
Abstract
Algorithms profoundly shape user experiences on digital platforms, raising concerns about their negative impacts and highlighting the importance of algorithm literacy. Research on individuals’ understanding of algorithms and their effects is expanding rapidly but lacks a cohesive framework. We conducted a systematic integrative literature review across social sciences and humanities (n = 169), addressing algorithm literacy in terms of its key conceptualizations and the endogenous, exogenous, and personal factors that influence it. We argue that existing research can be framed in terms of experiential learning cycles and outline how this approach can be beneficial for acquiring algorithm literacy. Finally, we propose a future research agenda that includes defining core competencies relevant to algorithm literacy, standardization of measures, integrating subjective and factual aspects of algorithm literacy, and task- and domain-specific approaches.
Keywords
Over the past few decades, algorithms have emerged as key elements shaping user experiences across digital platforms. While no single algorithm exclusively defines any platform, algorithms’ primary purpose is to optimize user engagement, enhance content relevance, and improve overall user experience, encouraging prolonged platform interaction. Consequently, the term “algorithmic media” underscores algorithms as computational routines to be these platforms’ overarching features without excessively emphasizing the significance of any individual algorithm within a system or the role of written code (McKelvey, 2014). This shift signifies a substantial transformation in how content is distributed, consumed, and interacted with on various platforms, including traditional social media sites (e.g., Facebook, Instagram), e-commerce websites (e.g., Amazon, Etsy, eBay), dating apps (e.g., Grinder, Tinder), and video streaming platforms (e.g., YouTube, TikTok). Simultaneously, algorithmic platforms have been identified as sources of challenges to citizens’ rights (Leslie et al., 2021), content diversity (Møller, 2022; Scalvini, 2023), information search (Bogers et al., 2020; Noble, 2018), and mobilization and polarization (e.g., Gagrčin et al., 2023; Törnberg, 2022), holding the potential to exacerbate existing inequalities and threaten democracy (Leslie et al., 2021; O’Neil, 2016).
Given the pervasive nature of algorithmic media across various domains, it is imperative that users can assert agency over their experiences in everyday algorithmic media use (Pronzato and Markham, 2023; Savolainen and Ruckenstein, 2024). Unsurprisingly then, and in addition to regulatory frameworks for ethical algorithmic systems (Elkin-Koren, 2020), we have seen a growing interest in users’ algorithm literacy (AL). AL research complements the extensive scholarship on media literacy. Following a skills-based approach, media literacy embraces “the ability to access, analyse, evaluate, and create [media] messages in a variety of forms” (Livingstone, 2004: 5; Aufderheide, 1993). With the diffusion of new technologies, a multitude of subconcepts have been put forward addressing the material particularities of these technologies (e.g., computer literacy, Johnston and Webber, 2005; social media literacy, Schreurs and Vandenbosch, 2021). Additionally, scholars have considered the overlapping skills referenced in the various literacy approaches (e.g., Koltay, 2011). When it comes to literate usage of algorithmic media, the intersection of media and digital literacy is of high relevance. Literate users command cognitive and affective structures and behavioral skills to mitigate risk and maximize opportunities in their media usage (Schreurs and Vandenbosch, 2021). AL can support an informed citizenry able to partake in the public discourse about the ethical implications of algorithms (Chung, 2023), advocate for policies and regulations that safeguard their rights (Leslie et al., 2021), and contest unfair practices in algorithmically driven platform work (Cotter, 2023; Qadri and D’Ignazio, 2022).
However, studying AL faces challenges due to the algorithms’ opaque nature (Just and Latzer, 2017). The process involves collecting extensive data in the input stage and algorithmic processing in the throughput stage, often deemed a “black box” since the exact functioning of algorithms is a proprietary secret (Reviglio and Agosti, 2020). Finally, users are presented with algorithmically generated output, continuously adapting based on user engagement. This dynamic feedback loop complicates defining parameters for AL. Despite these challenges in studying AL, the field has seen a surge in theoretical and methodological approaches. While conceptual ambiguity is common in emerging research areas, a lack of integration can impede scientific progress.
In the present study, we answer Oeldorf-Hirsch and Neubaum’s (2023: 12) call to “focus on further developing frameworks that incorporate sub-dimensions [of AL]” and set out to devise an overarching theoretical framework that integrates existing AL research and considers antecedents and outcomes proposed in the literature. To this end, we systematically reviewed 169 scientific contributions in the social sciences and humanities published between 2000 and 2023. Specifically, we were interested in the following research questions:
RQ1: How is algorithm literacy conceptualized and measured?
RQ2: How do users acquire algorithm literacy?
RQ3: What outcomes can users hope to have?
We proceeded to integrate the findings into an organizing framework, pinpoint knowledge gaps, and offer a future research agenda.
Review method
We conducted a systematic integrative review of the literature. This type of review is particularly valuable in emerging research fields as it helps assess, map, and bridge existing literature from different disciplines and epistemological frameworks (Torraco, 2005). Our approach combines elements of systematic reviews that aim to map the literature and identify relationships between constructs and gaps with integrative reviews that aggregate existing literature and connect disparate scholarly conversations (Cronin and George, 2023).
Data collection
The data collection for our literature review involved two distinct steps (Figure 1). In the first step, we used the Web of Science database to identify peer-reviewed academic papers in English published between January 1, 2000, and September 6, 2023, in the fields of social science and humanities (including the categories Communication, Political Science, Anthropology, Human Geography, Information Systems, Educational Science, Sociology). Drawing upon terms identified by Oeldorf-Hirsch and Neubaum (2023), we searched for articles in which the term “algorithm” appeared within two words (NEAR/2) of the terms “literacy,” “knowledge,” “competence,” “awareness,” “skill,” “education,” “belief,” “attitude,” “experience,” “folk theory,” or “imagination” in the abstract, title, and keywords. Our inclusion criteria in this step covered peer-reviewed empirical studies, reviews, theoretical works, and doctoral dissertations, while initially excluding preprints, unpublished work, reports, and conference proceedings due to variations in the quality of the peer-review processes associated with these products (Scherer and Saldanha, 2019; Paez, 2017).
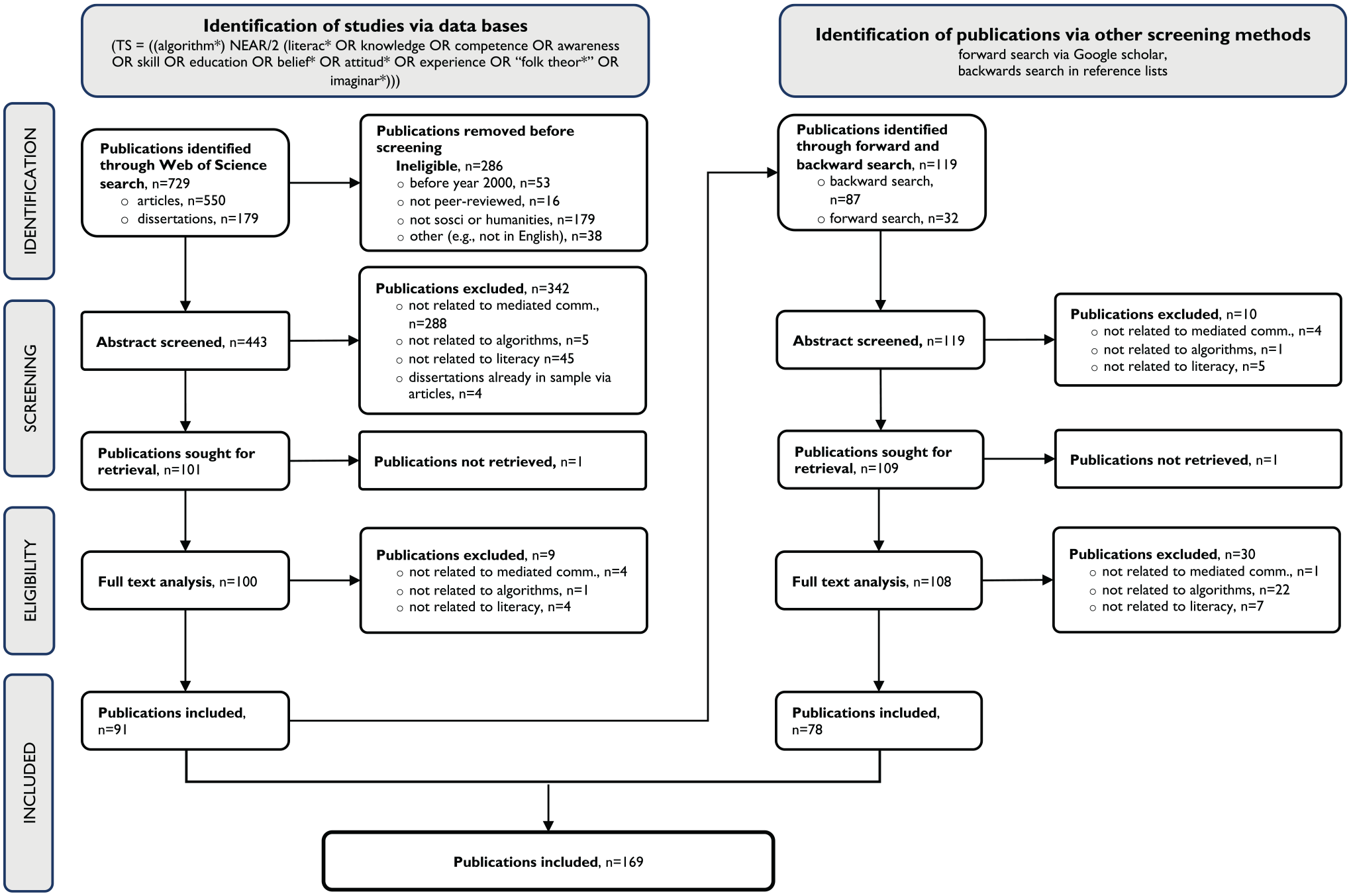
PRISMA flow diagram.
This search yielded a total of 729 publications. After applying formal criteria, including publication date, language, peer-review status, and alignment with humanities and social sciences, we excluded 286 items. The remaining 443 publications were further assessed for eligibility, using a sequence of exclusion criteria: 1) not related to communication on and through algorithmic platforms (e.g., the role of algorithmic mathematics in Wall Street’s financial system), 2) substantial content not related to algorithms (e.g., general media literacy pieces that do not address algorithms as object of inquiry), 3) not related to literacy relevant for using, evaluating, or navigating algorithmic media use (e.g., policy analysis of EU legislation on algorithms). All publications were double-coded for eligibility, which resulted in an acceptable Krippendorff’s alpha value (α = .71). After further discussing the differences in coding, 101 publications were selected for retrieval. After a full-text analysis, 91 publications (86 journal articles and five doctoral dissertations) met the substantive criteria for inclusion.
In the second step of data collection, we conducted forward searches (via Google Scholar) and backward searches (via reference lists and Connected Papers) using publications from our initial sample. In this step, we broadened our scope to include conference proceedings identified through these searches. This decision represented a compromise, as it involved a) acknowledging recommendations to incorporate conference proceedings in systematic literature reviews (Scherer and Saldanha, 2019); b) recognizing the interdisciplinary nature of AL research, spanning fields such as human-computer interaction at the intersection of social science and computer science/informatics, primarily published through conference proceedings; and c) acknowledging the impractical volume of proceedings beyond our resources. This search yielded 119 articles, which, after being subjected to our exclusion criteria sequence, resulted in the inclusion of 78 additional articles. Our final dataset, therefore, comprises 169 articles. (See the full sample list in Supplementary Materials or the dedicated Open Science Framework directory: https://osf.io/scxmu/).
Data analysis
We analyzed the sample using deductive and inductive coding. While we outlined these stages sequentially, our process was iterative, often involving simultaneous engagement with different phases and revisiting earlier stages as we incorporated new sources into our sample (Cronin and George, 2023). First, we coded the articles deductively based on key descriptors: the research paradigms (social constructivism, positivism), conceptual or empirical approach and methods (qualitative, quantitative, mixed methods), publication year, and national affiliation of the authors. Next, we performed an in-depth full-text examination. We randomly selected a subsample of articles, and each team member conducted open coding on this subsample guided by our RQs and theoretically defined focal categories (dimensions of AL, influencing factors, antecedents, and outcomes). This stage involved extensive note-taking. Through regular discussions, we inductively refined our focal categories. We also created subcategories based on our notes to identify patterns within these categories. For example, while we deductively identified the need to code for exogenous factors (based on DeVito et al., 2018), we further developed these categories inductively by reviewing the literature. Having developed a cohesive coding scheme, we systematically coded the remaining sample, distributing it among team members. To ensure rigor, two team members independently coded about 40% of the sample, resolving discrepancies through discussion. In the final stage, we revisited the focal categories of interest (e.g., dimensions of AL identified by Oeldorf-Hirsch and Neubaum, 2023) and used them to construct our organizing framework (Cronin and George, 2023). For a detailed overview of the category structure including references to exemplary publications, see Supplementary Material (SM-Tables 1, 2, and 3) or under the above provided OSF link.
Descriptive findings
Scholarly work on users’ perspectives toward algorithms and their practices has strongly increased since 2018 (Figure 2), presumably in parallel with an increased public awareness of algorithms and datafication, due, for example, to the Facebook Cambridge-Analytica scandal in 2018 (Hinds et al., 2020). Another contributor to the heightened interest was presumably the global launch of TikTok in 2016, which soon established itself as one of the most used apps worldwide (Bhandari and Bimo, 2022).
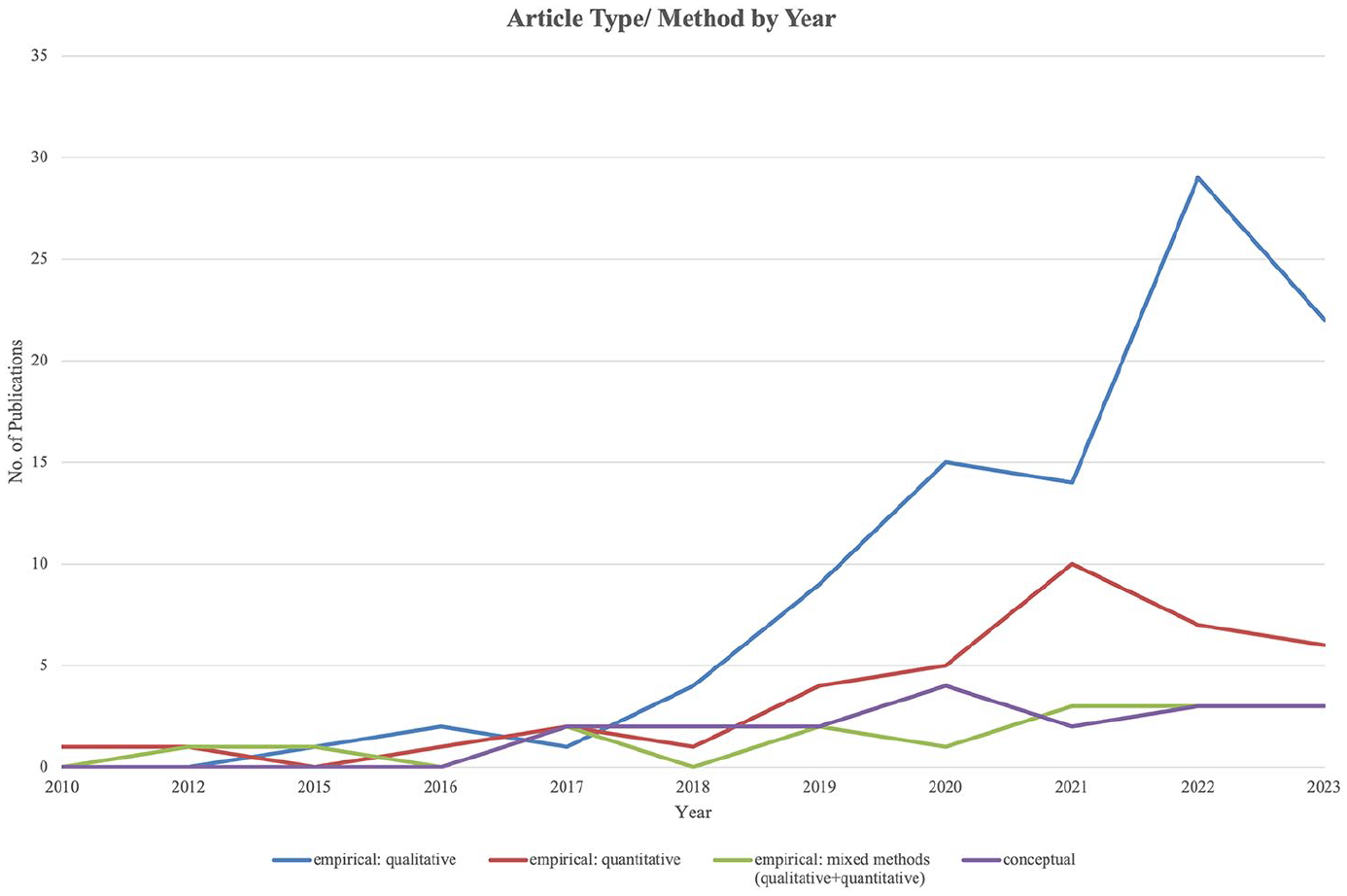
Number of publications per year by empirical method (2010–2023).
Regarding methodological approaches, conceptual work (n = 18, 10.7%) is far less prevalent than empirical work (n = 151, 89.3%). Empirical articles favor qualitative methods, such as interviews or qualitative content analyses (57.4%), followed by quantitative methods, such as surveys and experiments (22.5%; Table 1).
Applied methods.

Organizing the algorithm literacy landscape
In the following, we address our research questions (RQs) one by one. We then integrate the various dimensions of AL, endogenous and exogenous factors, and different AL outcomes into an organizing framework (Figure 3).
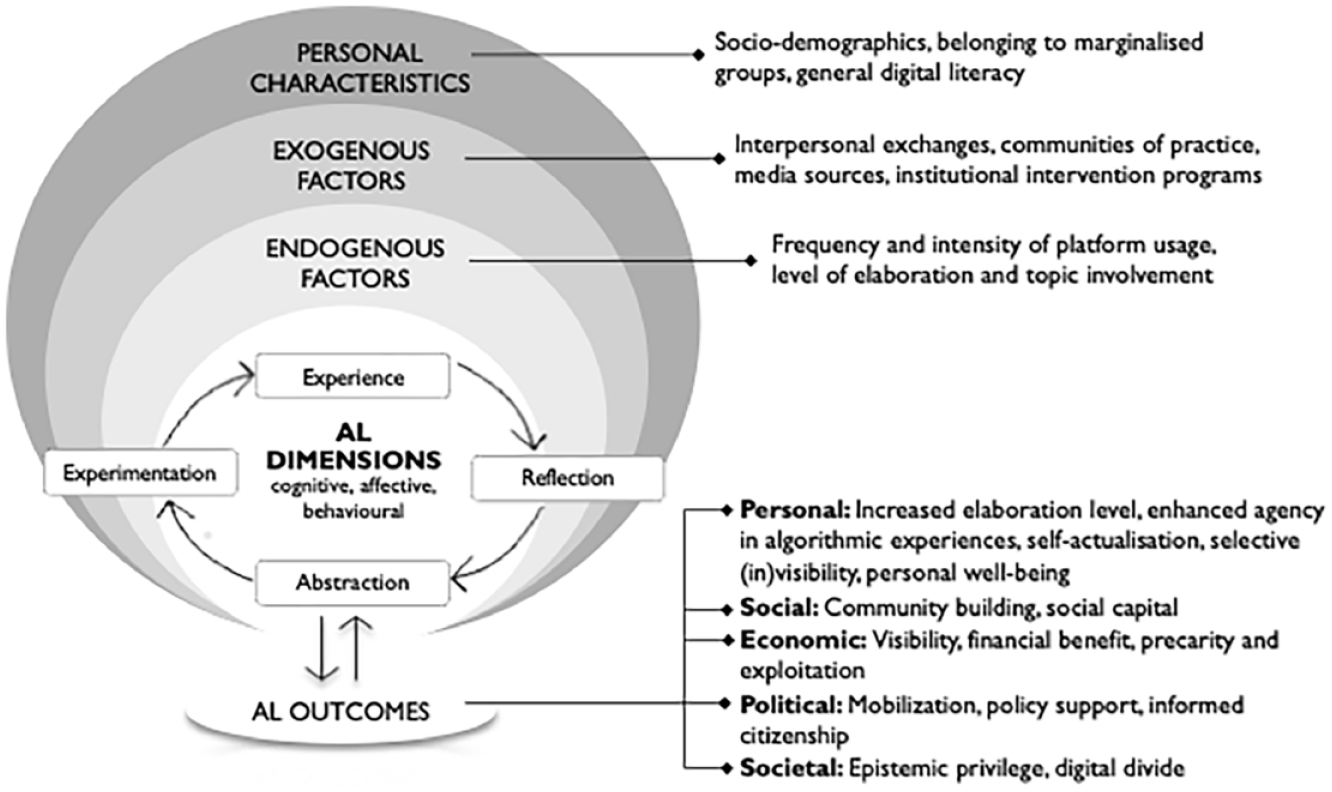
Integrative framework.
Defining and measuring algorithm literacy (RQ1)
Guided by the dimensions of AL conceptualized by Oeldorf-Hirsch and Neubaum (2023), we classified the sampled articles according to the cognitive, affective, and behavioral dimensions of AL. (For a summary, see Supplementary Materials, SM-Table 1). In addition, we assessed whether authors examined the users’ perceived, subjective qualifications of algorithmic functions or measured AL against a factual benchmark.
Cognitive dimension
Most analyzed publications extensively addressed the cognitive dimension of AL (n = 117, multiple coding possible), ranging from users’ basic awareness of algorithms to a deeper understanding of their mechanisms. As a starting point, scholars commonly consider general awareness of algorithms in the context of algorithmic media use and divergent awareness of algorithmic processes across platforms. Though lacking longitudinal studies, authors suggest increased public awareness in recent years (not least due to increased news media reporting, Nguyen and Hekman, 2024), albeit unevenly distributed in society (Hargittai et al., 2020). Furthermore, studies delve into users’ detailed understanding of algorithmic media, exploring how familiar mental frameworks influence the adoption and use of new technology, often indicated by users’ folk theories and algorithmic imaginaries (e.g., Bucher, 2017; for an overview of empirically found folk theories about algorithmic media, see Dogruel, 2021).
While many articles try to assess AL empirically, they face a particular challenge due to the absence of a definitive “ground truth” as a baseline for assessing cognitive AL (e.g., Ytre-Arne and Moe, 2021). Articles that address this issue mostly point to the opacity of proprietary algorithms, the dynamic nature of code, and the diverse algorithmic processes across platforms, which make it impossible even for researchers to make factually correct statements about particular algorithmic processes at work. Thus, most studies fall under “subjective AL” (n = 102), investigating how users reflect on algorithms. However, reflection does not imply that the users possess specific cognitive competencies or factual knowledge that would enable them to achieve desirable and mitigate undesirable outcomes through algorithmic media use. For instance, while integral to user engagement in media environments, folk theories about algorithms can be based on limited or misleading knowledge (e.g., Ytre-Arne and Moe, 2021).
A few articles pursue “objective AL” (n = 15), seeking factual benchmarks to assess and compare users’ cognitive AL, mainly concentrating on undisputed facts about algorithms (e.g., Dogruel et al., 2022). These authors accept that algorithm-literate users cannot fully know which exact input data is processed and which exact algorithmic throughput is at work; instead, they measure general awareness of algorithmic processes and of challenges associated with them (e.g., in survey and interview approaches, see Cotter and Reisdorf, 2020; Festic, 2022; Klawitter and Hargittai, 2018; e.g., in the analysis of content-creator videos addressing algorithms, Issar, 2023) or if users hold general misconceptions about algorithms (e.g., algorithms to be unbiased, Zarouali et al., 2021b; Facebook news feeds to be non-personalized, Brodsky et al., 2020).
The growing number of standardized studies on AL strengthens the need for validated instruments. Zarouali and colleagues (2021a) present a measure to grasp users’ awareness of content filtering, automated decision-making, human-algorithm interplay, and ethical considerations for media content recommendation. Dogruel and colleagues (2022) have validated a scale specifically assessing cognitive AL. This scale gauges awareness of algorithms in various areas and applications, encompassing knowledge about the input data algorithms generally process, their intended objectives, and the subsequent impact on media output.
Affective dimension
In coding for the affective dimension of AL (n = 79), we included articles on how users “feel” and “sense” algorithms (e.g., Bishop, 2019). This dimension captures the emotional responses and sentiments evoked by interactions with algorithmic media. Based on qualitative interviews and surveys with algorithmic media users, the literature repeatedly finds the following four affective responses to algorithms. Appreciation: Users perceive algorithms as helpful, trustworthy, and reliable (e.g., Avella, 2023). This response is closely associated with satisfaction and certainty, reflecting contentment as individuals rely on algorithms for specific tasks and recommendations (e.g., Yeomans et al., 2019). Apprehension: Users experience unease and anxiety, often rooted in uncertainties about how algorithms operate, including their ranking/sorting criteria, and concerns about their impact on various aspects of users’ lives (e.g., Bucher et al., 2021). Aversion: A heightened sense of discomfort and discontent represents a gradation of apprehension (e.g., Bishop, 2019). Resignation: Reflecting a perceived inability to influence or fully comprehend algorithmic systems, users experience feelings of powerlessness, frustration, or disillusionment (e.g., Das, 2023).
In line with Oeldorf-Hirsch and Neubaum (2023), we also coded for attitudes toward and personal assessments of algorithms as part of the affective AL dimension. These include perceptions about the quality of algorithms (e.g., their transparency, accountability, fairness, explainability, and credibility; e.g., Shin and Park, 2019), assessments of the usefulness of algorithmic outputs (e.g., Sundar and Marathe, 2010; Taylor and Choi, 2022), and their societal effects (e.g., Calice et al., 2021). While such perceptions may be based on cognitive assessments rather than purely emotional responses, studies in this area mainly focus on the subjective feeling toward the quality of algorithms and how users’ “emotional experiences of algorithms play into their norms and attitudes about how algorithms ought to function” (Swart, 2021: 6). In contrast, “affective encounters with algorithms entail evaluations” informing the meaning-making process (Lomborg and Kapsch, 2020: 752).
While assessing awareness and factual knowledge of algorithmic processes against objective benchmarks is possible (despite the aforementioned challenges), attitudes and perceptions toward technology inherently remain subjective. In defining “social media literacy,” Schreurs and Vandenbosch (2021) argue that being literate is not about showing the “right” affective responses. However, affective reactions can lead to behavioral consequences (e.g., Bucher, 2017; see below on behavioral AL), which might be more or less socially desirable or individually beneficial in the long run.
Behavioral dimension
The behavioral dimension of AL (n = 40) pertains to how users practically engage with algorithms, thereby shaping their experiences of using algorithmic media more or less intentionally. Across the sampled empirical literature, we found these four behavioral responses to algorithmic systems. Alignment: Users actively shape their experience to align with personal values, goals, or preferences, maintaining consistency with their beliefs and interests without harnessing a naive appreciation of algorithmic systems (e.g., DeVito et al., 2018). Compliance: Users adhere to algorithm-generated recommendations, content, or features, even when dissatisfied or frustrated. Compliance is often rooted in feelings of resignation. For example, Bucher et al. (2021) demonstrate anticipatory compliance among gig workers at Upwork when fear and unawareness of the algorithm’s material properties strengthen algorithmic influence (similarly, e.g., Cotter, 2019; Duffy and Meisner, 2023). Subversion: Users actively manipulate, undermine, or “game” algorithms to achieve their goals or express dissatisfaction (e.g., DeVito et al., 2017). Resistance: Users limit their interaction with or the influence of algorithms on their online experience. This may involve turning off algorithm-driven features or choosing not to use specific platforms. Resistance is related to aversion and is avoidance-oriented (e.g., Xie et al., 2022).
Based on the literature, we find that it is normatively desirable that users have the agency to act “in their best interest” when engaging with algorithmic media (e.g., Das, 2023; Pronzato and Markham, 2023). However, most studies describe how users cope day-to-day, without discussing whether the approaches users employ are actually effective and contribute to their “best interest.” When authors do discuss user agency, they tend to frame it in terms of tactics and strategies of resistance, often with an underlying (productive or agonistic) tension between users and the systems they are navigating (Adams-Grigorieff, 2023: 15-16; Velkova and Kaun, 2021). Thus, subversive practices are most likely to be seen as expressions of agency since they manifest in challenging the rationalities and mentalities imposed by algorithms (DeVito et al., 2017; Velkova and Kaun, 2021). For example, in algorithmic content moderation, users employ “algo speak,” intentionally modifying or replacing words in hashtags or post/video descriptions to circumvent algorithmic moderation and evade restrictions (e.g., Klug et al., 2023). In the labor domain, delivery couriers exert agency through both collective practices (aligning with fellow workers and sharing orders) and individual practices (disregarding algorithmic calculations and relying on their own experience) (e.g., Sun, 2019). However, it is acknowledged that the agency requires self-efficacy (Helsper, 2021), which can be challenging to attain under the constant pressure of algorithmic management (e.g., Bucher et al., 2021). Under what conditions users acquire and possess agency to act in their best interest remains open.
Developing algorithm literacy (RQ2)
In the following section, we outline the endogenous and exogenous factors of algorithmic media use and the user characteristics that shape AL. (For a summary and exemplary studies for each subcategory, see Supplementary Materials, SM-Table 2.)
Endogenous factors
Cotter and Reisdorf (2020: 754) and Swart (2021: 8) characterize algorithmic media as “experience technologies,” positing that individuals develop a basic understanding of algorithms through their engagement with algorithmic media. Thus, the characteristics of individual media use comprise relevant endogenous factors shaping experiential learning. Studies propose that
Usage episodes vary in
Exogenous factors
Exogenous factors influencing AL refer to elements beyond individuals’ direct experiences and actions that contribute to developing and enhancing their understanding and competence in navigating algorithmic media (DeVito et al., 2018). Our review suggests that interaction with others helps deepen critical reflection (Morris, 2020), including
Unlike peer exchanges, targeted
Finally, exogenous factors include information from
Overall, exogenous influences complement learning through algorithmic media by introducing external information and perspectives, potentially broadening individuals’ AL through exposure to diverse insights and knowledge beyond their immediate interactions with algorithmic media. More research is needed in this area since exogenous factors can balance the risks of self-referentiality and a lack of objective quality checks that come with learning from the personal use of algorithmic media. In this regard, Boulamwini (2022) takes a step further and advocates for evocative audits of algorithmic systems that “provide[s] personal/visceral evidence of algorithmic harms by using counter-demos to show real-world algorithmic systems failing in some way that expose systemic issues” (Boulamwini, 2022: 160) and create public awareness.
Personal characteristics
Various articles consider the influence of users’ personal characteristics on AL. Standardized empirical studies examine how
A relevant share of articles address the AL of
Research on digital inequalities indicates that homogeneous groups of lower socioeconomic status may not significantly improve their literacy through in-group exchanges (Helsper, 2021). Therefore, future research should explore how user characteristics moderate interpersonal and group interactions, identifying factors that foster awareness and factual knowledge. Here, it is crucial to consider both material resources, such as wealth, occupation, and formal education, as well as embodied resources, such as socialization based on education, ethnicity, and gender (Helsper, 2021: 182), since their interplay is crucial for understanding the dynamics of and inequalities in AL acquisition.
Outcomes of algorithm literacy (RQ3)
Outcomes of AL highlight the practical achievements enabled through algorithmic media in everyday contexts. Although often implied and serving as the normative basis for calls for increased AL, these outcomes are rarely explicitly examined, thus remaining a relatively uncharted territory. In our review, we align with Helsper’s (2021) argument on the importance of differentiating various outcome domains, as success in one literacy-related outcome may not necessarily translate into success in others. (For a summary and exemplary publications for each subcategory, see Supplementary Materials, SM-Table 3.)
To begin with, AL is linked with notable consequences on the individual level. Our analysis identifies heightened elaboration as a key
Finally, a segment of the literature examines personal well-being as an outcome of AL, albeit rarely as a focal variable. One exception is studies on challenges faced by women using algorithmic media to cope with pregnancy loss stigma, as algorithms targeting these women assume all pregnancies proceed as expected, thus leading to a decrease in their well-being (Andalibi and Garcia, 2021; Bogers et al., 2020). Additionally, research indicates that engagement in the platform economy negatively impacts well-being, inducing stress irrespective of individuals’ AL levels (e.g., Bishop, 2018; Curchod et al., 2020). We derive two observations from the reviewed literature: 1) the surprising underemphasis on well-being as a focal AL outcome, despite established links between media literacy and well-being (Schreurs and Vandenbosch, 2021), and 2) the predominant focus on adverse well-being outcomes of insufficient AL. In contrast, research on general digital literacy prioritizes resilience, akin to well-being, defined as “learning from past positive and negative experiences online to avoid negative outcomes and exploit ICT benefits in the future” (Helsper, 2021: 80).
Community building stands out as a central
Regarding
The extent of AL within a population can significantly influence broader
In summary, research on AL outcomes predominantly emphasizes the negative consequences of a lack of literacy, particularly for vulnerable groups. Indeed, the unequal adoption of AL is likely to exacerbate existing inequalities across diverse population strata since outcomes of AL are linked to individuals’ other resources, with disadvantaged individuals facing compound barriers in terms of access, competences, and norms in algorithmic media use (Helsper, 2021: 118). This points to the need to situate individuals within broader social and societal contexts to understand the dynamics of acquisition and outcome quality of AL.
Future research agenda
Toward an experiential learning framework for algorithm literacy
As illustrated previously, scholarship tends to treat algorithms as experience technologies (Cotter and Reisdorf, 2020; Swart, 2021), and while this idea is echoed within our sample, the literature needs a theoretical framework to integrate these findings. Based on our reading of the literature, we suggest that users acquire AL through algorithmic media use in a process that can be classified as experiential learning. We contend that the Experiential Learning Theory (ELT) proposed by Kolb (1984, 2015) offers a suitable framework for further thinking about AL in algorithmic media use. The core tenet of ELT is that “learning is the process whereby knowledge is created through the transformation of experience” (Kolb, 1984: 38). Accordingly, ELT treats learning as an ongoing, cyclical adaptation to the world through interactions between the individual and the environment (Vince, 1998). While this theory has been applied in other disciplines to explain learning experiences and outcomes (e.g., Morris, 2020), it has not received much attention in media and communication science outside of media pedagogy (for an exception, e.g., Greenberg, 2007).
ELT outlines four stages representing an idealized learning cycle: concrete experience, reflection on thoughts and feelings, abstraction by drawing conclusions, and experimentation involving behavioral adaptation based on prior conclusions (Kolb, 1984; Vince, 1998). Concrete experiences are “highly contextualized, primary, experience[s] that involve hands-on learner experience in uncontrived real-world situations” (Morris, 2020: 1070). In the context of AL (see Figure 4), concrete experiences involve encounters with algorithms in daily life through algorithmic media use, such as algorithmically curated news feeds, search engine results, or personalized content recommendations on streaming platforms. Based on these experiences, individuals become aware of algorithms and (ideally) reflect on these encounters. Reflection plays a central role in the learning process and is vital for making sense of the experience. With heightened awareness, individuals engage in abstract conceptualization (abstraction). ELT further suggests that learning is incomplete without applying knowledge in new situations. This involves testing the fit of abstract conceptualizations formulated against new concrete experiences (Morris, 2020). Concrete experiences with algorithms necessarily entail affective responses that accompany all learning cycle stages. In the preceding sections, we highlighted that literature suggests that people who use algorithmic media strategically are more likely to have a higher level of AL. This aligns with ELT, underscoring the importance of purposeful learning within specific contexts and concrete problems (Morris, 2020: 1069). The reviewed studies reveal that individuals engaging with algorithms in practical tasks or with specific goals are more motivated to learn and encounter more tangible learning opportunities. In the context of AL, active experimentation is manifested as (more or less) conscious adaptation in users’ engagement with algorithms. This involves experimenting with different online behaviors and observing algorithmic responses, refining one’s understanding and strategies in algorithmic interactions. In the preceding section, we categorized these strategies as alignment, compliance, subversion, and resistance.
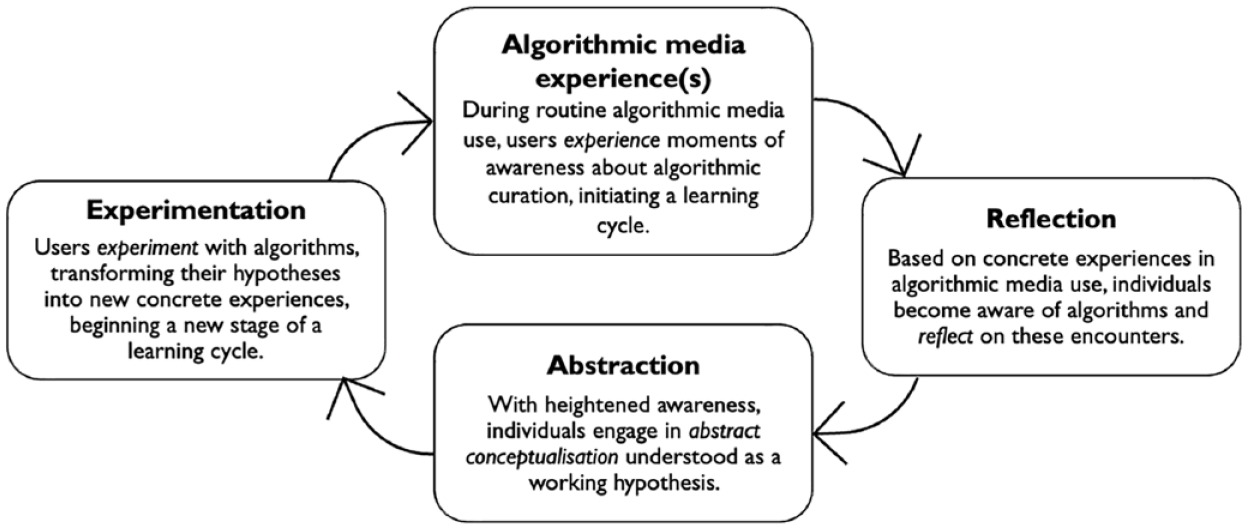
Experiential learning cycle.
The stages of the learning cycle are not rigidly delineated but rather fluid in nature, meaning that the learner “touches all the bases” in a “recursive process that is sensitive to the learning situation and what is being learned” (Kolb, 2015: 51). Since conditions of the context may change across time and place, “all knowledge is provisional and needs testing in context” (Morris, 2020: 1072). This aligns with literature describing learning through experience in algorithmic media use (specifically, see DeVito, 2021, on adaptive folk theorization). At the same time, because learning is always context-specific, ELT requires people to be comfortable with ambiguity and uncertainty related to new learning experiences (Morris, 2020: 1071).
By employing an established framework and aligning review findings with it, we hope to provide a structured foundation for future research endeavors to understand the acquisition and cultivation of AL. For example, the reviewed literature suggests that individual characteristics might moderate the learning cycle, with factors like the level of elaboration and topic involvement fostering abstraction and adaptation. At the same time, a lack of general digital literacy or a history of marginalization may hinder development (e.g., Helsper, 2021). Thus, future research should investigate individual factors and the circumstances under which user experiences, reflection, abstraction, and adaptation lead to an increased AL. In addition, according to Morris (2020), a fundamental aspect of the experiential learning process involves recognizing that knowledge is situated within specific contexts and evolves over time and space. Given that learning is context-dependent and involves managing ambiguity and dissonance (Morris, 2020), it is crucial to foster critical reflection on algorithmic experiences amidst the uncertainty often associated with them (Vince, 1998).
Beyond experiential learning: defining benchmarks and standardizing algorithm literacy
While we argue for the usefulness of ELT (Kolb, 1984, 2015) as a conceptual umbrella, experiential learning alone may not provide a comprehensive understanding of algorithms and one’s behavioral options. In fact, experientially developed AL might be self-referential and confined since it might drive adaptation based on impressions rather than a thorough grasp of the underlying algorithmic processes (cf. Morris, 2020). If being algorithmically literate ultimately means acting in one’s best interest through algorithmic media use (Das, 2023), AL must extend beyond establishing folk theorization, and we must determine what this best interest might mean in different domains. Thus, we see several critical avenues for 1) standardizing AL measures (e.g., developing scales and measuring AL across populations, cf. Dogruel et al., 2022) and 2) further elaborating on the relationship between subjective vs. objective (or “factual”) aspects of AL.
Related to standardization, we hope to have shown in this review that descriptive studies of AL are aplenty. Drawing from prior studies (Dogruel et al., 2022; Zarouali et al., 2021a), additional efforts are necessary to establish
The relationship between the subjective and objective aspects of AL requires better integration. While establishing absolute truths about algorithms is challenging (or perhaps impossible) due to their proprietary and dynamic nature, it is worthwhile trying to define a minimal set of competences as a baseline on top of which users can build. Consider the analogy of driving a car. Central to driving literacy is the objectively ascertainable knowledge of traffic regulations and the ability to operate a vehicle, typically acquired through formal instruction (exogenous factor). However, the effectiveness of this learning typically depends on the learner’s involvement and self-efficacy (endogenous factors). After acquiring basic knowledge, becoming a proficient driver requires further practice in various settings—driving different vehicles, traversing roads in different conditions, and customizing the driving experience to personal needs. The starting competencies remain central, but true proficiency develops through habituation and experimentation, resulting in individualized driving styles and preferences. Regarding AL, establishing fundamental competencies should go hand-in-hand with the development of contextual and experiential knowledge, where users refine their understanding through personal interactions with algorithms. This is contrary to the current situation, where users often lack a foundational baseline. With a solid base of objective knowledge, users could better develop their specific preferences, ideas, and strategies. This is to say that while we do not favor any specific dimension, we do wish to underscore that AL involves a mix of objective and subjective elements, shaped by endogenous and exogenous learning processes. In this context, formal education (exogenous) can provide a foundational understanding and create awareness for ethical considerations of algorithms (comparable, e.g., to knowledge on the environmental impact of cars), while personal experience and adaptation (endogenous) refine and deepen that knowledge to meet individual needs.
Researching algorithm literacy comparatively
The literature consistently suggests that cross-platform use enhances algorithmic learning. However, a systematic examination is warranted. To this end, we encourage scholars to carefully consider designations such as “the TikTok algorithm” or “the Facebook algorithm,” which, while acknowledging the context-dependent nature of algorithms shaped by specific platform affordances and vernaculars, can also reinforce the mystification of algorithms. Instead, we should consider algorithms as a collection of mechanisms that can be disentangled and studied separately, much like how we have learned to approach “the internet” not as a monolithic entity but as a bundle of mechanisms (Farrell, 2012). This shift in perspective would allow for a more systematic examination of how algorithms function across different platforms, and how algorithm literacy develops in various contexts. To this aim, we propose two approaches to cross-platform comparisons of AL. First, a user-centric approach would involve specifying focal-use goals (e.g., parenting, political information) and comparing individual user engagement, issue involvement, and affective assessments across platforms. This approach could directly examine the sought-after AL outcomes, enabling a finer understanding of how users interact with and learn about different algorithms. Second, an algorithm-centric approach would compare algorithms that execute specific tasks across platforms, focusing on how users understand these functions. While proprietary mechanisms often obscure the inner workings of algorithms, it is known that they are designed to fulfill specific roles for platform users. By systematically disentangling these mechanisms, we can begin to demystify algorithms.
Conclusion
Researching algorithm literacy in the ever more complex landscape of algorithmic media platforms is a formidable challenge, not least because these platforms often lack the bedrock of good governance principles—clarity, stable norms, and consistent enforcement (Cotter, 2023). Thus, the essence of AL contends with the underlying logic of platform capitalism, which thrives on intentional obscurity and frequent algorithmic changes designed to keep users uninformed and powerless (Curchod et al., 2020; Petre et al., 2019). It is in this intentional uncertainty that phenomena like algorithmic precarity find their roots, revealing that adverse outcomes do not solely stem from a lack of AL but from the deliberate ambiguity cultivated in algorithmic moderation. Furthermore, platform capitalism encourages different actors to play each other through and around algorithms (Ramizo, 2022), highlighting the ambivalence in how AL is applied and underscoring that it is not just about individual empowerment but also about reshaping power dynamics in algorithmically mediated interactions.
For us as researchers, this means that we must reflect on the extent to which our work and the way we frame it unintentionally normalize platform capitalism. This is particularly significant for groups with constrained resources, limited capacities, and heightened vulnerability to exploitation or misinformation. We also need an honest normative debate about attainable levels of AL relevant to different outcomes, all while considering inequalities in personal and structural capacities (Helsper, 2021). Also, while we have argued that AL is relevant for navigating various domains effectively, it is but one facet of competences needed to improve working conditions, mobilize for social causes, fight marginalization, or establish meaningful interpersonal connections. Thus, we encourage future research to pursue interdisciplinary inquiries to fully grasp the requirements for and implications of AL across diverse domains. Confronting these challenges urges us to delineate the boundaries between individual responsibility and collective demands directed at platforms and regulators. This implies a shift from merely prescribing what individuals should learn to advocating for systemic changes that foster an equitable, transparent, and informed digital society.
Supplemental Material
sj-pdf-1-nms-10.1177_14614448241291137 – Supplemental material for Algorithmic media use and algorithm literacy: An integrative literature review
Supplemental material, sj-pdf-1-nms-10.1177_14614448241291137 for Algorithmic media use and algorithm literacy: An integrative literature review by Emilija Gagrčin, Teresa K. Naab and Maria F. Grub in New Media & Society
Supplemental Material
sj-pdf-2-nms-10.1177_14614448241291137 – Supplemental material for Algorithmic media use and algorithm literacy: An integrative literature review
Supplemental material, sj-pdf-2-nms-10.1177_14614448241291137 for Algorithmic media use and algorithm literacy: An integrative literature review by Emilija Gagrčin, Teresa K. Naab and Maria F. Grub in New Media & Society
Supplemental Material
sj-pdf-3-nms-10.1177_14614448241291137 – Supplemental material for Algorithmic media use and algorithm literacy: An integrative literature review
Supplemental material, sj-pdf-3-nms-10.1177_14614448241291137 for Algorithmic media use and algorithm literacy: An integrative literature review by Emilija Gagrčin, Teresa K. Naab and Maria F. Grub in New Media & Society
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.