
Abstract
In modern hospitals, monitoring patients’ vital signs and other biomedical signals is standard practice. With the advent of data-driven healthcare, Internet of medical things, wearable technologies, and machine learning, we expect this to accelerate and to be used in new and promising ways, including early warning systems and precision diagnostics. Hence, we see an ever-increasing need for retrieving, storing, and managing the large amount of biomedical signal data generated. The popularity of standards, such as HL7 FHIR for interoperability and data transfer, have also resulted in their use as a data storage model, which is inefficient. This article raises concern about the inefficiency of using FHIR for storage of biomedical signals and instead highlights the possibility of a sustainable storage based on data compression. Most reported efforts have focused on ECG signals; however, many other typical biomedical signals are understudied. In this article, we are considering arterial blood pressure, photoplethysmography, and respiration. We focus on simple lossless compression with low implementation complexity, low compression delay, and good compression ratios suitable for wide adoption. Our results show that it is easy to obtain a compression ratio of 2.7:1 for arterial blood pressure, 2.9:1 for photoplethysmography, and 4.1:1 for respiration.
Introduction
The global datasphere increases at a compound rate of 24%, and it is predicted to reach nearly 180 Zettabytes by 2025. 1 While the actual distribution between data storage and data generation averages 1 to 49 ratio, in Healthcare, the ratio is 1 to 2.35, 2 meaning that the future health data generation possibility is vast and untapped today. Indeed, such a remarkable difference contributes to the reported annual compound growth specific to the global health datasphere: 36%, which is 50% larger than the global average. Wearable, non-invasive, Internet of medical things (IoMT), and big data analytics technologies contribute to more data being collected. In a society envisioned by the European Commission, flowering under the umbrella of the European Health Data Space (EHDS) regulation, 3 efficient data collection and storage will be a sine qua non-condition to see the future outlined by the EHDS, where progress is driven and sustained by access to health data.
Understanding the characteristics of biomedical big data can be considered the most critical requirement for harnessing the true potential of health data. 4 Biomedical signals, such as the electrocardiogram (ECG) signal has long been used for diagnosing cardiac complications 5 or as a vital sign in intensive care. 6 Using methods, such as signal processing or machine learning, we are now starting to understand that these continuous measurements carry more important information than what we know today. This does not only hold for ECG. Recently, Davies et al. 7 and Lee et al. 8 have shown that during surgery, the shape of the arterial blood pressure (ABP) curve can be used to predict the onset of hypotension ahead of time. Using sensor-fusion of multiple biomedical sensors, van der Ster et al. 9 reported a prognosis of hypovolemic shock before blood pressure starts to drop. Hence, curve data contain information revealing important clinical facts and must be collected and stored without loss of information.
Many biomedical signals are routinely measured continuously, generating time-series data, sometimes called high-frequency or curve data. Typical signals include ECG, ABP, photoplethysmography (PPG or sometimes PLETH), and respiration (RESP). Depending on the patient need, many more signals can be collected. However, storing all patient-generated data can be a challenge as typical hospitals may have several thousands of patients. Many of them will have one or more sensors. At the same time, data storage at hospitals needs high reliability and privacy protection due to patient safety and regulations, which makes storing large amounts of data expensive and cumbersome.
The focus of this article is to investigate the compression of biomedical signals for large-scale collection and storage of biomedical signals. Since there is a large body of research regarding the compression of ECG, 10 this article will focus only on compression of the remaining biomedical signals; in particular ABP, PPG, and RESP. The aim is not to propose yet another compression method with an minor compression improvements, but to validate several simple compression methods to these biomedical signals and identify the best available technique and configuration for each of them. However, the sometimes subtle changes in the signal should not be accidentally removed by the digitalization process and/or compression, since it is not known whether those subtle changes carry essential information. Therefore, we will mainly investigate lossless and near-lossless compression algorithms.
State of the art
There are numerous examples of ECG signal compression,10–15 consisting of multiple time series due to the many leads usually involved in medical ECG measurements. However, compression for other biomedical signals is almost non-existent in comparison. One exception is Gogna et al., 16 which compresses both ECG and electroencephalogram (EEG) signals. Other exceptions are Banerjee and Singh, 17 where lossless compression methods for ECG and PPG signals are proposed, and Nakatsuka et al., 18 where compression of the less common signals; intravesical pressure and rectum pressure are investigated. Some papers19,20 propose compression methods for electromyography (EMG) signals.
There are too many papers covering compression of ECG signals to mention them all here. 10 Most proposed lossless compression methods13–15 are based on linear prediction followed by coding the residual errors using variable length coding, such as Huffman or Golomb-Rice codes. In some proposals, 13 adaptive linear prediction is used where the prediction coefficients adapts to the signal for improved compression over time. Another approach is to use a transform-based approach, such as the one by Arnavut. 11
When it comes to lossy ECG compression, transform-based approaches are very common. 12 Discrete Cosine Transform (DCT) is one way to perform lossy ECG compression as proposed by many authors.21,22 Ranjeet et al. 22 explored the possibility of using the Discrete Fourier Transform and the Discrete Wavelet Transform, with the conclusion that all transforms can be used for compression while preserving necessary clinical information. Compressed sensing (CS) is another method that combines random sampling and the potential sparsity of a signal by sampling at sub-Nyquist rates and still reconstructing the original signal. Many authors12,16 have proposed CS for compressing ECG signals.
Gogna et al. 16 proposed to use a type of artificial neural network (ANN) called a stacked autoencoder for compressing ECG and EEG signals. They also proposed to extend the ANN for compression with classifier outputs for automated diagnosis of some common cardiac complications when used on ECG signals.
Not only compression is important, but also many other system aspects. The Hospital for Sick Children (HSC), Toronto, Ontario, Canada, developed a database named Atrium that stores, compresses, and retrieves physiological signals from one of its departments. 23 AtriumDB is vendor-neutral and integrates with existing bedside monitors. It uses lossless compression based on differential pulse code modulation (DPCM) and BZip2. Metadata is stored in a relational database, and signals are divided into 10-min segments and stored in a file system to allow for more efficient data handling, storing, and retrieval.
Biomedical Signals
Today’s hospital settings use extensive monitoring, such as perioperative care and intensive care, where biomedical signals are gathered with multiple leads or sensors. They are immediately digitized using an analog to digital converter (ADC) before being connected to a bedside monitor for feedback to the acting specialist or nurse. The digital signal may also be transferred to a central office, where all patients in the department are monitored simultaneously. Finally, the signal data may be sent to a hospital-based database for storage and future analysis, but that is not yet common practice.
Most biomedical signals are sampled with a 100-500 Hz sampling rate and an 8-16 bits ADC. The ADC will read the instantaneous amplitude and convert into a integer with a certain bit length. A longer bit length means better resolution, but also require more storage space. In pulse code modulation (PCM), every sampled value is stored as a long sequence of integers. Sometimes the curves are saturated by the upper and lower limits, and sometimes, they only utilize part of the full range of the ADC. Nevertheless, to store these values using 16-bit integers per sample is common, even when sampled with a 10 or 12-bit ADC. This by itself is a waste of storage space. Furthermore, the sampling rate is much higher than needed for many biomedical signals, that is, they are oversampled. Power spectral analysis of the biomedical signals reveals that many signals do not have high-frequency components and can be sampled with lower sample frequency, as long as not lower than the Nyquist rate (twice the frequency of the highest frequency component). For instance, the power spectrum of the ABP waveform shows that very little power exists in frequencies above 25 Hz, meaning that a sampling rate of 50 Hz is sufficient. Hence, a straightforward way to reduce storage requirements is to use a lower sampling rate or downsample if the signal is already sampled. The latter is possible by applying a low-pass filter followed by only saving every M:th sample. If the Nyquist requirement is still fulfilled, no essential information loss will occur.
The amount of compression possible for a medical signal depends on the signal characteristics, the sample rate, and the ADC bit-resolution. Typically, we measure the compression ratio (CR) as the fraction between the uncompressed bits and the compressed bits. Typical lossless compression methods of ECG signals of 360 Hz with 11-bits ADC have a CR range between 1.9:1 and 2.4:1, depending ECG channel and the used compression method. 13 This can be compared to reducing the sample rate from 360 Hz down to 125 Hz, which corresponds to a CR of 2.88:1. However, such a downsampling is of course not lossless.
HL7 Fast Healthcare Interoperability Resources (FHIR) 24 is an important health data standard that also defines how to transfer sampled data. However, FHIR specifies that sampled data should be transferred as space-separated integers coded as decimal numbers using ASCII characters. This means that the data transfer will be significantly larger than the uncompressed raw values. Typically, every sampled value will be represented by 5 bytes (including the space character). Hence, HL7 FHIR is not optimized to deal with large amounts of sampled data.
Methods
In this article, we will apply simple compression to different signal types in order to investigate the amount of compression that can be achieved. We will experiment with some common methods and try the relevant configurations for them in order to find the typical compression performance. The following sections will first discuss different lossless compression methods followed by a downsampling method. All methods will work for any biomedical signal, but their compression ratios will differ.
Lossless methods
Lossless compression for time-series data is usually based on reducing the variance of the values and then giving more frequently occurring values a shorter code. The latter is called variable length coding (VLC), which we discuss in a later subsection. A simple way to reduce variance is differential pulse code modulation (DPCM), which is the same as recalculating the sampled values x(n) as follows:

DPCM can also be said to predict the next value based on the previous value, i.e.,

The errors e(n) are clustered around 0 and their variance is hopefully small. This will lead to efficient compression when combined with an efficient VLC. Another straightforward, yet effective, method is to use the trend to predict future values, i.e.:
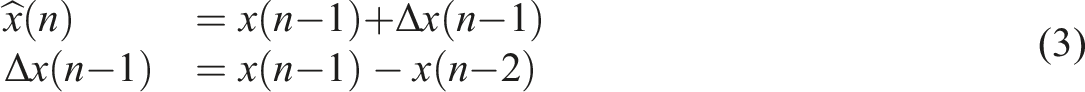

To use equation (4) for DPCM, we just set M = 1 and h1 = 1. For the linear trend prediction, we have M = 2, h1 = 2, h2 = −1. However, there may be better parameter configurations given the curve data, which we may try to find with optimization tools or machine learning.
Variable length coding
In variable length coding (VLC), each value is given codes of different lengths depending on the frequency of occurrence, where common values are given codes with shorter lengths. VLC will achieve a good compression ratio if a few values are very common.
In Huffman coding, you first go through all your values to check the frequency of every occurring value. An optimal code list is created in the form of a Huffman tree. This is the optimal VLC, but the Huffman tree needs to be coded too and added to the compressed values as overhead. Furthermore, it must pass through (at least part of) the sequence before the (semi-)optimal Huffman tree can be created and the compression starts. If we want to compress short sequences of values or reduce compression delay, we need to avoid Huffman.
Another popular method is Golomb-Rice codes
25
or a variant called Exponential-Golomb.
18
In our case, Exponential-Golomb is always more efficient, so we focus on only that variant. Exponential-Golomb only encodes positive integers larger than 1, and assigns smaller codes to smaller values. Since our residual errors are small and scattered around zero, we first need to convert them into positive integers as follows:
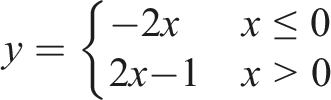
Exponential-Golomb has a parameter called order: k. It means that the k least significant bits are coded with normal binary coding and only the remaining bits are encoded with variable length codes. If we start with a positive integer y, we code y mod 2 k in binary format as usual. For the remaining bits, we add 1 to make it larger than zero: y′ = ⌊y/2 k ⌋ + 1. Then we count the number of bits in y′, that is, n = ⌊ log2y′⌋ + 1. The code is formed by a prefix of n zeroes followed by binary codings of y′ and y mod 2 k . The first part ensures that one code is never the prefix of another code, which is important for decompression. The number of prefix zeroes gives the number of bits for y′ and k gives the number of bits of the last part.
Downsampling
A very efficient way to reduce the space requirement is to downsample an already digitized signal if it is sampled at a high rate. 14 The process of reducing the sampling rate consists of two steps, where the first being a low-pass filter to avoid aliasing (distortion). The filter must remove any frequency components higher than half the new sample rate (i.e., the Nyquist frequency). In the second step, samples are removed and this will reduce the storage size requirement, but also remove signal information. After downsampling, we can compress further using any of the lossless methods, but with reduced compression ratio as there are much less redundant information.
In our implementation, we keep every N:th samples, where
Experimental setup
We conducted experiments on pre-recorded data to test the compression methods on real biomedical signals. In this section, we introduce the evaluated methods, the performance metrics, and the used data.
Evaluated methods
In the remaining of this article, the focus is on the following compression methods: • DPCM according to equation (1) • Trend, which is the linear trend prediction in equation (3) • LinP(k), which is the general linear prediction of equation (4) with either order M = 3 or 4. The h
k
parameters are determined from a separate set of data as mentioned in the Results section. • Down(N), which is the downsampling method mentioned earlier
All the above are combined with VLC approaches, namely Huffman, Golomb-Rice, Exponential-Golomb coding with order k, and Lempel-Ziv-Welch (LZW). The Huffman coding requires two passes of data and the resulting Huffman tree also needs to be stored. However, the storing of the Huffman tree is ignored. Therefore, we mainly consider this option as a theoretical upper limit of what VLC can achieve. Golomb-Rice and Exponential-Golomb coding with order k are not optimal, but has no overhead and is close to what can be achieved. LZW is included for comparison only. In the Results section, we tune the order parameters for the different methods and signals to maximize the compression ratio.
Performance measurements
The main measurement in this work is the compression ratio (CR), which can be expressed as the fraction between the uncompressed bits and the compressed bits, where a higher number means more compression. As uncompressed bits, we assume a compact storage of the PCM values. I.e., if the signal is sampled with an ADC of 12 bits, we assume that they are stored as 12-bits binary values. In practice, this is rarely the case. Instead, 12-bit values are typically stored as 16-bits values, such as most of the MIMIC-3 wfdb data,26,27 or as whitespace-separated (or comma-separated) ASCII-coded decimal numbers as with FHIR. Going from 16-bit to 12-bit values represents a compression ratio of 1.33:1 and going from a FHIR storage to 12-bits values gives an approximate compression ratio of 3.3:1. These numbers should be multiplied with the reported compression ratios below if compression from those storage methods is considered.
For the downsampling method, it is also necessary to measure the amount of information loss introduced by the filtering and downsampling steps. We reconstruct the signal to the original sampling rate by interpolating removed samples using a polyphase filter based on Kaiser with β = 5. Then the quality of the reconstructed signal is compared to the original signal. The quality reduction is calculated as the Percentage Root Mean Square Difference (PRD) as specified in the equation (5):
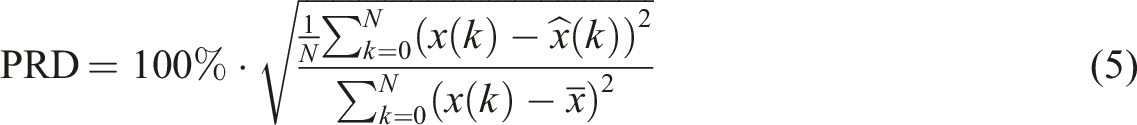
Test data
For the validation of the compression methods, we used biomedical signal data from version 1.0 of the MIMIC-III Waveform Database (WFDB).26,27 The database contains vital signs recordings from approximately 30,000 ICU patients from several U.S. hospitals. It is a de-identified dataset and is made public under the Open Data Commons Open Database License v1.0, which we adhere to. Requirement for patient consent was not needed because it did not impact clinical care and all data was de-identified. Under the US Health Insurance Portability and Accountability Act (HIPAA), this means research using this data does not constitute human subjects research. The same holds for the authors’ national ethical review authority.
For this study, we selected ABP, PPG, and RESP only. Those signals are sampled at 125 Hz using an ADC of either 8, 10, or 12 bits. We decided to ignore recordings of 10 bits and only focus on 8 and 12-bit recordings. Furthermore, there were very few 8-bit recordings of respiration, so we excluded that too.
The MIMIC-III WFDB contains the raw sampled data of vital sign waveforms, including noise, motion artefacts, and sometimes just nonsense data due to many different types of recording problems. However, this is typical for vital sign data being recorded at hospitals. Since it is difficult to determine whether a signal is good, it is better to collect and store everything. Because of this, it is important that the compression methods also can deal with this real-world data, which is an important part of the validation. Hence, we have not attempted to remove any noise as long as there is not only noise for a particular biomedical signal from a particular patient.
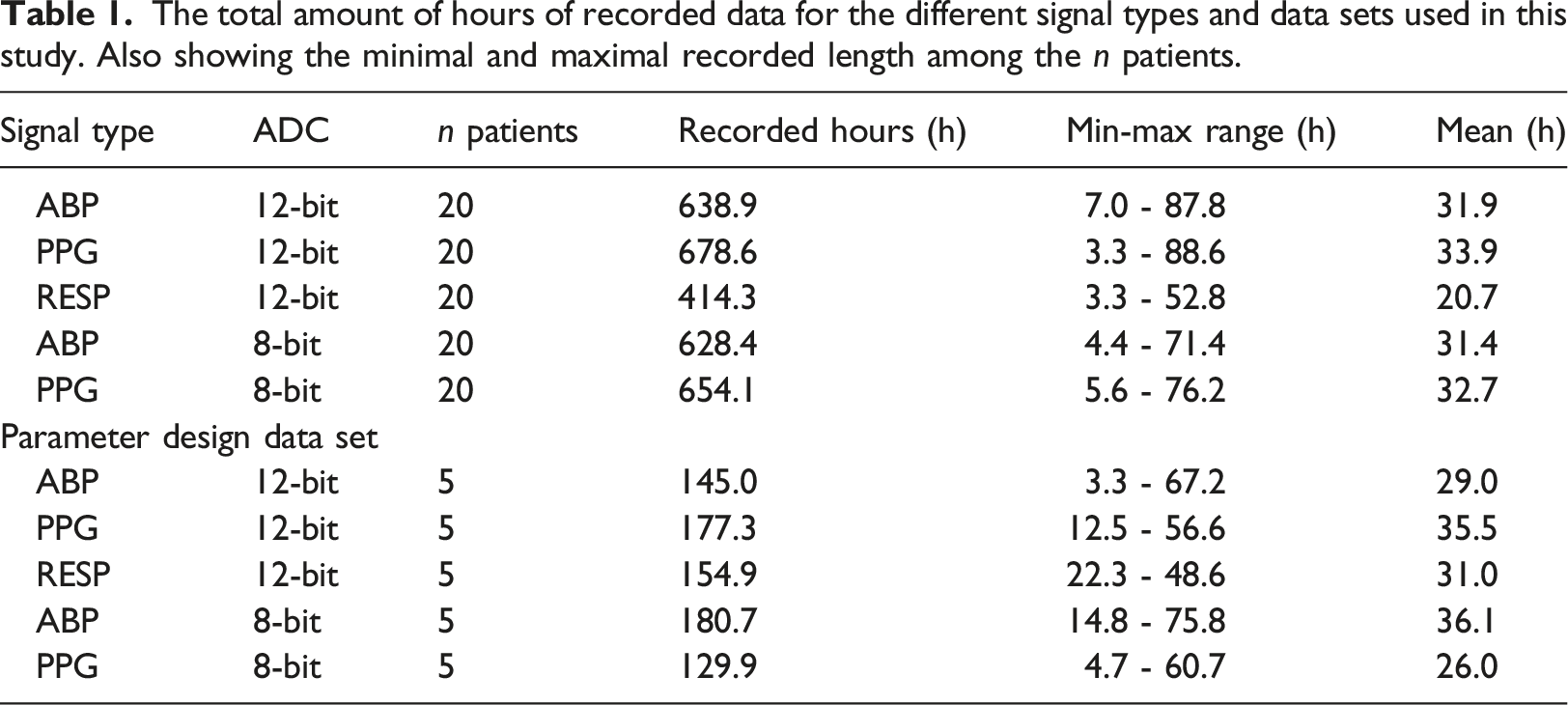
Using the Python WFDB API, signal data from 20 random patients for each signal type were identified and downloaded. Each patient recording was subdivided into segments by MIMIC. We excluded patients with less than 3 h of recorded values or more than 100 h to achieve some balance between the patient recordings. This exclusion will not alter the distributions in any significant way, since the signals share the same distribution regardless of the recorded signal length. Segments shorter than 10 s or containing data with zero variance were also removed, since they usually only contain noise or nonsense values. Since the latter is such a small amount of data compared to the total (maximum was 1% for 12-bit RESP), it will have a very marginal effect on the final results.
The total amount of hours of recorded data for the different signal types and data sets used in this study. Also showing the minimal and maximal recorded length among the n patients.
Results
The results in this section are based on calculations and simulations implemented in Python 3 and NumPy. In the first part, we find the best parameters for some of the methods based on the parameter design data set. Then, we apply the methods with their parameters on the validation data set to see how efficient the different compression methods perform on the MIMIC-III WFDB data.
Finding the optimal predictor coefficients
The first step was to find the best predictor coefficients in equation (4) for the methods LinP(3) and LinP(4). The optimal coefficients are different for different types of signals and ADC bit depths, so we searched for each of the five combinations on the parameter design data set. The minimization function is the achieved length of the compression of all the recorded signal values of the given type from the parameter design data set. The coefficients are provided as a vector, and we used Exponential-Golomb with order k = 0 as the VLC. The modified Powell search algorithm was used and we tried several initial values to increase the likelihood of finding the global minima. However, the function is not smooth, and a local minimum was often found.
Linear predictor coefficients for order 3 and 4 for all signal types and ADC bit-lengths.
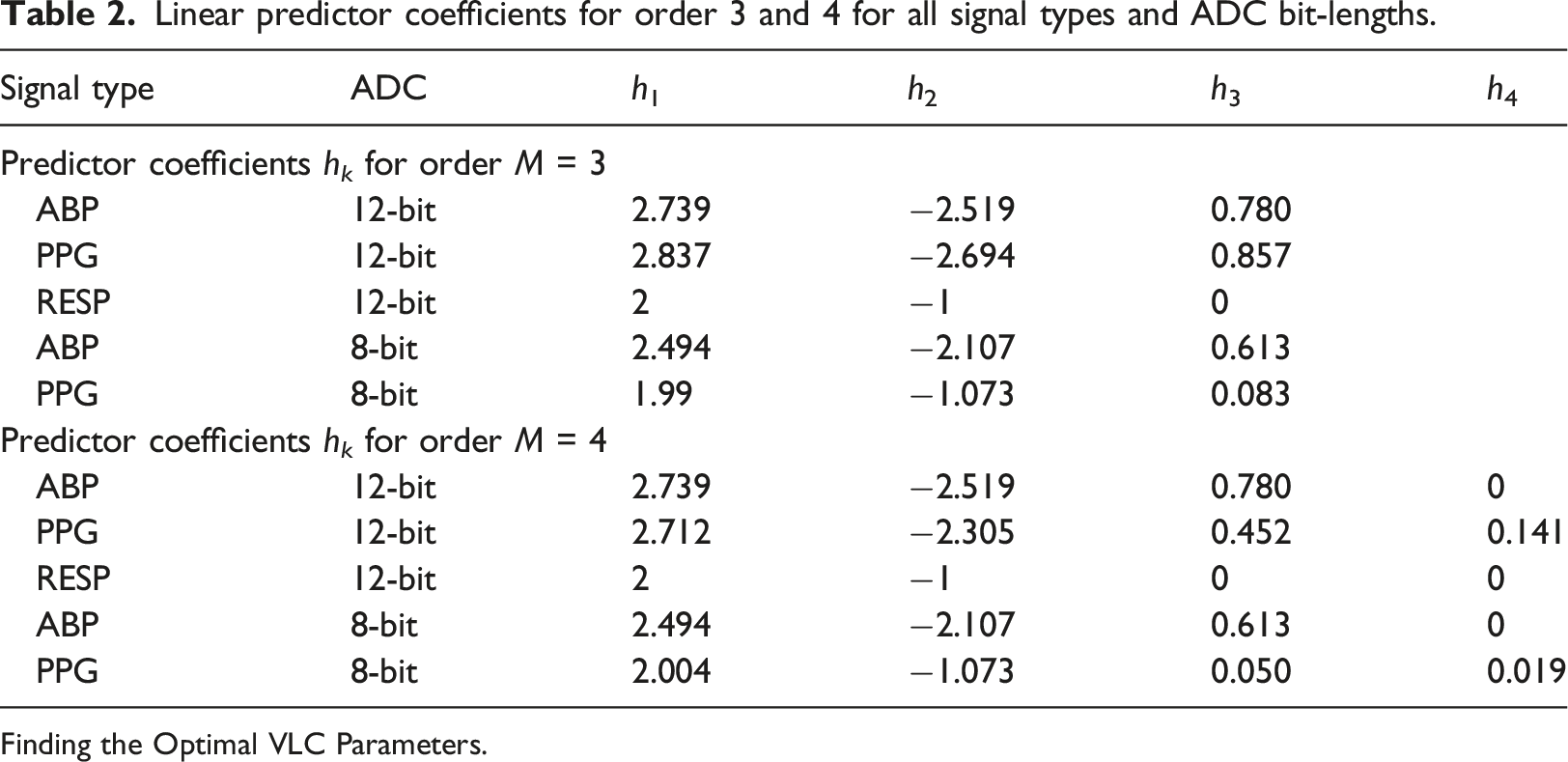
Finding the Optimal VLC Parameters.
The second step was to determine the best parameters for the different VLCs. We started with the Exponential-Golomb order k parameter and tried different values of k in the expected range 0 ≤ k ≤ 6. We calculated the average compression ratio for LinP(3) and LinP(4) to see which order k gives the best results. This was done per signal type, and the results of this from the parameter design data set are shown in Figure 1. Different order of Exponential-Golomb coding for various 12-bit signals. CR shows the average between LinP(3) and LinP(4).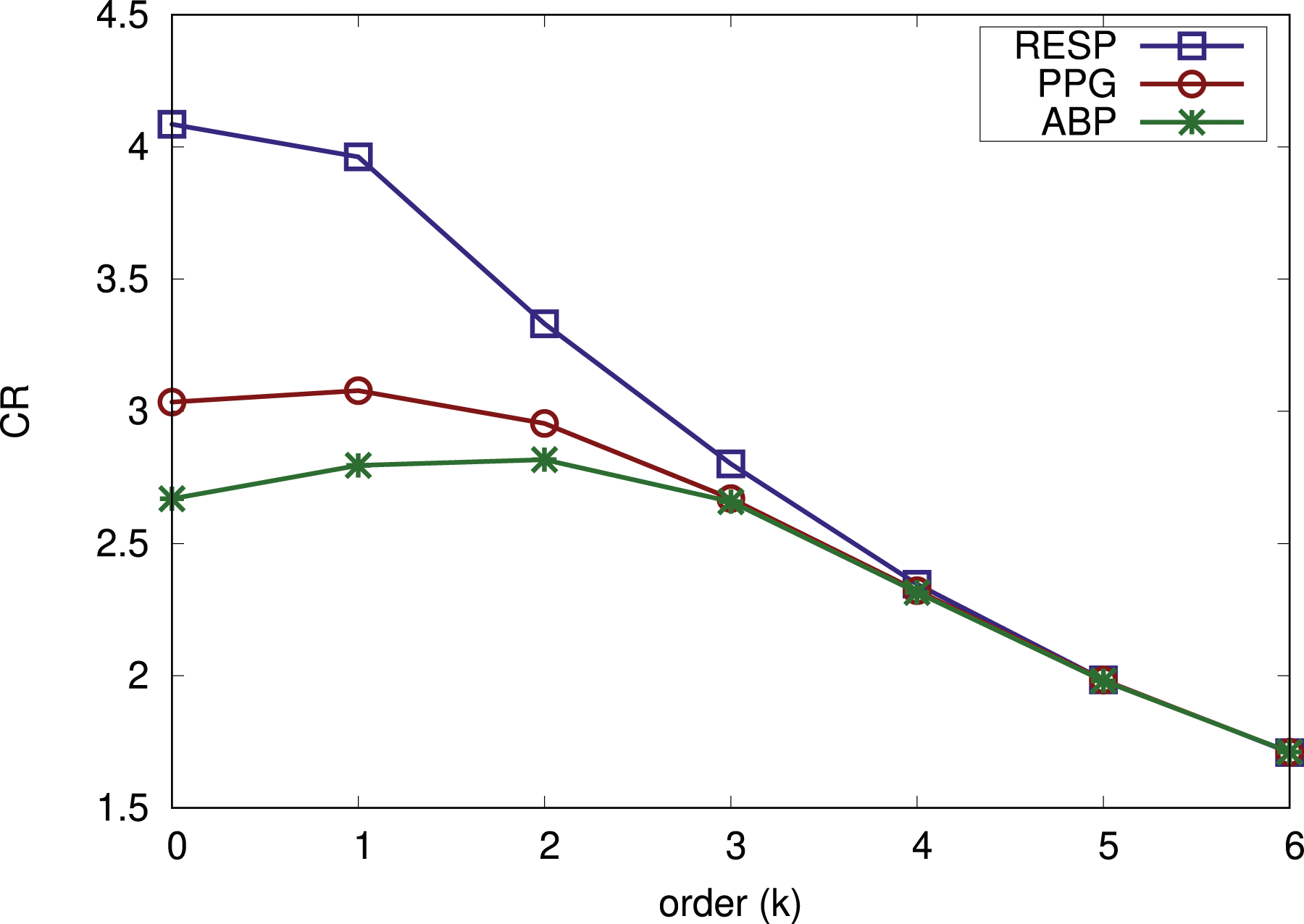
As can be seen in Figure 1, k = 1 is a good trade-off for signals sampled with 12-bits ADC. For respiration, k = 0 is better and for ABP, k = 2 is better. However, the gains are small and we believe it is better to keep parameter choices as similar as possible. Hence, we selected k = 1 for all 12-bit signals. The results for the 8-bit signal types are not shown. It is rarely the case for them that an Exponential-Golomb order larger than 0 is beneficial for the compression ratio. Hence, we use order k = 0 for both 8-bit signals. We also determined the best parameter configurations for Golomb-Rice and LZW in a similar way. For Golomb-Rice, b = 3 was best. For LZW, it was START_BITS = 8 and MAX_BITS = 12 that gave the best compression results.
Then we compared the different VLC methods with each other and this is shown in Figure 2 based on the validation data set. The error bars show the 95% confidence intervals. We show Exponential-Golomb with k = 1 for 12-bit signals and k = 0 for 8-bit signals. As expected, Huffman results in the biggest compression ratio for all types of signals. We also see that Exponential-Golomb is the second-best option for all signal types. Therefore, we will focus on Huffman and Exponential-Golomb. The compression ratio for some different VLC methods.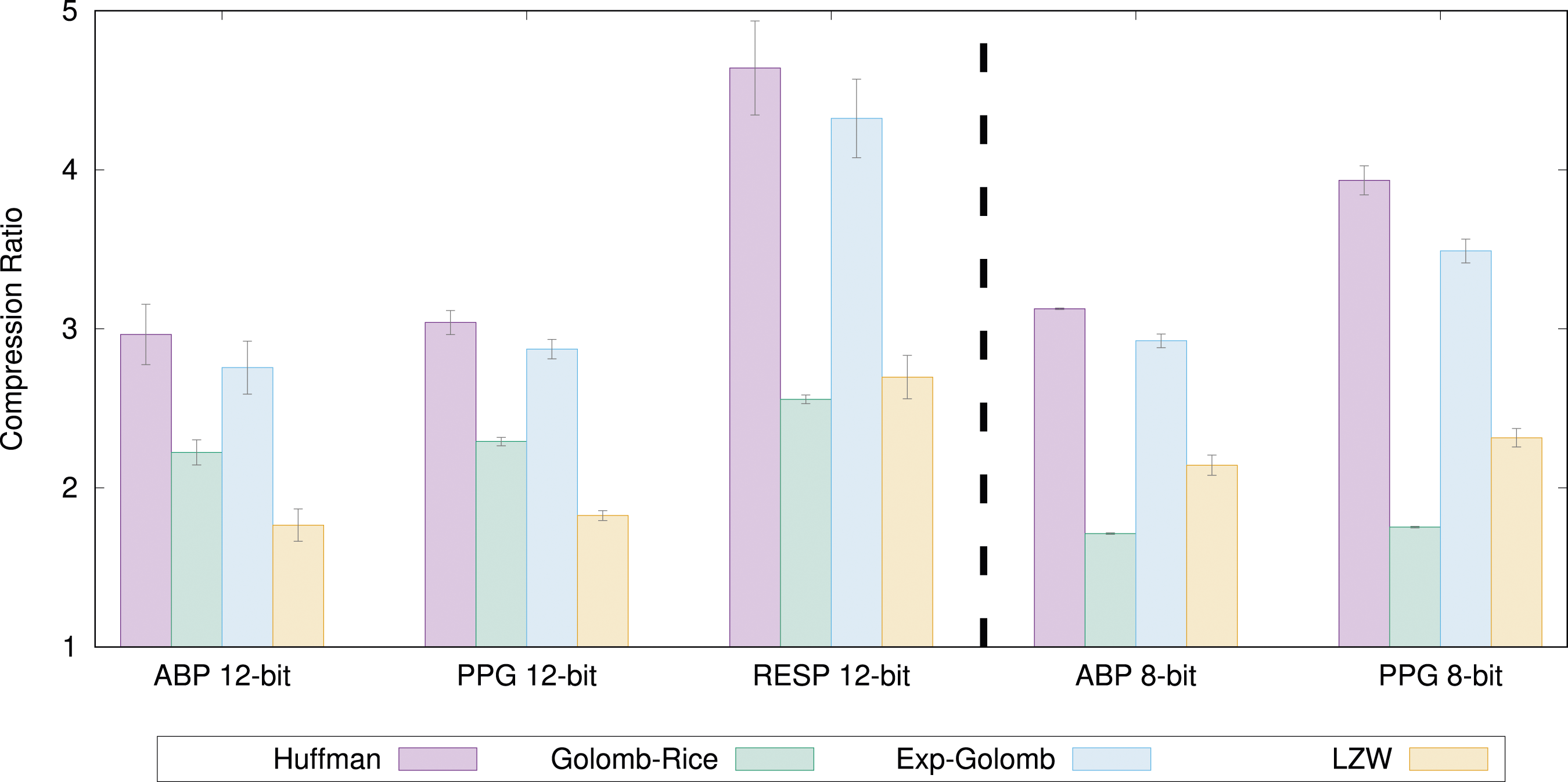
Linear prediction compression
In Figure 3, we show the compression ratio results of all the linear prediction methods on all biomedical signals types. The bars show the average compression ratio of all signal recordings from all n = 20 patients. The error bars show the 95% confidence intervals. The colored bars illustrate the compression ratio for the linear prediction method in combination with Exponential-Golomb with the found best order. The white bars above indicate how much more can be achieved if Huffman coding (excluding overhead) is used. The compression ratio of all linear prediction methods for all signals.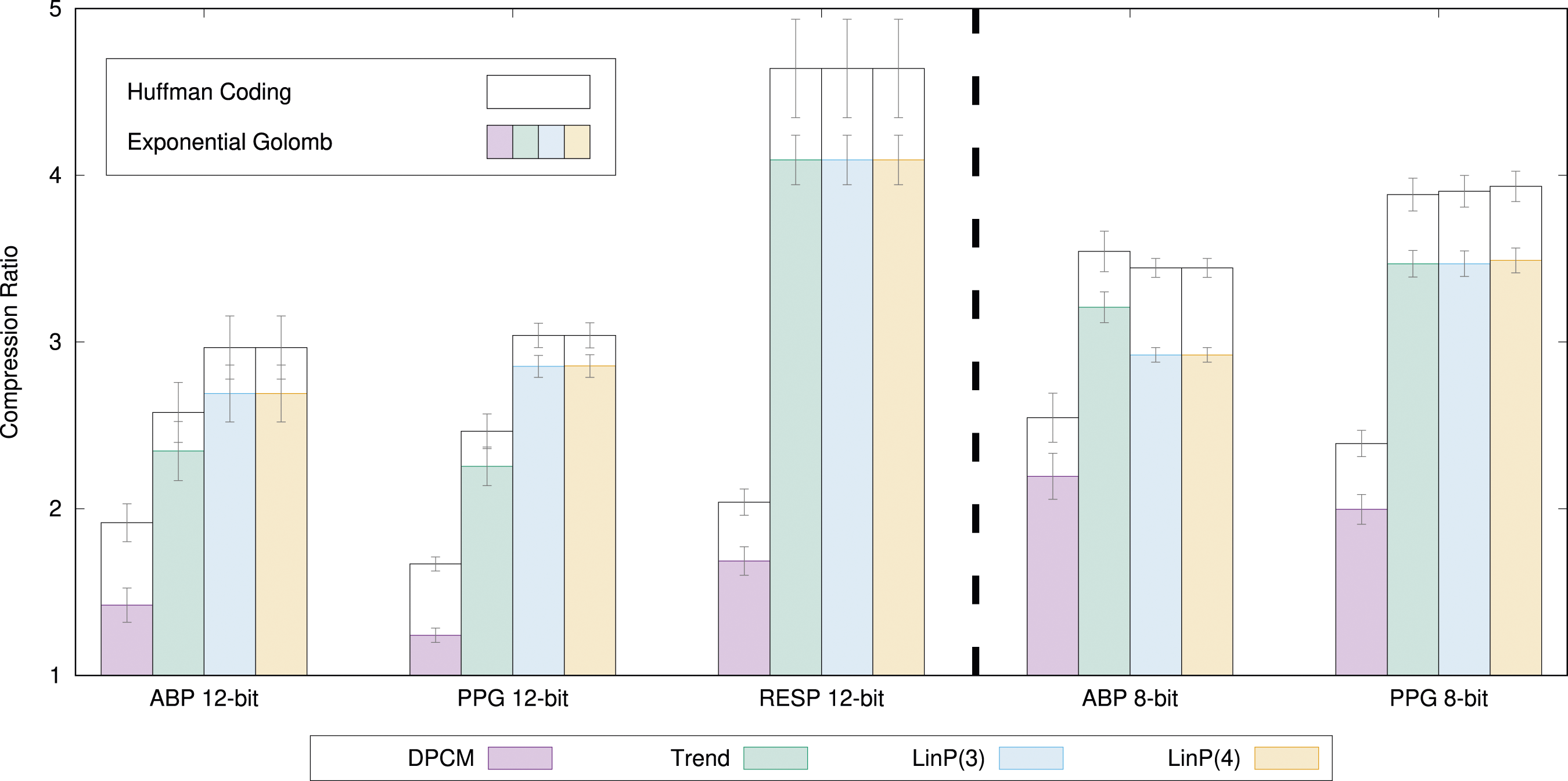
From the results of Figure 3, we can see that, in general, the more complex linear the prediction method, the better the compression ratio. However, there are a few exceptions. For 8-bit ABP, the LinP(3) and LinP(4) methods are worse than Trend, which is not intuitive. This is likely because the prediction coefficients were found from a different data set and are not optimal on the validation data set. This demonstrates the difficulty in designing appropriate prediction coefficients.
Downsampling results
Finally, we studied the compression ratio of downsampling. Since we filter the signal and remove every N:th sample, this is a lossy compression method as we cannot reconstruct the original signal in a perfect way. Figure 4 Compression results for downsampling the 12-bit signals and using LinP(3) together with Exponential-Golomb (k = 1) or Huffman.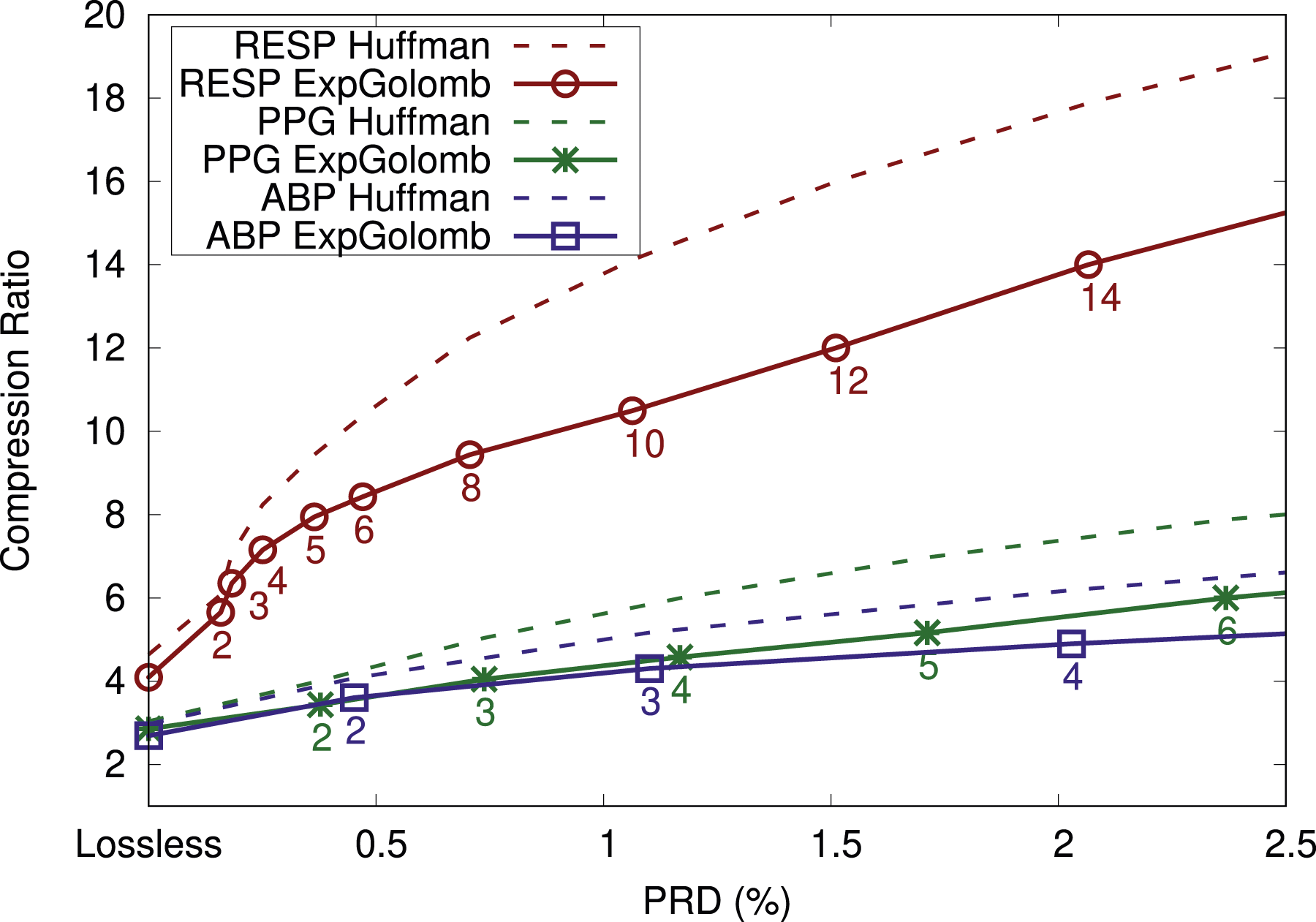
The process of downsampling means that we get different discrete signals and that different predictor coefficients are optimal compared to the non-downsampled signals. Hence, we again used the parameter design data set to find optimal predictor coefficients for each of the signal types and each of the downsampling amounts N. For heavily downsampled signals, a higher order k used by Exponential-Golomb would be more beneficial, but we stick to k = 1 (k = 0 for 8-bit signals) in order to make a solution for most signals. The drawback of always using k = 1 can be seen in that the gap between the Exponential-Golomb curve and the corresponding Huffman curve is increasing as more downsampling (a higher N) is used. Hence, with more tuning, higher compression ratios can be achieved. Since we did not fully tune all parameters, we assume no compression if the compression ratio drops below 1:1, which happens for heavily downsampled signals in Figure 4.
Discussion
Compression ratio for each of the biomedical signal types and three selected compression methods. The values in parentheses show the 95% CI. r is the Pearson correlation coefficient.
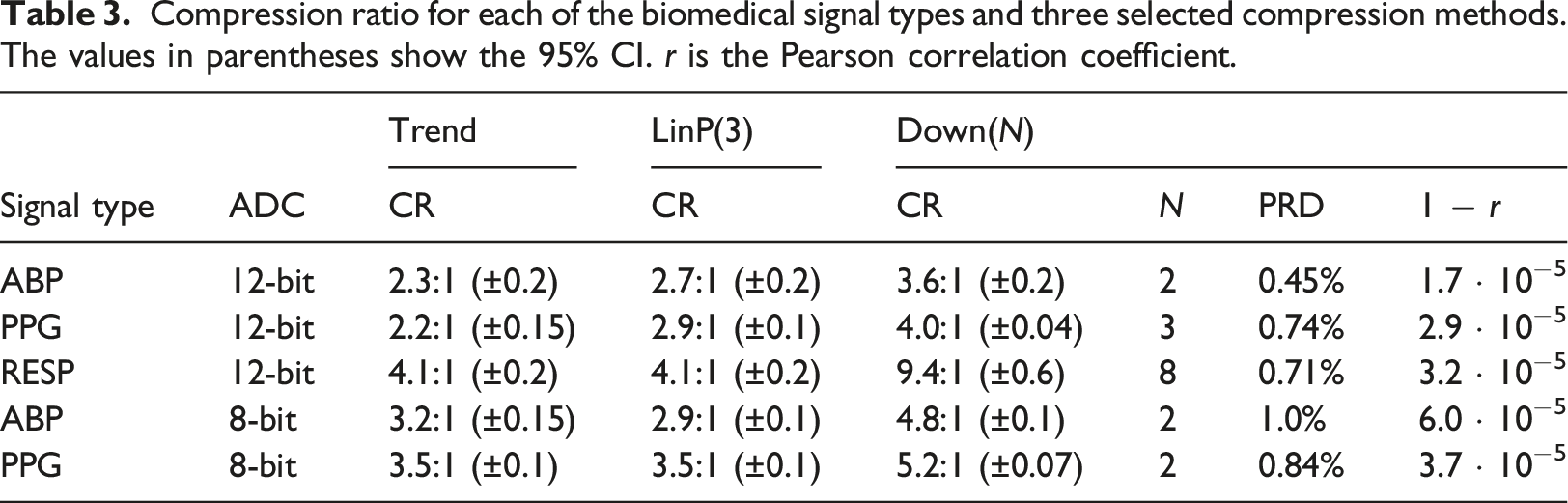
As we demonstrated in this article, there are differences between the signal types. For LinP(3), one would have to select different h k parameters for the different signal types to get good compression results. However, both Trend and LinP(3) are good options for all signals and achieve good compressions. Furthermore, a lossy method can be considered if one can tolerate some reconstruction errors. In this article, we tried only a downsampling method, but there are options for lossy compression methods available elsewhere, such as methods based on transforms and/or compressed sensing.12,16 However, such solutions usually need to be tuned differently to the different signals, which adds significant complexity to a final solution.
Nevertheless, the compression ratio is not the only aspect to consider. While Huffman coding would increase the compression ratio considerably, we still argue that it is not a good option as it requires two passes over the recorded data, which would add a considerable amount of compression delay, that is, the time between reading the value and the time it is compressed and sent or stored. Furthermore, the Huffman tree needs to be encoded, which adds overhead. The other approaches have a smaller compression delay. The current downsampling method uses a forward-backwards anti-aliasing filter, which adds significant compression delay, while the linear methods only have 2-4 samples delay (16-32 milliseconds). Finally, low complexity computations are also necessary, enabling implementations also on simple cheap battery-less wearables.
In summary, we find the linear prediction with order M = 3 combined with Exponential-Golomb with k = 1 to be a good candidate due to the trade-offs mentioned above. Increasing the order from 3 to 4 in the linear prediction only leads to a slight improvement, and we do not expect much more improvement for order 5, which is confirmed by Deepu and Lian. 13 Linear prediction can achieve a good compression ratio and is very simple to implement and compute. It could work well in hospital-wide biomedical signal collection and storage systems and should be a good candidate for the standardization of such protocols and systems. As a one solution for everything, it offers a good trade-off and simplifies wide adoption.
The focus of this study was to investigate the compression of biomedical signals for large-scale collection and storage, which will accelerate in the near future as new non-invasive sensors, wearables, and IoMT technologies, are popularized. The HL7 FHIR standard has become popular, even in persistent data storage. However, FHIR is not sustainable for storage. Instead, a comprehensive persistent storage approach should combine efficient data models, suitable sampling frequencies, and compression techniques to achieve practical results. Implementing a strategy combining FHIR for short-term storage and compression for long-term storage is an option.
To concretize our results, Figure 5 shows how much storage is generated per day for a hospital with 100 monitored patients. Here we assume only four biomedical signals similar to the ABP waveform sampled at 125 Hz and with 12-bit samples. If all signals are saved in FHIR-format (comma-separated values (CSV) would be similar), the hospital will generate about 20 GiB of uncompressed data per day. The amount does not include the metadata and overhead of the data if divided into segments. However, this number quickly drops if more efficient storage methods are selected. If the 12-bit values are stored as 16-bit integers, only 8 GiB/day is generated. The last two methods in Figure 5 use the LinP(3) compression method and assume a conservative compression ratio of 2.7:1. In the last method, we allow some loss of information (PRD 0.45%) and apply downsampling followed by LinP(3) compressing. Required storage space per day for hundred patients with four signals (125 Hz 12-bit). Measured in Gibibytes (10243 bytes) per day.
The rapid increase of health data being produced is steadily continuing and will further accelerate due to EHDS in Europe and by other similar initiatives worldwide. In summary, the main contributions of this article can be summarized as follows: • The vast amounts of biomedical signals that need to be collected and stored, makes it important to consider compression. • We have shown that simple lossless compression methods on typical biomedical signals does provide significant data size reduction. • Different configurations of compression has been tested and it is clear that configurations specific to the signal type only marginally improves the compression compared to a single configuration for all types of signals. • If a small loss is acceptable, improvements in compression ratios can be achieved by using lossy compression.
Conclusions
This article investigated the efficiency of several data compression methods on standard biomedical waveform signals generated from monitored patients. Most previous work has mainly focused on ECG signal compression, while many other biosignals are understudied. Common data format standards, such as FHIR and CSV, are inefficient for data storage. Changing to a binary representation is the first step in reducing the storage need. In this article, we proposed and investigated simple compression methods with low implementation complexity and low compression delay that can be used for many different signals and still achieve good compression ratios. It was found that Exponential-Golomb was better than Golomb-Rice, which is commonly used with ECG compression. The results indicated that it is easy to obtain compression ratios of 2.7:1 (±0.2) for arterial blood pressure curves, 2.9:1 (±0.1) for photoplethysmography, and 4.1:1 (±0.2) for respiration when using 12-bit sampling and lossless compression. We also experimented with a simple lossy compression method based on downsampling with small reconstruction errors. As part of managing an emerging avalanche of data, new simple storage strategies are needed. Many of the investigated methods allow this, which enables wide adoption.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.