
Abstract
This study presents the results of experimental evaluations of an ontology-based frequently asked question retrieval system in the domain of HIV and AIDS. The main purpose of the system is to provide answers to questions on HIV/AIDS using ontology. To evaluate the effectiveness of the frequently asked question retrieval system, we conducted two experiments. The first experiment focused on the evaluation of the quality of the ontology we developed using the OQuaRE evaluation framework which is based on software quality metrics and metrics designed for ontology quality evaluation. The second experiment focused on evaluating the effectiveness of the ontology in retrieving relevant answers. For this we used an open-source information retrieval platform, Terrier, with retrieval models BM25 and PL2. For the measurement of performance, we used the measures mean average precision, mean reciprocal rank, and precision at 5. The results suggest that frequently asked question retrieval with ontology is more effective than frequently asked question retrieval without ontology in the domain of HIV/AIDS.
Keywords
Introduction
Automated question answering systems are becoming common in the area of information retrieval (IR). Their popularity is gaining momentum as these systems allow users to present questions using natural language. However, the retrieval of an appropriate answer for a question posed by a user in natural language is still a challenging task. The challenge is mainly due to the difficulty of understanding users’ questions expressed in natural language and locating the source from which answers can be extracted. Toward this, a number of approaches have been proposed. Some focused on techniques for the understanding of users’ questions 1 while others focused on techniques for extracting answers.2,3
Since providing a correct answer to any question on any subject using an automated question answering system is still far from reality, most question answering systems focus on providing answers to questions on specific domains. In these types of systems, one common approach employed is the use of a frequently asked questions (FAQ) database for the extraction of answers to users’ questions by matching users’ questions to similar questions in the FAQ database. As indicated in the literature,4,5 users’ questions are usually repeated and hence organizing a comprehensive FAQ database on a particular domain can help in answering most of users’ questions in that particular domain. Question answering systems based on FAQs which are already in use cover a wide range of domains such as Agriculture, 6 Personal Computing, 7 Education,8,9 and Music. 10
One of the challenges in FAQ-based question answering systems is the matching of users’ questions to similar questions in the FAQ repository. In other words, in order to answer a user’s question, we need to find a similar question in the FAQ repository (if there is any) and retrieve the corresponding answer as an answer to the user’s question. This requires understanding the user’s question and computing the semantic similarity between the users question and the questions in the FAQ repository. Understanding and computing semantic similarity is very important as the same question can be written in different ways even though the meaning remains the same. One way of capturing such semantics is using ontology. Ontology provides a model of concepts and relationships between concepts. According to Gruber 11 and Studer et al., 12 ontology is defined as “a formal and explicit specification of a shared conceptualization.” As ontologies are becoming popular in providing semantic interpretation, they have been used in different question answering systems. However, their use in the area of HIV/AIDS question answering systems has been so far very limited.
In the context of HIV/AIDS in Botswana, there are government efforts to provide manual FAQs in the form of brochures so that people can read the FAQs to get answers for the questions they may have on the subject. Another initiative taken by the government is the establishment of a call center exclusively on HIV/AIDS which allows people to call and get answers from the call center. The call center provides answers basically based on pre-defined FAQs. Both initiatives have made positive contributions in increasing awareness among the population with regard to HIV/AIDS. However, they are very limited in their accessibility. An automated FAQ answering system on HIV/AIDS could help in alleviating the problem of accessibility as people can send their questions from anywhere and anytime. Therefore, our ultimate goal is the development of an automated question answering system based on FAQs that can be accessed through mobile phones using SMS. In this article, we focus on the development of an HIV/AIDS FAQ question answering system using ontology and its experimental evaluation we carried out.
The remainder of the article is organized as follows: section “Related work” discusses related work focusing on FAQ answering systems based on ontology. Section “HIV/AIDS FAQ retrieval system” presents our approach for the development of FAQ retrieval system based on an ontology emphasizing on the development of the ontology and its integration to an FAQ retrieval system. In section “Experimental evaluation,” we discuss the two types of experiments we conducted to evaluate the quality and effectiveness of the ontology. A discussion of the main issues resulting from the experiment is provided in section “Discussion.” Finally, section “Conclusion” provides a summary of our contribution and the main points of our work.
Related work
Related work on ontology-based FAQ retrieval systems is mainly on closed domain FAQ retrieval systems. Among these question answering systems, we focus on those that use FAQs as a knowledge base for answer extraction and those that use ontology as a user question expansion mechanism. In these systems, ontology is used for enhancing the semantic interpretation of users’ questions.
The most cited work on question answering systems based on FAQ knowledge base is FAQ Finder. 4 FAQ Finder is a natural language question answering system that uses files of FAQs as its knowledge base. FAQ Finder provides an interface through which a user can pose a question expressed in natural language (English) and provides an answer extracted from the FAQ knowledge base. If the user question is similar to a question in the FAQ knowledge base, the corresponding answer is retrieved. FAQ Finder uses also a semantic knowledge base (WordNet) to improve its ability to match questions to answers. A similar system was developed by Sneiders 5 which is an automated FAQ answering system designed to support customer service by providing web-based self-service for a company which provides products and services. Customers use the FAQ-based self-service to ask specific questions they may have on the products and services provided by the company. The FAQ answering is based on shallow natural language understanding. In our system, instead of WordNet, we use a domain ontology specifically developed for HIV/AIDS.
In their effort to provide an FAQ answering system on mobile phones, Contractor et al. 13 developed a question answering system that utilizes FAQs as a knowledge base to answer user questions formulated in SMS format. In their system, the FAQs are in Hindi while users pose SMS questions in English. To match the users’ questions to questions in the FAQ database, they introduced machine translation and treated the problem of matching user’s questions to questions in the FAQ database as a combinatorial search problem. Their system focused mainly on addressing bi-lingual issues and the inherent noise in SMS questions submitted by end users.
Bo and Yunqing 9 developed an ontology-based automatic question answering system to facilitate distance learning in China. Using their system, students can ask questions on a particular course in natural language and get answers from FAQs compiled for the teaching-learning process. To facilitate question answer matching, they developed domain ontology which is then used to expand keywords extracted from a user’s question so as to improve the recall rate of the system. The ontology defines the concepts and the relationship between the concepts in the curriculum. The ontology was developed using Protégé. In terms of the use of ontology, it is similar to our system in that we also use ontology to expand users’ questions so as to improve the semantic interpretation of the questions. However, they did not provide an evaluation of the quality of their ontology and it is not clear to what extent their ontology improved the performance of their system.
Another system 14 which is similar to the above-mentioned systems uses word segmentation together with a matching algorithm to compute the similarity between users’ questions and questions in FAQ knowledge base. A user’s question is expanded using synonyms of extracted words (terms are extended using the HowNet database) and a similarity function called sentence similarity is used for matching a user’s question to questions in the FAQ knowledge base. Experimental evaluation shows that the performance of the system is better than the traditional TF-IDF (Term Frequency—Inverted Document Frequency) 15 method in terms of recall and rejection. Similarly, Song et al. 16 used a combination of statistical and semantic similarity measures to answer questions using FAQs database.
Wang et al. 6 developed an ontology-based FAQ retrieval system in the domain of agriculture that can provide answers to questions farmers may have regarding agricultural labor, agricultural production process, and agricultural production materials for crops and animals. Their ontology is based on the ontology library from the Food and Agriculture Organization of the United Nations. For computing semantic similarity, they used a vector space model–based similarity computation.
Yang et al. 7 developed ontology-based FAQ answering system in the Personal Computing domain. FAQs are extracted from various web pages and structured into an ontological format (i.e. ontology database) so as to facilitate question answering. To understand the intent of users’ queries, they provide templates that capture six types of queries. Each query type is meant to capture intent types. The query types supported in the system include Could, How, What, When, Where, and Why. They also provided new partial keywords match-based ranking techniques for their system. In our case, the FAQ knowledge base is based on pre-defined FAQs compiled from different sources including the Ministry of Health and the IPOLETSE call center. Moreover, we do not restrict the types of questions based on query types, rather try to extract relevant concepts from users’ questions using the ontology. Our evaluation metrics are also based on standard metrics in IR.
Generally, we can observe that ontology-based FAQ retrieval systems have two important components that distinguish each question answering system from others. The first part is the construction of an appropriate ontology to capture knowledge in a particular application domain. Different models and tools have been used with varying degrees of success. The second part is the algorithm used for computing semantic similarity. Again, we have observed various similarity computation algorithms from the traditional statistical to combinations of statistical and semantic measures. For our system, we constructed a new ontology based on various documents collected on HIV/AIDS as we were not able to find an existing ontology that satisfied our requirements. For the computation of similarity between users’ questions and questions in the FAQ knowledge base, we used the best ranking functions—Okapi BM25 15 and PL2 (which is a variant of the Divergence From Randomness). 17 In terms of integration to IR platform, most used simplified forms of IR systems while others used Lucene as their IR platform. We chose Terrier 4.0 18 which is flexible and provides many components to deal with indexing, ranking, system performance measures, and so on.
HIV/AIDS FAQ retrieval system
In this section, we discuss the construction of HIV/AIDS ontology and its integration with the Terrier IR platform.
Ontology construction using Text2Onto
Ontology construction is a time-consuming process and hence requires appropriate tools. Based on experimental evaluations we carried out with different ontology building tools, 19 Text2onto 20 was found to be the most appropriate tool that can be used for HIV/AIDS ontology construction and management. Text2Onto uses natural language processing and text mining techniques to extract ontology elements (concepts, instances, relations) from knowledge sources. 20 Text2Onto represents ontology elements in a form that can be translated to any ontology language such as RDF, OWL, or F-Logic. It also supports interactive ontology development which enables a developer to validate the ontology while it is being built. Text2Onto provides basic linguistic processing such as tokenization or lemmatizing and shallow parsing and can be integrated with other tools such as GATE 21 and WordNet. 22 GATE provides some linguistic processing algorithms and WordNet provides large thesaurus of words and their meanings. For our work, we developed ontology for the HIV/AIDS domain using Text2Onto. Details of the ontology construction can be found in the literature.19,23
For the construction of the ontology, various sources have been used. We used the MASA booklet which consists of 205 FAQs prepared by the Botswana Ministry of Health. We also used the IPOLETSE call center manual which consists of 150 FAQs which is being used by the call center for answering questions on a toll-free line. Other data sources used for the construction of the ontology include FAQs from BONELA (Botswana Network on Ethics, Law and HIV/AIDS), BONEPWA (Botswana Network of People Living with HIV/AIDS), BONASO (Botswana Network of AIDS Service Organisations), ACHAP (African Comprehensive HIV/AIDS Partnerships), and National Aids Coordinating Agency (NACA).
When FAQ documents are uploaded into Text2onto, the tool tokenizes the sentences to make ontology elements. The tool suggests potential classes, subclasses, and properties which can be analyzed and filtered before being incorporated into the ontology. Text2onto uses TF-IDF weighting model to extract terms from the corpus and uses association rules and text patterns to suggest relations. It also uses WordNet and its hypernym network to extract classes and subclasses. The resulting ontology can be visualized and exported in RDF and OWL format. Figure 1 shows a graphical view of part of the ontology.
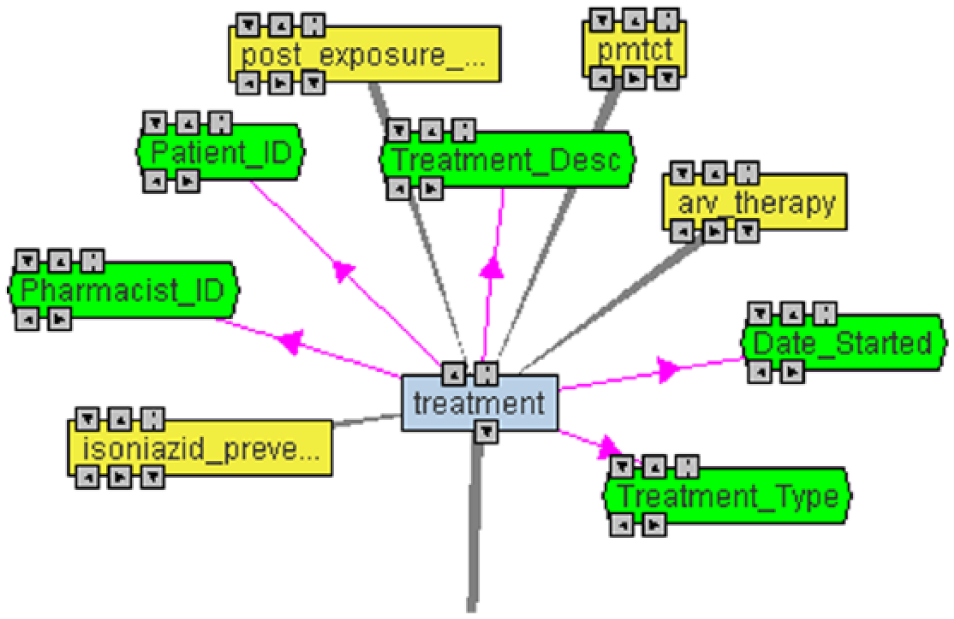
Graphical view of Treatment class.
Figure 1 depicts the class Treatment (colored light blue), which has subclasses of different types of treatments (colored yellow) that an HIV/AIDS patient may take. It also shows some of the properties of a treatment (colored green) which one would expect when taking medication such as the description of the medication, the pharmacist issuing the medication, the details of the patient, and so on. Figure 2 shows part of the HIV/AIDS ontology model, indicating some of the classes and subclasses.
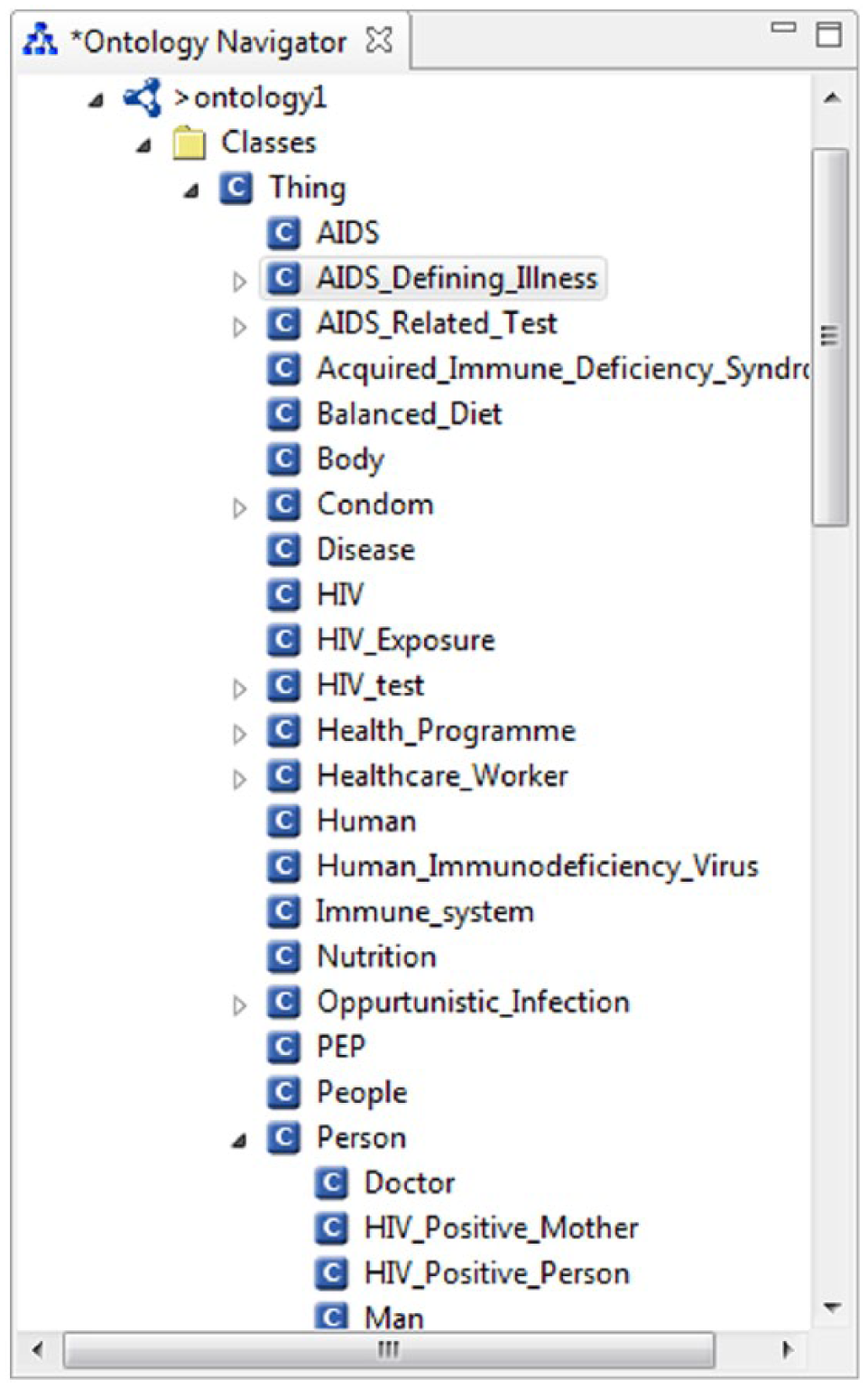
Some of the HIV/AIDS ontology elements.
Figure 3 provides a high-level view of part of the HIV/AIDS ontology.
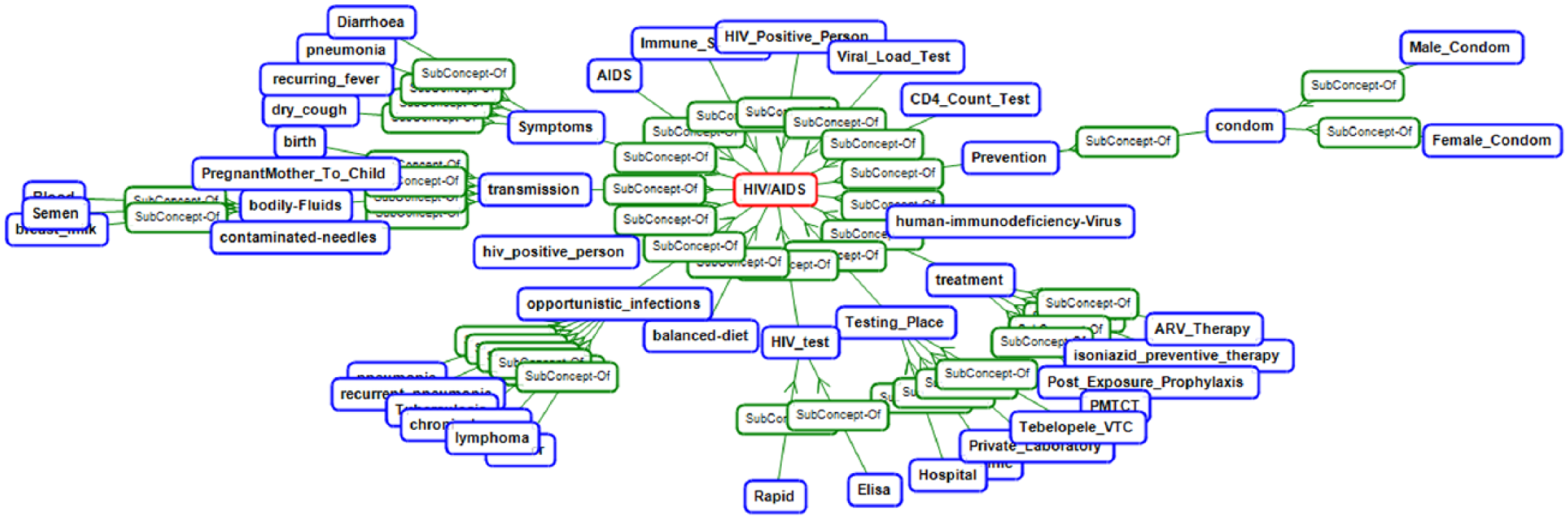
High-level view of the HIV-AIDS Ontology.
Text2Onto extracts ontology elements automatically and ranks them according to their probability of being candidate terms. It extracts terms using TF-IDF weighting model. TF-IDF is a statistical measure used to evaluate how important a word is to a document in a collection or corpus/knowledge source. The TF-IDF value increases proportionally to the number of times a word appears in a document, but is offset by the frequency of the word in the corpus, which helps to control for the fact that some words are generally more common than others. The TF-IDF technique uses various mathematical forms to calculate the words that appear frequently and their relevance.
From Figure 3, we can see that treatment, transmission, prevention, symptoms, AIDS, and so on appear at the top with higher TF-IDF values. Relations are extracted using association rules and text patterns.
Integrating ontology with FAQ retrieval system
Domain ontologies assit in resolving the syntactic and semantic differences between users’ questions and questions in FAQ document collections. 7 The use of ontology assists in understanding natural language documents; therefore, when integrated with FAQ retrieval systems, the performance of the FAQ retrieval system is expected to improve as it provides more accurate answers.
After constructing the HIV/AIDS ontology, the next step is to integrate the ontology with an IR system so as to be able to provide answers to users’ questions. Figure 4 provides a schematic description of our ontology-based FAQ retrieval system.
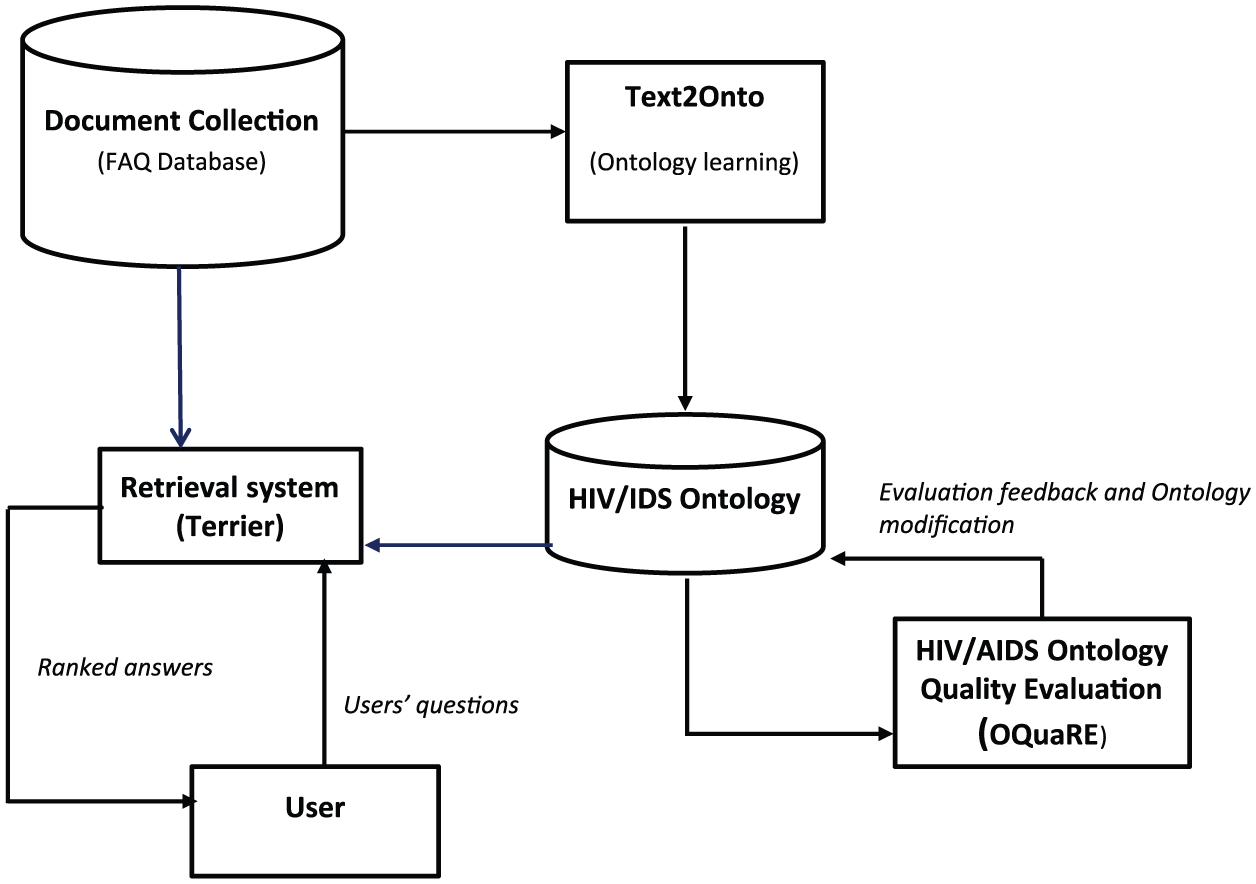
Architecture of ontology-based FAQ retrieval system.
In addition, the use of an IR system helps us to evaluate the effectiveness of the ontology in answering users’ questions. The effectiveness of an IR system is usually measured using recall and precision. Precision measures the number of retrieved relevant documents over the number of retrieved documents while recall measures the number of retrieved documents over the number of relevant documents in the repository. 24 For the evaluation of the effectiveness of question answering systems, a number of measures have been proposed based on recall and precision.
For our experiment, we adopted an open-source IR system called Terrier 4.0. Terrier provides indexing of a corpus of documents using different indexing methods and employs different retrieval (weighting) models such as TF-IDF, BM25, and PL2. In our experiment, we chose BM25 and PL2 as these models are very effective as demonstrated in various experiments. 18 BM25 is a ranking function commonly used in IR systems to rank matching documents according to their relevance to a given query. PL2 is one of the DFR (Divergence From Randomness) term weighting models which helps to measure the informative content of a term by computing how much the term frequency distribution departs from a distribution described by a random process. Terrier also provides various retrieval performance evaluation tools, which produce extensive analysis of the retrieval effectiveness of the tested models on given test collections.
Experimental evaluation
For the experimental evaluation of the effectiveness of the ontology on HIV/AIDS FAQ retrieval, we used two approaches. The first evaluation is an evaluation of the quality of the HIV/AIDS ontology we constructed. For this purpose, we used a software product quality metric-based evaluation. Once the quality of the ontology is assessed, we wanted to see how much it helps in answering users’ questions on HIV/AIDS. To evaluate how much the use of the HIV/AIDS ontology improves the performance of our FAQ retrieval system, we integrated the ontology with the Terrier IR system. The following sections present our experimental evaluation using the two approaches mentioned above.
Software quality metrics–based evaluation
Once ontology is constructed, it is important to evaluate the quality of the ontology. The HIV/AIDS ontology evaluation was carried out to ensure that the constructed model is correct (e.g. captures the required domain knowledge such as taxonomic aspects) and can be used or integrated with ontology-based applications. A commonly used approach is the OQuaRE 25 evaluation framework which is an integrated framework based on software quality metrics and metrics designed for ontology quality evaluation. The assumption behind this evaluation framework is that ontology is a software artifact which can be evaluated by adapting ontology metrics and software quality metrics to ontology quality evaluation. Other ontology quality evaluation methods26–28 have been proposed but OQuaRE is widely used as it provides a comprehensive framework. It provides an objective and standardized framework for ontology quality evaluation. It can also be adapted to the needs of a particular domain by selecting the relevant characteristics, sub-characteristics, and metrics. We use OQuaRE for the evaluation of the quality of the HIV/AIDS ontology.
OQuaRE incorporates different characteristics of quality and provides associated metrics. It uses the quality characteristics Structure, Functional Adequacy, Maintainability, Operability, Reliability, Transferability, Quality in Use, Performance Efficiency, and Compatibility. Each of these characteristics has sub-characteristics and associated metrics. For our purpose, the characteristics Structure, Functional Adequacy, Reliability, and Maintainability are adequate to assess the quality of our ontology. In addition, for each characteristic, we chose sub-characteristics which are more applicable to our domain. For details of the OQuaRE framework25,29 and the complete mapping of characteristics, sub-characteristics and metrics can be found in the literature. 30
Table 1 shows the characteristics, sub-characteristics, and the associated metrics of OQuaRE that have been used in our empirical evaluation of the HIV/AIDS ontology.
OQuaRE characteristics, sub-characteristics, and metrics used in our experiment.
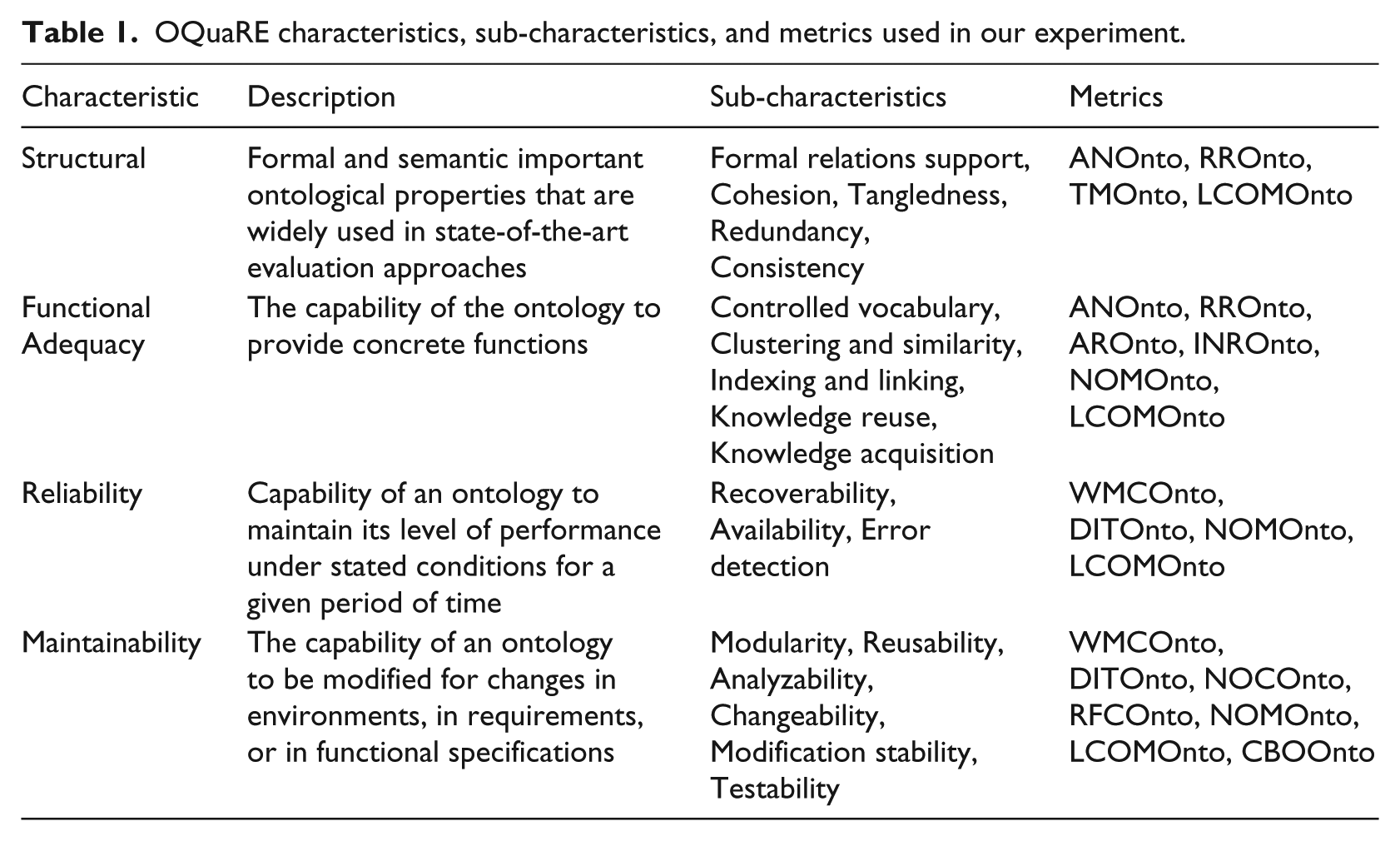
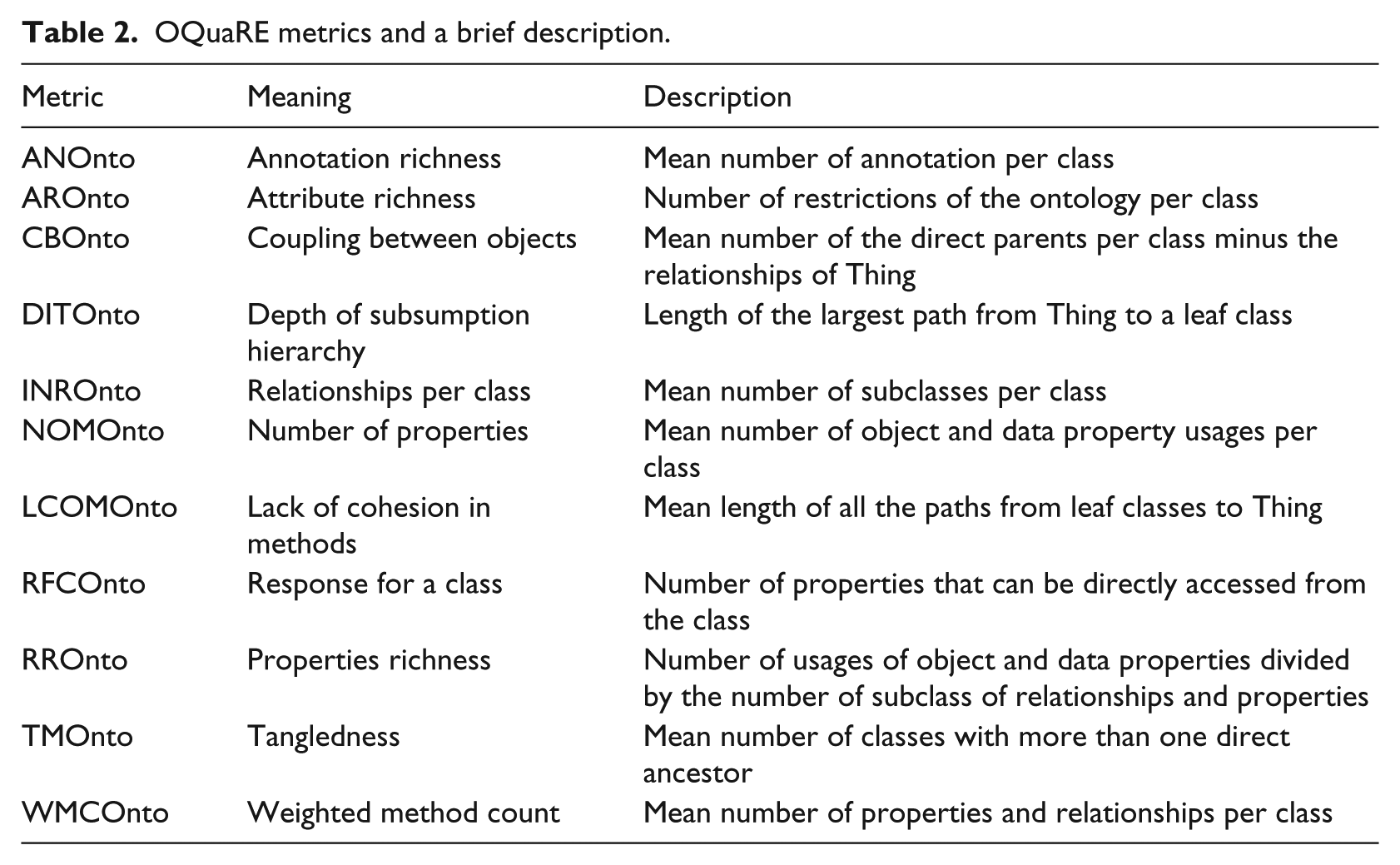
Note that one quality metric could be associated with several quality sub-characteristics which means a particular indicator contributes to multiple quality properties. For example, the metric ANOnto is associated with two sub-characteristics coming from different characteristics. It is also important to mention that each sub-characteristic is associated with its own metric(s). For the sake of space usage, we did not explicitly state the metrics associated with each sub-characteristic separately. Such a mapping can be found in the literature. 30 Table 2 provides the list of OQuaRE metrics which have been used in our experiment together with their descriptions.
OQuaRE metrics and a brief description.
For the four characteristics, we chose sub-characteristics which are more appropriate for our particular ontology. Table 3 shows the results of the HIV/AIDS ontology evaluation summary using the four ontology quality characteristics. The scores for each metric are in the range 1–5 where 1—not acceptable, 2—not acceptable and improvement required, 3—minimally acceptable, 4—acceptable, and 5—exceeds the requirements. Note that these scores are not direct measures; rather they represent a mapping scale to describe the degree of acceptability of the measurements. OQuaRE metrics generate quantitative values in different ranges but they are mapped into the range 1–5. For example, a score of 5 for LCOMOnto means that the average length of the path from leaf class to the root class is less than or equal to 2 which measures separation of responsibilities and independence of components of the ontology. For details of the mapping of OQuaRE metric values, refer to the literature. 30
OQuaRE quality characteristics scores.

For our experimental evaluation of the quality of the ontology, we compute the quality scores for each sub-characteristic and then the quality scores for each characteristic. The quality score for a sub-characteristic is the mean of all the metrics associated with that particular quality sub-characteristic. Then, the score for each characteristic is the mean of the scores of its quality sub-characteristics. The set of scores for each quality characteristic are meant to provide information about the strengths and weaknesses of the ontology.
Table 3 provides the scores of each quality characteristic for the HIV/AIDS ontology. The scores for all the characteristics, sub-characteristics, and metrics used in the experiment were generated using the tool provided in the study by Quesada-Martınez et al. 31 Figure 5 depicts a comparison of the quality characteristics.
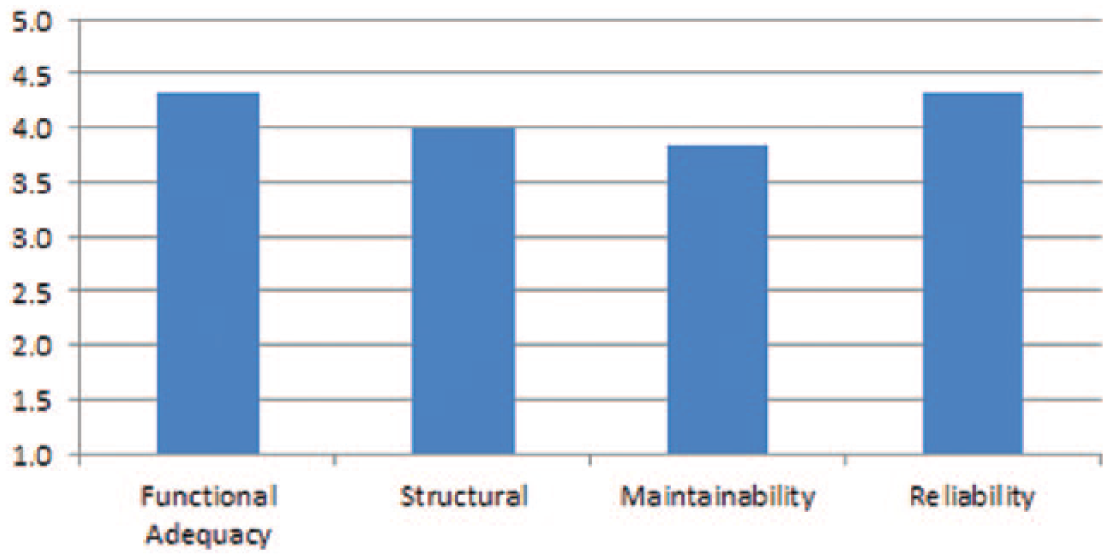
Quality score for HIV/AIDS ontology.
The evaluation results of the HIV/AIDS ontology show that most of the quality scores are above average (i.e. in the positive range for all characteristics) which indicates the adequacy of the quality of the ontology. However, for some characteristics such as maintainability, the evaluation results indicate that the ontology is maintainable but there is still room for improvement. For example, under maintainability, LCOMOnto and DITOnto score 3 which are minimally acceptable. Therefore, these indicators suggest the areas where improvement is needed.
Evaluation using FAQ retrieval system (Terrier 4.0)
To evaluate the effectiveness of the FAQ retrieval system using Terrier, a document collection consisting of FAQ documents from various sources has been created as indicated in section “Ontology construction using Text2Onto.” The document consisting of all these FAQ pairs was loaded into Terrier for indexing.
For testing the effectiveness of the system, 30 questions were chosen from the FAQ repository and fed into Terrier. Terrier was used for retrieval, first without the ontology and later with the ontology. The results from the two tests were compared to check the relevancy of the answers retrieved. Terrier uses TRECOLLECTION for indexing and uses a number of different weighting models to calculate scores for queries. The BM25 and PL2 weighting models were used during the experiment. The BM25 and PL2 weighting models calculate the relevance of retrieved answers for a query submitted. BM25 (sometimes referred to as okapi BM25) is a ranking function used by retrieval algorithms (e.g. search engines) to rank matching documents according to their relevance to a given search query. The PL2 method is a representative retrieval function of the divergence from randomness (DFR) retrieval model. It measures the informative content of a term by computing how much the term frequency distribution departs from a distribution described by a random process. 32
To compare the effectiveness of the retrieval with and without ontology, we used the most widely used retrieval effectiveness measures for ranked list of answers: mean average precision (MAP), mean reciprocal rank (MRR), and precision at 5 (P@5). According to Thom and Scholer, 33 MAP is the mean of average precision, where the average precision of a single query is the mean of the precision scores at each relevant answer returned in a query results list. The MAP measure provides a very succinct summary of the effectiveness of a ranking algorithm over many queries. The MRR is the average of the reciprocal ranks over a set of queries where reciprocal rank is defined as the reciprocal of the rank at which the first relevant answer is retrieved. This measure has been used for applications where there is typically a single relevant answer. P@5 refers to the mean of the precision of the first five answers retrieved.
Table 4 shows the evaluation measures on a per-query basis for a sample of five questions using BM25. In other words, it shows sample questions and the corresponding performance measures for the three metrics used in the experiment.
Evaluation measures on a per-query basis using BM25.
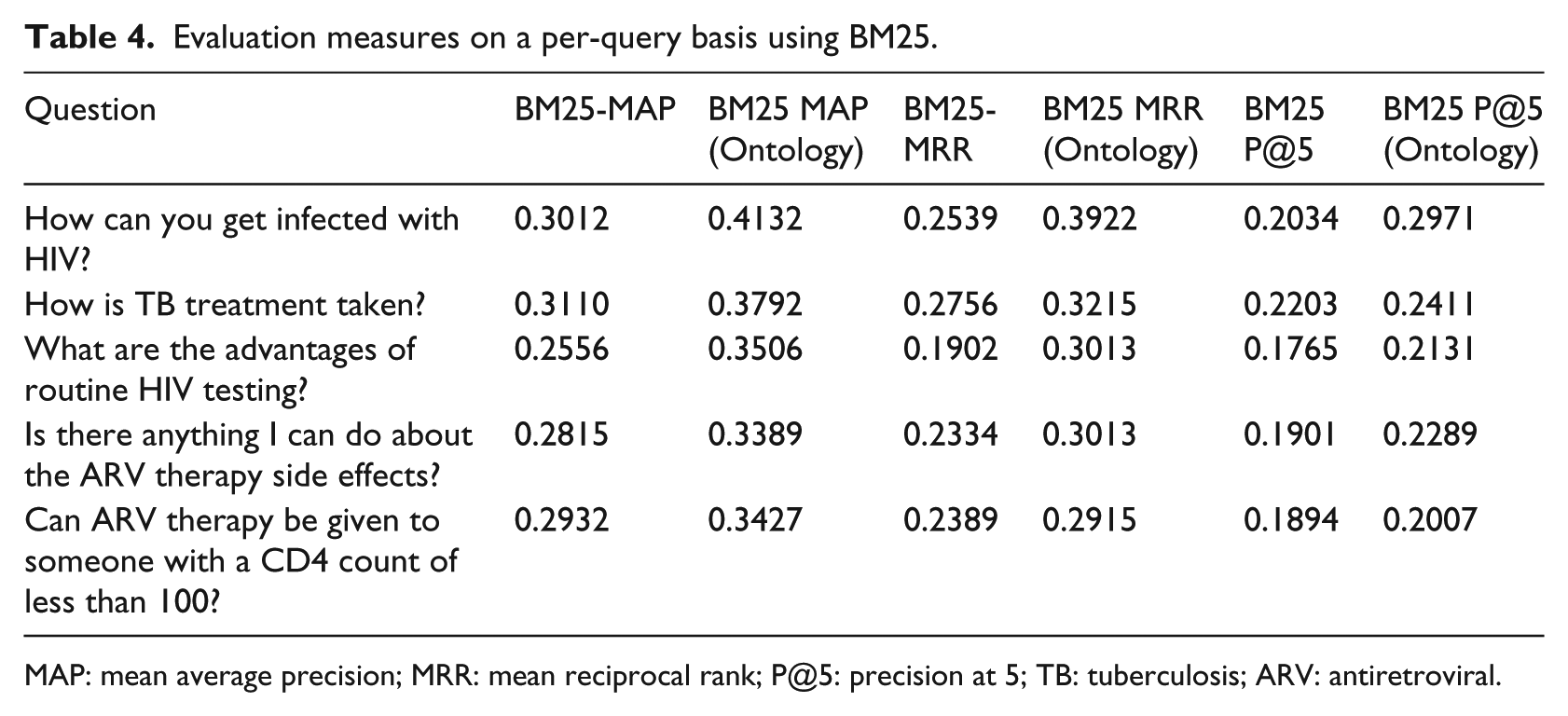
MAP: mean average precision; MRR: mean reciprocal rank; P@5: precision at 5; TB: tuberculosis; ARV: antiretroviral.
Table 5 shows the overall system performance based on the 30 questions used in the experiment (i.e. average over the 30 questions used in the experiment). The questions were selected randomly from the FAQ repository.
Overall performance of the question answering system.
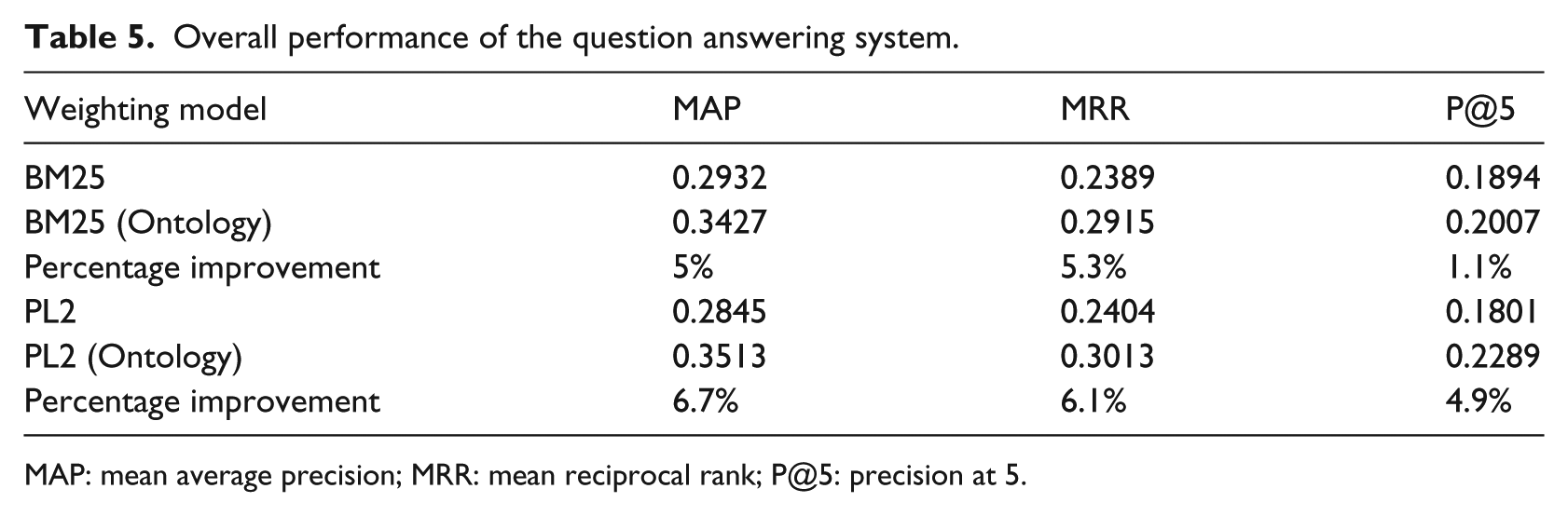
MAP: mean average precision; MRR: mean reciprocal rank; P@5: precision at 5.
Table 5 shows that, for both weighting models—BM25 and PL2, there is an improvement on the retrieval of relevant answers when the HIV/AIDS ontology is integrated with the FAQ retrieval system. The ontology-based approach achieved MAP performance of 0.3427 for the BM25 weighting model compared to a performance of 0.2932 without the ontology. Compared to without ontology performance, an increment of about 5 percent MAP was achieved. Similarly, compared to without ontology performance, an increment of 5.3 and 1.1 percent of performance was achieved with the BM25 model for MRR and P@5, respectively. A higher difference in the relevance of the retrieval between with ontology and without ontology was observed for the weighting model PL2 (6.7% for MAP, 6.1% for MRR, and 4.9% for P@5). The percentage difference between with and without ontology for P@5 is low compared to the other measures. For a question answering system where there may be only one relevant answer to be retrieved, perhaps P@5 is not a good measure as the position of the relevant answer in the ranking does not make any difference as long as it is included in the top five answers.
The results from our evaluation with Terrier suggest that using ontology with FAQ retrieval system resolves the term mismatch problem and improves the retrieval of relevant answers from FAQ documents.
The next question is whether the difference observed in the retrieval of relevant answers is statistically significant when ontology is integrated with Terrier. To examine the issue of FAQ retrieval effectiveness with and without ontology, the following hypotheses were evaluated:
H0 (Null hypothesis). There is no difference in retrieval effectiveness between FAQ retrieval without ontology and FAQ retrieval with ontology.
HA (Alternative hypothesis). FAQ retrieval with ontology is more effective than FAQ retrieval without ontology.
The result of a statistical analysis using the paired t-test is shown in Table 6 for the 30 queries we run using Terrier. The statistical analysis was carried out using Microsoft Excel 2010 data analysis component.
Paired t-test on FAQ retrieval with and without ontology for BM25 MAP.
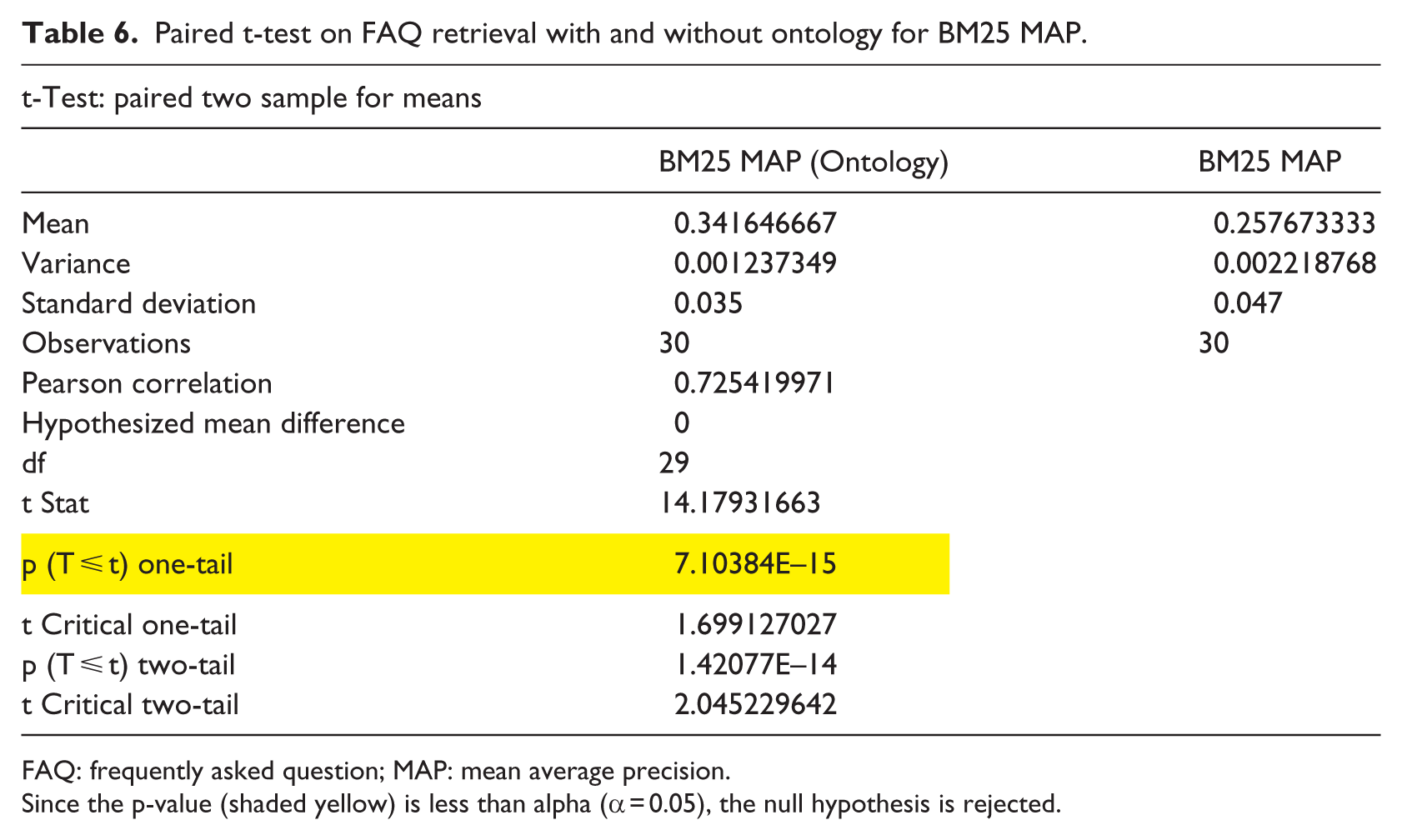
FAQ: frequently asked question; MAP: mean average precision.
Since the p-value (shaded yellow) is less than alpha (α = 0.05), the null hypothesis is rejected.
As can be seen from Table 6, a paired two-samples t-test was conducted to compare the effectiveness of FAQ retrieval with ontology and without ontology. There was a significant difference in the effectiveness of FAQ retrieval with ontology (M = 0.34, standard deviation (SD) = 0.035) and FAQ retrieval without ontology (M = 0.26, SD = 0.047; t(29) = 14.18, p = 7.10384E–15 < 0.05). These results suggest that FAQ retrieval with ontology is more effective. Specifically, our results suggest that when ontology is integrated into an FAQ retrieval system, more relevant answers can be retrieved from the FAQ repository. Therefore, we can say that with 95 percent certainty, FAQ retrieval with ontology is more effective than FAQ retrieval without ontology.
Similarly, we carried out a paired t-test for the other retrieval effectiveness measures MRR and P@5 under the BM25 weighting model. The results suggest that FAQ retrieval with ontology is more effective than FAQ retrieval without ontology. Moreover, for the PL2 weighting model with retrieval effectiveness measures MAP, MRR, and P@5, we got similar results suggesting that FAQ retrieval with ontology has a better chance of providing more relevant answers.
Discussion
The results of both experiments show encouraging results. First, for the evaluation of the quality of our ontology, OQuaRE provides a number of metrics associated with different characteristics of quality. The values of these metrics indicate that the quality of the ontology is more than average which can be used as indicator of the overall quality of the ontology. However, this framework does not provide a single value which is an aggregate of the values of the metrics. Rather, the quality scores corresponding to the different quality characteristics indicate strengths and weaknesses of the ontology.
Second, for the evaluation of the performance of the question answering system (where ontology is integrated with Terrier IR platform), we have observed that the retrieval of relevant answers improves when the ontology is integrated with Terrier for both the BM25 and PL2 weighting models. Higher improvement was observed for the PL2 weighting model. As our ultimate goal is to deploy the question answering system on mobile platforms, we have a plan to evaluate the performance of the system using measures such as P@1 which is the mean of the precision of the top ranked answer retrieved. However, previous experimental results indicate that P@1 and MRR have strong correlations. This means we can have some confidence that deploying the system on mobile platforms, where a top ranked answer is retrieved, will retrieve relevant answers. In fact, research by Thom and Scholer 33 indicates that measures such as P@1 and MRR are more appropriate evaluation measures for question answering systems. It was also demonstrated that there is a close correlation between the relevance of the first result returned (P@1) and user satisfaction.
Limitations of this study
There are two limitations in this study. The first limitation of our study is that the number of questions used during the experiment to evaluate the effectiveness of integrating ontology to FAQ retrieval system is small (i.e. 30 questions). Therefore, the results should be treated as indicative, rather than being conclusive as it will be difficult to generalize the results of our experiment based on such small sample size. However, as these questions were randomly sampled from the FAQ repository, it minimizes the bias toward certain types of questions.
The second limitation is that the questions used in the experiment are not questions submitted by actual users of an FAQ retrieval system. The questions were randomly taken from the FAQ repository. However, these FAQs were compiled by the Ministry of Health and other organizations in the country that have many years of experience in dealing with HIV/AIDS and hence these FAQs could be representative of questions that could be asked by people with interest in HIV/AIDS issues.
Practical significance
The ultimate goal of the research project is to deploy the ontology-based FAQ retrieval system into a public domain so that anyone who has any question on HIV and AIDS can query it. However, to reach that stage, there are additional works that need to be carried out on which our future work will focus. These include enriching the FAQ repository by incorporating more FAQs and conducting pilot studies with actual users who can pose their own questions related to HIV and AIDS. Nevertheless, the experimental results are promising and this is the first step toward realizing a system which can contribute to the much needed initiative in providing information access on HIV and AIDS.
Conclusion
In this work, we presented experimental evaluation of an ontology-based HIV/AIDS question answering system aimed at providing answers to users’ questions using an FAQ repository consisting of question-and-answer pairs collected from various sources. In this experiment, we investigated the effectiveness of ontology in improving the retrieval of relevant answers from an FAQ repository. To achieve this, we constructed HIV/AIDS ontology using the Text2Onto tool and integrated it to an open source IR system—Terrier.
The quality of the ontology constructed was evaluated using the OQuaRE framework which provides an objective and standardized framework for ontology quality evaluation. The results indicate that the quality of the HIV/AIDS ontology is adequate. Once the quality of the ontology was evaluated, we wanted to know to what extent the ontology helps in retrieving relevant answers by integrating the ontology into Terrier. To evaluate the performance of our system, we used commonly used IR performance evaluation measures for a ranked list of answers retrieved by a system. These measures are MAP, MRR, and P@5 together with the weighting models BM25 and PL2. The results indicate that the use of ontology improves the retrieval of relevant answers. However, such conclusions are only indicative as the number of queries used for the experiment is small. When the number of queries is small, the results can only be considered indicative rather than conclusive. In the future, we plan to conduct another experiment based on actual user-generated queries. In addition, we plan to develop a module for the automatic reading of ontology from Terrier so as to simplify the integration HIV/AIDS ontology into Terrier.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.