
Abstract
Previous research has highlighted the ambiguous experience of algorithmic news curation whereby people are simultaneously comfortable with algorithms, but also concerned about the underlying data collection practices. The present article builds on media dependency theory and news-finds-me (NFM) perceptions to explore this tension. Empirically, we analyze original survey data from six European countries (Germany, Sweden, France, Greece, Poland, and Italy, n = 2,899) to investigate how young Europeans’ privacy concerns and attitudes toward algorithms affect NFM. We find that a more positive attitude toward algorithms and more privacy concerns are related to stronger NFM. The study highlights power asymmetries in platformized news use and suggests that the ambivalent experiences might be a result of algorithm dependency, whereby individuals rely on algorithms in platformized news use to meet their information needs, despite accompanying risks and concerns.
Keywords
Introduction
Algorithmic curation has become the norm for how we consume media. Young people, in particular, are increasingly turning to social networks for news, with 39% of those between 18 and 24 years using social media platforms as their main source (Newman et al., 2022). On social media, audiences are consuming news in nonlinear, algorithmically mediated information flows (Thorson and Wells, 2016), and people’s digital traces structure their personalized news environment based on the continuous collection and processing of large amounts of user data (Thorson, 2020; Thorson and Wells, 2016). As a consequence of these structuring processes, users are under the impression that news are omnipresent and always within reach, which, in turn, has led to an increasingly passive news consumption among users (Ytre-Arne and Moe, 2018) based on the belief that news will find them without any active effort on their end (Gil de Zúñiga et al., 2017). However, while young people express positive attitudes to efficient recommender systems and benefit from news at “low cost,” they also feel uneasy and surveilled through the data collection practices that underlie algorithmic curation (Barnes, 2006; Monzer et al., 2020; Swart, 2021a).
The present article seeks to understand the dynamics behind these ambivalent experiences based on original survey data from six European countries. Combining media dependency theory with platformization scholarship, the study examines how power asymmetries between users and platforms are reinforced by the datafication of audiences and are associated to news-finds-me (NFM) perceptions, despite users’ privacy concerns. These privacy concerns are related to users’ awareness of algorithmic curation and the associated threats to their privacy arising from the data collection that algorithmic curation requires (Bodó et al., 2019). Following Gil de Zúñiga et al. (2017), we define NFM as the extent to which individuals believe they can indirectly stay informed—despite not actively following the news—through general social media use, including algorithmically mediated connections within social networks and information received from friends. The study contributes to the field by supporting previous qualitative findings on users’ experiences and perceptions of algorithmic curation (Kennedy et al., 2017; Swart, 2021a) with quantitative evidence. Moreover, it furthers the theorization of media dependency in the field of digital media. In light of our findings, we offer the concept of algorithm dependency as a heuristic to capture the degree to which individuals rely on algorithms in platformized news use to meet their information needs despite the perceived misgivings, such as a lack of control over their data, and discuss its implications for scholars and practitioners.
The platformization of news
Platformization is a process by which platforms become the central digital infrastructure of society, with consequences for the various economic, political, and cultural spheres of life (Poell et al., 2019), including news circulation and news use. As many news organizations are struggling economically, they are increasingly reliant on big social media platforms to ensure the circulation of news and measure audience engagement (Meese and Hurcombe, 2021; Moran and Nechushtai, 2022; Nielsen and Ganter, 2018). Accordingly, it is platforms that largely determine what kind of news content a user will come across by continuously aggregating and analyzing user data to enable algorithmic curation (Thorson, 2020). Audiences also increasingly rely on algorithmically mediated news consumption (Newman et al., 2022) that is structured by the mechanisms of platformization, which van Dijck et al. (2018) describe as datafication, commodification, and selection.
Data are a key resource for innovation and development and, thus, are an important economic commodity. Datafication promises to improve news professionals’ knowledge about audiences through the collection, processing, and analysis of audience data, so that audiences’ information needs and preferences are better served. However, datafication reinforces the view of audiences as consumers and sources of data for economic profit, which affects users’ ability to stay informed while protecting their privacy (Adams, 2020; Athique, 2018). Audiences are classified and stratified based on characteristics such as interests, income, or location, to maximize revenue. In turn, audiences that previously expressed interest in political news are more likely to be exposed to political information (Thorson, 2020).
While news organizations traditionally relied on audience commodification by selling the time audience spent consuming content to advertisers, the present-day commodification of audiences on platforms revolves around user data that can be personalized and aggregated in certain time–space locations (Nieborg, 2016). This is a relevant change because user engagement with news produces rich records of networks between users’ political positions, interests, beliefs, and behavioral patterns. Thus, the linked mechanisms of datafication and commodification on platforms affect the fundamental societal roles of journalism and citizens (Adams, 2020). Even if measures are implemented to protect users’ privacy, such as anonymizing and aggregating data, severe privacy harms through re-identification can occur (Crawford, 2021). These are crucial ethical and political issues that users are, at least to a certain extent, aware of (Kennedy et al., 2017). In turn, this may affect audiences’ relationship with journalism and reinforce power asymmetries between audiences, platforms, and news organizations (Moran and Nechushtai, 2022).
On a general level, communication scholarship has pointed out that media systems and audiences are mutually dependent, in the sense that “the satisfaction of needs or the attainment of goals by one party is contingent upon the resources of another party” (Ball-Rokeach and DeFleur, 1976: 6). At the same time, media dependency theory highlights a power asymmetry between them, in that media system players always have more access to and more control over resources than audiences (Kim, 2020; Kim and Ball-Rokeach, 2006). In platformized media systems, these relationships are further complicated, as both news organizations and social media platforms are dependent on users’ data to attain goals (cf. Ball-Rokeach et al., 1990). Still, platforms and actors (such as news organizations) who use data to reach out to audiences have more power over resources than the users who provide them (Andrejevic, 2014; Lv and Luo, 2018).
Media dependency in platformized news use
According to media dependency theory, individual dependency on mass media hinges on the relationship between individuals and media, which is shaped by the degree of perceived importance and helpfulness of mass media as resources for achieving personal goals (Ball-Rokeach et al., 1984). Here, individuals are considered active and goal-oriented agents who weigh the utility of various resources for achieving their objectives. Similarly, Kim and Jung (2017) conceptualize social media dependency as a degree of helpfulness of social media platforms for achieving personal goals. They also look at individuals as agents who actively create, share, curate, and monitor their environment.
However, algorithmic curation may reconfigure the character of dependency in the contemporary high-choice media environment, where an overwhelming amount of content competes for user attention so that the opportunity cost for actively seeking news has become higher than ever (Weeks and Lane, 2020). According to media dependency theory, the way individuals formulate their goals is contingent upon the structural resources and limitations of their environment (Ball-Rokeach and DeFleur, 1976; Kim, 2020). Thus, individuals may consider algorithms an essential resource for obtaining informational benefits at a minimum cost (Gil de Zúñiga and Cheng, 2021; Swart, 2021a). An alternative account of algorithmic news use is that of habitual convenience (Chun, 2016; Kaluža, 2022; Kant, 2020). In simple terms, users form a habit of relying on algorithms to curate their online experiences. This is because their online actions are constantly tracked and used by algorithms to predict and shape what they do next. As a result, they end up using algorithm-based media repeatedly out of habit (and convenience) (Kaluža, 2022). As we will argue, both accounts may manifest in the widespread belief that one does not need to actively seek news because news will find them regardless. At the same time, they also manifest tension between the convenience of algorithmic curation and privacy concerns stemming from the data collection at the heart of it.
NFM perception and algorithmic curation
News are an integral part of young people’s media use (Andersen et al., 2020; Kalogeropoulos, 2019), and young people heavily rely on social media to stay up to date (Newman et al., 2022; Swart, 2021b). At the same time, many young people do not intentionally follow the news (Boczkowski et al., 2018; Swart, 2021a, 2021b). Instead, algorithmically curated news use is perceived as pleasant and convenient (Oeldorf-Hirsch and Srinivasan, 2021; Swart, 2021a), leading users to adopt the view that they do not actively have to seek out information, but that news will find them (Gil de Zúñiga and Cheng, 2021; Gil de Zúñiga et al., 2017). The NFM perception is defined as “the extent to which individuals believe they can indirectly stay informed about public affairs—despite not actively following news—through Internet use, information received from peers and online social networks” (Gil de Zúñiga et al., 2017: 107). Notably, when users express that they do not need to actively seek out news, this does not necessarily reflect news avoidance (Gil de Zúñiga and Cheng, 2021). NFM is typically measured by items such as “I rely on information from my friends based on what they like or follow through social media” and “I don’t worry about keeping up with the news because I know news will find me.” This concept comprises three dimensions: reliance on peers for information needs, lack of motivation for seeking news, and a self-confirmation bias (believing to be informed even if this is not the case) (Song et al., 2020). Although items measuring NFM do not explicitly mention algorithms, we argue that these dimensions cannot be detached from algorithmic experiences, as young people engage with news via platforms, where information is de facto algorithmically curated. Because algorithms are experience technologies (Cotter and Reisdorf, 2020), users do not need to know about the exact technology in place in order to experience algorithmic curation and develop some degree of algorithmic awareness, appreciation, and irritation (Hargittai et al., 2020; Ytre-Arne and Moe, 2021). Research on incidental exposure shows that people effectively do encounter news on social media platforms (e.g. Boczkowski et al., 2018; Toff and Nielsen, 2018). These experiences further feed into users’ lack of motivation for actively seeking news and their perception that they are informed. In other words, users with a strong NFM perception are likely inclined to rely significantly on algorithmic curation to meet their information needs. Algorithmic curation and NFM perception are at the same time related to the habitual nature of algorithmic news use. Habit connects past and future, leading to the assumption that beliefs, interests, and customs are products of past repetition (Delanda, 2010). In the same vein, algorithm curation relies on habit’s principle of generating anticipation based on past activity or repetition to yield similar results (Chun, 2016; Delanda, 2010; Kaluža, 2022). Habits generate click-throughs, likes, and browsing histories that help determine future content (Kant, 2020), bridging human agency and algorithms and creating a feedback loop (Kaluža, 2022). This is especially true for people who habitually use social media for information purposes since their algorithms are more likely to indeed show them news. Hence, we expect that:
H1. The more people use social media for information purposes, the stronger their NFM perception.
Furthermore, according to the Mere Exposure Effect, people tend to become increasingly comfortable with things they are exposed to repeatedly (Zajonc, 1968). Multiple factors can contribute to users feeling comfortable with algorithms, such as their general knowledge about algorithms (Araujo et al., 2020), the familiarity that comes with repeated use, which allows users to understand and navigate the algorithms (Cotter and Reisdorf, 2020), or their belief in algorithmic objectivity (Jussupow et al., 2020; Logg et al., 2019). For an overview of (the often diverging) user attitudes toward algorithms in the context of news, see Mitova et al. (2022). Finally, research has shown that it can be the mere frequency with which people access news through social media platforms that increases their belief that algorithmic selection based on users’ past behavior is a better way to obtain news than editorial curation (Thurman et al., 2019). Along these lines, we hypothesize that this belief supports also NFM perceptions:
H2. The more comfortable people feel with algorithmic decision-making, the stronger their NFM perceptions.
Commodification of news use and privacy concerns
A third factor in our model is the privacy risk side of algorithmic news use. Findings of previous studies on NFM typically portray NFM news consumers as under-informed citizens that lack effort or simply do not care enough to seek out information independently. We believe this focus on individual responsibilities is too narrow and that we need to understand individual behavior within the larger systems in which it takes place. The assumption that NFM users are low-effort or apathetic might lead to the conclusion that NFM users do not care about the negative consequences of algorithmic curation. While algorithm comfort may increase when personalized algorithmic curation is perceived to work well, studies have shown that it may also lead to unease and privacy concerns. In several qualitative studies, users report unease and discomfort with being watched (Bell et al., 2023; Kennedy et al., 2017; Monzer et al., 2020; Swart, 2021a), for example, when personalized content touches on overly personal aspects (Swart, 2021a). Analyzing data from a 26-country survey, Thurman et al. (2019) found that preference for algorithmically selected over human-selected news is determined by multiple factors, including privacy concerns: The more people are concerned about privacy risks associated with algorithmic curation, the less they agree that any form of news selection is a good way to get news. Specifically, this effect was found to be strongest for automated personalization based on a user’s own behavior. However, users’ privacy concerns do not necessarily deter users from using platforms for news use and various other purposes (for an overview, see Barth and de Jong, 2017). For example, Bodó et al. (2019) show that privacy concerns are not a significant factor influencing user attitudes toward news personalization. This reflects, as media-dependency theory stipulates, that individuals’ behavior is contingent upon the structural resources and limitations of their environments (Ball-Rokeach and DeFleur, 1976; Kim, 2020). In fact, studies show that when users are aware of how algorithms work they partially expect algorithms to “work for them,” either as a part of the trade-off for platforms commodifying their data (Kennedy et al., 2017; Swart, 2021a) or based on narratives around personalization of content in the service of enhancing individual user experience (Chun, 2016; Kant, 2020). Thus, having an awareness of algorithmic curation and NFM perceptions does not necessarily signify a lack of concern over privacy and data collection (Bell et al., 2023; Bodó et al., 2019). In lieu, those who understand and expect algorithms to work (i.e. according to our argument, those with strong NFM perceptions) may be more likely to be worried about privacy than those who do not. Thus, we hypothesize:
H3. NFM perception is positively related to privacy concerns.
In essence, we argue that users in platformized news environments are reliant on an infrastructure they have little power over and that they are aware of its consequences. Consequently, we suggest that the use of social media for information purposes and privacy concerns play a role in how comfortable individuals feel about algorithmic decision-making, specifically in regard to discovering news on social media platforms (Kennedy et al., 2017; Schellewald, 2022; Swart, 2021a). The more someone uses social media for information and is aware of privacy concerns, the more it will shape their perceptions of algorithmic curation. Thus, we propose that the use of social media for information purposes and privacy concerns may act as catalysts for the relationship between comfort with algorithmic decision-making and NFM (as proposed in H1).
H4a. The more people use social media for information purposes, the stronger the relationship is between their comfort with algorithmic decision-making and their NFM perceptions.
Furthermore, we expect that the stronger reliance on and comfort with algorithms in the context of news use is also related to higher concerns about privacy:
H4b. The more privacy concerns people have, the stronger the relationship is between their comfort with algorithmic decision-making and their NFM perceptions.
Method
Sample and data
As part of a cooperation with the Goethe Institut’s project “Generation A=Algorithm,” we conducted an online panel survey in February and March 2021 (N = 2889), including six European countries: Germany (n = 481), France (n = 487), Greece (n = 477), Italy (n = 483), Poland (n = 463), and Sweden (n = 498). They were selected based on several criteria intended to ensure generalizability of the data for the European Union (EU) as far as possible, such as their size, region, and their similarities and differences regarding education systems and economic standards. The selected countries are also appropriate in regard to the diversity in the use of social media for news: 32% of respondents in Germany, 40% in France, 72% in Greece, 47% in Italy, 55% in Poland, and 45% in Sweden (Newman et al., 2022). We surveyed citizens between 18 and 30 years of age. We focused on this group (1) because it is the most active on social media and therefore confronted with algorithmic curation more often, and (2) because algorithmic curation potentially affects young people’s future attitudes and decisions the most. The online panel provider respondi was entrusted with drawing a final sample and generating a stratification according to the national censuses with quotas for age groups and education levels. The survey instrument was the same across all countries. The original survey was developed in English and then translated into the national languages of the selected countries. Since it was part of a broader project, the survey covered several fields of application of algorithms and artificial intelligence, and inquired about young people’s perceptions and feelings about, for example, microtargeting, news recommenders, and job application screening. Below we only report constructs relevant to the present study. For the full report, see Gagrčin et al. (2021).
Measures
Algorithm comfort measured the extent to which the participants felt comfortable with algorithms making decisions in their different life domains, ranging from 1 (very uncomfortable) to 7 (very comfortable). The 12-item scale based on Araujo et al. (2020) and Evans (2020) included, for example, “deciding about news recommendations you get at the end of an article” and “scheduling your working hours” and reflected a one-dimensional latent variable, Ω = .91. While this investigation focuses on algorithms in the context of news consumption, Confirmatory Factor Analysis (CFA) results show that people’s comfort with algorithms making decisions in their lives is not exclusive to specific areas, but embraces various areas overall. The average factor loading was .7, which corresponds to about 50% of the shared variance between the indicators and the latent variable and commonly represents a (more than) acceptable value (Kline, 2013). For this reason, we decided to operationalize algorithm comfort in a broader sense, encompassing people’s overall comfort with algorithms in their lives, not only regarding news consumption. This approach has the advantage of yielding more robust associations within the model as the variable is not conceptually tailored to the outcome, avoiding the proverbial self-fulfilling prophecy scenario.
Information use measured the extent to which the participants used social media for receiving and sharing different types of information, ranging from 1 (strongly disagree) to 7 (strongly agree). The five items adapted from Alhabash and Man (2017) and Whiting and Williams (2013) included, for example, “to share information about social and political issues” and “to get immediate knowledge of big events” and reflected a one-dimensional latent variable, Ω = .83.
Privacy concerns measured the extent to which the participants thought that the specific data collection practices of social media companies might harm them, ranging from 1 (not at all) to 7 (to a very large extent). The four items adapted from the privacy risk perceptions scale by Boerman et al. (2018) included, for example, “collecting data about my online behavior” and “sharing data about my online behavior with my government” and reflected a one-dimensional latent variable, Ω = .87. Items measuring privacy concerns were placed toward the end of the questionnaire, while items measuring algorithm comfort were placed at the beginning in order to avoid priming and order effects as much as possible.
NFM perceptions measured the extent to which the participants thought they did not have to actively pursue news since it would eventually find them anyway. While we did not explicitly define the term news, distinctions were made between news received directly through journalistic news outlets and news received through friends. Beyond that, we did not aim at measuring a uniform rendition of news, but rather users’ perceptions of their relationship with journalistic news content. We adopted four items from Gil de Zúñiga et al. (2017) which included: “I rely on my friends to tell me what’s important when news happens,” “I can be well informed even when I don’t actively follow the news,” “I don’t worry about keeping up with the news because I know news will find me” and “I rely on information from my friends based on what they like or follow through social media.” They ranged from 1 (strongly disagree) to 7 (strongly agree) and reflected a one-dimensional latent variable, Ω = .71.
Demographics were measured as follows: Age was indicated as an integer (M = 24.71, SD = 3.77). This standard deviation represents a good amount of variance within the age group selected, which avoids biases due to age. The participants’ education was assessed based on the categorization of the International Standard Classification of Education. As some degrees were only present in single countries, the degrees were aggregated for the analysis according to the European Commission’s National Qualifications Frameworks standard. Degrees 1–3 were assigned the value low, 4 and 5 medium, and the remaining high. The participants were offered the options male, female, and “prefer to self-describe,” where they could write an open-ended answer. A total of 49.6% of participants self-identified as female. The participants’ countries of residence were represented as a categorical variable with one value each; for example, “Greece” and “Italy.”
Analysis
We performed structural equation modeling (SEM) with a robust diagonally weighted least squares (DWLS) estimation. This technique was chosen so we could model all variables that were part of our theoretical assumptions as reflective latent variables (see, for example, Kline, 2023) and model the relationship of algorithm comfort, information use, and privacy concerns with NFM and their interactions along the hypotheses developed above. We expected the selected countries to differ from each other regarding NFM due to cultural conventions and economic standards. However, multilevel analysis with less than 30 to 50 observations in the Level-2 variable (in our case, country) is not recommended (e.g. Maas and Hox, 2005). Therefore, we created a fixed-effects model, controlling for education, gender, and countries, with one dummy variable each and Germany as a baseline. While this did not enable us to interpret the reasons for differences between countries, it accounted for all variance in NFM that could be explained by these differences and therefore enabled us to uncover effects that were not due to them. This contributes to more generalizability and the uncovering of relationships that approximate the European youth as a whole. For coding and data analysis, we used R (Version 4.1.1; R Core Team, 2021) and the R packages dplyr (Version 1.0.7; Wickham et al., 2021), knitr (Version 1.33; Xie, 2015), and lavaan (Version 0.6.9; Rosseel, 2012).
Results
To avoid inflated estimates in SEM, we first checked for possible multicollinearity among algorithm comfort, information use, and privacy concerns. No concerning relationships were found. We then created the SEM, which yielded satisfactory model fit, χ2 (509) = 7488.84, p < .001, CFI = .95, RMSEA = .07, 90% CI = [0.07, 0.07], SRMR = .03. According to a meta-analysis on model fit indices by Peterson, Kim, and Choi (2020), these figures are not ideal, but still well within the range of acceptable and typical model fit. We could easily have increased the model fit by including additional paths, but we decided against it in favor of a more parsimonious solution that does not overfit the model to the data.
There are, of course, countless other ways of combining the variables we selected. Testing any other arbitrary combination would have increased the risk of random success. We therefore chose to create only this exact model based on our theoretical assumptions and deductions.
The results showed that all countries save France scored significantly higher in NFM than Germany, which was employed as the baseline. Participants from Poland, β = .17, b = 0.34, 95% CI = [0.23, 0.44], z = 6.30, p < .001, and Sweden, β = .17, b = 0.33, 95% CI = [0.22, 0.43], z = 6.24, p < .001, were most prone to NFM.
H1 assumed that the use of social media for sharing and gaining information is positively related to NFM. The results confirmed this assumption: Information use was indeed positively and significantly associated with NFM, β = .36, b = 0.36, 95% CI = [0.32, 0.39], z = 17.67, p < .001. As expected, the more people use social media for information purposes, the more they count on algorithms to present them news without actively seeking them. This speaks for our assumption that people learn about and get more used to the mechanism behind algorithmic news curation the more they are actually exposed to it on social media.
H2 assumed that higher comfort with algorithms making decisions in various areas of one’s life is positively related to NFM. This assumption, too, was confirmed: Algorithm comfort was positively and significantly associated with NFM, β = .23, b = 0.30, 95% CI = [0.25, 0.35], z = 12.22, p < .001. This finding suggests that individuals who have positive attitudes toward algorithms in various areas of life tend to rely more heavily on their functionality to present them news. This speaks for our argument that NFM can be understood in the context of algorithms although the items do not explicitly mention algorithms. H3 assumed that privacy concerns are positively related to NFM. Our results confirmed this assumption, as privacy concerns were positively and significantly associated with NFM, β = .14, b = 0.12, 95% CI = [0.09, 0.15], z = 7.69, p < .001. This outcome underlines our suggestion that people give in to privacy threats posed by algorithmic news curation rather than weighing costs against benefits. In other words, the more people are concerned about the security of their data, the more they indicate a reliance on algorithmic news curation of news. However, this relationship could also be read the other way around—the more people rely on algorithmic news curation, the more they become aware of and (begin to) worry about related privacy threats. Regardless, both perspectives suggest that people rely on algorithmic news curation despite their privacy concerns.
H4a and H4b proposed that both the use of social media for information purposes and privacy concerns positively affect the relationship between the comfort with algorithmic news curation and NFM. Indeed, information use, β = .17, b = 0.20, 95% CI = [0.15, 0.25], z = 7.96, p < .001, and privacy concerns, β = .15, b = 0.16, 95% CI = [0.11, 0.20], z = 6.65, p < .001, positively and significantly moderated the relationship between algorithm comfort and NFM. As suggested, both information-seeking and privacy concerns may indicate deeper knowledge about the mechanisms behind algorithmic curation: The more users employ social media to seek information, the more they understand the processes behind algorithmic news curation, and that relying on it means accepting that algorithms make decisions in their lives, based on their data. They feel comfortable with the employment of algorithms in their lives, as they know that otherwise, the news could not find them.
Figure 1 visualizes the SEM and the results. Table 1 offers an overview of the results.
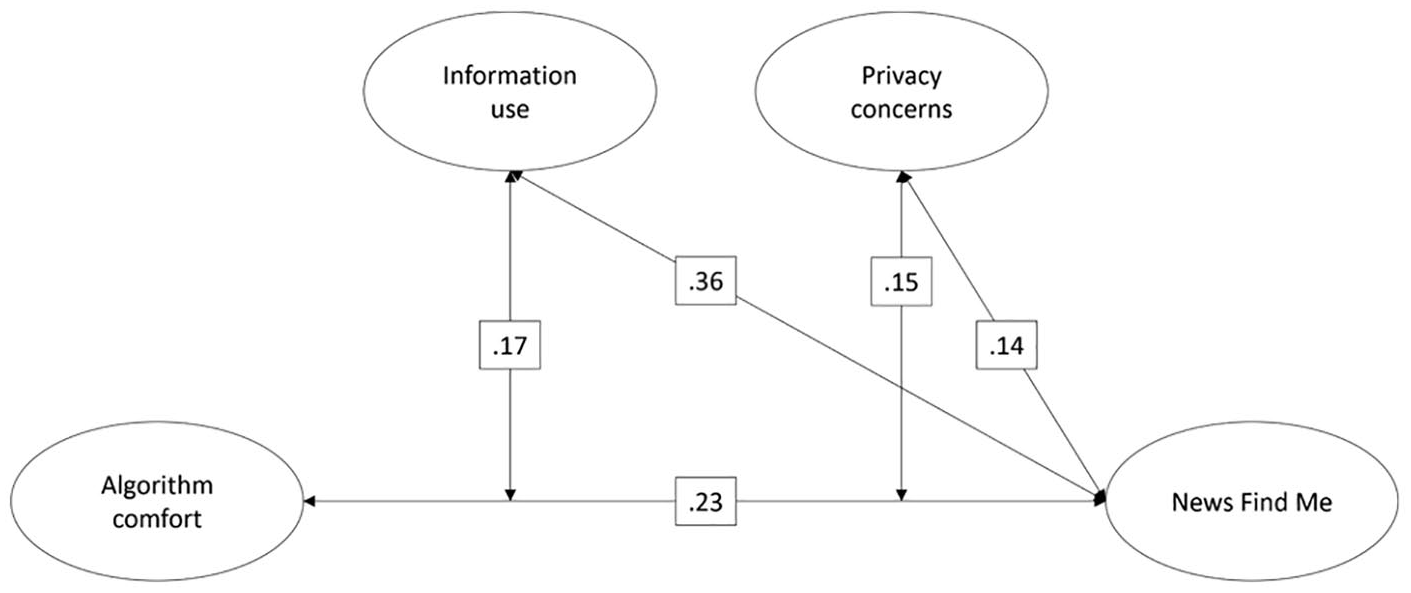
Algorithm comfort, information use, privacy concerns, and interactions predicting NFM.
Algorithm comfort, information use, privacy concerns, and interactions predicting NFM using SEM with robust diagonally weighted least squares estimation.
NFM: news-finds-me; SEM: structural equation modeling; CI: confidence interval; SE: standard error.
β represents standardized regression coefficients.
Discussion
Previous literature highlighted the tension between the convenience of algorithmic news curation on social media platforms and the discomfort people feel with the accompanying invasive data collection (Monzer et al., 2020; Oeldorf-Hirsch & Srinivasan, 2021; Swart, 2021a). Building on media dependency theory and platformization scholarship, we argued that people express NFM despite their privacy concerns related to the data collection on social media platforms (Bodó et al., 2019; Oeldorf-Hirsch and Srinivasan, 2021; Swart, 2021a).
Confirming our first hypothesis and corroborating previous research, our results show that stronger information use was found to be related to a stronger NFM perception (e.g. Gil de Zúñiga et al., 2017; Gil de Zúñiga et al., 2020; Lee, 2020). One could argue that NFM is simply part of using social media to achieve goals in everyday life, in this case, obtaining information (Kim and Jung, 2017). However, we contend that NFM has to do with a specific affordance of platforms: Users experience algorithmic curation, which fosters a feeling of an ambient informational environment and, in turn, the belief that news will find them (Gil de Zúñiga and Cheng, 2021; Gil de Zúñiga and Diehl, 2019; Hermida, 2010).
In accordance with previous studies on algorithmic appreciation (Logg et al., 2019), people embracing algorithmic decision-making in different areas were found to be quite convinced that news will find them (H2). There are similarities between this finding and Araujo et al.’s (2020) study, which showed that being aware of algorithmic decision-making is positively correlated with its perceived usefulness but not with risk perceptions. That is, users develop an awareness of algorithmic curation (Monzer et al., 2020; Swart, 2021a) but their appreciation of algorithmic mediation shapes their news consumption habits in ways that reduce their inclination to actively seek out news. In other words, platforms’ infrastructure fosters processes that weaken users’ agency in the context of news consumption and reinforces power asymmetries that benefit platforms.
Furthermore, findings illustrate that stronger privacy concerns are related to a stronger NFM perception (H3). While this might seem counterintuitive, it underscores the said power asymmetries as users rely on an infrastructure that they have little control over, regardless of their concerns. Moderation effects illustrate the relationship between algorithm comfort and NFM: Information use increases the positive effect between algorithm comfort and NFM (H4a). This supports the assumption that strong NFM perceptions are particularly prevalent among prudent user groups that are both information/news-oriented and maintain positive attitudes toward algorithms. Even in an information-seeking mode, young people rely on algorithmic curation to satisfy their information needs.
This paradoxical result may have several possible explanations. One could be reversed causality. Stronger privacy concerns, as Draper and Turow (2019) suggested, could be a result of strong reliance on algorithms: having a negative feeling about one’s own behavior but also feeling resigned about it. Another way to look at it is that the loss of control that users experience over data may raise the expectation that the algorithm will “work for you” (Swart, 2021a). In other words, the findings may illustrate that users expect a benefit from losing agency over their data (Kennedy et al., 2017; Swart, 2021a). Based on our data, users’ expectation of benefits (as represented by information-seeking and algorithm comfort) seems to outweigh users’ resignation (as represented by privacy concerns), with regard to the strengths of their associations with NFM. This is supported by H4b, which showed an even stronger interrelation of algorithm comfort and NFM perceptions among those with higher privacy concerns. These findings underscore that privacy considerations in the context of platforms’ data collection entail both resignation and a rational cost–benefit calculation (Kennedy et al., 2017; Swart, 2021a). However, our data cannot answer whether privacy concerns affect NFM or are a result of it.
Taken together, the findings underscore the relevance of the backend infrastructure of platformized media systems and how it may influence the media ecosystem by deepening and obscuring power asymmetries. We propose algorithm dependency as a heuristic to capture the degree to which individuals rely on algorithms in platformized news use to meet their information needs despite the perceived misgivings, such as a lack of control over their data. The relationship of dependency is reinforced and cultivated by users’ engagement with platforms, cementing power asymmetries between platforms and users, and potentially weakening users’ motivations to seek out news outside of social media platforms. Media dependency is a structural feature of the media system, not a personal, unconscious behavioral pattern. Thus, in speaking of dependency, we are referring both to instrumental patterns of news use to obtain information and dependency as well as habitual reliance on media for certain purposes such as gratifying time-consumption, and diversionary motives (Rubin and Windahl, 1986). In that sense, dependency “is a continuous concept since an individual may become dependent on communication channels or messages to varying degrees” (Rubin and Windahl, 1986: 187).
Thinking about news use in algorithmic environments through the lens of algorithm dependency helps account for the algorithmic practices that shape privacy issues, and to discern important implications for audiences. As users have become accustomed to the benefits of algorithmic curation, it is clear that they lack an information infrastructure that affords them these benefits while protecting their privacy and integrity. That people are becoming accustomed to giving up control over their data is a worrying finding. For example, political efforts toward a higher level of data protection may experience a decline in support; reversely, political efforts to increase surveillance of citizens may encounter less opposition.
Furthermore, it cannot be assumed that users are able to differentiate whether the news that finds them do so due to editorial decision-making, their own online behavior, platform mechanisms, or a combination of these factors. Hence, dissatisfaction with algorithmic curation on platforms may, in turn, also affect audiences’ relationship with journalism. Previous research suggests that users not only distrust algorithmic curation to some extent but also do not trust news organizations to use data for algorithmic curation responsibly (Monzer et al., 2020). It is worth asking how users’ experiences with algorithms via platforms, and their associated privacy concerns, will shape audiences’ trust in journalism over time. The study thus proposes that scholars as well as practitioners should pay more attention to the consequences of algorithm comfort for news consumption in tandem with privacy concerns as they might shape distrust in news as infrastructure in the long run (Moran and Nechushtai, 2022). While news professionals cannot control news distribution on platforms, the findings have implications for news organizations’ own use of algorithmic curation. That is, we see a need in journalism to channel more resources into privacy protection efforts, and close collaboration between editorial technologists (Lischka et al., 2022), privacy officers, and editorial teams, to assess how algorithmic dependency can be mitigated and how such strategies can be communicated to audiences to increase trust in journalism.
Limitations and directions for future research
The limitations of this study provide valuable insights for further avenues for research to develop our understanding of algorithm dependency. This study only addresses a small segment of the complex relationship between individuals, media systems, and platform infrastructures. As a first study of algorithm dependency in news use, we resorted to proxy items. For example, we did not measure the extent to which participants consumed news on social media but instead acknowledged that young audiences are active on social media, which increases their exposure to algorithmic curation on average. Moreover, it was beyond the scope of our study to distinguish and compare how platform-specific algorithms affect news consumption.
Critical readers might legitimately point out the absence of a cross-country comparison. Given the complexity of our research focus, it was beyond the scope of this article to add another level of theory and hypotheses. Although we did not examine the reasons for country- and culture-specific variations, we did control for these variations to extract relationships that are independent of them. We draw a special advantage from the combination of samples from several countries, as this reduces the cultural dependency inherent in almost every study conducted in a specific country. By controlling for several country contexts, we achieve a higher level of generalizability of our data than that of single-country datasets. That the EU constitutes a political entity sui generis, something less than a state but more than just a group of countries or an international organization (Risse-kappen, 1996), which becomes evident, for example, in the existence of strong EU-wide regulation such as the GDPR, justifies an EU focus for this study. However, generalizing users’ attitudes and perceptions at this level cannot identify nuances that can only be found by paying attention to the more granular country contexts. Accordingly, we welcome future research interrogating cross-country comparisons. Especially regarding privacy concerns, we expect relevant cross-cultural differences.
Finally, our cross-sectional data cannot validate causal relations of variables, particularly regarding the question whether privacy concerns support NFM or are a result of NFM. We hope this study encourages future research to consider longitudinal designs to investigate causal relationships.
Conclusion
The capacity of algorithmic curation to make users feel informed without actively seeking news is likely to remain an enduring feature of platformized news use. In contrast to the literature that emphasizes individuals’ deficiencies regarding news use, this study sought to understand users’ experiences with news use on a more structural level, by interrogating privacy concerns related to data collection that enables NFM in the first place. Based on the finding that privacy concerns and information-seeking orientations reinforce NFM, we propose that the tension between comfort with algorithms and concern about their underlying data practices suggests that users experience a form of algorithm dependency in platformized news use. The tension between high comfort with algorithms and strong privacy concerns highlights a need for more research and political debate on its implications. This study, we hope, motivates further research interrogating the tensions between users’ positive attitudes toward algorithms and the “costs” of algorithmic news curation—spanning from users’ loss of control over their data to dependency patterns, and the weakening of their motivation to actively seek out news.
Footnotes
Authors’ note
Emilija Gagrčin is now affiliated to Universität Mannheim, Germany.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by the Federal Ministry of Education and Research of Germany (BMBF), grant no.: 16DII131 and 16DII135. Data collection was supported with special funds from the Federal Foreign Office for the German EU Council Presidency 2020 granted to the Goethe Institut.