
Abstract
Avatar Therapy (AT) is a modern therapeutic alternative for patients with schizophrenia suffering from persistent auditory verbal hallucinations. Its intrinsic therapeutical process is currently qualitatively analyzed via human coders that annotate session transcripts. This process is time and resource demanding. This creates a need to find potential algorithms that can operate on small datasets and perform such annotations. The first objective of this study is to conduct the automated text classification of interactions in AT and the second objective is to assess if this classification is comparable to the classification done by human coders. A Linear Support Vector Classifier was implemented to perform automated theme classifications on Avatar Therapy session transcripts with the use of a limited dataset with an accuracy of 66.02% and substantial classification agreement of 0.647. These results open the door to additional research such as predicting the outcome of a therapy.
Introduction
Psychotherapies imply complex social interactions that require the mobilisation of several cognitive and communication skills from both the patient and the therapist. 1 Qualitative analysis of psychotherapy transcripts is often a methodology used to assess psychotherapies. 2 However, this type of analysis often relies on human resources and remains rather time-consuming. 3 Furthermore, qualitative approaches lack the generation of quantitative data to assess specific components of the intrinsic process of the psychotherapy. 4 A growing body of researchers is attempting to use mixed methods to account for this problem. Consistency and coherence with the qualitative methodology employed is crucial for the process and is often infringed by the limits of subjectivity, notably when conducted by novice researchers. 5 Inherent subjectivity biases from the researchers can also lead to issues in the validity and reliability of qualitative assessment of psychotherapeutic transcripts. 6 These issues can be found in the annotations of in-person therapies, which are time-consuming, and the identification of the different interactions which can be even more complex. Annotations conducted using machine learning could be a potential solution to these issues to diminish this labor-extensive work and develop a systematic method to account for the potential inherent subjectivity biases of human annotators.7–8
Classification of textual entities is currently achieved in many different areas of medicine.9–11 Automated classification of text consists of analyzing a textual entity and classifying it under a specific label. This can be done by either supervised learning (i.e. an algorithm is trained with pre-existing data to conduct the classification) or unsupervised learning (i.e. labels are generated by the data). 12 Text classification usually classifies text under two or more categories, which are also knowns as labels, features, or themes. 13 The classification of therapeutic interactions may be a complex task as therapy sessions can vary in length, as well as content and sessions are dependent on the intrinsic and extrinsic characteristics of both therapist and patient. 14 Few studies have attempted classify therapeutic interactions as large datasets consisting of human annotated transcripts, such as some seen in the field of internet-enabled cognitive behavioral therapy (IECBT), are required for complex machine learning algorithms to adequately learn and classify new information. 15 However, in-person therapies can yield databases that are smaller than the ones generated by IECBT because of the need for human driven annotations which are time and resource demanding. This creates a need to find potential algorithms that can operate on small datasets. A recent systematic review having identified seven studies with small datasets in a psychotherapeutic context highlighted that support vector machine classifier was the best performing algorithm for these constraints. 16 This opens the path for further studies on novel psychotherapeutic therapies for which limited data is available for analysis.
Avatar therapy (AT) is a type of virtual reality therapy. It is a modern therapeutic alternative for patients with schizophrenia suffering from persistent auditory verbal hallucinations (AVH) despite pharmacological treatment.17–19 Studies on Avatar Therapy taking place at our institution are currently analyzing the use of AT for patients diagnosed with schizophrenia with persistent auditory hallucinations and other mental illnesses. Patients currently enrolled in AT undergo nine weekly sessions of 45-min (one session to create the Avatar and 8 immersive sessions). An Avatar representing the most distressing voice of the patient is animated by the therapist to re-enact the voice in a secure therapeutic environment. The effects of AT on AVH are evaluated via the Psychotic Symptoms Rating Scale (PSYRATS total and PSYRATS-distress scores) and the Beliefs About Voices Questionnaire-Revised (BAVQ-R score) which are commonly used in the field to evaluate the effects of psychotherapy on schizophrenia patients. Other research teams such as Leff’s and Craig’s team in England are also using PSYRATS and BAVQ-R to assess AT.17,20 Current results demonstrate that therapeutic effects of AT on the distress associated with the voices were significant, as indicated by a net improvement in PSYRATS-distress score.21–22 In AT, the therapeutic process as a variable of effectiveness is of the upmost importance as there is an additional level of complexity added to the therapeutic dyad between the patient and the therapist, being the inclusion of an avatar. There are changes at a psychological level that are not captured by self-reported such as the PSYRATS and BAVQ-R. Traditional qualitative analyses consider these elements but have their own methodological limitations. The use of machine learning via text mining can be a complement to these analyses. Current attempts to evaluate the therapeutic processes of AT by the means of annotating interactions by themes has been entirely conducted by human evaluators.17,22,23 Furthermore, in AT, the complexity of having interactions between three individuals (avatar, therapist and the patient) and the fact that it is less readily available to the public limits the extent of useable data for constructing a dataset. The present study is therefore a first attempt at automated text annotation from a small dataset of AT transcripts.
The first objective of this study is to conduct the automated text classification of interactions in AT. Secondly, it is also important for us to assess if this classification is comparable to the classification done by human coders. This would provide an interesting solution for automated therapy annotations and could generate further data to evaluate AT process in relation to its effectiveness.
Methods
Dataset
A dataset was elaborated using 162 manually typed therapy transcripts of 18 randomly selected patients who undertook AT between 2017 and 2020 at our institution, which accounts for up to 10 therapy sessions per patient.
23
The language of the transcripts was Canadian French. Transcripts were manually annotated using the 28 themes described in Beaudoin et al. 2021. Please refer to Figure 1 in Beaudoin’s study for classification of the themes. In the latter study, prior qualitative analysis of AT was conducted.
23
Two research assistants coded each of the individual interactions independently. Robustness of the coding grid was cross validated by the same two research assistants. All the annotations were performed using QDA Miner version 5 (Provalis Research), a qualitative data analysis software. To improve the automated classification, annotations were then extracted as text files (containing from 1 to 40 interactions of the same theme) from QDA Miner and classified under three conceptual databases: Avatar, Patient and Therapist. The conceptual datasets were designed as per represented in Figure 1. Conceptual datasets design.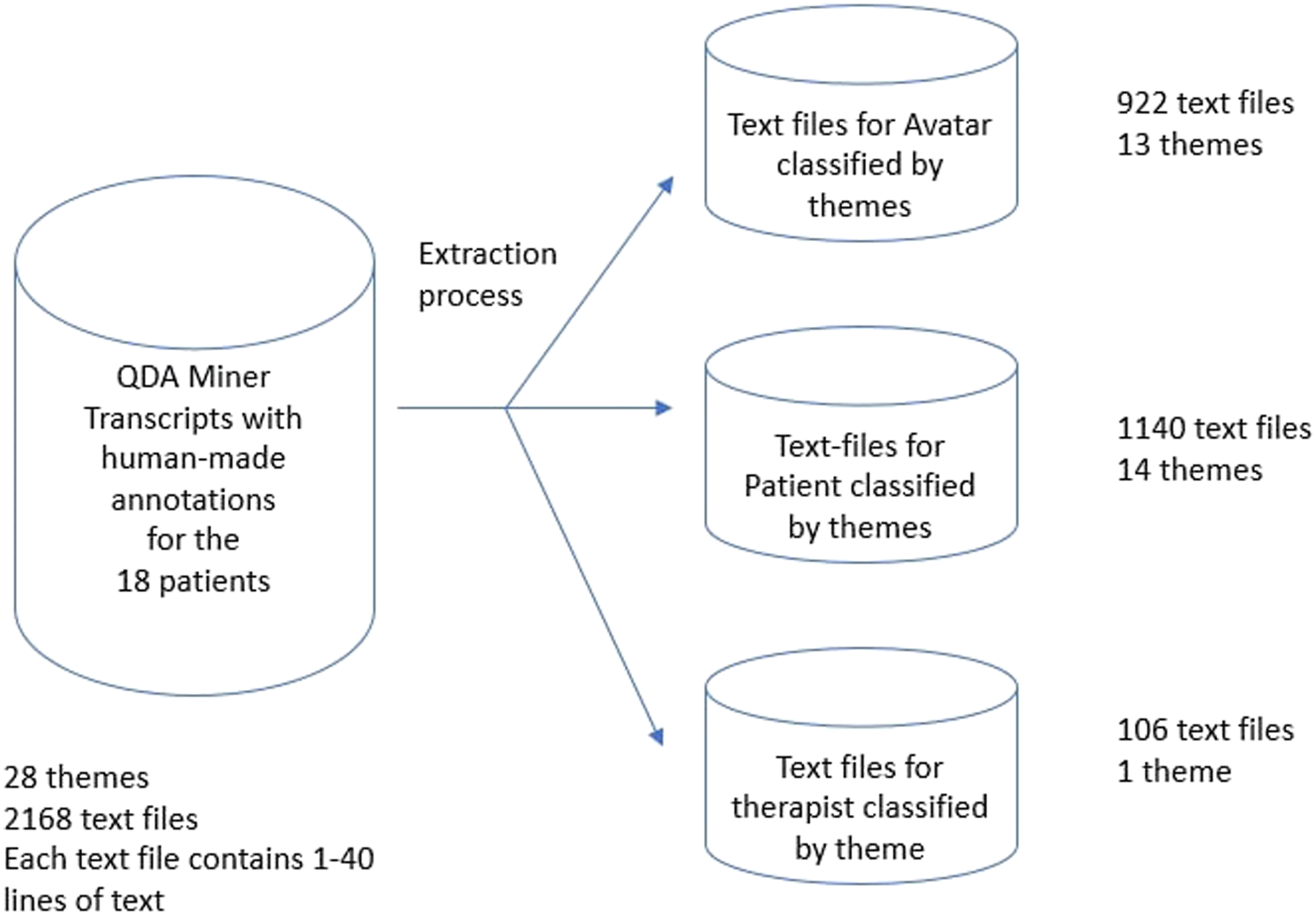
Distribution of text files per theme in the database.
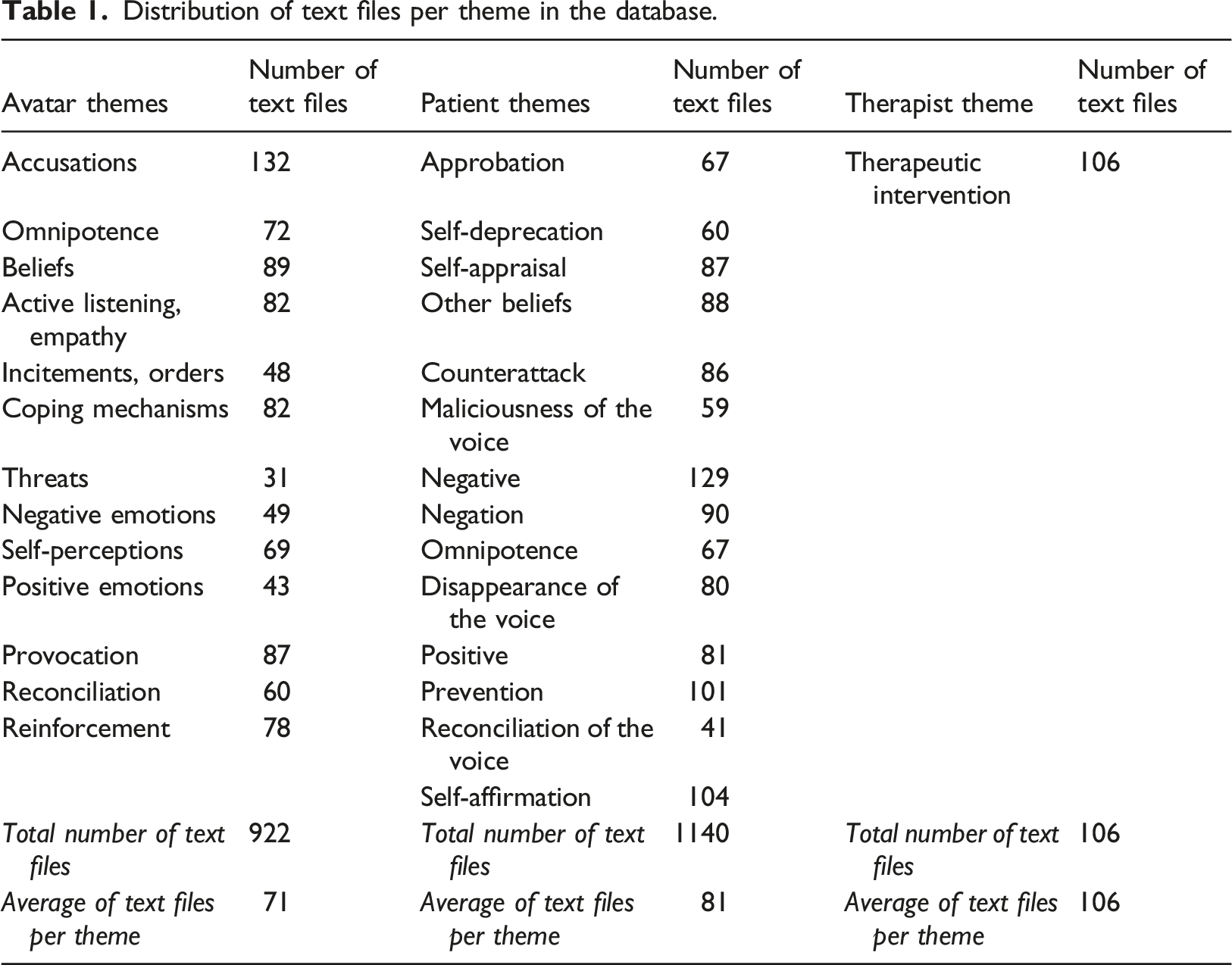
After reading from the database, the training sets for the Avatar, Patient and Therapist themes consisted of 691, 855 and 74 documents and the testing sets contained 231, 285, 32 documents respectively.
Machine learning algorithm
A support vector machine classifier was implemented to conduct the automated text classification (classify the different interactions under themes). Support vector machines encompass multiple algorithms that are often used in conjunction with tokenizers to evaluate the textual entities being classified. A tokenizer applies the process of tokenization, which is a method that breaks text into tokens to weight the value of a word or a sequence of words to compare it with other words or sentences. 24 A member of the SVM family is the linear support vector classifier (LSVC). LSVC have been consistently more successful in text classification for small databases, such as ours. 25 Prior review of algorithms for small datasets indicated that LSVC is the algorithm of choice for our study. LSVC was implemented using Python version 3.6.7 and Scikit-Learn open library. 26 It is noteworthy that Python was selected as the main programming language for our study because of its various uses in the domain of artificial intelligence, its flexibility as compared to other programming languages for scientific purposes and its support for many operating systems. 27 Combined with a term frequency-inverse document frequency statistic (TF-IDF), it is an algorithm that performs best with text classification as compared to other combinations of SVM with a tokenizer. 28 For the TDI-DF tokenization, the TfidfVectorizer offered in the Scitkit-Learn open library was selected as it enables to convert the raw text of the extracted interactions from the to-be annotated interview into numerical vectors. Vectorizers can be customized to account for stop-words. Considering the classification categories were designed in a way that text entities would be separated as per their intrinsic characteristics defined in Beaudoin et al. (2021) which are fundamentally different, the features are assumed to be linearly separable. 23
To ensure best performances for the LSVC algorithm and enhance search strategies, a GridSearchCV (GSCV) was used. A GSCV is useful as it enables the user to test for different hyper-parameters and cross-validate the classification made by the LSVC to determine the best combination of LSVC parameters and the TfidVectorizer parameter variables. 29
For each of the conceptual databases, LSVC has been trained using 70% of the available annotated documents and the remaining 30% has been used for testing purposes to establish a statistical probability (predictive score) that an interaction could be adequately classified. The training and testing sets did not overlap as per design recommendations.
30
The predictive score refers to the mean accuracy (F1-Score) of the themes being testing. It is to be noted that a 70% training set and 30% testing set is the default setting for the Scikit-Learn LSVC library and is common practice for text classification
31
This is modelized in Figure 2. A tenfold cross-validation was performed using the KFold model from the Scikit-Learn suite. Implementation of LSVC on conceptual databases to derive a Predictive score and a Scott’s Pi.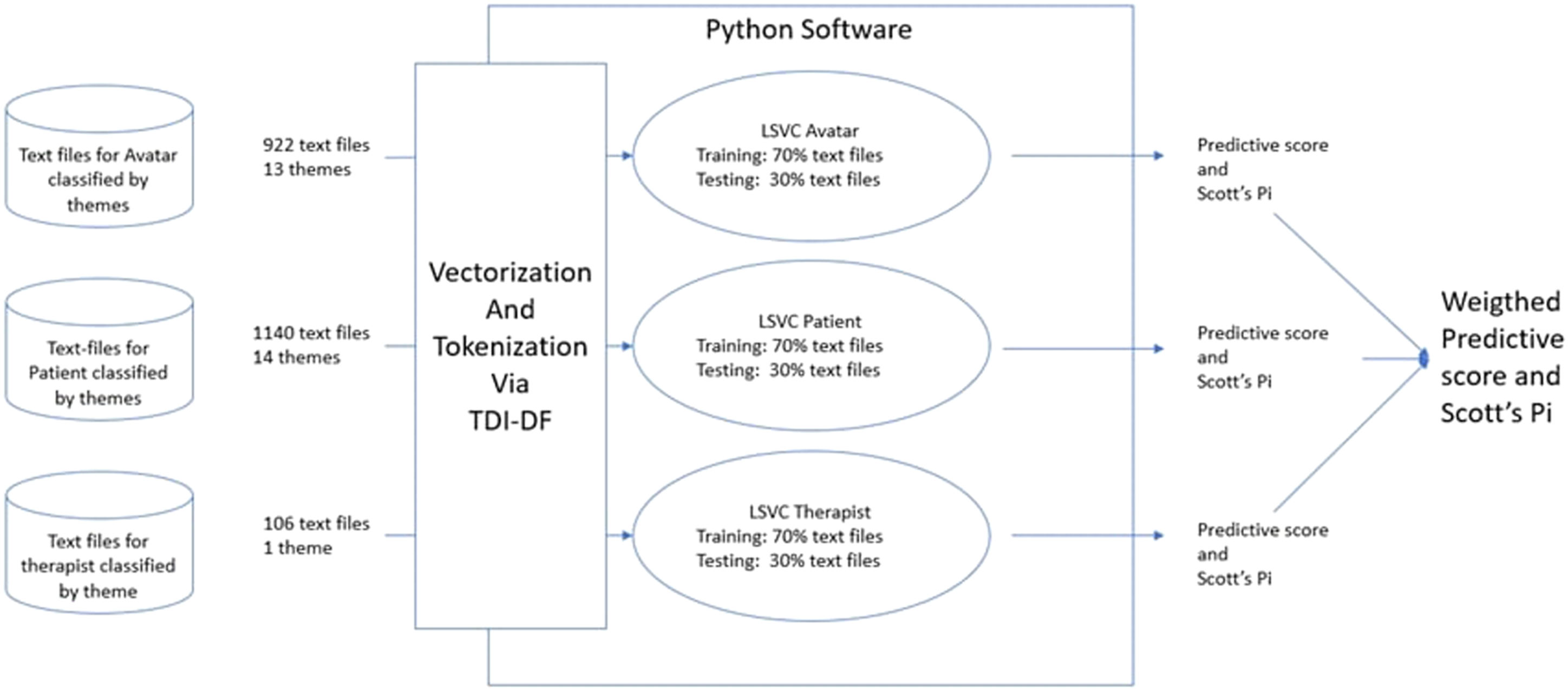
The annotation process is shown in Figure 3. Each sentence in the transcript was regarded as an interaction. Annotation process overview.
Performance analysis and inter-rater agreement
Information about the classification (precision, recall and F1-Score) for each theme was collected using the Classification Report tool, readily available in the Scikit-Learn metrics module. Precision refers to the positive predictive value, whereas recall refers to the sensitivity of the prediction and F1-score to the accuracy. The F1-score is the most widely used measure in text classification, reflecting the accuracy of theme classification and is a balance between precision and recall. 32
While the F1-Score reflects the accuracy of theme classification, it does not account for the expected chance agreement. A Scott’s Pi measure was therefore used to compare the degree of agreement between LSVC automatic classified annotation and the previously agreed ‘’correct’’ annotation by human referees. 33 The benchmark for the Scott’s Pi measure interpretation tends to vary. The benchmark provided by the SAGE Research Methods was used in which a Scott’s Pi of 0.81–1.00 is indicative of an almost perfect agreement, 0.61 to 0.80 of a substantial agreement, 0.41 to 0.60 of a moderate agreement, 0.21 to 0.40 of a fair agreement, 0.0–0.20 of a slight agreement and less than 0 as a poor agreement. This will be compared to the Scott’s Pi agreement obtained between human annotators that was of 0.58 for our database. 33
Results
The LSVC in combination with the TDI-DF was implemented and tested. An un-annotated transcript of an AT immersive session was automatically annotated. Training sets and testing sets are divided between Avatar themes (interactions involving the therapist animating the Avatar), Patient themes (patient’s interactions) and Therapist theme (interactions involving the therapist talking directly to the patients).
The GSCV best selection of parameters for our study and our dataset indicated that document frequency and tolerance parameters are more important than others for our vectorizer and our LSVC classifier. For our vectorizer, a minimum document frequency of 2 and maximum document frequency of 100 are applied. This ensures that a document appears at least 2 times to be considered by the LSVC and the limit of 100 is used to avoid documents that are repeated too frequently. The classifier tolerance was set to 0.001, dual parameters to false and intercept parameters to true. The mean squared error (MSE) training result was 0.88 and the MSE testing result was 0.96.
Precision, recall and F1-score for Avatar, patient and therapist themes.
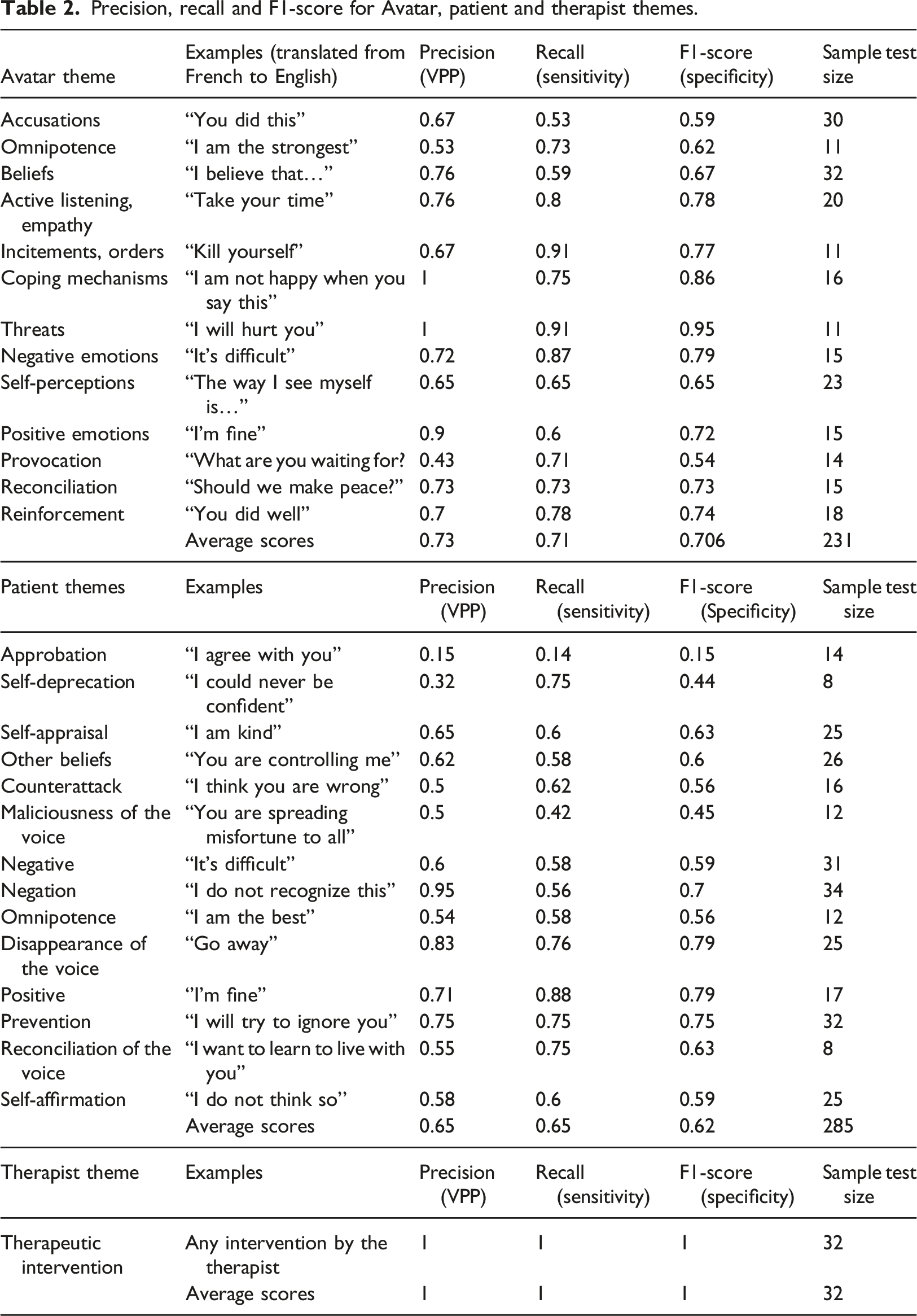
As it can be observed in Table 2, F1-Score for Avatar themes were on average better than for Patient’s themes (0.706 vs 0.62). The theme Provocation performed the worst for the Avatar whereas Maliciousness of the voice performed the worst for Patient.
Agreement between human referees and the classifier reached a Scott’s Pi of 0.647, which is ranked as substantial as per the SAGE Research Methods benchmark for Scott’s Pi interpretation.
Discussion
The objective of this study was to conduct the automated text classification of interactions held during sessions of AT. This was conducted by implementing an LSVC algorithm.
It was possible to obtain a fully automated annotation of an un-annotated AT transcript. The weighed F1 predictive score for the annotation of the themes of the Avatar of 70.1% outperformed the F1-score for the themes of the Patient by 8.8%. The themes of the Avatar scored accuracies ranging from 54 to 94%. Regarding the themes of the Patient, the interaction theme Approbation (interactions in which patients completely or partially approved what their avatar was saying in response to a verbal attack) scored worst than all the other themes with a specificity of 15%. Since this theme contained 67 text files but scored less than themes with much less text files (e.g. Reconciliation of the Voice with 41) this may indicate that our conception of Approbation was perhaps not as distinct and might overlap with other themes. Therefore, a therapist evaluating the therapeutic process of the therapy with the same set of descriptive themes such as the 28 themes used in this study could reflect on this and revise the requirements for an interaction to be classified as Approbation. Considering that the latter is a coping mechanism distinct from other interactions held by the patient, we decided to keep it to explore whether this classification theme would need to be re-evaluated or would increase in homogeneity with additional data. In a similar study, in which medical reports that targeted patient symptoms were classified by severity, reports in their severe category versus their moderate category were often incorrectly classified because there are elements similar to both severe and moderate data that overlap in the definition of these two categories. 34 This supports the idea for better homogeneity amongst individual themes. Other Patient themes that had an overall poor accuracy included Self-deprecation (accuracy of 44% with 19 trained items and 8 tested items), Maliciousness of the voice (accuracy of 45% with 28 trained items and 12 tested items) and Omnipotence 12 (accuracy of 56% with 28 trained items and 12 tested items). This may be justified by the lack of data for these themes as compared to other accurately classified themes. These imbalances may also be explained by the fact that classifiers tend to respond better when there is a similar amount of data for each theme in the database. 35 Fortunately, this gave us an initial insight on the therapeutic processes of the therapy as it outlined which interactions occurred potentially less during therapy sessions.
The secondary objective was to assess if this classification is comparable to the classification done by human coders.
Agreement between human referees and the classifier reached a Scott’s Pi ranked as substantial. This is consistent with the Scott’s Pi agreement of 0.588 between the two human referees having used QDA Miner. The fact that it was like the kappa agreement between human annotators indicates that both agreements for the annotation are comparable. For studies with datasets of similar size as the one used in this study (i.e. of less than 10 000 items) such as Balakrishnan, Zolnoori and Singh’s studies reached substantial to moderate agreements.36–38 Although these agreements appear higher than ours, they employed a different base calculation than the Scott’s Pi agreement. Pairwise agreement formula in Zolnoori’s study is an improvement on Cohen’s Kappa calculated at the level of entities rather than sentences to improve consistency and their result is also validated as substantial. This is also the case in Ewbanks et al.’s study in which they had 24 features and reached a kappa considered as moderate. 15 As a comparison, a small study had 100 document samples and reached a kappa agreement of 0.6 with a Naïve Bayesian algorithm which was noted as acceptable. 39
Limitations of this study include the classification F1-score for each theme that can be underestimated because of the 70% training and 30% testing set selection. It has been known to lead to class imbalances and sample representativeness issues. 35 Such division in training and testing data is common for text classification, which is the reason we opted for such method. Nevertheless, since our dataset improves with additional data, it will be interesting to test for different training set sizes. 31 It is to be noted that the transcripts analyzed in our study were typed in Canadian French and we did not find vectorizers that included stop-words (words not to be weighted during the process of tokenization as described above) for Canadian French language. This can yield a lower accuracy as there are insignificant words that can be weighed as part of a word vector. 40
Conclusion
Machine learning can be beneficial to the field of psychiatry. Automated text classification for AT is a promising avenue to generate quantitative and qualitative data in an efficient way to be readily available to analyze. Our study allowed to automatically annotate an un-annotated transcript basing ourselves solely on a database derived from the transcripts of 18 patients. Reaching an agreement in the same range as human agreement, this study highlights that the task of annotation can be done by a machine, saving resources, which can improve the focus on patients’ needs. It could also sharpen the therapeutic processes by reviewing what went wrong and what went well during AT based on automated text analysis. Nevertheless, this is to our knowledge the first study that outlined the possibility of automated annotation for AT and it highlights the need for more development in this field. These results open the door for additional research such as predicting the outcome of a therapy.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Fondation Pinel, Chaire Eli Lilly Canada de recherche en schizophrénie, Services et recherches psychiatriques AD, Otsuka Canada Pharmaceutical and Le Fonds de recherche du Québec – Santé (FRQS).
Ethical approval
This study was approved by the institutional ethical committee, and written informed consent was obtained from all patients.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.