
Abstract
With the advancement of internet technology, customers increasingly rely on online reviews as a valuable source of information. The study aims to develop a marketing data analytics framework to manage online reviews, especially fake reviews, which have become a significant issue undermining the creditability of online review systems. As small and medium-sized enterprises often lack the capabilities to automatically derive customer insights from online reviews, this study proposes a cost-effective, extensible Review-Analytics-as-a-Service (RAaaS) framework that can be operated by non-data specialists to facilitate online review data analytics. We demonstrate the framework’s application by using two datasets with more than 400,000 online reviews from Yelp to simulate live platforms and demonstrate an analytic flow of review fraud detection and understanding. The findings reveal insights into the influence of fake reviews on product ranking and exposure rate. Moreover, it was found that there was a higher concentration of sadness and anger in fake reviews (vs. organic reviews). In addition, fake reviews tend to be shorter, more extreme (with the use of strong adverbs), and have different patterns of topic distribution. This study has important implications for different stakeholder groups including, but not limited to, SMEs, review platforms and customers.
Introduction
Big data are high velocity, large volume and multiple source data resulting from digitising daily activities, including interactions, online transactions and communications (De Luca et al., 2021; McAfee et al., 2012). User-generated content is an important source of big data that can be converted into useful information for modern businesses (Kauffmann et al., 2020). Online review is one of the most crucial generated content that significantly affects brand engagement because it directly reflects the customer experience with products or services (de Vries et al., 2012). Moreover, with the advances in internet technologies, customers mainly rely on reviews as a primary source to explore product information (Robertson et al., 2021). A recent study (Ha et al., 2015) reveals that 52% of customers explore product information in advance via the internet, and 24% of them decide to buy products based on these online insights. Therefore, product reviews play a crucial role in the success of a business as they directly influence customers’ purchase decisions (Choi et al., 2017). Recent research has highlighted the shift to outside-in marketing, which focuses on sensing the market and creating connections with customers (Quach et al., 2022). Therefore, understanding what customers say about firms and their products in a timely manner constitutes a critical factor in succeeding in the era of big data. On the other hand, fraudulent reviews have become a significant issue undermining the creditability of online review systems (Luca & Zervas, 2016). Fake reviews give authentic firms and customers the wrong signals, which can manipulate the ranking and sales, thereby negatively impacting genuine businesses (He et al., 2022).
Nonetheless, deriving customer insights from online reviews and detecting fake reviews involved a complex process that requires big data capability (Kauffmann et al., 2020). Reviews of the same product may come from multiple data sources, ranging from online selling platforms (e.g. Amazon, eBay) to product review providers (e.g. Yelp, TripAdvisor). Therefore, conventional review analytic frameworks, which are designed and optimised for a specific domain of applications such as Yelp (Lee et al., 2022; Luca & Zervas, 2016), app store reviews (Kauffmann et al., 2020) and Amazon reviews (Kauffmann et al., 2020), are unable to generalise to multiple and diverse data sources, thereby suffering a limitation of extensibility. In addition, these approaches are not cost-effective as the company needs continuous infrastructure investment and maintenance, which hinders small and medium-sized enterprises (SMEs) from leveraging customer insights for business planning and development. Although SMEs could save their cost by leveraging emerging cloud services that enable the storage, analysis and visualisation of data, and paying per usage, they require specialised knowledge of analytics algorithms to conduct a review analysis pipeline. To sum up, designing a cost-effective analytics platform for marketing stakeholders who are not data analysis experts to conduct data analytic tasks is still an open problem.
Therefore, we aim to address the gap in the extant literature pertinent to fake reviews by developing the framework that allows marketers from SMEs to adopt fraudulent review detection and understanding. It is worth noting that marketing stakeholders are not required to be data experts as the proposed framework offers algorithm templates that are manageable to apply. The main research question (RQ) of our study is how to exploit the core values of big data and provide a proactive platform for non-data specialists to trigger enormous tasks on review analytics. While recent research (Kauffmann et al., 2020; Salminen et al., 2022) analysed fake reviews and proposed a detection method, and it does not necessarily help to understand fake reviews with multi-faceted insights, including textual patterns, topics and emotions. Therefore, this study aims to provide an in-depth understanding of fake reviews and focus on the additional sub-research questions as follows: RQ1: Can review fraud be automatically detected?; RQ2: How do review frauds affect the product ranking system?; and RQ3: What are the differences between fake and organic reviews?
The study contributes to the current body of knowledge in the following ways. First, overcoming the limitation of conventional framework (Kauffmann et al., 2020), we are among the first that propose a state of the art, cost-effective, extensible cloud-based platform consisting of data acquisition and data analytic planes, that can be operated by non-data specialists to facilitate online review data analytics in marketing. Although the main focus of the study is to support SMEs in implementing review data analytics without expert guidance, their potential adoption is open to businesses of all sizes that want to harness customer data with minimal investment cost. Second, via the use of a case study, we demonstrate the employment of multiple algorithms to detect fake reviews and provide insights into how contemporary detection methods’ accuracy can help detect and filter fake reviews. Finally, we evaluate the impact of fake reviews on business activities and determine multifaceted insights and characteristics that distinguish fake reviews from organic reviews, extending previous research such as Kauffmann et al. (2020) and Luca and Zervas (2016). The structure of our paper is as follows. The next section reviews the literature related to the study followed by our proposed RAaaS framework which details the necessary phases for the data acquisition plane and details analytics tasks available in the cloud plane. We then present a case study to demonstrate the use of the framework together with the analysis and intensive discussion on insights. Finally, we conclude our paper with some limitations and future research directions.
Background
In this section, we first review related work on big data analytics in marketing (section 2.2). As our case study is based on fake review detection and understanding, and we then discuss related work on fake review detection (section 2.3).
Challenges for SMEs in big data adoption
Although it would be incorrect to assume that all SMEs cannot afford a private-owned big data analytics framework, the cost typically plays a crucial role. Therefore, it is a possible barrier for SMEs to adopt big data analytics to facilitate their business activities. The reason could be that there is a natural cost-functionality trade-off, as the investment cost outweighs the potential benefits (Coleman et al., 2016), or it is simply that the cost is beyond the capability of an SME. Additionally, SMEs are concerned about the main challenge associated with adopting big data analytics, that is, the skills required to manage it. Not only because these expertises are challenging to locate, but they are also expensive to acquire (Del Vecchio et al., 2018). Moreover, SMEs frequently lack in-house capabilities for selecting, configuring and maintaining sophisticated IT systems; such considerations are another challenge for SMEs to apply big data analytics (Schmidt & Möhring, 2013). With the rise of Software as a Service (SaaS; Kasemsap, 2021) and cloud computing, SaaS could simplify access to elaborate data stores and computer networks. Prior studies suggested that many SMEs will adopt cloud computing due to its scalable nature and relatively low upfront costs (Sultan, 2011). In order to make big data analytics more accessible to SMEs, we propose the idea of big data analytics being given as a cloud-based platform, which is focused on online review analytics for customer behaviour understanding.
Big data analytics framework and online reviews
Big data analytics can transform data from multiple sources into actionable insights, which can be used to maximise the effectiveness of the marketing campaigns and, optimise the enterprises’ return on investment (Quach et al., 2022). Online reviews are essential in the era of big data revolution (Erevelles et al., 2016) as these data provide customers’ behavioural insights that directly affect their buying decisions. In addition, customer reviews allow firms to sense the market and to build lasting relationships with their customers (Munzel, 2016). Despite the importance of online reviews which often come from various sources such as business websites, social networking sites and e-commerce platforms, most existing works in literature to extract customer insights from online reviews are domain-specific. It means that they are designed to work with a specific data domain. For example, Barbado et al. (2019) proposes a framework for review analytics with applications on fake review detection, and the authors evaluate the framework’s performance using reviews on an electronic domain. Jimenez-Marquez et al. (2019) proposes a two-stage framework for analysing social network content and presents a case study to analyse online reviews for tourism-related businesses. Martens and Maalej (2019) proposes an analytic process for understanding online user feedback for supporting decisions for mobile app launching. As being optimised to a data domain, such approaches are hard to generalise and extend to multiple data sources, while reviews of the same product may come from multiple domains. The recent work (Kauffmann et al., 2020) proposes a generic framework that can be applied to multiple domains of online review. However, it requires continuous infrastructure investment and maintenance, which may not be cost-effective for the majority of SMEs, which often have limited technological and financial resources.
To resolve the limitations of existing approaches, we propose Review-Analytics-as-a-Service (RAaaS) – a platform to facilitate online review data analytics in the cloud that supports marketing-specialised data analytic algorithm templates and enables those not experts in analytic algorithms to discover the customers’ insights. Cloud technology offers ready-to-use resources, including computing power, applications and services in the cloud environment in which users can minimise their cost investment without worrying about resources’ availability (Quach et al., 2022). Cloud technology has been widely utilised in various fields such as manufacturing (Zulkernine et al., 2013), smart cities analytics (Khan et al., 2015), automation in construction (Chen et al., 2016), health-care (Bastwadkar et al., 2020), design innovation (Liu et al., 2020). This study is among the first to apply this framework in the marketing discipline.
Fake review detection
Internet technology has changed the way customers buy products, and fake reviews have gradually manipulated these purchasing decisions. Fake reviews might be written to promote or demote a business and to intentionally misinform consumers in their decision-making (Choi et al., 2017). Therefore, fraudulent reviews are detrimental because they introduce disturbance and false signals to systems that are meant to reduce information asymmetry, resulting in consumers’ purchase of unreliable products, disadvantaging genuine businesses by manipulating ranking and promoting unhealthy competition, and undermining customer trust in the platforms (He et al., 2022). Whereas a major research stream has focused on consumers’ perspectives, such as their ability to detect fake reviews (Malbon, 2013; Munzel, 2016) and intention to write fraudulent reviews (Choi et al., 2017), there has been increasing interest in how firms manage online reviews and detect fraudulent attempts (Kauffmann et al., 2020; Salminen et al., 2022). Specifically, online service firms are facing the alarming situation of purchasing fake reviews, which has been highlighted in a recent study (He et al., 2022). Fake review detection is the task of classifying online reviews into a class of fake and organic reviews. Fake review detection methods can be divided into two categories: supervised and unsupervised methods. Supervised methods (Saumya & Singh, 2018) learn a classifying model from labelled information (i.e. fake and organic reviews). Unsupervised methods apply clustering techniques (Liu & Pang, 2018) and graph-based analysis (Ye & Akoglu, 2015) for fake review detection without requiring labelled data. A graph partitioning approach (Manaskasemsak et al., 2023) is proposed to prevent the deceiving of untruthful reviews on product quality and fair commercial benefits. However, this approach focuses on distinguishing fake reviewers from benign ones rather than fake review detection. Similarly, more approaches are raised to combat the detrimental effects of fake reviews (Z. Wang et al., 2020; F. Zhang et al., 2020). Nevertheless, they focus on the group of reviewer detection by considering both time effects and network effects. More recent studies (Birim et al., 2022; W. Zhang et al., 2022) explore the feasibility of employing topic modelling as a trait for fraudulent review detection. Although these methods yield moderate performance, it is unclear how topic distributions affect fraudulent review detection, and the generalisation to various domains is inadequate (X. Wang et al., 2018). In this study, replying to the call of recent research in using machine learning for fake review detection (Salminen et al., 2022), we integrated state-of-the-art supervised and unsupervised methods and made them available in our framework using an algorithm template. A summary of the features used and characteristics of these methods shall be presented in section 5.3, where we reveal a variety of data analytic tasks to facilitate fake review detection and understanding.
The proposed framework
Towards a cost-effective and extendable review data analytics, we propose Review-Analytics-as-a-Service (RAaaS) framework. Before giving an overview of the framework, we summarise its underlying design principles.
Design principles
Reflecting on emerging applications of extracting insights from online reviews for SMEs (Jimenez-Marquez et al., 2019), the limitations of existing work in literature, and on the analytic results reported for state-of-the-art approaches (Kauffmann et al., 2020), we derive the following requirements for a practical framework:
(R1) Cost-effective. The framework shall allow a low-resource setting where high-resource required tasks will be performed within the cloud, and the cloud cost shall be shared between enterprises following a pay-as-you-go paradigm.
(R2) Non-expert required. The framework shall enable those not specialising in data science to ultilise data analytic techniques to derive customer insights to facilitate marketing intents.
(R3) Extensibility. The framework shall allow enterprises to extend to multiple data sources as reviews of the same product may come from multiple sources ranging from online selling platforms to specialised online review providers.
Framework overview
The overview of the proposed Review-Analytics-as-a-Service (RAaaS) framework is presented in Figure 1. The framework consists of two planes: the aquisition plane and the analytic plane.
Data acquisition plane: The function of this plane is to retrieve and structure data generated from various data sources. The enterprise can extend more data sources over time as long as they follow the data structure specified by the data transmission component of the plane. This way, we achieve extensibility (R3) as the enterprises shall be proactive in how many data sources they want to perform the analysis. Details of this component shall be given in section 4.
Data analytics plane: After receiving the high-quality data transmitted from the data acquisition plane, in this plane, we provide various services to perform analysis tasks. The enterprises only pay per their usage of analytic resources and thus, being cost-effective (R1). In addition, the analytical tasks are independent of the analytic experts as each analytic task is built in the form of an algorithm template. Quickly selecting the algorithm template and selecting minimum variable inputs are now open to a non-expert (R2) through the concepts of algorithm template. Details of this component shall be given in section 5.
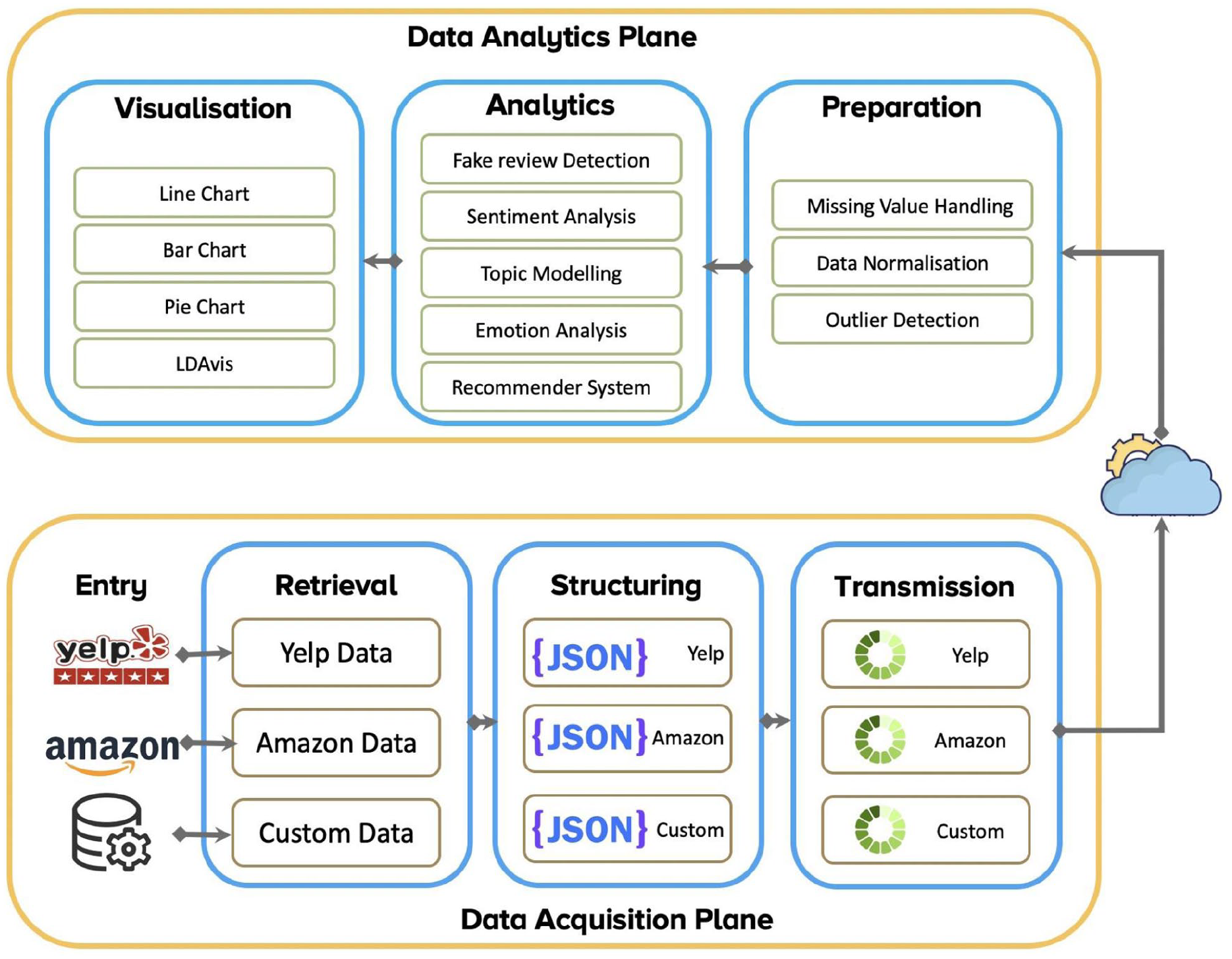
The big data analytic framework for fraudulent reviews.
Data acquisition plane
The first plane of RAaaS proposes sequential phases that represent the pipeline of data processing performed locally at the enterprise site, including data entry (section 4.1), data retrieval (section 4.2), data structuring (section 4.3) and data transmission (section 4.4) with buffering component. The purpose of this plane is to ensure the data availability and quality rather than the complex analysis and, therefore not required for an analytic expert which is satisfied with the (R2) of design principles.
Data entry
This work aims to propose a cloud-based framework that focuses predominantly, but not exclusively, on a collection of online reviews. The data input to the framework is mainly coming from the textual domain. These textual data can come from online selling platforms (e.g. Amazon, eBay) to product review providers (e.g. Yelp, TripAdvisor). As a demonstrated study, tourism data is chosen to perform data analytics, especially reviews on restaurants and hotels; however, the framework is well adapted to any data source such as questionnaires, surveys, or data collected from offline marketing campaigns.
Data retrieval
To analyse product reviews, it is essential to first accurately identify the reviews and collect them in a timely manner. Therefore, the initial phase of this plane is data collection, which involves adopting the necessary data collection techniques to obtain relevant data. Data collection techniques allow collecting diverse information using web scrappers (Kauffmann et al., 2020) or third-party services (Zulkernine et al., 2013). One of the most popular means for data collection is the Application Programming Interfaces (APIs) (Olmedilla et al., 2016). Therefore, the APIs for the most popular selling platforms (e.g. Amazon, eBay) and product review providers (e.g. Yelp, TripAdvisor) are made available in this phase. Enterprises are flexible and free to choose based on their capacity as long as it is sufficiently optimal to avoid irrelevant data.
Data structuring
Data analytics systems acquire data from multiple sources with diverse formats. This phase aims to obtain a consistent and standardised structure for a high volume of information that comes from multiple data sources. Although the reviews may come from different data sources, they share some similarities. For example, a review associated with a score value ranging from 1 to 5 indicates a user’s preference level for a specific product. A review text represents the assessment and experience of a customer about the product, and this textual review is widely known as a new type of online Word-of-Mouth (WoM) in marketing research (Li & Zhan, 2011). Together with other metadata of online reviews, the datasets of online reviews are structured and normalised using the well-known JSON format (https://www.json.org/json-en.html), where a fundamental online review is defined as follows:

Data buffering and transmission
This phase aims to transmit data from the data acquisition plane to the data analytic plane in the cloud in real-time. Due to high velocity, the data availability could be affected by network outages from the enterprise site or the bottleneck at the cloud host site. To eliminate such data loss, a data buffering component is employed to temporarily store data when outages occur and continue sending the data once the cloud host is accessible. Additionally, to avoid the risk of unexpected errors or data loss, we maintain a table structure that matches the data transmitted and data received in the cloud plane. The data buffering and transmission mechanism enables high speed, and real-time processing facilitates mass adoption in the era of big data analysis.
Data analytics plane
Different from data acquisition plane, which is located locally at the enterprise site to facilitate extensibility (R3), review analytic plane is deployed in cloud computing and enables a pay-as-you-go payment schema. In this way, the framework achieves cost-effectiveness (R1). Before revealing the algorithms supported in the framework, we present an essential concept of marketing-specialised algorithm template.
Concept of marketing-specialised algorithm template
The primary goal of the marketing-specialised algorithm template is to design a template in which the analyst can quickly define the analysis types and the expected outcomes. The template must also consider which algorithms shall be involved in the analysis flow and how these algorithms are connected together. In addition, the template must be simple enough for non-experts with little knowledge about data analysis to utilise available algorithms to conduct their analysis. To facilitate the template formulation, we divided the analytics plane into three stages: data preparation, data analysis and data visualisation. Each stage supports various types of algorithms that can be ultilised by simply specifying the algorithm template. The logical definition of an algorithm template can be formulated as follows.
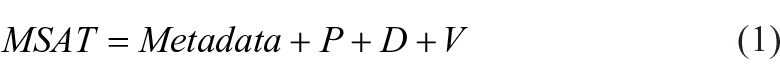
where each component of the equation is detailed below.
MSAT is Marketing-Specialised Algorithm Template,
P = {Pi|i = the cardinality of the set of preparation tasks},
A = {Aj|j = the cardinality of the set analytic tasks},
V = {Ak|k = the cardinality of visualisation set}.
Metadata is the essential data required for specifying the analysis type and the data input. We use extensible markup language file (XML; http://www.xml.org/) to store all configurations of the algorithm template. Details of XML example shall be provide in the case study design and implementation in section 6.2. In the subsequent sections, we present the details of algorithms supported by the framework including data preparation algorithms (section 5.2), data analytic algorithms (section 5.3), and visualisation algorithms (section 5.4).
Data preparation
Data preparation is a dominantly important step in a data analytics process. It allows for maintaining data quality, which is a crucial factor in the successful outcome of a data-driven framework. In this framework, the following operations are made available for the data preparation phase:
Missing values handling
Although the data is uniformly structured before transferring into the analytic plane, a considerable amount of missing value may occur, which degrades the quality of the hidden knowledge patterns. In this framework, a variety of missing value handlings are integrated and ready for adopting the analysis pipeline, including data elimination, sketching, and imputation-based methods (Roiger, 2017).
Data normalisation
The purpose of data normalisation is to transform data into the same distributions. It helps to improve the analytic results significantly as it brings equal importance and contribution to every variable during the analysis. The following normalisation methods are available in the framework:
Rescaling: This normalisation (“min-max normalisation”) transforms the mean and the standard deviation of the data to 0 and 1, respectively. More precisely, the transformation is formulated as follows.

Mean normalisation: This normalisation computes and subtracts the average value of every feature of the data input. The formulation is as follows.

where µ is the mean of all data items in the dataset.
Z-score normalisation: This normalisation is also known as standardisation. This method computed as the same process of mean normalisation and the standard deviation is adopted as the denominator:

where σ is the standard deviation of the dataset.
Outlier detection
Another important activity in data preparation is detecting and filtering outliers – abnormal values concerning the normal distribution of the data. In review data, we mainly work with numerical and textual data, and thereby, we integrate outlier detecting operations as follows:
Numerical outlier detection: Numerical values are frequently validated to be in a specific range of values that is suitable for the study (Roiger, 2017). Therefore, to avoid a significant deviation from the expected analytic results, values far exceed or below the typical indicators are identified and filtered out by the numerical outlier detector.
Textual outlier detection: We only consider reviews in English under the conditions of the present study. As a result, textual values that are null or correspond to different languages shall be detected and filtered out by the textual outlier detector.
The output of the data preparation phase after the outlier detection operations is ‘clean data’ with a homogeneous structure and not have outliers or noise data. In addition, the phase shall allow the data to be ready for analytics to find actionable knowledge, which is revealed in the next section.
Data analytics
Data analytic phase plays a central role in our proposed framework. A wide range of state-of-the-art tasks is integrated into the framework, including fake review detection, sentiment analysis, topic modelling, emotion analysis and recommender system.
Fake review detection
Fake review detection methods can be divided into two categories: supervised and unsupervised methods. The former requires a set of label data to differentiate between fake and organic reviews to train a machine learning model, while the latter does not. In our framework, we integrate six state-of-the-art methods belonging to both categories. The details of these methods are summarised in Table 1.
Description of Fake Review Detection Methods.
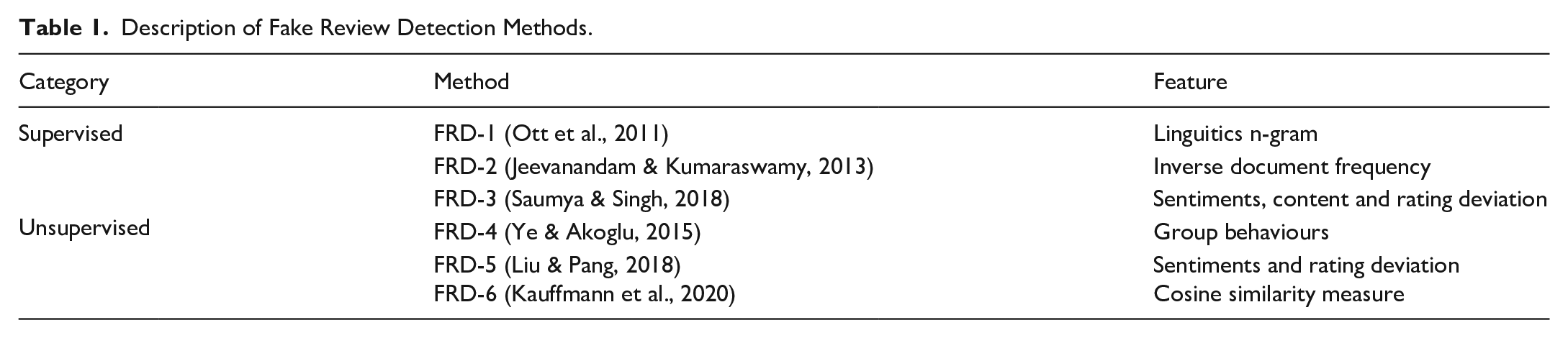
We integrate multiple fake review detection methods into our framework, following the ‘no winner takes all theorem (Bueno et al., 2022). The theorem implies that no algorithm dominates other algorithms in all scenarios. Therefore, SMEs have multiple options for using state-of-the-art techniques, as an algorithm’s selection should depend on the application. Although these integrated algorithms offer state-of-the-art performance, we acknowledge that they have some limitations. Firstly, although these algorithms could yield high accuracy, they lack the declarative information to explain their results due to deep learning techniques’ inherent ‘black-box’ nature. Secondly, they require a relatively large amount of data to train the model; therefore, their performances are affected if we have a small dataset. Finally, their performances are sensitive to the length of distribution of fake reviews. Therefore, besides demonstrating the fake review detecting capability, we equipped our framework with additional analytic tasks that help determine multi-faceted insights and characteristics that distinguish fake reviews from organic reviews, which are revealed next.
Sentiment analysis
Sentiment analysis techniques can be separated into main categories: (i) machine-learning-based and (ii) lexicon-based approach. We integrate three state-of-the-art sentiment algorithms in our framework including two lexicon-based methods and one machine-learning-based method, which are outlined below.
Vader (Hutto & Gilbert, 2014): In Vader sentiment analysis, a ready-built dictionary is leveraged to map lexical features to the intensity level of emotions. Then, we obtain the final sentiment scores by summing up the score of each word in the document.
Textblob (Loria, 2018): Textblob is a Python library that supports many natural language processing (NLP) tasks such as sentiment analysis and opinion mining. It adopts a lexicon-based approach to building a dictionary, matches the words with polarity scores, and averages these scores to produce the final sentiment.
BERT Sentiment (Nemes & Kiss, 2021): BERT is Bidirectional Representation for Transformers, which Google AI proposed. It is prevalent in its capacity to perform different NLP tasks with state-of-the-art accuracy.
Topic modelling
Topic modelling block aims to discover the hidden semantics behind a text document. In this work, we adopt the Latent Dirichlet allocation (LDA; Edison & Carcel, 2021) model, which is a state-of-the-art technique for context-based topic modelling. In addition, we use LDAvis to interactively visualise the modelled topics in which users could explore the content of each topic.
Emotion analysis
Besides extracting hidden topics from online reviews, it is essential to identify emotions embedded in fake and organic reviews. To this end, we integrate the lexicon-based emotion analysis – the research conducted by National Research Council Canada (Mohammad & Turney, 2013) – to discover a wide range of emotion types.
Recommender system
We include in the framework a state-of-the-art collaborative filtering recommendation system (Koren & Bell, 2021) to assess how fake reviews affect business activities in terms of product ranking.
Data visualisation
The previous phase extracts hidden and actionable knowledge from data in a series of values. To provide a clearly condensed representation of this hidden knowledge, a variety of visualisation techniques have been provided in RAaaS to facilitate the illustration, explanation, and communication of results (Kirk, 2016). The output of visualisation techniques shall be both tables and charts. In addition, different charts such as line charts (e.g. showing time series), bar charts (e.g. comparisons among discrete measurements), pie charts (e.g. comparisons among categorical variables) and topic visualisation (e.g. a webpage interface showing topic-to-document distribution and a local view of how words are associated with each topic using LDAvis) can be selected to provide insights according to the results. The visual analytic elements are then grouped into self-service dashboard, which provide the marketing manager a quick understanding of vast volumes of information in an intuitive and real-time manner to facilitate the decision-making process.
Case study: Fraud review detection and understanding
The impact of online reviews has attracted significant attention in the last years, and it is a crucial marketing factor in determining business success. But unfortunately, the ‘phenomenon of fake’ is taking over marketing (Salminen et al., 2022). More precisely, only credible reviews significantly impact consumers’ purchase decisions, while fake reviews are increasingly destroying the trustworthiness of online systems. For this reason, we select the topic of review fraud understanding to eliminate their effects on business activities as a case study to validate the working mechanism and efficacy of our proposed framework. Towards this goal, in this section, we first define how to set up the framework for the case study (in section 6.1). Then we design the analytic flow (in section 6.2) before specifying the algorithm template (in section 6.3) to fit the flow into our framework.
Framework setup
We use two datasets (https://www.yelp.com/dataset) in this study, that is, Yelpchi (67,393 reviews) and Yelpnyc (358,840 reviews), which are the most prevalent datasets for hotels and restaurants reviews. To simulate live platforms, we create two streams of data – each stream for each dataset – and publish APIs for the data retrieval phase. It is worth noting that although two datasets are employed in this study for demonstration purposes, the framework is quick to extend to additional data sources (if required).
Case study design and analytic flow
With the desired outcomes, this section requires defining the analytic flows and their sequential executions to achieve these goals. The process flow for the case study of fake review detection and understanding is presented in Figure 2. In the flow, we see that, in the analytic zone, we can define the necessary analytic steps together with their execution orders. We start with the fake review detection task to assess the detection accuracy, and then various analytic tasks are applied to understand the characteristics of fake and organic reviews. The mappings between outputs of each analytic task and a specific visualisation shall be specified in the visualisation zone.
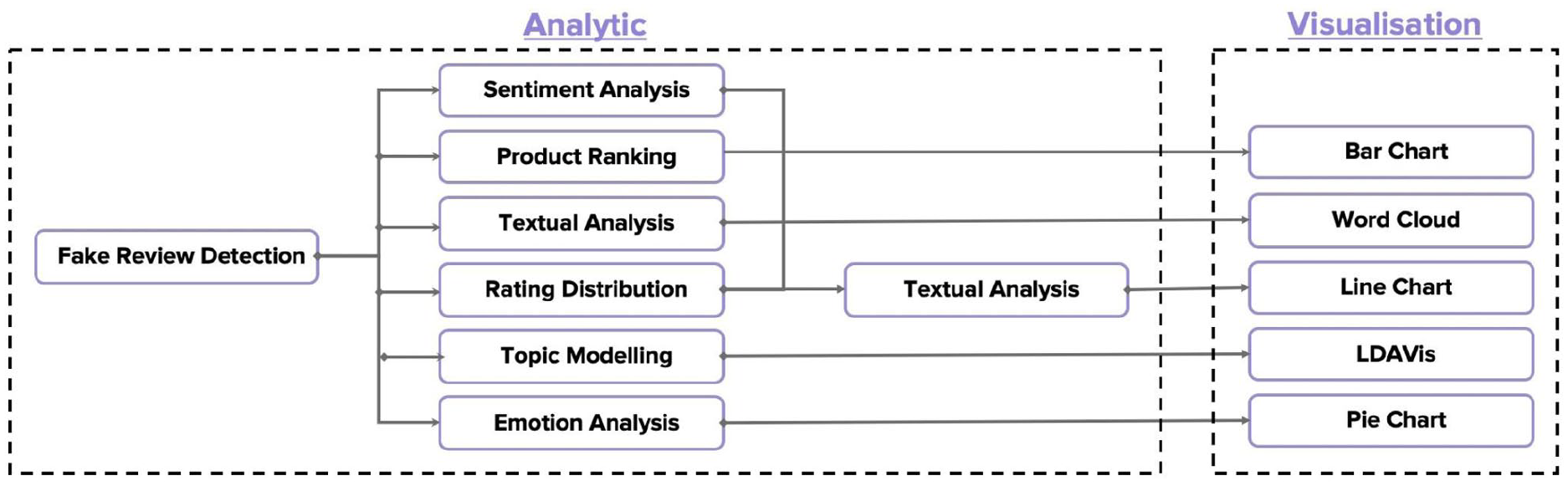
The analytic flow for the case study.
The definition of the algorithm template
As outlined below, an algorithm template needs to be defined using the extensible markup language (XML) to realise the analytic flow.

The template is made available with the framework, and therefore, it is quick for non-analytic experts to modify to fit with different flow and analytic intents. In addition, the tag names associated with the template are straightforward and easy to understand. For example, users can change the data input for analytics by changing the value property (line-10) or mapping to other dataset fields and types (lines 11–17). Considering the data preparation step, users can select which preparation algorithms to apply by including or excluding a task in the task list (lines 23–27). The necessary analytic steps (lines 30–43) and visualisation steps (lines 44–52) can be specified similarly using the task list. Finally, the chronic order of executions shall be defined using a connection tag (lines 53–58). It is worth noting that we omitted some repeated tags in the template due to brevity; however, the whole template will be recovered quickly based on the sequence activities of the analytic flow (as presented in Figure 2).
Results
This section discusses our main findings. Section 7.1 and section 7.2 provide the answer for RQ1 and RQ2, respectively. The remaining sections (7.3–7.6) reveal multifaceted insights between fake and organic reviews and support the answer for RQ3.
Fake review detection
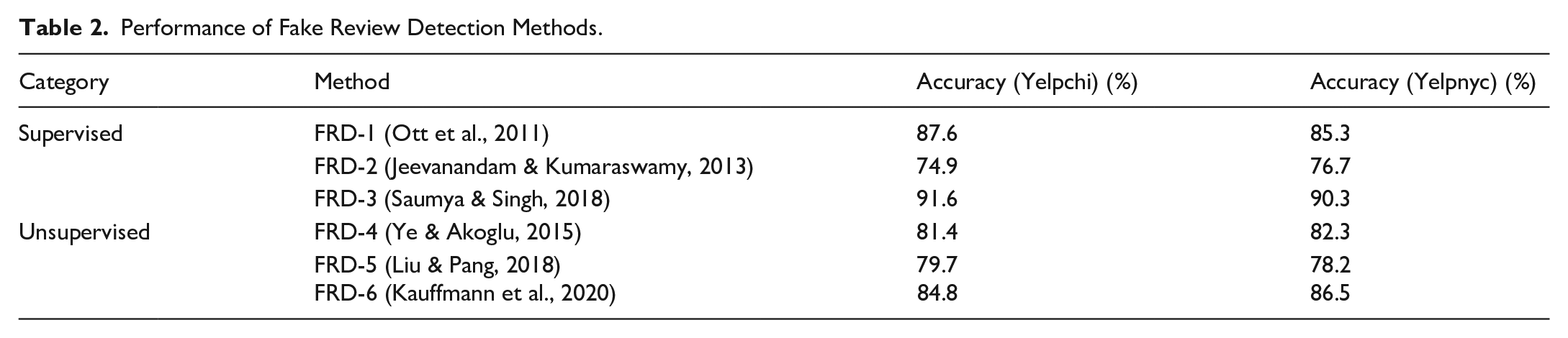
To answer for the RQ1, we evaluate the accuracy of contemporary fake review detection methods, and the results are presented in Table 2. Overall, we see that FRD-3 achieves much higher accuracy compared to other methods over all datasets. These results are consistent with prior works (Kauffmann et al., 2020), and this improvement originates from the combinations of detecting features, including sentiments, content and rating deviation. In addition, the performance of supervised methods is better than unsupervised methods in general. The difference in performance might result from the feature sets that each method uses in its implementation. The subsequent sections dive into the discrimination of each feature which provides a better understanding of the accuracy of detection methods.
Performance of Fake Review Detection Methods.
Exposure rate
This experiment aims to answer for RQ2 of how fake reviews affect business activities. To this end, we employ a recommender system and compare how product ranking changes with and without the existence of fake reviews in the online system. In line with previous research such as Kauffmann et al. (2020), it is revealed that the ranking of the top-10 products with the most reviews is shown in Figure 3. The key finding is that fake reviews can successfully promote a target item to a hit rate (i.e. visibility score) of up to 2.6%. In addition, there is a consistent increase in the product ranking with the existence of fake reviews in the system. The result demonstrates significant adverse effects on the reliability and trustworthiness of business providers.
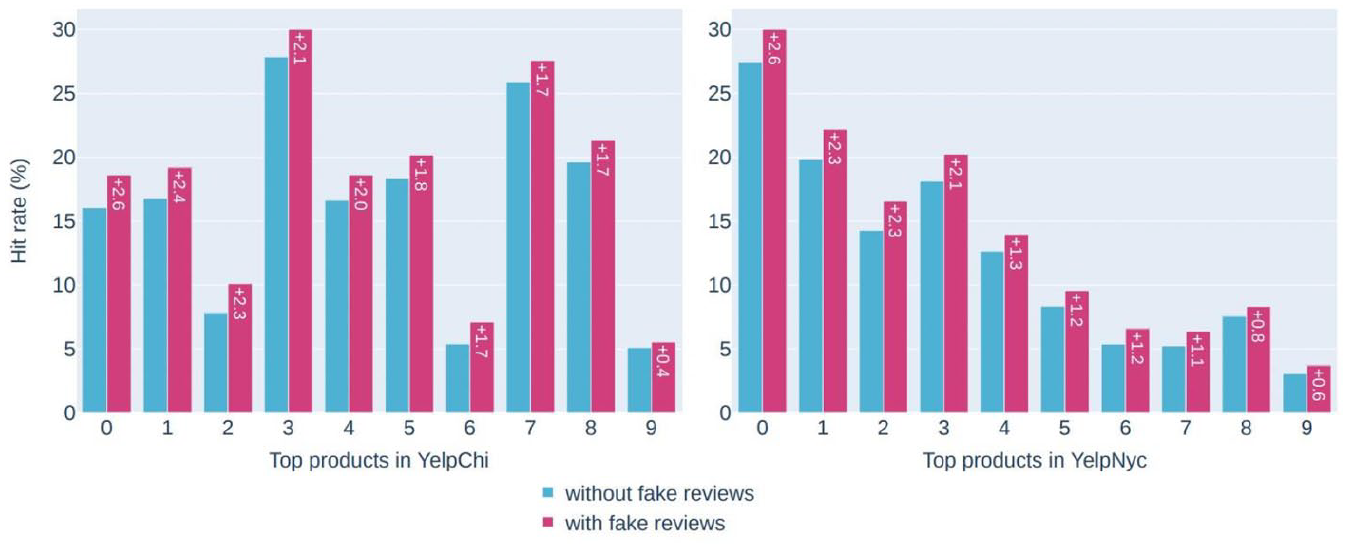
Exposure rate.
Sentiment analysis
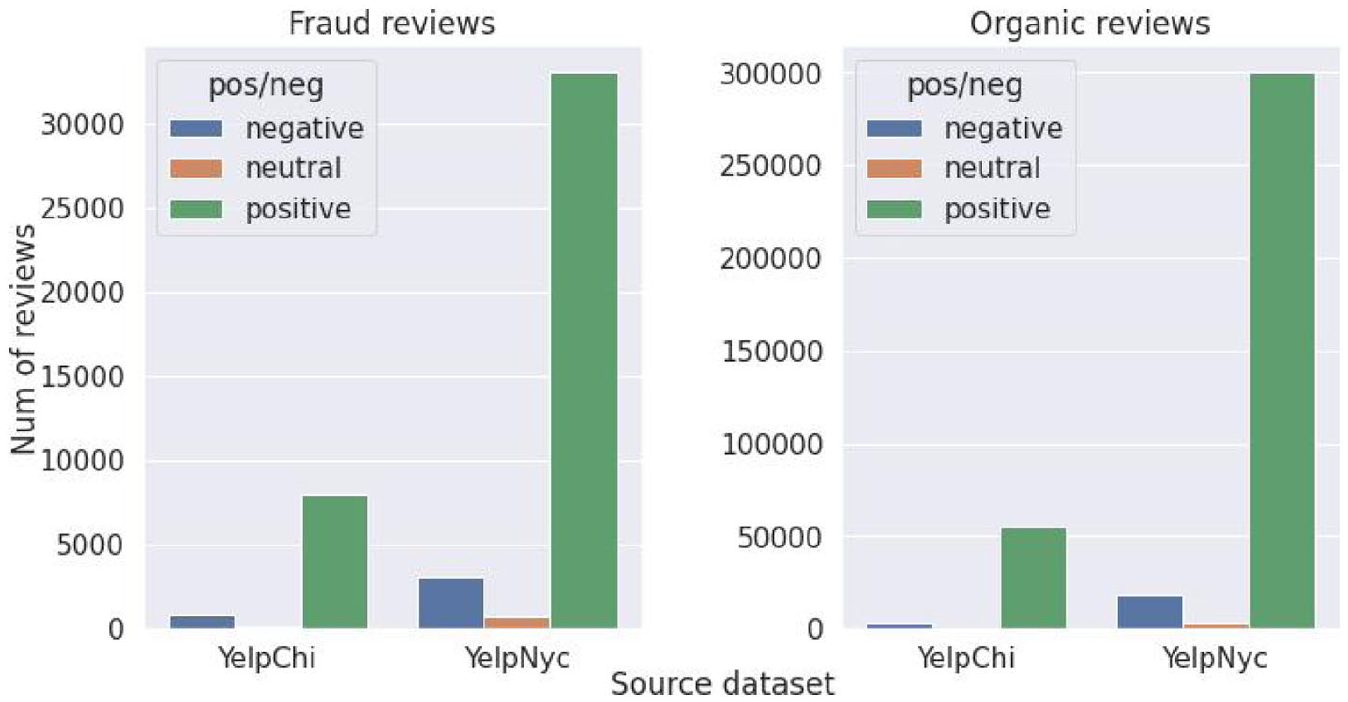
In this experiment, we apply sentiment analysis to understand the sentiment characteristic between fake and organic reviews, and the results are presented in Figure 4. The sentiment distributions between fraud and organic reviews are different but not significant. The reason could be that review texts recently have been generated by an AI-powered tool (Kreps et al., 2022) that mimics the actual data distribution rather than being written by a human. That is the reason why sentiment features are not sufficient for fraud review detection, and state-of-the-art approaches combine with other features such as rating distribution (Liu & Pang, 2018) or textual features (Saumya & Singh, 2018) to achieve competitive performance.
Sentiment analysis.
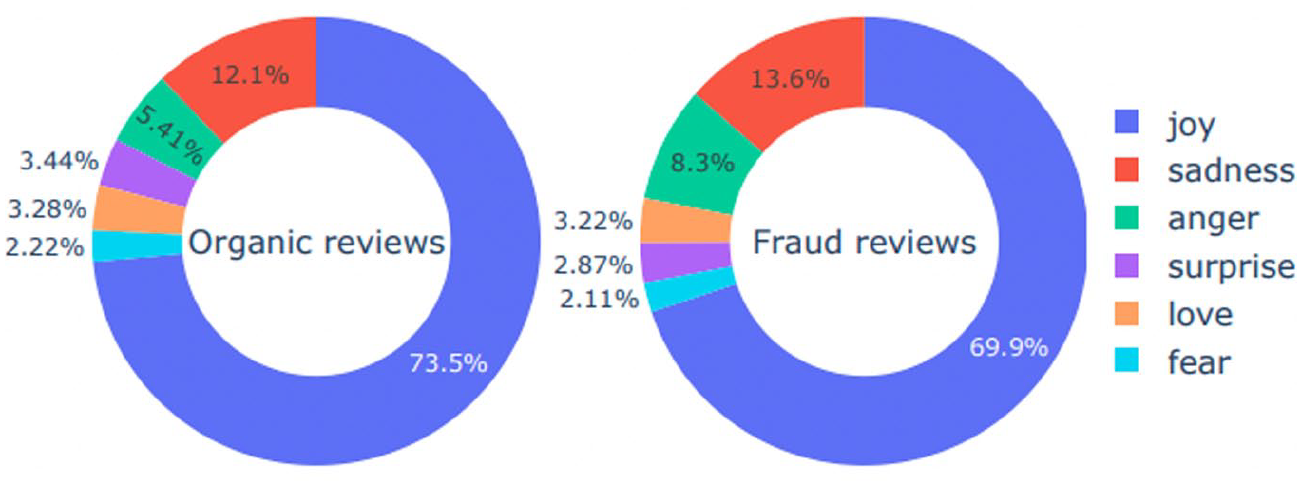
We further compare and contrast fake and organic reviews on six discrete emotions (i.e. joy, sadness, anger, surprise, love, fear), and Figure 5 shows the results.
Emotion analysis (Yelpchi).
Joy is the dominant positive emotion in fake and organic reviews. The second and third dominant in common is negative emotions – sadness and anger. Interestingly, the concentration of all two types of negative emotions is higher in fake reviews than in organic reviews. Our findings of sadness and anger are consistent with prior works as fraudsters adopt fake reviews to depromote competitors’ products and services (Luca & Zervas, 2016; Munzel, 2016). Different from previous research, which predominantly focuses on the level of positivity and negativity and overlooks the presence of specific emotions (Kauffmann et al., 2020; Luca & Zervas, 2016), our study shows that the detection of such discriminative features is essential for future explorations about developing fake review detection. Finally, we found that surprise, love, and fear are the least common emotions and have no significant concentration difference between the two types of reviews.
Textual analysis
In this section, we aim to understand the content characteristics of fake and organic reviews. To this end, computerised textual analysis is performed, and the results are presented in Figure 6. An interesting observation is that fake reviews tend to be shorter than organic reviews. Despite being shorter in length, prior research (Bilgihan et al., 2016) indicates that fake reviews that use complex language to demonstrate a high level of expertise may be perceived as credible. We will verify this finding in section 7.5 when we analyse text at the word level. Due to the difference in length, fraud reviews’ distribution is more diverse than organic reviews. This finding supports why the method that employed content as detecting features achieves higher detection accuracy (Saumya & Singh, 2018).
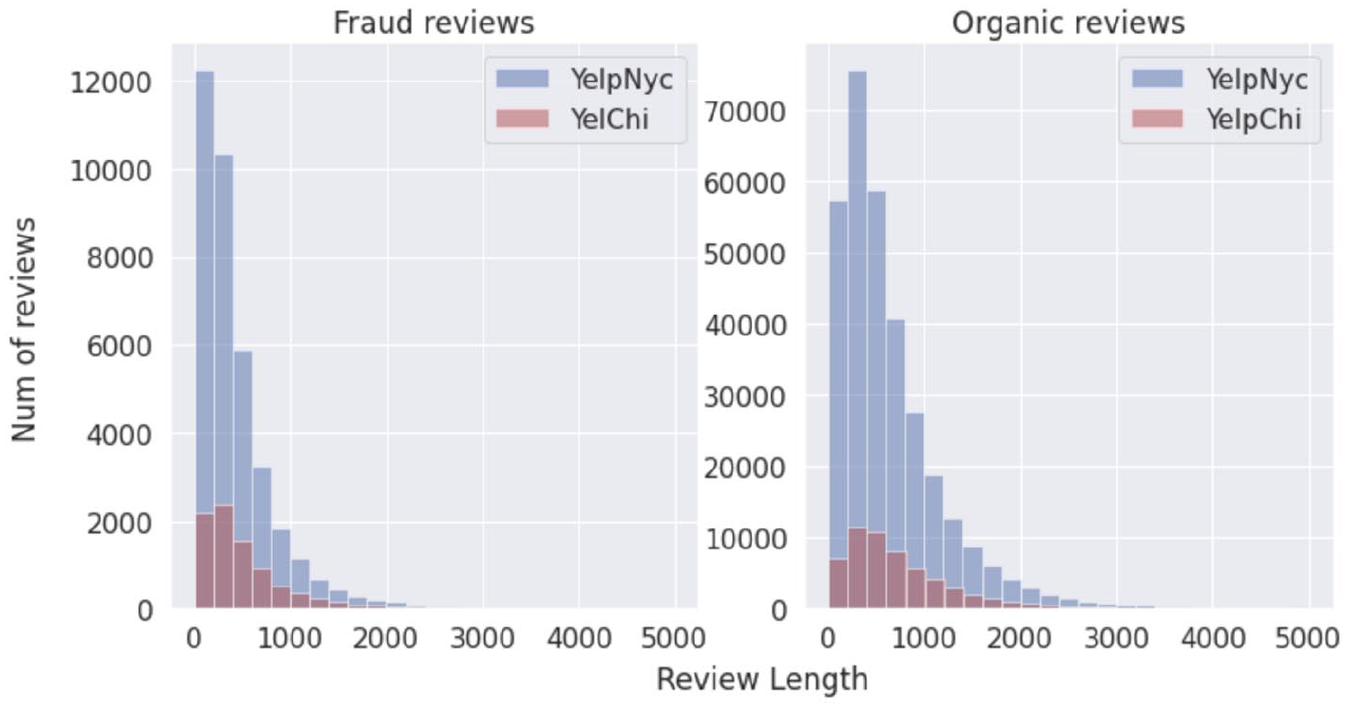
Textual analysis.
As the framework enables the capability of a hierarchy analysis, here we present the result of textual analysis in a sequential order – rating distribution first and then performing the textual analysis. The results are illustrated in Figure 7. We see a decrease in the review view length when the rating score increases. However, the length of the fraud review (versus organic reviews) is consistent with the previous findings.
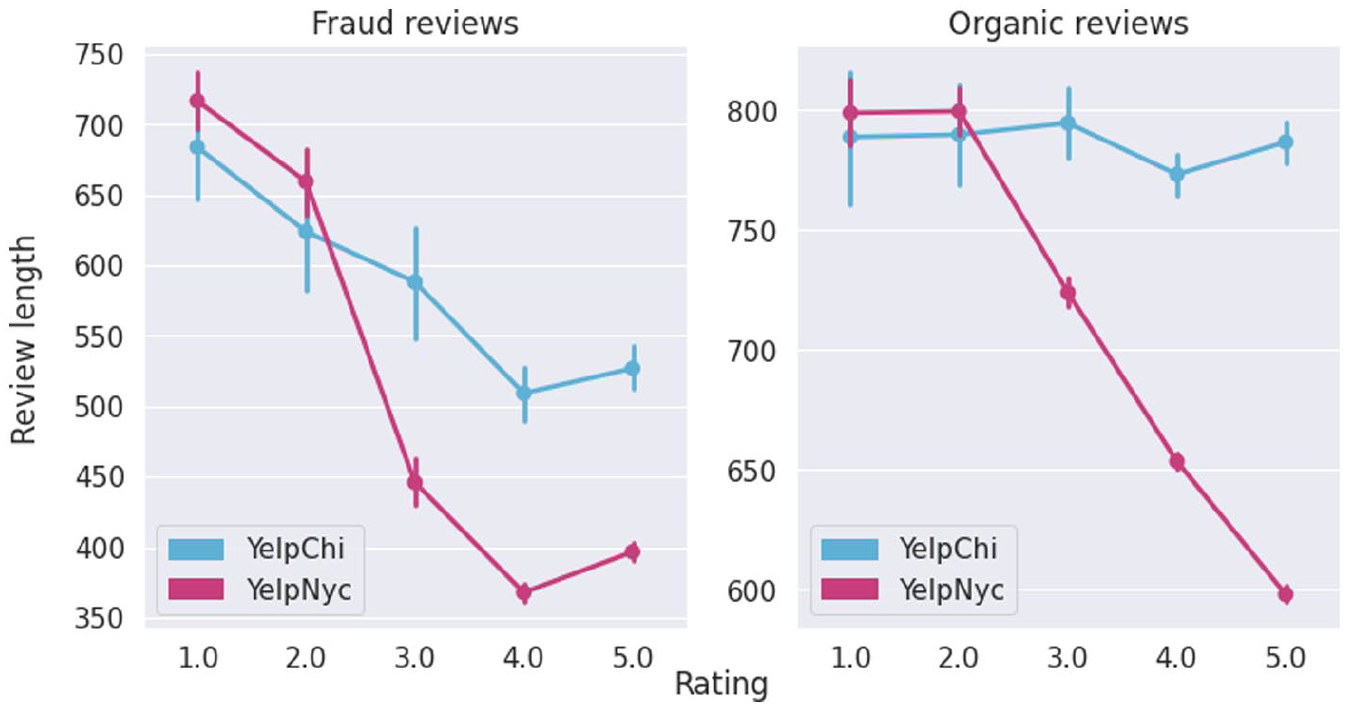
Hierarchy textual analysis.
Word cloud/Qualitative analysis
This experiment provides a closer look into the review content – the word level. The word cloud analysis between fake and organic reviews is presented in Figure 8 for the Yelpchi dataset (findings on Yelpnyc are discarded as they reveal the same characteristics). An interesting finding is that although both reviews employ favourable terms such as ‘good’ and ‘well’ to express a positive comment on goods or services, fraud reviews tend to use strong adverbs such as ‘really’ and ‘great’ to emphasise the emotions. Future lexical-based fake review detections could take advantage of such discriminative features to improve the detecting accuracy.
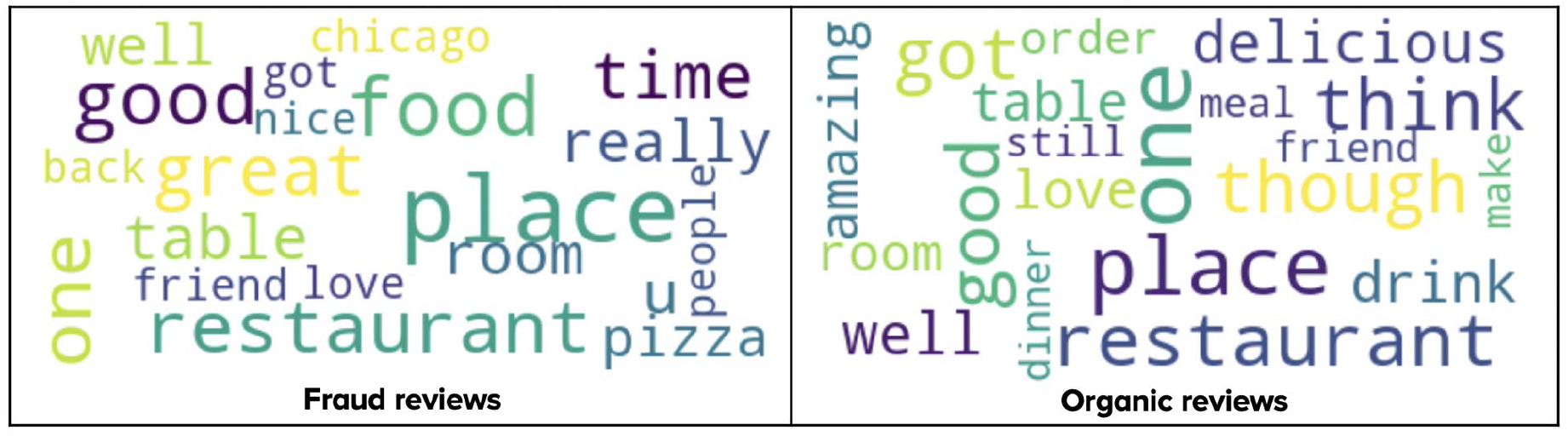
Wordcloud analysis.
Topic modelling
To investigate the difference between fake and organic reviews in terms of hidden topics, we extract the six most dominant topics in online reviews, scaling them into two-dimensional space where PC1 and PC2 are the two principal components (Abdi & Williams, 2010) of the topics, and visualise them using the LDAVis chart in Figure 9.
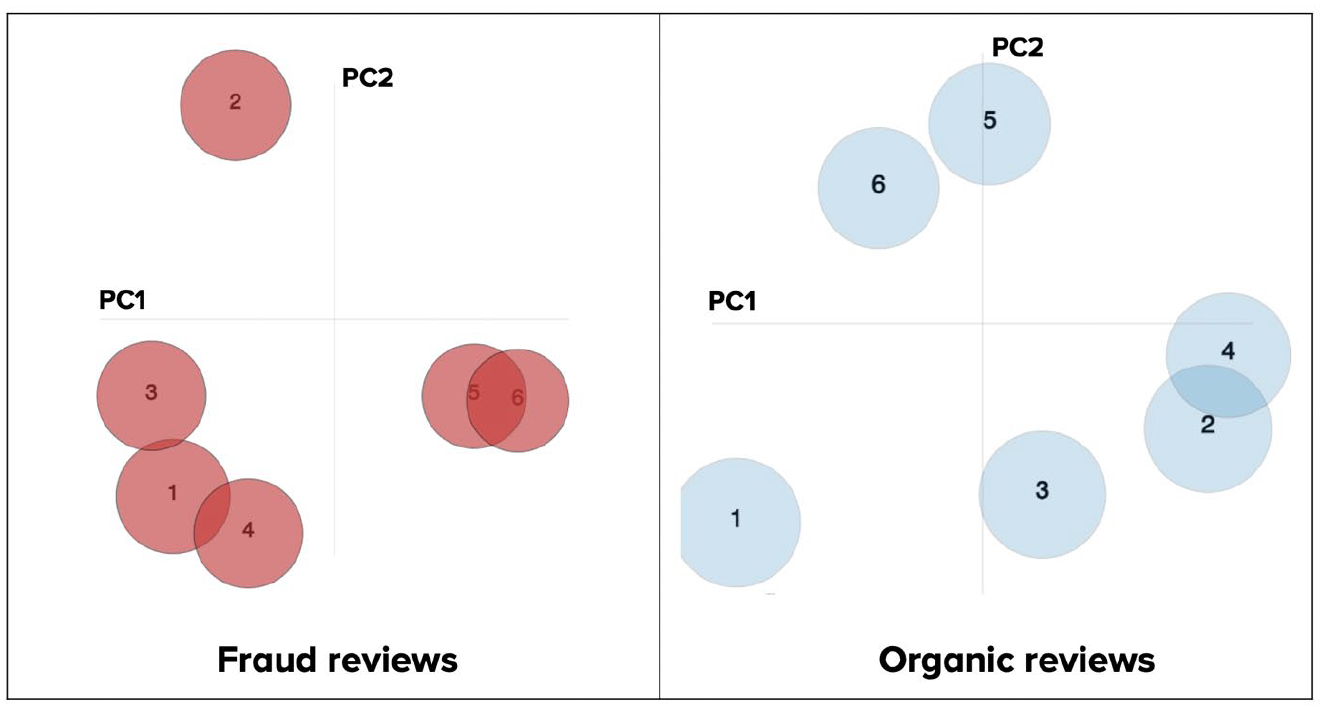
Inter-topic distance map of topic (Yelpchi).
The results reveal an inter-topic distance map of topics on the Yelpchi dataset (the result of the remaining dataset is omitted as it exposes the same trend). Each circle represents each topic, and circle size denotes the popularity of those topics in all review content. The distance between two circles represents the similarities of two hidden topics, and a closer distance suggests a more substantial level of similarity. The critical observation is that the spatial distribution of most popular topics reveals a high contrast between fraud and organic reviews. For example, the most similar topics in fraud reviews are topics 5 and 6, while the most similar topics in organic reviews are topics 2 and 4. Future works on fake review detection and understanding could consider this discrimination in terms of topic spatial distributions to improve the detection capability.
Discussion
Online reviews are an important source of information that can influence customer attitudes and purchase behaviour (Salminen et al., 2022). The reason is that prospective customers like to learn from former customers’ experiences before deciding to buy a product (Robertson et al., 2021). Due to the advent of the Internet and the openness of online review platforms (Schindler & Decker, 2013), customers are increasingly sharing their experiences through online reviews (van Esch et al., 2018). Because most customers consult online reviews before engaging with a brand, enterprises must understand their customer’s experience to make any necessary changes. On the other hand, fake reviews have become a significant concern in eroding the credibility of online review systems (Luca & Zervas, 2016). Fake reviews send the wrong message to legitimate enterprises and customers, which can distort the ranking system, resulting in negative consequences for genuine organisations, which has been pointed out in prior literature (He et al., 2022). Therefore, it is crucial for enterprises to understand what authentic customers say about their experiences, and how fake reviews could harm a brand’s reputation.
Studies on fake detections have gained significant attention in recent years to prevent the adverse effects of fake reviews on society (Mohawesh et al., 2021). The motivation behind these approaches is to eliminate the societal impact caused by fake reviews on the fair-trade environment. Because the significance of fake reviews grows, the prevalence of fake reviews written to appear authentic and informative is increasing, weakening consumers’ trust (Moon et al., 2021) in online reviews. Fraudulent reviews do not necessarily reflect the genuine opinion of consumers because they create a wrong impression about products or services. This causes consumers to make poor or incorrect decisions. The dissemination of misleading information has a detrimental effect on social behaviour (Javed et al., 2021). In recent years, many fake review detections have been proposed (Mohawesh et al., 2021) to prevent the negative impacts and restore the consumers’ trust.
However, deriving customer insights from online reviews and detecting false reviews required a complicated procedure that goes beyond the capability of SMEs (Kauffmann et al., 2020). To fill the gap, we design a framework that SME marketers can use for detecting and understanding fake reviews. To facilitate online review data analytics, the framework achieves cost-effectiveness by enabling the pay-as-you-go analytic schema (Hung et al., 2019; Nguyen et al., 2020) and can be handled by non-data specialists. Using a case study, we answer the research questions relating to the differences between fake and organic reviews and investigate their differences in multi-perspectives. Using six major summary dimensions (i.e. exposure rate, sentiment, emotion, textual characteristics, word cloud and topic modelling), the analytic results suggest significant differences between fake and organic reviews. Regarding detecting fake reviews, we found that modern detection techniques can identify fake reviews with high accuracy, while the performance of supervised methods is generally superior to that of unsupervised methods. The key finding regarding exposure rate is that fake reviews can effectively promote a target item to a hit rate (i.e. visibility score) of up to 2.6%. Not surprisingly, there is a consistent increase in the product ranking with the existence of fake reviews in the system, which is in line with previous research (Kauffmann et al., 2020).
The substance of the content of these online reviews is of tremendous relevance. Using computerised textual analysis, key differences between fake and organic reviews were found. For sentiment analysis, we discovered that the distributions of sentiment between fraudulent and organic reviews are distinct but not statistically significant. The reason could be that recent reviews were generated by an AI-powered technology that matches the actual data distribution (Bakpayev et al., 2022; Feng et al., 2021). For emotional analysis, by extending prior research that primarily focuses on the level of positive and negative sentiment (Kauffmann et al., 2020; Luca & Zervas, 2016), we put attention on the existence of specific emotions in the texts and highlight the higher concentration of sadness and anger in fake reviews compared to organic reviews. As seen in the textual analysis, it is also found that fake reviews tend to be shorter than organic reviews. Despite being shorter in length, previous work (Bilgihan et al., 2016) suggests that fake reviews employ complicated language to demonstrate a high degree of knowledge that may be viewed as credible. To verify this argument, we further look into the details of word cloud, and the finding is consistent – fake reviews tend to make use of strong adverbs. Finally, regarding the topic modelings, fake reviews have different patterns in terms of spatial distribution and correlation among the hidden topics. This finding is in line with recent works (Birim et al., 2022; W. Zhang et al., 2022) that employ topic distributions as features for fake review detection.
Research implications
Our study’s primary research question is how to harness the critical values of big data and create a proactive platform for non-data specialists to initiate massive review analytics jobs. Besides, we aims to response to additional research questions: Can review fraud be automatically detected? How do review frauds affect the product ranking system? What are the differences between fake and organic reviews? The analysis outcomes from computerised textual analytic of more than 400,000 online reviews reveal that fake reviews can be detected with high accuracy by contemporary techniques, the product ranking with the existence of fake review can be biased, and that fake views and organic reviews differ substantially. While we explored the findings of the study in the previous section, we here discuss the implications for marketing theory and practise.
Theoretical implications
As this research aims to propose a cost-effective cloud-based framework for online review analytics, the results of this study will enhance the cloud computing theory (Marinescu, 2022) with practice in marketing. In addition, we demonstrated our framework in a case study on fake review detection and understanding, offering additional important implications to marketing theory. First, marketing-specialised data analytic frameworks have been widely adopted in achieving a variety of marketing goals, including optimal budget allocation (Yang et al., 2022), maintaining corporate reputation (Rantanen et al., 2019), maximising sales revenue and profit (Quach et al., 2022). These optimisations are based on the positive and authentic sides of data (e.g. how to create value from customers’ positive feedback). However, we argue that exploring the other side of the coin – also known as the ‘phenomenon of fake’ – raises an equally important concern. Rather than maximising a marketing goal, a critical research question has been raised: how to minimise the value destruction caused by contemporary technology capabilities? Our study is situated in this context, exploring a specific case of review fraud understanding and alarming the negative impacts on business activities. Extending research on review fraud (Choi et al., 2017; Lee et al., 2022; Salminen et al., 2022), our study is among the first to propose a low-cost, automatic cloud-based framework for reviewing fraud detection and understanding at scale in marketing, which is crucial to scalable information processing theory (Z. Wang et al., 2015). Second, by looking beyond fundamental aspects such as positive versus negative sentiment (Kauffmann et al., 2020; Luca & Zervas, 2016), our findings provide important insights into the impact of review fraud and the characteristics of fake reviews, thereby laying the foundation for developing countermeasures against such fraudulent activities. Although we are not the first to address this concern as it has been highlighted and investigated in recent works (He et al., 2022), we go beyond existing literature by providing a deep understanding of fake reviews with multi-faceted insights. Finally, considering the framework’s extensibility, it can be adopted as a basic framework for future analytic tasks or even a future domain such as social feedback (McIntyre et al., 2016), customer engagement (de Ruyter et al., 2018; Ng et al., 2020), and recommender system (Koren & Bell, 2021; Toan et al., 2018). The proposed framework can act as a trigger for forthcoming studies, therefore promising to enhance knowledge in machine learning and AI theory in marketing (Ma & Sun, 2020), specialised for fake review detections.
Practical implications
Although this study’s goal is to benefit SMEs in applying review analytics to monitor their brand reputation and customer experience, this study also benefits different stakeholder groups. In this section, we outline substantial practical implications for these stakeholders that are the potential to utilise RAaaS as a core.
SMEs
From the study, businesses, especially SMEs who are constrained by limited financial and technological resources, are encouraged to adopt this framework to monitor their customer’s online reviews on a regular basis. This practice is essential as review fraud may quickly escalate into a crisis for a brand’s reputation without proper actions (He et al., 2022). Additionally, by understanding the importance of benign reviews and their characteristics, businesses should develop a rewarding programme for their customers willing to contribute their benign reviews to the system. That way, customers shall be encouraged to submit online reviews to increase their loyalty and motivate satisfaction. Businesses should adopt the framework to be transparent about who leaves online reviews, so future customers can see who wrote what – based thereon, the transparency in the processing of online reviews contributes to an essential characteristic for building customer trust.
Review platforms
Reviews platforms are the central stadium that connects buyers and sellers through online reviews. This framework can benefit review platforms in improving the timeliness of reacting to fake behaviours, as eliminating review fraud is central to maintaining transparency and creditability. The reason is that review platforms are in the best position to fix the phenomenon of fake in the online review ecosystem, and they can leverage the framework as a tool to tackle it. The framework can be used to filter out suspicious reviews and suspend or delist companies that exploit fake reviews to manipulate public trust. They can enhance the efficiency of the framework in multiple aspects. For example, platforms should provide simple, effective, and meaningful tools for individuals and legitimate businesses to report fraudulent reviews. Additionally, they can improve the fake review detection technology by hiring more people to label wrong actions and fraud patterns to produce more quality data for training the algorithm. Finally, they can provide more access to the outside research community to explore and enhance the capability of detecting emerging fake patterns to restore the customer’s trust.
Customers and society
Fraudulent reviews are characterised as misbehaving customer action that violates socially acceptable norms of conduct (Sigala, 2017). These actions have been assessed as potentially generating psychological or physical harm to society. A recent study (Sigala, 2017) emphasises the potential adverse consequences of untruthful reviews on SMEs and their societal impact situation. The widespread utilisation of cloud-based frameworks for fraudulent reviews monitoring will assist in consumer protection. Additionally, the characteristics and a deep understanding of fake reviews can be used to educate customers about the existence of review fraud (Anderl et al., 2016) and its influence on their purchasing decisions. Thus, consumers’ trust will be re-gained, and they will be more likely to utilise these platforms or businesses more consistently.
Conclusion, limitations and future research directions
In this paper, we propose RAaaS – a Review-Analytic-as-a-service framework that specialises in big data analysis and understanding reviews, to facilitate the marketing decision-making process for but not limited to SMEs, review platforms and customers. With the concept of marketing-specialised algorithm template, the framework enables non-data specialists to involve in a complex data analytics process to derive customer experiences from online reviews to facilitate brand engagement. Although the present study provides crucial implications, we acknowledge several limitations that can be considered in future works. The primary limitation of our work is the absence of online reviews written in other languages rather than English. It would be crucial for future research to incorporate our findings in the multi-lingual analysis. Another limitation includes the lack of understanding of review fraud under the propagation time perspective and the correlations between propagating time series. Motivated by the recent success in employing time burst characteristics for fake review detection (N. Wang et al., 2022), we intend to combine multivariate time series representation with graph neural networks (Wu et al., 2020) to perform time-series analysis to discover additional insights in a future study.
Our study also calls for promoting interdisciplinary research to reduce the spread of fake reviews and to address underlying damages they have uncovered. One important finding in our work is that fake reviews can successfully promote a target item to a hit rate (i.e. visibility score) of up to 2.6%. Given the potential impact, it may be prudent for digital marketers to respond first to reviews that are suspected of being fraudulent. Businesses are strongly encouraged to scrutinise and be on top of how customers express their experiences and proactively respond to the case when fake reviews are discovered.
Footnotes
Author’s Note
Vinh Khiem Tran is also affiliated to Vietnam National University, Ho Chi Minh City, Vietnam.
Sara Quach and Park Thaichon is now affiliated to Griffith University, Brisbane, QLD, Australia.
Bay Vo is now affiliated to HUTECH University, Ho Chi Minh City, Vietnam.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.