
Abstract
Objective
The goal of this study is to use summary generation and topic modeling to identify factors contributing to vaccine attitudes for three different vaccine brands, with the aim of generalizing these factors across different regions.
Methods
A total of 5562 tweets about three vaccine brands (Sinovac, AstraZeneca, and Pfizer) were collected from 14 December 2020 to 30 December 2021. BERTopic clustering is used to group the tweets into topics, and then contrastive learning (CL) is adopted to generate summaries of each topic. The main content of each topic is generalized into three factors that contribute to vaccine attitudes: vaccine-related factors, health system-related factors, and individual social attributes.
Results
BERTopic clustering outperforms Latent Dirichlet Allocation clustering in our analysis. It can also be found that using CL for summary generation helped to better model the topics, particularly at the center-point of the clustering. Our model identifies three main factors contributing to vaccine attitudes that are consistent across different regions.
Conclusions
Our study demonstrates the effectiveness of deep learning methods for identifying factors contributing to vaccine attitudes in different regions. By determining these factors, policymakers and medical institutions can develop more effective strategies for addressing concerns related to the vaccination process.
Introduction
The response to the COVID-19 pandemic has severely disrupted the daily lives of people and organizations worldwide 1 ; governments are making the vaccine available to all in the hope of curbing the spread of the disease and ending the pandemic. 2 Given the severity of COVID-19, a vaccine must be developed. Despite significant efforts in clinical trials and the remarkable success of the vaccine in terms of safety and efficacy, 3 a substantial obstacle to achieving global vaccination coverage is vaccine attitudes. 4 Besides, the World Health Organization (WHO) has identified vaccine hesitancy as one of the top 10 threats to global health care in 2020. Thus, it is crucial to investigate the factor of the vaccination process. 5 In particular, identifying positions that may lead to factors about vaccination, that several adverse events on social media relate to vaccine safety and can undermine vaccine confidence. 6 As a result, analyzing the attitudes to vaccine hesitancy reflected by users on social media is important.
Social media has become an enormous source of data due to its rapid information dissemination, and many people express their opinions through social media platforms. 7 Text mining on social media is a viable option for analyzing public opinion. 8 Due to the rapid development of artificial intelligence and natural language processing (NLP), 9 this technology can address analyzing public opinion. Meanwhile, Internet users need to read a minimum number of words to adapt to today's fast-paced life and glean the thrust of an article. Users can deploy automatic text summarization techniques to precise the main contents, 10 saving reading time, and improving the efficiency of information uptake. Hence, the tweet-oriented text auto-summarization model proposed in the present research is of great significance.
In the corresponding automatic summarization technology, the research also incorporates contrastive learning (CL), 11 evolving from extractive summarization to generative summarization. Our work's main contribution involves applying a combination of NLP methods to vaccines developed in different countries, 12 which discovers the factors related to vaccine attitudes. Collecting and monitoring data from short texts are superimposed for summary generation, such as Twitter.13–15 According to the literature, 16 three factors (vaccine-related, health system-related, and individual societal attributes) of vaccine attitudes are defined. These three factors are utilized to cluster the topics of three different brands. This can also provide various perspectives on vaccines that can benefit public health organizations in identifying factors that contribute to vaccine confidence in people.
This study community used Twitter primarily to collect data on COVID-19 vaccination. The data are based on three different brands (Sinovac, Pfizer, and AstraZeneca) of vaccine and sought to identify topics related to factors towards vaccination 14 in the different regions corresponding to the brand. These results best reveal the reasons for vaccine attitudes in each region. To adapt to today's fast-paced life, Internet users need to read a minimum number of words and glean the thrust of an article, therefore, the tweet-oriented text auto-summarization model proposed in this paper is important. 17 This study aimed to detect the main themes expressed by users of the three vaccines when expressing their positions and attitudes towards COVID-19 vaccination. These themes point to the main reasons for vaccine attitudes in China, the UK, and the USA. This could help local experts and governments better understand the factors influencing the public to vaccinate (the reasons for young people's attitudes thereto). Furthermore, our work can provide key decision-makers with the right tools to promote vaccination campaigns more broadly.
Literature review
Analysis of COVID-19 vaccine attitudes on social media
With the development and promotion of vaccines, many researchers have conducted research on social media discussions related to attitudes towards COVID-19 vaccines. 18 Previous literature mostly used sentiment analysis in machine learning, 19 Today, the main purpose of sentiment analysis is to understand people's attitudes towards this epidemic on social media. 20 Li et al. 21 analyzed the behavior of Americans and Chinese on different social media platforms during the COVID-19 pandemic, and the results of their sentiment analysis showed significant differences in the attitudes of the people of the two countries. Most people had confidence in controlling the spread of the virus. Zhou et al. 22 extracted tweets from the pandemic period, analyzed the emotional dynamics of Australians, and observed the temporal changes in emotions. Yin et al. 23 analyzed the sentiment of tweets related to COVID-19. They found that the positive tweets slightly outnumbered the negative ones, and provided examples of tweets with similar focuses, such as securing one's home and the people who died from the COVID-19.
Moreover, with the development and promotion of vaccines, many researchers have launched research work related to COVID-19 vaccines on social media. Kwok et al. 24 extracted COVID-19 vaccine-related topics and emotions from Twitter in Australia, and found that two-thirds of the tweets expressed positive opinions, while the rest expressed negative opinions. Lyu et al. 25 identified the emotions and topics surrounding COVID-19 vaccines over a long period of time on social media, with the aim of better understanding the emotions that may affect public immunity. Bonnevie et al. 26 quantified the opposition to vaccines during the COVID-19 pandemic in the USA. They found that the number of people opposing vaccines on Twitter had increased significantly. The above literatures are all about analyzing vaccine-related discussions, which ignores the public's attitude towards vaccines, especially the discussion of different regions.
Analysis of COVID-19 vaccine attitudes using machine learning
The COVID-19 pandemic has demonstrated the need for advanced technology to address emergency situations. 3 In order to address such situations, machine learning techniques can provide effective support for public health authorities and supplement traditional applications. 18 Tavoschi et al. 27 monitored public opinion on vaccine uptake in Italy using support vector machines. Bar-Lev et al. 28 used several machine learning methods (logistic regression, random forest, neural network, and linear regression) to assess how online content about vaccine uptake affects vaccine hesitancy. They found that hesitancy is associated with more social media traffic for most vaccine uptakes, and social media traffic improves the performance of most models. Piedrahita et al. 29 achieved an 85% classification accuracy using lexicon analysis and support vector machine (SVM), which found that the percentage of neutral tweets is decreasing, while the ratio of positive and negative tweets is increasing over time. Yuan et al. 30 compared five machine learning algorithms for tweet classification, SVM provided the best accuracy.
The above literatures all use machine learning, but due to factors such as poor classification effect and generalization ability of machine learning, 31 deep learning provides a feasible solution. 32 Hussain et al. 33 used a deep learning BERT model to analyze the public sentiment towards COVID-19 in the UK and the USA. Shahid et al. 34 used deep learning to predict the number of confirmed cases, deaths, and fatality rates in 10 countries. The experimental results showed that the Bi-LSTM model demonstrated stronger robustness and achieved higher prediction accuracy. Devaraj et al. 35 used a multivariate LSTM model to predict cumulative confirmed cases and deaths in COVID-19 cases, which also showed higher accuracy in their algorithm. Shastri et al. 36 conducted a comparative analysis of deep learning methods for predicting COVID-19 cases in the USA and India one month in advance, and the experimental results showed that the LSTM model performed better in predicting COVID-19 compared to the other two models. All the above literature used deep learning for classification or prediction, without using deep learning for topic clustering. Furthermore, the summary generation technology based on deep learning also helps the topics to be better clustered. Therefore, this paper adopts text generation by CL and topic modeling by BERTopic.
Methods
Three branded tweets about the COVID-19 vaccine were first collected. This research combined three datasets and applied two topic-modeling approaches (LDA and BERTopic) to ascertain reasons for underlying vaccine attitudes. Moreover, we revert to the original text based on the topic model, merge the texts of the same topic to generate a summary, and finally perform factorial induction (Figure 1). Each of the step-by-step vignettes is described in detail below:

Topic modeling and summary generation pipeline.
Data sources
COVID-19 vaccine-related tweets containing various predefined hashtags from 14 December 2020 (after the approval of the world's first COVID-19 vaccine) to 30 December 2021 were collected. These datasets include #CovidVaccine, # AstraZeneca, #Sinovac, and #Pfizer: 41,524 tweets were collected.
Tweets with vaccine attitudes are also manually annotated. There are two medical experts and six graduate students, and the group is composed of annotations. Those comments are discarded, and the two experts also have different opinions about those reviews with inconsistent labels. After the students complete the annotation, the experts will review all the content and correct any erroneous annotations.
Pre-processing steps for the text include removing forwards, URLs, and punctuation, converting emojis to words, removing stop words, and stemming. After data pre-processing, the dataset contains 5562 tweets, consistent with the literature.13,14
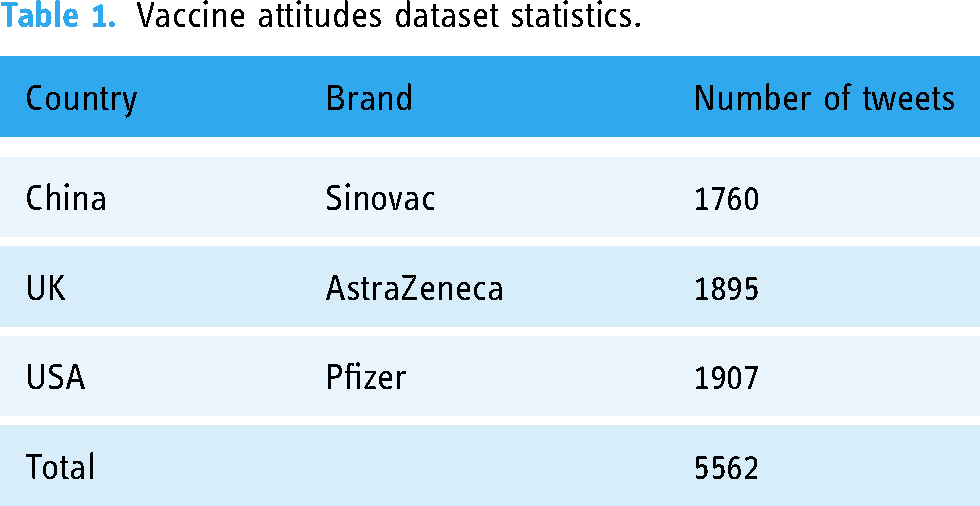
Although the user's account comment date is helpful for practical analysis of topic timeliness, we do not need this information at the topic-modeling stage. Therefore, we removed this information, only retaining the annotated text. Meanwhile, although pictures and emojis are helpful for sentiment analysis, 37 we only adopt text and leave the multimodal data to future work since the objective of the work is to analyze comments in English. Then, the data are separated by vaccine brand (Table 1).
Vaccine attitudes dataset statistics.
Topic modeling
In recent years, the Latent Dirichlet Allocation (LDA) 38 has been a standard method to identify the latent Dirichlet distribution in large-scale corpora. However, when dealing with short texts, it is easy to have the problem that the frequency of words cannot be the basis of the topic. The LDA model follows the bag-of-words assumption, which ignores the correlation between words. The Bidirectional Encoder Representations from Transformers (BERT) 39 topic model for the topic clustering of self-represented content. Thus, BERTopic clustering is used.
BERTopic relies on the attention mechanism model, using masked language model capture word and sentence-level representations, adopting noise-reducing self-encoding for model training. It can better adapt to the downstream tasks of NLP. In addition, BERTopic can be better based on short texts (less than 512 words in length) at the sentence or paragraph level processing tasks. Compared with static word embedding methods such as word2vec, 40 BERT's dynamic word embedding can also better understand the meaning of the sentence semantics.
Herein, we adopt the pre-training and fine-tuning approach of the BERTopic model 41 to reduce the dimensions of the resulting vectors (preserving the most important by using uniform manifold approximation and projection (UMAP)). 42 Moreover, clustering the reduced-dimensional content relied on a non-parametric hierarchical clustering algorithm, 43 which was originally developed in a different context. Cosine similarity is applied to identify the most “representative” words/phrases in a topic. Traditionally, LDA topic modeling requires a predefined number of topics, and an algorithm that clusters the corpus around several topics. BERTopic does not need a predefined k, only fine-tuning the model is required.
Number of topics selected
The literature
44
has proved that topic consistency is the most consistent measure of human understanding. Topic consistency is utilized to evaluate the optimal number of topics. The main idea of topic consistency is that if the generated topics are easy to interpret, words belonging to the same topic will co-occur more frequently in the corpus. The method of calculation of topic consistency is shown below
45
: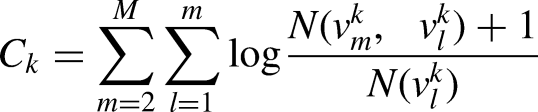
The consistency value of BERTopic under different numbers of topics is shown in Figure 2. This article also compares the consistency values of the two topic clustering results of BERTopic and LDA. The results demonstrate the consistency of LDA and BERT. The clustering performance of BERTopic is higher than that of LDA when the number of topics exceeds nine. When the peak is reached, the UK and USA brands are around 28, while Sinovac (in China) is at 35, which is different from the other three brands. American brands overlap at LDA, one at 17 and the other at 21: the interpretability clustering results become more robust when the number of themes increases, which also proves the superiority of the BERTopic method.

Clustering results of BERTopic and Latent Dirichlet Allocation (LDA). (a) Sinovac. (b) AstraZeneca. (c) Pfizer.
Summary generation
A language representation that can be processed by a computer is obtained. Language models are used to compute arbitrary language sequences
Encoder
The embedding vector is also input into the encoder, which encodes it into an intermediate semantic vector. The encoder utilizes a two-layer bidirectional long short-term memory, 46 which can better capture the semantic dependence.
Attention + decoder
Since the decoder cannot use the following steps in advance when executing each step input, the decoder adopts a two-layer unidirectional long short-term memory structure. The attention mechanism 47 applies to the hidden states of the encoder and gets the context, which is the input. The target word is connected in series as the output of the long short-term memory on the decoder enters and loops to obtain hidden states. The hidden states are bound to perform softmax to calculate the output probability.
CL
CL learns the feature representation of the sample so that the feature representation is as close as possible. 48 Inspired by previous work, 49 CL is incorporated into the summarization model. Figure 3 shows the model of CL. The proxy job establishes the similarity between samples. For example, similar models are positive, and the samples that are dissimilar are negative. Data augmentation is a typical means of implementing agent tasks. This model places closer topics having ‘similar’ meaning without the specific knowledge about the topic-based distances.

Summary generation based on contrastive learning (CL). 49
Moreover, a negative sample is designed. The M quality measure candidate can be defined in many ways. The candidate summary score 
Table 2 gives examples of summary generation, and each instance contains the topic number and its corresponding summary. The summary-generation model of proposed CL generates richer, more comprehensive, and more accurate summaries of English-language documents than other models. This result indicates that the model understands the complete text, the meaning of sentences and words within the context of the sentences; it portrays the sentences and words more carefully, which aligns with human understanding.
A typical summary generation (Pfizer).

Result
The experimental results are divided into four parts: topic analysis, factors induction, visualization analysis in CL, and group difference analysis.
Subject word analysis
Figure 4 shows the pre-processed dataset of the 20 most frequent words. The top 20 words include “effective, delta and variant” which differs from the vaccine brand across the dataset. This implies that the most frequent words reflect the dataset by impacting tweets and reflecting user sentiment.

Frequency of top-20 words by brand. (a) Sinovac. (b) AstraZeneca. (c) Pfizer.
Factor induction
By comparing LDA with BERTopic, BERTopic shows the best effect in terms of topic consistency. This method directly outputs the most prominent keywords for each topic. Topic names for each brand are defined by first looking at the top 20 keywords for each topic. The tweets are analyzed and categorized based on three factors, as extracted from the top-five topics in each database. Since we were interested in the most commonly discussed topics in the three datasets, which also point to the reasons for the central vaccination attitudes, the obtained topics are ranked by extracting the importance of each dominant text topic. This topic ranking is shown in Tables 3(a), (b), and (c), along with the original number of topics. The order of each topic is analyzed based on these data: their optimal number of topics is 35 (Sinovac), 39 (AstraZeneca), and 30 (Pfizer). The name is then checked against the 20 most popular tweets assigned to that topic. The BERTopic model topic is a matrix of the highest frequency of each subject term from using the subject term H, which allows us to understand the content of the topic.
(a) Top-five topics related to Sinovac by number of tweets.
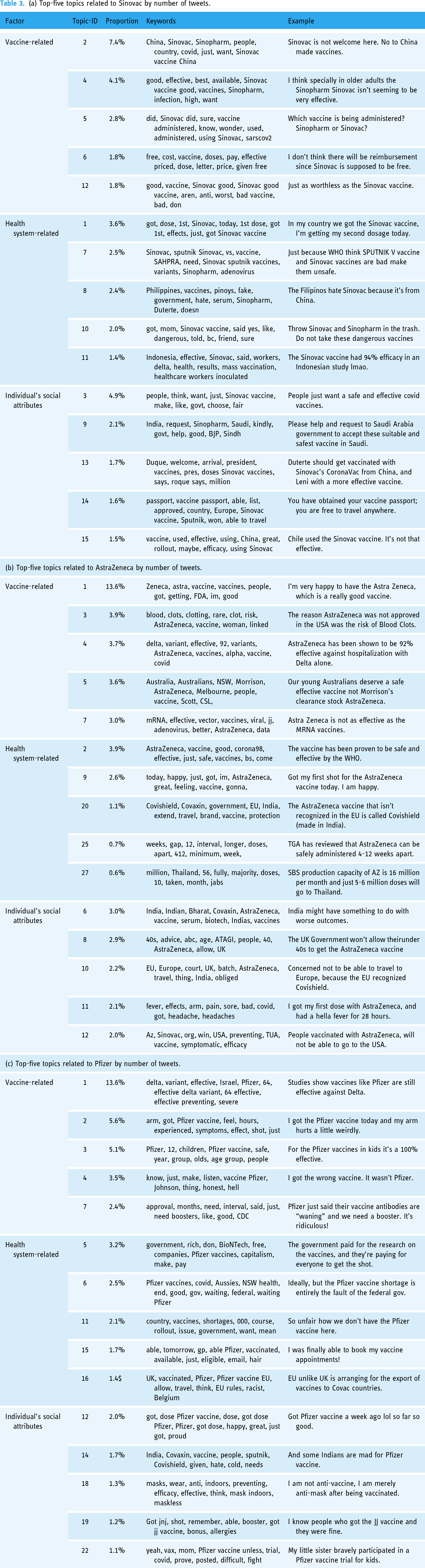
The first theme has a more significant proportion, which indicates a relationship with vaccines, implying that vaccines are effective. The second refers to the health system, indicating that the health system is also influencing people to try vaccines, and the third is the property of vaccines, expressing the satisfaction associated with vaccination. Comparing the three regions, the vaccine factor dominates, but the European and American ones rank higher than the Chinese brand.
The proportion of Sinovac is relatively tiny in vaccine-related factors. Since users of Twitter are mainly in the USA and the UK, people in China tend to use it less, resulting in fewer text samples. Users discussed the vaccine cost and whether they would spend money on vaccines. They are hesitant about which vaccine to get (Sinopharm or Sinovac). In particular, Sinovac has greater governmental support, and China is consistently in a state of popular trust in the government. As for users of AstraZeneca, discussions of its validity and efficacy predominate, such as, “Our young Australians deserve a safe effective vaccine not Morrison's clearance stock AstraZeneca.” Americans are concerned about its side effects (regarding Pfizer), with tweets such as, “I got the Pfizer vaccine today and my arm hurts a little weirdly.”
According to health system factors, Sinovac had the highest percentage of 4.9%, while the other brands were at 3.9% and 3.2%, mainly because China did not choose other vaccines, and the Chinese therefore have more reviews of Sinovac. However, Chinese vaccines are exported to South-east Asia. For instance, in Indonesia, “The Sinovac vaccine had 94% efficacy in an Indonesian study lmao.” AstraZeneca's primary market is in the EU, which is WHO-approved, but it also sells to Thailand. For example, “SBS production capacity of AZ is 16 million per month and just 5-6 million doses will go to Thailand.” Pfizer mainly discusses the cost to the government, with important keywords such as “rich.” For example, the government paid for the research on the vaccines, and they’re paying for everyone to get the shot. There's also the question of whether the government allows exports to the UK, for example, “EU unlike UK is arranging for the export of vaccines to covac countries.”
The factor of individual's social attributes is mainly the impact of social events, such as the situation in the Middle East. “Please help and request to Saudi Arabia government to accept individual's social attributes these suitable and safest vaccine in Saudi,” and “Chile used the Sinovac vaccine. It's not that effective.” These sentences arise mainly from the Middle East and South American countries with relatively good diplomatic relations with China. The countries where AstraZeneca mainly plays are the USA and India. The main political factor is that both countries were formerly British colonies and had the same political system. However, Pfizer targets children and needs to improve its effectiveness in the USA. For instance, “my little sister bravely participated in a Pfizer vaccine trial for kids.”
Visualization analysis in CL
To demonstrate the helpfulness of the framework of the CL model, the UMAP as a dimension-reduction technique is used. This algorithm is in three datasets by the embedding layer, with high-dimensional feature vectors for dimensionality reduction visualization. As shown in Figure 5, the distribution of topic models in the embedding space is reported. Before topic analysis, it is necessary to pre-train the text, specifically embedding the text and vectorizing it. This research selected the top-five topics, each color representing a different number of topics, squares representing word embeddings, and stars representing embeddings joined by CL.
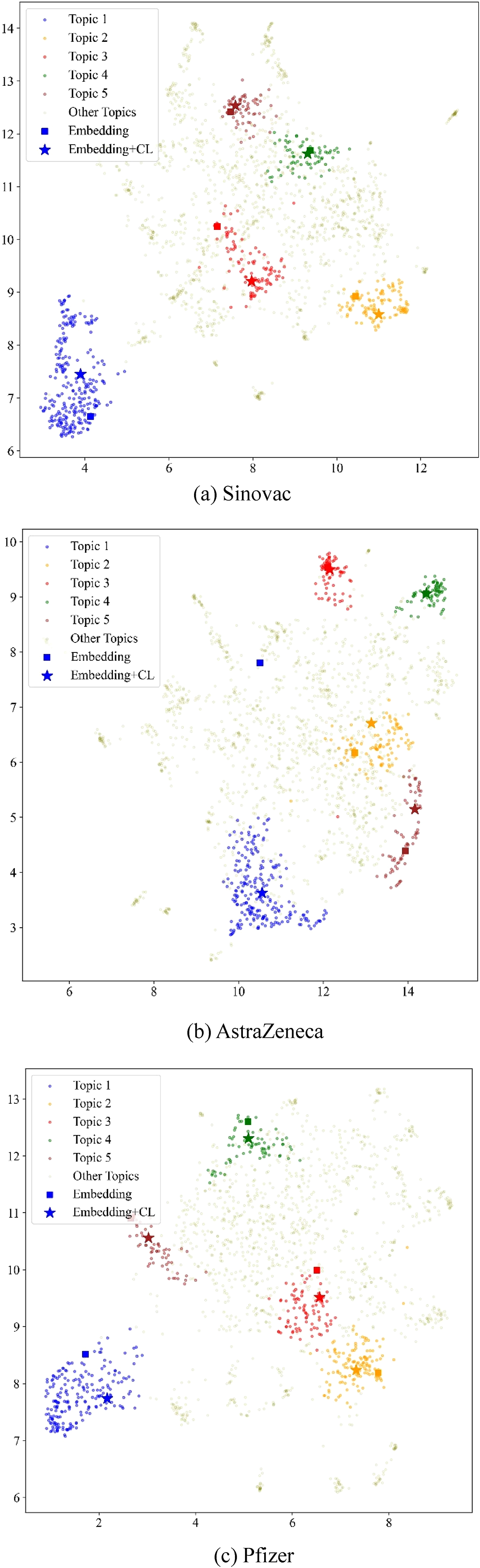
Visualization of each dataset. (a) Sinovac. (b) AstraZeneca. (c) Pfizer.
We also found that the points joined with CL are mainly closer to the center of the clusters or even overlap with the center, while only the word embeddings are far from the center. For example, the points of topic 1 pertaining to Pfizer lie outside the topic clusters. The CL strategy corrects the parameters of the pre-trained model, which strengthens clustering ability of the topic model and shows that the CL strategy also has a certain anti-noise ability. Thus, the fine-tuned model distinguishes different topic clusters better, and constrains the influences of outlier points on the clustering effect to some extent.
Group difference analysis
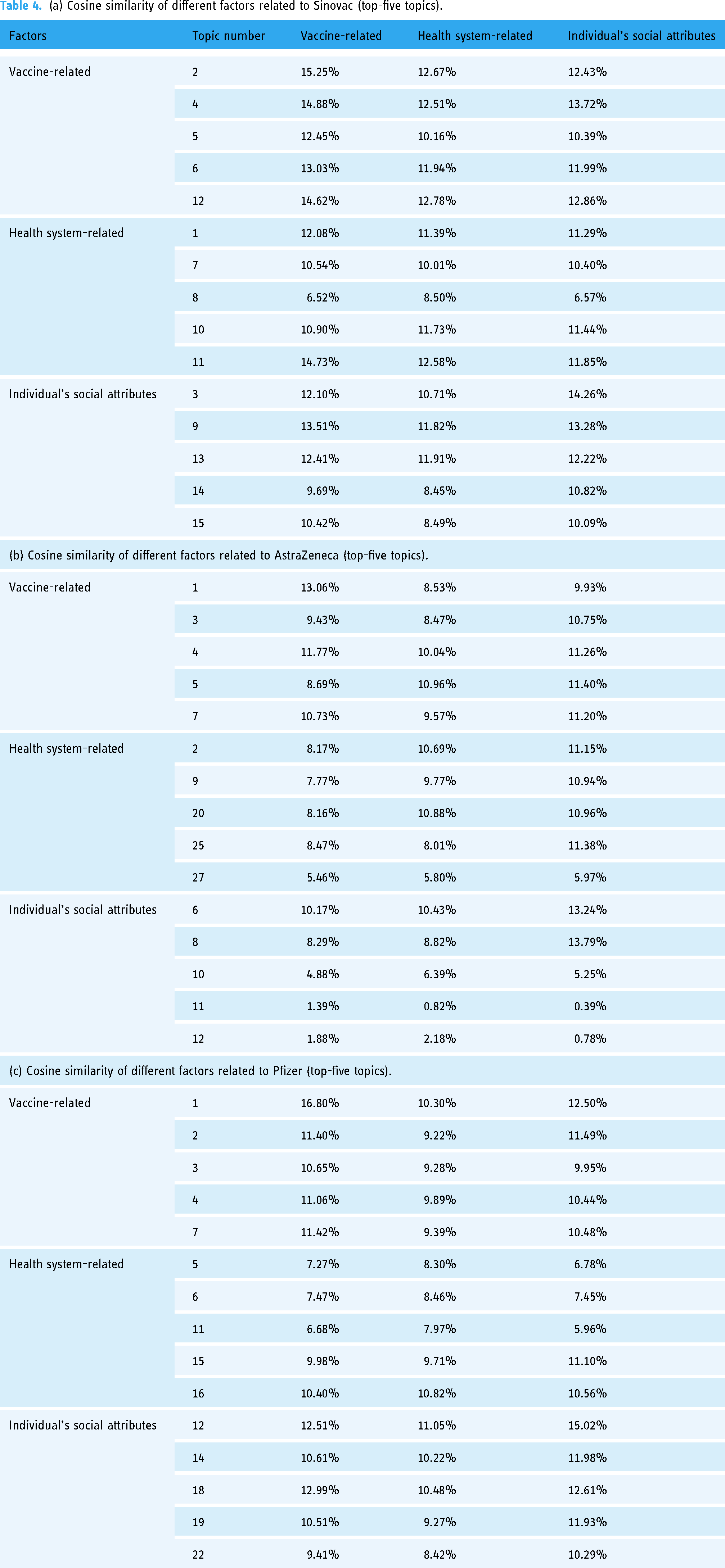
The cosine similarity method is used to explore the similarity between different topics and factors. The closer the obtained cosine similarity is to 1, the more similar the user group of that category is to the topic: the results are summarized in Tables 4(a), (b), and (c). For Sinovac (Table 4(a)) and correlations between the different factors, there is a high correlation in the vaccine factor, with the highest being 15.25% and the lowest being 14.62%, which indicates the most prominent element related to vaccines. Significantly, the correlation between the two health systems is higher among the health system factors. Also, among the social attributes, the correlation is higher for topic 5, so it can be determined that the correlation is higher for factor overlap. The same outside from AstraZeneca and Pfizer can be seen that also the two factors are much the same, which both are highly correlated between two identical factors. However, the factors of AstraZeneca are also found to be smaller, and the correlation is not significant.
(a) Cosine similarity of different factors related to Sinovac (top-five topics).
Discussion
Principal findings
This finding is higher than other previous on-line investigations from the UK, 50 the USA, 51 and France. 52 These countries arise probably because Twitter users are more prone to vent negative emotions on-line. The central theme of vaccination attitudes was identified by three groups in the discussion of the Tweets, including vaccine-related, health system-related, and individual societal attributes. Some themes demonstrate episodic changes and high degrees of co-occurrences in close association with vaccine developments. This study enriches our understanding of the public concerns related to vaccines. These shared concerns can inform public health organizations and professionals for more tailored health messages and vaccination policies.
Our results suggest that vaccine-related factors and effectiveness were the respondents’ main reasons for the professed attitudes. People hoped to confirm their willingness to vaccinate by extending the test time and ensuring the safety and effectiveness of the vaccine. From the perspective of individual factors, older people should be a priority group for vaccination, but they did not show a greater desire to be vaccinated than younger people. Considering individual societal attributes, people who were currently vaccinated against seasonal influenza are more likely to receive the COVID-19 vaccine, which is related to the perception of, and trust in, the vaccine among this population. A Finnish scholar 53 proposed that people's intention towards vaccination can be predicted by their perception of the risks around vaccine safety. The group with high confidence in the effectiveness and safety of vaccines had a lower probability of negative vaccine attitudes than the group with quiet confidence therein.
Summary generation and topic modeling
Although LDA introduces a way to attach topic content to a document, which treats each document as a hybrid of several different topics, the tweets alluded to here usually need to meet this requirement, and most of them are short documents with one main topic. In addition, LDA suffers from a disorderly effect, which means that different topics cannot be generated in order, leading to differences in topic names when the words defining the topics or the order of importance differ.
During the model learning process, the sentence is learned in both directions to understand the contextual information of the word so that the same word can be better reflected in different contexts. They used a masked language model and sentence prediction multi-task training objective for pre-training, applying the model to other specific tasks by fine-tuning to attain semantically richer word vector representations.
The present work is mainly applied to vaccine attitudes through summary generation, aiming to help users acquire information quickly and help the government promptly understand the factors affecting vaccine attitudes. The proposed algorithm is based on the characteristics of social media timeliness, which improves on previous scholars’ research with the algorithm incorporating CL. Visualization results show that the summary-generation technique can improve the timeliness of the summary, however, the research has many algorithmic limitations that need to be investigated in depth, such as how to make the abstracts more fluent and coherent when generating them. 54 Therefore, how to use semantic analysis to enhance the coherence of abstracts is a potential avenue of exploration for the future.
Implications for management
The more significantly to promote the demand, use, and equitable distribution of COVID-19 vaccines, the community public health strategy should use a health belief model to minimize the possibility of vaccine hesitancy. 55 Strully et al. 56 suggested that governments should increase funding to promote vaccine popularization, and reduce vaccine inequity caused by racial discrimination and the marginalization of some traditional communities, which plays a role in the fair distribution and use of vaccines by establishing social organizations with different functions.
Unlike traditional media, social media allows individuals to create and share content rapidly across the globe without editorial oversight. Users may choose their content streams, resulting in a separation of meaning. For this reason, if anti-vaccination messages flood these platforms, considerable public health concerns can arise and may lead to vaccine hesitancy, undermining public confidence in future vaccine development for novel pathogens. 6 In response to false information about COVID-19, many foreign social media companies have issued a joint statement to combat “misinformation about the virus,” provide verified information, and use tools to flag and remove tweets containing misleading information and highly damaging content. 57
Delivery of health knowledge of individual vaccination can reduce the incidence of negative vaccine attitudes and increase the rollout of any vaccination program. The public's high expectations for vaccines and the rapid progress of vaccine research and development in the context of the COVID-19 epidemic have made society pay closer attention to safety, immunogenicity, protective efficacy, and response to virus variation of different types of COVID-19 vaccines. In Europe, it has been suggested that organizing groups or experts to engage with undecided people, encouraging them to ask questions, actively listening to their concerns, and providing clear, easily understood, and evidence-based information are effective ways in which to promote acceptance of COVID-19 vaccines. 58
As an important disseminator of vaccine and vaccination knowledge and information, vaccinators are an important link to strengthening public confidence in vaccination. 59 Vaccinators should continue to learn and master the ability of vaccines to enhance their confidence in vaccines; in the face of patient consultation, they should be able to provide professional answers to alleviate the concerns of the patient.
Limitations and future work
This study is based on only Tweet users, so a selection bias prevails compared to the broader target group for vaccination. This research will expand our range of social media platforms, such as Reedit or Weibo in future work; the range of vaccine brands analyzed (including, e.g. Janssen, Sinopharm, and Moderna) can also be broadened. Regarding methodology, this research only adopts CL for summary generation and adopts BERTopic to extract topic models: in future work, we will use deep learning for sentiment analysis or attitude detection. Although, this paper discusses the vaccine attitudes of the public in different regions, which does not consider human mobility and behavioral characteristics. 60 Future work can be improved by using geotagged mobility data.
Furthermore, most Tweets topics covered three themes: vaccine factors, individual factors, and cognitive factors. However, there remain some topics unable to be covered by these factors. There should also be longitudinal research conducted in the future.
Conclusion
This paper presents a combination of NLP methods aimed at studying the reasons for vaccine attitudes in different regions, which focuses on information about users collected from Twitter and expressed by users. We first collect tweets from three brands with keywords: COVID-19 and vaccine. Moreover, this research establishes a text summary-generation model based on CL and then uses BERTopic to cluster topics automatically, which shows outstanding performance and provided high-quality results. The topic models are constructed for vaccine attitudes factors that can be best used in future opinion studies, especially for immunization programs, as the world remains uncertain about how pandemics evolve. For these reasons, our work can lead to a better understanding of the vaccination process. The findings will allow governments and pharmaceutical medical institutions to develop or redefine better solutions to the problem of vaccine attitudes. This work can improve the fight against the COVID-19 pandemic.
Footnotes
Contributorship
It is a single-author paper.
Data availability statement
The datasets generated for this article are not readily available because the raw data cannot be made public; if necessary, feature data can be provided. Requests to access the datasets should be directed to the corresponding author.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
This retrospective study was approved by the Research Ethics Commission Wuhan University. The requirement for informed consent was waived due to its retrospective design.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key Research and Development Program of China (No. 2021ZD0113304), the National Natural Science Foundation of China (No. 72204190), the Research Foundation of Ministry of Education of China (No. 22YJZH114), and the China Postdoctoral Science Foundation (No. 2022M722476).
Guarantor
All authors are the guarantors of this manuscript.