
Abstract
ChatGPT caused a worldwide sensation upon its launch, as evidenced by the extensive coverage across traditional and new media. This paper delves into the diverse evaluative discourses about this AI chatbot both in YouTube news videos (originally, television broadcasts) and in user comments facilitated by YouTube’s interactivity. The qualitative-quantitative discourse analysis probes diversified evaluations within YouTube broadcast talk, together with their impact on viewers’ perceptions of the broadcasts’ stance and viewers’ evaluations of ChatGPT and the broadcasts, as reflected by user comments. The findings present balanced effects, speaking to polarised opinions and mixed feelings about this AI development, but point to a potential boomerang effect in users’ evaluation of the new AI bot relative to the broadcasts considered to be biased. The study also reports low user engagement with the broadcasts. This challenges the notion of user engagement with broadcast content as lying at the heart of user interactivity on YouTube.
Keywords
Introduction
The topic of OpenAI’s ChatGPT hit the headlines after its public release on 30th November 2022. The new AI bot gained immense popularity, attracting over one million users within the span of merely 5 days. ChatGPT is an advanced form of Artificial Intelligence capable of creating new content instead of reproducing existing information and texts. As its creators assert, the model’s main appeal lies in its ability to engage in conversational exchanges with users. According to user experience, the bot can generate natural and lifelike conversational language, effectively mimicking human expression, but – unless instructed otherwise – it tends to maintain a polished tone, strictly adhering to the principles of political correctness. It offers a wide range of functionalities, including answering various questions, correcting grammar and style, paraphrasing texts, and debugging Python code. The core software behind ChatGPT has undergone extensive training based on AI and machine learning techniques. It draws on massive textual data from diverse sources and feedback from human interactions. However, the knowledge base of ChatGPT is limited to information available until 2021, which the software openly acknowledges. Also, ChatGPT admits its mistakes, challenges questions based on incorrect assumptions, and refuses to address inappropriate requests. Unlike its predecessors (Microsoft’s Tay and Meta’s BlenderBot 3), ChatGPT adheres to a safe-content policy which ensures that illegal, offensive or harmful responses are avoided. However, users have discovered methods to bypass content moderation and force the bot to disregard ethical guidelines.
In addition to enthusiastic responses praising its merits, ChatGPT has given rise to doubts about the potential threats and challenges it carries, ranging from mass unemployment (as the software may make various jobs redundant) to the facilitation of students’ cheating and cybersecurity loopholes. Many voices raise the problem of various dishonest, illegitimate uses of the software and their pernicious outcomes. These diverse sentiments are aired across traditional and new media, with a view to moulding public opinion about the new AI technology, whose capacity and effects are still veiled in mystery.
Trained to understand and generate human language, the new AI tool has triggered a deluge of news broadcasts and sparked a heated public debate filled with polarised evaluations. Capitalising on this fact, the present paper contributes to the research on digital news consumption by exploring the extent to which evaluative discourses about ChatGPT in YouTube broadcast videos impact the audience’s perception and evaluations of the new bot. Specifically, this study investigates user comments relative to the contents of YouTube broadcast videos, which present different (biased) stances (see Chae and Hara, 2024) to have a potentially biasing effect on the audience (with the term “bias” not carrying any a priori pejorative implication in this paper). The two-fold discourse analysis of broadcast talk and user comments aims to ascertain primarily whether broadcasts’ overarching positive/negative evaluative stances (recognised by subjects and validated by a qualitative analysis of broadcast talk) or specific evaluations passed therein do resonate with YouTube users, as evidenced by the latter’s comments, which constitute the product of their interactivity testifying to their (lack of) engagement with the videos. This goal is in line with Möller et al.’s (2019:511) apt observation that users’ “response to YouTube videos is an important outcome in its own right because it can provide insights into how video viewers use the platform.”
This paper is structured into five sections. The first section below gives a theoretical overview of the concepts relevant to this research endeavour, namely engagement and interactivity with regard to YouTube broadcasts, as well as the problem of objectivity and – most importantly – the notion of evaluation, as understood in discourse studies. The section that follows details the methodology of the exploratory study on the evaluative discourses of YouTube broadcasts on ChatGPT and of user comments. The qualitative and quantitative findings of the analysis are reported in the penultimate section (divided into two parts, one for each dataset). First, positive and negative evaluations of the AI bot are identified and quantified in YouTube broadcasts selected in the light of intuitive judgements of their overarching negative/positive stances. Second, a dataset of random user comments is analysed to gain insight into users’ engagement with the broadcasts and users’ evaluations of the broadcasts and ChatGPT. Some conclusions and general remarks, including directions for future research, are offered in the closing section.
Theoretical background
The scholarship on news consumption often invokes the idea of audience/user engagement, a polysemous and ambiguous notion (see Gajardo and Costera Meijer, 2023) that encompasses a plethora of manifestations of user attention to and involvement with the media (see Napoli, 2011). For the present purposes, in line with the research tradition of discourse and communication studies, user engagement is depicted as “the cognitive, emotional or affective responses that users have to media content” (Broersma, 2019:1). This view of user engagement represents the interest that journalism holds for audiences, the attention that journalism attracts from audiences, and the impact that journalism has on audiences (Gajardo and Costera Meijer, 2023).
A related notion, interactivity (see Kiousis, 2002), is considered a hallmark of user engagement with online news (Deuze, 2003). Users are so engaged with the news that they interact with the content of online/digital journalism beyond mere reception, facilitated by the interactive character of new media platforms (Jenkins, 2006; Thurman, 2008). Therefore, interactivity is studied as a prominent indicator of how users engage with online news, which is presupposed as the impetus for the interactivity. In addition to rating and further disseminating news, interactivity involves users’ posting comments in the online space provided, inspired by news articles or digital broadcasts (Chovanec, 2021; Massey and Levy, 1999; Schultz, 2000; Yoo, 2011) and/or in response to previous user comments (Han et al., 2023; Ksiazek et al., 2016). User comments criticise journalistic content and promote public discussion on the topic of the broadcast or a related one (Craft et al., 2015; Gutsche et al., 2022).
YouTube is a salient example of an online platform that offers public space for comments and discussions based on exchanges following uploaded videos (Chae and Hara, 2024), albeit often topically unrelated or oppositional thereto (e.g. Bou-Franch and Garcés-Conejos Blitvich, 2014). Known as post-television (Lister et al., 2009), YouTube is an alternative to the traditional television broadcast, displaying distinct characteristics (Peer and Ksiazek, 2011; Poell and Borra, 2012). Traditional television news channels use the new media landscape to upload their segments, clips, and complete broadcasts to their official YouTube channels, thereby extending the reach of the curated content to a wider online audience globally and enabling on-demand viewing. YouTube facilitates viewers’ interactivity through likes, reposts and comments so that users can share their thoughts directly on the platform. Previous studies have shown some interdependencies between the quality (their content, such as the evaluation of the videos as such) and the quantity of user comments following YouTube videos, also depending on the latter’s genre (Möller et al., 2019). In their posts, users may pass their observations and/or evaluations about the news topic or the broadcast per se, including the stance that it adopts.
The traditional, idealised view holds that news must be strictly factual and impartial (Lee, 2020; Lichtenberg, 1998; Ward, 2009), but this absolute objectivity ideal is impossible to attain (Boudana, 2016; Feng, 2022). Even when journalists aim at neutrality, refraining from passing any evaluative judgments, and/or even when the “push” versus “pull” rhetoric (Montgomery, 2007) is adopted, a broadcast must be media framed (Entman, 1993; Scheufele, 1999) in some way to systematically leave the audience with a general understanding of the topic (Price et al., 1997), which is particularly relevant when a controversial or polarising issue is addressed. This effect is brought about through various multimodal ploys, which include the choice of information and wording (Hamborg et al., 2019). In Entman’s (1993:52, emphasis added) words, “To frame is to select some aspects of a perceived reality and make them more salient in a communicating text, in such a way as to promote a particular problem definition, causal interpretation, moral evaluation, and/or treatment recommendation.” The framing of a news broadcast may then amount to a type of evaluation developed in a broadcast collectively by the authors of the various segments of the news discourse (e.g. anchorpeople, journalists, reporters, analysts, etc.). An evaluative stance, even if only subtle, is inevitable in any broadcast, performed explicitly or only implicitly and tacitly, for instance when selected facts and observations are presented or when third-party opinions are cited.
Evaluation, a textual or discursive notion (Bednarek, 2006), is essentially the expression of opinions (specifically, attitudes, stances, viewpoints or feelings) that reflect an individual’s value system (sets of values) and “involves comparison of the object of evaluation against a yardstick of some kind” (Thompson and Hunston, 2000:21). Importantly, following Labovian thought, evaluation involves comparison/contrast “with the norm” (Thompson and Hunston, 2000:13), which translates into both social and moral judgments. While various dimensions of evaluation have been proposed (see Bednarek, 2006), this paper follows a reductionist view which holds that all dimensions are reducible to the good–bad distinction, while evaluative expressions may be put on an intensity cline (Hunston, 2004; Thompson and Hunston, 2000). This good–bad dichotomy coincides with Bednarek’s (2006) evaluative parameter of emotivity, which is indicative of the text author’s approval/disapproval. It must be stressed that this binary good versus bad evaluation allows for much leeway in terms of the subordinate dimensions of evaluation and specific formulations, which are not universal. For instance, in terms of the expectedness dimension (Bednarek, 2006), the word “inevitably” may carry a positive or negative load depending on the context and the speaker’s intention emanating from it. Importantly, evaluation may reside in specific lexical items that are inherently evaluatively loaded or may come across as such in some contexts (White, 1998), or it may arise implicitly from a portion of discourse with no explicitly or implicitly evaluative lexemes.
Evaluation has, among other things, a persuasive function, inviting the receiver of a message to endorse the evaluation. Journalistic discourse is where this function of evaluation shows most prominently. This holds for YouTube broadcasts too, while user comments on YouTube very often perform an evaluative function as viewers pass judgements on broadcasts and issues addressed (e.g. Kolhatkar et al., 2020; McCambridge, 2022). This is the research area to which this study contributes.
Methodology
YouTube videos.
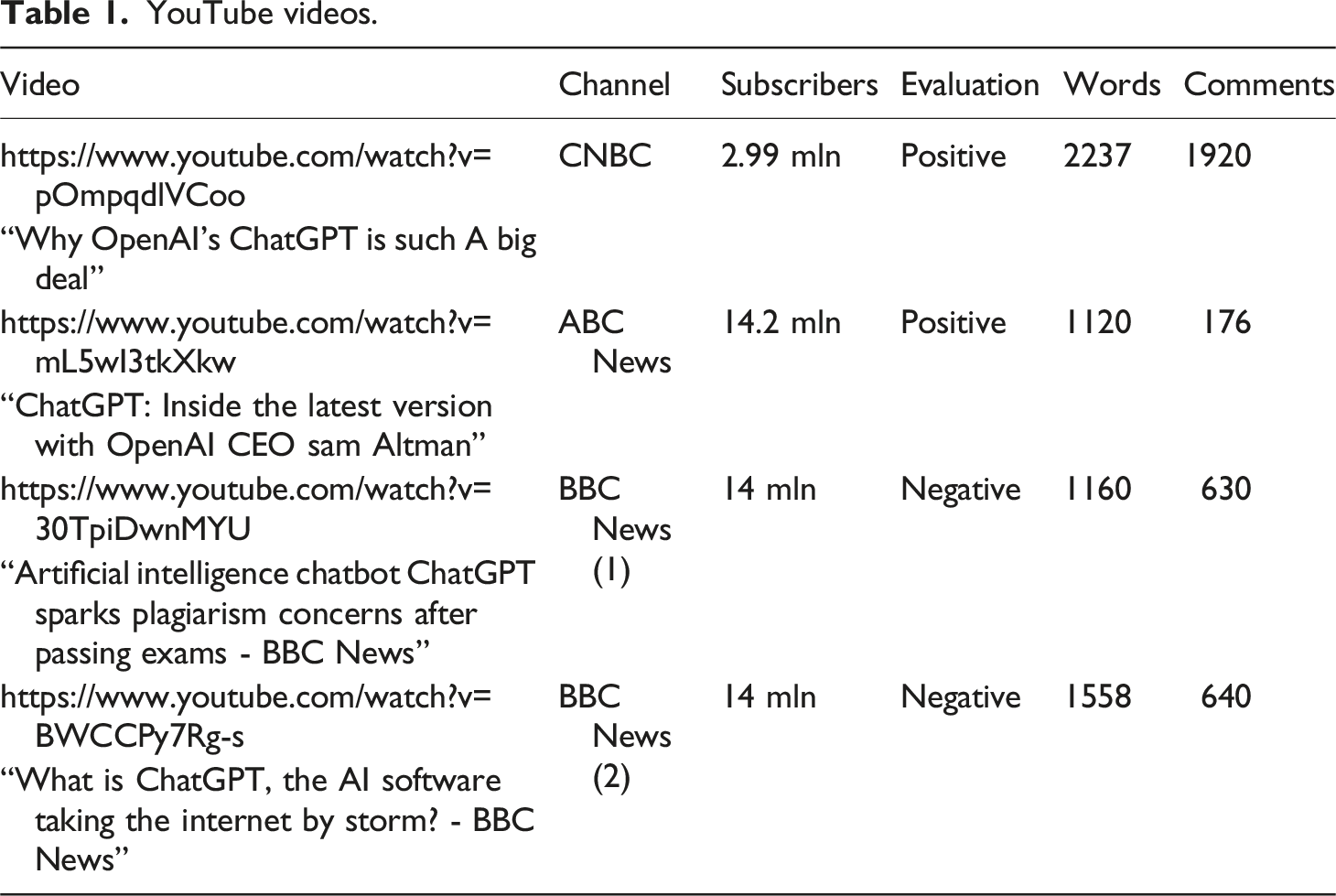
The first dataset comprises the manually transcribed videos (totalling 6032 words), with speaker shifts recorded. The second dataset encompasses YouTube users’ comments (3366 items in total) on the four videos. Random sampling was done through ExportComments to minimise research bias and aim at representativeness. 100 comments (this round number was dictated by the software’s free allowance and considered sufficient for the exploratory manual analysis) excluding nested comments (i.e. those posted in response to previous ones, topically germane to them or otherwise contextualised by them, which could have warped the results) for each video were downloaded into an Excel file and vetted manually to filter out spam, signposted by completely off-topic or nonsensical comments, as well as recurrent user nicknames. After such irrelevant items were discarded from the dataset, manual sampling was performed until the 100 slots for each video were filled in randomly, albeit ensuring that spam was omitted and no comment was repeated in the dataset.
The first aim of the analysis was to discern, quantify and qualify the positive and negative evaluations of ChatGPT arising from the four broadcasts, and thereby to account for the subjects’ perceptions of the generic stances. Further, an analysis of user comments was conducted to shed light on the nature of users’ engagement and interactivity, with an eye to their evaluations of the broadcast (or parts thereof) and ChatGPT.
The twofold study of evaluation conducted here is concerned essentially with what Bednarek (2006:46) calls “emotivity”, which is “not easily objectively verifiable or recognizable (there are no standardized procedures to identify such meaning), and its analysis is often highly subjective (…) The reason for this is that emotive meaning is a very complex phenomenon involving different clines.” Thus, emotive evaluations in both datasets were tagged independently by three trained coders, one of them being the author. Focusing on the good/bad polarity does not allow for nuanced understandings of individual evaluations. This may be perceived as a limitation at the coding stage, but it is mitigated when the quantitative findings are interpreted and the discourse is examined qualitatively.
The coders first watched the YouTube videos (to experience the broadcasts multimodally as a regular viewer does) and then examined the transcripts. The codebook for this part of the study was “positive evaluation” versus “negative evaluation” of ChatGPT recognised as being in line with the recognised authorial intent. Further on, user comments were coded following a six-fold codebook addressing three criteria: (1) the positive or negative evaluation of ChatGPT and/or its effects; (2) the positive or negative evaluation of the broadcast/element thereof, as well as (3) the presence/lack of evident engagement with the (content of the) broadcast. This last criterion, independent of evaluation, had proved necessary in the research design stage inasmuch as not all evaluative comments were indicative of user engagement with the videos. Raters could check the broadcast transcripts to confirm the posts’ topical (ir)relevance if need be.
The coders were instructed to ignore evaluations of targets other than ChatGPT (in the transcripts) or ChatGPT and the broadcasts (in the comments). They were also made aware that evaluation could transcend evaluative lexical items and be “distributed through the clause and across clause and sentence boundaries” (Lemke 1998:47). The coders were asked to isolate individual evaluative propositions/expressions as independent entities when those were clustered together in the transcripts. Repeated formulations were to be counted independently. This is because while such evaluative reiterations might not contribute much in terms of the content, they do strengthen the evaluative effect of the entire discourse. In the comment dataset, multiple coding was allowed to adequately capture complex comments encompassing more than one type of evaluation among the set of four categories based on two criteria (positive/negative; the broadcast/ChatGPT), in addition to the (lack of) engagement with the broadcast (cf. the six-fold codebook). However, multiple evaluative expressions of the same type (e.g. extended praise of ChatGPT) were coded collectively as one evaluative item (i.e. one post) as the four evaluations were gauged in a binary (yes-no) manner in this part of the study.
Bearing in mind that “the identification of both explicit and implicit evaluation will probably never generate perfect inter-rater reliability” (Bednarek, 2010:37-38), the inter-coder reliability was quite high. Measured through percentage agreement among the three raters, it was identified at approximately 84% (for the transcripts) and 74% (for the comments). Qualifying the comments appeared more problematic than tagging the broadcast talk. This seems to result from the unpredictability, diversity and creativity of users’ posts, which are often complex, implicit and multi-layered (Gutsche et al., 2022). In a few cases, determining the target of evaluation (e.g. “Nonsense” (ABC)) proved impossible, which is why these items (3 in total) had to be discarded. Duly, a consensus approach was used to resolve any coding discrepancies (typically caused by omissions). This involved discussing and reconciling coding differences with a view to reaching a unanimous decision on how to code specific data points in both datasets. Only those unanimously rated items are included in the quantitative results.
Thus obtained, the twofold coded data were ultimately viewed by the author through a discourse analytic lens (Coulthard, 2014; Taylor, 2013), which included a thematic analysis of posts (Lindlof and Taylor, 2017) to establish their topics and evaluative foci. This approach promoted several qualitative and quantitative findings reported in the next section. As examples are quoted to illustrate the recurrent patterns and general findings, each evaluative unit is labelled based on the type of evaluation it represents: [P] for “positive” and [N] for “negative” either about ChatGPT [C] or the broadcast [B]. In the comment dataset, each post is also marked for engagement [E] with the broadcast or its lack [NE]. In all cases, the source channel’s name is provided as well.
Analysis and discussion
Evaluation in broadcasts
Broadcast evaluations of ChatGPT broken into speakers.
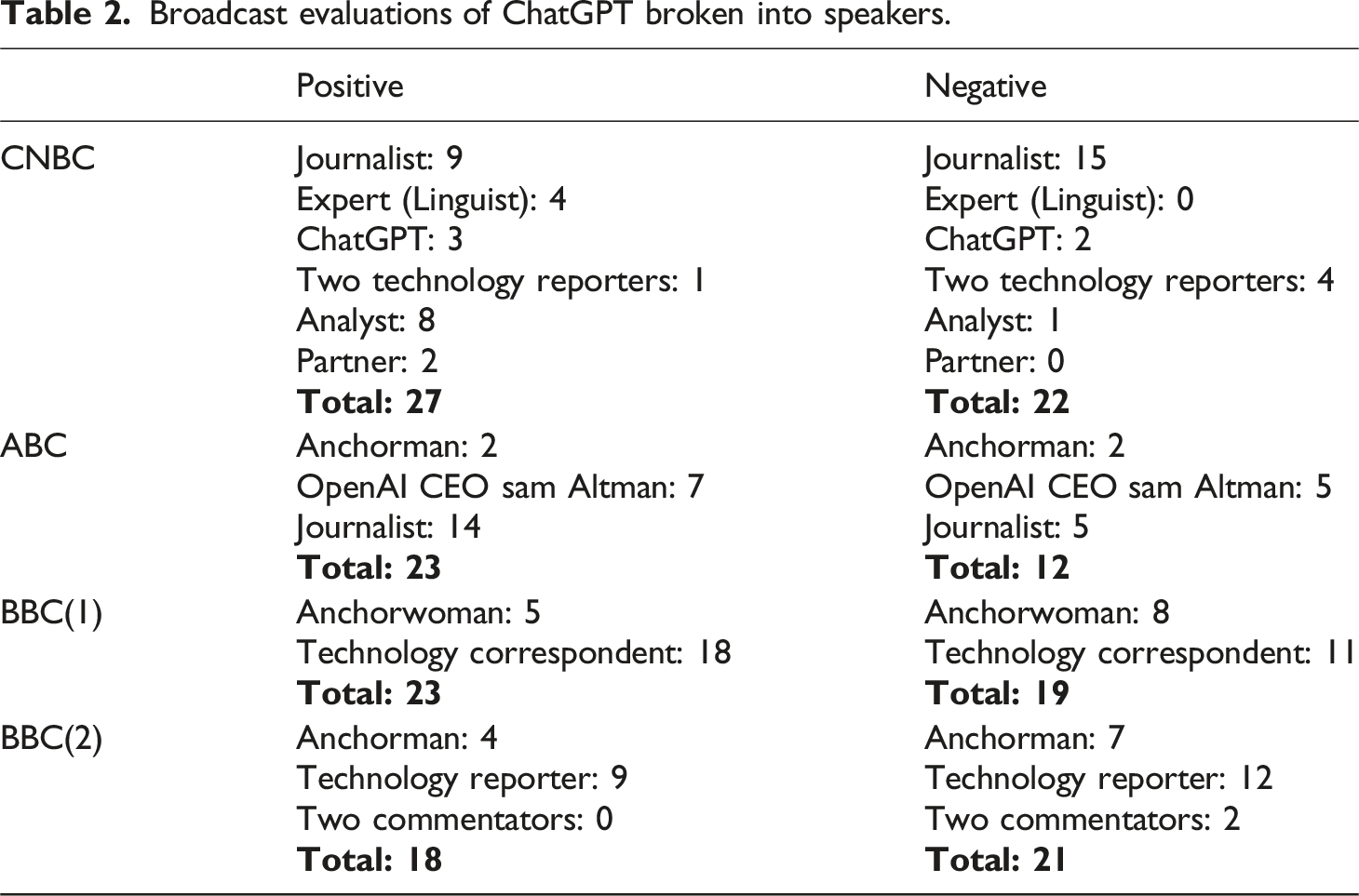
Given the varied length of the broadcast transcripts, the evaluative discourses of the individual videos are not to be compared quantitatively, even if it cannot be denied that one broadcast talk may be more evaluatively loaded (and hence biased) than another. The focus is on the positive versus negative evaluations for each video considered independently, based on the premise that the intuitively recognised overarching sentiment of the broadcast would translate into a higher number of relevant evaluative items in its discourse. This hypothesis seems to be disconfirmed, as there is no evident quantitative bias detected in favour of the evaluation originally recognised by five lay subjects (positive: CNBC and ABC; negative: BBC(1) and BBC(2)), except for the ABC video, which encompasses nearly twice as many positive evaluations (n = 23) as negative ones (n = 12). The similar quantitative results in the three other cases may speak to the broadcasts’ attempted objectivity; even though the broadcasts do contain evaluative statements, these are almost evenly distributed between positive and negative ones. The reasons for these broadcasts (with quantitatively balanced evaluative outcomes) being perceived by the subjects as biased either way should be sought in a qualitative discourse analysis of the evaluative broadcast talk. This close investigation reveals an interplay of several factors emanating from the dataset in a grounded-theory approach. These factors may explain why some evaluations rather than others must be more salient from the viewer’s perspective and affect their perception of each broadcast’s stance, as reflected by the subjects’ judgements.
Source of evaluation
One of the evaluative-salience criteria (determining viewers’ perception of the evaluative stances in broadcast talk) is who the source of each evaluation is. All the broadcast videos in the dataset include expert, accountability or affiliated interviews (Montgomery, 2007), while the anchorpeople and/or journalists act as interviewers and/or commentators, who interpret and comment on the information received. Thus, evaluation of ChatGPT could be found in the discourse of various individuals, translating into different degrees of salience and (lack) of appeal to the viewers, impacting their general impression of the broadcast’s stance. A statement may be ventured that evaluations by experts (with no vested interest) appeal to viewers more than evaluations by individuals without relevant expertise. In line with the principle of authority, evaluative opinions are interpreted as having more reliability, and thus both significance and salience, if passed by experts, who achieve greater credibility and thereby shore up their evaluations when they manifest their expert identities via discourse resources (Thornborrow, 2001), such as “the writing that I’ve gotten from students over decades” coming from a renowned scholar and university professor (Ex.1). On the other hand, evaluations passed by anchorpeople and journalists without the required expertise may be perceived as salient through being unwarranted (on perceived media bias, see Gil De Zúñiga et al., 2018), as in Ex.2, where the anchorwoman echoes the negative evaluation of a technology correspondent to express her own apprehension, claiming that unknown others share this feeling. She also issues a request that implies her critical attitude and sets the stage for specific criticisms. Also, social validation (Cialdini, 1995), that is an individual’s tendency to conform to the perceived behaviour and standards of others, may be another rhetorical strategy for passing evaluation persuasively, even if reported by the journalist, as in a conversation with the bot (Ex.3). (1) “The first thing that’s really impressive is how good it is at basic writing [P]. It’s better than most of the writing that I’ve gotten from students over the decades. [P]” (CNBC) (2) “But in terms of you saying I should be worried, I am worried [N]. I’m not the only one that’s worried though [N]. Just talk us through the concerns with this. [N]” (BBC(1)) (3) “So a lot of the people that have used your services seem to think that you’re pretty smart [P]” (CNBC)
Clashing evaluations
It is important to note that, while most of the evaluations in the dataset concern the speaker’s own perspective, in some cases, other viewpoints are invoked (like ChatGPT users’ in Ex.3). This may entail the presentation of conflicting vantage points (Tuchman, 1972), and hence evaluative clashes between the speaker’s own view and the reported one (Ex.4). (4) “So there are there are a few issues with it [N]. Number one is, it is so good [P], you know, that there are already examples of students using it to write their homework for them [N]. If I was a student right now, I think I’d be delighted [P]” (BBC(1))
The technology correspondent in Ex.4 merges her dominating negative evaluation of ChatGPT and critical moral judgement with marginalised positive evaluations. ChatGPT is described as being put to use in ways that the speaker appears to evaluate negatively, an implicature that needs to be drawn in the light of the preceding co-text. Having depicted the bot as “so good” as to be bad, the speaker takes the position of an individual with a positive stance on ChatGPT’s affordances, from which she dissociates herself. The mixed evaluations here necessitate a deeper reading to appreciate the speaker’s prevailing criticism. By contrast, developing incrementally in discourse, a negative evaluation can be rhetorically exploited for the sake of a positive one. This is the case with Sam Altman’s admission concerning the negative impact of ChatGPT (that echoes the interviewing journalist’s evaluation in her previous turn), followed by a positive outcome, which eclipses the negative aspect and puts ChatGPT in a positive light (Ex.5). (5) “It is going to eliminate a lot of current jobs. [N] That's true. We can make much better ones. [P]” (ABC)
On the other hand, conflicting evaluations may be placed back-to-back for balanced effects, giving an impression of objectivity (cf. the anchorman in Ex.6 and the reporter in Ex.7). (6) “Lots of upside [P]. Plenty of downside [N].” (BBC(2)) (7) “It’s both exhilarating [P] as well as terrifying [N] to people” (ABC)
Strength of evaluation
What adds further to the perception of each broadcast’s overarching evaluative effect is the strength of specific evaluations therein (Thompson and Hunston, 2000), which goes beyond the semantic load of evaluative lexemes. Examples 1–7 indicate that chunks of evaluative discourse can be placed on a cline of explicitness – implicitness, ranging from explicit self-explanatory evaluations of ChatGPT that reside in lexical items of varied intensity (“really impressive”, “better than” “pretty smart”, “exhilarating”, or “terrifying”) and phrasemes (“too good to be true”), negatively loaded lexical items that necessarily need to be read in context so that the evaluative meaning becomes clear (“fear”, “a few issues” or “worried”), to implicit ones (“eliminate a lot of current jobs” and “we can make much better ones”). Presumably, a non-explicit evaluation, which takes more cognitive effort to infer, makes less of an impact on viewers than explicitly evaluative expressions, which are more salient. Lastly, the evaluative effect may be bolstered by longer sequences of evaluative textual items clustered together (Ex.8). This list of demerits of ChatGPT and its consequences in various arenas may have a stronger critical effect than if the negative evaluations were scattered across a longer stretch of discourse. (8) “And so teachers are sort of saying, well, we can spot text that's plagiarised from the Internet because it just doesn't sound like the voice of the student, you know, we think we can tell. [N] It's difficult to know, isn't it, because we're never going to know the ones that they don't catch. [N] And there are also concerns that people could use it to write the university applications for them. [N] You know that it completely changes the model we use currently to test to test people's ability and achievement. [N] The other concern is it doesn't tell you where it’s got the information from, it presents it all as fact, so it can very easily spout out misinformation that is found somewhere on the Internet [N] and it wouldn't necessarily warn you that it might not be true [N]. And thirdly, there are some cyber security experts who are warning that it can be manipulated into writing malware computer viruses, which is also potentially a very serious problem if it actually happens for real. [N]” (BBC(1))
Multimodal effects
On a final note, among other factors that may sway viewers’ assessment of the overarching standpoint of a broadcast video are multimodal effects, such as speakers’ facial expressions, accompanying images, or – notably – YouTube video titles. The latter may impose a certain kind of understanding of the evaluation within a broadcast (cf. BBC’s negatively loaded title “Artificial intelligence chatbot ChatGPT sparks plagiarism concerns after passing exams”), which does not necessarily exhaust the actual points raised in the entire broadcast but gives the viewer an idea of the broadcast’s dominating stance.
Perception of evaluative bias
To take stock, the perception of evaluative bias in a broadcast is not restricted to the quantity of evaluative text, which must be vetted qualitatively as a discursive practice. The factors co-determining the nature and salience of evaluation in the news broadcasts on YouTube include: the source of evaluation (e.g. (non)expert evaluations, conflicting and mixed evaluations (whether or not balanced), and the strength of evaluation consequent upon its explicitness/implicitness and clustering of multiple evaluations. Also, multimodal factors, such as the broadcast’s title, may influence viewers’ perception of the evaluative bias. The interplay of these factors emergent in close discourse analysis accounts for lay viewers’ evaluations of the broadcast’s evaluative thrust. The pending query is whether the general stance of each broadcast and/or specific evaluations communicated therein have a bearing on users’ evaluations of the new AI bot and the broadcast in quantitative terms, which also necessitates a qualitative discussion.
Evaluation in user comments
This section reports the findings of the examination of users’ interactivity manifest in their comments (N = 400) that display these users’ evaluations of ChatGPT and the broadcasts, as well as their engagement with the broadcasts. Quantitatively, the evaluative comments present themselves as shown in Figure 1. Evaluation and engagement numbers in user comments.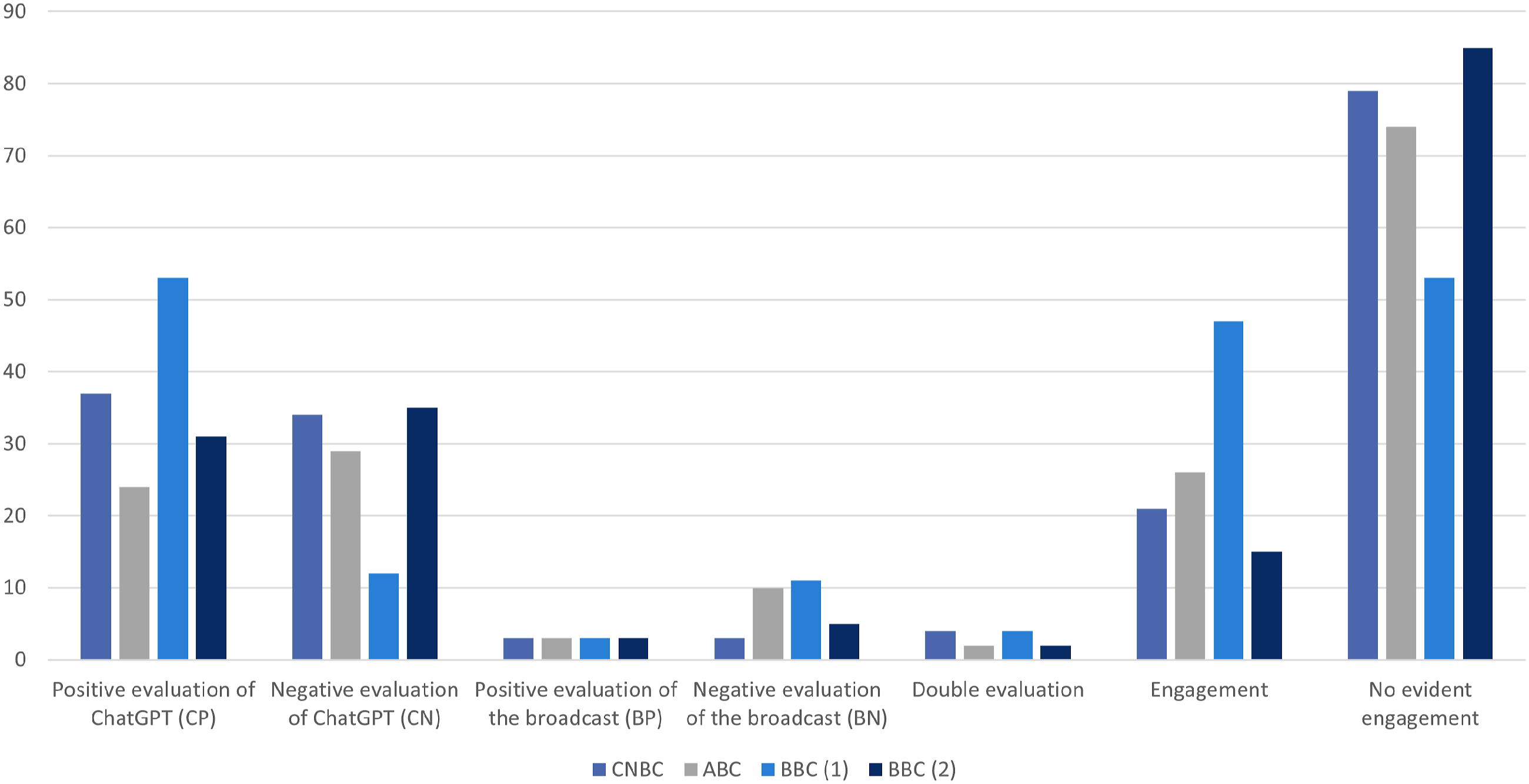
Comments evaluating the broadcasts
Within the group of comments evaluating the broadcasts (n = 41), quite small as such, negative evaluations (n = 29) are more frequent than positive ones (n = 12). It is the perceived flaws in journalism that attract more attention, as reflected by user interactivity. This may represent the general discursive propensity for negative, critical – rather than positive – comments in socio-political online fora (Kleinke, 2008), which aligns with negative bias as a psychological phenomenon (Baumeister et al., 2001). Essentially, users are more likely to comment if they disagree rather than when they agree with journalists or some aspects of the broadcast. Based on this premise, critical comments address specific shortcomings of the broadcasts (Ex.9 and 10) or express general opinions about the news videos or channels taken as a whole (Ex.11). (9) “The interviewer could have focused more on the positives rather than the negatives,but hey, that’s journalism today (10) “Those were the weakest examples to show what you can do with ChatGPT” [BN,E] (BBC(1)) (11) “NBC is fake news” [BN,NE] (CNBC)
 ♂” [BN,E] (ABC)
♂” [BN,E] (ABC)
Comments evaluating ChatGPT relative to the broadcasts’ stances
Comments evaluating ChatGPT (n = 255) considerably outnumber those evaluating the broadcasts. It appears that viewers watch broadcasts for the news content rather than to enjoy the quality of the videos, as may be the case with self-made individual YouTubers’ output. Both positive and negative comments on ChatGPT encompass reports on individual user experience (Ex.12 and 13) or present the users’ general thoughts about this AI technology and its consequences (Ex.14 and 15). (12) “It is amazing, i just used it so it can teach me to install a modpack for some game, and it’s better than any tutorial and stuff. This is revolutionary.” [CP,NE] (CNBC) (13) “You still have to fact check content produced by ChatGPT. I tried to query ChatGPT about a certain film with particular actors and actresses. It gave me specific details about a completely different movie with the same title. (…)” [CN,NE] (BBC(2)) (14) “This is like the Mandarax in Kurt Vonnegut’s “Galápagos.”” [CP,NE] (BBC(1)) (15) “In human history this is on par with harnessing the power of the atom.” [CP,CN;NE] (ABC)
These evaluative user comments can be placed on the explicitness (Ex.12) – implicitness (Ex. 13-15) cline. Many of the latter testify to users’ creativity, which is typical of social media posts (Vásquez, 2019). In Ex.14, the user draws a witty comparison through the intertextual reference to a polyfunctional device from the science-fictional novel by Vonnegut. In Ex.15, via another comparison, the user seems to give a negative-positive evaluation (double-coded) of ChatGPT, which is a breakthrough that benefits humanity but carries potentially pernicious consequences.
Regardless of the detected evaluative bias within the broadcasts, the various positive and negative evaluations of ChatGPT in user comments following each video are almost balanced quantitatively (and the differences are not significant), with the salient exception of the BBC(1) video. Interestingly, an overwhelming majority of these comments (n = 52) praised ChatGPT, rather than criticising it (n = 12), which does not appear to be consonant with the original raters’ perception of the broadcast as negative. The reason for this may be sought in the nature of the evaluations in the broadcast talk, in line with the factors listed in the previous section, notably the critical title and the anchorwoman’s saliently critical stance compounded by negative evaluations based on multiple arguments clustered together (Ex.8). Thus, this evident negative bias brings about a boomerang effect (see Byrne and Hart, 2009) in some YouTube viewers, who thus praise ChatGPT more than they do in comments following the other videos.
Incidentally, the BBC(1) video has received 11 negative comments, which may not be a lot but is the highest score in the dataset. Among other things, users advocate an opposing viewpoint on the alleged plagiarism in educational settings, a claim that the broadcast makes (Ex.16). (16) “typical BBC, it is NOT plagiarised. It's a machine learning model. It generates text based on the patterns learned from the vast amount of text data it was trained on, and not copied from any specific source. Also check your facts Microsoft have already invested approximately $13 billion why is the BBC so far behind and so poor at journalism? I swear they want to be taken over by AI? Do better. I can't believe this video is just three days old.” [BN,E] (BBC(1))
A similar, albeit much less intense, boomerang effect can be detected in the ABC video, both intuitively perceived and proven to be biased (quantitatively and qualitatively) in favour of ChatGPT, received more negative comments (n = 29) than positive comments (n = 24) addressing the AI bot, with 10 negative comments on the broadcast. This hostile reception must have been caused by the positive evaluations coming from the journalist, as well as Open AI’s CEO, regardless of their attempts to address both sides of the story. The interactivity result points to the users’ distrust of these speakers, and hence the perception of the broadcast as improperly favouring the AI technology.
Engagement with the broadcasts
While evaluations of the broadcasts are essentially indicative of the users’ engagement with the videos (Ex.9–11 and 16), evaluations of ChatGPT do not need to exhibit such engagement (Ex.12–15). Among the comments evaluating ChatGPT, only a small minority (n = 18) raise issues addressed in the broadcast, echoing them approvingly or dissociatively. In fact, an overwhelming majority of the comments (n = 291), whether or not evaluative, do not display any evident engagement with the broadcasts; they do not refer, not even indirectly through extrapolation, to any specific points raised in the broadcasts about ChatGPT or allude to the broadcasts otherwise, whether taking stock or focusing on details. There is no way of knowing whether these commenting users did watch the (whole) videos (carefully) before posting their thoughts. Most users choose not to engage with the content of the videos as they comment, sharing other independent thoughts that are not inspired by the broadcast, such as a meta-comment about the posts on the platform (Ex.17) or a rant about ChatGPT in general, infused with a sense of foreboding (Ex.18). (17) Imagine all these comments are written by chatgpt bots? (18) AI is very scary! It will strip all human of their human rights as everything will be controlled, robotic and will tell you what to do, what to say, where to do; a total control, no more freedom and also all fake because it will be loaded with they want which is not real but fake! [NE] (BBC(2))
 lol [NE] (CNBC)
lol [NE] (CNBC)
On the other hand, engagement with the broadcasts (n = 109) shows in (non)evaluative comments that take some aspect of the news or videos as their point of departure (Chovanec, 2021). For example, users’ engagement with the BBC(1) video is manifest in multiple comments addressing the topic of education in the ChatGPT era, essentially implicitly disagreeing with the claims made in the broadcast about the potential unethical use of the AI bot by students (Ex.19 and 20). (19) “Education now means stop children from being resourceful. Then when they go to work, they won’t have any skills that can compete with AI and won’t have the skills of using AI either. (20) “It’s better to upskill ourselves than be afraid of technology. Education needs to change from memorising facts to thinking creatively and focus on problem solving, that’s the only thing AI can’t properly do till now. And when AI does figure it out, we’ll ask them what humans should be doing after that” [E] (BBC(1))
 ” [E] (BBC(1))
” [E] (BBC(1))
Additionally, engagement does not need to involve topical comments addressing the ideas communicated about ChatGPT but rather display some kind of focus on the broadcast, such as the looks of the interviewee, Sam Altman (Ex.21) or the analyst’s quoted deprecating evaluation of ChatGPT, which – as the user humorously implies – might bring death upon him (Ex.22). (21) “Is it me or does the CEO of OpenAI look like Marilyn Manson in a suit, without makeup.” [E] (ABC) (22) Famous last words: “It’s a novelty. It’s a gimmick.” [E] (CNBC)
Conclusions
Contributing to the research on digital news consumption, this paper has reported an exploratory study of user interactivity and engagement with YouTube videos, as reflected in user comments. Specifically, zooming in on the timely topic of ChatGPT depicted in YouTube broadcast videos, this article has offered an analysis of the diverse, polarised and mixed evaluative discourses about the new AI bot in both broadcasts and user comments following them. The central inquiry in this study was to ascertain whether and how the assessments presented in YouTube broadcasts influence viewer evaluations of ChatGPT and broadcasts that users share in their comments.
Not surprisingly, the analysis of the selected broadcast transcripts corroborated the well-known assumption that complete impartiality in broadcast discourse is impossible to attain (Boudana, 2016; Feng, 2022), and various implicit and explicit evaluations are inevitably communicated. Little support was given to the hypothesis that an overarching sentiment recognised by lay subjects would directly correspond to the number of specific evaluative items found in broadcast talk. Beyond quantity, several qualitative factors are of key significance, potentially swaying viewers’ perception of the evaluative bias. These factors include the source of the evaluation, determining whether they have the requisite expertise and can be trusted. Other factors include juxtaposing different evaluations or perspectives on the same issue so that they are both relevant or one eclipses the other. The strength of evaluation (depending on the degree of implicitness/explicitness) and the accumulation of evaluative expressions in a stretch of discourse, as well as multimodal factors also play a crucial role in how viewers perceive broadcast evaluations. The latter need not tally with each viewer’s personal evaluations of the issues at hand, as reflected by user comments.
The analysis of comments following the videos at hand was meant to gauge user engagement with the YouTube broadcasts and to provide insights into viewers’ evaluations of both these broadcasts and ChatGPT. The findings suggest that users’ interactivity via comment posting, whether or not evaluative, rarely indicates evident engagement with the broadcast as such or its content. Engagement with the videos shows only intermittently in evaluative comments about the broadcasts or their topic. YouTube’s affordance of interactivity allows users to express their views, capitalising on the space provided, albeit not necessarily inspired by the arguments raised in the broadcast that the user comments follow. Typically, users tend to share some pre-conceived thoughts about AI, whether or not evaluative, as if impervious to and unaffected by the news content. These findings do not align with previous research on user responses to online news (e.g. Chovanec, 2021; Massey and Levy, 1999; Schultz, 2000; Yoo, 2011), questioning the idea that user engagement with broadcast videos is a fundamental aspect of YouTube interactivity. As they post comments in the discussion space, users often diverge topically from the broadcast and its content.
The (lack of) engagement aspect regardless, the number of comments assessing the subject matter (i.e. ChatGPT) significantly exceeds those appraising the broadcasts as such. Among the smaller group, the broadcasts received more criticism than praise, consistent with the negative bias typical of online fora (Kleinke, 2008). Positive and negative feedback regarding ChatGPT, which is quantitatively balanced, includes evaluations of individual user experiences and reflections on users’ overall opinions of this AI technology and its implications. Thus, positive and negative evaluations of ChatGPT in user comments may or may not be aligned with the specific sentiments expressed in the videos. However, boomerang effects can be observed where users recognise biased evaluations in the broadcast even if the comments still represent low engagement levels. These low engagement levels should not be seen as contradictory to the boomerang effect in the evaluative comments. Presumably, having developed an opinion about the broadcast’s biased stance (as a consequence of distrust of the speakers or criticism/praise that comes across as being excessively strong, unwarranted or otherwise prejudiced), whether in favour or against ChatGPT (and whether based on the video or its title alone), users tend to post comments to the contrary, not engaging with any specific arguments.
The findings presented here need further validation based on more extensive datasets. A pending query, which I leave for future studies to test, is whether viewers of traditional television broadcasts addressing AI, who may be a different target audience, have evaluations similar to those of YouTube viewers.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Science Centre, Poland (Project number 2018/30/E/HS2/00644).