
Abstract
Objective:
Breast cancer is the most common malignancy that is believed to be largely under genetic control. We therefore investigated both individual and interactive associations of six well-characterized polymorphisms in three genes of the renin-angiotensin system with breast cancer among Han Chinese women.
Methods and results:
This was a hospital-based study involving 606 patients diagnosed with sporadic breast cancer and 633 age- and ethnicity-matched controls. There were significant differences in genotype and allele distributions of ACE gene rs4343 (pgentoype = 0.002 and pallele < 0.001) and AGTR1 gene rs5186 polymorphisms (pgentoype < 0.001 and pallele < 0.001), even with a Bonferroni-corrected alpha of 0.0042 (0.05/12). Allele combinations of T-T-T-G-C-A (alleles in order of rs5050, rs699, rs4291, rs4343, rs188018 and rs5186), G-C-T-G-C-A and T-C-T-G-C-C, respectively, had the age-adjusted odds of 2.21 (p = 0.021), 3.01 (p = 0.021) and 5.24 (p = 0.015) for breast cancer, whereas allele combination T-C-T-A-T-A was associated with a 76% (p = 0.008) reduced risk. Interaction analysis revealed an overall best two-locus model including rs4343 and rs4291 polymorphisms, and this model had the maximal testing accuracy of 0.6259 with a cross-validation consistency of 10 (p = 0.0015).
Conclusion:
Our findings support a contributory role of the ACE gene, with its genetic polymorphisms acting synergistically, in predisposition to breast cancer among Han Chinese women.
Introduction
Breast cancer is the most common malignancy and the first-leading cause of cancer mortality in women, with an estimated mortality and five-year prevalence being, respectively, 13.7% and 33.9% worldwide. 1 As with the other types of cancer, breast cancer is believed to arise from an interaction between a genetically susceptible host and environmental factors. 2 The primary risk factors for breast cancer are female sex and older age. 3 Other well-established risk factors include lack of childbearing or breastfeeding, higher hormone levels and obesity.4,5 Evidence is growing suggesting a contributory role of genetics to inter-individual variability in predisposition to breast cancer. Although global scientists have conducted exhaustive research, the driving genes or genetic determinants that entail a potential risk for breast cancer so far remain a challengeable task.
The renin-angiotensin system has emerged as a promising signaling pathway implicated in homeostasis, angiogenesis and tumor metastasis, as well as in breast cell proliferation.6–9 Angiotensinogen (AGT) is converted into angiotensin I by renin, and then into angiotensin II by angiotensin-converting enzyme (ACE). Angiotensin II is the major active component of this system, and most of its known effects are mediated by angiotensin II type I receptor (AGTR1).10,11 There are data supporting a central role of the renin-angiotensin system in carcinogenesis. For example, administration of ACE inhibitors not only can reduce the risk of breast cancer in women,12,13 but also prevent tumor growth in animal models of cancer.14,15 Moreover, women with low-activity mutations of the ACE gene were observed to confer a reduced risk of breast cancer compared with those possessing the corresponding high-activity mutations. 16 Given that, it is reasonable to speculate that genetic defects in the renin-angiotensin system might be logical candidates for involvement in the underlying cause of breast cancer.
Although the candidate gene approach cannot replace the genome-wide scan strategy, the feasible pathway-based approach that examines the interactions of relevant genes has been proved more informative to help understand the genetic architecture of complex diseases. To shed some light on this issue, we sought to investigate both individual and interactive associations of six well-characterized polymorphisms in three candidate genes (AGT, ACE, and AGTR1) of the renin-angiotensin system with breast cancer in a case-control study among Han Chinese women.
Methods
Study population
A hospital-based case-control study involving a total of 1239 women without consanguinity was designed. This study was reviewed and approved by the Ethics Committee of Chengde Medical College, and each eligible subject read and signed the informed consent before entering this study, which was carried out in accordance with the principles of the Declaration of Helsinki.
All patients with breast cancer who reported no prior history of cancer and no family history of breast cancer were for their first time diagnosed as having invasive ductal carcinoma based on pathological confirmation, and then they received surgical intervention plus adjuvant chemotherapy at the Affiliated Hospital of Chengde Medical College. Clinical information of breast cancer was obtained via a full clinical examination by specialists. All controls were women who underwent breast cancer screening and were clinically confirmed to be free of breast cancer at the same hospital, and they had a negative history of all forms of cancer in their first-degree relatives. All study subjects were genetically unrelated women of Han Chinese descent who were consecutively recruited from the Affiliated Hospital of Chengde Medical College between September 2009 and March 2013.
All eligible subjects were classified into two study groups: the breast cancer group and the control group. Overall, 606 patients 54.36 (standard deviation: 12.33) years of mean age were diagnosed with sporadic breast cancer, and the remaining 633 subjects who had no manifestation of cancer formed the age- and ethnicity-matched control group with mean age of 55.15 (standard deviation: 9.38) years.
At enrollment, baseline data on age, family history of cancer, age at menarche and menopausal status were recorded. Moreover, additional data on tumor size (from T1 to T4), tumor grade (from G1 to G3) and lymph node (positive or negative) were exclusively presented for patients with breast cancer.
Selection of polymorphisms
Six examined polymorphisms included rs5050 (A-20C in the promoter region) and rs699 (M235T in exon 2) in the AGT gene, rs4291 (A-240T in the promoter region) and rs4343 (A2350G in exon 16) in the ACE gene, rs188018 (G-2228A in the promoter region) and rs5186 (A1166C in the 3’ UTR region) in the AGTR1 gene. The selection of six functional polymorphisms was based on their wide evaluation in associations with breast cancer.17–21
Genotyping
Ethylenediaminetetraacetic acid (EDTA) blood samples were obtained from all study subjects at the time of enrollment. Genomic DNA was isolated from peripheral blood leukocytes by using the TIANamp Blood DNA Kit (Tiangen Biotect Co., Beijing, China), and then was stored at −40°C until required for batch genotyping. The polymerase chain reaction-ligase detection reaction (PCR-LDR) method 22 was adopted to determine the genotypes of the six examined polymorphisms in this study.
To discriminate specific bases of each polymorphism, two specific probes and one common probe were synthesized, and the common probe was labeled 6-carboxy-fluorescein (FAM) at the 3’ end and phosphorylated at the 5’ end. The multiplex ligation reaction was conducted in a volume of 10 μl containing 2 μl of PCR product, 1 μl of 10×Taq DNA ligase buffer, 1 μM of each discriminating probe and 5 U of Taq DNA ligase. After then, 1 μl of LDR reaction product was mixed with 1 μl of ROX passive reference and 1 μl of loading buffer prior to denaturation at 95°C for three minutes and rapid chilling on ice. The fluorescent products of the LDR were differentiated using an ABI 3730XL sequencer (Applied Biosystems, CA, USA).
To test the accuracy of the PCR-LDR method, 48 DNA samples were randomly selected and run in duplicates with 100% concordance.
Statistical analysis
Dataset management and simple statistical calculations were completed with the SAS software for Windows version 8.1 (SAS Institute, Cary, NC, USA). The study power to detect significant differences in the distributions of genotypes/alleles and allele combinations between patients and controls was estimated by the Power and Sample Size Calculations (PS) software version 3.0.7. Continuous and categorical variables were compared between the two groups by the unpaired t-test and the χ2 test, respectively. A Pearson goodness-of-fit test was conducted to assess the Hardy-Weinberg equilibrium. Three genetic models of inheritance including additive (major homozygotes versus heterozygotes versus minor homozygotes), dominant (major homozygotes versus heterozygotes plus minor homozygotes) and recessive (major homozygotes plus heterozygotes versus minor homozygotes) models were regressed in the binary logistic analyses before and after adjusting for age at enrollment, and the risk estimates were expressed as the odds ratio (OR) and its corresponding 95% confidence interval (95% CI).
To examine the joint effects of the six polymorphisms under study on breast cancer risk, the frequencies of allele combinations were estimated by using the haplo.em program. This program computes the maximum likelihood estimates of allele combination probabilities using the progressive insertion algorithm that progressively inserts batches of loci into allele combinations of growing lengths. To minimize chance results, only allele combinations with an estimated frequency of at least 1% in all study subjects were analyzed in this study. Moreover, OR and 95% CI were computed by the haplo.cc and haplo.glm programs based on a generalized linear model. 23 P values were simulated based on 1000 replicates. Furthermore, the haplo.score program was used to model an individual’s phenotype as a function of each inferred allele combination, weighted by their estimated probability, to account for the combination ambiguity. This process is based on score statistics, which provide both global tests and allele combination-specific tests. 24 The haplo.em, haplo.cc, haplo.glm and haplo.score programs were implemented in the Haplo.Stats software version 1.4.0 operated in the R language version 3.0.1 (http://www.r-project.org/).
To better characterize the interactions of multiple genetic polymorphisms under study, a promising data-mining open-source approach multifactor dimensionality reduction (MDR) version 3.0 (http://www.epistasis.org) was adopted.25,26 This approach aims to construct all possible combinations of six examined polymorphisms and selects each best model. The accuracy of each model was evaluated by a Bayes classifier in the context of 10-fold cross-validation. A single best model simultaneously has maximal testing accuracy and cross-validation consistency. The cross-validation consistency is a measure of the number of times of 10 divisions of the dataset that the best model is extracted. Permutation testing corrects for multiple testing by repeating the entire analyses on 1000 datasets that are consistent with the null hypothesis.
In addition, an interaction entropy graph, which visually inspects the potential genetic interactions, was depicted to quantify the synergistic and non-synergistic interactions among polymorphisms. In this graph, information gain value expressed as a percentage in the node signifies the independent main effect of each polymorphism. The positive and negative information gain values (percentages) on the connected lines indicate synergistic interaction (the red or the orange line) and redundancy or lack of interaction (the green and the blue line) between study polymorphisms, with the zero value indicating independence (the yellow line).
Results
Baseline characteristics
Details of the study population are shown in Table 1. Age at enrollment did not differ significantly between patients with breast cancer and controls (p = 0.205). The percentage of family history of cancer was 10.56% in patients with breast cancer. The average age at menarche was 14.60 (standard deviation: 1.63) years. Patients with breast cancer with menarche age of 12 years or less, 13–14 years and 15 years or more accounted for 22.44%, 37.13% and 40.34%, respectively. Nearly half of the patients with breast cancer had postmenopausal status at enrollment (49.83%). Of the patients, 49.80% and 42.54% had tumor sizes of T1 and T2, and 50.18% and 44.32% of patients had tumor grade of G2 and G3, respectively. The percentage of positive lymph node was 42.13% in patients with breast cancer.
The baseline characteristics of all study subjects.

NA: not available. ap values were computed by the unpaired t-test for age and by the χ2 test for the family history of cancer. Age was expressed as mean ± standard deviation and median (interquartile range), and other data were expressed as percentage.
Single-locus analysis
The genotype distributions and allele frequencies of the six polymorphisms under study between patients with breast cancer and controls are summarized in Table 2. All polymorphisms met Hardy-Weinberg equilibrium both in patients and controls (p > 0.05). Significant differences were observed in the genotype and allele distributions of the ACE gene rs4343 (pgentoype = 0.002 and pallele < 0.001) and AGTR1 gene rs5186 (pgentoype < 0.001 and pallele < 0.001) polymorphisms, even with a Bonferroni-corrected alpha of 0.0042 (0.05/12). The power to reject the null hypothesis of no difference in allele frequencies for rs4343 and rs5186 polymorphisms between patients and controls was 95.7% and 99.1%, respectively. There was no significance for the other four polymorphisms under study.
Genotype distributions and allele frequencies of the six examined polymorphisms between patients with breast cancer and controls.

Genotypes and alleles were expressed as the count and percentage, respectively. bp values were computed by using the χ2 test based on the 3×2 contingency tables for genotype comparisons and on the 2×2 contingency tables for allele comparisons.
The risk prediction of examined polymorphisms, assuming additive, dominant and recessive models of inheritance, for breast cancer risk is presented in Table 3. Significance persisted for the rs4343 polymorphism across three genetic models irrespective of age adjustment, and the corresponding risk estimates exhibited a graded increasing trend. For example, the age-adjusted odds of having breast cancer were 1.33 (95% CI: 1.14–1.56; p < 0.001), 1.44 (95% CI: 1.15–1.82; 0.002) and 1.51 (95% CI: 1.11–2.04; p = 0.008) under the additive, dominant and recessive models, respectively. With regard to polymorphism rs5186, there was significance only under the additive (OR = 1.94; 95% CI: 1.41–2.67; p < 0.001) and dominant (OR = 2.05; 95% CI: 1.45–2.89; p < 0.001) models, and the risk estimates were roughly at the same level and were independent of age adjustment. As for polymorphism rs188018, the risk estimates were significant under the dominant and recessive models, whereas this significance failed to survive the age adjustment.
Individual risk prediction of six examined polymorphisms for the occurrence of breast cancer under three genetic models.

m: mutant allele; W: wild allele. Data were expressed as odds ratio; 95% confidence interval; p for three genetic models of inheritance. aRisk estimates were calculated with or without adjusting for age.
Allele combination analysis
To explore the joint effects of the six examined polymorphisms on breast cancer risk, the estimated frequencies of allele combinations were compared between patients and controls, and their risk predictions were quantified in Table 4. The most common allele combination was T-C-A-A-C-A (alleles in order of rs5050, rs699, rs4291, rs4343, rs188018 and rs5186), which was comparable between patients (22.50%) and controls (22.70%) (simulated p = 0.365), and thus was assigned as the reference group.
Frequencies of the derived allele combinations (≥1% in total subjects) from six examined polymorphisms between patients and controls, as well as their risk prediction for breast cancer.

OR: odds ratio; 95% CI, 95% confidence interval. aAlleles incorporated in a haplotype was in order of rs5050, rs699, rs4291, rs4343, rs188018, and rs5186. bRisk estimates were adjusted for age.
Allele combinations of T-T-T-G-C-A (simulated p = 0.020), G-C-T-G-C-A (simulated p = 0.002), and T-C-T-G-C-C (simulated p = 0.001) were significantly overrepresented in patients with breast cancer relative to controls, and the corresponding age-adjusted ORs were 2.21 (95% CI: 1.13–4.34; p = 0.021), 3.01 (95% CI: 1.18–7.65; p = 0.021) and 5.24 (95% CI: 1.38–19.82; p = 0.015), respectively. In contrast, the frequency of allele combination T-C-T-A-T-A was remarkably higher in controls than in patients (simulated p < 0.001), and this combination was associated with a 76% (OR = 0.24; 95% CI: 0.08–0.68; p = 0.008) reduced risk of breast cancer after adjusting for age. The power to reject the null hypothesis of no difference in the frequencies of allele combinations of T-T-T-G-C-A, T-C-T-A-T-A, G-C-T-G-C-A and T-C-T-G-C-C between the two groups was 90.2%, 99.7%, 96.3% and 95.1%, respectively.
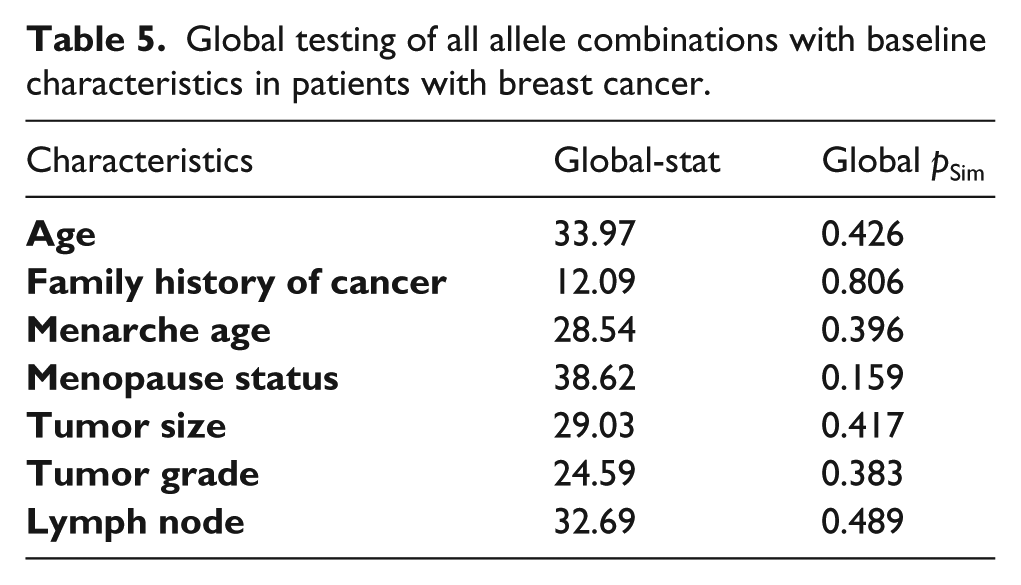
The correlation between the derived allele combinations and baseline characteristics in patients with breast cancer is shown in Table 5, and the omnibus analyses failed to identify any significance after permutation correction.
Global testing of all allele combinations with baseline characteristics in patients with breast cancer.
Interaction analysis
In view of the significant findings in allele combination analysis, it is of added interest to explore the potential interactions of the six examined polymorphisms in predisposition to breast cancer. To achieve this goal, a promising data-mining analytical approach MDR was employed (Table 6). Each best model is evaluated by testing accuracy, cross-validation consistency and significance level as determined by the permutation test.
The selection of each best model from six examined polymorphisms in renin-angiotensin system by MDR approach.

MDR: multifactor dimensionality reduction. aOverall best MDR model.
A two-locus model including the rs4343 and rs4291 polymorphisms in the ACE gene was selected as the overall best MDR model. This model had the maximal testing accuracy of 0.6259 with a cross-validation consistency of 10 out of 10. Moreover, this model was significant at p = 0.0015, indicating that a model this good or better was observed less than two out of 1000 permutations and thus was unlikely to hinge on the null hypothesis of null association.
Supplementary Figure S1 shows the interaction graph of the six polymorphisms under study according to their entropy measures. The independent main effect was largest for polymorphism rs5186 with the information gain value of 1.04%. A remarkable synergistic effect was observed between the rs4291 and rs4343 polymorphisms, because their interaction yielded an information gain value of as high as 5.37%, whereas the corresponding independent information gain values were 0.02% and 0.74%, respectively. In addition to this synergistic interaction, the other interactions were all independent as labeled by the yellow lines.
Discussion
The key finding of the current study was a remarkable synergistic interaction between the rs4291 and rs4343 polymorphisms in ACE gene, although our single-locus analysis failed to identify any suggestive association of polymorphism rs4291 with breast cancer risk. To the best of our knowledge, this is the most comprehensive study examining the potential interactions of multiple genes and polymorphisms in the renin-angiotensin system with the risk for breast cancer. Our findings not only deepen our understandings that complex genetic interactions might entail disease risk, but also yield strong evidence in favor of the potential involvement of the ACE gene in the pathogenesis of breast cancer.
The gene encoding ACE is mapped in chromosome 17q23, and its genomic sequence is polymorphic. Widely evaluated in the ACE gene is an insertion/deletion (I/D) polymorphism of a 287 bp fragment within intron 16. A recent meta-analysis by Pei and Li that evaluated the association of ACE gene I/D polymorphism with breast cancer among 1650 patients and 9238 controls concluded that this polymorphism may not be a risk predictor for breast cancer. 27 Because this polymorphism is intronic, it is unlikely to be functional but might act as a marker in linkage disequilibrium with other functional loci in ACE gene regulatory regions. We therefore examined another two functional polymorphisms in the ACE gene, viz. rs4291 (A-240T) in the promoter and rs4343 (A2350G) in exon 16. Our single-locus analysis found a significant association of rs4343 with breast cancer, and this polymorphism might be inherited in a codominant manner. Moreover, the predictive role of this polymorphism was also potentiated in our allele combination analysis, since the mutant allele G of polymorphism rs4343 harbored all significant risk-conferring combinations, suggesting that this polymorphism might play a leading role in predisposition to breast cancer. Although the sample size of this study was not large enough as it is suggested that to generate robust data, a much larger sample set involving >1000 subjects in each group might be required, 28 the power to detect significant associations both in single-locus and allele combination analyses was more than 90%.
It is worth noting that polymorphism rs4291 in the ACE gene was not associated with breast cancer in our single-locus analysis, which was in agreement with the finding of a comprehensive meta-analysis by Xi et al. 29 However, a previous study by Koh et al. that simultaneously considered the I/D and A-240T (rs4291) polymorphisms in the ACE gene among Chinese women in Singapore indicated that carriers of genotypes that corresponded to lower plasma ACE concentrations had a significantly reduced breast cancer risk, by 54%, independent of other environmental and familial risk factors. 30 In contrast, we, via a promising data-mining approach MDR, have identified a remarkable synergistic interaction between rs4291 and rs4343 polymorphisms in ACE gene among Han Chinese women, which suggests the evidence of epistasis, that is, the effect of one polymorphism may not be disclosed if the effect of another polymorphism is not considered.31,32 The MDR approach is nonparametric and model free in design, and has been successfully applied to detect and characterize the high-order gene-gene and gene-environment interactions in studies with relatively small samples.17,32 However, incomplete biological understanding makes the interpretation of this observational evidence challenging. In addition, this interaction should be interpreted with caution since in the present study, we only corrected for the impact of age at enrollment, and other confounders such as the use of ACE inhibitors are not available. Although residual confounding by incompletely measured or unmeasured physiologic and anthropometric covariates might exist, it seems unlikely that our results could be explained by confounding. In fact, as reasoned by Koh et al., if the use of ACE inhibitors were to exert a confounding effect on the observed ACE-breast cancer association, the inability to control for such confounding is likely to lead to an underestimation, rather than an overestimation. 15
There are several study limitations. First, the cross-sectional nature of our study did not allow us to make inference about the causality for the effects. 33 Second, it should be noted that this study of 1239 eligible subjects may be underpowered to discern a valid, medically important effect. Third, because of our design flaw, some clinical details on the patient population were not available to us, as well as other reproducible risk factors for breast cancer, which prevented further adjustment in risk estimates and may have overestimated the true effect size. Fourth, this study had a limited coverage of genetic markers in the renin-angiotensin system, and it is highly encouraged to incorporate other polymorphisms, especially some low-penetrance mutations. 34 It has been proposed that most of the genetic risk for cancer is caused by low-penetrance alleles.35,36 Moreover, characterizing the interactions of multiple genes from different chromosomes is deemed an effective means to unravel the final genetic architecture of breast cancer. Last but not least, our study includes only Han Chinese and may not be generalizable to other groups.
In summary, our findings support a contributory role of the ACE gene, with its genetic polymorphisms acting synergistically, in predisposition to breast cancer among Han Chinese women. As breast cancer is a multifactorial complex disorder, more emphases should be placed on the detection and characterization of multiple genetic and environmental interactions to predict high-risk individuals for the prevention and personalized treatment of breast cancer.
Footnotes
Conflicts of interest
None declared.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.