
Abstract
This study aims to combat health misinformation by enhancing the retrieval of credible health information using effective fusion-based techniques. It focuses on clustering-based subset selection to improve data fusion performance. Five clustering methods — two K-means variants, Agglomerative Hierarchical (AH) clustering, BIRCH, and Chameleon — are evaluated for selecting optimal subsets of information retrieval systems. Experiments are conducted on two health-related datasets from the TREC challenge. The selected subsets are used in data fusion to boost retrieval quality and credibility. AH and BIRCH outperform other methods in identifying effective IR subsets. Using AH-based fusion of up to 20 systems results in a 60% gain in MAP and over a 30% increase in NDCG_UCC, a credibility-focused metric, compared to the best single system. Clustering-based fusion strategies significantly enhance the retrieval of trustworthy health content, helping to reduce misinformation. These findings support incorporating advanced data fusion into health information retrieval systems to improve access to reliable information. The source code of this research is publicly available at https://github.com/Gary752752/DataFusion.
Introduction
Advancements in computing and networking technologies have enabled the generation and dissemination of information at unprecedented speeds. While this progress offers significant benefits to individuals and society, it also brings challenges, most notably the rapid spread of misinformation. Health-related misinformation is particularly harmful, as it can profoundly and negatively affect individuals, public health, and society in various ways. 1 For instance, exposure to misleading or inaccurate content can fuel vaccine hesitancy, encourage unsafe self-medication practices, and delay timely medical interventions.2,3 At a broader level, widespread misinformation erodes public trust in healthcare systems, exacerbates health disparities, and can undermine collective responses to crises such as pandemics.
In this context, the quality of information retrieval systems plays a critical role. Effective retrieval not only ensures that users are directed toward reliable, evidence-based health information but also supports health literacy outcomes by enabling individuals to make informed decisions about their well-being. Conversely, poor retrieval performance that elevates low-quality or misleading documents can amplify the negative consequences of misinformation. Thus, advancing retrieval methods that prioritize accuracy, credibility, and trustworthiness is essential for mitigating the societal risks associated with health misinformation. 4
Combating health misinformation requires sustained efforts across multiple sectors such as government policies, 5 education interventions,6,7 technology on credible information retrieval, 8 technical and especially AI ethics,9,10 along with individual awareness and responsibility.
In this paper, we focus on a specific technical challenge: enhancing information search engines to effectively deliver reliable and accurate health-related information. We investigate fusion-based approaches to address this issue.11,12
Search engines that can provide credible information can be a vital component in a wide range of health-related applications, including: • Clinical Decision Support Systems: Integrate authoritative evidence directly into a physician’s workflow. • Consumer Health Apps: Deliver safe, reliable self-care information sourced from vetted medical resources. • Drug Interaction Checkers: Provide authoritative data on potential drug–drug interactions. • Telemedicine Platforms: Rely heavily on accurate, timely, and personalized medical information to support both healthcare providers and patients. • General Health Chatbots: Reduce the risk of AI hallucinations by grounding responses in verified medical knowledge.
In the information retrieval research community, TREC (Text REtrieval Conference) is a major ongoing series of workshops that focus on various information retrieval research areas, or tracks. 1 Between 2020 and 2022, TREC hosted a Health Misinformation Track. 13
Each year, the organizers compiled a collection of health-related web documents and created a set of queries. These resources were distributed to participating research groups, who then used their retrieval systems and new technologies to produce ranked lists of documents for each query. The retrieval results were submitted to the organizers, who engaged domain experts to evaluate the relevance, correctness, and reliability of the retrieved documents. Based on these expert judgments, all submitted results were assessed. The queries, retrieval results, and relevance judgments are publicly available on TREC’s website, providing a valuable resource for conducting empirical research on fusion-based retrieval methods.
This study investigates clustering-based subset selection for fusion, aiming to identify a subgroup from the available candidates to achieve optimal performance. In standard retrieval tasks, relevance is the primary criterion for evaluating performance. However, the Health Misinformation Track introduces three equally critical factors: usefulness, correctness, and credibility. This shift in evaluation criteria may significantly influence the design of subset selection algorithms and data fusion methods, requiring approaches that effectively address these additional dimensions.
Experimented with five clustering methods including two variations of K-means, Agglomerative Hierarchical clustering (AH), Balanced Iterative Reducing and Clustering using Hierarchies (BIRCH), and Chameleon clustering on two datasets from TREC, we find that all of them are effective. The fused results are also better than the best constituent retrieval system by a clear margin. Among the five clustering methods, the Agglomerative Hierarchical method performs best on average.
The fusion approach has been used in various information retrieval tasks. However, credible information retrieval is very special in which three aspects including usefulness, correctness, and credibility need to be considered simultaneously for retrieval evaluation. There are two major contributions: • To the best of our knowledge, this is the first study to address the task of credible information retrieval to combat health misinformation by a clustering-based fusion approach. We demonstrate the effectiveness of the proposed methods. • A group of methods are evaluated for subset selection from a large pool. Our empirical results show that Agglomerative Hierarchical and BIRCH outperform other baseline approaches, including Chameleon-based methods and Top-J subset selection methods proposed before for other retrieval tasks.
The remainder of this paper is organized as follows: Section 2 reviews related work. Section 3 details the five clustering-based data fusion methods considered. Section 4 describes the experimental setup and presents the results of the proposed methods alongside the baseline methods. It also includes a discussion of the study’s limitations and mitigation measures. Section 5 provides additional analytical insights into the clustering methods. Finally, Section 6 concludes the paper.
Related work
This paper explores the application of data fusion in health information retrieval, particularly within collections containing substantial misinformation. To provide context, we first review prior research on misinformation detection and health information retrieval. Subsequently, we examine various data fusion methods and their applications in health information retrieval.
Misinformation detection
Misinformation detection has garnered significant attention in recent years due to its societal and political implications. Researchers have explored various approaches to identify and mitigate the spread of false information, focusing on computational models,14–16 social network analysis,17–20 and human-in-the-loop systems.21–23
Early works in misinformation detection concentrated on linguistic features. Specifically, Rubin et al. 24 analysed writing styles, lexical patterns, and rhetorical structures to identify deceptive content. Ott et al. 25 explored the use of n-grams, syntax, and psycholinguistic features to detect deception in online reviews, highlighting the potential of linguistic markers in identifying misinformation. Similarly, Zhou et al. 26 investigated deception in text-based computer-mediated communication, identifying significant linguistic cues used by deceivers and emphasizing differences between truthful and deceptive messages. Such studies laid the groundwork for automated systems by emphasizing textual analysis. However, linguistic models often struggled with context, particularly in cases involving satire or humour, leading researchers to explore more advanced methods.
The emergence of machine learning revolutionized the field. 27 These methods trained models on labelled datasets of misinformation, using features like source credibility, sentiment, and consistency across articles. Neural networks, such as Feed-forward neural networks and convolutional neural networks, 28 graph neural networks, 29 and transformers like BERT 30 have further enhanced detection capabilities by capturing nuanced relationships in text.
Social network analysis has been another critical avenue. Vosoughi et al. 31 examined the spread of true and false news on Twitter, revealing that misinformation spreads faster and reaches broader audiences than factual information. Friggeri et al. 32 explored the dynamics of rumour propagation on Facebook, finding that even after rumours are debunked, they continue to spread, largely due to users ignoring fact-checking interventions and interacting primarily with like-minded communities. Such studies highlight the importance of examining user behaviours, bot activity, and network structures to complement textual analysis.
Fact-checking systems have also played a pivotal role. Platforms like PolitiFact and Snopes provide labelled datasets for machine learning models, and automated fact-checkers such as ClaimBuster aim to scale the verification process. 33 However, reliance on static datasets limits adaptability to new forms of misinformation.
Despite progress, challenges remain. The adversarial nature of misinformation and cultural-linguistic diversity demand more robust, multilingual, and real-time detection systems. Future research is expected to focus on integrating explainable AI and collaborative strategies between academia, industry, and policymakers.
Health information retrieval
Health Information Retrieval (HIR), also known as Medical Document Retrieval (MDT), focuses on developing systems and methodologies to retrieve accurate and relevant health-related information from diverse and often complex sources. Previous work in this field has explored various techniques, including keyword-based search, natural language processing, and machine learning models, to improve retrieval precision and user experience. For example, Luo et al. 34 introduced MedSearch, a search engine designed for patients to retrieve medical information by considering layman-friendly language and ranking results based on their readability. Recent work has emphasized semantic search using ontologies such as SNOMED-CT or UMLS to better understand medical terminology and user intent, as seen in the work of Koopman et al., 35 who developed a system to enhance document retrieval in the clinical domain. Besides, Medical Subject Headings 2 36 the International Classification of Diseases (ICD), 37 and independently constructed resources 38 have also been used. Despite these advancements, challenges remain in addressing the linguistic complexity of medical language, the dynamic nature of health information, and the need to balance precision with the accessibility of results for different audiences.
In recent years, transformer-based IR models have gained popularity across many information retrieval tasks, and this trend is evident for health information retrieval tasks. For instance, in the 2021 Health Misinformation track, all participating teams employed transformer-based IR models, including BERT variants (such as RoBERTa and Bio Sentence-BERT) and T5 models (MonoT5, DuoT5, and T5-Large).
Recent research in Health Information Retrieval has also increasingly focused on assessing and enhancing the credibility of retrieved medical information, acknowledging the critical role of trustworthy data in healthcare decision-making.39–43
Health Information Retrieval has been the subject for some major information retrieval evaluation events, such as TREC and CLEF. 3 A variety of retrieval tasks have been addressed in these venues, such as Genomics, Medical Records, Clinic Decision Support, Precision Medicine, Health Misinformation, and Clinical Trials in TREC, eHealth in CLEF, Medical Case-based Retrieval track in ImageCLEF, to name but a few.
Data fusion
Data fusion in information retrieval (IR) refers to the process of combining results or outputs from multiple retrieval systems or methods to improve overall performance. The primary goal is to leverage the strengths of individual systems while mitigating their weaknesses. 11
Data fusion methods can be broadly categorized into supervised and unsupervised approaches. CombSum, 44 CombMNZ, 44 and the Reciprocal Rank method 45 are typical unsupervised methods, while linear combination 46 represents a common supervised method. Unsupervised methods are easy to implement, whereas supervised methods are better suited for scenarios where unsupervised methods may not perform well.
Data fusion methods have been applied to various tasks in information retrieval.47–51 They are also widely used in health information retrieval tasks.52–54 For instance, in the 2020 TREC Health Misinformation Track, the CiTIUS group 55 submitted two runs, CiTIUSCrdRelAdh and CiTIUSSimRelAdh, both of which used Borda Count to combine two types of rankings: usefulness and reliability (credibility and correctness). Another example is the h2oloo group. 56 Based on the BM25 baseline run, they applied query expansion and two types of machine learning techniques for re-ranking the results. All eight submitted runs were various combinations of these methods, utilizing equal or simple unequal weighting schemes.
Typically, the number of constituent retrieval systems involved serves as a good indicator of the complexity of a fusion-based system. When final performance is equal, it is preferable to involve fewer constituent retrieval systems. Juarez-Gonzalez et al. 57 investigated how to select a subset from a large group of retrieval systems to achieve better fusion performance, although their study was not focused on medical retrieval tasks. For this purpose, they defined a DCG-like metric (Discounted Cumulative Gain, a commonly used metric in information retrieval evaluation). Four datasets from CLEF (Cross-Language Evaluation Forum) were used for their empirical investigation. The method is referred to as Top(J) later in this paper. Xu et al. 12 proposed a clustering-based method, Chameleon Hierarchical clustering (CH), to select a subset of retrieval systems from the available ones. Two medical datasets from TREC (the Precision Medicine Track in 2017 and 2018) were used to evaluate the effectiveness of their proposed method.
In this work, we investigate how to achieve the best possible results using data fusion technology for the misinformation retrieval task. Specifically, we focus on the subset selection problem for effective fusion: given a group of N retrieval systems, how can we select n (n < N) of them to achieve the best fusion performance? The subset selection problem is the same as that addressed in 57 and 12. However, we apply it to a different task compared to 57 and. 12 Additionally, some special measures in different aspects are necessary for the specific task undertaken in this study. Our research is also more comprehensive, incorporating more clustering methods and data fusion methods.
Clustering-based subset selection
Selecting an optimal subset of information retrieval models (or systems) to maximize fusion effectiveness is a significant challenge. For example, given 50 retrieval models, selecting 10 for improved fusion performance involves an astronomically large number of possible combinations — specifically, 50 × 49× … × 41, which equals 37,276,043,023,296,000. Exhaustively evaluating all these combinations is computationally impractical. Therefore, Instead of relying on a brute-force approach, it is more practical to develop and apply heuristic methods that can efficiently identify promising subsets.
Previous research 58 has shown that the performance of individual constituent systems or results is not the only factor affecting fusion performance. The diversity among the constituent retrieval systems or results also plays a crucial role. To incorporate diversity into the selection process, clustering-based methods offer an effective approach.
These methods involve two main steps: • Clustering: All constituent systems or results are grouped into clusters based on their similarity. Systems or results within the same cluster are expected to be highly similar, while those in different clusters are significantly different. • Selection: A subset of retrieval systems is chosen for fusion. By selecting top-performing systems from different clusters, the method ensures that both performance (by selecting the best systems within each cluster) and diversity (by including systems from different clusters) are simultaneously accounted for.
To perform clustering of retrieval systems, we assume that the characteristics of a retrieval system are fully reflected by the results it retrieves. The similarity or dissimilarity between two retrieval systems can be analysed by comparing the ranked lists of results they produce for the same query.
In this work, scoring is used to define the dissimilarity between two ranked lists. Specifically, the Euclidean distance is employed, as defined below:

Here L1 and L2 represent the ranked lists of results retrieved by two systems for the same document collection D and query q. |D| is the total number of documents in D, s1 (d i ) is the score assigned to document d i in L1, and s2 (d i ) is the score assigned to d i in L2. For documents in D that do not appear in L1 (or L2), a default score (e.g., zero) is assigned. The computed distance, Dist (L1, L2), serves as an effective measure of dissimilarity between the two ranked lists. While a scoring-based distance is utilized here, alternative methods, such as ranking-based measures, can also be employed for the same purpose.
Another important consideration is the choice of clustering method, as many options are available. In this study, we evaluate five clustering methods: two variations of K-means (denoted as K1 and K2) and three hierarchical methods: Agglomerative Hierarchical clustering (AH), the Chameleon Hierarchical clustering (CH), and Balanced Iterative Reducing and Clustering using Hierarchies (BIRCH, also referred to as BI later in this paper).
In TREC, the results submitted by a participant using a specific retrieval model (system) are referred to as a run (corresponding to a collection of documents and a set of queries). The algorithms for K1, K2, AH, BI, and CH are described in Algorithms 1–5, respectively. Please refer to 59 for more details about the Chameleon Hierarchical method (CH).





Experiments and results
In this section, we describe the experimental setup and present the results obtained to validate the proposed methods. Specifically, we used the submissions, queries, and relevance judgments from the ad-hoc task of the Health Misinformation Track in TREC 2020 and TREC 2021.
The datasets for these events are based on the CommonCrawl News dataset, 4 which comprises news articles collected from websites worldwide. For TREC 2020, the dataset includes news articles crawled between January 1, 2020, and April 30, 2020. In contrast, the dataset for TREC 2021 is derived from the “no-clean” version of the C4 dataset, 5 originally created by Google for training the T5 model. This collection consists of plain text extracted from the April 2019 snapshot of CommonCrawl, encompassing over one billion English web pages.
For each event, the organizers provided a set of queries (see Figure 1 for an example of the queries used in TREC 2021). The datasets and queries were distributed to the participants, who then ran their information retrieval systems on the provided datasets using the queries. The participants submitted their retrieval results to the organizers for evaluation. Example of a topic for the TREC 2021 health misinformation track.
The organizers arranged for manual judgment of the retrieved documents by human experts. Each document was assessed for its relevance to the query, as well as its correctness and credibility. Based on these expert judgments, the organizers conducted retrieval evaluations for all submissions, assessing their performance against the defined criteria.
Evaluation measures & settings
The retrieval results were evaluated using four measures: MAP (Mean Average Precision), P@10 (Precision at the top 10 documents), CAM (Convex Aggregation Measure), and NDCG_UCC (Normalized Discounted Cumulative Gain based on the binary relevance of Usefulness, Correctness, and Credibility).
Both MAP and P@10 are classical measures commonly used for evaluating the effectiveness of retrieval results. In contrast, CAM and NDCG_UCC are specifically designed for the modern context of combating misinformation. 60
NDCG_UCC is defined as the NDCG score calculated by considering usefulness, correctness, and credibility collectively. A document is considered relevant only if it is simultaneously useful, correct, and credible; otherwise, it is deemed non-relevant. NDCG_UCC values are computed based on this binary relevance judgment. For brevity, NDCG_UCC is referred to as NDCG in the remainder of this article.
CAM is defined as

In this study, we adopt the TREC instantiation by using NDCG for each individual aspect. Specifically, M use is computed as standard NDCG with respect to usefulness, M cor as standard NDCG with respect to correctness labels, and M cre as standard NDCG with respect to credibility labels.
Statistics of the two groups of runs in the experiment.

For the 2020 and 2021 years groups, 51 and 71 runs were submitted to the event, respectively. From these, 37 runs from 2020 to 61 runs from 2021 were retained for this study. Using a given clustering algorithm, we generated 2 to 12 clusters for the 2020 group and 2 to 20 clusters for the 2021 group. The upper limits (12 and 20) were set as they are approximately one-third of the total number of runs — 37 for the 2020 group and 61 for the 2021 group.
From each cluster, the best-performing run (based on a specific metric such as MAP or CAM) was selected to carry out the fusion operation.
We tested three commonly used fusion methods: CombSum,
44
CombMNZ,
44
and linear combination.
46
In all cases, we applied the score normalization method proposed in 45, defined as:
For the linear combination method, training is required for each constituent retrieval system to determine appropriate weights. To achieve this, we employed a two-fold cross-validation strategy, commonly used in machine learning. In this approach, all the queries were divided into two equal parts: one part was used for training, and the other for testing; this process was then repeated by swapping the roles of the two parts.
We tested two different approaches for assigning weights using linear regression: • •
These two approaches effectively represent different linear models. The first approach is better suited to traditional evaluation metrics such as MAP and P@10, while the second approach aligns more closely with metrics like CAM and, in particular, NDCG, which considers multiple aspects of document quality.
Given that both clustering algorithms K1 and K2 involve randomness, we repeated the experiments 50 times and averaged the results to ensure greater reliability.
In 12, a clustering-based subset selection method was proposed as follows: first, all candidates were grouped using Chameleon hierarchical clustering, where a ranking-based approach was employed to determine the dissimilarity between ranked lists of documents. We adopt the same Chameleon hierarchical clustering approach in this study.
After clustering, the second stage involves selecting one candidate from each cluster. While 12 utilized a local search method for this step, we replace it with a simpler approach, selecting the best-performing candidate from each cluster to ensure consistency across all clustering methods in this study. This modification ensures a fair comparison among the methods.
For AH, two parameter needs to be set. For the 2020 dataset, we let T = 0.5 and B = 30; For the 2021 dataset, we let T = 0.5 and B = 18.
Experimental results
Average performance of data fusion methods CombSum and CombMNZ over 2–12 retrieval systems (2020).

Note. Top (J), Top (MAP), Top (CAM) and Top (NDCG) denote the methods of selecting a number of top performers based on J, MAP, CAM, and NDCG metrics, respectively. C (X) denotes using the clustering method C (K1, K2, AH, BI, or CH) to generate a number of clusters first, and then taking the top performer from each cluster based on the X (can be MAP, CAM, or NDCG) metric. Number in bold indicates the best performer among a group of clustering methods under the same condition.
Average performance of data fusion methods CombSum and CombMNZ over 2–20 retrieval systems (2021).

Note. Top (J), Top (MAP), Top (CAM) and Top (NDCG) denote the methods of selecting a number of top performers based on J, MAP, CAM, and NDCG metrics, respectively. C (X) denotes using the clustering method C (can be K1, K2, AH, BI, or CH) to generate a number of clusters first, and then taking the top performer from each cluster based on the X (can be MAP, CAM, or NDCG) metric. Number in bold indicates the best performer among a group of clustering methods under the same condition.
Average performance of data fusion methods LC(U) and LC(UCC) over 2–12 retrieval systems (2020).

Note. Top (J), Top (MAP), Top (CAM) and Top (NDCG) denote the methods of selecting a number of top performers based on J, MAP, CAM, and NDCG metrics, respectively. C (X) denotes using the clustering method C (can be K1, K2, AH, BI, or CH) to generate a number of clusters first, and then taking the top performer from each cluster based on the X (can be MAP, CAM, or NDCG) metric. Number in bold indicates the best performer among a group of clustering methods under the same condition.
Average performance of data fusion methods LC(U) and LC(UCC) over 2–20 retrieval systems (2021).

Note. Top (J), Top (MAP), Top (CAM) and Top (NDCG) denote the methods of selecting a number of top performers based on J, MAP, CAM, and NDCG metrics, respectively. C (X) denotes using the clustering method C (can be K1, K2, AH, BI, or CH) to generate a number of clusters first, and then taking the top performer from each cluster based on the X (can be MAP, CAM, or NDCG) metric. Number in bold indicates the best performer among a group of clustering methods under the same condition.
In LC(U), weights are trained based solely on the usefulness score. In contrast, LC(UCC) considers three aspects—usefulness, correctness, and credibility—when training the weights.
From Tables 2 and 3, we can see that CombSUM outperforms ComnMNZ in most cases. CombSum is consistently better than CombMNZ when considering all clustering methods together. By comparing Tables 2 and 4, as well as Tables 3 and 5, we observe that the linear combination method performs better than CombSum and CombMNZ.
For all five clustering methods including K1, K2, AH, BI, and CH, AH and BI perform better than the others in more cases, K2 and CH are in the middle, while K1 never performs the best in any case. More specifically, AH is the best in 25 cases, which is followed by BI (20 cases), K2 (6 cases), CH (4 times), and K1 (0 times). Besides, selecting top performers, such as Top (J), Top (MAP), Top (CAM), and Top (NDCG), without considering the diversity of all the selected components can be a good strategy in some cases, especially when P10 is used for retrieval evaluation. Intuitively, selecting top performers by a given metric, such as Top (MAP), should be beneficial for evaluating fusion results by the same metric. Consider Top (MAP), Top (CAM), and Top (NDCG) collectively and refer to them as the Top (X) method, where X is the metric for selecting top components and for retrieval evaluation. Top (X) performs the best in 10 cases. It is also apprears that LC (U) is more suitable for traditional metrics such as MAP and P10, while LC (UCC) is better suited for NDCG and CAM. All of these observations are confirmed in this experiment.
We compare several pairs head-to-head. The win/loss ratio between AH and CH is 56/24, while for BI and CH, it is 42/38. These results suggest that AH is likely superior to CH, whereas BI and CH exhibit comparable performance.
Further, comparing these clustering methods with Top (X), the win/loss ratio between AH and Top (X) is 60/20, while for BI and Top (X), it is 47/33, and for CH and Top (X), it is 51.3/28.5. These results indicate that all three methods are likely more effective than Top(X).
Additionally, when comparing Top (J) and Top (MAP), the win/loss ratio is 4/12, suggesting that Top (J) is not as effective as Top (MAP). This outcome is unsurprising, given that MAP serves as the performance evaluation metric in all 16 cases.
After reviewing the overall performance of the clustering-based methods, we further examine some specific aspects. First, we consider their performance with different number of constituent retrieval systems. The performance of the best run is also shown for comparison. Figures 2 and 3 present the results under various scenarios. Performance of a group of clustering-based fusion methods with different number of constituent retrieval systems (2020 dataset). (a) CombSum/MAP, (b) CombSum/NDCG, (c) LC (U)/MAP, (d) LC (UCC)/NDCG. Performance of a group of clustering-based fusion methods with different number of constituent retrieval systems (2021 dataset). (a) CombSum/MAP, (b) CombSum/NDCG, (c) LC (U)/MAP, (d) LC (UCC)/NDCG.

We observe that the performance of the linear combination method improves consistently as the number of constituent retrieval systems increases. In contrast, this trend is less evident for CombSum. This is expected, as CombSum is a centroid-based method in which all constituent systems contribute equally to the final results. Consequently, any system — especially those with exceptionally high or low performance, significant divergence from others, or strong similarity to a subset of systems — can significantly impact fusion performance. In contrast, the linear combination approach assigns learned weights, allowing it to better adapt to different scenarios.
Fusion performance generally surpasses that of the best individual system, with a few exceptions for BI (CombSum, 2020, measured by NDCG). This is an encouraging outcome, though the extent of improvement varies across different cases. For the 2021 dataset, the highest improvement rate reaches 62.73% ((0.6475-0.3979)/0.3979) when fusing 20 retrieval systems using AH (MAP)-LC(U). This involves generating 20 clusters via AH, selecting the top performer from each based on MAP, combining them using LC with weights trained on Usefulness scores, and evaluating the final results using MAP. Additionally, substantial improvements of approximately 30% are observed in NDCG when fusing 15-20 retrieval systems using BI(NDCG)-LC(UCC) or AH(NDCG)-LC(UCC) on the same dataset.
When comparing LC and CombSum, LC consistently outperforms CombSum by 2% to 10%, demonstrating the advantage of supervised learning over unsupervised methods. However, the degree of improvement varies depending on the specific scenario.
Discussions
As we demonstrated, the fusion-based credible retrieval techniques in this study involve two major steps: selecting a small number of candidates from a large collection, and fusing the selected systems using a data fusion algorithm. Both steps significant impact on final fusion performance. In this study, we focused on the first step and investigated the effectiveness of five clustering methods for the selection process.
One notable feature of both information retrieval systems and data fusion methods is the inherent uncertainty in their performance. To illustrate this, we consider two examples: four selected retrieval systems from BH in each of the two datasets. In the 2020 dataset, these are h2oloo.m10 (Run 1), h2oloo.m8 (Run 2), adhoc_run3 (Run 3), and adhoc_run13 (Run 4). In the 2021 dataset, they are WatSMC-Correct (Run 1), vera_mdt5_0.95 (Run 2), WatSMC-CALQAHC1 (Run 3), and citius.r1 (Run 4). Figures 4 and 5 show their query-by-query performance measured by NDCG, along with the performance of the fusion result obtained by LC (UCC). Performance of the LC(UCC) fusion method with four constituent retrieval systems selected by BH (2020 dataset, NDCG). Performance of the LC(UCC) fusion method with four constituent retrieval systems selected by BH (2021 dataset, NDCG).

For all runs and the fused results, performance varies substantially from one query to another. On average, the fused result outperforms all constituent runs by approximately 10% to 20% in 2020 and 20% to 40% in 2021, and it achieves the best score on most queries. However, it does not achieve the best performance for every query.
To help readers to better understand NDCG, we provide an example illustrating what a 30% increase in NDCG means. Note that in NDCG (or NDCG_UCC more exactly), a document is considered relevant only if it is simultaneously useful, correct, and credible.
We use binary relevance (1 = relevant, 0 = not) and assume there are 3 relevant documents in the corpus. Consider the top 5 retrieved results. NDCG is a ranking-based metric in which each relevant document contributes a score based on its position. For ranks 1 through 5, the normalized contributions of a relevant document are 0.469, 0.296, 0.235, 0.202, and 0.182, respectively.
If the relevant documents appear at ranks 2, 4, and 5, the total NDCG score is
If instead they appear at ranks 1, 3, and 5, the total score is
The relative improvement is
In this example, elevating relevant documents from rank 2 to rank 1 and from rank 4 to rank 3, while maintaining the document at rank five in its position, is expected to substantially enhance user utility. □
One limitation of this study—as with most studies in this area—is that we do not yet fully understand the collective impact of all factors contributing to fusion performance. 11 Different datasets have distinct characteristics that may require specialized handling, and elements such as corpus, query set, and relevance judgments can all have significant effects. Furthermore, there are numerous clustering and data fusion methods, and even within a single method, many parameters must be carefully tuned. The choice of evaluation metrics also adds to the complexity of the situation.
To address these challenges, we employed five clustering algorithms, three data fusion methods, and two groups of performance evaluation metrics, covering both traditional and credibility-based measures. This combination helps improve the reliability of our results. Nonetheless, further extensive research is needed to advance this field.
Clustering analysis
As we know, the performance of clustering methods is a key factor that affects fusion performance. In this section, we use some quality metrics to directly evaluate the performance of the clustering methods. We employed three internal clustering quality metrics: the Davies–Bouldin Index (DBI), the Calinski–Harabasz Index (CHI), and the Silhouette Coefficient (SC).
Evaluation of four clustering methods over 2–12 constituent retrieval results (2020, ranked by MAP).

DB1: Davies–Bouldin index, lower values means better results; CHI: Calinski–Harabasz index, higher values means better results; SC: Silhouette Coefficient, higher values means better results. Best performance for a given metric is shown in bold.
Evaluation of four clustering methods over 2–12 constituent retrieval results (2020, ranked by CAM).
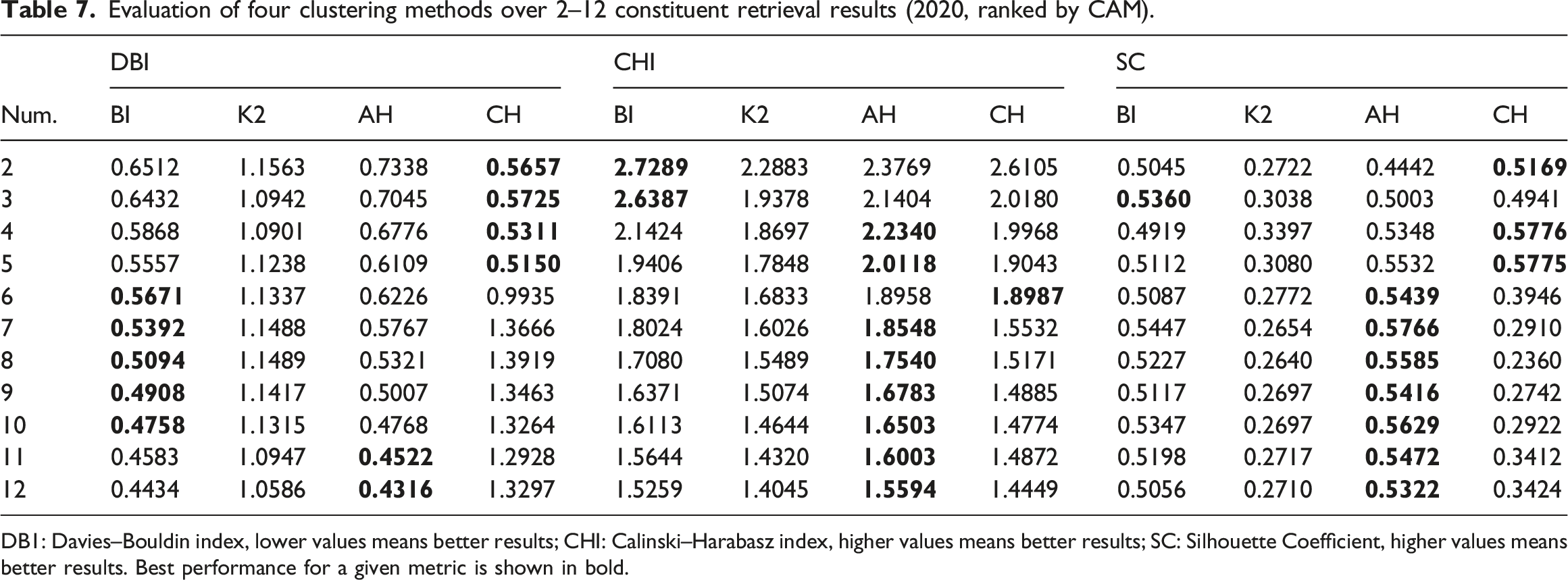
DB1: Davies–Bouldin index, lower values means better results; CHI: Calinski–Harabasz index, higher values means better results; SC: Silhouette Coefficient, higher values means better results. Best performance for a given metric is shown in bold.
Evaluation of four clustering methods over 2–20 constituent retrieval results (2021, ranked by MAP).

DB1: Davies–Bouldin index, lower values means better results; CHI: Calinski–Harabasz index, higher values means better results; SC: Silhouette Coefficient, higher values means better results. Best performance for a given metric is shown in bold.
Evaluation of four clustering methods over 2–20 constituent retrieval results (2021, ranked by NDCG).

DB1: Davies–Bouldin index, lower values means better results; CHI: Calinski–Harabasz index, higher values means better results; SC: Silhouette Coefficient, higher values means better results. Best performance for a given metric is shown in bold.
Overall, AH emerged as the best-performing clustering method in most cases, closely followed by BI. In contrast, CH and K2 performed best in only a few instances.
However, high-quality clustering does not always guarantee the best fusion performance. Fusion effectiveness is influenced by two key factors: the performance of individual retrieval systems and their diversity. Since only the top-performing system from each cluster is selected for fusion, this choice introduces an element of uncertainty. As a result, while AH and BI generally lead to the best fusion performance, other clustering methods produce the best results in some cases.
Conclusion
This paper explored fusion-based methods to address the challenge of combating health misinformation. Specifically, we investigated how to select an optimal subset of constituent information retrieval systems to maximize performance. Using the TREC Health Misinformation datasets from 2020 to 2021, our experiments demonstrated the effectiveness of the proposed approaches. When fusing up to 12 or 20 retrieval systems, agglomerative hierarchical clustering and BIRCH were the top two clustering methods. In particular, agglomerative hierarchical clustering consistently outperformed the best individual system by 10% to 60% across both traditional and credibility-enhanced metrics. Additionally, it achieved a significant improvement over the existing subset selection methods.
A key strength of our approach is its ability to balance both the performance of individual retrieval systems and the diversity of their results. The use of Euclidean distance to measure dissimilarity between result lists, combined with a agglomerative hierarchical clustering strategy, proved highly effective in forming diverse and well-structured clusters. This diversification enhances fusion performance, reinforcing the potential of data fusion as a powerful and reliable strategy for health misinformation retrieval.
For future work, we aim to further investigate the relationship between the performance of constituent systems and the diversity of their results. A deeper understanding of this relationship could lead to more efficient and effective subset selection methods. Additionally, exploring large language model-based approaches presents a promising direction. Currently, generating training datasets relies on costly relevance judgments from human experts. Developing automated performance estimation methods could reduce this burden, enhancing both the salability and practicality of the proposed framework.
Footnotes
Author contributions
YH, SW, HL, and XG collaboratively designed the study. YH implemented the program and did the empirical study. SW prepared the initial manuscript draft. SW and CN revised the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.