
Abstract
The article contributes both conceptually and methodologically to the study of online news consumption by introducing new approaches to measuring user information behaviour and proposing a typology of users based on their click behaviour. Using as a case study two online outlets of large national newspapers, it employs computational approaches to detect patterns in time- and content-based user interactions with news content based on clickstream data. The analysis of interactions detects several distinct timelines of news consumption and scrutinises how users switch between news topics during reading sessions. Using clustering analysis, the article then identifies several types of news readers (e.g. samplers, gourmets) and examines their news diets. The results point out the limited variation in topical composition of the news diets between different types of readers and the tendency of these diets to align with the news supply patterns (i.e. the average distribution of topics covered by the outlet).
Introduction
The increasing adoption of digital technologies by legacy media has significant implications for news dissemination and consumption. The formation of a high-choice information environment (Van Aelst et al., 2017) challenges users with the unprecedented amount of news content, whereas the rise of mobile devices enables them to consume news at a different pace and in different contexts compared with predigital times (Westlund and Färdigh, 2015). These factors fundamentally transform the media–audience relationship, yet their impact on user information behaviour online and the long-term societal consequences remain unclear. Using computational methods, this article contributes an observation of online reading habits of legacy media users and introduces new ways of studying them based on clickstream data.
Until now, empirical studies of online news consumption remain relatively limited in number and usually rely on self-reported or small-scale experimental data (see, for review, Mitchelstein and Boczkowski, 2010). While important, these studies provide limited possibilities for identifying the impact of digitalisation on news reading habits as participants are often unable to recognise their consumption patterns (Möller et al., 2020). More large-scale approaches are required to assess how legacy media users consume news online and in which ways digital environments change their reading habits, in particular considering the ongoing debate on the societal effects of the ‘algorithmic’ (Anderson, 2013) turn in news distribution. 1 Without this knowledge, it is hardly possible to evaluate the impact of more targeted ways of news distribution on how users inform themselves and assess if algorithms enclose users in ‘echo chambers’ (Sunstein, 2017) and facilitate ‘masked censorship’ (Makhortykh and Bastian, 2020) or diversify their information diets (Eskens et al., 2017) and enable more control over their information diets (Harambam et al., 2018).
Besides limited possibilities for identifying generalisable patterns of online news consumption, the current scholarship (Gil De Zúñiga et al., 2014; Möller et al., 2020; Trilling and Schoenbach, 2013) often focuses on the effects of personal characteristics (such as gender, age or race) of users on online news consumption. While the importance of these characteristics can hardly be questioned, in particular considering their prominent role in discussions about online consumption and selective news exposure, the role of other factors such as time- and content-based reading habits remains under-investigated. Yet, these factors are of particular importance for two reasons: first, they are used as major elements of user behaviour models used by algorithmic systems of news distribution (Karimi et al., 2018; Möller et al., 2018). Second, unlike personal characteristics, time- and content-based reading habits are particularly susceptible to the change because of algorithmic curation of users’ information diets.
To address this gap, we extend the few earlier studies (Epure et al., 2017; Esiyok et al., 2014) by employing more computational approaches for studying news readers’ habits. To do so, we use a large set of data on user click behaviour during their interactions with news content coming from two major legacy newspapers. Using a combination of clustering (TBCA and K-means) and stochastic modelling (Markov processes) techniques, we analyse these interactions to identify and compare time- and content-based patterns of news consumption between the users of the two newspapers. While doing so, we ask what types of users can be identified based on their click behaviour and discuss how these findings can advance our understanding of user information diets. In addition to the conceptual contribution to the field of online news consumption, our observations can be used for improving existing models of users’ interactions with news stories (e.g. for developing recommender systems) and evaluating the impact of algorithmic systems on information diets.
Literature review
Online news consumption and legacy media
The adoption of digital technologies has led to significant changes in the relationship between mass media and news consumers. Purcell et al. (2010) note three major changes brought about by the growing consumption of news online: (1) users are able to choose when and where to consume news, (2) news offers are increasingly personalised and (3) consumption mode switches from a passive to an active one. The proliferation of new channels for news consumption, in particular social media platforms, has been discussed intensively by scholars (Boczkowski et al., 2018; Gil De Zúñiga et al., 2014; Hermida et al., 2012). In our article, however, we focus on the legacy media and discuss the implications of digitalisation for information behaviour of their users.
A large number of studies discuss the impact of online news consumption on information diets and how it is influenced by individual characteristics of news readers, varying from age and gender to political interest and education level (Gil De Zúñiga et al., 2014; Möller et al., 2020; Ohlsson et al., 2017; Trilling and Schoenbach, 2013). Many of these studies examine the relationship between online news consumption and audience fragmentation as well as selective exposure and explore to what degree these phenomena can be affected by user characteristics (Helberger and Wojcieszak, 2018; Stroud, 2010). A related strand of research looks at the effects of algorithmic distribution systems on user information diets and discusses what is the role of individual characteristics in this process (Bodó et al., 2019; Möller et al., 2016).
At the same time, time- and content-based patterns of information behaviour remain under-studied despite them being essential for the above-mentioned debates. Time-based reading habits influence the spread of information within the society and determine the amount of information received by the users from the news (Dunaway et al., 2018; Molyneux, 2019). Similarly, content-based reading habits define the composition of individual news repertoires and impact user engagement with the public sphere by informing (or not informing) them about societal matters (Kim, 2016; Molyneux, 2019; Taneja et al., 2012).
Besides the above-mentioned reasons, time- and content-based reading habits are essential for implementation and optimisation of algorithmic distribution systems for news content. Content features and their attractiveness to the users serve as a basis for the most common implementations of news recommender systems, namely user- and content-based collaborative filtering approaches (Karimi et al., 2018; Möller et al., 2018). Similarly, the integration of time-based consumption patterns is viewed as an important condition for improving the quality of news recommendations by accounting for contextual information related to news consumption (Lommatzsch et al., 2017).
Time-based consumption habits
The transition towards online news consumption and the distribution of mobile devices led to significant changes in the ways users receive news on a daily basis (Westlund and Färdigh, 2015). Increasing mobility allows users to engage with news updates more frequently and leads to diversification of reading behaviour compared with predigital spatial and social configurations of news consumption (Van Damme et al., 2015). Instead of consuming news during fixed time slots (e.g. in the morning and in the evening), online consumption enables more spontaneous interactions with news as users expect to have access to news content throughout the day and independently of their physical location (Dimmick et al., 2011).
A number of studies (Dimmick et al., 2011; Van Damme et al., 2015) discuss the emergence of new time-based reading habits among users interacting with legacy media online. For instance, Schrøder (2015) demonstrates that the proportion of different media consumed depends on the location of the user (e.g. at home, at work, or commuting) and, thus, varies significantly throughout the day. Van Damme et al. (2015) shows that there is a dependency between time of news consumption and the device used for this purpose as well as the type of news consumed.
While some of the above-mentioned studies (Dimmick et al., 2011; Van Damme et al., 2015) look at the concrete distribution of news consumption throughout the day, they usually deal only with aggregated data about group consumption. A few studies that discuss time-based reading habits on the individual level do so via small samples of users providing self-reported data (Incollingo, 2018; Yadamsuren and Erdelez, 2011). By contrast, the question of a large-scale assessment of individual time-based reading habits and how these habits vary between different news outlets remains under-studied and leads us to our first research question.
RQ1: What kind of time-based news consumption habits can be identified based on clickstream data?
Content-based consumption habits
Another aspect of news consumption affected by digitalisation of news media is related to the changes in the composition of information diets. The increased number of available media channels enables more choices in terms of the format and content of news, including a greater supply of information associated with niche or partisan views (Van Aelst et al., 2017). Such a change in news supply raises concerns related to the potential fragmentation of the public sphere and the subsequent ideological segregation enhanced by the algorithmic systems of content distribution (Pariser, 2011). Yet, existing studies (Flaxman et al., 2016; Möller et al., 2016) suggest that users still consume predominantly mainstream content online and that possible shrinking of the common core does not necessarily threaten the public sphere.
The question of the changing composition of news diets and how it is impacted by digitisation, however, remains rather important. A number of recent studies (Kim, 2016; Taneja et al., 2012; Van Damme et al., 2015) look at the online user-defined news repertoires and discuss their impact on news distribution. Taneja et al. (2012) demonstrate that the growing supply of media content leads to the formation of distinct repertoires determined by the availability of specific media to users at a given time (e.g. more consumption of web news via desktop devices outside work). Kim (2016) shows that different media repertoires are indicative of different groups of media users and this leads to the significant variations in the news content consumed by these groups.
At the same time, the majority of existing studies focus on cross-media repertoires and little is known about different news repertoires within the same outlet. Esiyok et al. (2014), for instance, demonstrate that different categories of news have a strong effect on the user clicking behaviour that suggests the presence of content-based reading habits. Similarly, Epure et al. (2017) show how user preferences towards specific forms of thematic content provided by the single news outlet change over time. None of these studies, however, look at the content-based reading habits in the comparative perspective, thus raising the question of how similar/different are these habits between the users of different news outlets and leading us to the second research question:
RQ2: What kind of content-based consumption habits can be identified?
Time- and content-based typologies of news consumers
A growing number of academic studies look at the possible typologies = of online news consumers based on their reading habits. Tewksbury et al. (2008) propose the differentiation between the two types of users: (1) selectors (focused primarily on a specific topic) and (2) browsers (sampling across different topics). Van Damme et al. (2015) suggest three categories: (1) omnivores (with intense news diets relying on multiple news sources), (2) traditionals (relying on traditional news formats and sources) and (3) serendips (rarely engaging with news routinely, but mostly checking for updates). Bos et al. (2016) identify four types of media use profiles: minimalists (rarely interacting with news), public news consumers (actively consuming public news broadcasts), popular news consumers (actively consuming news via commercial channels) and omnivores (frequently engaging with public broadcasts/online news media).
These and other typologies, however, tend to focus on content-based reading habits, in particular cross-media ones. Little has been done to integrate observations on content- and time-based habits, even while several studies suggest a possible relationship between them. Dimmick et al. (2011) show that during certain time slots users rely on different devices for news consumption that leads to various ratios of specific types of news content consumed. Similarly, Van Damme et al. (2015) trace differences in consumption of hard, soft and service news throughout the day that can be attributed both to external factors and user preferences. Yet, the above-mentioned studies usually rely on a small selection of general content categories (e.g. general news and sport news). Thus, a typology acknowledging both content- and time-based reading habits is important for articulating differences in user information behaviour in relation to news and examining the consequences of these habits for information diets. This leads us to our last research question:
RQ3: What types of users can be identified based on time- and topic-based interactions with news content?
Methodology
Data acquisition
For implementing our study, we acquired data from Persroep, a Belgian publishing company owning news organisations in Belgium, Denmark, and the Netherlands. Persgroep provided us with clickstream data generated from 1 June to 31 August 2018 by users who accessed online versions of two Dutch legacy newspapers: Trouw and AD. Both newspapers are distributed in printed and digital formats and constitute important elements of the news ecosystem in the Netherlands.
Trouw (n.d.) is a daily quality newspaper rooted in Protestant tradition and pays ‘particular attention to democracy, sustainability and all forms of religion, philosophy and philosophy of life’. AD is a daily tabloid newspaper and one of the two largest Dutch newspapers in terms of subscribers together with Telegraaf. Unlike Trouw, AD has a strong regional focus and provides readers with a number of regional supplements which are also available online. In addition to the nation-wide edition of AD, there are 59 regional supplements each collecting local news from a particular region of the Netherlands. 2 These regional supplements and user interactions with them were also included in our dataset. While there is some variation in the content published by the regional outlets (for instance, for the period we obtained information about, the Amsterdam supplement put more emphasis on politics- and crime-related news, whereas the Rotterdam supplement published more on economics, crime and culture, and the Hague supplement published more sport stories than the other two supplements), for the majority of outlets the distribution of the top topics followed the aggregated pattern for AD described in Table 1. For future research we consider examining the potential differences in user interactions with news content between regional supplements, but for now we just treated them as part of the AD corpus (hence, its larger size compared with that for Trouw).
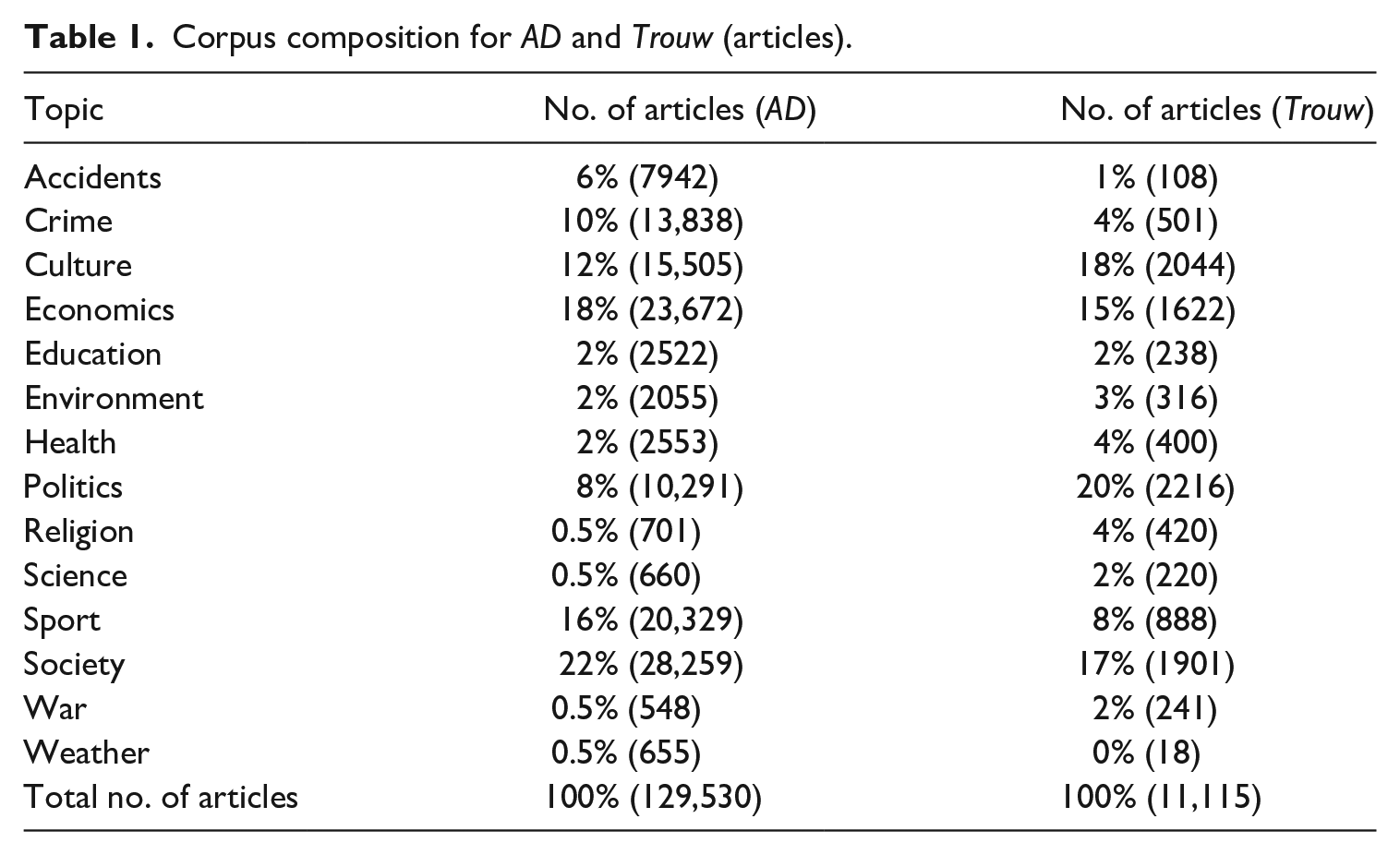
Corpus composition for AD and Trouw (articles).
The distinct feature of clickstream data is that these data capture all readers’ interactions – that is, clicks – with the newspapers’ websites. Because of this, it allows tracing how users interact with specific news items over time and identify patterns in their interactions. Unlike earlier studies which usually rely on clickstream data acquired for a short period of time and only from a single newspaper, we acquired data for 3 months and from two digital outlets. It allowed us to compare online information behaviour between AD and Trouw users and examine similarities and differences in how users consume news online.
Clickstream data provided to us by Persgroep included user interactions with two news websites via desktop/mobile browsers and mobile news applications. The process of data collection was consistent between the two newspapers. The data included four fields: a timestamp (i.e. when the click was made), a user id (i.e. a unique id automatically generated by the system for each user based on cookies), 3 a clicked item id (i.e. a unique id of each news story) and a brand (i.e. to which newspaper the clicked item belonged). The data were collected for all users who visited the online outlets during the period of study, including both registered and non-registered users. No further details about users (e.g. their demographic data) or the type of devices used were available. While these limitations do not allow us to relate our findings to specific demographic groups, it is still sufficient for examining time and content-based reading behaviours, which is the major focus of our study.
In addition to clickstream data, we were provided data about news stories published by Trouw and AD from 1 January until 31 August 2018. 4 Besides article texts, we acquired associated metadata including the text of the article, the author(s) name and the thematic tags (e.g. ‘war’, ‘politics’, ‘football’) automatically generated by the automated classification system used to identify the article’s subject by Persgroep. Both Trouw and AD used the same classification method and the same set of categories based on IPTC media topics taxonomy 5 to classify the articles. We used the metadata for dividing articles into thematic categories; before doing it, however, we went through the automatically detected categories in order to group related categories together and decrease the overall number of categories from a 100 to 14.
The decision to decrease the overall number of categories was related to the way the automated enrichment of articles with IPTC categories was implemented by Persgroep. Instead of assigning each article to a single top-level (or core) IPTC media topic, 6 the articles received multiple topic tags related to different levels of IPTC taxonomy (e.g. ‘sport’ and ‘soccer’; also the article could be assigned to several top-level IPTC topics such as ‘politics’ and ‘crime’) together with a score indicating the probability that the article belongs to this particular topic.
We assigned each article to the IPTC topic with the highest score – that is, the one classified as the most representative for a particular article. After doing so, however, we ended up with a large number of rather narrow categories (e.g. ‘ice hockey’ or ‘astronomy’), including only a few dozens of articles as contrasted by several metacategories (e.g. ‘politics’) constituted by thousands of articles and usually related to top-level IPTC media topics. We assumed that such disparity between categories together with their high granularity could have a detrimental effect on our analysis of content-based reading habits. 7
Hence, we examined all the categories occurring in our sample and manually combined the related categories to produce larger categories. The decisions concerning the relatedness of categories were made based on the discussion between the co-authors. The final set of categories generally followed the top-level categories of IPTC taxonomy with the exception of topics ‘lifestyle and leisure’, ‘human interest’, ‘labour’ and ‘society’, which were merged into a single category ‘society’. The decision to implement such a merge was related to these topics being thematically close and often overlapping (for instance, the same news story might have very similar if not the same scores for ‘lifestyle and leisure’ and ‘human interest’ topics or ‘society’ and ‘labour’ topics) as well as the scarce presence of some of these categories in our corpora (e.g. labour-related news).
Data analysis
To analyse time- and content-based consumption habits of AD and Trouw readers, we first used descriptive statistics to examine the key features of the articles’ corpus and the clickstream dataset for the two newspapers. Our goal here was to identify how similar or different are the general characteristics of data related to each of the two newspapers in order to avoid possible biases on the later stage of our analysis. An example of such biases is the different rate of supply of specific thematic categories of news stories: for instance, if AD publishes a significantly larger number of sport-related news than Trouw, then we can expect AD users to read more about sport just because the newspaper supplies them with the respective content.
Following the examination of the general features of the datasets, we looked at the time-based patterns of user interactions with news content. We started by examining a general distribution of interactions with news content depending on the time of day and the day of the week. Following this general overview of time-based news interactions, we employed trajectory-based clustering analysis (TBCA) (Genolini et al., 2016) to identify clusters of users based on the usual trajectories of their interaction with news throughout the day. Unlike other clustering approaches, TBCA is adapted for clustering longitudinal data based on the shape of its trajectories and not distances between points. Thus, we constructed trajectories of clicking behaviour on the hourly basis for each user in our dataset and clustered them using TBCA to examine the resulting clusters.
Following our analysis of time-based interactions, we looked at the content-based consumption patterns. For this purpose, we enriched our clickstream data by constructing reading sessions out of user clicks. In order to do so, we treated all user interactions with news content occurring in less than 15 minutes from each other as part of the same reading session. After constructing reading sessions, we again started with descriptive analysis and looked at the distribution of session lengths among users of AD and Trouw to see whether there are significant differences between them. We also examined the distribution of news topics between sessions of a minimal length (i.e. of one click) and the longer sessions to check whether very short ‘peeking’ sessions are characterised by the consumption of certain types of thematic news content.
Following this descriptive analysis, we used a first-order Markov model to estimate transition probabilities between news categories; specifically, we were interested in verifying the earlier claim by Esiyok et al. (2014) about varying degrees of loyalty towards different topics as well as the relationship between topics as a part of user information diets (e.g. if sport news tend to go together with politics news and so on).
Finally, we looked at what kind of user types can be identified based on time- and content-based reading habits. For this purpose, we again enriched our dataset with two additional features: the average length of the reading session for each user and the average number of different news topics consumed during a single session. We then used K-means clustering to identify distinct groups of users based on these two features. The idea of K-means clustering is to divide data points into k groups depending on the mean distance from the other points; because of its simplicity and robustness, this algorithm is frequently used to detect groups in the uncategorised data. To determine k, we calculated squared distance and then used an elbow method. The resulting graphs are provided in the supplementary materials; based on their examination, we decided to use eight clusters for AD and Trouw.
Findings
General characteristics of the datasets
We started our analysis by examining the general characteristics of two datasets: one describing the corpus of articles and the other on user interactions with the articles. As shown in Table 1 (in the ‘Methodology’ section), the two newspapers differ significantly in terms of the volume and topical distribution of content produced from 1 January to 31 August 2018. During the 8 months for which we acquired data, AD produced on average 533 stories per day, whereas Trouw produced on average 44 stories. Such a gap can be attributed to different newspaper profiles, in particular the large number of regional supplements of AD. These supplements serve as newspapers in themselves, thus resulting in the significantly higher number of articles published by AD.
In addition to the different volume of articles, Table 1 shows that the two newspapers differed in terms of the subjects covered. Compared with AD, Trouw published more content on politics, culture and religion. By contrast, AD devoted more attention to news about accidents, economics, sport, crime and society. 8 These distinctions again can be attributed to the different profiles of the two newspapers, in particular of Trouw being a quality newspaper with a strong historical focus on religious subjects and AD being a tabloid focusing on entertainment and regional news.
After this simple descriptive examination of the articles’ corpus, we looked at the data on user interactions with the articles from 1 June to 31 August 2018. As shown in Table 2, the large number of users who accessed online versions of Trouw and AD made only one click during the 3 months. The second largest category of users was those who made between two and five clicks during the period of study. These observations indicate the extremely high drop rate of potential news readers, many of whom do not return to the news outlet for a long time after checking a single news story. While both newspapers used cookie walls, their presence did not explain the drop rate: in the case of Trouw, users were allowed to read seven articles before being prompted to subscribe, whereas AD limited access only to premium articles. Such a high dropout has significant implications for the commercial model of digital distribution of news content, but it is even more important in terms of the long-term effects of online consumption for the societal role of legacy media.
Corpus composition for AD and Trouw (clicks).
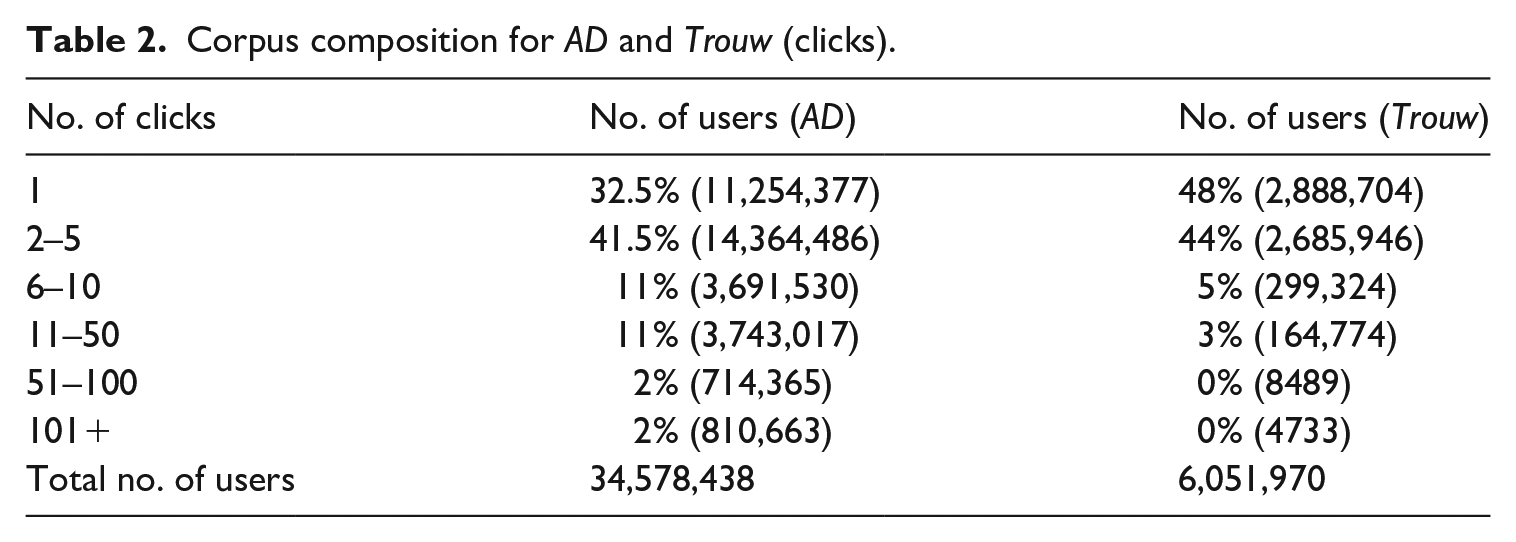
At the same time, AD had significantly more active users compared with Trouw both in absolute and relative numbers. The higher user engagement in the case of AD can be attributed to the newspaper’s strong regional following; however, it also raises the question of whether higher rates of news consumption lead to higher diversity in terms of content consumed.
In addition, these observations point out the importance of considering news consumption habits in the context of deploying algorithmic news recommenders. On the one hand, the high number of one-time news peekers emphasises the importance of the cold-start problem for news recommendations – that is, the task of making initial content suggestions under the condition of the lack of information of user consumption preferences and with a purpose of keeping the user engaged with the content. It can also be viewed as an indicator of the importance of helping users to deal with information overload and preventing them from being discouraged from news exploration because of it.
Time-based reading habits
Following our examination of the general characteristics of the datasets, we proceeded with the analysis of the time-based reading habits of AD and Trouw users. We started by using a descriptive approach, which is commonly used in existing studies on news consumption (Van Damme et al., 2015). Specifically, we looked at the distribution of user clicks on the hourly basis during weekdays and weekends and compared it between AD and Trouw as shown in Figures 1 and 2.
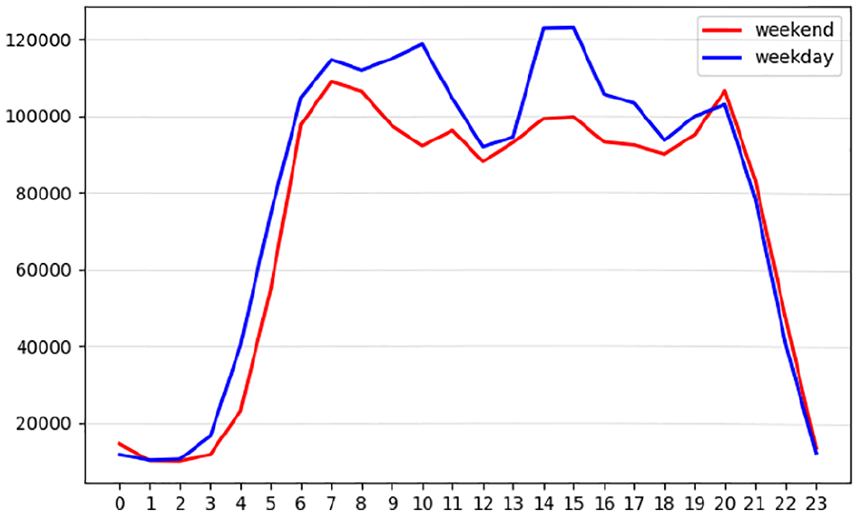
Time-based interactions by the hour and the weekday/weekend for Trouw.
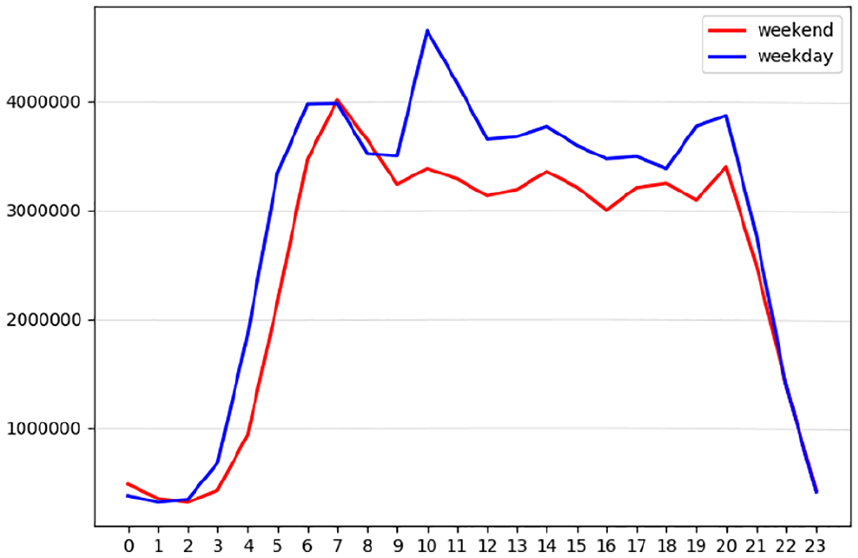
Time-based interactions by the hour and the weekday/weekend for AD.
The comparison shows that for the two newspapers, content consumption during the weekends was rather similar: in both cases, there were two activity peaks (from 7 a.m. to 8 a.m. and from 9 p.m. to 10 p.m.) with a decrease of activity in the afternoon. By contrast, the consumption during the weekdays showed more differences: for AD, news consumption peaked from 10 a.m. till 11 a.m. and then dropped, whereas for Trouw the second major peak was observed in the afternoon from 14 p.m. to 16 p.m. Such a difference in the weekday reading habits can be attributed to several factors, varying from the various rates of online content publication by AD and Trouw to different demographics of newspaper users. Specifically, these differences can be related to different social media strategies used by the two newspapers: while both of them use newsletters, Trouw tends to send its newsletter in the late afternoon (i.e. around 4 p.m.), whereas the majority of AD’s numerous newsletters are disseminated in the first half of the day (from 7 a.m. to 9 a.m. with some appearing around 1 a.m.).
The above-mentioned differences also emphasise the importance of acknowledging contextual factors when developing automated systems of content distribution. The comparison between Trouw and AD suggests that users of both newspapers might have different preferences in relation to the time slot when they consume news. Such differences can have implications for their willingness to engage with content recommendations as well as the scope of such engagement (e.g. it can be more beneficial to offer a broader selection of recommended items for Trouw users around the lunch break than in the evening).
After examining the general distribution of reading activity by time, we examined different reading trajectories of active readers (100+ clicks) using trajectory-based clustering analysis. The results of the clustering are shown in Figures 3 and 4: in both the cases we observed small groups of power users 9 (i.e. pink and teal clusters), which constituted slightly more than 1% of users for Trouw and less than 1% for AD users. The shape of these power user clusters, however, was different: in the case of Trouw, there was a strong ‘9 to 5’ reader cluster peaking around noon, whereas its analogue for AD was a ‘dawn’ cluster peaking around 6 a.m.–7 a.m. and then going down throughout the day. It is worth noting that two smaller – that is, teal – power user clusters reproduced the shapes of the larger purple clusters from the other newspaper – for Trouw, the teal cluster also had a ‘dawn’-like shape, whereas for AD the teal cluster was close to the ‘9 to 5’ shape.
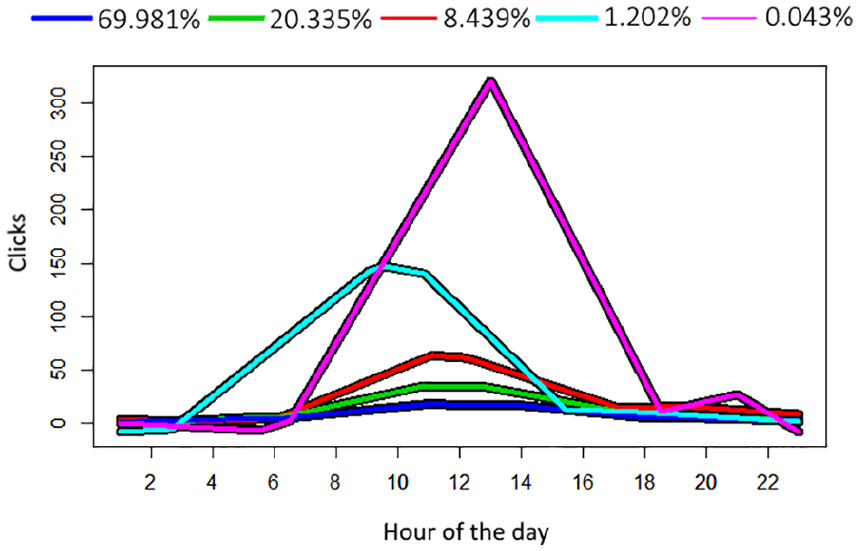
User clusters by time-based reading habits for Trouw.
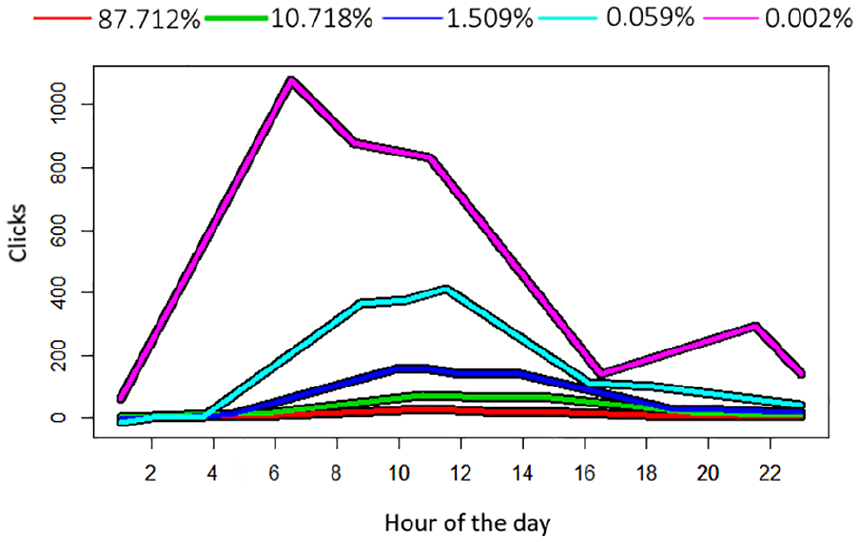
User clusters by time-based reading habits for AD.
In addition to the distinct clusters of power users, both AD and Trouw included clusters of less active news consumers. In both the newspapers, these clusters represented time-based consumption of the majority of users and had rather similar shapes. With the exception of a more pronounced red cluster for Trouw related to the ‘morning coffee’ readers, both the newspapers shared several low-profile clusters uniting users who consumed news in small sessions distributed throughout the day. This observation supports the earlier suggestions about online news consumption facilitating serendipitous news consumption (Van Damme et al., 2014) or the ‘news snacking’ (Molyneux, 2018).
Content-based reading habits
After examining time-based reading habits, we moved towards analysing content-based reading habits. To do so, we constructed reading sessions based on the criteria explained in the methodology: for Trouw, we constructed 9,059,748 sessions and for AD we constructed 203,129,610 sessions. The shortest session for the two newspapers consisted of a single click; the longest session consisted of 521 clicks for Trouw and 1653 for AD. 10
The distribution of sessions according to their frequency follows a power law (see the figures in the supplementary materials). Out of the constructed sessions, 6,793,747 (74%) of Trouw sessions consisted of a single click. For AD, the proportion was slightly different: 111,760,006 (55%) sessions were made of a single click. The distribution of topics between sessions consisting of 1 click and 2+ clicks is shown in the supplementary materials; to calculate it, we divided the number of clicks on articles from a specific thematic category by the overall number of clicks for the respective session type (i.e. 1 click type or 2+ clicks type). The tables show little difference between content consumed during the 1 and 2+ click sessions; however, there was quite some difference between the content published by the news outlets and the content consumed by the users.
In the case of Trouw, content related to the human interest such as news related to war, environment and health received more attention. Health in particular attracted more attention from Trouw readers: while stories on the topic constituted only 3% of content published during the period of study, they attracted 7% of clicks in 1-click session and 5% of clicks in 2+ sessions. Similar discrepancies were found for AD, where content related to weather (0.5% published stories attracted 3% of all clicks) and society (22% published stories attracted 32% and 31% clicks respectively) generated more engagement from the users.
Following examination of the lengths and content composition of constructed news reading sessions, we moved towards examining the transition probabilities between different news categories. We did not include 1-click sessions in the analysis of transitions between topics, because in the case of a single-click session no transition has occurred. Thus, we used information about sessions which consisted of 2 or more clicks (91,369,604 for AD and 3,122,916 for Trouw).
We first looked on non-normalised transition probabilities between topics using first-order Markov chains (i.e. by considering the conditional probability of topic B [vertical row] being clicked directly after topic A [horizontal row] in the same session). Our findings (for visualisations, see supplementary materials) support the earlier observations by Esiyok et al. (2014), who used data for 1 month of observations of user clicks on a major German news portal and found that the user clicking behaviour varies between the thematic categories of news content. The conditional probabilities we observed suggest the significant degree of consistency in user preferences – that is, users often tend to stick to the same topic while reading the news. The same tendency was observed by Esiyok et al. (2014), who labelled it as the topic ‘loyalty’.
While examination of the conditional probabilities of topic transitions highlights the significant differences between the two newspapers both in terms of preference consistency and directional relations between topics, these differences are also influenced by the unequal distribution of topical content between different topics in AD and Trouw and, most importantly, the varying degrees of user interaction with this content. 11 To address these discrepancies, we normalised the observed probability of transitioning into a topic with the expected probability of this topic apprearence based on the sample of sessions made of 2+ clicks.
The comparison provided by Figures 5 and 6 suggests that sport news seems to be particularly ‘sticky’ among both AD and Trouw users despite the significant difference in terms of their frequency (4% of clicks for Trouw and 16% for AD). The other consistently read topics tend to be more newspaper-specific: for instance, Trouw users tend to consistently read about politics and economics (and, to a lesser degree, about culture), whereas AD users tend to keep reading about society and, albeit less frequently, about crime and economics. While to a certain degree, these preferences reflect the expected probabilities of topic occurrence, this pattern did not hold true in all cases. For instance, despite society news composing a large chunk of Trouw content (17%) and a common target of 2+ click sessions (19%), the users did not stick to this specific news category.
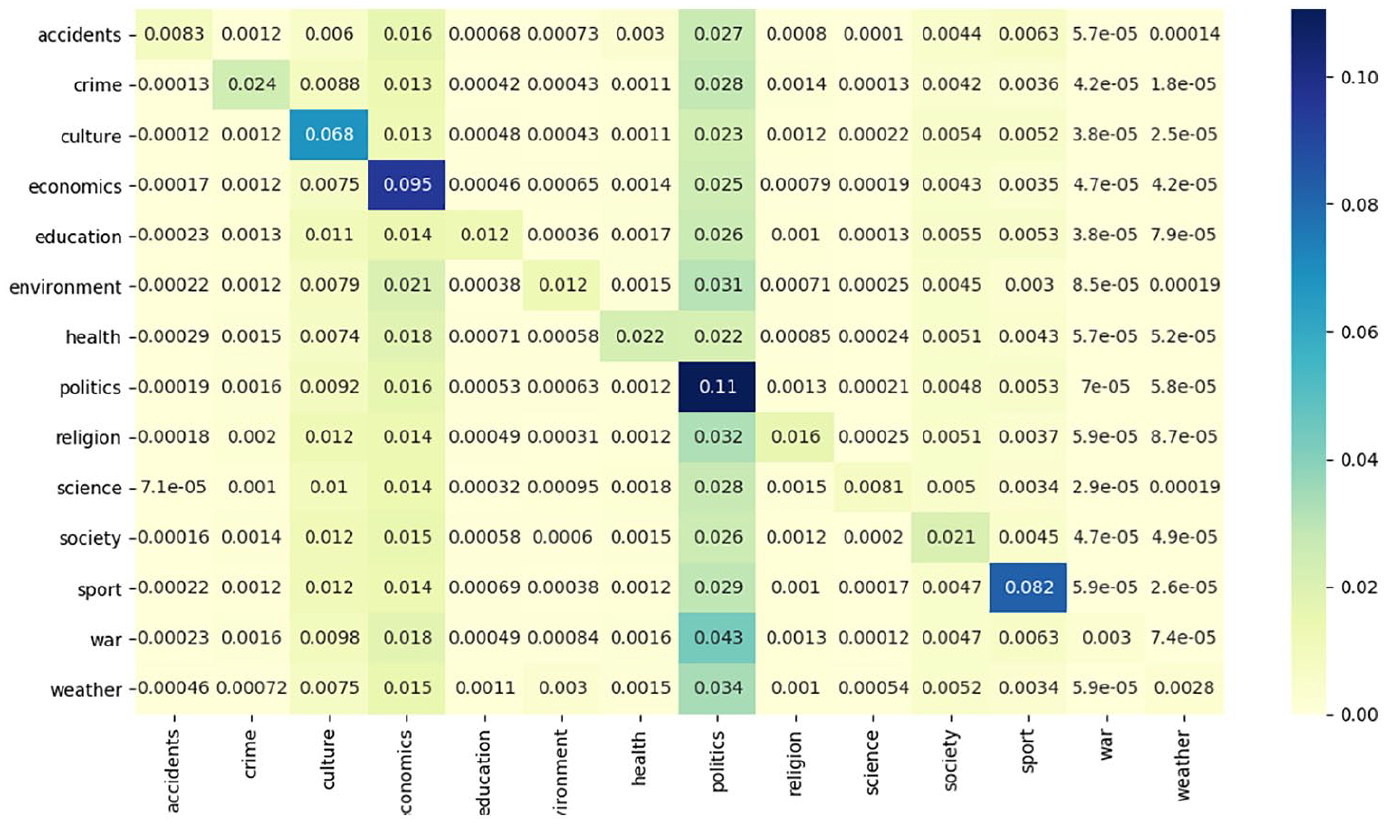
Normalised topic transition probabilities for Trouw.
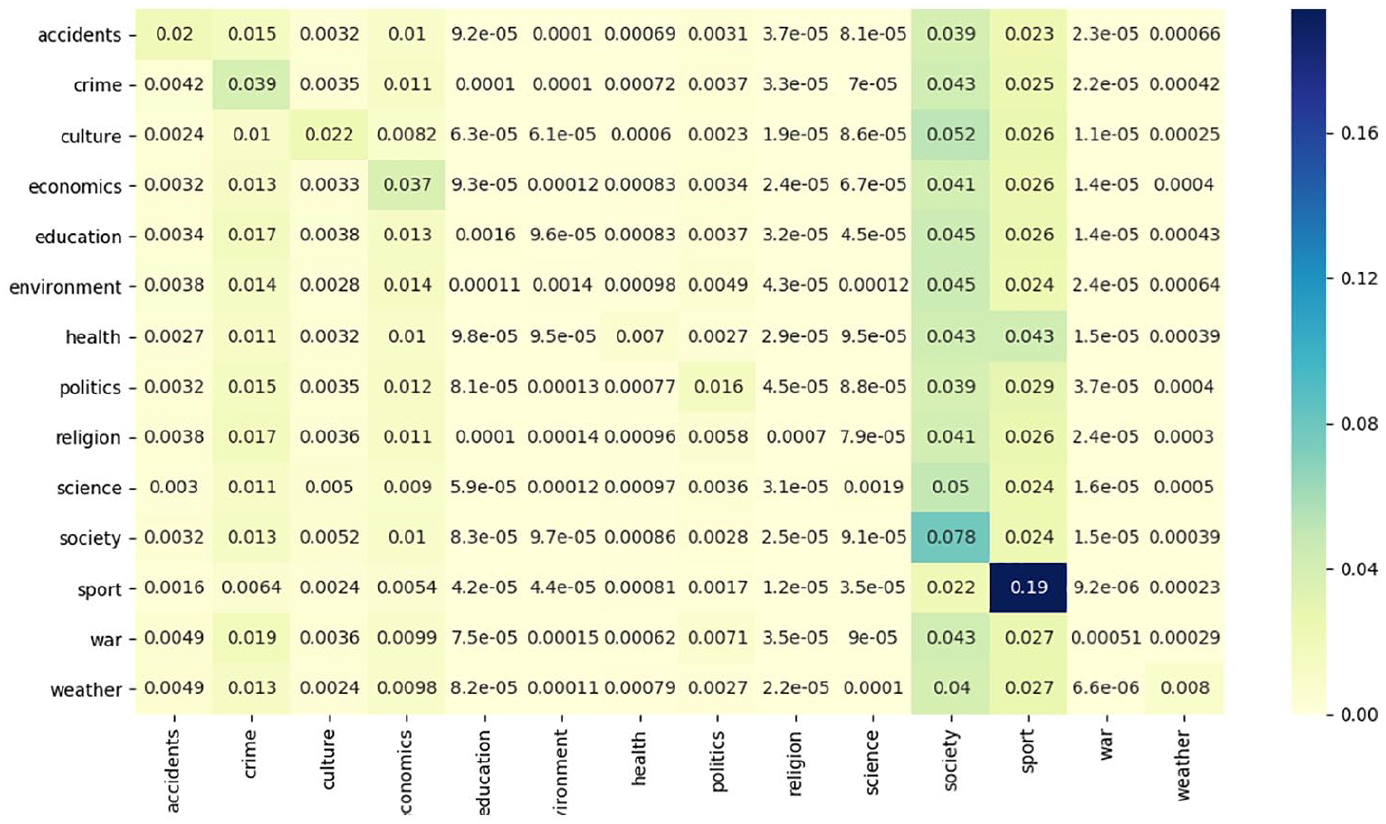
Normalised topic transition probabilities for AD.
We also looked on probabilities of transition between specific topics in the course of the reading sessions. Similar to Esiyok et al. (2014), we observed the presence of some ‘follow-up’ thematic categories – that is, those news categories that were particularly often switched to. For Trouw these categories were politics and, to a lesser degree, society and economics news; for AD it was primarily society news and, to a lesser degree, sport news. Considering that the majority of these categories were also the most numerous content-wise, these observations emphasise the importance of the content supply that defines the boundary conditions for user interactions with news. At the same time, we also observed some exceptions, in particular related to the society news category in the case of Trouw, which was not switched to that often, despite it being rather well-represented via the outlet.
We also observed differences in the probabilities of topic transition between particular topics. Some of these probabilities were similar for both Trouw and AD: for instance, the tendency to switch to the weather news following the environment news (and to the accident news following the weather news) or to read about politics following stories on religion and war. Other transition probabilities were more newspaper-specific: for instance, AD readers interested in sport were less eager to read about crime next compared with other possible transitions that was not the case for Trouw readers, whereas Trouw readers consuming news about war and religion more commonly switched to crime than readers consuming other types of news first.
Content- and time-based reading habits
After examining content- and time-based reading habits, we looked at how these habits interact and whether we can identify distinct groups of users based on the length and topical variety of a typical news reading session. To achieve this purpose, we calculated the average length of a reading session (in clicks) for each user and the average number of switches between topical categories within a single session. We then used K-means clustering to identify groups of users based on these two parameters.
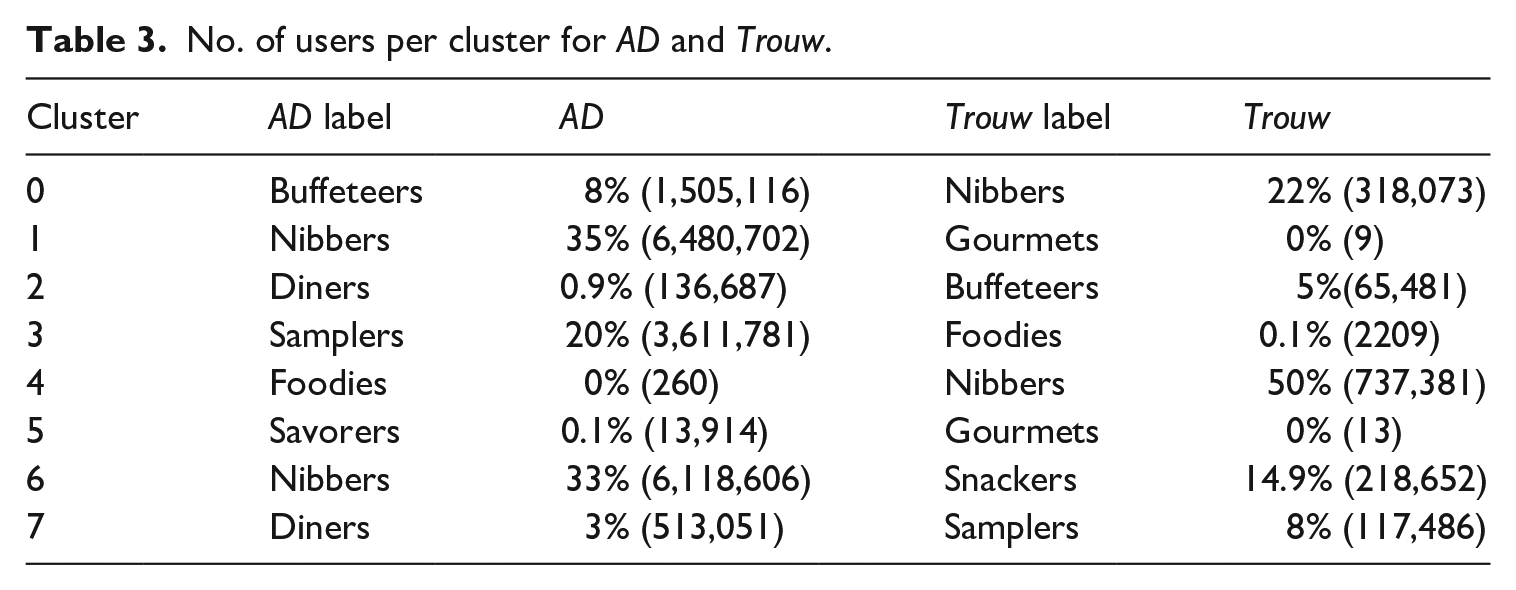
Figures 7 and 8 show the visualisations of user clusters for AD and Trouw users. Both the newspapers had clusters of users who consumed news in short sessions (2–4 clicks) on a single topic (#6 for AD and #4 for Trouw) or with one topic switch (#1 for AD and #0 for Trouw). We labelled these users as nibbers 12 according to their short and focused reading sessions. As shown in Table 3, nibbers were the most frequent type of users and constituted 68% of all users for AD and 72% for Trouw. Content-wise, single-topic nibbers focused on society (AD) and culture/economics news (Trouw) and consumed less political content (see Tables 4 and 5 13 ). The diet composition of two-topic nibbers was quite similar: in the case of AD, the only difference was slightly higher consumption of sport news, whereas for Trouw two-topic nibbers consumed more politics- and less culture-related news.
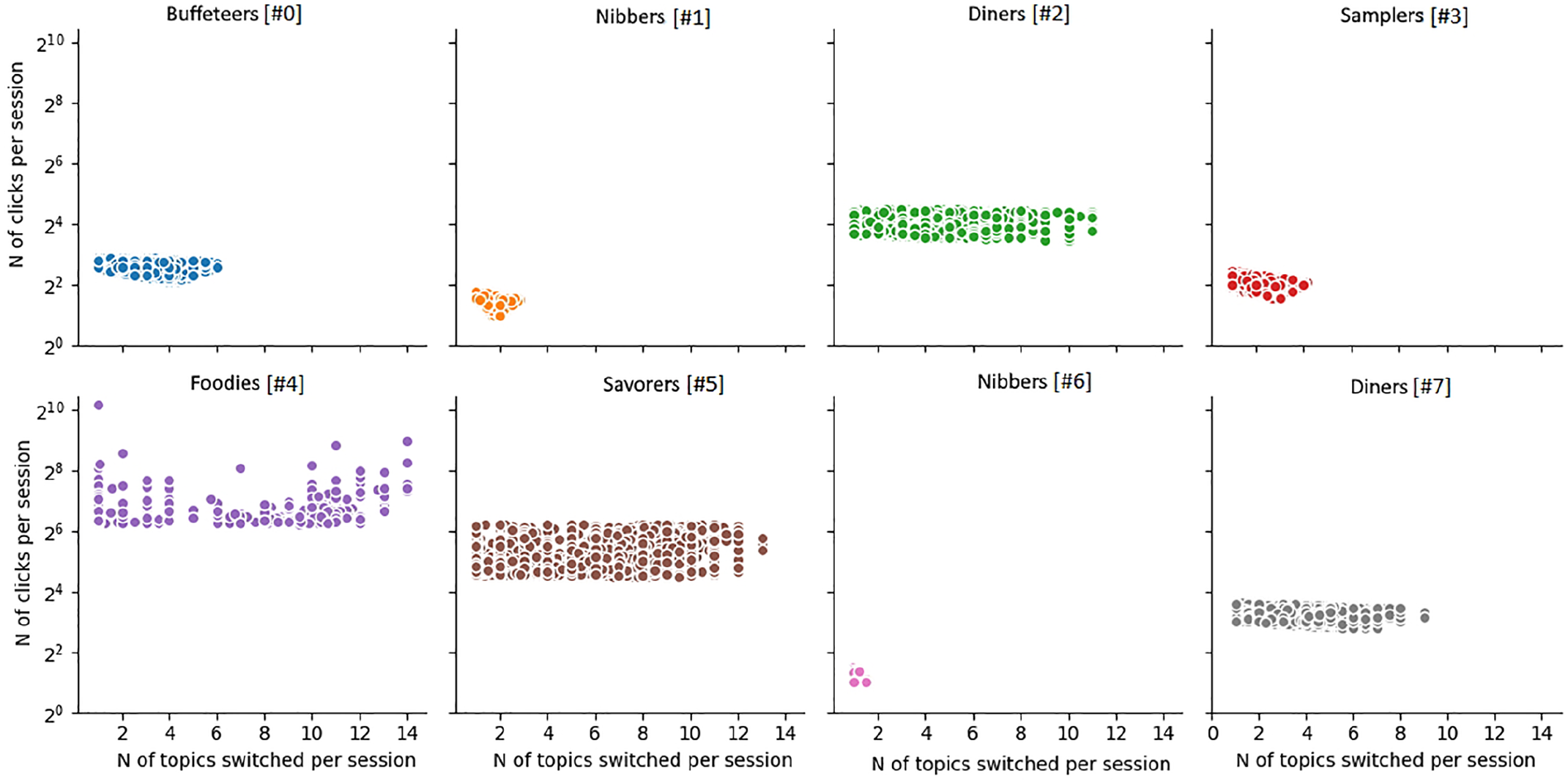
User clusters for AD.
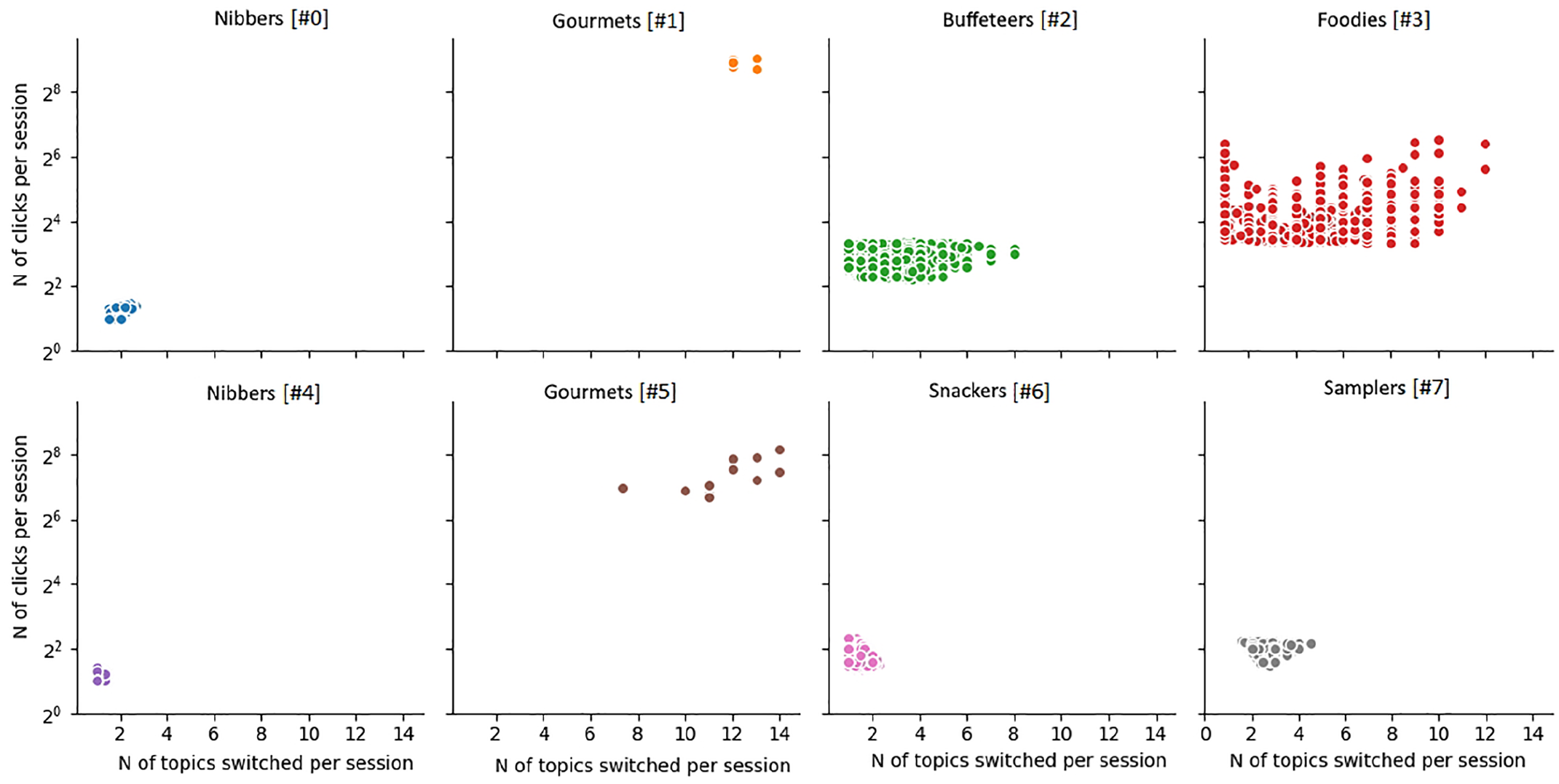
User clusters for Trouw.
No. of users per cluster for AD and Trouw.
Distribution of thematic categories per cluster for Trouw.
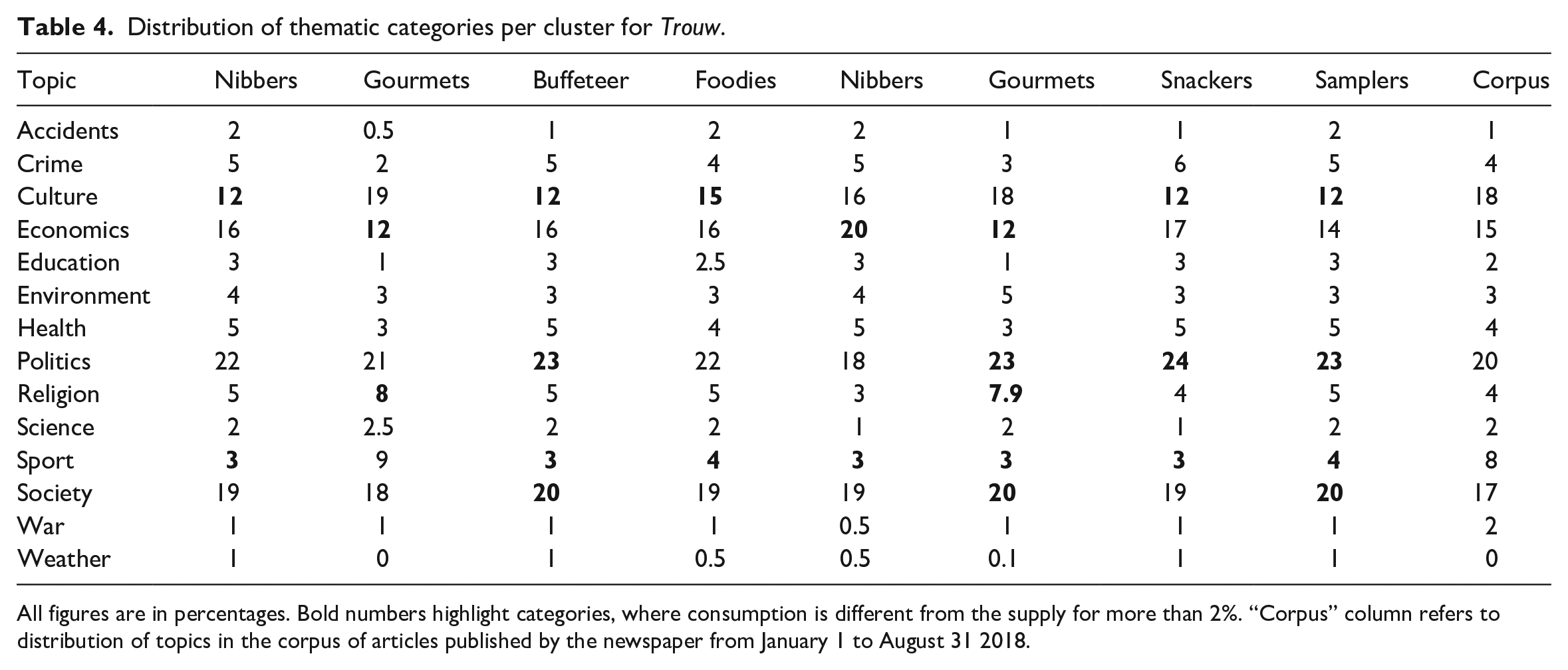
All figures are in percentages. Bold numbers highlight categories, where consumption is different from the supply for more than 2%. “Corpus” column refers to distribution of topics in the corpus of articles published by the newspaper from January 1 to August 31 2018.
Distribution of thematic categories per cluster for AD.
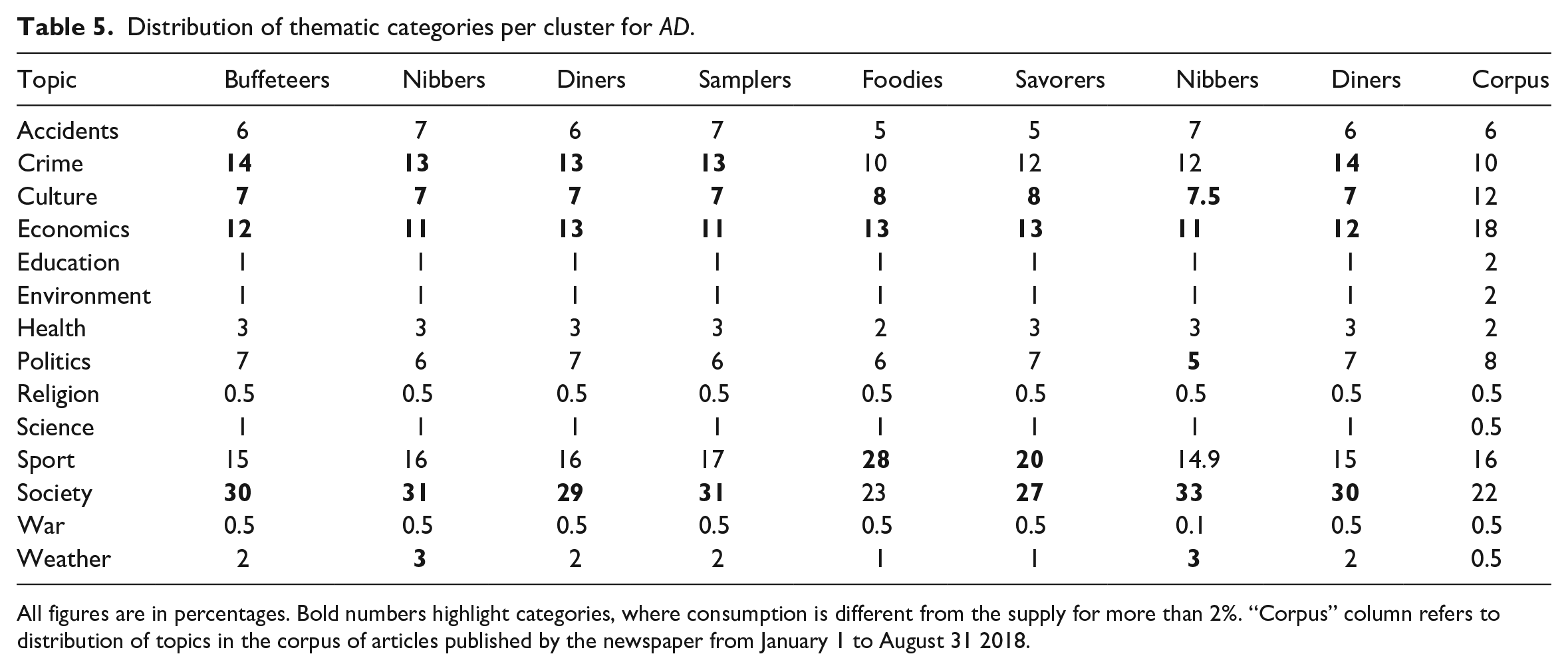
All figures are in percentages. Bold numbers highlight categories, where consumption is different from the supply for more than 2%. “Corpus” column refers to distribution of topics in the corpus of articles published by the newspaper from January 1 to August 31 2018.
Similarly, for both the newspapers we identified clusters of users who still had short sessions (3–5 clicks), but switched topics rather frequently (2–4 switches per reading session) (#3 for AD and #7 for Trouw). These users were labelled as samplers according to their short, but fluctuant reading sessions. Like nibbers, samplers constituted a rather common user group: 20% users for AD and 8% for Trouw. In terms of content, AD samplers primarily focused on sport and society, whereas Trouw samplers preferred reading about politics and society.
Finally, both the newspapers had clusters of users with medium (4–10 clicks) and long sessions (16–256+ clicks) and the high variety of topic switches during a single session (from 0 to 6 and from 0 to 14 switches) (#0 and #4 for AD and #2 and #3 for Trouw, respectively). Based on the medium-to-high session lengths with the varying degree of topic fluctuations, we labelled these user groups as buffeteers and foodies. Buffeteers – that is, users with medium-sized sessions and the broad range of topic switches – constituted 8% of users for AD and 5% for Trouw. AD buffeteers focused on society news and showed slight less interest in sport compared with samplers. In the case of Trouw, we observed the same usual focus on politics and society news.
The last cross-newspaper cluster was made of foodies who consumed news via long reading sessions. Some of these sessions were rather focused and included only 1–2 topic switches, whereas other foodies switched up to 14 topics per session. Unlike earlier clusters, foodies were rather rare and constituted less than 0.1% of users for AD and approximately 0.1% for Trouw. AD foodies consumed the large number of news on sport as well as a slightly higher number of news related to culture and economics compared with earlier clusters. For Trouw, politics and society news categories remained prevalent.
The rest of the identified clusters were newspaper-specific ones. Trouw, for instance, included two distinct clusters of power users: one with particularly long sessions (256+ clicks) and the high number of topic switches (12–14 per session) (#1) and shorter sessions (64–256 clicks) and frequent topic switches (10–12 per session) (#5). Because of their extensive session lengths, we labelled these users as gourmets. Both the gourmet clusters for Trouw occurred rather infrequently and composed less than 0.1% of Trouw users. Content-wise, gourmets consumed more news on ‘high’ topics such as culture, economics and religion and read less frequently about weather or crime.
Finally, Trouw had a variation of a sampler user type, but the one switching topic less frequently during medium-(3–5 clicks) sized sessions (#6). Because of their slightly longer and more focused sessions, we labelled these users as snackers. Snackers were the second-most common Trouw cluster after nibbers and constituted 14.9% of all users. Content-wise, snackers were the most active politics readers for Trouw and the second-most active consumers of economics-related news.
In the case of AD, we also observed two newspaper-specific groups of readers. The first of these groups included two clusters of users (#2 and #7) with medium-sized reading sessions (10–30) and a varying number of topic switches (0–10). Labelled as diners, these clusters included 3.9% of AD users. The topical composition of diets for the two clusters was similar: diners with longer session lengths (#2) consumed slightly less society-related and more economics-related news, whereas for diners with shorter sessions (#7), society was a more prevalent subject similar to the majority of other AD clusters.
The last AD cluster (#5) was composed of users with medium- to long-sized sessions (30–70) and varying number of topic switches (0–12). Because of the similarities with the previous cluster (i.e. diners) with a single exception of the longer session lengths, we labelled this user group as savorers. Similar to other longer session user groups, savorers were not numerous and constituted around 0.1% of users for AD. Society was a prevalent news topic among savorers, seconded by sport news and economics.
Overall, we did not observe significant differences in terms of the aggregate distribution of topics between different groups of users following the same outlet. While there was some variation between certain user groups, these variations tend to concern 1–2 content categories, whereas the rest of the categories usually follow the average distribution within the articles’ corpus and, thus, are defined by content supply (with a few exceptions of, for instance, lesser consumption of sport-related news compared with supply for Trouw and higher consumption of society-related and lower consumption of culture-/economics-related news compared with supply for AD). This observation suggests that variations between reading behaviours do not necessarily lead to profound differences in the composition of information diets (at least on the aggregate level). While more active users acquire volumes of information that is slightly different from the average ones published by the newspaper, these distinctions are minor.
Discussion
Our analysis points out a number of distinct time- and content-based patterns of online news consumption among legacy media users. We found that time-based consumption habits seem to be rather similar between the two newspapers we examined. While there are some differences between AD and Trouw users in terms of when they consume content, these differences are mostly present only during weekdays and can be (at least partially) attributed to different social media strategies used by the newspapers, whereas news consumption of weekends follows the same pattern. In terms of individual consumption habits, we found that differences mostly concern power users (‘9 to 5’ readers for Trouw and ‘dawn’ readers for AD). For both the newspapers, power users constitute the minority, whereas the majority of users tend to engage in short-time reading sessions throughout the day, thus supporting earlier arguments about online media stimulating spontaneous news consumption.
By contrast, content-based consumption patterns turn to be more different between AD and Trouw. For both the newspapers, we observed a tendency among readers to stick to a single topic while reading news that is similar to earlier observations by Esiyok et al. (2014) and Epure et al. (2017). In both the cases, sport news was among the most ‘sticky’ type of content, whereas other consistently read topics varied between newspapers (politics/economics/culture for Trouw and society for AD). Often, these ‘sticky’ topics were the ones that were the most extensively covered by the outlet, but we also observed some exceptions from this case (e.g. society news in the case of Trouw). We also noted differences in terms of transition probabilities between individual topics as well as which topics users switched to more frequently. Together, these distinctions suggest that unlike time-based reading habits, content-based ones are more specific for certain news outlets.
Finally, we looked at what types of users can be identified based on time- and topic-based interactions with news content. Using clustering analysis, we determined several groups of users based on how long they tend to consume news and how frequently they switch between news categories in the course of a single news session. Some of these groups (e.g. nibbers, samplers and buffeteers) were present among the readers of both newspapers, whereas others (e.g. gourmets or savorers) were specific for a certain news outlet. However, our observations suggest that despite behavioural differences, on the aggregate level there is not much variation in terms of distribution of IPTC-based news categories consumed by different user groups. This does not mean that there is no difference between individual users, in particular those with very short and focused sessions (e.g. nibbers) and those with very long and changeable sessions (e.g. gourmets), especially on the level of individual news items. Instead, our observations indicate that, besides some exceptions, the average proportions of news categories consumed by different groups of users tend to be relatively close and generally follow the overall news supply by the respective outlet.
The results of our analyses point to the presence of distinct time- and content-based news consumption habits in non-personalised online environments. Some of these habits (e.g. time-based ones) seem to be more common between outlets, whereas others (e.g. content-based ones) are more distinct. Our analyses also emphasise the essential role of content supply that aligns with earlier arguments about the importance of availability factors for the composition of individual news repertoires (Taneja et al., 2012). Independently of how different users consume news, their information diets seem to generally align with the distribution of the supplied content (with the exception of a few news categories which tend to be either under- or over-consumed – e.g., society for AD or politics for Trouw). These observations can be useful for tracing similarities/differences with studies using self-reported and small-scale experimental data and can be potentially used for modelling/simulating news readers’ behaviour to trace how it can be affected by personalised news supply.
Our observations also raise a number of questions concerning the possible impact of algorithmic news recommenders on the user reading habits. For instance, to what degree the goal to increase users’ engagement and the rate of return to news websites via personalised content suggestions is contradictory to user information behaviour, which usually involves very infrequent and spontaneous encounters? And, what is even more important, how significant will the impact of news recommenders be on the existing reading habits? To answer these questions, more empirical observations of user information behaviour similar to the ones provided in the current study are required.
Another question that is worthwhile exploring in the future studies is how similar or different the habits of the same users reading different newspapers are. Our observations indicate differences in the way users consume news, but will Trouw users keep their bimodal time-based reading habits while consuming content provided by AD or will they adapt to the unimodal mode of consumption typical for AD readers? The answer to this question is also important both for measuring the impact of algorithmic news recommenders and for designing them as it relates to the matter of how universal (or non-universal) can be algorithmic system designs to remain helpful for the users of specific media outlets.
At the same time, several limitations of our study should be acknowledged. First and foremost, we agree with Kormelink and Meijer (2018), who note that clickstream data provide limited insights into users’ information diets as multiple reasons influence users’ decisions to click or not to click. The quality of data provided to us also limited our possibilities for news reading habits analysis: for instance, we lacked data about the device used to access content as well as time spent by the user on a specific news page. Similarly, we lacked information about positioning of specific stories on the online newspage that can affect the distribution of user clicks.
The lack of granularity of clickstream data collected by AD and Trouw is particularly limiting in terms of isolating the effect of different forms of browsing behaviour on news consumption. While both the newspapers measure user clicks in the same way, thus restricting potential measurement biases, the inability to relate information behaviour data generated by the same user via different devices and/or from different browsers is a significant limitation of clickstream data. Even while in the current state of data it was still possible to acquire a number of insights into online news consumption, better data quality is important for improving the quality of future analyses.
The improvement of data quality is also important for enabling more fine-grained comparison of information behaviour between different news outlets. Multiple factors can influence the differences in news consumption between AD and Trouw, varying from the difference in readership to various promotion techniques and news formats. All these factors can influence the composition of clickstream data and the insights drawn from them concerning user behaviour. Hence, the enrichment of clickstream data and their matching with other forms of information about the audience is an important prerequisite for future comparative research on news consumption.
Supplemental Material
Supplementary_materials_updated – Supplemental material for We are what we click: Understanding time and content-based habits of online news readers
Supplemental material, Supplementary_materials_updated for We are what we click: Understanding time and content-based habits of online news readers by Mykola Makhortykh, Claes de Vreese, Natali Helberger, Jaron Harambam and Dimitrios Bountouridis in New Media & Society
Footnotes
Acknowledgements
The authors would like to thank three anonymous reviewers and Aleksandra Urman (University of Bern) and Olga Krasa-Ryabets (University of Amsterdam) for valuable feedback and insights. Additionally, the authors would like to thank Anne Schuth and Frank Mekkelholt from Persgroep for assisting with data acquisition and data analysis.
Author’s note
Jaron Harambam is now affiliated with the Institute for Media Studies at the KU Leuven.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Netherlands Organisation for Scientific Research (grant 400.17.605).
Supplemental material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.