
Abstract
This study investigates users’ artificial intelligence (AI)-related competencies (i.e., AI knowledge, skills, and attitudes) and identifies the vulnerable user groups in the AI-shaped online news and entertainment environment. We surveyed 1088 Dutch citizens over the age of 16 years and identified five user groups through the latent class analysis: the average users, the expert advocates, the expert skeptics, the unskilled skeptics, and the neutral unskilled. The most vulnerable groups with the lowest levels of AI knowledge and AI skills (i.e., unskilled skeptics and neutral unskilled) were mostly older, with lower levels of education and privacy protection skills, than the average users. Overall, the results of this study resonate with the existing findings on the digital divide and provide evidence for an emerging AI divide among users. Finally, the societal implication of this study is discussed, such as the need for education programs and applications of the explainable AI.
Introduction
In recent decades, artificial intelligence (AI) has become ingrained in our everyday lives (Müller and Bostrom, 2016). In the online news and entertainment context, AI shapes the communication environment by influencing media users’ choices (Zarouali et al., 2022), providing conditions for information consumption (Wiard et al., 2022; Thorson, 2008), and impacting users’ participation in their public lives (Feezell et al., 2021). As more and more users are continuously exposed to automated recommendations, personalized content, and algorithmically shaped social media platforms, it is crucial for communication scientists to understand how users make sense of this AI-shaped online communication environment.
Due to the black-box nature of AI systems (Pasquale, 2015), not all users can interact with AI confidently and effectively (Eiband et al., 2019). Previous studies found that users without an adequate level of literacy can be especially susceptible to risks caused or aggregated by AI-curated information, such as the filter bubble, data-driven manipulation, misinformation and disinformation diffusion, and the reinforcement of stereotypes and discrimination (e.g. Eubanks, 2017; Hoffmann, 2019; Mohamed et al., 2020; Pariser, 2011; Susser, 2019). In this context, scholars argue that the prevalence of AI technologies could lead to an emerging “AI divide” (i.e. the AI-related access, capability, or outcome divide among users, Carter et al., 2020) and perpetuate structural inequalities among users with different sociodemographic backgrounds (Cotter, 2022; Cotter and Reisdorf, 2020; Gran et al., 2021; Lutz, 2019; Ragnedda, 2020; Zarouali et al., 2021).
However, although previous studies have examined how users interact with particular AI systems in sparse case studies (e.g. Ashfaq et al., 2020; Dogruel et al., 2020; Liu et al., 2023; Swart, 2021), only a few studies have empirically examined whether there are systematic AI-related competencies disparities among users (Cotter and Reisdorf, 2020; Gran et al., 2021). To gain insights into the existence divides among users in terms of their different levels of AI-related competencies, the current study aims to (1) identify different user groups in terms of users’ level of AI knowledge, skills, and attitudes in the online news and entertainment context through a latent class analysis (LCA) and (2) explore these different user groups’ demographic characteristics and identify the vulnerable groups.
The current study is relevant to several stakeholders. On one hand, from AI designers’ perspective, acknowledging the sociodemographic characteristics of the vulnerable user groups could facilitate better human-centric AI designs that entail more transparency and accountability. On the other hand, it is essential for researchers and policymakers to consider the vulnerable and disadvantaged user groups when researching and discussing the risks and opportunities of AI innovations. Finally, addressing the potential AI divide could prompt ordinary readers and users to improve their AI competence to better adapt themselves to the AI-shaped communication environment.
Related research
AI competence
In recent decades, digital competence, encompassing knowledge, skills, attitudes, abilities, strategies, and awareness required when using Information and communications technology (ICT) and digital media (Ferrari, 2012), has gained significance. With the rise of AI technologies, AI-related competence has emerged as a frontier within digital competence (Lyons et al., 2019). AI features non-human intelligence programmed to mimic human cognitive functions, such as learning, reasoning, decision-making, and problem-solving (Russell and Norvig, 2022). The terms AI, algorithms, machine learning, and big data are often used interchangeably or simultaneously in many cases (see, for example, Liu et al., 2020; Tambe, 2018; Valtonen et al., 2019). In this study, the term AI refers the collection of computational algorithms using (big) data to identify patterns and train machines for autonomous decision-making (Helm et al., 2020). We use the term AI competence to underscore users’ proficiency in applying AI.
Previous work has explored the concept of AI competence. Swart (2021) categorizes interactions with AI algorithms into cognitive, behavioral, and affective dimensions. The cognitive dimension is regarding users’ knowledge or cognitive comprehension of AI systems, while the behavioral dimension represents the skills involved in engaging with AI systems. The affective dimension is related to users’ attitudes toward the AI systems. This classification is also in line with Lomborg and Kapsch (2020) framework of knowing, doing, and feeling algorithms. Long and Magerko (2020) synthesized extant literature into a set of core abilities in interacting with AI systems. They proposed the concept of AI literacy, defined as “a set of competencies that enable individuals to critically evaluate AI technologies; communicate and collaborate effectively with AI; and use AI as a tool online, at home, and in the workplace” (p. 2). This literacy encompasses knowledge and skills from recognizing AI systems, evaluating AI applications critically, and reflecting on AI innovations’ risks and opportunities.
Based on previous framework related to AI literacy (e.g. Long and Magerko, 2020; Zarouali et al., 2021), we outlined a set of prerequisite knowledge and practical skills in interacting with AI in this study. We define AI knowledge as users’ factual knowledge about how AI functions in a recommender system and the operational logic behind it, and we define AI skills as users’ capability to recognize and interact with AI, such as changing AI settings or influencing the AI decision-making process.
Users’ attitude toward digital technology is considered the third dimension of digital competence (Ferrari and Punie, 2013). Although attitude per se is not a measure of capability, it can influence a user’s willingness to use the technology, which results in a gain or loss of competence in the long run (Fox and Connolly, 2018). In the context of AI competence, users’ attitudes toward AI are also closely related to AI knowledge and AI skills (Espinoza-Rojas et al., 2023). For example, attitudes toward AI technologies play an important role in their interaction with AI (Gran et al., 2021; Siles et al., 2022). When individuals possess negative attitudes toward new technologies such as AI, they are less likely to adopt them and become sophisticated users, and vice versa (Donat et al., 2009; Silva et al., 2022). For instance, those who consider AI-driven recommendation systems unfavorable may quit using them and, in turn, are less likely to become competent users through user experiences. In line with the previous research, we construct the concept of AI competence through the three dimensions: AI knowledge, skills, and attitudes. See Figure 1 for the conceptualization of AI competencies.
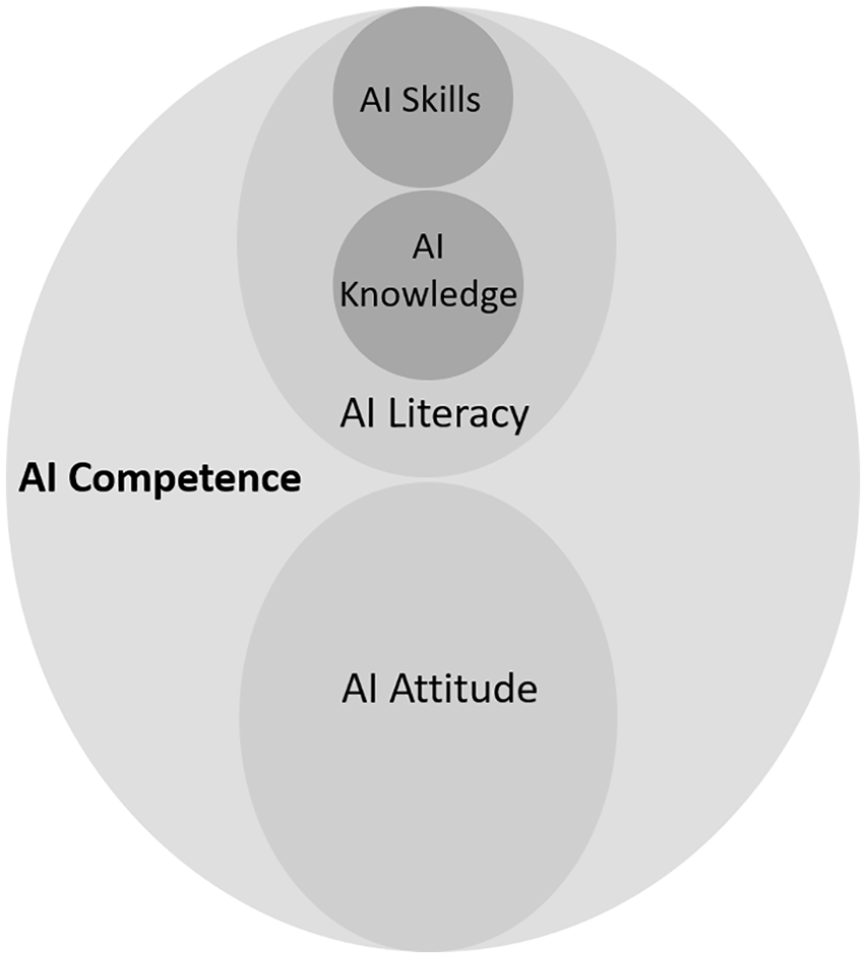
Conceptualization of AI competence.
The AI divide
Users’ AI-related knowledge, skills, and attitudes vary notably (Fast and Horvitz, 2017; Gran et al., 2021; Zarouali et al., 2021). Previous research indicates that people have difficulties to recognize AI systems (Dogruel et al., 2020; Gran et al., 2021; Gruber et al., 2021; Powers, 2017), understand algorithmic reasoning (DeVito et al., 2017; Eslami et al., 2016; Gruber and Hargittai, 2023; Siles et al., 2020), and critically evaluate AI-curated online information (Shin, 2022). Understanding and mapping structural inequalities in competencies around technology and democratic skills have a long tradition in social science. Tichenor et al.’s (1970) knowledge gap hypothesis posits that “segments of the population with higher socioeconomic status tend to acquire this information at a faster rate than the lower status segments . . . the gap in knowledge between these segments tends to increase rather than decrease” (pp. 159–160). Building on this, the concept of the digital divide emerged, defined as the access, skills, usage patterns, and outcome divide in ICT usage (e.g. Hargittai, 2001; Van Dijk, 2020, 2005; Wei et al., 2011).
With the growing societal influence of AI being widely acknowledged (e.g. Gillespie, 2014; Pasquale, 2015), several scholars have begun to explore the intersection of the digital divide and AI. Some argue that an algorithmic knowledge gap (Cotter and Reisdorf, 2020) or an algorithmic awareness gap (Gran et al., 2021) is emerging as a new type of digital divide. Others investigated the misconceptions of AI in media contexts as the source of a new digital divide (Zarouali et al., 2021).
Most empirical studies on this topic have merely focused on a single dimension of AI competence and did not capture a comprehensive picture of the AI-related digital divide. Carter et al. (2020) proposed a comprehensive framework and conceptualized the AI divide as a subdimension of the digital divide. They define the AI divide as “AI-related inequalities about access to AI (the first level divide), the ability to use AI (the second-level divide), and the outcomes of AI engagement (the third level divide)” (p. 259) at the individual level, institutional level, or country level. Extending the traditional digital divide model, Carter et al. (2020) emphasize the significance of individuals’ perceptions, beliefs, and AI attitudes in the AI divide. Given today’s rapidly increasing deployment of AI technologies, a mere examination of the first-level divide regarding access to AI technologies could be inadequate. Therefore, in this study, we concentrate on the second-level divide in terms of users’ AI knowledge and skills and the third-level divide in terms of their attitudes toward AI.
In particular, this study takes a first step in examining the AI divide in terms of AI knowledge, skills, and attitudes disparities among individuals in the news and entertainment context. Here, AI systems can facilitate users’ information acquisition efficiency by providing personalized content based on users’ own behavioral choices and interests (Patel and Patel, 2020). Competent AI users demonstrate better recognition and comprehension of AI systems within recommender systems. They understand key functions, such as content filtering, personalization, and automated decision-making based on users’ data. Competent users are more likely to understand why certain recommendations are made to them, and to hone their AI skills when interacting with AI and proactively influence AI-driven decisions. Eventually, competent users have more chances to benefit from automated recommender systems and have better information acquisition efficiency (Patel and Patel, 2020).
Users with lower AI competencies do not experience these benefits (Ragnedda, 2020). As such users are less likely to recognize AI’s role in automated recommendation systems and understand how recommendations relate to their profile or browsing data, we consider them as a relatively vulnerable group when interacting with AI systems. Vulnerability indicates susceptibility to harm and results from “an interaction between the resources available to individuals and communities and the life challenges they face” (Mechanic and Tanner, 2007: 1220). Such heightened vulnerability increases the risk that such users are influenced, persuaded, or even manipulated by the automated recommendations, possibly leading to issues related to data-driven manipulation, misinformation and disinformation diffusion, and the reinforcement of stereotypes and discrimination (e.g. Eubanks, 2017; Hoffmann, 2019; Mohamed et al., 2020; Pariser, 2011). This vulnerability in the context of AI describes the exploitation of power imbalances that are the result of increasing automation of the online environment (Helberger et al., 2022). In addition, when vulnerable users are exposed to automated recommendations of entertainment, they are more likely to form addiction behavior that negatively impacts their psychological and mental well-being (Tso et al., 2022).
In the long run, the AI divide can accelerate other socioeconomic problems and may impact the sustainability of society. Therefore, it is essential to examine the AI divide by investigating group-based differences in users’ AI competence composed of AI knowledge, skills, and attitudes. We take the Netherlands with a highly digitalized society and near-universal Internet access (DataReportal, 2022) as a case, and probe to answer the research questions:
Research Question 1 (RQ1). (1) Which different groups can be distinguished based on AI knowledge, AI skills, and AI attitudes and (2) what is the prevalence of these groups?
Describing the different groups
Demographic and socioeconomic factors play a key role in digital divides (e.g. Hargittai, 2001; Van Dijk, 2020, 2005; Wei et al., 2011), and specifically the AI divide (Carter et al., 2020). Research suggests that the most disadvantaged and vulnerable users in the digital age are normally the elderly, less educated, women, population with lower income, and ethnic minorities, given their disadvantaged status in society (Elena-Bucea et al., 2021; Mubarak et al., 2020; Park and Humphry, 2019). Empirical evidence was also found regarding the link between users’ sociodemographic differences and their levels of algorithmic awareness (Gran et al., 2021), algorithmic knowledge in online search (Cotter and Reisdorf, 2020), and their attitudes toward automated decision-making (Araujo et al., 2020). Moreover, users’ demographic differences influence their adaptability to algorithmic curation (Liu et al., 2023). To gain a better understanding of the compositions of the different groups, and specifically explore the composition of vulnerable groups with low AI competencies, we probe to answer the research questions:
Research Question 2 (RQ2). To what extent can demographic and socioeconomic factors (i.e. gender, age, education) predict respondents’ membership to different groups distinguished based on AI knowledge, AI skills, and AI attitudes?
AI competence and privacy protection skills
Research into the digital divide has addressed users’ perceptions of information privacy as an element shaping the digital divide (Redmiles et al., 2017; Scheerder et al., 2017). Managing and protecting online privacy has also become essential in everyday life, especially when interacting with AI systems (Smith et al., 2012). Information privacy refers to users’ control over their personal information online (Baruh et al., 2017). AI-driven news and entertainment platforms curate information and make predictions of users’ preferences based on users’ static background information and dynamic online behavioral data (Knijnenburg and Kobsa, 2013). As these data-driven processes often require user data and users’ consent to collect and use these data, the effectiveness of AI technology depends on both the algorithms’ ability to capture and analyze user data, and users’ willingness to share their data (Chellappa and Sin, 2005).
We argue that people’s ability to protect their information privacy is related to their AI competencies. AI skills and privacy protection skills seem to be intertwined with each other closely (Hargittai and Micheli, 2019). Users with a higher level of AI knowledge could be more capable of managing and protecting online information privacy when interacting with AI systems. Users with a high level of AI skills are also more likely to have a high level of privacy protection skills, such as adjusting privacy settings.
In addition, research has also suggested that users with one digital skill more easily develop other related skills (Gruber et al., 2021; Van Deursen et al., 2017). Therefore, we assume that users who can better protect their personal data can better understand and handle the data used in training machine learning models applying to AI systems, and vice versa.
To understand how users’ privacy protection skills are related to the AI divide, we aim to answer the research question:
Research Question 3 (RQ3). What is the relationship between users’ privacy protection skills and their membership to different groups distinguished based on AI knowledge, AI skills, and AI attitudes?
Method
Data for this study were collected in a survey that was part of a larger project called Digital Competence across the Lifespan (Piotrowski et al., 2022). The project included several surveys with different samples from the Dutch population. The larger study uses surveys on paper or online and in Dutch or in English. Respondents were recruited in three different ways: (1) adult panel members, (2) children (age 10–17 years) of panel members, and (3) address sample. The current study was based on the first two rounds of the survey, collected in June 2021 (De Vries et al., 2021a) and November 2021 (De Vries et al., 2021b). Only respondents over 16 years old were included in our sample. Data from the first round of the survey were used to answer our research questions, while data from the second round of the survey were used to check the robustness of our findings. The current study was pre-registered at https://osf.io/tvw8p.
Sample
To answer the main research questions of the study, we use data collected in the initial wave from a sample of 1088 respondents (50.5% females) ranging from 16 to 92 years old (M = 51.02 years, SD = 16.93). Of all the respondents, 45.1% (N = 491) had or were completing a bachelor’s degree or higher. This sample is slightly older and less educated than the general Dutch population.
To check the robustness of our results, we include data from a second wave consisting of 1425 respondents (710 female respondents) from 16 to 93 years old (M = 51.66 years, SD = 17.60). 41.8% of the respondents (N = 596) had or were completing a bachelor’s degree or higher. The sample in Wave 2 was not significantly different from the sample in Wave 1 regarding respondents’ gender distribution, X2 (1) = 0.12, p = .733, age, t (2510) =−.92, p = .180, and education level, X2 (2) = 2.67, p = .263.
Measures 1
AI knowledge
AI knowledge was measured by four items extracted from the DigIQ-Know scale developed by De Vries et al. (2022). Respondents were asked to indicate whether they thought the statements, such as “Websites and apps for news and entertainment show the same content to everyone,” were “definitely true” (1) or “definitely false” (2). Two alternatives, “I do not know” and “I do not understand the question,” were also provided. In the introductory text, respondents were discouraged from guessing. We first recoded the factually correct answers as correct (1) and all other answers as incorrect (0) for each item. Then the total number of correct responses was computed to measure users’ AI knowledge (sum score ranging from 0 to 4). Finally, we recoded this variable (1 = “zero correct answers”, 5 = “four correct answers”) to run the LCA (Mwave1 = 3.80, SDwave1 = 1.26, Mwave2 = 3.64, SDwave2 = 1.33).
AI skills
AI skills were measured by asking respondents to assess six items (e.g. “I know where to find the settings to change or turn off personalization by AI”) from “completely untrue” (1) to “completely true” (5). The items (Cronbach’s α = .90) were extracted from the DigIQ-Skill scale (De Vries et al., 2022). Two alternatives, “I don’t understand the question” and “I’d rather not answer,” were provided as alternatives and were coded as missing values. The six items were averaged, and higher scores indicated higher levels of self-perceived AI skills (Mwave1 = 2.61, SDwave1 = 1.15, Mwave2 = 2.52, SDwave2 = 1.09).
AI attitude
AI attitudes were measured by asking respondents to assess three items (e.g. “I like it when online media shows me content that was adjusted to my interests and online behavior by AI”) from “completely untrue” (1) to “completely true” (5). The items were based upon scales used by Smit et al. (2014) and Thurman et al. (2019). Again, respondents could also provide alternative answers, “I do not understand the question” and “I’d rather not answer,” which were coded as missing values. The three items were averaged, and a higher score indicated a more positive attitude toward AI (Cronbach’s α = .84; Mwave1 = 2.46, SDwave1 = 1.14, Mwave2 = 2.47, SDwave2 = 1.11).
Privacy protection skills
Privacy protection skills were measured by asking respondents to assess the seven items from the Safety and Control of Information and Devices subscale of the DigIQ-Skill (De Vries et al., 2022) (e.g. “I know how to delete the history of websites that I have visited before”) from “completely untrue” (1) to “completely true” (5). “I don’t understand the question” and “I’d rather not answer” were provided as alternatives and were coded as missing values. The seven items were averaged, and higher scores indicated higher levels of self-perceived privacy protection skills (Cronbach’s α = .85, Mwave1 = 4.39, SDwave1 = 0.76, Mwave2 = 4.23, SDwave2 = 0.85).
Demographics
Respondents were asked to indicate their gender (male, female, or gender-neutral), age in years, and educational level (1 = primary school and below, 7 = university master and higher). Education level was re-coded into a categorical variable: low educational level (secondary education and below), middle educational level (pre-university education), and high educational level (Bachelor’s degree and higher). “I don’t know” and “I’d rather not answer” were also provided as alternatives and were coded as missing values.
Analytic strategy
To answer RQ1, we performed LCA in R studio 4.1.2 to analyze (1) what user groups can be distinguished based on their AI knowledge, skills, and attitudes and (2) the prevalence of these groups. The LCA was based on three clustering variables: AI knowledge, AI skills, and AI attitudes. LCA is considered as an explorative procedure to identify subgroups based on the underlying patterns in the data (Kongsted and Nielsen, 2017). When using continuous variables for clustering, LCA is also referred to as latent profile analysis or latent class cluster analysis (Masyn, 2013).
There is no absolute consensus about how to evaluate the fit of an LCA model (Oberski, 2016). In this study, we adopted the most commonly used statistics, the log-likelihood (LL), Bayesian information criterion (BIC), Akaike’s information criteria (AIC) (Schwarz, 1978), Lo–Mendell–Rubin adjusted likelihood ratio test (LRT), and the entropy score (Celeux and Soromenho, 1996). Overall, the lower the LL, BIC, and AIC, the better the model fits. The LRT compares whether a model with K groups is significantly better than a model with K-1 groups (a significant p-value indicating a better model fit). Finally, the entropy score indicates how well the cluster variables predict membership of the latent classes, with a value closer to 1 meaning better fit (Hagenaars and McCutcheon, 2002).
To answer RQ2 and RQ3, we conducted a multinomial logistic regression with gender, age, and educational level as predictors, privacy protection skills as covariate, and membership to the user groups as dependent variable.
Results
Descriptive statistics
One of our stated research objectives is to investigate users’ level of AI knowledge, skills, and attitudes. The data reveal an explicit distinction between the knowledgeable respondents and the unknowledgeable ones. On one hand, a considerable proportion of respondents indicated that they “do not know the answers” to the questions about recognizing AI (32%), content filtering (23.3%), automated decision-making (33.3%), and human-AI interplay (9.2%), or “do not understand the questions” (ranging from 0.3% to 4.5%). On the other hand, over one-third (38.5%) of the respondents showed respectable levels of AI knowledge and correctly answered all questions. This observation reveals a considerable AI knowledge gap among users.
Regarding self-perceived AI skills, only a fraction of respondents indicated that they were completely able to recognize personalized pages (9.7%), recognize AI recommendations (12.8%), understand AI-driven decisions (14.3%), influence AI-driven decisions (6.8%), change AI-related settings (9.7%), and access personal data (3.8%). In addition, a considerable proportion of respondents considered themselves completely lacking skills in changing AI-related settings (40.7%) and accessing personal data (51.2%).
Furthermore, we found a nonnegligible negative attitude toward AI among almost a quarter (22.2%) of the respondents who were completely unsatisfied with AI applications in all given situations. Only a fraction of respondents reported being completely satisfied with AI on online media (4.4%), news platforms (3.0%), and entertainment (8.6%).
Furthermore, in line with the previous research (Gran et al., 2021), we found that AI knowledge, skills, and attitudes were significantly but weakly to moderately correlated, r(1069)knowledge-skills = .34, p < .001, r(1069)knowledge-attitudes = .19, p < .001, r(1069)skill-attitudes = .39, p < .001.
User groups
To answer RQ1, we conducted an LCA on data of Wave 1 to identify different user groups based on users’ AI knowledge, skills, and attitudes. We ran the model successively until an appropriate fit was found. Table 1 shows that the five-class model had an entropy score closer to 1 than the six-class model. Although LL, BIC, and AIC were further reduced in the six-class model, the changes were marginal (LL: 1.9% less; BIC: 1.6% less; AIC: 1.8% less). In addition, the five-class model also produced a theoretically meaningful grouping structure in terms of the response patterns in different groups. Altogether, we considered the five-class model the best fit (see Table 2 for the count, proportions, and average latent class probabilities for each group).
Comparison of latent cluster models.
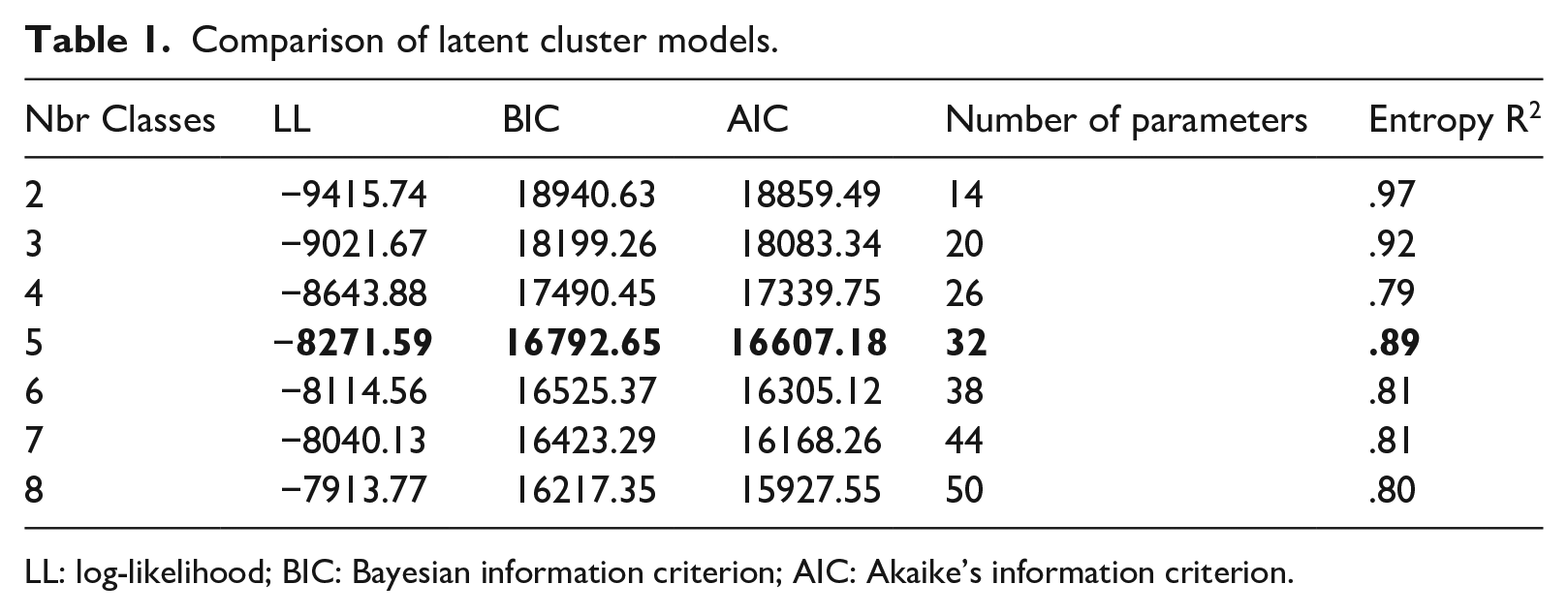
LL: log-likelihood; BIC: Bayesian information criterion; AIC: Akaike’s information criterion.
Count, proportions, and average latent class probabilities for most likely membership (row) by class (column).
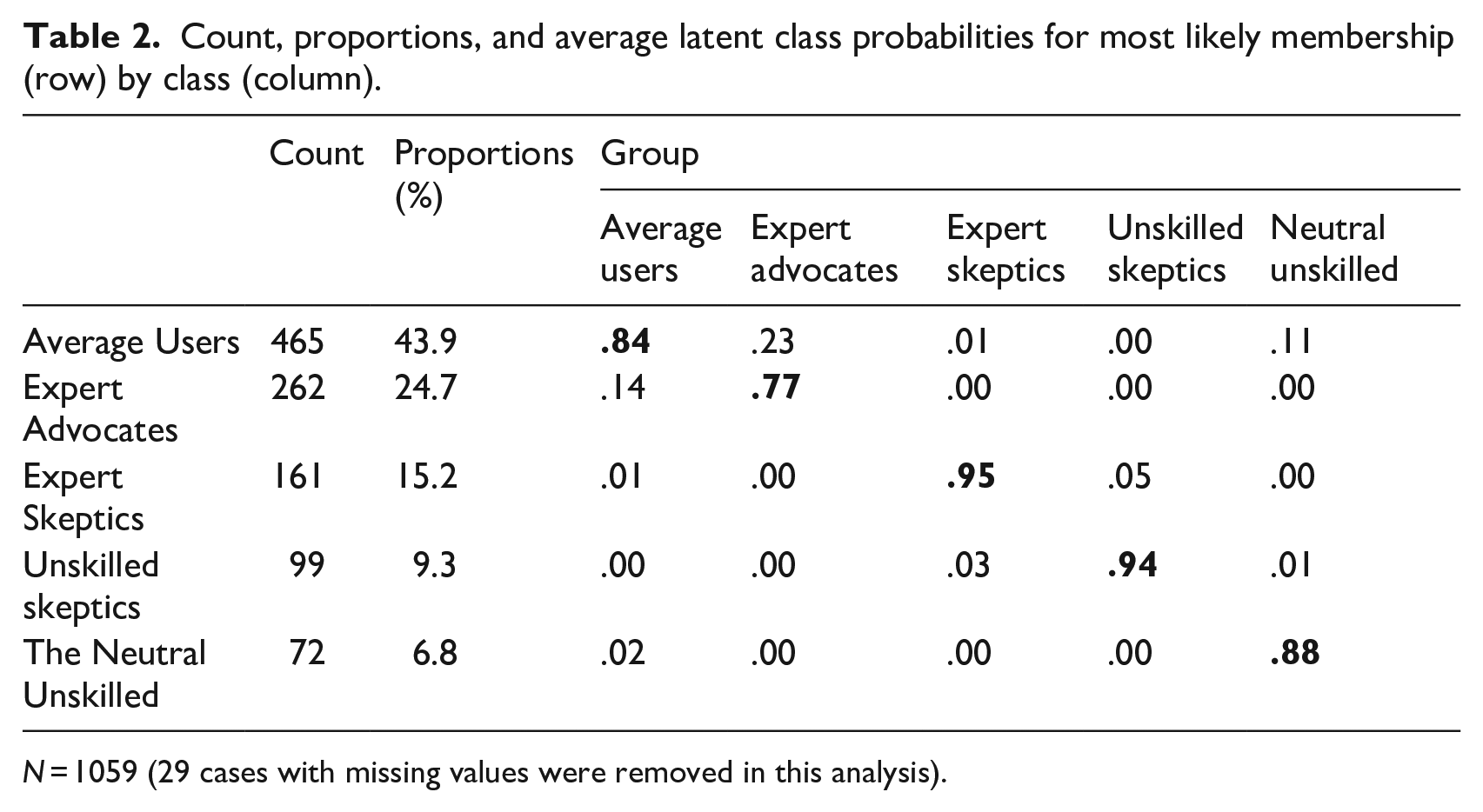
N = 1059 (29 cases with missing values were removed in this analysis).
The resulting five groups were labeled based on group members’ average level of AI knowledge, skills, and attitudes (see Table 3 and Figure 2). First, we used the term “expert” or “unskilled” to indicate users with higher or lower levels of AI knowledge and skills. Overall, five groups were identified and labeled as: the average users, the expert advocates, the expert skeptics, the unskilled skeptics, and the neutral unskilled. The largest group with medium scores on AI knowledge, skills, and attitudes was named the “average user.” We chose the term “(un)skilled” over “(un)knowledgeable” since AI skills had a larger variance and was a better indicator than AI knowledge.
Means and standard errors for AI knowledge, skills, and attitudes for each group.
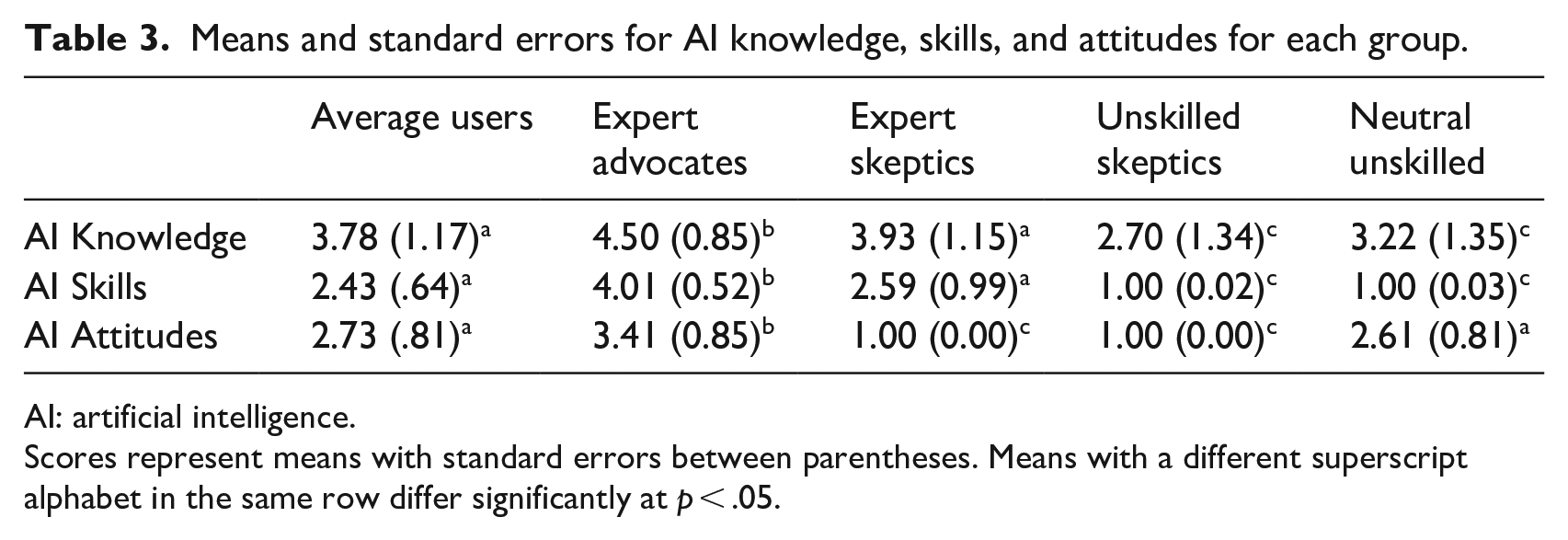
AI: artificial intelligence.
Scores represent means with standard errors between parentheses. Means with a different superscript alphabet in the same row differ significantly at p < .05.
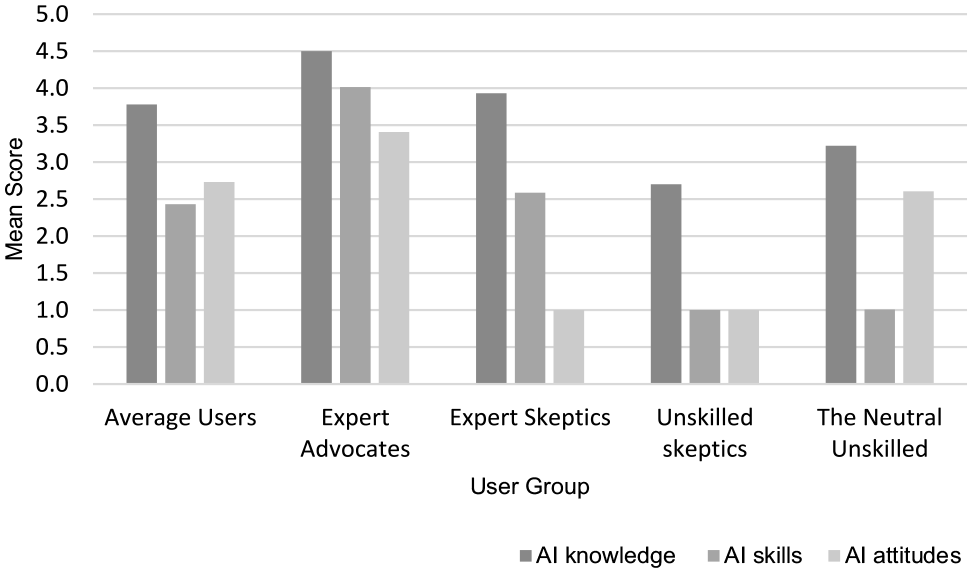
Means of AI knowledge, skills, and attitudes for each group.
Moreover, to answer RQ2 and RQ3, we conducted a multinomial logistic regression analysis taking the “average user” group as the reference group (see Table 4). To provide more insights into the composition of each group, Table 5 shows the sociodemographic profiles of different user groups.
Multinomial regression predicting membership of the groups.
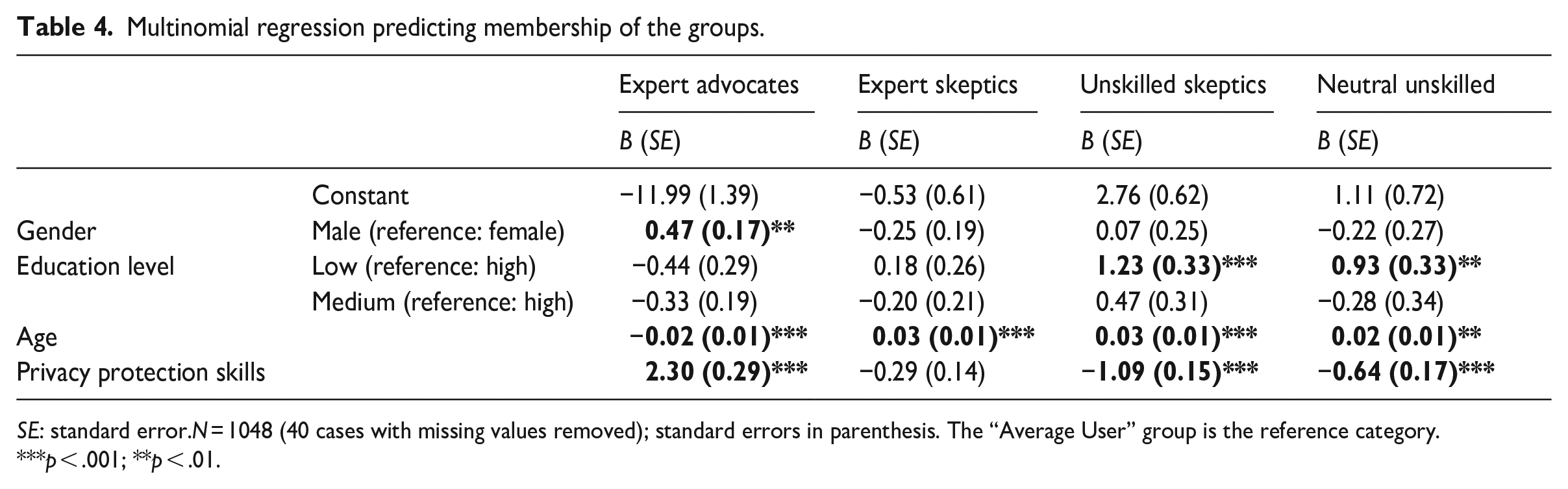
SE: standard error.N = 1048 (40 cases with missing values removed); standard errors in parenthesis. The “Average User” group is the reference category.
***p < .001; **p < .01.
Sociodemographic profiles of the groups, count (% within group), and mean (SD).
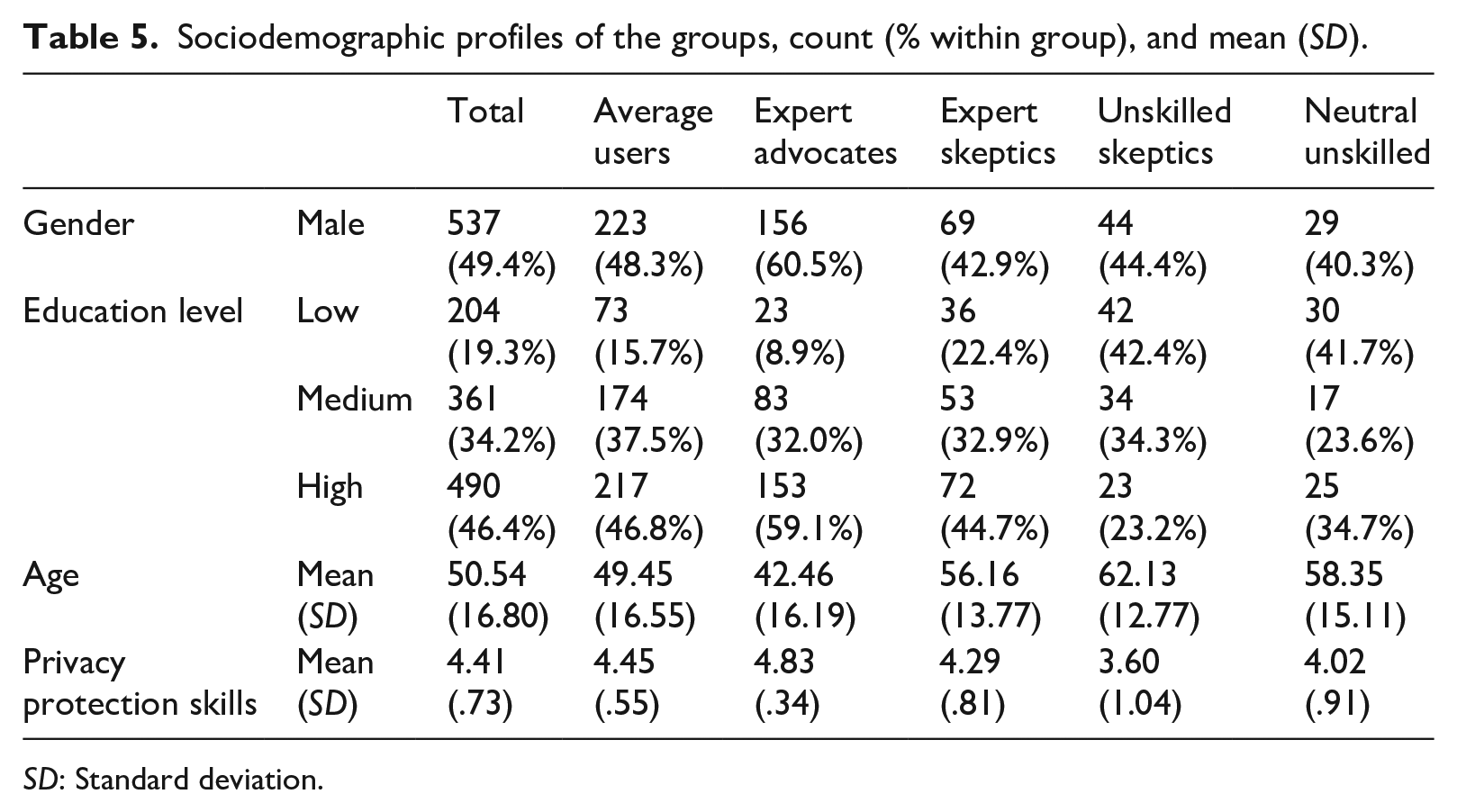
SD: Standard deviation.
Average users
The average user group has the largest size: 43.9% of the sample belongs to this group (N = 465). On the scales from 1 to 5, the average user group has a medium–high level of AI knowledge (M = 3.78, SD = 1.17) and a medium level of AI skills (M = 2.43, SD = 0.64), and neutral attitudes toward AI (M = 3.13, SD = 0.81). The demographic composition of this group is not significantly different from the sample composition. In particular, a total of 51.7% of the average users are female, have an average age of 49.95 years (SD = 16.55), and 46.8% are highly educated.
Expert advocates
The expert advocate group is the second largest group: 24.7% of the sample belongs to this group (N = 262). The expert advocate group has the highest level of AI knowledge (M = 4.50, SD = 0.85) and AI skills (M = 4.01, SD = 0.52) and the most positive attitudes toward AI (M = 3.41, SD = 0.85). Taking the average user group as the reference, multinomial logistic regression analysis showed that male (B = 0.47, SE = 0.17, p = .007) respondents were significantly more likely (OR = 1.59, 95% CI = [1.34, 2.24]) to be expert advocates, while older respondents (B = −0.02, SE = 0.01, p < .001) were significantly less likely (OR = 0.98, 95% CI = [0.97, 0.99]) to be expert advocates. Finally, those with higher levels of privacy protection skills (B = 2.30, SE = 0.29, p < .001) were more likely (OR = 9.99, 95% CI = [5.64, 17.69]) to be expert advocates.
Expert skeptics
The expert skeptic group is the third-largest group: 15.2% of the sample belongs to this group (N = 161). The Expert skeptic group has a lower level of AI knowledge (M = 4.50, SD = 0.85) and skills (M = 4.01, SD = 0.52) than the expert advocate group, but is still more knowledgeable and skillful than the average user group. Expert skeptics have extremely negative attitudes toward AI (M = 1.00, SD = 0.00). Compared with the average user group, multinomial logistic regression analysis shows that older respondents (B = 0.03, SE = 0.01, p < .001) are significantly more likely (OR = 1.03, 95% CI = [1.01, 1.04]) to belong to this group.
Unskilled skeptics
The unskilled skeptic group is the second smallest group: 9.3% of the sample belongs to this group (N = 99). The unskilled skeptic group has the lowest level of AI knowledge (M = 2.70, SD = 1.34) and AI skills (M = 1.00, SD = 0.02) and carry extremely negative attitudes toward AI (M = 1.00, SD = 0.00). Compared with the average users, multinomial logistic regression analysis shows that older respondents (B = 0.03, SE = 0.01, p < .001) and low-educated respondents (B = 1.23, SE = 0.33, p < .001) are significantly more likely (ORAge = 1.03, 95% CI = [1.01, 1.05]; OREducation = 3.41, 95% CI = [1.80, 6.47]) to be unskilled skeptics. Finally, those with higher levels of privacy protection skills (B = −1.09, SE = 0.15, p < .001) are significantly less likely (OR = 0.34, 95% CI = [0.25, 0.45]) to be unskilled skeptics.
Neutral unskilled
The neutral unskilled group is the smallest group: only 6.8% of the sample belongs to this group (N = 72). On average, the neutral unskilled group has a slightly higher level of AI knowledge (M = 3.22, SD = 1.35) but extremely low AI skills (M = 1.00, SD = 0.02). Unlike the unskilled skeptics, the neutral unskilled hold neutral attitudes toward AI (M = 2.61, SD = 0.81). Compared with the average users, older respondents (B = 0.02, SE = 0.01, p = .024) and low-educated respondents (B = 0.93, SE = 0.33, p = .004) are significantly more likely (ORAge = 1.02, 95% CI = [1.00, 1.04]; OREducation = 2.54, 95% CI = [1.34, 4.82]) to be neutral unskilled. Finally, those with higher levels of privacy protection skills (B = −0.64, SE = 0.17, p < .001) are less likely (OR = 0.53, 95% CI = [0.38, 0.73]) to belong to the neutral unskilled group.
Robustness check
We used data from the second wave of the survey to check the robustness of our findings. The LCA replicated three groups: the expert skeptics, the unskilled skeptics, and the neutral unskilled (see Supplemental Material for detailed results). As the primary focus of our study is to identify the disadvantaged and vulnerable groups when dealing with AI, the robustness check verified the consistency and reliability of our key findings centered on the vulnerable groups with the lowest AI knowledge and skills (i.e. the unskilled skeptics and the neutral unskilled) and the skeptical group (i.e. the expert skeptics).
Given the explorative nature of the LCA (Hagenaars and McCutcheon, 2002), it is reasonable that not all groups we identified in our main study were discovered in the robustness check. The results from the robustness check deviated from our original study in several ways (see Supplemental Material). The largest group (59.1% of the sample) distinguished by the LCA based on Wave 2 exhibits significantly higher scores on AI knowledge, skills, and attitudes compared with largest group in the original study (i.e. the average user group). In addition, a new group (10.7% of the sample) emerged from the unskilled skeptics and the neutral unskilled groups, with a relatively higher level of AI knowledge, AI skills, and a more positive attitude toward AI than these two groups.
Conclusion and discussion
The current study aimed to identify the disadvantaged and vulnerable groups in the AI-shaped online communication environment by investigating group-based differences in users’ AI knowledge, skills, and attitudes. The findings provide four important insights.
First and foremost, we provided empirical evidence for the presence of the AI divide in the online news and entertainment context. We identified five user groups varying in AI knowledge, skills, and attitudes: the average users, the expert advocates, the expert skeptics, the unskilled skeptics, and the neutral unskilled. A robustness check with data collected from a different sample 6 months later, replicated three groups: the expert skeptics, the unskilled skeptics, and the neutral unskilled. While the AI divide might be dynamic, the most skilled and skeptical group, and the two vulnerable groups with the lowest AI skills (i.e. unskilled skeptics and neutral unskilled) proved relatively stationary. Although the vulnerable groups are not the most prevalent among the respondents, they are especially worth our attention since vulnerable groups are normally the minor groups within the population (Kuran et al., 2020).
Second, our study verified the theoretical assumption that users’ perceptions and beliefs can be important factors influencing and driving the AI divide (cf. Carter et al., 2020). We found that attitudes play an important role in the AI divide. For instance, although the expert advocate and expert skeptic groups have high levels of AI knowledge, the expert skeptic group possesses a significantly lower level of AI skills than the expert advocate group. Likewise, although both unskilled skeptics and the neutral unskilled have the lowest levels of AI skills, the unskilled skeptics possess lower levels of AI knowledge than the neutral unskilled. Such observations can be explained by the fact that although attitude is not a measure of vulnerability per se, it can lead to a more (less) willingness to use the technology, resulting in higher (lower) competence in the long run (Fox & Connolly, 2018). Moreover, it is also important to understand the reasons behind the skeptical attitudes toward AI. Future research can explore the skeptics’ concerns and criticisms about AI to better support and guide their interactions with AI.
Third, this study is in line with previous research on the digital divide (Elena-Bucea et al., 2021; Van Deursen and van Dijk, 2014) and found that gender, age, and education significantly predicted users’ membership in different groups. Specifically, compared with the average user, the most vulnerable groups with the lowest levels of AI knowledge and AI skills (i.e. unskilled skeptics and neutral unskilled) were mostly older, with lower levels of education and privacy protection skills. In addition, expert skeptics appear to be mainly males and had higher levels of privacy protection skills than the average user. As we expect that this explanatory model may change over time along with the rapid development of AI technologies, we recommend future studies to further examine whether the model in the context of the AI divide will differ from conventional digital divide studies in the future.
Fourth and final, our findings emphasize the importance of privacy protection skills in the AI divide. We found that relative to the average users, those with higher levels of privacy protection skills are more likely to be expert advocates and are less likely to be unskilled skeptics or neutral unskilled. This result confirmed previous work suggesting that one digital skill can help the development of related skills (Gruber et al., 2021; Van Deursen et al., 2017). It also inspires us that improving vulnerable users’ privacy protection skills can lead to higher AI competence, and vice versa. Future studies could investigate other skillsets that potentially drive or are related to the AI divide and eventually build skillsets for ordinary users to map their skills and improve their digital competence in general.
Our findings have several practical implications. In recent years, the European Commission has planned to boost investment in implementing AI in society (European Commission, 2020). However, the main question is whether the disadvantaged and vulnerable users can benefit from this procedure and moreover, whether they are qualified to protect themselves from the potential negative consequences of these technologies. Scholars argue that users without an adequate level of AI competence can be especially susceptible to the risks brought by AI, such as the filter bubble, data-driven manipulation, and misinformation diffusion (e.g. Eubanks, 2022; Hoffmann, 2019; Mohamed et al., 2020; Pariser, 2011). Our studies revealed that disadvantaged and vulnerable groups are likely to persist over time, and it underlines the urgency of external support and more attention to the vulnerable or disadvantaged user groups from AI designers, educators, and policymakers to ensure that they have equal chances with the others to gain AI knowledge and skills over time. From the perspectives of policymakers and educators, these initiatives can be implemented within education programs empowering unskilled users. Furthermore, transparency is often considered an essential element in overcoming information gaps (Diakopoulos and Koliska, 2017). Therefore, from the perspective of AI designers, an effective approach to deal with the AI divide is to develop Explainable AI (XAI) systems that provide laymen users’ explanations for AI-driven decisions (Bianchi and Briere, 2021; Haque et al., 2023). In addition, we need to pay more attention to the skeptics’ AI-related concerns and criticisms and provide more guidance and assistance to their interaction with AI. Previous research demonstrated that XAI could notably increase users’ trust in and satisfaction with AI systems (Shin, 2021). Hence, encouraging the development of XAI not only benefits vulnerable users but can also alleviate skeptic users’ concerns when they interact with AI.
Limitations
Notwithstanding its contributions, the current study has a few limitations. First, our sample contained a larger proportion of highly educated and older people compared with the general Dutch population. Therefore, less-educated and younger users could be under-represented in our analysis. Since our study mainly focuses on gender, age, and education as the key sociodemographic factors related to the AI divide, this bias might reduce the external validity of our study when generalizing the findings to the population level. For example, we found that elderly and less-educated users are more likely to belong to vulnerable groups, and the proportion of such groups in our sample is relatively small. However, the proportion of such groups could be either larger or smaller in the population, considering the underrepresentation of less-educated and younger users.
In addition, the Netherlands is one of the top countries with a highly digitalized society and near-universal Internet access (DataReportal, 2022). It also scored one of the highest in a study measuring basic digital skills among 27 EU member countries (EUROSTAT, 2022). Therefore, we believe that our findings are more transferable to countries that have similar features to the Netherlands, namely, countries that are highly digitalized with universal Internet access and composed of citizens with high levels of digital skills. We recommend future studies be conducted in various countries to verify our assumptions empirically.
Second, our study mainly focused on gender, age, and education as the key sociodemographic factors related to the AI divide, while previous research on the digital divide found that other factors such as income, occupation, location, and ethnicity also have the potential to drive the divide among users (Elena-Bucea et al., 2021; Enoch and Soker, 2006). Therefore, future research should consider the full breadth of the role of sociodemographic factors in the AI divide and take another look at other relevant factors.
Moreover, this study investigated users’ AI competence in the entertainment and news context simultaneously, while research suggests that users can have a different mindset when they follow news online relative to when they entertain themselves on the Internet (Festic, 2022). Therefore, future studies could further examine users’ AI competence in the news context and in the entertainment context, respectively, and examine nuanced findings in different contexts.
Third, we adopted a self-reported questionnaire to measure self-perceived AI and privacy protection skills. However, the perceived skills have intrinsic limitations in reflecting users’ actual level of skills (Atir et al., 2015). For example, the respondents with higher self-confidence may score higher in AI skills and mislead our group classification. And the unskilled groups may consist of a certain proportion of low self-esteem respondents reporting lower levels of skills than they actually possess. Therefore, future studies can combine self-reported measures with observational studies or experiments to better measure users’ actual level of AI-related skills. However, seeing the complexity of AI technologies and the constantly changing imaginaries of AI and algorithms among users (e.g., DeVito et al., 2017), whether the scales and items used in the current study are capable of capturing users’ level of AI competence are dubious. Hence, the conceptual framework of this concept is expected to be refined over time and across context to ensure it captures users’ essential competencies required when interacting with AI systems.
Finally, we applied the LCA to identify user groups as we focused more on the AI divide among user groups rather than providing an overview of users’ AI competence among the population. Therefore, we cannot make conclusions about the current state of users’ AI knowledge, skills, or attitudes without a pre-defined benchmark. We hence recommend future research provide a clearer overview of the state of AI competence with the adoption of a benchmark.
To conclude, the future of online communication is entangled with the increasing availability of AI technology and computational infrastructures. Hence, there is a more compelling need than ever to explore the users’ side of the story in human-AI interactions and have a better understanding of the social power of AI. As an explorative study intending to investigate the AI competence and AI divide, our findings point to several important directions for future research as follows: (1) developing alternative research designs (e.g. longitudinal design) for measuring AI knowledge, skills, and attitudes divides in the long term, (2) capturing the disadvantaged and vulnerable groups in the AI divide and understanding their concerns and demands in human-AI interactions, and (3) searching for approaches, such as the XAI, to provide external support and guidance for the vulnerable and the skeptic user groups in the AI-shaped online communication environment (Haque et al., 2023). Building on the contribution of the current study, we hope to advance the emerging research field of AI competence, AI divide, and XAI.
Supplemental Material
sj-docx-1-nms-10.1177_14614448241232345 – Supplemental material for The artificial intelligence divide: Who is the most vulnerable?
Supplemental material, sj-docx-1-nms-10.1177_14614448241232345 for The artificial intelligence divide: Who is the most vulnerable? by Chenyue Wang, Sophie C Boerman, Anne C Kroon, Judith Möller and Claes H de Vreese in New Media & Society
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is funded by the digicomlab, University of Amsterdam. The data in this study were funded by the Ministry of the Interior and Kingdom Relations (Principal Investigator: Dr. Jessica Taylor Piotrowski).
Supplemental material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.