
Abstract
Thermal comfort is a critical determinant of human health, well-being and productivity, and is also integral to promoting energy efficiency. The predicted mean vote is the most recognized method for estimating the average thermal experience amongst a group of individuals within built environments. However, the method's reliance on climatic parameters that are difficult and resource-intensive to measure, as well as physiological parameters that require self-reporting, introduces significant practical limitations for real-world applications. The present work aims to address these limitations by proposing a lightweight predictive framework for effective, streamlined thermal comfort classification that relies on a reduced input feature space comprising the easy-to-measure and low-cost climatic parameters of air temperature and relative humidity, and the seasonal standardized approximation for the physiological parameter of clothing insulation. Leveraging an ensemble learning architecture with random forest, k-nearest neighbours, CatBoost and multi-layer perceptron as weak learners and logistic regression as a meta-learner, the proposed framework demonstrated an overall predictive accuracy of 85.8% in estimating the average thermal experience. It adequately handled the class imbalance across thermal discomfort states, particularly those underrepresented, further underscoring its robust performance. The proposed framework could emerge as a scalable and efficient approach for estimating thermal comfort in real-world applications.
Introduction
With modern people spending almost 90% of their time indoors, including residential settings, workplaces and offices, educational institutions and commercial facilities, ensuring comfortable indoor thermal environments emerges as a cornerstone for advancing health, well-being, productivity and promoting energy efficiency.1–2 Thermal comfort is defined as a state of mind that expresses an individual's satisfaction with the prevailing thermal conditions in ambient environments. 3 Besides the profound influence of climatic conditions on shaping this subjective experience, the intricate interplay of physiological, psychological, behavioural, socio-economic and demographical determinants also affects thermal perception.4–6 While these inherent human determinants could serve as valuable predictors for a more precise and human-centric thermal comfort assessment, the conventional thermal comfort approaches omit them, concentrating instead on parameters obtainable through sensing devices or are minimally intrusive for self-reporting. 7
Prior research studies have underscored thermal comfort implications on physical and mental health, cognitive function and well-being. Thermal discomfort has been associated with adverse health effects, such as accelerated respiration and heart rate, aggravated skin disorders and increased stress levels and depression.8–9 Ensuring comfortable thermal spaces in offices and workplaces could result in substantial productivity improvement, lower fatigue, enhance job satisfaction and long-term organizational efficiency.10–11
In 2022, the average household across the EU allocated almost 65% of the total annual energy consumption for cooling and heating purposes emphasizing the vital connection between thermal comfort and energy efficiency in the residential sector.12–13 Informed, proactive management strategies for optimizing the operation of heating and cooling systems under the dual objective of minimizing energy costs while maintaining comfortable thermal environments for occupants constitutes a prominent research area that bridges the gap between theoretical thermal comfort models and real-world applications. Incorporating thermal comfort as a constraint in energy optimization frameworks, such as the day-ahead scheduling of household loads and appliances, and tariff adjustments in dynamic electricity markets, holds a promising potential to advance collective sustainability goals and alleviate energy poverty.14–17 Furthermore, the thermal comfort optimization is integral to sustainable building design, employing smart technologies and digital solutions to respond in the face of varying outdoor environmental conditions, thereby contributing to climate resilience.
To date, researchers have proposed numerous models, methods and frameworks for thermal comfort assessment in built environments, spanning from straightforward empirical approaches dedicated to capturing average thermal experiences to advanced and adaptive approaches oriented towards personalization. No single approach can be considered superior, as each distinct approach entails specific strengths and limitations. Instead, they should be evaluated based on the trade-off between predictive gains, computational overhead and model complexity in response to the specific application's requirements and context. Even simple models relying on the fundamental climatic parameters of air temperature and relative humidity can deliver adequate predictive performance under relaxed thresholds in thermal comfort assessment. Incorporating more complex, refined climatic parameters, such as air velocity and mean radiant temperature, could further enhance predictive performance. More advanced modelling approaches for thermal comfort also consider subjective personal characteristics such as physiological, psychological and behavioural, tolerance and preferences with respect to the thermal conditions, and demographics such as gender and age.18–19
The most widely recognized and adopted model in thermal comfort studies is the predicted mean vote (PMV), introduced by P.O. Fanger in 1970.20–21 This model produces an index ranging between
Despite the widespread adoption of PMV model in thermal comfort studies, it operates under the assumptions of stable thermal environments and steady-state occupants’ response to environmental conditions that constrains its effectiveness in practical applications when these assumptions do not hold for the examined environment. Lack of personalization represents another critical limitation of the PMV model, as it overlooks the idiosyncrasies and stochasticity inherent in human nature that give rise to diverse thermal responses instead of a uniform average one amongst a group of individuals. The standard effective temperature (SET) model developed by Gagge et al.
23
in 1980 aimed to provide a more physiologically-oriented estimation for thermal comfort extending beyond the traditional PMV approach by quantifying thermal comfort based on a heat balance model of the human body. This model expresses the temperature of a standard reference room, i.e., a room under the assumptions that the relative humidity is
While both PMV and SET models have advanced the mechanistic understanding of human thermal comfort, their reliance on steady-state assumptions, population averages and hard-to-measure physiological parameters limits their practical usage in real-time and personalized applications. To address these limitations, data-driven approaches have been proposed, compensating for these shortcomings by directly learning the intricate, nonlinear relationships between environmental, physiological, psychological, behavioural and other contextual variables in response to subjective thermal experiences. Such methods enable: (i) real-time inference using sensed information and data streams; (ii) personalization by incorporating individual-specific characteristics or and human feedback loops; and (iii) adaptability as models can be retrained or adjusted to account for the temporal and contextual variability in the ambient environment. This mechanistic-to-data-driven transition emerges as a promising pathway towards more precise, scalable and human-centric assessment of thermal comfort in dynamic built environments.
Recent advancements in artificial intelligence (AI) and machine learning (ML) have transformed the thermal comfort domain shifting from static, model-driven approaches to data-driven, adaptive ones.24–25 These methods leverage advanced modelling paradigms and algorithms to process large volume of sensed data collected from the humans surroundings, enabling personalized recommendations, optimizing the operation of cooling and heating systems, and reinforcing energy efficiency objectives. The integration of AI-enabled thermal comfort models into Building Management Systems emerges as a promising pathway to enhance occupants’ satisfaction while achieving substantial reduction in energy and operational costs, and advance sustainability through predictive modelling and intelligent decision-making. 26 Additionally, these systems can facilitate long-term climate adaptability, making buildings more resilient to environmental fluctuations and contributing to broader energy conservation goals. 27
The selection of PMV as the underlying thermal comfort model for the presented study was grounded in three main pillars. First, the PMV is a benchmark model confined to international standards and guidelines and the most widely used in prior research studies, which ensures that the results from the present study are compatible with recognized frameworks in the thermal comfort domain and comparable with prior research works. Second, the PMV is incorporated as an easy-to-obtain input parameter or is reasonably estimated from measurable ones unlike approaches relying on subjective, behavioural or psychological personal characteristics. Third, the PMV model is more flexible and generalizable compared to adaptive and human-oriented ones, thus serving as a cornerstone for integration with ML and optimization frameworks in real-world applications.
The motivation behind this approach was to deliver a lightweight and cost-effective predictive framework for PMV estimation, which formulated as a classification task adhering to the mapping of PMV index to discrete thermal sensation states as expressed in ASHRAE 55 standard. This framework leverages a reduced input space compared to the one used in deterministic PMV approach, including climatic parameters that are easy and readily measurable without requiring any specialized or costly instrumentation along with an estimation for the physiological parameter of clothing insulation with a minimal trade-off in predictive accuracy.
The main contributions of the presented study are summarized as follows: Undertaking a comprehensive sensitivity analysis on the deterministic PMV model to reveal the most influential climatic and physiological parameters through assessing linear and non-linear dependencies, monotonic relationships, information-sharing metrics and ensemble-based permutation importance. Implementating a hyperparameter optimization and a performance evaluation for random forest (RF), k-nearest neighbours (kNNs), CatBoost and multi-layer perceptron (MLP) weak learners in classifying PMV into thermal comfort categories under a reduced input feature space. Proposing a stacked ensemble learning model in which a logistic regression (LR) meta-learner aggregates the predictions of diverse weak learners, yielding an accurate and reliable thermal comfort classification of
Literature review
This section presents prior research findings and conclusions from studies with similar scope and objectives as the present work. Particular emphasis was placed on the research outcomes concerning the most critical and influential determinants for data-driven estimation of thermal comfort along with the predictive performance attained from different ML classification models and algorithms. This exploration informed the present work with valuable insights on effective methodological approaches for indirect, data-driven estimation of thermal comfort and allowed the comparison of the predictive outcomes from the present with those attained earlier.
Most studies identified climatic conditions as the dominant factors influencing thermal comfort when data-driven approaches are applied in mechanically ventilated built environments, with the air temperature, relative humidity, airspeed and solar radiation emerging as the most critical ones. 28 These findings are consistent with PMV model that incorporates a similar set of climatic parameters for thermal comfort estimation. In naturally ventilated built environments, outdoor climatic conditions of air temperature and relative humidity also affect the occupants’ thermal experience underscoring the importance for incorporating outdoor conditions as additional predictors in thermal comfort models. 29 Doing so offers a more nuanced understanding on the cumulative effect of external climatic conditions on thermal comfort levels, enabling a more comprehensive and holistic approach on estimating thermal comfort. Also, demographic attributes such as age, gender and ethnicity shape an individual's thermal perception and response to thermal conditions and lead to variations in comfort preferences across different population groups.30–32 The building envelope exerts an indirect influence on thermal comfort shaping the baseline level, with well-designed envelopes acting as thermal barriers that protect interior from direct solar radiation, reduce glare, enhance natural ventilation and mitigate external heat gains. 33
As discussed, two dominant approaches are identified in thermal comfort studies: model-driven and data-driven ones. The model-driven approaches employ deterministic, physics-based models to formulate the heat transfer between the human body and the surrounding environment using either refined variations of the PMV model or simulations through computational fluid dynamics (CFD).34–37 The data-driven approaches leverage AI/ML to process sensed measurements collected through IoT and smart devices enabling a dynamic and evolving learning process that uncover patterns and dependencies underlying in an individual's thermal responses and corresponding predictors, moving beyond generalization.
Luo et al.
38
evaluated nine different ML algorithms in predicting thermal comfort utilizing data from the ASHRAE DB II, the most comprehensive data collection with experimental recordings from multiple research studies in the thermal comfort domain. The RF resulted in optimal performance surpassing even the more sophisticated MLP model attaining an accuracy of
Xiong and Yao
41
applied the non-parametric kNN algorithm to devise informed personalized strategies for air-conditioning achieving an accuracy of
Park and Park
44
used a hybrid learning framework with convolutional neural network (CNN) and SVM models, using CNN for feature extraction and SVM as the final thermal comfort predictor, achieving
Methodology
Architecture of the ensemble learning framework for PMV estimation
Figure 1 illustrates the high-level architectural design of the proposed ensemble learning framework to deliver estimations for the thermal comfort category using a reduced set of easy-to-measure and low-cost climatic parameters and an approximation for the physiological parameter of clothing insulation. The ASHRAE Global Thermal Comfort Database II was utilized as the core data collection serving modelling purposes and underwent critical preliminary, sequential steps to pre-process, explore and transform raw data. These steps were grouped under a unified structural block component representative of the data preparation procedure prior to modelling with the clean, processed data collection allocated to training and validation sub-sets for models training and validation. Each weak learner was fitted on the same training sub-set with their parameters being optimally configured using grid search cross-validation (CV). The individual predictions from weak learners were aggregated using two different ensemble approaches; a soft-voting scheme and a stacked scheme with a LR as meta-learner.
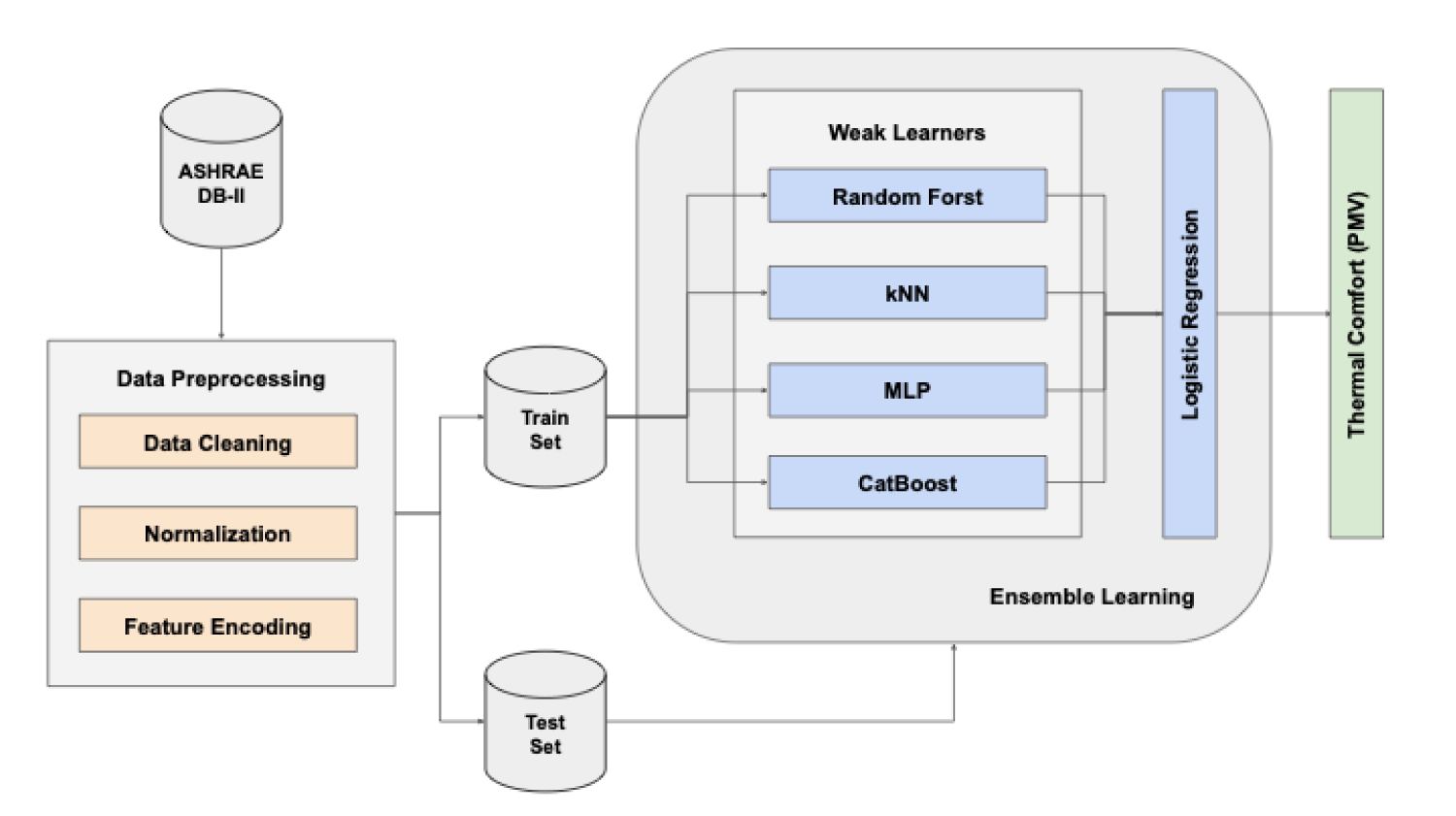
The high-level architecture of the proposed stacking ensemble learning framework for thermal comfort classification.
The selection of the specific weak learners was based on their distinct, complementary advantages and particular effectiveness in capturing diverse patterns and dependencies within data leveraging distinct modelling paradigms that mitigates limitations and potential biases inherent to individual state-of-the-art models. The kNN model is a non-parametric model with strong capabilities in uncovering local similarities and intricate patterns that makes it particular effective in approximating similar thermal comfort states that arise from proximities in the input feature space. The RF is an ensemble technique aggregating the predictions from multiple decision trees and demonstrates particular robustness in noise and overfitting. Besides being a powerful approach for capturing non-linear and complex dependencies, its collective intelligence offers significant added-value in discriminating thermal comfort states with enhanced stability and reliability. For both kNN and RF models, prior research studies underscored their superior performance in thermal comfort classification problems.38–43 The MLP is a feedforward neural network adept in learning intricate patterns in high-dimensional data through multiple hidden layers and non-linear activation functions. Unlike tree- and distance-based models that performing partitioning and exploring local similarities, the MLPs perform global function approximation that enables them capturing non-additive effects amongst features. In ensemble learning, MLPs are integral components, typically implemented with lightweight architectures to balance predictive gains against computational overhead. Prior studies also demonstrated the effectiveness of deep learning approaches on thermal comfort prediction.44–46 The CatBoost is an advanced gradient boosting algorithm for classification problems that constructs sequential decision trees with each iteration correcting the error of its predecessor. Incorporating ordered boosting and exhibiting efficient handling of categorical features, CatBoost is regarded as one of the most robust approaches for classification when categorical features are included in the input space.
Data collection
The ASHRAE Global Thermal Comfort Database II 47 was the core data foundation utilized in the present work for training and validation of each individual weak learner and the stacked meta-learner. It represents the most comprehensive data compilation in the thermal comfort domain including a total of 107,436 recordings collected from 66 on-field studies that conducted between 1979 and 2016 worldwide. A rich feature set was included, comprising, amongst other, studies metadata, indoor and outdoor climatic conditions at different spatial and temporal resolutions, occupants demographics and their physiological parameters of metabolic rate and clothing insulation, their subjective responses on the thermal comfort, acceptance and preferences, region, climate zones and seasons, operation of heating, cooling and ventilation systems, building structural characteristics and PMV. The heterogeneous recordings collected from thermal comfort studies across diverse built environments, regions, seasons, climate zones and occupant groups constitutes a predominant factor for selecting this compilation as the core material for modelling, since it captures significant contextual variability that promotes generalization.
Data preparation and pre-processing
The ASHRAE Global Thermal Comfort Database II has incomplete recordings due to the different experimental designs and sensing instrumentation used across the contributed research studies. Out of 107,436 recordings, 52.2% corresponded to missing values for the target variable of PMV, instead of PMV, self-reported thermal sensations and preferences were collected to determine thermal comfort in almost half of these studies. Entries with missing values for the target variable were left out from the original data collection in the absence of contribution for the subsequent modelling resulting in a reduced data collection of 51,354 recordings. In this reduced collection, air temperature was the only PMV parameter that was fully recorded reflecting both its central role in shaping thermal experiences and its relative ease and low-cost measurement. For mean radiant temperature detected, 37,990
To impute the missing values for mean radiant temperature and air velocity, their corresponding measurements captured at different heights above the floor were utilized, and in particular those obtained at heights of 0.6 m and 1.1 m above the floor, omitting those obtained at 0.1 m to ensure that the replacements reflect the climatic conditions to which the human body is directly exposed. A hierarchical substitution approach was applied for missing values imputation, prioritizing measurements at 1.1 m above the floor and if not available, measurements at 0.6 m were used instead. Following this, the number of missing values was reduced to
Another important step in the data preparation and pre-processing phase is the identification of invalid and potential outliers. The invalid values represent those falling outside the plausible ranges of a specific parameter, such as negative values for the physiological parameters of metabolic rate and clothing insulation, or for the climatic parameters of air velocity and relative humidity. The outliers represent measurements underlying at the distribution tails and substantially deviating from the typical ranges, however, are plausible. Although no invalid measurements identified in the reduced data collection probably attributable to a prior data curation from contributors, multiple measurements were treated as outliers following a defensible strategy that structured upon two main pillars: domain-based thresholds for each specific PMV parameter and fundamental statistical approaches commonly used in ML pipelines.
The ASHRAE 55 standard documents explicit thresholds and valid ranges for both climatic and physiological parameters when these are incorporated as input features in the PMV model to ensure that the thermal comfort estimation would range between
The most conservative and defensive statistical approaches for handling outliers in ML problems are z-score and Tukey's interquartile range (IQR) rule, with IQR rule representing the most common, interpretable and transparent one. Retaining outliers in training and validation datasets could distort estimation of the model's parameters, introduce model bias, inflate error metrics and constraint models generalization. Although the IQR rule typically defines as outliers those values ranging outside the
Let
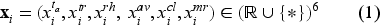

Data exploration
The initial step of the data exploration was to confirm the heterogeneity amongst the ASHRAE Global Thermal Comfort Database II recordings with respect to diverse regional, seasonal and climate contexts, which provides the essential foundation for robust modelling and supports further generalization rather than adapting to narrow contextual characteristics of specific studies. The most recordings originated from studies conducted in Asia
Further exploration of descriptive statistics and distributional characteristics for the indoor climatic conditions of air temperature, relative humidity, mean radiant temperature and air velocity in
Turning to the descriptive statistics and distributional characteristics of the physiological parameters, the average and the median metabolic rate was
As shown in Figure 2, with a mean PMV of
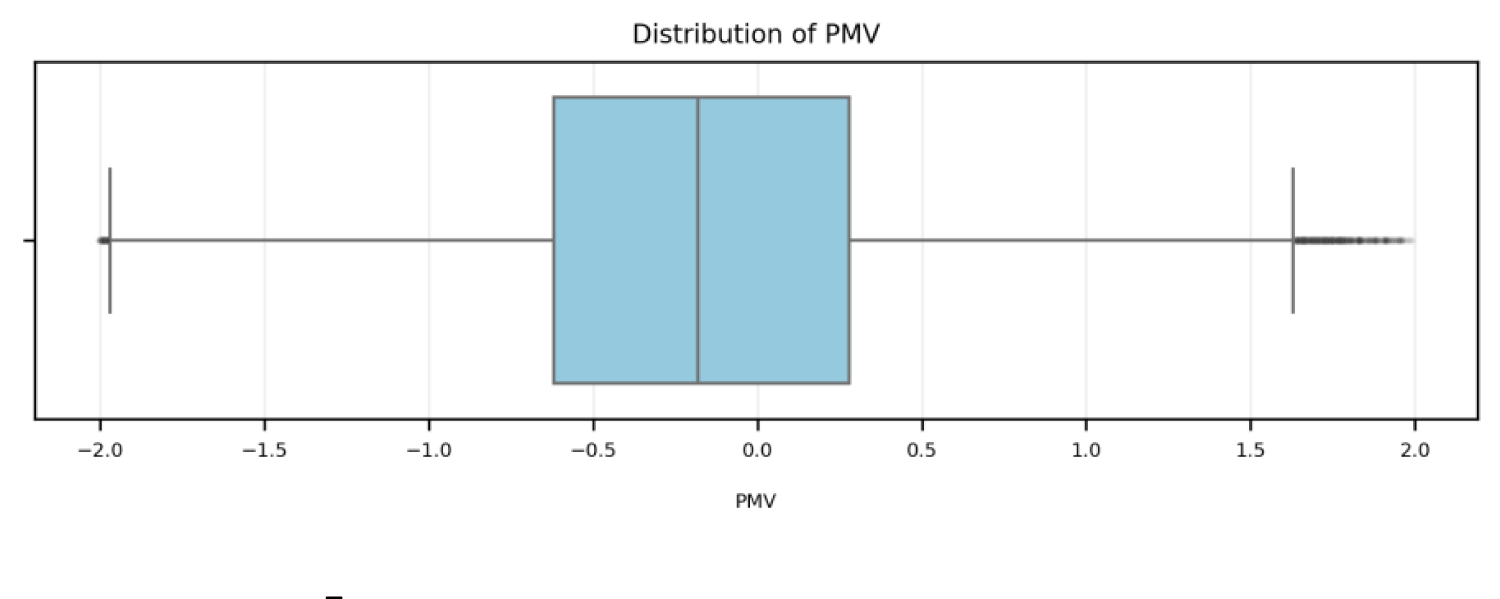
A boxplot representing the distributional characteristics of the PMV values.
Frequency analysis in PMV revealed a significant decrease in samples as the thermal experience diverges from neutral towards thermal discomfort states. A total of
The mapping of thermal comfort states original to merged states for the extreme thermal discomfort states.

Sensitivity analysis
A sensitivity analysis was conducted aiming to assess the influence of each specific climatic and physiological parameter on the deterministic PMV model that combined linear and monotonic dependencies, measures for the shared information and rankings for the predictive contributions as derived from feature importance.
Although PMV is a deterministic function using climatic and physiological parameters as inputs, the correlation analysis could provide valuable insights on how its empirical variations aligns with individual parameters and measures how sensitive is PMV to each specific parameter from a statistical perspective. Pearson's correlation coefficient r was computed to measure the strength for linear correlations underlying between PMV parameters and itself. Spearman's rank correlation coefficient
The sensitivity analysis was further extended to explore the absolute
The permutation analysis on climatic and physiological parameters also confirmed the dominant predictive contribution of the air temperature on PMV yielding the highest permutation importance score of
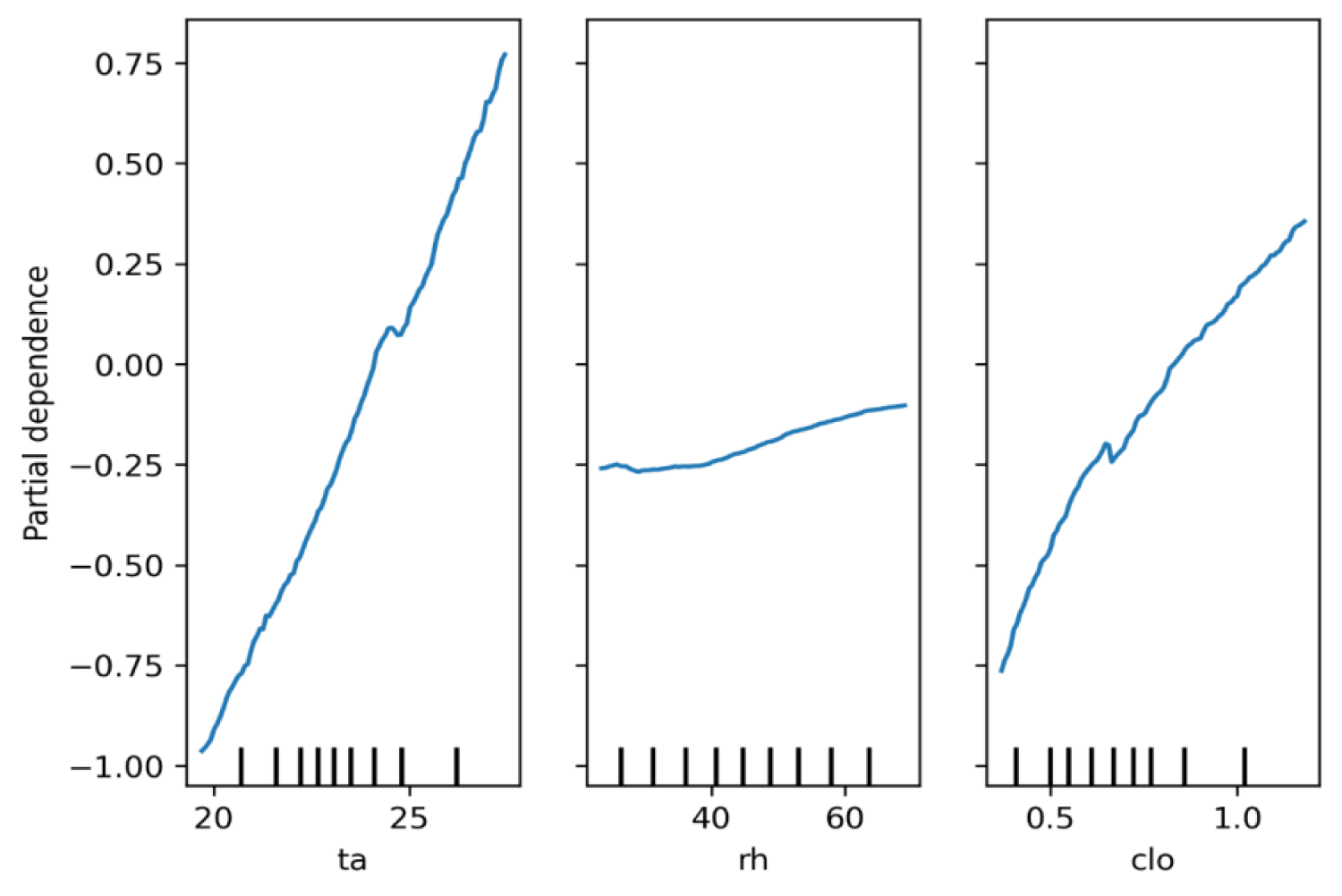
Partial dependence plots of PMV for the air temperature, relative humidity and clothing insulation parameters.
Given the consistent evidence for weak associations and predictive gains between the air velocity and PMV, it was excluded from the input feature space
Feature engineering
The feature engineering involved selecting those PMV determinants with the strongest predictive contribution to construct a reduced input feature space
Let 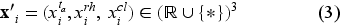
Let 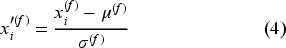
The numerical feature of clothing insulation 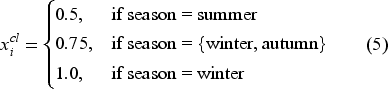
The target variable of PMV 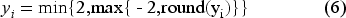
Modelling
All the recordings containing at least one missing value for an input features 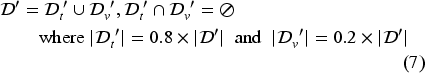
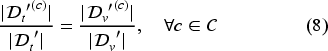
Evaluation metrics
To evaluate and report the predictive performance for each individual weak learner and the overall ensemble learning framework, the four standard classification metrics were used: (i): accuracy to measure the proportion of samples classified correctly across all the thermal comfort classes; (ii): precision to measure the proportion of correctly classified samples amongst those predicted to belong to a specific thermal comfort class; (iii): recall to measure the model's ability to identify all relevant samples for a specific thermal comfort class; (iv): and F1-score to represent the harmonic mean of precision and recall, providing a balanced measure of performance. In the 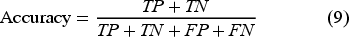
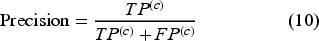
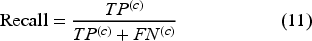
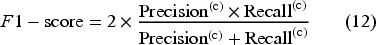
To quantify uncertainty in PMV predictions, all the standard evaluation metrics were reported using the mean value together with its 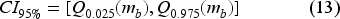
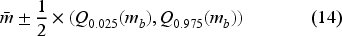
Results and discussion
RF classifier
The RF classifier is a tree-based model with particular effectiveness in uncovering complex and non-linear dependencies and robust performance against overfitting. An RF variant comprising
The hyperparameter space 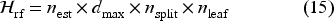
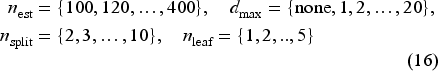
Although the optimized RF exhibited marginally reduced overall accuracy compared to the baseline model, it delivered a more consistent predictive performance across the thermal comfort classes, markedly improving predictions for thermal discomfort classes at the expense of only minimal degradation in the majority class. For the neutral thermal comfort class, it achieved a precision of
The confusion matrix of Figure 4 confirmed the optimized RF model's strong ability to deliver a more balanced and consistent predictive performance relative to the baseline model. In particular, it markedly enhanced the recognition of the extreme thermal discomfort classes, with recall increasing from 45% to 70% for the cold thermal discomfort class and from 54% to 73% for the warm thermal discomfort class. Moreover, it reduced the tendency of the baseline model to misclassify mild discomfort instances into the dominant neutral thermal comfort class, thereby mitigating class imbalance effects.
Comparative confusion matrices of the baseline and optimized RF weak learners.
kNN classifier
The second weak learner implemented was a kNN, a model that captures local neighbourhood structures and decision boundaries in the feature space and is particularly effective for discriminating thermal comfort states. A non-optimized variant with
The hyperparameter space 
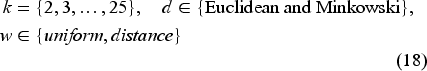
Even the optimized kNN model exhibited an identical overall accuracy compared to the baseline model, it provided an enhanced predictive performance across the thermal comfort classes with the fewer samples, as also presented in Figure 5, sharing a common observation with the RF weak learner. In addition, it attained a strong performance in the dominant neutral thermal comfort class with a recall of
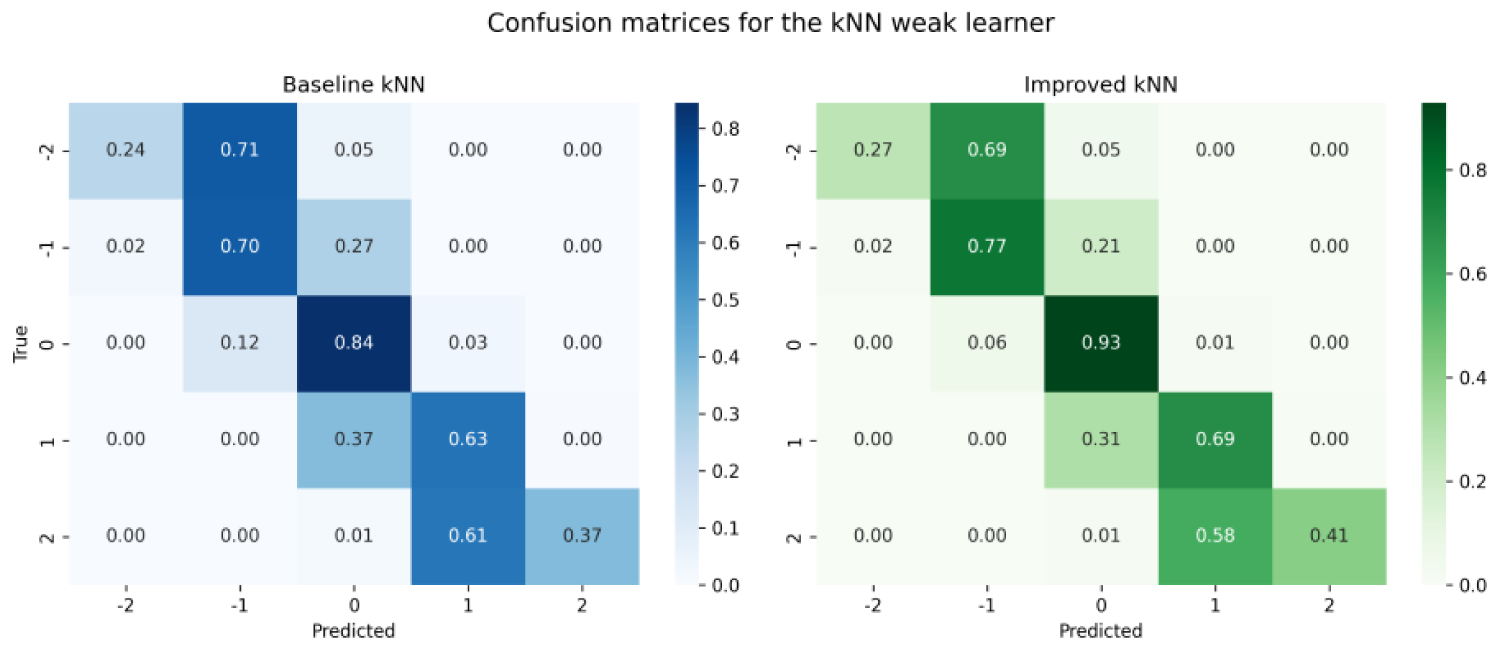
Comparative confusion matrices of the baseline and optimized kNN weak learners.
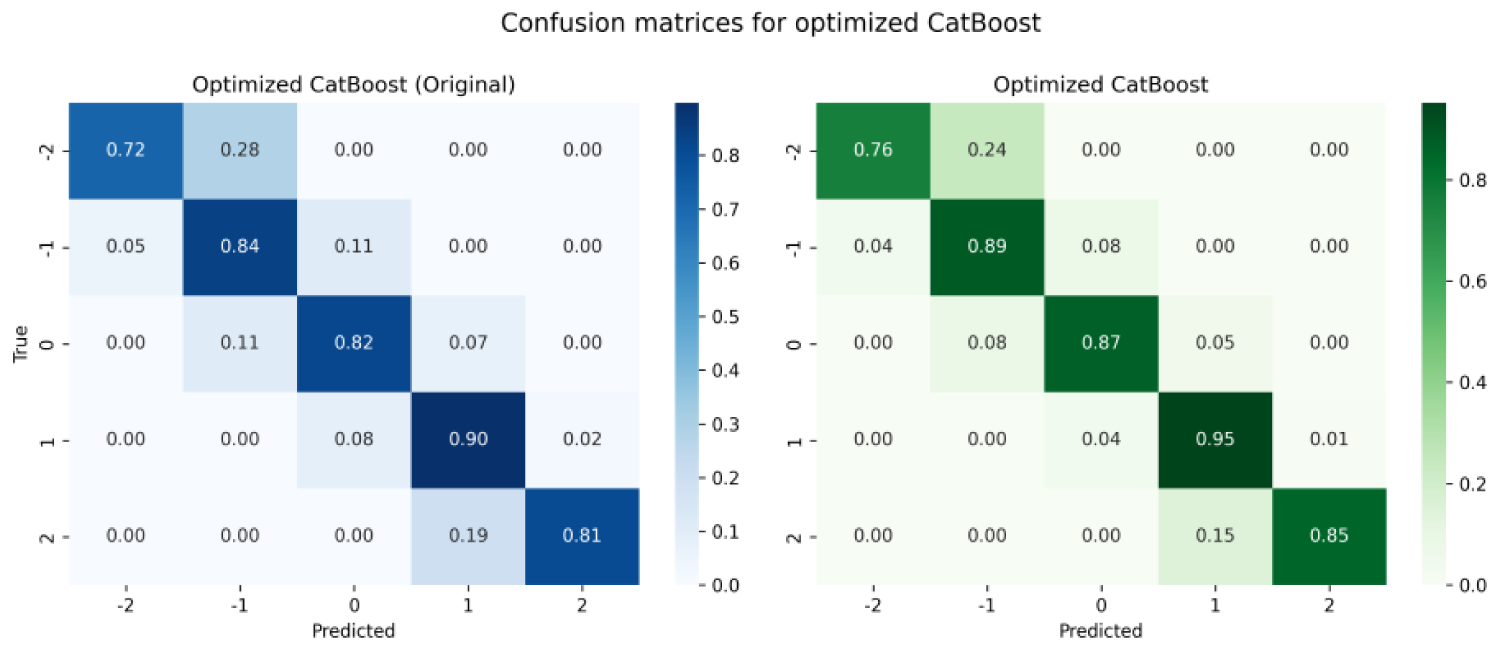
Comparative confusion matrices of the baseline and optimized CatBoost weak learners.
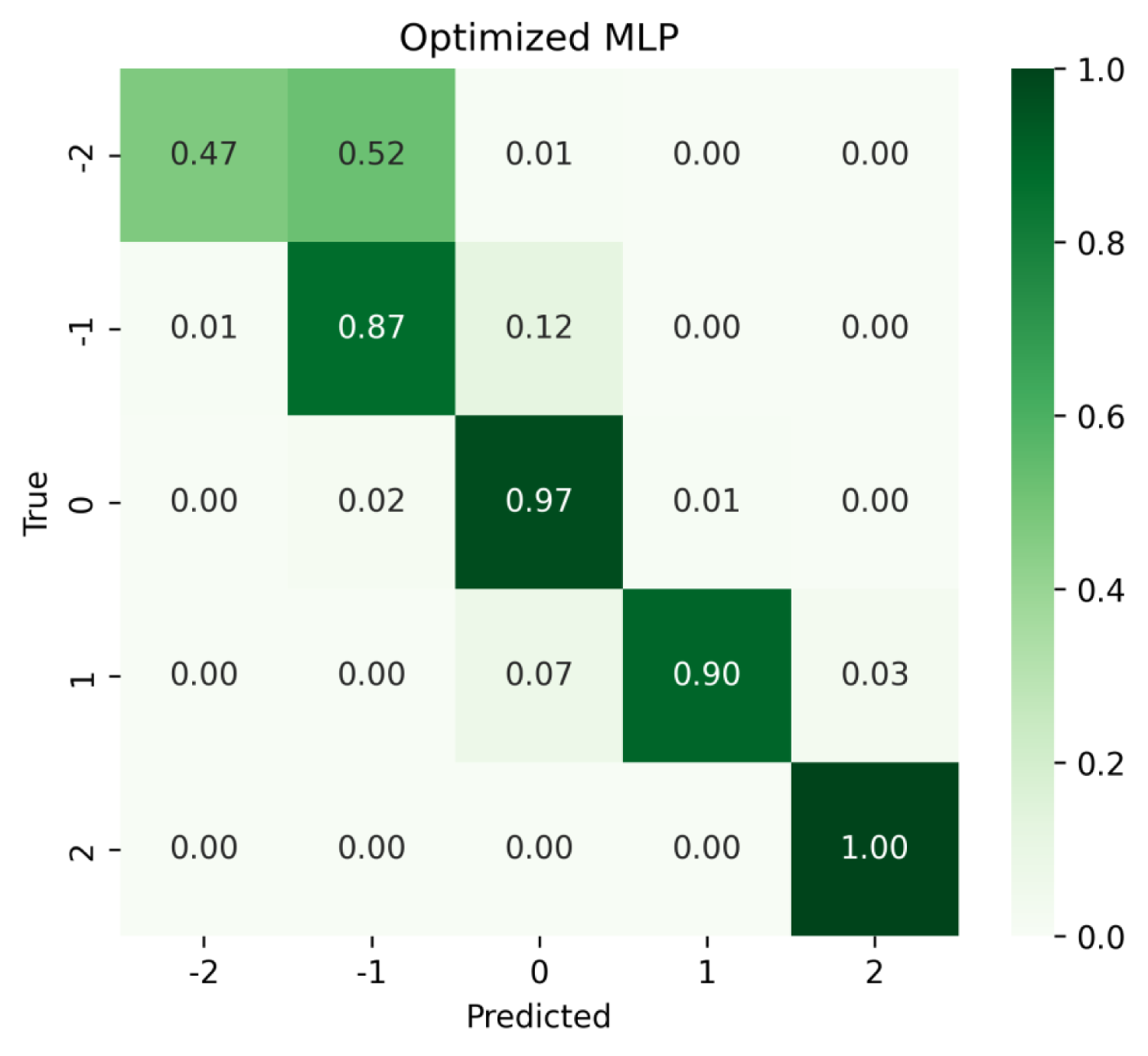
The confusion matrix for the fine-tuned MLP weak learner.
CatBoost classifier
The third weak learner implemented was a CatBoost, a model with particular effectiveness dealing robustly with imbalanced data distributions, which is advantageous for thermal comfort classification. The performance benchmark for this weak learner established using a minimal model configuration with
The hyperparameter space 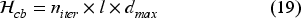
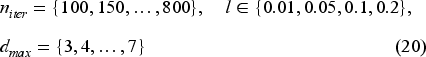
The optimized CatBoost resulted in an overall accuracy of
MLP classifier
A feedforward neural network also incorporated as weak learner in the ensemble learning framework to provide significant benefits related to capturing nonlinear relationships and complex feature interactions beyond those modelled by tree- and distance-based weak learners. The hyperparameter space
The MLP weak learner showed a strong predictive performance across all the thermal comfort states besides the extreme cold thermal discomfort class, as illustrated in Figure 7. For the neutral thermal comfort class, it attained a precision of
Ensemble learning
Two ensemble learning paradigms were adopted and evaluated exploiting their strong capacity to improve predictive robustness by aggregating the strengths of multiple individual classifiers and mitigating the weaknesses of individual models. Within the proposed ensemble framework, both bagging and boosting were already represented through RF and CatBoost weak learners, respectively, complemented by kNNs and a neural network to ensure algorithmic diversity. While bagging and boosting alone enhanced predictive accuracy compared to single learners, their formulation is typically restricted to a single family of models. By contrast, the proposed stacked architecture integrates heterogeneous learners through a meta-learner, enabling complementary strengths across tree-based, distance-based and neural network architectures to be combined.
The first learning approach employed was a soft voting scheme in which the predicted class probabilities of the four individual weak learners were averaged and the class with the highest aggregated probability was selected as the final prediction. This simple yet effective aggregation rule leverages the collective confidence from diverse modelling paradigms, thus reducing the variance and improving the predictive stability. The second learning approach utilized was a stacked ensemble with a meta-learner, where predictions from the individual base learners served as input features, enabling the meta-learner to identify complex relationships and dependencies amongst the individual predictions of weak learners and yielding enhanced performance and more flexible decision boundaries, particularly for minority classes.
Ensemble learning using soft voting scheme
The predictive performance of the soft voting scheme was first evaluated using samples included in the validation set
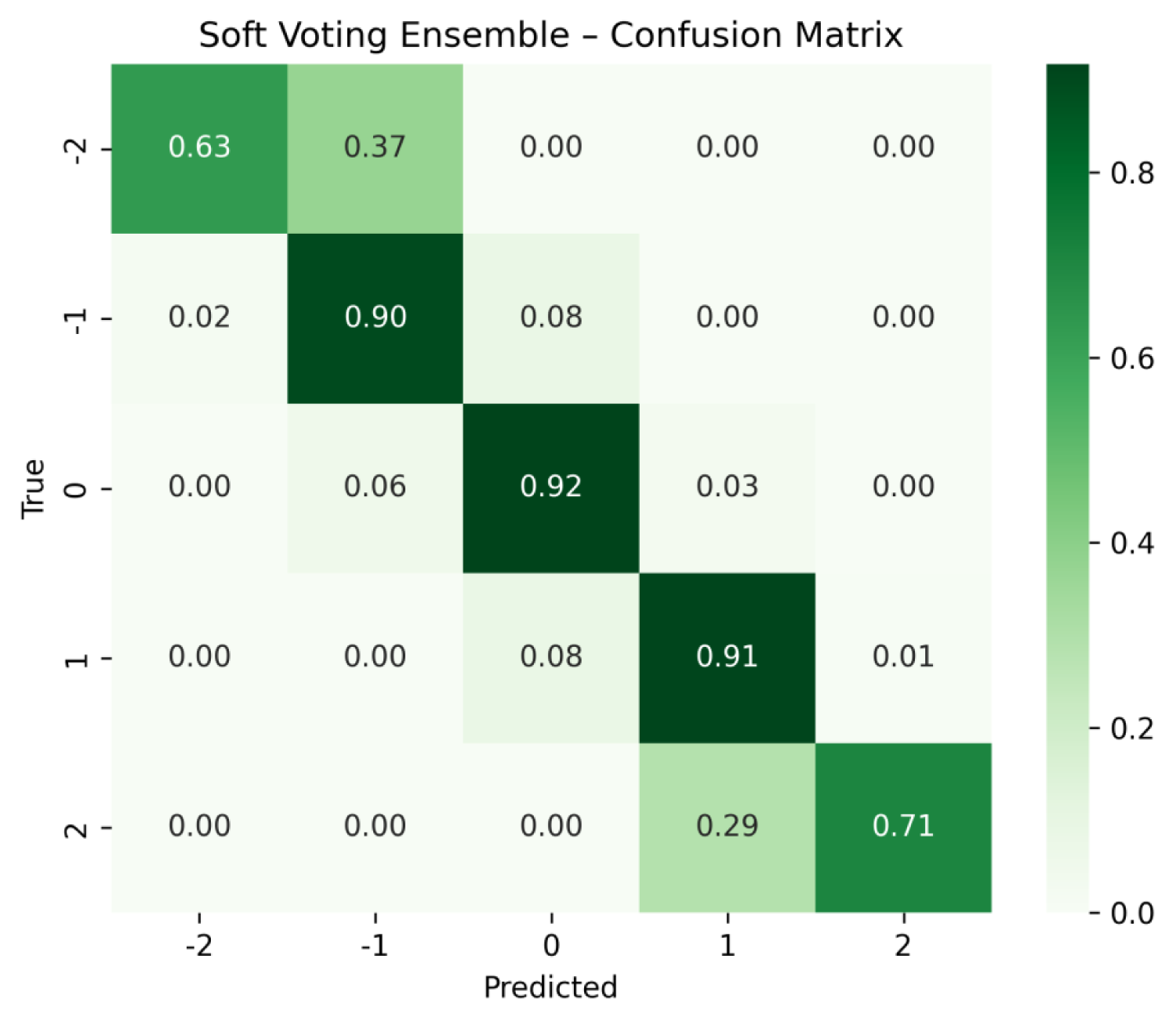
The confusion matrix for the soft voting scheme.
To further examine the robustness of the soft voting scheme, additional validation was performed under both 5-fold and 10-fold CV, presenting the results with
Ensemble learning using LR as meta-leaner
LR was selected as the meta-learner due to its simplicity, interpretability and low variance make it particularly well suited for stacking frameworks. The meta-learners operating on the out-of-fold predictions of the base learners using more complex models such as XGBoost, LightGBM or SVR at this stage risks overfitting to these predictions rather than effectively integrating them. By contrast, LR provides a stable linear combination of the base models’ outputs, ensuring that the improvements in predictive performance are due to the diversity of the weak learners rather than the complexity of the meta-learner. This design choice is consistent with best practices in ensemble learning, where a simple, regularized meta-model is often preferred to achieve robust generalization.
The predictive performance of the stacked ensemble approach with LR as meta-learner was first evaluated using the samples included in the validation set
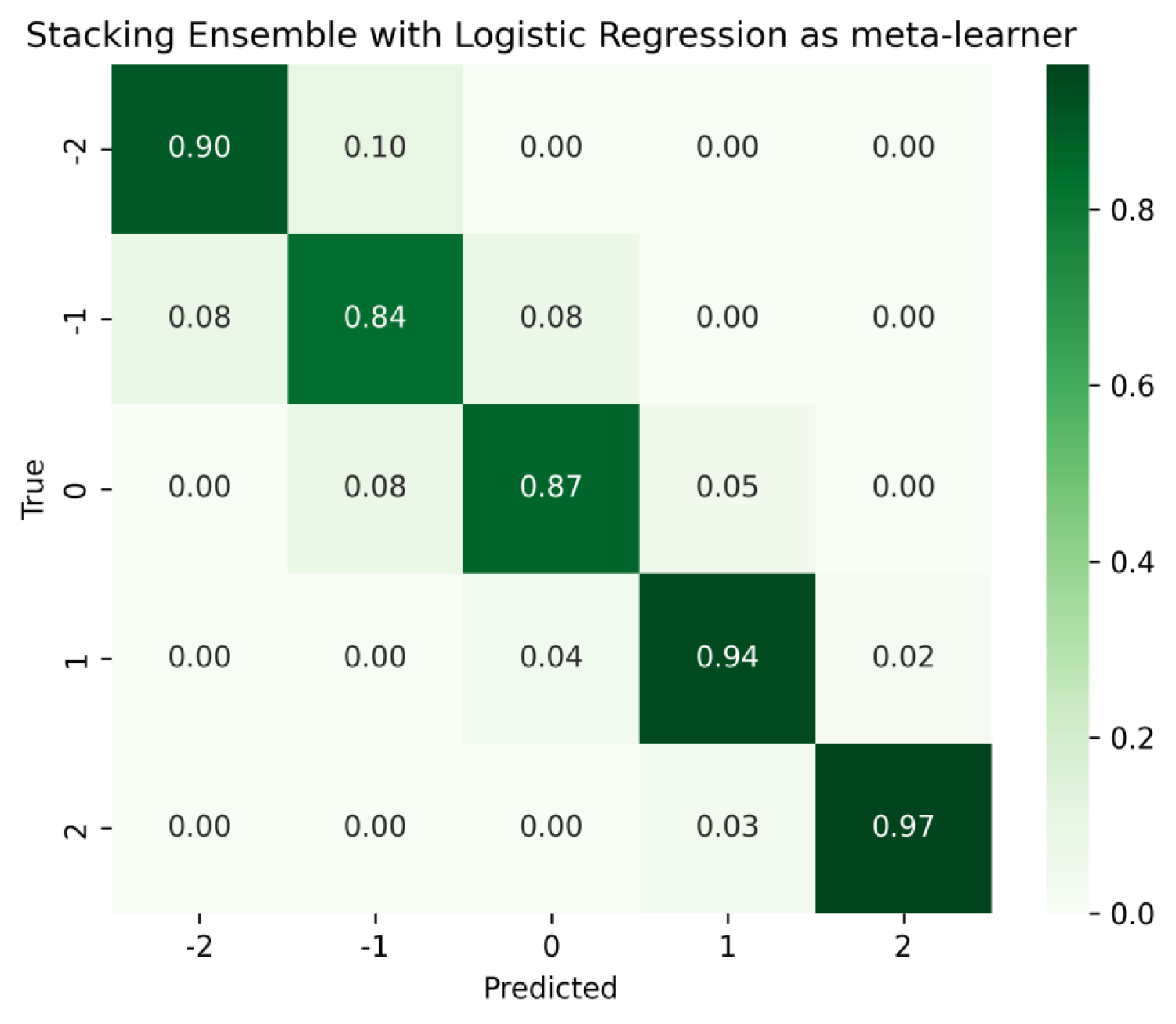
The confusion matrix for the stacked ensemble with LR as meta-learner.
Importantly, this behaviour remained consistent under both 5-fold and 10-fold CV attaining an overall accuracy of
Conclusion
As highlighted in this paper, thermal comfort plays a vital role in improving occupants’ satisfaction, health, well-being and productivity in enclosed spaces while supporting energy-efficient operations in built environments. Conventional thermal comfort assessment methods often depend on models that require either challenging-to-measure environmental parameters or self-reported personal thermal factors, which can be subjective and unreliable. This study has developed an innovative, data-driven approach to assessing an individual's thermal comfort state through an ensemble learning framework. The framework utilized an LR meta-learner to aggregate predictions from four diverse base learners, RF, kNN, MLP and CatBoost, achieving an accuracy exceeding
Footnotes
Authors’ contribution
Stylianos Karatzas: writing – review & editing, writing – original draft, visualization, validation, supervision, resources, methodology, funding acquisition, formal analysis, data curation, conceptualization. Christos Mountzouris: writing – review and editing, visualization, software, data curation. Grigorios Protopsaltis: writing – review and editing, validation, formal analysis, data curation. John Gialelis: writing – review and editing, supervision. Ajith Kumar Parlikad: supervision, conceptualization.
Consent for publication
Not applicable.
Consent to participate
Not applicable.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical considerations
Not applicable.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the UKRI [Grant Ref: EP/X024075/1] under the project entitled ‘TwinBAS: Digital Twins enabled Building Automation System for comfortable, healthy and energy efficient buildings’.