the complex semiotic work that repositories perform in facilitating cross-modal communication, as they must organize visual representations that can adequately convey auditory emotional communications.
To address these gaps, this study examines how paralinguistic utterances are visually encoded as emotional reactions across two major GIF repositories, Giphy and Tenor. Building on multimodal communication theory, this research introduces the concept of “emotional transcoding” and examines how it operates in GIF repositories through the conversion of sound-based expressions to visual performances. Specifically, this study addresses two interconnected questions: First, what multimodal semiotic strategies characterize the emotional transcoding of paralinguistic vocal expressions in GIF repositories? Second, how do demographic and cultural patterns in performer selection reveal the infrastructural work of GIF repositories, and whose bodies and performances become available as standardized emotional resources in digital communication? The study documents the visual techniques involved in emotional transcoding and analyzes the socio-cultural patterns of those whose bodies perform these expressions. Unlike traditional self-expression through personal recordings such as selfies or videotelephony (e.g. Frosh, 2015; Zappavigna, 2016), GIF-based expression primarily appropriates scenes from cinema and television, creating standardized emotional shorthand for online discourse. By treating GIF repositories as sites of emotional transcoding rather than neutral tools, this research contributes to understanding how infrastructural processes of cross-modal conversion shape emotional expression in digital environments, highlighting their implications for communicative standardization, cross-cultural interaction, and online identity formation.
Theoretical framework
Visual representations in digital written communication
Digital communication platforms alter the conditions under which nonverbal elements contribute to interpersonal exchange. In face-to-face conversation, emotional meaning emerges through a multimodal coordination of vocal tone, facial expressions, and gestural movement (Baym, 2010). Text-based digital communication has taken on roles traditionally associated with face-to-face interaction in the Internet age. While mediated digital communication may initially appear as a diminished form of face-to-face conversation, visual elements such as emojis or GIFs serve as nonverbal components that add “visual tone,” enhancing rather than replacing the communicative capacity of written messages by introducing social and affective cues to text-dominated interactions (Baym, 2010; Danesi, 2017). This shift represents what Garde-Hansen and Gorton (2013) describe as a transformation in how affective communication operates in digital environments, where technological affordances simultaneously enable and constrain emotional expression.
The importance of facial expressions and embodied gestures in nonverbal communication is well-established through extensive research in communication studies (e.g. Ekman and Friesen, 1969; Goffman, 1967; Mehrabian, 1971). These findings demonstrate that a significant portion of emotional meaning in face-to-face interaction derives from visual and vocal cues that operate alongside verbal content. Digital communication environments, however, face the challenge of representing these embodied elements through alternative semiotic modes to maintain emotional expressions in mediated interaction (Baym, 2010).
Contemporary messaging interfaces respond to this challenge by embedding visual communication tools directly within text input systems. Emoji keyboards offer standardized symbolic representations of basic emotional states, while GIF repositories provide more complex animated sequences that can convey nuanced emotional responses. GIFs differ significantly from static visual elements like emojis through their distinctive technical characteristics: their looping motion, absence of sound, and temporal dimension. These features enable GIFs to intensify emotional expressions through mode-specific resources for conveying intensity, as Kress and van Leeuwen (2020) note, “in gesture we might use the extent and the velocity of the gestural movement” (p. 42). GIFs harness this gestural intensity through their repetitive motion, allowing users to emphasize specific actions, reactions, or emotional states that would be impossible to convey through static images alone. As Stark and Crawford (2015) observe, these visual elements function not as decorative additions but as compensatory communication systems that restore nonverbal dimensions to text-dominated interactions. The visual element keyboards for GIFs capitalize on the well-established importance of facial expressions in nonverbal communication by drawing from repositories that tag images with associated words or phrases, creating a platform language. This transformation has enabled nonverbal expression through visual means, converting words into visual form and making visual emotional expression a routine component of everyday digital interaction (Highfield and Leaver, 2016; Stark and Crawford, 2015).
Such developments create a particular communicative environment where visual representations typically function alongside written text to create coherent conversational meaning. Unlike face-to-face interaction, where multiple semiotic modes operate simultaneously and naturally, digital communication requires users to deliberately select and deploy visual elements that will be interpreted within primarily textual contexts. This selection process reveals the underlying tension between user agency and platform constraints, where users exercise apparent choice in selecting visual expressions yet can only choose from pre-existing options structured by technological architectures that shape available communicative possibilities (Van Dijck, 2013).
Transcoding the self on social media: from direct to borrowed embodiment
The conversion of emotional expressions across different semiotic modes requires “transcoding” – the process of transforming content from one communicative system to another while preserving functional meaning. This process differs from remediation (Bolter and Grusin, 1999), which involves representing one medium within another. Transcoding specifically focuses on preserving affective and communicative functions when converting emotional content across different modal systems, particularly from auditory-based expressions to predominantly visual formats. This concept builds on Kress and van Leeuwen’s (2020) multimodal framework, which establishes that the place of visual communication in any given society must be understood within the context of available communicative modes and their social valuations. Digital communication platforms represent a fundamental transformation in this semiotic landscape, where traditional multimodal resources from face-to-face interaction – gesture, vocal tone, facial expression, spatial positioning – must be transcoded into platform-compatible visual formats through semiotic work that maintains both communicative function and affective dimension.
Camera-based images, such as photographs and films, present challenges for understanding this transcoding process in digital communication. While camera-based images may appear as direct representations of reality – what Barthes (1977) characterized as “a message without a code” (p. 17) due to photography’s indexical relationship to the physical world, they are in fact encoded with multiple signifiers that operate simultaneously. Kress and van Leeuwen (2020), building on the work of photography theorists and semioticians (including Barthes himself), show that photographs, despite presenting themselves as “naturalistic and unmediated” (p. 153), are “coded” representations where signifiers (visual forms such as composition, framing, and perspective) work together with signifieds (cultural meanings) to create complex semiotic messages. Contemporary smartphone and social media environments encompass a multitude of signs and modalities, creating what can be understood as a convergent multimodal ecosystem that further challenges traditional camera-based imagery. This development represents a shift in contemporary writing practices, where “new forms of writing have emerged and continue to be developed that blend alphabetic writing with various kinds of visual marks” (Kress and van Leeuwen, 2020: 28). Photography within this environment has therefore evolved beyond its traditional functions of documentation and memory-making to become a component of what Van Dijck (2013) calls a “culture of connectivity.” This transformation demonstrates how camera-based images on digital platforms have shifted from simple documentation to sophisticated forms of social signaling and community participation.
A prominent example of this camera-based multimodal evolution is the selfie, which demonstrates the expansion of photographic practices beyond simple naturalistic self-representation and reveals modes of interaction on digital platforms. According to Frosh’s (2015) analysis, selfies primarily function through “corporeal sociability” (p. 1609), establishing the photographer’s physical presence and inviting viewers to make communicative, gestural responses. This interactive dimension between producers and viewers reflects Kress and Van Leeuwen’s (2020) observation “that images involve two kinds of participants, represented participants (the people, places and things they depict) and interactive participants (the people who communicate with each other through images, the producers and viewers of images)” (p. 113, italics in original). Thus, selfies privilege what Zhao and Zappavigna (2018) term the “intersubjective function” that is particularly prevalent in the primarily conversational milieux of contemporary digital interactions. They emphasize the photographer’s performance and perspective, creating for viewers a position of seeing “as the photographer.” These “first-person” photographs enable visual representations to express a subjective “I” that was historically marginal, creating a visual perspective comparable to first-person narrative in literature (Kress and van Leeuwen, 2020: 121).
These expanded selfie conventions show how digital photography enables sophisticated forms of self-representation that maintain the emotional and social functions of direct self-documentation while operating through more subtle visual strategies. In particular, such conventions establish what can be termed “direct embodiment” – where the creator’s physical presence serves as both medium and message of emotional expression. GIFs represent a departure from this direct embodied relationship, extending communicative functionality beyond static visual elements like emojis and emoticons. Tolins and Samermit (2016) analyze how users employ animated GIFs to depict embodied actions and affective responses difficult to convey in written format, functioning as embodied reenactments. Unlike selfies, which rely on the creator’s actual body and immediate environment, GIFs simultaneously serve as animated quotations, references, and personal commentary – a multifunctional role unavailable through other communicative tools. This creates what can be conceptualized as “borrowed embodiment,” where users deploy others’ emotional performances to represent their own communicative intentions. “Borrowed embodiment” echoes the arguments of Silvio (2010) that “animation” – broadly, the generation of life-likeness through movement – is a new “structuring trope” (p. 422) of digital culture and is increasingly important to identity, embodiment, and the construction of public selves in digital interactions.
While GIFs often feature close-up or medium shots that emphasize facial expressions, reminiscent of selfies, they differ in providing a metaphorical rather than literal self-representation (Kanai, 2015). The animated, looping nature of GIFs transforms brief moments of embodied expression into persistent communicative resources that intensify emotional gestures through repetition. This conversion of diverse audiovisual content into standardized emotional vocabularies constitutes a form of emotional transcoding that preserves affective content while transforming its modal expression.
From universal emotions to infrastructural transcoding
The possibility of emotional transcoding rests partially on established research regarding the nature of emotional expression itself. Ekman and Friesen’s (1969) work on categorizing nonverbal behavior established frameworks for understanding how emotional expressions operate systematically. Subsequent research has proposed evidence for universal facial expressions across cultures (Ekman, 1992), documenting cross-cultural agreement about emotions displayed in facial expressions and reporting consistent findings across investigators for at least five emotions: happiness, surprise, fear, sadness, anger, and disgust. However, the universality thesis faces significant challenges from scholars who argue that emotional expressions are culturally constructed rather than biologically determined (e.g. Leys, 2011; Ratner, 1989). This tension becomes relevant for digital transcoding because platforms must navigate between claims of universal emotional patterns and the reality of cultural variation in emotional performance. The resulting standardization processes may privilege certain cultural expressions while marginalizing others, raising questions about whose emotional vocabularies become globally accessible through digital infrastructure. These complexities extend beyond simple recognition of universal facial expressions to encompass communicative challenges, particularly when platforms must create standardized visual vocabularies that operate across diverse cultural contexts.
Such difficulties are especially evident with paralinguistic vocal expressions – auditory reactions like “aww,” “duh,” “wow,” and “yay” – which represent boundary cases between linguistic expression and spontaneous emotional utterance. These expressions function as emotional communications that carry recognized meaning while resisting formal linguistic categorization. They derive their emotional significance from specifically auditory qualities – vocal tone, pitch modulation, duration, and breath patterns – that disappear entirely when represented through silent visual media. The transcoding of paralinguistic expressions into visual GIF repositories requires platforms to solve complex semiotic problems: how to preserve the emotional signifieds or “content” of auditory expressions while converting them to visual representations, how to make these representations readable across cultural contexts, and how to organize them into searchable databases that support routine deployment in digital communication. Such transcoding work performs what Jakobson (1960) identified as multiple communication functions: maintaining social connection (phatic function), expressing emotion (emotive function), and referencing shared cultural knowledge (referential function). The organization occurs within structured repositories organized by text-image logic, where GIFs are tagged to specific words. These word-image relationships potentially contribute to the cultural structuring of how words are visually represented (Shifman, 2013), though this process requires empirical investigation.
Digital platforms can be analyzed as infrastructural systems that organize and mediate these emotional transcoding processes. GIF repositories like Giphy and Tenor cannot be understood as neutral content databases. Following Gillespie (2010), these platforms strategically position themselves as impartial intermediaries while actively performing editorial work. Rather than simply storing content, they organize it according to what Manovich (1999) calls “database logic” – computational categorization that shapes how emotional expressions become searchable and deployable. This organizational work functions as what Foucault (2002 [1969]) described as archival: creating “the general system of the formation and transformation of statements” (p. 146) that determines which expressions become possible, recognizable, and repeatable. When platforms organize visual content under categories like “aww” or “wow,” they create definitional templates that establish what these emotional expressions look like within digital communication systems. This process functions as what Frosh (2001) describes in relation to stock photography as “a generative matrix which fundamentally determines and orders the production of new images” (p. 636). The systematic categorization of visual content shapes the conditions for future emotional representation.
Platform selection of particular bodies to represent paralinguistic emotional expressions also reveals what Butler (2011) identifies as the performative nature of identity representation within digital systems. When platforms choose specific performers to embody paralinguistic expressions like “aww” or “duh,” they engage in “performative citation” – repetitively invoking particular bodies to naturalize assumptions about emotional expression. This selection determines whose bodies become available as representational resources for users’ emotional communication and whose performances are deemed appropriate for standardized emotional categories. This reflects how platforms systematically convert diverse emotional expressions into standardized, computationally organized formats – what Stark and Crawford (2015) identify as informational capital’s drive to “instrumentalize, analyze, monetize, and standardize affect” (p. 8).
Drawing on this theoretical foundation, the study’s research questions can now be reframed more precisely: The first examines multimodal semiotic strategies through which paralinguistic vocal expressions are transcoded into visual emotional vocabularies, while the second interrogates how demographic and cultural patterns in performer selection reveal the archival and performative work of GIF repositories’ transcoding processes – specifically, what these patterns suggest about the infrastructural pre-packaging of “borrowed embodiment”: whose bodies become available as standardized emotional resources in global digital communication?
Methods
Building on the theoretical framework of emotional transcoding, this study employs a multimodal content analysis to examine patterns in how paralinguistic vocal expressions are visually represented within two major GIF repositories: Giphy and Tenor. These repositories were selected due to their widespread integration into smartphone social media keyboards, with Giphy embedded in Android and iOS, and Tenor available on macOS, Android, and iOS, positioning them as primary infrastructural systems for routine digital emotional communication. By focusing on paralinguistic expressions, this research examines the most theoretically complex case of cross-modal conversion, which involves transforming auditory-based emotional communication into purely visual representation. This conversion challenge makes visible the patterns involved in translating emotional content across semiotic modes, providing optimal conditions for analyzing how emotional transcoding operates.
Data collection and sampling
This study examined 10 paralinguistic vocal expressions that appear as standardized categories within both repositories: “aww,” “duh,” “EW,” “LOL,” “oops,” “ouch,” “sigh,” “wow,” “yay,” and “yuck.” These expressions represent a curated subset of paralinguistic terms available as preset categories, indicating institutional recognition as standardized transcoding templates that repositories have prioritized for easy user access. The convergence of these specific expressions across competing platforms (Google-owned Tenor and Shutterstock-owned Giphy) suggests industry-wide consensus about which paralinguistic terms merit visual representation, revealing standardization processes that operate beyond individual corporate decision-making to reflect broader institutional approaches to emotional transcoding.
For each expression, the first 100 GIFs appearing in search results were collected, representing the content most promoted by repositories and most accessible to users. Given that approximately 10 filmed GIFs appear when users scroll once on a smartphone screen, this sample size captures roughly 10 screens’ worth of the most prominent content for each expression. By focusing on the first 100 results, the analysis captures the content that repositories prioritize through their ranking algorithms and that users are most likely to encounter, making these the most significant examples of how each expression is transcoded. Data were collected from official websites (giphy.com and tenor.com) over 5 weekdays across 5 weeks (October 2024) to account for algorithmic variation. Analysis focused on filmed GIFs featuring human performers to maintain indexical relationships with embodied emotional performance, excluding animated cartoons and digitally manipulated content. This created a corpus of 1000 GIFs for analysis.
Analytical approach
Following Kress and van Leeuwen’s (2020) multimodal framework, content analysis examined patterns in visual encoding techniques and demographic characteristics of performers. The analysis documented observable patterns in how repositories organize emotional content and the visual conventions used to represent auditory expressions, rather than attempting to infer underlying transcoding processes directly. Two trained coders independently analyzed the corpus, following a codebook covering performer demographics (gender, apparent age, racial/ethnic representation), visual encoding techniques (facial expression intensity, mouth configuration corresponding to vocal production, gestural emphasis patterns), contextual elements (source, character, genre, year), embodied performance techniques (gesture types that create representational meaning, body positioning that affects social distance, movement patterns that establish interactive relationships), and cinematic features (shot distance as social distance marker, camera angles affecting power relationships, editing patterns influencing compositional meaning). In addition, subtitle usage was examined to determine how textual elements function as “anchorage” to clarify visual meaning (Barthes, 1977).
The final analysis included only variables with acceptable intercoder reliability (α ⩾ .75), emphasizing observable visual elements consistent with Kress and van Leeuwen’s (2020) multimodal analysis. 1 This approach grounds the analysis in reliable observational data, providing a basis for examining how repositories employ visual design principles to create standardized emotional vocabularies.
Findings
Visual grammar in emotional transcoding
The analysis reveals how repositories employ coherent multimodal strategies rather than random assemblages to convert paralinguistic vocal expressions into standardized visual representations. Instead of relying on user-driven variation, repositories employ approaches to cross-modal conversion that privilege specific visual techniques, demographic selections, and performance styles, creating what Kress and van Leeuwen (2020) would recognize as a coherent “visual grammar” (p. 4) for digital emotional expression.
Reaction GIFs exhibit consistency in temporal and compositional structure, with an average duration of 1.86 seconds, resulting in concise emotional expressions that prioritize peak emotional intensity over narrative development. The technical uniformity extends to visual composition: 97.5% of analyzed GIFs consist of single, unedited shots, showing a consistent preference for clear composition that reduces interpretive ambiguity. Visual composition shows a preference for facial expressions and upper-body shots through medium close-ups (52.7%), followed by medium shots (21.7%) and close-ups (14.6%). This framing hierarchy creates an interaction between “social distance” and “close personal distance” (Kress and Van Leeuwen, 2020: 124) that enables emotional interaction without excessive intimacy, while maintaining sufficient detachment to permit appropriation of another’s body rather than direct interpersonal engagement.
Gaze patterns provide crucial evidence for understanding how repositories manage user-GIF relationships through visual design. Unlike selfies or videotelephony, which typically feature direct eye contact to establish viewer connection, most reaction GIFs (75.6%) depict subjects looking elsewhere. According to Kress and van Leeuwen’s (2020) interactive meaning system, this indirect gaze creates “offer” rather than “demand” relationships (pp. 117–118), positioning GIF subjects as emotional resources to be observed and appropriated rather than interlocutors demanding direct engagement. This observational quality reflects a distinction between “reaction” and “response” in digital communication. When users deploy them, reaction GIFs typically function as embodied avatars – borrowed performances that mediate the user’s physical reaction in online conversation. The depicted subject of the GIF becomes a prosthetic body through which users express emotional reactions to shared content, posts, or conversational developments. Unlike considered responses that invite further dialogue, reaction GIFs stand alone as nonverbal emotional stances that do not require a reciprocal response. Both gaze and framing patterns in repositories prioritize emotional accessibility over intense personal connection, facilitating “borrowed embodiment” rather than direct emotional confrontation. By avoiding extreme close-ups and direct address, these visual strategies enable rapid emotional conversational exchanges while minimizing the social obligations and complexities of simulated interpersonal relationships that could disrupt the platform’s content flow.
The embodied paralinguistic expressions that are offered by the repositories span an emotional spectrum, ranging from extremely positive expressions (“LOL,” “wow,” “yay”) to extremely negative ones (“EW,” “yuck”), with intermediate expressions (“aww,” “oops,” “sigh,” “duh,” “ouch”) that convey more complex or ambiguous emotional valences. This spectrum reveals the multidimensional nature of how GIF repositories organize and standardize emotional expression, extending beyond simple positive-negative binaries (Table 1). This coverage suggests that repositories approach emotional transcoding as vocabulary construction rather than ad hoc content selection, creating a structured lexicon for digital emotional communication that operates according to multimodal principles. However, this embodiment function operates alongside a second dynamic: GIFs that elicit rather than embody emotional response (e.g. using a cute puppy as the visual for “aww”). In instances of elicitation, users present the GIF as an independent emotional object designed to provoke a reaction in recipients, rather than as an embodiment of their own emotion. Such GIFs shift from communicating “this represents my emotion” to “this should evoke emotion in you.” This distinction between embodied and eliciting functions reveals two approaches to emotional transcoding: one that enables users to appropriate others’ performances to represent their own personal emotional states, and another that creates emotional stimuli designed to elicit responses in viewers.
Reaction GIFs: Visual Lexicon of Paralinguistic Expressions.
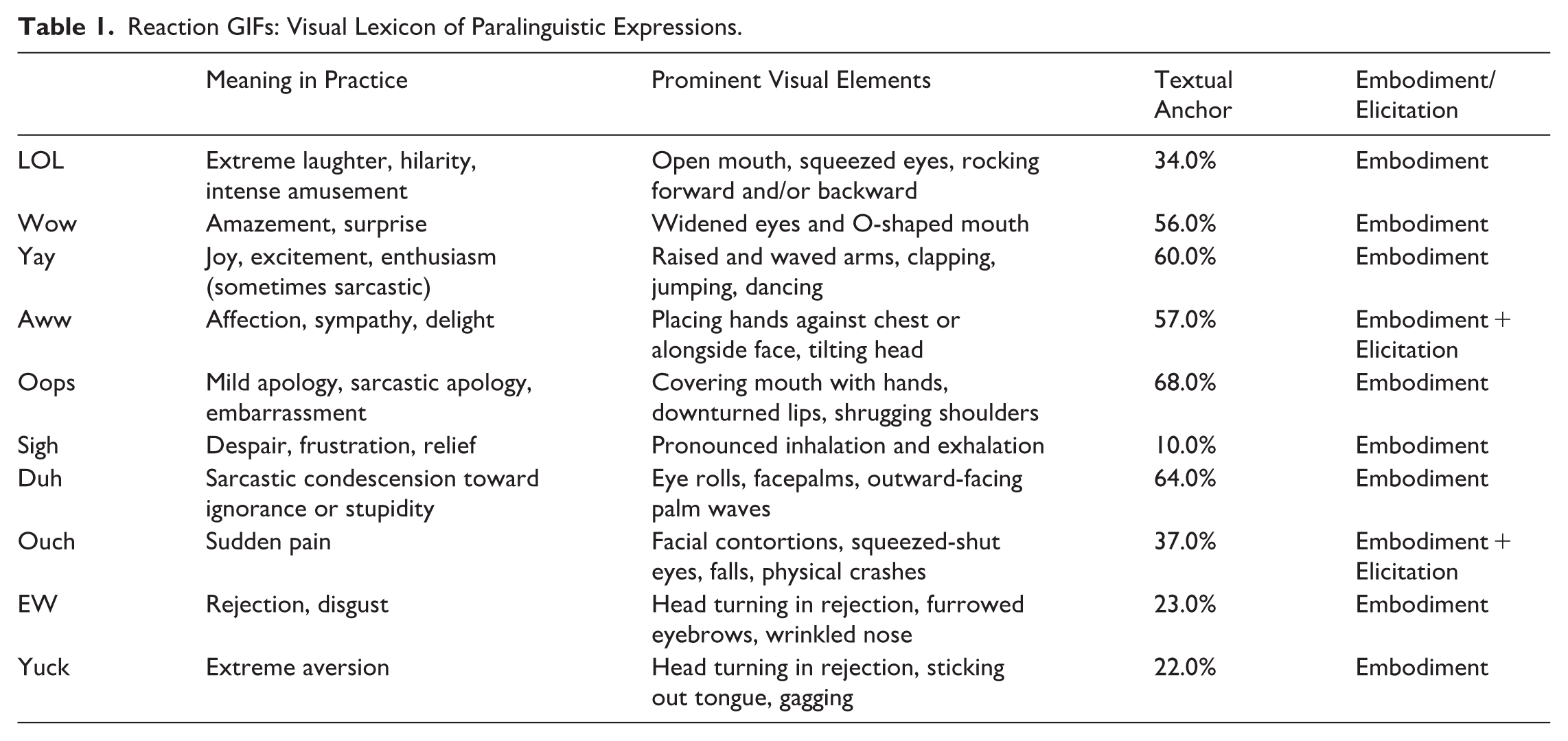
This distinction between embodied and eliciting functions, along with structural elements, shapes this emotional lexicon through coordinated semiotic work across multiple modes. The analysis reveals that emotional transcoding operates through a complex multimodal coding system that coordinates four primary modes: auditory elements (the original paralinguistic sounds being transcoded), visual elements (facial expressions and physical gestures), textual elements (subtitles), and embodied performance (the selection and framing of performing bodies). Table 1 illustrates how these modes interact systematically across different expressions, with each paralinguistic utterance requiring specific combinations of visual, textual, and embodied strategies to preserve emotional meaning in the absence of sound. These organizational choices demonstrate how repositories actively construct emotional vocabularies through embodiment, privileging emotions observed from the side, reactions rather than responses.
The analysis of visual tropes across the emotional spectrum reveals consistent approaches to cross-modal conversion challenges, demonstrating multimodal strategies. High-intensity expressions (“LOL,” “wow,” “yay”) demonstrate clear visual correlates to vocal production through what can be identified as “validity” strategies (Kress and Van Leeuwen, 2020: 154), which here are a visual form of exaggerated, theatrical presentations to maximize visual accessibility across cultural contexts (Figure 1).

Screenshot of reaction GIF “LOL” that shows Rachel Reilly, a television personality from the reality competition show Big Brother (2010–2011). This exemplifies a high-validity visual representation of laughter through exaggerated bodily movement – specifically, rocking forward and spitting beverage from her mouth. These physical actions transcode vocal laughter into an unambiguous visual form.
Similarly, emphatic gestural embodiment is a key strategy for converting auditory celebration into visual performance in high-intensity expressions. For instance, “yay” GIFs predominantly feature subjects expressing elation through arm gestures – enthusiastically raised skyward, waved energetically, or engaged in rhythmic clapping, full-body jumping, spontaneous dance movements, or recognizable choreography, such as exuberant celebrations of Rachel and Phoebe from the sitcom Friends (1994–2004) (Figure 2) or Carlton’s iconic dance from The Fresh Prince of Bel-Air (1990–1996).

Screenshot of reaction GIF “yay” that represents Rachel Green (played by Jennifer Aniston) and Phoebe Buffay (played by Lisa Kudrow), from the sitcom Friends (1994–2004).
Conversely, expressions involving social evaluation (“duh,” “oops”) rely more heavily on textual anchorage to clarify meaning. The variation in subtitle usage (from 10% to 68%) across all expressions indicates the application of cross-modal disambiguation, where expressions with clear physical correlates require minimal textual support, while culturally specific expressions require texts to limit polysemic interpretation. “Oops” reveals the highest subtitle inclusion rate (68.0%) due to its frequent deployment in sarcastic contexts. When “oops” has ironic intent, this is understood through textual anchoring, as the image alone does not convey a distinct physical expression. Therefore, captions become essential to distinguish between genuine embarrassment and intentional sarcasm (Figure 3).

Screenshot of a sarcastic “oops” GIF played by Hugh Laurie as Dr. Gregory House, from the medical drama television series House, M.D. (2004–2012).
Beyond these technical solutions to transcoding challenges, the embodiment/elicitation categorization reveals a fundamental expansion of digital communication possibilities. Most expressions primarily enable users to appropriate emotional performances and represent personal states, while expressions with dual functionality (“aww,” “ouch”) can operate both as personal representations and as stimuli designed to evoke viewer responses. Elicited images reach their fullest expression with “ouch” GIFs, which include two representational structures. The first shows characters directly embodying pain reactions through facial contortions, squeezed-shut eyes, and occasionally tears. When these embodied expressions carry a sarcastic connotation, subtitles are added to clarify the ironic intent. The second employs elicitation, where a significant portion (32 of 50 GIFs) on Giphy features unintentional physical mishaps, unexpected moments, and pranks. Among these mishap-centered GIFs, 22 originate from private home videos, content resembling the genre popularized by America’s Funniest Home Videos, an American television series that combines comedy and reality formats and has maintained popularity since 1989 (Figure 4). These GIFs do not depict someone saying or expressing “ouch,” but rather present scenes that position the audience to witness and experience sympathy with the depicted discomfort.

Screenshot of an “ouch” GIF that represents bike riding fall and crash (unknown source). This exemplifies an elicitation strategy where viewers are positioned to experience sympathy rather than witnessing direct emotional expression.
This distinction transforms digital emotional expression from purely self-representational communication into a system that includes tools for emotional influence, where users can deploy affective stimuli to shape recipients’ emotional responses rather than simply expressing their own feelings. This reveals the difference between what Kress and van Leeuwen (2020: 113) identify as “represented participants” (those depicted in images) and “interactive participants” (the people who communicate with each other through images), with the elicitation function specifically targeting the emotional response of interactive participants.
Beyond the elicitation pattern demonstrated in “aww” and “ouch” expressions, the GIF repertoire encompasses expressions that vary in their relationship between vocalization and visual representation. This variation reveals how repositories manage different types of cross-modal transcoding challenges through systematic application of visual and textual resources. While expressions like “duh” represent sounds that are directly vocalized as distinct utterances, the analysis identifies expressions that typically function as descriptions. Among the 10 paralinguistic expressions examined, two stand out: “sigh” and “LOL.” “Sigh” demonstrates how repositories prioritize visual embodiment when the physical manifestation itself carries sufficient meaning-making potential. Unlike utterances that require vocalization, sighing is transcoded entirely through exaggerated chest movements, eye rolls, and facepalms – that achieve high validity (Kress and Van Leeuwen, 2020). This is reflected in the lowest subtitle presence (10.0%) among all categories examined.
In contrast to the clear visual distinctiveness of sighing, condescension via “duh” GIFs requires more textual support due to their potential ambiguity. Without textual anchoring (Barthes, 1977), repositories cannot reliably communicate the specific social evaluation (condescension toward ignorance) that distinguishes “duh” from other negative expressions, particularly when sarcasm intensifies the condescending tone. Consequently, “duh” exhibits one of the highest subtitle rates (64.0%) in the corpus. This reveals a strategic deployment of multimodal resources: repositories use textual anchorage most heavily precisely when visual embodiment alone cannot reliably convey culturally specific meanings. Unlike “sigh,” where physical action directly correlates with emotional meaning, “duh” requires text to specify the condescending stance itself, distinguishing it from other expressions of negativity.
Moving beyond direct embodiment expressions, the final category pair demonstrates how platform categorization systems both rely on and override visual meaning-making. The paralinguistic utterances “EW” and “yuck” reveal how repositories’ organizational logic operates independently from the multimodal content itself. Both expressions convey disgust through similar visual patterns: subjects turning heads away from unpleasant stimuli while furrowing eyebrows and wrinkling noses, with mouths assuming characteristic downward pulls at corners (Figure 5). Both categories show low subtitle rates (“EW” at 23.2%, “yuck” at 22.0%), indicating that distinctive facial expressions communicate meaning effectively without textual support. “Yuck” expressions distinguish themselves from “EW” primarily through intensity rather than type: where intensity differentiation occurs, “yuck” incorporates gagging or pre-vomiting reflexes – typically an extended tongue combined with a pointing finger directed toward the open mouth, signaling imminent physical rejection rather than mere distaste (Figure 6). However, with several identical GIFs appearing in both categories (four GIFs per repository, eight in total) and some instances where GIFs with the subtitle “EW” appear under the “yuck” search term, the overlap demonstrates that organizational categorization – not visual content or textual subtitles – primarily determines meaning. The same visual representation can signify either “EW” or “yuck” depending solely on which repository category it occupies. As Kress and van Leeuwen (2020) observe, “each mode of representation has a continuously evolving history, in which its semantic reach can contract or expand or move into different areas of social use as a result of the uses to which it is put” (p. 40). Here, platform categorization operates as a distinct layer of meaning-making beyond the visual, textual, and embodied modes present in the GIFs themselves.

Screenshot of reaction GIF “EW” featured by Jimmy Fallon as Sara, a teenage girl in the recurring sketch “EW!” from The Tonight Show Starring Jimmy Fallon (started in 2014).

Screenshot of reaction GIF “yuck” portrayed by Jim Carrey from the comedy film Liar Liar (1997).
Standardizing affect: the bodies and cultural references of emotional expression
The analysis of performer demographics reveals patterns in whose bodies become available as standardized emotional resources (Table 2), operating through systems of exclusion that simultaneously privilege specific demographic categories and cultural frameworks. These patterns illustrate how visual representation fosters cultural hierarchies through demographic concentration, where certain identity categories are positioned as suitable vehicles for “universal” emotional expression. Across the sample, multiple categories of representation were identified, including human bodies, drag performers, puppets, Muppets, and animals. Within human representation, males dominate at 51.7% compared to females at 33.2%, with the remaining 15.1% comprising undefined gender presentations (10.6%), babies (3.0%), drag performers (0.2%), cross-dressing or gender portrayal performances (1.1%), and unknown or costumed subjects (0.2%). Age distribution indicates that young adults (20–39) are the most dominant, at 46.7%, followed by middle-aged adults (40–59) at 24.7%, and children (3–9) at 9.1%. Racial and ethnic representation demonstrates significant disparities and overwhelming White dominance, with White individuals comprising 69.4% of human subjects, Black individuals 15.4%, and other ethnic representations totaling 4.6%.
Demographic Representation in Paralinguistic Reaction GIFs.

Examining gender representation across specific paralinguistic expressions reflects broader assumptions about emotional authority embedded within visual communication systems. While overall male dominance (51.7%) might suggest a systematic bias, the distribution varies considerably across expression types, resulting in the deployment of gendered visual authority based on emotional intensity requirements. Only one expression demonstrates a female advantage: “yay” shows 37 female versus 31 male representations, although this constitutes just 37% female representation due to the inclusion of babies, non-human, and animal categories. The most gender-balanced expressions include “duh” (47 female vs 48 male), “EW” (39 female vs 43 male), and “LOL” (40 female vs 44 male), suggesting that certain reaction types achieve a kind of “naturalistic coding” (Kress and Van Leeuwen, 2020: 156), where gender becomes less relevant to emotional authenticity. Conversely, expressions associated with physical discomfort or amazement reveal stark male dominance: “ouch” (68 male vs 17 female), “sigh” (68 male vs 21 female), and “wow” (64 male vs 21 female). This variation suggests that repositories employ what Kress and van Leeuwen (2020) call “coding orientations” (p. 164), the frameworks through which institutional contexts shape how specific social groups produce texts, in this case, privileging White masculine embodiment. The concentration of male performers in expressions requiring dramatic physical embodiment shapes how gender categories exercise visual authority in representing extreme emotional states for global audiences, thereby creating gendered hierarchies of emotional credibility within the transcoding infrastructure.
These demographic hierarchies in performer representation operate in conjunction with cultural standardization through source material selection. The infrastructure does not simply privilege certain bodies but embeds those bodies within specific cultural and temporal frameworks, creating compound systems of exclusion. Professional entertainers comprise 77.3% of performers, meaning that the demographic biases observed reflect not only individual representation but the institutionalized representational patterns of American entertainment industries. This intersection between performer demographics and source material reveals how emotional transcoding infrastructure naturalizes particular configurations of identity and culture as emotionally authentic while marginalizing alternatives. With American television comedies and entertainment programming providing 53.5% of source material, predominantly from the 1990s–2010s period, this concentration presents particular visual traditions as universal emotional languages while creating a temporal hierarchy where specific historical moments in American entertainment production become naturalized as appropriate emotional standards for contemporary global communication (e.g. Shifman et al., 2014). This temporal focus reflects generational targeting of millennial cohorts, featuring content from their formative years of childhood, adolescence, and early adulthood – when media products become part of collective generational memory (Bolin and Skogerbø, 2013). Figure 7 demonstrates this temporal concentration, which functions as cultural gate-keeping where effective emotional expression requires familiarity with American millennial media touchstones.
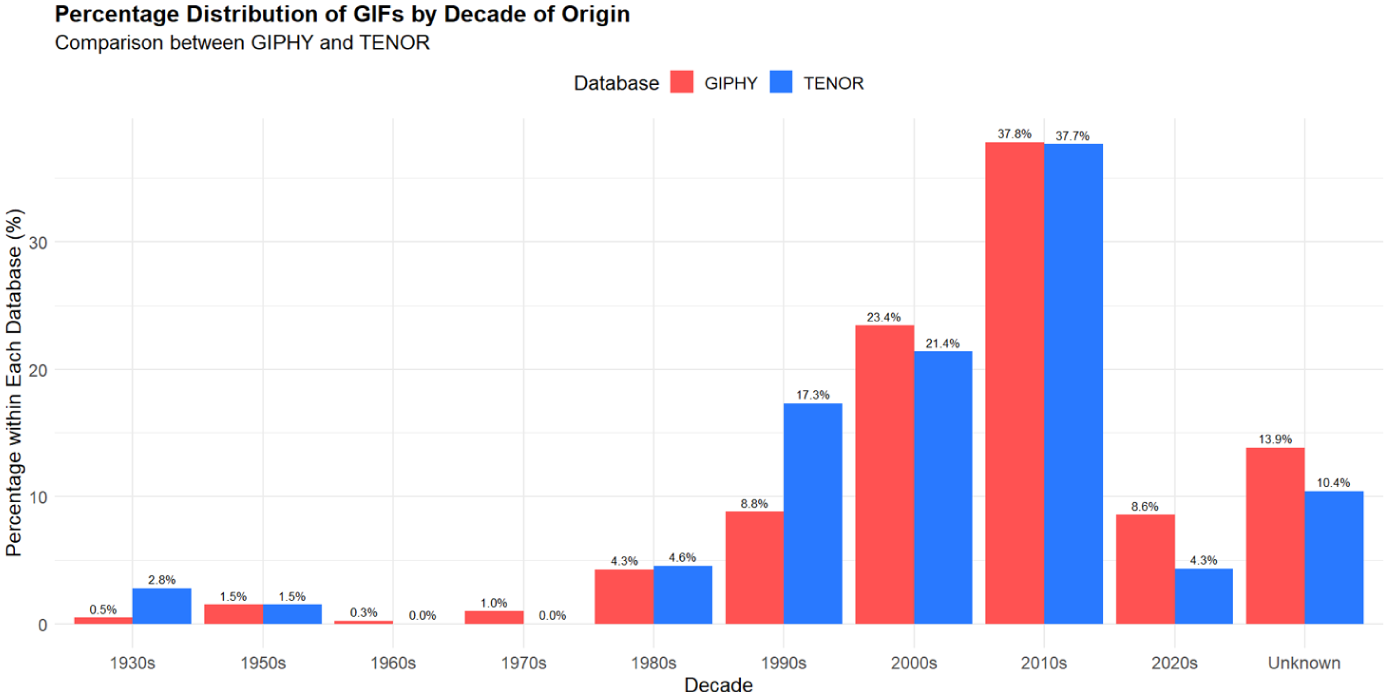
Distribution of GIFs’ sources by decades.
As Miltner and Highfield (2017) note, “using specific GIFs is like a camp wink at the audience” (p. 7), establishing in-group communication through shared media references while potentially alienating users outside the millennial demographic or unfamiliar with American popular culture. This reveals how users worldwide must adopt American millennial media literacy as a prerequisite for accessing standardized emotional expression, naturalizing culturally specific requirements as technical necessities.
GIF repositories: infrastructural systems for emotional transcoding
This study has examined GIF repositories as infrastructural systems that perform emotional transcoding: converting paralinguistic expressions into visual vocabularies while embedding representational hierarchies. GIF repositories operate as emotional infrastructure with the apparent simplicity and invisibility characteristic of infrastructural systems that users need not think about – they are simply available, effortlessly integrated into everyday communication. Yet these platforms perform extensive curatorial work while presenting themselves as neutral tools, a curation that extends beyond technical organization to encompass cultural gatekeeping.
A critical tension emerges in the assumption that emotion is universally translatable across modes without loss or transformation. GIF repositories present emotions as seamlessly transferable from paralinguistic utterance to visual representation, obscuring how their infrastructure actually fixes and standardizes emotional expression through distinctly Western, male, and generationally specific prisms. The technological infrastructure thus performs ideological work, suggesting that every culture shares identical emotions while simultaneously naturalizing particular representations as universal. The analyses presented in this study – examining both paralinguistic expressions and performative cultural patterns – demonstrate this technological-political connection, revealing how infrastructural operations shape the boundaries of emotional communication.
This relationship between platform materiality and emotional expression resonates with the concept of “affective infrastructure” (Bosworth, 2023) – systems that operate bidirectionally by generating specific affects through their material organization while conditioning which forms of emotional expression become available. Understanding GIF repositories as affective infrastructure reveals their dual operation: they produce affects through curatorial choices and algorithmic organization while simultaneously establishing the foundational conditions that determine which emotional communications become possible, recognizable, and repeatable in digital discourse.
Socio-cultural patterns in GIF repositories exhibit “regimes of representation” (Hall, 1997: 232) that normalize certain bodies as default signifiers while marginalizing others through the mechanism of “borrowed embodiment.” Overrepresentation of White subjects, male dominance, and the prevalence of young adults reflect curatorial decisions that embed racialized, gendered, and ageist biases in digital communication. These patterns operate through what Butler (2011) identifies as performative citation, where “performativity is thus not a singular ‘act,’ for it is always a reiteration of a norm or set of norms” (p. xxi). Each deployment of a GIF constitutes a “citation” of these socio-cultural norms, simultaneously “miming that norm” while creating “an occasion to expose the norm itself as a privileged interpretation” (Butler, 2011: 71). These deployments reiterate representational hierarchies, with repetitive citations serving to reinforce rather than challenge these embedded biases. The overrepresentation of White subjects echoes hooks’ (1992) critical examination of how whiteness becomes racially privileged in media representations. The technical characteristics of GIFs amplify these representational politics through their distinctive features. The silent, looped format intensifies the importance of visual representation by eliminating auditory function. The endless repetition serves not merely as an attention-capturing device but as a mechanism for cultural reinforcement, transforming fleeting media moments into persistent communicative resources that ground popular cultural memory.
The dominance of two primary repositories in controlling GIF selection for embedded keyboards represents algorithmic selectivity (Gillespie, 2014), where curatorial decisions shape how emotions and reactions become visually coded in digital communication. This control raises important questions about content curation, representational patterns, and the standardization of emotional expression in digital visual communication (e.g. Nissenbaum and Shifman, 2018). The prevalence of American television content in GIF repositories represents what Shifman et al. (2014) describe as “powerful agents of globalization and Americanization” (p. 739). This Americanization extends beyond mere content distribution to shape how new languages of intimate and everyday interpersonal communication are formed and instituted. Unlike other digital phenomena, such as memes, American cultural references become embedded in everyday repertoires of expression through their integration into smartphone and computer keyboard interfaces. This technological mediation perpetuates gender and racial biases prevalent in that era’s programming, as GIF repositories institutionalize historical representational inequities within contemporary communication systems. As Papacharissi (2009) argues, Web 2.0 technologies often inherit and amplify pre-existing cultural and social biases, rather than emerging as neutral platforms – a pattern exemplified by GIF repositories.
The temporal concentration of GIF content around 1990s–2010s television programming creates distinctive generational communication vernaculars that function as both inclusive and exclusionary mechanisms. This temporal focus features content familiar to those who grew up during this period – childhood, adolescence, and early adulthood – when media products become part of collective generational memory (Bolin and Skogerbø, 2013). These repositories appear to preserve what Mannheim (1952) calls “generational entelechies,” understood here as collective media memories that connect age cohorts, particularly millennials (Volkmer, 2006), though empirical investigation of user demographics would be required to confirm this relationship. The GIF format itself, created in 1987 and initially constrained by patents before experiencing widespread adoption in the 2000s, follows a similar developmental trajectory. The format functions as a distinctly millennial expression, echoing communication patterns of a generation that developed alongside television content and digital communication platforms. The qualities of reaction GIFs – immediate, playful, expressive, and reactive – coincide with communication characteristics that Liu et al. (2012) associate with this generation’s digital communication. What appears to emerge is a “cultural-technical recursion” – the technical looping of GIFs mirrors their cultural function of preserving and recirculating millennial media touchstones. This preservation both demonstrates “affective meaning” (Katz and Shifman, 2017), showing how repeated circulation of cultural references creates shared understanding among in-group members, and contributes to nostalgic generational memory-making, potentially signaling a reluctance to move beyond formative media experiences.
This study’s focus on visual content analysis provides insights into repository organization and representation patterns, but it cannot address several important dimensions of GIF usage. The analysis examines what repositories offer rather than how users deploy these resources in conversational contexts. Claims about generational communication patterns and user behavior require empirical investigation beyond the scope of visual content analysis. In addition, this study cannot access the official organizational practices, algorithmic functions, or commercial decision-making processes of GIF repositories, limiting insights into how curatorial choices are made. Future research can examine actual usage patterns, cross-cultural reception of these visual vocabularies, and the relationship between repository offerings and user appropriation in diverse communicative contexts.
This study advances understanding of digital platforms as active cultural agents by conceptualizing GIF repositories as infrastructural systems that perform emotional transcoding – revealing how platforms transform paralinguistic expression into standardized visual vocabularies while embedding systematic representational biases. The seemingly humorous and playful deployment of GIFs operates within systems of technological mediation and cultural reproduction, where platform infrastructure invisibly shapes the boundaries of expressibility. By examining the curatorial politics of emotional transcoding, this research demonstrates how repositories function not as neutral databases but as gatekeepers that determine which bodies, cultural references, and temporal frameworks become available for global emotional expression. The performative nature of GIF deployment reveals the intricate negotiation between user agency and platform constraints, where each citation reinforces or contests embedded hierarchies of representation. As digital communication continues to evolve, understanding repositories as infrastructural systems that actively structure emotional expression becomes essential for interrogating how technological affordances, communicative practices, and identity performance intersect in contemporary media culture. Future research directions can examine how users navigate these platform-imposed constraints, whether visual interpretations align with algorithmic categorizations across demographic groups, and how different cultural contexts receive and appropriate these standardized emotional vocabularies – questions critical to understanding platform power in an increasingly mediated communicative landscape.
Footnotes
Acknowledgements
The author is very grateful to Paul Frosh and Limor Shifman for their valuable guidance, to Tommaso Trillò for his advice and help with scraping the GIFs, and to Alexandra Danzig and Renana Atia for their meticulous coding and assistance with quantitative analysis.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Israel Science Foundation under Grant number 1724/21.