
Abstract
Medication errors often occurred due to the breach of medication rights that are the right patient, the right drug, the right time, the right dose and the right route. The aim of this study was to develop a medication-rights detection system using natural language processing and deep neural networks to automate medication-incident identification using free-text incident reports. We assessed the performance of deep neural network models in classifying the Advanced Incident Reporting System reports and compared the models’ performance with that of other common classification methods (including logistic regression, support vector machines and the decision-tree method). We also evaluated the effects on prediction outcomes of several deep neural network model settings, including number of layers, number of neurons and activation regularisation functions. The accuracy of the models was measured at 0.9 or above across model settings and algorithms. The average values obtained for accuracy and area under the curve were 0.940 (standard deviation: 0.011) and 0.911 (standard deviation: 0.019), respectively. It is shown that deep neural network models were more accurate than the other classifiers across all of the tested class labels (including wrong patient, wrong drug, wrong time, wrong dose and wrong route). The deep neural network method outperformed other binary classifiers and our default base case model, and parameter arguments setting generally performed well for the five medication-rights datasets. The medication-rights detection system developed in this study successfully uses a natural language processing and deep-learning approach to classify patient-safety incidents using the Advanced Incident Reporting System reports, which may be transferable to other mandatory and voluntary incident reporting systems worldwide.
Keywords
Introduction
The World Health Organization has regarded patient safety as a major public health issue that requires global attention.1,2 In March 2017, medication safety was launched as the third global patient-safety challenge that aims to promote medication without harm to the world. Errors in drug management pose a great risk to patients receiving medical care 3 and the basic five ‘rights’ of medication administration remains a widely acceptable standard for safe medication practice. These include the right patient, the right drug, the right time, the right dose and the right route (additional rights include right duration, right documentation, right reason and right response). The overall goal is to assure that the right patient receives the right dose of the right drug via the right route at the right time.
Indeed, medication errors can be potentially prevented in many instances. 4 It is important to learn from the causes, contributory factors, consequences and mitigating actions via incident reporting.5,6 Many developed countries/territories (such as the United Kingdom, Australia, Japan and Hong Kong) have set up national/regional medical incident reporting systems.7–10 These systems are designed to determine the background and causes of near-misses and actual incidents in a bid to prevent future occurrences. Typical incident report systems rely heavily on the free-text reporting to provide a description of incident background, outcomes and action. Presently many incident reporting systems in the world capture incidents of medication errors using free text without indicating the medication-rights errors structurally. The associated medication-rights information remains in the narrative text part of the incident reports. Analysis of reported incidents enables hospitals to implement measures to minimise risk and develop strategies to prevent recurrence. However, due to the large volume of textual data collected, identification of relevant reports that share the same markers can be very time-consuming and labour intensive. Text classification has proven to be a useful means of interpreting patient-safety reports.7,8,10–13 A previous probing study demonstrated that certain important event types, such as incidents caused by ‘look-alike, sound-alike’ medication, can be retrieved from a group of medication-incident-related documents using text classifier. 13 The aim of this study was to develop a medication-rights detection system to classify medication incidents using the real-world incident reports collected by the Hong Kong Hospital Authority (HA). It is envisioned that the approach is transferable towards other mandatory and voluntary incident reporting systems worldwide.
The Advanced Incident Reporting System (AIRS), 9 operated by the HA, is a centralised incident reporting system used to collect information on clinical and nonclinical incidents and near-misses in public hospitals in Hong Kong. The system has operated since 2000. Various standard reporting templates are available for the different types of incident that may occur in hospitals, such as medication-related incidents, falls, biomedical events, drug reactions, missing patients and suicide. In addition to the standard templates developed by the HA, text-input boxes are available for reporters to provide supplementary information in free-text form on a wide range of incidents. The AIRS database provides a very valuable source of information on how, why and how often patients are harmed. Compared with other types of incidents/near-misses, medication-related incidents have potentially more severe health consequences, and their analysis should thus be prioritised to improve the quality of treatment and patient safety in hospitals. Using selected rights markers as class indicators for the free-text incident reports, we attempted to develop a text-based medication-rights detection system using advanced deep-learning methods to aid patient-safety information management. Our study also demonstrates deep-learning methods, can be practical candidate for incident classification and information retrieval, contributing to advance incident report learning.
Background and significance
Text classification8,11,13 remains the state-of-the-art quantitative method to analyse patient-safety reports. 5 These classifiers would require a well-designed feature engineering to achieve reasonable classification performance. However, developing good engineering features is inherently time-consuming and highly domain/subject-specific. Modern deep-learning approaches are capable of bypassing tedious feature engineering steps and learning effective features from random assignments or word embedding methods. 14 Deep Learning, typically achieved by artificial neural network (ANN) methods, makes sense of data by learning multiple levels of representation and abstraction. 15 A ‘deep’ architecture is regarded as those neuron networks which have more than 1 hidden layer. 16 Thanks to the advancement of computation power, deep learning has been receiving high attention in the recent decades. Typical deep-learning methods include deep neural networks (DNNs), recurrent neuron networks (RNNs) 17 and bidirectional encoder representations from transformers (BERTs). 18 Recently, the use of deep-learning algorithms has led to major advances in the extraction of intricate structures from large datasets, particularly those containing high-dimensional data,19,20 such as textual, 21 image recognition and speech recognition 22 applications. Deep learning, which has been successful in various domains, has also shown to be promising in health informatics applications. 17
DNN is a kind of the deep-learning method. Fundamentally, DNN is an ANN that attempts to make sense of data in multiple levels corresponding to different levels of abstraction and it comprises multiple hidden layers of neurons between the input and output layers. Starting from an input layer, DNNs consist of layers of interconnected neurons to match the feature space with a classification layer via a nonlinear activation function. DNN, a multilayer perceptron method, uses feedforward networks of connected layers with no loops. 23 These act as classifiers and make different contributions to prediction outcomes. DNN can be used to solve binary and multi-class classification problems. Figure 1 shows the simplified structure of a DNN with a single output node for our study task. Several studies have suggested that DNNs outperform standard classifiers because they have more layers, enabling nonlinearity functions to be nested and the network to represent more complex functions. For instance, Iyyer et al. 24 demonstrated promising results from applying a simple DNN to a typical text-classification problem and identified nonlinear input transformation as the factor responsible for the observed high performance.
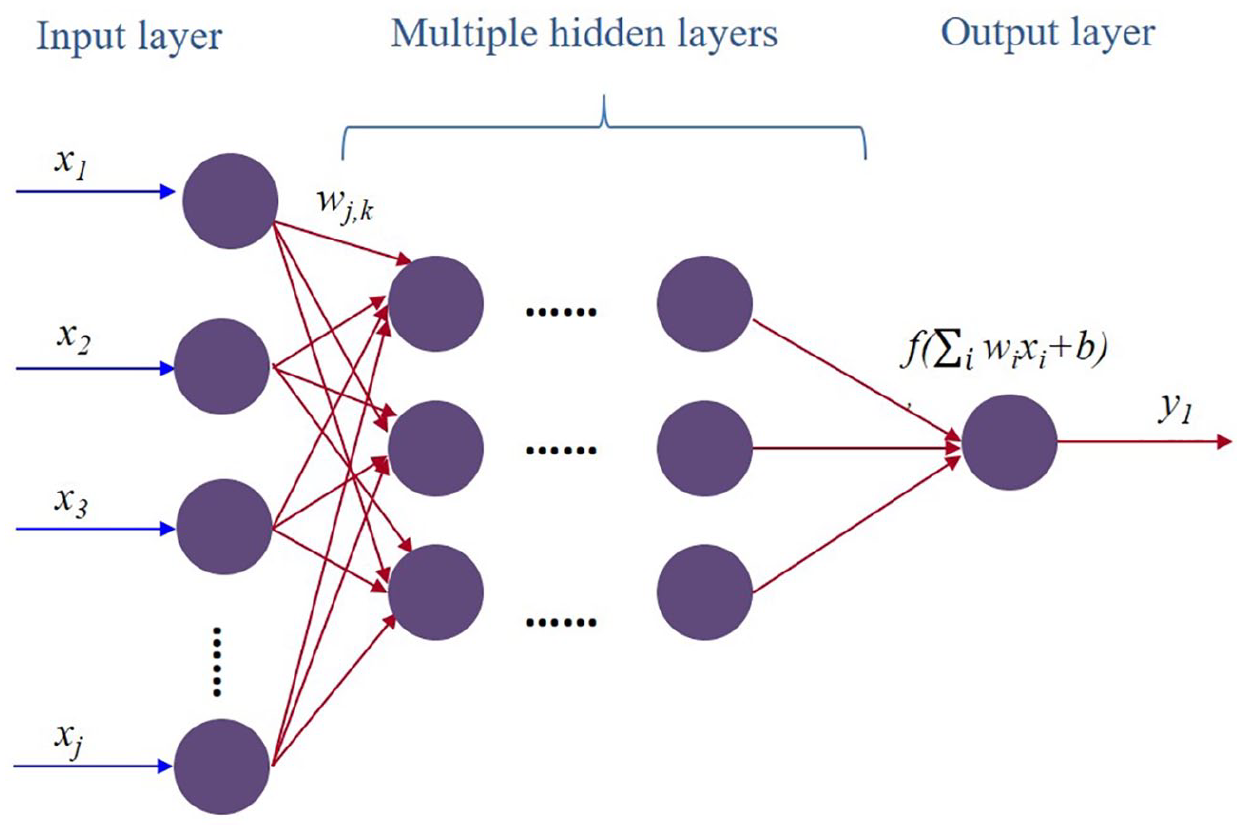
Typical structure of a deep neural network with a single output node.
Typical statistical classification techniques involve the training of high-dimensional data with very sparse features.12,25 However, due to the intensive computation required, training a DNN with large number of hidden layers is often time-consuming and it is difficult to reach convergence with some existing packages (such as neuralnet in R). It was only recently that the algorithmic advances of the Java-based H2O platform, 23 which is an open-source machine-learning and deep-learning platform, have allowed supervised training of DNN models more efficiently. The platform runs scalable machine-learning and DNN models and allows installation via R and Python platforms. The H2O R package 26 can be downloaded from CRAN to control the H2O engine and run high-performance deep-learning models. The use of deep learning as well as DNN has not yet received attention as a candidate method of medical incident text classification for improving patient-safety information retrieval. The DNN model we developed in this study is a feedforward ANN model with multiple hidden layers. 23 The key innovation of this study is the exploration of efficient medication-incident classification with DNN method using hospital incidents on five medication rights.
The aim of this study was to develop a medication-rights detection system via DNN that is able to automate medication-rights incident identification using free-text incident reports. Classification of incident occurrence is an important means of quantitatively analysing a large amount of mined textual data on reported patient incidents. 4 The state-of-the-art studies used machine-learning models, such as logistic-regression models, 12 support vector machines (SVMs) 8 and decision trees, 13 to model high-level abstractions of textual incident data. The use of DNN, which has had promising outcomes in other complicated machine-learning fields, has to date received little attention as a method of patient-safety information retrieval. We developed the DNN medication-rights classification as a means of analysing AIRS medication-incident reports and to compare the performance of DNN models with that of other standard classifiers. We also aimed to provide practical guidelines for training DNN models to classify patient-safety incidents, which may be transferable to other mandatory and voluntary reporting systems worldwide for effectively understanding medical incidents.
Materials and methods
Datasets
Our medication-incident textual data were obtained from the New Territories East Cluster (NTEC) through the HA database. The NTEC consists of seven hospitals providing a wide range of medical services. The incident reports were extracted from AIRS version 2 (AIRS v.2) and AIRS version 3 (AIRS v.3) in November 2014. AIRS v.2 was being remodelled to the current AIRS v.3 edition in 2013, with a similar basic framework and common textual input items. However, AIRS v.3. (the latest version) captured less structured items than AIRS v.2 (the former version) to simplify the reporting workload of clinical staff. In the medication-incident template, both versions collected structured data attributes and unstructured free text to record patient demographic, medication name, dosage used, a brief description of the incident and the immediate action taken. We only selected mutual structured data attributes and unstructured textbox items across the two systems for our analysis (specifically, the medication-rights markers and the free-text summary of the medication incident). The AIRS v.2 reports covered all medication incidents between January 2011 and December 2013, and the AIRS v.3 reports covered medication incidents between January 2014 and September 2014.
We analysed only reports in English; all reports containing Chinese characters were excluded. Only incidents associated with medication errors and near-misses were selected. A clinical near-miss was defined as an incident corrected before it affected the patient, and a clinical incident was defined as an event that affected a patient and did or did not cause harm to the patient. All of the medical incident data were anonymised by truncating the associated patient names and removing other identifying information before analysis. A member of staff at the HA double-checked that the dataset contained no individually identifiable information. Each of the reports addressed one single medication incident that may have involved one or more than one medication-rights markers (coded as wrong patient (WP), wrong drug (WD), wrong time (WT), wrong dose (WE) and wrong route (WR)) at the same time. The medication rights were directly denoted by the same attribute names in the ‘type of event’ reporting section, as shown in the AIRS user interface in Figure 2. The research was approved by the Joint Chinese University of Hong Kong–NTEC Clinical Research Ethics Committee (CREC). The clinical research approval number awarded by the CREC was No: 2014.470.
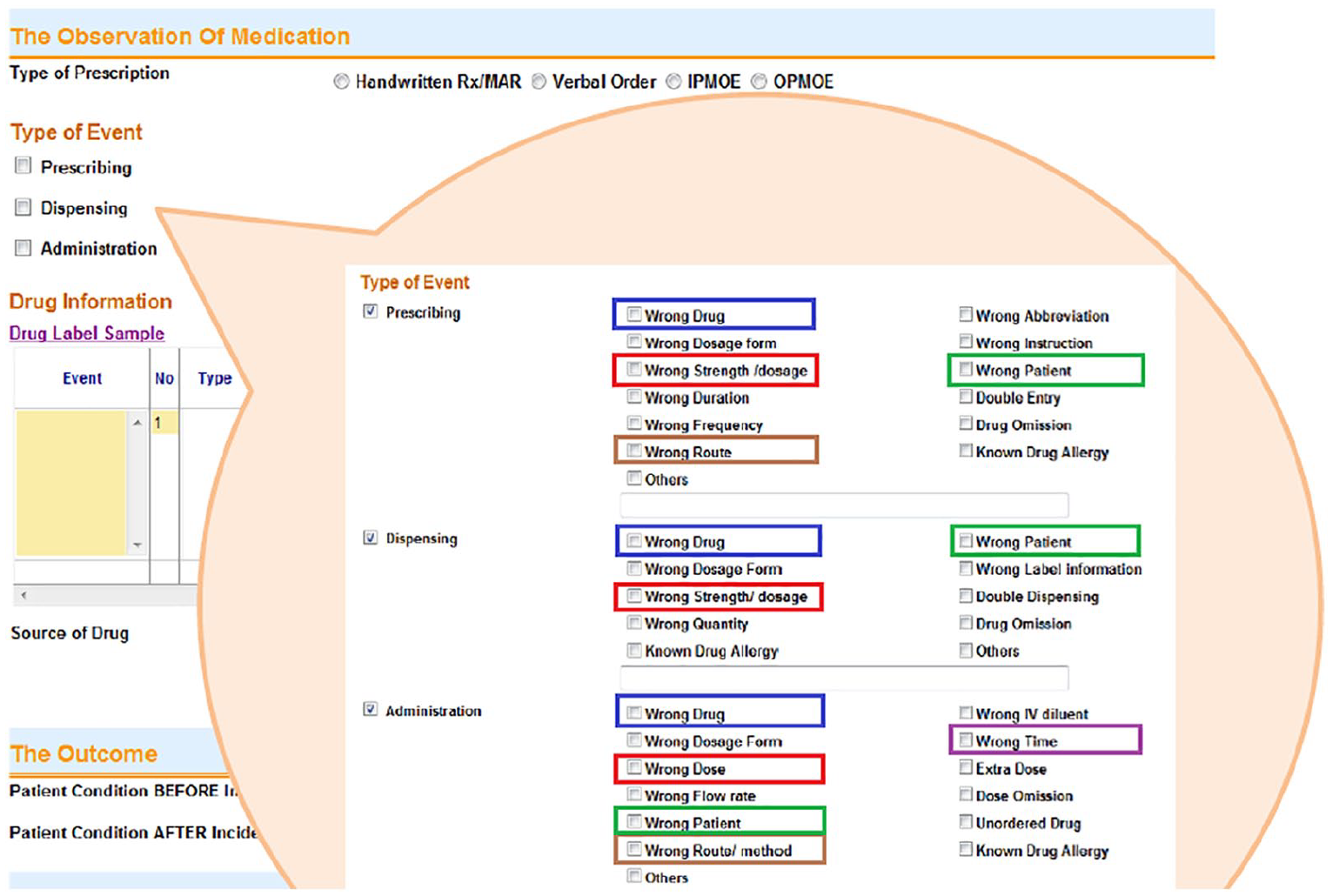
Screenshot of the AIRS interface showing events related to the ‘rights’ of medication use.
Experimental workflow
The experimental workflow comprised four steps: structuring unstructured textual data by natural language processing (NLP) method, feature selection, DNN model development and performance evaluation. Both AIRS v.2 and v.3 text datasets contained clear indications of medication-rights markers when the incident reports were captured at the hospital level. The dependent variable (output node) of each medication-rights marker model was a binary response variable (i.e. positive (cases) or negative (no cases)) and depended on the rights marker undertaken. We used AIRS v.2 incident reports to predict the marker class of each AIRS v.3 medication-incident report. Subsequently, we used the trained model to predict the medication-rights marker using the training set text reports (AIRS v.3) and compared the prediction outcomes against the true (originally indicated) medication-rights markers. The workflow is illustrated in Figure 3. The analysis was performed using an R v.3.4.1 64-bit platform with the packages H2O, tm, snowball and Rstem on a desktop personal computer (processor: Intel® Core™ i3-2330M; CPU: 2.2 GHz).
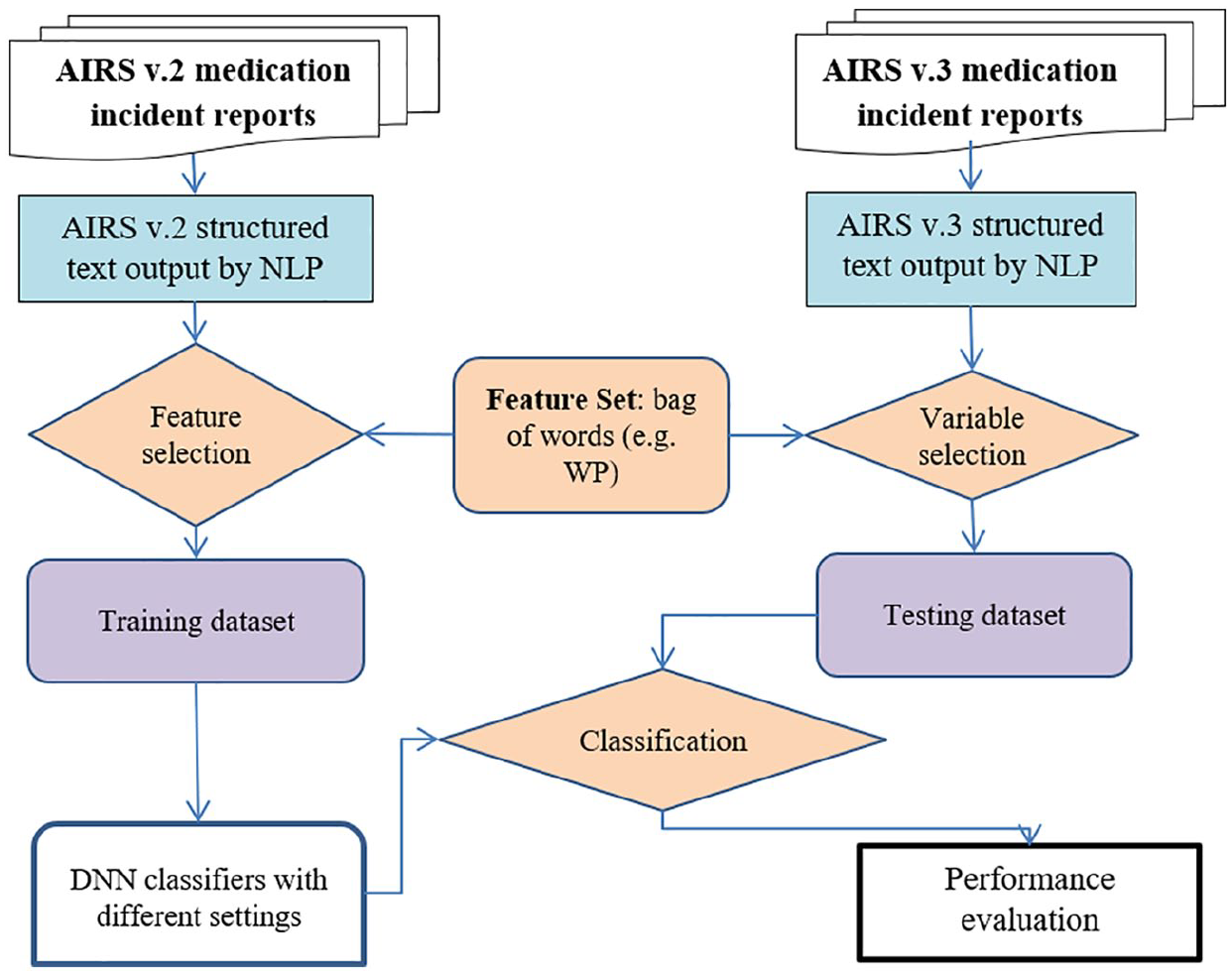
Experimental workflow.
Structuring incident text
We used NLP algorithms written in R to structure the free-text descriptions provided in the AIRS reports. We followed the text-mining procedure given in Wong 13 to produce structured summaries of the AIRS free-text data. The original incident reports were processed by removing English stop words, converting words to their stems, converting words to lower case, trimming white space and removing numbers and punctuation. The resulting structured data summarising the term-document matrices of AIRS v.2 and AIRS v.3 were prepared as the training and testing datasets, respectively.
Model input/feature set
The inputs of the models came from the analysed ‘bags of words’ (bow) 8 of the training set text reports (AIRS v.2). As a result, different medication-rights markers have different feature sets (e.g. the feature set of WP is different from WE because the free text used in WP is different from that used in WE). These reports were subjected to the text conversion and structuring procedure described above. The structured text outcomes (i.e. bow) were the source of the classifier’s input variables. We developed models for all five markers independently using the same experimental workflow. Finally, five bow were prepared for the entire analysis: one bag (bow) each for WP (bow_WP), WD (bow_WD), WT (bow_WT), WE (bow_WE) and WR (bow_WR). Word weighting was determined by calculating term frequency–inverse document frequency (TFIDF). 27 TF refers to the number of times that each stemmed term occurs in the corpus and the IDF was calculated as log N/Nt, where N denotes the total number of documents in the corpus and Nt the number of documents in which the term appears.
DNN basic model
The deep-learning computations were performed in the H2O cluster and initiated by the H2O R package.23,26 Beginning with an input layer that matches the feature space, DNN applications require weight matrix and column vector of biases to be computed in each layer and the representation in each layer to be differentiated from the representation in the previous layer. The weighted combination
We used a purely supervised training protocol provided by H2O that allows every node to train on the entire dataset. The default suggested distribution functions that primarily associate with each loss function were employed. We launched the training dataset and testing datasets to the H2O platform and preprocessed and standardised our input layer nodes into a standard normal distribution of N(0, 1) to ensure its compatibility with the activation functions (because activation functions cannot map into the full spectrum of real numbers). The second phase of standardisation process was then carried out after the network propagation phase. The model performance metrics of the trained model were captured using the validation data as the programme output.
Parameters
When training a DNN model, a number of possible parameter arguments must be specified. We aimed to explore a choice of algorithms, parameters and settings (including activation functions, hidden-layer size, dropout control and regularisation) for DNN medication-incident classification. We varied the following key parameter arguments one at a time:
Number of layers and hidden-layer size: We varied the level of complexity of the DNN model by the number of hidden layers (1–5) and number of neurons in each hidden layer (50, 100, 150, 200, 250 and 300). We only tested the same number of neurons in each layer if there was more than 1 hidden layer. The base case number of hidden layers was 2 and the number of neurons was 200 in each layer.
Activation and loss functions: We examined the impact of various nonlinear activation functions, namely Tanh, Rectifier and Maxout. The mathematical formulae of the activation functions are shown in Table 1. The selected activation function was applied to process the nested network values in the output classification layer. We only selected one activation function once at a time for the experiment. The base case activation function is Tanh.
Dropout regularisation control and ratio: In this study, regularisation by dropout 28 was considered. Dropout control generally allows averaging a large number of models as an ensemble during forward propagation. It helps to improve model overfitting and increase DNN model generalisability. The dropout function is controlled by the activation function argument as ‘TanhWithDropout’, ‘MaxoutWithDropout’ or ‘RectifierWithDropout’. We specified the amount of hidden dropout per hidden layer to be 0.5. The base case incorporates dropouts using Tanh function.
Mathematical formulae for activation functions.

Other classification methods
We also compared the performance of the DNN classifier with that of several machine-learning methods (logistic regression, SVMs and decision-tree method), without heavy problem-specific tuning. We followed the same experimental workflow procedure given by Figure 3 for free-text extraction, feature selection and performance evaluation schemes. We developed these classifiers for each medication marker based on the R code used in the previous probing study (the detailed procedures are given in Wong 13 ). Due to a lack of existing results for the non-DNN classifiers, we used stratified (10-fold) cross-validation 13 for training the AIRS v.2 data, and the resultant models were tested against the AIRS v.3 data. We compared the performance of the classifiers using ROC curves, which provide a graphical display of sensitivity on the y-axis against (1 – specificity) on the x-axis by setting the testing probability to 0.5.
Performance evaluation
We explored the effects of DNN model settings, including number of layers, number of neurons in each layer and activation algorithms, on the performance of the trained DNN model. We examined classifier performance using the metrics of specificity, sensitivity, F1 score, accuracy and area under the receiver operating characteristic (ROC) curve (AUC). These metrics were reported relative to the threshold of the highest F1 score. Specificity (or true-negative (TN) rate) measures the proportion of negatives that are correctly identified, whereas sensitivity (also known as recall or true-positive (TP) rate) measures the proportion of actual positives that are correctly identified, that is, the fraction of actual positives that are correctly identified. The geometric mean of specificity and sensitivity is also reported. Precision is also considered to be the positive predictive value that represents the fraction of retrieved instances that are relevant. The F1 score is the harmonic mean of precision and recall. Accuracy is a statistical measure of how well a classifier correctly identifies a condition. Since the dataset of this binary classification task is unbalanced, AUC, which indicates the overall ability of a classifier to discriminate between positive and negative cases, would be a fair measure to determine the DNN model performance. A perfect classifier, yielding zero false positives (FPs) and zero false negatives (FNs), would achieve an AUC value of 1.
Patient and public involvement
This is a retrospective study based on incidents reports collected from incident reporting system. Patients were not involved in the development of the research question and outcome measures.
Results
Descriptive statistics
We drew 348 reports from AIRS v.2 and 226 from AIRS v.3 as shown in Table 2. We summarised the information provided on patient gender, patient age, departments involved, event type, severity and the five medication-rights markers in the selected reports. A two-sided Fisher’s test was used to determine whether the use of AIRS v.2 or AIRS v.3 was significant for any of these categories. The differences found in the proportions of AIRS v.2 and AIRS v.3 reports were nonsignificant for most of the categories (patient gender, severity and the five rights markers) but significant for the >70 patient age group and incidents classified as administration-related (we did not observe any apparent contributing factor for such differences).
Descriptive summary of incidents.
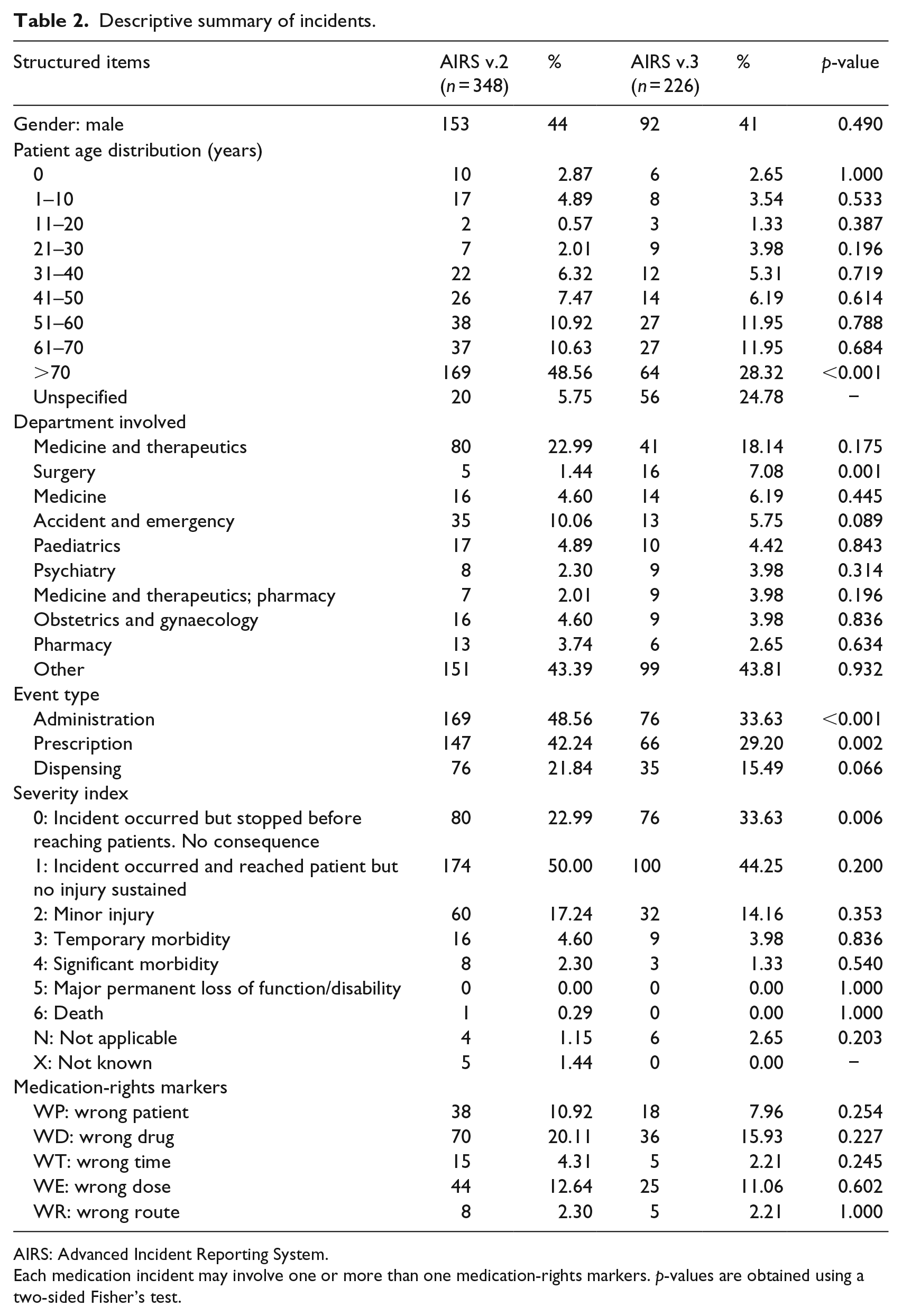
AIRS: Advanced Incident Reporting System.
Each medication incident may involve one or more than one medication-rights markers. p-values are obtained using a two-sided Fisher’s test.
Free-text summary
Table 3 shows examples of AIRS reports with the WP marker, and Figure 4 visualises ‘clouds of words’ of the AIRS medication incidents. The size and colour of the words are stratified by word importance based on TFIDF, using the R package ‘wordcloud’.
Examples of AIRS WP incident reports (narrative text).
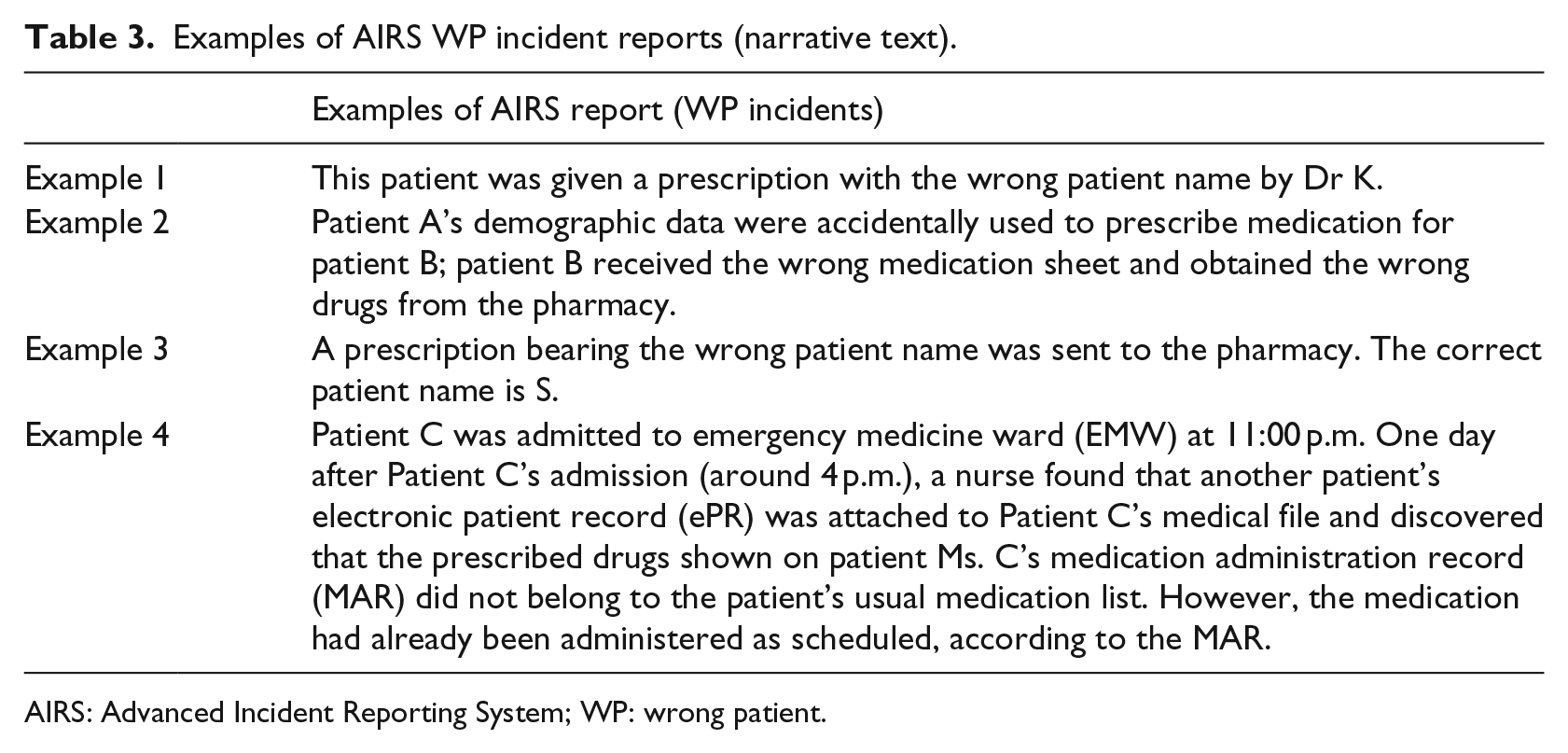
AIRS: Advanced Incident Reporting System; WP: wrong patient.
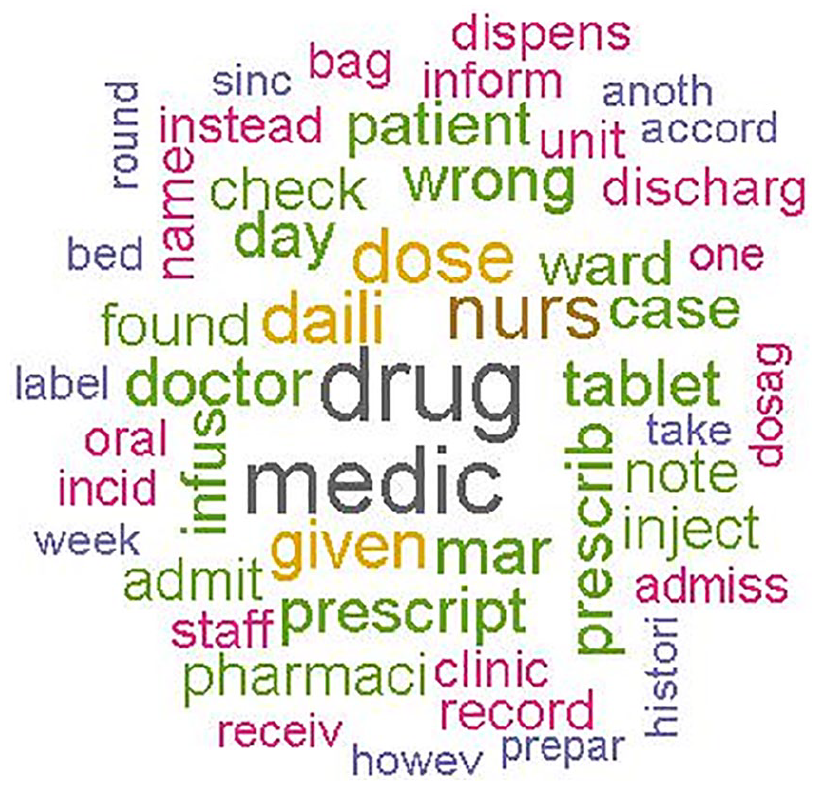
Word cloud for AIRS medication-incident reports (created using the R wordcloud package; size of words stratified by word importance).
The 10 terms with the highest TFIDF used to describe medication incidents in the AIRS v.2 and AIRS v.3 reports are listed in Table 4 and include ‘drug’, ‘medi’, ‘nurs’ and ‘dose’. The 10 terms with the highest TFIDF used to describe the group of incidents with the WP marker included ‘drug’, ‘medic’, ‘bed’, ‘check’ and ‘found’. The terms with the highest TFIDF were fairly similar between AIRS v.2 and AIRS v.3, indicating that a limited number of terms were used repeatedly for incident reporting. The important keywords found in AIRS v.2 were also weighted heavily in AIRS v.3. This suggested that text classification using the terms of the training data set (AIRS v.2) as predictor variables for predicting the medication markers of AIRS v.3 was justifiable. We also reported the top 10 TFIDF terms in each of the other classes (WD, WT, WE and WR) in Table S1 of Supplementary Document 1.
Top 10 TFIDF terms (background).
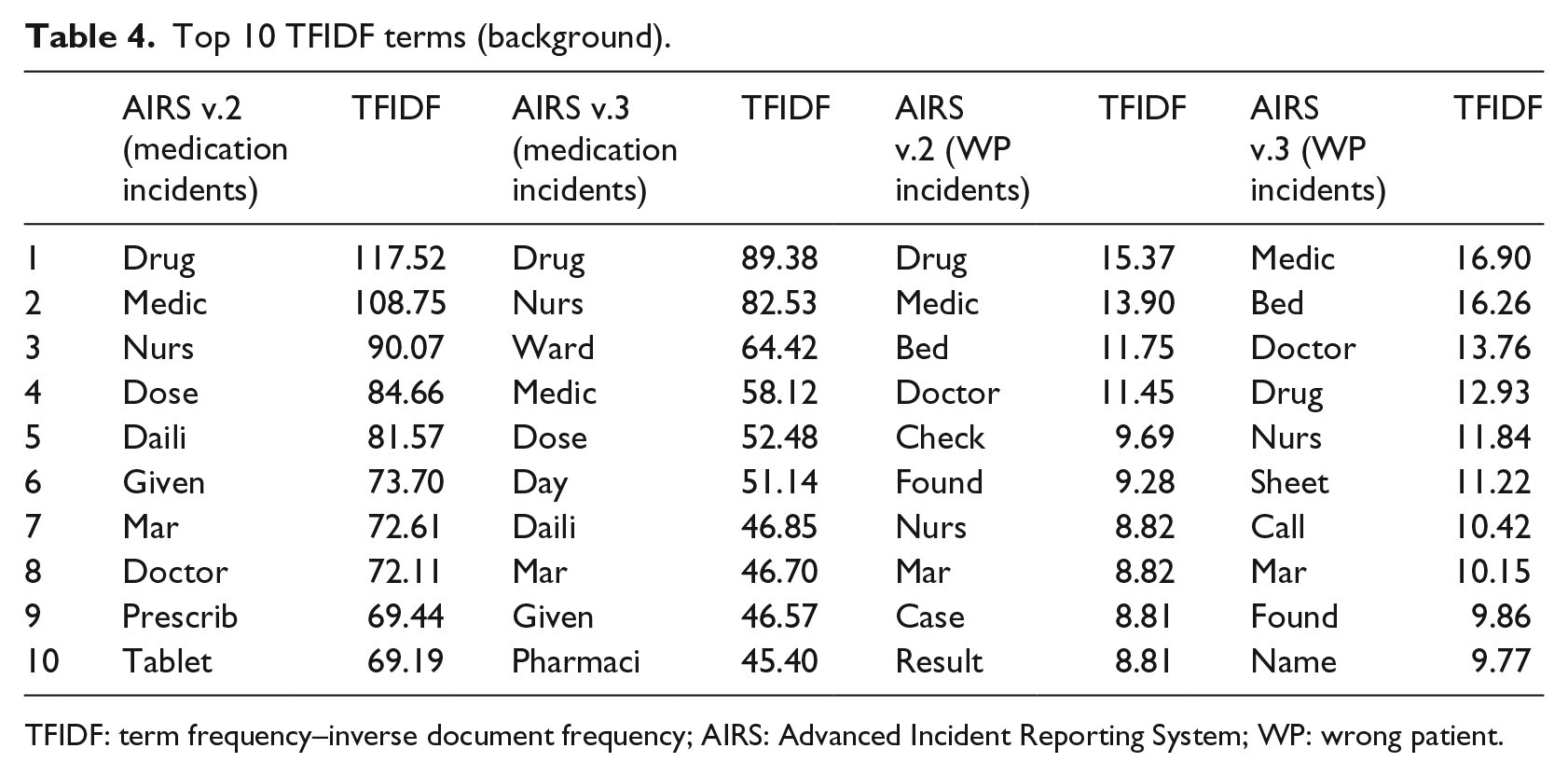
TFIDF: term frequency–inverse document frequency; AIRS: Advanced Incident Reporting System; WP: wrong patient.
DNN model performance with different settings
Table 5 shows the experimental results for WP class label. We used a DNN model with 2 hidden layers and 200 neurons in each layer to test the effects of different activation functions and dropout control. The best AUC value of 0.960 was achieved using a Rectifier algorithm with a dropout ratio of 0.5. Furthermore, we examine the number of hidden layers and neurons under the base case setting. In the WP class label experiments, the highest value for AUC (0.925) was in the model setting with 5 hidden layers and 150 neurons per layer and the highest value for accuracy (0.956) was found using the DNN model with 5 hidden layers and 250 neurons per layer. The average AUC using setting of Tanh with dropout ratio was 0.911 (standard deviation 0.019) and the average accuracy value was 0.940 (standard deviation 0.011). This indicated that the DNN model in general performed well in classifying AIRS v.3 reports based on AIRS v.2 reports. However, it is observed that the performance of different medication-rights detection would perform differently under the same modelling procedure. The optimal accuracy of all the medication rights ranged from 0.820 to 1, as shown in Table 6. These best trained DNN algorithms for each medication right are made publicly available from GitHub.
Experimental results for WP class label.
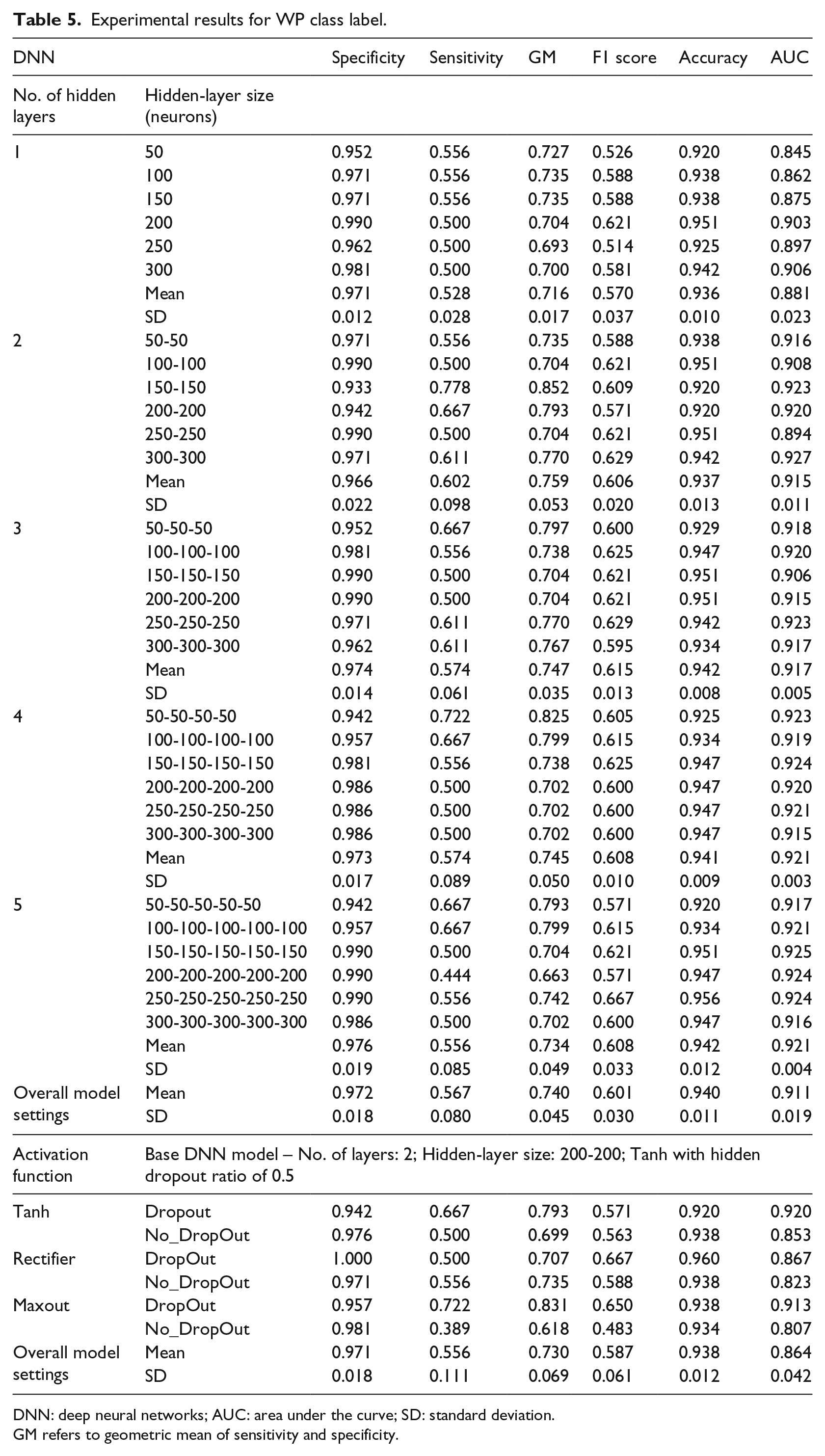
DNN: deep neural networks; AUC: area under the curve; SD: standard deviation.
GM refers to geometric mean of sensitivity and specificity.
Summary of the optimal model setting and accuracy for each medication right.

WP: wrong patient; WD: wrong drug; WT: wrong time; WE: wrong dose; WR: wrong route.
The optimal models (in binary form) are available in the following GitHub site: https://github.com/zoiewong/Optimal-5-medication-rights-models-for-incident-reports.
Comparison with other classification methods
As shown in Figure 5, the ROC curve obtained for the DNN model exceeded the space occupied by the curves for the other classifiers, which implied that the DNN model outperformed the standard classifiers across the entire range of class labels. AUC indicates the efficacy of a trained classifier in discriminating between positive and negative cases using a training dataset. The AUC of the DNN model, 0.925, was also greater than that of the standard classifiers, again indicating that the latter were outperformed by the DNN model. We compared the accuracy of the models and found that the DNN model was consistently more accurate than the other classifiers across all of the tested class labels (i.e. WP, WD, WT, WE and WR).
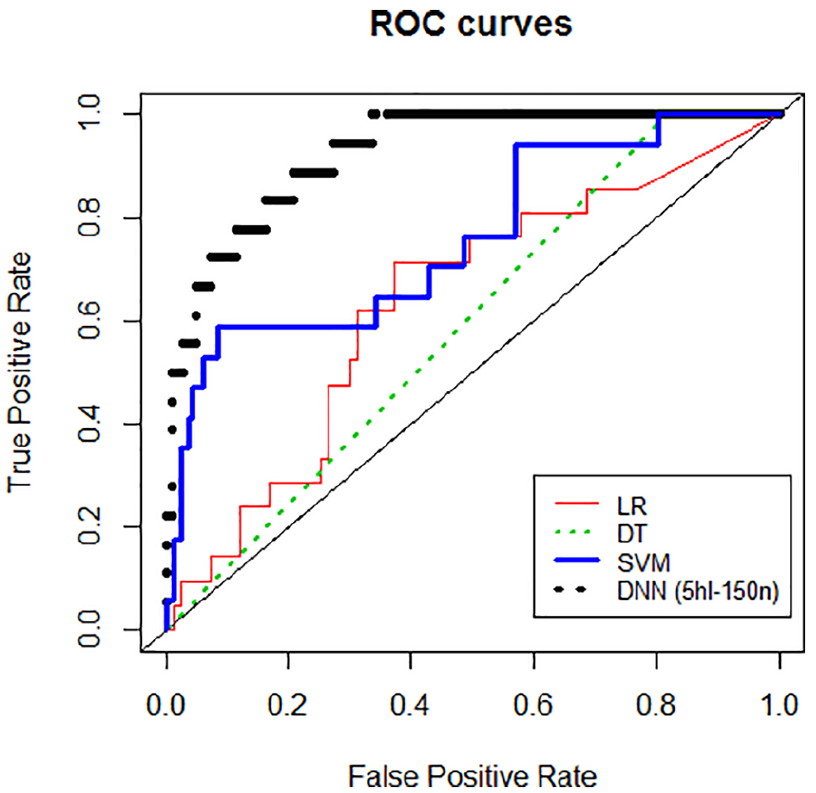
ROC curves.
Discussion
DNN models have been used in textual NLP and have achieved superior classification accuracy in other application areas. This study is by far the largest scale DNN modelling study examined on practical patient-safety incident reports. In this study, we developed a medication-rights detection system to automate medication-incident identification using free-text incident reports. The findings of this study indicate that a DNN model can be effectively and efficiently used to perform classification tasks on five rights medication incidents. It was shown that DNN method consistently outperformed other text classifiers (including logistic regression, SVMs and the decision-tree method). We suggest that DNN method has potential for the efficient exploration of textual reports of medication incidents. The default base case model and parameter arguments setting generally performed well for our dataset.
Both DNN methods and traditional classification methods have advantages and disadvantages. For instance, the coefficient of a logistic-regression model indicates the odds and probability of an event’s occurrence. However, in textual data applications, due to differences in syntactic composition and individual variation in language usage, the use of different wording is not necessarily relevant. Running regression models on such high-dimensional data often violates many underlying model assumptions and is subject to overfitting problems. However, black-box models are much more difficult to interpret than a simpler statistical model. Deep-learning methods usually provide good prediction outcomes, but do not fully address subjective knowledge or thoroughly explain the causal relationships between variables. In free-text example, DNN bypasses the assumption of causative relationships between the terms used and provides outcome predictions based on combined variation in the usage of terms.
We also provided reference guidelines for training DNN models to classify patient-safety incidents and explored several potential model settings, namely number of layers, number of neurons, activation functions and regularisation. This research result does not show any obvious advantages on using various activation function, dropout control, number of hidden layers and neurons across different datasets. Future research should focus on investigating DNN development workflow framework that allows searching for model with optimal performance – it would be beneficial to achieve efficient classification task consistently across sets of incident reports. We found that processing time increased with the number of layers and the number of neurons in the DNN model within our experimental range. Nevertheless, the use of deep-learning training algorithms and deep-learning platform ensured that the most complex model took less than 2 min to run in a typical desktop computer environment.
As recommended by the Institute of Medicine, 6 mandatory and voluntary reporting systems have been implemented in many developed countries to capture clinical near-misses and incidents. An informed culture, which can be fostered by incident reporting, plays an important role in ensuring a safe environment and situational awareness of patient-safety issues. All AIRS reports are currently reviewed and screened manually by designated staff in various subject offices of the HA. Different readers may interpret textual descriptions differently. Manual review is often a subjective, expensive and time-consuming process that drains human resources. 13 Similar to other reporting systems worldwide, the AIRS system accumulates a large number of free-text reports every year (more than 10,000 reports). Free-text reports carry rich information on incidents and near-misses (such as information on a patient’s diagnosis, reason for admission and the nature of the incident/near-miss) that awaits exploration. Due to the heavy workload of reviewers and the unstructured format of free text, the process of analysing records of similar incidents is slow. Therefore, an efficient and reliable method of managing and categorising the information in incident records is undoubtedly valuable. 29
WHO Minimal Information Model for Patient Safety (MIM PS) 30 provides a list of the minimal meaningful data features of incident reporting. The suggested incident report structure heavily relies on narrative text to capture the background, progression of event, causes and contributing factors of the incident. Unlike AIRS with the indication of medication rights, many incident reporting systems from various countries do not register medication rights in a structured manner. The indication of the mismanagement related to the medication rights retains in the narrative text part that requires manual efforts to uncover. This increases the difficulties to retrieve similar cases for further analysis. One of our key contribution is that the proposed medication-rights detection system and the training procedure are transferable to understanding the medication-rights errors of other mandatory and voluntary incident reporting systems worldwide. Artificial intelligence-based health informatics applications, which enable efficient information retrieval, 31 show promising potential for incident reporting understanding. Apart from high efficiency and accuracy classification of reports, some possible research applications, such as named entity recognition, 32 are potentially useful to automatically tag entities in report. Our study demonstrates that advanced deep-learning methods for information retrieval and case classification may be of practical assistance.
Although the five ‘rights’ described in this study are recognised target for the safe administration of medication and are also referenced in guidelines for prescribing and dispensing drugs, the rights system has been criticised for offering very little practical guidance on ensuring drug safety. 3 It is essential to reform the ways in which we understand and analyse near-misses and errors, using proper health information technology and a well-designed reporting format. Currently, some patient-safety systems offer tailor-made templates for specific incident categories and we observe a tendency to simplify incident report structures in some countries. The general reporting structure covers both structured items eliciting background and other relevant information on the incidents (such as patient details, hospital and ward information and indices of the severity of harm to the patient) and unstructured space in which users can describe the nature of the event and the immediate response. The learning objectives of these mandatory and voluntary reports have rarely been clearly articulated, 33 despite widespread criticism of incident reporting as an additional burden for healthcare professionals. Synergising with continuous learning from incident reports, it will thus be advantageous to establish clear guidelines for reporting to clarify report structure, ensure the quality of reports, minimise the effort involved in reporting and aid in the assessment of reports. This research offers a scientific solution for analysis of the rich free-text data contained in incident reports, which may facilitate the development of an efficient approach to the exchange of patient-safety information that increases understanding of medical errors.
Deep-learning methods previously were not being used in incident report learning, and one of the contributions of this study is to examine the performance of deep-learning approaches in incident report learning to justify future use of advance related methods in understanding detailed categories and causes of incidents. Currently we employed NLP methods as well as bow for limited feature selection. Future researchers working on patient-safety informatics are advised to further explore the information retrieval and feature extraction power of deep learning directly from free-text data 34 and the optimal way to configure the set of parameter arguments. It appears that different medication topics would require different model settings to achieve better prediction outcomes. It would be worthwhile to carry out extensive experiments to examine what kind of model setting scenarios would be more beneficial across different incident reports datasets. Experiments using different network algorithms and different datasets with grid searches may provide insights into the optimised modelling approach. 23 Studies exploring the use of other advanced deep-learning methods,17,35 topic-based semantic analysis 36 and incorporating clustering and association rules are potentially useful to improve model performance. Networks with convolutional and pooling layers may be useful for classification tasks in which strong local clues to class membership are needed. Traditional NLP methods may offer a useful means of identifying such clues in different parts of the input. For instance, the Ngram algorithm, which quantifies certain sequences of words and a single key phrase, can help to determine the topic of a document, 25 and association rules may be useful for uncovering relationships between statements or wordings.
Using deep-learning methods for incident report learning would also contribute to classifying the type of medication errors. We envision forthcoming research to automate the identification of medication errors using advanced deep-learning approaches in the future. To achieve this, it would be necessary to overcome some significant hurdles in annotating training incident reports dataset (in a way for revealing the type of incidents and the associated important details of the incidents) based on appropriated named entities related to the medication errors. 37 This probing study successfully showcased the significant potential of introducing deep-learning methods to incident report learning. We envision a promising future of widely using advanced artificial intelligence methods in patient-safety incident report learning.
Apart from the H2O platform, we acknowledge that there are other open-source platforms and libraries potentially suited to deep-learning model development, such as TensorFlow open-source software library. This study only demonstrated the possibility of using deep learning using H2O platform. Due to the limited number of data collected from the real-world AIRS system, we were unable to apply more advanced forms of deep-learning methods to this problem, such as BERT and RNN. It is noted that the DNN algorithms have been trained and tested on data arising from the AIRS system designed to capture the medication rights we set out to analyse. The scalability and generalisability of the built optimal models to other free-text incident reports have yet to be explored. Future research should focus on externally validating the trained models and the experimental workflow using global medication errors’ incident reports collected by other systems in the world.
Conclusion
This study developed a medication-rights detection system via DNN to automate medication-incident identification using free-text incident reports and provide reference guidelines for training DNN models to classify patient-safety incidents. The deep-learning method shows promise for the efficient exploration of textual reports of medication incidents. Our findings provide insights into training DNN models to classify patient-safety incidents, which may be transferable to other mandatory and voluntary reporting systems around the world.
Supplemental Material
Supplementary_document1 – Supplemental material for Medication-rights detection using incident reports: A natural language processing and deep neural network approach
Supplemental material, Supplementary_document1 for Medication-rights detection using incident reports: A natural language processing and deep neural network approach by Zoie Shui-Yee Wong, HY So, Belinda SC Kwok, Mavis WS Lai and David TF Sun in Health Informatics Journal
Footnotes
Author contributions
The study was conceived by Z.S.-Y.W., H.Y.S., B.S.C.K., M.W.S.L. and D.T.F.S.; Z.S.-Y.W., H.Y.S. and D.T.F.S. contributed to the study design; research data or information was retrieved and interpreted by Z.S.-Y.W., B.S.C.K. and M.W.S.L.; and Z.S.-Y.W. led the writing of the article. All authors revised and refined the arguments, and they approved the article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards. The research was approved by the Joint Chinese University of Hong Kong–New Territories East Cluster (NTEC) Clinical Research Ethics Committee (CREC). The clinical research approval number awarded by the CREC was ‘2014.470’.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This research was supported by the Japan Society for the Promotion of Science KAKENHI (Grant No. 18H03336) and the Research Grants Council Theme-Based Research Scheme (Ref. T32-102/14 N).
Informed consent
This is a retrospective incident reports analysis study. Incident reports database is contributed by clinical staff. Informed consent was obtained from all individual contributors included in the study (HIJ-19-0169.R1).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.