
Abstract
While data-driven personalization strategies are permeating all areas of online communication, the impact for individuals and society as a whole is still not fully understood. Drawing on Facebook as a case study, we combine online tracking and self-reported survey data to assess who gets targeted with what content. We tested relationships between user characteristics (i.e. socio-demographic and individual perceptions) and exposure to branded content on Facebook. Findings suggest that social media use sophisticated algorithms to target specific groups of users, especially in the context of gender-stereotyping and health. Health-related content was predominantly targeted at older users, females, and at those with higher levels of trust in online companies, as well as those in poorer health conditions. This study provides a first indication of unfair targeting that reinforces stereotypes and creates inequalities, and suggests rethinking the impact of algorithmic targeting in creating new forms of individual and societal vulnerabilities.
Keywords
The continuous and ubiquitous tracking of our online activities has initiated public and scholarly debates about big data, privacy, and fairness. The opportunities of leveraging the large amounts of personal data we produce online are tremendous, for example, when large-scale, detailed, and highly integrated patient data are combined in electronic health records to deliver personalized care to patients (Dzau and Ginsburg, 2016). Or when personalization algorithms are used to help users to handle the abundance of information online and find the content that matters to them (Thurman et al., 2018). Users, while concerned about their privacy, also appreciate the advantages of more personally relevant advertising and branded content (Aguirre et al., 2016; Strycharz et al., 2018). Data analytics and personalization strategies, however, do not only decide who receives what kind of care, or gets to see particular selections of content, but also who is included in treatment, news, advertisements, and special deals, and who gets excluded from them. In doing so, tracking and targeting users cannot only create new opportunities but potentially also new disparities and vulnerabilities in society, and in users (Bol, Helberger, et al., 2018). To better identify the opportunities and also risks of targeting, for individuals and society, there is a need for critical research to better understand who gets targeted with what content.
Ongoing debates about online targeting are often emotion-driven and based on assumptions and moral panic of what happens inside the “black box,” and what algorithms might and could do in terms of targeting ill-informed, vulnerable users (Bodo et al., 2017). At the same time, research on the implications of algorithmic targeting is challenging, as the exact nature of such algorithms is more often than not hidden from public oversight (Bucher, 2012), and also requires new research methods to bring into the light. As a result, empirical research substantiating various assumptions is scarce, but is direly needed to assess to what extent targeting occurs and to what kind of users. Scholars have pointed out repeatedly and urgently the need for new research designs to study the black box (Moore, 2016; Pasquale, 2015; Resnick et al., 2015). Put sharply, we need to think outside the box to look inside the box. In doing so, our article contributes to previous research in two distinct ways.
First, this study uses a unique design by combining tracking and survey data to assess who gets targeted with what content on online platforms. Although there is already research focusing on the sender side (i.e. the type of content on online platforms such as social media) or on the receiver side of targeted messages (i.e. the impact of type of content on user attitudes and self-reported behavior), research that has examined both sides simultaneously is scarce. Studies so far that have investigated online targeting typically rely on users’ online behavioral data such as website visits, search activity, advertising exposure, and online purchases (e.g. Lipsman et al., 2012), or conducted (automated) content analyses of social media content created by brands (e.g. Shen and Bissell, 2013). Drawing on Facebook as a case study, the current study moves a step further by integrating insights from both sender and receiver sides, which offers a more profound understanding of the workings of algorithms used for targeting and the implications thereof for user vulnerability online.
Second, we provide a theoretical framework that informs our understanding of the individual and societal impact of online targeting on vulnerabilities. So far, the ways in which algorithmic architectures are being used to target specific audiences remain unclear, and theoretical underpinnings explaining the potential opportunities and risks for users as well as for the society have only begun to emerge. As a result, there is little understanding of why users are exposed to certain content online, and also why it matters, and how to evaluate the status of the tracked society from a normative point of view. The question arises if groups, who are typically said to be more vulnerable to persuasive attempts such as less knowledgeable or older users (Duivenvoorde, 2013), are also the groups that are particularly vulnerable to targeting strategies, either because of greater perceptiveness or concentrations of targeting activities on particular consumers. The current study indeed shows that vulnerability factors, such as age and health condition are related to, for example, being targeted with health-related content. Informing consumers with a health condition about potentially helpful practices can be a useful thing to do. The point that we make in this article is that such a practice can amount to a (societal) problem if vulnerabilities, as result of a health condition, are identified and (ab)used trough data-driven advertising practices.
Next to implications for individual users, another urgent question is the one about the societal implications of targeting certain, and including, but also excluding other categories of users, and whether this can result in new forms of (digital) inequality. The question if we accept the situation in which different market segments are treated differently is not only of academic relevance, but also of societal relevance. In fact, research into the tracked society and its individual and societal implications offers critical input for ongoing policy debates, as the question of data-driven targeting strategies triggers the need for new policy measures to protect consumers’ autonomous decision-making. These are vital questions particularly in light of the pending review of the Unfair Commercial Practice Directive, and overhaul of the current consumer law acquis in Europe. Therefore, the current exploratory study aims to identify factors associated with targeting to assess whether vulnerable groups are exposed to certain content more avidly, which would result in both individual and societal consequences.
Targeting users on social media
Facebook has become one of the main channels for companies to target consumers. In particular, companies can create a page and use it to share so-called branded content—in the form of text, images, and/or videos—to promote and inform about products and services (Cvijikj and Michahelles, 2011; Luarn et al., 2015). Besides, Facebook allows brands to create posts that look like content posted by other users from a person’s network, but that are in fact promotional, “sponsored” messages with commercial intent (Boerman et al., 2017). According to Forbes, over 50 million companies used Facebook in 2015 to connect with their customers, and over 4 million pay for social media advertising on Facebook (Chaykowski, 2015).
A particular strength of Facebook as a tool for advertising and brand communication is that the social network allows targeting, that is, companies can define who their target audience is. Branded and sponsored posts can be subsequently distributed among pre-defined audiences (Sashittal et al., 2012), which makes Facebook a popular marketing tool. Such algorithmic targeting based on group-level and individual-level characteristics is particularly common on social media. In 2017, a study among marketing practitioners concluded that all branded messages on social media are targeted (Strycharz et al., 2017). For example, in the “Priorities for News in 2018” section, Facebook specifically mentioned that local news would be prioritized as a way of targeting users based on their geographical location (Reuters, 2018).
At the same time, consumers are not necessarily content with these developments. Social media users generally do not consider posts by brands with marketing purposes in social media applications as desirable (Akar and Topçu, 2011). This was one of the reasons for Facebook to adjust its News Feed algorithm, and promised to focus on “meaningful interactions” by prioritizing content from friends, families, and groups (Chaykowski, 2018). However, brands and organizations are still avidly visible on Facebook and use it as a tool to reach their target audiences.
From the perspective of consumer protection, data-driven targeting strategies have raised additional concerns regarding the potential of these strategies to identify and exploit particular consumer characteristics to increase the persuasiveness of the message, or even manipulate consumers in taking decisions that they would otherwise not have taken (Calo, 2014; Yeung, 2017). In other words, these are concerns about the (ab)use of targeting strategies to exploit individual consumer characteristics, or even vulnerabilities. Another concern relates not so much to the exploitation of individual vulnerabilities, but what we call here societal vulnerability. Thanks to targeting strategies, marketers can also decide to target only certain proportions in society, and not others. Examples are the targeting of so-called “profitable consumers” (Harrison and Gray, 2010), or, more in the political realm, the practice of “redlining” (Gorton, 2016; Zuiderveen Borgesius et al., 2018). This can result in a situation in which certain groups of users may be excluded from the economic benefits stemming from personalized advertising, such as offers and discounts (Wilson and Valacich, 2012), or certain political messages (Kreiss, 2012). Societal vulnerability in the sense as we introduce it here thus refers to the creation of new divisions or inequalities in the society or markets, as a result of targeting strategies. Both individual and societal perspectives on vulnerability are important concerns that need further studying.
Vulnerabilities online: individual and societal perspectives
While algorithmic personalized communication opens up numerous opportunities for Internet users, it also carries the risk of disempowerment and exploitation of vulnerable groups (Pierson, 2012). Based on an extensive literature review into the different conceptualizations of vulnerability in consumer research, Baker et al. (2005) define consumer vulnerability as a state of powerlessness that arises from an imbalance in marketplace interactions or from the consumption of marketing messages and products. It occurs when control is not in an individual’s hands, creating a dependence on external factors (e.g. marketers) to create fairness in the marketplace. The actual vulnerability arises from the interaction of personal states, personal characteristics, and external conditions within a context where consumption goals may be hindered and the experience affects personal and social perceptions of self. (p. 134)
To classify the types of exploitations of vulnerability, Cartwright’s (2015) distinction between informational and pressure vulnerabilities offers a helpful framework. More specifically, Cartwright’s classification explains how vulnerability can translate into unfair outcomes. On the one hand, informational vulnerability refers to situations in which consumers, because of their individual characteristics such as their age, education and also the level of their digital literacy, are not able to assess the information upon its value. An example is that information about targeted advertising is offered in such complicated language that consumers are not able to make meaning out of it, and also, they do not have the information they need to assess targeted advertising (e.g. because they are not privacy experts). On the other hand, in instances of pressure vulnerability, it is less information asymmetries that can result in potentially unfair outcomes, but the application of physical or psychological pressure. The feeling of pressure may result from individual characteristics and motives, such as a feeling of insecurity, fears, low self-esteem, and also from external factors (e.g. being involved in an accident or in financial difficulties).
So far, it remains unclear how vulnerabilities relate to new developments, such as algorithmic targeting. Seeing that data analytics can uncover information about personal biases, preferences, fears, or emotions, such knowledge could be used to create new information or pressure vulnerabilities. We argue that the construct of vulnerability can serve as a useful normative concept to assess the effects that targeting can have on consumers, and also on society. Due to the extensive knowledge that advertisers have about the individual characteristics, preferences, and biases of consumers, targeting strategies can (ab)use the aforementioned internal (e.g. low self-esteem) or external sources (i.e. being in financial difficulties) to influence behavior, for example, by applying (psychological) pressure (Yeung, 2018).
Next to exploiting vulnerabilities, targeting can potentially result in other situations of unfairness. One example can be the creation or reinforcement of digital inequality. While digital inequalities have been studied to explain differences in access and use of the Internet and social media (e.g. Hedman and Djerf-Pierre, 2013; Van Deursen and Van Dijk, 2014), social and individual vulnerabilities have mostly been studied in the context of social media use by youth. In fact, Livingstone and Helsper (2007) concluded that factors such as gender and digital efficacy contribute to vulnerability of young Internet users, with the effect that this is a group that may be less able to manage personal information online. In such a situation, targeting a particular group cannot only result in individual unfairness, but also in societally unfair situations. The case of Facebook selling the profiles of Australian teenagers that feel insecure to advertisers (Machkovech, 2017) is an example hereof, to the extent that there is an entire, and particularly vulnerable group in society that can be exposed to commercial content targeted specifically at them.
Another potential form of unfairness can be stereotyping in the sense of reinforcing and emphasizing existing differences in society. Targeting individual groups with branded content such that it addresses and exploits their individual concerns (e.g. woman are interested in news about diets) can result in the reinforcement of stereotyping. The concern about stereotyping is that it can shape and amplify consumer attitudes and worldviews (Windels, 2016). As such, it can contribute to creating (old or new) digital inequalities and situations of societal unfairness, if they shape societal expectations or restrict opportunities regarding particular groups over other groups (Grau and Zotos, 2016). The question that this article is interested in is about the role of algorithmic targeting in potentially reinforcing stereotyping.
The current study
Building on past research, we focus in particular on four socio-demographic factors that may be associated with targeting: age, gender, education level, and income. This selection corresponds with the result of an extensive study of factors that contribute to consumer vulnerability in European online markets, which identified age, gender, education, and income next to factors that are more specifically related to the specific conditions of the European online market, such as language skills and living in low-density regions (London Economics, VVA Consulting and Ipsos Mori co, 2016). The Commission reports, among other findings, that men were less likely than women to have problems comparing deals in the online sector, and that consumers with a middle level of education were more likely than those with high education to compare deals using only advertising as a source, while at the same time less likely to select the correct offers. Furthermore, these factors as well as family income have been shown to correlate with digital divides, that is, user access to technology but also the skills to deal with and benefit from technology (e.g. Cooper, 2006; Hargittai, 2001; Martin and Robinson, 2007). Similarly, age is named as one of the vulnerability sources in the context of the relation between companies and consumers (see Unfair Commercial Practice Directive, Art. 5(3)). To explore whether these factors of vulnerability are also related to online targeting, we put forth the following exploratory question:
RQ1. To what extent are socio-demographic factors of vulnerability (i.e. age, gender, education, and income) associated with the type of content users are exposed to?
In addition, we explore three individual perception factors that might relate to targeting, namely digital efficacy, user knowledge about targeting, and trust in online companies who are the senders of the targeted messages. In fact, less able users have been shown to be more vulnerable online (Livingstone and Helsper, 2007). At the same time, trust is closely related to vulnerability as trusting individuals accept the fact that in the risk situation (e.g. risk of personalized manipulation) they are vulnerable and they still have positive expectations toward the trustee (Colquitt et al., 2007), which could be exploited. To also explore the potential relationships between individual perception factors and online targeting, we propose a second research question:
RQ2. To what extent are individual perception factors of vulnerability (i.e. digital efficacy, personalized marketing knowledge, and trust) associated with the type of content users are exposed to?
Departing from this differentiation, this study aims to identify vulnerabilities that are associated with being targeted on social media. Consequently, the study will enable establishing relationships between user characteristics and the type of branded content the user sees online. Branded content was chosen as it is the content that can be targeted according to different user characteristics. Establishing these relationships is crucial in understanding both the workings of the black box of algorithms as well as their impact from individual and societal perspectives. To nuance our understanding of who are exposed to what type of branded content, and conclude if certain more vulnerable groups are more frequently exposed to certain content online, we therefore explore factors associated with the type of branded content users are exposed to. As it is one of the primary platforms on which targeting is happening, we draw on Facebook as a case study.
Methods
Research design
To answer our research questions, we used a unique design by combining data from an online tracking tool and self-reported survey responses. The tracking tool was used to unobtrusively collect users’ Facebook posts. The survey data captured societal and individual factors that represented vulnerability.
Participants and procedure
Tracking data
Between February and June 2017, 712 members of CentERdata’s LISSPANEL agreed to participate in a larger online tracking study as part of a larger research project (“Personalised Communication” project, see personalised-communication.net). The LISSPANEL consists of approximately 4500 households, comprising 7000 individuals, representative of the Dutch population. The panel is based on a true probability sample of households drawn from the population register by Statistics Netherlands (2018). Participants agreed to install a browser-based plugin that unobtrusively captured the HTTP(S) traffic of individual users and transferred this traffic to our servers when a whitelisted website was visited. Whitelisted website included social media websites, such as Facebook, but also included news websites, health websites, and price comparison websites. This plugin collected the URLs people accessed, the URLs where people came from (i.e. the referrers), as well as the actual content of the pages they visited (e.g. Facebook posts). Participants could at all times deactivate the plugin or use private mode to browse untracked. To ensure participants’ privacy and that of their online contacts (e.g. their Facebook friends), raw data were filtered to exclude personal user information, such as user names, passwords, and other sensitive information. Furthermore, all data were stored in an Elasticsearch database on a server that was not directly accessible by the researchers of the project. Instead, the data were only accessible through a Python library that was made available on a secured server.
Between January and February 2018, we collected online Facebook data from 97 members of the panel who were actively generating data with the plugin and visited Facebook at least once in these 2 months (i.e. 615 did not generate Facebook data, meaning that they either uninstalled, deactivated, or stopped using the plugin, or did not visit Facebook using the browser in which the plugin was activated).
Survey data
In November 2017, 712 members of CentERdata’s LISSPANEL who were invited to install the plugin were also invited to fill out an online survey. In total, 567 participants (79.6%) completed the survey. Of the 97 participants who generated Facebook tracking data, 80 completed the survey. The survey contained questions on digital efficacy, knowledge about personalized marketing, and trust in online companies. Demographic variables such as age, gender, education level, and income were extracted from the LISSPANEL database.
Participants were on average 48 years old (standard deviation [SD] = 18.26) and about half were female (51.3%, n = 291). Most completed a higher level of education (45.0%, n = 255) and the median individual income per month was €2700 (which is about US$3074). Of the full sample (N = 567), 80 participants generated data through the online tracking tool. Compared to those who only generated survey data (N = 487), participants who generated tracking data were on average younger, t (565) = 3.58, p < .001, more likely to be female, χ2(1) = 6.35, p = .012, and reported higher levels of digital efficacy, t (455) = −2.46, p = .014. Descriptives of the full sample (N = 567) as well as the full sample divided by those that generated tracking data (N = 80) and those that only generated survey data (N = 487) are presented in Table 1.
Descriptives of the full sample (N = 567), tracking sample (N = 80), and survey only sample (N = 487).
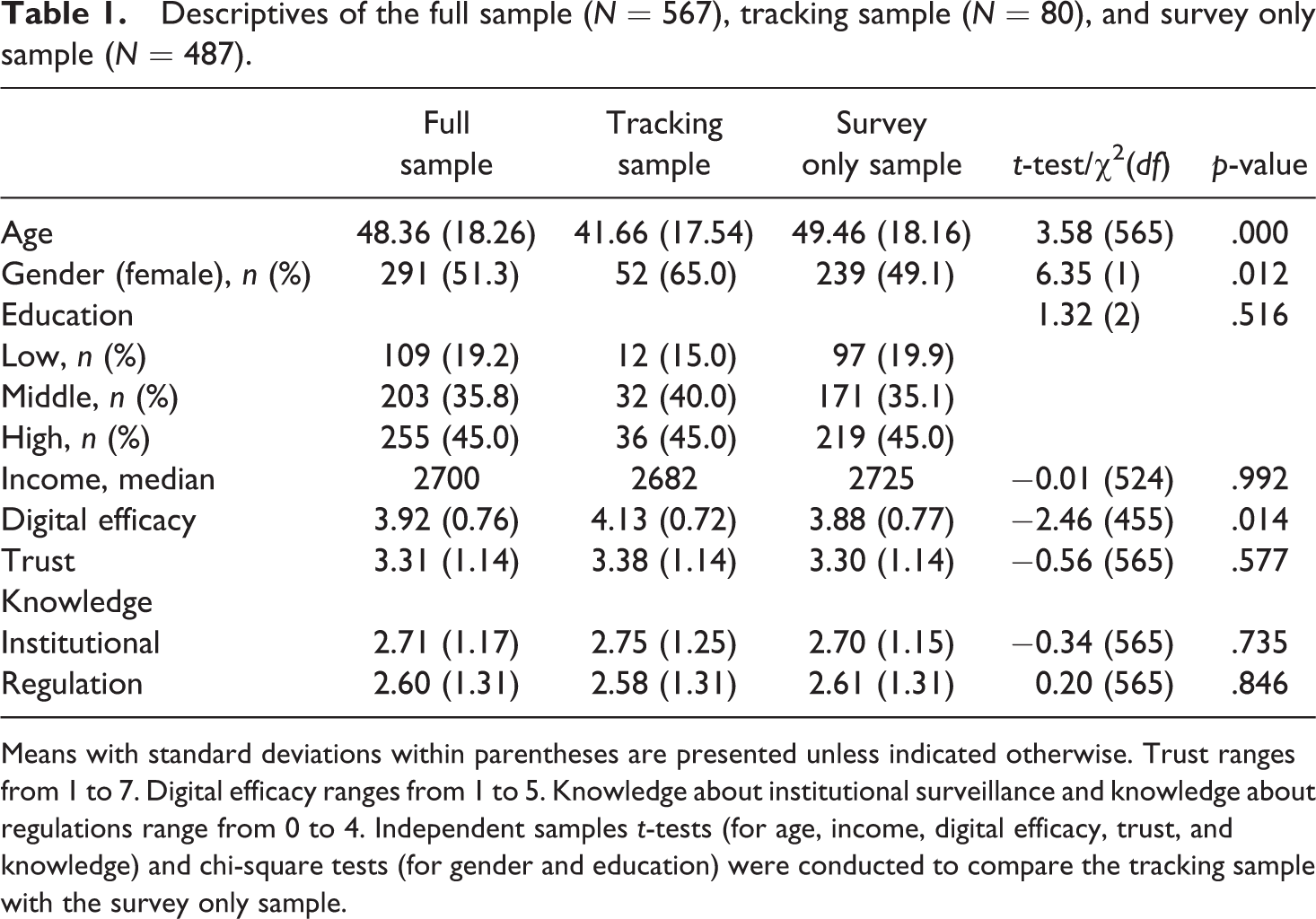
Means with standard deviations within parentheses are presented unless indicated otherwise. Trust ranges from 1 to 7. Digital efficacy ranges from 1 to 5. Knowledge about institutional surveillance and knowledge about regulations range from 0 to 4. Independent samples t-tests (for age, income, digital efficacy, trust, and knowledge) and chi-square tests (for gender and education) were conducted to compare the tracking sample with the survey only sample.
Measurements
Our dependent variable comprised the exposure to branded content on Facebook and was assessed by coding and categorizing branded posts extracted from the online tracking tool. The independent variables included the factors on vulnerability, and were all assessed through the online survey. Participants answered items that comprised socio-demographic aspects, that is, age, gender, education, and income, as well as items related to individual perceptions, that is, digital efficacy, knowledge, and trust perceptions.
Exposure to branded content
To assess the branded content people were exposed to through their Facebook News Feed, we first categorized all posts that originated from organizations based on earlier classifications of industries (see Analytical Procedure). Next, posts within the same categories were merged for each participant to change the unit of analysis from posts to participants. Shapiro–Wilk test of normality indicated violations of normal distribution for all category variables, as all of them were skewed to the left (skewness ranges between 2.97 and 8.67). We therefore dichotomized the category variables, with 0 indicating that a person was not exposed to branded posts of a certain category, and 1 indicating exposure to branded posts of a certain category.
Demographics
Age, gender, education, and income were extracted from the LISSPANEL database. Education was based on the categories used by CBS Statistics Netherlands (2013): primary education, preparatory secondary vocational education, higher secondary general education or pre-university education, secondary vocational education, higher vocational education, and university. Income represented the net individual income per month.
Digital efficacy
Digital efficacy was measured with eight items on a 5-point scale ranging from not at all confident to very confident, with an additional answer option “I don’t know,” regarding the following activities: “Finding information online,” “Communicating with others online,” “Downloading and uploading files online,” “Talking about Internet hardware, like a network or router,” “Talking about Internet software, like a search engine or Web browser,” “Troubleshooting Internet problems,” “Using a specific Internet program or app, like Facebook,” and “Knowing where to get help on Internet questions if you need it.” (Hoffman and Schechter, 2016) For the factor validity and scale construction, we left out those who selected “I don’t know” and identified those as missing values. Confirmatory factor analysis (CFA) among the remaining cases (n = 457) showed satisfactory model fit: χ2(17) = 185.52, p < .001, comparative fit index (CFI) = .921, Tucker–Lewis index (TLI) = .870, root mean square error of approximation (RMSEA) = .147, standardized root mean square residual (SRMR) = .093. The items were computed into a reliable mean scale (M = 3.92, SD = 0.76, range = 1–5, α = .88).
Knowledge
Knowledge about personalized marketing was measured by a two-dimensional construct including knowledge about institutional surveillance and knowledge about regulations (Strycharz, 2018). Participants were presented with eight statements adapted from Park (2013), which could be answered with “True,” “False,” or “Don’t know.” Correlational analyses were performed for each dimension to test whether the items were related to each other. The correlation coefficients of the statements (i.e. recoded to dummy variables indicating correct answers) within knowledge about institutional surveillance varied between .20 to .40, and within knowledge about regulations from .20 to .44, suggesting that the items within each dimension are moderately correlated with each other.
Knowledge statement about institutional surveillance included the following: “News websites know which articles are read and how long” (correct answer = True, 68.8%), “When you go to a website, it can collect information about you even if you do not register” (correct answer = True, 67.5%), “Popular search engine sites, such as Google, track the sites you come from and go to” (correct answer = True, 91.5%), and “E-commerce sites, such as Bol.com or Zalando, may, under certain circumstances, exchange your personal information with law enforcement” (correct answer = True, 43.0%). Participants answered on average three of four statements correctly (M = 2.71, SD = 1.17).
Knowledge statements about regulation included “Government policy restricts how long websites can keep the information they gather about you” (correct answer = True, 61.9%), “When I give personal information to a website, it is free to do anything with this information” (correct answer = False, 68.4%), “By law, e-commerce sites, such as Bol.com or Zalando, are required to give you the opportunity to see the information they gather about you” (correct answer = True, 61.6%), and “Privacy laws require website policies to have easy to understand rules and provide the same information” (correct answer = True, 68.3%). On average, participants answered three of four statements correctly (M = 2.60, SD = 1.31).
Trust
Trust in online companies was measured using four items from Malhotra et al. (2004), which had been adopted for previous studies (Bol, Dienlin, et al., 2018; Kruikemeier et al., 2018). Items were as follows: “Online companies handle my personal information confidentially,” “I trust that online companies handle my personal information correctly,” “Online companies are always honest to me about how they use my online information,” and “Online companies protect my personal information I share with them.” CFA showed adequate factor validity and reliability based on common fit criteria (e.g. Kline, 2016): χ2(2) = 11.45, p = .003, CFI = .990, TLI = .970, RMSEA = .091, SRMR = .022. The items were averaged into a scale (M = 3.31, SD = 1.14, range = 1–7, α = .84).
Analytical procedure
Tracking data
To collect Facebook posts, the aforementioned plugin was used. Self-written Python codes were used to retrieve and filter all posts collected by the plugin between 1 January and 28 February 2018. The collected data included the written content of all posts, their senders, and various metadata (e.g. number of likes, if the post was public, if it was shared, time and date). In total, 5611 posts were retrieved as seen by 97 active plugin users. These were all items on users’ News Feed, which included content posted or shared by friends, posts by organizations, and sponsored posts, as well as items placed right from the News Feed, called sidebar advertisements. For the purpose of this study, we only selected branded content on users’ News Feed, which included content posted by an organization directly, branded content shared by a friend, or sponsored content. To meet these requirements, the following selection criteria were used: (1) posts had to originate from a branded page; (2) posts had to be public; (3) posts had to appear in the News Feed (and not in the sidebar). After applying such filters, we identified 2814 branded posts seen by 80 unique users. To categorize the branded posts, we focused on the sender of the post and coded this information according to a codebook. First, we coded the industry the sender represents based on lists of 20 industries by the International Labour Organization (International Labour Organization, n.d.) and the website Adsoftheworld (Ads of the World, n.d.). One coder made judgments about all posts in the sample, and 240 posts (8.5%) were randomly selected and independently coded by a second coder, resulting in adequate inter-coder reliability (Krippendorff’s α = .93). Second, to give an indication of the popularity of the posts (see Sabate et al., 2014), the number of likes and comments per posts were reported.
Of the 2814 posts, 2771 could be categorized as one of the 20 industries. The reason for not being able to categorize 43 posts was parsing errors (i.e. when the post sender used a link with shortened URL in the post, it was consequently parsed as, for example, bit.ly). A substantial number of posts were sent by the entertainment industry (25.3%), the beauty and fashion industry (13.3%), and the e-commerce and retail industry (7.9%). These included posts about media, movies, music and games (entertainment industry), fashion, beauty and personal accessories (beauty and fashion industry), and traditional and online retailers (e-commerce and retail industry). Table 2 presents an overview of all industries with an example posts, the total number of posts, and the number of likes and comments posts from each of the industries received.
Classification of Facebook posts based on industry, likes, and comments.
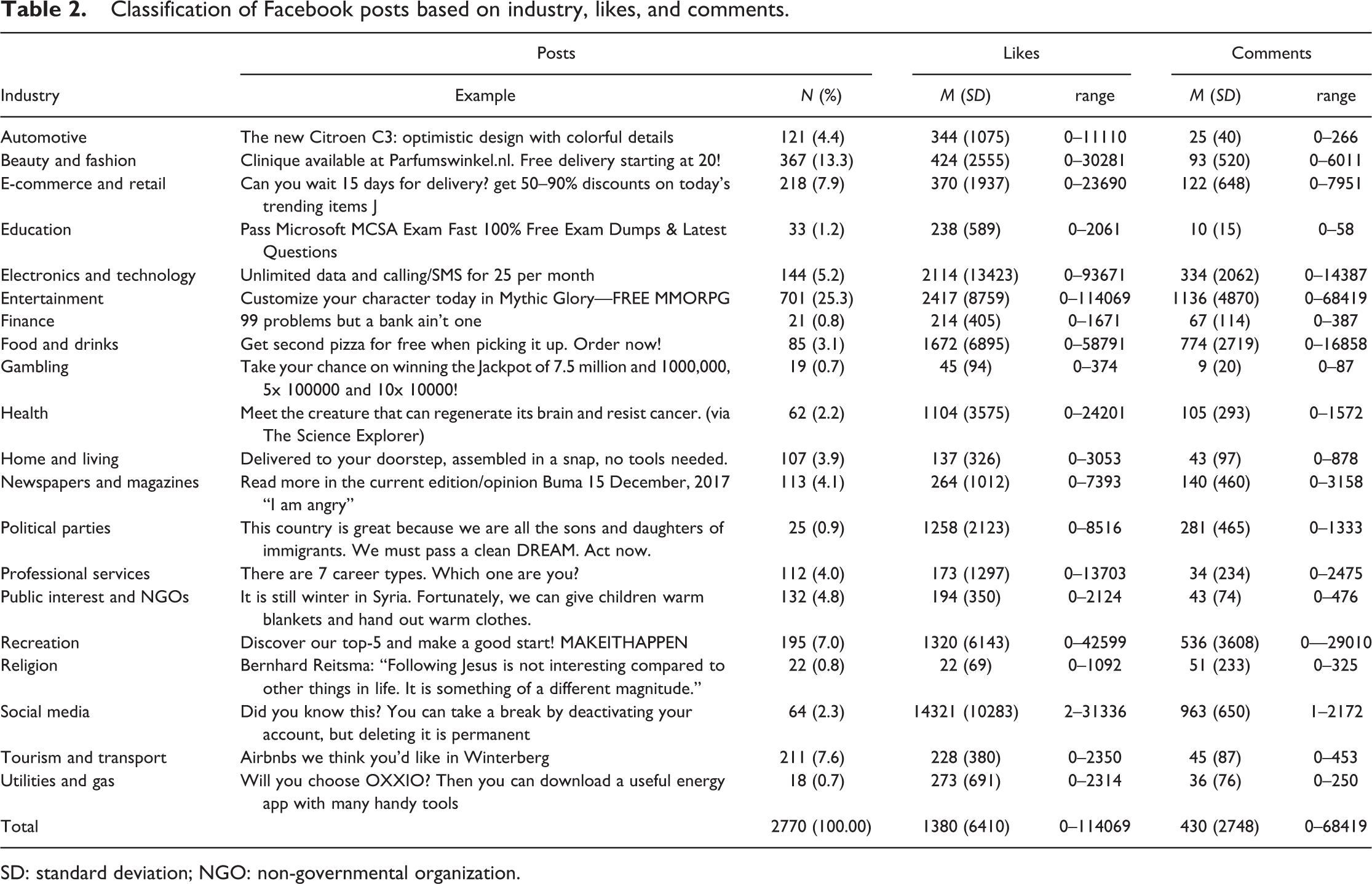
SD: standard deviation; NGO: non-governmental organization.
Survey data
Logistic regression analyses were conducted to assess the relationships between socio-demographic and individual perception factors of vulnerability, on the one hand, and branded content categories exposed to on Facebook, on the other hand. As the content categories were heavily skewed to the left, these were all dichotomized to compare non-exposure and exposure (regardless of the frequency of posts) to branded posts. Socio-demographic and individual perception vulnerability factors were entered into the model in two separate stages, with all variables entered into the model as continuous covariates, except for gender, which was included as a dichotomous factor. These two-stage logistic regression models allowed us to assess the added value of the different types of vulnerability in understanding who sees what content on Facebook. In the result section, we present unstandardized coefficients with standard errors and odds ratios (ORs) with 95% confidence intervals (CIs), where any number greater than 1 suggests a higher likelihood to be exposed to a certain branded content category, whereas a number less than 1 suggests a lower likelihood to be exposed to certain branded content.
Results
Who gets targeted with what content
In this section, we look at the relationship of socio-demographic and individual perception factors of vulnerability and branded content categories concurrently. Based on the classification of branded content categories, we ran 20 two-stage logistic regression models, one for each branded content category. Of these, we found significant relationships between the socio-demographic and individual perception vulnerability factors, on the one hand, and exposure to six of the branded content categories, on the other hand. These categories included automotive, electronics, entertainment, fashion and beauty, health, and political industries. In general, socio-demographic vulnerability factors (i.e. age, gender, education, income) were more commonly associated with exposure to certain branded content on social media than individual perception vulnerability factors (i.e. digital efficacy, knowledge, trust).
With regard to the socio-demographic factors of vulnerability (RQ1), exposure to branded content from the fashion, health, and political industries were significantly related to age. Where younger users were more likely to be exposed to branded content on Facebook about beauty and fashion (b = −0.05, SE = 0.03, OR = 0.95; 95% CI = [0.91, 1.00]), older users were more likely to be targeted with branded content about health (b = 0.08, SE = 0.03, OR = 1.08; 95% CI = [1.02, 1.15]) and political parties (b = 0.29, SE = 0.15, OR = 1.34; 95% CI = [1.01, 1.79]). Exposure to branded content from the automotive, electronics, and health industries were significantly associated with gender, such that males were more likely than females to be exposed to branded content about cars (b = 2.26, SE = 0.80, OR = 9.55; 95% CI = [1.99, 45.86]) and electronics (b = 2.05, SE = 0.77, OR = 7.73; 95% CI = [1.72, 34.75]), while females had higher chances than males to be targeted with branded content about health (b = −2.91, SE = 1.15, OR = 0.05; 95% CI = [0.01, 0.51]). Education was significantly associated with branded content from the entertainment industry: those with lower education levels were more likely to receive branded content about entertainment than those with higher education levels (b = −0.78, SE = 0.33, OR = 0.46; 95% CI = [0.24, 0.89]). Income was never significantly related to branded content exposure.
With regard to the individual perception vulnerability factors (RQ2), we only found a significant relationship between trust and exposure to branded content related to health. People with higher levels of trust in online companies were more likely to be targeted with branded content on social media from health industries than people with lower levels of trust (b = 0.77, SE = 0.40, OR = 2.17; 95% CI = [1.00, 4.70]). Table 3 provides an overview of the factors related to exposure to these six branded content categories. Table 1-4 of the Supplemental material provides an overview of all results regarding the logistic regression analyses of the effects of socio-demographic and individual perception factors on exposure to the 20 branded content categories.
Logistic regression models of the effects of socio-demographic and individual perception factors on the type of content users are exposed to (N = 77).
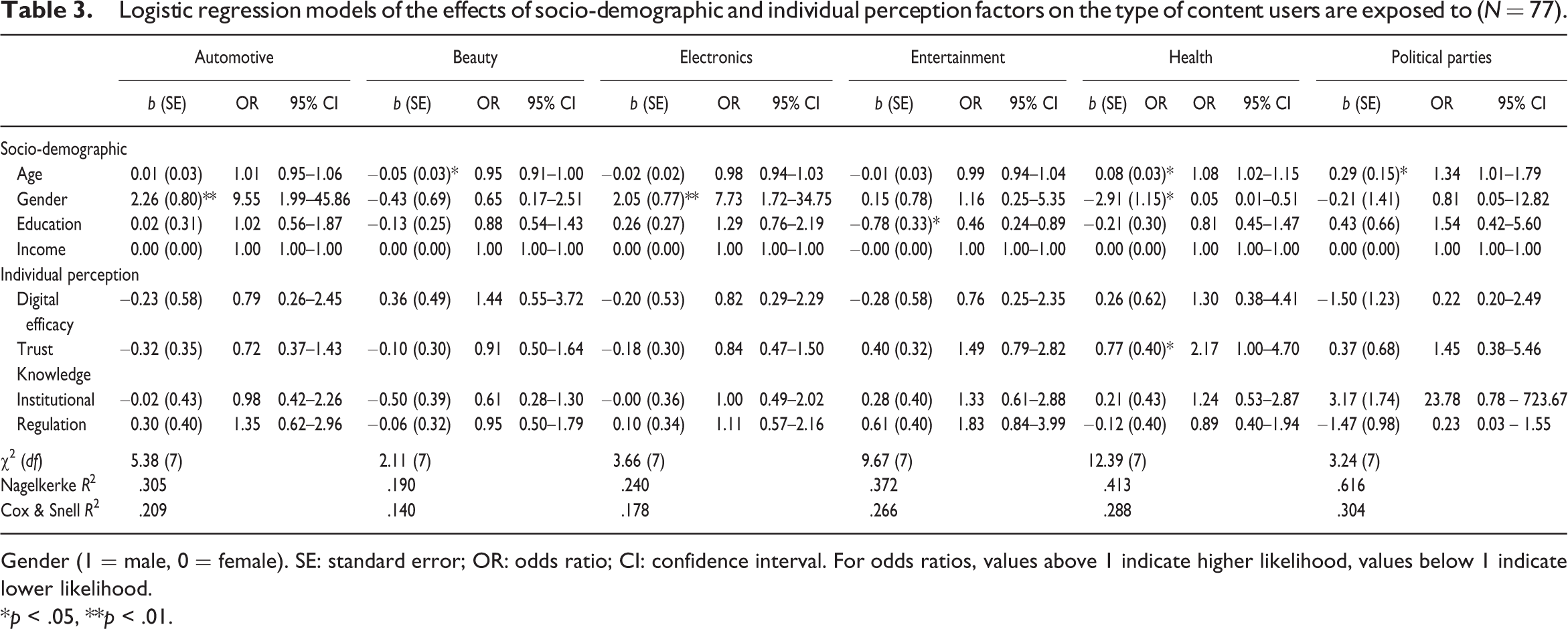
Gender (1 = male, 0 = female). SE: standard error; OR: odds ratio; CI: confidence interval. For odds ratios, values above 1 indicate higher likelihood, values below 1 indicate lower likelihood.
*p < .05, **p < .01.
Discussion
This study combined tracking and survey data to substantiate claims regarding the individual and societal impact of algorithmic targeting that takes place on social media. Drawing on Facebook as a case study, we categorized branded content users were exposed to on their Facebook’s News Feed, and identified characteristics that were associated with this exposure. More specifically, a number of socio-demographics and individual perception factors were brought in relation to the type of content one receives on Facebook. Significant relationships emerged between the socio-demographic factors, on the one hand, and exposure to six of the branded content categories, on the other hand, namely automotive, electronics, entertainment, fashion and beauty, health, and political industries. At the same time, trust was found to be associated with exposure to branded content from health industries.
A person’s age, gender, education level, and trust in online companies were significantly associated with exposure to certain branded content categories. In contrast to the digital divide literature, where consistent patterns of user characteristics seem to be associated with the digital divide (e.g. lower age and education are typically related to lower use of and benefits from technologies, Van Deursen and Van Dijk, 2014; Van Dijk and Hacker, 2003), we found more refined patterns. With regard to age, we found that older users were more likely to be exposed to branded content from health industries and political parties, while younger users were likely to be exposed to content from fashion and beauty industries. Differentiated patterns for gender emerged as well: while males were more likely to be exposed to branded content from automotive and electronics industries, females were more likely to receive health-related branded content on their Facebook’s News Feed. Education and trust perceptions were only related to one specific industry, such that lower education was associated with exposure to entertainment content and higher trust was related to exposure to health content. Digital efficacy and knowledge about personalized marketing were not associated with exposure to specific types of branded content on social media.
These findings nicely demonstrate the potentially nuanced and differentiated patterns of algorithmic targeting on online platforms such as Facebook. Enabled by our online tracking tool, we were able to give a first indication of the personalized nature of such targeting, which we will discuss in light of individual and societal vulnerabilities below. However, since most of the significant relationships between user characteristics and the type of content one received were only incidental (i.e. there was often only one characteristic per content category that was significantly related to exposure to that content category) and most of them at the group-level rather than highly individualized, the effects should be interpreted with caution.
The world according to Facebook: women get health, men get cars
Regarding what content is presented on Facebook in general, a first relevant finding is that the social medium is predominantly used for entertainment. In fact, posts coming from firms within the entertainment industry are most commonly present in users’ News Feed. Such posts, which include branded messages from the music industry, film industry, or blogs, are also on average most popular among users (popularity being operationalized as the number of likes and comments, see Sabate et al., 2014). Only few other industries such as recreation or electronics spark similar levels of popularity. The fact that entertainment is most common and popular on Facebook confirms what other studies found: Facebook is mostly used for entertainment purposes and as a time filler (Sheldon, 2008; Tosun, 2012). Hence, while Facebook is often mentioned in the context of information seeking and news, and while companies use Facebook for product sales, its entertainment function remains most prevalent and popular on users’ News Feed.
With regard to specific targeting of users on Facebook, our findings suggest two main conclusions. First, we observe targeting based on gender. More specifically, while women see content related to fashion and beauty on their News Feeds, men are exposed to ads and posts by car manufacturers and tech brands. One has to note that in advertising research, these domains have long been stigmatized as female or male (see studies on gender-stereotyping in TV and print ads, e.g. Knoll et al., 2011). Gender-stereotyping is thus just as much prevalent on social media as it is in television commercials, and is reflected either in choices made by marketers or in algorithms responsible for targeting that determine what type of content users are exposed to on social media. Thus, one could argue that social media targeting is no different than defining a target audience by “old media” based on simple demographics. Nonetheless, both the scale and sophistication of algorithmic targeting may contribute to stronger amplification of existing stereotypes. Moreover, unlike in the traditional media, only the targeted groups will see these particular messages (e.g. woman see beauty advertisements), while being excluded from others (e.g. women see no advertisements about cars or technology), which could further reinforce stereotyping within a particular group to the extent that also social media play a role in shaping people’s perception about themselves (Grau and Zotos, 2016, on the impact of media on self-perception more generally). Indirectly, this aspect of stereotyping is also at the basis of concerns about filter bubbles (Pariser, 2011)—only that in the situation here that would be marketing bubbles—and new forms of unfairness in the form of social sorting (Barocas and Selbst, 2016; Citron and Pasquale, 2014).
Second, and most importantly, we can conclude that health industries are clearly targeting specific users for their products, and they make no effort to conceal the fact that they are. Particularly, people of older age, females, and those with higher trust in online companies are significantly more likely to receive branded posts from health-related industries than people of younger age, males, and those with lower trust in online companies. Even more concerning is that a post hoc test shows that participants’ subjective health is also significantly related to exposure to health content on Facebook (b = −1.17, SE = .57, OR = 0.31; 95% CI = [0.10, 0.94]; see also Table 5 of the Supplemental material). More specifically, people who reported to have poorer health conditions were more likely to be targeted with health-related branded content than people with better health conditions. As we cannot make inferences about causality, these targeting practices could also be explained by people’s past online search behavior, as the digital traces we leave behind when we are online can follow us onto other online platforms. Since we know that health-related information-seeking behavior is typically associated with being older, female, and in poorer health conditions (Bundorf et al., 2006), it is not unlikely to consider that health industries picked up on people’s online searches into health-related information and used this as input for online targeting through Facebook.
Implications for the vulnerable user
When it comes to discussing the implications for individual and societal vulnerabilities, it should be first noted that algorithmic targeting is mostly related to socio-demographics and not so much to individual perceptions. While age and gender are associated with exposure to different branded content categories, only one industry (i.e. health) is related to one of the individual perceptions, that is, trust. While past research has shown that less knowledgeable users often lag behind in terms of technology adoption and use (Van Deursen and Van Dijk, 2014), and may be in danger of being exploited online and easily persuaded (Duivenvoorde, 2013), our research indicates that such factors are not used by organizations to target their users via social media. In fact, such scandals as the Cambridge Analytica case have shown that algorithmic targeting based on psychographic profiles by predicting what users know and feel, remains highly controversial, which may be a reason for companies to avoid doing so.
At the same time, we have concluded that—to a certain extent—targeting occurs particularly in relation to socio-demographic factors. As such factors (e.g. gender or education level) operate on the individual level, Cartwright’s distinction between individual informational and pressure vulnerabilities is particularly useful for discussing implications of such targeting (Cartwright, 2015). One example of informational vulnerability are information asymmetries, that is, situations in which the seller holds disproportionally more information about the consumer than she does; for instance, when companies have access to information about individual biases, motives (e.g. need to book a ticket on a certain date), or concerns (e.g. fear of overweight) (Helberger, 2016). Our study findings suggest that information about the consumer, it either being their age or health status, can be used by advertisers to disseminate branded content, which may hint at informational vulnerability of consumers, who may not be fully aware of the information advertisers have access to (Smit et al., 2014).
To the contrary, targeting strategies that appeal to personal fears may exploit not only information asymmetries but also use the superior knowledge about individual or external consumer characteristics to pressure consumers into marketing activities, that is, exploit pressure vulnerability. In particular, targeting consumers in the context of health should be seen in such terms. By targeting users with certain health-related fears and exposing them to health-related content, advertisers use and exploit users’ fears, which may lead to users growing the need to perform certain market activities, such as trying out a fitness tracker or selecting a certain health-care provider.
The relationship between vulnerabilities and algorithmic targeting also has implications for reinforcing existing stereotypes and low self-esteem. As discussed above, stereotypical gender roles are indeed confirmed by the findings. Furthermore, targeting may also reinforce existing individual and external divides. More specifically, stereotyping may lead to certain groups receiving incomplete information purely because of user characteristics such as, for example, gender. Such incompleteness can result in diminished choice and opportunities in the marketplace. For example, cars, a product seen as predominantly male, are targeted on social media accordingly, while more than 80% of car buying decision is now influenced by women (Singh, 2014). These females, who are actually interested in the automotive industry, are thus deprived of certain product information. Such a situation, in which particular segments of the market (males) are offered extra information, economic advantages, or promotional offers from which others (females) are excluded, can result in new situations of societal unfairness and unequal distribution of advantages and assets. In fact, Futures (2001) referred to this as “imperfect markets,” that is, markets that reinforce and cause disadvantage for certain consumers. While the current study offers insights into who gets targeted with what content, future empirical research should dive deeper into what that content of targeted posts on social media precisely entails. Such future research would allow to assess if such posts feature information, promotions, and opportunities that may create asymmetries between consumers who are and who are not targeted.
Limitations and future research
Using an online tracking tool allowed us to take a next step into researching the algorithmic nature of online tracking by assessing who gets targeting with what content specifically. However, as with all innovative approaches, our tracking tool comes with some limitations that need to be acknowledged. First, the drop-out of participants generating plugin data was particularly high. While all 712 participants were invited to install the traffic monitoring plugin, only 97 were generating data at the time of data collection. The remaining participants stopped using the plugin (e.g. by uninstalling it, deactivating it, or by using a different browser). Thus, even with extensive privacy and information procedures, the high drop-out rate could not be avoided. This, in turn, has resulted in a rather small sample size and loss of statistical power. As the effects of socio-demographic and individual characteristics on targeting on social media cannot be expected to be large, the lack of power may have led to falsely accepting the null hypothesis.
Second, the participants that eventually signed up to install the online tracking tool and generated actual data at the time of data collection were not representative of the Dutch population. Although with the recruitment process we aimed to do so, the tracking sample ended up to be relatively younger, female, and reported higher levels of digital efficacy. As a result, we may have over- or underestimated the extent to which certain groups were targeted with specific content, in particular, as age and gender were found to significantly predict exposure to targeted content of multiple industries. For example, as the tracking sample was on average younger, we may have missed content particularly targeted at older social media users. Furthermore, our results might thus not translate to other populations, and warrants further research to extend our findings.
Third, despite the sophisticated tool and Python code to retrieve Facebook content, we could not discern whether a post originated from a company directly, it was shared by the user’s network, or whether it concerned a sponsored post. This type of information could have given the results even more depth, and we could have specified and discussed the role of the origin of a post. Nonetheless, as users are not fully able to differentiate between branded content shared by a company or a friend (Boerman et al., 2017), our findings provide an important first step into researching the prevalence and impact of targeted branded content on social media.
Supplemental material
Supplementary_File_nms_(1) - Vulnerability in a tracked society: Combining tracking and survey data to understand who gets targeted with what content
Supplementary_File_nms_(1) for Vulnerability in a tracked society: Combining tracking and survey data to understand who gets targeted with what content by Nadine Bol, Joanna Strycharz, Natali Helberger, Bob van de Velde and Claes H de Vreese in New Media & Society
Footnotes
Acknowledgements
We would like to thank Mats Willemsen, Maarten de Jonge, and Mykola Makhortykh for their work on writing the Python code for the Facebook post extraction.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by and made possible through the University of Amsterdam Research Priority Area “Personalised Communication” (![]() ), principal investigators Natali Helberger and Claes H. de Vreese, as well as through the Amsterdam Academic Alliance Data Science (AAA-DS) Program Award.
), principal investigators Natali Helberger and Claes H. de Vreese, as well as through the Amsterdam Academic Alliance Data Science (AAA-DS) Program Award.
Supplemental material
Supplemental material for this article is available online.
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.