
Abstract
Aim:
Systematic reviewing is a time-consuming process that can be aided by artificial intelligence (AI). There are several AI options to assist with title/abstract screening, however options for full text screening are limited. The objective of this study was to evaluate the performance of a custom generative pretrained transformer (cGPT) for full text screening.
Methods:
A cGPT powered by OpenAI’s ChatGPT4o was tested with subsets of articles assessed in duplicate by human reviewers. Outputs from the testing subset were coded to simulate cGPT as an autonomous and an assistant reviewer. Cohen’s kappa was used to assess interrater agreement.
Results:
For the inclusion/exclusion decision, the human–human kappa scores ranged from 0.87 to 0.96, exceeding the ranges of kappa scores for autonomous cGPT–human pairings (0.59 to 0.67) and assistant cGPT–human pairings (0.62 to 0.72). For exclusion reason classification, the human–human kappa scores ranged from 0.71 to 0.78, exceeding the ranges of kappa scores for autonomous cGPT–human pairings (0.47 to 0.53) and assistant cGPT–human pairings (0.52 to 0.63).
Conclusions:
Background
Systematic reviews (SRs) are critical for synthesizing evidence that should form the basis for up-to-date best practice and policy [1]. This type of secondary research starts by broadly identifying all potentially relevant articles before screening for title/abstract relevancy and full text inclusion. The process of independent screening in duplicate and resolution of discrepancies through consensus may translate to hundreds, if not thousands, of human work hours [2]. With the current explosion in artificial intelligence (AI) tools, there is now a high expectation for improved cost-efficiency.
Various AI tools are already present in SR software, developed to assist in title/abstract and full text screening [3]. Commonly, these tools provide predictions of article relevancy, however, they do not provide determination of inclusion status. Nevertheless, their training parameters may serve as a guide when creating conceptually novel AI models. The training material required to initiate relevancy predictions in these models ranges from 50 included and 50 excluded articles [4] to a single article [5]. In the case of Nested Knowledge, determinations of inclusion or exclusion at the full text stage can be made after human reviewers have categorized 40 excluded and 10 included articles [6].
It is generally agreed that the current capabilities of AI tools and models are not in a position to totally replace human reviewers for either title/abstract or full text screening [7 –10]. It has been reported that the reliability of text mining AI tools is better for intervention studies than for complex health service topics [7,9,11,12].
Typical performance metrics of AI in screening tasks are reported in Table I [7,8,10 –14]. Additionally, evaluation of interrater reliability between human and AI decisions can be done using Cohen’s kappa statistical analysis [15]. The benefit of kappa is adjustment for random agreement [16]. AI tools used in screening for reviews tend to have high specificity but lower (<90%) sensitivity [11,14,15,17,18].
Test performance metrics with mathematical definitions for binary outcomes.
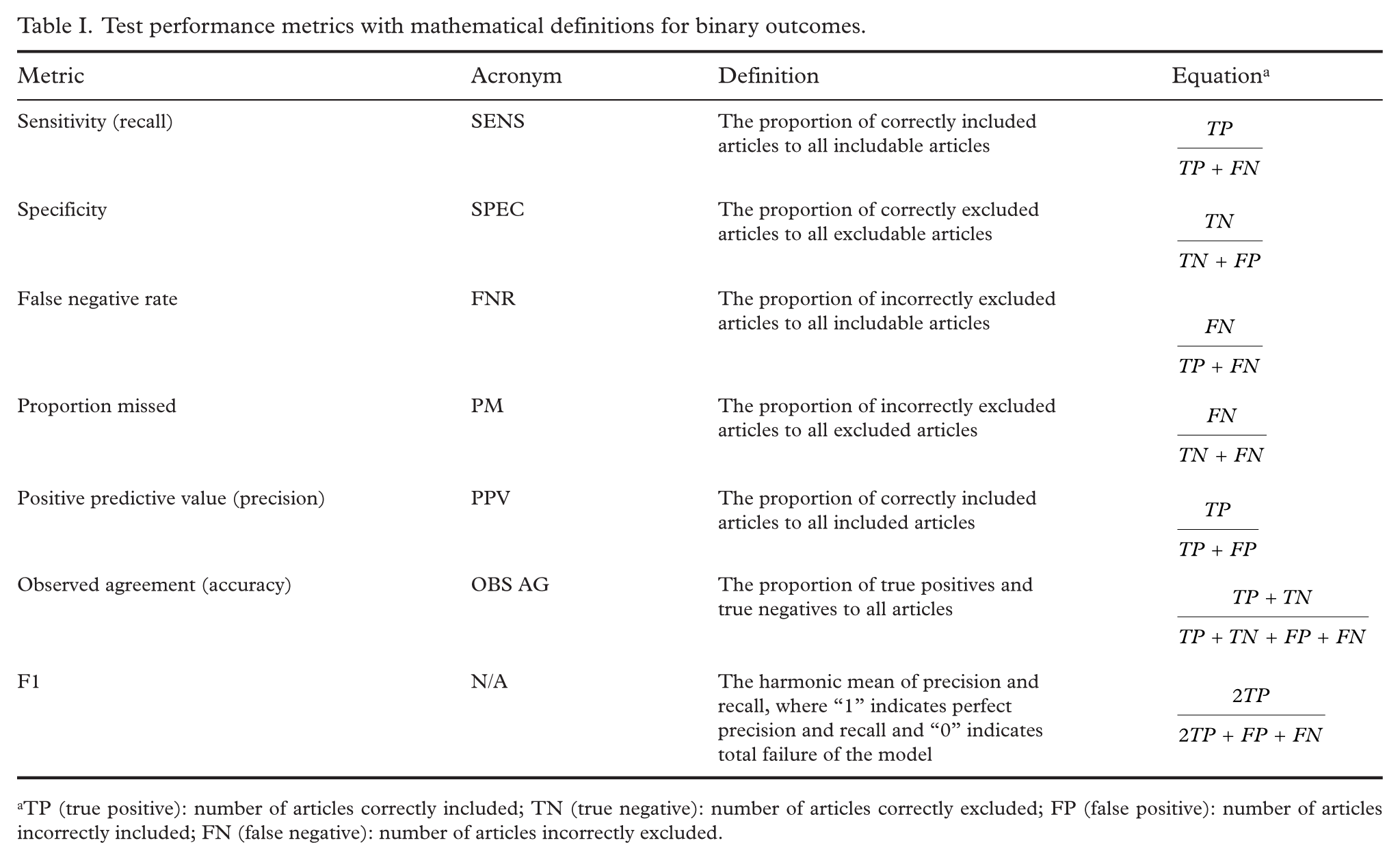
TP (true positive): number of articles correctly included; TN (true negative): number of articles correctly excluded; FP (false positive): number of articles incorrectly included; FN (false negative): number of articles incorrectly excluded.
One promising AI model to aid in systematic reviewing is ChatGPT—a large language model (LLM) with the ability to analyze and generate human-like text [19]. A retrospective study of several different LLMs’ ability to identify inclusion criteria in title/abstract screening reported ChatGPT4o to be the model with the best combined sensitivity and specificity [20]. The major limitations of ChatGPT (versions 3.5 and 4o) have been identified in data extraction, limited recall, and incomplete responses [8,13]. Insufficient training may have led to poor observed agreement [15].
One must consider these limitations within the context of how ChatGPT is used. As of November 2023, it has been possible to create a custom generative pretrained transformer (cGPT) that tailors responses based on input instructions and uploaded files. These cGPTs will not “forget” instructions in the same way as a non-custom ChatGPT model, which begins each new conversation without background information on the question’s context [21].
Aims
The purpose of this study was to evaluate the performance and time-saving potential of a tailor-made cGPT in full text screening within an SR. The work was motivated by the need to assess more than a thousand articles in full text.
Methods
The articles used in this study were selected from an ongoing SR that began in 2023. Briefly, the SR aims to describe the global meta-mean and dispersion of its outcomes (population-level habitual 24-h urine volume, population-level habitual 24-h creatinine excretion) identified in primary studies of adult populations globally. The outcome variables mainly appear as intermediary outputs in the includable articles. This requires the cGPT to identify defined concepts rather than just the primary studies’ main outcome(s) [22].
The SR’s corpus is screened in duplicate at the title/abstract and full text stages. The articles selected were published between 2020 and 2024 and consisted of a prompt engineering set and a testing set. We use the phrase “prompt engineering” throughout this article since the AI model has already been “trained” by OpenAI and the process of prompt engineering is meant to align the pretrained model’s outputs with the study’s outcomes of interest. Articles were coded into their inclusion status (“included” as 1, “excluded” as 0) and exclusion reason (coded as 1 to 9). In the event of an included article, the exclusion reason was coded “10” (Table II).
Distribution of the different categories of exclusion in the testing set from the human–human consensus.
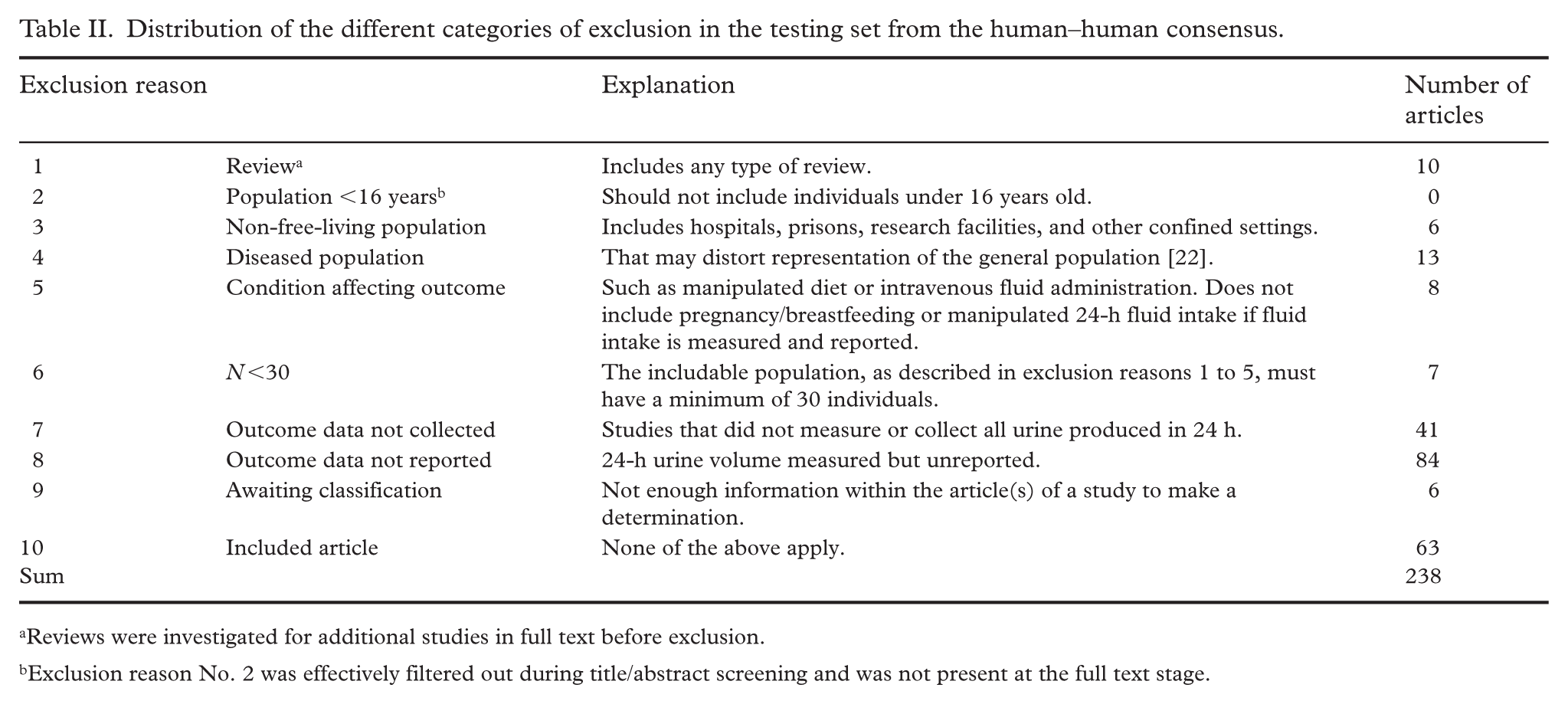
Reviews were investigated for additional studies in full text before exclusion.
Exclusion reason No. 2 was effectively filtered out during title/abstract screening and was not present at the full text stage.
The researcher responsible for uploading, recording, and interpreting responses from cGPT is called the cGPT operator. cGPT’s performance was evaluated in two screening roles: (1) autonomous reviewer, where cGPT’s analysis of inputted articles was coded without any interpretation by the operator; and (2) assistant reviewer, where the cGPT analysis was interpreted by the operator who decided to code the article in agreement with cGPT or not. cGPT’s ability as a reviewer in these roles was quantified and described as interrater agreement (Cohen’s kappa), observed agreement, classification performance metrics, and time savings. All screening took place within the Covidence environment, a platform for conducting screening and data extraction in reviews, between June and September 2024.
Aggregation of prompt engineering and testing data
Beginning in the full text screening stage, four human reviewers (EH, RD, SL, and KG) kept a log of article ID number, status, exclusion reason, study design, and field of study. Once a total of 250 articles were classified and cataloged in duplicate by reviewers, a subset of 40 excluded and 10 included articles was selected as the prompt engineering set. The articles purposefully encompassed all possible study designs, fields, and exclusion reasons to expose cGPT to the greatest variety of scenarios. The 200 test articles were augmented with an additional 38, representing all articles screened in duplicate by human reviewers at that point in time. The human–human consensus status of the testing set was 63 included and 175 excluded. Exclusion reasons for the testing set can be found in Table II.
Prompt engineering
The first version of our cGPT was created on August 23, 2024 using the paid feature on OpenAI’s ChatGPT platform (San Francisco, CA, USA). The cGPT was powered by ChatGPT4o. Initially, cGPT received abridged versions of the protocol and relevant supplements with a short description included in its “Instructions” text field in the “Configuration” tab of the general cGPT environment. cGPT provided incomplete and inconsistent responses when assessing the articles from the prompt engineering set. A more structured prompt–response configuration produced more accurate and complete responses and an evolving flowchart was developed to aid cGPT in navigating each article to a final decision (Supplemental file 1).
cGPT was instructed to “Navigate this article through the exclusion flowchart.” Its responses provided explanations for its reasoning for excluding or proceeding at each step of the flowchart. Errors in these responses were addressed by creating “patches” in the instructions, explicitly advising cGPT on how to proceed when faced with a certain scenario.
The team trialed differing levels of complexity with the flowchart. A persistent issue was cGPT’s reluctance to identify includable subpopulations within a study when following the flowchart, resulting in the inappropriate exclusion of a study altogether. Therefore, cGPT’s primary prompt was changed to “Navigate each population in this article through the exclusion flowchart individually.” The complete configuration of cGPT can be found in Supplemental file 2.
Testing
Testing ran from September 25 to 30, 2024. The cGPT operator was blind to the consensus status and exclusion reason decisions throughout testing. A new “conversation” with cGPT was opened and the 238 articles were uploaded one at a time using the final prompt, described previously. Conversations are separate windows that initially have no history of dialogue, like sending a new email instead of continuing in a thread. No feedback was provided to cGPT and no other prompts were used for the duration of testing. The cGPT operator coded both cGPT’s raw evaluation of the articles as well as the operator’s interpretation of status and exclusion reason based on cGPT’s evaluation. The latter was supported by notes and tags left by the first human reviewer in the Covidence environment. Notes and tags could include pertinent information about the population, the context of the study, or the study outcomes. In this way, the roles of cGPT as an autonomous reviewer and cGPT as an assistant reviewer were coded in parallel. The testing set was assessed two separate times by cGPT so that kappa statistics could be calculated between cGPT Test 1 and Test 2. Test 1 was completed before beginning Test 2.
Upon testing completion, the operator was unblinded and the decisions of the operator and cGPT were pooled from Test 1 to identify the “best response.” This served as the testing results of cGPT in the assistant role. Best response was defined as selecting which response, either cGPT or the operator, agreed most closely with the consensus decision. The best response was meant to simulate what would happen in a live environment should a discrepancy occur between the operator and cGPT. In the case of such a discrepancy, the operator would select the decision believed to be most accurate and leave a note that the article could be classified in one of two ways. If the selected classification was in disagreement with the other human reviewer, the consensus decision could be expedited by referring to the second possible classification described in the note.
Statistical analysis
Cohen’s kappa and observed agreement were calculated across cGPT in its two roles and the human reviewers. The kappa score assumes no “true” classification in the interrater comparison. Therefore, we calculated additional classification performance metrics using the consensus as the “truth,” in accordance with the definitions found in Table I. These metrics were calculated from the binary variable status.
When performing kappa statistics for exclusion reason classification, both excluded articles with exclusion reasons coded 1 through 9 and included articles with reason coded 10 were included in the analysis. Included articles were kept in the exclusion reason analysis due to the potential for discrepancy in the status decision between cGPT and the human reviewer.
When assessing and interpreting Cohen’s kappa values, the following conventional designations were used: <0.00 signifies poor strength in agreement, 0.00–0.20 slight agreement, 0.21–0.40 fair agreement, 0.41–0.60 moderate agreement, 0.61–0.80 substantial agreement, and 0.81–1.00 almost perfect agreement [16].
R version 4.3.3 for Windows was used for all statistical calculation. Packages used in analysis included “psych” and “irr.” The observed agreement, kappa statistic confidence intervals (CIs), and classification performance metrics were calculated directly from equations in the R environment. Findings are reported in-text as point estimate (95% CI).
Results
Experiential observations
An important observation was that cGPT tended to have obvious output errors, either with truncated responses or failure to respond to the prompt altogether. When this occurred, the operator would reissue the prompt with the article attached. cGPT was observed to be more likely to have an output error after it had had one previously and with conversations of increasing length. There did not, however, appear to be a set length that would precipitate output errors. Longer conversations appeared to cause longer response times. After observing these trends, it was determined that upon the first instance of an output error, the most time-efficient response was to begin a new conversation. Test 1 required reinitiating the conversation four times to complete the testing set while Test 2 required five.
cGPT was able to reliably divide populations within an article when prompted to do so before navigating populations through the exclusion flowchart. Engineering its prompt in this way allowed for simplification of the flowchart when coupled with detailed instructions. This combination produced responses that were delivered in a prescribed format, with explanations for its decisions that allowed the cGPT operator to identify errors in its logic. cGPT would only continue down the exclusion reason list until it identified an exclusion reason that rendered the article ineligible. In observational studies cGPT most often divided populations based on how the study reported its outcomes and in intervention studies by intervention and control group(s). Supplemental file 3 contains an example of an interaction between the operator and cGPT concerning one article .
cGPT had a tendency to drift in its exclusion reason assessment, randomly favoring one reason over another. The most favored exclusion reasons were No. 3. (non-free-living population) and No. 5. (condition affecting outcome; see Table II). This random favoritism did not carry over when a new conversation was initiated.
cGPT at times would report logical fallacies within the boundaries of its responses. The three most common logical errors observed were as follows: a population comprised of 30 or more individuals was classified as less than 30, resulting in an inappropriate exclusion reason No. 6. (Table II); identifying that one of the outcomes was reported but excluding for reason No. 8, since the study did not report both outcomes (Table II); and inclusion based on reporting of urine analytes other than creatinine (calcium, iodine, etc.) in the absence of 24-h urine volume reporting, resulting in inappropriate inclusion rather than exclusion due to exclusion reason No. 8 (Table II).
cGPT reproducibility
The autonomous cGPT’s status decisions between Test 1 and Test 2, had an observed agreement (95% CI) of 0.777 (0.719, 0.829) and a Cohen’s kappa of 0.493 (0.368, 0.618). The autonomous cGPT’s exclusion reason classifications between Test 1 and Test 2 had an observed agreement of 0.622 (0.56, 0.684) and a Cohen’s kappa of 0.495 (0.429, 0.562).
Results of testing
Classification performance metrics are presented using the binary variable status (Table III). This provides a comprehensive overview of how cGPT compares to human reviewers when both are compared against the consensus decision.
Classification performance metrics of status decisions.
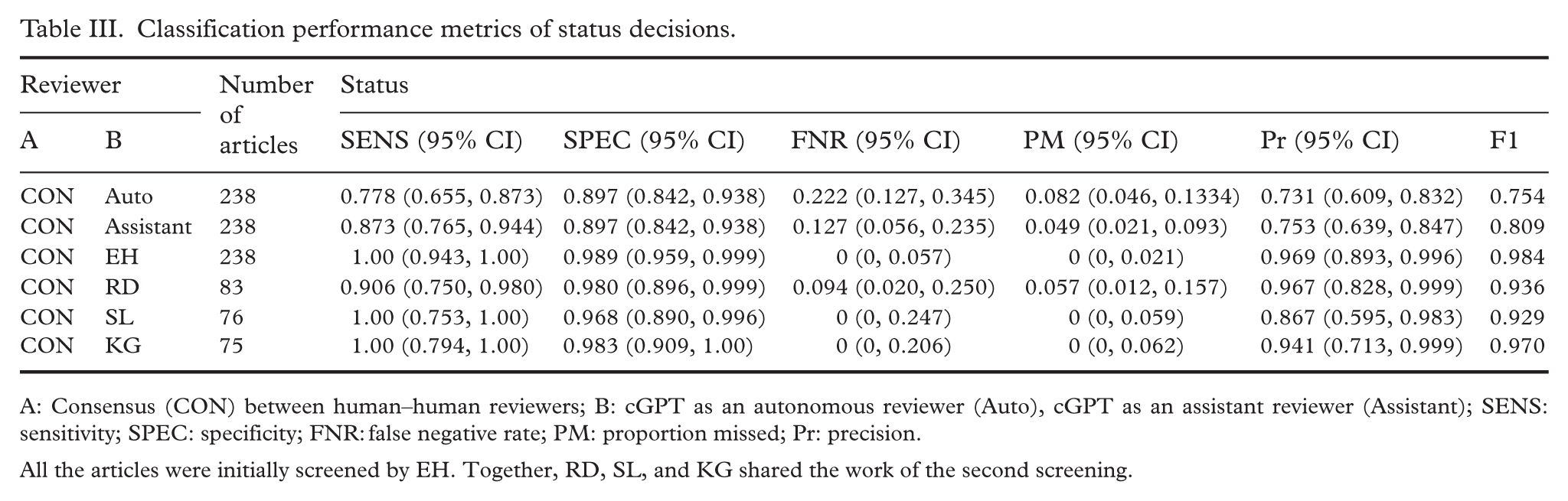
A: Consensus (CON) between human–human reviewers; B: cGPT as an autonomous reviewer (Auto), cGPT as an assistant reviewer (Assistant); SENS: sensitivity; SPEC: specificity; FNR: false negative rate; PM: proportion missed; Pr: precision.
All the articles were initially screened by EH. Together, RD, SL, and KG shared the work of the second screening.
Human–human kappa scores are presented, both with their status decision and exclusion reason classification (Table IV). Table IV also contains kappa scores (both status and exclusion reason) of human reviewers paired with cGPT in the role of autonomous reviewer, followed by cGPT as an assistant reviewer.
Observed agreement (OBS AG) and kappa scores of status and exclusion reason decisions between human–human pairings, autonomous cGPT–human pairings, and assistant cGPT–human pairings.
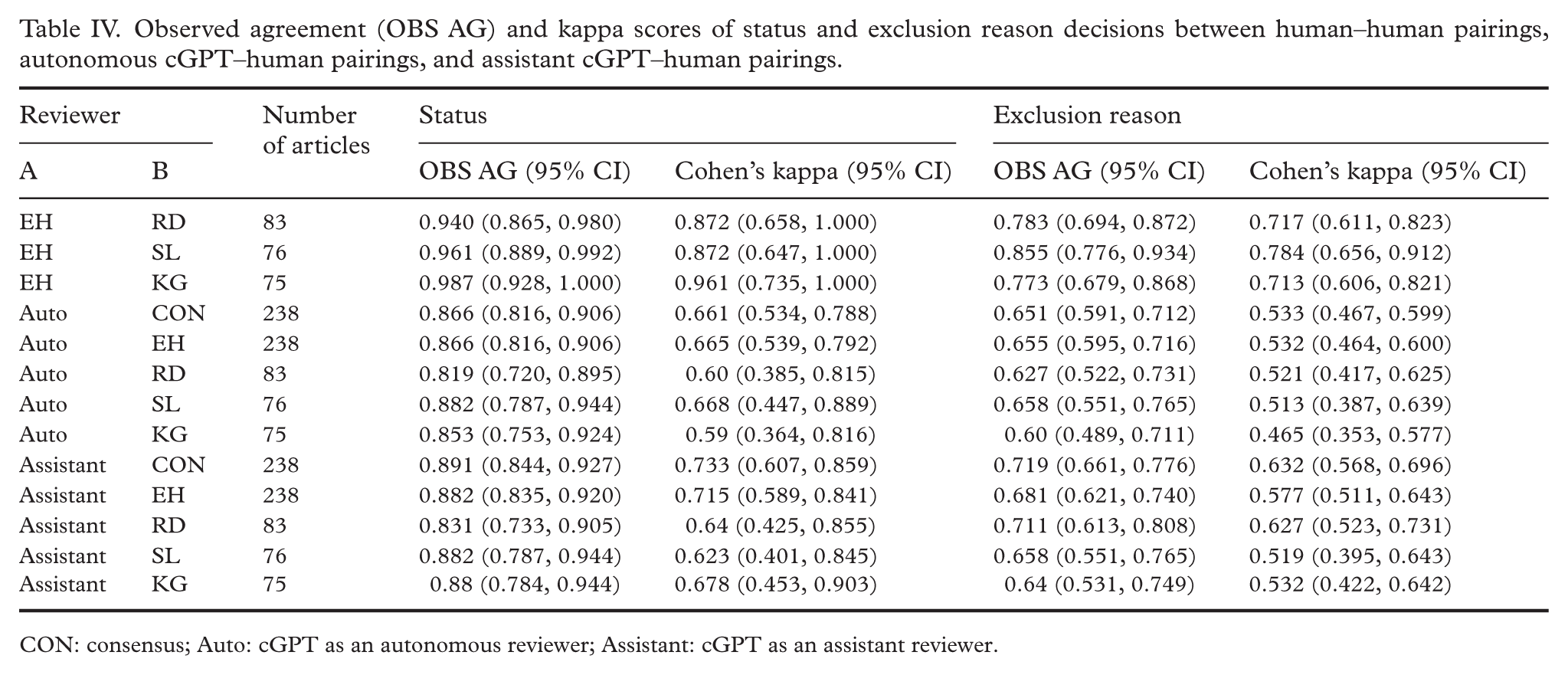
CON: consensus; Auto: cGPT as an autonomous reviewer; Assistant: cGPT as an assistant reviewer.
Time and workload savings
The time required to screen a fixed number of articles was determined by the total number of articles screened divided by the number of articles screened per hour. Time savings was calculated as the difference in the time required to screen the testing set between human reviewers and cGPT. For cGPT, internet quality, type of article, number of populations within the article, and variability in generative speed of responses were unforeseen variables that impacted the number of articles screened per hour. For human reviewers, type of article (including whether the full text could be located), internet quality, and other environmental factors influenced how many articles were screened per hour. Due to this high variability, time savings was described as minimum and maximum. Out of six total observations, the minimum documented number of articles completed by a human reviewer in 1 h was 9 while the maximum was 31. Out of four total observations, the minimum number of articles screened by cGPT was 32 and the maximum was 44. The 2020–2024 time-strata corpus of the present SR contains 1057 full text articles for screening. Considering our minimum and maximum values, this translates to between 34.1 and 117.4 effective human hours and 24 to 33 cGPT hours to conduct a single screening on this time strata corpus. The time savings then can be described as between 10.1 and 84.4 h saved when using cGPT instead of a human reviewer. While the human reviewers can only keep their top screening speed for a few hours at a time, cGPT, by its nature, has only the duration limitations of the operator and the number of prompts permitted hourly by the server.
Discussion
The cGPT in this study scored below 90% sensitivity, with specificity outperforming sensitivity in both reviewer roles, consistent with what has been observed in another study of LLMs [20]. The opposite was observed for human reviewers, who in three out of four instances had higher sensitivity than specificity, meaning, when in doubt, they included the article. Specificity was identical for both cGPT as an autonomous reviewer and as an assistant reviewer. Sensitivity, however, was higher in the assistant role, so the true strength of using cGPT as an assistant rather than as an autonomous reviewer lies in its ability to include more relevant articles, rather than to discard more irrelevant articles. This phenomenon was also reflected by cGPT’s higher F1 score as an assistant than as an autonomous reviewer. The risk of inaccurate screening from cGPT’s lower sensitivity compared to other reviewers was partially mitigated by requiring the screening to be done in duplicate, with one reviewer mandatorily being an unassisted human.
While Nested Knowledge gives determinations on article inclusion or exclusion during full text screening, its validation is reported almost exclusively with binary statistics (recall, precision, and F1), the exception being observed agreement [13,23]. Furthermore, looking at cGPT’s roles as autonomous and assistant reviewers in our study, observed agreement with the consensus status decision, used as the “truth,” was 86.6% and 89.1%, respectively, compared to a human reviewer and a consensus agreement range of 95.2% to 99.2%. This means that for the best human-consensus agreement, cGPT will miss one additional article for every 10 articles screened. For exclusion reason, the cGPT and consensus pairing of observed agreement was 65.1% (autonomous cGPT) and 71.9% (assistant cGPT). The range of human reviewer and consensus exclusion reason agreement was 86.7% and 94.7%. While status agreement was quite similar across all pairings, the same cannot be said for exclusion reason agreement.
A total of 12 possible combinations existed for comparisons between the three paired human reviewers and the four cGPT–human pairings. Regarding status decision, the bounds of the Cohen’s kappa 95% CI were crossed in all 12 combinations for both autonomous and assistant cGPT. This suggests that a difference in status decision performance between human pairings and any cGPT pairings could not be established with certainty. Regarding exclusion reason decisions, assistant cGPT 95% CIs overlapped with paired human reviewers in 9 of 12 possible Cohen’s kappa combinations, while autonomous cGPT overlapped in 4 of 12 combinations. This creates uncertainty about trends in performance between human pairings and cGPT pairings for the more nuanced exclusion reason decisions.
According to Cohen’s kappa classifications, the strength of human–human agreement was “almost perfect” (0.81–1.00) for status decisions and “substantial” (0.61–0.80) for exclusion reason decisions. The strength of agreement for status decision in autonomous cGPT and human pairings was “moderate” (0.41–0.60) to “substantial,” and assistant cGPT and human pairings was “substantial.” The strength of agreement for exclusion reason was “moderate” for pairings with both autonomous and assistant cGPT. Although these designations are arbitrary, they can provide useful performance benchmarks. In this case, they signify that human–human pairings had greater strength in agreement in all areas compared to cGPT–human pairings.
To compare interrater agreement with 10 alternative responses, a Cohen’s kappa is necessary as it takes into account random chance agreement. There will always be a risk of bias when using human decision as the “truth” by which to compare a screening tool. While this bias is partially mitigated by using the consensus decision, there nevertheless remain borderline decisions that could be interpreted in one of two ways. The kappa score captures this uncertainty within its metrics, while observed agreement does not. For this reason, a threshold for acceptable use of a cGPT assistant may be most appropriately determined using a Cohen’s kappa rather than observed agreement.
The study of LLMs like ChatGPT in full text screening is still largely uncharted territory with limited study comparability, preprints excluded. Further validation studies need to be conducted so that results such as those presented here can be compared and a threshold for acceptable use established.
Limitations and future directions
cGPT was observed to randomly favor one exclusion reason over others. This bias is addressed in part by using cGPT as an assistant rather than as an autonomous reviewer; however, since cGPT responses terminate when an exclusion reason is reached, the operator would be required to ask follow-up questions to discern the true exclusion reason. Since starting a new conversation with cGPT makes it “forget” this favoritism, a potential solution may be to initiate a new conversation at fixed intervals.
The logical fallacies occasionally reported by cGPT most likely contributed to the performance gap between cGPT as an autonomous reviewer and cGPT as an assistant reviewer. It is entirely possible that the newly released ChatGPT5.1, with its stronger complex reasoning, will not make such mistakes. There is value in rerunning the test set with this novel model, using the present study as a benchmark.
Despite efforts to encourage reproducibility in its configuration, cGPT had a poorer kappa score with itself between Test 1 and Test 2 of the testing set than it did with consensus in either the assistant reviewer or autonomous reviewer role. Care must be taken by researchers who choose to employ a cGPT for any purpose due to this inconsistency in its responses. It has been put forward that perhaps using a “majority vote” with five different LLMs evaluating articles together may produce improved sensitivity scores and could address the issue of inconsistent responses [20]. Alternatively, it is possible that this issue may be abated by prompting cGPT with the same article five or more times and accepting the majority vote for classification. The present study was not streamlined to such a degree that requesting five iterations of analysis on a single article was feasible, nor were there sufficient resources to produce five different custom LLMs catered to the project. These may be opportunities to explore in the future.
cGPT’s testing as an assistant reviewer occurred after all 238 articles had been screened for the first time by human reviewers. The operator had the opportunity to read the notes and tags left behind by the first human screener to confirm the scoring decisions guided by cGPT. Access to this information certainly influenced the operator’s decision to agree with cGPT or not, and therefore the performance of cGPT as an assistant reported here is dependent on this order of operations. Hence, the present study can only provide assistant cGPT benchmarks when the operator is placed in the second role. Due to the suboptimal performance of the assistant cGPT compared to human reviewers even when first reviewer information was available, a team looking to employ a cGPT-assisted reviewer would likely have the most advantageous results by also placing this individual in the role of the second screener.
Since screening is done in duplicate, the potential time savings only covers half of the workload of full text screening. Even with the fastest examples of human reviewing compared to the slowest example of cGPT/operator reviewing, cGPT still outperformed human reviewers’ screening speed. Furthermore, resolution of cGPT-generated discrepancies was first investigated by the cGPT operator. If the operator was in agreement with the unassisted human reviewer, resolution was reached by the operator without consultation. In practice, this saves time for the human reviewer who is not obliged to perform consensus on any but the most nuanced cases of disagreement, however, this was not evaluated quantitatively.
Even with the potential to save human work hours, time savings in vivo will depend on several factors including internet speed, availability and content of articles, and the unpredictability of cGPT-generated responses as described throughout this article. It is now possible to use an application programming interface with cGPTs that allows one to pull in articles from a cloud server, thus negating the need for an operator to manually upload one article at a time into the cGPT conversation and allowing for greater time-saving potential [20,24]. The purpose of the present study was both to evaluate the legitimacy of cGPT as a full text screener as well as describe the time-saving potential of the method used. While its performance is evaluated in detail here, further exploration into optimizing cGPT’s time-saving potential is needed.
The outcomes of interest in our SR are mostly intermediary steps in the studies being examined. If the SR’s and the studies’ outcomes were aligned, as is often the case, cGPT may have achieved a kappa score closer to those of the human–human reviewer pairs.
The method used to develop the cGPT was designed to be one that researchers who do not have a significant computer science background could reproduce or mimic. Indeed, creating a cGPT using a flow diagram similar to that employed in the present article has recently been explored in one health education study [25]. The use of a flow diagram can be valuable in the screening stage of any SR that ranks their exclusion reasons, as has been done here. Further research is needed to determine how best to configure cGPTs for the purpose of full text screening. Additionally, flow diagrams create an opportunity to methodologically constrain cGPT responses, opening the possibility for these to be used in other research domains.
The present SR is a considerably large study with data from 1990 to 2024 and thousands of articles requiring full text screening. It was feasible to take several hundred articles for the use of creating a custom AI model that could then be employed in the remaining articles. Many SRs will not have screening needs as demanding as those presented here, so there is likely to be a minimum threshold for size of SRs where the benefits of using a cGPT outweigh the initial time investment.
Using LLMs like ChatGPT in this way does not come without cost. The environmental impact of operating LLMs is not transparent, however water consumption, carbon emissions, and strains on the power grid are all known consequences of powering large models [26]. Furthermore, there are financial costs, social consequences, and the potential for disruption in what is prioritized in this type of research [27,28]. While the production of energy required to power the servers that support LLMs is becoming greener, it is unclear whether the costs outweigh the benefits from a larger systems perspective. This conversation is increasingly relevant as LLMs are used in novel ways for optimizing research [8,29].
The cGPT operator configured their data controls to deny OpenAI use of their content for training new models. Additionally, all conversations containing uploaded files were deleted, placing them on a 30-day countdown to be erased from OpenAI’s servers [30]. Despite these measures, providing full text article access to LLMs presents an ethical dilemma of data sharing and intellectual property rights. In the present study, it was realized after the fact that several articles uploaded to ChatGPT were paywalled (i.e., purchase or subscription required for access). The authors hope that transparency about this error may encourage researchers to critically evaluate the appropriateness of uploading articles to LLM environments. There appears to be an urgent need to strengthen education on the ethical concerns of granting companies like OpenAI access to paywalled content.
Conclusion
The improved speed of systematic reviewing with the use of LLMs like ChatGPT has implications for directing timely public health policy decisions. cGPT powered by ChatGPT4o performed best when employed as a second reviewer’s assistant. More research is needed to establish standardized performance guidelines for the practical use of cGPTs, possibly in the form of a Cohen’s kappa threshold. There is evidence of the time-saving potential to utilizing cGPT. A more sophisticated system for inputting articles and coding cGPT’s responses is needed to maximize the potential time-saving benefits. Investigating cGPT’s role as either an assistant or autonomous reviewer in a less complex SR may provide improved reliability and time-saving potential that outpace the results of the current study. Repeating the testing with the most updated ChatGPT model holds exciting promise.
Supplemental Material
sj-docx-1-sjp-10.1177_14034948261423410 – Supplemental material for Evaluating the performance of a custom GPT in full text screening of a systematic review
Supplemental material, sj-docx-1-sjp-10.1177_14034948261423410 for Evaluating the performance of a custom GPT in full text screening of a systematic review by Rachel C. Davis, Saskia S. List, Kendal G. Chappell, Ahmed Madar, Sigrun Henjum and Espen Heen in Scandinavian Journal of Public Health
Supplemental Material
sj-docx-2-sjp-10.1177_14034948261423410 – Supplemental material for Evaluating the performance of a custom GPT in full text screening of a systematic review
Supplemental material, sj-docx-2-sjp-10.1177_14034948261423410 for Evaluating the performance of a custom GPT in full text screening of a systematic review by Rachel C. Davis, Saskia S. List, Kendal G. Chappell, Ahmed Madar, Sigrun Henjum and Espen Heen in Scandinavian Journal of Public Health
Supplemental Material
sj-docx-3-sjp-10.1177_14034948261423410 – Supplemental material for Evaluating the performance of a custom GPT in full text screening of a systematic review
Supplemental material, sj-docx-3-sjp-10.1177_14034948261423410 for Evaluating the performance of a custom GPT in full text screening of a systematic review by Rachel C. Davis, Saskia S. List, Kendal G. Chappell, Ahmed Madar, Sigrun Henjum and Espen Heen in Scandinavian Journal of Public Health
Footnotes
Acknowledgements
Haakon Meyer provided useful comments on the manuscript.
Contributions
All members of the team contributed to the study’s conceptualization, data curation, reviewing, and editing. Rachel Davis was responsible for methodology, software, formal analysis, investigation, resources, visualization, original draft writing, and project administration. Espen Heen was instrumental in developing the methodology, visualization, validation, project administration, editing, and supervision.
Data availability statement
All data produced in the present study are available upon reasonable request to the authors.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Use of artificial intelligence tools
A custom GPT (Pro-version), powered by ChatGPT4o from OpenAI, was used as described throughout this article, but was not used in the generation of text, tables, or in any other content of the article.
Supplemental material
Supplemental material for this article is available online.