
Abstract
The sharp rise in coronavirus cases in the United States, as well as other countries, is driven by variants such as the Omicron substrain, BA4 and BA5. Keeping up to date with COVID-19 vaccination and wearing masks are essential tools for mitigating the pandemic. Social media plays a vital role in sharing and exchanging information, but it also affects perceptions of social phenomena. In this study, we conducted sentiment analysis and topic modeling to investigate vaccine perception using 338,465 COVID-19 vaccine-related comments collected from January 2020 to May 2021 on Reddit. This study stands apart from prior COVID-related research on social media, particularly on Reddit, as it conducted separate analyses for each COVID vaccine and examines public sentiment with various societal events, including vaccine development progress and government responses to COVID. The findings reveal two notable spikes in the number of comments containing the keyword “vaccine”. This suggests that discussions about vaccines tend to increase during times of significant social and political events, indicating that people’s attention and interest in the topic are influenced by current events. Understanding the public perception of vaccines and identifying factors influencing vaccine perception could help propose appropriate interventions to promote vaccination.
Introduction
The global race for a COVID-19 vaccine began after the first outbreak in December 2019, following WHO’s declaration of a pandemic on March 11, 2020. The Pfizer COVID-19 vaccine, the first vaccine for COVID-19 in the US, has been available under Emergency Use Authorization (EUA) since December 2020. Different types of COVID-19 vaccines have been developed all over the world. Although there is some time lag in vaccine development, four vaccines have been available in the US: Pfizer, Moderna, Novavax, and Johnson & Johnson. Vaccines are one of the most effective ways to prevent serious illness. As non-pharmaceutical interventions such as mask mandates and social distancing have limitations, and rapidly spreading virus mutations such as Omicron and Deltacron are continuously being reported, concern and interest in vaccination are inevitably rising. While vaccination coverage has increased, people still do not get vaccinated and are hesitant to get vaccinated for various reasons. Social media sites have become reliable platforms for sharing information and popular data sources for scientific studies and health issues. Vaccine hesitancy refers to a delay in acceptance or refusal of vaccination despite the availability of vaccination services.1–3 Vaccine hesitancy poses a growing concern as it prevents herd immunity, which is critical for protecting the whole community, accelerated by misinformation on the Internet and social media. 4 A variety of factors contribute to vaccine hesitancy, including mistrust of health authorities, 5 the compulsory nature of vaccines, 6 the safety and efficacy of a new vaccine,5,7,8 and lack of information.8,9
Social media plays a crucial role in the dissemination and sharing of information in the Internet era. A growing number of people rely on social media platforms to access various types of information, including health-related information. However, social media also acts as a powerful catalyst for the anti-vaccination movement 10 and is susceptible to fake news, misinformation, and disinformation. Some studies have demonstrated the positive impact of web-based vaccine information and social media interventions on vaccine acceptance, 11 while others have highlighted the association between anxiety, fear of health-related consequences, and higher vaccine acceptance. 10 Conversely, several studies have reported the widespread sharing of anti-vaccine content across social media platforms.12–14 Therefore, it is crucial to understand how public sentiment regarding health topics has evolved.
Text or information shared on social media platforms constitutes unstructured data that lacks a predefined structure. Natural Language Processing (NLP), a branch of artificial intelligence, enables computers to comprehend text in a manner similar to humans and has found extensive applications in areas such as COVID-19 social media analytics. In a study by Cinelli et al., 15 user interest in the COVID-19 topic was analyzed utilizing epidemic models to examine the spread of information across different social media platforms, including Twitter, Instagram, YouTube, Gab, and Reddit. Another study Zhang et al. 16 characterized how Reddit users choose between two closely related communities, namely r/China_flu and r/Coronavirus with a specific attention on membership changes within Reddit. Additionally, a series of studies investigated the extent of COVID-19 misinformation on Twitter.17–21 Some of these studies, however, were limited by their use of a very small subset of Twitter or manually annotated data.18,20 This study employs text mining techniques to extract meaningful information from unstructured data, focusing on the perception of health topics, particularly focusing on COVID-19 vaccines. Numerous studies have utilized text mining to investigate vaccine sentiment across various social media platforms such as Twitter,22–25 Facebook, 23 and Reddit.26,27 To gain deeper insights into people’s perceptions of COVID-19 vaccines over time since the outbreak, this study employs sentiment analysis and topic modeling to analyze comments posted on Reddit.com, a popular platform for information sharing with user-generated content. Reddit allows users to leave publicly viewable comments without the need for identity verification. By investigating 338,465 COVID-19 vaccine-related comments collected from January 2020 to May 2021 on Reddit, this study aims to uncover how people’s perceptions of COVID-19 vaccines have evolved.
Materials and methods
Data and preprocessing
Data source
The public sentiment towards the COVID-19 vaccine was investigated through comments on Reddit. Reddit is a social media platform where members can share news, content, and comment on other members’ posts, which are publicly viewable. With approximately 430 million active users, nearly half of whom are from the US, Reddit consists of communities or subreddits that cover various topics. Subreddit members can post links, text, images, and videos, which can be voted on by other members. Text posts are classified as hot, best, controversial, or rising based on these votes.
Data extraction
We collected a total of 338,465 comments from two of the most active subreddits, namely r/Coronavirus and r/CoronavirusUS, using the Reddit API. The r/Coronavirus subreddit has approximately 2.4 million members, while r/CoronavirusUS has 144k members. The data collection period spanned from January 2020 to May 2021, encompassing the critical stages of the major outbreak and the peak of the COVID-19 pandemic. We specifically selected this time frame as it captured the onset of the pandemic in January 2020 and extended up to May 2021, providing the most recent data available at the time of the study. These subreddits were selected based on their high activity levels and large communities discussing COVID-19.
Summary of dataset.

Data preprocessing
Initially, the number of comments used for analysis amounted to 333,407 after excluding comments from the collected 338,465 comments that lacked substantive content due to a low character count (e.g., ‘yeah,’ ‘agree,’ ‘no,’ etc.). Text data obtained from social media often contains noise, such as hashtags, emojis, and URLs, due to informal posting styles. Therefore, several text preprocessing methods were applied to clean the raw data and prepare it for the topic models. Initially, URLs and punctuation marks were removed from the text. The text was then tokenized, meaning it was split into sentences and further split into words. In order to treat lowercase and uppercase letters as the same, all uppercase words were converted to lowercase. Stopwords, including pronouns, prepositions, and commonly used words, were eliminated as they contribute little or no meaning. Additionally, lemmatization was performed to group words with the same root or lemma, for example, “buys,” “bought,” and “buying” all mapped to the root word “buy.” The text preprocessing steps were implemented using spaCy, a Python library designed for information extraction and general-purpose natural language processing (NLP). 28 Figure 1 provides an illustration of the data preprocessing steps.
Sentiment analysis
Sentiment analysis was conducted using the Stanza library, a Python NLP library for human language. 29 Stanza assigns polarity values to each sentence, with 0 representing negative sentiment, one representing neutral sentiment, and two representing positive sentiment. For each comment, which consists of multiple sentences, sentiment analysis was performed by taking the majority vote of the sentence-level sentiments. Weekly-based sentiment analysis was carried out to understand users' reactions to COVID-19 vaccine events announced by public media, such as entering phase three for each vaccine or the first shot for emergency use authorization (EUA). The sentiment analysis was conducted separately for comment scores, sentence scores, and keywords.
Latent dirichlet allocation topic modeling
A widely used probabilistic topic modeling algorithm called Latent Dirichlet allocation (LDA) using Gensim. ldamodel, which is a Python library specialized for topic modeling, document indexing, etc.,
29
was used to extract topics the unstructured text data, that is comments. The training phase was done in a bagging approach - an iterative k-fold top-down fashion for the appropriate topic model number. A bagging method trains a model using the number of random subsamples with replacement to reduce the variance and noises. Five subsamples (80% of the raw data) were generated, and eight different topic models were made iteratively on each subsample starting from 7-topic models. In each iteration, the stopwords list was extended by adding the last two lowest-weighted keywords and the coherence value, a score measurement of a topic by the degree of similarities between the highest scoring words and the topic, was evaluated. After finding the final topic models, the dominant topic and its contribution percentage for each comment were determined. Then, topics were clustered using K-means, and similarities between topics were measured by Principal Component Analysis (PCA). The data preprocessing and research methods used for this study are shown in Figure 1. Flowchart of research.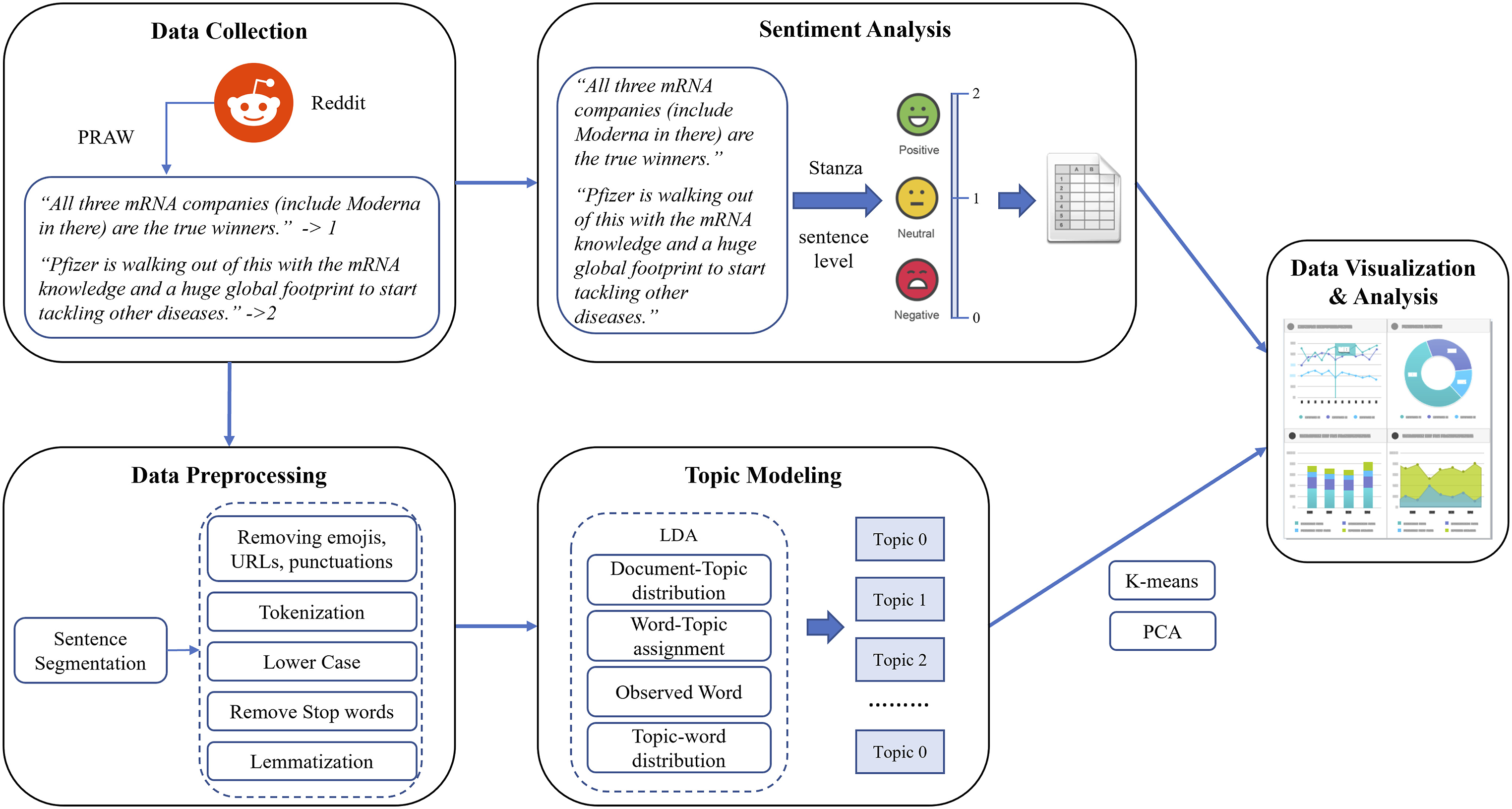
Results
Sentiment analysis
Monthly summary of the dataset. Columns (1) the month and year, (2) the total count of negative sentences, (3) the total counts of neutral sentences, (4) the total counts of positive sentences, (5) the total number of comments, (6) k - the number of keywords that appeared in comments, the minimum and the maximum combination of keywords, (7) N 0 , N 1 , N 2 - stanza scores for comments, categorized as negative, neutral, and positive, respectively.
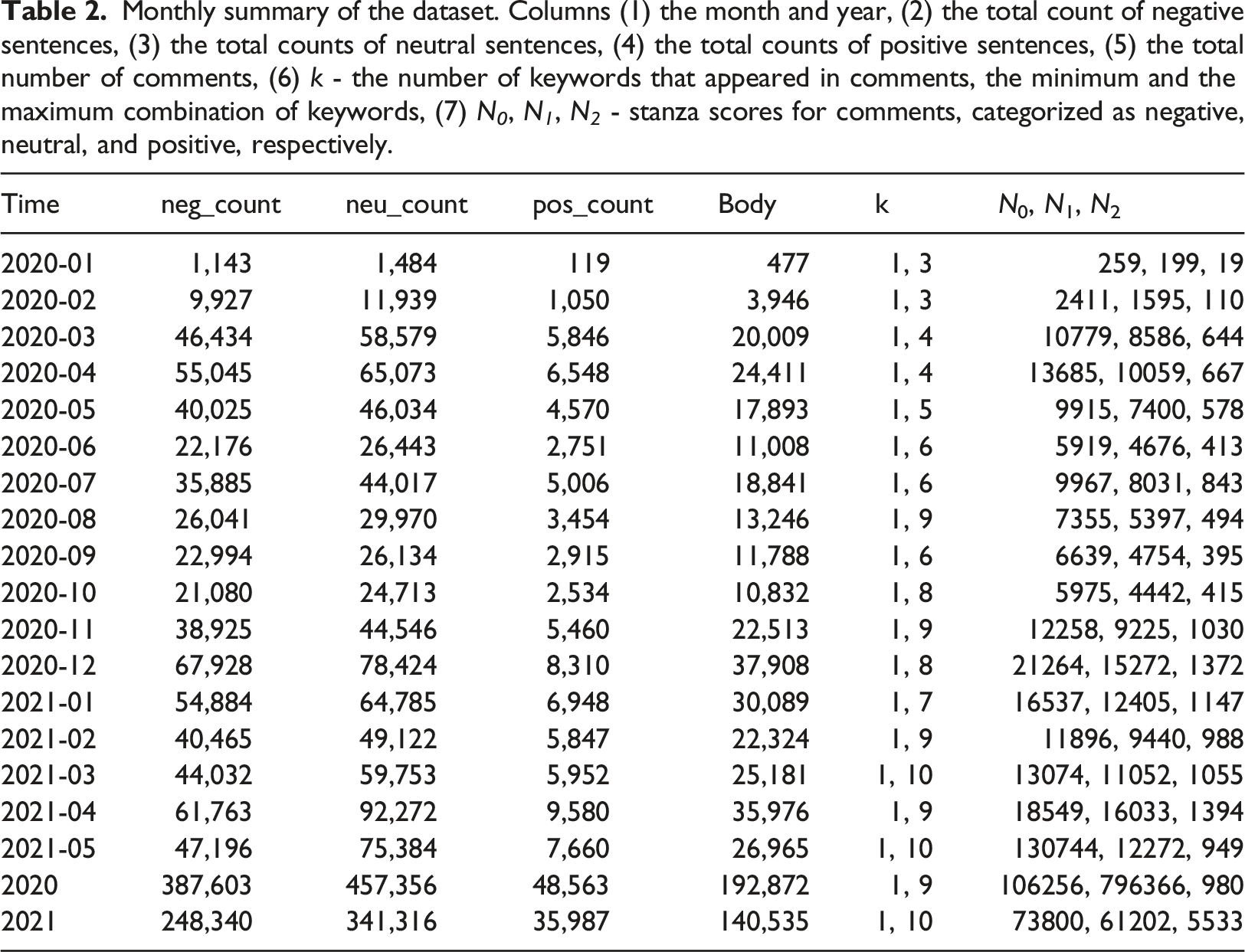
There were a total of 11 keywords used for data collection. Figure 2 illustrates that the dominant keyword was “vaccine” with a percentage of 72.19%. The next most frequently used keywords, in order, were Oxford (10.82%), Pfizer (8.78%), Moderna (5.39%), and Janssen (1.05%). The remaining keywords, including Novavax, Sputnik, Sinovac, Sinopharm, Convidecia, and Covaxin, accounted for 1.77%, slightly higher than the proportion attributed to Janssen. It should be noted that comments may contain multiple keywords, resulting in the total count of comments exceeding the value shown in Table 2. Percentage of keywords appearance: This figure represents the total number of comments containing each keyword and the percentage of appearance during the data collection time period.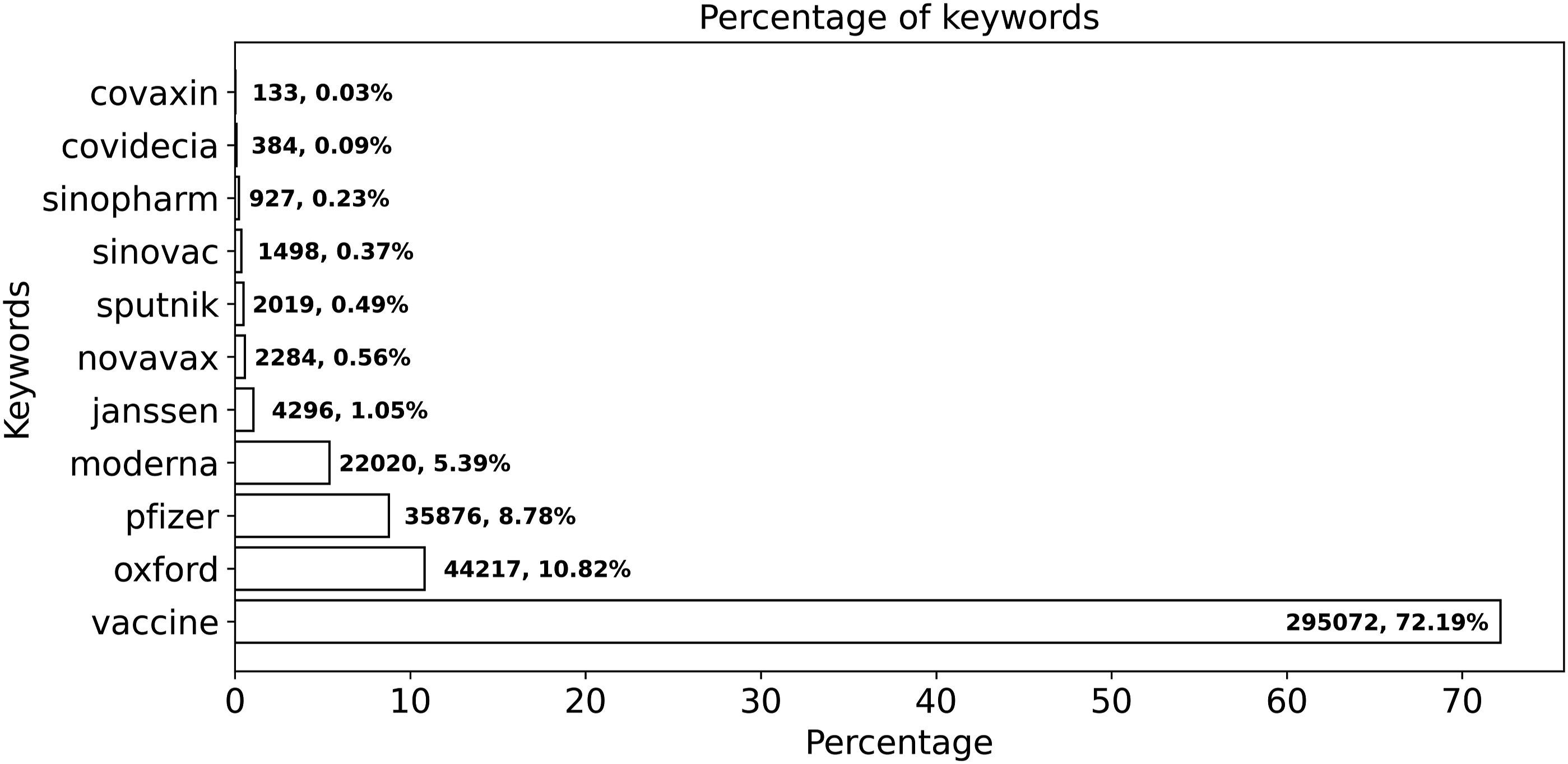
For detailed visual analysis, the distribution of comments based on keyword combinations is depicted in Figure 3. The comment counts are displayed above the bars, indicating the distribution of sentences for each combination. The blue dashed line represents the overall proportion of comments. It can be observed that the majority of comments (approximately 96% of the dataset) have a keyword combination of two or less. Among these comments, only 12% do not include the keyword “vaccine.” As the number of keywords in a comment increases, the number of negative sentences decreases, while the count of neutral sentences tends to increase, and the number of positive sentences remains relatively consistent. The ratio of sentences by the number of keywords: This figure summarizes the distribution of sentences and comments with different combinations of keywords from 1 to 10.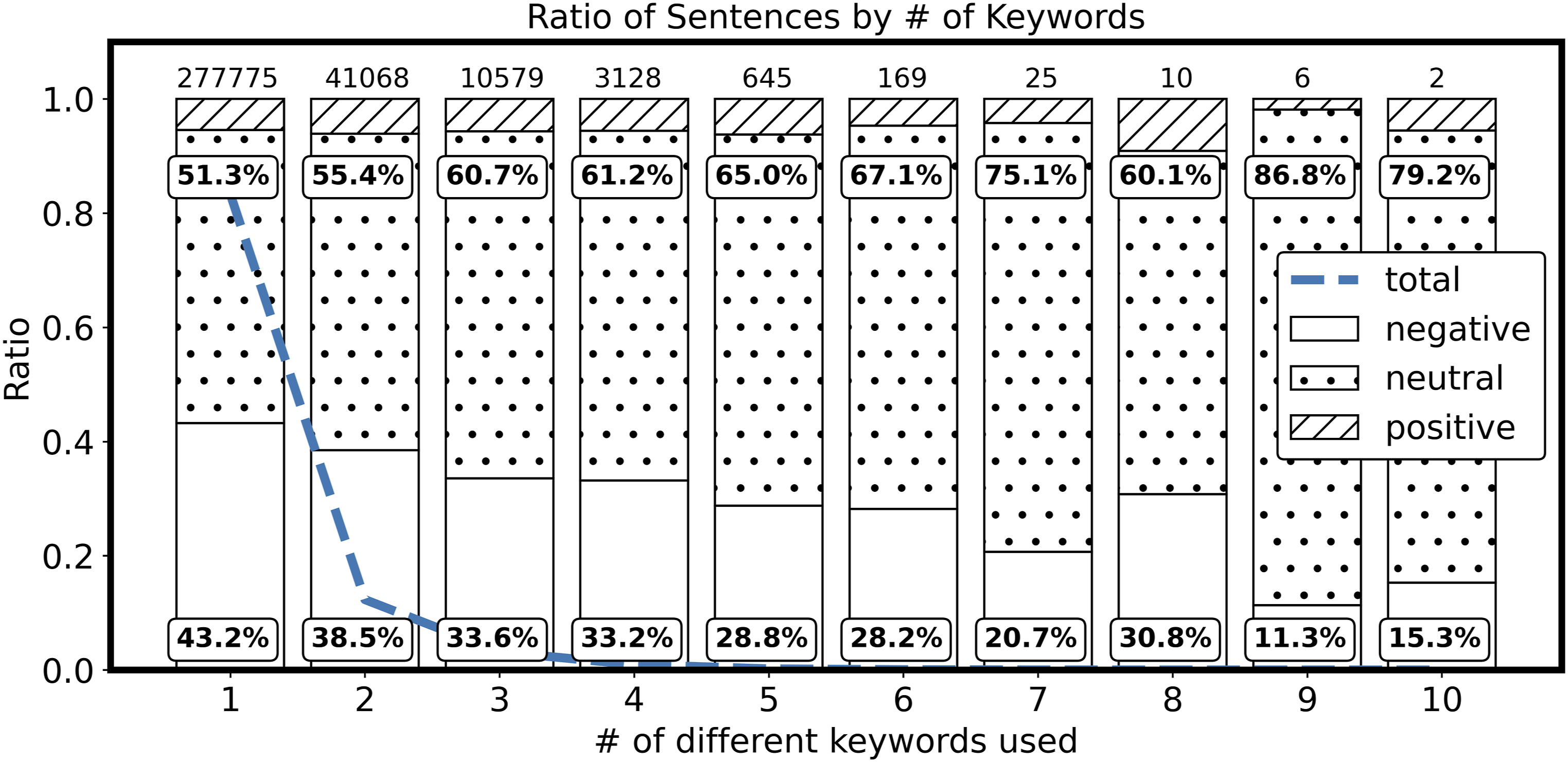
Figure 4 illustrates the trend of comments in relation to vaccine-related and political events over time. The top panel represents the normalized number of comments for each type. It can be observed that the number of posts started to significantly increase after election day, which occurred during the week of November 2, 2020, for all types of comments. The middle panel displays the counts of sentences categorized by Stanza scores. It indicates that users generally expressed negative sentiments throughout the analyzed period. The gap between the number of negative and neutral sentences becomes relatively wider after the approval of the first vaccine shot. The bottom panel focuses on the usage of individual keywords, excluding comments containing only the keyword “vaccine” or more than two keywords. Prior to election day, the keyword “Oxford” was the most frequently used, as many people showed interest in the Oxford vaccine, which was nearing commercialization at that time. Following election day, the use of keywords such as “Pfizer,” “Moderna,” and “Janssen” started to increase. Weekly-based sentence counts: This plot contains three panels showing the count of sentences during the week starting from Monday when comments had two or fewer keywords. The vertical dashed lines indicate the historical vaccine events during the data collection period.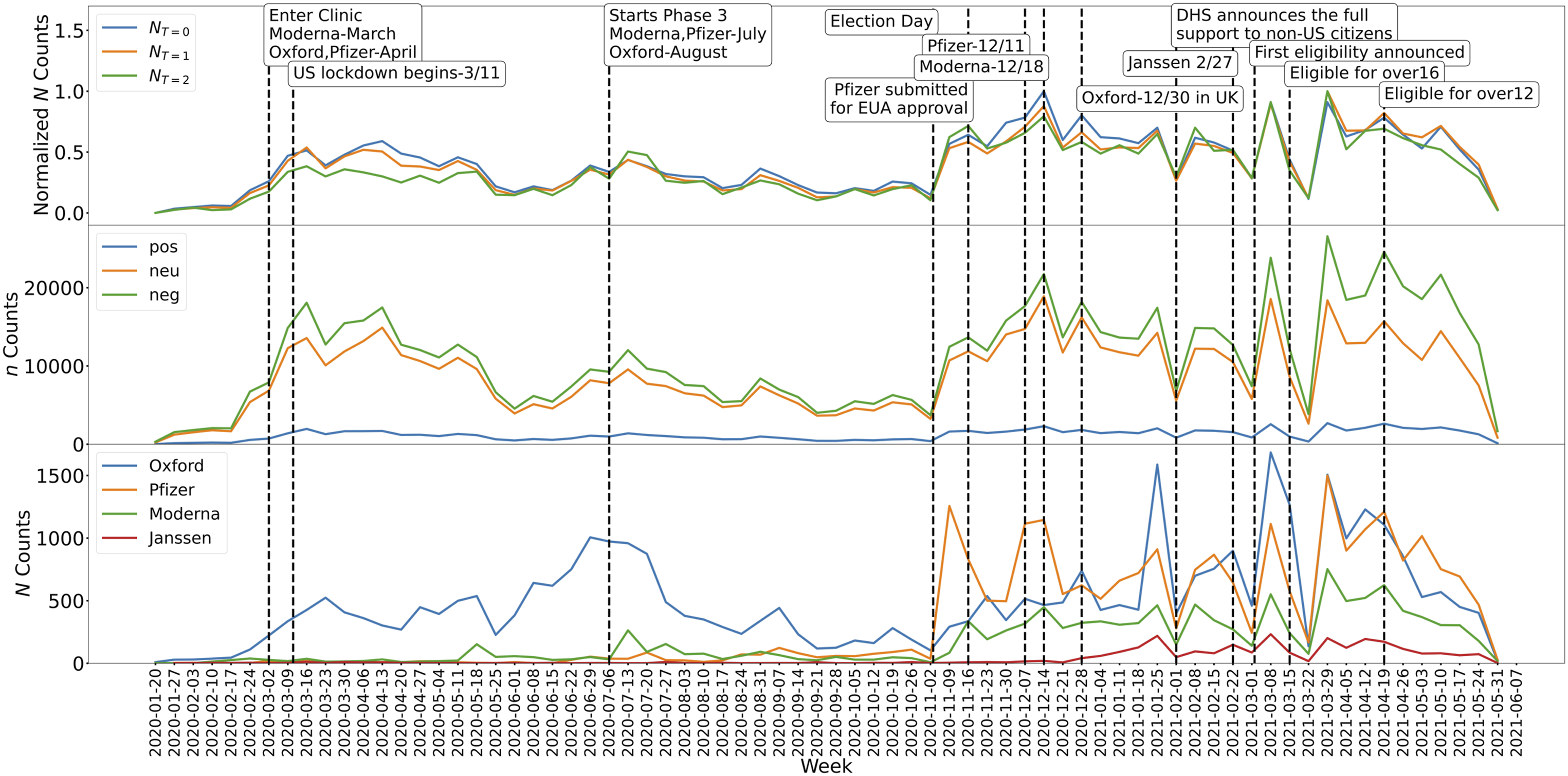
Topic modeling
The left panel of Figure 5 presents the coherence values for each subsample, ranging from 7 to 15 topics. The coherence values were measured to determine the optimal number of topics. The final topic number was selected based on the average maximum coherence value across the five subsamples. To investigate the similarities between topics, K-means clustering was employed. The middle panel of Figure 5 depicts the K-means inertia against the number of clusters, ranging from one to eight. The elbow method suggests that the model topics can be effectively grouped into two clusters, referred to as Cluster 0 and Cluster 1. The right-most panel of Figure 5 utilizes principal component analysis to visualize the similarity between topics. Topic IDs 2, 3, 4, 5, 7, and 8 are clustered in Cluster 0, while IDs 0, 1, and 6 belong to Cluster 1. The distance between topics serves as an indicator of similarity, with shorter distances indicating greater similarity. Cluster 0 exhibits a relatively closer grouping, with Topics 4 and 8 displaying the highest level of similarity, while Topics 5 and 7 exhibit lower similarity. In Cluster 1, Topics 0 and 1 are the closest in similarity, although they are less similar compared to Topics 5 and 7 in Cluster 0. LDA modeling analysis results. The first plot shows the LDA model coherence values for a number of topics. Each colored dash line represents a different model by cross-validating the sample by excluding the lowest weighted words in each topic where the number of topics increased from 7 to 20. The solid line represents the average score of five models. The second plot shows the clustering results via k-means using the assembled model with Topic number 9. The third plot demonstrates the PCA result of topics labeled in the order of cluster ID and topic ID.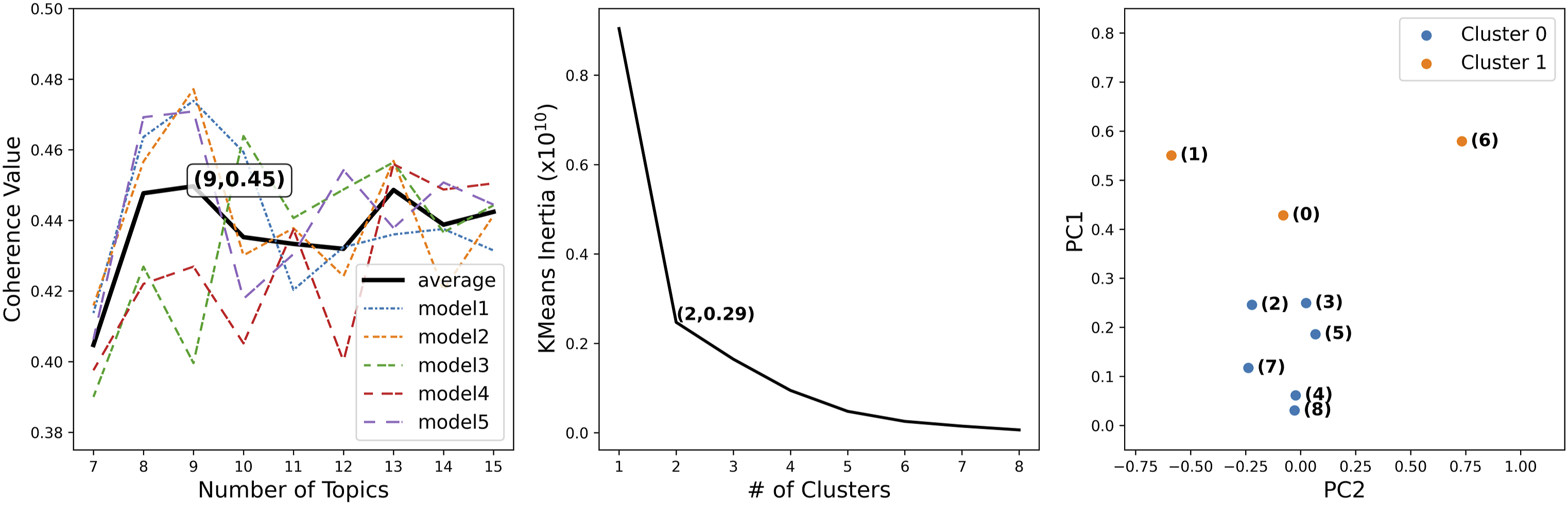
Furthermore, an investigation was conducted to cluster topics into three groups, but no significant differences were observed, except for Topic 1 being included as the third group. As a result, the decision was made to retain the two-cluster configuration.
Topic model keywords and weights: Each column has the first 10 keywords and their weights in the LDA model in decreasing order.
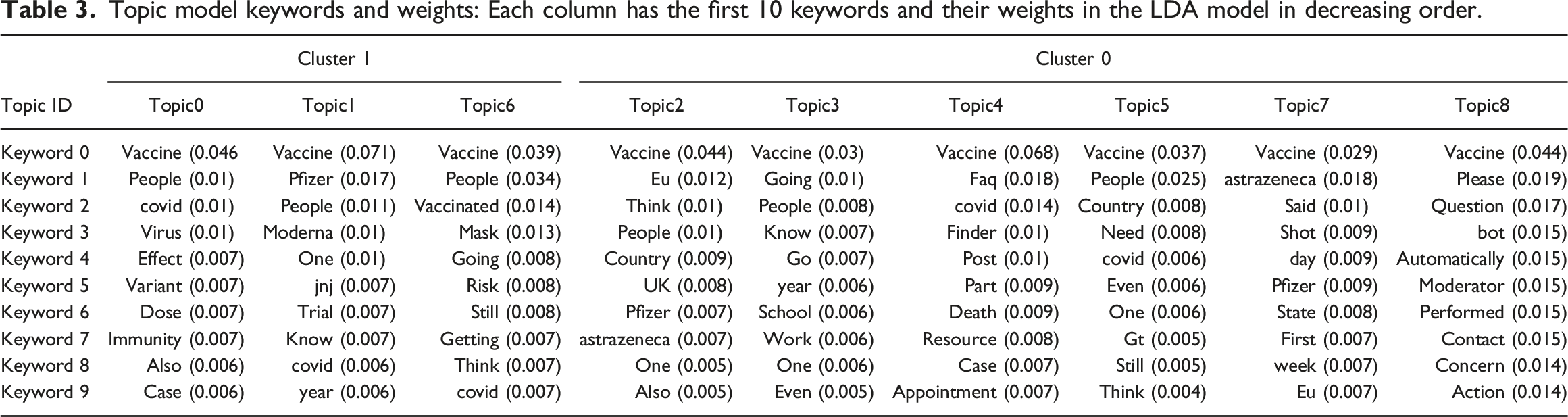
Figure 6 illustrates the distribution of topics in the dataset. The left panel presents the number of comments for each topic. It is observed that Topics 0, 1, and 6 in Cluster 1 have a substantially larger number of comments compared to topics in Cluster 0, even when considering the larger number of topics in Cluster 0. In fact, the combined number of comments carrying Topics 4, 5, 7, and 8 is less than the number of comments for a single Topic 0, which has the lowest comment count in Cluster 1. The right panel of Figure 6 displays the distribution of topic contribution within each comment. It shows that in over half of the comments, the percentage contribution of the dominant topic is more than 70%. The majority of these comments fall within the range of 80% to 100% topic contribution. Notably, the contribution percentages between 90% and 100% exhibit significantly larger counts than any other percentage range. The distribution of topics: The left panel shows the number of comments for each topic ID. The right panel presents the number of comments by the topic percentage contribution.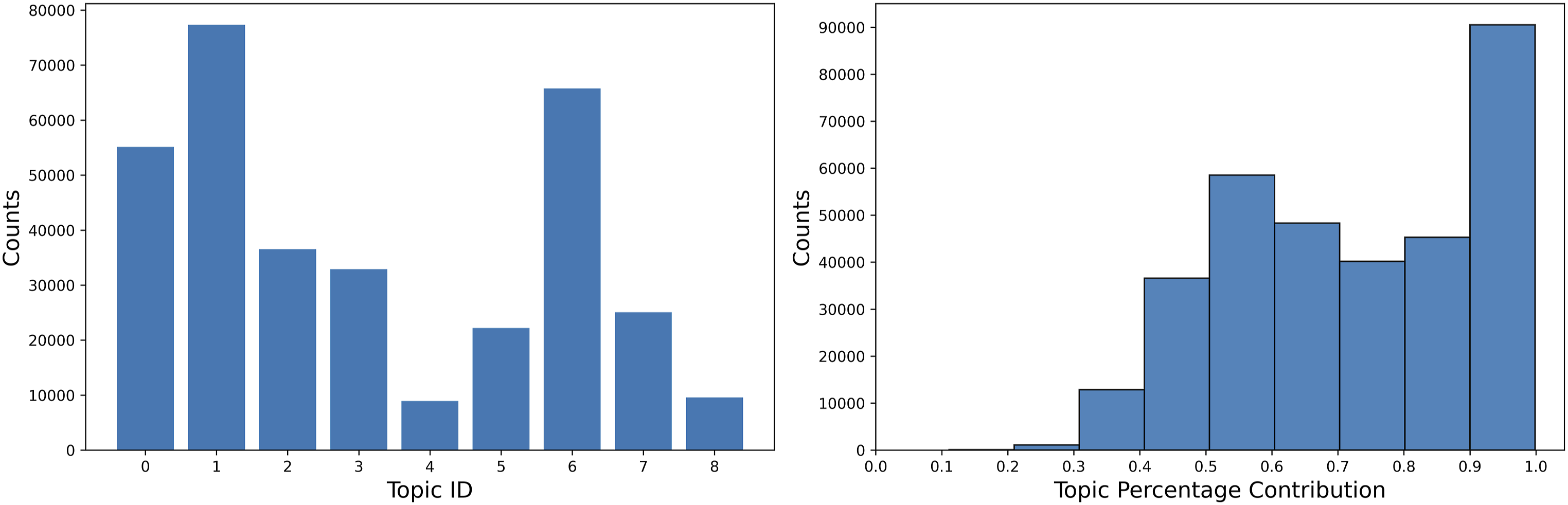
Figure 7 displays the weekly-based dominant topic in each cluster using the comments with a topic contribution percentage of 70% or higher. The time-series format allows for the observation of trends over the data collection period. Throughout the duration of data collection, the number of comments in Cluster 0 is generally larger than the number of comments in Cluster 1. However, there is a notable similarity in the number of comments between the two clusters in March 2021. In Cluster 1, the dominant topic is Topic 1, which holds this position for 54 weeks. Only for 2 weeks in early February 2021, Topic 0 emerges as the dominant topic in Cluster 1. In Cluster 0, Topics 2 and 3 are the most frequently contributed topics, with 38 and 24 weeks respectively, where they hold the position of dominant topic. Topics 4 and 8, on the other hand, do not appear as the most dominant weekly topics during the entire data collection period. Weekly-based dominant topics: The dominant topic each week for each cluster is presented in this plot.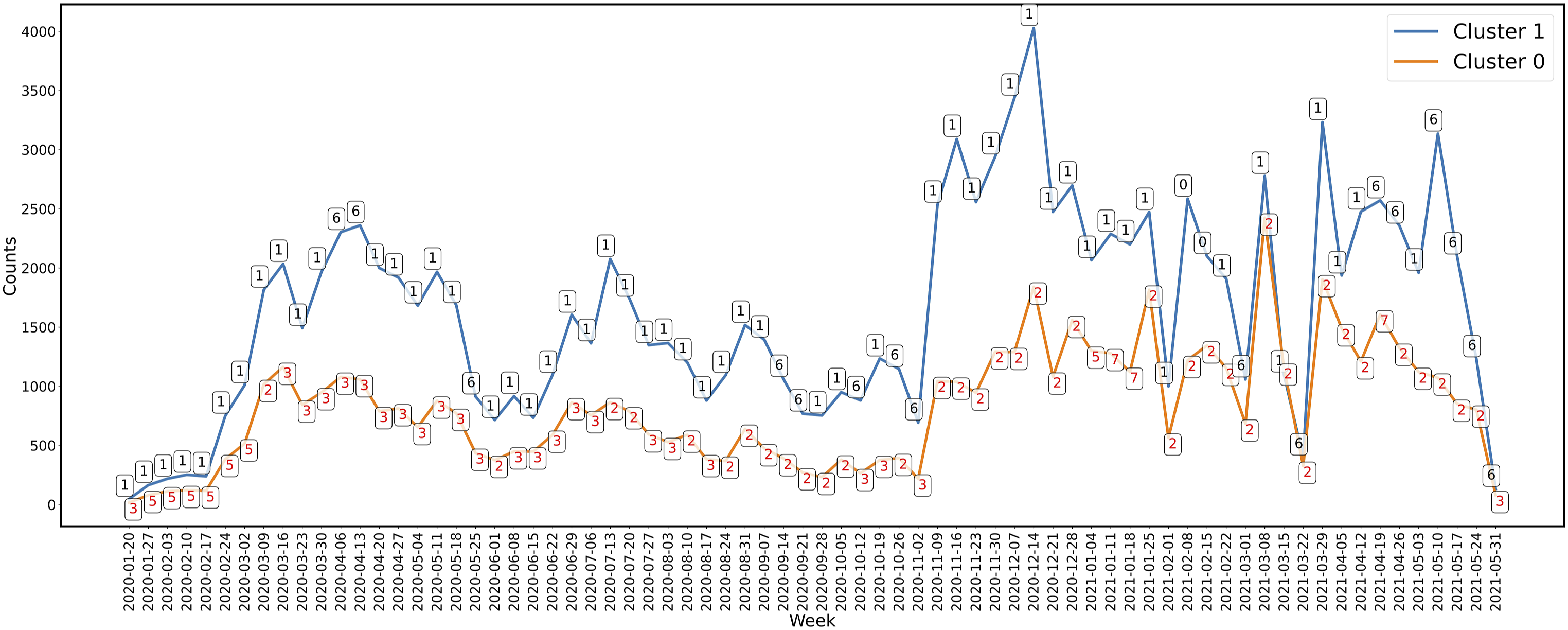
Comments on reddit
We examined how people perceive COVID-19 vaccines based on comments on Reddit. Although the proportion of positive comments increased over time, negative and neutral comments dominated throughout the data collection period. In subreddits such as CoronavirusUS, the keyword ‘Oxford' appeared more frequently than any US vaccine, even though Oxford/AstraZeneca was not approved for use in the US. One of the reasons for this is that Oxford/AstraZeneca was at the forefront of COVID-19 vaccine development, leading to more frequent discussions from the early stages. Reddit users often discussed topics such as the production or distribution of Oxford/AstraZeneca, as well as its side effects and efficacy. Below are some notable comments from Reddit.
“I'm not too sure tbh, I know Oxford recently partnered with AstraZeneca. They haven't started production yet as they wait for the preliminary results. But fingers crossed it's as effective as they hope it is..”
“'I’m no anti-vaxxer, but I would definitely be extremely mindful of taking a new vaccine. The speed at which this new vaccine has advanced into late-stage clinical trials by AstraZeneca is somewhat alarming……My advice - Don't be the first to jump at ANYTHING new. I think a year is probably reasonable. My brother and sister-in-law did the same when the HPV vaccine came out. There was no way they were giving it to their girls until it had a proven track record.”
The number of comments on vaccines increased during two distinct periods: the period when the lockdown started and the clinical trial of a COVID-19 vaccine began, and the period after election day when vaccines by Pfizer and Moderna were approved for use in the US. A plausible explanation for the peak in the second period is that vaccination and public health became critical political issues.
30
Here are a couple of examples from comments on Reddit “Polls show decreasing support for getting vaccinated as battles between science and politics have weakened trust in government agencies that evaluate and recommend vaccines.” “The concern was always about a vaccine being unsafely rushed for political purposes”
Discussion
Building upon prior work, where Melton et al. 26 and Wu et al. 27 used 6-months and 8-months Reddit datasets, respectively, we collected and utilized a more extensive 16-months dataset. Also, in contrast to studies 26 and, 27 which focused on vaccines in general, our study extracted data related to vaccine manufacturers and names. The results indicate that the proportion of negative comments regarding vaccination outweighed the number of positive comments, aligning with the findings of study. 26 Many individuals still express hesitancy towards getting vaccinated, raising concerns about the effectiveness and safety of the vaccines. As more vaccines approached commercialization, discussions surrounding various vaccine options emerged. Figure 7 illustrates that Topic 1 in Cluster 1 consistently dominated over time, especially during the second period. In Cluster 0, two dominant topics emerged: Topic 3 during the first period and Topic 2 towards the end of the first period. Prior to the availability of multiple vaccines, people were primarily interested in returning to school or work, but their focus shifted towards comparing different vaccine options. The second period witnessed a higher number of positive comments compared to the first period.
Although the nine models could have been grouped into three categories based on Figure 5, the results would not significantly differ, except for potentially assigning Topic 6 to a different cluster. Topics 4 and 8 received relatively fewer comments compared to other models, suggesting that they could potentially represent the same topic if the number of topics were reduced to eight. Topic 1 from Cluster 1 and Topic 2 from Cluster 0 emerged as the dominant topics throughout the period. Topic 1 included vaccine names such as Pfizer, Moderna, and Johnson & Johnson (J&J) developed by US companies. Topic 2 encompassed AstraZeneca, a vaccine developed by a UK company. While Cluster 1 exhibited a relatively even distribution of various Topics (0, 1, 6) over the entire period, Topic 2 in Cluster 0 consistently dominated.
The distribution of topic percentage contributions in Figure 6 is skewed, with a majority of contributions exceeding 90%. The left panel of Figure 6 clearly demonstrates that Topics (0, 1, and 6) in Cluster 1 dominate over topics in Cluster 0. One way to address the skewed distribution of topic percentage contributions is by increasing the number of topics in the topic modeling process.
Regarding Topic 8, during the initial phase of vaccine availability to the public, even eligible individuals may encounter difficulties in securing appointments and getting vaccinated. Some individuals resort to using a computer program known as a “bot” to track the latest vaccine availability and automatically book vaccine appointments. These bots autonomously monitor websites for available slots and promptly make appointments without requiring human intervention. Below is an example of comments related to such bots (spelling and grammar unedited): “Over in MA, I made a bot that checks vaccine appointments ever 15 min or less and sends a notification to all of your devices. I support CVS appointments for 39 states and state appointments for MA, NYC and CT. You may find this useful. Good luck and let me know if you have problems / find it useful.”
Even though some individuals may be able to secure vaccination appointments with the assistance of vaccine bots, relying on bots to automatically schedule appointments can lead to issues such as redundant multiple appointments for the same person or create unfair advantages for those who are tech-savvy. This finding aligns with a news article that highlights how bots can make vaccine appointments more challenging for others. 31
Conclusion
Social media platforms have gained popularity among the public and have become essential for discussing and disseminating information. Numerous studies have utilized these platforms to capture public opinion. This study specifically applies text mining techniques to analyze Reddit’s comments on public health issues, such as vaccination. Our research aims to monitor the polarization of public opinion regarding vaccine hesitancy and understand the trends in this polarization. By tracking these trends, healthcare professionals can identify changes over time and evaluate the effectiveness of interventions. Notably, two spikes were observed in the number of comments containing the keyword “vaccine.” These findings suggest that vaccine discussions tend to increase during social and political events.
In April 2022, Anthony Fauci, President Biden’s chief medical adviser, stated that the United States was moving out of the explosive phase of the pandemic. He emphasized the importance of vaccination in managing the coronavirus, even though complete eradication may not be possible.
The analysis of public opinion through social media platforms offers a quick and cost-effective method to gain insights. Continuous monitoring of social media and analyzing public opinion will contribute to the development of valuable policies aimed at improving health literacy and addressing vaccine hesitancy.
Limitations and future research
Despite applying all the required data preprocessing steps in this research, we acknowledge certain limitations. Firstly, when dealing with data sourced from social media, it is essential to recognize the potential presence of fake posts, fueled by powerful text-generative models, which remains a potential aspect that cannot be entirely eliminated in this study. These text-generative models can enable individuals to generate realistic fake posts and potentially manipulate public opinion on social media. Secondly, this research does not address word sense disambiguation issues, which involve determining the correct meaning of a word when it possesses multiple interpretations, as these issues fall outside the scope of our investigation. In addition, our study was constrained by a limited timeframe. However, extending the analysis to cover a broader period would enable the segmentation of distinct periods, such as the early COVID phase, pre-trial period, trial period, trial result phase, and pre-vaccine deployment phase. Such segmentation could offer deeper insights into the temporal dynamics of vaccine-related discourse and the impact of major events on public perception. In future research, it would be valuable to explore other social media platforms, such as Twitter or Facebook, and broaden the scope of topics examined to include mask usage, quarantine measures, and other relevant subjects. Also, we plan to investigate other state-of-the-art sentiment analysis approaches, such as BERT-based models, which have shown promising results in capturing fine-grained sentiment information.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.