
Abstract
This research investigates the dynamics of COVID-19 misinformation spread on Twitter within the unique context of Finland. Employing cutting-edge methodologies including text classification, topic modeling, social network analysis, and correspondence analysis (CA), the study analyzes 1.6 million Finnish tweets from December 2019 to October 2022. Misinformation tweets are identified through text classification and grouped into topics using BERTopic modeling. Applying the Leiden algorithm, the analysis uncovers retweet and mention networks, delineating distinct communities within each. CA determines these communities’ topical focuses, revealing how various groups prioritized different misinformation narratives throughout the pandemic. The findings demonstrate that influential, diverse communities introduce new misinformation, which then spreads to niche groups. This agenda-setting effect is amplified by social media algorithms optimized for engagement. The results provide valuable insights into how online communities shape public discourse during crises through the strategic dissemination of misinformation.
Introduction
In the complex landscape of the digital age, understanding the dynamics of online communication is crucial, particularly during significant global events (Burwell et al., 2023; Carrasco-Polaino et al., 2021; Cinelli et al., 2020). This research presents a distinct perspective, concentrating on the influence of Twitter (now called X)—a platform recognized for its capacity for instantaneous information propagation—within the Finnish context over the 3-year trajectory of the coronavirus disease (COVID)-19 pandemic. The pandemic, a global health crisis of unprecedented scale, provides a fertile ground to examine the influence of social media in shaping public perception and behavior (Bruns et al., 2022; Pierri et al., 2022; Walter et al., 2021).
Undertaken in the unique milieu of Finland—a linguistically distinct environment characterized by the predominant use of Finnish—this research facilitates a focused examination of the phenomena under study. The linguistic singularity creates a virtual isolation that allows for a controlled exploration of the dynamics of misinformation spread within a well-defined virtual ecosystem. This isolation minimizes potential influences from other linguistic or geographic contexts, thereby offering a purer investigation into these dynamics.
Despite the potential of Twitter as a rich data source, sifting through its vast volumes to discern patterns of misinformation spread presents a formidable challenge (Broniatowski et al., 2018). This challenge underscores the need for advanced methodologies capable of effectively analyzing such large-scale data (Rains, 2020). To this end, the study deploys cutting-edge techniques including text classification, topic modeling, social network analysis, and correspondence analysis (CA). The methodologies employed herein facilitate the classification of tweets based on their misinformation content, the extraction of salient topics from this classified data, the detection of hidden communities within the Twitter network, and the determination of topics that these communities prioritize. This multifaceted approach considerably advances our understanding of digital discourse dynamics in the context of a crisis (Gagliardone et al., 2021).
The research contributes significantly to the literature by demonstrating the potential of innovative methodologies in social science research, particularly in navigating and analyzing complex online discourse. Furthermore, it offers valuable insights into the dynamics of misinformation spread on social media during a crisis, a critical area of inquiry in today’s digital age (Bruns et al., 2022; Rosenberg et al., 2020). By identifying communities within the Twitter network and analyzing their interactions, the study unravels groups involved in the spread of misinformation about COVID-19 and vaccinations.
Rooted in the agenda-setting theory (AST), which posits that media’s focus on certain issues can shape public perceptions of their importance (McCombs, 2014), the study extends this theory to the realm of digital communities and their interactions. Such an application provides a nuanced understanding of how public discourse and perception are formed in the digital space—an understanding that is crucial in the context of a health crisis, where the spread of misinformation can have serious implications for public health communication strategies.
This research seeks to elucidate the following queries: (a) What constitutes the primary characteristics of digital communities in the context of misinformation retweet and mention networks on Twitter? Furthermore, how do these communities diverge in their modes of interaction? (b) What misinformation themes are prioritized by these digital communities during the COVID-19 pandemic? How extensively do these prioritized themes intersect with the agendas of other communities? and finally, (c) How does the agenda-setting theory articulate the characteristics and discourse patterns of these latent communities? What implications does such articulation hold for these communities’ influence on public perceptions amid the pandemic?
AST and digital communities
The ubiquity and pervasiveness of social media platforms have reshaped the landscape of information dissemination, sparking a shift from the traditional media’s monopoly over agenda-setting media (Van Den Heijkant et al., 2019). This shift is particularly noteworthy in the context of the COVID-19 pandemic, where uncertainty and fear have fostered a fertile environment for misinformation propagation (Šķestere and Darģis, 2022; Suarez-Lledo and Alvarez-Galvez, 2021). While traditional media once held the authority to influence public perception, social media platforms like Twitter now offer a decentralized stage where influencers and various groups form distinct communities, each setting their unique agendas and impacting public opinion significantly. The influence of social media on agenda-setting extends beyond merely shaping the perceptions of their user base; it significantly impacts political actors (Barberá et al., 2019), political groups (Vargo et al., 2018; Vargo and Guo, 2017), governmental bodies (Zhou and Zheng, 2022), social movement (Elliott et al., 2021), and the mass media (Stern et al., 2020; Van Den Heijkant et al., 2019).
AST posits that media outlets shape public perception not only by choosing which stories to cover, but also by defining the salience of those stories. Lippmann (1922) suggested that our responses to events are significantly influenced by the “pictures in our heads” shaped by the media, highlighting the media’s pivotal role in bridging our understanding of the external world.
As the media landscape has evolved, so too has the study of agenda-setting theory. Traditional media outlets still play a significant role in shaping public perception, but the rise of social media has prompted new studies that explore the interactive relationships between media and public agenda networks. For instance, Intermedia Agenda Setting research focuses on the interaction of agendas between different types of media, focusing on their mutual influencing roles, such as which news content transfers from one media to another, or from traditional media to social media (Šķestere and Darģis, 2022; Stern et al., 2020; Vargo and Guo, 2017). Likewise, Network Agenda Setting theory examines the interactive relationships between media and public agenda networks.
The rise of social media has transformed the media landscape in a number of ways. On one hand, it has empowered users to become active content creators (Yang and Sun, 2021). On the other hand, it has led to a more fragmented media environment, where people are increasingly exposed to content that aligns with their personal interests and beliefs (Woo et al., 2020). This has created a situation where group consensus is increasingly promoted and sustained through the sharing of similar content, a process known as “agenda melding” (McCombs, 2014), which can lead to the formation of strong group identities (Zhou et al., 2016).
In their formulation of the AST, researchers highlight the significance of people’s reliance on established social connections for acquiring news and information. This suggests that a direct agenda-setting effect from mass media to the general public audience may not necessarily be supported (Sousa et al., 2010). Rather than directly shaping public opinion, mass media guide public sentiment through individual opinion leaders embedded within diverse interpersonal networks (Yang and Sun, 2021). On social media platforms, certain high-profile figures, including celebrities, politicians, and renowned journalists, have emerged as salient origins of news content. These influential opinion leaders can facilitate the diffusion of media agendas, while also instituting agendas for mass media.
Recent research on the intersection of social media and social networks has expanded the agenda-setting framework to include a third level: network agenda-setting (Guo, 2012, 2013). However, these methodologies rely on known and predetermined actors as sources of news and information. This reliance constrains analyses to examining the influence of one network over others, such as government affiliated accounts over public accounts (Liu et al., 2022; Wang, 2022; Zhou and Zheng, 2022), World Health Organization (WHO) over networks of professionals (Tahamtan et al., 2022) or Pfizer over global public (Pontoh, 2022).
As demonstrated in our dataset of extracted COVID-19 and vaccination misinformation posts from Twitter, the actors in misinformation networks are ambiguous. Bots, malicious bots, trolls, anonymous activists, and political groups all participate in these networks, making it difficult to identify the true source of misinformation Unlu et al., (2024). Instead, users form online groups or communities based on a variety of motivations. These motivations can include conspiracy theories, far-right ideology, opposition to vaccination, or interest in specific topics (Unlu et al., 2023). Individual users do not require exclusive group membership. Their online engagement through following, liking, replying, retweeting, and mentioning results in affiliation with multiple groups across an array of subjects.
This study operationalizes AST at three levels. The basic AST process involves two levels: first, the agenda must be set, and then the effects of the agenda on public opinion can be examined. At the first level, we focus on the amount of coverage an issue receives. This suggests which issues the public is more likely to be exposed to. Second-level agenda-setting examines how these topics are framed, specifically the influence of attribute salience—the properties, qualities, characteristics, and relations of an issue (Elliott et al., 2021; McCombs, 2002, 2014). At the third level, we use online communities as a unit of analysis to examine how they establish salience in the public communication sphere and influence the formation of public opinion. Specifically, we analyze the focus of attention of communities on Twitter to determine how they shape the Twitter misinformation sphere.
The identification of communities is a core component of our social network analysis (Ozer et al., 2016). Within this context, a community is typically characterized as a collective of users: (a) who interact with each other more frequently than with those outside the group and (b) who are more similar to each other than to those outside the group (Girvan and Newman, 2002). Through the application of community detection analysis, we aim to delineate distinct structural characteristics of communities (Leskovec et al., 2010) in misinformation networks based on their engagement types such as retweet and mention.
These two theoretical perspectives will serve as a foundation in our exploration of how various Twitter communities set their respective agendas during the COVID-19 pandemic. We employ community detection analysis to identify distinct communities on Twitter and use topic modeling to understand their specific agendas, focusing particularly on how these groups disseminate misinformation. In our study, the principal object of interest—misinformation pertaining to COVID-19 and vaccination—exhibits numerous attributes (i.e. side effects, efficiency, government response) delineated within the specified agendas, which assumes a pivotal role in our analytical framework (Guo et al., 2012). We aim to discern not only the prominent misinformation topics within these communities but also their ranking and frequency of appearance as measurement instrument (Guo et al., 2012).
This study focuses on Twitter, a platform chosen for its accessible nature for both the public and researchers alike. While the platform has acknowledged limitations, such as issues of representativeness and susceptibility to manipulation by social media bots, it nonetheless played a pivotal role throughout the pandemic and continues to function as a significant media outlet (Kouzy et al., 2020; Theocharis et al., 2023; Weng and Lin, 2022). Despite these constraints, the invaluable insights that can be gleaned from Twitter data warrant its use in this research context (Ferrara, 2020).
Methodology
In this study, we employ a four-fold analytical strategy to dissect the role of communities in shaping the social media discourse during the COVID-19 pandemic. Initially, we use text classification analysis to distinguish between tweets containing misinformation. Following this, topic modeling identifies the key themes in misinformation tweets discussed during the pandemic. Subsequently, community detection analysis, a form of social network analysis, allows us to uncover the structure of communities in terms of retweets and mentions regarding misinformation. Finally, CA aids in discerning which topics were prioritized by each community during the COVID-19 crisis. In the following sections, we provide a concise overview of these methodologies due to length constraints.
Data and text classification
In the data collection stage, we utilized the R package academictwitteR (Barrie and Ho, 2021) to extract tweets containing specific query words within a 3-year time frame, from December 1st, 2019, and October 24th, 2022. Our search strategy evolved to capture discourse on COVID-19 and vaccinations on Twitter. We began with terms sourced from media outlets, subsequently enriching our dataset with additional relevant terms identified manually. We observed that terminology associated with misinformation, such as fake cures and conspiracy theories, frequently appeared alongside keywords related to COVID-19 and vaccination. Through our manual reviews, we ensured that our keywords provided comprehensive coverage. Nonetheless, we incorporated new keywords that fell outside of this established category. For instance, terms, such as “spike,” “vaccination side effects,” and “poison spike,” were included to address this gap. For this study, 147 query words were constructed through phrasing, conjugation, and inflection from a set of 14 Finnish terms 1 From these queries, we collected 1,683,700 tweets originating from 60,560 unique Twitter accounts. The collected data contains 901,621 original tweets, 57,865 quoted, and 724,214 retweets.
An extensive discussion about text classification techniques for COVID-related misinformation can be found in our earlier work Unlu et al., (2024); in this article, an overview of our approach, analysis, and findings is discussed. Misinformation is defined in this study as inaccurate information or conspiracy theories regarding COVID-19 and vaccination in this context. We utilized a misinformation codebook initially introduced by Memon and Carley (2020) and adopted in other research (Moffitt et al., 2021). Though misinformation can have different forms, including sarcasm, false treatments/cures, and conspiracy theories, our study is not designed to separate them. In response to the dynamic nature of COVID-19 misinformation, our team has undertaken a revision of our misinformation database to accurately capture the situation as of January 2023. This update utilized resources from fact-checking websites, including those from Finnish Health Institute for Health and Welfare, to guide our annotators. Acknowledging the ongoing challenge posed by the need for a consistent annotation framework in the face of continually emerging information about COVID-19, we have also streamlined our methodology. This involved training our annotators to identify misinformation across various dimensions, drawing on the categories outlined in their codebook. However, to simplify the process, the classification of misinformation was conducted on a binary basis. Consequently, in this context, misinformation refers to any information related to COVID-19 and its vaccination that is false, inaccurate, or falls within the realm of conspiracy theories.
To utilize computational methods for text classification, a subset of 4150 tweets was extracted and manually examined by four Finnish native annotators for misinformation.
The annotation training was conducted based on codebook (Memon and Carley, 2020) and annotators labeled a tweet as yes (for containing misinformation) and no (for not containing misinformation). We held six training rounds and evaluated the inter-rater reliability with the Krippendorff’s α test. On average, Krippendorff’s α result of all training rounds for misinformation labeling is .668, indicating a good agreement 2 among the annotators.
For natural language processing applications, BERT, a pre-trained transformer-based neural network model created by Google AI Language, is commonly used for text categorization tasks due to its good performance (Devlin et al., 2018). As BERT models can be trained for a variety of languages, the Turku University FinBERT pre-trained embeddings model was utilized in this study (Virtanen et al., 2019) in Python. We further enhanced the performance of the FinBERT model utilizing the annotated data. The performance of this fine-tuned model is tested on 623 separate samples and reported in detail in Table 1 of the Supplemental Material. Consequentially, our text classification model identifies 460,087 tweets as misinformation, which accounts for over 27% of our dataset.
Furthermore, we employed a two-stage process to differentiate malicious bots from regular bots, as outlined in the authors’ previous work. Initially, using Botometer (version 4), our study distinguished between bot-like and human-like Twitter accounts by evaluating features such as account metadata and tweet content to assign scores indicating the likelihood of automation. To identify malicious bots—those proliferating negative sentiments or misinformation—we applied additional criteria, including misinformation spread, sentiment ratio, age of the account, and account activity status, guided by recent literature for feature selection. Accounts that surpassed a defined penalty score threshold were classified as malicious (Figure 1 in the Supplemental Material).
Topic analysis
Topic modeling is a technique used to isolate and analyze topics from a collection of text. BERTopic, a Python library, is a topic-modeling technique that clusters documents according to their semantic similarity across BERT embeddings (Grootendorst, 2022). Recent research by Egger and Yu (2022) indicates that compared with alternative approaches, including Top2Vec, non-negative matrix factorization, and latent Dirichlet allocation, BERTopic produces not only distinct topics but also novel insights from similar texts. In this project, the BERTopic library 3 is used for extracting topics from misinformation tweets.
BERTopic contains a series of customizable steps to generate the topic representation of text documents. These steps include extracting document embeddings, reducing the dimension of embeddings, clustering, tokenizing, applying a weighting scheme, and fine-tuning representation. Moreover, BERTopic library enables different alternative algorithms and customizable parameters for each of these steps.
Following the sequence of steps, the misinformation tweets are converted to embedding vectors using FinBERT model. The UMAP algorithm is used to reduce the dimensions of embedding, with the parameters set to 25 for n_neighbors and 10 for n_components, which determine the local neighborhood size and target output dimension, respectively. The embeddings are clustered using HDBSCAN, with the parameter min_cluster_size set to 100, indicating the minimum number of documents in each cluster. Topic representations are derived using the CountVectorizer algorithm, with max_features set to 20,000, specifying that the top 20,000 words with the highest frequency will be included.
Network analysis
The Leiden algorithm, adept for complex, directed networks like those from Twitter activities, was selected for its ability to effectively handle directionality, a feature critical for analyzing Twitter retweet and mention dynamics (Traag et al., 2019). This preference is due to its superior performance with directed data compared with the Louvain and Newman algorithms, which are optimized for undirected networks, and they are more commonly examined in this field. Notably, when implemented in the R programming language using the leidenAlg package, 4 it allows for an in-depth analysis of these networks, including retweet and mention structures. This analysis becomes particularly illuminating when applied to the exploration of misinformation spread during the COVID-19 pandemic. Directional Leiden analysis, recognizing retweets as endorsements and mentions as direct engagements, enables the segregation of the Twitter community into discernible clusters (Porter et al., 2009).
Correspondence analysis
CA is a data visualization method suitable for cross-tabular data, providing a two-dimensional graphical representation of counts or ratio-scale data (Greenacre, 2010). Similar to principal component analysis for quantitative data, CA allows summarizing and visualizing information from datasets with multiple inter-correlated variables (Kassambara, 2017). By extracting a set of principal components, which are linear combinations of the original variables, CA helps express the important information from the multivariate data in a more manageable form.
To perform inference tests for CA, we utilized the factorextra package in R. 5 The algorithm produces various outputs, including eigenvalues, χ2 test statistics, and plots, with the biplot being commonly used to visually represent the overall structure of data by plotting rows (categories) and columns (variables) as points in a lower-dimensional space. The horizontal and vertical axes of the biplot correspond to Dimensions 1 and 2, respectively, representing the largest and second-largest sources of variation in the data.
In addition, the squared cosine (cos2) quantitatively measures the extent to which each topic is associated with different dimensions or axes in a multidimensional scaling space. For each topic, the cos2 value is calculated as the square of the cosine of the angle between the topic vector and a particular axis in this space. This metric, ranging from 0 to 1, essentially assesses the quality of representation of a topic on a given axis. A high cos2 value indicates that a significant proportion of the topic’s characteristics or variance is aligned with or captured by that axis. The biplot visualization highlights the relationship between topics uncovered from misinformation data and the communities in the existing network.
Result
Text classification and topic modeling
Out of 1,683,700 tweets, our text classification model identifies 460,087 tweets containing misinformation. Within these tweets, BERTopic extracts 101 coherent topics. Because BERTopic algorithm assigns a topic label per tweet, 208,910 tweets with coherent topics are further analyzed.
The tweet count in each topic ranges from 139 to 41,409, while the most significant accumulation is observed in Topic 1—death (41,409 tweets), Topic 2—preventing the spread of COVID (39,448 tweets), and Topic 5—side-effects of COVID vaccine (7957 tweets), the smallest topics are pneumonia (158 tweets), mercury in vaccines to brain (150 tweets), and EU Astra vaccine (139 tweets). We also identify the top 20 topics that represent 74.9% of the total tweets in all topics (More information about the top 20 topic labels and keywords can be found in the Supplemental Material).
Communities in interactions and their agendas
Given that our study quantifies Twitter interactions on two distinct dimensions, namely retweets and mentions, we have separately analyzed these networks. Retweets typically signify a passive form of information dissemination, whereas mentions demand more active engagement, encompassing activities such as raising questions, commenting on, or challenging to information or sentiment (Burwell et al., 2023).
Topics in each dimension of the Twitter interactions are also analyzed at two levels: a comprehensive evaluation encompassing all topics and a focused review of the top 20 topics. The distribution of all topics provides insight into the extent of diversity in discussion topics covered by different communities, thereby giving us a broad understanding of the content landscape during the pandemic. However, a targeted examination of the top 20 topics allows us to delve deeper into the most salient content that communities prioritized during the pandemic. Such a dual-level approach facilitates a nuanced understanding of the discourse dynamics and thematic priorities of these communities amid the COVID-19 pandemic.
Using the directional Leiden community detection algorithm, we identified 256 communities within the mention tweets and 136 communities within retweets. While the total number of communities may appear large, it is noteworthy that only a few of them encompass a significant percentage of users. Thus, we focused our topic analysis on the nine communities within the mention tweets and five communities within retweets that consisted of more than 1000 accounts.
Similarly, when examining the distribution of topics within the identified communities, we found that the majority of tweets were concentrated around a select few topics. Of the 101 identified topics, the top 20 accounted for a significant proportion of tweets across both types of communities. This suggests that the Twitter conversation about the topic of interest is largely dominated by a small number of communities and topics.
Retweet communities
Our analysis of retweets identified 13,655 accounts across 136 communities. The five largest communities, each containing over 1000 members, collectively account for 96.38% of all retweet community members. The community ranked sixth comprises merely 121 members, and all subsequent communities host a maximum of 35 members each. Further insights into the distribution of member counts of the five major communities are shown in Figure 1.
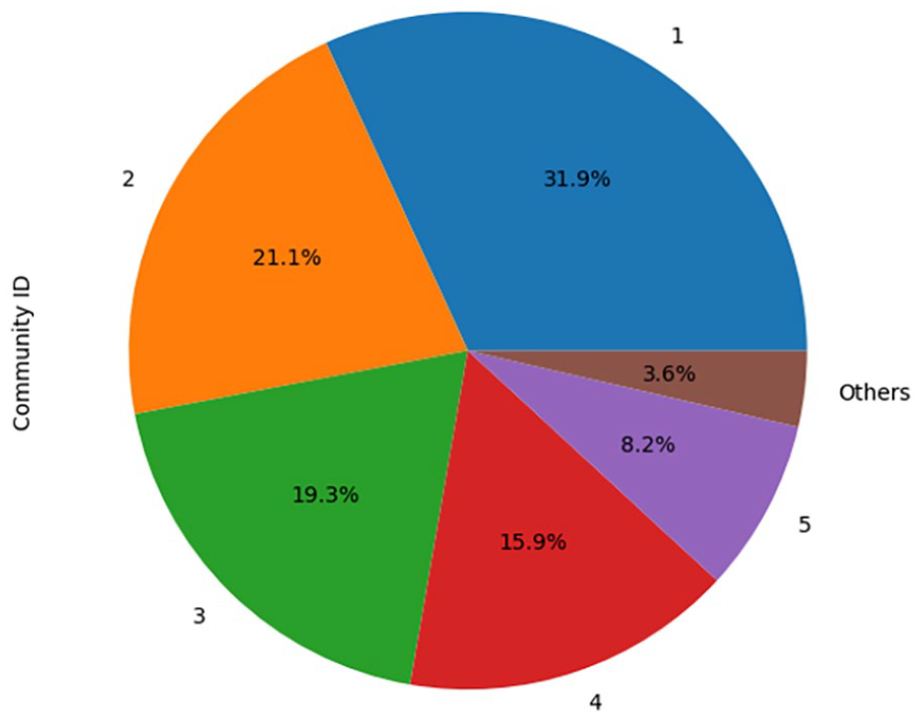
Retweet communities by member count.
Being the two largest communities in terms of member count, Communities 1 and 2 occupy a central position within the network as illustrated in Figure 2, indicative of their pivotal role in the information dynamics. However, Community 3 demonstrates a more diffused presence, stretching across the entire network, suggesting a wider reach or influence. When the focus is narrowed to more active accounts, specifically those with more than three retweets, a higher prevalence of malicious bots is detectible within Communities 1 and 2. 6 This raises critical concerns about the authenticity and integrity of the information propagated within these communities.
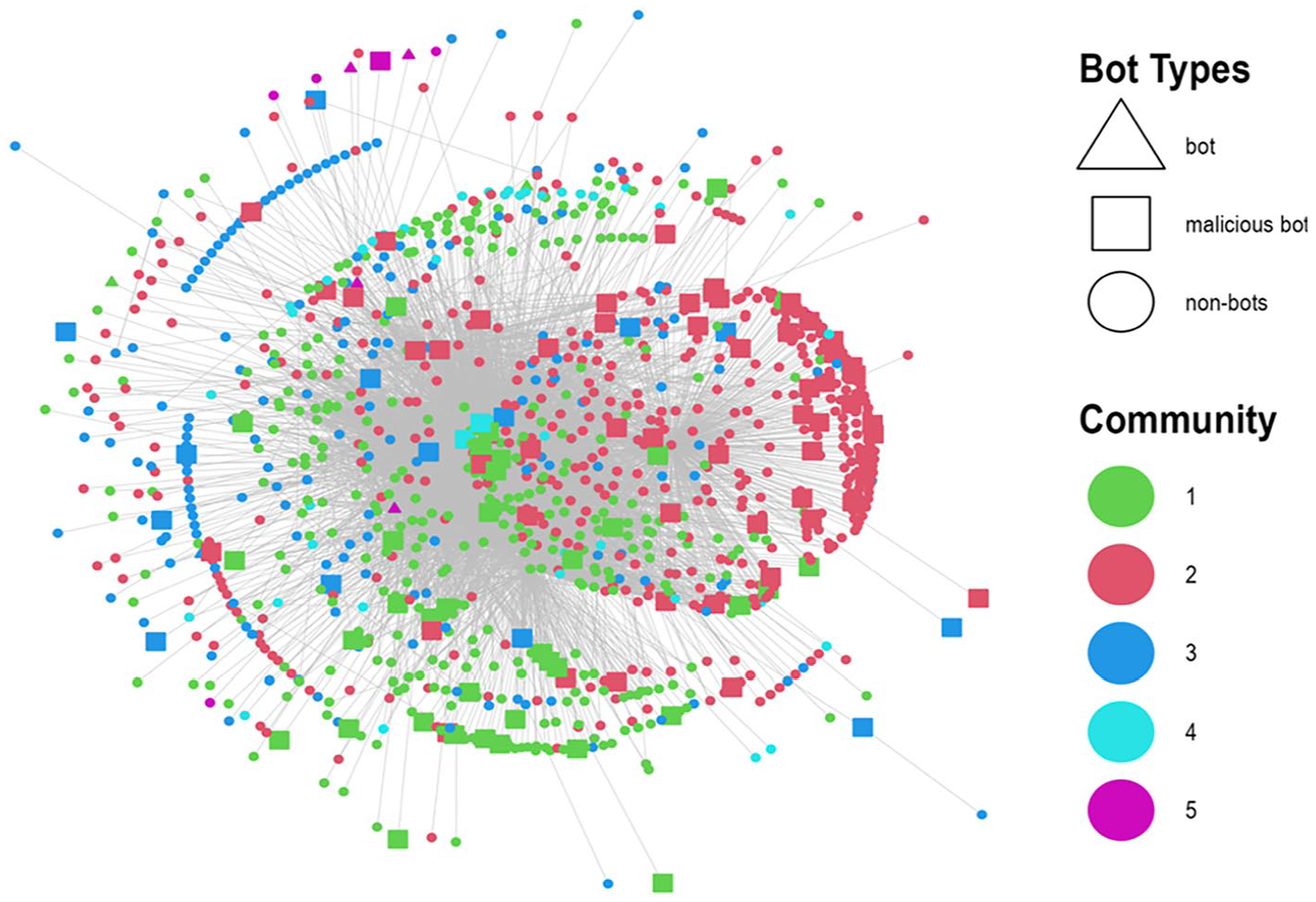
Misinformation retweet communities.
The five most prominent retweet communities in the network shared 78,513 tweets. The top 20 topics comprised 75.14% of these tweets, suggesting that a select number of topics were highly influential in shaping the community discourse during the pandemic. Regarding the diversity of misinformation topics conversed within each community, Figure 3 presents the frequency of top 10 topics within individual communities (further investigation into the distribution of top 20 topics is reported in Table 5 of the Supplemental Material). To focus on topics with substantial contributions within a community’s tweet distribution, we applied a threshold of 2%. For example, if a community has 1000 tweets in total, a topic is considered substantial if there are at least 20 tweets about the topic. With this threshold, Community 1 covers the widest range, with 12 topics having a tweet frequency of over 2%, while Community 2 has 11 topics. Communities 4 and 5 both have nine substantial topics each. Community 3 is the least diverse, with only eight topics exceeding a tweet frequency of 2%. Noticeably, Community 1 has the lowest tweet count of 5290.
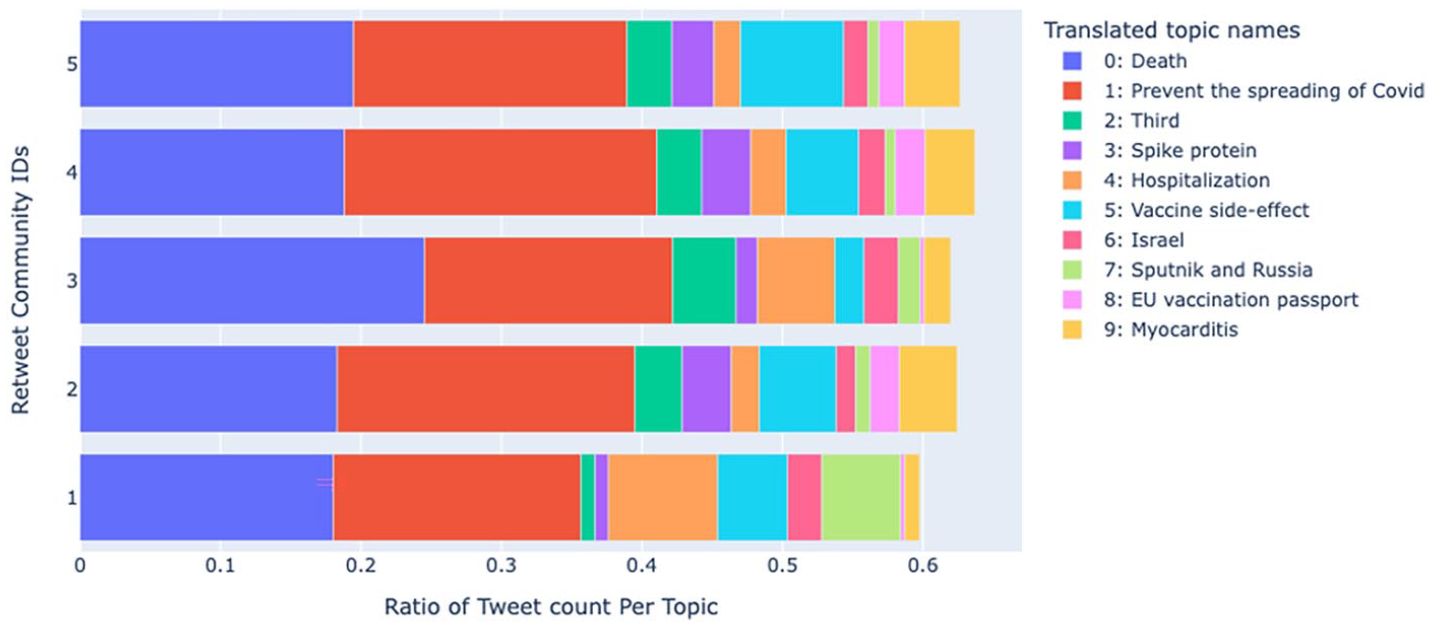
The distribution of top 10 topics in retweet communities.
In analyzing the topics of discussion, we concentrated on the top 20 topics, as shown in Figure 4. This figure features a biplot that provides a visual representation of the similarities and disparities in topic frequencies among retweet communities. Dimension 1 explains 70% of the variance in topic distribution, with Dimension 2 accounting for a further 21%. The biplot is annotated with green arrows pointing to distinct retweet communities, while pink and violet markers denote a spectrum of topics, demonstrating their intersection and divergence across communities. The cos2 color gradient signifies the extent of each topic’s influence on the overall variance, with darker shades indicating topics with a significant explanatory impact, such as “money,” “hospitalization,” and “EU vaccination passport,” in contrast to those with minimal influence, including “pandemics,” “poison injection,” and “works.”
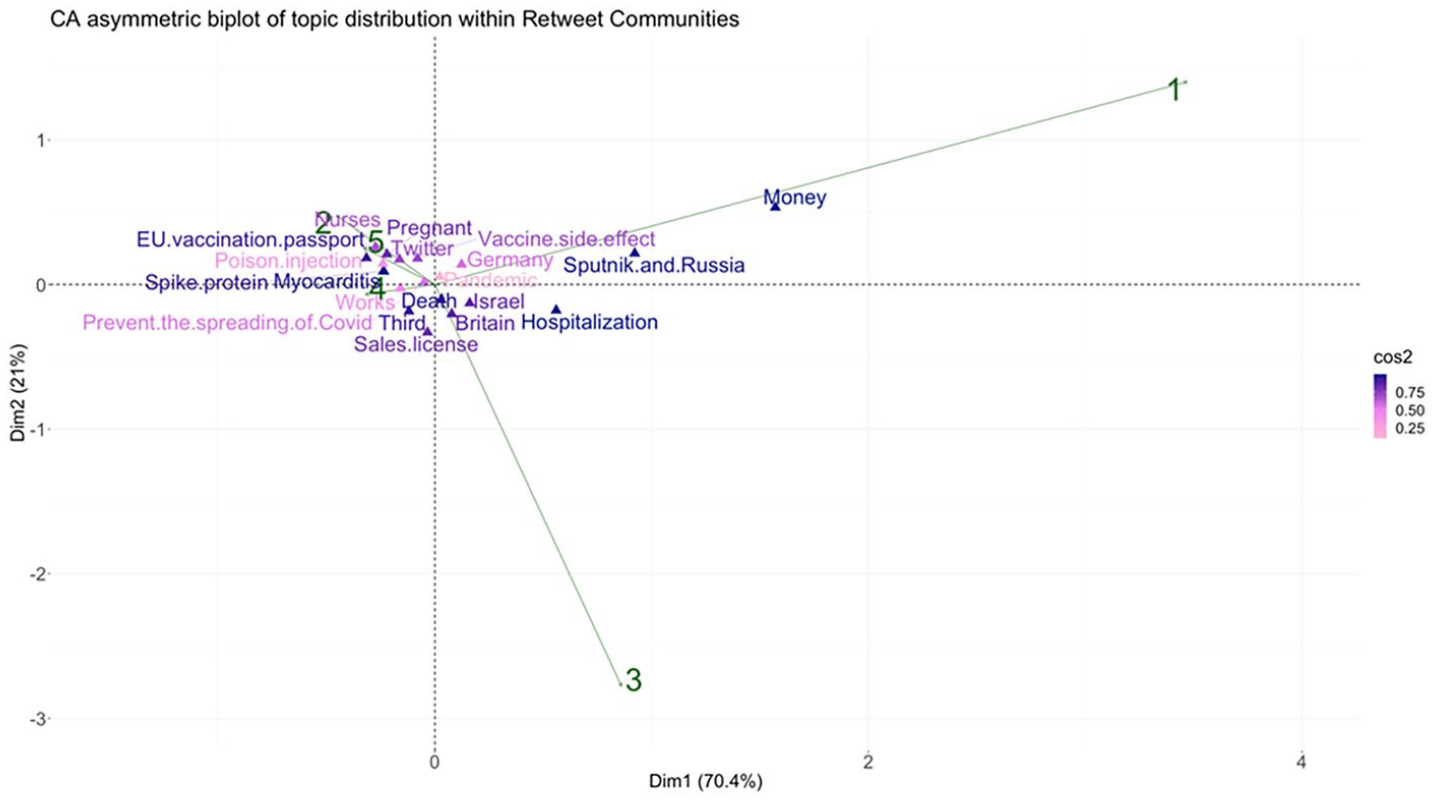
Asymmetric biplot of top five retweet communities and top 20 misinformation topics.
To explore the relationship between topic distribution within the retweet community space, we can analyze the distance between a community ID and the projections of topic points along the green arrow leading to the respective community. Specifically, the topics of money, Sputnik (Russian developed vaccine) and Russia, hospitalization, Germany, Israel, and Britain are ordered in descending fashion based on their significance in Community 1. An analysis of tweets associated with these topics revealed underlying themes prevalent within Community 1. Topic money predominantly contains tweets propagating conspiracy theories regarding pharmaceutical companies’ profits from vaccine sales by not making the vaccine patent public. Furthermore, the community employs a cherry-picking approach to undermine the effectiveness of the COVID-19 vaccine, highlighting specific examples from other countries. For instance, they associate the Sputnik vaccine with Russian political propaganda in the context of Russia, compare individuals experiencing side effects with victims of Nazis in the case of Germany, highlight new cases of infection within a heavily vaccinated population in Israel, and mention a new COVID-19 variant in Britain, all as means to cast doubts on the vaccine’s efficacy. Moreover, vaccine effectiveness was discussed by comparing hospitalization rates between vaccinated and unvaccinated individuals.
In Community 3, the order of topic importance is as follows: hospitalization, money, Sputnik and Russia, sales license, Britain, Israel, death, and third (referring 3rd occurrence of certain events, such as vaccination, COVID wave, death, or hospitalized cases). Similar to Community 1, Community 3 questions vaccine effectiveness by selectively focusing on examples from other countries. Likewise, they propagate conspiracy theories about pharmaceutical company profits. In addition, this community promotes the notion of experimental vaccines by questioning the lack of official marketing authorization for the booster doses of the COVID-19 vaccine in the EU. Notably, they have the highest proportion of tweets related to the topic of death, contributing to the dissemination of skepticism regarding vaccine safety.
Communities 2, 5, and 4 exhibit similar topic distributions, except for Community 4, which differs in the influence order of specific topics. However, we group these communities together for topic analysis, considering only significant topics with a cos2 value above 0.5. In this group, major topics include EU vaccination passport, nurses, pregnant, spike protein, myocarditis, Twitter, vaccine side-effects, third and preventing the spreading of COVID-19.
These communities advocate for the notion that vaccination should be a personal choice, framing it as a matter of freedom or human rights. Concurrently, they challenge the effectiveness of vaccines, aiming to cast doubt on their efficacy and bolster skepticism. They particularly emphasize the obligation of a vaccine passport when they believe vaccines are ineffective. In addition, they attributed the nurse shortage to nurses being compelled to receive experimental vaccines and experiencing COVID-19 or vaccine side effects. Another shared theme is conspiracies about vaccine side effects and doubts about vaccine safety with topics like spike protein (e.g. changing human DNA), pregnancy (e.g. causing miscarriage or infertility), and myocarditis (e.g. causing heart attacks and infection). Moreover, tweets labeled with topics “Twitter” and “third” further cherry-pick side-effect cases by mentioning specific examples from certain Twitter accounts or specifying the number of side-effect fatalities. Notably, these communities exploit the previously discussed topic, hospitalization, to disseminate conspiracies about the safety of the COVID-19 vaccine, exaggerating hospitalization rates purportedly attributable to vaccine adverse effects.
Mention networks
In our analysis of mention-tweets, we identified 27,670 accounts spread across 256 communities. The nine largest communities represent 94.73% of all community members, with each community hosting over 1000 accounts. The subsequent communities feature significantly fewer members, with the 10th community comprising 732 members, the eleventh community with 117 members, and the remainder of the smaller communities housing a maximum of 12 members each. Detailed insights about these top nine communities can be gleaned from Figure 5.
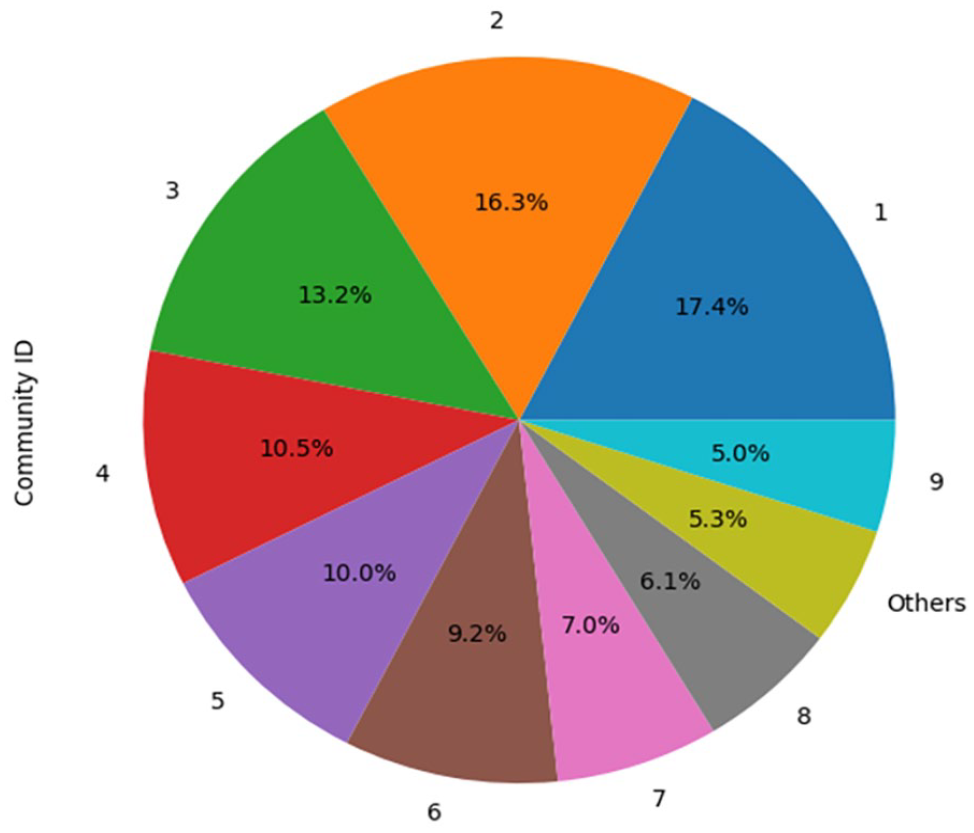
Mention communities by member count.
In comparison to retweet activities, the interaction ratios associated with mention activities are markedly higher, suggesting a greater level of user engagement. This observation is congruent with previous discussions by Unlu et al., (2024), which highlight the participation of malicious bots in online discussions primarily through mention activities. While the interconnection among communities is highly intricate, with certain communities (Communities 1, 2, and 5) holding significant centrality roles as seen in Figure 6, it is also critical to note the visible presence of malicious bots within these communities. There are also smaller communities on the edges of network such as Communities 8 and 9.
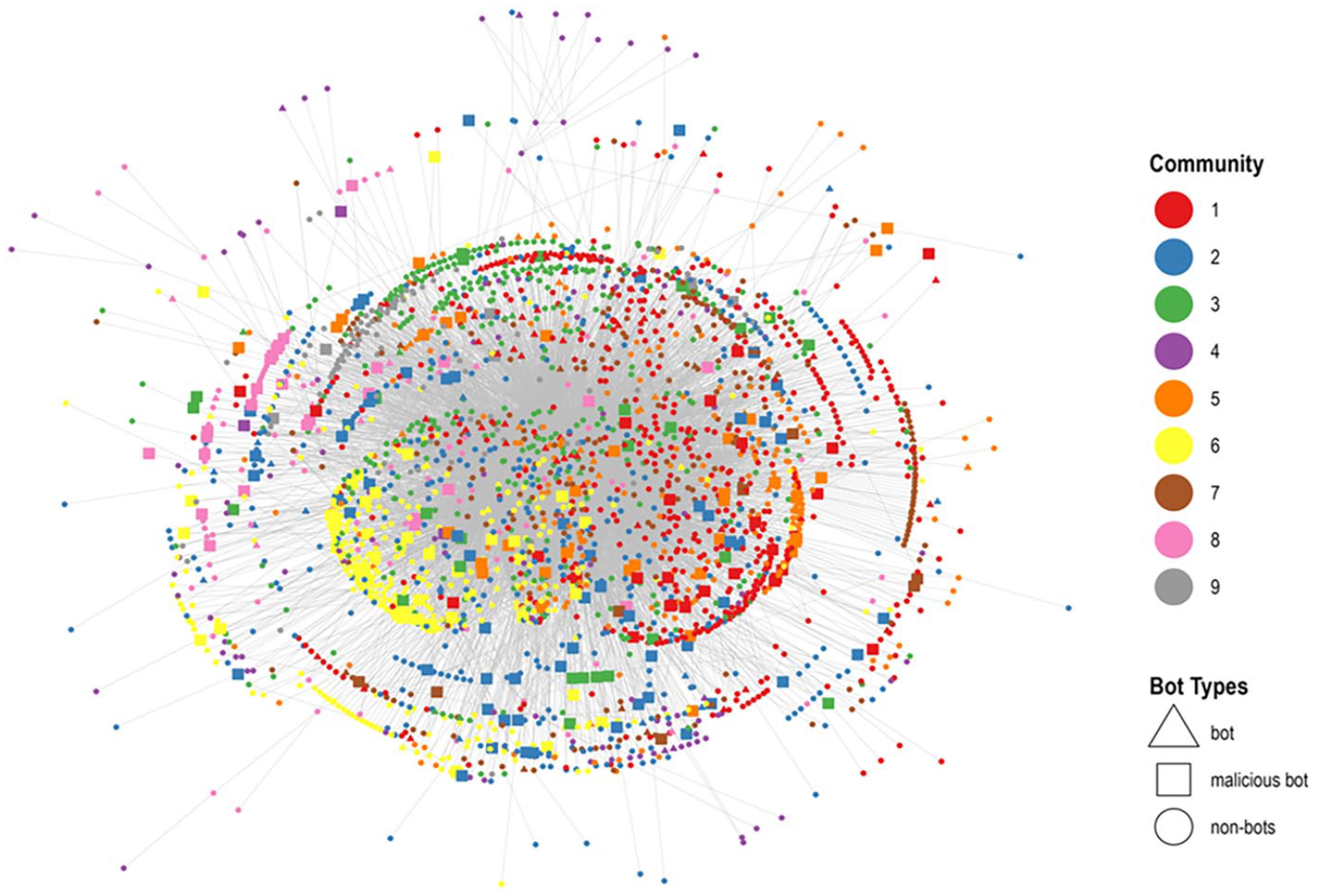
Misinformation mention communities.
When we narrowed our analysis to the mention tweets—a total of 100,822 tweets propagated by the nine largest mention-focused communities—we found that 75.55% of the discourse revolved around the top 20 topics (see Table 6 from the Supplemental Material). Figure 7 illustrates the frequency of the top 10 topics per community. Using the 2% threshold to filter out minor topics, Community 8 demonstrates the highest topic diversity, having 10 out of 101 topics with tweet frequencies exceeding 2%. In contrast, Communities 4 and 5 exhibit less diversity, with eight topics. For the remaining communities, each has nine substantial topics out of 101.
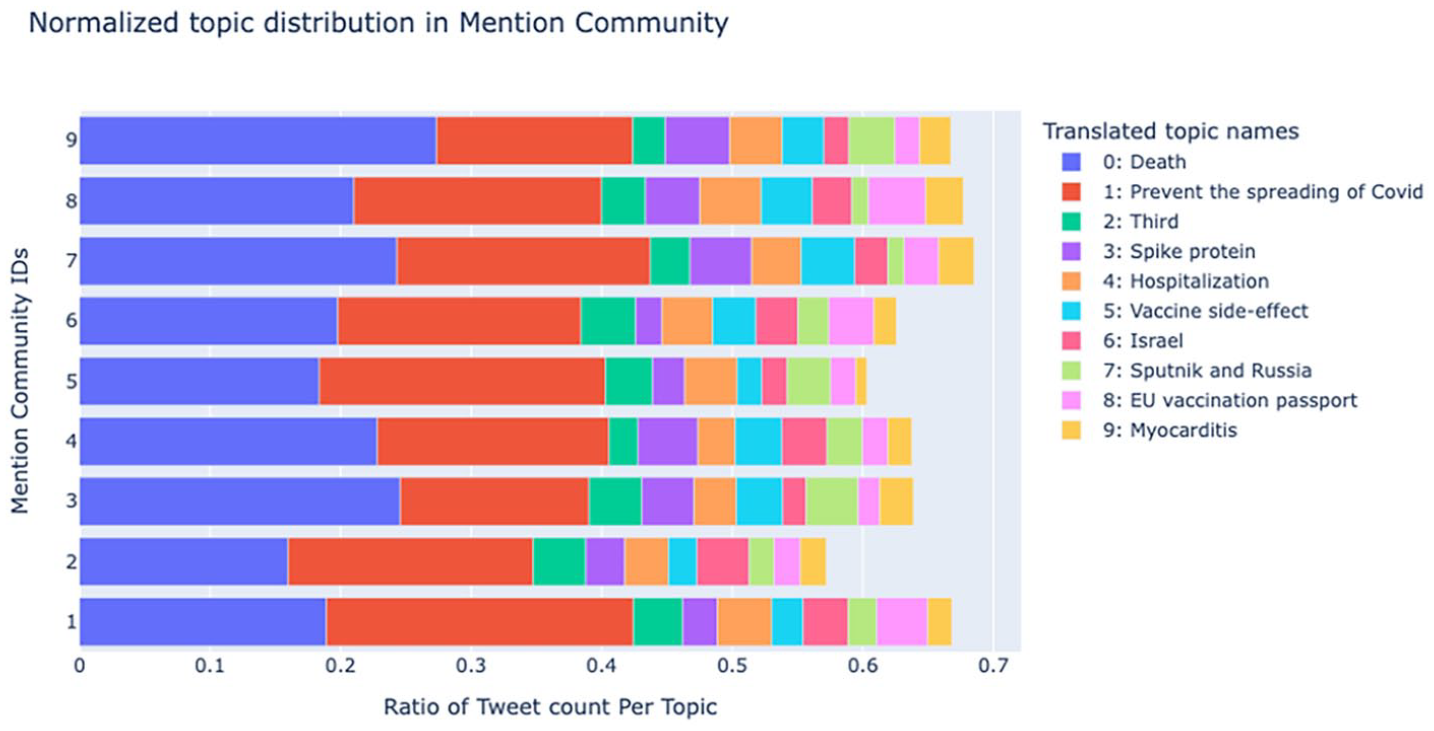
The distribution of top 10 topics in mention communities.
Figure 8 presents the connection between mention communities and tweet topic distribution, using formats and notations similar to Figure 4. In this illustration, the primary dimension (Dim1) explains 46% of the variation in topic distribution within communities, while the second-dimension accounts for an additional 21% of the variation in topic data. Topics with low quality of representation (cos2) are works and Britain, whereas topics with high representation quality include death, and Sputnik and Russia.
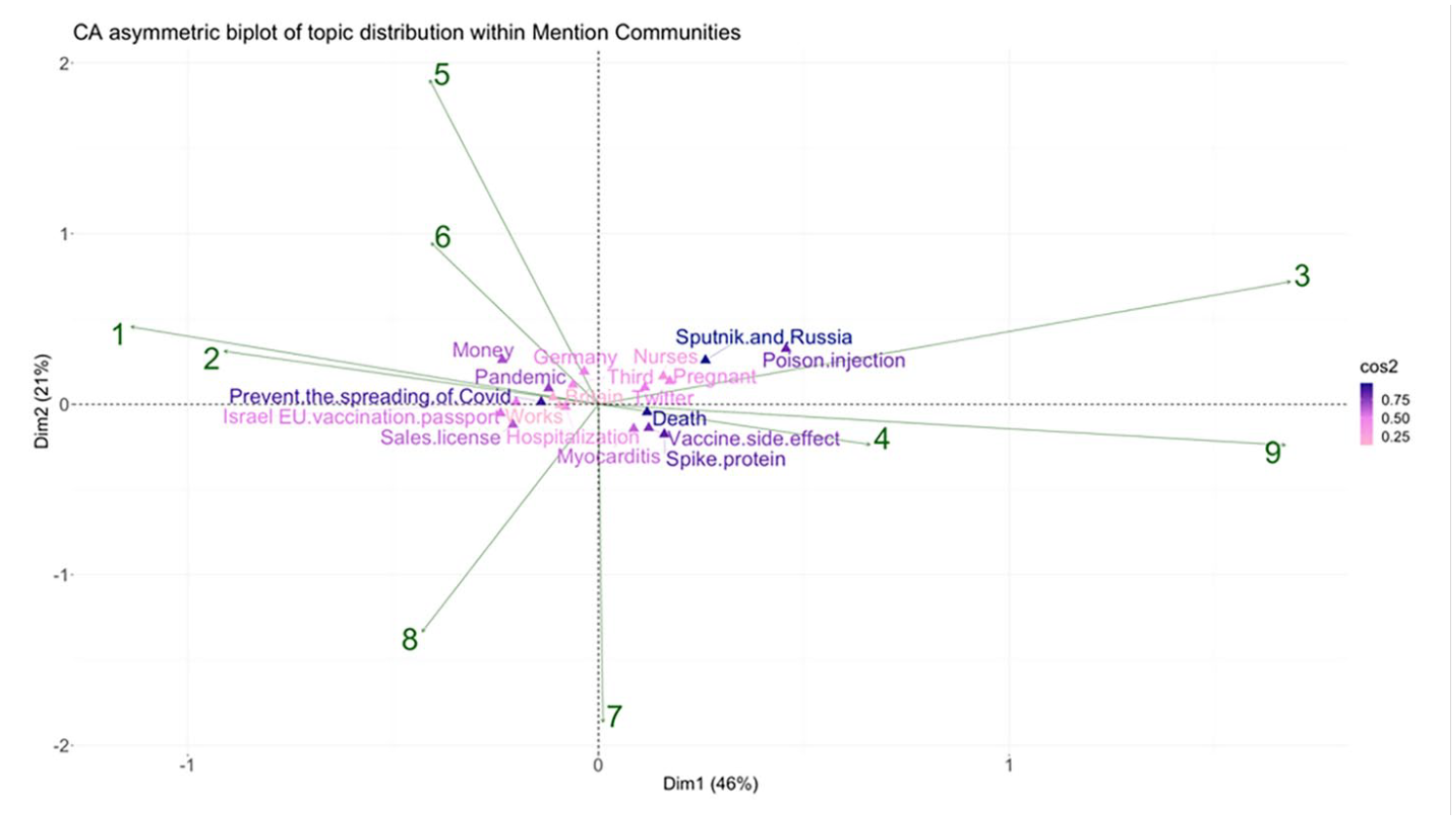
Asymmetric biplot of top five mention communities and top 20 misinformation topics.
Based on the findings from Figure 8, Community 3 exhibits a descending order of topics with significant impacts, including poison injection, Sputnik and Russia, pregnant, nurses, Twitter, spike protein, death, vaccine side effect, Germany, and myocarditis. Communities 9 and 4 share similar topics with Community 3, with some variations in the order of importance following Sputnik and Russia. Overall, these communities are primarily focused on disseminating doubts about the safety of vaccines, employing negative terms such as poison injection to liken vaccines to poisonous substances. In addition, topics related to vaccine side effects (e.g. pregnancy, death, and myocarditis) and vaccine content conspiracy theories (e.g. spike protein) are commonly discussed within these communities. Moreover, they selectively highlight examples from other countries, such as Germany and Russia, and utilize unverified information on Twitter to amplify concerns about vaccine side effects and effectiveness.
Notably, the term Nazi passport has been observed in tweets labeled with the topic Germany, indicating thematic similarities with the EU vaccine passport topic. Another observation pertains to Sputnik and Russian tweets, where discussions about the Ukraine war and the North Atlantic Treaty Organization were observed, potentially serving as a tactic to divert attention from COVID-19 vaccines and propagate political conspiracies.
Furthermore, the topic of nurses encompasses various themes, including personal freedom, such as compulsory vaccination among caregivers and the termination of unvaccinated nurses. In addition, it involves the dissemination of doubt regarding vaccine effectiveness, with mentions of corona-positive nurses infecting patients. Finally, it spreads concerns about vaccine safety, with accounts of nurses suffering severe side effects.
In Community 7, the primary topics are spike protein, myocarditis, vaccine side effect, sales license, death, EU vaccination passport, and Twitter. Alongside their primary focus on disseminating vaccine safety misinformation pertaining to specific side effects, spike protein conspiracy, and tweets from unverified sources, this community also incorporates the Conditional Marketing Authorization of COVID-19 vaccines in the EU to cast doubt upon the safety and effectiveness of vaccinations. Furthermore, within tweet content associated with EU vaccination passport, the discourse encompasses both the theme of personal freedom and the propagation of doubts regarding the efficacy of vaccination.
In Community 8, the primary topics include sales license, EU vaccination passport, Israel, preventing the spreading of COVID, hospitalization, Twitter, pandemic, myocarditis, and third. In addition to sharing some topics with neighboring Community 7, this community also disseminates misinformation about vaccine effectiveness through the topic of preventing the spread of COVID-19. This topic encompasses claims that COVID-19 vaccines do not protect against infections, fail to establish herd immunity, and the long-term effects remain unknown. Moreover, they employ the cherry-picking approach by selectively quoting results from COVID-19-related reports from Israel out of context and utilize the term “pandemic of the vaccinated” to raise doubts. The generic topic “third” encompasses tweets related to three occurrence events, such as deaths, side-effect sufferings, or vaccinations. Within this community, the tweets express further skepticism toward vaccine effectiveness.
The last four communities, including the two largest ones (1 and 2), and Communities 5 and 6, exhibit similar substantial topics, with the primary distinctions lying in the order of these topics. The common topics are money, EU vaccination passport, Israel, sales license, preventing the spreading of COVID-19, the pandemic, Twitter, third, and Germany. Among these topics, “money” emerges as the predominant theme, with tweets claiming the financial incentives of pharmaceutical companies engaged in producing, lobbying, and promoting potentially dangerous or ineffective vaccines to the general population. Subsequently, the discourse shifts to disseminating misinformation about vaccine effectiveness, followed by discussions regarding personal freedom, predominantly articulated through references to the EU vaccination passport and Germany.
Discussion
In the context of the COVID-19 pandemic, often termed an “infodemic” due to the overflow of information (Purnat et al., 2021), social media has become a critical platform where individuals acquire, disseminate, and seek information, thereby collaboratively constructing knowledge (Kolbitsch and Maurer, 2006). Social media platforms, by virtue of their participatory nature and backchannel communication capabilities, have endowed both the general public and policy makers with the means to engage collaboratively in content creation and discourse (Tangcharoensathien et al., 2020; WHO, 2021). The collective knowledge generated and shared on social media has the potential to either facilitate or inhibit shifts in public attitudes (Bruns et al., 2022), thereby influencing collective behaviors ultimately (Happer and Philo, 2013). Thus, our research allows us to examine how social media affects agenda-setting connected to misinformation on a collective scale rather than only at the level of individual tweets (Shakeri, 2020).
Digital communities can act as gatekeepers who employ agenda-setting to influence public opinion by informing the public about critical issues facing a country. This is done by selecting and emphasizing certain issues in the news, which can lead to the public viewing those issues as more important than others. This can have a significant impact on how the public thinks about and responds to those issues (McCombs, 2002). In this study, we identified 101 topics that were discussed during the pandemic. However, the communities in mentions and retweets prioritized certain topics, as shown by the fact that the top 20 topics covered more than 75% of the total discussions in both networks. This suggests that a small number of topics were highly influential in shaping the public discourse during the pandemic.
The study’s findings offer a broader perspective on the role that digital communities play in shaping public opinion, particularly in the context of COVID-19. While each community exhibits distinct priorities in their discourse, overarching patterns emerge in the thematic landscape. Community 1, the most expansive in the retweet network, illustrates a multifaceted approach, primarily engaging in the propagation of narratives centered around pharmaceutical companies’ financial gains from vaccine sales and the selective critique of vaccine efficacy, drawing examples from diverse global contexts. This community also delves into vaccine safety misinformation, spotlighting specific issues such as the purported link between AstraZeneca and blood clots, especially beyond the most prevalent 20 topics.
Conversely, the dynamics in smaller communities, particularly Community 5, which aligns closely with Community 2, reveal a concentrated focus on vaccine safety concerns and the circulation of misinformation regarding vaccine efficacy. These communities also partake in the dissemination of conspiracy theories, notably around the autonomy of choice in vaccination policies, as seen in discussions about mandatory vaccine passports and vaccination mandates for healthcare workers. In essence, while larger communities like Communities 1 and 3 are more inclined toward discussing pharmaceutical profits and fostering skepticism about vaccine effectiveness, the smaller communities, namely 2, 4, and 5, predominantly engage in debates around vaccine safety and related conspiracies.
In mention network, the two largest communities also prioritize their attention on three themes: the conspiracy of financial gain, misinformation regarding the effectiveness of COVID-19 vaccines, and misinformation regarding the safety of COVID-19 vaccines. In addition, these communities also discuss misinformation pertaining to freedom of choice. Community 9, the smallest one, shares common topics with larger communities—3 and 4—and primarily focuses on disseminating concerns about the safety of vaccines. Another less pronounced theme shared among these communities pertains to freedom of choice, partly expressed through the topics of Germany and nurses.
Overall, among the Mention communities, Communities 1, 2, 5, and 6 predominantly mention tweets about vaccine efficacy and conspiracy theories related to profits. However, Communities 3, 4, and 9 are more prone to disseminating conspiracy theories related to vaccine safety. Finally, Communities 7 and 8 exhibit a mixture of content encompassing both vaccine safety and effectiveness. This differentiation in focus across communities underscores the complex and varied ways in which digital platforms can influence public perceptions and dialogues around critical health issues.
Literature underscores the influence of elite media on smaller news organizations (Vargo and Guo, 2017). This influence is partly attributed to a journalistic culture that seeks validation from its peers, particularly those associated with established, prestigious media outlets (McCombs, 2014). Our analysis reveals variances in group size and topic coverage across interaction types, despite group interactions not being a central focus. For instance, in mention communities, Community 8 covers 10 topics, Communities 4 and 5 cover eight topics each, while the remainder communities address nine topics per community. Although smaller than most counterparts (excluding Community 9), Community 8 exhibits a broader topical focus. This implies that the more purposeful, organized nature of mentions leads members to interact around specific agendas, as highlighted by our prior work showing government and public accounts frequently targeted by malicious bots via mentions Unlu et al, (2024). Meanwhile, larger communities demonstrate more diverse topic coverage in the retweet network. Community 1 addresses 12 topics, Community 2 examines 11, Community 3 covers eight, and Communities 4 and 5 explore nine topics each. These findings suggest that for spreading misinformation, larger groups provide a wider informational base for passive audiences. Prior research has documented the relationship in which large, elite media outlets attend to the agendas of smaller online news sources (Stern et al., 2020; Vargo et al., 2018; Vargo and Guo, 2017).
Two potential explanations for this phenomenon emerge. First, the participatory nature of online conversations on platforms like Twitter could potentially enrich content coverage, resulting in information heterogeneity (Jones-Jang and Chung, 2024). However, attention is often selectively focused on specific types of information, like misinformation, shaping social discourse around the pandemic (Messing and Westwood, 2014). In response to information overload, users increasingly rely on their communities for filtered, relevant content. The sharing of content within a network amplifies its relevance (An et al., 2014). However, this can create “filter bubbles,” driven by algorithms that personalize content based on user engagement, further influencing discourse (Bakshy et al., 2015).
Public response to COVID-19 misinformation spread on Twitter notably correlates with “Issue Attention Cycle” theory (Downs, 1972). This theory elucidates the public’s reaction to new issues like misinformation. Typically, this begins with heightened urgency and interest, manifesting as a wave of attention and concern (Downs, 1972). In this context, Twitter operates as the stage for this “alarmed discovery” phase. As communities spread novel misinformation, they incite this phase among audiences, often amplified by algorithms designed to promote engagement over accuracy (Broniatowski et al., 2018; Rosenberg et al., 2020). The resulting emphasis and alarm perpetuate the spread.
Second, accessibility to varied misinformation aside, community characteristics (e.g. politically oriented, prone to conspiracy theories) might influence a group’s alignment around certain issues, as densely connected networks are associated with reduced diversity (Freiling et al., 2023; Stern et al., 2020). This phenomenon of “confirmation bias” tends to incline users toward the retransmission of information to which they are selectively exposed (Sikder et al., 2020). Consequently, this engenders the fragmentation of societies into online “echo chambers.” In these echo chambers, opinions circulate in a recurrent pattern, reinforcing the same viewpoints and ideas, thus perpetuating a cycle of biased information flow (Del Vicario et al., 2016). Therefore, it merits further investigation to understand the transition of topics across different communities within a specified timeframe. This could provide invaluable insights into how misinformation agendas evolve and propagate within and across online communities.
As media technologies and platforms continue to advance, media outlets have proliferated into highly specialized niches that cater to individuals’ specific interests and preferences (Liu et al., 2022). This increasing personalization of media diets enables users to self-select content that aligns with their existing perspectives and affinities. Consequently, scholarly attention should prioritize examining the role of the public agenda in holding collective attention during major societal crises, such as the COVID-19 pandemic. Previous research has illuminated the dynamics of how information spreads online. Studies have shown that while most social media users passively consume content, a small minority of hyperactive users exert outsized influence on the diffusion of information (Haupt et al., 2021; Nazar and Pieters, 2021). Our own research substantiates this finding and further demonstrates how these highly engaged users coalesce into digital communities that attract sizable passive audiences. Once formed, these communities can sustain the prominence of certain themes, narratives, and ideologies over extended periods. More research is needed to understand the factors that motivate hyperactive users and how their messaging cascades through social networks to shape public discourse. Investigating the formation and resilience of these online communities will shed light on how collective attention forms around pressing societal issues.
When public health emergencies like COVID-19 arise, emotions are frequently the initial reaction mobilized in populations due to numerous factors. Pervasive media coverage detailing coronavirus-related deaths and hospitalizations galvanized public sentiment through intense emotional responses during the pandemic (Liu et al., 2022). Particularly during crises when publics are especially susceptible to intense emotional appeals and actively seeking information and perspectives, understanding the agenda-setting processes on social media could inform strategic communication efforts to provide guidance through turbulent events. Our findings demonstrate that emotional sentiments are used to attract attention and encourage users to follow the community. However, other topics are also sustained within the community, depending on its characteristics. For example, conspiracy theory-driven groups tend to focus on topics related to their shared beliefs.
Limitations and future studies
This study has several key limitations that should be taken into consideration in utilizing our findings. First, relying on Twitter data raises concerns about representativeness beyond the platform’s demographics. Furthermore, while Twitter provided substantial accessibility to researchers during the period of our study, facilitating the data collection process, it is important to note that this level of access has since diminished. Consequently, this change presents a limitation for replicating similar research on the platform in the future.
In addition, focusing solely on Finnish-language content on Twitter restricts the findings to a distinct cultural context, meaning they primarily reflect the values and behaviors of Finnish-speaking users. Longitudinal and qualitative analyses could provide richer insights on topic evolution and misinformation narratives. Despite these limitations, this study marks an advance in investigating social media ecosystems during crises.
Future research could apply Network Agenda Setting, Quadratic Assignment Procedure, and Granger causality tests to analyze how topics diffuse across communities and which communities influence each other during crises. However, due to space constraints, this study focused on how communities structured and maintained topic salience during the pandemic.
Conclusions
This study demonstrates how online communities on Twitter can influence public opinion by prioritizing certain topics related to COVID-19 misinformation. Through network analysis, we identified distinctive topical focus areas among different retweet and mention communities. Our findings suggest that larger, more diverse communities introduce new issues that then spread to smaller niche communities. This agenda-setting effect is amplified by social media algorithms designed to maximize engagement. The introduction of novel misinformation by influential communities initiates the “alarmed discovery” phase posited by issue-attention cycle theory. Furthermore, selective exposure within ideologically aligned echo chambers perpetuates biased flows of information. As personalization algorithms proliferate across media platforms, research should continue examining the role of public agendas in commanding collective attention during major societal crises. A deeper understanding of how online communities form and exert influence can inform strategic communication efforts during public health emergencies.
Supplemental Material
sj-docx-1-nms-10.1177_14614448241232079 – Supplemental material for Setting the misinformation agenda: Modeling COVID-19 narratives in Twitter communities
Supplemental material, sj-docx-1-nms-10.1177_14614448241232079 for Setting the misinformation agenda: Modeling COVID-19 narratives in Twitter communities by Ali Unlu, Sophie Truong, Nitin Sawhney and Tuukka Tammi in New Media & Society
Footnotes
Acknowledgements
The authors wish to acknowledge the scientific computing support provided by the team at the Aalto University Research Software Engineer (RSE).
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Academy of Finland (grant 339931).
Supplemental material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.