
Abstract
An empirical correlation and a set of machine learning (ML) models were developed to estimate droplet size and count distributions over an extended duration after a cough at different relative humidities (RHs), air temperatures and locations within an indoor environment. Experiments covered RHs of 20%–80% and air temperatures of 21 °C–26 °C. Droplet count distributions for 4 size bins (0.3–0.5, 0.5–1, 1–3 and 3–5 μm) were recorded for 70 min within the distance of 2 m from the cough source. Different ML models, including decision tree, random forest and artificial neural network, were trained for each size bin to predict the associated count distribution. Amongst these models, random forest showed a slight superiority in performance. The coefficient of determination for the random forest models ranged from 0.912 to 0.989, indicating robust correlations between the features and the response variables. An empirical correlation was established linking the count distribution of 0.3–0.5 μm droplets to time, RH and distance along the cough direction. Both ML models and the correlation accurately predicted the trends and the distributions, providing valuable data for validating computational simulations and informing indoor environment control systems to reduce the risk of virus transmission.
Introduction
The COVID-19 pandemic has proven that understanding the exact transmission routes of airborne diseases is extremely important to limit the spread of infectious pathogens. Viruses like these are carried in respiratory droplets with diameters ranging from 0.2 μm to several hundred microns and can be transmitted via exposure to environmental fomites, close contact with virus-carrying droplets, and/or aerosol transmission.1–7 The latest mechanism is known as inhalation of very small droplets (generally droplets smaller than 5 μm).1–7 Various studies show that the SARS-CoV-2 virus can remain active in aerosols for several hours, with longevity influenced by factors such as droplet size distribution, ultraviolet (UV) index, air temperature and relative humidity (RH).1,8–13 Other variables, such as human physiology, the utilization of face coverings, the proximity of people, airflow properties within a given space and ventilation strategies, can also affect aerosol transmission of disease.14–21 Understanding the influence of these factors is crucial for developing effective strategies to control the spread of infectious pathogens.
Several numerical and experimental studies have been conducted to understand the effects of indoor environmental factors, such as air temperature and RH, as well as time and distance, on the lifetime and dispersion of cough-generated droplets and aerosols.1,2,8,22–37 Dabisch et al. 8 used a rotating drum aerosol chamber to investigate the influence of temperature, sunlight and RH on the lifetime of SARS-CoV-2 in droplets. By injecting fine droplets with a mass median aerodynamic diameter (MMAD) of 2 μm into the chamber and measuring the virus concentration, they found that the time required for a 90% reduction in infectious virus ranged from a few minutes to over 2 hours, depending on environmental conditions. However, the authors noted that their findings were limited to a single droplet size distribution and that droplet size has a significant influence on the results.
Chong et al. 25 used direct numerical simulations to investigate the effects of RH on the lifetime of respiratory droplets. They found that increasing the ambient RH significantly prolonged the lifetime of droplets and aerosols, mainly due to the effects of humidity on droplet evaporation. It was demonstrated that the extension of the droplet lifetime with humidity is so pronounced that 10 μm droplets rarely evaporated and were carried in an aerosolized way. This result contradicts the World Health Organization’s classification (WHO), 18 which indicates that droplets with a diameter greater than 5–10 μm fall ballistically to the ground. Chong et al. 25 also showed that as droplet size decreases, its lifetime increases, and it travels a longer distance from the cough source. This finding was consistent with previous experimental results. 1
Zhao et al. 24 investigated the influence of ambient temperature and humidity on the lifetime and trajectory of respiratory droplets produced by speech. They considered a wide range of temperatures (0−40°C) and RH (0−92%) and found that droplets can travel farther downstream in low-temperature and high-humidity conditions, while the number density of droplets increases in high-temperature and low-humidity environments. Mesgarpour et al.32,33 studied the effects of ambient conditions on the spatio-temporal distributions of exhaled droplets in a bus. They demonstrated that a 10% increase in RH caused a 30% increase in droplet concentration at the farthest point from a coughing passenger. Trivedi et al. 37 also assessed the size and position distributions of droplets after a cough in room conditions at 20°C and 40% RH. After analysing 10 independent coughs, they showed that although turbulence intensity decreases far from the coughing person, significant changes in the position distributions of the droplets can still be observed.
In a previous study, 1 the present authors experimentally investigated the spatial and temporal dispersion of cough-emitted droplets over a long duration (70 min) at various locations in front of- and behind the cough source. The experiments were performed under ambient conditions on several days where the air temperature and RH were in the range of 21°C–26°C and 20%–78%, respectively. In this case, the effects of initial droplet size distribution, RH, air temperature, distance from the cough source and time on the dispersion of droplets were taken into account. Our findings showed that aerosols with sizes ranging from 0.3 to 10 µm persisted for a long time in a still environment. After 70 min, about 20% of the maximum nuclei counts were found to be almost uniformly distributed in the sealed enclosure. Furthermore, it was numerically demonstrated that an increase in ambient temperature led to a decrease in both droplet counts and average diameter. In addition, increasing RH resulted in an enhancement of the number density of suspended droplets.
Most studies in this field primarily focus on the in-flight behaviour of cough-generated droplets and aerosols for only a few seconds after the cough. Particularly for numerical simulations, the computational expense of tracking thousands of particles for 1–2 h in a room is onerous. As a result, in the previous paper (similar to other numerical works), 1 droplet in-flight behaviour was simulated for only 6 s after the cough. However, as stated above, small droplets can remain suspended in the air for several hours, potentially carrying active virus. Therefore, to better understand the transmission of respiratory viruses over long periods, more analytical, experimental and machine learning (ML) studies are needed.
Over recent years, ML models have found widespread application in detecting COVID-19 through various means, including voice, cough, breathing patterns, X-ray and CT images (often addressing classification problems).38–40 The ML models have also been integrated with computational fluid dynamics (CFD) simulations to predict the spread of respiratory droplets under different conditions, such as in public transport.32,33,41–43 Nevertheless, the complexity of collecting experimental data has led to a notable scarcity of studies focusing specifically on the development of ML models based on experimental results for predicting the spread patterns of respiratory droplets. In a study by Liu et al. 44 a series of machine learning (ML) models were developed using experimental data to forecast the concentrations of exhaled aerosol exposure amongst healthcare workers in an operating room. The focus of their investigation was specifically on breathing patterns, enabling them to anticipate aerosol concentrations in six different locations within the healthcare workers' breathing zones. The study highlighted the potential utility of machine learning in predicting aerosol concentrations. However, the challenge arises as a specific model was recommended for each location, making it difficult to extrapolate predictions to locations not covered in their experimental measurements. Additionally, the study did not consider the impact of time and was confined to PM0.3 concentrations exclusively. Moreover, ML models have been applied to analyse the effects of environmental factors on disease transmission at broader scales, such as in cities. In a study conducted by Hariharan, 45 the impact of daily mean temperature, absolute humidity and average wind speed on the attack rate and mortality rate of COVID-19 in Delhi, India, was investigated. The study utilized a random forest algorithm to compare epidemiological and meteorological parameters. Notably, it was found that absolute humidity is the most influential variable for both the attack rate and mortality rate in the analysis.
The objective of the current study is to develop an ML model and an empirical correlation to estimate the size and count distributions of cough-generated droplets over a long duration in a still environment at different air temperatures, RHs and locations. In a comprehensive review article, Wang et al. 2 analysed the literature regarding the transmission of respiratory viruses by aerosols and it was revealed that for most respiratory activities, such as breathing, speaking and coughing, most exhaled aerosols are smaller than 5 μm, and a significant portion is less than 1 μm. Moreover, studies have indicated that viruses are abundant in small aerosols (<5 μm). Therefore, the current study was focused on droplets smaller than 5 μm.
Methodology
Collecting data from experiments
Over a 7-month period, 55 experiments were conducted at Toronto Metropolitan University across several days to investigate the spatial and temporal dispersion of aerosol droplets under various environmental conditions and to forecast their behaviour for prolonged periods (i.e. more than 1 h). In these experiments, which were conducted in real conditions, the air temperature ranged from 21.9 to 25.8°C and the RH varied from 20% to 78%. The experimental setup and droplet count measurements for different size bins were thoroughly described in our previous paper 1 ; therefore, only a summary of the experimental methodology and measurement data is given here.
Experimental setup
An artificial cough generator was designed to simulate respiratory activity with droplets. It comprised two parallel pressurized air flow lines, respective flow controllers for calibrating air flow rates, solenoid and manual valves to control the flow duration, an aerosol/droplet generator to produce desired size distribution (using a Laskin-type nozzle), an HEPA filter to remove any dust and particles from the flow, a control box and a digital delay generator for synchronizing the cough with a camera and laser/LED-based lighting system, and a manikin to release the droplet-laden flow (a section of the setup is shown in Figure 1-(a)). By atomizing a solution of propylene glycol, small droplets were generated with diameters less than 10 μm (since the surface tension of propylene glycol is less than that of water) and the droplet size distribution fell within the range of interest. For this study, the cough flow rate and the average velocity at the manikin mouth were 3 m3/h and 4.8 m/s, respectively.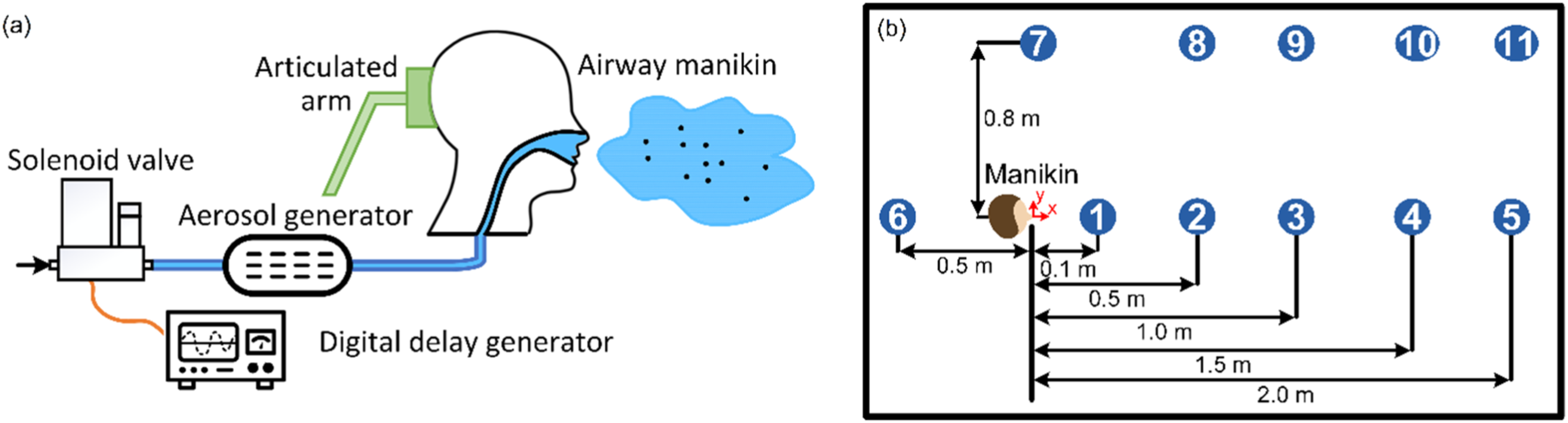
The experiments were carried out inside a sealed enclosure with dimensions of 2.5 m in length, 1.6 m in width and 1.9 m in height. The manikin’s mouth was set at a height of 1 m. As shown in Figure 1-(b), which depicts a top view of the chamber layout, 11 locations were selected to measure droplet count and size. The first five locations were arranged in the direction of the manikin’s cough, the sixth location was positioned behind the manikin, while locations seven through 11 were set 0.8 m to the side of the manikin’s mouth.
Experimental measurements and data structure
A commercial droplet counter (Kanomax brand) was used to collect samples from these 11 locations, measuring droplet number density in six bin sizes ranging from 0.3 to 10.0+ μm. The droplet counter was programmed to collect data at 7-s intervals for each location, with a total sampling time of 70 min. The experiments were repeated five times for each location.
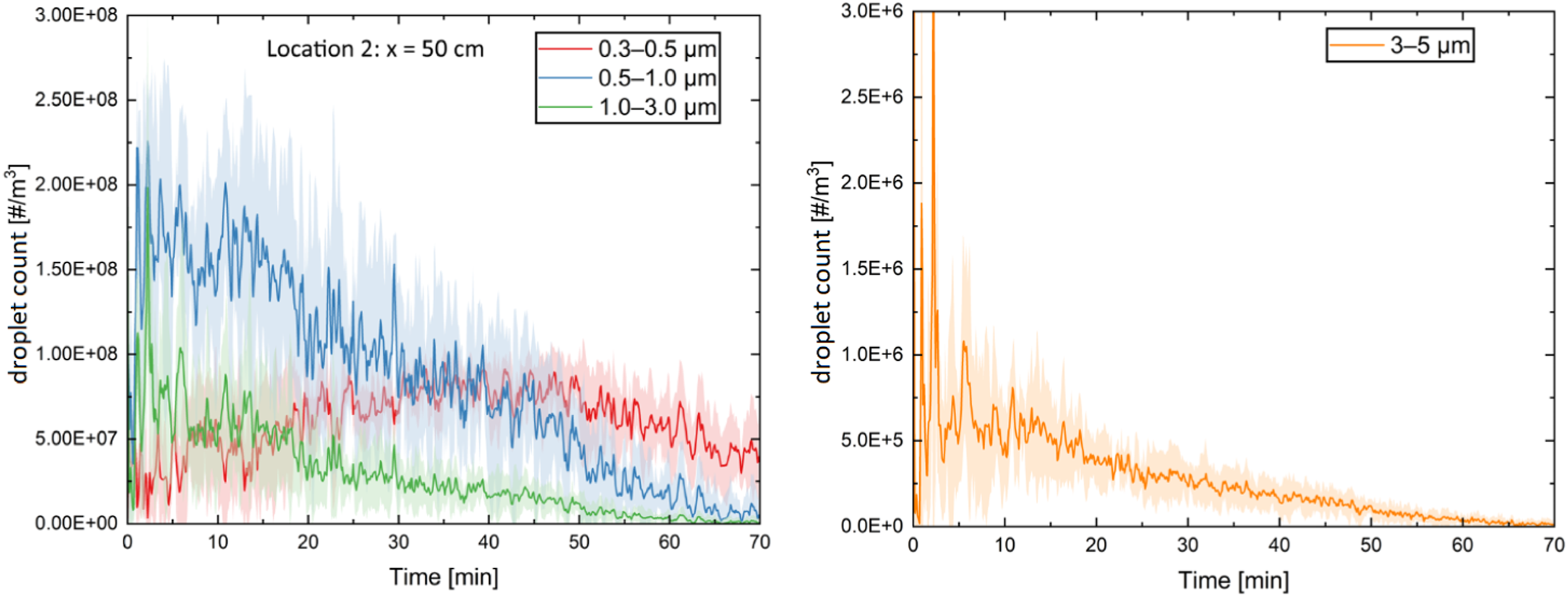
Figure 2 shows the variations in droplet count over time at location 2 for the size bins of 0.3–0.5, 0.5–1.0, 1.0–3.0 and 3.0–5.0 μm.
1
The shaded region in this figure represents the standard deviation of the average over five measurements. It is clear from the highly variable nature of the curves that turbulence and droplet diffusion have a significant impact on droplet count. Moreover, in certain cases, such as 3–5 µm, noticeable spikes can be seen, which are attributed to the bulk transport of the droplet plume after coughing.
1
For additional details on the forecast and experimental results (e.g. droplet count at other locations), readers are referred to the previous study.
1
The rationale behind placing Figure 2 in this section is to showcase the output data and its structure before delving into the explanation of ML approaches and results. It aligns with common practices in machine learning studies, in which providing an overview of the data helps readers understand the nature of the information being processed. Droplet count measured at 0.5 m in front of the cough source (location (2)) for four size bins. The shaded area shows the standard deviation of the averaged results over five measurements.
1
Moreover, it is crucial to highlight that the distribution of droplet sizes and counts in our research aligns with results reported in existing literature. Gralton et al., 46 in a review of 26 studies, revealed that particle sizes generated during activities like breathing, coughing, sneezing and talking by healthy individuals ranged between 0.01 and 500 μm, while individuals with infections produced particles in the size range of 0.05 to 500 μm. Additionally, in the study by Liu and Novoselac, 47 which explored the spread of a simulated cough, particle trajectories for sizes of 0.77, 2.5 and 7 µm were observed, with results indicating that 0.77 µm particles remained entirely suspended. Furthermore, the reported droplet concentration in our work aligns with the outcomes of Lee et al. 48 and Yang et al. 15 Lee et al. 48 discussed that the number of particles expelled per cough when subjects had a cold ranged from 731,000 to 18,756,000. They also reported that most particles generated by coughing are small enough to be suspended in the air, and they found that patients with a cold can release airborne transmission-available particles, with transmission detected at a distance of 3 m. The values of droplet concentrations reported in the work of Yang et al. 15 are in the same order of magnitude as our data.
Complexity in interpretation of experimental results and necessity of developing machine learning models
Although the experimental study was conducted under real indoor conditions, the effects of RH and air temperature on the spatial and temporal dispersion of aerosol droplets cannot be determined precisely from the experimental data due to their overlapping influence. 1 For instance, it remains ambiguous how the dynamics of droplets and aerosols evolve over a long duration (70 min) if the RH varies from 30% to 60% while the air temperature remains constant. Similarly, predicting the spatial and temporal dispersion of aerosol droplets under a new set of conditions (for instance, when the air temperature and RH are 21°C and 40%, respectively) that were not experimentally tested is not straightforward. Numerical simulations were conducted in our previous study to understand the droplet in-air behaviour at various ambient temperatures and RHs. 1 However, the numerical simulations typically only show the droplet behaviour for a few seconds (typically less than 10 s), due to computational limitations.
To address the aforementioned issues and predict the in-flight behaviour of droplets over a prolonged period, ML models have been developed in this study. Specifically, a comprehensive and diverse dataset has been collected from the experimental study, which can be used to train an ML model and predict the temporal and spatial distributions of cough-generated droplet size and count under different RH and air temperature conditions over the course of an hour.
Developing machine learning models
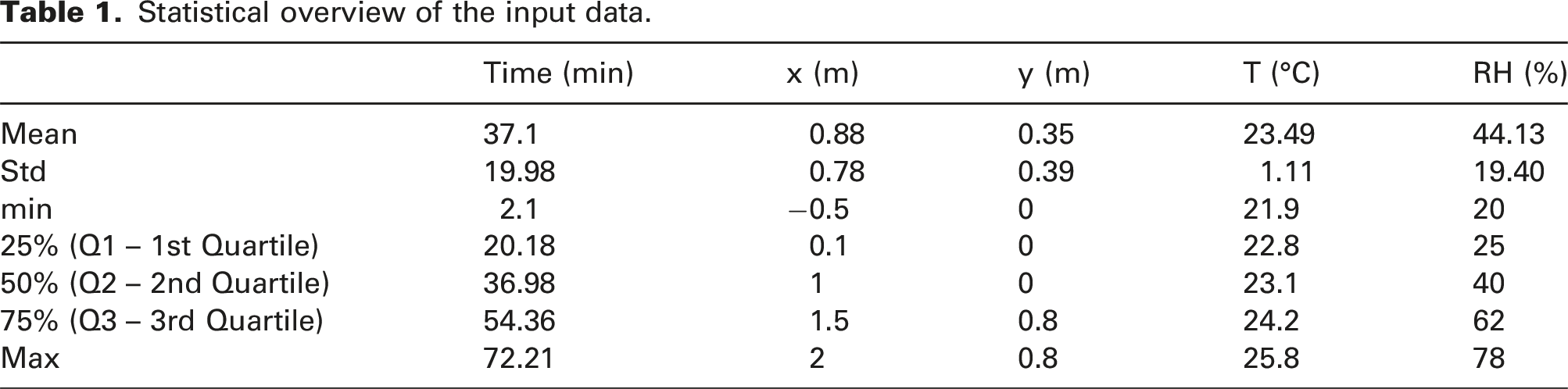
Statistical overview of the input data.
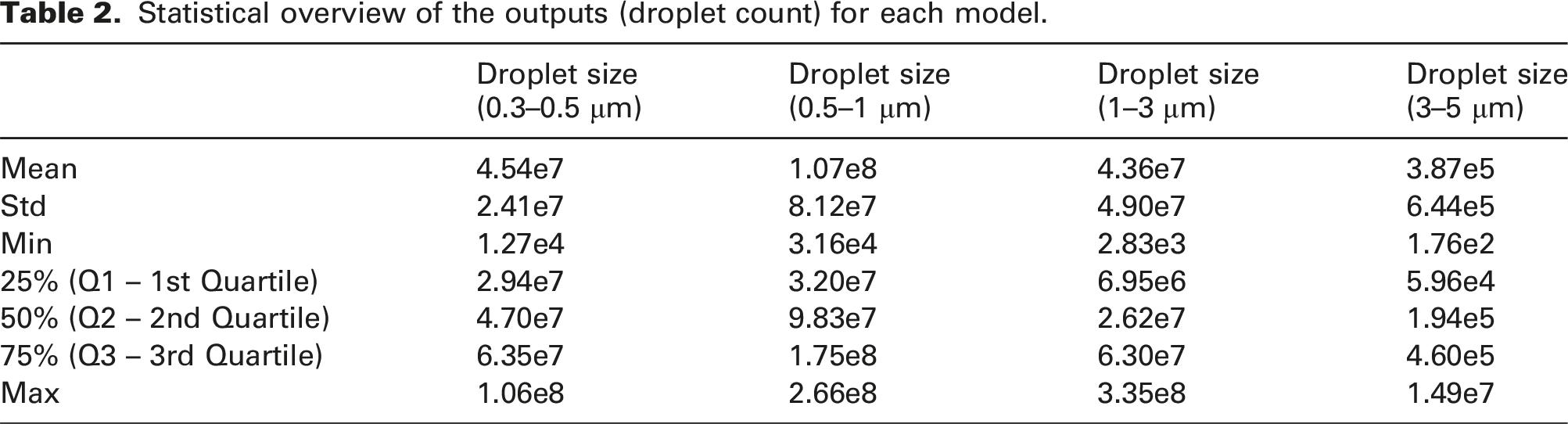
Statistical overview of the outputs (droplet count) for each model.
In the supervised learning approach, for the development and assessment of ML models, the entire dataset was typically divided into two parts: the training set and the testing set. The training set, which typically comprises around 70%–90% of the entire dataset, was used to train the ML model by minimizing the error between predicted and actual data. The testing set contains unseen data (i.e. 10%–30% of the entire dataset, which was not used in the training phase) and was utilized to evaluate the performance of the model. In this study, 80% of the entire dataset was used to train the ML models, with the remaining 20% reserved for testing.
To develop and evaluate the ML models, several algorithms, including Decision Tree (DT), Random Forest (RF) and Artificial Neural Network (ANN), were tested.50–54 The performance of the models was assessed using the R2 score, mean absolute error (MAE), mean squared error (MSE) and maximum error for both training and testing. These parameters are defined by equations (1)–(4), as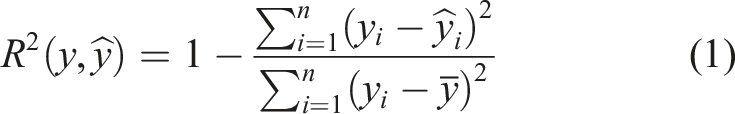
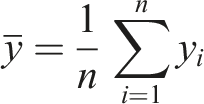
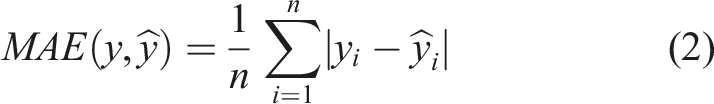
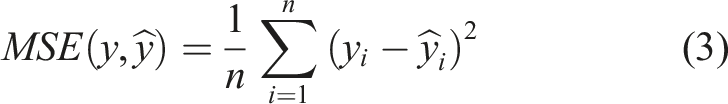
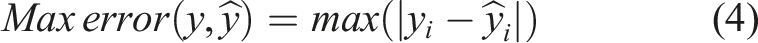
Overfitting is one of the key reasons why ML algorithms perform poorly.58,59 This phenomenon happens when the ML model over-trains itself to the point that it fits the training data too closely, subsequently failing to make reliable predictions for testing data. In the current investigation, various methods were employed to prevent overfitting. For the DT model, the maximum depth of the tree and the minimum number of samples required at a leaf node were examined. For the RF model, the number of trees in the forest, the maximum depth of the tree, as well as the minimum number of samples needed at a leaf node were analysed. For the ANN approach, L2 regularization technique was applied. In the ANN approach, various numbers for hidden layers, neurons, learning rates, alpha (the parameter related to L2 regularization) and epochs (iterations) were analysed in the grid search. Moreover, different activation functions, including the identity, the logistic sigmoid, the hyperbolic tangent and the rectified linear unit (relu), and two solvers for optimization (stochastic gradient descent (sgd) and ADAM (this name was derived from adaptive moment estimation) 60 were tested. Clearly, many terms, parameters and models related to ML algorithms have been mentioned so far. Explaining the details of these parameters and models is beyond the current scope of the article, so interested readers are referred to several books and papers.50–55,58,60–62
Developing an empirical correlation along the x axis
To estimate the number of droplets (N) as a function of space and time, with a diameter of 0.3–0.5 μm for a prolonged period (e.g. 1 h), an empirical correlation was developed. Very fine droplets were considered since they could easily spread through the room and remain in the air for several hours. To develop this correlation, the experimental data along the cough direction (y = 0 and x > 0; locations 1–5 shown in Figure 2) was used. Additionally, experiments were performed at an ambient temperature of 23 ± 1°C but different RHs (20%–78%) were selected. In this case, since the temperature variation is not significant, it can be assumed that N is a function of distance (x), time (t) and RH. The main reason for this simplification (ignoring the effects of air temperature) is that in most indoor environments, RH changes in a wide range, but the change in ambient temperature is not considerable (typically between 22 and 24°C). Using the entire dataset (locations 1–11 in Figure 2) makes the regression problem more challenging, requiring more advanced methods like ML. The development of ML models based on the entire experimental data was discussed in the previous section.
As shown in Figure 2, the signal of the droplet count is extremely irregular. Although it might not be a big challenge to train the ML models (all these fluctuations were included in the training of the ML models), these fluctuations adversely affect the accuracy of the empirical correlation. To develop an empirical correlation, the initial step is to eliminate these fluctuations using appropriate filters and identify the key trends. In the current study, similar to our previous work,
63
the Savitzky–Golay (SG) filter in MATLAB was employed to smooth out those signals.
64
The SG filter was typically applied to a noisy signal whose frequency span is large. In this method, the least-squares error in fitting a polynomial to frames of noisy data was minimized to perform the filtering.
64
In the present work, the SG filter of polynomial order 3–6 was utilized for data frames of length 61–71. Figure 3 shows the signals of droplet count after applying the SG filter. As can be seen, this filter is effective in extracting the main trend from such a noisy time-series data, which is an essential step in developing the empirical correlation. An example for using an SG filter to extract the main trend from the experimental data.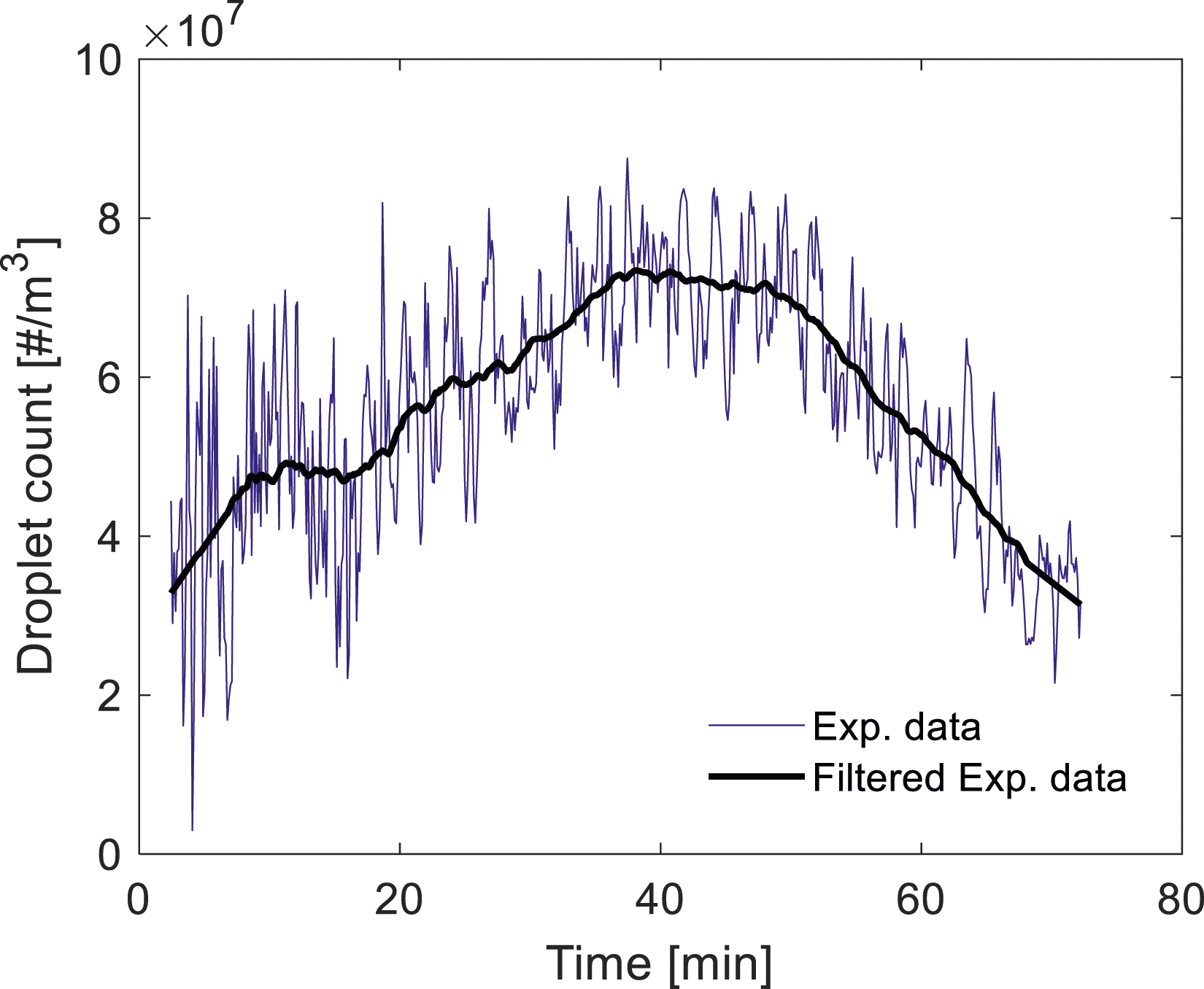
Results
The ML models
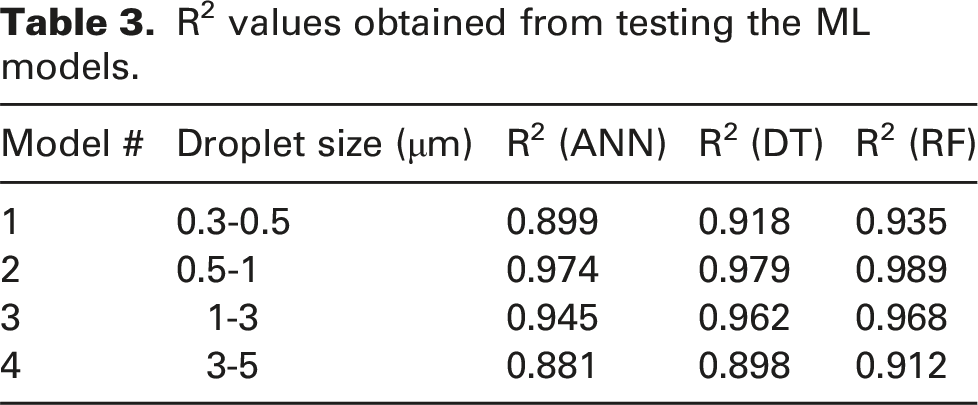
R2 values obtained from testing the ML models.
MSE values ([#/m3]2) obtained from testing the ML models.

Maximum error ([#/m3]) values obtained from testing the ML models.

Figure 4 demonstrates the ability of the four RF models to predict the droplet count and size distributions at varying locations, times, relative humidities and air temperatures with high accuracy. The figure displays the outcomes of the tests carried out on the chosen RF models, using 20% of the entire dataset. The horizontal axis represents the actual data from the experiments, while the vertical axis shows the predicted values from the RF models. The data in this study (as depicted in Figure 2) exhibit pronounced irregularities, fluctuations and remarkable spikes. This nature presents challenges for regression analysis.68,69 However, despite these complexities, Table 3 and Figure 4 demonstrate achieving an R2 score greater than 0.9 which attests to the high accuracy of the RF models in performance and predictions. The predicted values resulting from the RF models versus the experimental data where 20% of the entire dataframe was used as a test set.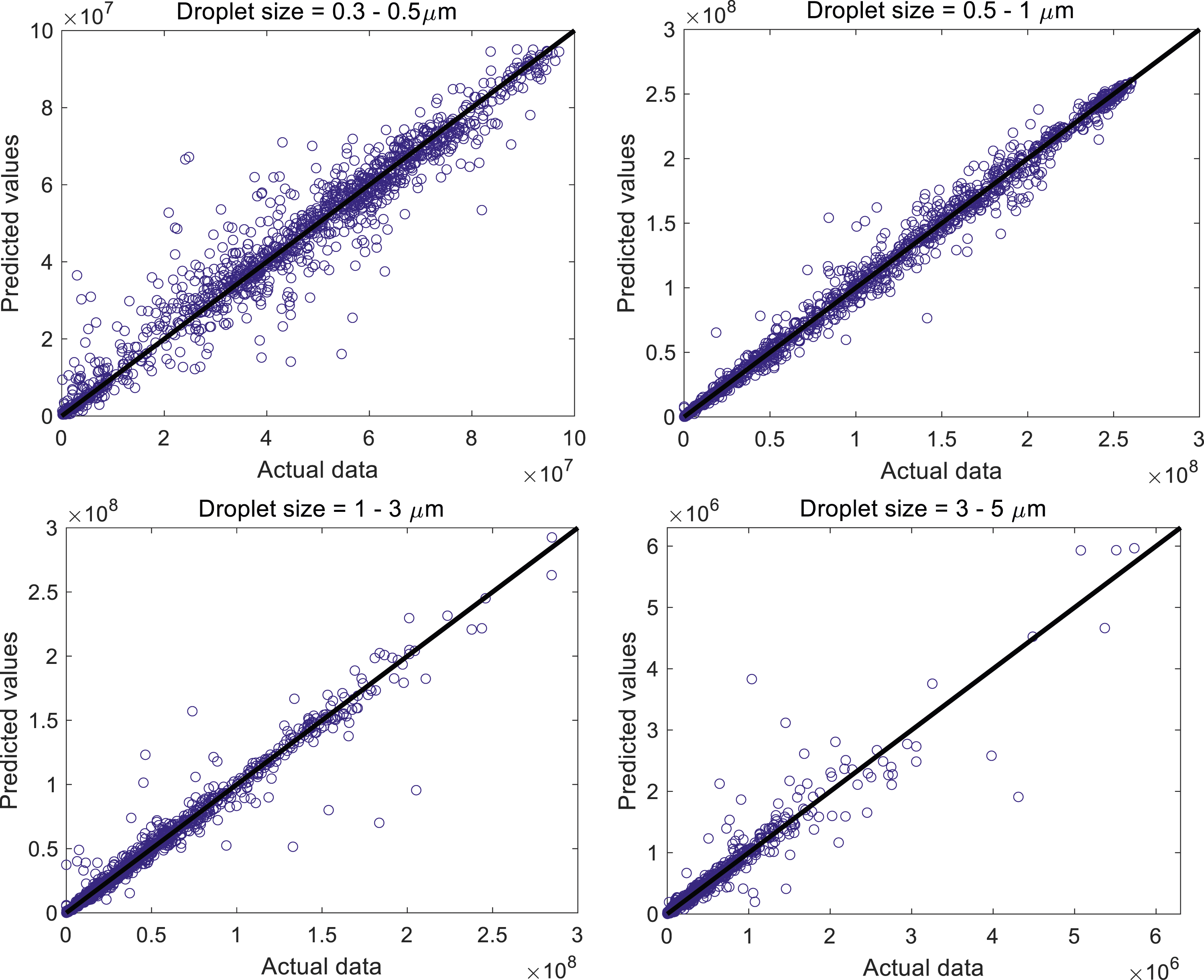
The R2 score and accuracy achieved in the current study are comparable to those reported in similar works within the existing literature. For example, Liu et al. 44 developed various machine learning models to forecast healthcare workers' exposure to exhaled aerosols in an operating room, with a particular focus on breathing patterns. Cough typically results in higher turbulent intensity compared to breathing; therefore, the data presented in the current study were expected to be more chaotic and irregular. Evaluating four algorithms: random forest, adaptive boosting, gradient boosting decision tree (GBDT) and extreme gradient boosting (XGboost), Liu et al. 44 found that the random forest model exhibited the best overall performance, aligning with our observations in the current study. Their random forest models achieved R2 scores ranging from around 0.78 to 0.98. In contrast, our random forest models demonstrated higher accuracy, with R2 scores ranging between 0.912 and 0.989, underscoring the robustness of our models. In another study, Hariharan 45 explored the impact of daily mean temperature, absolute humidity and average wind speed on the attack and mortality rates of COVID-19 in Delhi, India, using a random forest algorithm. The R2 scores for that random forest model were 0.92 for the attack rate and 0.88 for the mortality rate, which are lower compared to the values obtained in the current study.
An additional test was also conducted to evaluate the performance and accuracy of the four RF models for a prolonged period of time. To carry out this test, the experimental data obtained from the measurements at a specific location, RH and air temperature were employed. Clearly, since the location, RH and air temperature were fixed, the droplet count and size distributions depended only on time. Here, the experimental data obtained from location 3, which was 1 m away from the manikin mouth (x = 1 m and y = 0), at RH = 67% and air temperature of 24.2°C were considered. These data were not included in the training and testing phases mentioned above and were only used to verify the predictions of the four RF models for a prolonged period. Figure 5 presents a comparison of the RF models’ predictions with these experimental data. As can be seen, there is a good agreement between the predicted values and the experimental data, revealing that the models can accurately predict the trends and the distributions. The predicted values obtained from the RF models (red dots) versus the experimental data (blue dots) where x = 1 m, y = 0 (i.e. location 3), RH = 67% and air temperature was 24.2°C.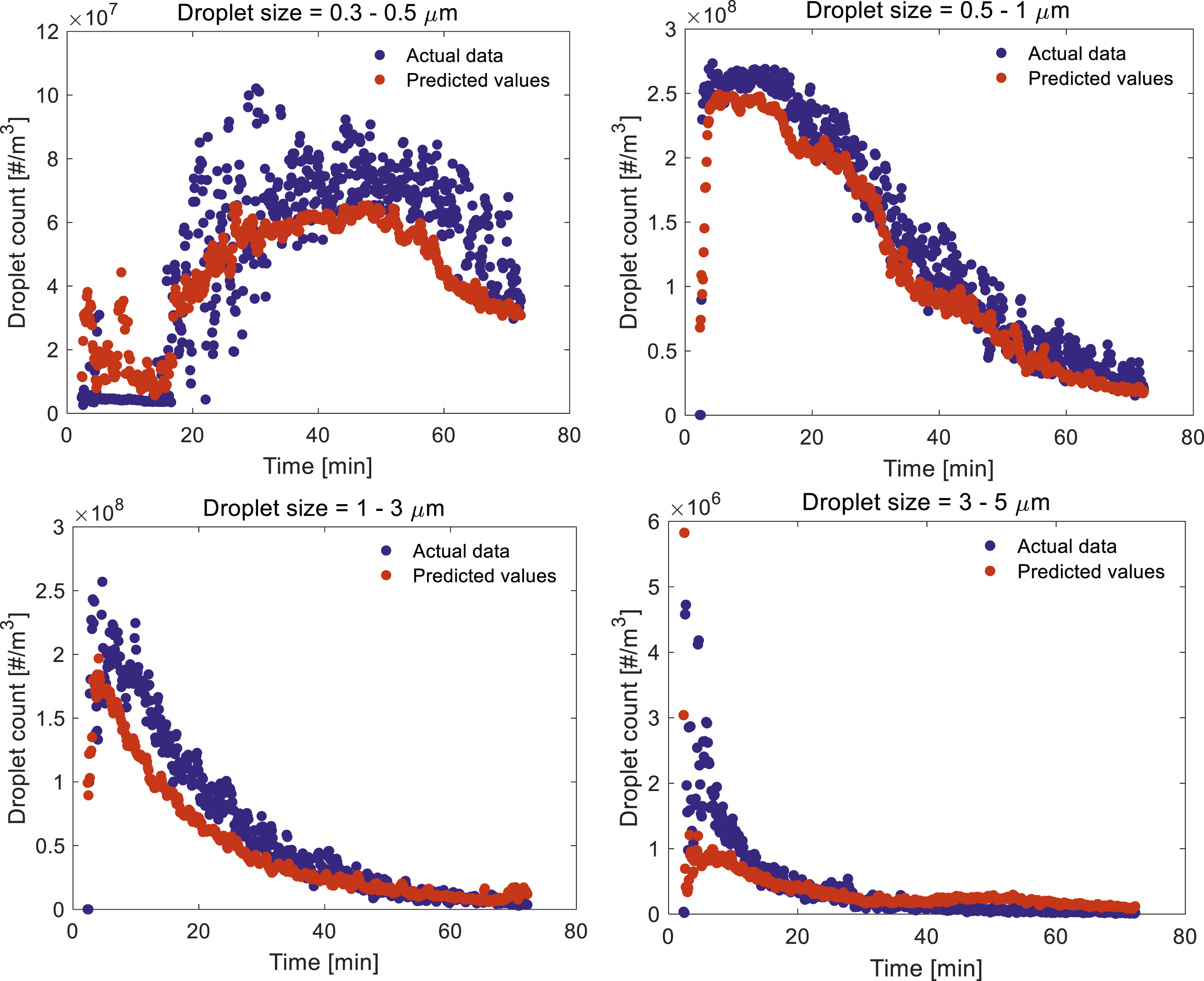
The empirical correlation
With the aid of the SG filter, we can have more practical discussions regarding the variations in droplet size and count distributions as different parameters are varied. For instance, in Figure 6, the effect of axial distance from the manikin mouth (x) on droplet count at different RH values is shown after filtering. The droplet size range in this figure was between 0.3 and 0.5 μm. As demonstrated, if we kept the RH constant and increased the axial distance x, the distribution of droplet counts shifted towards the left and its peak value was increased. Effect of axial distance (x) on droplet count distribution at various RH values.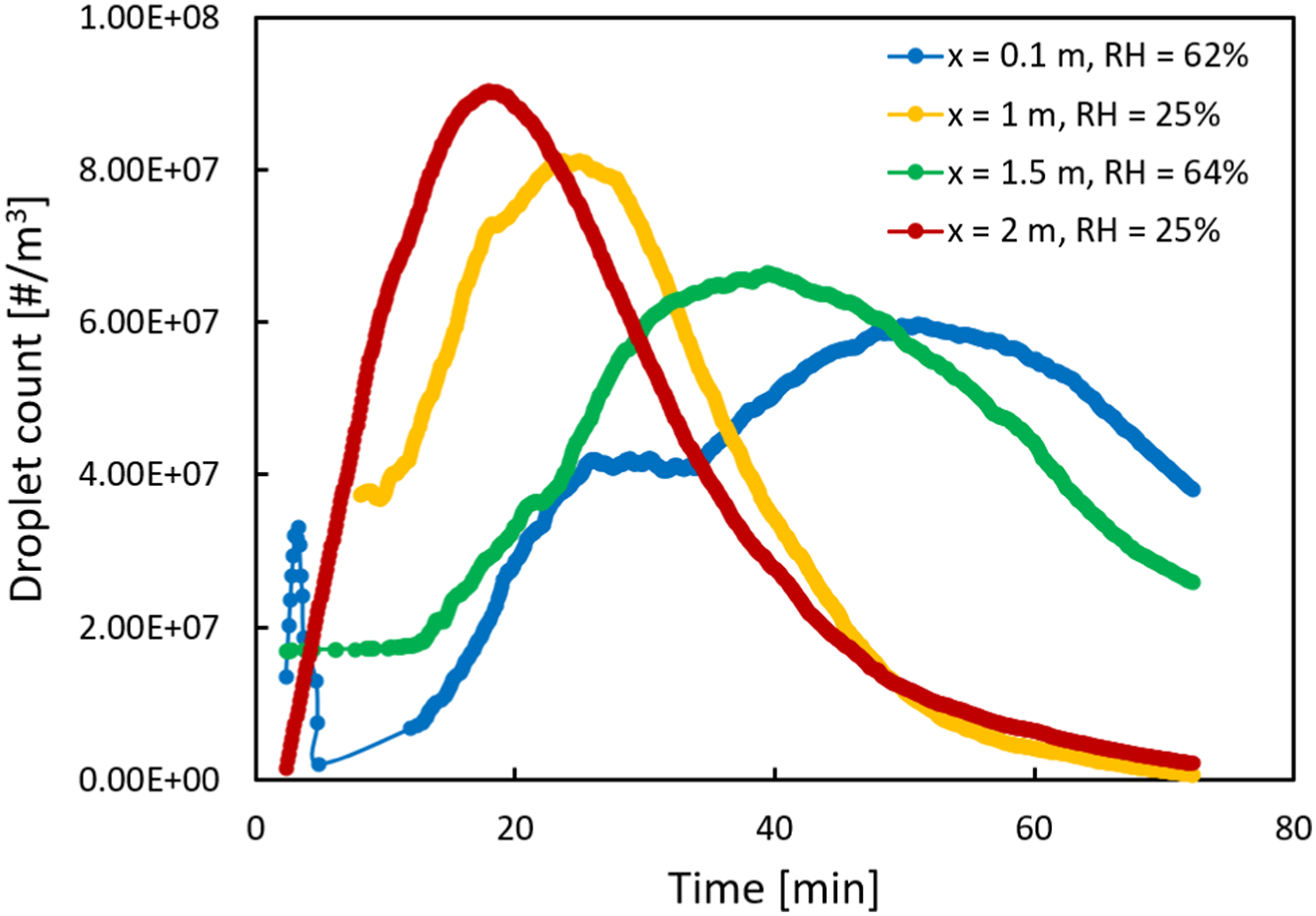
In general, it is demonstrated that the number of droplets tends to increase initially with time, but then decreases. The following two functions, equations (5) and (6), which were derived from the general forms of the probability density function (PDF) for log-normal and normal distributions, can be used to describe this trend: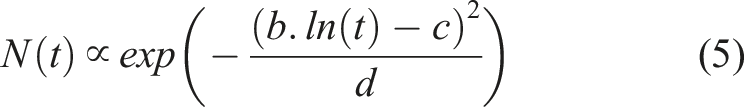
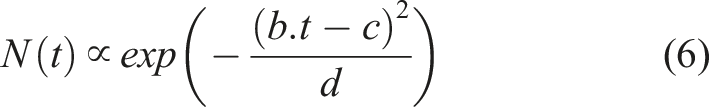
By increasing RH or decreasing x, the dependency of droplet counts on time shifts from the function given in equation (5) to the function in equation (6). As a result, both 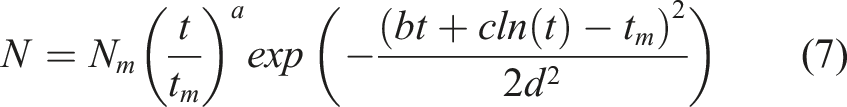

Here, RH is in %, x is in m, t and Comparison between the predictions of the empirical correlation and the filtered/unfiltered experimental data.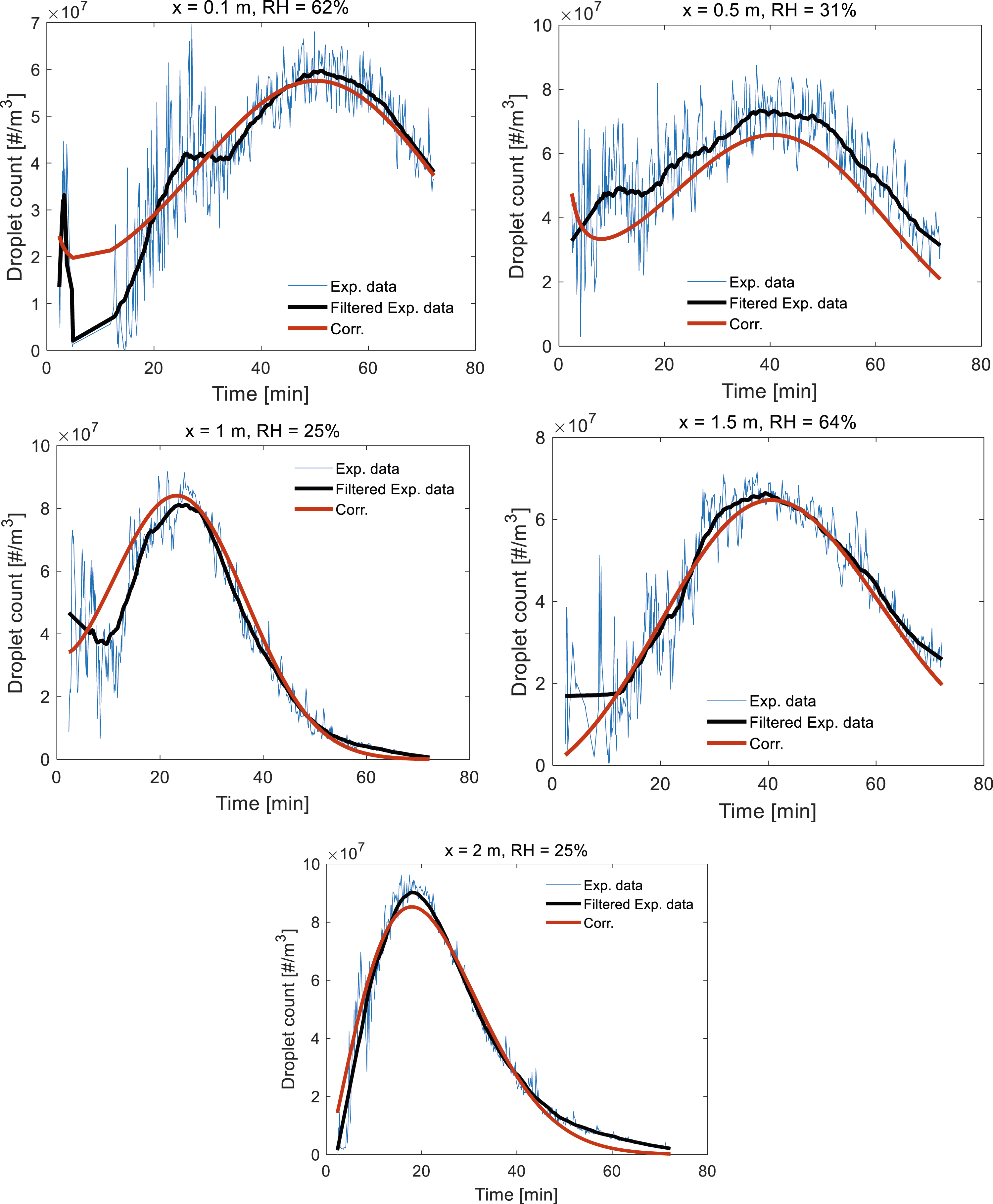
Summary and conclusions
In summary, this study has developed both a Machine Learning (ML) model and an empirical correlation to predict the temporal and spatial distributions of droplet count and size following a cough in an indoor environment over an extended period, at varying relative humidity levels and air temperatures. The dataframe was built using the experimental data obtained under real conditions. Three different ML algorithms, namely, Decision Tree, Random Forest and Artificial Neural Network, were tested, and it was found that the Random Forest model performed slightly better than the other approaches. The correlation and the ML model developed in the present study are useful to estimate the cough-emitted droplet in-flight behaviour in an indoor environment, which can aid in developing effective strategies to control and reduce the spread of infectious pathogens. In addition, these models can be used to validate numerical and Computational Fluid Dynamics (CFD) simulations.
Footnotes
Acknowledgements
The authors thank Mr Kai Lordly for his assistance with this research.
Authors contributions
Mehdi Jadidi: Conceptualization, Methodology, Validation, Analysis, Writing – original draft. Ahmet E. Karataş: Data collection, Material preparation, Writing – Review & Editing. Seth B. Dworkin: Supervision, Writing – Review & Editing, Funding acquisition. All authors read and approved the final manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.