
Abstract
In this article, the author presents a multimodal discourse analysis of a student-produced video, drawing upon Jacques Derrida’s theorization of différance. He analyzes the film as a signifying chain, drawing specifically upon the differing and deferring aspects of différance in order to conceptualize the movement of signification in the video. The focus of his analysis is on how différance, as a constitutive force, splits and divides attempts to discursively construct a present through coordination of signifiers from across multiple modes. His application of différance illustrates how the present, as constructed in the focal video, is ill-defined and always blurred since presently occurring, visible, and audible signifiers in the video do not signify in and of themselves, but rather refer to past signifiers and anticipate future signifiers for their constitution as they engage the dynamic and complex operations of différance. This analysis adds to approaches to multimodal discourse analysis of student-produced videos by accounting for the interaction of visual, actional, bodily, and spoken signifiers, as well as the pedagogical implications for understanding how discursive agencies act upon student video-composers.
Introduction
In this article, I present an analysis of a short digital video, ‘Lost’, produced by two students (Anna and Carmen, pseudonyms, age 13), in a public-school classroom setting. In this short video, Anna and Carmen (featured in the video as the principal actors) repeatedly search for one another, yet just miss one another each time. The video begins with Anna waiting outside the restroom door for Carmen while she goes in. After waiting for a while, Anna decides to go into the restroom (two-sided, double door) to look for Carmen, only to enter just as Carmen comes out. Since they enter and exit at exactly the same time, they just miss each other, a pattern that is repeated with comedic or absurd effect throughout the video. The video thus takes on a circular or repeating structure that results in the characters’ perpetual state of being ‘lost’. In my analysis of this video, I draw upon Derrida’s (1973, 1978, 1981) theorizations on the concept of différance in order to analyze the ways in which the focal video’s uses of speech, images, body locations, and actions are constituted by a complex interaction of signifiers that unwittingly act as a useful metaphor or heuristic for understanding the operation of différance.
In this article, I apply différance to the analysis of the operation of signifiers in the focal video, ‘Lost’. Signifiers are single material elements or ‘minimal significant units’ (Barthes, 1977: 48), such as a word or image that indicates or signals toward meaning or communication. De Saussure (1983[1916]), who analyzed speech, defined signs as consisting of two parts, a signifier and a signified: the signifier, which is a ‘sound pattern’, and the signified, or the concept associated with that sound pattern. Barthes (1977) has since theorized the sign to include other sign systems, such as fashion, furniture, food, and architecture systems, referring to ‘mixed systems in which different kinds of matter are involved (sound and image, object and writing, etc.)’ (p. 47). Barthes has thus referred to signifiers from across sign systems as, for example, ‘a slice of sonority, visuality, etc.’ (p. 48) that can be ‘endowed with one meaning’ (p. 39).
Post-Sausurrian theorizations of the sign have also since problematized the concept of the signified in particular (Derrida, 1973, 1981; Lacan, 1993, 2002[1966]; Laclau and Mouffe, 2001; Metz, 1982; Silverman, 1983). This re-theorization of the signified has pointed out the difficulty or impossibility of the identification of a fixed concept that represents the meaning of a sign, noting that there is no ‘transcendental signified’ (Derrida, 1981). Rather, the signified is produced through interactions amongst signifiers and is not predetermined, a priori, or existent anywhere outside of the actual play and interaction of signifiers in subjective and social language-use processes. Meaning is thus elusive, indefinite, and indeterminate. Rather than having a meaning that is indicated by a clear or transcendental signified, the signified is, instead, indicated by another signifier. In light of this reconceptualization of the signified, the analysis of the operations signifiers can be achieved only by looking to other signifiers that are related to the signifiers in question. I thus focus my analysis on the signifier and do not attempt to identify signifieds. Instead, I apply différance as a way to understand the operation, movement, and interaction of signifiers in the focal video.
Derrida uses the term différance in order to make a series of complex and subtle arguments about the operations of language and the ways that we usually think of and represent concepts like being and presence. The French spelling of difference is ‘différence’. Derrida introduces a ‘spelling mistake’ (introducing an ‘a’ in order to spell différance) – which results in a word that is pronounced the same as différence, but spelled differently – by which he introduces a new term that he uses to reconceptualize classical and metaphysical notions of the operations difference in language. With différance, Derrida goes beyond addressing differences between signs, and theorizes différance as an ungraspable shift between vanishing signs that are never fully present. Derrida thus avoids the logical approach of identifying present signs and determining their meaning or sense. Instead, he takes the approach of identifying absent or partially absent signs and a dynamic force that is characterized by a constantly dividing and deferring action that is external to, yet also constitutive of the signs being constructed and used. This external, constitutive force, différance, causes signifieds to slide and to be ultimately unidentifiable. However, Derrida demonstrates how discourse offers opportunities to create and conceive of illusory certainties in meaning, thus covering up the work of différance. This is necessary since différance fractures, frays, and defers attempts to pin down meaning: différance always divides meaning, and meaning resides nowhere prior to the particular interaction of and uses of signifiers in situated discursive practices.
Derrida (1973) theorizes how, in all uses of language, stable meanings are generated through the construction of the present in discourse, which is actually constructed from a complex interplay of past and future elements. Discursive attempts towards meaning attempt to pin down a present as a starting point from which signification can proceed, thus working against the dividing and deferring forces of différance. However, différance, as an outside, constitutive force, is always dividing and splitting attempts to discursively construct a present and pin down the meaning of signs. In the video, ‘Lost’, the present is blurred since the actors never stay still, and are always in motion. The video is structured such that Anna and Carmen’s ‘present’ actions do not signify in and of themselves, but rather refer to past actions and anticipate future actions in their constitution. ‘Lost’ thus blurs the present and any potential meanings that arise from it, instead engaging in signifier dynamics that make the video an apt metaphorical representation for the exploration of the processes of différance.
Researchers have begun to study how signs or semiotic resources are produced, combined, and assembled by student video-creators in educational and pedagogical settings. These studies have examined how semiotic elements interact within videos, producing particular effects (Burn, 2003, 2009; Burn and Parker, 2003; Hull and Nelson, 2005; Mills, 2011; Ranker, 2008, 2017, 2018a). For example, Hull and Nelson (2005) examined a student-composed video, attending to how signs drawn from the visual, audio, and linguistic modes were brought into interaction with one another, producing a synergy and new, creative composition potentials. Hull and Nelson’s (2005: 230) research interests were in ‘processes of transformation and transduction (the shaping of semiotic resources and the migration of semiotic modes, respectively) as the locus of creativity in multimodal communication.’ In addition, Burn (2009: 230), in his study of student video production, closely examined how ‘the moving image has its signmaking systems in space and time, which combine different modes (image, sound, music, dramatic gesture, lighting)’. Burn’s analysis specifies each frame and its components as signs that are arranged with one another into syntagms, or groups of related signs that are coordinated across synchronic and diachronic dimensions.
Ranker (2017) examined the ways that signifiers drawn from multiple modes were interwoven in a student-produced video, noting how the signifiers’ relations with one another could be described along a continuum of divergence to convergence. The focus of this analysis was to determine how ‘these signifiers come into relation, combination, and association with one another across varying degrees of difference and similarity’ (p. 196). Ranker (2018a) also examined another student-produced video, conducting a multimodal analysis that focused on various types of signifier interactions and operations, such as floating signifiers, networks of signifiers, and signifier condensation complexes.
In this article, I seek to build upon the available studies of semiotic operations of signifiers by applying différance to my signifier-based analysis of ‘Lost’. In so doing, I explore two aspects of différance: differing and deferring. Applied to a semiotic context, two signs can differ from one another, which means that they are in a relationship of non-identity, characterized by ‘distinction, inequality, discernability’ (Derrida, 1973: 129). The other aspect of différance refers to the action of delaying or deferring, which ‘puts off until later what is presently denied’. Différance thus constantly splits the present, or the illusion of the present, which is actually constituted by a complex interplay of past and future signifying elements.
Derrida (1973, 1978, 1981) notes how the discursive construction of the present is an illusion that is created by attempting to resist the splitting force of différance. This creation of the illusion of the present allows for signifieds to be pinned down and assigned to signifiers so that meanings are more stable and identifiable – while différance is constantly undercutting this effort, splitting the present, and causing signifieds to slide. In ‘Lost’, as in many videos, the ‘present’ is considered to be that which is presently occurring, and occurring simultaneously with a presence or presences of the characters. Thus, when one of the characters is present and engaging in acts, this marks the present in the video. However, différance subverts this connection between presence and the present because the characters are always in motion, never holding still, and movement (toward a past and future) is always simultaneously repeated and anticipated.
This analysis illustrates how différance structures time in the focal video through the relation and arrangements of signifiers that occur over time. Specifically, each signifier that emerges as the ‘present’ signifier is actually referred to or comprised by disparate past and future signifiers and complexes of signifiers that form networks across modes. Derrida (1994: 20) refers to this phenomenon as the ‘dis-located time of the present’: a sense of time that is ‘heterogeneous’, which Holland (2015: 42) has described as ‘overlapping, multiple, and no longer one, temporalities that cannot be accounted, calculated, or evenly spatialized along a grid or projected onto the horizon of a telos’.
The analysis of ‘Lost’ that I present in this article examines how this heterogeneous or dis-located time of the present has research and pedagogical implications pertaining to student video compositions. For example, time and sequence are often analytical elements that are used when analyzing videos from a research perspective or considering student video compositions from a pedagogical perspective. However, my analysis of ‘Lost’, which involved the charting out of signifiers along a signifying chain (chronology), revealed that each signifier reverberated through the others through the operation of différance. This offers a new perspective on time as multiple or heterogeneous (comprised of past, present, and future signifiers that defer to one another) in each of its present moments. In ‘Lost’, each signification is heterogeneous and multiple, constantly deferring to another: no signifier acts alone, is never one, originary, or single. The constant deferring of one signifier to another creates a heterogeneity in a single signifier that makes it part of a larger complex or network of other signifiers that cut across time.
The concept of a signifier complex (Ranker, 2014) – or network of related signifiers that cut across modes – that I employ in this analysis thus illustrates the heterogeneity or multiplicity that is evident at any given time/frame/place in the chain, which I identified during analysis, through trying to pinpoint individual signifiers in time along a signifying chain. Because of its repetitive structure and resistance to a logical story format, ‘Lost’ is an especially apt lens for understanding how différance engages time in multimodal discourse that constitutes student video compositions.
Detecting or attending to this unseen operation of différance requires a detailed understanding of signifier operations as they occur in student-produced videos, which can also offer an insight into describing the ‘signifying work’ (Burn, 2003) that students engage in as they compose videos – work that is ignored by the official curriculum due to an absence of an understanding of the semiotic processes and a vocabulary for describing them. This article thus offers additional terms for such a vocabulary: in particular, a vocabulary that can be used to describe the complex and unconscious – and thus covered, unseen, and hidden – ways in which discourse shapes the play of signifiers in video through the operation of différance. Such an understanding offers educators a new perspective on and lens for understanding the complexity of students’ video-making processes, thus opening the door to new pedagogical responses that take these understandings and complexities into account.
Methods
In this article, I present a signifier-based discourse analysis (Neill, 2013; Parker, 2010; Ranker, 2017, 2018a, 2018b, 2019) that focuses on a student-produced video, ‘Lost’, which was created by two students, Anna and Carmen (pseudonyms, age 13) in an urban public school in the United States. This analysis derives from a broader qualitative case study (Glesne, 2016; Merriam, 2008; Stake, 1995) of sign operations in students’ digital-video production in an urban, public school class made up of students ages 12–14. This focal class was a multi-age, alternative class with multiple options for students to pursue during the designated class time, including the following: digital video creation, other independent projects, art projects, and catching up on work from other classes. During the study period, Anna and Carmen (along with several other students) chose the option of creating a short digital video. These videos were completely student-led, without teacher direction, and about any subject matter that the students chose. This project resulted in the creation of short digital videos that took on a playful or artistic character. Students developed videos over the course of the study and then showed them to others in the class and outside of class by posting them on the class blog.
Each week, I visited the class as a participant observer for a 2-hour period one or two days each week over the course of 4 months. During this period, the focal students composed digital videos while I helped with the technical aspects of the project, observed their digital video production process, and took observational and analytical fieldnotes. My primary data source was the completed video itself, which allowed for the close identification of signifiers that this multimodal discourse analysis entailed. I also drew upon analytic and observational fieldnotes, based upon my close observation of the students throughout the composing process, which provided important qualitative contextualization about the process, audience, and purposes of the project and video.
Description of the focal video
Table 1 is a transcription of the entire video, and includes column headings for the following: speaker, speech, actions/body positions, and screenshots. The short video, ‘Lost’ (2 minutes 36 seconds in length), which was composed in English, begins with Anna and Carmen walking together down the hallway, arriving in front of the restroom doors. Since the crux of the video relies upon Anna and Carmen entering and exiting the restroom at exactly the same time without seeing each other, it is important to note that the restroom doors are swinging double-doors that open opposite ways (see images in Table 1). When they first arrive at the restroom, Anna says, ‘OK Carmen, I’m gonna wait here while you go to the bathroom, OK?’ (Table 1, line 1). After standing outside of the restroom doors for a while, waiting for Carmen to return, Anna looks puzzled and goes into the restroom to look for her. At exactly the same time, Carmen exits the restroom, looking for Anna, and the girls miss each other, continuing to be puzzled, and continue to look for one another (Table 1, lines 2–4). This sets off the central sequence for the video, which consists of Anna and Carmen perpetually missing one another and looking for one another as they go in and out of the restroom double-doors, perpetually ‘lost’. Anna and Carmen’s actions are thus paired and always related to one another, alternating (Table 1, lines 1–21). For example, they call out each other’s names, waiting for responses that never come, and their body locations are always necessarily opposite: when Carmen is outside of the restroom, Anna is inside, and vice versa.
Multimodal transcription of the focal video, ‘Lost’.

Data analysis
The focal video, ‘Lost’, was selected because of its salience for understanding how différance can operate in student-created videos. I conducted a signifier-based discourse analysis (Ranker, 2017, 2018a, 2018b, 2019; see also, Neill, 2013; Parker, 2010) that maps signifiers across spoken and visual (visually represented actions and body positions) modes. In this analysis, I attempted to map the differing and deferring play of différance in a specific way related to my interest in understanding the relations between signifiers by examining the operations of différance amongst the identified signifiers.
The video embeds the signifiers, creating a signifying system in which each new signifier or signifier complex repeats and resonates with previous signifiers or signifier complexes. I identified a signifier complex as a group of related signifiers, or a semiotic resource complex, a constellation of ‘semiotic resources drawn from across modes and assembled around a particular node of meaning in the process of composing a completed multimodal text’ (Ranker, 2014: 130). The signifier complexes that I identified were thus coordinated units made up of spoken signifiers and signifiers of body position and action. Although made up of individual signifiers that also operated independently, the coordinated signifiers can thus be thought of as a complex in order to acknowledge how they worked together as a signifying unit. The signifier complex as a unit also provided a way of meaningfully grouping the large number of signifiers encountered in analysis.
This discourse analysis aims at understanding how the differing and deferring aspects of différance operate as relations between signifiers and signifier complexes that successively emerge as the signifying chain unfolds. The purpose of my analysis is thus to conceptualize how différance operates in the video, and to illustrate its operation. During analysis, I first created a multimodal transcription (Bezemer and Mavers, 2011; Flewitt, 2006) of the entire video (see Table 1), which I will discuss in more depth in the next section. This transcript identifies each signifier complex as it occurred in the video, presented chronologically from beginning to end (the basis for determining each signifier complex is a single row of the table). This multimodal transcript, as seen in the headings in Table 1, identifies the name of the speaker, speech, action and body position. The transcript also includes a screenshot for each presented signifier complex.
Through continuous viewing of the video alongside the multimodal transcript, I then produced maps of the signifier chains that comprised the video (see Figures 1 to 2). This process required the identification of signifiers and signifier complexes in the video transcript. These signifiers occurred in the video in the following forms: (1) actors’/participants’ speech (statements, questions); (2) visually-depicted actions (entering/exiting the restroom double-doorway); and (3) visually-depicted body locations (inside/outside restroom). Within the spoken mode, I identified each utterance (one or a few words organized at the phrase or sentence level) as a signifier. Discourse analysts who work at the signifier level have noted how the phrase or sentence, in addition to individual words, can act as a signifier (Barthes, 1983; Fink, 2004; Lacan, 2002[1966]) since sometimes ‘it is only the phrase as a whole that carries a particular meaning’ (Fink, 2004: 85). The following are examples of spoken signifiers (questions, statements, declarations) that I identified in ‘Lost’: ‘Where are you’; ‘Anna?’; ‘Carmen?’; ‘Carmen! Aaah!’; and ‘Aaah! Anna! Aaah!’. Once I identified the signifiers, I could then map the signifiers and signifier complexes (see Figures 1 to 2 for examples of the maps) so that I could analyze their sequence and the operations of differences between and amongst them along the chain of signifiers or multimodal ‘signifying chain’ (Lacan, 2002[1966]: 145) that comprises the video.
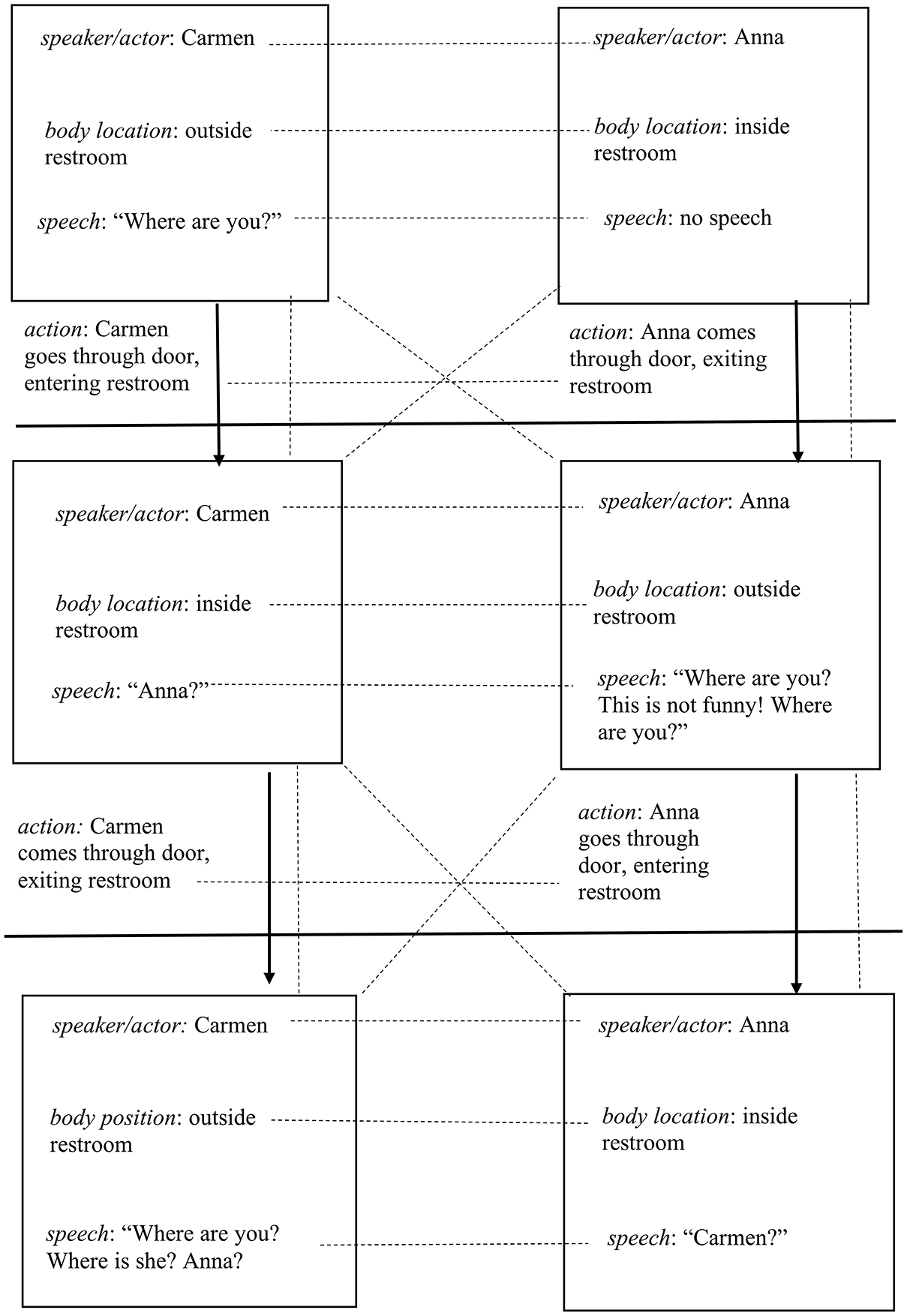
Signifier chain map (transcript lines 4–7).
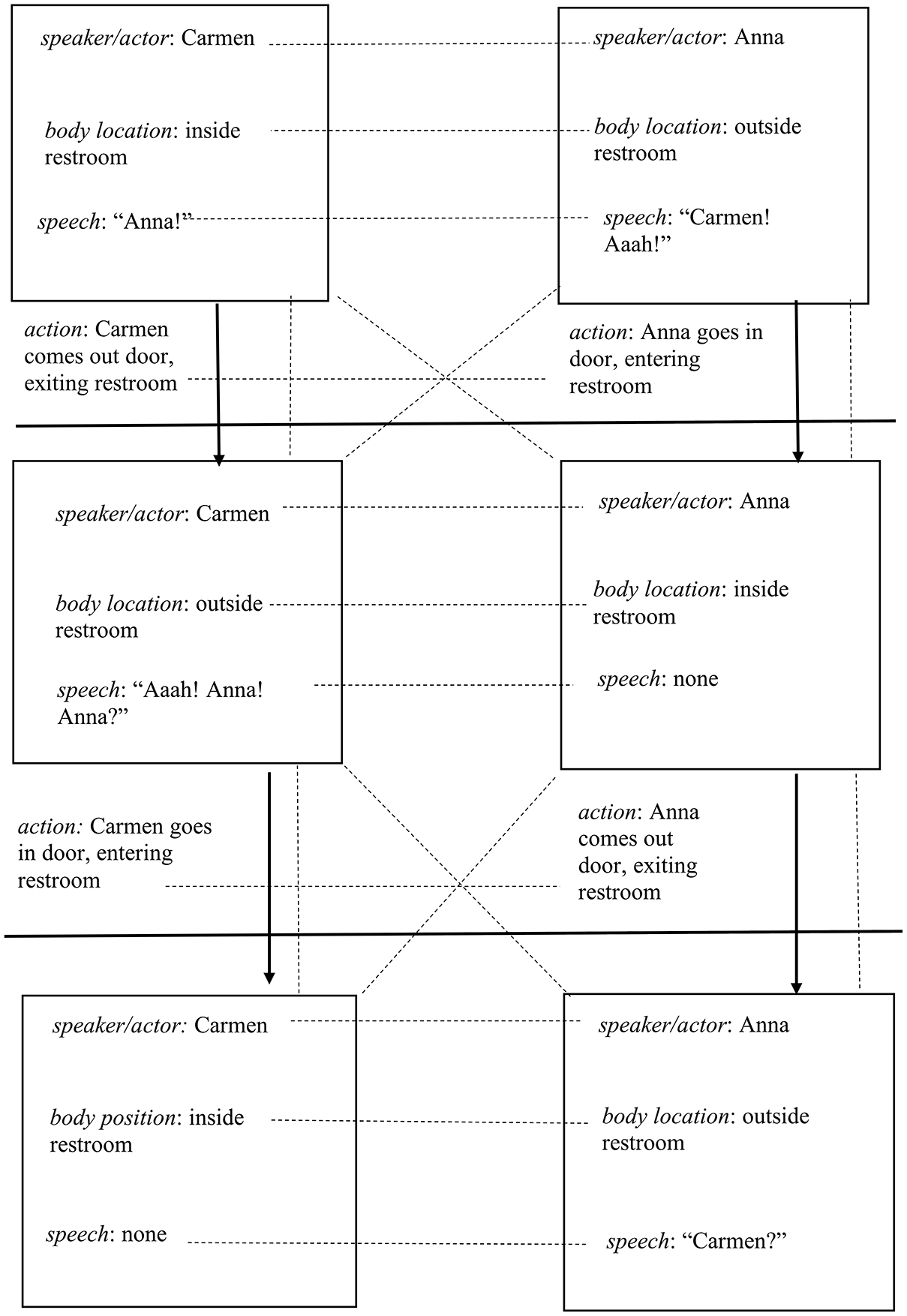
Signifier chain map (transcript lines 16–19).
Findings
In this section, I present two mapped signifier sequences that were selected from the overall signifying chain as typical for the purpose of illustrating the patterns, play, and movement of différance. Figure 1 is a map of three sets of paired signifier complexes that were selected in order to further analyze the operation of différance across at this sequence in the chain (see Table 1, lines 4–7). (The signifier complexes are paired because of the structure of the video and back-and-forth dialogue rather than for theoretical reasons.) Each signifier complex is illustrated using a rectangle, which indicates the speaker (Anna or Carmen) at the top, and includes a summary of the signifiers that make up that complex (visually depicted body location and speech) below that. In the middle of each rectangle, the label, ‘body location’, is indicated, along with an indication of whether Anna or Carmen is inside or outside of the restroom. Toward the bottom of each rectangle, the label, ‘speech’, is indicated along with Anna or Carmen’s speech (spoken signifier). Each rectangle thus represents signifiers that are coordinated together as a complex, and can be seen as a signifying unit made up of signifier subunits.
In Figure 1, the signifying chain is illustrated as moving from top to bottom (downward) in the direction of the arrows. The interval between each paired set of signifier complexes is illustrated using a dark line. The figure thus illustrates three pairs of signifier complexes that are part of the longer chain that makes up the whole video. The actions, body location, and speech (as signifiers) that are associated with Carmen are represented on the left (and moving downward on the left-hand side of the figure), and those associated with Anna are represented on the right. The signifiers associated with Carmen and Anna’s actions, body locations, and speech are thus illustrated as occurring simultaneously. These signifiers are linked in various ways, which is illustrated using dotted lines.
As represented at the top of Figure 1, Carmen is standing outside the restroom, and says, ‘Where are you?’ At the same time, as depicted in the rectangle at the top right of Figure 1, Anna is inside the restroom, and says nothing. Carmen’s body position and speech as signifiers are thus cast against Anna’s body position and speech as signifiers. Carmen’s body is outside of the restroom, which only has a potential meaning in relation to and as different from Anna’s body location as inside the restroom. The differential relation between these two signifiers is represented with a dotted line that connects them. The differential and deferring relation between Anna and Carmen’s speech as signifiers is also evident within this signifier complex and at this juncture in the signifying chain. Any potential meaning of Carmen’s spoken signifier (‘Where are you?’) can only be conceived of in relation to Anna’s silence as a signifier, by deferring to Anna’s silence as a signifier, and vice versa.
The darkened, horizontal line separates the movement from the first to the second set of signifier complexes, represented in the middle of Figure 1. The transition across the line is depicted by the first set of arrows, and is accompanied by the actions that initiate the movement. The act of going in/out of the restroom door initiates a new presentation of a set of paired signifier complexes. These actions are thus named and placed near the darkened, horizontal line that marks the interval between presentations of signifier complexes. The actions are labeled below the rectangles (signifier complexes). They are labeled with the word, ‘action’, and then with a description of the action that initiates the movement forward in the signifying chain. The first set of simultaneous actions is labeled as, ‘Carmen goes through door, exiting restroom’ and ‘Anna comes through door, exiting restroom’, respectively.
With the movement from the top to the middle set of paired signifier complexes, as represented in the rectangles in the middle of Figure 1, Carmen is now inside the restroom, saying, ‘Anna?’ At the same time, Anna, who is now outside of the restroom, looks around for Carmen and says, ‘Where are you? This is not funny! Where are you?’ (middle right of Figure 1). Carmen’s body position (inside the restroom) and speech come into a differing relation to Anna’s body position and speech, as illustrated with the dotted lines connecting these elements. The spoken signifier, ‘Anna?’, can only be conceived of as having a potential meaning in relation to Anna’s response, ‘Where are you? This is not funny! Where are you?’ The signified that might be assigned to Anna and Carmen’s paired body position as signifiers are also set in a differing relation with one another (inside/outside). In addition, any signified that might be assigned to either Carmen or Anna’s body positions as signifiers is deferred to the other’s body position, since Anna’s body position (outside of the restroom) means nothing except in relation to Carmen’s body position (inside of the restroom). The important thing for the signifying structure of the video is that they are in different places, and not seeing or noticing one another.
The last two simultaneously presented, paired signifier complexes (in this section of the chain) are featured at the bottom of Figure 1. Again, this sequence is divided by an interval marked with a dark horizontal line accompanied by a notation of the moving bodies (indicated by the second set of arrows near the bottom of the figure). With this movement, Carmen comes out the door (exiting the restroom) and, at the same time, Anna goes through the door into the restroom. The rectangle at the bottom left of Figure 1 thus represents the third and last signifier complex in this section of the signifying chain presented by Carmen’s act, and includes her body location (outside of the restroom) and speech (‘Where are you? Where is she? Anna?’) as signifiers. These signifiers are paired with the signifiers associated with Anna, presented in the rectangle at the bottom right-hand side of Figure 1, which includes Anna’s body location (inside the restroom) and speech (‘Carmen?’) as signifiers. Carmen and Anna’s body locations follow the same pattern, and are again set into a differing relation with one another (inside/outside), but are also deferred to one another. Carmen’s speech (‘Anna?’) as a signifier is also set in a differing relation with Anna’s speech (‘Carmen?’). These paired speech signifiers include not only the two distinct names, but a deferral process whereby each question is deferred to the other for an answer, which never comes since Anna and Carmen cannot hear each other. With the repetition of this deferral structure, the video creates a circularity as signifiers refer back and forth amongst one another, without closure.
Figure 1 thus illustrates the differing and deferring operations of signifiers in this section of signifying chain. This operation is depicted in the movement between the signifiers and signifier complexes, illustrated with the dotted lines to draw attention to how the signifying elements that are connected by a dotted line are related to and defer to one another. For example, when Anna is outside of the restroom, Carmen is inside the restroom, and vice versa, which is indicated with the dotted lines connecting the signifiers of their body locations. One or the other’s body is invisible, absent, yet central to the operation of signification at any moment. The meaning or significance of Carmen’s presence is thus constituted by and deferred to Anna’s absence, and vice versa, and back and forth, without closure. In Figure 1, dotted lines are also used to illustrate how Anna and Carmen’s speech is related to the other’s as they call out each other’s name. They are calling to one another, searching for a response that doesn’t come. Their speech-produced signifiers thus defer back and forth, for example, between ‘Anna?’ and ‘Carmen?’ and ‘Where are you?’ with a response of ‘Where are you?’ This paired or deferral structure creates the anticipation of a future repetition of similar signifiers once the pattern is set.
In addition to illustrating the differing and deferring relations between signifiers, in Figure 1, dotted lines are also used to illustrate these same relations as they occur between the signifier complexes as a whole. For example, the first, second, and third signifier complexes associated with Anna (along the left-hand side of the figure) are set into a differential relation with one another. This includes connections between Anna’s previous body positions: outside in the first presented complex, inside in the second, and then back to outside in the third. The same structure or pattern is apparent in the way that the first, second, and third signifier complexes associated with Carmen (along the right-hand side) differ from one another, again alternating between inside and outside body positions so that the alternation of body positions is established as a key signification process.
Figure 2 features a signifying chain map that was created from a later-occurring section of the video (transcript lines 16–19). Figure 2 illustrates how the same paired differing and deferring structure or pattern is continued, developed, and stylized – thus furthering the sliding effect created by the operation of différance. As seen in Figure 2, and throughout the video, signifiers are set into a deferring relation with one another, whereby each speech signifier is referred to the other for its response, which never comes, causing the signifiers to slide, without closure. For example, as depicted in the first signifier complex (upper-left) featured in Figure 2, Carmen is inside the restroom and shouts, ‘Anna!’ At the same time, as depicted in the simultaneously-occurring signifier complex (upper-right), Anna is outside the restroom door, saying, ‘Carmen! Aaaah!’ Carmen’s speech as signifier (‘Anna!’) is thus brought into a deferring relation with Anna’s speech as signifier (‘Carmen?’). In addition, Carmen’s body position (inside the restroom) as signifier is brought into a differential relation with Anna’s body position (outside the restroom): the signifiers of Carmen’s body position are thus always relational to Anna’s, and vice versa.
As is evident in Figure 2, the significance of each action-based signifier is deferred to the other’s action-based signifier, and vice versa, creating a circuitous pathway of non-closure, a structural pattern that was repeated consistently throughout the video. Visually-represented actions thus also play a key role in driving the movement of time forward in the video. This can be seen for example, with the second set of arrows toward the bottom of Figure 2, which initiates the third paired set of signifier complexes (seen at the bottom of Figure 2). Carmen’s action (going through the door, entering the restroom) as a signifier is paired in a differential relation with Anna’s action (coming out through the other side of the door, exiting the restroom) as a signifier. In addition, as seen in the signifier complex (rectangle) depicted at the bottom-left of Figure 2, Carmen is now inside the restroom and says nothing, while Anna is outside the restroom, looking around, and says, ‘Carmen?’ It is through these signifier relations that we can see how the signifier complexes ‘move’ in the video, and how the video engages directly in a play of differences, creating a ‘movement of play’ (Derrida, 1973: 141) throughout the video. In one sense, différance is thus a signifying movement in the video, a process across presentations and disappearances of constantly moving signifiers and signifier complexes that are initiated by actions.
Discussion
This analysis of ‘Lost’ reveals how time shapes and interacts with the presentation of signifiers in the video due to the operation of différance. The signified that might correspond to each signifier or signifier complex that occurs in the present is thus deferred to signifiers that are elsewhere, not present, and not visible at the current (viewing) moment in the video. For example, when Carmen is outside the restroom, this is of no significance except in relation to Anna’s body location (inside the restroom), which is not visible. When Carmen goes in the restroom, her ‘presence’ is no longer there – she is no longer present in the sense that her body location as signifier is visible in the video: her presence is ‘dis-located’ (Derrida, 1994) and does not hold together. However, the fact that she was just outside of the restroom continues to signify, and affects Anna’s body location (outside the restroom) as a signifier. Thus, each precise body location in and of itself is of no significance: each body position as signifier is deferred to signifiers that are not present, and is linked to previous and future body positions as signifiers. Each body position as a signifier is thus ephemeral, moving, and passing, with each signifier and signifier complex vanishing before it is replaced by another. Discrete signifiers and body locations thus do not carry the signifying weight in and of themselves: it is in the relations between body locations as signifiers, and the accumulation of these differential and deferring relations, that a glimpse is offered into the operations of différance.
One aspect of the operation of différance is temporal, and relates to a detour, delay, or deferring. Derrida (1973) thus theorizes différance as having a temporalizing effect. This detour, delay, or deferral in the signifier pathways can be seen in ‘Lost’. Each signifier or signifier complex is thus constituted by and marked with traces of the previous, similar signifier presentations, as well as future or anticipated signifier presentations, which creates an appearing/disappearing pattern characteristic of the signifier operations in the video. Any particular moment that might be identified as the present is thus always deferred to the past or future, toward another signifier. The significance of each act of going into or out of the restroom is constituted not by what is presently occurring, but by acts that have already occurred and have yet to occur (past and future acts): each act as a signifier incorporates all of the previous in/out movements and body positions, as well as their previous relations. Thus, the present is not constituted in and of itself, but only in a complex relation to the past and the future.
In ‘Lost’, the ‘present’ is always blurred, and any attempt to identify a sign that is simply present is impossible since the signified is always elsewhere, sliding. ‘Lost’ thus illustrates how the operation of difference divides the present such that it cannot be pinpointed, or located precisely. There is no single discrete moment in time when the identified signifier or signifier complex emerges. It is always emerging, vanishing, and changing its form, and divided into disparate, disjointed past and future elements. Each act is constituted by and marked with a trace of the previous, similar signifier and signifier complex presentations, and is thereby ‘haunted’ by these previous elements (Donaldson-McHugh and Moore, 2006; Holland, 2015: 42), which return to the moving present and always continue to signify. ‘Present’ signifiers and signifier complexes thus retain a trace, or ‘a mark of what is set aside’ (Derrida, 1973: 156), by referring to past signifiers and signifier complexes. Each signifier or signifier complex refers to others for its completion, and then sets it aside, just after it is presented. Each act of coming out of the door as a signifier retains a mark of all of the previous acts of coming out of the door and of going back through the door as signifiers. In addition, the effect is cumulative: as more and more signifiers are accumulated with the progression of the video, the material available for leaving traces increases, and the traces reach back further into the past. Each presentation of signifiers and signifier complexes becomes more stylized and briefer because it has the others to turn back on for signification.
Any signifier that might be attached to any particular body position as signifier (inside or outside the restroom) is deferred not only to past elements, but also to future elements. Thus, any particular signifier or signifier complex presented at a given time will also be shaped by a trace of the future element, letting ‘itself be hollowed out by the mark of its relation to a future element’ (Derrida, 1973: 142). In other words, any particular signifier of body position, for example, by the mechanism of anticipation, is already inscribed or hollowed out by anticipated, future signifiers of body locations (future acts of being/going inside or being/going outside). Once the entering/exiting the restroom pattern has been established, Anna and Carmen’s next moves can be anticipated, thus shaping the present signifier as it emerges. Each instance of coming out of the restroom, for example, is also marked with the future, next act: going back in.
Through this splitting of the present into past and future elements, difference blurs time by making it spatial, a process that Derrida refers to as temporalizing. Through its dividing force, difference separates each signifying element by an interval that blurs time further by equating it with space. Derrida (1973: 143) notes that an interval must separate it from what it is not; but the interval that constitutes it in the present must also, and by the same token divide the present in itself . . . this interval is what could be called spacing; time’s becoming-spatial or space’s becoming-temporal (temporalizing).
In ‘Lost’, this temporalizing operation of difference is evident as time is marked by cumulative differences in locations of bodies. At the same time, space becomes temporal because it marks the passage of time, and, in the process, time and space become indistinguishable. This is evident in how different moments in time are constituted by different locations in space, and in how different locations in space create the illusion of time. Time is marked in the video through changes in body locations in space, since changes in body locations in space create the sense of time as moving forward.
The mapping of the signifier operations in ‘Lost’ as they occurred along a chronological signifying chain thus revealed how time in the video is ‘heterogeneous’ (Derrida, 1994), or marked by disparate and multiple signifiers that are not currently ‘present’ at any given moment in time. In other words, no single signifier can stand on its own, is comprised of a complex of heterogeneous signifiers, and thus has no true beginning, end, or sequence. This heterogeneity of the signifier consists of signifiers networked across time, including into the future, which occurs as signifiers that mark the pattern of going into/out of the restroom are predictably repeated. Each ‘present’ signifier complex thus consists of disparate signifiers linked across time and is thus a plurality, occurring as a network or collective of heterogeneous sets of signifiers that cut across time as they mark past and future moments.
This analysis revealed that the attempt to locate the singularity of the signifier in time leads to the ‘more than one’ or ‘posing at the same time the other time that is not counted by beginning with one’ which results in a ‘pluralization’ (Kamuf, 2005: 219). ‘More than one’ signifier and signifier complex is always included in a single signification: which signifier is originary is essentially indeterminable and blurred by time as différance exerts its force ‘in between’ moments in time and on another plane. Derrida (1994: 10) discusses this point in noting that the ‘singularity of any first time, makes it also a last time. Each time is the event itself, a first time and a last time’.
From a film design or composition perspective, a film is traditionally conceptualized as a chronology or sequence, as evident in such approaches as continuity editing (Bordwell, 2001) and montage (Eisenstein, 1949). These approaches are attentive to time in a foundational way, exploring the various ways that effects can be created through the linkage of images across a chronological sequence. The analysis that I have presented in this article suggests that a sense of time as applied to the linkage of images in film could benefit from a reconceptualization as a multimodal signifying chain through which différance operates. This would open up additional approaches to the consideration of time in student video composition, and thus new possibilities for the creation of particular effects. Specifically, it would create the possibility of considering how ‘present’ video elements, as well as video elements that are used to construct the ‘present’ in narratives, are comprised of signifier complexes that cut across time, into the past and anticipating the future. In addition, though not specified at the level of the sign (but rather at the level of the utterance), this consideration of time also has resonance with a Bakhtinian (1981) approach to language, which illustrates how present utterances draw upon already-available (past) utterances, while simultaneously anticipating possible or future utterances.
For a signifier-based discourse analysis, this article offers a heuristic for understanding how the differing and deferring aspects of différance influence the relations of spoken, visual, actional, and bodily signifiers in videos as signifying chains that occur in time. This adds to other approaches to understanding and describing the operations of signifiers in video discourse, including the operations of condensation, metonymy, and metaphor (Metz, 1982; Ranker, 2018a; Silverman, 1983) – as well as how signifiers are chained into statements and used as nodal points to fix discursivities (Ranker, 2018b). A more detailed vocabulary for describing signifier operations provides tools and insights for discourse analysts who aim to understand how signifiers and semiotic resources have agency, and shape uses of multimodal video discourse. In addition, a signifier-based approach to discourse can offer unique insights into the infinitely complex question of how signifier operations occur across and concurrently with modes as multimodal discourse.
Without articulation of this expanded vocabulary for describing multimodal discourse in student videos, signifier operations such as those that I have considered in this article remain unseen, under the radar, and risk ‘being misunderstood, unplanned for, unrecognized, beyond the reach of pedagogy’ (Burn and Parker, 2003: 11). Increased attention to signification in student video-making requires that educators develop new ways of reading student videos that are attentive to detail at the level of the signifier as revealing the unseen and unsuspected dynamics of différance. Derrida notes: Blowing up the detail is something both the movie camera and psychoanalysis do. By blowing up the detail one is doing something else besides enlarging it; one changes the perception of the thing itself. One accedes to another space, to a heterogeneous time. (cited in De Baecque and Jousse, 2015: 38–39)
Pedagogical attention to detail, or ‘blowing up the detail’ in the reading of student-created videos, opens the door to a new form of reading student-created videos that Dillon (2019) refers to as ‘metonymic reading’ – which is also a feminist approach to reading film – in which the whole can be perceived in each of its parts. This form of reading student-created videos can be conceived of as part of a ‘critical film practice that pays metonymic attention to detail’ (p. 144), where each detail can be magnified to reveal that it contains the whole: ‘doing so opens up the signifying possibilities of film beyond those imposed by the closure of narrative and demands and develops the interpretive power of the feminist spectator’ (p. 34). Metonymic reading thus opens up new possibilities for teachers and students to approach and understand the films that are produced in the classroom, and from a feminist perspective: to read or approach the videos differently as audience members, in such a way that positions ‘the singular subject as an empowered spectator paying attention to the metonymic potential of singular filmic details’ (p. 34). Such an approach has implications for pedagogy, offering new ways of interpreting student videos, which has the potential to generate new types of teaching actions that are attuned to previously unseen or covered-over video elements.
As the analysis of ‘Lost’ revealed, each detail, signifier, or arrangement of signifiers was nothing in and of itself. Rather, the single signifier referred to the entire web of signifiers that comprised the video as a whole, reverberating across time and across the whole chain of signifiers. Reading student videos metonymically offers an approach that is attentive to detail, the sequence of images, and the exchangeability and repeatability of signifiers. With this approach, new layers of signification can be revealed, understood, and appreciated. ‘Lost’ is particularly well suited to this illustration and exploration of différance. However, différance as a function of language is always already operating in this way, in all videos and beyond (all discourse) – though this operation may sometimes be covered or difficult to detect. Approaching student video compositions as significations – and through the lens of différance – is thus a process of uncovering or revealing that opens up important pedagogical and interpretive avenues.
Footnotes
Funding
The author received no financial support for the research, authorship and publication of this article, and there is no conflict of interest.
Biographical note
JASON RANKER is a Professor in the College of Education at Portland State University in Portland, Oregon, USA. His scholarship focuses on multimodality and multimodal discourse in pedagogical settings. His work appears in journals such as Linguistics and Education, Social Semiotics, and Visual Communication, amongst others.
Address: College of Education, Portland State University, PO Box 751, Portland, OR 97207-0751, USA. [email: