
Abstract
As a sociotechnical practice at the nexus of humans, machines, and visual culture, text-to-image generation relies on verbal prompts as the primary technique to guide generative models. To align desired aesthetic outcomes with computer vision, human prompters engage in extensive experimentation, leveraging the model’s affordances through prompting for style. Focusing on the interplay between machine originality and repetition, this study addresses the dynamics of human-model interaction on Midjourney, a popular generative model (version 6) hosted on Discord. It examines style modifiers that users of visual generative media add to their prompts and addresses the aesthetic quality of AI images as a multilayered construct resulting from affordance actualization. I argue that while visual generative media holds promise for expanding the boundaries of creative expression, prompting for style is implicated in the practice of generating a visual aesthetic that mimics paradigms of existing cultural phenomena, which are never fully reduced to the optimized target output.
Keywords
Silicon-based intelligence of AI-enabled image generators is often described as magic. A discourse of enchanted determinism (Campolo and Crawford, 2020) serves AI impresarios to capture public trust, framing visual AI as a new medium of thought to “expand the imaginative power of the human species” (Midjourney), “translate ideas into exceptionally accurate images” (DALL·E 3), and “provide users with a variety of options for scalability and quality to best meet their creative needs” (Stable Diffusion 3). In Heidegger’s sense of Being and Time, machines can indeed be conceptualized as tools since they, like humans, operate on the basis of language. However, in a world in which machines are becoming more computationally powerful, claims about accuracy and superhuman creativity are increasingly paired with the inability to understand how deep neural networks lead to such extraordinary visual outputs. The magic of visual generative media lies in their enigmatic and unpredictable processes (Chesher and Albarrán-Torres, 2023) and manifests in a visual aesthetic of AI images invoked through prompting.
As the main algorithmic technique to direct foundation models of text-to-image generators, prompting entails crafting natural language descriptions of the desired visual outputs by adding prompt “modifiers,” or short key phrases (see Oppenlaender, 2023), which specify representational content (e.g., subject matter, setting), technical aspects (e.g., aspect ratio, region variation), and visual aesthetic (e.g., style, art movement) (Feng et al., 2023; Liu and Chilton, 2022). Among these, style modifiers raise the most questions because, in addition to specifying technical aspects of visual composition, they allow users to mimic the style of human artists, serving as a shortcut to achieving desired visual outputs. This shortcut is either enabled by the system through associations made from training data containing copyrighted artworks scraped from the web, or by the human prompter, through style modifiers introduced to a prompt, such as –stylize on Midjourney or in the style of on DALL·E 2. Both practices are far from unproblematic and require critical appraisal.
Drawing on the earlier work on text-to-image generation as a sociotechnical practice at the nexus of humans, machines, and visual culture (Laba, 2024), I address style modifiers as an entry point into a critical study of human-model interaction through prompting. This investigation primarily focuses on the nuances of such interaction in relation to what this paper terms prompting for style, which involves adding style modifiers to a text prompt to achieve a particular visual aesthetic in AI-generated images. More specifically, I ask:
RQ1: Which style modifiers do users of visual generative media add to their prompts to produce desired visual outputs?
RQ2: How might prompting for style be more adequately thought through in both practice and theory?
The primary objective of this study is to enhance the current understanding of human-model interaction 1 dynamics through prompting and to explore the extent to which generative models can be seen as facilitators or arbiters of originality. Focusing on user discussions about the platform affordances of Midjourney (version 6), a popular generative AI model hosted on Discord, I examine the practice of prompting for style on the #prompt-chat channel of Midjourney’s Discord server, a “dedicated discussion room for talking about how to craft prompts.” This space offers an insight into a user perspective on AI image generation, pointing to the value of community learning in the context of unpredictable machine behavior while also revealing affordances that enable questionable production practices around style recontextualization without proper attribution. I argue that while visual generative media holds promise for expanding the boundaries of creative expression, prompting for style is implicated in the practice of generating a visual aesthetic that mimics paradigms of existing cultural phenomena, which are never fully reduced to the optimized target output. Discussed next, prompting for style as a technique to produce desired visual outputs positions this work within the existing literature.
Prompting for style as a pixel predictor
As direct-to-consumer interfaces, visual generative media enable creation of novel images, providing opportunities for both novices and experienced users to supplant previous visual production methods with generation (Burkhardt and Rieder, 2024) in response to verbal prompts initiated by human actors. The growing interest in semantics of natural language as a form of human-model interaction has seen emergent research efforts to tackle the open problem of prompting in large foundation models, mostly from computer science and human-computer interaction (HCI) perspectives. This body of research advances the current understanding of how people interact with generative models, contributing to practitioner knowledge of text-to-image generation. In other words, its focus is on how to maximize the system’s capacity to render accurate representations, enhance aesthetic quality, and achieve cohesive visual outputs.
For example, Pavlichenko and Ustalov (2023) experimentally demonstrate how a set of keywords for Stable Diffusion (version 1.4) improves the aesthetics of generated images, most of which relate to visual effects (e.g., cinematic, colorful background, dramatic lighting, high detail) and art references. Feng et al. (2023) offer computational and practice-based solutions to interactive prompt engineering, such as PromptMagician, a visual analysis system that provides a multi-tiered visualization of retrieved images with suggested prompt words, supporting users in setting various criteria for personalized prompt refinement. Liu and Chilton’s (2022) design guidelines on prompt engineering identify successful themes across styles, such as salient color palettes, relevant textures, appropriate lighting and perspective, and motifs. Their extensive experimentation involves prompt modifiers and model hyperparameters across three partitions of styles, understood by the authors as “keywords” to suggest an aesthetic within a generation, such as abstract versus figurative, Western versus non-Western, and styles partitioned by period (premodern, modern, and digital). Similarly, Oppenlaender (2023) proposes a taxonomy of prompt modifiers (or “keywords” in Liu and Chilton’s sense). This (auto)ethnographic study makes references to a collection of style modifiers or details about “art periods, schools, and styles, but also art materials and media, techniques, and artists” (p. 7), demonstrating how these can help to reproduce a characteristic style (e.g., #pixelart) and artistic medium (e.g., oil on canvas).
Perceptual attributions of creativity to the machines—what Natale and Henrickson (2024) term the Lovelace Effect—have been studied through techniques like image quality assessment (IQA) (Comb et al., 2024), demonstrating that people assign AI images higher ratings on certain metrics compared to human-made art (Elgammal et al., 2017) but negatively assess “artwork” produced by generative models due to the lack of ascribed mind in terms of machine agency and experience (Messingschlager and Appel, 2023), which are traditionally seen as human qualities. From a user-model interaction perspective, Oppenlaender (2022) argues for machine creativity arising from “the text-based interaction of human users with text-to-image generation systems” (p. 196). Hence, determining whether the value of a specific AI image framed as “AI art” should be based on the technological intricacy and innovation employed in its creation, or solely on its perceptions by humans, proves challenging (Cetinic and She, 2022).
The ongoing debate about the interplay of machine originality and repetition corresponds with contemporary discourses on posthumanism that contrasts with anthropocentric AI (see, e.g., Mellamphy, 2021), the proponents of which aim to safeguard communities against the overshadowing of human values and potentially distorted perception of the world by AI (Boddington, 2021). Viewed this way, creations of generative models are “forms of aesthetic mimicry” (O’Meara and Murphy, 2023: 1070), where celebrated aesthetic brilliance of machine originality emerges from repetition, and “one repeats because one doesn’t know or cannot do and becomes equal or similar through becoming identical, acquiring an identity as fixity” (Goriunova, 2012: 49).
When particular style modifiers are introduced, a generative model produces visual outputs that emulate aesthetic qualities of existing works on which the model has been trained. As such, the system operates on the basis of procedural imitation of what it has “seen” at training through a statistical pattern distribution (Pasquinelli, 2019). In other words, the model does not copy the training data directly but looks for patterns between pixels and verbal captions compared against prompt words during image generation. According to Tilford (2024), this results in “a synthetic imagination” that mimics existing cultural products, thereby granting users “a form of artistic subjectivity previously unavailable to them because of its practical unattainability” (p. 130). Similarly, for Zeilinger (2021), text-to-image generators are “generative adversarial copy machines” capable of both conformity and subversion to established norms of creativity, as “aligned with a progressive (posthumanist) notion of expressive agency that contradicts romantic ideals of creativity and originality, and which, in doing so, also challenges the cultural logic of intellectual property” (p. 12).
In sum, the practice of human-model interaction raises complex questions regarding the distribution of agency and the extent to which generative models serve as facilitators or arbiters of originality, highlighting the unresolved tension between innovation and imitation inherent in visual generative media. In the context of the machine originality/repetition debate, 2 Denson (2023) argues that a turn to art and creativity might be misguided altogether because the notion of machine intelligence obfuscates the agency of people—both those holding authority and those being exploited to sustain that authority. Any examination of AI’s role in shaping the future of creative practice, as suggested by Atkinson and Barker (2023), should consider the contexts of AI’s use and application. Entanglement with practice—that is, how users reshape their practices to manipulate the algorithms they depend on (Gillespie, 2014: 168)—can elucidate which interactions with a generative model are possible through the system’s interface. Seen from a media practice perspective, the power of visual generative media does not reside solely within the algorithm itself but in the “ever-changing outcome of its enactment” (Passoth et al., 2012: 4) through platform affordances (i.e., perceived action potentials) of different prompt modifiers. Affordance actualization theory, introduced next, helps to identify key constructs involved in AI image generation and how the relationships between these constructs can be addressed to explain the dynamics of human-model interaction.
Theoretical framework: Affordance actualization
An overarching theoretical framework for this study is affordance actualization theory (AAT), useful for addressing the relationship between an actor and a technological system (Bao et al., 2023; Strong et al., 2014). AAT is concerned with how users of technological systems perceive and utilize affordances (i.e., possibilities for action signaled by a technological environment), and how, in turn, affordances relate to action possibilities for goal-directed actors rather than actual actions, objects, or states (Volkoff and Strong, 2017). Affordance actualization involves an interplay between affordance perception, which is shaped by users’ goals and capabilities, and affordance enactment, where these perceived opportunities are acted upon to produce desired outcomes (Bernhard et al., 2013).
While AAT has been instrumental in fields such as HCI and organization studies, 3 it has the potential to complement media studies approaches to critical issues around liminal technologies such as generative AI. The relational actor-affordance property is essential in technological system implementation and use (Bao et al., 2023), and, in the context of AI image generation, prompt modifiers offer action possibilities to direct the opaque foundation models toward desired visual outputs. Seen from an AAT perspective, a human prompter is a goal-oriented actor who perceives a style modifier as an affordance to be acted upon to achieve certain stylistic outcomes. Such affordance is also “imagined” because it evokes “expectations for technology that are not fully realized in conscious, rational knowledge but are nonetheless concretized or materialized in socio-technical systems” (Nagy and Neff, 2015: 1). Importantly, affordance actualization in visual generative media environments does not necessarily lead to desired visual outcomes due to the technological complexity of the system (Ananny and Crawford, 2018) and model uncertainty (Combs et al., 2024).
An examination of prompt affordances identified from user discussions rather than user manuals and guidelines will provide an insight into which style modifiers human prompters experiment with to enact envisaged stylistic outcomes. The study proceeds with the analysis of the most widely used affordances of Midjourney, one of the most popular image generators to date. More specifically, the focus is on how human prompters identify the system’s capacity to manipulate the style of AI images through Midjourney’s affordance actualization.
Midjourney uses: Parameters of style and their effects
Midjourney (MJ hereafter), created by the independent San Francisco–based research lab Midjourney Inc., differentiates itself by hosting its image generator on a Discord chat server (Salkowitz, 2022). As a communication platform designed for community building, Discord has been valuable in enabling and facilitating chat-based groups centered around particular topics (Oppenlaender, 2023), with features like servers (communities centered around particular topics), channels (discussion spaces within a particular server), and customizable roles (permissions and labels assigned to users that define what users can see and do on a server). While other prominent image generators such as Adobe Firefly and Leonardo AI also have dedicated Discord servers, real-time image generation is only enabled on MJ’s Discord. In this way, MJ provides a unique platform where users both generate images and learn from each other about how to design effective prompts, with the ambient co-presence of the founder David Holz (@DavidH) across its seventy-nine channels.
On MJ’s Discord, image generation unfolds across channels labeled #general and #newbies. In April 2024, twenty channels under #general (#general 1–20) and four newcomer rooms (labeled as #newbies-8, #newbies-38, #newbies-68, and #newbies-98) were available. Image generation is only possible on these twenty-four channels, with other channels serving other purposes, which vary in terms of participatory power distribution, from top-bottom (e.g., announcements, rules, support, community guidelines, prompt-faqs) to community discussions (e.g., #prompt-chat, #discussion). User guidelines (https://docs.midjourney.com) specify that the MJ bot generates images by breaking down “the words and phrases in a prompt into smaller pieces, called tokens, that are compared to its training data and then used to generate an image.” After users input verbal prompts starting with a command
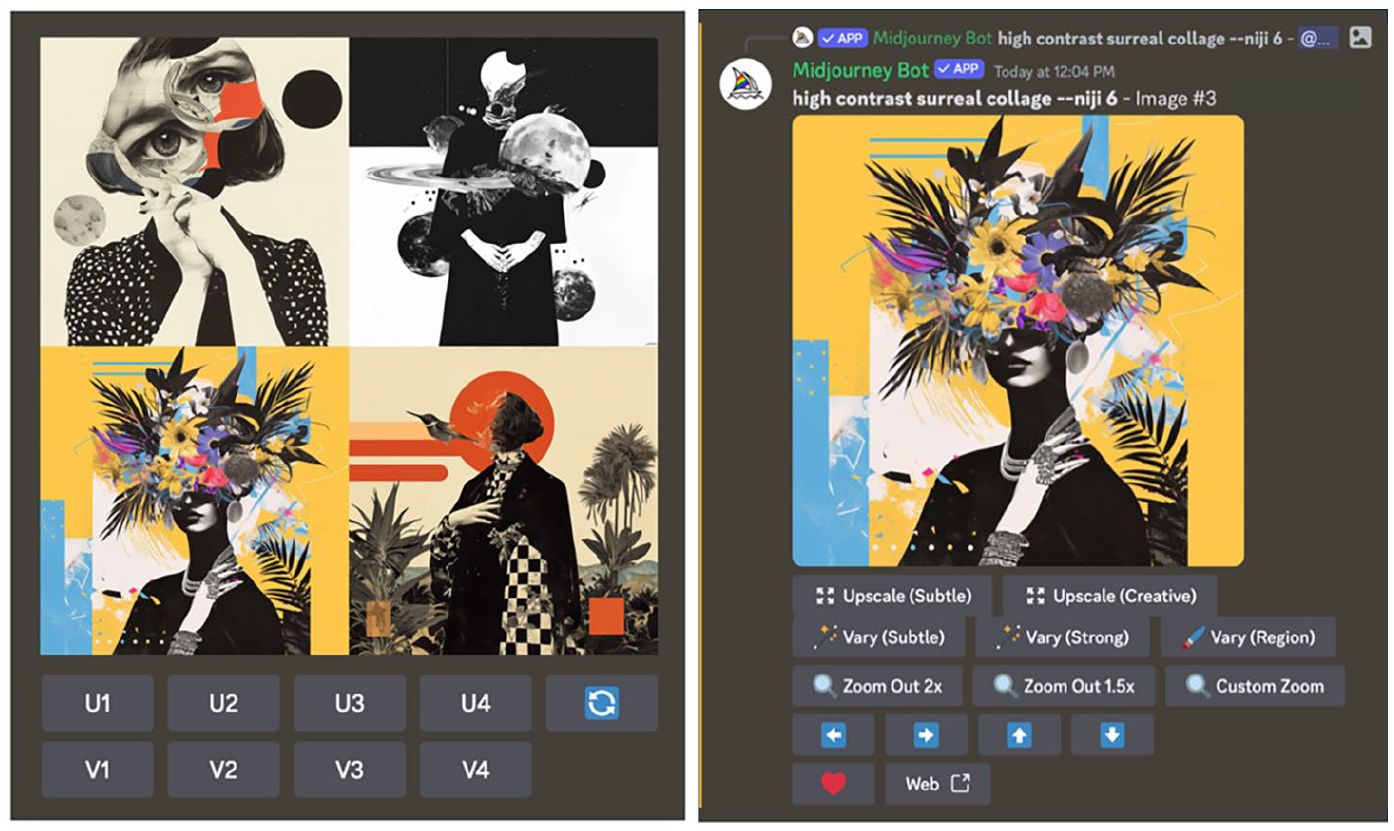
Model-to-human feedback options on Midjourney. Prompt: A high-contrast surrealist collage –niji 6 (Author, 22 April 2024). Left: first-order options. Right: second-order options.
First-order options (Figure 1, left) include: (i) select any of the four images generated to the initial prompt with the U+image number command, (ii) generate different versions of any of the four images with the V+image number command, and (iii) repeat the generation process for the same prompt with the ♻ command. Unlike traditional visual production tools and photo editors that aim at a refined version of the original image, the edited AI-generated outputs result in entirely new images that meet prompt criteria with varying degrees of accuracy.
Second-order options (Figure 1, right) include upscalers, variations, custom zoom, and panning (i.e., expanding) any of the four zones of visual composition (indicated by arrows). Among these, subtle and creative upscales enhance the quality of the original image and double the size of the image to 2048 x 2048 pixels; variations (subtle, strong, and region) are guided by the content in the original image and the area selected for variation; zoom-out options change the positioning of the image subject in relation to the user. On the whole, possibilities for human-centered editing of the original designs of AI-generated images in MJ are limited to several options across two orders (Table 1).
A summary of the model-to-human feedback options on Midjourney.

Second-order options resemble a simplified version of traditional Adobe Photoshop, the use of which requires some level of expertise in graphic design, with human input guiding every aspect of the editing process. In contrast to Photoshop, the MJ algorithm has disproportional control over the final output, with a limited set of affordances for modifying generated images. Similar to the overarching logic of human-computer interaction, the feedback loops from the model to the user rather than the other way around, which often distorts human insight and intention (Kittler, 2006). Unlike traditional error messages in the computational code, the feedback from image generators materializes as a visual output in the form of four images generated in response to a prompt, along with a limited set of options to edit the selected images.
Given the importance of prompting for the actualization of MJ’s affordances, the #prompt-chat is where discussions around prompt experimentation are most pronounced. To identify the most widely discussed prompt modifiers, I analyzed over 13,000 chat messages exchanged between users on the #prompt-chat channel over two weeks from April 1 to April 14, 2024. The period and volume were selected due to two reasons.
Firstly, I aimed to access the most recent discussions of MJ’s affordances at the time of writing. The then-default model of MJ, version 6 (v 6), released in December 2023, introduced a new feature called the style raw parameter (discussed in the next section), which is relevant to the study of prompting for style. Collecting the data about four months after the release of this new feature ensured that regular users had time to experiment with different style parameters and form opinions about their effects on the visual aesthetics of AI images. Secondly, to collect the data, I used the Google Chrome extension Discordmate, a Discord chat exporter that provides access to the chat history, allowing the capture of data organized in HTML and CSV files. Because Discordmate supports exporting only 1,000 chat logs between certain dates, only 13,695 chat messages could be captured out of 15,730 messages shared in two weeks (see Appendix I). During this period, an average of 900 messages were exchanged daily, with the number ranging from 874 to 1,484 messages per day.
The analysis was conducted with Voyant, an open-source software managed by Sinclair and Rockwell (2016). Identifying handles were removed during the data cleaning process to preserve user anonymity. Six users were found to be the most active on the #prompt-chat channel, accounting for 40.4% of mentions (5,545 total; min = 400 mentions per user). From their Discord profiles, these users appeared to be human prompt engineering enthusiasts, with five of them holding the roles of a pro-member and a guide. Presumably, these roles were assigned by the server moderators for active participation and meaningful contribution, although this kind of information is not available to laypersons. The six most active commenters on the channel were found to regularly participate in promptcraft volunteer rosters and engage in playtesting new channel activities, with no indication that they could possibly be MJ’s employees or bots like Charon the FAQ Bot.
Out of 400,941 total words and 14,919 unique word forms, the top five most frequent words in the corpus were prompt (2,095), image (1,666), like (1,454), style (1,251), and get (1,067). Figure 2 shows a word cloud of the fifty most frequent words in the corpus (see also Appendix II). The terms that appeared most frequently are positioned centrally and are sized the largest.

Fifty most frequently used words on the #prompt-chat channel 1–14 April 2024. Produced with Voyant (http://www.voyant-tools.org/?view=Cirrus), 20 April 2024.
To unpack user discussions around affordances of prompting for style, I examined the top five collocates co-occurring with the word “style” over a hundred times. In Table 2, “count” shows the raw frequencies of words that appear near “style” in the proximity of five words (“~5”), and “relative” stands for the relative frequency of this term per million.
Top five collocates with the term style on the #prompt-chat channel of Midjourney’s Discord server between 1–14 April 2024.
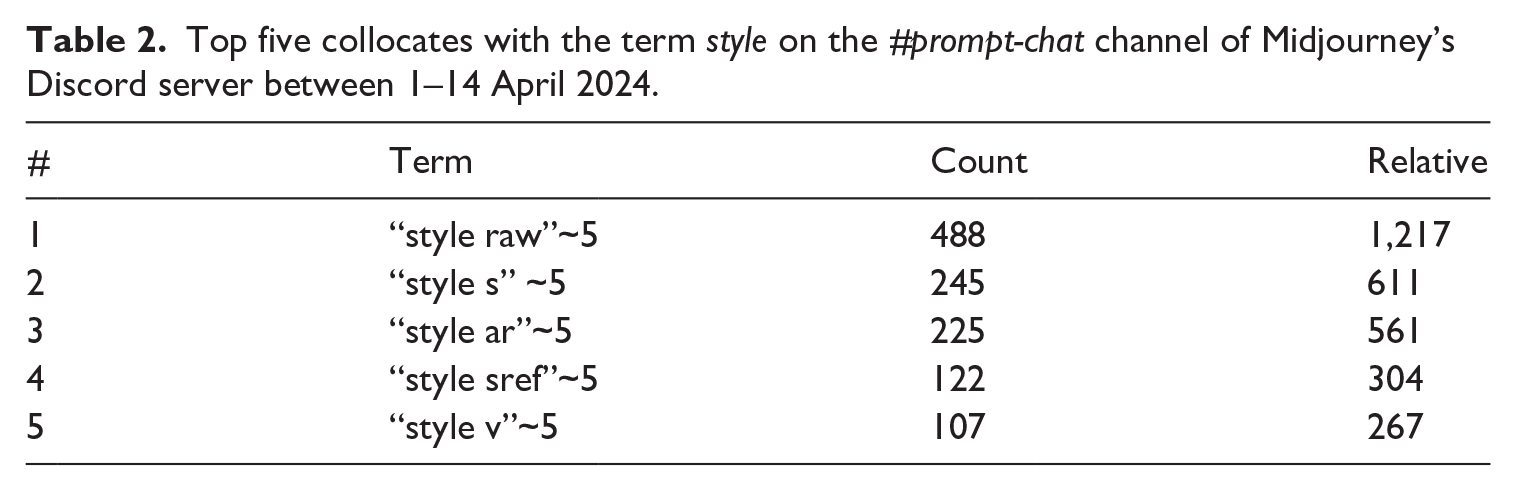
The frequencies of five collocates with the term
On MJ, style refers to a specific parameter, or an option that can be added to the prompt to impact the visual output. By default, when the style is not specified, MJ’s “house style” is applied. In MJ model version 6, the new
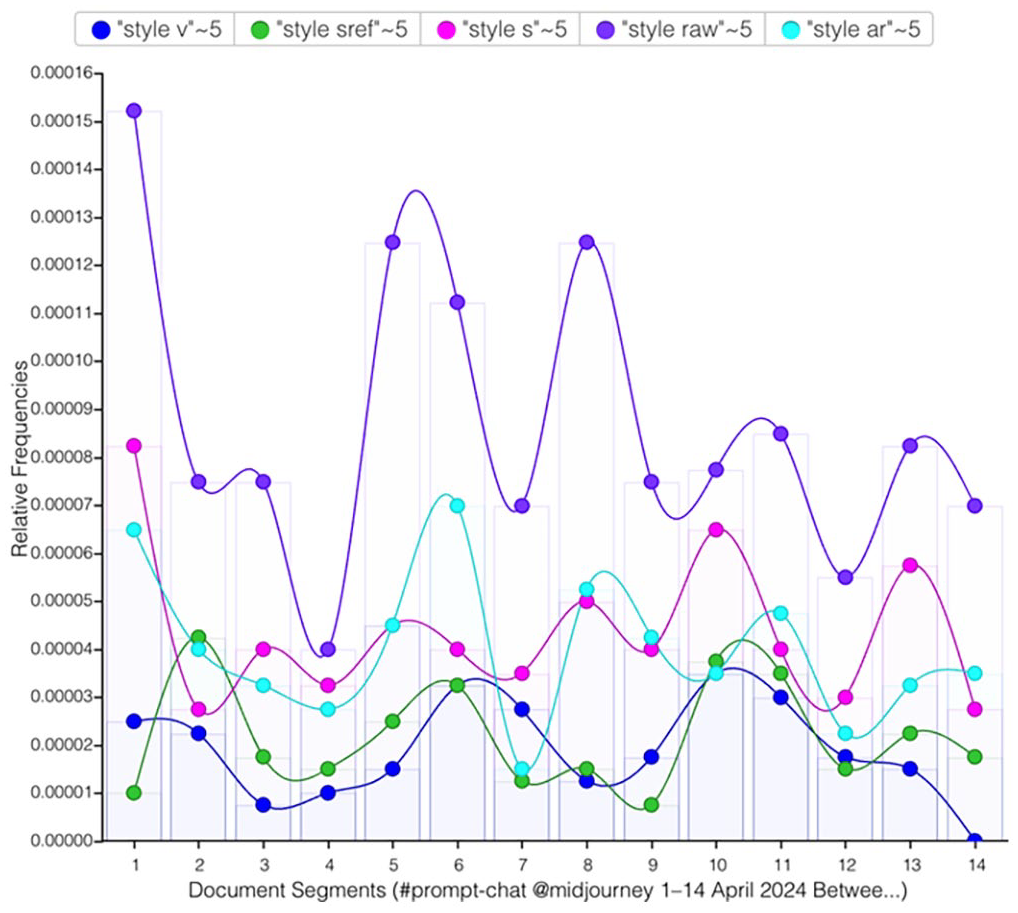
Five most frequently discussed style-related parameters on the #prompt-chat channel. Produced with Voyant (http://www.voyant-tools.org/?view=Trends).

Effects of the –style raw parameter on the visual aesthetics of AI images generated with Midjourney. Prompt: The flower bomb, graffiti-style painting, in the style of Tom Swain / Dript (Author, 3 May 2024). Artist’s work: https://driptart.wixsite.com/dript-art.
The

Effects of the stylize (–s) parameter on the visual aesthetics of AI images generated with Midjourney. Prompt: A finite slice of infinite space, in the style of Bram Braam, –s <value> (Author, 3 May 2024). Original artwork: https://www.brambraam.com/artwork/a-finite-slice-of-infinite-space.
Another technical parameter that refers to the aspect ratio or the canvas size is

Aspect ratio chart of the most typical values in Midjourney. Prompt: Girl with the balloon, Banksy –ar <value>:<value> (Author, 3 May 2024).
Discussions of style often revolved around troubleshooting, which gives an additional insight into the inconsistent workings of MJ despite user specification of prompt modifiers. For example, in a thread below, @user1 (the most engaged discussant of the #prompt-chat channel, with 3,302 mentions across two weeks) shares advanced solutions around style manipulation:
This discussion indicates that the model does not always actualize specified style affordances, and users devise their own techniques to produce desired outputs while also developing literacies around the quality of prompts and their robustness.
The
To test the impact of the –sref parameter on the aesthetics of the visual output, I used Martine Mooijenkind’s collage as a style reference. The resulting images closely resembled original artwork’s style, content, and composition (Figure 7).

The style reference parameter –sref < URL > in Midjourney. Prompt: A surrealist collage –sref <URL> (Author, 23 April 2024). Original artwork She was the World by Martine Mooijenkind: https://www.saatchiart.com/art/Collage-She-was-the-world/1033395/8344210/view.
From Figure 7 the –sref parameter mimics original artworks without proper attribution, which raises questions about intellectual property and artist rights. The character references –cref, a parameter that can be used with MJ and Niji version 6 4 , also features prominently in the #prompt-chat discussion (569 mentions), which suggests that this parameter is widely applied to copy image subjects (i.e., characters).
The last most frequently discussed and perhaps least problematic parameter is
From earlier observations of MJ’s prompting style, the ChatGPT style was often used by newcomers who appeared to have little experience with prompting. The upgraded instruction-like prompt style in –v 6 contrasts with the prompt tips for earlier versions, which preferred clipped prompt semantics (see, e.g., Parsons, 2022). As generative models evolve, users adapt their prompting techniques to mitigate model unpredictability and maximize its efficiency.
Discussion: Directing the visual aesthetic and composition of AI images
The analysis reveals that users of visual generative media have two avenues for directing the visual aesthetic and composition of AI-generated images—(i) integrating several technical parameters (i.e., style modifiers) into prompts and (ii) selecting from predetermined options outlined in Table 1. Human control over the output is proportional to the level of abstraction—while straightforward options to select, regenerate, zoom out, pan, and specify the aspect ratio are generally executed with a high degree of precision, the options to vary, upscale, and stylize are far more unpredictable. Because the system is set to optimize for opaque associations between its parameters produced during deep learning (Jacobsen, 2023), machine visions and visions of the human prompters often diverge.
Due to nuances of deep learning and the increasing complexity of proprietary models, prompt actualization involves considerable experimentation as each model behaves differently after it learns new patterns from the new data, “both to discover and optimize capabilities and to understand what renders a particular outcome satisfying or “authentic” (Burkhardt and Rieder, 2024: 8). The value of community learning is arguably heightened precisely because unpredictable behavior of generative models poses practical challenges in aligning human vision with built-in functionality. As such, MJ’s Discord server points to a dynamic community that emphasizes peer learning, with some users taking on mentor roles, fostering discussions around the aesthetic outcomes and styles of AI images.
On the #prompt-chat channel, style is conceived of as a problem that can be solved by manipulating image composition and visual aesthetic through a set of perceived affordances. These affordances are actualized through technical parameters such as –style raw, –s, –v, –ar and –sref, which vary in their purposes and outcomes. The most popular affordances range from image modality (–style raw and –s) to size of the frame (–ar) to “calling” a model version (–v) known for its aesthetic particularities and recontextualizing styles without proper attribution (–sref). The parameters –ar and –v can be seen as purely technical, subject to most human control, evoking system functionality, while the –style raw and –s parameters are far more ambiguous. Alongside the opportunity for a more realistic or less detailed aesthetic, –s influences the extent to which artistic composition, forms, and color are applied, while –style raw has the potential to contribute to visual deception, allowing to generate less polished images that approximate photos taken by everyday users. 5
The –sref parameter raises the most questions, particularly around intellectual property and copyright, as it is a direct way to mimic any image available on the web, art or otherwise. The prompt-faqs community forum states that style references only “roughly transfer aesthetic style to your canvas,” but in reality, –sref also transfers composition, subject, and style, bypassing the limitations of its training data (see Figure 7). This means that even if the model has not been trained on a particular artist’s piece, MJ provides its users with a quick way to access, scan, and copy the style of any artist who publicly shares their work online, as long as it is available in a .jpg format. Equally alarming are additional options to bypass even this limitation, shared on the same channel. Users are provided with an option to upload any image and send it to the MJ bot in a private message, akin to a private interaction with other Discord users. They can then generate a link to the uploaded image in one click and use the –sref parameter to copy the artist’s style. In sum, MJ has the computational power to both generate images and analyze external data, copying not only the salient features of referenced images but also their characters (i.e., subjects), backgrounds, visual compositions, and styles.
Overall, discussion on the#prompt-chat channel revolves around maximizing the system’s capacity to render visual outputs more closely aligned with the vision of human prompters. In this sense, MJ serves as a medium that precludes the human vision or, as Paul Klee might say, makes the invisible visible, opening onto a future that should not be constrained to a solitary, perfected endpoint (Amoore, 2019). As a dynamic but ambiguous entity responsive to changes in context (Kim et al., 2023), generative models also enact time in that they produce visual outputs in a matter of seconds, challenging temporalities of traditional visual production, and in doing so, provide several shortcuts to producing a desired visual aesthetic. This is particularly evident in user discussions around style, featuring prominently on the #prompt-chat channel. For MJ users, style is thought of not as an artistic skill driven by “the motivation of a human artist to make human connections” (Volz, 2018) but as a series of predictive values associated with verbal descriptors to generate desirable outputs.
Affordance actualization theory, which emphasizes the interplay between the social and material aspects of technology use, offers a valuable lens for understanding the dynamics of human-model interaction, contributing to a more nuanced picture of how generative models afford new possibilities for action. As the first (to the best of my knowledge) study to theorize prompting for style as affordance actualization, this work establishes a foundation for future scholarly inquiries and encourages further research on how evolving technical features of generative media impact the dynamics of agency in the context of human-model interaction.
Conclusions, limitations, and future research
Taken on the whole, the results of this study suggest that visual generative media hold potential for expanding the boundaries of creative expression through both design features of the system and prompt parameters. However, what should not go unnoticed are the hidden processes of technical layering involved in the generation and questionable practices of style mimicking through affordances framed as innovations that benefit the users. It is imperative to address the questions of originality and creativity in the context of visual generative media together with how computation takes place (Kittler, 2006), beyond a glossy veneer that presents deep learning techniques as magical, seemingly beyond the scope of present scientific knowledge (Campolo and Crawford, 2020: 3). In an environment where data takes precedence and human artistic skill is relegated to the background, creativity should not be conflated with the mastery of technical parameters—some of which encourage questionable visual production practices.
Shifting the focus from the ontological creativity of generative models to human-model interaction allows us to address the originality of AI images as a multi-layered construct resulting from affordance actualization. On a deeper level, the originality of AI images can be understood as a cline that instantiates prompt modifiers with varying degrees of human control over visual output. Among the five main technical parameters, –ar executes human vision with a high degree of precision; –s, –v, and –style raw guide the model toward certain values with a lesser degree of model certainty; and –sref mimics existing cultural phenomena without proper attribution. Ultimately, the originality of visual generative media lies in its ability to detect statistical patterns in the extensive datasets on which it has been trained. The disproportional power rests with the platform and its creators, who determine which artistic works can be mimicked and which prompts are deemed appropriate (see note 5).
The current study engaged in a critical examination of the capabilities of Midjourney, addressing how its users leverage platform affordances to enact a visual aesthetic through sociotechnical assemblages comprising different components, including data, algorithms, fellow users, platform creators, and cultural phenomena entangled with data objects. Focusing on people’s practices around prompting for style, I demonstrated how style is conceptualized as an end goal that can be reached through prompt parameters, some of which (–style raw, –s, –ar, and –v) orient toward maximization of the system’s capacity to produce desired outputs while others (–sref) directly abstract people away. Future research could further examine affordance actualization practices among a more diverse range of lay users, as this study found that a select group of prompt experts seemed to dominate the conversation. It is possible that the most active and experienced users prefer certain solutions. An in-depth qualitative study and thematic analysis of user discussions about platform affordances would complement the current findings.
While this study investigated affordance actualization practices of MJ’s users, it is essential to acknowledge the limitations in generalizing findings to other visual generative media. Due to nuances of deep learning, each model behaves differently after it learns new patterns from the new data. Consequently, it is important to recognize and address these dynamics as well as new features that will become available with the release of new models.
Future research could expand the analysis to other prominent image generators such as DALL·E 3, Adobe Firefly, or DreamStudio by Stability AI, as well as external prompt discussion channels such as Reddit or X, to investigate whether these platforms provide options for style recontextualization without proper attribution equivalent to MJ’s –sref. Such insights could inform regulatory acts and policies aimed at “provably beneficial AI” (Russell, 2022) to ensure that its “habitual use by individuals and society does not warp or eclipse our values and our goals and does not distort or obscure our view of the world” (Boddington, 2021: 109). As AI capabilities become increasingly integrated into existing products like Adobe Photoshop and Pixlr, how users respond to these innovations and the implications that follow also remain open for critical investigation.
Footnotes
Appendix
Top fifty most frequent words on the #prompt-chat channel, Midjourney’s Discord server, between 1–14 April 2024 (raw count).
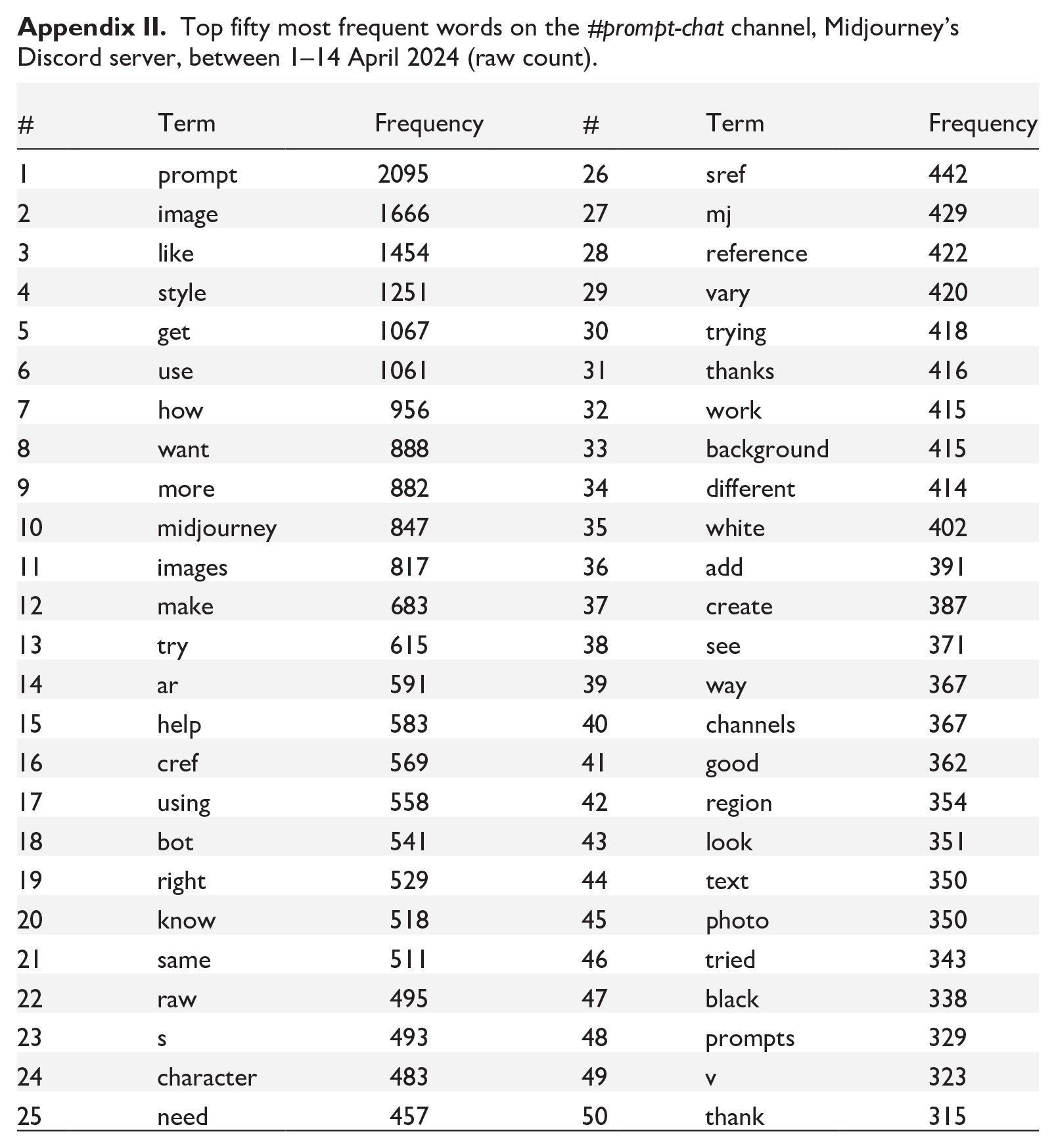
| # | Term | Frequency | # | Term | Frequency |
|---|---|---|---|---|---|
| 1 | prompt | 2095 | 26 | sref | 442 |
| 2 | image | 1666 | 27 | mj | 429 |
| 3 | like | 1454 | 28 | reference | 422 |
| 4 | style | 1251 | 29 | vary | 420 |
| 5 | get | 1067 | 30 | trying | 418 |
| 6 | use | 1061 | 31 | thanks | 416 |
| 7 | how | 956 | 32 | work | 415 |
| 8 | want | 888 | 33 | background | 415 |
| 9 | more | 882 | 34 | different | 414 |
| 10 | midjourney | 847 | 35 | white | 402 |
| 11 | images | 817 | 36 | add | 391 |
| 12 | make | 683 | 37 | create | 387 |
| 13 | try | 615 | 38 | see | 371 |
| 14 | ar | 591 | 39 | way | 367 |
| 15 | help | 583 | 40 | channels | 367 |
| 16 | cref | 569 | 41 | good | 362 |
| 17 | using | 558 | 42 | region | 354 |
| 18 | bot | 541 | 43 | look | 351 |
| 19 | right | 529 | 44 | text | 350 |
| 20 | know | 518 | 45 | photo | 350 |
| 21 | same | 511 | 46 | tried | 343 |
| 22 | raw | 495 | 47 | black | 338 |
| 23 | s | 493 | 48 | prompts | 329 |
| 24 | character | 483 | 49 | v | 323 |
| 25 | need | 457 | 50 | thank | 315 |
Acknowledgements
I sincerely thank two anonymous reviewers for their constructive and thoughtful feedback.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The author received no financial support for the research, authorship, or publication of this article.
Data availability statement:
Please contact the author if you wish to access the corpus used for this study.