
Abstract
Data mining methods in biomedical research might benefit by combining genetic algorithms with domain-specific knowledge. The objective of this research is to show how the evolution of treatment rules for autism might be guided. The semantic distance between two concepts in the taxonomy is measured by the number of relationships separating the concepts in the taxonomy. The hypothesis is that replacing a concept in a treatment rule will change the accuracy of the rule in direct proportion to the semantic distance between the concepts. The method uses a patient database and autism taxonomies. Treatment rules are developed with an algorithm that exploits the taxonomies. The results support the hypothesis. This research should both advance the understanding of autism data mining in particular and of knowledge-guided evolutionary search in biomedicine in general.
Introduction
Genetic algorithms have been applied to rules from decision trees to improve diagnosis in health care. 1 This research extends that work by adding domain knowledge to the genetic algorithm.
Genetic algorithms that incorporate domain knowledge may be called memetic algorithms, 2 and this research contributes to the study of memetic algorithms. Specifically, the discovery of new rules will be facilitated through the use of domain knowledge to guide the choice of concepts to incorporate in a rule.
The machine learning research here is applied to the domain of autism. Autism is a neurodevelopmental disorder that first appears during childhood and generally follows a steady course without remission. Broadened to include “autism spectrum disorders,” the disease affects 11 of 1000 children in the United States. 3 Decision-support tools can support management of such widespread, pediatric disorders. 4
The knowledge about autism that is used for this work comes from the Interactive Autism Network (IAN) dataset. IAN is an online, research registry that connects family members of autistic people with researchers in an effort to help solve the many problems associated with autism. 5
The No Free Lunch Theorem states that a universal optimization strategy is not possible. 6 Therefore, one method can only outperform another method if it is designed to solve a particular problem or somehow structured to be specialized. Evolutionary algorithms that incorporate heuristic-based knowledge can outperform ones without such knowledge. 7 The domain knowledge can be injected at any phase of the genetic algorithm—including initialization, representation, selection, crossover, and mutation phases. 8 The idea of incorporating domain knowledge into an evolutionary process has also been applied to neural network applications in medicine. 9
The role of domain knowledge for the medical domain has been investigated in a number of studies including the use of evolving sub-ontologies for traditional Chinese medicine. 10 Verb selection patterns were used within a genetic algorithm to classify newly recognized biomedical terms co-occurring with domain-specific verbs. 11 Of course, other problem domains, such as finance, have been approached with memetic algorithms. 12
In the work to be presented here, the memetic algorithm is used to produce classification rules for autism treatment efficacy. Within the medical domain, classification rules have frequently aided clinicians and medical researchers. For example, neuro-fuzzy rule-based classifiers provided linguistically interpretable rules for one medical field. 13 Classification rules have been extracted from trained neural networks for breast cancer diagnosis. 14 A genetic programming algorithm was developed for discovering classification rules in breast cancer, dermatology, and pediatric adrenocortical tumors. 15
Several studies have incorporated artificial intelligence methods for the autism domain. Text mining was applied to biomedical literature for the construction of an ontology which identified rare relations in autism, 16 which led to a literature mining method for uncovering hidden relations from a set of articles in a given domain. 17 Self-organizing maps were used to model attention shift impairment and familiarity preference, 18 both hallmarks of autistic behavior.
Artificial intelligence and genetic databases have been combined in applications to autism. Decision trees 19 were created to predict the severity of autism based on single nucleotide polymorphisms. 20 Genetic and environmental factors were examined using combinatorial fusion analysis and association rule mining to determine associations between autism prevalence and the exposure to mercury and lead during critical stages of a child development. 21 Another genetics study found that association rules were able to successfully predict autism susceptibility genes. 22
Support vector machines were able to categorize infants in high- and low-risk groups for autism via an analysis of electroencephalogram (EEG) data. 23 An expert system was developed as a screener for autism. 24 Heart rate patterns were compared with common autism behavioral problems, such as self-injury and aggression. 25 The performance of various machine learning algorithms in a healthcare application has been compared. 26
One parameter of a knowledge-guided, evolutionary search algorithm is the size of conceptual changes to a rule. 27 This article compares the effects of knowledge-guided mutation to the traditional method of random mutation. The algorithm operates on a population of classification rules (for autism treatment efficacy) created from the IAN dataset. The fitness measure is the classification rule accuracy. The hypothesis is that mutations that implement a small conceptual change will result in small changes in rule accuracy. The results of these empirical tests will assist in the determination of how to best incorporate domain knowledge for both classification rules and genetic algorithms.
The remainder of this article is structured as follows: theory, methodology, results, discussion, and conclusion. The “Theory” section introduces and defines the concepts of domain knowledge, semantic distance, classification rule, and accuracy. The “Methodology” section describes the databases, taxonomies, and algorithms used in the experiments. In the “Results” section, the results of experiments and the analysis of those results are presented. Finally, the “Discussion” and “Conclusion” sections put those results in perspective.
Theory
The fundamental goal was to determine how domain knowledge can be usefully incorporated in knowledge-guided mutation in order to constrain the search and thereby constrain the associated fitness. Mutations involving random changes often lead to extreme fluctuations in the associated fitness measure to the detriment of the overall goal of discovering the optimal solution. The empirical results will help illuminate the relationship that exists between exploration and exploitation within the solution space. The hypothesis is that for a given set of classification rules, a systematic, incremental change in semantic distance will result in parallel change in accuracy.
Next, important terms are defined as follows:
Domain knowledge
Domain knowledge can be conceptualized as meta-data or data regarding the data that pertain to a particular domain. The domain data itself should be specific and relevant to the problem being solved.
Systematic
A systematic change is implemented based on the information contained in the IAN Semantic Diagram (presented in the “Methodology” section). Four categories of knowledge guidance (KG) control the amount of change that may be applied to a classification rule for autism treatment efficacy:
KG1: Knowledge-guided mutation level 1—Involves the minimum amount of change to the classification rule. This method will only allow a medication to be replaced with another medication from the same category. KG2: Knowledge-guided mutation level 2—Allows a greater change to the classification rule than KG1. This method will allow the medication to be replaced with any other medication. KG3: Knowledge-guided mutation level 3—Allows a greater change to the classification rule than KG2. This method will allow the medication to be replaced with any other treatment. KG4: Knowledge-guided mutation level 4—Allows the greatest amount of change to the classification rule. This method will allow the medication to be replaced with non-treatment data attributes (such as “patient diagnosis” and “parent expectation of outcome”).
Semantic distance
The semantics for the IAN data are formally presented in the drug taxonomy and KG levels (KG1–KG4). Semantic distance relates to the relative change between one KG level to another (i.e. KG1, …, KG2).
Parallel
Parallel refers to the relationship between the change in a rule antecedent and the resulting change in that rule’s accuracy. For each degree of change to a classification rule (i.e. KG1–KG4), a similar change is hypothesized to occur in the resulting accuracy. In other words, the smallest degree of change (i.e. KG1) will result in the smallest (relative to KG2 through KG4) amount of change in accuracy.
Accuracy
Accuracy can be defined as follows
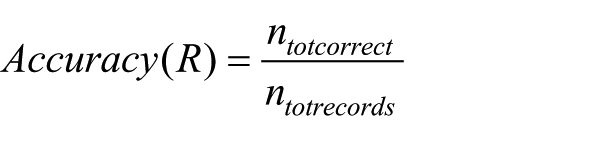
where R represents a single classification rule, ntotcorrect represents the total number of records correctly classified by R, and ntotrecords represents the total number of records including those not correctly classified. For any given experiment, where P represents a population of initial classification rules, an individual change in accuracy is computed and an absolute change in accuracy is captured as a1 to an where n represents the total number of records in P. For each rule, this individual accuracy measure is computed using 10-fold cross-validation. The overall average measure, AvgAcc, can be formally defined as follows
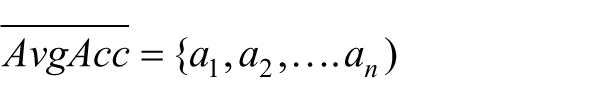
Classification rule
A classification rule consists of an antecedent(s) and a consequent which predict the class of instances covered by that rule. It is represented in IF–THEN form where multiple antecedents together form a logical conjunction.
Methodology
The research involved accessing a large database, developing a learning algorithm, and analyzing the results, as will explained in this section. The database comes from IAN and the taxonomies from IAN and the National Library of Medicine. The algorithm involves initializing the population of classification rules and then generating new rules in various ways. Finally, a working example is provided of knowledge-guided mutation.
Data
The IAN Project collects data from families with autism including information on demographics, parent medical data, sibling information, as well as a vast quantity of data on the autistic child including treatment information. Although the primary reason for the creation of IAN is to link researchers in the field of autism to potential subjects, the non-identifiable data stored on these families are accessible to any researchers that have proper Institutional Review Board approval.
The IAN data for this experiment covered approximately 9800 children between the ages of 0 and 18 years who have been diagnosed with some form of autism. The dataset has over 60,000 individual treatment records and thus approximately 6.3 treatments per autistic child.
In the data release that is being used for this research (date of version: 19 March 2012), there are 334 attributes. Some are categorical, some are binary, and some are numeric. Understanding the data requires some intimacy with the phenomenon of autism. For example, the categorical attribute of patient diagnosis included these entries: autism, Asperger’s syndrome, childhood disintegrative disorder, pervasive development disorders, and autism syndrome disorder. These different diagnoses reflect the variations of autism as identified by healthcare professionals. Across the database, these different diagnostic categories appear with a wide, relatively even distribution which makes that attribute a useful one for classification purposes.
For the purposes of data mining, identifying the appropriate outcome measure is an important pre-processing step prior to model building. There are a number of outcome measures for the autistic child present in the IAN data that can be derived from IAN’s Social Communication Questionnaire, its Social Responsiveness Scaling, or its treatment outcomes.
The Social Communication Questionnaire is utilized as a tool to screen for autism spectrum disorders. It consists of 40 “Yes/No” questions to be answered by the parent and will give a resulting score. The questionnaire is designed to classify a child as autistic or not and does not allow for gradations of severity. Due to the fact that this tool cannot indicate improvement or worsening in a child (a movement in the raw score is not an accurate measure), it will not be used as an outcome measure in any of the analyses.
Social Responsiveness Scaling could be used for diagnosing the severity of the autism disorder in children. It categorizes autistic children as non-autistic, mildly autistic, or severely autistic. However, in the dataset, the breakdown for the autistic children is heavily skewed toward severe autism.
Treatment outcome is a complex outcome measure that tracks the parent’s perception of treatment efficacy over time (horizontally) and by treatment (vertically). A parent rates each treatment that the autistic child receives at three distinct time periods: (1) when the treatment is first entered into the system; (2) every year when the parents are requested to update their child’s treatments; and (3) when the treatment is stopped. The treatment efficacy measure is provided by the parent using a 9-point Likert scale with four ratings for worsening, 1 for no change and 4 for improvement. Given the limitations of the other outcomes and despite the challenges of using subjective data,28,29 the treatment outcomes proved to be the appropriate outcome measure for these experiments.
A 9-point Likert scale was mapped to a categorical measure clinical outcome. Outcome measures with high cardinality typically suffer from over-fitting when used in various data mining activities. Classification rules are particularly susceptible to this phenomenon. Over-fitting would lead to classification rules that will perform well on training data, but when tested on separate data perform very poorly.
Initialization
The semantic net for this research (Figure 1) relates to the data structure in IAN. The circle at the top level represents all the IAN data, whereas at the second level the circles represent the sub-entities present in the IAN dataset:
Autistic child;
Mother;
Father;
Sibling.

IAN semantic net.
The circles at the third level represent the sub-entities associated with the main entity. The autistic child has a number of sub-entities including the following:
Social Communication Questionnaire;
Vaccine history;
Social Responsive Scale;
Height and weight history;
Treatment information.
Treatment information includes two sub-entities: medicinal treatments and non-medicinal treatments.
The Medical Subject Headings (MeSH) is a massive thesaurus from the National Library of Medicine. 30 Drug information was obtained from MeSH that was associated with the treatments in the IAN database. The 56 distinct medicinal treatments were then classified into nine categories based on MeSH (Table 1).
Drug taxonomy.
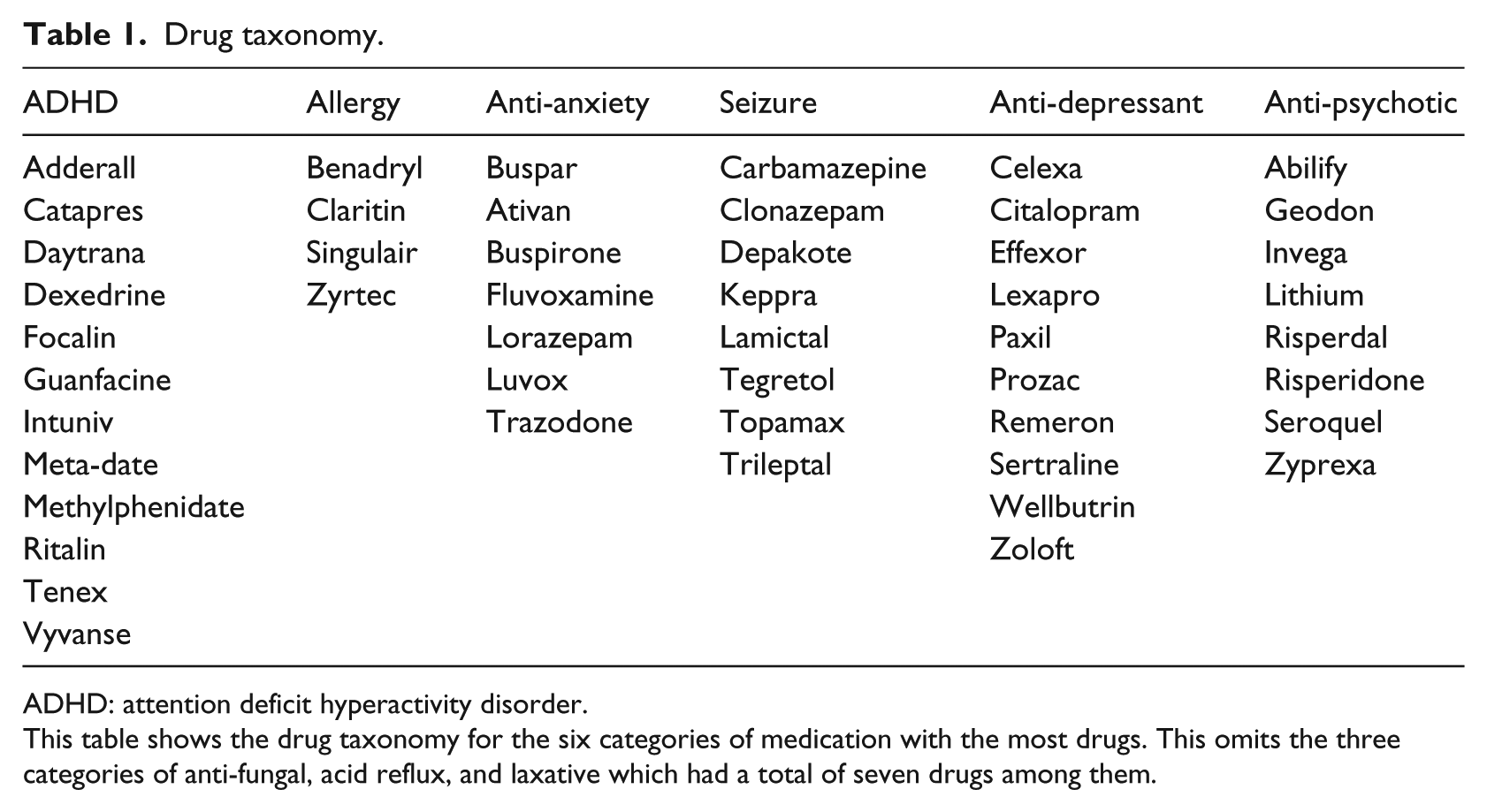
ADHD: attention deficit hyperactivity disorder.
This table shows the drug taxonomy for the six categories of medication with the most drugs. This omits the three categories of anti-fungal, acid reflux, and laxative which had a total of seven drugs among them.
The experiments used a classification rule with two predicates in the IF-part and one in the THEN-part. The first IF predicate was the First Autism Diagnosis Category (DiagnosisPredicate). The second IF predicate was treatment. The outcome predicate was one of three values: improvement, no change, or worsening. By combining all the variations of predicates, 1027 distinct rules were created.
Experiment parameters
Knowledge may be exploited to constrain evolutionary search, and this experiment will use domain knowledge to constrain the mutation operation. 31 The genetic algorithm implementation isolated the effects of mutation and did not use the crossover operator. The software to run the experiments was coded in Microsoft Access Visual Basic for Applications. The experiment parameters are presented in Table 2.
Experimental details.
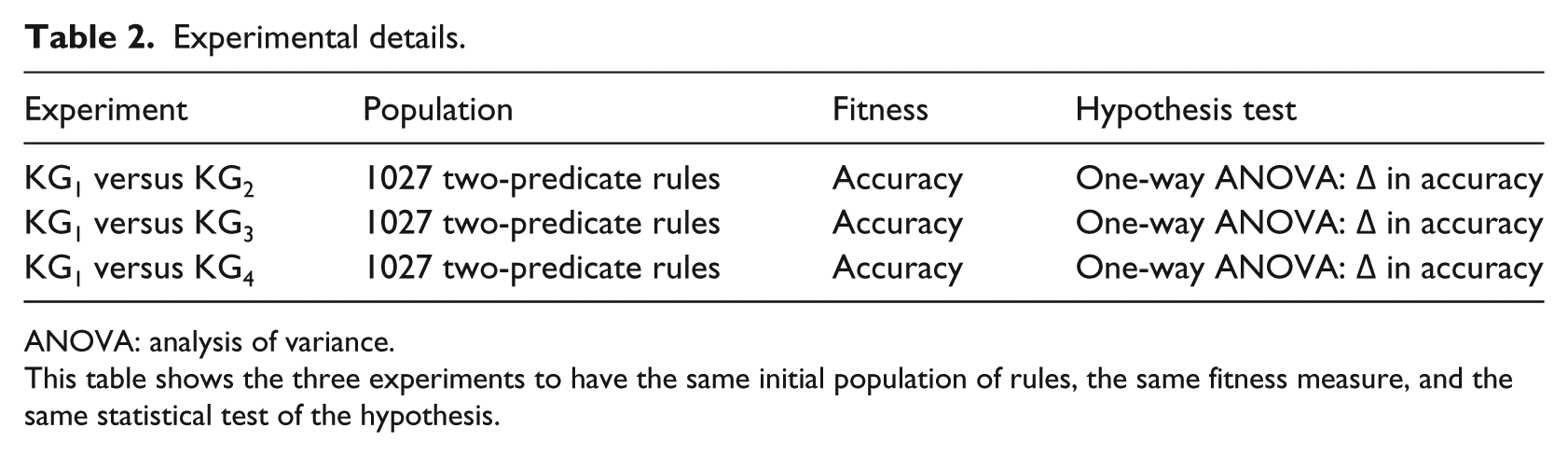
ANOVA: analysis of variance.
This table shows the three experiments to have the same initial population of rules, the same fitness measure, and the same statistical test of the hypothesis.
For each knowledge level of guidance, mutations were performed on the second predicate. The pseudo-code in Figure 2 describes the mutation process and the fitness measure. Each time a rule was mutated, the offspring rule was tested for accuracy. Information about the rule, its mutation, and the performance of the offspring rule was recorded for every mutation and rule. A one-way analysis of variance (ANOVA) test was then conducted in SPSS to determine whether the variability between accuracies at the different knowledge levels was statistically significant.

(a) Definitions for pseudo-code: These acronyms appear in the pseudo-code that describes the memetic algorithm used in this experiment. The acronyms are defined in this figure. (b) Pseudo-code: This pseudo-code describes the memetic algorithm of this experiment. The algorithm is essential one “Do Loop.” The lines beginning with “//” are comments. “y++” means to add one to y. “ABS” means absolute value. The other acronyms are defined in (a).
Working example
A simple example illustrates the method presented in Figure 2. First, the starting classification rule with a baseline accuracy of 80 percent is

This classification rule is mutated under the guidance of KG1 which is the smallest amount of change that can be applied. KG1 dictates that the TreatmentName attribute should be changed to another medication in the same family as Adderall. Since Adderall belongs to the category attention deficit hyperactivity disorder, another medication from this same category will be randomly selected—in this case Intuniv. The new classification rule with the calculated accuracy of 82 percent is

The absolute change between the two rules is 2 percent. A similar methodology has been used in the financial domain where rules were mutated under constraints of domain-specific taxonomy, but the domain was finance. 32
Results
In this section, the results of the experiment comparing the different knowledge-guided mutation levels (KG1 through KG4) will be presented. The experiments support the hypothesis. Additionally, an analysis of the issue of evolving poor rules is discussed.
In Table 3 and Figure 3, a summary of the experimental results is presented. Since the sign would alter the average significantly, the absolute value is also reported. The results indicate that there is an increase in (absolute) change in accuracy across all experiments.
Summary of results.

The leftmost column indicates the experiment. The second column is the average change in accuracy, while the third column is the average change in absolute accuracy. In each case, the accuracy is being compared.
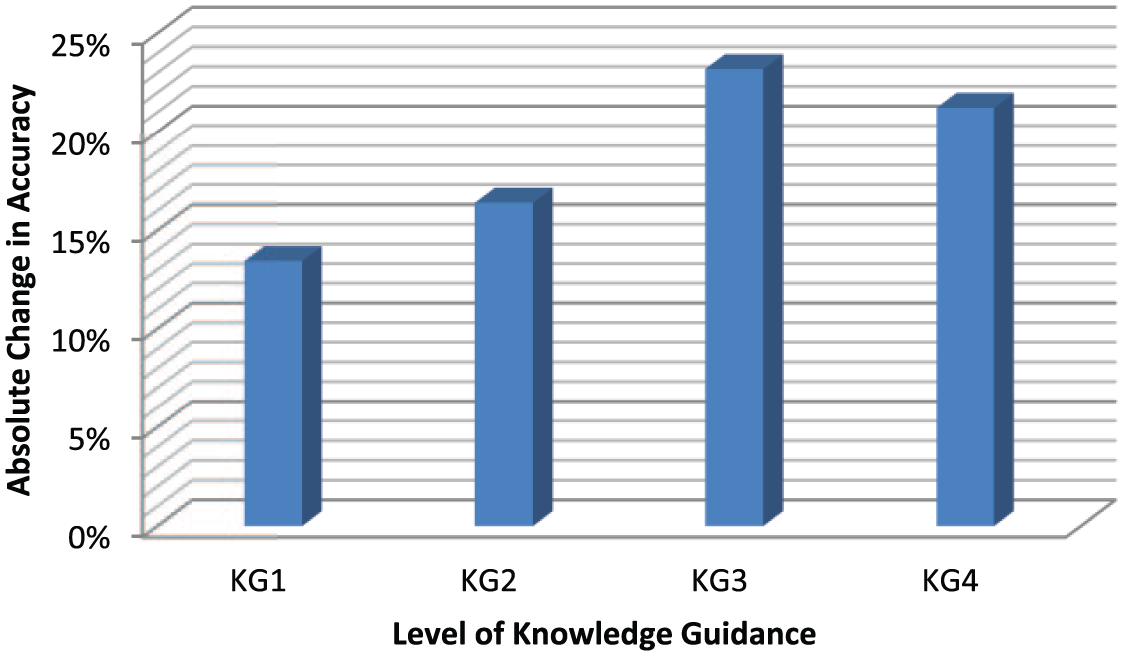
Change in accuracy by level of knowledge guidance.
To establish statistical significance, a one-way ANOVA was conducted in SPSS for the experimental results for KG1, KG2, KG3, and KG4. The data contained in four separate data files captured the absolute change for each. In Table 4, the descriptive statistics are presented.
Descriptive statistics.
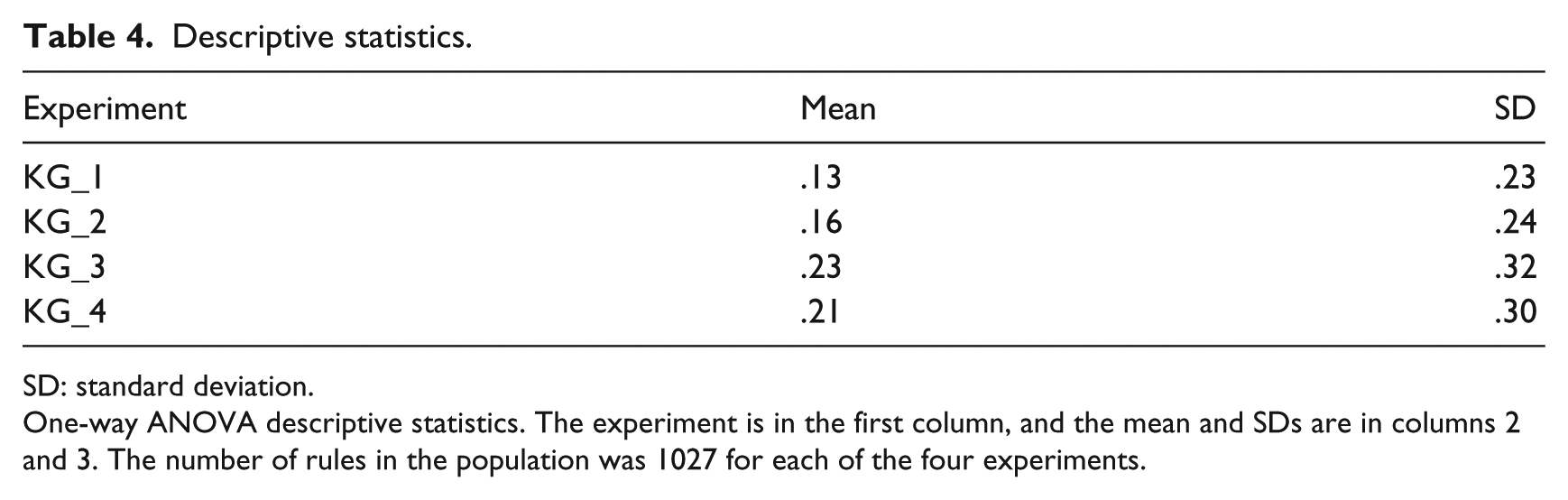
SD: standard deviation.
One-way ANOVA descriptive statistics. The experiment is in the first column, and the mean and SDs are in columns 2 and 3. The number of rules in the population was 1027 for each of the four experiments.
Table 5 reports the results of the pairwise comparison (t-test). The results report the mean difference, standard error, and statistical significance. For each of the comparisons, the p value is below .05, thereby confirming statistical significance of the variances. The results of the one-way ANOVA indicate that the variances in absolute change that occurred in the four experiments (KG1–KG4) could not have been due to random fluctuation.
Pairwise comparison.
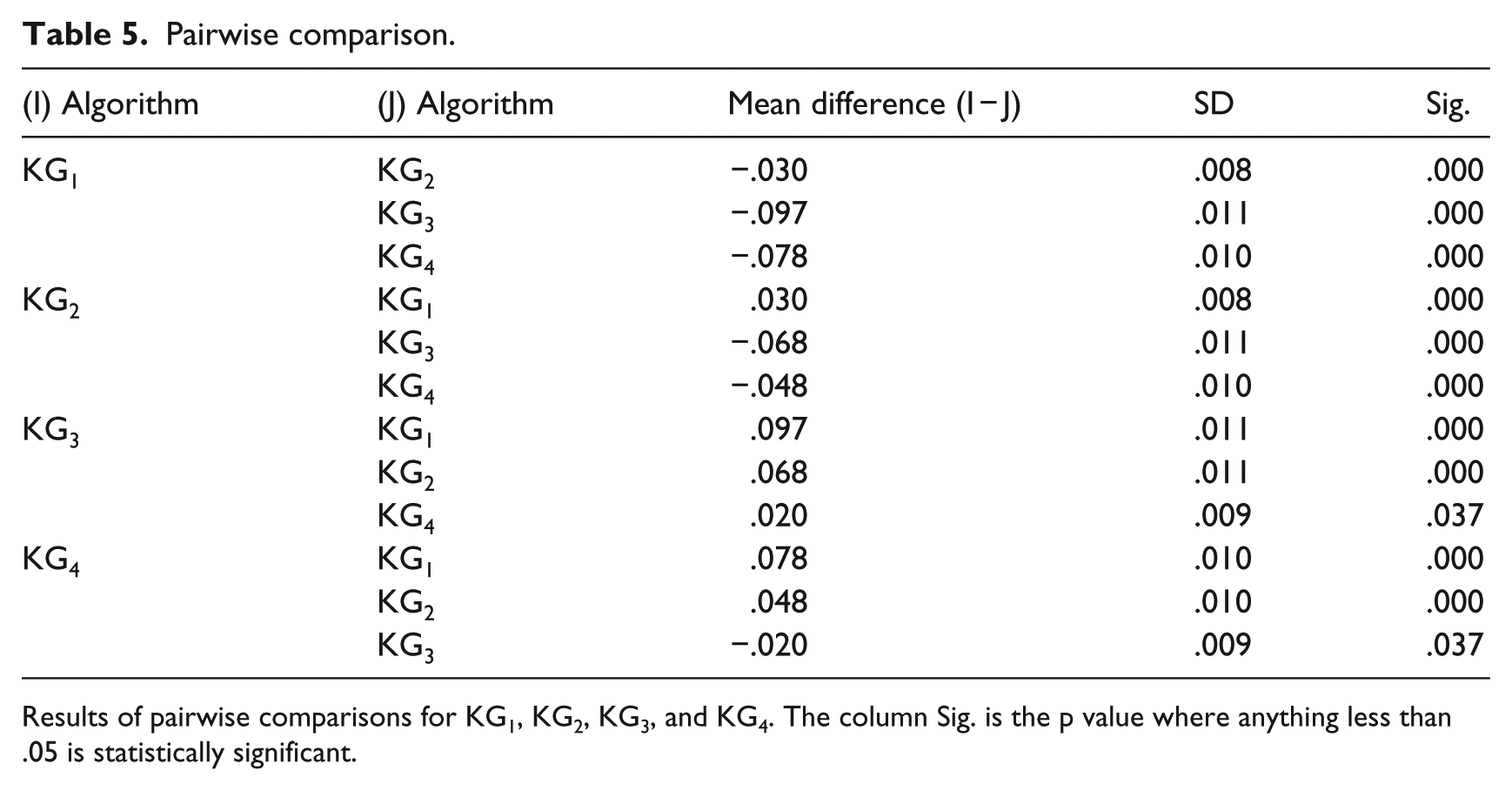
Results of pairwise comparisons for KG1, KG2, KG3, and KG4. The column Sig. is the p value where anything less than .05 is statistically significant.
Many of the beginning rules in the dataset as well as number of the mutated rules suffered from extremely low accuracy. These rules can be described as poor rules. Poor can be defined in two ways: (1) rules that suffer from extremely low accuracy (i.e. 0%) or (2) rules that suffer from extremely low support (.001 or less). In the initial dataset of 1027 rules, 261 suffer from extremely low support. Subsequently, there are 427 rules with an accuracy of 0 percent. The two reasons for including these poor rules in the experiments are presented next.
First, the initial population in a genetic algorithm should exhibit diversity to provide sufficient variation in the mutation phase. In other words, starting with a population of all good parents (i.e. classification rules) who exhibit both high accuracy and high support is not desirable since this will overly constrain the search space. Ideally, the beginning population of classification rules should cover a wide spectrum of the desired search space.
Second, due to the multidimensional nature of the classification rules (i.e. two predicates), it cannot be assumed that poor support or accuracy is due to the first predicate. It is possible that by mutating the second predicate, a rule may be generated that is significantly more robust. Discarding rules with poor support or accuracy could constrain the search space unnecessarily.
Discussion
Limitations to this research could affect its generalizability but could be readily addressed in future experiments. One logical next step would be to expand the experimental results to include different attributes in the first predicate. Another step would be to expand the generations of mutation by one of two methods:
The first would include creating a set of multiple distinct populations (i.e. 100 datasets consisting of 100 rules). KG1, …, and KG4 would be separately applied to each of these datasets. The measures would be collected as they were in the current experiment, and the one-way ANOVA test is applied to determine statistical significance.
The second method to incorporate multiple generations would begin with the initial population (i.e. the dataset of 1026 rules) and apply KG1, …, KG4 as was done in this experiment. The results from each of these experiments will become the new populations for further experiments.
The experimental results follow a clear trend for KG1, KG2, and KG3. However, the trend was broken for KG4, and future experiments could explore this anomaly. From the data and knowledge perspective, a limitation of the experiment was the extent of domain knowledge exploited; in other words, incorporating new sources of domain knowledge might lead to new insights.
Conclusion
This article’s section “Discussion” emphasized the limitations of the study, while this section will highlight the generalizability of the results. This article presents the results of an experiment that uses knowledge-guided mutation on classification rules for an autism database. Domain knowledge is shown to constrain and guide the mutation operator.
The step-size of the mutation operator tended to correspond to the step-size in the change of performance of the rule that was mutated. A mutation that is restricted to make a small semantic difference in the classification rule tends to lead to a small change in accuracy of the offspring rule. In other words, when the semantic change is allowed to be slightly greater, then the change in accuracy is slightly greater (13% for KG1, 16% for KG2, and 23% for KG3).
The domain knowledge refers to the drug taxonomy or semantic net that was created for the medications in the IAN database. This domain knowledge could be utilized by other autism researchers looking to augment other artificial intelligence methods, such as Naïve Bayes, decision trees, or clustering. This work contributes to the growing body of science about incorporating domain knowledge in machine learning.
Although this research has focused on how to apply the memetic algorithm to the autism domain, the method presented here could be extended to other medical domains, such as cancer and aging. The process of creating a drug taxonomy using MeSH could be applied to other medical domains where the data include medications. This research might help health informatics researchers build prediction or classification models that combine evolutionary algorithms and domain knowledge.
Footnotes
Acknowledgements
The authors would like to thank Dr Paul Law, Founding Director of the Interactive Autism Network and Professor of Pediatrics at Johns Hopkins University, for his help with accessing and using the data.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.