
Abstract
Keywords
Introduction
Electronic medical record (EMR) systems are increasingly being adopted in clinical settings. 1 Physician’s document clinical encounters in the EMR. A single clinical encounter often generates different types of data in the patient record (for example: demographics, symptom/problem lists, vitals, labs, prescriptions, referral/consult notes, family history, and medical imaging reports). In this study we focused on two types of data structures: (1) unstructured clinical text data which describe the clinical encounter, and (2) structured diagnostic codes associated with the encounter. These two types of data are often simultaneously collected in the EMR, because physicians will chart an encounter and then bill, using a diagnostic code, for that encounter.
In this study we focused on the use of topic models to characterize emergent themes in a large collection of clinical notes. Topic models encompass a powerful class of methods from unsupervised machine learning that can automatically cluster words to discover and summarize latent structures/patterns in large document collections. These clusters of words, also called topical/thematic vectors, once validated, can be used for document retrieval, document clustering and corpus description/exploration.
Efforts should be made to generate evidence regarding the validity of the subjective interpretations assigned to the latent topical constructs.2,3 Various approaches exist for validating learned topic models, including: (1) human judgement validation (whereby, subject matter experts inspect, label and ascribe meaning to learned topical vectors), (2) internal validation (whereby, the model learned quantities are inspected with respect to internal robustness, stability, predictive, or semantic/coherence properties), and (3) external validation (whereby, external information independent of the model fitting process are used to illustrate correlative/predictive validity of the latent quantities).4,5
In this study we focused on external validation of learned clinical topic models. We estimated the extent to which our latent topical/thematic constructs were correlated with concurrently collected physician assigned ICD-9 diagnostic codes. Hence, we focused on two types of concurrent validity, namely, convergent validity and discriminant validity. Convergent validity was used to estimate the extent to which two variables purporting to measure the same underlying construct were statistically associated. Discriminant validity was used to estimate the extent to which two variables related to different constructs were statistically uncorrelated. While this study focused on concurrent validity, we also discussed predictive validity (an alternative form of external/correlative validity), which measures the extent to which a latent topical/thematic construct can predict some clinical measure obtained in the future.2,3
The primary objective of this study was to illustrate how researchers can leverage physician assigned ICD-9 diagnostic codes collected contemporaneously to primary care EMR clinical text data, to investigate concurrent validity, convergent validity, and discriminant validity of learned topic models. We discussed alternative clinical EMR measures which could be utilized to establish concurrent validity. Further, we discussed leveraging the EMR structure and alternative EMR variables for demonstrating predictive validity and alternative forms of correlative validity. As a secondary objective, we explored mean topical prevalence estimates in strata of clinical notes with-versus-without an assigned ICD-9 diagnostic code. This secondary analysis allowed us to descriptively characterize certain types of primary care roles and activities more likely to be recorded in clinical notes, while less likely being coded/billed in primary care clinical settings.
Methods
Study design
This study used a retrospective open cohort design. 6
Study setting, timeframe and data sources
Study data were collected from the EMRs of 12 primary care clinics in Toronto, Ontario, Canada, from January 1, 2017 to December 31, 2020. The study used clinical notes from encounters and ICD-9 diagnostic codes, the encounter date, patient age/sex, and a selection of identification (ID) variables (i.e. encounter ID, de-identified patient ID, de-identified physician ID and de-identified clinic ID). We included all patient encounters which resulted in the simultaneous generation of a clinical note and a primary diagnostic code. Encounter-level records were excluded if they corresponded to patients who were missing demographic information (e.g. age or sex), encounter date, or core study identifiers (e.g. encounter ID, patient ID, physician ID, clinic ID).
Clinical text processing and construction of the document term matrix
Raw clinical text data existed as a sequence of digital characters. We transformed the digital character sequences into a numeric array – a document term matrix (DTM) - where the row dimension encoded the number of unique clinical notes in the corpus (d = 1…D) and the column dimension encoded the number of unique words/tokens in the empirical vocabulary (v = 1…V). Individual elements of the DTM (Xdv) counted the number of times word/token (v) occurred in document (d).
A subjective aspect associated with creation of the DTM involved the specification of words/tokens included/excluded (i.e. specification of the vocabulary of the corpus). In this study we adopted a simplistic, hybrid pipeline for text processing, and DTM vocabulary specification. To begin, we computationally tokenized the input digital character sequences on whitespace boundaries (i.e. space, tab, or newline characters). We normalized the resulting token set using lowercase conversion, removed all non-alphanumeric characters, and removed stop words. Finally, we examined the top-10k most frequently occurring words in the list and subjectively included a subset of words that represented predominantly medical/clinical concepts (e.g. disease conditions and symptoms, pharmaceutical agents, medical procedures, clinical specialties, physiological/anatomical terms, etc.). We have provided the list of V = 2210 words/tokens included in our analytic DTM as a supplementary file to this manuscript.
Non-negative matrix factorization topic modelling
Non-negative matrix factorization (NMF) was used to decompose the D*V dimensional DTM into two latent sub-matrices of dimension D*K (
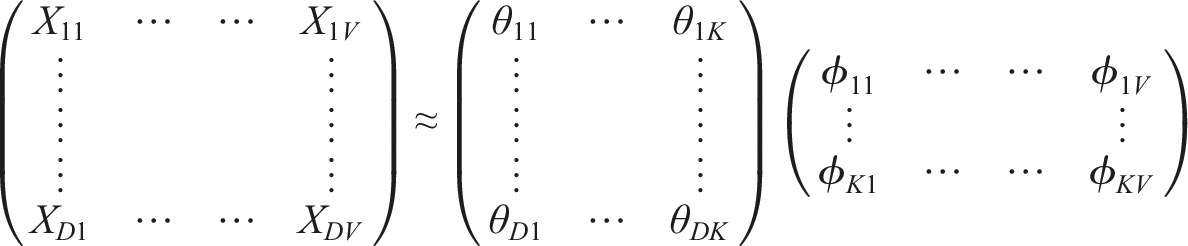
Many iterative algorithms have been proposed for estimating the parameters of the NMF model. Most algorithms attempt to optimize the value of the latent parameter matrices with respect to a least squares objective function (as shown below). Standard iterative updating algorithms for NMF models are described in Berry
7
; whereas, Udell et al
8
discuss more flexible generalized low rank models. Original research studies describing NMF methods/algorithms include Paatero & Tapper
9
and Lee & Seung.10,11
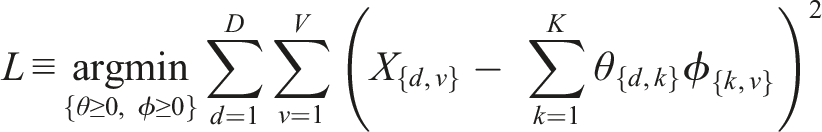
Post-hoc, we normalized row-vectors of
Non-negative matrix factorization models were fit using the Python sklearn function sklearn.decomposition.NMF(). The model described in this study used K = 50 latent topical/thematic bases. We did not use any regularization. We randomly initialized latent parameter matrices. We used a gradient descent update routine, iteratively optimizing a Frobenius norm (least squares) loss function. Optimization routines were terminated according to a loss function convergence tolerance of 1e-5.
Construction of the diagnostic code matrix
Three-digit ICD-9 primary diagnostic codes documenting the most responsible reason for a patient-physician primary care encounter were often collected alongside clinical narrative data. The ICD-9 diagnostic codes used in this study represented a high dimensional clinical nomenclature. In total there existed 496 unique three-digit ICD-9 diagnostic codes observed in the sample; and we focused on 260 unique codes which occurred 50 or more times. We constructed a high dimensional “ICD-9 diagnostic code matrix” of row dimension (D = 248,998) and column dimension (P = 260). Individual entries of the ICD-9 code matrix denoted whether a given ICD-9 diagnostic code was labelled the most responsible reason for a given clinical encounter (for which a clinical document/note was simultaneously collected). The diagnostic code matrix was constructed as a type of indicator matrix (i.e. all entries were Boolean valued, indicating whether a code, associated with a unique document/encounter, was assigned as the most responsible diagnosis). Row sums of the diagnostic code matrix equalled one, signifying only a single primary diagnostic code was assigned for each encounter.
The row dimension of the diagnostic code matrix was less than the row dimension of the DTM (and the low-dimensional matrix of per-document topic proportions). This was because certain clinical notes were not associated with an ICD-9 diagnostic code in our sample. In this study, our primary objective focused on the D = 248,998 encounters for which both a three-digit ICD-9 diagnostic code and a note/document were simultaneously generated; and we utilized the ICD-9 diagnostic code matrix to facilitate external validation of trained clinical topic models. We demonstrated how to leverage the diagnostic codes collected alongside the clinical notes to assess convergent and discriminant validity of the model, by manually inspecting the semantic association between the observed diagnostic codes most associated with each latent topical vector.
As a secondary objective, we compared K-dimensional mean topical prevalence estimates in the strata of N = 248,998 (65.1%) clinical notes with a three-digit ICD-9 diagnostic code recorded versus the strata of N=133,668 (34.9%) clinical notes where no three-digit ICD-9 diagnostic code was recorded. We estimated the mean difference in topical prevalence (a length-K vector) between the strata of clinical notes with/without an ICD-9 diagnostic code and estimated a pointwise 95% bootstrap confidence interval about this mean difference vector.
Topic model validation
Topic models used in this study represented a class of unsupervised machine learning model which were applied to large text corpora to facilitate characterization of document collections and enhance document retrieval, clustering, and browsing.
In the context of unsupervised topic modelling, validity refers to the extent to which empirical evidence can be generated to support the interpretation of the estimated latent quantities. Two principal uses associated with fitting a topic model to an empirical document collection include: (1) discovering the dominant latent topical/thematic vectors permeating the corpus, to facilitate improved characterization, description and understanding, and (2) tagging/embedding documents in the latent topical space, facilitating enhanced retrieval, clustering, and browsing. For example, certain questions which clinical researchers might use topic models to investigate include: - What are the dominant topics/themes in a large unstructured clinical document collection? - What are the most relevant documents associated with a specific thematic query? - How do documents geometrically cluster according to learned thematic bases?
To satisfactorily achieve the first target use, the fitted topic model must learn a latent basis providing a meaningful characterization of the document collection. The matrix (
The second primary use case involves using the latent matrix (
The most common strategy for validating a topic model involves the use of human judgement. Under this evaluative framework, subject matter experts in concert with data analysts review and critique latent matrices learned from topic model fitting: (1) reviewing top-5/top-10 most probable words under each of the k = 1…K topical/thematic row vectors of
Internal validation is another common approach for validating a fitted topic model (where model learned quantities are inspected with respect to internal robustness, stability, predictive, geometric or semantic properties). Several sensible internal validation schemes exist, for demonstrating topic model validity. Topic coherence metrics can be estimated for each of the k = 1…K topical vectors of
In this manuscript we focus on external validation of topic models fitted to clinical text data from primary care EMRs. Primary diagnostic codes (p = 1…P) can be used as empirical evidence to build trust, and enhance confidence, in the validity of the learned topics (k = 1…K). In this study we focused on two types of correlative validity assessments: (1) convergent validity, and (2) discriminant validity. Convergent validity estimates the extent to which two variables purporting to measure the same underlying construct are statistically associated. Discriminant validity measures the extent to which two variables related to non-overlapping constructs are statistically uncorrelated.2,3
To empirically investigate convergent and discriminant validity in the context of clinical topic models fit to primary care EMR text data, we estimated the association between k = 1…K learned topics and p = 1…P contemporaneously specified ICD-9 diagnostic codes. The K = 50 topical vectors exist in continuous space, whereas the p = 260 ICD-9 diagnostic codes were Boolean valued (indicating the presence or absence of a given primary diagnostic label). We employed Cohen’s d effect size estimate, the mean difference in topical prevalence between the two groups divided by an estimate of their pooled SD. The standardized effect measure is defined below (zkp); where
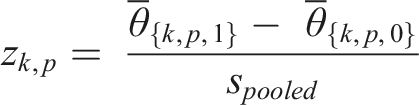
We constructed a K*P matrix of standardized effect measures, estimating the association between each topical/thematic vector and each ICD-9 diagnostic code. We hierarchically clustered the rows and the columns of the K*P matrix of association statistics (using a Euclidean distance metric and Ward’s agglomeration method), and we used a heatmap to demonstrate how specific topics (and words) associated with sets of ICD-9 codes (Figure 1). For each of the K topics we rank ordered the primary diagnostic codes by decreasing strength of association with the given topical vector, and presented the top-5 ICD-9 diagnostic codes most strongly associated with each topic (k = 1…K). We also computed a simple metric, which summed the Cohen’s d association statistics of the top-5 ICD-9 diagnostic codes loading most strongly on a given topic; and we sorted the latent topical vectors by decreasing magnitude of this composite metric (Table 1). Subject matter experts and data analysts reviewed the K topical summary vectors (i.e. the top-5 words/tokens loading most strongly on a given topic), as well as the top-5 ICD-9 diagnostic codes most statistically associated with the selected topics, and subjectively interpreted whether semantic correlations seemed reasonable, demonstrating convergent and discriminant validity of the learned latent topical vectors. Heatmap of Cohen’s d statistics estimated between each of the K = 50 topics and p = 260 ICD-9 diagnostic codes used in this study. Top-5 words/tokens loading most strongly on K = 50 latent thematic vectors extracted from our fitted non-negative matrix factorization topic model; top-5 primary ICD-9 diagnostic codes most strongly associated with each continuous latent thematic vector (where strength of statistical association/dependence is measured using Cohen’s d metric). We summed the top-5 Cohen’s D statistics from ICD-9 diagnostic codes loading most strongly on each topical vector and sorted the rows in Table 1 according to this custom metric.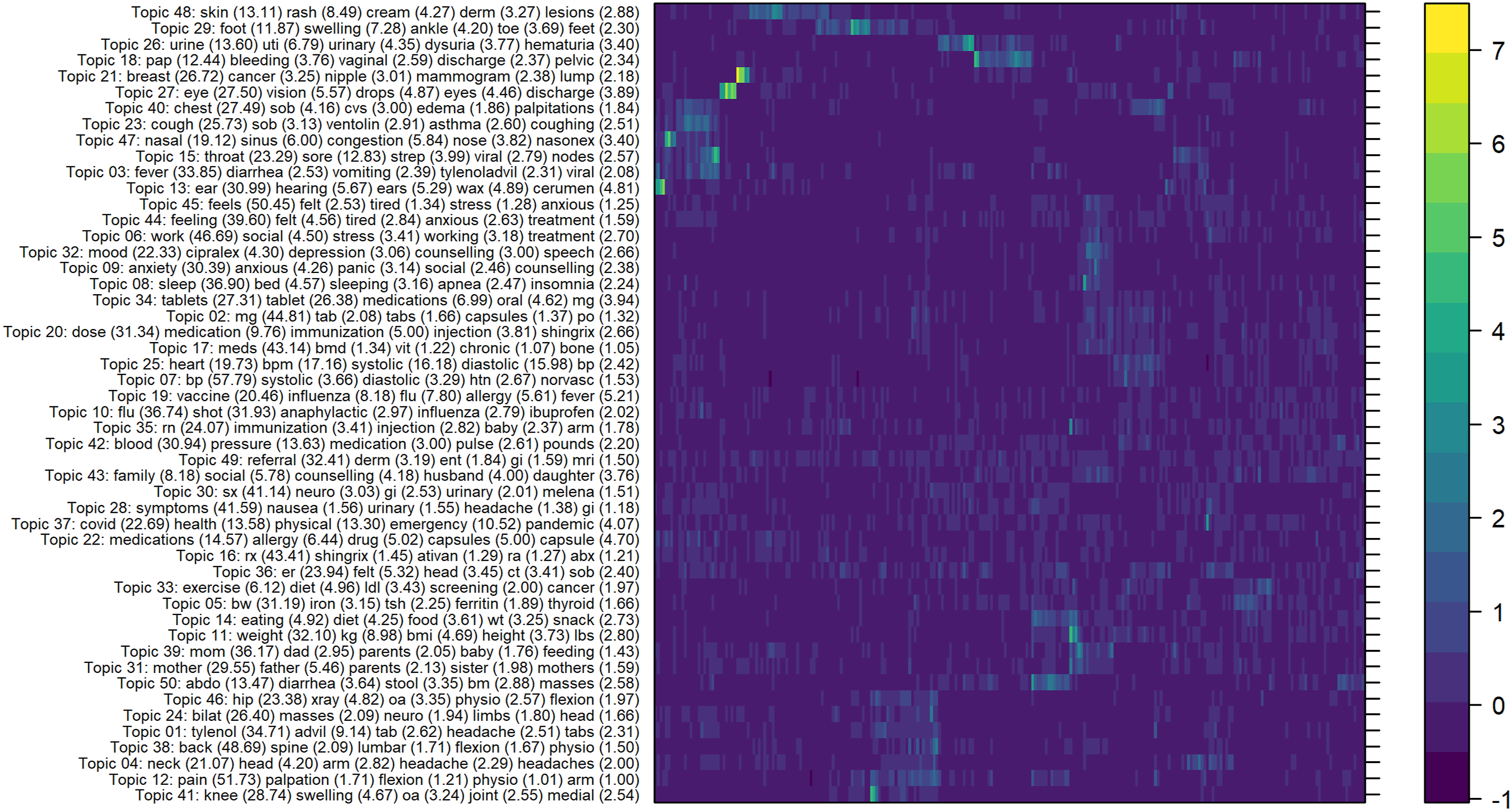
Results
Description of study sample and document corpus
During the study timeframe we observed 382,666 clinical notes recorded in patient EMRs. These clinical notes were collected from 44,828 unique patients, 54 unique physicians, during patient-physician encounters occurring at 12 primary care clinics located in Toronto, Canada. Most clinical notes were obtained from females (67.8%) compared to males (32.2%). Clinical notes were obtained from patients of median age 58 years (inter-quartile range: 38–73 years). A roughly equal proportion of clinical notes were present during each year of observation (e.g. approximately 25% of notes obtained in 2017, 2018, 2019 and 2020).
Following text processing our final analytic vocabulary consisted of 2210 words/tokens. These tokens were observed over 382,666 clinical notes in our document collection. The entire corpus, following text pre-processing, consisted of 10,574,614 words, and the resulting DTM was 99.1% sparse.
Topic model summarization, and association between learned topics and primary diagnostic codes
We fit a topic model consisting of K = 50 latent bases to the corpus of 382,666 primary care progress notes. The top-5 words loading on each of the k = 1…50 latent topics were described in Table 1. The topics were characterized by semantically correlated words, which described focused/specific roles and processes carried out by the primary healthcare system in Toronto, Canada over our study timeframe (e.g. management of acute/chronic disease, prescription management, immunizations, preventative healthcare, personal/familial counselling, coordination of medical referrals, treatment and management of COVID-19, etc.).
248,998 of the total 382,666 (65.1%) primary care progress notes had a corresponding three-digit ICD-9 diagnostic code. In this sample we observed 496 unique codes. Several ICD-9 codes occurred frequently; however, most were rarely recorded. We focused on 260 ICD-9 codes which were observed at least 50 times in the sample. We estimated a standardized mean difference statistic, capturing the magnitude of association between each of the K = 50 topical prevalence vectors and each of the P = 260 Boolean-valued ICD-9 diagnostic codes. For each of the K = 50 topical vectors, we sorted the P = 260 diagnostic codes according to decreasing magnitude of the standardized mean difference statistic. We presented the top-5 ICD-9 diagnostic codes most strongly associated with each topical vector in Table 1. We constructed a composite measure of topical quality, by summing the top-5 standardized mean difference statistics most strongly associated with a given topical vector, and sorted the rows of Table 1 according to this composite measure. For many of the K = 50 thematic vectors we observed that the primary diagnostic codes most strongly associated with the learned latent topics were semantically related, suggesting that they may encode the same underlying clinical construct. Further, we observed that several of the most semantically coherent topics tended to be situated in the initial rows of Table 1, corresponding to those topical vectors where the set of top-5 ICD-9 diagnostic codes were most strongly correlated with the topical vector.
In Figure 1, we plotted the matrix of standardized mean difference statistics, quantifying the strength of association between each of the k = 1…K topics and each of the p = 1…P ICD-9 diagnostic codes. In this study, the matrix was of dimension K = 50 topics (row dimension) by P = 260 ICD-9 diagnostic codes (column dimension). We hierarchically clustered both the rows and columns of the association matrix, using a Euclidean distance metric and Ward’s agglomeration method. The color intensity in the heatmap depicted the magnitude of association between a given topic and a given ICD-9 diagnostic code. Dark blue colors indicated topic/ICD-9 associations of lesser magnitude; whereas, bright yellow colors indicated topic/ICD-9 associations of greater magnitude. Column labels corresponding to ICD-9 diagnostic code labels were supressed to avoid over-plotting. In Figure 1, we observed several focused clusters of ICD-9 diagnostic codes which loaded on single/few topical vectors.
For many of the learned thematic vectors we observed a strong degree of semantic overlap between the words/tokens (summarizing fitted topical vectors) and the ICD-9 diagnostic codes identified as being most strongly associated with the thematic vector. Subjectively, the following topical vectors demonstrated reasonable convergent/discriminant validity: (21, 27, 13, 18, 26, 15, 47, 48, 11, 50, 41, 23, 39, 3, 14, 32, 38, 4, 5, 8, 46, 25, 7, 9, 45). Below, we identified a subset of thematic vectors for which the words/tokens loading strongly on topical basis appeared semantically associated with assigned primary diagnostic codes, suggesting they may be measuring the same latent construct: - Topical vector 21 loads highly on words such as “breast”, “cancer”, “nipple”, “mammogram” and “lump” and seemingly encodes a latent “breast health/disease” construct; correspondingly, this vector is associated with diagnostic codes describing “benign neoplasm of breast (217)”, “benign mammary dysplasia (610)”, “other disorders of the breast (611)”, “infection of the breast (675)” and “malignant neoplasm of the female breast (174)”. - Topical vector 27 loads highly on words such as “eye”, “vision”, “drops”, “eyes” and “discharge” and seemingly encodes a latent “ocular health/disease” construct; correspondingly, this vector is associated with diagnostic codes describing “disorders of the eye/eyelids (379, 374)”, “disorders of the conjunctiva (372)”, “inflammation of eyelids (373)”, and “blindness and low vision (369)”. - Topical vector 13 loads highly on words such as “ear”, “hearing”, “ears”, “wax” and “cerumen” and seemingly encodes a latent “ear health/disease” construct; correspondingly, this vector is associated with diagnostic codes describing “disorders of the external ear (380)”, “other disorders of the ear (388)”, “non-suppurative/suppurative otitis media (381, 382)”, and “hearing loss (389)”. - Topical vector 47 loads highly on words such as “nasal”, “sinus”, “congestion”, “nose” and “nasonex” and seemingly encodes a latent “nasal health/disease” construct; correspondingly, this vector is associated with diagnostic codes describing “chronic sinusitis (473)”, “acute sinusitis (461)”, “allergic rhinitis (477)”, “deviated septum (470)” and “common cold (460)”. - Topical vector 48 loads highly on words such as “skin”, “rash”, “cream”, “derm” and “lesions” and seemingly encodes a latent “skin health/disease” construct; correspondingly, this vector is associated with diagnostic codes describing “contact dermatitis and other eczema (692)”, “atopic dermatitis and related conditions (691)”, “pruritis and related conditions (698)”, “other viral exanthemata (057)”, and “other disorders of the skin (709)”. - Topical vector 41 loads highly on words such as “knee”, “swelling”, “oa”, “joint” and “medial” and seemingly encodes a latent “osteoarthritis and other conditions of the knee” construct; correspondingly, this vector is associated with diagnostic codes describing “sprains and strains of the knee/leg (844)”, “osteoarthritis and allied disorders (715)”, “derangement of joint (718)”, “non-allopathic lesions (739)” and “symptoms of the nervous/musculoskeletal system (781)”. - Topical vector 23 loads highly on words such as “cough”, “sob”, “ventolin”, “asthma” and “coughing” and seemingly encodes a latent “health/disease of the respiratory system” construct; correspondingly, this vector is associated with diagnostic codes describing “acute bronchiolitis (466)”, “respiratory/chest symptoms (786)”, “laryngitis/tracheitis (464)”, “acute nasopharyngitis (460)”, and “other diseases of the respiratory system (519)”. - Topical vector seven loads highly on words such as “bp”, “systolic”, “diastolic”, “htn” and “norvasc” and seemingly encodes a latent “hypertension” construct; correspondingly, this vector is associated with diagnostic codes describing “essential hypertension (401)”, “myocardial infarction (410)”, “angina pectoris (413)”, “atherosclerosis (440)”, and “symptoms of the cardiovascular system (785)”.
In this empirical illustration, half of the learned latent thematic vectors from our fitted topic model demonstrated reasonable semantic relatedness with associated primary diagnostic codes (an indication that the latent topics demonstrated convergent validity). Further, for many of the identified topics there did not appear evidence that semantically unrelated codes were strongly statistically associated with the latent thematic vectors (an indication of discriminant validity). However, not every learned thematic vector demonstrated reasonable properties consistent with the achievement of convergent and discriminant validity. Two types of failed validation arose in this empirical demonstration: (1) a few “intruder” codes, semantically unrelated to the underlying construct, appeared strongly statistically correlated with the topical vector, and (2) many/all statistically correlated codes were semantically unrelated to the topical/thematic vector. A single “intruder” code appearing associated with a topic vector, when other codes demonstrated expected semantic relatedness, was likely a minor problem from a validation perspective. When none of the codes demonstrated semantic relatedness with the topical vector under investigation, this suggested that the topic was not reliably measuring the construct that the top-loading words/tokens suggested.
Intruder codes appeared in the following topics (29, 40, 12, 6). Below we provided several illustrations of topical vectors where intruder codes may be present (for an otherwise well validated construct): - Topical vector 29 loads highly on words such as “foot”, “swelling”, “ankle”, “toe” and “feet” and seemingly encodes a latent “podiatry” construct; correspondingly, this vector is associated with diagnostic codes describing “sprains and strains of the ankle and foot (845)”, “fracture of the ankle (824)”, “flat foot (734)”, and “corns and callosites (700)”. However, a single intruder code appears describing “fracture of the hand (816)”. - Topical vector 40 loads highly on words such as “chest”, “sob”, “cvs”, “edema” and “palpitations” and seemingly encodes a latent “cardio-respiratory disease” construct; correspondingly, this vector is associated with diagnostic codes describing “cardiovascular symptoms (785)”, “angina pectoris (413)”, “diseases of respiratory system (519)”, and “acute bronchitis/bronchiolitis (466)”. However, a single intruder code appears describing “fracture of the ribs/sternum (807)”.
Topics which failed to validate tended to be comprised of primary diagnostic codes, which did not appear to be semantically correlated with the learned topical vectors. In many cases, these topics tended to be vague and semantically unfocused. Further, when standardized mean differences were estimated between codes and topics, we observed the magnitude of dependence between top-ranked codes and associated topics was small. Subjectively, topics which failed to validate under this empirical exercise included: (33, 31, 36, 35, 43, 37, 1, 24, 42, 28, 22, 2, 17, 20, 49, 10, 44, 30, 16, 34, 19). Below we provided several illustrations of topical vectors where the top-ranked codes did not semantically correlate with learned topical vectors: - Topical vector 34 loads highly on words such as “tablet”, “tablets”, “medication”, “oral” and “mg” and seemingly encodes a latent “pharmaceutical prescribing” construct; correspondingly, this vector is associated with diagnostic codes describing the following heterogeneous concepts “chronic liver disease and cirrhosis (571)”, “essential hypertension (401)”, “diabetes mellitus (250)”, “malignant neoplasm of the kidney (189)”, and “cerebrovascular disease (437)”. - Topical vector 49 loads highly on words such as “referral”, “derm”, “enr”, “gi” and “mri” and seemingly encodes a latent “specialist referral” construct; correspondingly, this vector is associated with diagnostic codes describing the following heterogeneous concepts “female infertility (628)”, “derangement of the joint (718)”, “benign neoplasm of the skin (216)”, “glaucoma (365)”, and “psoriasis (696)”.
Comparing topical prevalence vectors in clinical notes with versus without an ICD-9 diagnostic code
248,998 clinical notes out of 382,666 (65.1%) had a three-digit ICD-9 diagnostic code recorded during the clinical encounter. Demographic statistics appeared roughly similar between those clinical notes with/without a recorded ICD-9 diagnostic code. Notes with an ICD-9 diagnostic code were observed on a slightly higher proportion of female patients, compared to notes without an assigned ICD-9 code. Notes with an ICD-9 diagnostic code were observed on slightly older patients, compared to notes without an ICD-9 diagnostic code.
In Appendix Table 1, we estimated the mean difference in topical prevalence between the strata of clinical notes with/without a three-digit ICD-9 diagnostic code. We observed large positive and negative topical mean difference estimates for a subset of the k = 1…50 latent topical prevalence vectors. Particularly, latent topical vectors encoding social work, personal/familial counselling, promotion of healthy diet and exercise, immunizations, and aspects of chronic disease prevention and screening were more prevalent in the strata of notes without an ICD-9 diagnostic code (perhaps suggesting certain primary care roles/functions which are less likely to be coded/billed in primary care EMR systems).
Discussion
In this study we illustrated how researchers could leverage routine clinical EMR documentation processes to investigate validity of learned topic models. We demonstrated how ICD-9 diagnostic codes assigned at the same time a clinical note was generated could be used in external validation of clinical topic models (which were learned in an unsupervised manner from only the clinical notes). We observed that many learned thematic vectors demonstrated satisfactory convergent/discriminant validity, in the sense that top-loading words/tokens from the fitted topic model appeared semantically correlated with primary diagnostic codes assigned during the clinical encounter. For several thematic vectors, we observed poor convergent/discriminant validity in the sense that top-loading words/tokens under a given topic did not appear semantically related to highly ranked diagnostic codes. When conducting any model validation exercise, it is possible that certain components of the model validate better than others – this is what was observed in this study. In this context, we ought to place more trust/belief in the utility of the models topical/thematic vectors which semantically correlated in an expected manner with ICD-9 diagnostic codes, compared to those topical vectors which demonstrated unexpected semantic correlations with ICD-9 diagnostic codes (a potential sign of poor validity for certain model components).
Our Identification of thematic vectors illustrating good/satisfactory validity was necessarily subjective. Two aspects we noted which contributed to the subjective assessment of a valid thematic vector included: (1) the magnitude of the estimated association between top-ranked primary diagnostic codes and the learned topical vector; and (2) the semantic coherence of top-ranked primary diagnostic codes most strongly associated with the topical vector. For example, consider topic-13 (encoding aspects of ear health/disease) and topic-27 (encoding aspects of eye health/disease) which demonstrated reasonable convergent and discriminant validity in our context. For topic-13 each of the five primary diagnostic codes reported in Table 1 are highly statistically associated with the topical vector (i.e. standardized mean differences between 2.10 and 5.85), and further, strongly semantically coherent (i.e. all top five identified diagnostic codes are in the ICD-9 380-389 class, encoding disorders of the ear). Similarly, for topic-27 each of the five primary diagnostic codes reported in Table 1 were highly statistically associated with the topical vector (i.e. standardized mean differences between 3.32 and 6.14), and further, strongly semantically coherent (i.e. all top five identified diagnostic codes are in the ICD-9 360–379 class, encoding disorders of the eye). Both examples provided evidence that the latent topical vectors demonstrated convergent and discriminant validity: the words/tokens measuring vision/hearing systems, respectively, are correlated with primary diagnostic codes related to eye/ear disorders (convergent validity) and illustrated relatively lower statistical associations with codes not related to vision/hearing disorders (discriminant validity).
Concurrent validity assessments became less straightforward under our proposed methodology when (1) the magnitude of statistical association between learned topical vectors and primary diagnostic codes became more modest and/or (2) when the ICD-9 diagnostic codes associated with a given topical vector became semantically less coherent (i.e. top loading diagnostic codes were observed under different ICD-9 disorder categorizations). An example of the former issue was observed for topic-25 (where words/tokens suggest the thematic vector is associated cardiovascular system health/disease), and top-five ICD-9 diagnostic codes all encoded “disorders of the circulatory system”; however the magnitude of association between identified ICD-9 diagnostic codes and the thematic vector were relatively low (i.e. 0.91–1.20). An example of the latter issue related to topic-26 (where words/tokens suggested the thematic vector encoded a urinary tract infection topic), and four of the top-five codes were semantically related to “other diseases of the urinary system”, whereas, a single code was from a distant ICD-9 categorization, albeit encoding a semantically related condition (“non-specific findings on examination of the urine (791)”).
In instances where we classified a topic as “failing to validate”, we often observed that the underlying topic vector itself was semantically vague, with associated words/tokens representing sets of non-specific clinical entities. When the thematic vector was itself unfocused, we often observed that the top-5 primary diagnostic codes identified as being most strongly associated with the topic demonstrated small metrics of statistical dependence and/or were comprised of semantically unrelated code sets. For example, topics (2, 17, 20, 34) encoded aspects of prescribing/medications and correspondingly correlated strongly with heterogeneous ICD-9 diagnostic codes, encoding a multitude of pharmaceutically managed disorders. Similar issues existed with topics-(28 and 30) encoding heterogeneous symptoms, topic-36 encoding aspects of emergent/ambulatory care, and topic-49 encoding medical specialist referrals. If a thematic vector consistently demonstrated poor validity under a variety of assessment methodologies, then the analyst/researcher may not want to rely heavily on the topic in downstream uses/interpretations.
Few studies have focused on the leveraging routine data collection processes embedded in clinical practice (mainly vis-à-vis the use of EMR systems) to facilitate assessment of clinical topic models. We planned to use the learned clinical topic model for (1) corpus level summarization, and (2) enhanced retrieval, clustering, and browsing. As such, we required the learned topical/thematic vectors to accurately measure the latent constructs they purported to encode. To assess whether learned thematic vectors achieved the aforementioned goals, we correlated the latent topical vectors with observed ICD-9 diagnostic codes simultaneously collected in the clinical EMR system. Our approach to assessment of concurrent validity (in particular convergent/discriminant validity) was inspired by work in the psychological and education statistics literature, 2 and the qualitative content analysis literature. 3 Researchers in computational social sciences have also begun to consider methods for validating learned topics, such that they can be perceived as latent measures. 17 Additional work is needed to investigate how clinical researchers can use topic models in valid and meaningful ways. We have suggested a single, flexible mechanism applicable to externally validating clinical topic models. However, we emphasize that no single approach is sufficient for demonstrating the validity of a learned topic model. Rather, applied researchers should likely balance the need for human judgment validation, as well as internal/external validation. Ultimately, validity assessments should align with downstream interpretations and use cases for fitted latent variable models.
An interesting tangential inference emerging from this research study is presented in Appendix Table 1; and investigated mean differences in estimated topical prevalence vectors between notes with/without an associated diagnostic code. For certain topical domains, there were large differences observed in mean topical prevalence between encounters where a diagnostic code was/was-not recorded. Particularly, latent topical domains potentially encoding social work, personal/familial counselling, promotion of healthy diet and exercise, immunizations, and aspects of chronic disease prevention and screening often had a clinical note in the EMR but no associated diagnostic code. Hence, studies utilizing only information contained in diagnostic codes may potentially under-represent certain roles/processes taking place in primary care settings (which are more likely to be captured in clinical text datasets). 18 Contextually, these clinical functions/processes were more likely to be conducted by non-physician members of the multi-disciplinary primary care practice (e.g. social workers, nurses, dieticians, etc.). While some topics highlighted above did not externally validate particularly well in our study, we do not believe other researchers have explored the use of clinical text data and topic models to investigate potential issues/limitations involving studies conducted using only codified primary care EMR data.
Limitations
Our approach to clinical text processing was necessarily subjective. The text processing pipeline employed in this study was adopted because of its simplicity, computational scalability, and transparency. We have included a list of words/tokens included in our analytic DTM as a supplemental file, published with the manuscript. Our decisions have impacts on the vocabulary specified, and subsequently learned latent topical vectors. It is conceivable that alternative approaches to text processing may result in subtly different inferences regarding the dominant topics learned in the primary care clinical note corpus, and further their associations with primary diagnostic codes. Little research exists on the impact of text pre-processing on downstream topic model inferences, and we encourage future research in this area.
We chose to use primary diagnostic codes (three-digit ICD-9 codes) in our convergent/discriminant validity assessments. It is possible that other concurrently collected EMR measures could be used in place of ICD-9 codes. Depending on the jurisdiction and/or EMR vendor, other nomenclatures may be conceivably substituted, for example: Read codes, SNOMED codes, or procedural codes. Alternatively, as a more general-purpose approach, one could create Boolean-valued measures indicating whether vitals, labs, screening tests, etc. were performed during an encounter (not focusing on their absolute results, rather their measurement (yes/no) during a clinical encounter) and correlate these bespoke indicators against latent topical vectors to demonstrate convergent/discriminant validity.
This study has focused on design and methodological considerations for investigating concurrent validity of learned topic models. Depending on the intended use of the topic model, predictive validity (an alternative form of correlative validity) may be important. Predictive validity involves assessment of whether learned topical vectors correlate with future clinical measures. In our clinical context, one opportunity for predictive validity assessment would involve learning a topic model, and investigating whether learned topics correlate with ICD-9 codes measured at time-lagged visits (e.g. first/second/etc. subsequent primary care visits). Similarly, one could investigate whether learned topics correlate strongly with alternative EMR measurements (e.g. future vitals, future labs, future screening tests, future referrals, etc.).
Our approach to estimating the magnitude of dependence/association between continuous topical prevalence vectors, and Boolean-valued primary diagnostic codes used the Cohen-d effect size measure. Effectively this measure estimated the mean difference in topical prevalence, scaled by its pooled SD. Alternative dependence measures could have been employed for this two-sample problem, such as: Student’s t-test (possibly with the Welch correction), the Wilcoxon rank sum test, and others. Admittedly, the primary diagnostic codes determined to be most associated with a given topic vector will change depending on the statistical metric chosen for measuring association. Hence this choice can be viewed as a discrete tuneable parameter in the external validation process. And various measures can be implemented and compared to further corroborate validity of learned topics.
In this study, we investigated external validity of topic models estimated using NMF. Alternative statistical frameworks exist for estimating topic models from large clinical document corpora, for example: Latent Dirichlet Allocation (and related models),19,20 and neural topic models.21,22 The quality of the learned thematic vectors may vary according to the statistical framework used for estimating the topic model. That said, the general framework proposed in this study for externally validating clinical topic models could easily be transported to topic models estimated using alternative statistical methods.
Conclusions
Researchers fitting topic models to EMR clinical text datasets should attempt to leverage routine clinical data collection processes, and EMR data structures, to demonstrate the validity of their topic models. The wealth of information collected in modern clinical EMR systems presents an opportunity for conducting various correlative diagnostics to illustrate the validity of learned clinical topic models.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study was supported by funding provided by a Foundation Grant (FDN 143303) from the Canadian Institutes of Health Research (CIHR). The funding agency had no role in the study design, the collection, analysis, or interpretation of data, the writing of the report, or the decision to submit the report for publication. Dr. Austin was supported by a Mid-Career Investigator Award from the Heart and Stroke Foundation.
Ethical approval
This study received ethics approval from North York General Hospital Research Ethics Board (REB ID: NYGH #20-0014).
Mean topical prevalence estimates for each of the K = 1…50 topics,stratified according to clinical notes with/without an ICD-9 diagnostic code. Estimated differences in topical prevalence vectors across strata and constructed pointwise 95% bootstrap confidence intervals about the estimated mean differences. We rank-ordered latent topical constructs in increasing order of the mean difference statistic.
Topic labels and Top-5 most probable words/Tokens
Mean topical prevalence in clinical notes without a diagnostic code
Mean topical prevalence in clinical notes with a diagnostic code
Mean difference in topical prevalence
Lower limit 95% bootstrap confidence interval
Upper limit 95% bootstrap confidence interval
Topic 12: pain (51.73), palpation (1.71), flexion (1.21), physio (1.01), arm (1.00)
0.068
0.120
−0.052
−0.054
−0.051
Topic 02: mg (44.81), tab (2.08), tabs (1.66), capsules (1.37), po (1.32)
0.159
0.210
−0.051
−0.054
−0.047
Topic 07: bp (57.79), systolic (3.66), diastolic (3.29), htn (2.67), norvasc (1.53)
0.029
0.066
−0.037
−0.037
−0.036
Topic 04: neck (21.07), head (4.20), arm (2.82), headache (2.29), headaches (2.00)
0.025
0.061
−0.035
−0.036
−0.034
Topic 15: throat (23.29), sore (12.83), strep (3.99), viral (2.79), nodes (2.57)
0.013
0.036
−0.023
−0.024
−0.022
Topic 41: knee (28.74), swelling (4.67), oa (3.24), joint (2.55), medial (2.54)
0.015
0.038
−0.023
−0.024
−0.022
Topic 40: chest (27.49), sob (4.16), cvs (3.00), edema (1.86), palpitations (1.84)
0.021
0.042
−0.021
−0.021
−0.020
Topic 05: bw (31.19), iron (3.15), tsh (2.25), ferritin (1.89), thyroid (1.66)
0.056
0.076
−0.021
−0.022
−0.019
Topic 30: sx (41.14), neuro (3.03), gi (2.53), urinary (2.01), melena (1.51)
0.015
0.031
−0.016
−0.017
−0.016
Topic 23: cough (25.73), sob (3.13), ventolin (2.91), asthma (2.60), coughing (2.51)
0.010
0.026
−0.016
−0.016
−0.016
Topic 45: feels (50.45), felt (2.53), tired (1.34), stress (1.28), anxious (1.25)
0.027
0.042
−0.015
−0.016
−0.014
Topic 38: back (48.69), spine (2.09), lumbar (1.71), flexion (1.67), physio (1.50)
0.034
0.047
−0.014
−0.014
−0.013
Topic 25: heart (19.73), bpm (17.16), systolic (16.18), diastolic (15.98), bp (2.42)
0.009
0.023
−0.014
−0.014
−0.013
Topic 50: abdo (13.47), diarrhea (3.64), stool (3.35), bm (2.88), masses (2.58)
0.020
0.033
−0.013
−0.014
−0.013
Topic 34: tablets (27.31), tablet (26.38), medications (6.99), oral (4.62), mg (3.94)
0.010
0.022
−0.012
−0.013
−0.012
Topic 22: medications (14.57), allergy (6.44), drug (5.02), capsules (5.00), capsule (4.70)
0.011
0.021
−0.010
−0.010
−0.009
Topic 24: bilat (26.40), masses (2.09), neuro (1.94), limbs (1.80), head (1.66)
0.010
0.019
−0.009
−0.010
−0.009
Topic 48: skin (13.11), rash (8.49), cream (4.27), derm (3.27), lesions (2.88)
0.014
0.024
−0.009
−0.010
−0.009
Topic 47: nasal (19.12), sinus (6.00), congestion (5.84), nose (3.82), nasonex (3.40)
0.005
0.014
−0.009
−0.009
−0.009
Topic 42: blood (30.94), pressure (13.63), medication (3.00), pulse (2.61), pounds (2.20)
0.021
0.029
−0.008
−0.009
−0.008
Topic 28: symptoms (41.59), nausea (1.56), urinary (1.55), headache (1.38), gi (1.18)
0.022
0.030
−0.008
−0.008
−0.007
Topic 16: rx (43.41), shingrix (1.45), ativan (1.29), ra (1.27), abx (1.21)
0.011
0.018
−0.007
−0.008
−0.007
Topic 29: foot (11.87), swelling (7.28), ankle (4.20), toe (3.69), feet (2.30)
0.012
0.018
−0.006
−0.006
−0.006
Topic 49: referral (32.41), derm (3.19), ent (1.84), gi (1.59), mri (1.50)
0.020
0.026
−0.006
−0.006
−0.005
Topic 46: hip (23.38), X-ray (4.82), oa (3.35), physio (2.57), flexion (1.97)
0.006
0.011
−0.005
−0.006
−0.005
Topic 27: eye (27.50), vision (5.57), drops (4.87), eyes (4.46), discharge (3.89)
0.007
0.011
−0.005
−0.005
−0.004
Topic 21: breast (26.72), cancer (3.25), nipple (3.01), mammogram (2.38), lump (2.18)
0.016
0.020
−0.004
−0.005
−0.003
Topic 37: covid (22.69), health (13.58), physical (13.30), emergency (10.52), pandemic (4.07)
0.012
0.016
−0.004
−0.004
−0.004
Topic 26: urine (13.60), uti (6.79), urinary (4.35), dysuria (3.77), hematuria (3.40)
0.016
0.020
−0.004
−0.004
−0.003
Topic 36: er (23.94), felt (5.32), head (3.45), ct (3.41), sob (2.40)
0.019
0.023
−0.004
−0.004
−0.003
Topic 17: meds (43.14), bmd (1.34), vit (1.22), chronic (1.07), bone (1.05)
0.018
0.022
−0.004
−0.004
−0.003
Topic 13: ear (30.99), hearing (5.67), ears (5.29), wax (4.89), cerumen (4.81)
0.022
0.026
−0.003
−0.004
−0.002
Topic 08: sleep (36.90), bed (4.57), sleeping (3.16), apnea (2.47), insomnia (2.24)
0.027
0.031
−0.003
−0.004
−0.003
Topic 32: mood (22.33), cipralex (4.30), depression (3.06), counselling (3.00), speech (2.66)
0.012
0.014
−0.003
−0.003
−0.002
Topic 11: weight (32.10), kg (8.98), bmi (4.69), height (3.73), lbs (2.80)
0.037
0.039
−0.001
−0.002
−0.001
Topic 01: tylenol (34.71), advil (9.14), tab (2.62), headache (2.51), tabs (2.31)
0.104
0.104
0.000
−0.002
0.002
Topic 44: feeling (39.60), felt (4.56), tired (2.84), anxious (2.63), treatment (1.59)
0.023
0.023
0.000
0.000
0.001
Topic 18: pap (12.44), bleeding (3.76), vaginal (2.59), discharge (2.37), pelvic (2.34)
0.020
0.019
0.001
0.000
0.001
Topic 03: fever (33.85), diarrhea (2.53), vomiting (2.39), tylenoladvil (2.31), viral (2.08)
0.061
0.058
0.003
0.002
0.004
Topic 09: anxiety (30.39), anxious (4.26), panic (3.14), social (2.46), counselling (2.38)
0.030
0.026
0.004
0.003
0.005
Topic 33: exercise (6.12), diet (4.96), ldl (3.43), screening (2.00), cancer (1.97)
0.033
0.025
0.007
0.007
0.008
Topic 14: eating (4.92), diet (4.25), food (3.61), wt (3.25), snack (2.73)
0.017
0.009
0.008
0.007
0.008
Topic 39: mom (36.17), dad (2.95), parents (2.05), baby (1.76), feeding (1.43)
0.021
0.013
0.009
0.008
0.009
Topic 31: mother (29.55), father (5.46), parents (2.13), sister (1.98), mothers (1.59)
0.016
0.007
0.009
0.009
0.010
Topic 10: flu (36.74), shot (31.93), anaphylactic (2.97), influenza (2.79), ibuprofen (2.02)
0.021
0.008
0.014
0.013
0.014
Topic 19: vaccine (20.46), influenza (8.18), flu (7.80), allergy (5.61), fever (5.21)
0.018
0.003
0.015
0.014
0.015
Topic 20: dose (31.34), medication (9.76), immunization (5.00), injection (3.81), shingrix (2.66)
0.036
0.021
0.015
0.014
0.015
Topic 06: work (46.69), social (4.50), stress (3.41), working (3.18), treatment (2.70)
0.075
0.055
0.020
0.019
0.021
Topic 43: family (8.18), social (5.78), counselling (4.18), husband (4.00), daughter (3.76)
0.034
0.014
0.021
0.020
0.021
Topic 35: rn (24.07), immunization (3.41), injection (2.82), baby (2.37), arm (1.78)
0.033
0.008
0.025
0.025
0.026