
Abstract
This article examines interpreters’ embodied displays of trouble in hospital encounters in Norway. In these meetings, participants speak different languages, and the interpreters, that is multilinguals with interpreter education and other formal qualifications, produce utterances in either of the languages in question. As such, the specific interaction in which these embodied displays of trouble occur is mediated in two ways, it is both interpreter-mediated and video-mediated. Video-recordings of hospital settings where the interpreting is carried out through use of video-technology are analyzed using multimodal conversation analysis. The interpreters’ embodied displays of trouble are found resemble recruitmens and are found to initiate repair. The article shows that while the embodied display of trouble might be a versatile device to initiate repair within the video-mediated environment, the video-mediated environment provides a complex interactional space for the perception of the embodied action.
Keywords
Introduction
This article explores interpreters’ embodied displays of trouble in a video-mediated environment. The study is based on video-recordings of video-mediated interpreting in Norwegian hospitals. In these meetings, the interpreter is located at a different site than the other participants and participates in the interaction through use of video-technology. As such, the interaction takes place in a complex linguistic, spatial, and audiovisual setting.
Specific to the organization of video-mediated interaction is that participants in interaction use technology to facilitate the interaction and orient to technological artifacts, such as cameras, screens, microphones and loudspeakers, both as representations of their co-participants and devices that facilitate the interaction. The technology does not simply provide a space for interaction; the technology serves as a resource with which participants in interaction can create an interactional space relevant for their work (Mondada, 2007). Participants in video-mediated encounters have been found to use the technology to accomplish various activities, for instance a patient might manipulate the technology to show their physiotherapist a specific point on the body (Due and Lange, 2020) and public service professionals use the visual affordances of the technology to give citizens instructions regarding how to use a scanner (Due et al., 2019).
Participants in interaction orient to the affordances of the technology as a resource to accomplish various activities. By doing so, they demonstrate not only how they orient to the technology as a device for facilitating certain activities, but also how they orient to their co-participants in interaction. Participants’ understanding of the interpreter’s role or their task in the interaction is reflected by participants’ actions in interaction and their orientation to the technology representing the interpreter. For instance, in a French courtroom setting with the defendant participating remotely, the participants demonstrated their view of the interpreter’s role as the camera operator actively framed the interpreter in ways linked to the ongoing talk-in-interaction (Licoppe and Veyrier, 2017). The interpreter ‘is “enough of a speaker” that s/he should be made visible, but not “enough of a speaker” that the other parties for whom s/he is interpreting may be visually ignored’ (Licoppe and Veyrier, 2017: 162). In hospital encounters with static camera settings, participants in interpreter-mediated interaction have been found to create an interactional space that does not visually display all participants while at the same time relying on embodied resources in the interaction that consequently are not accessible to their co-participants (Hansen, 2020, 2021; Klammer and Pöchhacker, 2021). While participants’ lack of visual access to each other has been found to cause trouble for the participants in video-interpreted encounters, the participants rarely address this explicitly (Hansen, 2020).
This article addresses interpreters’ embodied displays of trouble within the video-mediated environment. When trouble occurs in the interaction and prevents the interpreter from rendering other participants’ turns, the interpreter may produce an action more or less explicitly initiating repair or addressing a problem. On the explicit side, the interpreter may produce utterances such as ‘kunne du gjentatt? tolken fikk ikke med seg hva som ble sagt’ (‘would you repeat? the interpreter did not get what was said’) or ask participants to speak louder. The interpreters’ verbal repair initiators are often produced together with or following embodied displays of trouble, such as shift of gaze, head pokes, head turns and leaning forward. On the less transparent side, some embodied displays of trouble do engender repair without the accompaniment of a verbal repair initiator. In this article, three instances of embodied displays of trouble are investigated using multimodal conversation analysis. The article deals with this embodied practice within the complex spatial and audiovisual setting as well as the complex participation framework of interpreted interaction. The article contributes to our knowledge about video-mediated interaction in general and more specifically to the understanding of the interactional accomplishment of interpreting within the video-mediated environment.
The orderliness of interpreting
Turn taking is fundamental for the organization of talk (Sacks et al., 1974). As interpreting is realized through the production of talk, the organization of interpreting depends on the organization of talk in turns. In order to interpret, the interpreter will need to gain access to the floor every now and then. The interpreter may need to intervene into the turn space of other participants so they can interpret what has been said so far (Davitti, 2019; Hansen and Svennevig, 2021; Licoppe and Veyrier, 2020; Licoppe et al., 2018). The temporary suspension of other participants’ longer turns is negotiated locally by participants in interaction and may be initiated by the interpreter through use of various resources or by the other participants producing their turns in installments (Hansen and Svennevig, 2021). Consequently, the turn space for interpreters’ turns is under constant negotiation.
In general, the video-mediated environment is ‘an environment that nurtures the occurrence of turn-taking problems’ (Seuren et al., 2021: 63). Problems regarding the timing of turn-taking has been found in several studies of video-mediated social interaction (e.g. Ruhleder and Jordan, 2001; Rusk and Pörn, 2019). In interpreter-mediated interactions, the slight delay caused by the video-technology has also been found to challenge the ‘fine-tuned moment-by-moment negotiation of turn space’ (Hansen and Svennevig, 2021). Furthermore, the distribution of participants in video-mediated environments has proven to be relevant for what resources the interpreter has available for instance in the management of turn-taking (Hansen and Svennevig, 2021; Licoppe and Veyrier, 2020; Licoppe et al., 2018). As the system for turn-taking is relevant for all interaction, so too is it for the timing of embodied actions and their possibility of receiving uptake within the video-mediated environment.
Repair or recruitments
While interpreters’ turns in interaction are often found to respond to other participants’ turns in the form of renditions of the prior speakers’ turn, they may also conduct other actions, such as request clarification (Gavioli and Baraldi, 2011: 211). In order to produce an interpreted utterance, the interpreter must hear or perceive what was said and understand (to some extent) this, and based on this be able to interpret what was said into the other language.
The organization of ‘repair’ in interaction attends to recurrent problems in speaking, hearing and understanding (Schegloff et al., 1977: 361). Embodied repair-initiators have been found to engender repair unaccompanied by verbal utterances. In ESL tutoring sessions, two different gestures, a sharp head turn or tilt to the side and a head poke accompanied by the movement of the upper body forward, have been found to initiate repair addressing trouble understanding (Seo and Koshik, 2010). A teacher’s use of cupping of the hand behind the ear in the foreign language classroom engendered repair targeting problems hearing (Mortensen, 2016). In international meetings and interactions at a customs post, participants’ lifted eyebrow was treated as trouble hearing while a freeze display suspending movements was treated as trouble understanding (Oloff, 2018). Oloff (2018: 41) argued that the repairs following these embodied displays were not simply reactions to a co-participant’s lack of response, ‘they react to specific embodied displays with which the co-participant other-initiates repair in a possible response slot’. Similarly, Seo and Koshik (2010: 2221) argue that the gestures ‘are not merely embodied displays of puzzlement, but are systematically produced actions that engender particular types of responses’.
Recruitments have commonly been studied within the context of requests (e.g. Drew and Couper-Kuhlen, 2014; Enfield, 2014; Kendrick and Drew, 2016) and have been found to be embodied ways to elicit someone’s help with something often immediate and local without having to ask. Recruitments at their most explicit have been found to make a physical need, problem or wish overt and publicly available, thereby providing co-participants with an opportunity to assist in meeting the need to resolve a problem (Drew and Couper-Kuhlen, 2014: 28). Recruitments have varied degrees of transparency; ‘The more transparent the display of a need is, the more it assumes an on-record character that is accountable’ (Drew and Couper-Kuhlen, 2014: 28).
Drawing up a continuum between offers and requests, Kendrick and Drew demonstrate how less transparent displays of need, such as recruitments, may need a higher degree of involvement from another party in order to achieve a solution to the problem (Kendrick and Drew, 2016). Recruitments have been found to target concrete objects that all the participants have equal access to (Drew and Couper-Kuhlen, 2014: 28–29). Within this understanding of recruitments, linguistic information or permission to do something cannot be recruited, ‘although they can be requested’ (Drew and Couper-Kuhlen, 2014: 28). In this article, I argue that the opaque nature of interpreters’ embodied displays of trouble resembles that of recruitments, and that the interpreters use embodied displays of trouble as a resource to recruit repair.
While varieties of repair occur in interpreted talk and are mentioned in several studies (e.g. Friedland and Penn, 2003; Li, 2015; Majlesi and Plejert, 2018; Plejert et al., 2015; Wadensjö, 1998), few studies focus specifically on the nature of interpreter-initiated repair and the interactional trajectory that follows. This article explores interpreters’ displays of trouble in the video-mediated environment and the displays’ sequential positions and interactional trajectories.
Data and methods
The analysis is based on video recordings of interpreting in hospital encounters. The study is granted approval by the Norwegian Centre for Research Data and the involved hospitals and wards. All participants have given informed consent. The dataset consists of video-recordings of 11 hospital encounters with the interpreters participating through video-technology. The video-recordings are made at different wards in Norwegian hospitals. The languages spoken in the meeting are Norwegian and seven other languages: Albanian, Arabic, Bosnian/Croatian/Serbian, Mandarin, Polish, Thai, and Vietnamese. Some of the meetings are with admitted patients while some are from outpatient clinics. All the interpreters included in the study have formal qualifications such as interpreter education.
The data have been collected through two rounds. The first round included video-recordings from the interpreters’ studios. Recognizing that there were different perspectives to the video-mediated setting (see Hansen, 2016, 2021), the latter round of data collection included recordings from both the hospital ward and from the interpreter’s studio (see Hansen, 2021). In total, three of the meetings are video-recorded from the interpreter’s point of view, one is recorded from the ward, and seven are recorded from both the ward and the interpreter’s point of view.
The analysis builds on the theoretical framework of multimodal conversation analysis (e.g. Deppermann, 2013; Hazel et al., 2014; Mondada, 2014) and the transcripts are made using Mondada’s (2001) system for multimodal transcription. In order to analyze this multilingual set of data, the initial analytical inquiries began with the Norwegian spoken language and embodied resources. When having identified relevant sequences for analysis, I consulted linguistic help with the languages I do not know. The analytical process has in many ways been reiterative, where revisiting the data and transcripts and returning to people with the linguistic expertise has been an important part of the process (for more on this process, see Hansen, 2021).
While the meetings in question take place at various hospitals and can be labeled as interpreter-mediated and hospital interaction, from a conversation analytic perspective the institutionality of the interaction is not determined simply by the setting or institution in which it occurs but whether the ‘participants’ institutional or professional identities are somehow made relevant to the work activities in which they are engaged’ (Drew and Heritage, 1992: 3–4). In this analysis the interpreters’ professional identities are perhaps those most clearly made relevant by participants in interaction, for instance through turn organization. The medical professionals’ institutional identities are not made relevant in the same way in the selected extracts. In the transcripts, I have given participants names beginning with N (participants speaking Norwegian) and other letters for those speaking other languages, and refer only to the interpreters by their institutional role (INT).
Analysis
Various ways to deal with interactional trouble have been observed in the data. Issues that may cause trouble for the interpreter when about to produce a rendition of a participant’s utterance include noises causing trouble hearing (coughing, sniffling, scuffling of objects), turn-management problems and problems understanding or perceiving specific terminology. Interpreters’ indications of trouble range from the subtle shift of gaze to the production of explicit verbal repair initiators. Interpreters’ repair initiators may emerge as complex multimodal Gestalts (Mondada, 2014) displaying embodied actions, such as grimace, head poke, head turn, pointing gesture to ear, leaning forward, produced successive to or simultaneously with the interpreters’ verbal utterances (Hansen, forthcoming). Nevertheless, interpreters’ displays of trouble are in some cases perceived and acted upon without the further emergence of action. This analysis presents three extracts where interpreters produce embodied displays of trouble in video-mediated environments. The first example demonstrates how the interpreter’s head poke engenders repair. The following two examples demonstrate how the video-mediated environment and orders of interpreted interaction may challenge the embodied display of trouble as a resource to recruit repair.
Displaying that there is a problem
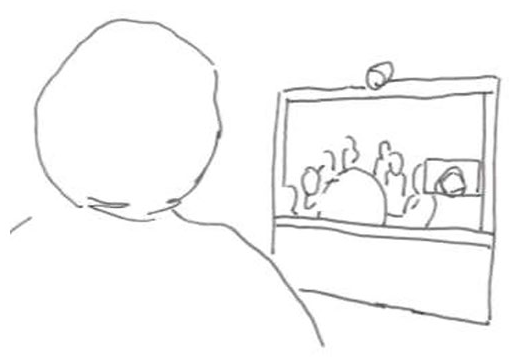
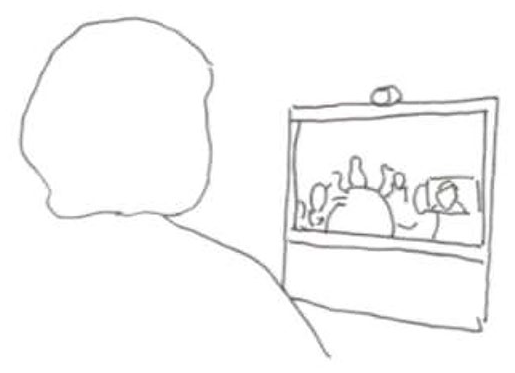
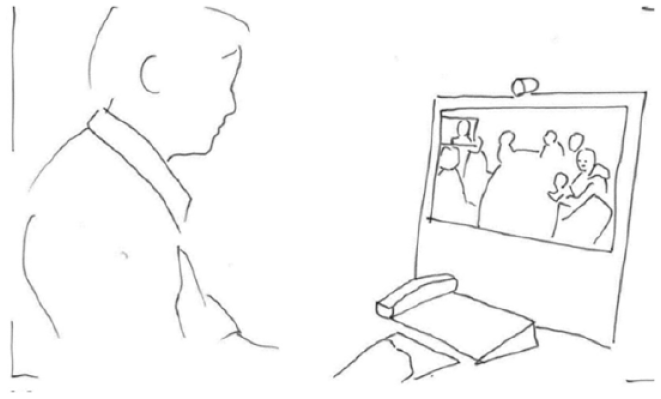
The first extract demonstrates how the interpreters’ embodied display of trouble engenders repair. Patrycja (PAT) who speaks Polish is meeting with several participants who are speaking Norwegian. They are in a meeting room equipped with a videoconference system. The interpreter (INT) participates in the meeting from a different location using video-technology and sees the participants at the ward on her screen. At the ward, the camera and the screen displaying the interpreter are placed at the end of the table, and Patrycja is seated at the other end of the table, facing the camera and screen. Figure 1. 1 below illustrates what the setting looks like from the interpreter’s perspective. The extract is from the opening of the meeting. One of the Norwegian speaking participants, Nora (NOR), has just welcomed Patrycja to the meeting and this has been interpreted into Polish. When asked if she knows all the participants, Patrycja refers to Nina (NIN) as unknown. The meeting is recorded, transcribed and analyzed from the interpreter’s point of view.
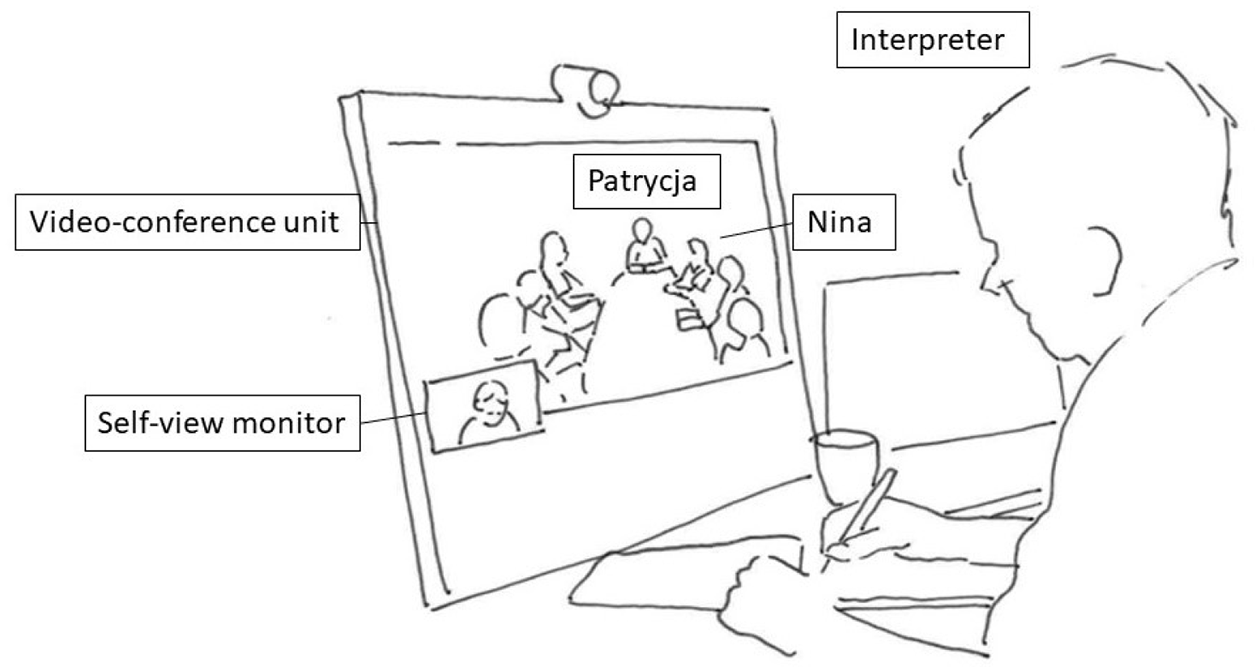
The interpreter’s perspective.
Orienting to the possible relevance of the other-introduction of parties in the meeting (Pillet-Shore, 2011), Nora suggests that Patrycja knows all the people present and completes the utterance with a turn final tag question (line 1). The Norwegian utterance is directed to Patrycja through use of the second person singular pronoun, ‘du’ (you), in combination with bodily orientation and gaze. While the question format might ordinarily allocate the turn to the addressee or at least suggest that a response is relevant, the speaker speaks Norwegian and the addressee speaks Polish. The interpreter will therefore interpret the utterance into Polish before Patrycja responds.
The interpreted utterance (line 4–5) is designed in Polish with a structure similar to Nora’s utterance including a turn final tag question. The interpreter uses the female honorific form of address in Polish, ‘pani’ (feminine, singular). With an ambiguous utterance, Patrycja responds in Polish, indicating that there is someone in the setting that she does not know (line 7). It seems that she jokingly mirrors the interpreter’s polite phrasing, referring to herself with the honorific pronoun ‘pani’ (line 7). Although the Norwegian-speaking participants most probably do not understand what Patrycja said, Patrycja identifies Nina to her left as relevant to the question that was asked through bodily orientation, gaze and touch. Nina confirms immediately without waiting for the utterance to be interpreted, as such displaying some understanding of the content, possibly based on the combination of the content of the initial question and Patrycja’s embodied actions. Patrycja’s response to Nora’s initial question both addresses the topic raised, plays on the interpreter’s formal phrasing in Polish and identifies through gaze and gesture the speech therapist as unknown. As such, different participants have different possible levels of access to Patrycja’s multimodal utterance at different times.
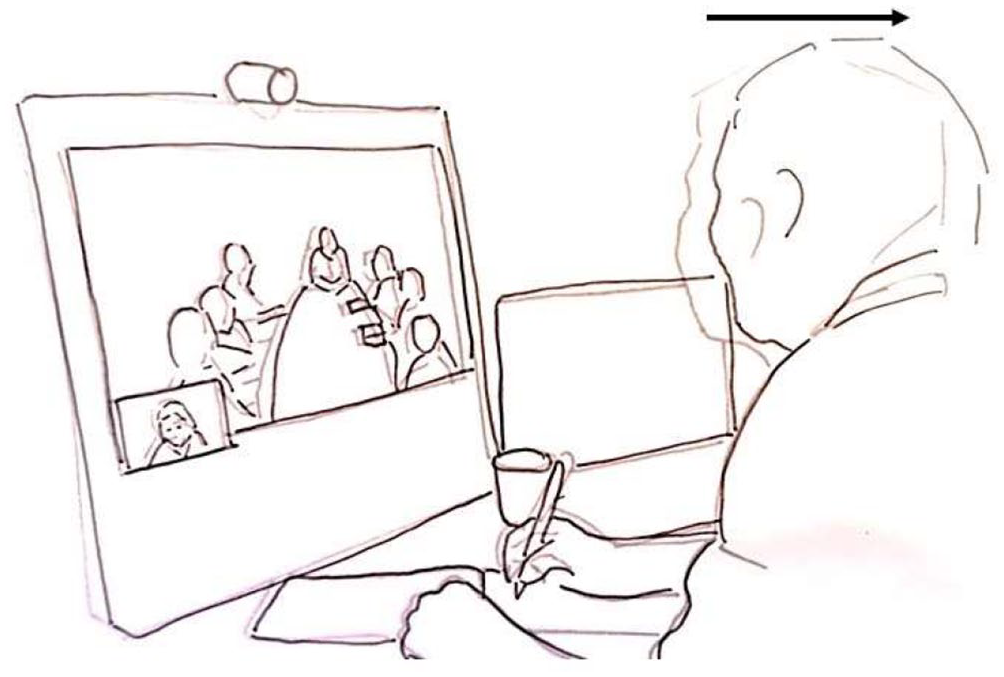
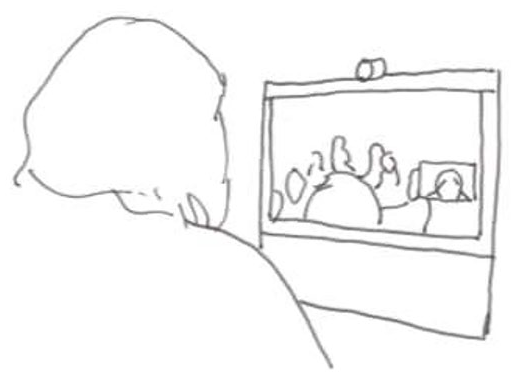
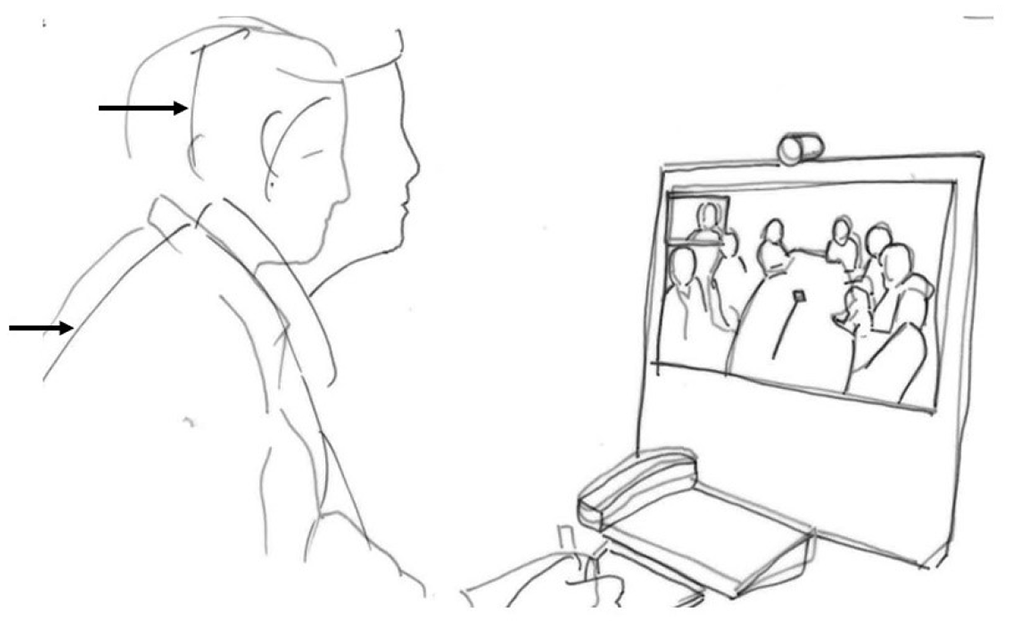
Patrycja and Nina laugh (line 9–10). Nina has already responded, but does not go on to introduce herself, and Nora who opened the meeting does not reclaim the floor. The interpreter does not begin to interpret. Rather, during the silence following the laughter, she leans forward toward the desktop unit displaying the participants at the hospital ward (line 11). She pokes her head forward. She does so during the silence and holds the position through the silence that follows (Figure 1.2). The movement is interactionally organized in that it is produced during a transition relevance space and indicates that the interpreter orients to this as a point in the interaction relevant for her to act. The movement itself, however, is not transparent regarding the actions it may conduct nor to whom they may be directed. To her, the participants at the ward are displayed on a monitor and her movement is directed toward the videoconference unit. To the participants at the ward, the movement is displayed on a screen and cannot be directed to any specific of the participants at the ward. It is up to the participants at the ward to make sense of the her changed body position.
While the interpreter is still leaning forward, Patrycja self-selects as the next speaker (line 12) and elaborates on her initial utterance (in line 7) in Polish. By doing so, she displays an orientation to the interpreter’s head poke as an embodied display of trouble and furthermore as interpreting of her utterance as still relevant although she and Nina have already identified Nina as a person Patrycja has not yet met. The interpreter’s embodied display of trouble did not make clear what about the previous utterance was problematic. Patrycja’s repair is formatted to solve the problem by elaborating on her initial utterance, and as such she treats the problem as a problem with the comprehensibility of her utterance. She repeats that there is someone present that she does not know, now using a more common phrasing than she did initially and does not repeat or explain the wordplay (line 12–13). She suggests that the status of their acquaintance will soon change, perhaps downplaying the urgency of this matter. By having to repeat and explicate what was initially a short and joking remark, the content of Patrycja’s comment is emphasized and may perhaps be perceived as more serious and even urgent. Patrycja directs the utterance to the interpreter by looking up toward the screen and camera while speaking. Although Patrycja has designed and produced the utterance seemingly for the interpreter, the interpreter treats this as an interpretable utterance and renders Patrycja’s utterance into Norwegian (line 14–15). The interpreted utterance makes relevant a new action by Nina who now introduces herself as a speech therapist (line 16).
The interpreter’s embodied display of trouble resembles the format of an open class repair initiator leaving it up to the producer of the trouble source utterance to identify the problem (Drew, 1997). Although the open-class repair initiator may often be treated as a problem with hearing (Drew, 1997; Svennevig, 2008), in this case, Patrycja does not merely repeat her previous utterance. As a repair initiator, the interpreter’s head poke leaves it to the participants at the ward to identify who was the producer of a trouble source utterance and what was the problem.
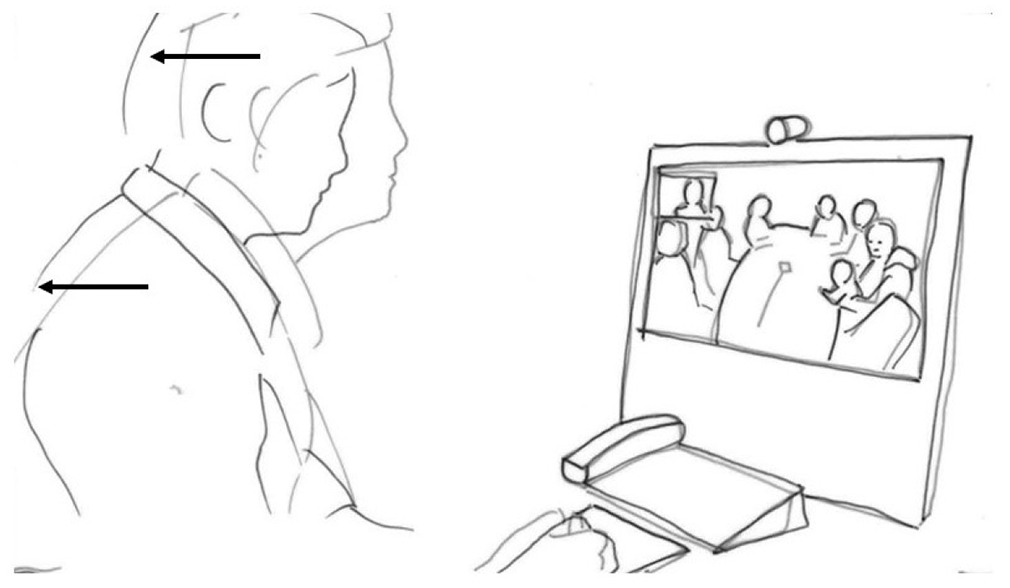
The interpreter releases the embodied display of trouble and sits back again as Patrycja reformulates her utterance (line 13, Figure 1.3). While the interpreter’s initial head poke indicates that there is a problem, it leaves open to the participants at the ward to propose a solution to the problem. In this way, the interpreter’s embodied display of trouble resembles the format of a recruitment. The interpreter’s action enables other participants to recognize or anticipate that there is a problem, but does not make clear what the resolution may be (Kendrick and Drew, 2016: 11). The sequential positioning of the interpreter’s change of posture indicates that the problem is interactional. The interpreter moves forward during the silence relevant for producing a next utterance, possibly an interpreted rendition. However, producing an interpreted utterance now depends on, if not the assistance of other participants, at least the actions of others in the interaction. The problem is solved when the previous speaker reformulates the previous utterance and, in this way, treats the problem as a problem of understanding. The interpreter’s embodied display of trouble resembles a recruitment in format while it engenders repair.
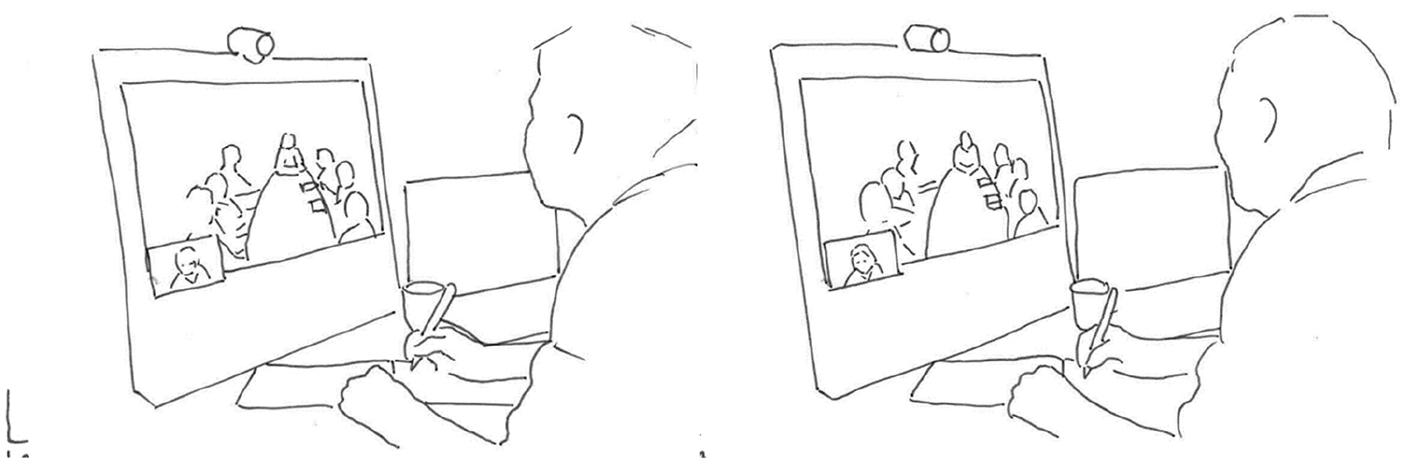
The interpreter pokes her head forward and releases.
The interpreter releases head poke.
Making sense of actions in a video-mediated environment
Similar to extract 1, extract 2 demonstrates how the interpreter’s embodied display of trouble does engender repair. However, the participants have trouble timing their actions due to delay in the technologically mediated space. While still holding the embodied display of trouble, the interpreter produces several verbal repair initiators as she and the speaker of the trouble source turn have problems synchronizing the repair sequence. This meeting is video-recorded from both the ward and from the interpreter’s studio. In this example, extracts from the interpreter’s studio and the ward are juxtaposed to demonstrate how the sequence emerges differently at the two sites due to delay in the transmission of signals between sites.
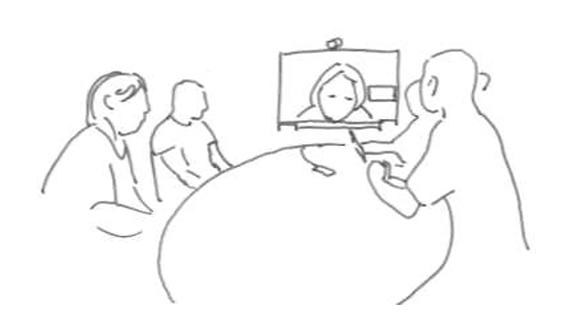
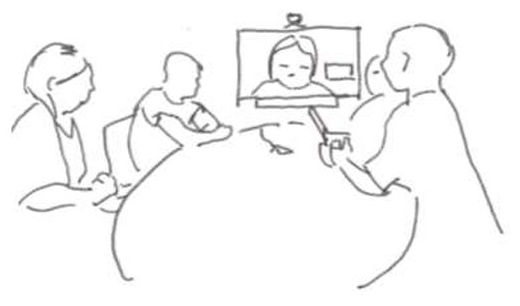
Alesandro (ALE) who speaks Albanian is meeting with six participants who speak Norwegian. Just prior to the sequence in this extract, one of the Norwegian speaking participants asks another, Nadia (NAD), if she has a plan B if Alesandro is not accepted for the treatment for which they have applied. The interpreter (INT) has interpreted this from Norwegian to Albanian, and after a long silence, both Alesandro and Nadia begin to speak at the same time. In Figure 2A, the image to the left illustrates the setting from the ward’s perspective. The interpreter is displayed on the screen at the end of the table, and Alesandro is seated to the left of the screen. The image to the right (Figure 2A) demonstrates how the participants are displayed on the screen in the interpreter’s location. The first extract in this example is transcribed from the interpreter’s perspective.
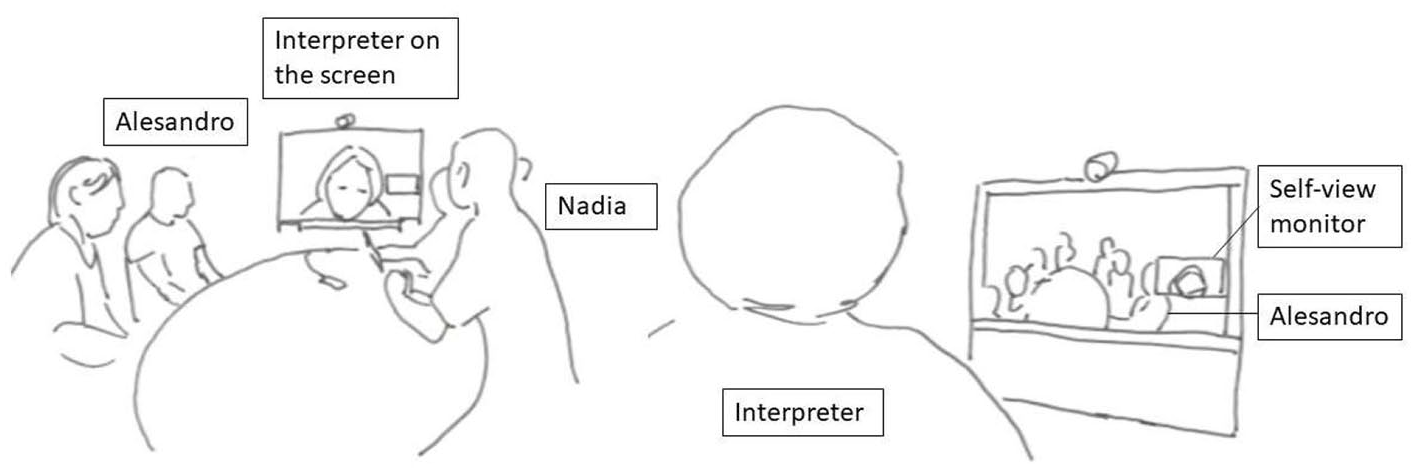
Ward’s perspective to left: Alesandro is seated to the left. Interpreter’s perspective to the right: Alesandro is displayed to the right partially covered by interpreter’s selfview.
Before the interpreter leans forward.
The interpreter leans forward.
Alesandro gazes toward the camera and the screen displaying the interpreter (line 3), before he turns away from the screen and back to the table where the medical professionals are seated and suggests ‘fitness’ as an alternative to the treatment (line 3). Nadia produces a pre-beginning vocal sound at the same time (line 2), which overlaps with Alesandro’s utterance. She cuts herself off and lets him complete. By turning to the table while producing his utterance, Alesandro has directed the utterance to his co-participants at the ward. Right after having made this suggestion, he turns back to the camera and screen (line 4) indicating that the interpreter will be the next speaker. Overlapping talk can be difficult to perceive through video-technology. Both utterances were short, making it difficult to make out even parts of their utterances. Rather than interpreting, the interpreter leans forward, displaying that there is a problem. Alesandro is facing the screen, so this is visually available to him. After having held the position for 0.3 second, the interpreter produces a verbal repair initiator in Norwegian, ‘unnskyld’ (sorry), while still holding the position (line 5). The interpreter speaks Norwegian and is gazing to the left side of the screen where only Norwegian speaking participants are displayed, which indicates that she has not yet identified Alesandro as the speaker of the trouble source turn. Overlapping with the final syllable of the interpreter’s verbal repair initiator, Alesandro reiterates his suggestion ‘fitness’ (line 6). While these two utterances are partially overlapping from the interpreter’s perspective, extract 2B reveals how the utterances are ordered differently at the ward.
The interpreter leans forward.
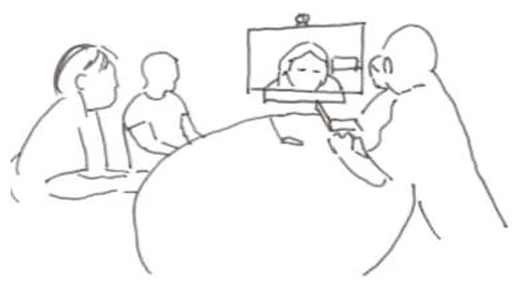
The interpreter holds the position.
Alesandro is gazing at the screen representing the interpreter in the ward, and her embodied display of trouble becomes visible on the screen after a second of silence (line 5). Alesandro does not treat the silence alone or the movement itself as a display of trouble, but repeats his utterance only after the interpreter leans forward and holds the position. Alesandro repeats his utterance (line 6) and as such treats the interpreter’s posture change as a repair initiator. By repeating what he said the first time, Alesandro treats this as a problem hearing. The interpreters’ displays of trouble leave it up to the speakers of trouble source turns to identify what the problem with the previous utterance might be, and, as such, the displays of trouble are not indicative of the nature of the problem.
Latching onto Alesandro’s utterance, the interpreter now produces an open-class verbal repair initiator in Norwegian (line 7), ‘unnskyld’ (sorry). From the interpreter’s point of view, she began to produce the Norwegian repair initiator before Alesandro produced the repair, and the two utterances overlapped. From the ward’s point of view, Alesandro repeated the word before the interpreter produced the verbal repair initiator. Due to delay in the transfer of signals, the two utterances have a different order at the two sites. The interactional problem has not yet been resolved. Returning to the interpreter’s perspective, extract 2C demonstrates how the repair sequence continues to emerge as the interpreter identifies Alesandro as the speaker of the trouble source turn.
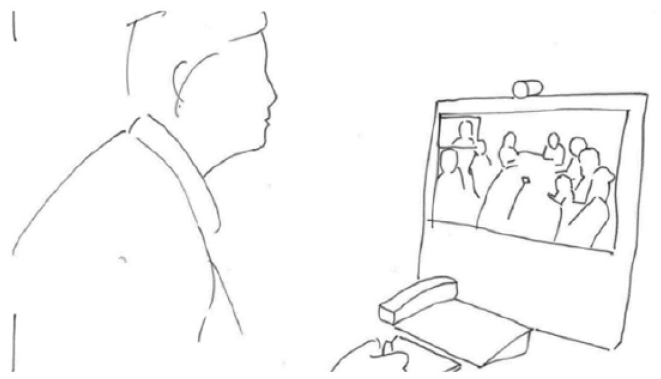
After yet another silence, while still holding the position, the interpreter now turns her head, seemingly gazing toward participants displayed on the right side of her screen (line 7. This is the area of the screen where Alesandro is displayed. Still holding the position leaning forward, the interpreter now produces an open-class repair initiator in Albanian (line 8). Through change of visual orientation and language choice for the production of the repair initiator, she displays that she has identified Alesandro as the speaker of the trouble source turn. From the interpreter’s perspective there is a 0.4 second silence following her utterance (line 8) before Alesandro responds, now choosing a different word, the more typical Albanian word ‘palestër’ (line 9). Returning to the ward’s perspective, the following extract shows how the problem is resolved and the sequence is closed.
The interpreter retracts the position.
The interpreter retracts her position.
The silence that follows Alesandro’s utterance is 1.1 seconds long from the ward’s perspective (line 1). However, Alesandro does not treat this as an indication that there is still a problem. Following the silence, the interpreter first repeats the word Alesandro used last, ‘palëster’, and retracts the position as she repeats the word he used first, ‘fitness’ (line 2), displaying an orientation to the problem as solved. Simultaneously, Alesandro turns away from the screen and back to the medical professionals seated around the table (line 2) displaying that he also recognizes that the problem has been resolved. By repeating the word Alesandro first used, the interpreter shows that she has not only perceived what he said, but also made sense of what he was saying earlier. After yet some silence, she continues ‘ja’ (yes) 1 in Norwegian (line 4) although the repair sequence was between her and the Albanian speaker and continues to produce a Norwegian word for gym, ‘treningsstudio’ (line 7). The example has shown that although the interpreter’s embodied display of trouble may engender repair, delay caused complications. The interpreter expanded the embodied display of trouble and produced a verbal repair initiator while still holding the position.
Escalating to verbal modality
Extract 3 demonstrates how the embodied display of trouble depends on other participants’ gaze and visual attention and furthermore how the embodied display of trouble can be expanded with a verbal utterance. In extract 3, three Norwegian speaking participants, three Polish speaking participants and a child are present at the hospital ward. Pawel (PAW), the speaker of the trouble source turn is seated near the videoconference system. This requires him to turn to the left in order to see the interpreter.
In this extract, Pawel is responding to a question from one of the Norwegian speaking participants concerning how he is planning to keep active when he returns home from the hospital. He mentions a range of activities he will carry out at home before he mentions one he will not be doing at home. The meeting is recorded, transcribed and analyzed from the interpreter’s point of view.
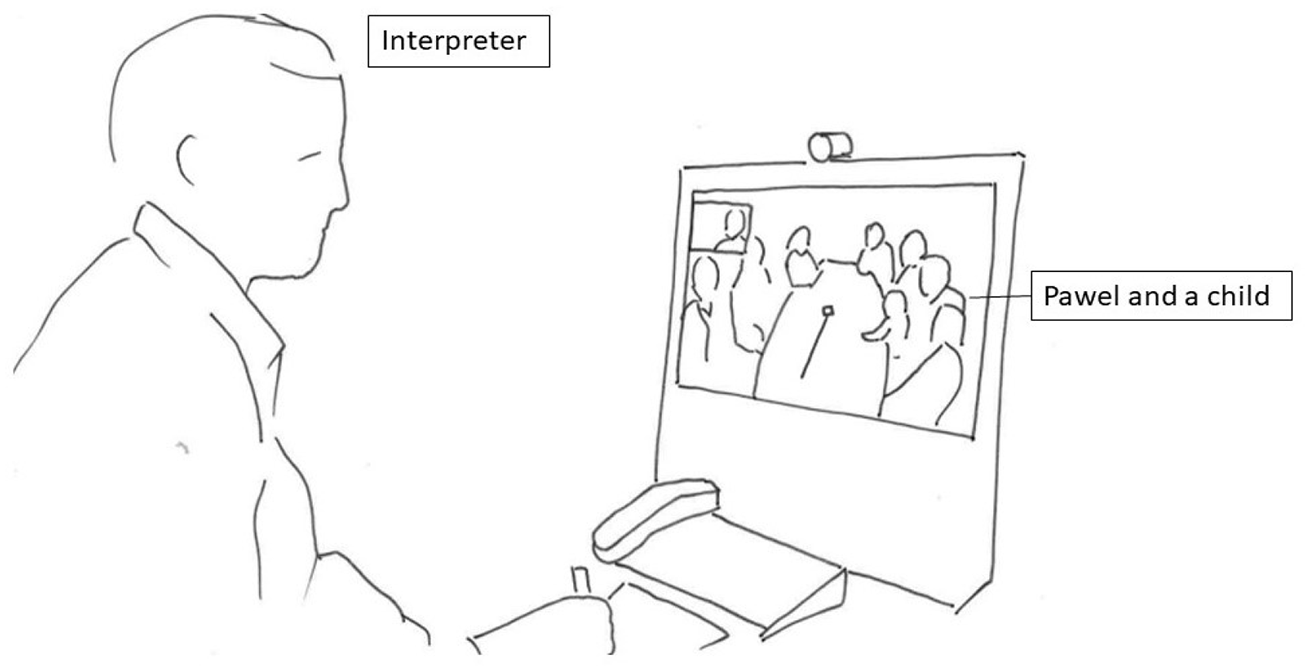
The interpreter is in a neutral position.
Pawel is visually oriented to the camera and the screen displaying the interpreter while talking, before he turns away from the technology and back to the participants at the ward as his utterance comes to completion (line 2). During the silence following Pawel’s turn, rather than interpreting the utterance, the interpreter leans forward toward the videoconference unit (line 3, Figure 3.2). Facing away from the screen and camera, Pawel cannot perceive the interpreter’s change of posture. Resources that might be effective in face-to-face interaction, for instance to get the attention of a co-participant, are not always effective in the video-mediated environment (Heath and Luff, 1993; Hutchby, 2001). Upper body movement is more prominent when carried out by participants who are physically co-present than when depicted on a screen in participants’ peripheral vision. In the prior examples, the speakers of the trouble source turns were facing the screen representing the interpreter at the moment when the movement was relevant. Within this specific socio-material setting, the interpreter has only limited possibilities to coordinate the display of trouble with the co-participants’ line of sight (Kendrick and Drew, 2016: 15). Possibly recognizing that Pawel will not be able to see her gesture when he is turned away from the screen, the interpreter begins to produce a verbal repair initiator before her movement comes to a halt (line 4). She produces a short verbal open-class repair-initiator in Polish ‘przepraszam’ (sorry) while holding the position leaning forward. The open class repair initiator does not identify the specific problem in the interaction but leaves it up to the speaker of the trouble source turn to identify the problem. Pawel turns back to the interpreter and repeats what he initially said and accounts for the supposition of his prior statement (line 5–6). The interpreter responds to his utterance by producing a change-of-state token, ‘åja’ (oh), in Norwegian before she releases her position, indicating that the problem has been resolved, and interprets the utterance (line 7, Figure 3.3). 2
The interpreter leans forward.
The intepreter releases the position.
The interpreter leans forward.
The interpreter releases the position.
The absence of interpreting in itself does not seem to engender repair (extracts 2 and 3). In extract 3, the producer of the trouble source turn did not display an orientation toward a possible problem until the interpreter produced the verbal repair initiator. By supporting or expanding the display of trouble with a verbal repair initiator while still moving forward, the interpreter utilizes an assumedly more effective resource within the specific setting. In both extracts 2 and 3, the interpreters hold the embodied display of trouble until the point where the problem has been resolved.
In these settings, participants speak several languages. In order to address verbally problems that arise, the interpreter has to choose a language for the production of the utterance. In order to do so, the interpreter must be able to identify the speaker and the language they speak. Extract 2 demonstrated how, when overlapping talk occurs in this complex material and linguistic setting, identifying the speaker and accordingly the relevant language might be difficult in the mediated environment. The extracts above have demonstrated how embodied displays of trouble can engender repair within a complex participation framework and that embodied resources allow the interpreter to display that there is a problem quickly without producing a verbal turn and consequently without choosing a language. However, in extract 2 and 3, the interpreters expand the displays of trouble verbally in order to secure the attention of the speaker of the trouble source turn and to enhance the display of trouble after assumed lack of uptake. In both cases, the expansion is produced as a verbal repair initiator drawing not only on the symbolic affordances of verbal talk as such but as auditory cues as a way to attract attention.
As the verbal repair initiator seems to have affordances that work well in this environment, why do not interpreters begin with the verbal repair initiator? Considering the complexity of the setting, producing an embodied display of trouble may simply be easier. The modality of the action allows it to be produced simultaneously to speech and as such does not require the same attention to the unclear boundaries of turn taking in interpreted talk and hence the risk for overlapping talk. Furthermore, the embodied display of trouble does not require the interpreter to identify the speaker of a trouble source turn and choose a language. Finally, the embodied display of trouble does not require a response and can be carried out simultaneously to ongoing talk. As such, the interpreters may be trying the easiest solution first (Svennevig, 2008).
Discussion and conclusion
In this study, I have explored three instances of interpreters’ embodied displays of trouble in complex interactional settings. The analysis has demonstrated how interpreters use embodied displays of trouble to recruit repair in instances where the interpreter for some reason is not able to interpret the preceding utterance. The extracts in the analysis demonstrated how the interpreters’ gestures addressed problems that could be solved through repair. The embodied displays of trouble were produced at a point in the interaction relevant for interpreting and were as such organized relative to the temporality of the ongoing talk. In all cases, the problems could only be solved with assistance from participants at the ward. Embodied displays of trouble have been found in the data in different formats and in different sequential positions, among other cooccurring with ongoing disturbances at the ward. However, in many cases they do not receive uptake and are either followed by or combined with a verbal repair initiator or abandoned all together.
Since embodied resources afford simultaneity without interrupting ongoing talk, embodied resources run less of a risk of resulting in overlapping talk. With the unclear turn boundaries of consecutively interpreted talk, embodied displays of trouble could be a useful resource to solve problems. However, the interactional settings in which embodied displays of troubles are produced are quite complex. The participants use technology to create an interactional space for their conduct. While the technology affords the participants with visual and auditory access to each other, visual access depends on the camera frames participants choose and how they use the screen displaying each other in the organization of interaction. The participants at the ward are seated around a table, and direct their utterances to each other, gazing toward the interpreter now and then. Securing the sightline of participants at the ward is not always possible for the interpreter, and the embodied display of trouble does not attract attention from a participant gazing in another direction. Embodied actions have different affordances when being displayed on a screen compared to what they do when perceived by a co-participant at the same location and do not seem to get attention in the same way in the video-mediated environment (Heath and Luff, 1993). Transmission delay is a feature of the video-mediated environment that may change the temporal unfolding of actions at each site.
The embodied display of trouble serves as a versatile device that can engender repair addressing trouble hearing and trouble understanding. Furthermore, the embodied display of trouble does not require the interpreter to choose a language in which to produce a verbal repair initiator. These examples have shown how initiating repair can be quite complex in these interactional, linguistic, and material settings and that embodied displays of trouble may serve as a recruitment to elicit the help of others in performing repair. Participants treat the embodied displays of trouble as less intrusive than verbal requests and accounts. However, embodied displays of trouble, being opaquer than a verbal requests or repair initiators might easily be overlooked. In several of the examples, the embodied displays of trouble were expanded with a verbal utterance in order to elicit the needed assistance.
The concept of ‘recruitment’ is developed to encompass the linguistic and embodied ways in which assistance may be sought – requested or solicited – or in which someone comes to perceive another’s need and offer or volunteer assistance (Kendrick and Drew, 2016: 1). Kendrick and Drew suggest that recruitments for assistance are distributed along a continuum from the most explicitly articulated requests to the less explicit articulations, such as embodied displays of trouble and even projectable trouble where a problem is projected by other participants (Kendrick and Drew, 2016). Recruitments rely to a larger degree on others anticipating that there is a problem and what it might be the solution to the problem. Similarly, in the examples above, interpreters’ embodied displays of trouble, although targeting interactional problems, leave it up to other participants to identify the trouble source and to assist in solving the problem. Repair initiators can be produced distributing different levels of responsibility for identifying a problem on the producer of the repair initiator and the producer of the trouble source turn. Embodied actions have been found to initiate repair and different embodied actions have been found to elicit different types of repair within different settings. Based on the analysis above, it might be relevant to consider continuums similar to those of recruitments in the study of the organization of repair.
Footnotes
Acknowledgements
I am grateful to all of those who have read and commented on this article in its various stages, especially Jan Svennevig. I am also grateful to Pawel Urbanik and interpreters for their invaluable help with transcripts and translation.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partly supported by the Research Council of Norway through its Centers of Excellence funding scheme, project number 223265.