
Abstract
Machine learning techniques offer significant potential for improving the diagnosis of coronary heart disease by enabling earlier detection and timely intervention. This study presents a machine learning-based method utilizing clinical records to evaluate the impact of different data preprocessing sequences on predictive accuracy. Two clinical datasets were examined: one comprising heart failure patient data with 14 clinical features, and the Cleveland Heart Disease Dataset. The investigation compared two preprocessing strategies: standardisation prior to balancing, and balancing prior to scaling. Six machine learning models (XGBoost, GBDT, AdaBoost, Random Forest, KNN, and RaSE) were trained on an 80:20 data split and assessed using accuracy, precision, recall, and F1-score. Hyperparameters were optimized with Bayesian Optimisation. Results showed that both preprocessing designs achieved perfect accuracy on the Cleveland dataset. For the heart failure dataset, balancing before scaling led to improved accuracy (95%) compared with standardising before balancing (93.33%), and yielded higher macro-average and weighted-average F1-scores, signifying better overall classification performance. Among the evaluated models, XGBoost consistently provided the most robust predictions across conditions. These findings highlight the critical influence of preprocessing sequence on model effectiveness in imbalanced clinical data and suggest that balancing before scaling significantly enhances classification accuracy. XGBoost stands out as a reliable model for potential implementation in clinical decision support systems. Overall, this study advances the development of AI-driven tools for digital health applications, contributing meaningful insights to the field of health informatics.
Introduction
Introduction of heart disease
Heart disease caused approximately one-third of death on the world annually. 1 Most of heart disease require immediately treatment, making it a medical emergency for physicians.2,3 As emergency it is, though, there are several predicable signs for physicians to judge the possibility of an individual to have heart disease, and furthermore, the severity of the disease.4,5 The signs, or risk factors can make it a powerful material for predicting heart disease event. Scientists utilise these risk factors combining with machine learning technique to develop predicting models, aiming to build an accessory diagnosis system to assist physicians and speed up evaluating process.
Data-preprocessing approaches
Data-preprocessing is crucial in elevating the performance of training models by decreasing any possible misunderstanding data. 6 The common data-preprocessing approaches includes data scaling, feature extraction, and data balancing. 7 Data scaling includes methods such as Standardisation, MinMaxScaler, MaxAbsScaler, and RobustScaler.8–10 Another important approach is data balancing, which is particularly significant in disease prediction research due to the substantial difference in quantity between disease and healthy classes.11,12 In 2020, Ambesange, Sateesh, et al. applied several data-balancing techniques and achieved 100% accuracy on the Indian Liver Patient Dataset (ILPD). 13 The approaches of data-balancing included up-sampling, or so-called over-sampling, and down-sampling. Up-sampling aims to increase the quantity of the minority class, with methods such as Random over sampling (ROS), 14 Synthetic Minority Over-sampling Technique (SMOTE), 15 Border Line SMOTE (BLSMOTE)16,17 and Adaptive Synthetic Sampling Approach (ADASYN). 18 Conversely, down-sampling aims to decrease the quantity of the majority class, including methods like Random under-sampling (RUS),19,20 Cluster under-sampling (CUS) , Cluster centroid under-sampling (CCS), 21 and NearMiss 1, 2, 3. 22
Ensemble learning
Ensemble learning is a powerful machine learning technique that combines the predictions from multiple models to improve the overall performance and accuracy. 23 This approach is widely used in various applications, including classification, regression, and anomaly detection. Budholiya, et al. in 2022, utilised XGBoost as model on detecting heart disease and achieved 91.8% accuracy. 24 Pal, et al. in 2021, applied Random Forest as model also on heart disease detection, and achieve 93.3% accuracy. 25 The primary reason for using ensemble learning is its ability to reduce errors and improve predictive performance. By aggregating the outputs of several models, ensemble methods can mitigate the risk of overfitting and enhance generalisation to new data. 26 Current common ensemble learning techniques include XGBoost.27,28 Gradient Boosting Decision Trees (GBDT), 29 Random Forest,30,31 Adaptive Boosting (AdaBoost), 32 K-Nearest Neighbours (KNN), 33 and Random Subspace Ensemble (RaSE). 34 These techniques collectively enhance the robustness, versatility, and predictive power of machine learning models in various fields.
Model enhancement through data balancing and technique optimisation
To refine the accuracy of heart disease classification, we employed the techniques. We begin by demonstrating the significance of data balancing by comparing the training outcomes of the heart failure dataset with and without data-balancing techniques. Following this, we assess the impact of different sequences of the applied techniques to determine their influence on model performance. Our objective is to propose a methodology that enhances the predictive accuracy of heart disease classification, thereby contributing to more reliable diagnostic support systems.
Contribution to digital health and health informatics
This study offers a novel contribution to the field of health informatics by integrating advanced machine learning algorithms with real-world clinical datasets to enhance the prediction of coronary heart disease. Unlike previous research that predominantly employed traditional statistical methods or relied on single-center data, our approach uses a dual-dataset comparative framework and systematically examines how the sequence of preprocessing steps, specifically the order of data balancing and scaling, affects model performance. This methodological aspect has received limited attention in cardiovascular prediction research, highlighting the originality and practical value of our design.
By incorporating automated preprocessing pipelines, ensemble learning models, and interpretable artificial intelligence techniques such as SHAP analysis, we propose a scalable and transparent diagnostic framework. These innovations directly address the gap between advancements in machine learning and their integration into clinical workflows. The superior performance of Design II, which applies data balancing before scaling, provides a validated framework for developing accurate and clinically applicable diagnostic tools.
From the perspective of digital health, our findings support the development of artificial intelligence–based clinical decision support systems that emphasize both accuracy and interpretability, which are essential for clinical adoption. The results have practical implications for integration into electronic health records, telemedicine services, and mobile health applications, where personalized and real-time cardiovascular risk assessment is increasingly vital. As healthcare continues to advance toward digitalization, this study provides essential insights into how predictive analytics can be translated into routine clinical practice to support data-informed and patient-centered care.
Material
Dataset and ethical considerations
This study utilised two distinct medical records databases: the Heart Failure Dataset 35 and the Cleveland Heart Disease Dataset. 36 The datasets were selected based on their relevance to cardiovascular diseases and their availability for research purposes. The study focused on heart failure and heart disease, which are common cardiovascular conditions. The following ICD-10 codes were used to define the diseases: Heart Failure: I50 (Heart Failure), coronary artery disease (CAD): I25 (Chronic Ischemic Heart Disease). These codes were used to classify patients into disease and healthy categories within the datasets.
Descriptive statistics of heart failure dataset.

Descriptive statistics of Cleveland heart disease dataset.

Ethical approval for the use of these datasets was obtained from the respective governing bodies, ensuring that patient data was anonymized to protect privacy. Inclusion criteria for both datasets included adult patients with complete clinical records. Exclusion criteria included patients with incomplete or missing data. Both datasets were processed using a series of scaling and balancing techniques to prepare them for modelling.
Data scaling
Algorithm of four data scaling approaches.

Up-sampling processing
Random over-sampling (ROS)
Random over-sampling is the simplest technique to increase the quantity of samples through randomly duplicating samples in the minority class.
Synthetic minority over-sampling technique (SMOTE)
SMOTE is a widely recognized oversampling method. Instead of oversampling the minority class by simple duplication, it generates “synthetic” samples. This is achieved by taking each minority class sample and creating synthetic examples along the line segments connecting the sample to its nearest minority class neighbours. The number of neighbours used is randomly selected based on the required level of oversampling.
Border line SMOTE (BLSMOTE)
Borderline SMOTE enhances the original SMOTE method by addressing the issue of noise. While SMOTE randomly selects minority class samples to generate new ones without checking for outliers (NOISE), which can result in new noisy samples within the majority class and complicate classification, Borderline SMOTE categorizes samples into three types: (1) Safe samples, where the majority of neighbours are also minority samples; (2) Danger samples, where most neighbours belong to other classes; and (3) Noise samples, where all neighbours are from other classes. By generating new samples only near Danger samples and avoiding Safe and Noise samples, Borderline SMOTE aims to balance the dataset and sharpen the decision boundary.
Adaptive synthetic sampling approach (ADASYN)
The core concept of ADASYN is to generate synthetic data based on a weighted distribution that prioritizes minority class examples according to their learning difficulty. More synthetic data is created for the harder-to-learn minority class examples than for the easier ones. This method enhances learning by: (1) minimizing the bias caused by class imbalance, and (2) adaptively moving the classification decision boundary closer to the challenging examples.
Under-sampling processing
Random under-sampling (RUS)
Random under-sampling is a technique used to address class imbalance by randomly selecting instances from the majority class and removing them. This reduces the number of instances in the majority class, making it more balanced with the minority class. While this method is simple and effective, it can potentially remove informative instances, which may negatively impact the performance of the model.
Cluster under-sampling (CUS)
Cluster under-sampling uses clustering algorithms, such as k-means, to group instances from the majority class into clusters. Once the clusters are formed, a subset of these clusters is selected, and all instances within the selected clusters are used for training. This method can help preserve the structure of the data and reduce the risk of losing important information.
Cluster centroid under-sampling (CCS)
Cluster centroid under-sampling also uses clustering algorithms, like k-means, to group instances from the majority class into clusters. However, instead of using all instances within the selected clusters, this method calculates the centroid (mean or median) of each cluster. The centroids represent the central point of each cluster and are used as the training instances. This approach reduces the data size while retaining representative information from the original data.
NearMiss (1,2,3)
NearMiss is a family of methods designed to address class imbalance by selecting instances from the majority class based on their proximity to instances in the minority class. Specifically, NearMiss-1 focuses on selecting majority class instances that have the smallest average distance to the three closest minority class instances. In contrast, NearMiss-2 targets majority class instances that have the smallest average distance to the three farthest minority class instances. Lastly, NearMiss-3 selects majority class instances that are closest to each minority class instance until all minority class instances are surrounded.
Ensemble learning
Extreme gradient boosting (XGBoost)
XGBoost, short for Extreme Gradient Boosting, is a powerful and efficient implementation of the gradient boosting framework. It is widely used for supervised learning problems, particularly in regression and classification tasks. XGBoost improves upon the traditional gradient boosting approach by implementing optimizations such as regularization, parallel processing, and tree pruning, which enhance its performance and speed. Its ability to handle missing values and prevent overfitting makes it a popular choice in machine learning competitions and real-world applications.
Gradient boosting decision trees (GBDT)
Gradient Boosting Decision Trees (GBDT) is an ensemble learning technique that builds a model from weak learners, typically decision trees. By sequentially adding trees, each new tree corrects the errors made by the previous ones. The key idea is to optimize a loss function by adding weak learners that reduce the overall error. GBDT is known for its robustness and accuracy, making it suitable for a variety of predictive modelling tasks.
Random forest (RF)
Random Forest is an ensemble learning method that constructs multiple decision trees during training and merges their results to improve accuracy and control overfitting. Each tree in the forest is built from a random subset of the training data and features, ensuring diversity among the trees. The final prediction is made by averaging the outputs (regression) or taking the majority vote (classification) of the individual trees. Random Forest is known for its high accuracy, scalability, and ability to handle a large number of input variables.
Adaptive boosting (AdaBoost)
AdaBoost, short for Adaptive Boosting, is an ensemble learning method that combines multiple weak classifiers to form a strong classifier. It works by iteratively adjusting the weights of misclassified instances, allowing subsequent classifiers to focus on the more difficult cases. The final model is a weighted sum of the individual classifiers. AdaBoost is effective in improving the accuracy of algorithms but can be sensitive to noisy data and outliers.
K-nearest neighbours (KNN)
K-Nearest Neighbours (KNN) is a simple, non-parametric classification and regression algorithm. It works by identifying the ‘k' closest training instances to a given query point and assigning the majority label (classification) or averaging the values (regression) of these neighbours. The algorithm’s simplicity and effectiveness make it a popular choice for various applications, although it can be computationally expensive and sensitive to the choice of ‘k' and the distance metric.
Random subspace ensemble (RaSE)
Random Subspace Ensemble (RaSE) is an ensemble learning technique that creates diverse classifiers by training each classifier on a random subset of the feature space. This method aims to improve the robustness and generalization of the model by reducing the correlation between individual classifiers. By combining the predictions from multiple classifiers, RaSE enhances the overall performance, particularly in high-dimensional data scenarios.
Methodology
The preprocessing phase aimed to investigate the impact of different orders of preprocessing techniques on model performance. As descript in Figure 1. Two preprocessing designs were considered: Study design.
Design I: In this design, the original datasets were first scaled using one of the following scaling techniques: Standardisation, MinMaxScaler, MaxAbsScaler, or RobustScaler. After scaling, data balancing was performed using one of the following techniques: up-sampling methods (ROS, SMOTE, Borderline-SMOTE, ADASYN) or down-sampling methods (CCS, RUS, CUS, NearMiss).
Design II: In this design, data balancing was performed first, followed by scaling. This order allowed for exploring the impact of balancing before scaling on model performance.
The clinical features used for scaling and balancing included variables such as age, blood pressure, cholesterol levels, and ejection fraction. These features were selected based on their clinical relevance to cardiovascular health.
Model evaluation
For model evaluation, the data were randomly split into an 80% training set and a 20% validation set. The validation sets were used to assess the performance of various preprocessing and machine learning combinations. Evaluation metrics including accuracy, precision, recall, and F1-score were calculated, as shown in Table 2. A 5-fold cross-validation (5-fold CV) procedure was conducted, where in each fold, 80% of the training data was used for model training, and the remaining 20% was used for validation.37,38 Bayesian Optimisation was employed to efficiently tune the hyperparameters for XGBoost, GBDT, AdaBoost, Random Forest, KNN, and RaSE. After identifying the optimal hyperparameters, the final model was retrained using the entire training dataset (the original 80%) and used for final predictions.
Algorithm of four evaluation approaches.

Result
Study design
Cleveland heart disease dataset (Balanced dataset).

Heart failure dataset (Imbalanced dataset).

The importance of the order of data-preprocessing approaches
Comparison of highest result (Balance: SMOTE, Scaler: StandardScaler).

macro average (averaging the unweighted mean per label), weighted average (averaging the support weighted mean per label).
Evaluation of machine learning process
Figures 2 and 3 present the analysis results from the balanced and imbalanced datasets, respectively. The data clearly indicate that XGBoost consistently outperforms other machine learning models, including Random Forest, RaSE, and GBDT. In the balanced dataset, although RaSE exhibits strong performance, XGBoost demonstrates robustness across all performance metrics, underscoring its adaptability. In the context of the imbalanced dataset, XGBoost’s superiority is even more pronounced, particularly in addressing the challenges associated with predicting minority classes. This evidence supports XGBoost as the most effective and reliable machine learning method for both balanced and imbalanced datasets, establishing it as the preferred choice for predictive modelling across varied data scenarios. MLapplied in Top 3 best result. XGBoost and RaSE have a significant presence among the highest-performing models. ML applied in Top 3 best result. XGBoost and Random Forest have a substantial presence among the highest-performing models.
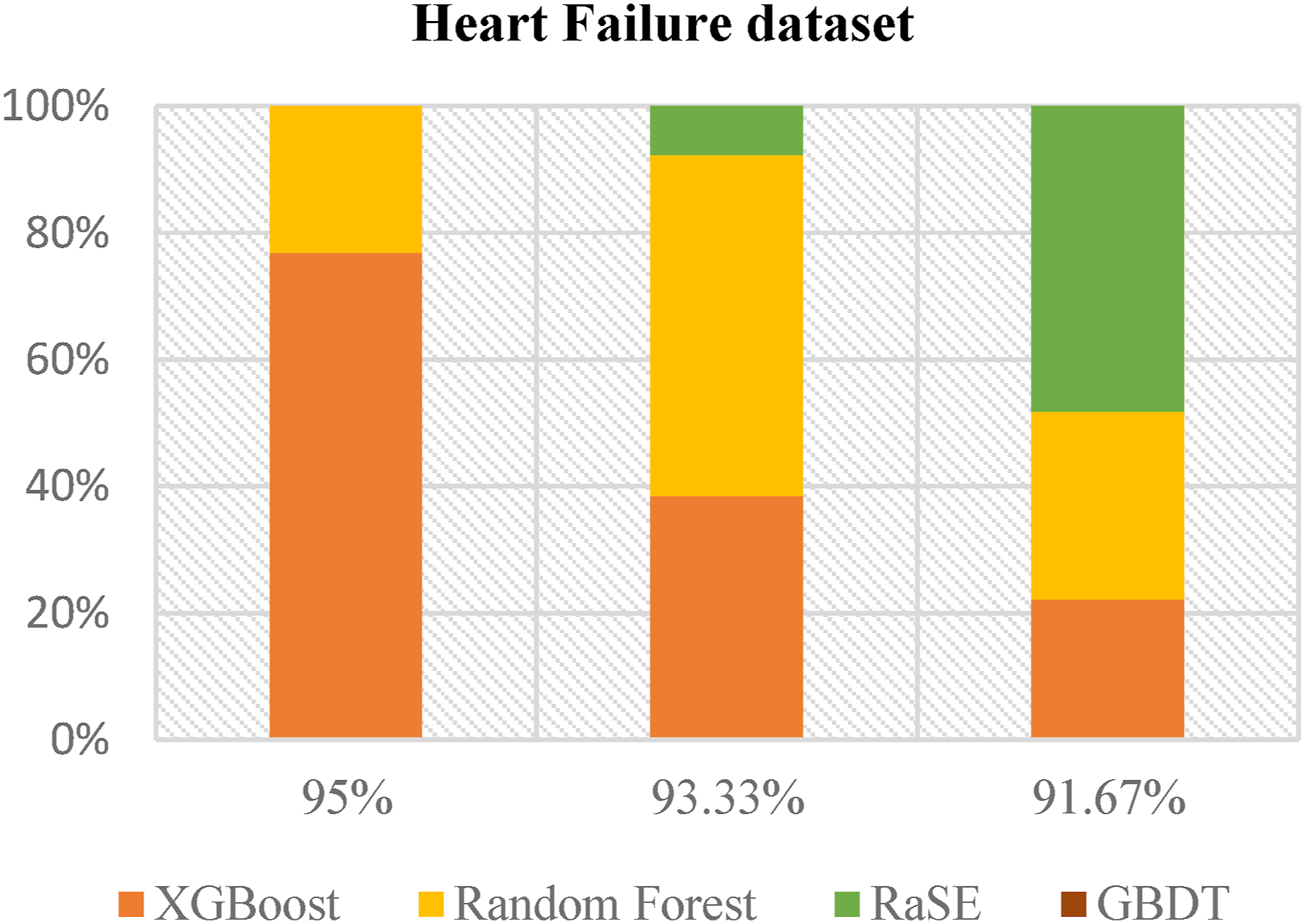
ROC & PR curves on highest result of heart failure dataset
Figures 4 and 5 provide a detailed evaluation of six machine learning models—AdaBoost, XGBoost, GBDT, RaSE, KNN, and Random Forest—using ROC and PR curves. XGBoost and Random Forest demonstrate superior performance with AUC values of 0.9535 and 0.9590, respectively, indicating strong discriminative power, while KNN, with the lowest AUC of 0.7770, shows the weakest performance. XGBoost again be as the top performer with an AP of 0.9429, followed closely by Random Forest at 0.9059, while KNN has the lowest AP score of 0.5775, indicating challenges in maintaining a favorable precision-recall trade-off. This analysis highlights XGBoost and Random Forest as the most effective models. ROC curve of the highest result. The AUC values of XGBoost and RF achieving the highest, signifying better predictive accuracy. PR curve of the highest result. XGBoost and RF exhibit the highest AP, indicating superior performance in distinguishing.

Predictive device development
Figure 6 illustrates the design and functionality of our detection device. Leveraging the results of our training, we developed this device to enable users to input their basic information and personal health data. The device then provides a preliminary diagnosis based on the entered details. Content of the predictive device.
Discussion
Key findings and interpretation
Comparison of using pre-processing approaches on imbalanced data.

Model A: Utilizes SMOTE for oversampling, StandardScaler for feature scaling, and XGBoost as the classifier. Model B: Employs ADASYN for oversampling, StandardScaler for feature scaling, and XGBoost as the classifier.
Feature importance and clinical relevance
To assess the contribution of individual features to model predictions and their impact on heart disease and heart failure outcomes, we conducted a SHAP (SHapley Additive exPlanations) analysis. Figures 7 and 8 illustrate how various features influence model predictions. In both plots, the “sex” feature indicates that males are generally associated with a higher predicted risk, whereas females are linked to lower risk. This effect is more pronounced in our heart disease models than in our heart failure models, suggesting that while gender consistently plays a role in heart-related conditions, its influence varies in magnitude depending on the specific disease context. Results of SHAP analysis for heart disease risk prediction (a) summary plot of SHAP analysis, displaying the distribution of how the value of each risk factor influences the model output across various test instances (b) force plot illustrating the explanation for a low-risk prediction (c) force plot illustrating the explanation for a high -risk prediction. Results of SHAP analysis for heart failure risk prediction (a) summary plot of SHAP analysis, displaying the distribution of how the value of each risk factor influences the model output across various test instances (b) force plot illustrating the explanation for a low-risk prediction (c) force plot illustrating the explanation for a high-risk prediction.

Feature importance analysis: Impact of sex variable removal
Comparison about removing specific feature of dataset.

Comparison with existing literature
Recent progress on Cleveland heart disease and heart failure dataset.
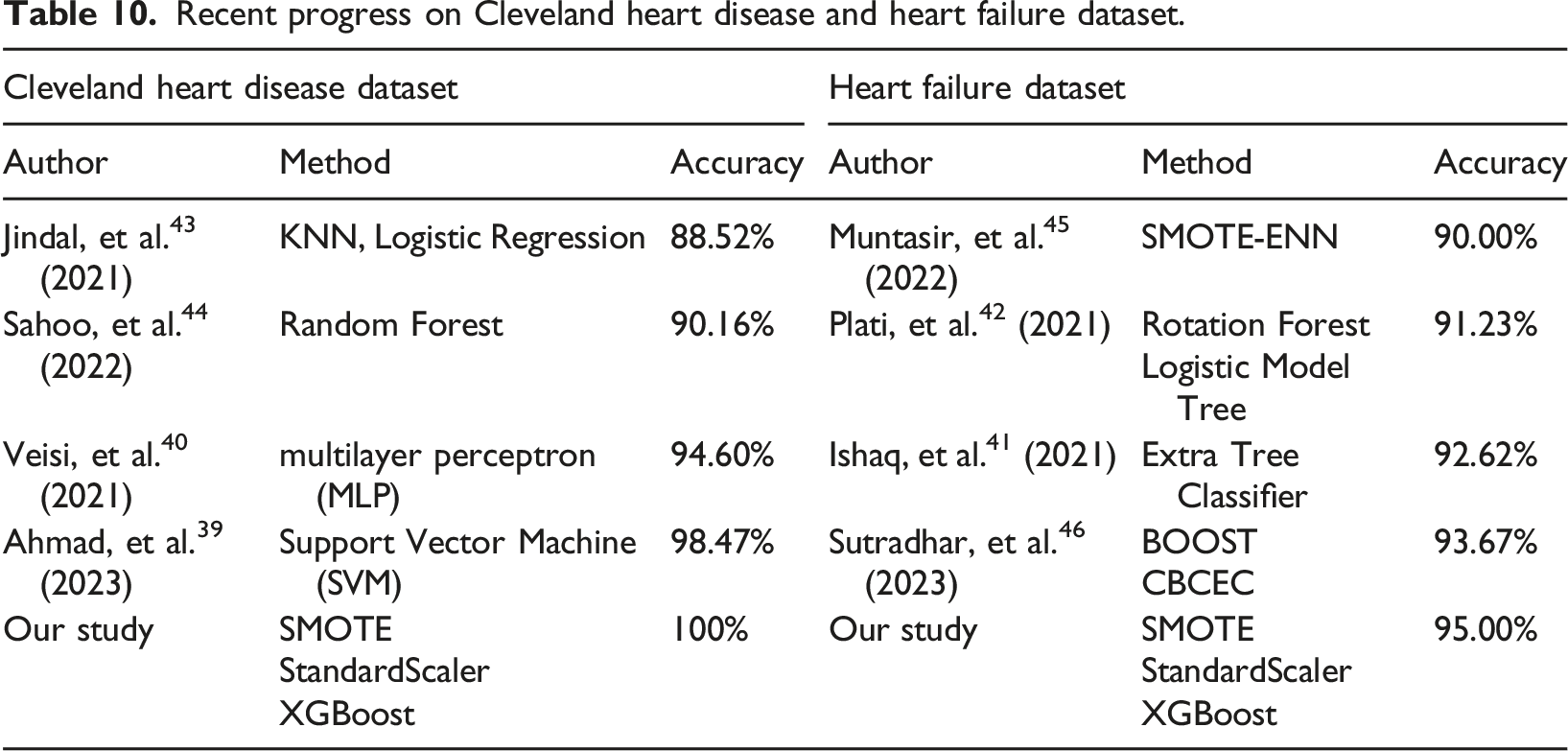
These results highlight the robustness of our approach and raise important considerations for real-world clinical applications. The superior performance of our method is likely attributable to the synergy of SMOTE’s ability to mitigate class imbalance, StandardScaler’s role in feature normalisation, and the predictive power of XGBoost. Notably, while SVM and MLP models have been shown to perform well, they may be more sensitive to data imbalance and lack the adaptability of XGBoost’s boosting mechanism. The clinical implications of these findings are substantial, as enhanced predictive accuracy in heart disease and heart failure models could facilitate earlier diagnosis, more targeted interventions, and improved patient outcomes.
Furthermore, our results underscore the importance of model interpretability in clinical decision-making. The SHAP analysis not only validates the significance of key features such as sex but also offers insights into how predictive models align with existing medical knowledge. Given that sex differences in cardiovascular disease are well-documented in clinical research, our findings reinforce the necessity of including sex as a feature to improve the reliability of heart disease and heart failure prediction models.
Implications for digital health innovation and clinical decision support
Our research shows that improved preprocessing techniques enhance the reliability of AI cardiovascular risk assessment tools, advancing digital healthcare delivery. The superior performance achieved through our Design II approach (balancing before scaling) provides a practical framework for developing more accurate clinical decision support systems that can assist healthcare providers in early diagnosis and risk stratification. The integration of machine learning models, particularly XGBoost, with optimized preprocessing strategies offers a pathway for implementing real-time cardiovascular risk assessment tools in clinical settings, aligning with the contemporary shift toward patient-centered digital health solutions that leverage AI to provide personalized care recommendations based on individual risk profiles.
Furthermore, our methodology addresses the critical need for interpretable AI in healthcare by incorporating SHAP analysis, ensuring that clinical decisions supported by our models remain transparent and clinically meaningful. The practical implications extend to the development of mobile health applications and telemedicine platforms, where accurate and rapid cardiovascular risk assessment is essential. Our research provides the methodological foundation for deploying robust prediction models in diverse digital health environments, from hospital-based clinical decision support systems to consumer-facing health monitoring applications.
Conclusion
This study contributes significantly to health informatics by demonstrating that preprocessing sequence critically impacts cardiovascular disease prediction accuracy. Design II (balancing before scaling) achieved superior performance (95% vs 93.33% accuracy) and established a methodological framework applicable to clinical decision support systems. The consistent reliability of XGBoost across both balanced and imbalanced datasets, combined with SHAP-based interpretability, provides healthcare informatics professionals with a validated approach for developing reliable AI-driven diagnostic tools.
Future research should explore the generalisability of these findings across other datasets and machine learning models. Additionally, the development of more sophisticated preprocessing techniques tailored to specific data characteristics may further enhance predictive performance in complex data environments.
Footnotes
Acknowledgements
We thank all individuals who participated in this study.
Author contributions
PNC, CWT and LCS performed the experiments and wrote the manuscript. KFL and PNC provided the concept and experimental design of the study and reviewed the paper prior to submission. All authors discussed the results, analyzed the data, and commented on the manuscript. All authors have read and approved the submitted version.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The design and costs of collection, analysis and interpretation of data and writing are funded by the Ministry of National Defense-Medical Affairs Bureau (MND-MAB-D-113143).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
All data generated or analyzed during this study are included in this published article. It also available in- https://www.kaggle.com/datasets/andrewmvd/heart-failure-clinical-data and ![]() .
.