
Abstract
Concerns about potential health risks from infrasound exposure require objective investigation methods for the perception of infrasound by humans. Neural-network methods were applied to identify weak infrasound evoked potentials and to investigate the efficacy of these techniques. Two simple networks – a fully connected three-layer feed-forward network and a two-layer autoencoder – were designed for the analysis of electroencephalography (EEG) data recorded in response to infrasound stimuli presented. Late auditory evoked potentials (LAEPs) were detected and correlation factors between the target and the output of the networks were determined to assess the differentiation ability of the two networks. Both networks were able to differentiate infrasound evoked potentials from noise but showed different performance levels with respect to a differentiation threshold. The results can be applied to objectively identify perception events by infrasound in humans.
Introduction
Transitioning to carbon-neutral energy production is essential for mitigating climate change and a sustainable production and life; however, renewable energy converters often produce noise specifically at low frequencies including infrasound. Serious concerns and complaints by those living in the vicinity of planned facilities often complicate the expansion and development of environmentally friendly energy production. Since objective knowledge about humans’ infrasound perception mechanisms is still limited in this field, the current debate mostly relies on assumptions; furthermore, experts are divided in their opinions as to whether infrasound has a negative impact on humans. 1
A basic but essential element of this debate is an understanding of infrasound perception mechanisms to allow a better estimation of the impact of infrasound on vulnerable anatomical structures in the human body and on processes critical for quality of life such as sleeping and leisure time. Neuroscience methods and brain imaging can play an important role2–4 in the modelling of perception mechanisms because they focus on the processing of infrasound perception in the brain. These activities document whether infrasound commonly considered non-audible is perceived. Here, different methods such as magnetic resonance imaging (MRI)3,4 and magnetoencephalography (MEG) 5 have been used. Electroencephalography (EEG) is of particular interest because it involves simple detection set-ups; however, identifying related signals is difficult because the signals are weak and a reasonable signal-to-noise ratio can only be obtained via a long averaging process. 6 Thus, EEG studies using infrasound stimuli often apply an analysis in the frequency domain. Kasprzak 7 investigated the influence of narrow-band signals with frequencies between 4 and 8 Hz on α -waves in EEG signals. Kolesnik et al. 8 investigated the correlation between infrasound exposure events and the time-development of various bands of EEG signals. Nagamatsu et al. 9 used EEG data for an evaluation of the impact of wind park noise on humans. Jurado et al. 6 evaluated the use of the brain’s frequency-following response (FFR) as an objective correlate of individual sensitivity to infrasound and determined (cervical) vestibular-evoked myogenic potentials (cVEMPs) 10 in response to infrasound stimuli. In case of a time-dependent analysis, quite strong signals around a delay of 100 ms (N1) and 200 µs (P2) were expected 5 and were clearly recognisable at audible frequencies. This raises the question as to whether it is possible to transfer knowledge of the pattern in the audible frequency range at (for example) 256 Hz into the infrasound frequency range where identifying evoked potentials is much more difficult. Methods which can exploit learned information during processing of signal patterns in EEG signal analysis help to objectively analyse results of infrasound perception studies.
A trained neural network has been used to analyse unknown data to find structures or patterns within a dataset or to classify input data into different categories. 11 An alternative approach is the application of unsupervised learning to reduce unintended signal contents such as noise and artefacts.12,13 Machine learning has already been used extensively to process EEG data; here, most studies have focussed on classification or feature extraction from time data (for example, for seizure detection, sleep stage scoring and mental workload determination).14–16 The different network configurations used were often finally adapted to specific applications via a trial-and-error methodology. Other studies have focussed on improving processing tools 14 used for artefact reduction (among other tasks). 17
Another motivating factor behind applying neural networks to analyse EEG data is that such data can be used to establish brain-machine interfaces. In comparison to other brain imaging methods, EEG is a simple technique for extracting information from the brain; sophisticated procedures have been established to recognise specific brain responses which can be assigned to isolated environmental input elements. 18 Of particular interest in this field is, for example, the recognition of emotional reactions and the decoding of cognitive states. 19
Speech recognition is a very general task with many applications which has been part of everyday life20,21 for many years. Most speech recognition systems process time data and denoising is an essential element of this processing to which autoencoders have successfully been applied (Ref 11, section 14). In principle, the autoencoding process consists of two stages: In the first, the input data is encoded, after which a decoding system reconstitutes the (essence of the) signal and a cost function is created by comparing the input and the output. Here, it is assumed that the encoding process reduces the information of the input signal and concentrates it in the essential elements, removing unnecessary parts such as noise in the process. Autoencoders have been applied to tasks such as the analysis of seismological signals, 12 ultrasonic signal processing, 13 EEG feature extraction 22 and noise suppression. 23
In nearly all of the above discussed studies, the algorithms applied23,24 implemented sophisticated network designs; furthermore, applying such algorithms requires expert knowledge and extensive experience. A more general deployment of this promising but difficult to create technology requires simple models and algorithms which can be used to better understand complicated experimental results. In this technical paper, simple neural-network methods are applied to identify infrasound evoked potentials and the efficacy of these networks is investigated. Two simple networks – a three-layer feed-forward fully connected network and a two-layer autoencoder – were designed to analyse EEG data recorded in response to the infrasound stimuli presented. Late auditory evoked potentials (LAEPs) were detected; here, the aim was to identify typical responses such as N1 or P2. Responses obtained at a frequency of 256 Hz were used as learning data and the qualified average was defined as a target and a reference. Correlation factors between this target and the output of the networks were determined for frequencies of 256 Hz, 64 Hz and 16 Hz; this allowed the differentiation ability of the two networks to be assessed.
Experimental set-up
EEG data acquisition
Participant information
All infrasound hearing experiments conducted to date have shown a wide distribution of all potential variables.25,26 To limit the variability, data from only one test subject were used in this study. The approval of the local ethics committee was given under the reference 2018–1.
Stimuli
Short stimuli were presented as tone bursts. Since the period length increases with decreasing frequency, only three half-waves of a sinewave were included to limit the overall presentation time. To cover the low-frequency and infrasound frequency ranges, a stimulus at audible frequencies (256 Hz) was selected and combined with a low-frequency stimulus (64 Hz) and a stimulus in the infrasound frequency range (16 Hz). 300 stimuli were presented with a repetition rate of 1.0 s using a specially designed headphone system developed for the presentation of infrasound signals. 27 For this purpose, a RadioEar DD45 earphone transducer was mounted in an aluminium housing unit which had been developed in-house. This transducer was coupled to an ER3-14A ear-tip using a 50 cm sound-delivery tube containing several synthetic fibres at both ends. The test subject was awake but advised to be calm and relaxed.
EEG data acquisition
EEG signals were detected 28 in a vertical configuration (for discussion of LAEP see Sect 11 in 29) with a Tucker Davis system (RZ6 with an RA4PA head stage). Electrodes were positioned at both mastoids at TP 9 and TP 10 in accordance with the 10–20 electrode system. 30 The reference electrode was set at vertex (Cz). The 300 stimuli were presented in one batch and data were sampled with a sampling frequency of fs = 24.4 kHz. Finally, 300 trials were extracted with a length of 500 ms starting at the moment when the electrical burst signal was generated. Note, that data of only one test person was used because of the general high inter-individual spreading of infrasound related experimental quantities. An improvement of statistical power of the experiment could only be achieved with about more than 20 test persons which is beyond the scope of this first study.
Learning data and test data preparation
Because LAEP signals are slowly varying time signals, the data could significantly be down sampled to fsL = 122 Hz without loss of information to reduce the calculation time. The length of one trial was finally Nt = 62 points. The data of the learning set were not corrected with respect to artefacts; thus, no trial was excluded. 80% of the data obtained for a frequency of 256 Hz (240 trials) were used as learning data for the autoencoder (see Section Design of networks) and the remaining 20% formed the validation data. Note that the data at 64 and 16 Hz (preparation described below) act as test data.
The learning data for the feed-forward network comprised a combination of the data obtained at 256 Hz and the data measured when no stimulus was present, but all other EEG data acquisition parameters remained the same (zero measurement). So, the network also learned which signals do not contain LAEP-information. Although this strategy seems to deteriorate the learning data quality, it significantly improved the learning efficiency. The zero-measurement data were also prepared as described and 300 trials were available of which 80% (240 trials) were again used as learning data. These trials were randomly merged with the 240 learning trials of the 256 Hz case to obtain a final training set of 480 trials. The remaining 20% of the zero-measurement data were used as validation data to test the network’s robustness against fluctuations and high variance. To investigate the effect of reducing the variance of the data, an additional alternative data set was subsequently created by summing up 10 trials of the original data set; thus, 48 averaged trials were available as alternative learning data.
The targets were created by averaging all trials of every frequency and artefacts were corrected by hand. The mean square average deviation was calculated using Fieldtrip routines 31 and all values with a particular deviation were excluded. In sum, about 40 trials were removed from each data set and the remaining trials were averaged to generate the targets.
Data at f = 64 Hz and f = 16 Hz were prepared in the same manner to be used as test data; 300 trials for each frequency were available as two test data sets. Visual inspection of all data (see Figure 3, red curves) revealed a clear LAEP at 256 Hz and a potential signal at 64 Hz. At the infrasound frequency of 16 Hz, the LAEP seemed to be completely overwhelmed by noise or coherent artefacts. The trials without a stimulus (zero measurement) seemed to be composed only of noise or artefact components.
Note that the learning process only applied data obtained at 256 Hz; the targets were used in the sense of ‘to meet by optimisation’ only for supervised learning. When the network is tested at the other frequencies, and for the zero-measurement data, the ‘target’ is simply a representation of the measured data and only used for investigating the performance of the network application.
Design of networks
Feed-forward network
A feed-forward network was designed for training by means of supervised learning. This network comprised three layers to allow the input and the output to have the same number of points; in this way, a time-dependent data trace could be retrieved as the time waveform of a filtered signal for analysis. The hidden layers were designed to allow a significant reduction of information to avoid overfitting. Optimising tests using a different number of layers revealed that two hidden layers were sufficient for this purpose.
Figure 1 shows the basic architecture of the network. Sizes of the matrices are given in square brackets. The number of input time points is given in the first number (row) and the number of neurons corresponds to the second number (column). Design of the feed-forward network: the first number in brackets above 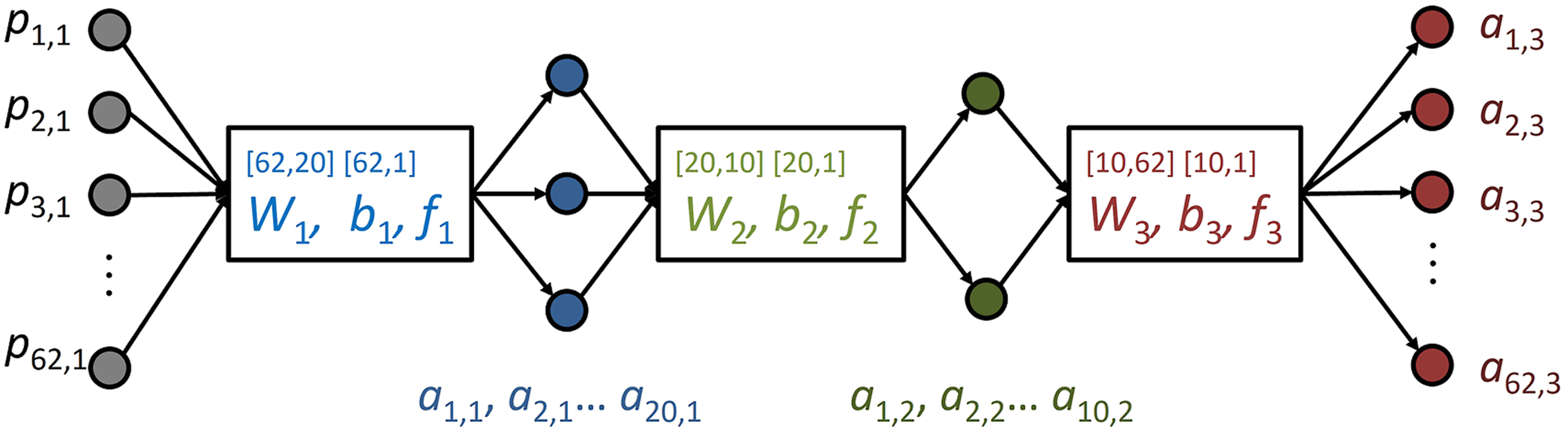
Fully connecting layers (ref. 32, section 2) were realised as

The network was trained via a supervised learning rule using the trials at 256 Hz merged with the zero-measurement data (see Section Experimental setup) as learning data and their qualified average as the target

The loss function L was minimised using a backpropagation method based on a least-mean-square optimisation via a steepest descent algorithm. 32 The start values for the weightings and biases were random numbers in the interval (0,1). A momentum was introduced to reduce oscillations during calculation (ref 32, section 12), and a variable learning rate was optimised to reduce the processing time.
All calculations were carried out via a specially designed MATLAB code following the mathematical formulation of the problem by Hagan et al. 32 No toolbox subroutines were used to allow the properties of the calculation and the script design to be better understood.
Autoencoder
An autoencoder with only two layers (NL = 2) was designed (Figure 2); decoding and encoding took place with only one layer each. Fully connected layers as defined in equation (1) were used. The number of neurons in the hidden layer was varied; the correlation between the network output Network design of the autoencoder network: the first number in brackets above 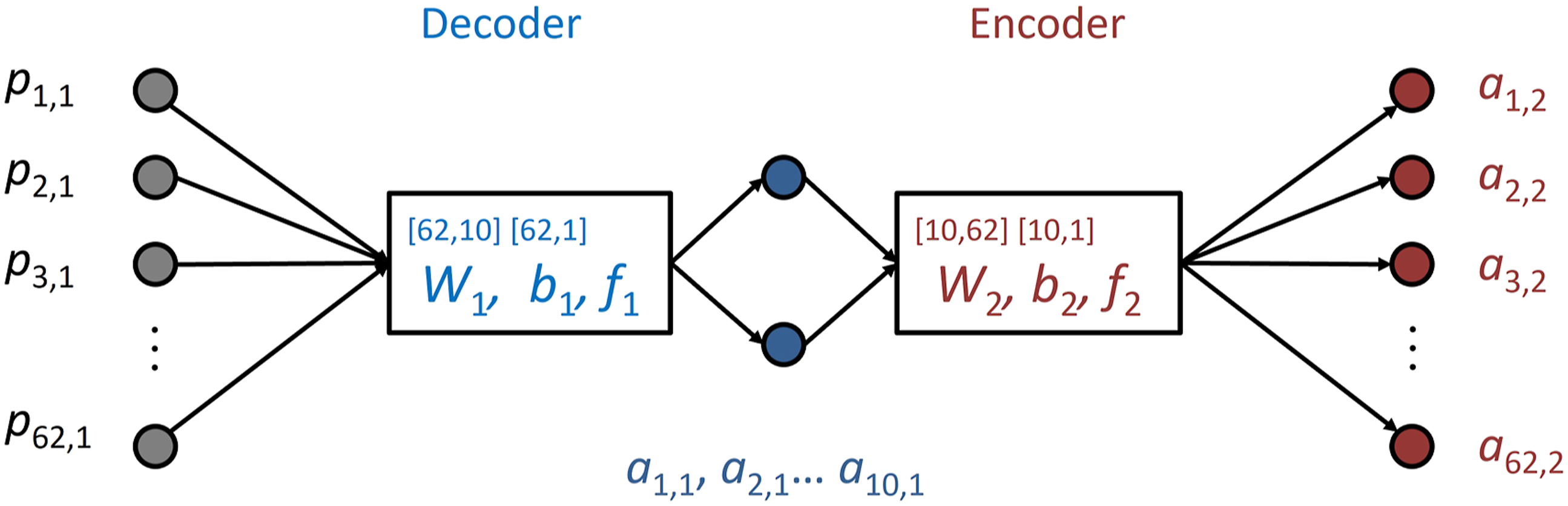
The weightings in the decoding and encoding layer were independent; to increase the degrees of freedom, no coupling via transposing of the weighting matrix or bias took place.
The loss function compared the input and the output of the network. Here, several different loss functions were considered – for example, a loss function based on the Kullback–Leibler divergence
12
or on cross entropy.
13
However, the best results were obtained via the following simple mean-square-error concept

As in the case of the feed-forward network, the loss function was minimised using a backpropagation method using random start values. Several stopping criteria for the loss function were investigated (ref 32, section 17). A specified limit Llim was defined and the moment at which the performance improvement became small was determined. However, the best results were obtained with a fixed number of cycles and by observing the improvement in the performance during convergence.
Analysis of network output
To investigate the efficacy of a neural-network analysis of time-dependent data, qualitative means are often applied because they allow N1 and P2 responses to be indicated clearly – for example, via visual inspection. However, to allow a more quantitative analysis to be performed, the similarity between the network outputs and the target traces at 256 Hz was investigated as a representation of a true LAEP signal. The correlation coefficient which describes the linear dependence between two signals can give a quantitative measure of how accurately the network can identify an LAEP in the test data.
The correlation coefficient between both data traces was calculated using the standard MATLAB routine. The correlation coefficient between the network output and the target values, calculated as the qualified averages of all trials per frequency, was determined to assess the learning process. The data given in Figure 5 consist of average values obtained from five independent runs of creating network weightings and biases using different random initial values.
Results
Feed-forward network
The feed-forward network was applied to the validation data, the two test data sets and the zero measurement. For all data, high correlation between the target at 256 Hz (as the LAEP signal) and the network output was obtained. Unfortunately, this was also the case for the zero measurement, thus clearly indicating an overfitting of the network. The network ‘learned’ to find the LAEP for every signal form, including incoherent noise.
To reduce the variance of the learning data, pre-averaging was carried out and the training was repeated with the alternative data set containing 48 trials. Then, the network was applied to the test data and the zero measurement. Figure 3 shows the results obtained. Visual inspection of the targets (red lines) revealed a clear LAEP at 256 Hz for the validation data and a potential signal at 64 Hz. At the infrasound frequency of 16 Hz, the LAEP seems to be completely overwhelmed by noise or coherent artefacts. For the validation data, the network clearly identifies an LAEP, while for the 64 Hz test data, an appropriate signal can be seen. For 16 Hz, an LAEP is recognisable, whereas for the zero measurement, the LEAP is lost, as expected. The similarity to the target, as represented by the averaged trials specific to each frequency, decreases with decreasing frequency; however, for the zero measurement, it increases again significantly. Here, the network seems to recognise the ‘other’ signal type it learned, which represents the noise and the coherent disturbances inherent to the EEG system. Network output (in blue) of the feed-forward network and targets (in red) for four data cases with pre-averaging (10 times); upper left: validation data at 256 Hz; upper right: test data at 64 Hz; lower left: test data at 16 Hz; lower right: zero measurement; on all horizontal axes, the time values start with the start of the stimulus, while the vertical axis represents the normalised EEG electrode voltage at TP9.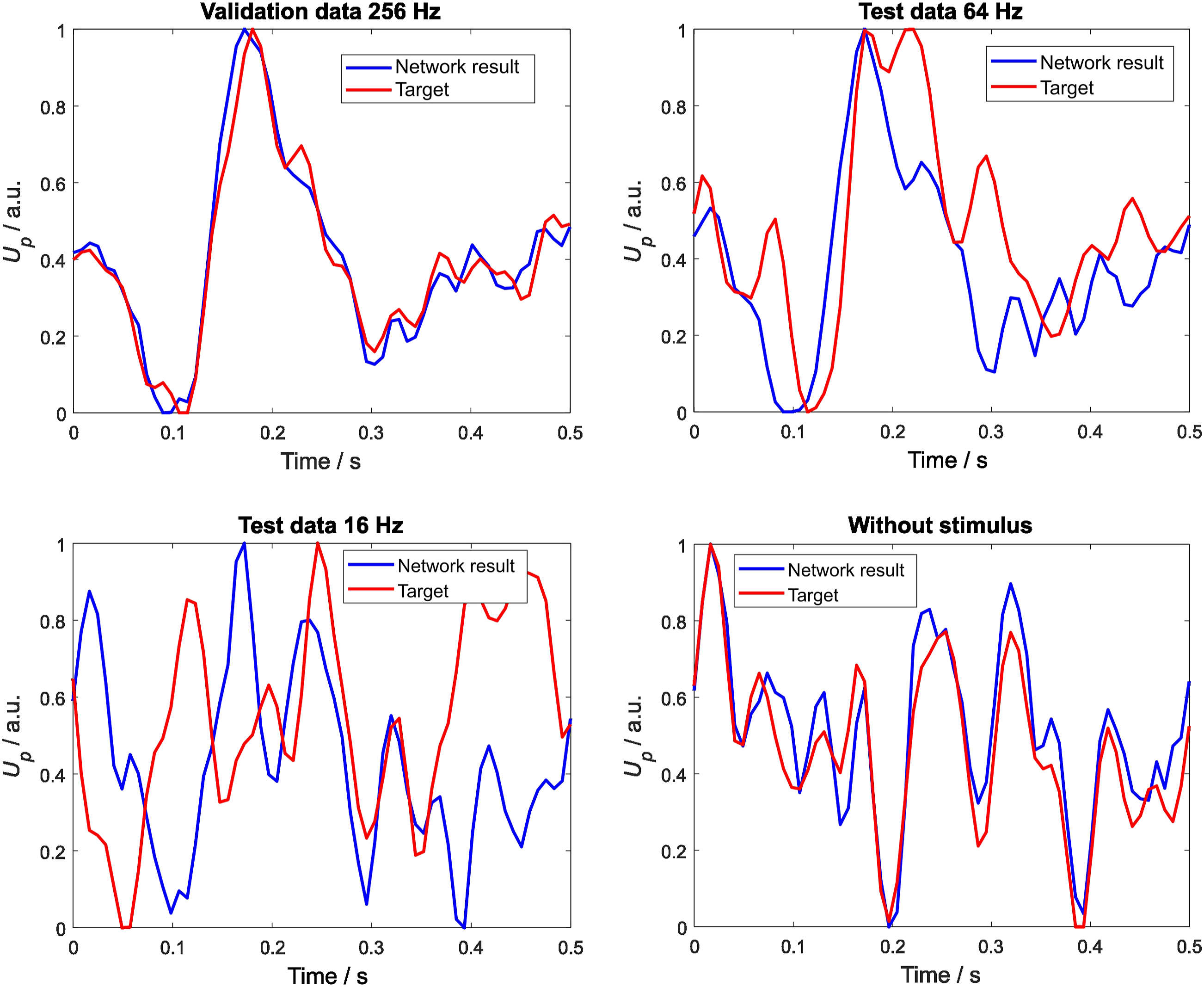
Autoencoder
The autoencoder network was applied to a data arrangement which was similar to the feed-forward network but whose first step involved no pre-averaging using 240 training trials. Note that, in this case, only data with stimulus presentation were used. As shown in Figure 4 in the validation data, a clear LAEP signal can be identified, which also holds for the 64 Hz test data. Inspection of the 16 Hz test data no longer reveals an LAEP structure for the network output, while for the zero measurement, a structured signal cannot be found. In contrast to the feed-forward results, no obvious correlation to the target (averaged values) of the noise data was observed for the zero measurement. Network output (in blue) of the autoencoder and targets (in red) for four data cases without pre-averaging; upper left: validation data at 256 Hz; upper right: test data at 64 Hz; lower left: test data at 16 Hz; lower right: zero measurement; at all horizontal axes, time values start with the start of the stimulus; the vertical axis represents the normalised EEG electrode voltage at TP9.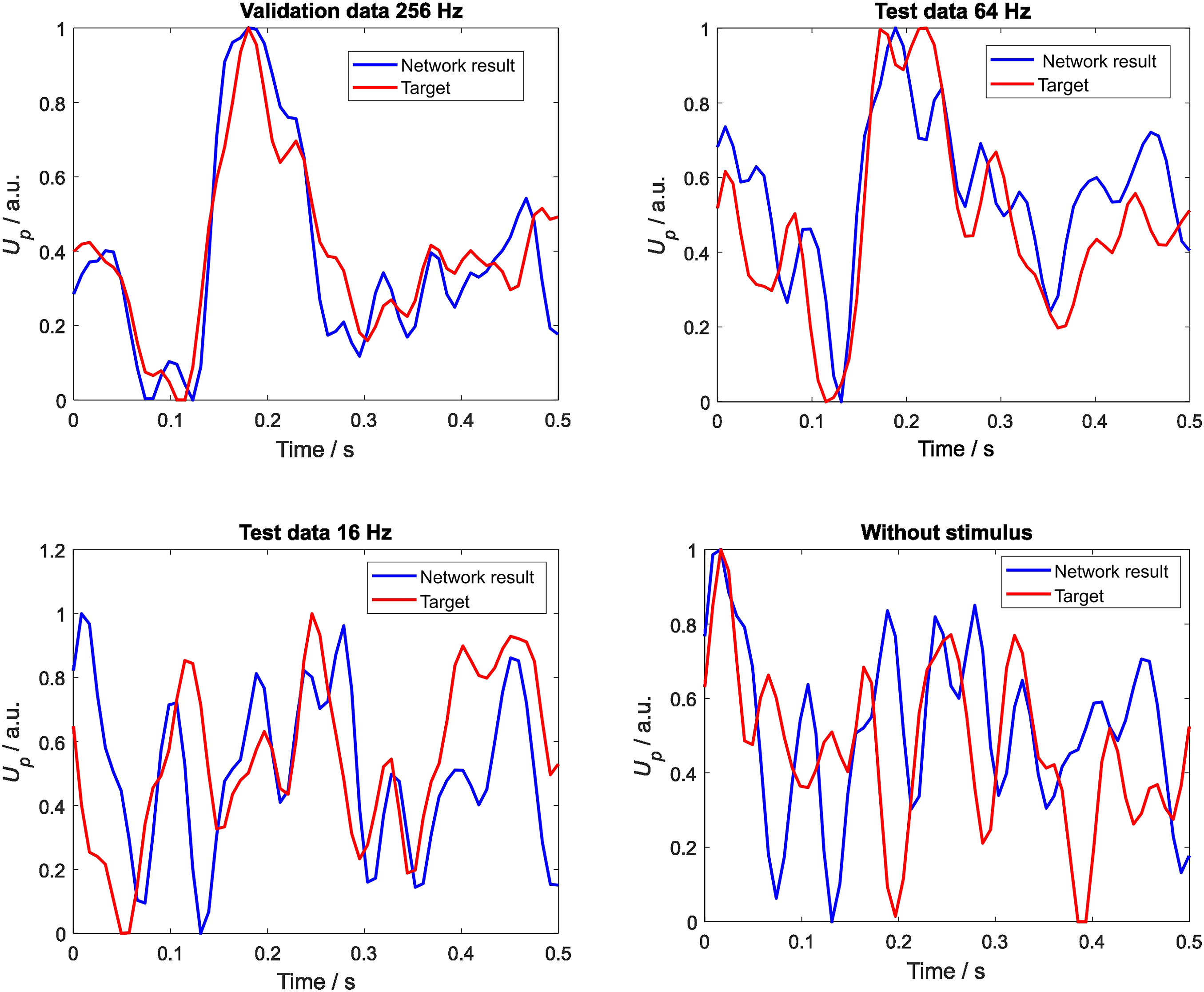
To test the dependence of the network performance on the variance of the data, a similar calculation was carried out with a pre-averaging of 10 times using the alternative data set (no figure). The differences between the network outputs of the four cases decreased (see Section Correlation analysis for performance evaluation), which can be interpreted as a decreased differentiation ability of the network.
Correlation analysis for performance evaluation
Figure 5 summarises the correlation coefficients for the various configurations calculated. The circles give the values for the autoencoder without pre-averaging. Starting from nearly perfect congruence for the validation data, the correlation coefficient decreases for 64 Hz and further for 16 Hz. There is nearly no difference between 16 Hz and the zero measurement. In contrast to this behaviour, a pre-averaging (squares) strongly reduces this decrease and only slight changes in the correlation coefficients are observed for this case. Correlation coefficients for various configurations; circle: autoencoder network output with target 256 Hz without pre-averaging; square: autoencoder network output with target 256 Hz with pre-averaging; triangle: feed-forward network output with target 256 Hz with pre-averaging; star: feed-forward network output with average value of test data with pre-averaging.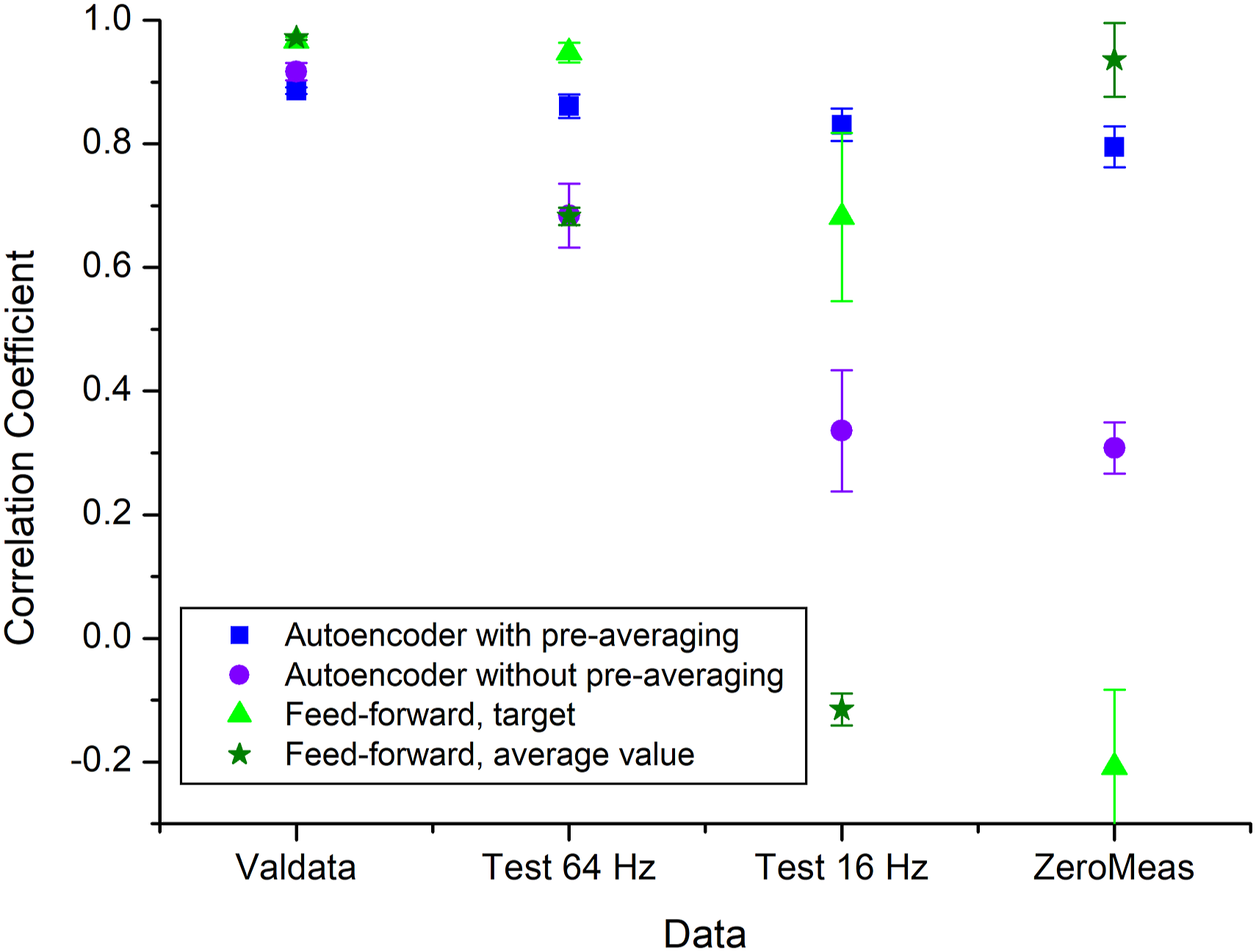
The feed-forward network shows nearly the same correlation values for the validation data and for 64 Hz; however, for 16 Hz and for the zero measurement, a strong decrease can be observed. The correlation between the feed-forward network output and the target (average values), on the other hand, follows a U-shaped curve. For the zero measurement, the correlation increases, and the network output nearly reproduces the average value of the zero measurement.
Discussion and conclusions
Two different networks representing two learning principles were applied to acoustically evoked potentials produced via an acoustic stimulus with low frequencies and one infrasound frequency. Here, the aim was to identify an LAEP signal for which the time signal could be reproduced. Both networks identified signals correctly and distinguished them from a noisy zero-measurement obtained under identical acquisition conditions but without a stimulus. However, the differentiation thresholds were different for both networks and showed general differences in functioning. The autoencoder did not differentiate between the 16 Hz test data case and the zero measurement, but the feed-forward network did not distinguish between the validation data and the 64 Hz test case. The differentiation threshold is strongly dependent on the parameters which seemed to be specific to the network.
Pre-averaging the data reduced the differences in correlation coefficients of the four data cases in the autoencoder. This can be interpreted as a loss in the differentiation ability of the network. In principle, the autoencoder gains information from the noise and its qualitative difference to coherent signal contributions. This feature relate to the applied unsupervised learning process which associates examples using the data structure or property information.11,33 In contrast, the feed-forward model trained via supervised learning is sensitive to the amount of variance; only a low level of noise is tolerated for an acceptable differentiation ability of the network. In this sense, both networks used in this paper are complementary; the analysis of the application of both networks to data can help to set important parameters of network design to appropriate values. This is particularly useful for the final output question concerning whether an LAEP is present or not. It would be useful to define a differentiation threshold and a strategy to find such a threshold could be to optimise the signal-to-noise ratio in combination with the number of neurons in the network to bring the differentiation threshold of both types of networks to one level. This could be used as a quality assessment strategy to ensure the correct prediction of an LAEP in a signal.
Based on the properties of the learning process, it can also be observed that the feed-forward network reproduces the target (average of all trials) in case of the zero measurement. Because the zero-measurement data comprise 50% of the learning data, this target is one of the learning goals. The network reduces the variability of the data by focussing on the main properties of the signal which seem to be reflected by the average value. This can also be interpreted as a reduction in degrees of freedom. In contrast, the autoencoder does not extract the average of the zero measurement, as can be expected from unsupervised learning principles; furthermore, the network suppresses the noise. This process revealed that coherent unwanted contributions were present as artefacts in the EEG system; neural networks were applied to reduce and identify artefacts.17,34
The amount of data was limited for this experiment, which was the first of its kind. It was not possible to investigate what amount of learning data was necessary to achieve a sufficient differentiation ability of the networks. One reason for this was the fact that obtaining data at infrasound frequencies was very time-consuming. Since the amount of time necessary for this data acquisition increases with decreasing wavelengths, long measurement times were necessary, leading to long session times for the test subjects.
During the design phase, several parameters were optimised. The numbers of the neurons of the hidden layers were varied and the correlation between the network output and the target for the validation data was maximised as a design criterion. The stopping criteria for the iteration number influenced the output results and a strong dependence of the convergence on limits Llim was found. Setting a maximum number of iterations provided extremely stable and reliable results when the performance improvement became low. The situation was not significantly improved by introducing sparsity means such as the Kullback–Leibler divergence nor by limiting (i.e. minimising) the weighting matrix norm.11,13 However, a careful and systematic quantitative investigation of the impact of sparsity means was not carried out and is left to further studies.
The aim of this article was to reproduce time signals to allow a comprehensive evaluation of the network. This, however, complicated the task of creating a network; in future, it may be easier to design a network which can handle pure classification tasks such as decisions on whether an LAEP exists as well as parameters or features such as MNN recognition. This, in turn, will allow a more broadly applicable network to be designed, including a combination of convolutional or recurrent network elements. However, one drawback is that the observation of the time signals allowed a better judgement of the network output and the processes taking place within the network. Ideally, future studies should also have more data available for supervised learning.
It can be concluded that neural networks can help to identify highly concealed auditory evoked potentials. Networks based on both supervised and unsupervised learning can be applied and provide complementary results. The comparison of network outputs can provide criteria for parameter settings and for the differentiation threshold required for a reliable prediction of evoked potentials. Further development of network designs can help improve the sensitivity necessary to allow results to be classified unambiguously and to reproduce time-dependent signals.
Footnotes
Acknowledgements
The author is very grateful to Marion Bug and Sven Vollbort for contributing the EEG raw data and to Marvin Rust for careful reading of the manuscript and valuable discussion.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.